1. Introduction
Over the last decade, the research and applications of multimodal emotion recognition have become increasingly emerging to cater emotional states [
1]. Real-time analysis of emotional states through diverse data sources has become one of the most demanding and important research fields [
2]. With the appearance of such a diverse technology ecosystem, the concept of multimodality arose very naturally and has brought us numerous breakthroughs for the use of emotions in the fields like affective computing, human–computer interaction (HCI), education, gaming, customer services, healthcare, user experience (UX) evaluation, etc. The application of emotion recognition methods in UX evaluation, however, has not always been so straightforward. As UX has become an essential process to measure the user’s satisfaction and usability, for which emotion can act as a key aspect for evaluating practical applications or software products [
3].
Most of the applications adopt human emotion recognition by automatically detecting, processing and performing analysis of human emotions obtained through raw sensory data. The possibility of integrating emotions from multimodal data for UX evaluation to assess the user’s satisfaction and engagement is further reinforced by an overall recognition accuracy and robustness [
4]. A possible solution to improve multimodal emotion recognition accuracy is to deal with misclassification defects in some modalities, which may be compensated by some other modality. Finally, obtained emotions from multimodal data might offer helpful feedback for future UX enhancements [
5].
Physiological signals analysis, face expression analysis, audio signal analysis, and text input analysis are some of the most frequently used multimodal emotion sensing modalities that might be taken into account while designing a method for UX evaluation. For these, numerous machine learning and deep learning methods have been employed to track features derived independently from each sensory modality and then fuse them either in feature level or decision level [
6].
On the other hand, each of the learning method has its own advantages and disadvantages, hence, drawing a general conclusion about the emotions obtained from multi-modalities is challenging. Using different algorithms for each modality usually show inconsistent classification confidence due to the nature of different feature set used, obtained for each modality. From this point of view, it becomes necessary to adopt ensemble-based system for the fusion of output from multiple classifiers [
7]. In the literature, various ensemble-based systems have proven themselves to be very effective and have shown their importance in reducing variability, thereby improving the accuracy of automatic human emotion recognition in a multimodal environment. The majority of classifier ensembles apply procedures to define static weights, which are used along with the outputs of the individual classifiers to define the final output of the classifier ensembles. As the accuracy of a single classifier might fluctuate in the testing search space, a static method of generating weights may eventually become inefficient for a classifier ensemble. One way to improve the efficiency is to use the dynamic weights in a combination methods, for this we aim to use a dynamic weighting method supported by generalized mixture (GM) functions [
8]. The main advantage of the GM functions is the ability to specify dynamic weights at the member output, which increases the effectiveness of the combination process.
The objective of this article is to enhance the precision of decision fusion. To achieve this goal, we have implemented a novel approach for multimodal fusion in UX evaluation, using GM functions as an efficient combination procedure. Secondly, to improve the UX evaluation process by recognizing and understanding users’ emotions in real-time, we developed a multimodal input collection module that supported cross-modality sensing (CMS) and conducted temporal alignment (TA) of stream events to acquire multimodal data. We evaluated our proposed method on a dataset consisting of individuals’ audio, video, and body language recordings while interacting with stimuli designed to elicit various emotions. Our study revealed that the emotional UX can be enhanced through our proposed approach, which involves real-time detection and understanding of user emotions. We suggested combining data from various modalities through feature-level and decision-level fusion to improve the accuracy of emotion recognition.
The rest of the paper is structured as follows,
Section 2 describes related work.
Section 3 discusses the proposed approach.
Section 4 compares experimental evaluations. Finally,
Section 5 draw conclusions and future work.
2. Related Work
Much effort has focused on developing frameworks for extracting human emotions from a single modality such as text, video, and audio. However, the robustness of unimodally recognised emotions is still lacking and making it more challenging for multimodal emotions recognition due to inter-modality dependencies. There are various ways in which human emotions have been suggested to be used for different purposes in the literature, such as: emotion recognition, sentiment analysis, event detection, semantic concept detection, image segmentation, human tracking, video classification, and UX enhancement.
UX evaluation, one of the aforementioned approaches, utilizes human emotions, to cover various aspects for the effective use of a product, service, or complete system [
9]. The movement of facial muscles, specifically the inner and outer brows, is utilized by humans to deliberately or unintentionally communicate emotional cues. Consequently, a thorough facial expression analysis may effectively identify active muscle groups involve in different emotional responses, such as
Anger,
Sadness,
Joy,
Surprise, and
Disgust. So, a deeper understanding of human emotional reactions can be produced through an automatic facial expression analysis. Similarly, speech with different voice characteristics such as intensity, speech rate, pitch, spectral energy distribution, prosodic and acoustic features, also plays an important role to identify human emotions [
10].
Non-verbal body gestures, or body language, are equally crucial to emotion recognition as visual and audio-based modalities. They can also provide a critical context for understanding how users engage with the applications mentioned previously. Most of the applications deploy cameras, or depth cameras, to detect emotions by capturing user’s body language. With the increasing number of sensing modalities, the integration of these modalities poses more challenges in multimodal environments. Therefore, a mechanism for multimodal fusion is necessary to process features, make decisions, and perform analysis tasks [
11].
Prior studies on multimodal fusion have adopted different research approaches and methods. Among these methods, feature-level fusion (early fusion) and decision-level fusion (late fusion) are the two most common studies that researcher mostly focused on. Ma et al. [
12] proposed a cross-modal noise modeling and fusion methodology over multimodal audio and visual data. For this, they trained a 2D convolutional neural network (2D-CNN) model using the image-based mel-spectrograms as input data and a 3D-CNN for detecting emotions from facial expressions in an image sequence. They, however, worked mainly on preprocessing tasks such as handling noisy audio streams and reducing redundancy by proposing time-based data segmentation. Deep convolutional neural network (DCNN) was also utilized for automatic feature learning using discriminant temporal pyramid matching (DTPM) in speech emotion recognition tasks [
13].
Li et al. [
14] suggested a novel approach to perform multimodal fusion through the utilization of multimodal interactive attention network (MIA-Net). They only considered the modality that had the most impact on the emotion to be the primary modality, with every other modality termed as auxiliary. It may, however lead to a bias towards primary modality and potentially overlook important information from auxiliary modalities. Therefore choosing an appropriate approach for multimodal fusion may lead to certain benefits such as (1) possibility of more accurate predictions; (2) ability to collect information that is not observable in each modality alone; and (3) ability for a multimodal application to continue functioning even if, any of the modalities is absent [
15].
A comprehensive review of emotion identification system with underlining basic neural network classification models are described in a study by Gravina et al. [
16]. They offered a framework for standard comparison and a methodical classification of the literature on data-level, feature-level, and decision-level multi-sensor fusion approaches. A strategy of utilizing data from vision and inertial sensors for feature-level fusion was also adapted by Ehatisham et al. [
17]. They examined and validated the effectiveness of feature-level fusion in contrast with the results obtained from decision-level fusion methods. Radu et al. [
6] proposed a modality-specific architecture to demonstrate the capabilities of feature learning to produce accurate emotion recognition results. They demonstrated feature concatenation irrespective of sensing modality and ensemble classification for integrating conflicting information from diverse sources.
As described earlier, each multimodal fusion strategy has its merits and demerits. However, multimodal decision-level fusion overcomes the drawbacks of early fusion techniques to improve the performance of any emotion recognition system. The outcomes of each emotion model are combined for prediction, using various integration techniques including averaging, majority voting, ensemble classification, weighting based on channel noise, signal variance, or through a learned model [
18]. Thuseethan et al. [
19] have used a hybrid fusion approach to extract and appropriately combine correlated features from face, body pose, and contextual information. Wang et al. [
20] designed hybrid fusion model, which combined feature-level fusion and decision-level fusion by finding correlation properties between the features extracted from different modalities. The final emotion state is computed with the help of a combination strategy based on either an equal weights or a variable weight scheme. Przybyla et al. [
21] proposed a fusion method for a joint prediction which is provided through a group of classifiers using multiplicative weighting method where weights are assigned iteratively.
The main disadvantage of ensemble-based decision-level fusion is the use of weighting strategies to combine independent and stand-alone classification decisions related to each sensory modality with aim of generating a precise prediction [
22]. Therefore, N-classifiers must be trained and evaluated individually on each sensing modality to perform decision-level fusion. There are several methods for computing weights to increase the confidence of each class belonging to a classifier. These decisions are combined by minimizing an error criterion or using weighted voting schemes in ensemble classification [
23,
24].
In the presented study, to evaluate the performance of emotions, we performed empirical analysis of ensemble classifier using the GM functions combination method for the LeanUX platform [
25]. In this method, the output from many independent classifiers is combined using GM functions as a mean of combination. The key benefit of these GM functions is the ability to define dynamic weights at the member classifier outputs, which increases the effectiveness of the combination process. The weight of each classifier is dynamically determined throughout the combination process and does not even require any training. These GM functions generalize dynamic weights based on mixture functions and ordered weighted averaging (OWA).
Overall, the main contribution of this article is fourfold: (1) We propose a hybrid multimodal emotion recognition (H-MMER) framework with multi-level fusion such as unimodal emotion recognition, multimodal feature fusion, and decision-level fusion. (2) An ensembling method within the H-MMER framework utilizing the GM functions has been adopted, which is capable of producing more accurate and consistent emotion recognition predictions. (3) A novel weight combination approach using the GM functions is suggested to assign dynamic weights to each emotion from an individual modality. The proposed framework captures multimodal time-varying data and estimates the joint emotions with high accuracy even without constructing or training an additional model. (4) As a practical contribution, we evaluated our framework in an ongoing research platform called the “LeanUX platform”, which uses acquired emotions for UX measurement, while users interact with the system, product, or a service.
4. Experimental Evaluations
This section presents the implementation methods to evaluate the proposed framework using three experiments performed to determine accurate human emotions. These experiments included unimodal methods for individual modalities, multimodal feature-level fusion, and GM function-based decision-level fusion. To evaluate these methods, we used confusion matrices for each emotion. The fused emotion accuracies and decision fusion emotion scores supported each modality’s through detailed analysis. Moreover, the section also presents the datasets, framework validation using suitable evaluation metrics, and finally, comparisons are drawn with state-of-the-art.
4.1. Dataset and Implementation
The recognition process involved 4 candidate emotions
Happiness,
Neutral,
Sadness, and
Anger, portrayed by 10 participants with ages between 22 and 35 years. They included university-enrolled students, equal in gender (five male and five female) of mixed race to evaluate the Lean UX Platform [
25]. All experiments were performed in a controlled lighting environment, with each participant guided about different frontal face positions and upper body movements in front of the webcam at a minimum distance of 1.5 m. These users were allowed to move and react freely at a maximum distance of 4 m. The dataset was collected from different modalities by deploying devices such as Kinect v2, webcam, and microphone within the sessions of approximately 15 min for each participant. A special desktop application under the LeanUX framework was developed to collect data. The proposed H-MMER framework was deployed on a computer running the Windows 10 OS, and is equipped with an Intel i-7 processor, 16 GB of RAM, and a 6 GB graphics card.
The dataset pool for detecting body language and face images consist of a total of 216,000 frames captured at a rate of 30 fps from webcam and Kinect v2. These frames were collected from 10 users performing each emotion for approximately 3 min according to list of actions. To elaborate, there are 55,300 frames that have been categorized as expressing Happiness, 55,700 frames that depict a Neutral emotion, 54,240 frames that display Sadness, and 50,760 frames that exhibit Anger. The framework is designed to update the emotion result each 3 s, i.e., features are extracted from each 90 frames to be classified into an emotion label.
Each body language frame comprises 45 parameters, which include the x, y, and z coordinates of 15 skeleton joints that are used to represent one of the four emotions. It is important to observe that in each frame, all 15 3D points are detected completely without any overlaps or missing points. After preprocessing we extracted around 280 features using MDF and MAF methods. Similarly, webcam collected a stream of frames of size at a rate of 30 fps for human face detection and facial emotion recognition. In total, we obtained 512 HoG and SIFT features for ROIs in a frame for detecting face.
Additionally, the voice samples were also recorded using a microphone by each of the participants who were instructed to speak approximately 40 pre-scripted sentences in the Korean language, 10 for each emotion. These sentences were spoken at varying levels of intensity (high, medium, and low) and speech rate. Around 2750 voice samples were finalized by the LeanUX platform’s expert team, who categorized them into different emotions. Specifically, there were approximately 620 voice samples for
Happiness, 830 for
Neutral, 760 for
Sadness, and 540 for
Anger. After undergoing preprocessing, approximately 100 features were computed for audio emotion recognition. These features consisted of 52 MFCC, 4 LPC, 4 Energy, and 4 Pitch, each evaluated for 4 statistical measures such as standard deviation, mean, minimum, and maximum with detailed discussion in
Section 3.2.2.
We pre-processed the data and independently extracted different features depending on the modality. We obtained video feature vectors of dimensions m × n, skeletal features p × q, and audio features s × t, where m, p, s represent number of features and n, q, t represents number of instances, respectively. These feature vectors are fed to individual classifiers for emotion recognition, whereas for a multimodal feature and decision fusion, these feature vectors undergo transformation by keeping n, q, and t equal to a feature vector size based on the lowest estimated size. The equal-sized feature vectors are then concatenated to perform multimodal feature and decision fusion.
4.2. Multimodal Emotion Recognition Results
In our comprehensive evaluation discussions, we described multiple evaluation tasks, firstly for each modality and then for a multimodal feature and decision fusion. We reported confusion matrices and accuracies for predicted emotion categories.
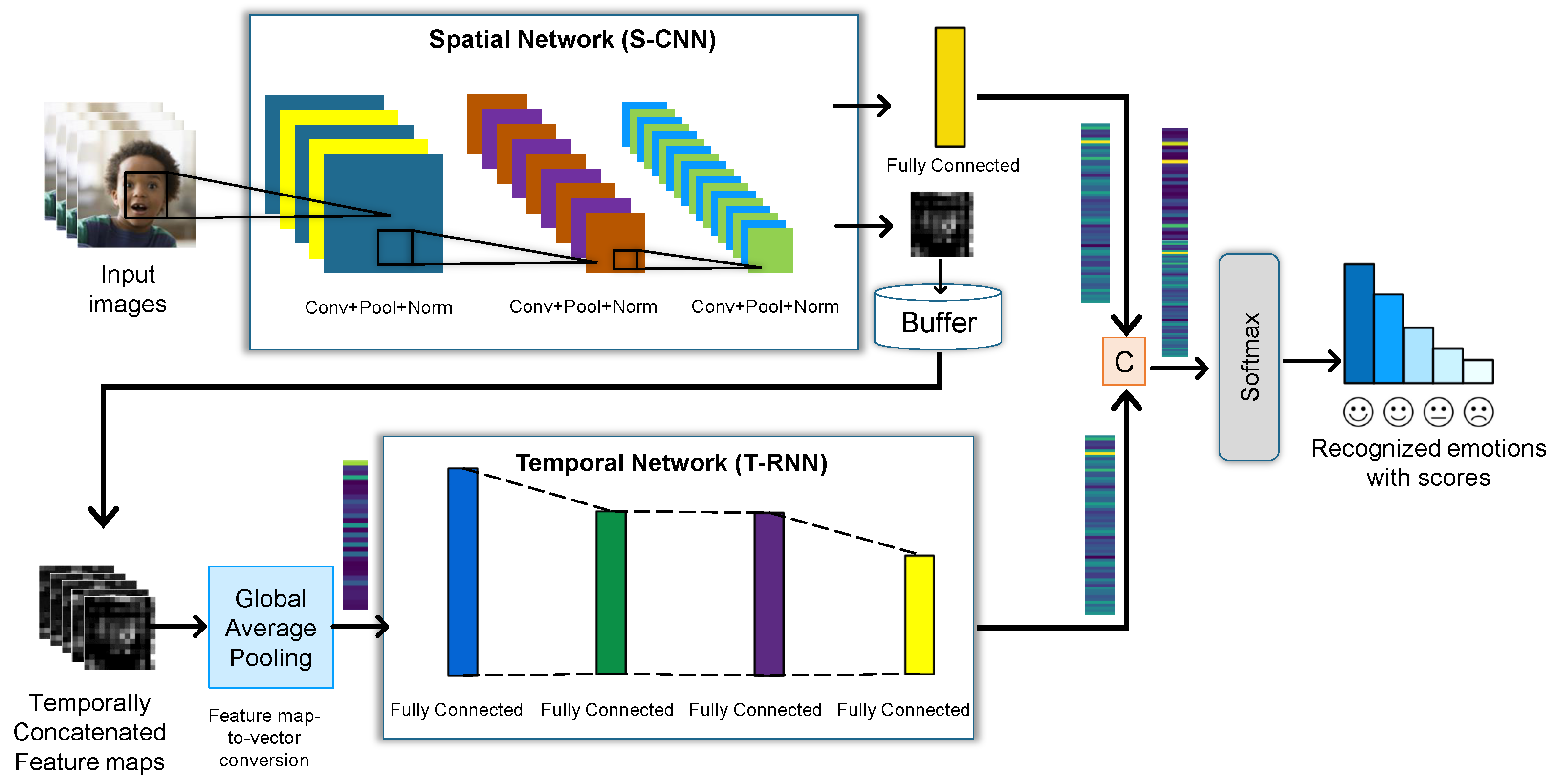
4.2.1. Performance Analysis of Video-Based Emotion Recognition
In order to recognize video-based emotions, the developed component extracted feature from an input image and recognize emotion using multi-class logistic regression (softmax) classifier. The softmax classifier uses information theory-based ranking criteria to calculate probabilistic emotion scores. These scores represented multiple outputs with specific confidence for each predicted emotion label. So the output of the FER-Dual-Net model interpreted the user’s facial emotions more objectively using a multi-class logistic regression classifier. The confusion matrix for video-based emotions is shown in
Table 1. It is found that among the accuracies of four emotion labels, the
Happiness and
Anger classes get higher accuracies of 95% and 94.95%, respectively. The classifier well-recognized these emotions due to the discriminative facial characteristics within the spatio-temporal domain.
Neutral and
Sadness emotions, however, have lower accuracies of 89.13% and 86.75%, respectively. These two emotions are indistinguishable due to normal facial expressions, eyebrow motions, landmarks, and wrinkles around the nose region or head pose.
To demonstrate the effectiveness of the proposed approach, partial AffectNet [
47] dataset is utilized for the evaluation by comparing mean emotion accuracy with the state-of-the-arts. We utilized a subset of facial expression images in AffectNet, a large database of facial expressions, arousal, and valence in the wild that allows for automated facial expression recognition. We used 4 basic emotion labels for evaluation, which includes
Happiness,
Neutral,
Sadness and
Anger. For each emotion category, we randomly selected 1000 images (80% for training and validation while the remaining 20% for testing) to train the proposed facial expression recognition model. Furthermore, the benchmark dataset was evaluated and the proposed model achieved a total accuracy of 91.46%, surpassing the state-of-the-art models listed, including Gan et al. [
48] with 88.05% and Hua et al. [
49] with 87.27% as shown in
Table 2. It can be implied that the coordination between spatial feature maps and temporal feature vectors is facilitated by the effective capture of underlying properties of facial emotions in the spatio-temporal domain.
4.2.2. Performance Analysis of Audio-Based Emotion Recognition
We reported the classification performance of audio emotions for the extracted features as described in
Section 3.2.2. Audio emotions are recognized using the two-fold method, first, speech-text emotions are recognized over the segmented 3-s audio stream. Secondly, Speech signal-based emotions are recognized over the segmented 3-s audio stream and scores are obtained for speech-text emotions. The text sentiment was recognized using Text-CNN in Tensorflow evaluated by 4-fold cross-validation, whereas the final Audio Signal based emotion was recognized using KNN supported by WEKA API with 10-Fold cross-validation over 80% training and 20% test data. The KNN classifier model utilizes speech-text emotion-based scores as a basic heuristic rule.
Table 3 shows the confusion matrix of speech signal-based emotion recognition with an accuracy of 66.07%. According to the findings, the emotion
Anger received the highest recognition rate of 71.5%, while
Happiness was recognized with a lower accuracy of 68.2%. Among all the emotions,
Sadness had the lowest accuracy, measuring at 58.7%.
The findings in bold as shown in
Table 4 indicate that deep learning based hierarchical structure proposed by Singh et al. [
50] has the potential to recognize emotions from speech with greater accuracy than our proposed method using simpler algorithm. However, our proposed approach for audio-based emotion recognition requires low computational resources since it utilizes a dataset with 4 emotions that is less complex, making it suitable for real-time LeanUX evaluation.
4.2.3. Performance Analysis of Skeletal-Based Emotion Recognition
In order to prove the proposed methodology, the experiments were carried out to correctly classify skeletal-based emotions using skeletal joint sequences of similar actions. The BiLSTM framework was applied to classify these multi-class labels for emotions. We can consider the human skeleton as series of interconnected of joints, where the motion and position of one joint may impact the others in a specific order. In our case, BiLSTM framework utilizes skeletal join data to train network for evaluating the body language emotions required for the LeanUX Platform. BiLSTM scaled well with the variable sizes of training data and proved efficient experimentally. We divided joint, skeletal data into two halves, i.e., 80% for training and validation while the remaining 20% for testing. The proposed methods, MDF and MAF, were utilized to extract features concatenated linearly to represent similar emotions. A 3-layer BiLSTM implemented in PyTorch was employed to train the softmax classifier, using the Adam optimizer with an initial learning rate of 0.01. The training process utilized a dropout rate of 0.1 and was carried out over 5 epochs with a split size of 5.
The detailed accuracy analysis is presented in
Table 5, which shows an accuracy reaching 97.01%. The
Happiness,
Neutral, and
Sadness emotion had better accuracies, which were 97.71%, 98.67%, and 96.22%, respectively. The
Anger emotion, however, could achieve 95.42% lower accuracy.
The results presented in
Table 6 demonstrate the effectiveness of the deep learning BiLSTM framework in the proposed method for the recognition of emotions using the LeanUX dataset. The mean recognition accuracy obtained through this approach is higher mentioned in bold to that achieved by other methods employed for skeletal-based emotion recognition.
4.2.4. Performance Analysis of Multimodal Emotion Feature Fusion
The implementation of the
Multimodal Feature Fusion for emotion recognition was done using
Deep Neural Network supported by an open-source, distributed deep-learning library
Deeplearning4j, written for Java and other languages [
41]. After extracting features from different modalities, we used feature fusion methods to combine high-level features from different modalities into a long feature vector to form a joint feature representation.
After receiving the multimodal features from facial, skeletal, and audio modalities, the size of the feature vector was determined in terms of length. We received features of order
where m represents a number of features and n represents a number of tuples in a sliding window of 3 s. For equal-sized feature vectors, concatenation was performed. Whereas for variable sizes, selected the n-tuples of feature vectors were using a threshold set by the modality having the lowest tuple size from the buffer within the sliding window. So, concatenation was performed based on the lowest estimated number of tuples. The resulting feature vector as discussed in
Section 3.3.1 is set for an input into the DNN algorithm for training to classify 4 emotions.
In order to train the DNN model, we used 3-layered architecture, with the first two fully connected dense layers and the third one for output, together with back-propagation to adjust the entire framework. We set the batch size to 1500 over the training dataset consisting of epochs. The aforementioned dense layers employed the Xavier weight initialization method in addition to the TANH activation function for the convergence over the normalized feature vectors with a learning rate of 0.01. These hyper-parameters were used in batches over the initial number of training rows to classify emotions using the softmax classifier with a negative log-likelihood loss function. The multimodal emotion feature fusion output is a corresponding emotion vector coming from different modalities.
The confusion matrix in
Table 7 shows higher accuracies for emotions of
Happiness,
Neutral, and
Sadness with values of 98.21%, 98.85%, and 98.08%, respectively, as they were identified by the model well. Meanwhile, the Anger emotion received an accuracy of 95.68% in the multimodal feature fusion lag behind slightly.
A comparison of accuracies is reproduced in
Table 8 for different experiments performed involving several modalities. The results suggest a higher accuracy is achieved for the multimodal feature fusion method.
4.2.5. Performance Analysis of Multimodal Decision Level Fusion with GM Functions
Multimodal decision-level fusion does not require feature vectors as the multimodal feature fusion method. Instead, obtaining emotion feature vectors from different modalities with an individual classification probability value requires another merging technique. In our experiments, we used dynamic weighting as a combinational input method for merging the probabilities of each emotion vector obtained from individual modalities and then selected the emotion label with the highest computed score.
In order to investigate and illustrate the feasibility of the proposed approach as a combination module of an ensemble system, an empirical analysis is also conducted. In this analysis, the obtained ensembles are applied to multimodal datasets gathered for the LeanUX project as described in
Section 4.1. As described, each dataset’s number of instances, classes, and attributes were applied for multimodal decision fusion using GM functions [
8].
Three-membered ensembles were composed of three classification algorithms an individual classifier and a multimodal feature fusion output. Thus, the proposed framework for multimodal decision fusion evaluated unimodal, multimodal feature fusion and compares it with multimodal decision fusion methods using functions such as Maximum (Max), Product (Prod), Arithmetic mean (Arith), and Product (Prod). It further utilized a re-sampling procedure similar to bagging, so a change in the parameter setting of an individual classifier for the aforementioned individual classifier for ensembles is not thus required. The combination module, however, used the following GM functions , , and .
In our experiments, we analyzed that GM functions achieved better statistical significance over a single combination method or on an individual classifier. The study conducted by Costa et al. [
8] proved
and
to be the best performers, with the GM functions combination method having a smaller number of ensembles. Furthermore, an increase in the number of classifiers had a positive effect on the performance of combination methods,
,
, and
. On the other hand, an increase in the number of classifiers negatively affected the performance of classical combination methods.
A detailed analysis using different columns in
Table 9 suggests improved and stable accuracies for bimodal, trimodal, and multimodal decision fusion using GM functions. For
and Prod with ensemble sizes 2, 3, and 4 provided higher accuracies. An interesting aspect is that the classical combination method, such as
Prod proved to be a better performer in lower ensemble sizes as we have limited modalities, so there is less variation in the ensemble size. For this reason, uniform patterns in the accuracies can be observed using classical combination methods and GM functions.
Finally, an analysis is performed over the results obtained from multimodal decision fusion as depicted in the confusion matrix shown in
Table 10. The matrix indicates a higher accuracy for each emotion without abrupt accuracy changes. Our proposed approach achieved an overall accuracy of 98.19% using the GM function combination method. The higher accuracy indicates the efficacy of the dynamic combination method for the emotion recognition process.
4.3. Comparison of Unimodal, Multimodal Feature Fusion and Decision Level Fusion Results
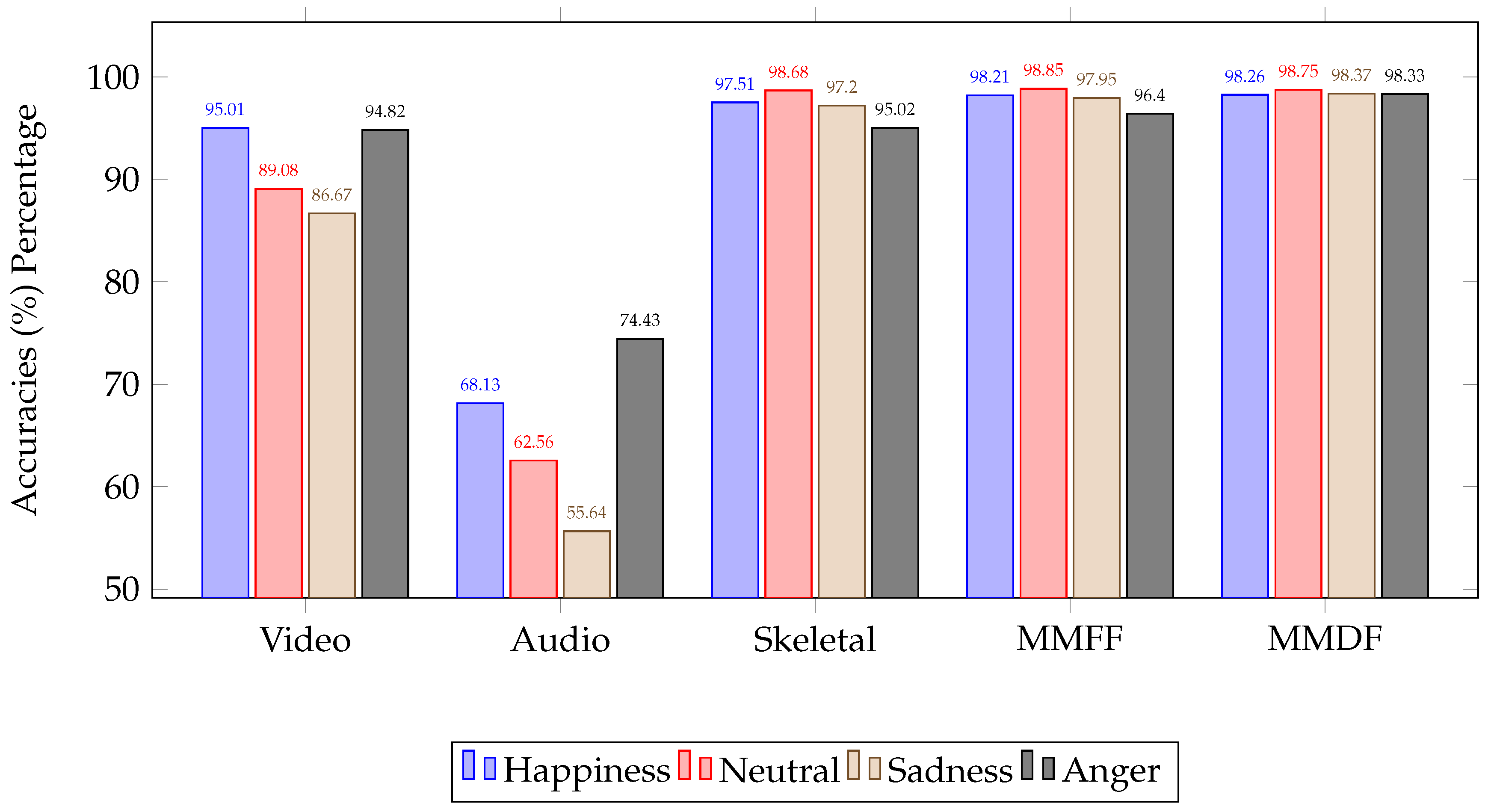
The accuracy for all of the obtained emotions using different experiments, as described in the earlier sections, is summarized in the plot shown in
Figure 7. This plot shows accuracies of individual emotions for unimodal classification, combined accuracies for multimodal feature fusion, and final emotion results obtained from multimodal decision fusion. The graphical representation proved multimodal decision fusion as the most significant among the other individual models and fusion methods.
This research provides a detailed investigation and analysis of the combination method using dynamic weight selection in variable ensembles based on GM functions. The final decision is built on combination method of each modality prediction using GM functions
,
, and
. High-performance results are achieved using multiple levels of fusion. These results demonstrated that GM function-based multimodal decision fusion outperformed unimodal and multimodal feature fusion for human emotion recognition
accuracy. The high performance of the proposed methodology resulted in dynamic weight selection through an ensemble technique using GM functions for multimodal decision-based emotion fusion. Furthermore, the performance results obtained demonstrated that the combination method also provided a generalization of emotion fusion performance for better classification using multimodal decision fusion. As demonstrated, the proposed method has been proven for promising results in developing a comprehensive emotion fusion framework in comparison with state-of-the-art studies as shown in
Table 11.
5. Conclusions and Future Work
In this paper, we studied challenges associated with multimodal fusion, one of the main research issues on multimodal emotion recognition. We introduced the Hybrid Multimodal Emotion Recognition (H-MMER) framework, which fuses features at the decision level, the multimodal feature level, and the unimodal feature level. This research added two significant new contributions to an earlier multimodal fusion work on emotional recognition. To begin with, we considered the input modalities (sensors) as sources of rich temporal event streams that included important multimodal data. Therefore, to gather multimodal data as user session logs required for defining the appropriate UX metrics, we developed a multimodal input collection module that allowed cross-modality sensing (CMS) and conducted temporal alignment (TA) of stream events. Second, we specified several fusion modes and levels to increase fusion’s accuracy. We presented a novel approach using Generalized Mixture (GM) functions in User Experience (UX) domain. These GM functions included combination methods ; and to perform decision-level fusion in classifier ensembles. In the analysis, we compared the proposed approach with unimodal, bimodal, traditional combination methods, Maximum (Max), Arithmetic mean (Arith), Majority vote (Vote), and Product (Prod). We have included the suggested framework in an ongoing research platform known as the "LeanUX platform" for modeling UX metrics based on multimodal data for emotional UX evaluation. The empirical analysis suggested that the generalized mixture functions ; , and can be used as a combination method to design an accurate classifier ensemble. The experiment demonstrates that the suggested framework has an average accuracy of 98.19% in simulating emotional states. Overall assessment results demonstrate our ability to precisely identify emotional states and improve an emotion recognition system required for UX measurement.



 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}