1. Introduction
Hyperspectral imaging (HSI) provides higher spectral resolution with contiguous and narrow bands, enabling a wealth of information to be captured for applications such as semantic segmentation [
1,
2], scene classification [
3,
4,
5], object detection [
6,
7] and target tracking [
8,
9]. Nonetheless, due to the limitations of the spectral imaging mechanism, the trade-off between spatial and spectral resolution is a challenge in remote sensing. The increased number of spectral bands results in an information bottleneck due to the space-bandwidth product of the detector arrays. As shown in
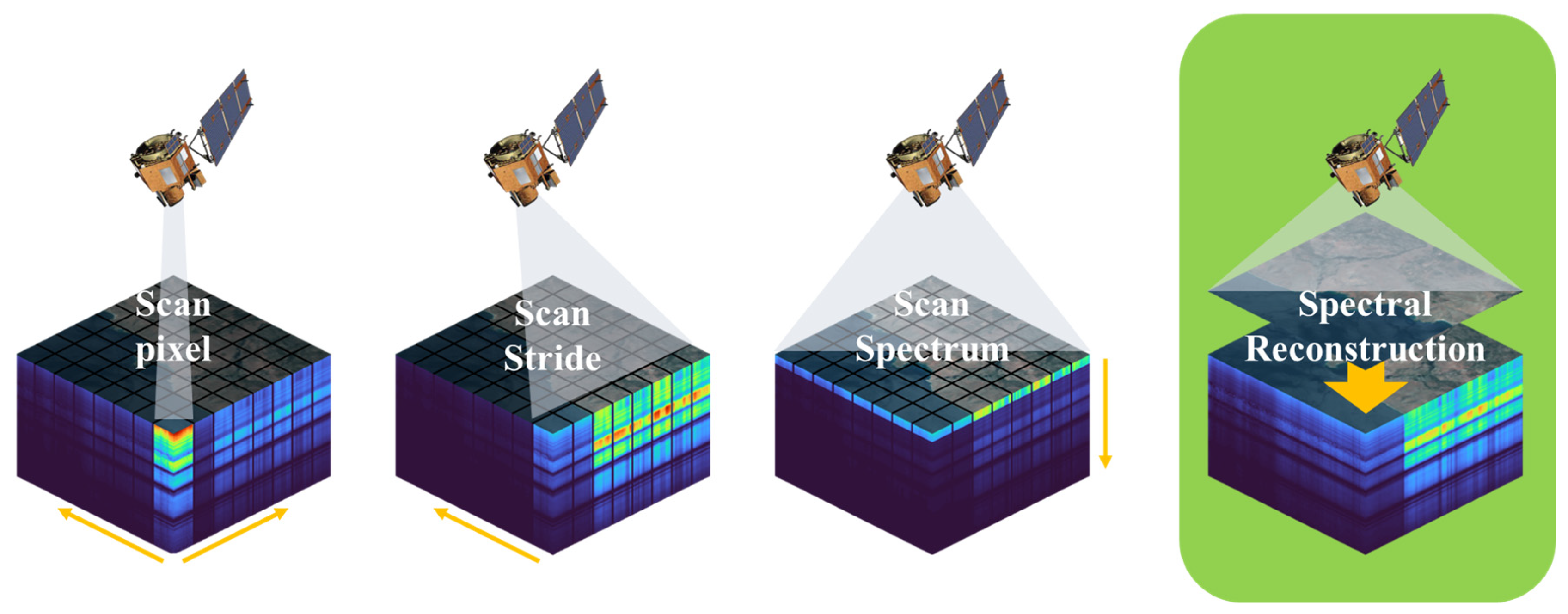
Figure 1, conventional hyperspectral imaging techniques, such as push-broom detectors and digital array detectors, rely on scanning spatial or spectral dimensions to generate the three-dimensional data cube. This imaging process is time-consuming and limited to static objects. In time-sensitive applications and situations where there is relative motion between objects and the environment, the introduction of time-series hyperspectral imaging introduces the possibility of spatial misalignment and subsequent distortion of recorded spectra. To address these limitations, there is a need for new and innovative approaches that can enhance spectral resolution without sacrificing spatial resolution.
The pursuit of high spatial resolution, spectral resolution and imaging speed in hardware is cost-intensive and relies on rigorous environmental conditions and extra equipment. An attractive option for solving the addressed problem is to use lower-cost, more available multi-spectral images (MSI) or RGB images to directly reconstruct hyperspectral information, widely known as the spectral reconstruction technique (SR). Spectral reconstruction techniques provide a cost-effective solution to the hardware limitations in remote sensing. By leveraging a wider range of data sources, SR methods allow for more efficient utilization of sensors, leading to the improved overall utilization of remote sensing satellites.
The mainstream research of hyperspectral image reconstruction includes spectral super-resolution [
10,
11,
12,
13] and computational spectral reconstruction from RGB to HSI [
14,
15,
16,
17,
18]. In general, recovering hyperspectral information is an ill-posed inverse problem. The spectral reconstruction approaches are usually categorized into two kinds [
19]: prior-based and data-driven methods.
Traditional hyperspectral reconstruction employs prior knowledge of HSIs as a regularizer to solve such a seriously ill-posed problem. The representative prior-based methods include dictionary learning [
20,
21,
22,
23,
24], Gaussian Process [
25] and manifold mapping [
26]. Dictionary learning methods express the spectral signal with multiple combinations of base spectra. The accuracy and abundance of the dictionary representation determine the reconstruction quality of the spectral signal. The subsequent research work enhanced the dictionary representation by combining a priori knowledge such as local Euclidean linearity [
20], spatial structure similarity [
23], texture [
22], spatial context [
24], etc. Manifold learning methods characterize hyperspectral images as unique low-dimensional manifolds. It solves the spectral reconstruction problem to a many-to-many mapping problem and simplifies the mapping complexity by recovering low-dimensional embedding. Gaussian Process methods use a priori knowledge of spectral physics and spatial structure similarity. Gaussian Process methods model the spectral characteristics of the material categories contained in the image. In training, it divides the images into different clusters by algorithms such as K-means and learns spectral response functions in the different clusters. In test, the hyperspectral image is reconstructed using the characterization parameters and the Gaussian Process.
These hand-crafted priors have limitations and often need to reflect all the characteristics of the data. In the case of an unknown camera sensitivity function, the reconstruction performance and accuracy will be reduced. These severely restrict the performance and generalization ability of the prior-based methods mentioned above.
Pioneering works have proved that the performance of data-driven priors exceeds that of hand-crafted priors. Embracing more and more datasets, data-driven methods acquire powerful feature representation ability and good adaptability. Various deep learning networks have been proposed to improve reconstruction accuracy, from simple network models to more advanced deep learning networks using a variety of techniques. These data-driven methods, which primarily use supervised learning, include CNN-based methods [
14,
27], GAN-based methods [
16,
28,
29] and Attention-based methods [
18,
30,
31]. CNN-based methods have strong nonlinear characterization capability and are widely used in SR. Compared to RGB images, CNN methods for hyperspectral images tend to use higher dimensional convolution kernels to adapt to the spectral dimension. Given the recent advances in deep learning, various variants of the SR method based on CNN models have been derived. U-Net models [
32] combine multi-scale information through sampling transformation. Dense Networks [
17] and Residual Networks [
33] avoid the vanishing of the gradient and richer image details. Multi-branch networks [
34] fuse multi-path signal flow to obtain diverse features. The above approaches can be applied as a general framework for subsequent SR network design. The GAN-based methods consist of a generator and a discriminator. The reconstruction of images is enhanced by adversarial learning between two networks. The Attention-based methods, which introduced patterns from the NLP, can be more capable of modeling at long-range distances. Compared to CNNs, the Attention mechanism can focus differently on the spatial and spectral dimensions.
However, the limitations of the above-mentioned model should also be considered. One of the primary drawbacks is that the mapping relationship between the target and input spectra is fixed and unidirectional, rendering the model invalid in the event of changes to the imaging device or input spectral bands. Additionally, the spectral reconstruction performance can be significantly impacted by missing or disturbed input bands resulting from interference or attacks. Thus, there is a pressing need for more robust spectral reconstruction techniques capable of handling such scenarios and providing reliable results.
Moreover, data-hungry issues plague increasingly complex neural network models. Hyperspectral datasets much smaller than visible images limit the accuracy of SR models. A common way is to pre-train the model on another larger dataset. In recent years, self-supervised learning (SSL) [
35] has emerged as an attractive approach for visual pre-training and has been shown to outperform its supervised counterpart. This is an active area of research and holds promising potential for improving the accuracy of hyperspectral image reconstruction models.
With the goal of improving the adaptability of SR models to the inputs of different spectral sensors and enhancing the utilization of remote sensing data, we propose a novel approach, the masked autoencoder-based spectral image reconstruction model (SpectralMAE). SpectralMAE reconceptualizes the spectral reconstruction problem based on the mask-then-predict strategy. This model leverages the power of autoencoder and masked modeling to provide a more robust and flexible solution for hyperspectral image reconstruction.
Figure 2 illustrates the capabilities of SpectralMAE in addressing three typical problems with a single model. First, it can generate remote sensing hyperspectral images directly from RGB images. Second, it can selectively input band combinations when dealing with partially damaged or incomplete band images. Third, it can fuse and reconstruct data from multiple sensors with spatial registration using spectral position encoding.
The contributions of our proposed SpectralMAE method can be summarized in three points:
Improved potential adaptability to various spectral sensors: The SpectralMAE model offers a more robust and flexible solution for hyperspectral image reconstruction, as it supports arbitrary combinations of spectral bands as inputs, including inputs from different numbers of multi-spectral data sources, RGB images and even a mixture of two sensors. Furthermore, compared to spectral super-resolution, SpectralMAE performs better in predicting spectral curves in non-overlapping spectral regions.
Maximizing the utilization of hyperspectral remote sensing data: The SpectralMAE model adopts a new paradigm of self-supervised learning for the spectral reconstruction problem. The model incorporates a mechanism of random masking during the training process. This mechanism leads to an exponential increase in the number of input combinations that the model must consider during training, resulting in a deeper understanding of the association between local and global features.
Improved reconstruction accuracy: The SpectralMAE model employs a two-stage training process, with pre-training using random masks followed by fine-tuning with fixed masks. By incorporating a positional encoding strategy for the spectral dimension and a transformer network architecture, the model is able to effectively capture and differentiate spectral information, even in the presence of masked positions. The proposed SpectralMAE model can outperform existing supervised learning methods on several remote sensing hyperspectral image datasets and can surpass 95% of the random masking rate in the spectral dimension.
3. Experimental Results and Analysis
In this section, we compare our proposed method with 10 state-of-the-art methods, including 3 HSI reconstruction algorithms (MST++ [
18], MST [
31] and HDNet [
12]); 3 super resolution methods (HSCNN+ [
17], AWAN [
15] and HRNet [
41]); and 4 image restoration models (MPRNet [
42], Restormer [
43], HINet [
44], and EDSR [
45]). Among them, MST++ is the winning algorithm of NTIRE2022 [
46]; HSCNN+ and AWAN are the winning algorithms of NTIRE in 2018 [
47] and 2020 [
48], respectively.
Table 1 presents an overview of above methods, categorized by their network architecture, along with a concise explanation of their basic idea and the year of publication. It is evident from the trend of development that attention and transformer structures have been extensively employed in spectral reconstruction models in recent years.
3.1. Dataset
We evaluate our proposed method on three multispectral remote sensing datasets (Chikusei [
49], Washington DC Mall [
50] and XiongAn [
51]) and two hyperspectral remote sensing datasets (HyRANK [
52] and GF2Hyper [
53]).
The original Chikusei, Washington DC Mall and XiongAn airborne hyperspectral datasets have been down-sampled to the same number of channels as the Compact High Resolution Imaging Spectrometer (CHRIS), which contains 62 spectral channels ranging from 406 nm to 1003 nm. The processed Chikusei dataset comprises a total of 1016 training data. The processed Washington DC Mall dataset consists of 2424 training samples. The XiongAn dataset includes 1216 training samples. These three processed multispectral datasets were derived from the Sen2CHRIS dataset [
53]. In the experiments, we used multispectral data from the dataset and extracted the corresponding visible wavelengths as input.
The HyRANK satellite hyperspectral data were obtained from the Hyperion sensor. After the band removal process, a total of 176 bands were derived. Five Hyperion surface reflectance datasets were obtained from the EarthExplorer platform. The GF2Hyper datasets include hyperspectral images captured by the Gaofen-1 and Hyperion sensors on the EO-1 satellite. In the dataset, 148 useful bands were selected through spectral sampling, and 1152 training samples were included. With these two datasets, we evaluated the model’s performance on satellite-based hyperspectral remote sensing images.
3.2. Implementation Details
During the training procedure, HSIs are spatially divided into non-overlapping patches as input data, which are then linearly rescaled to [0, 1]. The batch size is set to 32, and the input patch size of the model is 8 pixels. The Adam algorithm is used for parameter optimization. The learning rate is initialized as 0.00001, and the Cosine Annealing scheme is adopted for 500 epochs. The weight decay ratio is 0.0005, and the momentum is 0.9.
Additionally, gradient clipping is used to avoid the gradient explosion problem. In the first 200 epochs, random masking is performed in the spectral dimension of the data, and the masking rate is gradually increased from 75% to 90%. In the last 100 epochs, fixed masking is used, and the visible band is the input band of the reconstructed spectrum. The proposed SpectralMAE has been implemented on the Pytorch framework running in the Windows 10 environment and a single NVIDIA RTX A6000 GPU. In the experiment, the encoder of the SpectralMAE model contains 12 layers of the Transformer encoder network, where the embedding dimension of each network is 768, and the MSA module contains 12 attention heads. The lightweight decoder contains 8 layers of Transformer encoder networks, where the embedding dimension of each network is 512, and the MSA module contains 16 attention heads. The same number of training epochs and optimization methods are used for the comparative models, and the optimal results are obtained by adjusting the hyperparameters.
3.3. Qualitative Results
3.3.1. Results of Hyperspectral Remote Sensing Image Datasets
We present the results of the HyRANK dataset with the proposed SpectralMAE and other state-of-the-art methods. Visual comparisons of error maps for five scenes in the HyRANK dataset are shown in
Figure 7. All methods use the same three spectral channels as input to reconstruct a hyperspectral image with 176 channels.
Among the visualization results of the five bands, SpectralMAE shows less local variation than other compared methods. Most models exhibit different reconstruction errors for marine and terrestrial areas. The effects of topography and surface material types pose a more significant challenge to the spectral reconstruction of terrestrial regions. However, SpectralMAE still handles the differences between terrestrial and marine regions better, with the main errors originating from the over-region at the surface edge.
To compare the performance in the spectral dimension, we present visualizations of spectral curves for the five scenes in
Figure 7. As shown in the
Figure 8, these curves represent the average value of each band in the image. While all methods are able to match the overall trend of the ground truth spectral curve, the reconstructed spectra of the comparison methods exhibit significant shifts in the wave peaks (e.g., at wavelengths between the 800 nm and 1000 nm and wavelengths between 1100 nm and 1300 nm). Additionally, these methods produce large fluctuations in the adjacent intervals. In contrast, the SpectralMAE method reconstructs spectral curves that closely match the ground truth. This is evident in the consistency of peaks and valleys of the spectra, as well as the smoothness of the excesses in the continuous region.
Figure 9 illustrates the visual comparison results of the GF2Hyper dataset. The first two columns showcase pseudo-color images synthesized using wavelengths 763 nm, 1289 nm and 1530 nm. The last three columns depict error maps of the reconstructed image when compared to the ground-truth image. The error is primarily present in areas with solid undulations on the ground surface. Additionally, reconstruction errors can be observed at distorted locations on the edges of the original image.
3.3.2. Results of Multispectral Remote Sensing Image Datasets
Figure 10 visualizes the results of the spectral reconstruction of airborne multispectral images. The figure displays the error maps of the three visible bands, as well as their synthesized color images. For the Chikusei dataset, SpectralMAE demonstrates low errors for various types of land, with the majority of errors arising from buildings containing a small number of pixels in the images. For the XiongAn dataset, the errors primarily originate from the junction of lake and land surfaces, which occur less frequently in the scene. Additionally, the XiongAn dataset has a higher resolution of the ground surface, resulting in significant light and shadow effects, leading to additional errors due to the difference in brightness of the forest. In the Washington DC dataset, most areas are buildings and streets in the city, and most errors are found at the edges of buildings.
3.4. Quantitative Results
As for quantitative comparisons, we utilize four commonly used picture-quality indices (PQIs), including mean peak signal-to-noise ratio (mPSNR), mean structure similarity (mSSIM), root mean square error (RMSE) [
54] and Spectral angle mapper (SAM) [
55]. These PQIs enable us to evaluate the reconstructed HSIs in terms of their similarity to the ground truth. mPSNR and mSSIM are calculated on each 2D spatial image, which evaluates the similarity between the reconstructed HSIs and the ground truth based on MSE and structural consistency, respectively. SAM calculates the average angle between the spectrum vectors of the reconstructed HSIs and the ground truth.
Table 2 presents the average quantitative results on the HyRANK dataset. The HyRANK dataset contains five hyperspectral images, which we split into 128-pixel spatially-resolved patches for training and testing. We reserved 10% of the images as a test set and applied the same data augmentation techniques, such as image flipping, to all models. We optimized hyperparameters for comparison models and used the Adam algorithm with a batch size of 16, learning rate initialized to 0.00004 and Cosine Annealing scheme. After training, all models reached stable convergence.
Like many hyperspectral remote sensing datasets, the HyRANK dataset has a limited number of images. Training a model to reconstruct 172 spectral bands from this limited data is a challenging ill-posed problem. When facing higher-dimensional reconstruction problems with even smaller datasets, SR methods may exhibit prediction bias, as shown in
Figure 7 and
Figure 8. The proposed SpectralMAE outperforms all other competing supervised methods, not only in mPSNR, mSSIM and RMSE but also in SAM.
The prediction biases observed in other models may be attributed to their limited utilization of the data. In contrast, the SpectralMAE model achieved improved accuracy by implementing a “random mask-then-predict” strategy, which enabled the model to learn various combinations of mappings from the limited dataset.
Based on the principle of unordered permutation and combination, the number of mapping types on the spectral dimension increased to , where N is the number of spectral dimensions and r is the masking rate. Assume that mapping from RGB channels to 176-dimensional hyperspectral images constitutes one mapping type. Then the mapping types obtained by the self-supervised learning method of SpectralMAE contain types. Additionally, because the mask rate increases continuously during pre-training, the model eventually learns even more mapping types. Moreover, the fixed-masking strategy further improved the results.
In another aspect, SpectralMAE only considered the patch size in the spatial dimension, resulting in larger implicit parameters than models that read the entire image. By focusing the local windows during each batch, the original spatial structure of the image was disrupted, resulting in further data augmentation in the spatial dimension.
3.5. Ablation Study
3.5.1. Quantitative Results of the Training Strategy
In this section, we conduct simulated experiments to show the effectiveness of our training strategy.
Table 3 and
Table 4 present the quantitative results of random masked hyperspectral image reconstruction at 75% and 90% masking rates, respectively. SpectralMAE achieves a higher mask ratio than imageMAE based on the assumption of high redundancy of spectral information. A higher masking rate means that the model acquires less information, making it more difficult to predict the unknown bands accurately. As a result, the results of a 90% masking rate are generally lower than those of a 75% masking rate. Due to the continuity of the spectrum, SpectralMAE can achieve a higher masking rate than imageMAE, which makes the reconstruction of spectral images possible.
Table 5 shows the reconstruction results under a fixed masking strategy. The input provided to the model comprises three images in the visible band. The model is a pre-trained model obtained by training with a 90% masking rate. Some datasets (e.g., Chikusei, XiongAn) have higher metrics than the random mask results, while some datasets (e.g., Washington DC Mall, GF2Hyper, HyRANK) have lower metrics than the random mask results. This is because the model trained using the random masking strategy is optimized to minimize training error for all input band combinations, including the average result between the best and worst combinations.
By utilizing the random mask model as a pre-trained model and fine-tuning it using the fixed mask strategy, we are able to obtain improved results, as evidenced by the results displayed in
Table 6. These results highlight the effectiveness of our proposed training strategy, which effectively balances the trade-off between generalization and specialization, thus leading to improved performance.
3.5.2. Spectral Curve Comparison Results of the Training Strategy
This section visually represents the reconstructed results under different strategies by comparing the spectral curves. As depicted in
Figure 11 and
Figure 12, the yellow curve illustrates the reconstruction outcome when utilizing a 75% masking rate and a pre-trained model with a 75% masking rate. The green curve illustrates the reconstruction outcome when utilizing a 90% masking rate, and the model is a pre-trained model that was trained with a 90% masking rate. The red curve represents the reconstruction results obtained by utilizing a fixed masking strategy, and the model used is a pre-trained model that was trained with a 90% masking rate. Furthermore, the purple curve represents the reconstruction results of a fine-tuned model that was obtained using the fixed masking strategy. It should be noted that the input for the reconstruction under the fixed masking strategy is limited to three-channel images.
As depicted in
Figure 11, the results of the spectral curve reconstruction for the four scenes in
Figure 9 are presented. It is evident that the reconstructed curves produced by the untuned pre-trained model deviate significantly from the true results.
As illustrated in
Figure 12, the results of the spectral curve reconstruction for the six scenes in
Figure 9 are presented. With regard to the Chikusei dataset, it is observed that the errors are concentrated in the wavelengths from 900 nm to 1000 nm, where the pre-trained model exhibits superior performance compared to the fine-tuned results. However, when considering the overall cumulative error results of the curves, the fine-tuned model demonstrates superior performance compared to the pre-trained model. For the XiongAn dataset, it is noted that the errors are primarily located within the wavelengths from 400 nm to 500 nm, where the fine-tuned model exhibits the best performance. Additionally, for the Washington DC dataset, it is observed that the errors are concentrated in wavelengths from 800 nm to 900 nm, where the values fluctuate significantly, and the fine-tuning significantly improves the results.
4. Conclusions
This paper proposed a spectral masked autoencoder network called SpectralMAE to deal with image reconstruction problems of hyperspectral remote sensing. Previous researchers have recently focused on developing supervised learning algorithms to address spectral reconstruction and super-resolution problems. The SpectralMAE method uses a self-supervised learning strategy that allows the model to acquire a holistic understanding beyond low-level spectral and spatial statistics. This self-supervised strategy is built on the spectral random masking mechanism proposed in this paper, and the spectral reconstruction effect with a 90% random masking rate is tested in experiments. The spectral random masking mechanism also enables the model to constitute a window-based spectral-wised attention, which can significantly reduce the model parameters compared to the imageMAE model.
Based on a random masking strategy, SpectralMAE can acquire pre-trained models for any combination of spectra. SpectralMAE can further train fine-tuned models to adapt to specific tasks, such as spectral reconstruction based on RGB images, using a fixed mask strategy. The study demonstrated the effectiveness of this strategy through comparative trials on multiple datasets.
The study was carried out in five public datasets of spectral images, including airborne and satellite remote sensing images. The study compared the HyRANK remote sensing spectral image dataset with 10 current state-of-the-art spectral reconstruction algorithms and super-resolution algorithms. It achieved optimal results in mPSNR, mSSIM, RMSE and SAM metrics. In the future, we will further improve our approach to the problem of spectral reconstruction after fusion between different sensors. We will further consider the integration between spatial blocks in the next study.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}