1. Introduction
Industrial wireless sensor networks (IWSNs) are a special type of wireless sensor networks (WSNs) [
1,
2] that monitor the manufacturing process in a distributed manner, which can effectively reduce the deployment cost of traditional industrial Ethernet, Profinet, or other wired networks [
3]. With the growing demand for large-scale ubiquitous production process monitoring in industrial networks, IWSNs have been extensively studied and applied. As the important supporting technology of fundamental service in IWSNs (e.g., low-power dormancy mechanism [
4], multi-source data fusion [
5], and time-slot-based transmission scheduling [
6]) and new industrial applications (e.g., equipment fault tracing [
7] and multi-robot cooperation [
3]), time synchronization aims at keeping the IWSNs nodes be consistent in time. At the same time, plug and play in industrial network equipment is the general requirement of customizable flexibility manufacture in Industrie 4.0, that is, the faster the failure detection and recovery of network nodes, the better. In addition, IWSNs are mostly composed of resource-constrained nodes. Hence, convergence speed, robustness, and low overhead cannot be ignored for time synchronization in IWSNs.
In view of the significant role of time synchronization, many time synchronization algorithms in WSNs have been proposed for decades, which can be simply summarized as centralized and distributed time synchronization algorithms.
In centralized synchronization algorithms, such as
Flooding Time Synchronization Protocol (FTSP) [
8],
Per-Hop Delay Compensation scheme (PHDC) [
9], and
Rapid-flooding Multiple one-way broadcast Time-Synchronization (RMTS) [
1], reference nodes or root nodes are selected or designated as the time source for the entire network. This kind of algorithm usually maintains a spanning tree to realize a fast convergence rate, whereas, new nodes joining and node failure in the network may bring about frequent topology reconstruction. Therefore, poor robustness and scalability are inherent defects of centralized algorithms. To enhance the robustness and scalability, distributed synchronization algorithms, such as
Average TimeSync (ATS) [
2],
Maximum Time Synchronization (MTS) [
4], and
Gradient Time Synchronization Protocol (GTSP) [
10], achieve the entire network relative synchronization by adjusting the node’s local clock with neighbor’s information. Distributed algorithms are independent of topology and suitable for flexible network topologies and large-scale IWSNs. However, these algorithms require periodic iterations, which results in high cost, slow convergence, and low efficiency. In addition, variable and uncertain link delay may induce the synchronization error in distributed algorithms divergence.
As the algebraic connectivity of the network is positively related to the convergence rate of consensus-based time synchronization algorithms,
Virtual Topology-based Time Synchronization Protocol (VTSP) [
5] and
Multi-hop Average Consensus Time Synchronization (MACTS) [
11] increase the algebraic connectivity by forming virtual connections between nonadjacent nodes to accelerate algorithm convergence. Nevertheless, the information complexity and data redundancy inevitably raise. Clustering algorithms used in WSNs are effective methods of management, data integration, and information optimization. In [
12,
13], the synchronization process includes two parts: intra-cluster and inter-cluster with the overlapping clustered network topology. The cluster head bears more computing and communication costs, which reduces the communication traffic between nodes and accelerates the convergence rate of network synchronization. In spite of this, the inter-cluster synchronization accuracy is interfered by the intra-cluster synchronization accuracy, since intra-cluster synchronization is prior to inter-cluster synchronization. In addition, due to the lack of overlapping nodes, these algorithms tend to cause communication interruptions between adjacent clusters, which ultimately interferes with the time synchronization behavior between clusters.
Wireless networks for industrial automation-process automation (WIA-PA) is one of the representative industrial wireless standards. Different from the traditional distributed and clustered network topologies, WIA-PA supports the mesh–star hybrid architecture [
14]. The upper mesh layer is formed by routing devices and has a strong anti-interference ability. The lower star layer can quickly broadcast the upper layer information to the local network with only one hop, while overcomes the uncertainty of the multi-hop transmission path. In this paper, we propose a fast and low-overhead time synchronization (FLTS) algorithm based on the mesh–star network structure. FLTS is initiated by routing nodes (including edge routing nodes that be responsible for accessing the star network) in the upper mesh layer, and the clock is adjusted in a distributed way. The nodes in the local star network only need to listen to the synchronization messages broadcasted by the edge routing nodes. The main contributions are as follows:
(1) We present a novel FLTS algorithm aimed at accelerating the convergence rate of time synchronization for IWSNs with mesh–star hybrid architecture that is widely used in WIA-PA industrial network. A two-layered time synchronization model is developed to improve the robustness and reduce the communication of synchronization.
(2) Normally, communication delay adversely affects the synchronization process. We propose a linear regression based relative clock skew estimation during the star layer time synchronization to make FLTS more resilient to communication delay. Furthermore, we prove the convergence and low communication overhead of FLTS theoretically.
The remainder of this paper is organized as follows.
Section 2 describes the literature related to this work. The network model, clock model, and problem formulation are discussed in
Section 3, while the proposed FLTS for IWSNs with mesh–star architecture is detailed in
Section 4, including mesh layer synchronization, star layer synchronization, convergence analysis, and communication traffic.
Section 5 carries out simulation to analyze and verify the performance of the proposed FLTS algorithm in terms of convergence rate and communication traffic under static and dynamic network, respectively. In
Section 6, we conclude our work and discuss the future work.
2. Related Work
Consensus-based time synchronization algorithms have been widely studied for various demands in WSNs, e.g., robustness and scalability. Sommer et al. [
10] proposed GTSP to accurately synchronize the clocks between neighbors in a completely decentralized fashion. It updates the local node’s clock states after receiving all neighbors’ beacons during a predefined synchronization period. In [
2], adopting pseudo-periodic broadcast manner, each node in ATS broadcasts its time information based on its own clock and estimated the clock compensation values after receiving messages from any neighbor. He et al. [
4] described a novel maximum-value-based consensus time synchronization algorithm, MTS. This algorithm can synchronize the skew and offset simultaneously with a faster convergence speed than ATS. In [
15], a sequential least squares algorithm based on the recursive solution is applied to estimate the relative skew under bounded communications. The estimator calculates the initial value from direct solution with the same convergence performance. Subsequently, an average consensus-based scheme [
2] utilizes the estimated skew to synchronize the network. Although the proposed algorithms [
2,
4,
10,
15] can meet different application requirements, time-consuming and message overload caused by iteration were not well handled.
In order to overcome the major drawback of consensus time synchronization algorithms, i.e., slow convergence caused by frequent iteration in large scale or sparse WSNs, various methods have been proposed. For instance, Xie et al. [
16] formulated the synchronization in WSNs as a finite average consensus problem. A spanning tree, i.e., acyclic graph, is first constructed by a fast distributed depth-first-search algorithm. The synchronized clock rate and offset is the geometric mean and arithmetic mean, respectively. The convergence time is independent of the network topology and fully depends on the network diameter. However, generating a spanning tree needs additional computing and communication costs. The network topology varying with factory environment are also not conducive to the maintenance of a stable spanning tree.
Further, increasing the network connections, i.e., enhancing the algebraic connectivity, is an effective way to accelerate the convergence speed of consensus algorithms [
17]. Phan et al. [
5] designed VTSP based on GTSP, and attempted to improve the algebraic connectivity of network topology by creating virtual links between each node and its two-hop neighbors. But it needs additional optimization techniques to reduce the data redundancy and exclude edge nodes. Shi et al. [
11] used the multi-hop communication model to generate virtual connections between non-adjacent nodes to against the slow convergence in ATS. In addition, a multi-hop controller is developed to simplify the message complexity and decrease the by-hop error accumulation. Nonetheless, each node has to forward its neighbor’s timing information to form virtual links, resulting in high information complexity.
Incorporating clustering techniques into distributed consensus algorithms are also frequently used to reduce the communication traffic and improve the convergence rate in WSNs time synchronization. For example, Wu et al. [
12] firstly divided the network into overlapping clusters by low-energy adaptive clustering hierarchy algorithm, and then realized the intra-cluster synchronization and inter-cluster synchronization successively in average consensus. Wang et al. [
13] proposed cluster-based maximum consensus time synchronization method (CMTS). The overlapping nodes undertake the message exchange between adjacent clusters. Besides, a Revised-CMTS is proposed to against the bounded communication delays. The synchronized virtual clock has the maximum value of initial clock parameters instead of the average value in [
12]. To further reduce the overhead in CMTS, Wang et al. [
18] proposed threshold-based intra-cluster synchronization to reduce the message broadcast and presented one-way synchronization in intra-cluster. In practical different line-of-sight (LOS) communication conditions, Chalapathi et al. [
19] studied two-way synchronization in intra-cluster. It presents a simple and lower computational complexity method to estimate the relative clock parameters. Jia et al. [
20] proposed threshold-based K-means clustering algorithm to achieve packet-efficient time synchronization. It utilizes the varying rate of all clocks to form clusters as well as to detect malicious node. The security of time synchronization has been strengthened, while the synchronization phase is not detailed.
Despite cluster-based synchronization algorithms are more message efficient and faster convergent, several deficiencies still exist. Clustered network is divided into two layers: inter-cluster layer and intra-cluster layer. The synchronization path from intra-cluster to inter-cluster renders the algorithm unable to resist node failure and movement [
12]. Two-way synchronization consumes more communication energy in comparison to one-way synchronization [
19]. In contrast with average consistency [
2], the maximum-based algorithms [
4] are more likely to be affected by communication interference, as the essence of average consistency is a low-pass filter. In addition, WIA-PA standard has defined the typical industrial network scenario: mesh–star hybrid architecture. In order to solve the problem of slow convergence speed of distributed algorithms, and enhance the robustness of cluster-based synchronization algorithms, we propose a clustered topology without overlapping nodes based time synchronization algorithm called FLTS, which aims to provide a new idea for the design of time synchronization and compensate for the deficiencies in literature.
3. System Model
Two-layered IWSNs with mesh–star architecture involved in this paper consists of a mesh level composed of routing nodes, and a star level composed of low-power sensing nodes. The network topology can be described as a connected undirected graph , where represents the set of nodes in IWSNs, and R, S define the node sets of the upper mesh network and the lower star network, respectively. For edge routing node l, , denotes the set of sensing nodes in star network, . denotes the set of edges between nodes, means that node x and node y are adjacent. is the set of neighbors for node i.
A typical IWNSs topology diagram is shown in
Figure 1. Note that the nodes in the mesh level are divided into general routing nodes responsible for network interconnection (i.e., nodes
E,
F, and
G) and edge routing nodes intended to access the star network (i.e., nodes
A,
B,
C, and
D). Frequent iterations are the key point that causes the slower convergence speed of distributed time synchronization algorithms. Consequently, the core idea of our design is to make fewer nodes bear the distributed iterations, in contrast, more nodes obtain synchronization by overhearing. For two-layered IWSNs with a mesh–star hybrid architecture, a few routing nodes with strong communication capability can be used to cover the industrial network with large-scale low-power sensing nodes. Furthermore, it employs the routing nodes participating in the synchronization iteration process to reduce the number of packet exchanges effectively.
In IWSNs, each node records its time by counting the periodic pulse signal generated by the crystal oscillator, which is called hardware time. While, even if two oscillators have the same nominal value, the beating frequency may vary due to the influence of manufacturing engineering, ambient temperature, crystal aging, and supply voltage [
4]. As a consequence, the hardware time of the node would deviate over time. Here, node
i’s hardware time
is described as a linear function of absolute time
t [
21]
where,
is the hardware clock skew which represents the ratio between the actual frequency of the oscillator and its desired design at time
t,
is the initial hardware clock offset. Ideally,
and
should be 1 and 0, respectively. Actually, crystal oscillators typically have a drift from the nominal value in the range of 10 ppm to 100 ppm [
4], where
satisfies
,
ppm. Since the absolute time
t is not available to the node, the values of
and
cannot be obtained and adjusted directly [
2,
4]. Accordingly, we define the logical time to represent the synchronization time. The logical time
of node
i is modeled as
where,
and
are the clock skew and offset compensations, respectively;
and
are logical clock skew and offset, respectively. The purpose of synchronization is to make the logical time of all nodes consistent by updating the clock skew and offset compensation parameters, namely,
To update the compensation values, it is necessary to understand the relationship between two hardware clocks, which means that acquiring the relative clock skew
. Since the hardware clock skew
cannot be acquired directly, the above formula is not suitable for the computation of relative clock skew
. To accomplish the objective of Equation (3), by collecting two consecutive timing messages containing hardware clock timestamps from adjacent nodes
j, node
i calculates the relative skew
as follows
Traditional distributed time synchronization algorithms synchronize the logical clocks of nodes by employing the linear consistency model [
2,
12,
22]
where
denotes the state of node
i. Each node can use the information of its neighbor nodes to continuously update its state at each iteration. However, in large-scale networks, distributed synchronization requires frequent iterations to make the logical time of the whole network achieve an average value, which induces slow convergence speed and large communication traffic unfortunately.
4. Proposed FLTS Algorithm
To achieve fast convergent and low-overhead time synchronization for large-scale IWSNs, a novel FLTS algorithm, which is based on a two-layer mesh and star structure, is proposed in this paper. The FLTS algorithm consists of two parts: mesh layer time synchronization and star layer time synchronization, respectively. Therein, the routing nodes of the mesh network adopt the distributed consensus synchronization process, and the edge routing nodes send their updated time information to the connected star network nodes in realizing the synchronization of the whole network. In this section, the two steps of the proposed FLTS scheme are described in detail, and then the performance of the FLTS scheme is analyzed.
4.1. Mesh Layer Time Synchronization
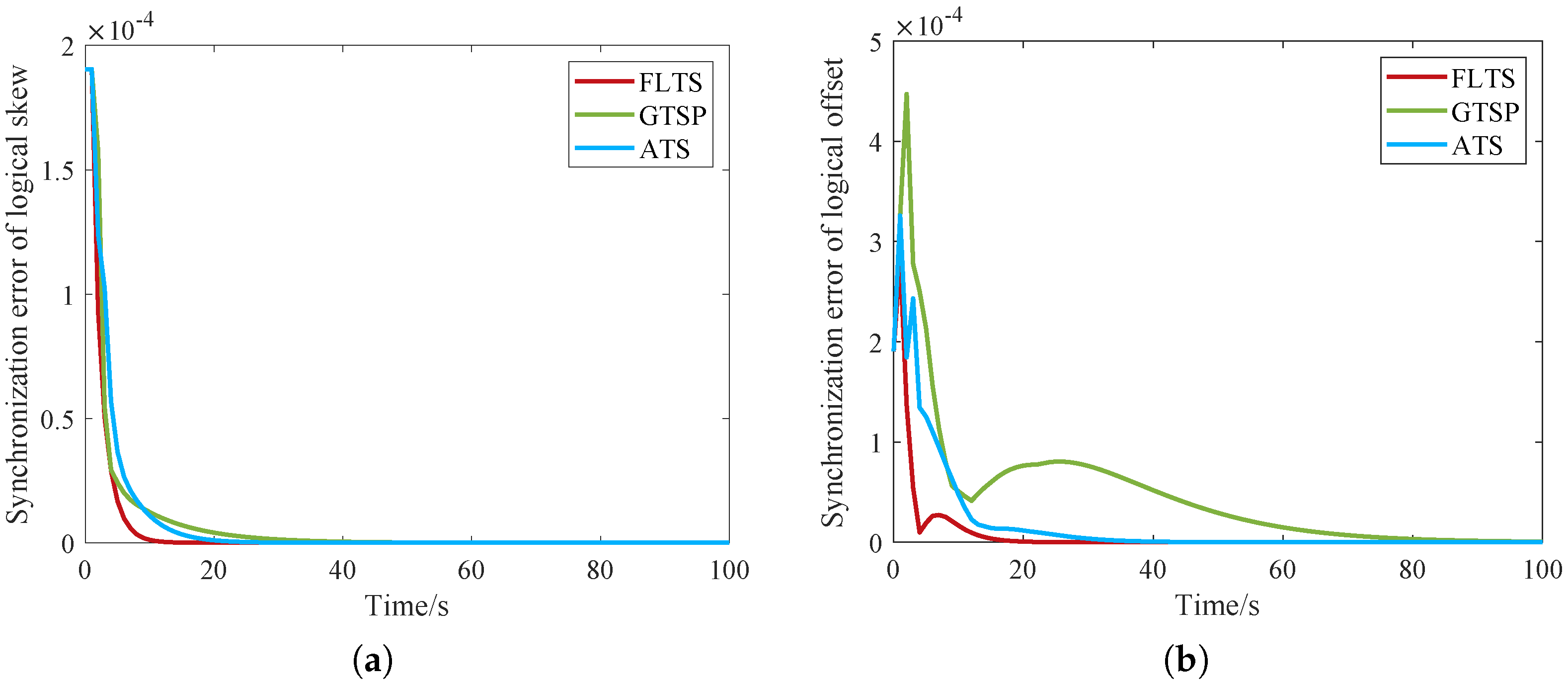
Different from the MTS algorithm [
13] with a fast convergence speed, due to the existence of communication delay, the maximum logical skew error increase continually, namely, the synchronization error diverges gradually, which eventually affects the synchronization of star network nodes in the next step. In order to have a certain anti-disturbance ability, we use ATS [
2] as the basic time synchronization algorithm in the mesh layer (
lines 1–7 in Algorithm 1). Specifically, the routing node
B sends time information
to their neighbor routing nodes during each predefined period
T, and the neighbor routing node updates its logical skew and offset compensation parameters once receiving the message twice. It should be noted that the star network nodes do not participate in this step. Obviously, the algorithm can synchronize all routing nodes within a limited time.
| Algorithm 1 FLTS Algorithm |
Input: ; , , , ; T; , , v
Output: , , - 1:
Upon routing node B triggering a broadcast task - 2:
It broadcasts time information , , to neighbor routing nodes. - 3:
Upon routing node A receiving B’s information - 4:
It stores , and calculates: - 5:
Updates: - 6:
Updates: - 7:
Updates: - 8:
if A is the edge routing node, it then - 9:
broadcasts time information , , to the star network. - 10:
end if - 11:
Upon star network node i receiving A’s information - 12:
It stores , and calculates: - 13:
Updates: - 14:
Updates:
|
4.1.1. Skew Compensation in the Mesh Layer
When routing node
A received two consecutive synchronization messages from its neighbor routing node
B, including hardware time
, skew compensation parameter
, and offset compensation parameter
. Node
A calculates the relative clock skew
with recorded local time synchronization:
Node
A utilizes the newly calculated estimation and reserved prior value to update the existing relative clock skew:
where,
is the artificially selected iteration weight parameter for the average operation. The initial relative clock skew
is 1. According to
and
, node
A updates
where,
is the logic skew compensation value of routing node
A in the previous cycle and
is the predefined iteration weight parameter.
4.1.2. Offset Compensation in the Mesh Layer
After the convergence of skew compensation, all routing nodes have a consistent logical clock skew, and the logical clock offset of the routing nodes starts to converge gradually. The updating formula for offset compensation
is
where,
is the logic offset compensation value of routing node
A in the previous cycle,
is the logic time of routing node
A, and
is the weight parameter.
During the synchronization phase, each routing node broadcasts its own timing information periodically. Large amounts of data are frequently transferred between adjacent nodes, which inevitably leads to data conflicts. To tackle this, we can adopt time-division multiple access (TDMA) communication protocol and allocate transmission time slots for different messages according to time. Moreover, the asynchronous broadcast (also called pseudo-periodic) can be another effective way to avoid the conflict [
2]. For each routing node, the real message broadcast instant is
. Since each node’s clock skew
i is different, the real broadcast instant is asynchronous. Consequently, integrating TDMA communication and asynchronous broadcast can avoid data conflicts successfully.
4.2. Star Layer Time Synchronization
Star layer network synchronization adopts a one-way mechanism (
lines 8–14 in Algorithm 1). The edge routing node broadcasts its time information to the local star network once updating the clock information, and node
i in the star network records the time information when receiving the message. Node
i calculates the relative clock skew
according to the received two consecutive time information, and then updates its skew and offset compensation
and
as follows
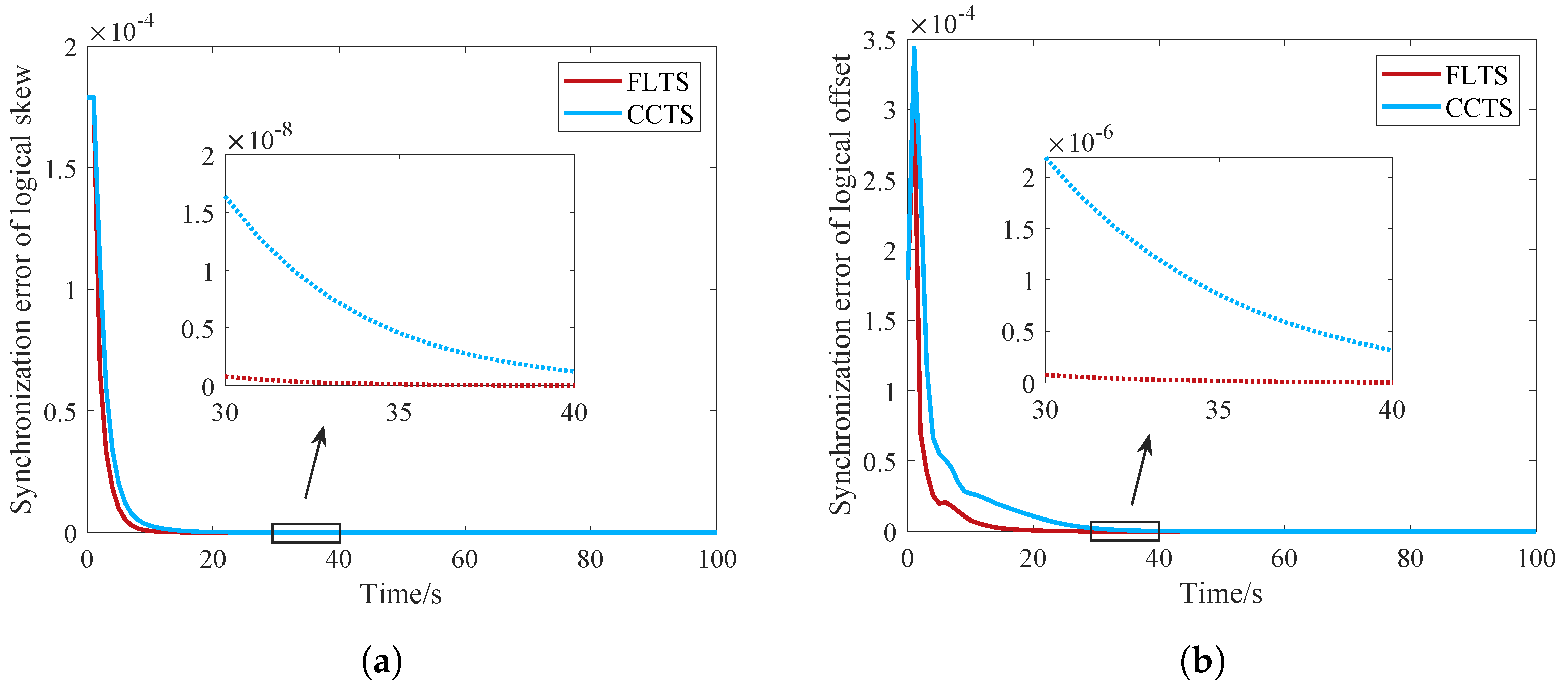
Compared with existing time synchronization algorithms, FLTS algorithm constructs the mesh network by connecting routing nodes directly, which solves the problem of time synchronization failure caused by the loss of overlap nodes between neighboring clusters, due to energy consumption in the synchronization algorithms based on cluster network topology. The lower layer star network nodes only monitor the time information to synchronize passively, so the failure and movement of star network nodes would not interrupt the synchronization process, which ensures the robustness of FLTS.
The packets are subject to various interferences during transmission between nodes, namely, the communication delay will cause the packet receiving time distortion. As a consequence, the calculation of the relative skew as Equation (
4) may mistaken, which further affects the updating of the logical clock in star network as Equations (
10) and (
11). As shown in Equation (
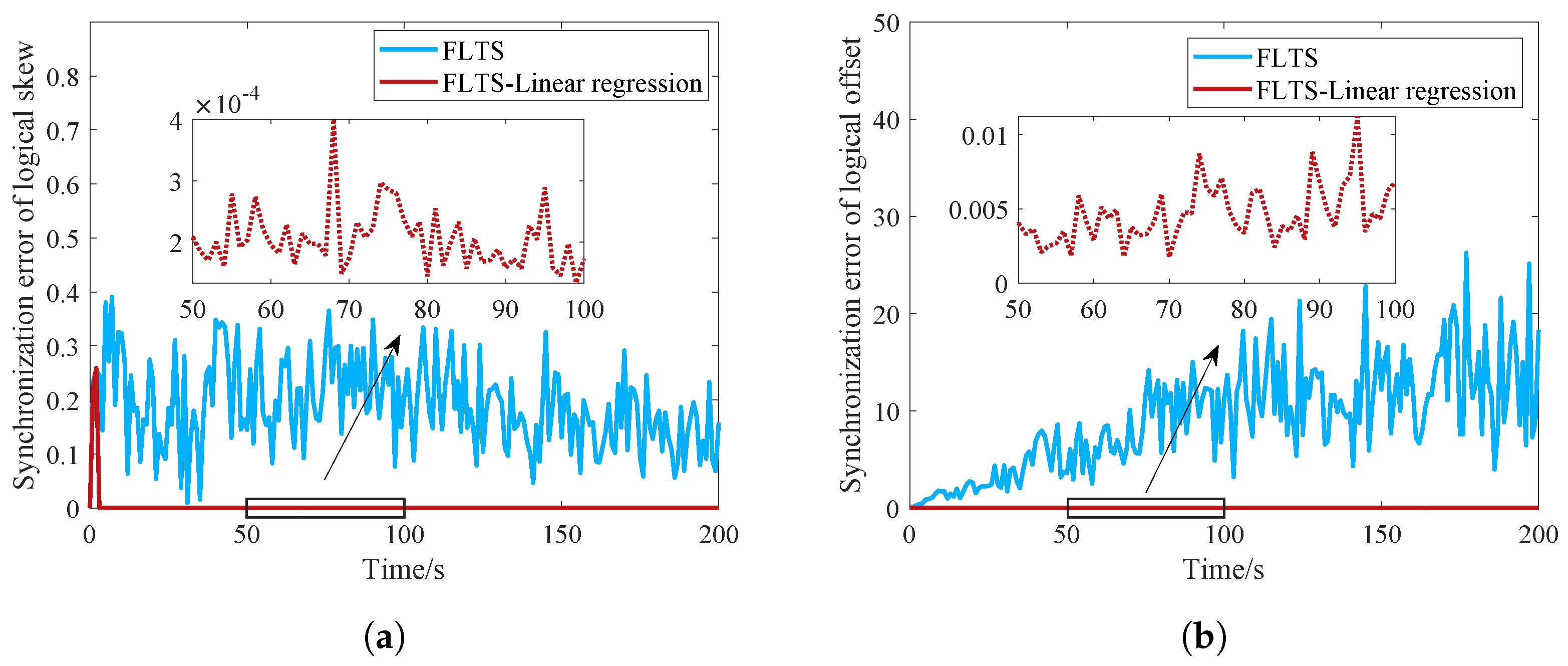
12), the hardware time between two nodes obeys a linear relationship. To expand the practicability of FLTS, we adopt a linear regression method to estimate the relative clock skew against the communication delay.
where
n is the number of samples required for linear regression,
is the mean value.
4.3. Convergence Analysis
The iterative process of FLTS is mapped into the state transition process of Markov chain [
23].
where, the node
in the network corresponds to each state
of the Markov chain, the transition probability matrix of the Markov chain is represented by
, where
is obtained by:
where,
is the degree of node
i. The eigenvalues of the transition probability matrix
of
satisfy
. The convergence rate of
depends on the second largest eigenvalue
of the matrix
, and its iteration number is
. The second largest eigenvalue
satisfies Cheeger’s inequality, namely
. Where
is called the conduction coefficient of the Markov chain, which is approximately equal to
, and then
.
d represents the average number of node’s neighbors, and
n is the number of nodes in the network. In a large-scale network,
and
approach 0, the convergence speed is
, and
.
For the synchronization process in the mesh layer, there are N routing nodes, and each routing node has M neighbor routing nodes. Although the network is not a recurrent network, the whole network is deployed randomly and can be regarded as a uniform-like network. Hence, the conclusion of the iteration number m obtained above is also applicable to a uniform-like network, namely, . Furthermore, star network nodes only need to synchronize with the edge routing nodes in one-way, and then a finite time synchronous convergence is achieved.
4.4. Communication Traffic
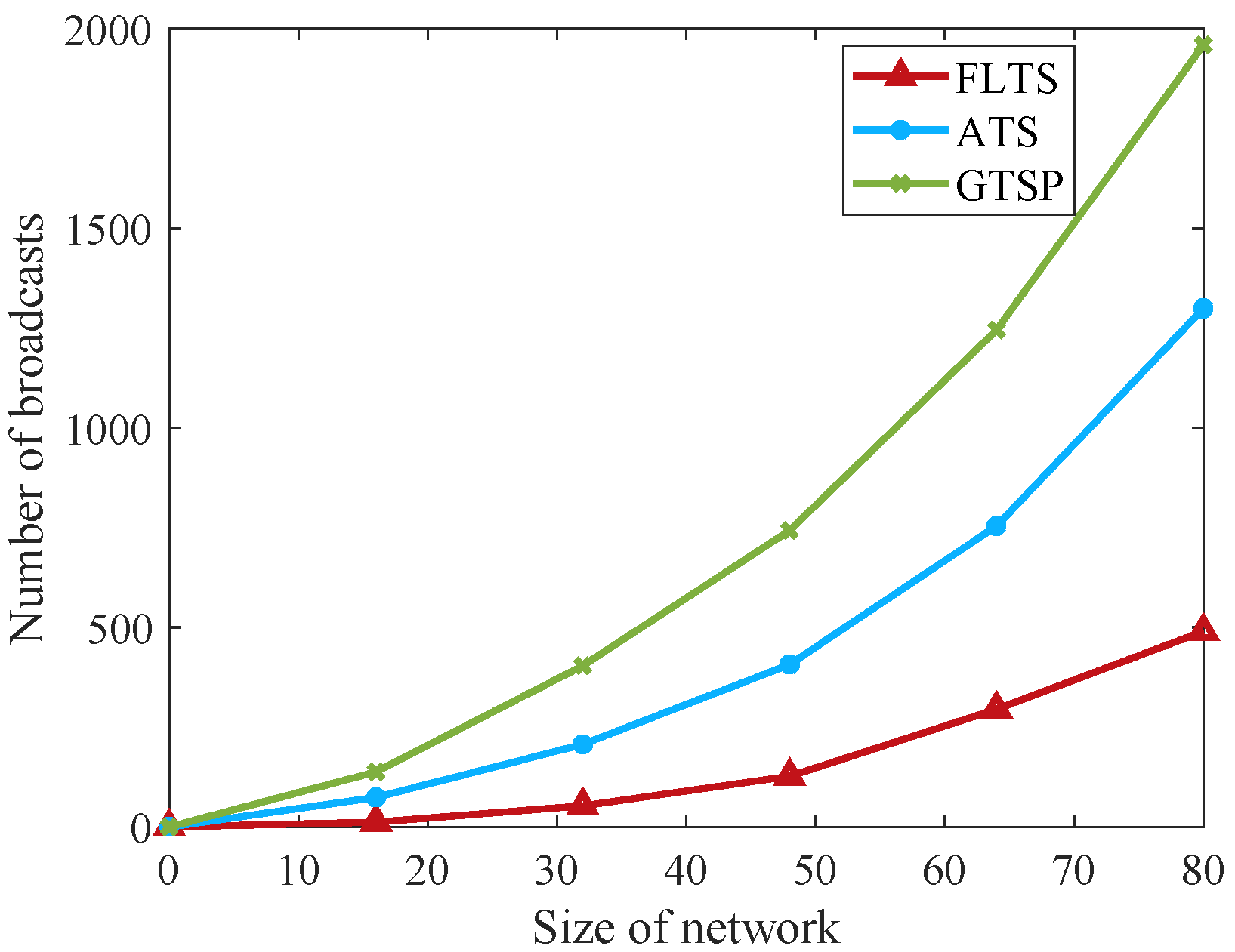
During the synchronization in the star network, each edge routing node sends time information to the star network nodes after updating its logical clock. During each synchronization period, the edge routing node
i and its neighbors announce their local time information once. As a result, the packet exchange times in each iteration of the mesh layer and the star layer are
N and
, respectively, where
is the number of routing neighbors for edge routing node
i,
L is the number of edge routing nodes. Therefore, FLTS algorithm needs
packet exchanges for network-wide synchronization. Concerning to the analysis in distributed consensus time synchronization algorithms, the comparison of FLTS, GTSP, and CCTS on communication traffic in a single-step iteration is shown in
Table 1.
It should be noted that represents the number of neighbor clusters in CCTS, is the ordinary neighbors’ number in GTSP, and n is the number of nodes in the network. Obviously, and , FLTS is communication efficient. Through the above analysis, increasing the neighbors of the routing node, namely, improving the network density, or reducing the routing nodes, can effectively reduce the number of network iterations.
6. Conclusions
A novel time synchronization algorithm, i.e., FLTS, is proposed to solve the problems of slow convergence and high cost in large-scale IWSNs. The main idea of FLTS is to perform the synchronization process into two layers, that is, the average iteration in the mesh layer and one-step monitoring in the star layer. It can reduce communication traffic and accelerate convergence effectively. Extensive analysis and simulations demonstrate the effectiveness of FTLS algorithm in comparison with ATS, GTSP, and CCTS.
Although FLTS is robust under ordinary node mobility in the star layer, the impact of the routing nodes’ statuses in the mesh layer cannot be ignored. For example, when an edge routing node moves or breaks down, the nodes in the star layer accessing to the edge routing node may lose synchronization with the network. It requires additional overhead to maintain the stability and reliability of the upper mesh network. Moreover, the communication delay in industrial network is a fundamental restriction in time synchronization. It is difficult to establish an accurate delay model in the complex factory environment. Various delay distribution models have been proposed, e.g., random bounded delay, exponential delay, normal distribution delay, et al. Meanwhile, most research results including FLTS, are verified through simulation. How effective the algorithm is in a real factory environment still needs further verification. Future directions include solving the influence of mesh layer network fluctuation, experimental validation, and extending the idea to more complicated time-delay industrial networks.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}