Abstract
The convolution module in Conformer is capable of providing translationally invariant convolution in time and space. This is often used in Mandarin recognition tasks to address the diversity of speech signals by treating the time-frequency maps of speech signals as images. However, convolutional networks are more effective in local feature modeling, while dialect recognition tasks require the extraction of a long sequence of contextual information features; therefore, the SE-Conformer-TCN is proposed in this paper. By embedding the squeeze-excitation block into the Conformer, the interdependence between the features of channels can be explicitly modeled to enhance the model’s ability to select interrelated channels, thus increasing the weight of effective speech spectrogram features and decreasing the weight of ineffective or less effective feature maps. The multi-head self-attention and temporal convolutional network is built in parallel, in which the dilated causal convolutions module can cover the input time series by increasing the expansion factor and convolutional kernel to capture the location information implied between the sequences and enhance the model’s access to location information. Experiments on four public datasets demonstrate that the proposed model has a higher performance for the recognition of Mandarin with an accent, and the sentence error rate is reduced by 2.1% compared to the Conformer, with only 4.9% character error rate.
1. Introduction
In a corpus with sufficient data and in a quiet environment, current speech recognition technology can achieve good recognition results [1]. However, people’s accents are often influenced by regional dialects or their native languages. In contrast to standard Mandarin, the vowels and rhymes of pronunciation will change due to different accents, and the performance of the model will be affected as a result, with a lower recognition accuracy [2]. To address the challenge of accents, Wang et al. [3] proposed the method of maximum likelihood linear regression based on a Gaussian mixed-hidden Markov model. Using this as a basis, Zheng et al. [4] combined the maximum posterior probability and maximum likelihood linear regression methods to further improve the system performance in the study of speech recognition of Mandarin with a Shanghai accent. With the development of a deep neural network (DNN), Chen et al. [5] added an accent discrimination layer to the DNN model and recognized the specific features of the person speaking. The accent-dependent feature layer proposed by Senior et al. [6], which filters specific accent features, has promoted the research of multi-accented Mandarin speech recognition [7]. These speech recognition technologies mostly focus on modeling only one accent; this requires the integration of various modules to handle different accents when building a comprehensive speech processing system. However, China has approximately seven significant dialects, including Guanhua, Wu, Xiang, Gan, Kejia, Yue, and Min dialects, as well as several variant dialects derived from these [8]. This poses a significant challenge to speech recognition systems since they not only require specialized linguistic knowledge to classify different accents and construct corresponding pronunciation dictionaries or phoneme annotations in the modeling process, but also cannot be optimized together since different dialect recognition modules operate independently. This class of models is also known as hybrid models. As a result, hybrid dialect speech recognition systems are overly complex and difficult to train [9].
The current end-to-end speech recognition framework is based on connectionist temporal classification (CTC) and attention mechanisms; it solves the problem of joint optimization and does not require a rigorous annotation of the corpus and attention to the underlying linguistic content when performing acoustic modeling. End-to-end speech recognition research has gained significant attention among scholars and has emerged as a prominent topic in this field. In 2017, Google proposed the Transformer model [10], which uses a self-attentive mechanism instead of a long short-term memory neural network, thus enabling the better capture of long-term dependency speech feature information, Due to the advantages of convolutional neural networks (CNN) for local feature extraction, Google proposed the Conformer model in 2020; it is able to capture global as well as local features and has an improved recognition performance [11]. However, most studies on Mandarin speech recognition with accents are based on traditional speech recognition architectures. Less research has been conducted on end-to-end speech recognition frameworks.
Hence, this study aims to investigate the effectiveness of the SE-Conformer-TCN end-to-end speech recognition method in enhancing the recognition accuracy of accented Mandarin. Typically, the differences between dialects stem from variations in vowel pronunciation, such as the character “mountain” pronounced as “shan” or “san”, in different dialects. However, ignore its context, the pronunciation of “san” can imply the character “three”. Therefore, the proposed SE-Conformer-TCN method uses TCN to improve the network’s ability to handle lengthy sequences and to enable it to fully learn contextual information. Next, a squeeze-excitation block (SE block) is utilized to enhance feature representation, model dependencies for convolutional features, and calibrate vowel features via the feature recalibration capacity of SE. Additionally, the end-to-end speech recognition approach overcomes the challenge of hybrid models’ separate optimization by directly converting speech sequences to text sequences without pronunciation dictionaries or phoneme annotation, thus enabling more effective network training.
This paper’s main contributions are as follows:
- (1)
- Embedding SE block into the Conformer model enables the network to recalibrate the extracted channel features;
- (2)
- Without changing the parallelism of the Conformer model, temporal information is modeled using a temporal convolutional network (TCN) to enhance the acquisition of location information by the model and reduce the disappearance of location information in the post layer;
- (3)
- A state-of-the-art performance is achieved in four public datasets, especially in terms of the character error rate.
2. Related Works
2.1. Temporal Convolutional Network
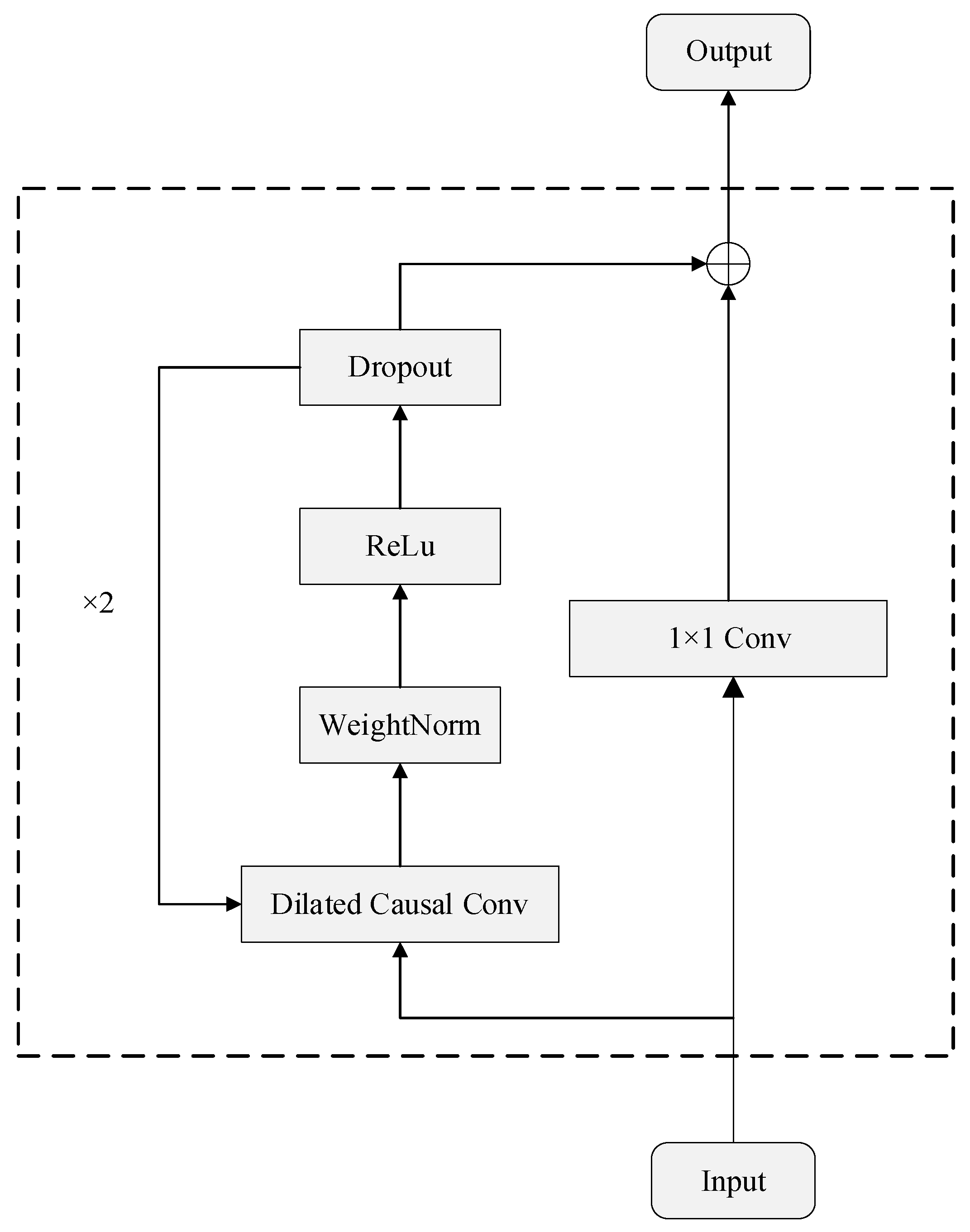
TCN is a model with a unique dilation causal convolution structure based on the CNN proposed by Bai et al. [12], therefore, it is more suitable for solving temporal problems, and its structure is shown in Figure 1.
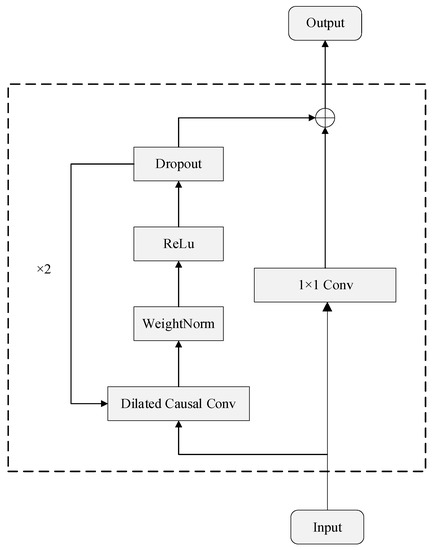
Figure 1.
Architecture of TCN model.
The convolution is defined as:
where the input feature sequence X is convolved with a dilated causal convolution kernel f. Here, the expansion factor d and convolution kernel size k are denoted, and represents the corresponding location point in the input sequence. The expansion factor d is exponentially increased with the number of network layers i, which enables the TCN to effectively capture longer time series dependencies.
2.2. Squeeze-Excitation Block
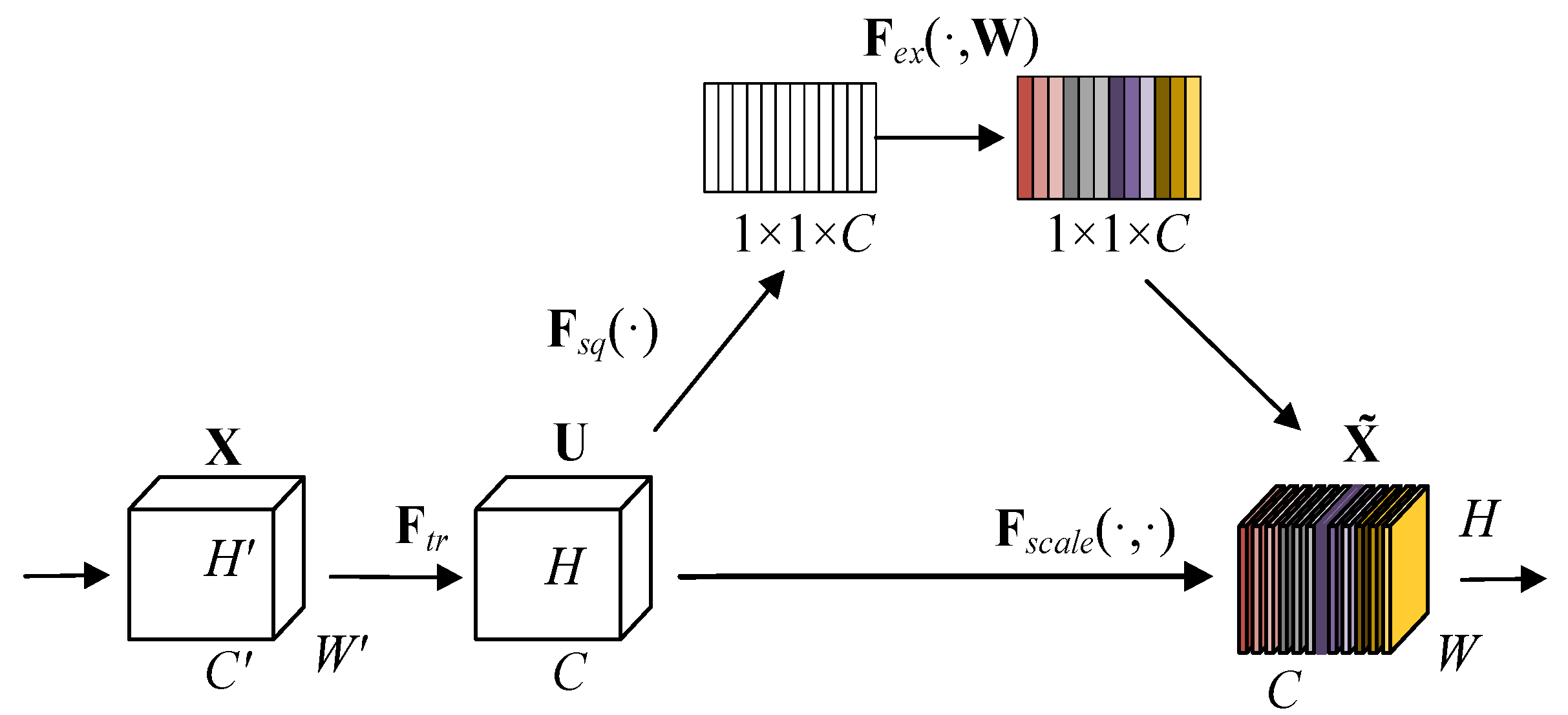
The SE block proposed by Hu et al. [13] to rescale the features and its module schematic are shown in Figure 2.
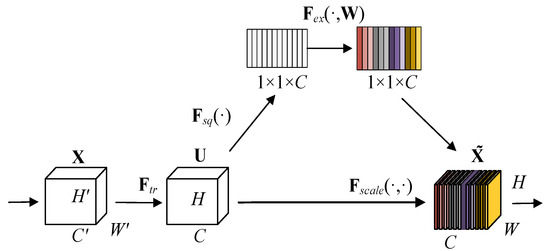
Figure 2.
Architecture of SE Block.
The SE block recalibrates the input features in four steps as follows.
Firstly, for a convolutional operator , use to denote the mapping process of X to U, and let refer to the parameters of the c-th filter. We can then write the outputs of :
In this equation, the variable x denotes the input feature vector, while u represents the resulting output value obtained through convolution.
The global averaging pooling operation is used in the squeeze process to compress the feature channels, and the overall ensemble operation is used to obtain a series of values with a global sensory domain. This process is calculated as follows:
where H and W can be interpreted as the spatial dimensions and represents the value obtained by compression after global average pooling.
Third, in the excitation process, the information obtained using the squeeze operation is passed through two fully connected layers, as well as the activation function, to obtain s of dimension as the weight characterizing the importance of the feature channel:
where refers to sigmoid function, represents the ReLu function, and W is the weight representing the feature.
Finally, the reweighting operation is performed to multiply each channel weight obtained in excitation with each of its corresponding elements, and the calculation process is shown as:
where denotes the rescaled feature vector in the channel dimension.
3. Materials and Methods
3.1. Dataset
The details of the dataset are shown in Table 1.

Table 1.
Information about datasets.
The dataset was divided into training, testing, and validation sets without crossover, and the 80-dimensional Fbank [18] was used in all experiments. All data have a 16 kHz sample rate, 25 ms frame length, 10 ms frame shift length, and are in 16-bit monaural WAV format.
3.2. Experimental Environment
The experiments were conducted on Centos 7.8.2003 operating system (Centos, Raleigh, NC, USA) using Intel(R) Xeon(R) CPUE5-2640v4@2.40 GHz (Santa Clara, CA, USA) processor and a single block of NVIDIA Tesla V100 (16 GB) (Santa Clara, CA, USA) with end-to-end WeNet [19] speech recognition tool for training the model.
3.3. Model Construction and Speech Recognition
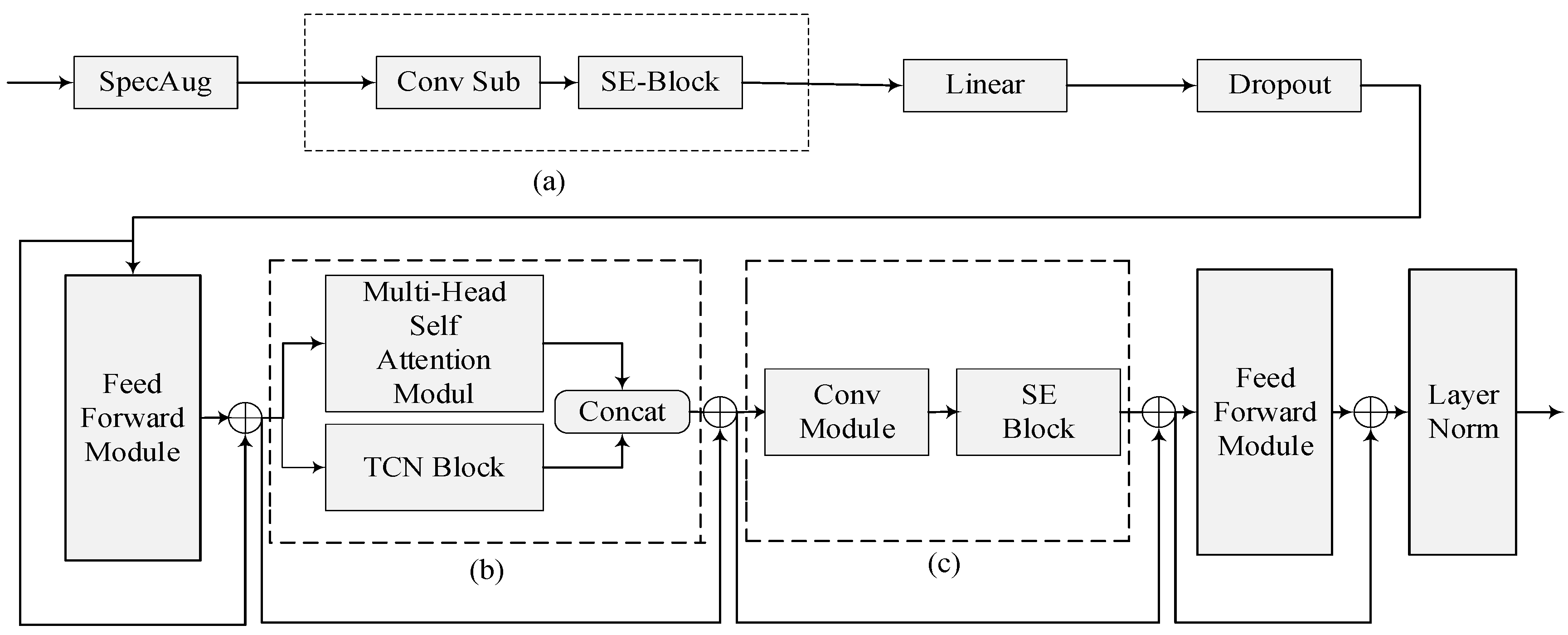
The architecture of the proposed model is illustrated in Figure 3. The SE-Conformer-TCN model consists of a SpecAug layer that enhances the input spectral features, the SE-Conv substructure (parts a and c in the figure), a linear layer, a dropout [20], and a feedforward neural network layer with a “sandwich” structure [21], an MHSA-TCN substructure (part b in the figure), a second feedforward neural network layer, and a LayerNorm [22] layer for normalization.
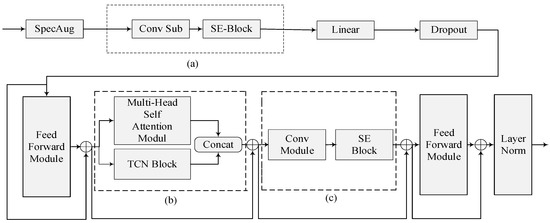
Figure 3.
Architecture of proposed model. (a) First SE-Conv; (b) MHSA-TCN; (c) Second SE-Conv.
The main differences between the SE-Conformer-TCN model architecture and the original Conformer model are the SE-Conv and MHSA-TCN substructures.
3.3.1. SE-Conv
Accurate dialect recognition requires contextual features, as the same pronunciation of a word may have different meanings depending on its context. Context-dependent features are more informative than audio features alone. In order to enhance the network’s ability to extract dependencies between channels, SE-Conv integrates the SE block into the convolution process. SE-Conv allows the network to adaptively recalibrate the importance of features between channels, with the goal of extracting more relevant contextual information, whose processing mainly comprises two phases: squeeze and excitation.
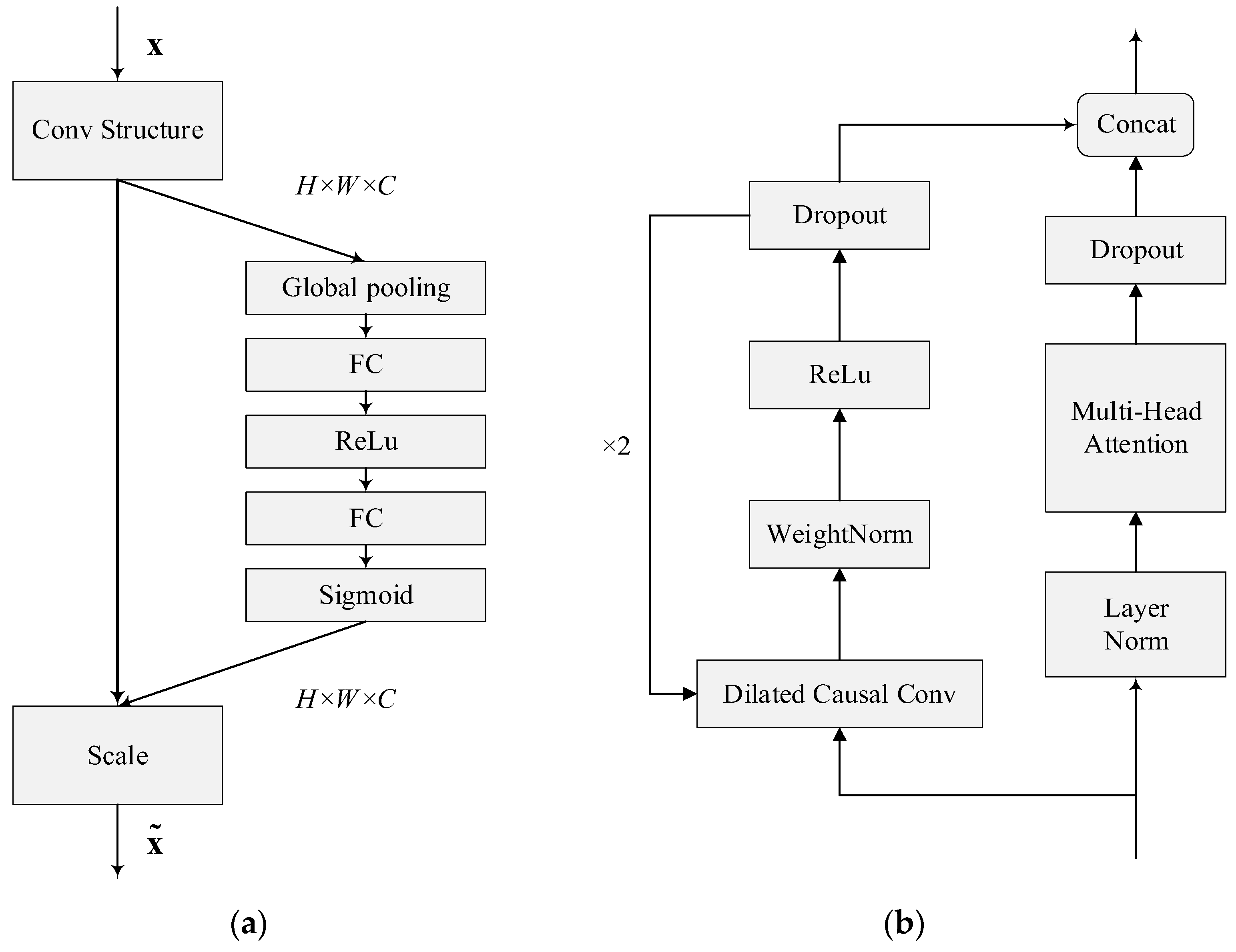
Among these, the squeeze stage is the global average pooling layer, as shown in Figure 4. We know that in the convolution process, each filter operates in a certain region, and it is difficult to obtain enough information to extract the relationship between channels, which is more significant in the front layers of the network because the perceptual field is smaller. Therefore, squeeze uses global average pooling to generate statistical information for each channel, considering it as a global feature. This process is shown in Equation (3).
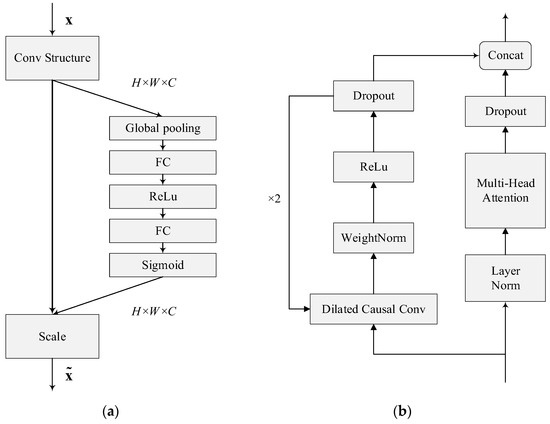
Figure 4.
Architecture of SE-Conv and MHSA-TCN. (a) SE-Conv; (b) MHSA-TCN.
The FC-ReLu-FC-Sigmoid layer shown in the figure is the excitation phase and uses a bottleneck structure containing two fully connected layers to reduce the complexity of the model and improve its generalization capability. The role of the fully connected layer is to predict the importance of each channel, obtain the weights of different channels, and apply them to the corresponding channels of the feature map. One of the purposes of using a gating mechanism with Sigmoid as well as ReLu [23] functions is to learn the nonlinear as well as nonreciprocal relationships between channels. This process is shown in Equation (4).
In summary, the SE block employs a squeeze operation to extract features from all channels, and subsequently uses an excitation operation to compute the importance weight for each feature, thereby modeling the correlation between features and selecting the relevant channels for dialect feature recalibration.
3.3.2. MHSA-TCN
Attention mechanisms are currently a widely discussed topic in the field of deep learning and there exist various types of attention mechanisms, including bottom-up attention [24], global attention [25], and self-attention [26]. The concept of attention is inspired by the human visual attention mechanism, where people tend to focus on and observe a particular part of a scene instead of viewing it in its entirety [27]. By incorporating attention mechanisms into deep learning models, the network can learn to selectively focus on the most relevant information, improving its performance in various tasks [28,29,30] such as image recognition and natural language processing [31,32,33]. The attention calculation can be defined as follows:
where Q represents a query, K and V are key–value pairs, and d is the dimensionality of K. Intuitively, Q, K, and V represent three matrices obtained from the input data through a fully connected network. However, when the input dimension is large, the dot product will cause the amount of data to dramatically increase, and the gradient available after the softmax function is too small. Therefore, it is necessary to multiply the product of the transpose of Q and K by the inverse of the square root of d, and finally multiply it by the matrix V through the softmax layer to obtain the attention score.
Unlike the attention mechanism, TCN can control the sequence memory length by changing the size of the receptive field. Our strategy was to make full use of these two algorithms to solve our problems: the ability of the attention mechanism to select key characteristics and the ability of TCN to extract characteristics. The original TCN structure used a 1 × 1 convolutional module to perform the dimensionality reduction operation on the input of the lower layer. In order to maintain compatibility for fusing with the feature data processed by the multi-headed attention layer, the dimensionality reduction processing operation was removed in the MHSA-TCN structure. The TCN and the multi-headed self-attention were built using parallelism to process the input sequence in parallel, and thus improve the speed of the model.
The dilated causal convolution module in the MHSA-TCN structure shows an exponential growth of the expansion factor as the number of network layers increases, which can achieve better results with fewer network layers. It accelerates both the training speed and expanding perceptual domain of the model via the increase in the expansion factor; the convolution kernel can cover the input time series, and thus learn the temporal information better, fusing the features learned by this process with the features processed by the multi-headed self-attentive layer. This enhances the learning of implicit location information via the network model and extracts more features at the same time.
3.4. Audio Augmentation and Loss Function
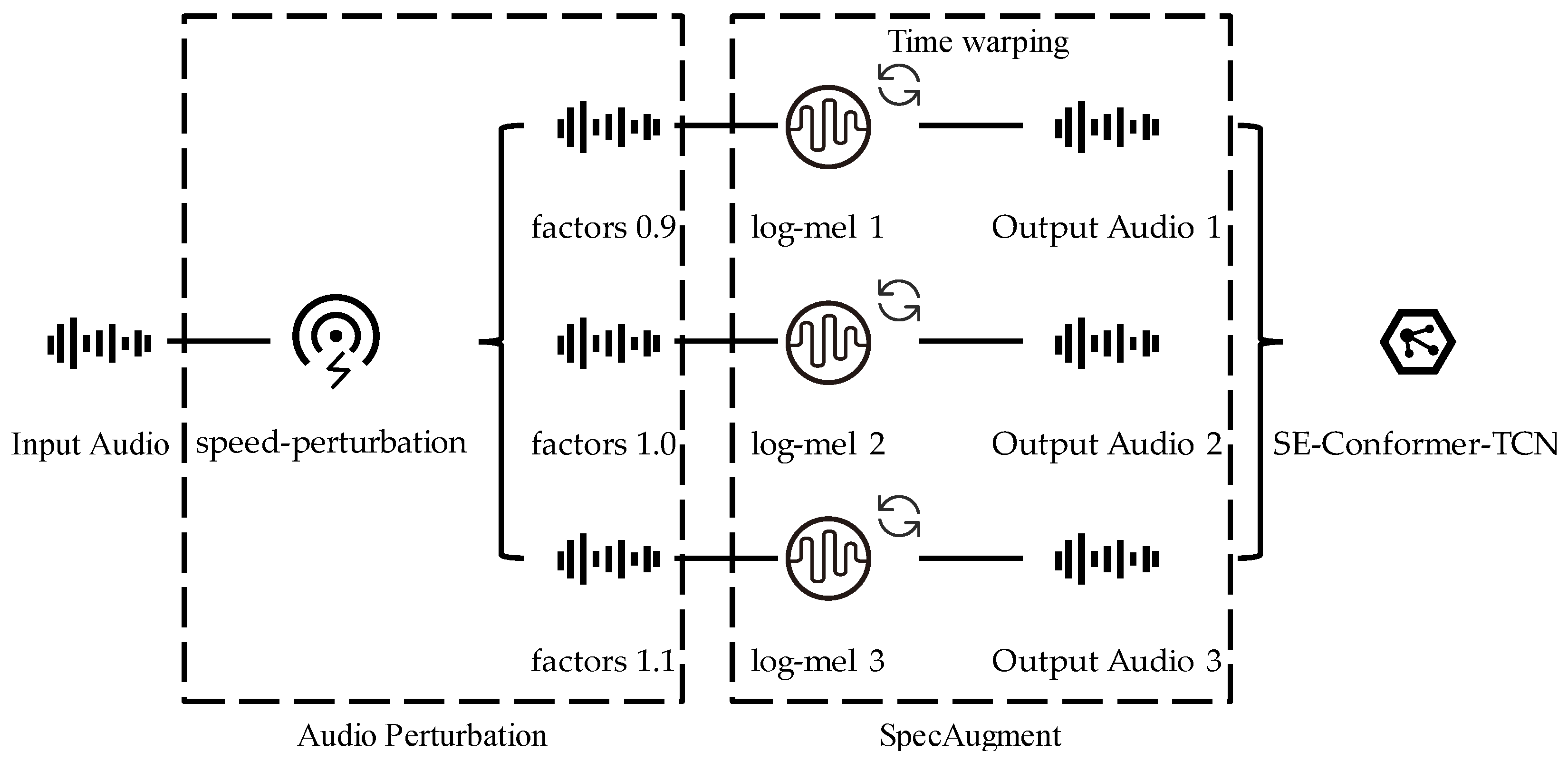
It has been shown that the use of audio perturbation [34] and SpecAugment [35] spectral data augmentation can effectively improve the performance of the model. Therefore, we conducted experiments based on these two data augmentation methods. In order to implement speed perturbation, we resampled the signal using the speed function of the Sox audio manipulation tool [36] to produce three versions of the original signal with speed factors of 0.9, 1.0, and 1.1, allowing the size of the training set to be expanded to three times the original size and to more fully utilize the data for model training. The audio was then converted into a log-mel spectrogram, and time warping and other operations that help the network learn useful features were performed on the spectrogram to make the data more robust to deformation in the time dimension. Finally, the data were converted back into audio form and fed into the model. Figure 5 shows the specific process of data augmentation.
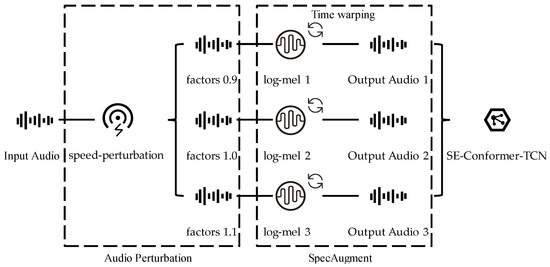
Figure 5.
Audio Augmentation Process.
In addition, CTC loss function is used to force the alignment of the labels [37], speed up the training of the model, and enhance the robustness of the model. For the feature vector and target sequence y, the CTC likelihood is defined as:
where is the set of alignment, a to y, including the special blank token. The alignment probability is represented as:
where t denotes the t-th symbol of a and the t-th representation vector of . At training time, we minimize the negative log-likelihood induced by CTC:
4. Experiments
4.1. Evaluation Metrics and Hyperparameter Settings
The recognition accuracy of the model was evaluated based on character error rate (CER) and sentence error rate (SER) [38], expressed as follows:
where S denotes the number of characters replaced, D refers to the number of characters deleted, I represents the number of characters not in the original text but inserted, and N is the number of all characters in the statement. Error in SER is the number of statements with word or character errors, and Total represents the number of entire statements.
Drawing on our previous experiments, we established the system parameters employed by the SE-Conformer-TCN model. The attention mechanism used a hidden layer size of 256 and had four attention heads, while the SE block employed a reduction rate of 16. The TCN network comprised three residual units with a convolutional kernel size of three and expansion factor coefficients of (one, two, three), and the filter size was set to 256. The model was trained 50 epochs and utilized a beam search strategy for decoding with a beam size of 10.
For fair comparison, we attempted to tune all the other hyperparameters to obtain the best performance for each baseline model. We repeated each experiment five times and reported the average score.
4.2. Baseline Preparation
Firstly, the training based on the Conformer model for the Aidatatang_200zh dataset was carried out by setting different CTC weights to derive the optimal CTC parameters to build the baseline system, and the experimental results are shown in Table 2.
Table 2.
Different CTC weights for Conformer settings.
Based on the Conformer model trained on the Aidatatang_200zh dataset, the model performed best when the weight size of CTC set was 0.4, achieving a character error rate of 6.2%. The performance of the model does not show a monotonic increasing or decreasing trend as the CTC weight increases, because the text labels and speech data in the manually labeled dataset are not strictly aligned. The introduced CTC enables the use of dynamic programming to cover various cases of alignment between inputs and outputs to address finer-grained alignment, thus enabling the modeling of multiple reading slices of information of a character. Then, the corresponding probability of input/output sequences is maximized by computing the loss function to improve the performance of the model. However, CTC cannot obtain the sequence global information. When the weight share of CTC increases, the gradient obtained by the self-attentive part of the model will be reduced when calculating the inverse gradient, and the model will reduce the parameter optimization of self-attentive. Therefore, when the weight of CTC was too large, the performance of the model was reduced.
In addition, we compared our method with various representative studies, including traditional speech recognition models and recent studies based on self-supervised learning.
- GMM-HMM: Phoneme recognition model based on a hidden Markov model and a hybrid Gaussian model.
- TDNN [39]: Time-delay neural networks, where phoneme-recognition-based implementation enables the network to discover acoustic-phonetic features and the temporal relationships between them independently of position in time.
- DFSMN-T [40]: Lightweight speech recognition system consisting of acoustic model DFSMN and language model transformer with fast decoding speed.
- CTC/Attention [41]: Uses a hybrid of the syllable, Chinese character, and subword as modeling units for end-to-end speech recognition system based on the CTC/attention multi-task learning.
- TCN-Transformer [42]: Transformer-based fusion of temporal convolutional neural networks and connected temporal classification.
5. Results
5.1. Recognition Results of the Model
To further illustrate the effectiveness of the proposed model architecture, the SE-Conformer-TCN model is compared with related studies in recent years in the following, and the experimental results are shown in Table 3.
Table 3.
SE-Conformer-TCN comparison with recent work.
It can be concluded that the experimental results based on the SE-Conformer-TCN model have performance advantages over the recent DFSMN-T, CTC/attention (character), and TCN-Transformer-CTC models, with reductions of 2.9, 1.4, and 1.3 percentage points in character error rate, respectively, confirming the validity of the proposed models. Compared with the traditional speech recognition models GMM-HMM and TDNN, the proposed model still shows better recognition of Mandarin with dialects without pronunciation dictionaries and phoneme annotation.
In order to demonstrate the generalization ability of the proposed SE-Conformer-TCN model on different datasets, this paper retrained the SE-Conformer-TCN model on the Aishell-1 dataset. To make the experiments more reliable, the model parameters were kept consistent with Conformer except for the TCN and SE block modules. The models were trained for 50 epochs, and the experimental results are shown in Table 4.
Table 4.
Experimental results on dataset Aishell-1.
The speech recognition system trained on the Aishell-1 dataset based on the SE-Conformer TCN model has a character error rate reduced by 1.2% compared to the Conformer, and the model architecture also has a better recognition effect on Chinese speech datasets in comprehensive domains, proving that the SE-Conformer-TCN model has a certain generalization ability.
5.2. Parameter Sensitivity
We conducted a series of experiments based on the CTC with a weight of 0.4 to investigate the impacts of major hyperparameters on our framework, including the reduction ratios in the SE block, and the size of TCN unit, filter, and kernel in TCN module.
The best results were achieved when the deceleration ratio size was 16, and a character error rate of 5.6% was reached.
The model performs best when the number of units of TCN is three, the filter size is 256, and the convolutional kernel size is three, achieving a character error rate of 6.0%.
Table 5 and Table 6 show the integration of the SE block and TCN into the Conformer for the best hyperparameter configuration, respectively. Both modules were integrated simultaneously and compared to the baseline model, and the experimental results are shown in Table 7.
Table 5.
Different reduction ratios of SE-Conformer settings.
Table 6.
Different hyperparameter settings for Conformer-TCN.
Table 7.
Performance of Conformer with different modules.
The SE-Conformer model reduced the sentence error rate of the baseline system by about 3.1%, while the Conformer-TCN reduced it by about 1.8%, verifying the effectiveness of SE and TCN in the model. By adding both modules to the Conformer model, the final SE-Conformer-TCN model architecture achieved a significant performance improvement compared to Conformer, SE-Conformer, and Conformer-TCN, with a sentence error rate of 36.5%. This validates the proposed SE-Conformer-TCN model.
In a comprehensive analysis, the embedding of the SE block recalibrates the features extracted from the convolutional structure of the model, increases the weight of accent features in the speech data, and decreases the weight of invalid features. As a result, the model shows a significant improvement in the recognition performance of accented Mandarin. The added TCN can accurately learn the length dependence of time sequences and the location information implied by the sequences. When fused with the features processed by the multi-headed self-attentive machine layer, the model can obtain more features and location information; this is beneficial for improving the model’s performance. However, it can also be seen from the experiments that the TCN has less effect on the model’s performance improvement compared to the SE because the TCN has limitations in acquiring more position information since the multi-headed self-attentive layer in the model already captures the relative position information of sequences.
As can be seen in Figure 6, CTC can effectively solve the problem of the model being difficult to converge due to the different speech speeds or different lengths of time between words, thus speeding up the training speed of the model and making it possible to train the model with fewer epochs to achieve better results. We can also see that the loss of the model changes faster with the addition of the SE block and TCN, and the CER during training is lower compared with other models, because the SE block and TCN are more accurate in extracting the features of speech sequences with accents and more sensitive to capturing the location information in the sequences, which makes the model more efficient in training each epoch than the Conformer model. This demonstrates that the SE-Conformer-TCN model is effective in improving the recognition performance of accented Mandarin speech.
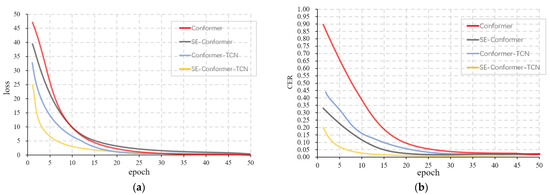
Figure 6.
Convergence process for four experimental models. (a) Loss convergence process; (b) CER convergence process.
6. Conclusions
In this paper, we propose a novel approach for accented Mandarin speech recognition that utilizes a combination of a temporal convolutional network and squeeze-excitation block. The motivation behind our approach was to tackle the challenge of dialect recognition based on end-to-end model, which may significantly affect the accuracy and robustness of speech recognition systems.
To this end, our proposed model can recalibrate the features extracted from the convolutional structure, increase the weight of accent features, and decrease the weight of useless features in speech data. Additionally, the TCN can also better learn the location information implied in the sequences, which achieves a good recognition of Mandarin without extensive knowledge of accents and acoustics, while ensuring a simple and efficient network structure compared to traditional recognition methods. To evaluate the effectiveness of our method, we conducted experiments on four public datasets: Ai-datatang_200zh, Aishell-1, CASIA-1, and CASIA-2.
The experimental results show that our method achieved different degrees of improvement for these datasets, demonstrating its accuracy and robustness in speech recognition of accented Mandarin. Furthermore, we performed in-depth comparison experiments on the hyperparameter settings of various modules within the proposed model to confirm the effectiveness of each module in enhancing the performance of Conformer for dialect recognition. Specifically, our approach outperformed state-of-the-art methods in terms of multiple evaluation metrics, such as CER and SER. These results validate the effectiveness of our approach in handling challenging scenarios.
Author Contributions
Conceptualization, X.-Y.Y., R.X.; methodology, X.-Y.Y., R.X. and S.-D.Z.; data curation, J.Y.; formal analysis, Z.-Y.L.; investigation, J.Y. and Z.-Y.L.; validation, X.-Y.Y., S.-D.Z. and R.X.; writing—original draft, all authors; writing—review and editing, all authors; supervision, X.-Y.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (Grant No. 61862060, 62262064) and the Natural Science Foundation of Xinjiang Uygur Autonomous Region of China (Grant No. 2022D01C56), the Education Department Project of Xinjiang Uygur Autonomous Region (Grant No. XJEDU2016S035), the Doctor-al Research Start-up Foundation of Xinjiang University (Grant No. BS150257).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
This study did not report any data. We used public data for research.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Li, J. Recent advances in end-to-end automatic speech recognition. APSIPA Trans. Signal Inf. Process. 2022, 11, e8. [Google Scholar] [CrossRef]
- Yi, J.; Wen, Z.; Tao, J.; Ni, H.; Liu, B. CTC regularized model adaptation for improving LSTM RNN based multi-accent mandarin speech recognition. J. Signal Process. Syst. 2018, 90, 985–997. [Google Scholar] [CrossRef]
- Wang, Z.; Schultz, T.; Waibel, A. Comparison of acoustic model adaptation techniques on non-native speech. In Proceedings of the 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing, 2003. Proceedings. (ICASSP’03), Hong Kong, China, 6–10 April 2003; p. I. [Google Scholar]
- Zheng, Y.; Sproat, R.; Gu, L.; Shafran, I.; Zhou, H.; Su, Y.; Jurafsky, D.; Starr, R.; Yoon, S.-Y. Accent detection and speech recognition for shanghai-accented mandarin. In Proceedings of the Ninth European Conference on Speech Communication and Technology, Lisbon, Portugal, 4–8 September 2005. [Google Scholar]
- Chen, M.; Yang, Z.; Liang, J.; Li, Y.; Liu, W. Improving deep neural networks based multi-accent mandarin speech recognition using i-vectors and accent-specific top layer. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Senior, A.; Sak, H.; Shafran, I. Context dependent phone models for LSTM RNN acoustic modelling. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 4585–4589. [Google Scholar]
- Yi, J.; Ni, H.; Wen, Z.; Tao, J. Improving blstm rnn based mandarin speech recognition using accent dependent bottleneck features. In Proceedings of the 2016 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA), Jeju, Republic of Korea, 13–16 December 2016; pp. 1–5. [Google Scholar]
- Fung, P.; Liu, Y. Effects and modeling of phonetic and acoustic confusions in accented speech. J. Acoust. Soc. Am. 2005, 118, 3279–3293. [Google Scholar] [CrossRef] [PubMed]
- Gao, Y.; Parcollet, T.; Zaiem, S.; Fernandez-Marques, J.; de Gusmao, P.P.; Beutel, D.J.; Lane, N.D. End-to-end speech recognition from federated acoustic models. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 7227–7231. [Google Scholar]
- Subakan, C.; Ravanelli, M.; Cornell, S.; Bronzi, M.; Zhong, J. Attention is all you need in speech separation. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–12 June 2021; pp. 21–25. [Google Scholar]
- Gulati, A.; Qin, J.; Chiu, C.-C.; Parmar, N.; Zhang, Y.; Yu, J.; Han, W.; Wang, S.; Zhang, Z.; Wu, Y. Conformer: Convolution-augmented transformer for speech recognition. arXiv 2020, arXiv:2005.08100. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Aidatatang-200zh. Beijing DataTang Technology Co., Ltd. 2022. Available online: https://www.datatang.com/opensource (accessed on 8 September 2022).
- Bu, H.; Du, J.; Na, X.; Wu, B.; Zheng, H. Aishell-1: An open-source mandarin speech corpus and a speech recognition baseline. In Proceedings of the 2017 20th Conference of the Oriental Chapter of the International Coordinating Committee on Speech Databases and Speech I/O Systems and Assessment (O-COCOSDA), Seoul, Republic of Korea, 1–3 November 2017; pp. 1–5. [Google Scholar]
- CASIA-1: Southern Accent Speech Corpus. Chinese Academy of Sciences. 2003. Available online: http://www.chineseldc.org/doc/CLDC-SPC-2004-016/intro.htm (accessed on 1 April 2003).
- CASIA-2: Northern Accent Speech Corpus. Chinese Academy of Sciences. 2003. Available online: http://www.chineseldc.org/doc/CLDC-SPC-2004-015/intro.htm (accessed on 1 April 2003).
- Sarangi, S.; Sahidullah, M.; Saha, G. Optimization of data-driven filterbank for automatic speaker verification. Digit. Signal Process. 2020, 104, 102795. [Google Scholar] [CrossRef]
- Yao, Z.; Wu, D.; Wang, X.; Zhang, B.; Yu, F.; Yang, C.; Peng, Z.; Chen, X.; Xie, L.; Lei, X. Wenet: Production oriented streaming and non-streaming end-to-end speech recognition toolkit. arXiv 2021, arXiv:2102.01547. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Wu, Z.; Liu, Z.; Lin, J.; Lin, Y.; Han, S. Lite transformer with long-short range attention. arXiv 2020, arXiv:2004.11886. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6077–6086. [Google Scholar]
- Luong, M.-T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2017; Volume 30. [Google Scholar]
- Wang, W.; Sun, Y.; Qi, Q.; Meng, X. Text Sentiment Classification Model based on BiGRU-attention Neural Network. Appl. Res. Comput. 2019, 36, 3558–3564. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, R.; Yuan, Z.; Liu, T.; Xiong, Z. End-to-end lane shape prediction with transformers. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 3694–3702. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2019; Volume 32. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Ko, T.; Peddinti, V.; Povey, D.; Khudanpur, S. Audio augmentation for speech recognition. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.-C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. Specaugment: A simple data augmentation method for automatic speech recognition. arXiv 2019, arXiv:1904.08779. [Google Scholar]
- SoX, Audio Manipulation Tool. 2015. Available online: https://sox.sourceforge.net/ (accessed on 25 March 2015).
- Lee, J.; Watanabe, S. Intermediate loss regularization for ctc-based speech recognition. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–12 June 2021; pp. 6224–6228. [Google Scholar]
- Romero-Fresco, P. Respeaking: Subtitling through speech recognition. In The Routledge Handbook of Audiovisual Translation; Routledge: Abingdon, UK, 2018; pp. 96–113. [Google Scholar]
- Waibel, A.; Hanazawa, T.; Hinton, G.; Shikano, K.; Lang, K.J. Phoneme recognition using time-delay neural networks. IEEE Trans. Acoust. Speech Signal Process. 1989, 37, 328–339. [Google Scholar] [CrossRef]
- Hu, Z.; Jian, F.; Tang, S.; Ming, Z.; Jiang, B. DFSMN-T:Mandarin Speech Recognition with Language Model Transformer. Comput. Eng. Appl. 2022, 58, 187–194. [Google Scholar]
- Chen, S.; Hu, X.; Li, S.; Xu, X. An investigation of using hybrid modeling units for improving end-to-end speech recognition system. Proceedings of ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–12 June 2021; pp. 6743–6747. [Google Scholar]
- Xie, X.; Chen, G.; Ssun, J.; Chen, Q. TCN-Transformer-CTC for End-to-End Speech Recognition. Appl. Res. Comput. 2022, 39, 699–703. [Google Scholar]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).