Abstract
Detecting salient objects in complicated scenarios is a challenging problem. Except for semantic features from the RGB image, spatial information from the depth image also provides sufficient cues about the object. Therefore, it is crucial to rationally integrate RGB and depth features for the RGB-D salient object detection task. Most existing RGB-D saliency detectors modulate RGB semantic features with absolution depth values. However, they ignore the appearance contrast and structure knowledge indicated by relative depth values between pixels. In this work, we propose a depth-induced network (DIN) for RGB-D salient object detection, to take full advantage of both absolute and relative depth information, and further, enforce the in-depth fusion of the RGB-D cross-modalities. Specifically, an absolute depth-induced module () is proposed, to hierarchically integrate absolute depth values and RGB features, to allow the interaction between the appearance and structural information in the encoding stage. A relative depth-induced module () is designed, to capture detailed saliency cues, by exploring contrastive and structural information from relative depth values in the decoding stage. By combining the and , we can accurately locate salient objects with clear boundaries, even from complex scenes. The proposed DIN is a lightweight network, and the model size is much smaller than that of state-of-the-art algorithms. Extensive experiments on six challenging benchmarks, show that our method outperforms most existing RGB-D salient object detection models.
1. Introduction
Salient object detection aims to locate and segment the most visually distinctive objects in an image. It often serves as a pre-processing method, that focuses the attention on semantically meaningful regions and provides informative visual cues to the downstream tasks, such as scene classification [1,2], visual tracking [3,4], foreign object detection [5], etc. In recent years, the rapid development of convolutional neural networks (CNNs) has facilitated the significant improvement of various computer vision tasks, e.g., object detection [6], brain tumor segmentation [7], and point cloud segmentation [8]. Salient object detection also benefits from the powerful representation ability of CNNs [9]. However, many problems still exist to be solved to accurately detect salient objects in complex image scenes, such as similar appearances between foreground and background areas, low-intensity environments, multiple objects of different sizes, etc. Due to the limited representation ability of existing saliency models, it is challenging to discriminate salient objects from cluttered background regions with only RGB images. Recently, benefiting from the development of depth sensors, it has been convenient to obtain dense depth images. Pixel-wise depth values, provide spatial information and geometric cues of the scene, which are complementary to the appearance features of the RGB data. Compared with only using appearance features from RGB images, saliency models based on RGB-D cross-modalities, can capture more relevant information about objects and avoid redundant noise. For example, in the very complex scene in Figure 1, where salient objects are not distinctive in the local area, we can observe obvious contrast between the foreground and background regions in the depth space (Figure 1b).

Figure 1.
Effectiveness of absolute depth information and relative depth information. (a) Input image; (b) depth image; (c) ground truth; (d) saliency map generated by baseline network; (e) saliency map using absolution depth information; (f) saliency map using both relative depth information and absolute depth values.
This paper proposes a cross-modal fusion strategy for RGB-D salient object detection. Specifically, we consider two kinds of depth information, pixel-wise absolute depth values from depth images and relative depth values (also known as spatial distance in 3D space) between pair-wise pixels. The interaction between absolute depth information and RGB images is a hot topic for scene understanding, such as person re-identification [10], 3D object detection [11,12,13], etc. Most existing methods learn to extract depth and RGB features by separate networks, and directly fuse them in each scale using different fusion modules [14,15,16], ignoring the message transmission across different scales. Moreover, because of the large gap between the distribution of RGB and depth data, it will inevitably introduce noisy responses in prediction results. For example, the saliency map in Figure 1d, which is generated by the baseline network (simply integrating RGB and depth features with concatenation and convolution blocks), cannot effectively capture the entire salient object in the scene. As comparison, the network with the proposed (Figure 1e) can respond to most salient regions, by reasonably combining RGB-D cross-modal features. Besides the information provided by absolute depth values, we argue that relative depth values between short-range pixels also contribute to recognizing distinctive saliency cues in the local area. However, these have rarely been studied in recent work. For example, the left person in Figure 1a is less discriminative in the RGB feature space, but presents obvious disparity around the object boundary in the depth space. Therefore, by introducing relative depth information, the proposed method manages to recognize the person as a salient object (Figure 1f).
To this end, we propose a depth-induced network (DIN) for RGB-D salient object detection, which consists of two main components, the absolute depth-induced module () and the relative depth-induced module (). Unlike directly fusing features from the depth and RGB images, the enforces in-depth interaction of the two modalities in a coarse-to-fine manner. Specifically, a set of gate recurrent units (GRU) [17] are employed, to hierarchically integrate depth and RGB features across multiple scales. The gate structure adaptively selects informative features from the RGB and depth images, and thus controls the fusion of multi-modalities and avoids cluttered noise being introduced, caused by the asynchronous properties of the two feature spaces. The is implemented in a recursive manner. The fusion results in the shallower layer, are subsequently input into the next integration step in the deeper layer, ensuring effective information transfer across different scales. By this means, the degree of integration goes deep through the network, and we can explore saliency cues from the combined features at different scales. The aims to capture the spatial structure information of the image and detailed saliency cues, by utilizing relative depth information. Since adjacent pixels in 2D space may not be strongly associated with 3D point cloud space, we project image pixels into 3D space based on their spatial positions and depth values. Then, a graph model is constructed on the feature map level, to enforce information propagation in the local area, according to the relative depth relationship. We implement it by a spatial graph convolutional network (GCN), based on the relative depth and semantic affinities between pair-wise pixels. The feature representation ability is successively enhanced by exploring spatial structure and geometry information across multi-scales. By this means, detailed saliency cues are exploited by the , which facilitates the accurate prediction of the final results. Unlike the commonly used two-stream networks, which encode the RGB and depth images with the same architecture [18,19,20,21], the proposed DIN is a single-stream network. It thus dramatically reduces the computation costs without sacrificing the model performance.
In summary, the main contributions of this work are three-fold:
- We propose an which adopts the GRU-based method and adaptively integrates absolution depth values and RGB features, to combine the geometric and semantic information from multi-modalities.
- We propose an which employs spatial GCN to explore semantic affinities and contrastive saliency cues, by leveraging the relative depth relationship.
- The proposed DIN for RGB-D salient object detection is a lightweight network and outperforms most state-of-the-art algorithms on six challenging datasets.
2. Related Works
This section reviews some representative works on salient object detection and RGB-D salient object detection, respectively. We also give a brief discussion on the graph convolutional network.
2.1. Salient Object Detection
Early salient object detection approaches [22,23,24,25] mainly used hand-crafted features, such as brightness, color, and texture, to locate and segment salient objects in an image. In recent years, thanks to the development of CNNs, various deep learning-based saliency models [26,27,28] have been proposed, and they outperform the traditional methods by a large margin. Zhang et al. [26], explored multi-level features in each scale and recursively generated saliency maps. Feng et al. [27], proposed an attentive feedback module to explore the structure of salient objects better. Kong et al. [28], designed propagation modules to combine multi-scale features of the network. The authors of [29], proposed an integrity cognition network, to enhance the integrity of the predicted salient objects. In [30], a dual graph model was established, to guide the focal stack fusion for light field salient object detection. The authors of [31], developed a salient object detector without any human annotations by a novel supervision synthesis scheme.
Although the above works study various multi-scale fusion models and learning strategies, they still face challenges where the scenarios are complicated. To address this issue, we resort to depth images to explore the spatial structure and geometric information of the scene, and thus improve the effectiveness and robustness of the network.
2.2. RGB-D Salient Object Detection
Traditional hand-made RGB-D salient object detection methods [32,33,34] have inferior representation ability of semantic and geometric features. Recently, CNN-based methods have been developed, that are powerful in modeling the RGB-D multi-modalities and thus improve the detection performance to a large extent. Effectively integrating depth and RGB features is one of the critical issues in this task. In [35], Piao et al. hierarchically integrates the depth and RGB image, and refines the final saliency map by a recurrent attention model. The work [19], designed an asymmetric two-stream network for learning the multi-scale and multi-modal features by a ladder-shape module and attention strategies. Sun et al. [20], explored the depth-wise geometric prior, to refine the RGB feature, and employed automatic architecture search to improve the performance of the saliency model. To reduce the model size and improve the performance, Zhao et al. [36] proposed a one-stream network for RGB-D salient object detection and designed effective attention models to combine multi-modalities. The work [37], proposed a novel mutual attention model, to fuse cross-modal information. Besides, effective learning strategies are also crucial for a high-quality detection model. Ji et al. [38], proposed a novel collaborative learning framework, to enhance the interaction of edge, depth, and saliency cues. The authors of [18], trained a depth distiller, which modulated the RGB representation by the features in the depth stream. In [39], two kinds of self-supervised pre-training processes were conducted, to learn semantic information and reduce the inconsistency between multi-modalities.
The mutual learning method was employed in [40,41], to align RGB and depth features. Liu et al. [42], proposed a unified transformer architecture for both RGB and RGB-D salient object detection, to propagate global information among image patches. The work [43], proposed a transformer-based network, to learn implicit class knowledge for RGB-D co-saliency detection. Although saliency models can benefit from depth information and distinguish objects from cluttered scenes, sometimes depth images are inaccurate or hard to obtain, thus introducing inevitable noise in the prediction results. Considering this situation, Hussain et al. [44] proposed to leverage only RGB images during both training and test stages, first predict depth values, and generate final saliency maps based on the intermediate depth information. This method employed a combination of Transformer and CNN, leading to satisfactory predicting results. Most of these methods exploit discriminative cues from the absolute depth values but ignore the structure information indicated by the relative depth values. In our work, we make full use of both absolute and relative depth information in images, with a single-stream architecture, to facilitate the accurate saliency detection of RGB images.
2.3. Graph Convolutional Network
A GCN aims to learn geometry information on non-Euclidean structural data. Because of the flexible application of the relationship between nodes, GCNs have received more and more research interest in recent years. Generally speaking, GCNs can be categorized into spectral approaches and spatial approaches. Kipf et al. [45], proposed a spectral GCN which performed the convolution operation in the spectral domain on the constructed graphs, with the help of Fourier transformation. Velickovic et al. [46], designed a spatial GCN that fused features between neighbor nodes with an attention mechanism. A multi-layer perceptron was trained to learn the affinity relationship between adjacent nodes. Battaglia et al. [47], utilized multiple blocks to update and transfer information on the graph alternately. Due to the effectiveness of GCNs, many researchers employ them in computer vision tasks. Yao et al. [48], used a GCN to integrate both semantic and spatial relationships of objects, to generate a more accurate image caption. Qi et al. [49], represented the image as a graph model with the depth prior. By constraining the GCN with invisible depth information, a more accurate image segmentation result is obtained. In ref. [50], a GCN is employed to model the semantic relationship on both language and visual modalities and then infers the referred regions in the image. Inspired by these works, we design a spatial GCN for the RGB-D saliency detection task. This network fully uses relative depth information, to explore detailed saliency cues in the local area and obtains satisfactory detection results with much clearer object boundaries.
3. Algorithm
We propose a DIN that leverages depth images to induce spatial relationships for RGB saliency detection. We first introduce the overall architecture in Section 3.1. We discuss the , which fuses the image and absolute depth features, in Section 3.2, and we elaborate on the , which refines the fused features based on the guidance of relative depth information, in Section 3.3.
3.1. Overall Architecture
The overall architecture of the proposed DIN is shown in Figure 2. We employ a ResNet [51]-based network as the backbone, to encode the input RGB image. The backbone network consists of five convolution blocks, including Conv, Conv,⋯, Conv. Fed with an RGB image I, with size , it generates multi-scale feature maps with size , respectively. We removed the fully connected layers of the original ResNet [51] to fit this task. The depth image D, is first encoded with a set of convolutional layers and then successively warped and integrated with the hierarchical image feature maps by the proposed , generating the fused feature maps .
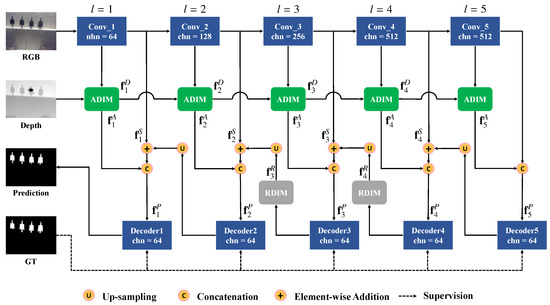
Figure 2.
Architecture of the proposed DIN model. There are three main components in the network: the backbone network; the , which fuses RGB and depth images in the encoding stage; and the , which complements relative depth cues in the decoding stage.
Since features from different levels represent meaningful information, we recursively integrate multiple feature maps in the decoding stage. Specifically, the image feature maps are first fed into a convolutional layer with kernel size , to reduce the channel number to 64, and the generated side output feature maps are denoted as . Then the multi-level feature maps of RGB and depth images are integrated in a top-down manner,
in which is the activation function, is the convolution layer, is the concatenation operation that concatenates feature maps on the channel dimension, and is the up-sampling operation with bilinear interpolation. + represents the element-wise addition operation. The feature map , denotes the integrated RGB-D features in the l-th scale.
To further exploit the spatial structure information and detailed saliency cues, we refine the integrated feature maps , with the proposed , by considering the relative depth values. The output feature maps are denoted as . To balance the computation costs and performance, we apply the on the 3rd and 4th-levels. Then, the integrated feature maps are fed into a set of convolutional layers, with kernel size , to generate saliency maps , at multiple scales. The proposed depth-induced network (DIN) is trained in an end-to-end manner. All the saliency maps are directly supervised by the ground truth, and the losses are summarized and optimized jointly. Considering that the feature maps , incorporate high-level semantic information and low-level detailed knowledge, we choose as the final prediction result.
3.2. Absolute Depth-Induced Module
The goal of the absolute depth-induced module (), is to integrate appearance features from the RGB image and depth information from the depth image. Since there is a large gap between the distribution of RGB and depth data, flat feature fusing methods will introduce cluttered noise in the final prediction. Therefore, we propose to recursively fuse features of the two modalities, by employing a series of s to enforce the in-depth interaction between RGB and depth features. As shown in Figure 2, the depth information is embedded in the hierarchical RGB feature maps, and updated step-by-step in the encoding stage. Specifically, given the feature map of an RGB image in the l-th level , and the updated depth feature map in the previous level , the integrates the RGB-D multi-modalities as followins,
in which is the integrated feature map, is the updated depth feature, and is the depth image.
The detailed structure of is shown in Figure 3. The implementation of is inspired by the gated recurrent unit (GRU), which is designed for dealing with sequential issues. We formulate the multi-scale feature integration process as a sequence problem and treat each scale as a time step. By this means, the iteratively updates the depth features of the previous state, and selectively fuses meaningful cues of two modalities with the memory mechanism.
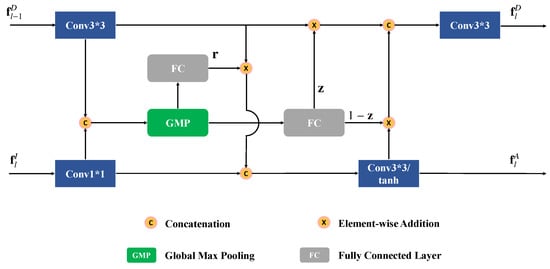
Figure 3.
Structure of the .
In each time step, we feed image features , into the GRU, and depth features , can be regarded as the hidden state of the previous step. The output feature maps and , in Equation (2), are the updated states. First, feature maps and , are encoded by a convolutional layer and an activation layer, and the output feature maps are denoted as and , respectively. Then the two feature maps are concatenated and transformed by a global max-pooling (GMP) operation, and a feature vector is generated. Subsequently, two separate fully connected layers, followed by the sigmoid function, are applied on the feature vector, to generate the resent gate and the update gate . In fact, gate controls the integration of the depth and RGB features, and controls the update step of . Based on them, the fused multi-modal feature , and the updated depth representation , are output. Formally, the above process can be formulated as:
in which is the fully connected layer with learnable parameters , is the global max-pooling operation, and ⊗ is the channel-wise multiplication operation. The feature map , generated by the hidden layer, memorizes valuable multi-modal information of previous scales, which is adaptively integrated with the features of the current scale. Such an operation enhances the interaction between cross-modalities as the network goes deeper. The depth feature , is also updated according to the corresponding appearance information in , and further facilitates the cross-modal learning in the next scale.
3.3. Relative Depth-Induced Module
Besides the absolute depth values, we can learn contrastive and structural information about the scene from relative depth values in the local area. Relative depth information can be extracted from the depth image and reveals the spatial relationship between pixels. Intuitively, closer pixels in the depth space should have a more compact feature interaction, as they tend to have the same saliency label. This observation is essential for separating salient objects in extremely cluttered image scenes. In this work, we proposd an that utilizes the GCN, to ensure message propagation, by using relative depth information. As shown in Figure 2, are employed in the 3rd and 4th levels of the decoding stage. Given the feature map , in Equation (1), and the depth image, the refines the integrated multi-scale feature maps to boost the performance of the saliency model.
Graph Construction. To explore the relative depth relationship between pixels, we represent the feature map , generated as an undirected graph , with the node set V, and edge set E. First, the depth image is resized to the size of . Then, each pixel in is regarded as a node in the graph, and the node set is denoted as , where K is the total pixel number. Each node , corresponds to a 3D coordinate and a feature vector , where is the 2D spatial coordinate in the feature map, is the depth value of the pixel, and is the feature vector on the channel dimension, of the i-th pixel in the feature map .
To allow message transmission in the local area, we define edges between each node and their m nearest neighbors, according to their 3D coordinates. The weight on edge , is defined as the relative depth value , to measure the spatial correlation between the nodes and .
Graph Convolutional Layer. The proposed spatial GCN consists of a series of stacked graph convolutional layers (GCLs). For each GCL, we first define the semantic affinity , for the edge , to characterize the semantic discrepancy between nodes and . Specifically, to further consider the global contextual information of the image, a global average pooling (GAP) operation is applied on the feature map , to extract high-level semantic information, and the output feature vector is denoted as . The semantic affinity is formulated as
where and are feature vectors of and , and is the fully connected layer with learnable parameters . Then the feature of each node , is updated by the fully connected layer
where is the set of neighbors of the node . In the updating process, both semantic and spatial affinities are considered, which helps to improve the discrimination ability of the feature.
In the , three GCLs are sequentially applied, to update the global semantic feature , the semantic affinity , and the node feature . We adopt the output feature of the last GCL as the refined one, and denote it as . Note that, is the channel-wise feature vector in the location . We then re-arrange features of all nodes to form a feature map , which has the same size as . According to Equation (4), the feature map , is the final output of the at scale l.
Intuitively, the constructed graph on feature map , reveals the affinity between nodes in terms of both spatial correlation and visual association. By transferring messages between nodes using the GCN, the feature of each node is refined, according to its affinity with short-range neighbors. This encourages similar nodes (in both spatial and visual space) to have the same saliency labels.
The generated feature maps , of the , are then input into the next decoding stage. To balance the computation costs and performance, we employ the in the 3rd and 4th scales in the decoding stage. We set m to be 64 in the 3rd scale and 32 in the 4th scale.
3.4. Training and Inference
To constrain the network and learn effective saliency cues, we generate a saliency map in each scale of the network and supervise it by the ground truth image. Specifically, the feature map of the l-th level in the decoding stage, is transformed by a convolutional layer, into one channel. This is followed by an up-sampling operation, to resize the output into the size of the input image, and we denote this result as the saliency map of the l-th level, . This saliency prediction is supervised by the ground truth image , by the cross-entropy loss function
The total loss is the summation of the loss in each scale, and the proposed DIN is trained in an end-to-end manner, by minimizing the total loss.
Considering the saliency map , generated by the feature map , incorporates both multi-level and multi-modal information, we employ it as the final prediction result of the network.
4. Results and Analysis
4.1. Experiment Setup
Implementation Details. The parameters of the backbone network are fine-tuned by the pre-trained ResNet-50 [51], on the Imagenet [52] dataset. The rest of the parameters are randomly initialized. The input images are resized to , by the bilinear interpolation operation. We utilize the same data augmentation methods as in [35], to prevent the network from overfitting, including randomly flipping, cropping, and rotating. The Adam algorithm [53] is employed to optimize the loss function. The base learning rate is set to be and is decreased by ten times every 20 epochs. Our network converges within 40 epochs. The weight decay is , and the batch size is four. All experiments are implemented on the PyTorch platform, with a single NVIDIA GTX 2080Ti GPU. The model size of the proposed DIN is 99.55 Mb, and the speed is 11 FPS.
Datasets. We evaluate saliency models on six large-scale datasets, including NLPR [33], NJUD [34], STERE [54], SIP [55], LFSD [56], and SSD [57]. NLPR includes 1000 images, most of which contain multiple salient objects, and the corresponding depth images are captured by Kinect. NJUD incorporates 1985 images, which are collected from the internet, 3D movies, and photographs taken by a Fuji W3 stereo camera. STERE consists of 1000 pairs of binocular images. SIP includes 1000 images, with salient persons in real-world scenes. LFSD is composed of 100 light field images, which are taken by the Lytro light field camera. SSD contains 80 images that are extracted from stereo movies. As suggested in [35], we employ 1485 images from the NJUD and 700 images from the NLPR as the training set. The rest of the images are used as the test set.
Evaluation Metrics. We employ four metrics to evaluate the performance of the different algorithms, including max F-measure [58], structural measure (S-measure) [59], enhanced-alignment measure (E-measure) [60], and mean absolute error (MAE).
Saliency maps are first binarized by a set of thresholds ranging from 0 to 255, and compared with ground truth images. Then, precision and recall values are computed. F-measure considers both precision and recall values, to evaluate the performance of saliency models comprehensively. F-measure is defined as the weighted harmonic mean of the precision and recall,
where is set to 0.3 following [58]. S-measure evaluates the structure similarity between objects detected by saliency maps and those in ground truth images. It considers both object-aware similarity , and region-aware similarity , by a linear system,
in which is the constant parameter that balances the importance of the object-aware and region-aware similarity. E-measure computes the enhanced alignment matrix , to capture the pixel-level matching and image-level statistics of the foreground map, and uses the mean value of the matrix , to reflect the quality of the saliency prediction,
MAE computes the mean absolute difference between the prediction result , and the ground truth image ,
4.2. Evaluation with State-of-the-Art Models
We compare the proposed DIN model with 17 state-of-the-art saliency models, including DANet [36], PGAR [61], CMWNet [62], ATSA [19], D3Net [55], DSA2F [20], DCF [63], HAINet [64], CDNet [65], CDINet [66], MSIRN [67], SSP [39], FCMNet [68], and PASNet [44]. For a fair comparison, saliency maps of the evaluated methods are provided by the authors, or obtained by implementing the codes.
Quantitative Evaluation. We compare the proposed DIN model with the evaluated methods on six large-scale datasets. The max F-measure, S-measure, E-measure, and MAE values are demonstrated in Table 1. The quantitative experiments show that our method is able to achieve competitive performance against recent state-of-the-art algorithms on most datasets, demonstrating the effectiveness of the proposed method. Especially on the challenging NJUD [34] and LFSD [56] datasets, which incorporate semantically complicated images, the performance of our method is superior to other algorithms, indicating that the proposed DIN is able to learn informative semantic cues from cluttered scenarios.

Table 1.
Quantitative results of the evaluated methods in terms of the F-measure (), S-measure (), E-measure (), and MAE () on six datasets. The top three scores of each metric are marked as red, green, and blue. Higher scores of F-measure, S-measure, and E-measure are better, and lower scores of MAE are better.
Table 2 shows the model size of the evaluated methods. The model size of the proposed DIN is much smaller than the comparison saliency models, except for the PGAR, which employs the VGG-16 [69] as the backbone network. Figure 4 illustrates the scatter diagrams of model size and performance of the evaluated methods in terms of F-measure, S-measure, E-measure, and MAE. The comparisons in Figure 4 intuitively demonstrate that DIN is able to achieve satisfactory performance with fewer parameters. This observation demonstrates a potential for the DIN to be deployed on mobile devices.
Table 2.
Model size of the evaluated methods.
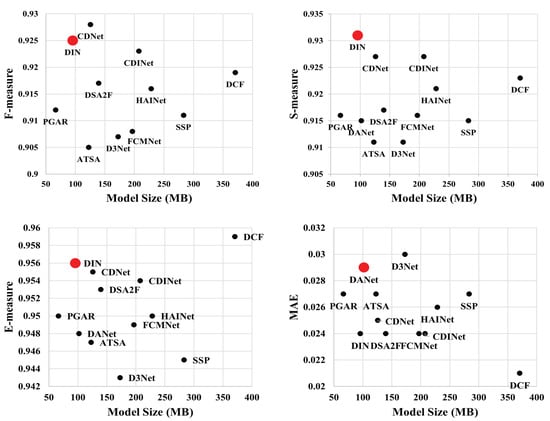
Figure 4.
Scatter diagrams of model size and performance (F-measure, S-measure, E-measure, and MAE) on the NLPR dataset. The DIN achieves state-of-the-art performance with fewer parameters.
Qualitative Evaluation. To qualitatively evaluate our method, we show some visual examples of our DIN model and other algorithms in Figure 5. Compared with other algorithms, our method is able to detect entire salient objects, with well-defined boundaries, accurately. As shown in Figure 5, the proposed DIN model is effective in various challenging scenarios, including multiple objects (1st column), salient objects with different colors (2nd column), distractors in the background (3rd, and 6–7th columns), low contrast between the foreground and background (5th column), and cluttered background (3rd, 4th, and 6–7th columns). For example, in the 1st column in Figure 5, most other algorithms cannot capture all salient regions of the two objects. In contrast, our method consistently highlights multiple salient objects. In the 2nd example, although there are various appearances in the foreground, the proposed DIN is able to detect all parts of salient regions. In the 3rd and 4th examples, our model successfully suppresses the distractors in the background regions. In the low contrast and low illumination scenarios (5th and 7th example), the proposed DIN can segment the entire salient regions from the background, because of the combination of the RGB and depth information. The foreground in the 6th example is not salient in the depth space. However, our method can still capture salient regions according to the contrast cues in the RGB and semantic space. The above visual results verify the effectiveness and superiority of the proposed DIN method against the comparison algorithms.

Figure 5.
Visual examples of our method and the evaluated algorithms. From top to bottom: RGB image, depth image, GT, DIN (ours), DANet [36], PGAR [61], CMWNet [62], ATSA [19], D3Net [55], DSA2F [20], DCF [63], HAINet [64], CDNet [65], CDINet [66], and SSP [39].
4.3. Ablation Studies
In this section, we demonstrate ablation studies, to verify the effectiveness of each main component of the proposed DIN model.
4.3.1. Effectiveness of
The goal of the is to integrate absolution depth information and the RGB image, and explore complementary cues from the multi-modalities. In order to verify the effectiveness of the , two networks are trained for comparison:
Baseline: we utilize the backbone network as the baseline network, which replaces the as the concatenation and convolution block, and deletes the from the DIN. The baseline network takes the RGB and depth images as inputs and generates a final saliency map.
+: referred to as the + network, which takes both RGB and depth images as inputs, and employs to fuse multi-modal features hierarchically in the encoding stage based on the baseline network.
As shown in Table 3 (1st and 2nd rows), + outperforms the baseline network by up to 3% on F-measure, 3% on S-measure, 4% on E-measure, and 32% on MAE, verifying the effectiveness of the proposed . Figure 6 shows visual results of the baseline and + network. In the 1st example in Figure 6, the baseline network captures two persons as salient objects (Figure 6d). However, the left one is not salient in both semantic and depth spaces. Thanks to the , the saliency map of the + network (Figure 6e) focuses more on the true object. In the 2nd example, the saliency map generated by the baseline network (Figure 6d) wrongly responds to the background regions. In contrast, the is able to alleviate this drawback by adaptively integrating the RGB and depth features, resulting in more accurate saliency prediction results (Figure 6e).
Table 3.
Ablation studies in terms of F-measure, S-measure, E-measure, and MAE on NLPR, NJUD, and STERE datasets.

Figure 6.
Visual effects of ablation studies. (a) Input image, (b) depth image, (c) ground truth, (d) baseline, (e) +, (f) +, (g) +, and (h) DIN.
We also compare the proposed with existing cross-modal fusion modules, including the depth attention module () [19], cross reference Module () [63], and cross-enhanced integration module () [21], in the encoding stage. Specifically, we replace the in the + network, with , , and , and denote the networks as +, +, and +, respectively. Table 4 (b–d) show their performance in terms of F-measure, S-measure, E-measure, and MAE, respectively. By contrast, the performance of + in Table 4, is higher than the comparison modules by up to 1%, 1%, 2%, and 20%, on the four metrics, respectively. We attribute the increase to the message transmission of latent features across different scales, which is implemented by the GRU-based structure of the . In contrast, , , and only focus on the information transfer between the two modalities.
Table 4.
Comparisons of and with other multi-modal fusion modules in the encoding and decoding stages, respectively.
4.3.2. Effectiveness of
The aims to refine the multi-modal features by exploring the local contrast information indicated by relative depth values. To verify the effectiveness of the , we train + and + as baseline networks for comparison.
+: remove all s in the encoding stage of the DIN.
+: compared with the +, in the GCN, the weight on edge is defined as the spatial distance in 2D space, .
As shown in Table 3, compared with the baseline network (1st row), the + (3rd row) achieves up to 3%, 3%, 4%, and 34% improvement on F-measure, S-measure, E-measure, and MAE, respectively. It is also superior to the + network (2nd row). This observation indicates that local contrast information is important for exploring detailed image cues and contributes more to obtaining accurate predictions. Figure 6 demonstrates the visual results of the + network. Compared with the saliency results of the baseline and + networks, those of the + (Figure 6f) present more accurate details around the edges of the objects. This is because the employs relative depth information to learn contrastive information in the local area, and improve the discriminative ability of multi-modal features by GCNs.
We also investigate the importance of relative depth values. In the + in Table 3, we construct the graph in the without considering the relative depth values. In other words, we only use the spatial distances of pair-wise pixels to reflect their affinities. According to the quantitative experiments in Table 3, the performance of + is lower than that of +, demonstrating the contribution of the relative depth values. The saliency detection results of the + in Figure 6g, also present cluttered noise around object boundaries and the background.
We compare the proposed with two existing modules in the decoding stage, including the multi-modal feature aggregation (MFA) module [21] and consistency-difference aggregation () module [39]. These two modules are applied to the decoding stage of the network, to further integrate and enhance the feature representation of multi-modalities. For a fair comparison, we replace the in the + network with the and modules, and denote them as + and +, respectively. Table 4 (f–g) demonstrate the quantitative performance of these networks. It can be seen that + outperforms the comparison networks by up to 1%, 1%, 2%, and 16% in terms of F-measure, S-measure, E-measure, and MAE, respectively. This is because the utilizes relative depth values to update the feature representation in consideration of its spatial and semantic affinities with other regions, modeling structural information of the scene, which is crucial for saliency prediction. By comparison, and only make use of absolute depth values and integrate them with RGB features, inevitably introducing clutter noise, because of the large gap between multi-modalities.
4.3.3. Effectiveness of Combination of and
The DIN in Table 3 (5th row) is the proposed method in our work, which employs both and in the network. As shown in quantitative results, the DIN achieves the best performance compared with all of the other evaluated baseline networks, which indicates that the and are complementary.
Compared with the saliency maps of the baseline, +, and + networks (Figure 6d–f), the prediction results generated by the DIN in Figure 6g suppress the responses on cluttered background regions and accurately capture entire salient objects, with well-defined boundaries. In the 4th example in Figure 6, the baseline network (Figure 6d) is confused by the image background regions, and outputs blurry prediction results. The + (Figure 6e) captures both the man and helicopter as salient objects, since they are salient in the depth space. The + (Figure 6f) can alleviate the negative predictions on the image background by exploring the local contrast in both RGB and depth spaces. However, the prediction result is still inaccurate compared with the ground truth. Due to the reasonable interaction between and , the DIN (Figure 6g) can accurately capture the true salient object and eliminate the incorrect responses in the background regions. This observation verifies that the DIN takes full advantage of the complementary nature between the absolute and relative depth information and thus achieves satisfactory performance.
4.4. Failure Cases
Figure 7 shows some failure cases of our method. In the first example, the salient object has low-depth contrast with the surroundings. In the second example, the depth values of the salient object are not correctly captured by the sensor. The salient object in the third example is hard to recognize in the RGB space. Our proposed DIN fails to detect the true objects with clear boundaries in these scenarios. This is because, in these situations, depth maps do not provide valuable information and even introduce noisy responses, which limit the accuracy of the saliency model. Moreover, the based on relative depth values will magnify prediction errors.

Figure 7.
Failure cases of our method. (a) Input image; (b) depth image; (c) ground truth; (d) the proposed DIN.
5. Conclusions
In this work, we propose a DIN for RGB-D salient object detection. The DIN consists of two main components, and . The utilizes a GRU-based method, to successively integrate the RGB and absolute depth values at multiple scales. In the , we propose a spatial GCN, to explore detailed saliency cues with the help of relative depth values and semantic relationships. These two modules are complementary and lead to an effective saliency model which is able to detect entire salient objects with well-defined boundaries. The DIN is a lightweight model, because of the single-stream architecture. Extensive experiments show that the performance of the DIN is competitive with the state-of-the-art algorithms on six large-scale benchmarks. In future work, we will improve the robustness of the and in complex scenarios, and extend the proposed models to other cross-modal tasks. Moreover, we will explore more possibilities of the RGB-D salient object detection on engineering applications.
Author Contributions
Conceptualization, Y.K., L.K. and Y.L.; methodology, L.K., Y.K. and H.W.; software, L.K., Y.K. and H.W.; validation, H.W. and C.Y.; investigation, H.W. and C.Y.; writing—original draft preparation, L.K. and Y.K.; writing—review and editing, Y.K. and H.W.; visualization, L.K. and Y.K.; supervision, Y.L. and B.Y.; project administration, Y.K., Y.L. and B.Y.; funding acquisition, B.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the Ministry of Science and Technology of China no. 2018AAA0102003, National Natural Science Foundation of China, under Grant no. 62006037, no. 62172073, and no. U19B2039, the Fundamental Research Funds for the Central Universities no. DUT22JC06, and the National Key R&D Program of China no. 2022YFC3106101.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data sharing not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ren, Z.; Gao, S.; Chia, L.; Tsang, W. Region-Based Saliency Detection and Its Application in Object Recognition. IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 769–779. [Google Scholar] [CrossRef]
- Siagian, C.; Itti, L. Rapid Biologically-Inspired Scene Classification Using Features Shared with Visual Attention. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 300–312. [Google Scholar] [CrossRef] [PubMed]
- Mahadevan, V.; Vasconcelos, N. Biologically Inspired Object Tracking Using Center-surround Saliency Mechanisms. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 541–554. [Google Scholar] [CrossRef] [PubMed]
- Borji, A.; Frintrop, S.; Sihite, D.N.; Itti, L. Adaptive object tracking by learning background context. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 23–30. [Google Scholar]
- Zhang, K.; Wang, W.; Lv, Z.; Fan, Y.; Song, Y. Computer vision detection of foreign objects in coal processing using attention CNN. Eng. Appl. Artif. Intell. 2021, 102, 104242. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, Z.; Qin, J.; Zhang, Z.; Shao, L. Discriminative Fisher Embedding Dictionary Learning Algorithm for Object Recognition. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 786–800. [Google Scholar] [CrossRef] [PubMed]
- Zhang, D.; Huang, G.; Zhang, Q.; Han, J.; Han, J.; Yu, Y. Cross-modality deep feature learning for brain tumor segmentation. Pattern Recognit. 2021, 110, 107562. [Google Scholar] [CrossRef]
- Atik, M.E.; Duran, Z. An Efficient Ensemble Deep Learning Approach for Semantic Point Cloud Segmentation Based on 3D Geometric Features and Range Images. Sensors 2022, 22, 6210. [Google Scholar] [CrossRef]
- Ji, Y.; Zhang, H.; Zhang, Z.; Liu, M. CNN-based encoder-decoder networks for salient object detection: A comprehensive review and recent advances. Inf. Sci. 2021, 546, 835–857. [Google Scholar] [CrossRef]
- Uddin, M.K.; Bhuiyan, A.; Bappee, F.K.; Islam, M.M.; Hasan, M. Person Re-Identification with RGB–D and RGB–IR Sensors: A Comprehensive Survey. Sensors 2023, 23, 1504. [Google Scholar] [CrossRef]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum pointnets for 3D object detection from rgb-d data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 918–927. [Google Scholar]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S.L. Joint 3D proposal generation and object detection from view aggregation. In Proceedings of the International Conference on Intelligent Robots and Systems, Madrid, Spain, 1–5 October 2018; pp. 1–8. [Google Scholar]
- Luo, Q.; Ma, H.; Tang, L.; Wang, Y.; Xiong, R. 3D-SSD: Learning hierarchical features from RGB-D images for amodal 3D object detection. Neurocomputing 2020, 378, 364–374. [Google Scholar] [CrossRef]
- Chen, H.; Li, Y.; Su, D. Multi-modal fusion network with multi-scale multi-path and cross-modal interactions for RGB-D salient object detection. Pattern Recognit. 2019, 86, 376–385. [Google Scholar] [CrossRef]
- Han, J.; Chen, H.; Liu, N.; Yan, C.; Li, X. CNNs-based RGB-D saliency detection via cross-view transfer and multiview fusion. IEEE Trans. Cybern. 2018, 48, 3171–3183. [Google Scholar] [CrossRef] [PubMed]
- Qu, L.; He, S.; Zhang, J.; Tian, J.; Tang, Y.; Yang, Q. RGBD salient object detection via deep fusion. IEEE Trans. Image Process. 2017, 26, 2274–2285. [Google Scholar] [CrossRef] [PubMed]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Piao, Y.; Rong, Z.; Zhang, M.; Ren, W.; Lu, H. A2dele: Adaptive and attentive depth distiller for efficient RGB-D salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9060–9069. [Google Scholar]
- Zhang, M.; Sun, X.; Liu, J.; Xu, S.; Piao, Y.; Lu, H. Asymmetric two-stream architecture for accurate RGB-D saliency detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 374–390. [Google Scholar]
- Sun, P.; Zhang, W.; Wang, H.; Li, S.; Li, X. Deep RGB-D saliency detection with depth-sensitive attention and automatic multi-modal fusion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 15–20 June 2021; pp. 1407–1417. [Google Scholar]
- Zhou, T.; Fu, H.; Chen, G.; Zhou, Y.; Fan, D.; Shao, L. Specificity-preserving RGB-D saliency detection. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 4661–4671. [Google Scholar]
- Scholkopf, B.; Platt, J.; Hofmann, T. Graph-based visual saliency. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 4–7 December 2006; pp. 545–552. [Google Scholar]
- Krahenbuhl, P. Saliency filters: Contrast based filtering for salient region detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 20–26 July 2012; pp. 733–740. [Google Scholar]
- Itti, L.; Koch, C.; Niebur, E. A Model of Saliency-Based Visual Attention for Rapid Scene Analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef]
- Wu, J.; Han, G.; Liu, P.; Yang, H.; Luo, H.; Li, Q. Saliency Detection with Bilateral Absorbing Markov Chain Guided by Depth Information. Sensors 2021, 21, 838. [Google Scholar] [CrossRef] [PubMed]
- Zhang, P.; Wang, D.; Lu, H.; Wang, H.; Xiang, R. Amulet: Aggregating multi-level convolutional features for salient object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 202–211. [Google Scholar]
- Feng, M.; Lu, H.; Ding, E. Attentive feedback network for boundary-aware salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1623–1632. [Google Scholar]
- Kong, Y.; Feng, M.; Li, X.; Lu, H.; Liu, X.; Yin, B. Spatial context-aware network for salient object detection. Pattern Recognit. 2021, 114, 107867. [Google Scholar] [CrossRef]
- Zhuge, M.; Fan, D.P.; Liu, N.; Zhang, D.; Xu, D.; Shao, L. Salient Object Detection via Integrity Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3738–3752. [Google Scholar] [CrossRef]
- Liu, N.; Zhao, W.; Zhang, D.; Han, J.; Shao, L. Light field saliency detection with dual local graph learning and reciprocative guidance. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 4712–4721. [Google Scholar]
- Zhang, D.; Han, J.; Zhang, Y.; Xu, D. Synthesizing Supervision for Learning Deep Saliency Network without Human Annotation. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 1755–1769. [Google Scholar] [CrossRef]
- Feng, D.; Barnes, N.; You, S.; McCarthy, C. Local background enclosure for RGB-D salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2343–2350. [Google Scholar]
- Peng, H.; Li, B.; Xiong, W.; Hu, W.; Ji, R. Rgbd salient object detection: A benchmark and algorithms. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 5–12 September 2014; pp. 92–109. [Google Scholar]
- Ju, R.; Ge, L.; Geng, W.; Ren, T.; Wu, G. Depth saliency based on anisotropic center-surround difference. In Proceedings of the IEEE International Conference on Image Processing, San Antonio, TX, USA, 16–19 September 2014; pp. 1115–1119. [Google Scholar]
- Piao, Y.; Ji, W.; Li, J.; Zhang, M.; Lu, H. Depth-induced multi-scale recurrent attention network for saliency detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7254–7263. [Google Scholar]
- Zhao, X.; Zhang, L.; Pang, Y.; Lu, H.; Zhang, L. A single stream network for robust and real-time RGB-D salient object detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2020; pp. 646–662. [Google Scholar]
- Liu, N.; Zhang, N.; Shao, L.; Han, J. Learning Selective Mutual Attention and Contrast for RGB-D Saliency Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 9026–9042. [Google Scholar] [CrossRef]
- Ji, W.; Li, J.; Zhang, M.; Piao, Y.; Lu, H. Accurate RGB-D salient object detection via collaborative learning. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2020; pp. 52–69. [Google Scholar]
- Zhao, X.; Pang, Y.; Zhang, L.; Lu, H.; Ruan, X. Self-supervised pretraining for RGB-D salient object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2022; pp. 3463–3471. [Google Scholar]
- Liu, N.; Zhang, N.; Han, J. Learning selective self-mutual attention for RGB-D saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13753–13762. [Google Scholar]
- Zhang, J.; Fan, D.; Dai, Y.; Yu, X.; Zhong, Y.; Barnes, N.; Shao, L. RGB-D saliency detection via cascaded mutual information minimization. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 4318–4327. [Google Scholar]
- Liu, N.; Zhang, N.; Wan, K.; Shao, L.; Han, J. Visual saliency transformer. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 4722–4732. [Google Scholar]
- Zhang, N.; Han, J.; Liu, N. Learning Implicit Class Knowledge for RGB-D Co-Salient Object Detection With Transformers. IEEE Trans. Image Process. 2022, 31, 4556–4570. [Google Scholar] [CrossRef] [PubMed]
- Hussain, T.; Anwar, A.; Anwar, S.; Petersson, L.; Baik, S.W. Pyramidal attention for saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Nashville, TN, USA, 20–25 June 2022; pp. 2878–2888. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Battaglia, P.W.; Hamrick, J.B.; Bapst, V.; Sanchez-Gonzalez, A.; Zambaldi, V.F.; Malinowski, M.; Tacchetti, A.; Raposo, D.; Santoro, A.; Faulkner, R.; et al. Relational inductive biases, deep learning, and graph networks. arXiv 2018, arXiv:1806.01261. [Google Scholar]
- Yao, T.; Pan, Y.; Li, Y.; Mei, T. Exploring visual relationship for image captioning. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 711–727. [Google Scholar]
- Qi, X.; Liao, R.; Jia, J.; Fidler, S.; Urtasun, R. 3D graph neural networks for RGBD semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5209–5218. [Google Scholar]
- Liu, S.; Hui, T.; Shaofei, H.; Yunchao, W.; Li, B.; Li, G. Cross-Modal Progressive Comprehension for Referring Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 4761–4775. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Li, F.F. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2009; pp. 248–255. [Google Scholar]
- Kingma, D.P.; Ba, J.L. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Niu, Y.; Geng, Y.; Li, X.; Liu, F. Leveraging stereopsis for saliency analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2012; pp. 454–461. [Google Scholar]
- Fan, D.; Lin, Z.; Zhang, Z.; Zhu, M.; Cheng, M. Rethinking RGB-D salient object detection: Models, datasets, and large-scale benchmarks. IEEE Trans. Neural Networks Learn. Syst. 2020, 32, 2075–2089. [Google Scholar] [CrossRef]
- Li, N.; Ye, J.; Ji, Y.; Ling, H.; Yu, J. Saliency detection on light field. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2806–2813. [Google Scholar]
- Zhu, C.; Li, G. A three-pathway psychobiological framework of salient object detection using stereoscopic technology. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 3008–3014. [Google Scholar]
- Borji, A.; Sihite, D.N.; Itti, L. Salient object detection: A benchmark. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 414–429. [Google Scholar]
- Fan, D.; Cheng, M.; Liu, Y.; Li, T.; Borji, A. Structure-measure: A new way to evaluate foreground maps. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4548–4557. [Google Scholar]
- Fan, D.; Gong, C.; Cao, Y.; Ren, B.; Cheng, M.; Borji, A. Enhanced-alignment measure for binary foreground map evaluation. In Proceedings of the International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 698–704. [Google Scholar]
- Chen, S.; Fu, Y. Progressively guided alternate refinement network for RGB-D salient object detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2020; pp. 520–538. [Google Scholar]
- Li, G.; Liu, Z.; Ye, L.; Wang, Y.; Ling, H. Cross-modal weighting network for rgb-d salient object detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2020; pp. 665–681. [Google Scholar]
- Ji, W.; Li, J.; Yu, S.; Zhang, M.; Piao, Y.; Yao, S.; Bi, Q.; Ma, K.; Zheng, Y.; Lu, H.; et al. Calibrated RGB-D salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2021; pp. 9471–9481. [Google Scholar]
- Li, G.; Liu, Z.; Chen, M.; Bai, Z.; Lin, W.; Ling, H. Hierarchical Alternate Interaction Network for RGB-D Salient Object Detection. IEEE Trans. Image Process. 2021, 30, 3528–3542. [Google Scholar] [CrossRef]
- Jin, W.; Xu, J.; Han, Q.; Zhang, Y.; Cheng, M. CDNet: Complementary Depth Network for RGB-D Salient Object Detection. IEEE Trans. Image Process. 2021, 30, 3376–3390. [Google Scholar] [CrossRef]
- Zhang, C.; Cong, R.; Lin, Q.; Ma, L.; Li, F.; Zhao, Y.; Kwong, S. Cross-modality discrepant interaction network for RGB-D salient object detection. In Proceedings of the ACM Multimedia, Virtual, 24 October 2021; pp. 2094–2102. [Google Scholar]
- Liu, Z.y.; Liu, J.W.; Zuo, X.; Hu, M.F. Multi-scale iterative refinement network for RGB-D salient object detection. Eng. Appl. Artif. Intell. 2021, 106, 104473. [Google Scholar] [CrossRef]
- Jin, X.; Guo, C.; He, Z.; Xu, J.; Wang, Y.; Su, Y. FCMNet: Frequency-aware cross-modality attention networks for RGB-D salient object detection. Neurocomputing 2022, 491, 414–425. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representation, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).