

Signal Novelty Detection as an Intrinsic Reward for Robotics

Abstract
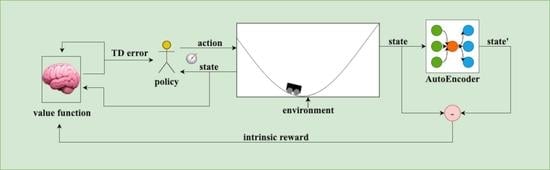
:
1. Introduction
2. Materials and Methods
2.1. Benchmark Set of Test Environments for Simulated Robots
2.2. AutoEncoder Architecture
2.3. Application of Intrinsic Reward by the AutoEncoder Architecture
3. Results
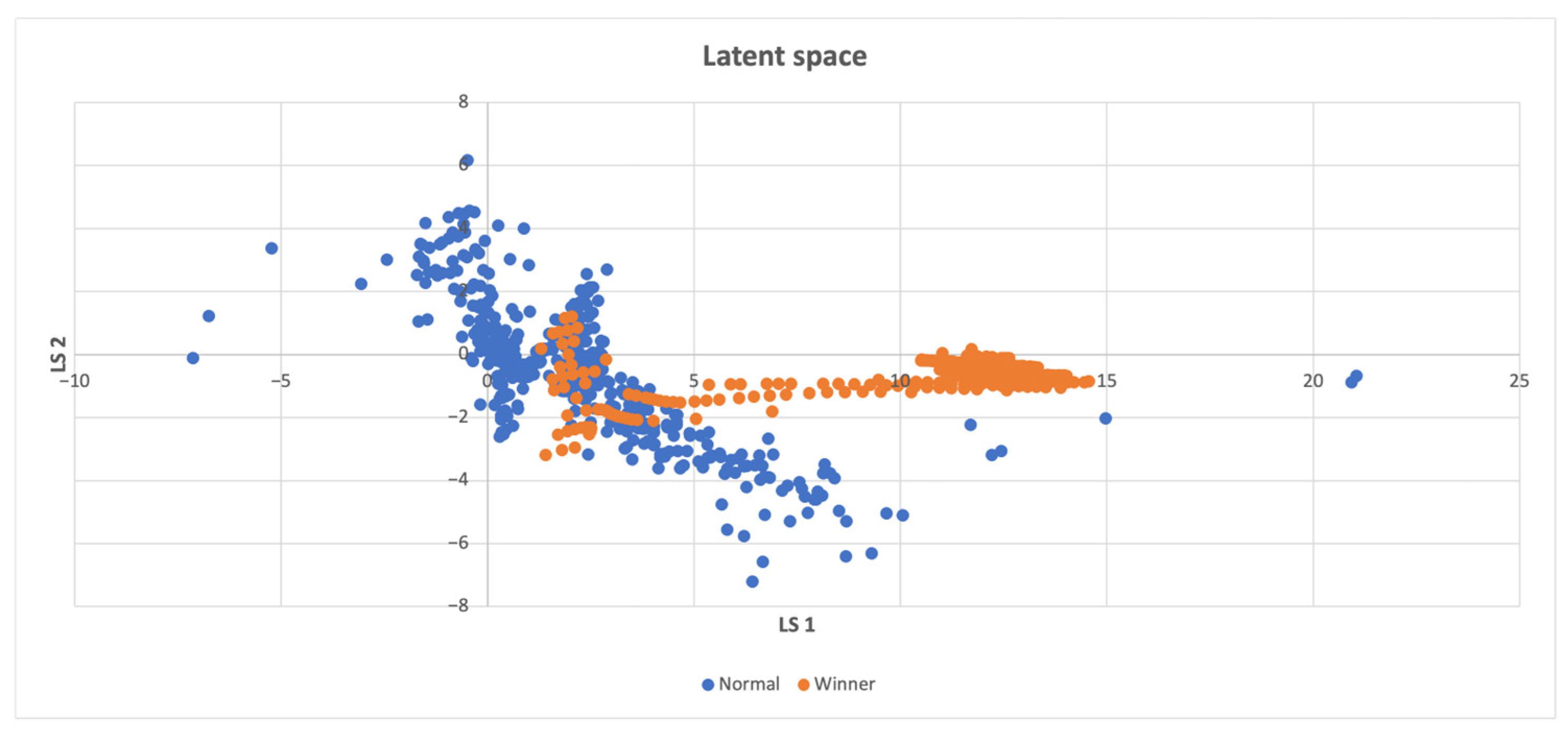
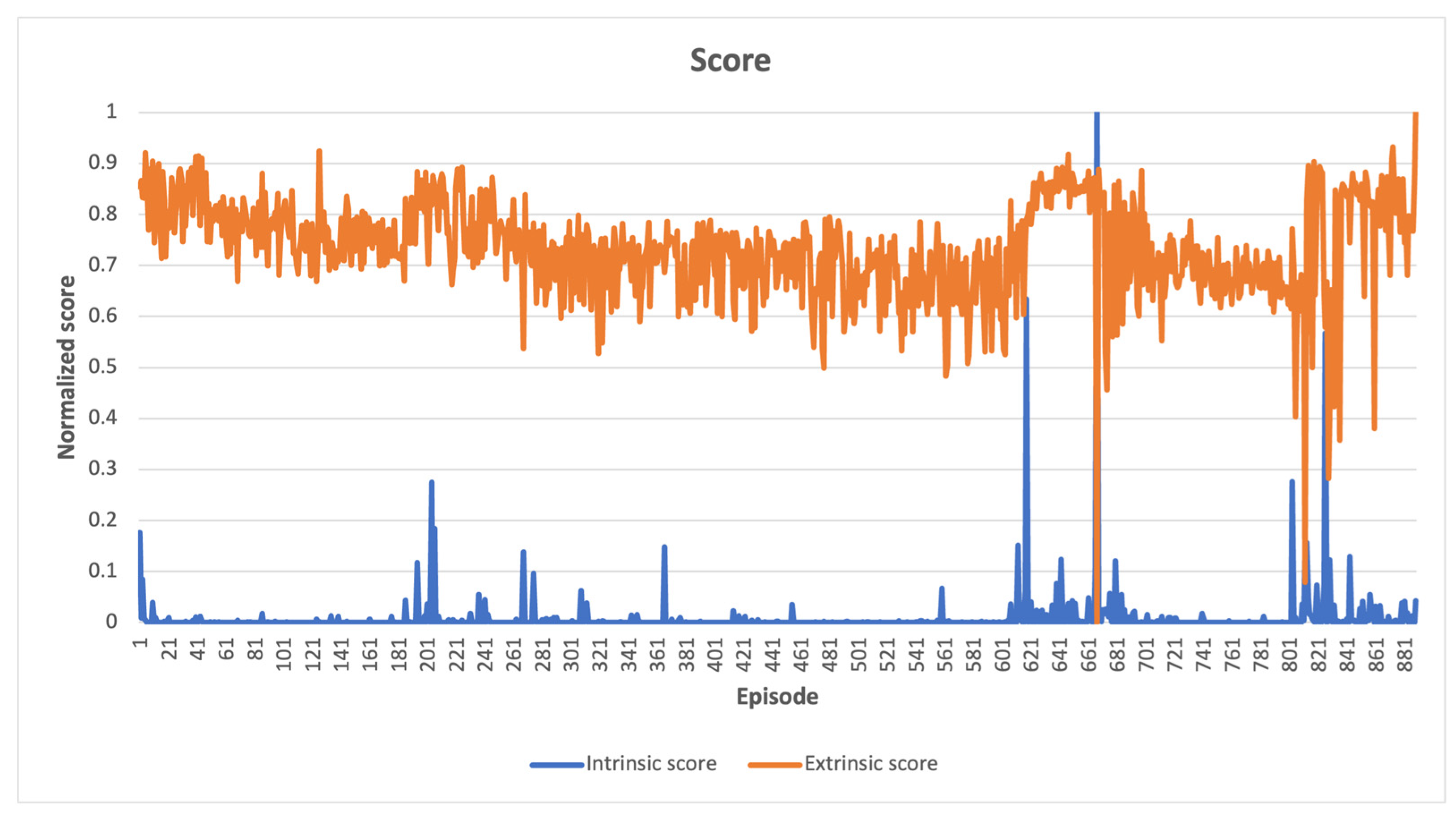
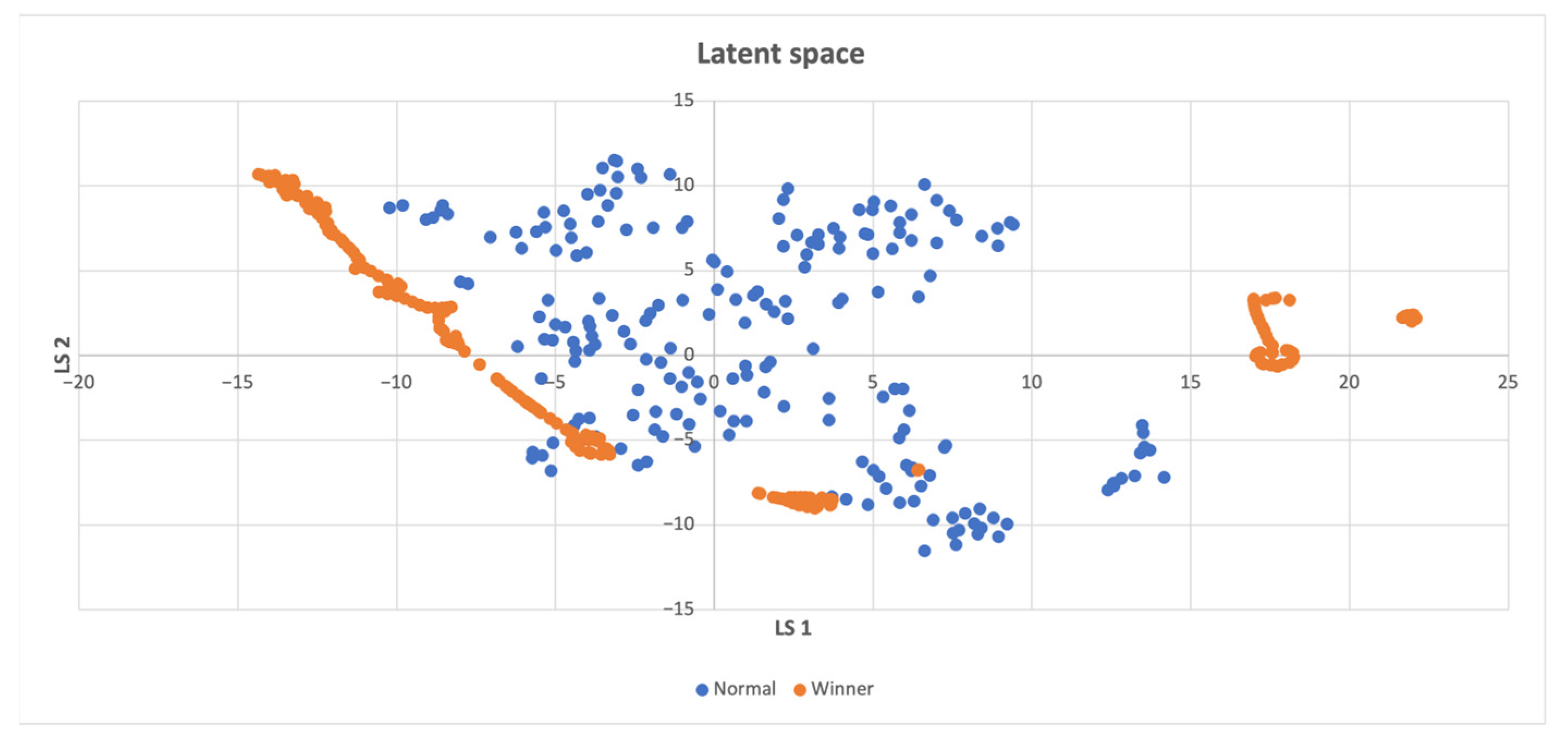
When to Compute the Intrinsic Reward
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pathak, D.; Agrawal, P.; Efros, A.A.; Darrell, T. Curiosity-Driven Exploration by Self-Supervised Prediction. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 2778–2787. Available online: https://arxiv.org/pdf/1705.05363.pdf (accessed on 7 March 2023).
- Burda, Y.; Edwards, H.; Storkey, A.; Klimov, O. Exploration by Random Network Distillation. 2018. Available online: https://arxiv.org/abs/1810.12894 (accessed on 7 March 2023).
- Bellemare, M.; Srinivasan, S.; Ostrovski, G.; Schaul, T.; Saxton, D.; Munos, R. Unifying Count-Based Exploration and Intrinsic Motivation. Adv. Neural Inf. Process. Syst. 2016, 29. Available online: https://arxiv.org/abs/1606.01868 (accessed on 7 March 2023).
- Tang, H.; Houthooft, R.; Foote, D.; Stooke, A.; Xi Chen, O.; Duan, Y.; Schulman, J.; DeTurck, F.; Abbeel, P. # Exploration: A Study of Count-Based Exploration for Deep Reinforcement Learning. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://arxiv.org/pdf/1611.04717.pdf (accessed on 7 March 2023).
- Oudeyer, P.Y.; Kaplan, F.; Hafner, V.V. Intrinsic motivation systems for autonomous mental development. IEEE Trans. Evol. Comput. 2007, 11, 265–286. [Google Scholar] [CrossRef] [Green Version]
- Houthooft, R.; Chen, X.; Duan, Y.; Schulman, J.; De Turck, F.; Abbeel, P. Vime: Variational Information Maximizing Exploration. Adv. Neural Inf. Process. Syst. 2016, 29. Available online: https://arxiv.org/abs/1605.09674 (accessed on 7 March 2023).
- Choshen, L.; Fox, L.; Loewenstein, Y. Dora the Explorer: Directed Outreaching Reinforcement Action-Selection. 2018. Available online: https://arxiv.org/pdf/1804.04012.pdf (accessed on 7 March 2023).
- Kamar, D.; Üre, N.K.; Ünal, G. GAN-based Intrinsic Exploration for Sample Efficient Reinforcement Learning. 2022. Available online: https://arxiv.org/pdf/2206.14256.pdf (accessed on 7 March 2023).
- Kamalova, A.; Lee, S.G.; Kwon, S.H. Occupancy Reward-Driven Exploration with Deep Reinforcement Learning for Mobile Robot System. Appl. Sci. 2022, 12, 9249. [Google Scholar] [CrossRef]
- Liu, Q.; Liu, Z.; Xiong, B.; Xu, W.; Liu, Y. Deep reinforcement learning-based safe interaction for industrial human-robot collaboration using intrinsic reward function. Adv. Eng. Inform. 2021, 49, 101360. [Google Scholar] [CrossRef]
- Chen, Z.; Subagdja, B.; Tan, A.H. End-to-End Deep Reinforcement Learning for Multi-Agent Collaborative Exploration. In Proceedings of the 2019 IEEE International Conference on Agents (ICA), Jinan, China, 18–21 October 2019; pp. 99–102. Available online: https://ieeexplore.ieee.org/abstract/document/8929192 (accessed on 2 April 2023).
- Shi, H.; Shi, L.; Xu, M.; Hwang, K.S. End-to-end navigation strategy with deep reinforcement learning for mobile robots. IEEE Trans. Ind. Inform. 2019, 16, 2393–2402. [Google Scholar] [CrossRef]
- Nguyen, T.; Luu, T.M.; Vu, T.; Yoo, C.D. Sample-Efficient Reinforcement Learning Representation Learning with Curiosity Contrastive forward Dynamics Model. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 3471–3477. Available online: https://ieeexplore.ieee.org/abstract/document/9636536 (accessed on 2 April 2023).
- Zhang, C.; Ma, L.; Schmitz, A. A sample efficient model-based deep reinforcement learning algorithm with experience replay for robot manipulation. Int. J. Intell. Robot. Appl. 2020, 4, 217–228. [Google Scholar] [CrossRef]
- Burgueño-Romero, A.M.; Ruiz-Sarmiento, J.R.; Gonzalez-Jimenez, J. Autonomous Docking of Mobile Robots by Reinforcement Learning Tackling the Sparse Reward Problem. In Advances in Computational Intelligence: 16th International Work-Conference on Artificial Neural Networks, IWANN 2021, Virtual Event. Proceedings, Part II; Springer International Publishing: Cham, Switzerland, 2021; pp. 392–403. Available online: https://link.springer.com/chapter/10.1007/978-3-030-85099-9_32 (accessed on 2 April 2023).
- Huang, S.H.; Zambelli, M.; Kay, J.; Martins, M.F.; Tassa, Y.; Pilarski, P.M.; Hadsell, R. Learning gentle object manipulation with curiosity-driven deep reinforcement learning. arXiv 2019, arXiv:1903.08542. [Google Scholar]
- Szajna, A.; Kostrzewski, M.; Ciebiera, K.; Stryjski, R.; Woźniak, W. Application of the Deep CNN-Based Method in Industrial System for Wire Marking Identification. Energies 2021, 14, 3659. [Google Scholar] [CrossRef]
- Hessel, M.; Modayil, J.; Van Hasselt, H.; Schaul, T.; Ostrovski, G.; Dabney, W.; Horgan, D.; Piot, B.; Azar, M.; Silver, D. Rainbow: Combining Improvements in Deep Reinforcement Learning. Proc. AAAI Conf. Artif. Intell. 2018, 32, 3215–3222. Available online: https://arxiv.org/pdf/1710.02298.pdf (accessed on 7 March 2023). [CrossRef]
- Pang, G.; van den Hengel, A.; Shen, C.; Cao, L. Toward Deep Supervised Anomaly Detection: Reinforcement Learning from Partially Labeled Anomaly Data. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 1298–1308. Available online: https://arxiv.org/pdf/2009.06847.pdf (accessed on 7 March 2023).
- Michalski, P. Anomaly Detection in the Context of Reinforcement Learning. 2021. Available online: https://www.researchgate.net/profile/Patrik-Michalski/publication/354694975_Anomaly_detection_in_the_context_of_Reinforcement_Learning/links/6148336fa595d06017db791d/Anomaly-detection-in-the-context-of-Reinforcement-Learning.pdf (accessed on 7 March 2023).
- Wang, Y.; Xiong, L.; Zhang, M.; Xue, H.; Chen, Q.; Yang, Y.; Tong, Y.; Huang, C.; Xu, B. Heat-RL: Online Model Selection for Streaming Time-Series Anomaly Detection. In Proceedings of the Conference on Lifelong Learning Agents, Montreal, QC, Canada, 22–24 August 2022; pp. 767–777. Available online: https://proceedings.mlr.press/v199/wang22a/wang22a.pdf (accessed on 7 March 2023).
- Ma, X.; Shi, W. Aesmote: Adversarial Reinforcement Learning with Smote for Anomaly Detection. IEEE Trans. Netw. Sci. Eng. 2020, 8, 943–956. Available online: https://ieeexplore.ieee.org/abstract/document/9124651 (accessed on 7 March 2023). [CrossRef]
- Rafati, J.; Noelle, D.C. Learning Representations in Model-Free Hierarchical Reinforcement Learning. Proc. AAAI Conf. Artif. Intell. 2019, 33, 10009–10010. Available online: https://ojs.aaai.org/index.php/AAAI/article/view/5141 (accessed on 7 March 2023). [CrossRef] [Green Version]
- Badia, A.P.; Piot, B.; Kapturowski, S.; Sprechmann, P.; Vitvitskyi, A.; Guo, Z.D.; Blundell, C. Agent57: Outperforming the Atari Human Benchmark. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, PMLR, Virtual Event, 13–18 July 2020; pp. 507–517. Available online: https://arxiv.org/abs/2003.13350 (accessed on 7 March 2023).
- Lindegaard, M.; Vinje, H.J.; Severinsen, O.A. Intrinsic Rewards from Self-Organizing Feature Maps for Exploration in Reinforcement Learning. arXiv 2023, arXiv:2302.04125. [Google Scholar]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. Openai Gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Barto, A.G.; Sutton, R.S.; Anderson, C.W. Neuronlike aDaptive Elements That Can Solve Difficult Learning Control Problems. IEEE Trans. Syst. Man Cybern. 1983, 5, 834–846. Available online: https://ieeexplore.ieee.org/document/6313077 (accessed on 7 March 2023). [CrossRef]
- Sutton, R.S. Generalization in Reinforcement Learning: Successful Examples Using Sparse Coarse Coding. Adv. Neural Inf. Process. Syst. 1995, 8, 1038–1044. Available online: https://papers.nips.cc/paper/1995/hash/8f1d43620bc6bb580df6e80b0dc05c48-Abstract.html (accessed on 7 March 2023).
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018; Available online: http://www.incompleteideas.net/book/the-book-2nd.html (accessed on 7 March 2023).
- Moore, A.W. Efficient Memory-Based Learning for Robot Control; Technical Report No. UCAM-CL-TR-209; University of Cambridge, Computer Laboratory: Cambridge, UK, 1990; Available online: https://www.cl.cam.ac.uk/techreports/UCAM-CL-TR-209.pdf (accessed on 7 March 2023).
- Jakovlev, S.; Voznak, M. Auto-Encoder-Enabled Anomaly Detection in Acceleration Data: Use Case Study in Container Handling Operations. Machines 2022, 10, 734. [Google Scholar] [CrossRef]
- Fedus, W.; Ramachandran, P.; Agarwal, R.; Bengio, Y.; Larochelle, H.; Rowland, M.; Dabney, W. Revisiting Fundamentals of Experience Replay. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, PMLR, Virtual Event, 13–18 July 2020; pp. 3061–3071. Available online: https://arxiv.org/pdf/2007.06700.pdf (accessed on 7 March 2023).
- Feeney, P.; Hughes, M.C. Evaluating the Use of Reconstruction Error for Novelty Localization. 2021. Available online: https://arxiv.org/pdf/2107.13379.pdf (accessed on 7 March 2023).
- Krizhevsky, A. Convolutional Deep Belief Networks on Cifar-10. Unpublished Manuscript. 2010, pp. 1–9. Available online: http://www.cs.utoronto.ca/%7Ekriz/conv-cifar10-aug2010.pdf (accessed on 7 March 2023).
- Clevert, D.A.; Unterthiner, T.; Hochreiter, S. Fast and Accurate Deep Network Learning by Exponential Linear Units (Elus). 2015. Available online: https://arxiv.org/pdf/1511.07289v5.pdf (accessed on 7 March 2023).
- Lu, L.; Shin, Y.; Su, Y.; Karniadakis, G.E. Dying Relu and Initialization: Theory and Numerical Examples. 2019. Available online: https://arxiv.org/pdf/1903.06733.pdf (accessed on 7 March 2023).
- Saxe, A.M.; McClelland, J.L.; Ganguli, S. Exact Solutions to the Nonlinear Dynamics of Learning in Deep Linear Neural Networks. 2013. Available online: https://arxiv.org/pdf/1312.6120.pdf (accessed on 7 March 2023).
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. 2013. Available online: https://arxiv.org/pdf/1312.5602v1.pdf (accessed on 7 March 2023).
- Usama, M.; Chang, D.E. Learning-Driven Exploration for Reinforcement Learning. In Proceedings of the 2021 21st International Conference on Control, Automation and Systems (ICCAS), Jeju, Republic of Korea, 12–15 October 2021; pp. 1146–1151. Available online: https://arxiv.org/pdf/1906.06890.pdf (accessed on 7 March 2023).
- Steinparz, C.A. Reinforcement Learning in Non-Stationary Infinite Horizon Environments/submitted by Christian Alexander Steinparz. BSc. Master’s Thesis, Johannes Kepler Universität Linz, Linz, Austria, 2021. Available online: https://epub.jku.at/obvulihs/download/pdf/6725095?originalFilename=true (accessed on 7 March 2023).
- Wang, Z.; Schaul, T.; Hessel, M.; Hasselt, H.; Lanctot, M.; Freitas, N. Dueling Network Architectures for Deep Reinforcement Learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1995–2003. Available online: https://arxiv.org/pdf/1511.06581.pdf (accessed on 7 March 2023).
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Jang, B.; Kim, M.; Harerimana, G.; Kim, J.W. Q-learning algorithms: A comprehensive classification and applications. IEEE Access 2019, 7, 133653–133667. [Google Scholar] [CrossRef]
- Weights & Biases: Tune Hyperparameters. Available online: https://docs.wandb.ai/guides/sweeps (accessed on 7 March 2023).
- Zhao, X.; An, A.; Liu, J.; Chen, B.X. Dynamic Stale Synchronous Parallel Distributed Training for Deep Learning. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019; pp. 1507–1517. Available online: https://ieeexplore.ieee.org/abstract/document/8885215 (accessed on 7 March 2023).
- Šimon, M.; Huraj, L.; Siládi, V. Analysis of performance bottleneck of P2P grid applications. J. Appl. Math. Stat. Inform. 2013, 9, 5–11. [Google Scholar] [CrossRef]
- Skrinarova, J.; Dudáš, A. Optimization of the Functional Decomposition of Parallel and Distributed Computations in Graph Coloring With the Use of High-Performance Computing. IEEE Access 2022, 10, 34996–35011. [Google Scholar] [CrossRef]
- Van Otterlo, M.; Wiering, M. Reinforcement Learning and Markov Decision Processes. In Reinforcement Learning: State-of-the-Art; Springer: Berlin/Heidelberg, Germany, 2012; pp. 3–42. Available online: https://link.springer.com/chapter/10.1007/978-3-642-27645-3_1 (accessed on 7 March 2023).
- Pardo, F.; Tavakoli, A.; Levdik, V.; Kormushev, P. Time Limits in Reinforcement Learning. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4045–4054. Available online: https://arxiv.org/pdf/1712.00378.pdf (accessed on 7 March 2023).
- Van der Maaten, L.; Hinton, G. Visualizing Data Using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. Available online: https://www.jmlr.org/papers/volume9/vandermaaten08a/vandermaaten08a.pdf (accessed on 7 March 2023).
- Huang, S.; Dossa, R.F.J.; Ye, C.; Braga, J.; Chakraborty, D.; Mehta, K.; Araújo, J.G. CleanRL: High-quality Single-File Implementations of Deep Reinforcement Learning Algorithms. 2021. Available online: https://www.jmlr.org/papers/volume23/21-1342/21-1342.pdf (accessed on 7 March 2023).
- Raffin, A.; Hill, A.; Gleave, A.; Kanervisto, A.; Ernestus, M.; Dormann, N. Stable-baselines3: Reliable reinforcement learning implementations. J. Mach. Learn. Res. 2021, 22, 12348–12355. [Google Scholar]
- Balis, J. Gymnasium. Available online: https://github.com/Farama-Foundation/Gymnasium/blob/main/gymnasium/envs/__init__.py (accessed on 7 March 2023).
- Raffin, A. DQN Agent Playing LunarLander-v2. Available online: https://huggingface.co/araffin/dqn-LunarLander-v2 (accessed on 7 March 2023).
- Badia, A.P.; Sprechmann, P.; Vitvitskyi, A.; Guo, D.; Piot, B.; Kapturowski, S.; Tieleman, O.; Arjovsky, M.; Pritzel, A.; Bolt, A.; et al. Never Give Up: Learning Directed Exploration Strategies. 2020. Available online: https://arxiv.org/abs/2002.06038 (accessed on 7 March 2023).
- Carsten, J.; Rankin, A.; Ferguson, D.; Stentz, A. Global Path Planning on Board the Mars Exploration Rovers. In Proceedings of the 2007 IEEE Aerospace Conference, Big Sky, MT, USA, 3–10 March 2007; pp. 1–11. Available online: https://www-robotics.jpl.nasa.gov/media/documents/IEEEAC-Carsten-1125.pdf (accessed on 7 March 2023).
- Liu, J. Research on the Development and Path Exploration of Autonomous Underwater Robots. ITM Web Conf. 2022, 47, 01029. Available online: https://www.itm-conferences.org/articles/itmconf/pdf/2022/07/itmconf_cccar2022_01029.pdf (accessed on 7 March 2023). [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Intrinsic Reward | Extrinsic Reward | Result |
|---|---|---|
| 0 | 0 | A frequently recurring state leading to a loss |
| 1 | 0 | New unseen state leading to a loss |
| 0 | 1 | Frequently recurring state leading to a win |
| 1 | 1 | New unseen state leading to a win |
| Name | Description | Value |
|---|---|---|
| Epochs | Number of training episodes | 2000 |
| Buffer size | The capacity of experience replay buffer | 1,000,000 |
| Min. temperature | The minimal value of temperature for Boltzmann exploration | 0.01 |
| Init. temperature | The maximal value of temperature for Boltzmann exploration | 1.0 |
| Decay temperature | The value of temperature reduction | 1 × 10−5 |
| Batch size | Number of samples applied during training at once | 256 |
| Learning rate | The learning rate for training process | 3 × 10−4 |
| Global clipnorm | Clipping applied globally on gradients | 1.0 |
| τ | Soft target update value for coping original to target DQN | 0.01 |
| γ | Discount factor for Bellman equation | 0.99 |
| No. neurons in DQN | Number of neurons for each hidden layer | 512, 256 |
| No. neurons in AutoEncoder | Number of neurons for each hidden layer | 128, 64, 32, 16, LS, 16, 32, 64, 128 |
| Environment | Score (w/Extrinsic Reward Only) | Score (This Paper) | Score Threshold |
|---|---|---|---|
| MountainCar-v0 | −194.95 ± 8.48 [51] | −96.684 ± 7.028 | −110 |
| Acrobot-v1 | −91.54 ± 7.20 [51] | −86.12 ± 4.604 | −100 |
| CartPole-v1 | 488.69 ± 16.11 [51] | 499.483 ± 3.05 | 475 |
| LunarLander-v2 | 280.22 ± 13.03 [54] | 234.881 ± 33.86 | 200 |
| Environment | Method | Percentage Success Rate |
|---|---|---|
| Acrobot-v1 | Stored in RB | 100 |
| Calculated during DQN model update | 100 | |
| CartPole-v1 | Saved in RB | 75 |
| Calculated during DQN model update | 60 | |
| LunarLander-v2 | Saved in RB | 11 |
| Calculated during DQN model update | 14 | |
| MountainCar-v0 | Saved in RB | 61 |
| Calculated during DQN model update | 98 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kubovčík, M.; Dirgová Luptáková, I.; Pospíchal, J. Signal Novelty Detection as an Intrinsic Reward for Robotics. Sensors 2023, 23, 3985. https://doi.org/10.3390/s23083985
Kubovčík M, Dirgová Luptáková I, Pospíchal J. Signal Novelty Detection as an Intrinsic Reward for Robotics. Sensors. 2023; 23(8):3985. https://doi.org/10.3390/s23083985
Chicago/Turabian StyleKubovčík, Martin, Iveta Dirgová Luptáková, and Jiří Pospíchal. 2023. "Signal Novelty Detection as an Intrinsic Reward for Robotics" Sensors 23, no. 8: 3985. https://doi.org/10.3390/s23083985
APA StyleKubovčík, M., Dirgová Luptáková, I., & Pospíchal, J. (2023). Signal Novelty Detection as an Intrinsic Reward for Robotics. Sensors, 23(8), 3985. https://doi.org/10.3390/s23083985