
Facial Expression Recognition Methods in the Wild Based on Fusion Feature of Attention Mechanism and LBP
Abstract
:1. Introduction
- (1)
- Proposed is a residual attention mechanism for facial expression detection in the field that combines a hybrid attention mechanism generated by progressively coupling a channel attention mechanism and a spatial attention mechanism with a residual network. The hybrid attention mechanism may learn the key information of each channel and spatial feature separately to boost the capability of feature expression. Furthermore, inserting the hybrid attention mechanism into the residual network can cause the network to focus on the important regions of facial characteristics.
- (2)
- Proposed is a feature fusion network of a locally increased attention mechanism for fusing the hybrid attention mechanism network model with LBP features. The attention method enables the model to focus more on crucial aspects of facial expressions and suppress irrelevant features, which can substantially increase recognition ability. LBP can capture fine texture details and effectively extract feature information on facial expression images to increase the identification rate of a network.
- (3)
- This paper conducted comprehensive experiments on four public datasets, including both laboratory and wild datasets, to evaluate the proposed approach in this research. The dataset acquired under laboratory conditions is CK+, and the datasets collected in field environments are RAF-DB, FER2013, and FERPLUS. Compared with the current state-of-the-art methods, the suggested method of this paper has superior generalization ability and robustness, and the explanatory power is also improved.
2. Related Work
2.1. Traditional Methods for FER in the Wild
2.2. LBP Fusion for Facial Expression Recognition in the Wild
2.3. Attention Mechanism for Facial Expression Recognition Methods
3. Proposed Method
3.1. Overview
3.2. Residual Attention Mechanism Model
3.2.1. CBAM Attention Module
3.2.2. Residual Attention Module
3.3. Locally Enhanced Residual Network
3.3.1. Local Binary Patterns
3.3.2. Network Architecture
3.4. Loss Function
4. Experiments
4.1. Datasets
4.2. Implement Details
4.3. Evaluation and Comparison
4.4. Ablation Study
4.5. Visualization
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, S.; Deng, W. Deep Facial Expression Recognition: A Survey. IEEE Trans. Affective Comput. 2022, 13, 1195–1215. [Google Scholar] [CrossRef]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The Extended Cohn-Kanade Dataset (CK+): A Complete Dataset for Action Unit and Emotion-Specified Expression. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition—Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 94–101. [Google Scholar]
- Lyons, M.; Akamatsu, S.; Kamachi, M.; Gyoba, J. Coding Facial Expressions with Gabor Wavelets. In Proceedings of the Third IEEE International Conference on Automatic Face and Gesture Recognition, Nara, Japan, 14–16 April 1998; pp. 200–205. [Google Scholar]
- Valstar, M.F.; Pantic, M. Induced Disgust, Happiness and Surprise: An Addition to the MMI Facial Expression Database. In Proceedings of the 3rd International Workshop on Emotion, Paris, France, 29 October 2010. [Google Scholar]
- Zhao, G.; Huang, X.; Taini, M.; Li, S.Z.; Pietikäinen, M. Facial Expression Recognition from Near-Infrared Videos. Image Vis. Comput. 2011, 29, 607–619. [Google Scholar] [CrossRef]
- Li, S.; Deng, W.; Du, J. Reliable Crowdsourcing and Deep Locality-Preserving Learning for Expression Recognition in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2584–2593. [Google Scholar]
- Benitez-Quiroz, C.F.; Srinivasan, R.; Martinez, A.M. EmotioNet: An Accurate, Real-Time Algorithm for the Automatic Annotation of a Million Facial Expressions in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 5562–5570. [Google Scholar]
- Barsoum, E.; Zhang, C.; Ferrer, C.C.; Zhang, Z. Training Deep Networks for Facial Expression Recognition with Crowd-Sourced Label Distribution. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, New York, NY, USA, 31 October 2016; pp. 279–283. [Google Scholar]
- Mollahosseini, A.; Hasani, B.; Mahoor, M.H. AffectNet: A Database for Facial Expression, Valence, and Arousal Computing in the Wild. IEEE Trans. Affective Comput. 2019, 10, 18–31. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution Gray-Scale and Rotation Invariant Texture Classification with Local Binary Patterns. IEEE Trans. Pattern Anal. Machine Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Ruicong, Z.; Flierl, M.; Ruan, Q.; Kleijn, W.B. Graph-Preserving Sparse Nonnegative Matrix Factorization with Application to Facial Expression Recognition. IEEE Trans. Syst. Man Cybern. B 2011, 41, 38–52. [Google Scholar] [CrossRef]
- Shojaeilangari, S.; Yau, W.-Y.; Nandakumar, K.; Li, J.; Teoh, E.K. Robust Representation and Recognition of Facial Emotions Using Extreme Sparse Learning. IEEE Trans. Image Process. 2015, 24, 2140–2152. [Google Scholar] [CrossRef]
- Niu, B.; Gao, Z.; Guo, B. Facial Expression Recognition with LBP and ORB Features. Comput. Intell. Neurosci. 2021, 2021, 8828245. [Google Scholar] [CrossRef]
- Yang, H.; Zhu, K.; Huang, D.; Li, H.; Wang, Y.; Chen, L. Intensity Enhancement via GAN for Multimodal Face Expression Recognition. Neurocomputing 2021, 454, 124–134. [Google Scholar] [CrossRef]
- Abiram, R.N.; Vincent, P.M.D.R. Identity Preserving Multi-Pose Facial Expression Recognition Using Fine Tuned VGG on the Latent Space Vector of Generative Adversarial Network. MBE 2021, 18, 3699–3717. [Google Scholar] [CrossRef]
- Li, Y.; Zeng, J.; Shan, S.; Chen, X. Occlusion Aware Facial Expression Recognition Using CNN With Attention Mechanism. IEEE Trans. Image Process. 2019, 28, 2439–2450. [Google Scholar] [CrossRef] [PubMed]
- Wang, K.; Peng, X.; Yang, J.; Meng, D.; Qiao, Y. Region Attention Networks for Pose and Occlusion Robust Facial Expression Recognition. IEEE Trans. Image Process. 2020, 29, 4057–4069. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.J.; Erhan, D.; Carrier, P.L.; Courville, A.; Mirza, M.; Hamner, B.; Cukierski, W.; Tang, Y.; Thaler, D.; Lee, D.-H.; et al. Challenges in Representation Learning: A Report on Three Machine Learning Contests. In Neural Information Processing; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Dhall, A.; Goecke, R.; Ghosh, S.; Joshi, J.; Hoey, J.; Gedeon, T. From Individual to Group-Level Emotion Recognition: EmotiW 5.0. In Proceedings of the Proceedings of the 19th ACM International Conference on Multimodal Interaction, Glasgow, UK, 3 November 2017; ACM: Glasgow, UK; pp. 524–528. [Google Scholar]
- Tang, Y. Deep Learning Using Linear Support Vector Machines. arXiv 2015, arXiv:1306.0239. [Google Scholar]
- Kanou, S.E.; Ferrari, R.C.; Mirza, M.; Jean, S.; Carrier, P.-L.; Dauphin, Y.; Boulanger-Lewandowski, N.; Aggarwal, A.; Zumer, J.; Lamblin, P.; et al. Combining Modality Specific Deep Neural Networks for Emotion Recognition in Video. In Proceedings of the Proceedings of the 15th ACM on International conference on multimodal interaction—ICMI ’13, Sydney, Australia, 9–13 December 2013; ACM Press: Sydney, Australia, 2013; pp. 543–550. [Google Scholar]
- Yang, B.; Cao, J.; Ni, R.; Zhang, Y. Facial Expression Recognition Using Weighted Mixture Deep Neural Network Based on Double-Channel Facial Images. IEEE Access 2018, 6, 4630–4640. [Google Scholar] [CrossRef]
- Bazzo, J.J.; Lamar, M.V. Recognizing Facial Actions Using Gabor Wavelets with Neutral Face Average Difference. In Proceedings of the Sixth IEEE International Conference on Automatic Face and Gesture Recognition (FGR 2004), Seoul, Republic of Korea, 17–19 May 2004. [Google Scholar]
- Luo, Y.; Wu, C.; Zhang, Y. Facial Expression Recognition Based on Fusion Feature of PCA and LBP with SVM. Opt.—Int. J. Light Electron Opt. 2013, 124, 2767–2770. [Google Scholar] [CrossRef]
- Mehta, D.; Siddiqui, M.F.H.; Javaid, A.Y. Recognition of Emotion Intensities Using Machine Learning Algorithms: A Comparative Study. Sensors 2019, 19, 1897. [Google Scholar] [CrossRef]
- Kimura, A.; Yonetani, R.; Hirayama, T. Computational Models of Human Visual Attention and Their Implementations: A Survey. IEICE Trans. Inf. Syst. 2013, E96.D, 562–578. [Google Scholar] [CrossRef]
- Fernandez, P.D.M.; Pena, F.A.G.; Ren, T.I.; Cunha, A. FERAtt: Facial Expression Recognition with Attention Net. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–20 June 2019; pp. 837–846. [Google Scholar]
- Zhu, X.; He, Z.; Zhao, L.; Dai, Z.; Yang, Q. A Cascade Attention Based Facial Expression Recognition Network by Fusing Multi-Scale Spatio-Temporal Features. Sensors 2022, 22, 1350. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; Volume 11211, pp. 3–19. ISBN 978-3-030-01233-5. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond Empirical Risk Minimization. arXiv 2018, arXiv:1710.09412. [Google Scholar]
- Pramerdorfer, C.; Kampel, M. Facial Expression Recognition Using Convolutional Neural Networks: State of the Art. arXiv 2016, arXiv:1612.02903. [Google Scholar]
- Meng, H.; Yuan, F.; Tian, Y.; Yan, T. Facial Expression Recognition Based on Landmark-Guided Graph Convolutional Neural Network. J. Electron. Imag. 2022, 31, 023025. [Google Scholar] [CrossRef]
- Chang, T.; Wen, G.; Hu, Y.; Ma, J. Facial Expression Recognition Based on Complexity Perception Classification Algorithm. arXiv 2018, arXiv:1803.00185. [Google Scholar]
- Miao, S.; Xu, H.; Han, Z.; Zhu, Y. Recognizing Facial Expressions Using a Shallow Convolutional Neural Network. IEEE Access 2019, 7, 78000–78011. [Google Scholar] [CrossRef]
- Wang, W.; Sun, Q.; Chen, T.; Cao, C.; Zheng, Z.; Xu, G.; Qiu, H.; Fu, Y. A Fine-Grained Facial Expression Database for End-to-End Multi-Pose Facial Expression Recognition. arXiv 2019, arXiv:1907.10838. [Google Scholar]
- Hasani, B.; Negi, P.S.; Mahoor, M.H. BReG-NeXt: Facial Affect Computing Using Adaptive Residual Networks with Bounded Gradient. IEEE Trans. Affective Comput. 2022, 13, 1023–1036. [Google Scholar] [CrossRef]
- Zhu, Q.; Gao, L.; Song, H.; Mao, Q. Learning to Disentangle Emotion Factors for Facial Expression Recognition in the Wild. Int. J. Intell. Syst. 2021, 36, 2511–2527. [Google Scholar] [CrossRef]
- Khaireddin, Y.; Chen, Z. Facial Emotion Recognition: State of the Art Performance on FER2013. arXiv 2019, arXiv:2105.03588. [Google Scholar]
- Huang, C. Combining Convolutional Neural Networks for Emotion Recognition. In Proceedings of the IEEE MIT Undergraduate Research Technology Conference (URTC), Cambridge, MA, USA, 4–6 November 2017; pp. 1–4. [Google Scholar]
- Albanie, S.; Nagrani, A.; Vedaldi, A.; Zisserman, A. Emotion Recognition in Speech Using Cross-Modal Transfer in the Wild. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 15 October 2018; ACM: Seoul, Republic of Korea, 2018; pp. 292–301. [Google Scholar]
- Ma, F.; Sun, B.; Li, S. Facial Expression Recognition with Visual Transformers and Attentional Selective Fusion. IEEE Trans. Affective Comput. 2021, 1-1. [Google Scholar] [CrossRef]
- Xia, H.; Li, C.; Tan, Y.; Li, L.; Song, S. Destruction and Reconstruction Learning for Facial Expression Recognition. IEEE MultiMedia 2021, 28, 20–28. [Google Scholar] [CrossRef]
- Gera, D.; Balasubramanian, S.; Jami, A. CERN: Compact Facial Expression Recognition Net. Pattern Recognit. Lett. 2022, 155, 9–18. [Google Scholar] [CrossRef]
- Nan, Y.; Ju, J.; Hua, Q.; Zhang, H.; Wang, B. A-MobileNet: An Approach of Facial Expression Recognition. Alex. Eng. J. 2022, 61, 4435–4444. [Google Scholar] [CrossRef]
- Rodriguez, P.; Cucurull, G.; Gonzalez, J.; Gonfaus, J.M.; Nasrollahi, K.; Moeslund, T.B.; Roca, F.X. Deep Pain: Exploiting Long Short-Term Memory Networks for Facial Expression Classification. IEEE Trans. Cybern. 2022, 52, 3314–3324. [Google Scholar] [CrossRef] [PubMed]
- Shao, J.; Qian, Y. Three Convolutional Neural Network Models for Facial Expression Recognition in the Wild. Neurocomputing 2019, 355, 82–92. [Google Scholar] [CrossRef]
- Turan, C.; Lam, K.-M.; He, X. Soft Locality Preserving Map (SLPM) for Facial Expression Recognition. arXiv 2018, arXiv:1801.03754. [Google Scholar]
- Liu, X.; Cheng, X.; Lee, K. GA-SVM-Based Facial Emotion Recognition Using Facial Geometric Features. IEEE Sens. J. 2021, 21, 11532–11542. [Google Scholar] [CrossRef]
- Kabakus, A.T. PyFER: A Facial Expression Recognizer Based on Convolutional Neural Networks. IEEE Access 2020, 8, 142243–142249. [Google Scholar] [CrossRef]
- Dharanya, V.; Joseph Raj, A.N.; Gopi, V.P. Facial Expression Recognition through Person-Wise Regeneration of Expressions Using Auxiliary Classifier Generative Adversarial Network (AC-GAN) Based Model. J. Vis. Commun. Image Represent. 2021, 77, 103110. [Google Scholar] [CrossRef]
- Filali, H.; Riffi, J.; Aboussaleh, I.; Mahraz, A.M.; Tairi, H. Meaningful Learning for Deep Facial Emotional Features. Neural. Process. Lett. 2022, 54, 387–404. [Google Scholar] [CrossRef]
- Yu, W.; Xu, H. Co-Attentive Multi-Task Convolutional Neural Network for Facial Expression Recognition. Pattern Recognit. 2022, 123, 108401. [Google Scholar] [CrossRef]
- Zhao, Z.; Liu, Q.; Wang, S. Learning Deep Global Multi-Scale and Local Attention Features for Facial Expression Recognition in the Wild. IEEE Trans. Image Process. 2021, 30, 6544–6556. [Google Scholar] [CrossRef]
- Li, Z.; Han, S.; Khan, A.S.; Cai, J.; Meng, Z.; O’Reilly, J.; Tong, Y. Pooling Map Adaptation in Convolutional Neural Network for Facial Expression Recognition. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 1108–1113. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Year | Accuracy (%) |
|---|---|---|
| ResNet [34] | 2016 | 72.40 |
| CPC [36] | 2018 | 71.35 |
| SHCNN [37] | 2019 | 69.10 |
| Fa-Net [38] | 2019 | 71.10 |
| BReG-NeXt-50 [39] | 2020 | 71.53 |
| DisEmoNet [40] | 2021 | 71.72 |
| VGGNet [41] | 2021 | 73.28 |
| Landmark-guided GCNN [35] | 2022 | 73.26 |
| Ours | 2022 | 74.23 |
| Method | Year | Accuracy (%) |
|---|---|---|
| ResNet+VGG [42] | 2017 | 87.40 |
| SENet [43] | 2018 | 88.80 |
| SHCNN [37] | 2019 | 86.54 |
| RAN [19] | 2020 | 88.55 |
| VTFF [44] | 2021 | 88.81 |
| ADC-Net [45] | 2021 | 88.90 |
| CERN [46] | 2022 | 88.17 |
| A-MobileNet [47] | 2022 | 88.11 |
| Ours | 2022 | 89.53 |
| Method | Year | Accuracy (%) |
|---|---|---|
| VGG Net+LSTM [48] | 2017 | 97.2 |
| SLPM [49] | 2018 | 96.1 |
| Pre-trained CNN [50] | 2019 | 95.29 |
| GA-SVM [51] | 2020 | 97.59 |
| PyFER [52] | 2020 | 96.3 |
| AC-GAN [53] | 2021 | 97.39 |
| CNN+SAE [54] | 2022 | 98.65 |
| CMCNN [55] | 2022 | 98.33 |
| Ours | 2022 | 99.66 |
| Method | Year | Accuracy (%) |
|---|---|---|
| gACNN [18] | 2018 | 85.07 |
| APM-VGG [57] | 2019 | 85.17 |
| MA-Net [56] | 2020 | 88.42 |
| DisEmoNet [40] | 2020 | 83.78 |
| RAN [19] | 2020 | 86.90 |
| VIFF [44] | 2021 | 88.14 |
| A-MobileNet [47] | 2022 | 84.49 |
| CMCNN [55] | 2022 | 85.22 |
| Ours | 2022 | 88.20 |
| Model | FER2013 | FERPLUS | CK+ | RAF-DB |
|---|---|---|---|---|
| Baseline | 68.29% | 86.84% | 92.29% | 82.92% |
| ResNet+CBAM | 72.69% | 88.47% | 97.14% | 85.82% |
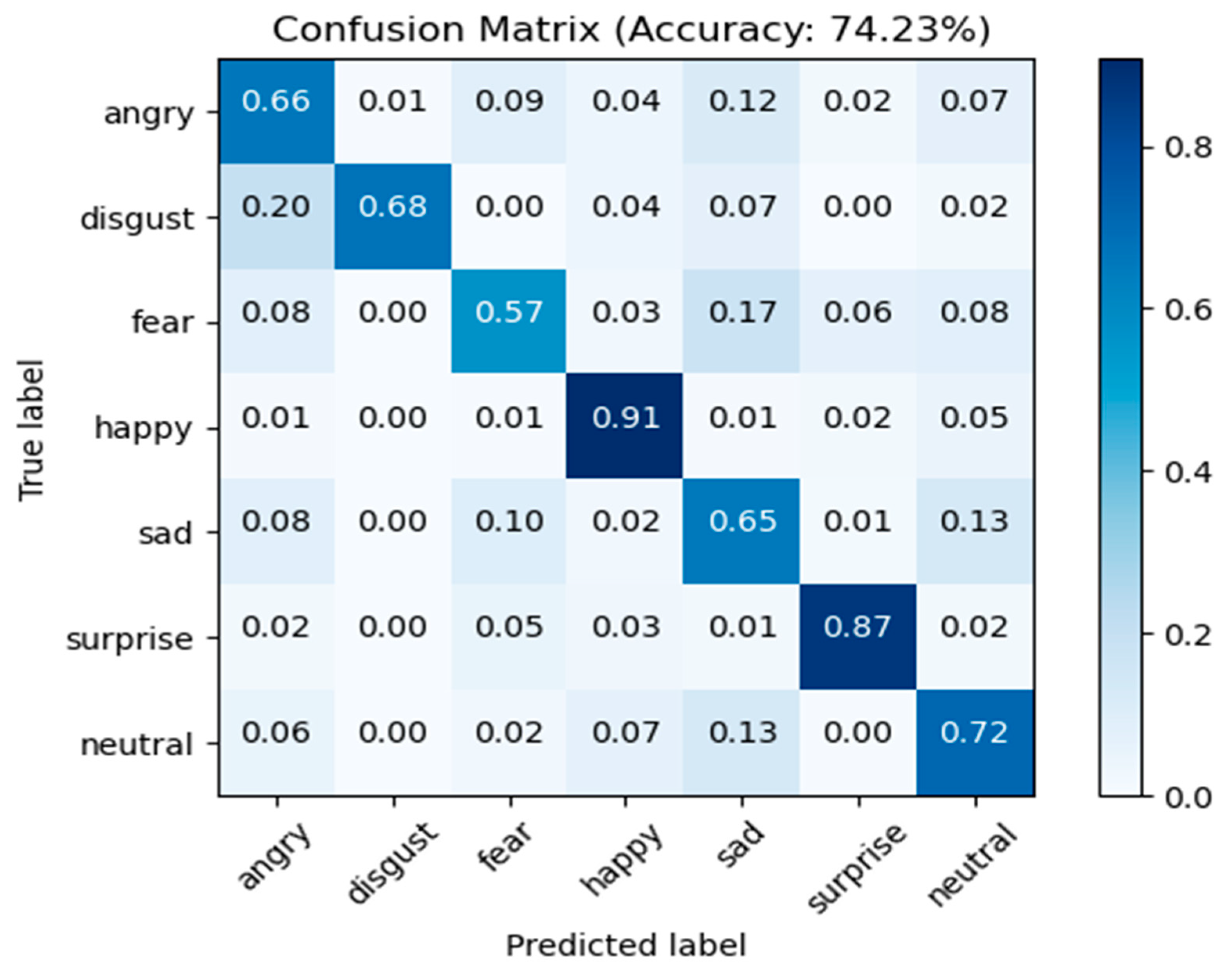
| ResNet+CBAM+LBP | 74.23% | 89.53% | 99.66% | 88.20% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liao, J.; Lin, Y.; Ma, T.; He, S.; Liu, X.; He, G. Facial Expression Recognition Methods in the Wild Based on Fusion Feature of Attention Mechanism and LBP. Sensors 2023, 23, 4204. https://doi.org/10.3390/s23094204
Liao J, Lin Y, Ma T, He S, Liu X, He G. Facial Expression Recognition Methods in the Wild Based on Fusion Feature of Attention Mechanism and LBP. Sensors. 2023; 23(9):4204. https://doi.org/10.3390/s23094204
Chicago/Turabian StyleLiao, Jun, Yuanchang Lin, Tengyun Ma, Songxiying He, Xiaofang Liu, and Guotian He. 2023. "Facial Expression Recognition Methods in the Wild Based on Fusion Feature of Attention Mechanism and LBP" Sensors 23, no. 9: 4204. https://doi.org/10.3390/s23094204