1. Introduction
In today’s digital age, the demand for high-speed data transmission is increasing rapidly, leading to an increased strain on the limited bandwidth available. To address this challenge, multiplexing has become an indispensable technique in modern communication systems for improving the spectral efficiency of the channel. The primary goal of multiplexing is to simultaneously transmit multiple signals over the same communication channel, thereby increasing the channel utilization. Multiplexing a multiple number of signal streams to multiple resources is a promising technology for wireless networks, which must support massive connections such as for the Internet of Things (IoT) [
1]. In particular, a sparse code multiple access (SCMA) scheme was proposed as one of the non-orthogonal multiple access schemes to be used in 5G mobile communication standards [
2]. SCMA investigates multiple signal streams to a limited number of resources, but it has very a weak point to use in practice, because the codebook needs to be generated according to a specific factor graph. Moreover, SCMA cannot be applied to the system which has an asymmetric factor graph between signal streams and resources.
In this paper, a novel deep learning-based deep spread multiplexing (DSM) is proposed. DSM can be considered as a generalization of the SCMA system which can outperform SCMA in terms of BER performance and applicability. Furthermore, it should be noted that DSM uses the same number of resources as the SCMA system such that the performance gain of DSM can solely be beneficial. DSM has deep neural network (DNN) blocks as the encoder and decoder, which is known as an autoencoder-based [
3] communication system [
4,
5].
Once DNNs are sufficiently trained, each DNN-based encoder and decoder can perform just like a normal encoder and decoder. Furthermore, various training methods for systems which consist of DNN-based encoders and decoders are investigated in order to improve the training procedure.
The main contributions of this paper are summarized in three points as follows:
We proposed DSM, which spreads multiple independent data to multiple orthogonal resources using DNN-based encoder and decoder. Since DSM is built with DNNs, it can be universally applied to a system with any number of data layers and resources.
We used simulations to show that the DSM can outperform conventional spreading schemes in terms of BER.
We investigate various methods to train the autoencoder better in many aspects such as noise type used for generating training datasets, overfitting problem and utilization of channel information.
The remainder of this paper is organized as follows. In
Section 2, we describe the system model considered in this paper. In
Section 3, a deep autoencoder architecture is proposed for the DSM system and various training methods are investigated. In
Section 4, we evaluate the performance of the proposed DSM and the effects of the training aspects, which is followed by a summary of the paper in
Section 5.
2. System Model
In the DSM system, we consider a system with multiple orthogonal resources so that multiple signal streams can be multiplexed. The orthogonal resources can be considered as time resource or frequency resource (divided as subcarriers) or any orthogonal type of resources. Since DSM is developed from the SCMA model, we compare two systems and address the differences.
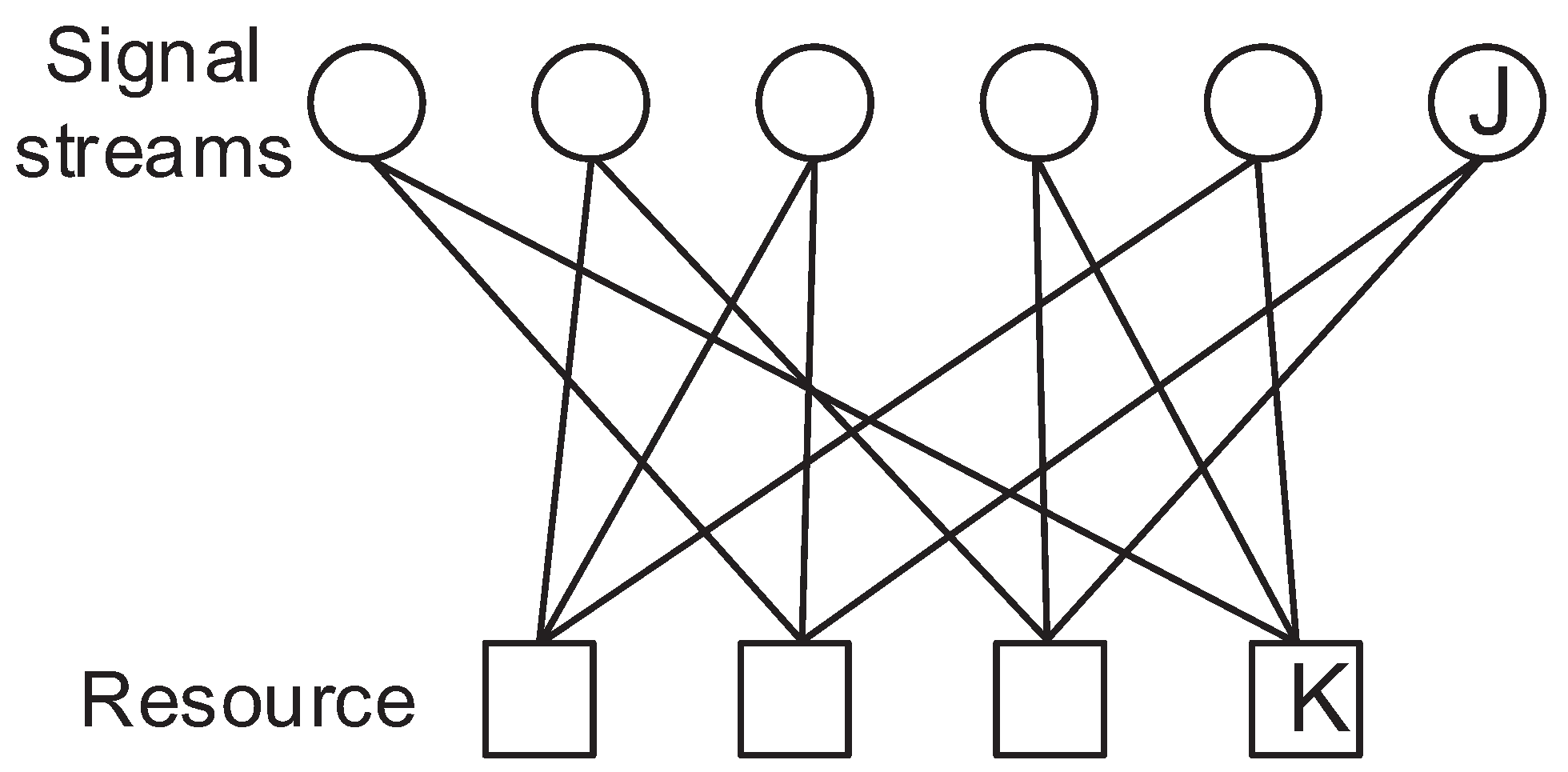
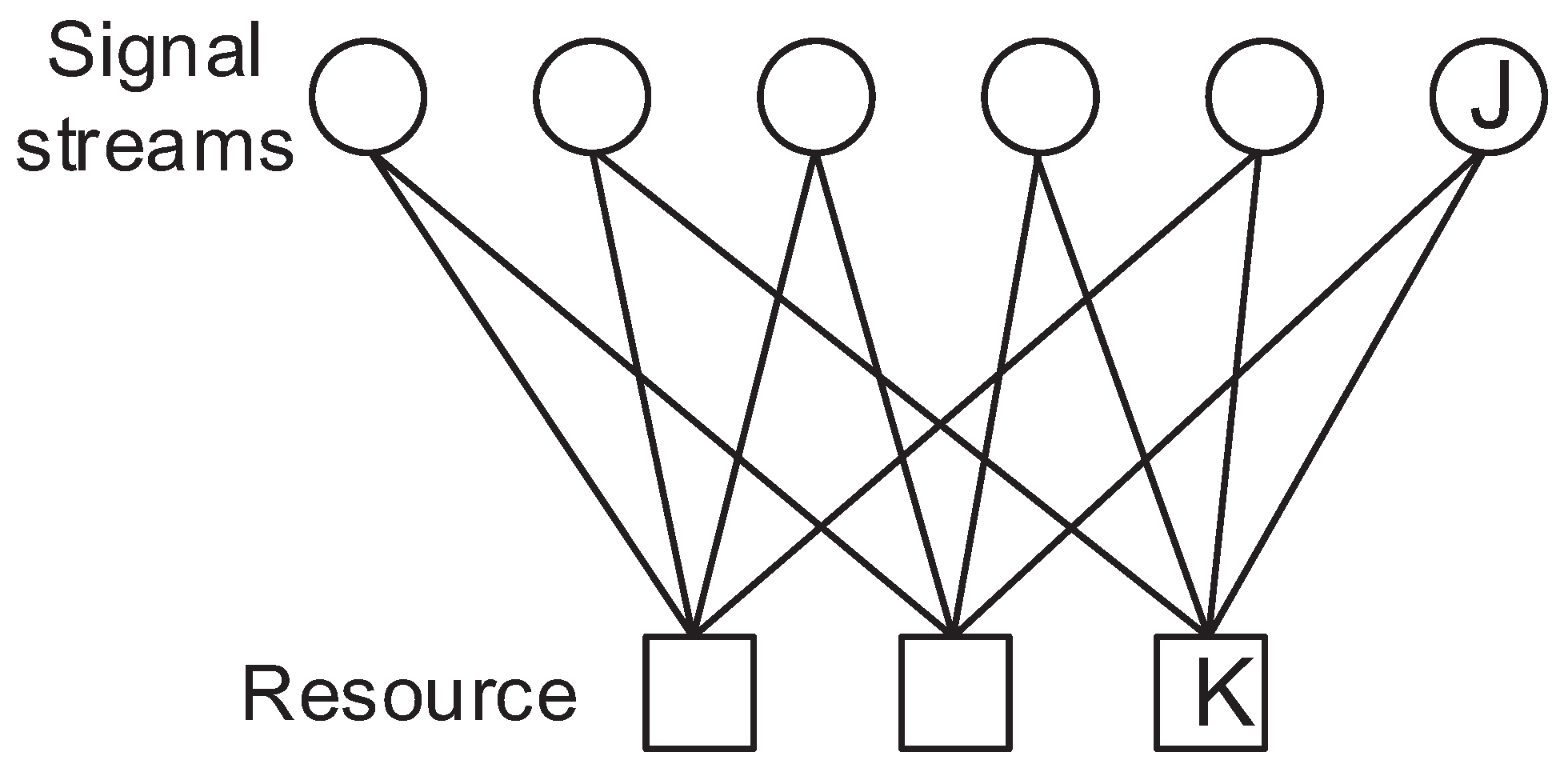
In the DSM system,
J signal stream nodes and
K resource nodes are fully related. A signal stream is multiplexed into all the resources regarding other signal streams. Then, the received signal model can be expressed as seen below [
6].
Here,
is the channel coefficient for the resource
k which can be considered as orthogonal subcarriers in the OFDM system or spatial layers in MIMO,
is the signal vector of
which is the signal at the
j-th stream,
is the constellation mapper (encoder) regarding
and
is the noise for resource
k which follows the distribution of Gaussian with a mean of 0 and a variance of
. The signal factor graph of SCMA and DSM is depicted in
Figure 1 and
Figure 2. As can be seen by comparing these figures, the signal streams are multiplexed by DNN which is different from the SCMA system, in which only some of the signal streams are summed to a resource. Therefore, all received signals are required to decode a signal stream since all the signal streams have a relation with rest of the signal streams.
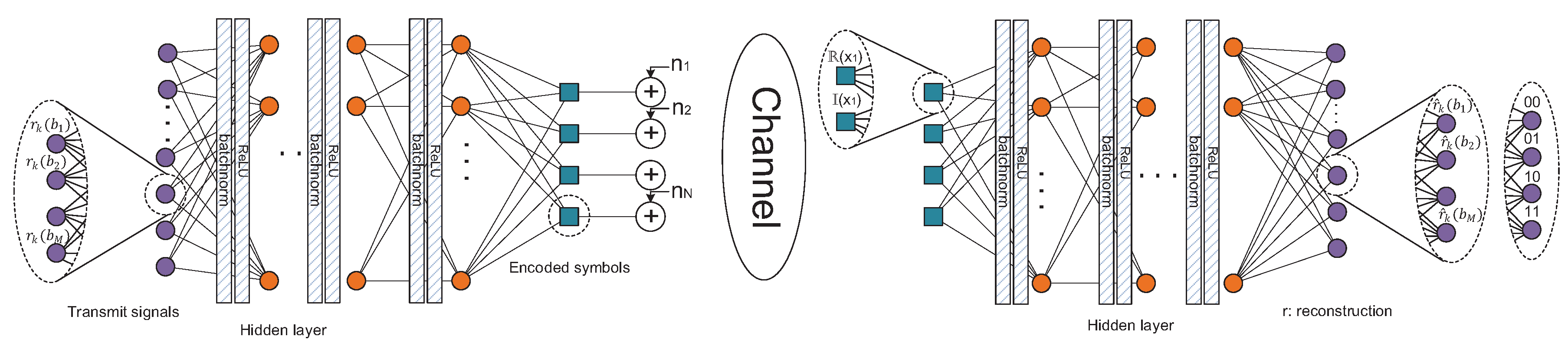
We propose a deep neural network-based encoder and decoder which are inspired by the denoising autoencoder (DAE), which is the most well-known generative model in deep learning [
3]. Originally, the DAE is used for denoising the corrupted data such as recovering the corrupted images into clear images; however, it has been adopted for wireless communication systems [
7]. The proposed DSM is composed of a basic DNN unit formed of multiple repetitive hidden layers. Each hidden layer of a basic DNN unit is composed of a weight matrix,
, a bias vector,
and an activation function,
, where
denotes the index of the hidden layer. In our proposed scheme, a rectified linear unit (ReLU) is used for the activation function [
8]. Then, a basic DNN unit with
L hidden layers can be represented as
. The encoder and decoder of the DAE can be built using this DNN unit; the structure of the encoder and decoder are explained in detail in the following section.
3. DSM Training Methods
In this section, we present BER minimization for the DSM system which can be viewed as the generalization of the SCMA system. Furthermore, we investigate various training methods such as generation of training datasets for different types of noise, investigate overfitting by applying a dropout scheme and propose methods to utilize the channel information, i.e., other than the AWGN channel. The principle of the training procedure is similar as in [
9], which proposed an autoencoder-based SCMA.
3.1. BER Minimization in DSM System
The role of the encoder in the DSM is to encode the input information bits into the constellation plane of the resource regarding all other information bits that are multiplexed. Furthermore, the decoder in the DSM decodes the received signal at resources and reconstructs the signal regarding all the multiplexed signals of the resources. We build the encoder with a DNN using multiple layers of perceptrons where each layer consists of an FC-layer, a batch-normalization layer and an activation layer in which we use a ReLU layer. Then, the
-layered DNN-based encoder of the DSM can be mathematically expressed as follows:
Here,
is the original symbol,
is the
l-th FC layer with weight and bias,
refers to the batch norm layer and
is the activation layer. Furthermore, the DNN-based decoder of the DSM system has the similar structure as the encoder. We assume that the decoder is composed of
sub-blocks like the encoder such that the output of the decoder,
, can be expressed as
where
denotes the input of the decoder and
and
are the weights and bias for the
-th FC of the decoder, respectively. The detailed description of the DNN structure is depicted in
Figure 3.
We follow a similar training procedure as a training procedure in the D-SCMA system. The loss function of the autoencoder structure in the DSM system can be defined as the mean squared error (MSE) between original signals and the estimation signals
, which are denoted as the first input parameter and second input parameter of
, respectively.
Equation (
5) is the loss function for the end-to-end learning of the DSM system, which updates the DNN parameters of the encoder and decoder simultaneously. The parameters
can be updated by the stochastic gradient descent (SGD) variant algorithm, e.g., Adam optimizer [
10], which can be expressed as the following equation.
The major difference between SCMA and DSM is that the total number of possible constellation points is
for SCMA and
for DSM, as shown in
Figure 4 and
Figure 5, respectively.
Figure 4 looks like a cloud of points because it has relatively many points in a limited space; however, it can still be decoded accurately by examining the received signal of other resources. The same framework can be applied to different configurations such as
Figure 6 and
Figure 7 as well.
3.2. Generation of Trainset with Different Noise Types
In the training phase of the DNN-based encoder and decoder, an intentionally corrupted training dataset is generated, so that the DNN encoder and decoder can operate well in the channel involved environment. As can be seen from [
9], too large a corruption level, which is defined as noise power over average transmit signal power
for training data, degrades the BER performance of the DNN, and too small a corruption level also degrades the BER performance since the DNN cannot learn exact boundaries in the constellation plane.
In order to generate a good quality training dataset, we propose truncated Gaussian noise as the data corruption. Truncated Gaussian distribution has the same probability distribution as the Gaussian distribution, but when the value exceeds a certain threshold, the value is regenerated according to the Gaussian distribution so that all generated data are truncated under the threshold. Truncated Gaussian noise can be expressed mathematically as seen below.
The difference of truncated Gaussian distribution and Gaussian distribution is plotted in
Figure 8, where
. When the noise is truncated within a certain range, we can expect that the bad training samples, i.e., received signals at constellation points which overlap the boundaries of the original symbol detection region, can be decreased.
3.3. Overfitting
In deep learning, the training samples are usually used multiple times because a higher number of training epochs can lead to a more accurate DNN model. Such training method induces overfitting, which degrades the accuracy of the DNN when a new sample of data is evaluated. In order to overcome such defects of the overfitting problem, dropout is the most widely used training method.
The dropout scheme can be divided into two stages. First, in the training stage, some portion of the hidden nodes are considered as “dead” nodes, in other words, the connections regarding the “dead” nodes are eliminated. The “dead” nodes are selected randomly for every batch update while fixing the dropout rate. In the second stage, the dropped nodes become alive in the evaluation stage. Therefore, the new training samples are evaluated with the dropout rate 100%. Here, we investigate the effect of dropout scheme in training DSM.
3.4. Utilization of Channel Information
In the previous simulations, we have considered the AWGN channel, which does not require specific channel information. We propose a DNN model such that it can utilize the channel information, such as a Rayleigh multipath fading channel. When the system uses
K orthogonal resources, the total number of channel coefficients is
K, for instance, four channel coefficients can be utilized in six by four DSM systems.As depicted in
Figure 9, the number of input nodes is increased as high as the number of channel information. Then, the DNN is able to reconstruct the signal given all the information from the input node, so we can expect that if channel information is processed properly by the DNN, it can be helpful to decode signals that experience a multipath fading channel. Furthermore, the decoder is also fed with the channel information which is concatenated with the received signal so that DNNs are able to utilize channel information to both encode and decode adaptively to the varying channel environments.
Then, the channel information-aided DSM loss function can be defined as seen below.
4. Performance Evaluation
In this section, we evaluate the BER performance of the DSM and compare it with the conventional SCMA and D-SCMA to verify the training methods mentioned in the previous sections. First, different types of noise are used for generating the training dataset; moreover, the channel information-aided DSM system is evaluated. For both DSM and D-SCMA simulations, we use 4-QAM modulation, and 50,000 training samples are used to train for 10 epochs with a 400 batch size, which was enough to confirm the convergence of loss function. Furthermore, 100,000 test samples were used to test for each SNR environment. The learning rate, which refers to the step size of the Adam algorithm, is set to 0.0001 while the learning rate of 0.001 shows similar performance. However, we used 0.0001 to ensure that the cost function converges. D-SCMA has six hidden layers with 32 hidden nodes per layer for encoder and five hidden layers with 512 hidden nodes per layer for decoder. DSM has five hidden layers with 512 hidden nodes per layer for both encoder and decoder. To address complex signal, we separated a complex number into two independent real numbers and combine them at the end. Throughout the simulations, the average transmit power of DSM, D-SCMA and SCMA were set to be equivalent. Nevertheless, it should be noted that the complicated structure due to the DNNs could lead to higher power consumptions for DNN-based methods. For the performance comparison, we consider the message-passing algorithm (MPA) [
11,
12] detection method, which is know to be near the optimum detection method and D-SCMA for the baseline.
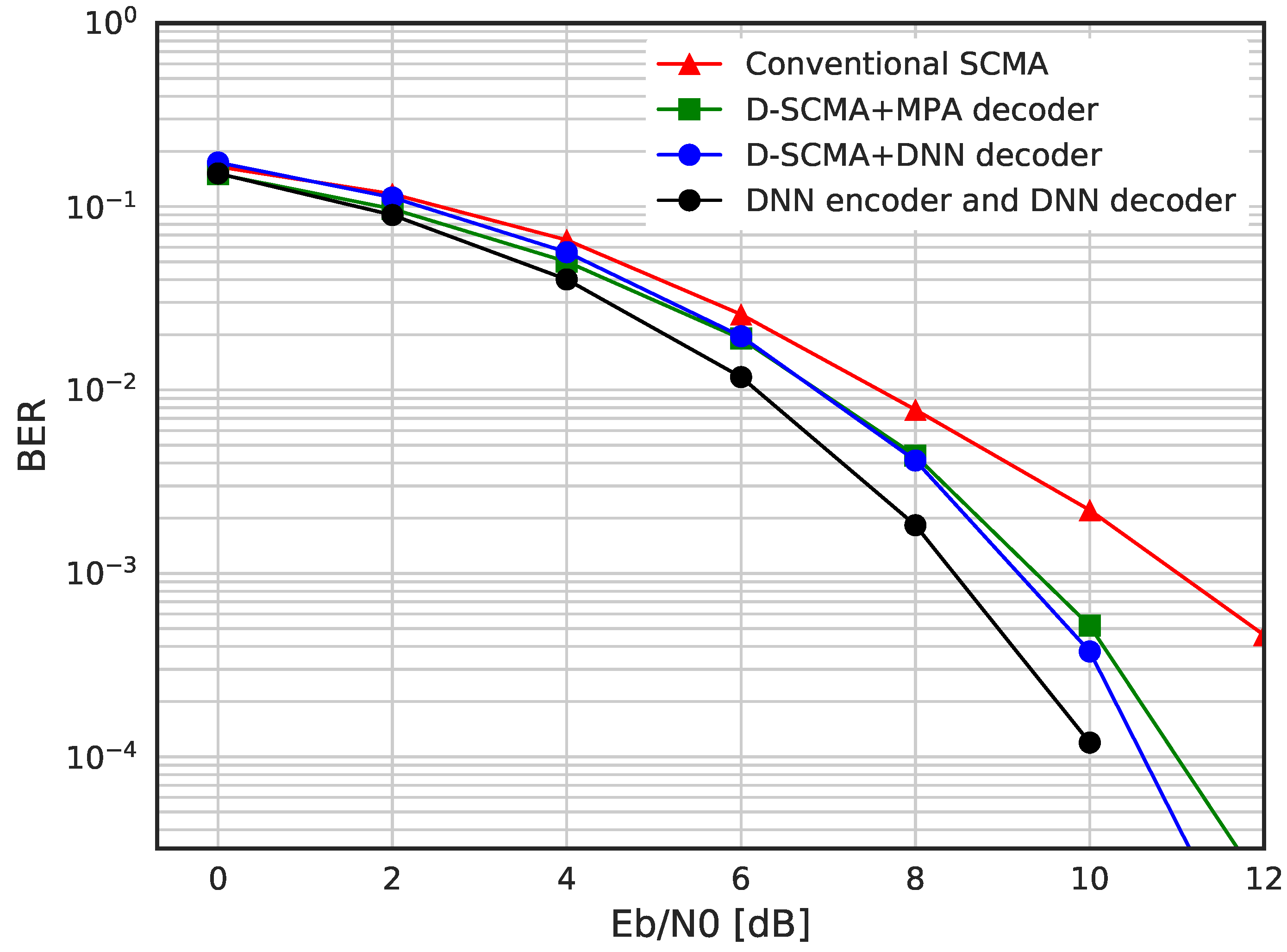
In
Figure 10, we evaluate the BER performance of conventional SCMA, DNN-based SCMA and DSM. We can see that the proposed DSM (denoted with a black circle marker) outperforms the rest of schemes based on SCMA, which implies that fully connected multiplexing is better than a sparsely connected system. DSM has shown about 1 dB SNR improvement compared with other schemes in the AWGN channel.
In
Figure 11 and
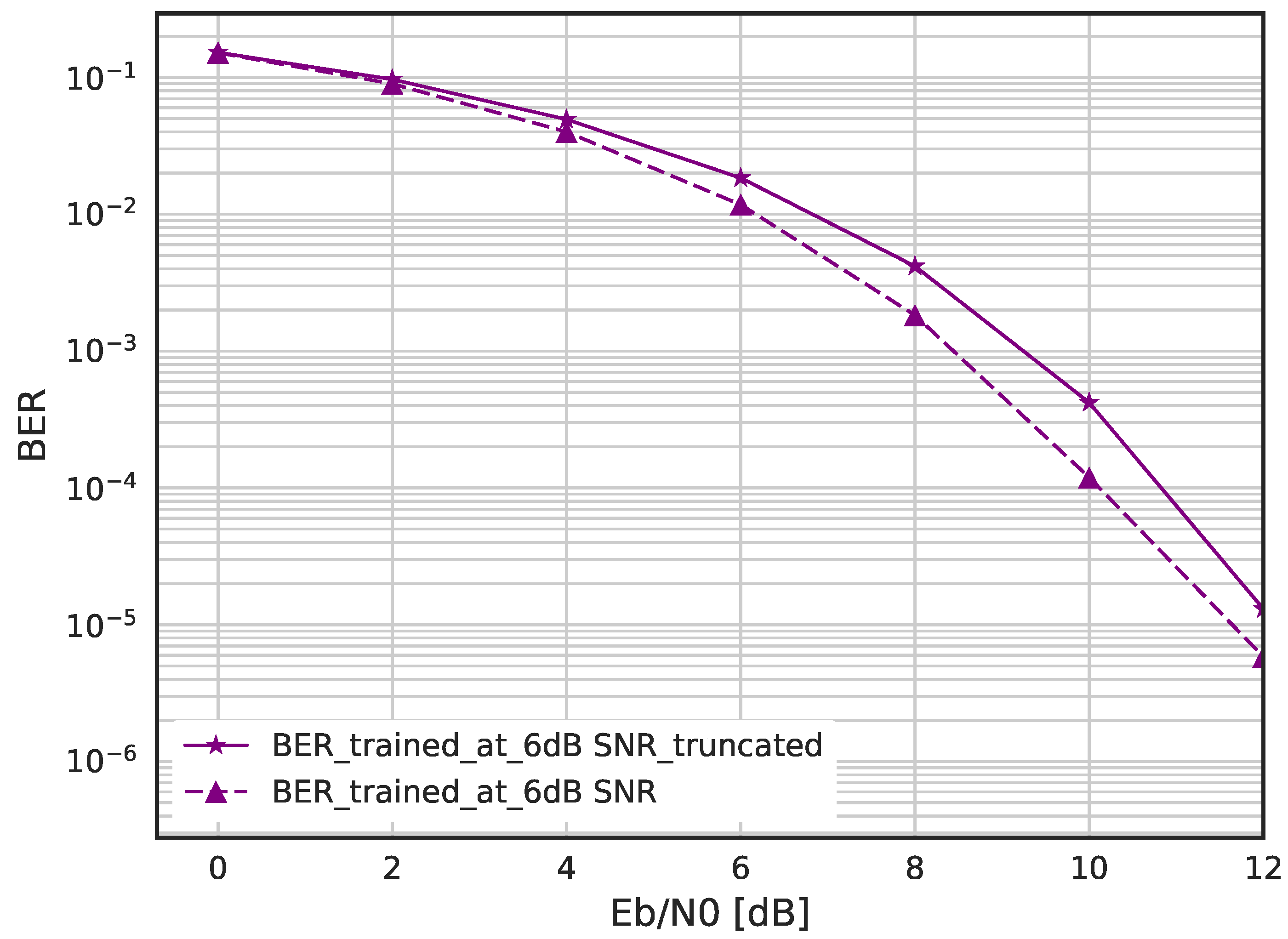
Figure 12, we evaluate the BER performance when the DSM is trained with Gaussian noise and truncated Gaussian noise.
Figure 11 shows the BER when the DSM is trained with corruption level
= −6 dB using Gaussian and truncated Gaussian noise, where each are the best-performing DNNs among each group. It should be noted that the truncated threshold is fixed as
and
= −6 dB was found by exhaustive search. We can see that the DSM trained with pure Gaussian is better than that with truncated Gaussian. On the other hand, for large corruption levels such as
= 0 or −4 dB, as shown in
Figure 12, the DSM with truncated Gaussian noise is trained better than that with pure Gaussian noise.
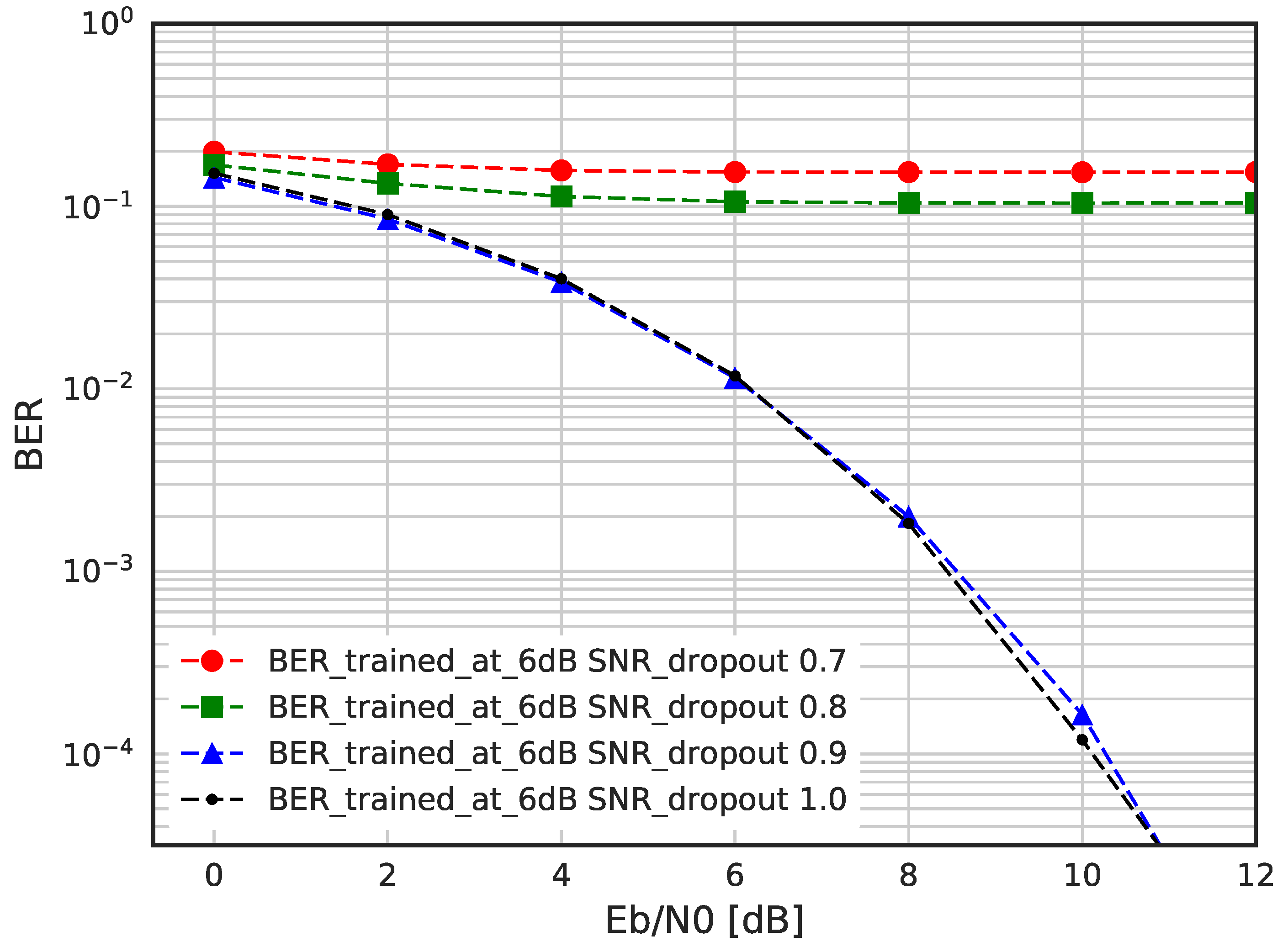
In
Figure 13, we evaluate BER performance of DSM when dropout is applied, which prevents the overfitting. As we can see from the result, as the dropout rate decreases below 0.9, DNN cannot function as encoder and decoder. Therefore, we can see that the proposed DNN based encoder and decoder does not suffer from overfitting problem. The use of enough training data and the proper stoppage point on training epochs have helped to avoid overfitting problem.
In
Figure 14, we evaluate BER performance of channel information-aided DSM and compare it with SCMA in the Rayleigh fading channel environment. Unlike the AWGN channel results, the BER performance of the trained DSM varies heavily depending on the corruption level. Since the multipath fading channel has a much larger variance compared to the AWGN channel, the proper selection of corruption level is very important and, as can be seen from the results, the −15 dB, −18 dB and −21 dB corruption levels are best for training the DNN-based encoder and decoder.
In
Figure 15, the complexity of conventional MPA detection and the DNN-based detector are evaluated. The complexity of the conventional MPA scheme is proportional to the number of message-passing update iteration,
I, which can be expressed as
[
13] while the DNN decoder has
where
refers to the number of superposed layers in a resource. As can be seen, the experimental results verify the practical usage of the DNN-based encoder and decoder.
5. Conclusions
In this paper, we proposed a novel multiplexing scheme for the generalization of the SCMA system. An autoencoder architecture is adopted to implement the DNN-based encoder and decoder so that the MSE of original signal and estimated signal can be minimized. Furthermore, various training methods were investigated to improve the performance of the trained DSM system. Gaussian noise and truncated Gaussian noise were used for generating the training dataset and the overfitting problem was studied. Lastly, a method to use channel information for the DNN-based encoder and decoder was proposed. Through simulation results, we showed that any number of signal streams and resources can be used in the DSM system and traits of the truncated Gaussian noise-based training dataset were discovered. Moreover, the overfitting problem was revealed to be of no harm to the DNN-based encoder and decoder system. Channel utilization for the DSM was successfully performed by the proposed architecture.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}














