1. Introduction
Today, semiconductor manufacturing represents the highest level of microfabrication in the world. Wafer production is a key step in semiconductor manufacturing, which includes many complex processes, such as lithography, etching, deposition, chemical mechanical planarization (CMP), oxidation, ion implantation, diffusion, etc. Processes such as etching, deposition, and oxidation result in wafers with uneven surfaces, including higher steps and larger trenches. CMP technology is an important way to build wafer structures.
The material removal rate (MRR) is a critical variable in the CMP process. Each wafer needs to be polished to the target thickness; thus, an accurate MRR estimation is required to accurately set the polishing time. However, the MRR is difficult and costly to measure, and at the same time, it may cause damage to the wafers. In this stage, the MRR relies on engineering experience and actual measurements with a very low frequency (e.g., only one wafer is selected for measurement in one lot, or one wafer is measured at fixed time intervals) as a reference to complete the setup and adjustment.
In industrial production, to accurately estimate an important but difficult-to-measure variable, it is customary to model the relationship between the variable and easily accessible environmental variables, equipment parameters, intermediate variables, etc., and complete the prediction with physical laws or historical data. This process is called virtual metrology (VM). VM consists of two main forms: physics-based models and data-based models. Physics-based models establish mathematical expressions by analyzing the physical and chemical reactions of the process. Preston proposed that the MRR is related to pressure and the relative velocities of wafers and polishing pads and established the Preston equation [
1]. Teh and Chen et al. investigated the dressing process of polishing pads by designing pad simulation modules to investigate the effect of key geometrics [
2]. Shin and Kulkarni et al. tested the effects of different diamond structures on the polishing pad and polishing performance [
3]. Liu et al. established the relationship of the MRR of fused silica with the polishing pressure, chemical reagents, and their concentrations, as well as the relative velocity between the wafer and the polishing pad [
4].
Some of the existing physics-based models build global-based mathematical expressions by analyzing the physical and chemical reactions of the CMP process. Other models focus on the role of certain variables in the CMP process and the effects on the MRR. However, the CMP process involves so many variables that explicit mathematical expressions and physics-based models can hardly cover all of them. At the same time, the duration of the CMP process is very long. In an operating cycle, the CMP process passes through multiple operating points, dividing the process into multiple phases. The different relationships between variables in different phases also lead to continuous changes in the physical models. The global-based physical models are difficult to describe in detail in terms of process changes. With the continuous development of data science, researchers are increasingly placing emphasis on mining knowledge and information from large amounts of historical data, and therefore, data-based VM models are increasingly favored.
Since individual machine learning models do not suitably fit the CMP process, some studies have used stacking models. Zhao and Huang performed one-hot encoding of the “stage” and “chamber” variables in the feature creation and feature encoding stages to transform the process data into multidimensional information, and the stacking integration model was chosen for the regression [
5]. Li and Wu et al. also used a stacking integrated learning regression model with primary learners including random forest (RF), gradient boosting tree (GBT), and extreme random tree (ERT), and meta-learner as extreme learning machine (ELM) and classification and regression tree (CART), and the features in the model included the frequency domain features of the three rotation variables and feature selection using RF [
6].
The CMP process runs continuously, and the dynamic prediction of the MRR is necessary. Cai and Feng et al. combined k-nearest neighbors (kNN) and Gaussian process regression (GPR) to dynamically predict the MRR, where kNN searched historical data as reference samples and a multi-task Gaussian process (MTGP) model incorporated the training data and reference sample information [
7]. The authors proposed another dynamic prediction model, in which reference samples from historical data were fused with data samples through support vector regression (SVR), and a particle filter (PF) estimated and updated the prediction results and ensured that the model could track changes in the CMP process [
8]. Lee and Kim addressed the problem of the degradation of the model’s prediction performance due to process drift and proposed a VM model combining the recurrent neural network (RNN) and the convolutional neural network (CNN), extracting time-dependent and time-independent features with a two-stage training method to alternately update the network weights [
9]. The existing stacking models and dynamic prediction models in the literature focus on extracting global features and are insensitive to the phase changes in the CMP process. Therefore, a more adequate feature extraction method is needed.
Several researchers have proposed prediction methods based on a combination of physical models and data models [
10]. Yu and Li et al. derived a formula for MRR using a pad and conditioner. This model considers the contact between the polishing pads, abrasives, and wafers, and the polishing pad surface topology term in the formula is estimated using RF [
11]. Lim and Dutta proposed that the kinetics and contact between the wafer and polishing equipment are applied based on knowledge obtained a priori and a physical model for wafer classification, and they also proposed classification and regression methods, where the feature extraction is obtained by downsampling and expanding the dosage and pressure variables [
12]. These methods add physical analysis of the CMP process to the data models. However, similar to the physics-based VM model, the physical analysis focuses on some important variables but cannot cover all the variables’ effects on the MRR.
Research on neural networks and deep learning has provided new ideas [
13,
14]. Lim and Dutta used autoencoder and k-means clustering to determine the feature space of the training samples and combined the reconstruction loss of the encoder–decoder and the clustering error to form a loss function [
15]. Xia and Zheng et al. applied hypergraph convolutional networks to MRR prediction [
16]. In the data preprocessing stage, the piecewise aggregate approximation (PAA) method was used for time series alignment and dimensionality reduction. In the prediction stage, a hypergraph model was used to represent the complex relationships between the devices and variables. Maggipinto et al. used deep learning methods to model images of optical emission spectra (OES) with spatial and temporal evolution to build VM models of visual 2D data [
17]. Wu et al. designed a VM model combining CNN and Gaussian process regression (GPR) to address the mismatch between VM models and features, using CNN for feature extraction and GPR for the prediction of quality variables [
18]. The deep learning methods can fully explore the process features and the relationships between variables but require a large amount of data; otherwise, there is a risk of overfitting. However, due to the difficulty of measuring the MRR, there are less data for the CMP process.
There are some points for improvement regarding the established MRR prediction methods. First, the CMP process is a batch process, and its process data have three dimensions: the batch, variable, and time. Meanwhile, the CMP process involves several phases, and the work points change over time. The different batches and phases are not equal in duration. Most of the existing prediction methods extract the overall features of the process and ignore the phase features. Second, feature extraction with machine learning only involves statistical features, as well as other features such as the duration and nearest neighbors, and the mining of deep features and deep information in the CMP process data is not sufficient. Third, it is worth noting that a large number of wafers lack an MRR and become unlabeled samples because the MRR is not easy to measure. If labeled samples alone are used to build VM models, this will cause information wastage.
In this paper, a semi-supervised deep kernel active learning (SSDKAL) method is proposed for MRR prediction, with the following main contributions:
First, the semi-supervised active learning framework can fully exploit and utilize information regarding unlabeled samples. In this framework, semi-supervised regression (SSR) incorporates the uncertainty of the unlabeled samples into the loss function, while active learning (AL) can compensate for the weakness of the insufficient representativeness and diversity of samples in SSR. Second, clustering-based phase partition and phase-matching algorithms are used to extract phase features. Third, neural networks provide more in-depth identification and fitting of complex multi-phase processes through complex network connections. Our experiments based on CMP process data show that the proposed method achieves good results in terms of the prediction accuracy for the MRR. In actual production, many batch processes have the characteristics of multiple phases and unequal lengths, and there are a large number of unlabeled samples. Therefore, the proposed method can be extended to these processes. In the feature extraction stage, feature data are extracted using phase partition and phase matching, and in the prediction stage, a combination of DKL, SSR, and AL are used for prediction.
The rest of this paper is organized as follows. Chapter 2 presents the related works, including deep kernel learning and active learning regression. Chapter 3 describes the procedure of the SSDKAL method in detail. Chapter 4 presents the experimental results and the discussion. Chapter 5 concludes the paper.
3. Methods
3.1. Feature Extraction
The data for the CMP process have three dimensions: the batch, variable, and time. Usually, the data of a batch represent the production process of a wafer, i.e., the data matrix of
, corresponding to an MRR value. The main processing method for 3D data is to expand the data in the variable direction or batch direction and recover them as 2D data. Multiple principal component analysis (MPCA) and multiple partial least squares (MPLS) are then used for early batch process statistical monitoring and regression analysis, respectively [
31,
32].
Due to variations in the equipment and environment, the duration of each wafer is different. The above-mentioned MPCA, MPLS, and most other methods are not feasible for a CMP process that is unequal in length. At the same time, the CMP process is divided into several phases, and the variable relationships are different in different phases, with different operating points of the devices. The extraction of global features will only lead to the loss of information. In this paper, we adopt a feature extraction method based on phase partition and phase matching.
In phase partition, a combination of wrapped k-means (WKM) [
33] and the phase partition combination index (PPCI) are used. The dimensionality of each wafer data matrix is different because the wafers have different operation times. The purpose of phase partition is to obtain more accurate phase features; thus, phase partition is performed separately for each wafer. The data of the
I-th batch are
, where
denotes the sampling length, i.e., the number of sample points contained in the batch, and
, where
J is the number of variables contained in each sample point. The basic idea of phase partition is that the sample vectors in the batch are clustered, and different categories correspond to different phases. However, it is worth noting that the process data need to satisfy the temporal order constraint. Given the number of clusters, i.e., the number of phases
C, the batch data are initially divided according to the cumulative error, and then the sampling points are moved. Here, the sum of squared error (SSE) is used to calculate the clustering error and acts as the basis for the sampling point movement. The SSE is calculated as shown in Equation (
11):
where
is the center point of the
c-th phase. The following rule is used for sample point movement, when the movement condition is met, the first half of the sample points of each phase can only move to the previous phase, and the second half can only move to the latter phase. If a sample point does not meet the move condition, the remaining sample points in that half will no longer move. After a sample point
moves from phase
c to phase
b, the centroids will change, as shown in Equations (
12) and (
13):
where
and
are the numbers of sampling points in phase
c and phase
b before the move, respectively. After that, the SSE is recalculated, and if the SSE decreases,
will be moved to phase
b. Otherwise, the move will be rejected.
The CMP process contains stable phases with small changes in variable relationships and transition phases with fast changes in variable relationships. In the WKM algorithm, given the number of clusters C, a wafer can be divided into C phases, but the effectiveness of the partition is related to the size of C. When C is larger, the partition is detailed, and more transition phases are divided. When C is small, more transition phases are merged into the stable phases. We weigh the phase number C and the clustering error SSE and use PPCI for the metric. With the increase in C, PPCI shows a trend of decreasing and then increasing. The phase number corresponding to the smallest PPCI is chosen as the phase partition number of the wafer.
Due to the presence of PPCI, the optimal phase number differs from wafer to wafer. In the CMP process, many wafers have more transition phases with drastic changes, and the PPCI still decreases when the cluster number is large. The ultimate goal of phase partition is to extract the features of key phases; therefore, the phases of different wafers need to be matched. First, we must eliminate the effect of transition phases. Given a minimum length , the phase with a number of sampling points no lower than is considered as a stable phase; otherwise, it is a transition phase. Next, the standard stable phase number (SSN) and the standard stable phase center (SSPC) are determined. For all wafers, the plural of the stable phase number is selected as SSN. All wafers with stable phase numbers equal to SSN are selected, the mean value of the centroid of each stable phase is calculated, the wafers far from the mean value are discarded, and the process is iterated to finally obtain the SSPC.
After that, all wafers that have completed phase partition are matched with the SSPC. The basic method of phase matching is to calculate each phase center and identify the SSPC with the closest distance to it. However, at the same time, the time series constraint needs to be maintained. Two phases with backward and forward orders of time cannot be matched with SSPCs with opposite time orders. The optimization problem of phase matching is as shown in Equation (
14):
where
i denotes the matching process of the
i-th wafer,
denotes the
h-th SSPC, and
denotes the
h-th phase center of the
i-th wafer after phase matching is completed.
,
, and
denote the start point, end point, and the length of the
h-phase after the matching, respectively.
is the distance threshold of the two centers,
denotes the balance parameter of the distance and phase length, and
and
denote the starting and ending phases of the original wafer that match the
h-th standard phase. We use a greedy algorithm to continuously compare the distance between the center of the phases and the SSPC to complete the phase matching.
3.2. Semi-Supervised Deep Kernel Active Learning
It is worth noting that, due to the sampling detection of the MRR, a large number of samples are missing the MRR. Attention should be paid to semi-supervised regression (SSR) methods using both labeled and unlabeled samples. Kostopoulos et al. divided SSR into four categories: semi-supervised kernel regression, multi-view regression, graph regularization regression, and semi-supervised GPR [
34]. Among them, the semi-supervised GPR model consists of two components in the log-likelihood function: the joint distribution of independent and dependent variables with labeled samples based on the requested parameters, and the joint distribution likelihood function with unlabeled samples based on the requested parameters. The parameter value that maximizes the log-likelihood function is obtained via derivation [
35,
36,
37].
The semi-supervised deep kernel learning (SSDKL) method combining deep learning and the Gaussian process uses the deep neural network (DNN) as a kernel function, and the optimization objective function includes both the log-likelihood function and the prediction variance of the unlabeled samples, the latter being used as a regularization term to suppress the overfitting of the model [
38]. The loss function is adjusted to Equation (
15):
where
is the equilibrium parameter controlling the two types of losses.
In SSR, information on unlabeled samples is captured by adding the prediction variance as the regularization term of the loss function. In contrast toSSR based on co-training [
39], the unlabeled samples and pseudo-labels in SSDKL are not added to the labeled sample set, but by changing the loss function, they have an impact on the parameters of the model. The unlabeled samples provide an informative basis for model improvement but do not take into account the representativeness and diversity. At the same time, the small number of labeled samples in SSR are likely to be unevenly distributed and cannot fully cover the overall distribution of the samples. Active learning (AL) can compensate for this weakness. AL allows the model to select the important samples itself, thus obtaining a higher performance with less training samples.
Considering the three sample selection criteria, this paper uses a sample query strategy based on a combination of query by committee (QBC) and greedy sampling (GS).
Suppose that there are
N samples in the training set, constituting
, where the set of labeled samples
contains
L labeled samples, and the set of unlabeled samples
contains
U unlabeled samples,
. According to QBC,
M regressors are trained according to
, and the prediction variance of the unlabeled samples is as shown in Equation (
16):
where
is the average of the predicted values of the
M regressors for the
i-th unlabeled sample. QBC selects the sample with the largest prediction variance for the query. Here, the prediction variances of all unlabeled samples are sorted from largest to smallest, and the set of unlabeled samples with the largest variance are selected and denoted as
.
Next, from the set
, GS selects the sample farthest from the existing labeled sample for the query. The distance is calculated as shown in Equation (
17), and the unlabeled sample corresponding to the largest
will become the queried sample.
The semi-supervised deep kernel active learning (SSDKAL) method is proposed. In each round of iterations, a combination of QBC and the GS sample selection strategy are used. QBC focuses on the performance improvement of the model with respect to the query sample, i.e., informativeness, while GS takes into account the representativeness and diversity. The training process starts by training a set of SSDKL regressors using a small number of labeled samples. All regressors make predictions based on the unlabeled samples, select a set of samples with the largest variance, and choose a subset of unlabeled samples from this set, which are farthest from the existing labeled samples. The sample labels in this subset are queried and added to the labeled sample set. The learning, prediction, and sample selection process are repeated until the accuracy constraint or the upper limit of the query capability is reached.
The algorithm of SSDKAL is shown in Algorithm 1. Without loss of generality, we assume that there are only two regressors in the AL committee,
and
.
| Algorithm 1 SSDKAL |
Input: After phase partition and phase matching, the input data X, which have completed phase feature extraction, feature selection, and normalization, include the labeled dataset , unlabeled dataset , learning rate , unlabeled sample loss term weight parameter , maximum number of iterations , maximum AL query sample number , and error threshold . Output: Final model parameters , . - 1:
Initializing model parameters , . - 2:
The query number of AL . - 3:
while do - 4:
Construct semi-supervised deep kernel regression models , using . - 5:
Iteration number . - 6:
while do - 7:
Calculate the loss function of the models based on the labeled and unlabeled datasets. - 8:
- 9:
- 10:
- 11:
Compute the derivative of the loss function with respect to the parameter and update the parameter using stochastic gradient descent (SGD). - 12:
- 13:
- 14:
if then - 15:
End the training. - 16:
end if - 17:
- 18:
end while - 19:
Calculate the outputs of the models for unlabeled data, , . - 20:
Sort and take the first K maxima to form the unlabeled data subset. - 21:
Calculate the sample farthest from in the subset, query its label, add it to the labeled dataset , and remove it from . - 22:
- 23:
end while - 24:
return: Model parameters ,
|
Figure 1 shows the algorithm flow of SSDKAL. First, the training samples pass through the steps of phase partition, phase matching, and feature extraction to obtain the initial dataset, which includes the labeled sample set and the unlabeled sample set. According to the SSDKAL algorithm, the DKL model is built using the labeled sample set, and the model parameters are updated based on the log marginal likelihood function of the labeled samples and the uncertainty of the unlabeled samples. The model predicts the outputs of the unlabeled samples and selects the samples that satisfy the informativeness, representativeness, and diversity according to the AL strategy of combining QBC and GS, querying the labels, and adding them to the labeled sample set. For the test set, the phase partition, phase matching, and feature extraction are similar to the training set. After the phase partition for each wafer, the SSN and SSPC obtained from the training set are applied to complete the phase matching, and the final model is used for the prediction.
4. Experiments and Discussion
4.1. Datasets
The dataset is from the 2016 Prognostics and Health Management (PHM16) Data Challenge and contains a set of CMP process data. The dataset is divided into a training set, a validation set, and a test set, each of which contains process data from several wafers. The number of sampling points for each wafer is between roughly 200 and 400, and each sampling point contains 25 variables, as shown in
Table 1. Among them, 6 variables are device and wafer information, and the remaining 19 variables are process variables, which are divided into 5 groups, including usage, pressure, flow, rotation, and status. Each wafer is identified based on two variables, “Wafer_ID” and “Stage”, and corresponds to an MRR value.
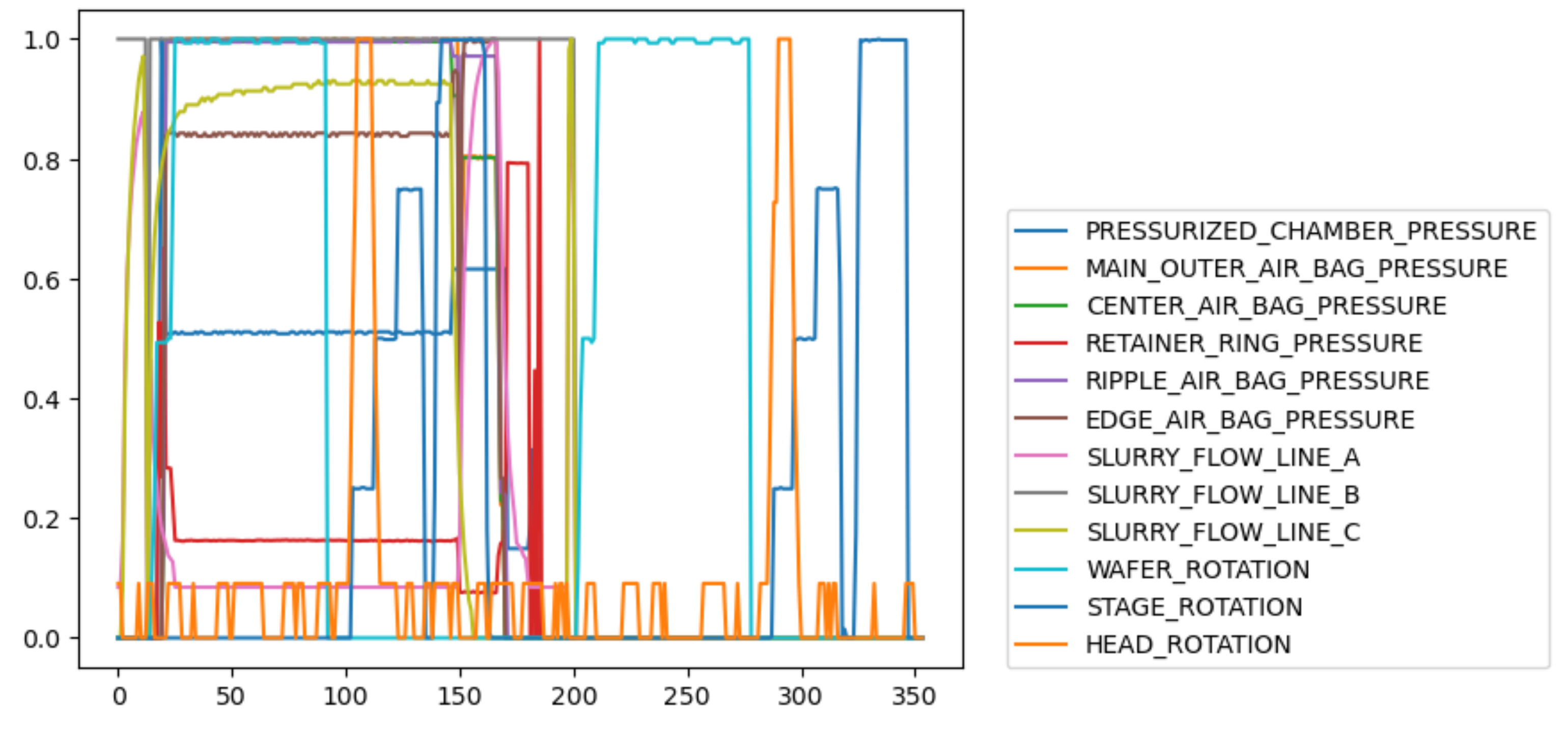
Figure 2 shows the trajectories of some variables of a wafer, including six pressure variables, three flow variables, and three rotation variables. It can be seen these variables have different relationships in different phases, which also indicates that the CMP process is a multi-phase process.
All wafers can be divided into three modes based on the “Chamber” and “Stage”.
Table 2 shows the distribution of three modes, including the chamber, stage, and the range of the MRR, as well as the numbers of samples in the training set, validation set, and test set.
4.2. Feature Extraction
For each wafer, we perform phase partition using the WKM-PPCI algorithm. During the CMP process, different variables have different trends. Among them, the usage variables have an increasing trend and do not conform to the phase change characteristics. The pressure, flow, and rotation variables have phase change characteristics, and the pressure variables have more obvious changes and coincide with the switching of chambers at certain change time points. Therefore, six pressure variables are used for clustering and phase partition.
Given the phase number C, integers of are taken, and the number corresponding to the smallest PPCI is chosen as the phase number of this wafer. After the phase partition, the minimum number of sampling points contained in the stable phase is selected according to the phase alignment algorithm to distinguish the stable phases and the transition phases for each wafer. The plural of all the wafers’ stable phases is chosen as the SSN, and in this experiment, the SSN = 5. The SSPC is calculated iteratively, and the phases of all the wafers are matched with the SSPC using a greedy algorithm. Finally, all the wafers are divided into five phases.
Figure 3 shows the phase partition and phase match of a wafer. In
Figure 3, the horizontal axis indicates the time order of the sampling points, and the vertical axis indicates the normalized variable values. The colored solid lines indicate the variation of the 6 pressure variables along time. The vertical dashed line indicates the optimal phase partition results after using the phase partition algorithm with the combination of WKM and PPCI. It can be seen that due to the presence of the transition phases, the phase partition is very detailed in the transition phases, and the optimal number of phases is large, which is 15 in the case of this wafer. The solid line on the vertical axis and the number between the solid lines indicate the results of the phase match. After the phase match, 15 phases are matched with 5 standard stable phase centers.
As shown in
Table 3, for each phase, the pressure, flow, and rotation variables coincide with the change in the phases, and five statistical features are extracted, including the mean, standard deviation (std), median, peak-to-peak (PtP), and area under the curve (AUC). The status variable has only two states of 0 and 1, the median and PtP are meaningless, and the mean and AUC are redundant variables; only the mean and std features are retained. The usage variable is an incremental variable independent of the phase change, and only the initial value feature is extracted. In addition, the start time and duration are extracted from the timestamp variable. Seventy variables are extracted for each phase, forming a large feature set. The filtered feature selection method is used, which can filter out single numerical features, low-variance features, high-linear-correlation features, etc.
4.3. Prediction Results of Different Regression Models
After obtaining the phase features, we apply different models to the PHM16 Dataset.
Table 4 and
Table 5 show the prediction results of different types of regression models for Mode I and Mode II. The prediction results of each regression model are the average predicted values obtained after running several experiments. In this paper, the criterion for comparing the prediction results is the mean square error (MSE), as shown in Equation (
18):
where
is the number of samples in the test set, and
and
are the prediction and true values of the
i-th test sample, respectively. The bold numbers in
Table 4 and
Table 5 indicate the prediction error values with the best prediction performance. In our experiments, we chose four supervised regression models, including k-nearest neighbor (kNN) regression [
40], support vector regression (SVR) [
41], ExtraTree (ET) [
42], and Gaussian process regression (GPR), and three SSR models, including Coreg-kNN, Coreg-SVR, and SSDKL, in addition to the proposed method, SSDKAL. “Global Features” indicate that the models do not use phase partition or phase match methods, and only global features are extracted from the process data. The regression models used for the “Global Features” are four supervised regression models, including kNN, SVR, ET, and GPR.
The models use multiple experiments to obtain the mean value as the prediction results. Among them, Coreg is a semi-supervised method based on co-training and involves multiple regression models [
43]. Coreg-kNN and Coreg-SVR denote the regression models of kNN regression and SVR, respectively.
“Label_Ratio” indicates the proportion of labeled samples in the training set, and the formula is shown in Equation (
19):
where
L and
U denote the numbers of labeled samples and unlabeled samples in the training set, respectively.
In the supervised regression models, the number of nearest neighbors of kNN is 15, the penalty parameter of SVR is 1.0, the minimum number of samples of split points in ET is 2, and the minimum number of samples of leaf nodes is 1. In SSR, the numbers of nearest neighbors of the two kNN models chosen by Coreg-kNN are 10 and 15, and the penalty parameters of the two SVR models chosen by Coreg-SVR are 0.1 and 1.0, respectively. The front-end network of SSDKL uses multiple fully connected layers, the parameter of the activation function LeakyReLU is 0.2, and the optimizer chooses stochastic gradient descent (SGD) with a learning rate of 0.01. The main parameters of SSDKAL are the same as those of SSDKL, but multiple models need to be included as committees of AL, and the main difference between the models is the number of layers and nodes of the fully connected layers.
The results in
Table 4 and
Table 5 show that the prediction errors of the different models basically show a decreasing trend as the proportion of labeled samples increases. This is an expected result, because the increase in the amount of labeled data causes the models to obtain more accurate information, and the models can fit the real variable relationships more accurately. However, there are also some models for which the prediction results fluctuate as the proportion of labeled samples increases. On the one hand, supervised regression is more prone to fluctuations, because when there is less valid information, the fitting effect of the model is far from the real situation, and an effective prediction model cannot be built. On the other hand, the labeled samples were obtained by random sampling in these experiments; thus, the informativeness and representativeness of the extracted samples vary with different proportions, leading to a situation in which the prediction results fluctuate with the proportion of labeled samples.
In
Table 4 and
Table 5, the comparisons of the prediction results of the "Global Features" and supervised regression models based on phase features demonstrate the role of the phase features in the proposed framework. For the same regression model and label ratio, the phase features contribute to the accuracy of the prediction results. The proposed phase partition and phase match methods can more fully exploit the trend of the time series data in the CMP process and obtain accurate phase features.
Meanwhile,
Table 4 and
Table 5 show that the SSDKAL algorithm, which incorporates SSR, GPR, and DKL together with AL, obtains more accurate prediction results than supervised regression and SSR for different labeled sample proportions in both Mode I and Mode II. Compared with the corresponding supervised regression methods (kNN and SVR), the semi-supervised Coreg algorithm, which obtains pseudo-labels of unlabeled data, leads to a substantial improvement in the prediction performance. The addition of DKL leads to a further reduction in the prediction error. The SSDKAL algorithm takes the features initially extracted after phase partition and phase matching and, through information mining via DNN, fitting with a Gaussian process kernel function, and adding the uncertainty information of the unlabeled data, with a very small amount of AL query information, achieves a more accurate MRR prediction.
For comparison,
Table 6 shows the prediction results for Mode III. Mode III involves fewer samples, and the multi-phase characteristic is not obvious. For Mode III, we only extracted global features and did not use phase partition or phase matching. The feature number is small.
Table 6 shows that the simple model (e.g., kNN) has better prediction results, and the addition of other modules increases the model’s complexity and the risk of overfitting, which prevents the extraction of more feature information. Therefore, the SSDKAL algorithm is more suitable for datasets with a larger data volume and a larger number of features.
Taking Mode I as an example,
Table 7 shows the time consumption of different regression models, and the unit of data is seconds. The time for the “Global Features” and supervised regression models is the average of a single run time. The time for the SSR models and SSDKAL is the time for each training round, and the number of training rounds is set to 30. Each round of Coreg-kNN and Coreg-SVR includes the training of multiple models based on labeled data. The models select unlabeled data with high confidence, as well as their pseudo-labels, and add them to the labeled dataset. Each training round of SSDKL consists of training DKL models based on labeled data, predicting unlabeled data, calculating a loss function containing the uncertainty of the unlabeled data, and performing backpropagation. Each round of SSDKAL includes the forward computation and backpropagation of multiple models and query sample selection based on a combination of QBC and GS. Bold numbers indicate the time required by the SSDKAL model. The bold numbers in
Table 7 indicate the time consumption of SSDKAL.
The time consumption in
Table 7 shows that the simple supervised regression models take very little time but have a lower prediction accuracy. The SSR models and SSDKAL require the prediction, selection, and training of unlabeled samples, and the time required for each training round is long. SSDKAL incorporates deep neural networks for feature extraction and applies the results of multiple regression models to the sample selection strategy of combining QBC and GS, and therefore, the time consumption is higher. However, the SSDKAL method can fully exploit the data features and improve the prediction accuracy by using unlabeled samples.
4.4. Ablation Experiments
In the ablation experiments, we split SSDKAL to test the prediction performance of the GPR, DNN, and DKL models separately. DNN uses multiple fully connected layers, with the top-layer features as input to the DKL model. DKL, SSDKL, and SSDKAL optimize all the hyperparameters of the deep kernel and train the network using the log marginal likelihood function to derive the parameters and perform backpropagation. The models are experimentally implemented using GPytorch [
44]. The experimental results of the ablation experiments are shown in
Table 8 and
Figure 4 for Mode I.
As shown in
Table 8 and
Figure 4, the ablation experiments based on Mode I demonstrate the prediction performance of each model when the proportion of labeled samples is consistent, and the approximate performance ranking is SSDKAL > SSDKL > DKL > GPR > DNN. The GPR model is a typical machine learning model, which requires additional data cleaning and feature engineering. When the modeled data distribution is too complex, the availability of a priori knowledge regarding the data distribution directly determines the accuracy of the data feature engineering, which, in turn, affects the model’s performance. DNN can reduce manual involvement to a greater extent via multi-level feature extraction. DKL gives full play to the advantages of both models by organically combining DNN and GPR and maintains the strong generalization performance with respect to the data, keeping the model performance high while maintaining strong generalization in regard to the data.
The model prediction performance of SSDKAL is best when the proportion of labeled samples is kept the same. In the semi-supervised scenario, pure machine learning has a performance limitation. SSDKAL further enhances the model’s utilization of unlabeled data by incorporating AL methods into the training mechanism of DKL by combining the prediction uncertainty of unlabeled samples with actively learned expert queries and thus improves the comprehensive modeling capacity of the dataset.
4.5. Comparisons of Different AL Strategies and Kernel Functions
Table 9 and
Table 10 show the prediction performance of the models with different AI query strategies and different kernel functions. The models used in the experiments are all SSDKAL, and the proportion of labeled samples is 0.3.
In
Table 9 and
Table 10, “QBC + GS” indicates the query strategy using a combination of QBC and GS, i.e., the group of unlabeled samples with the largest prediction variance between different models is selected first; then, that which is farthest from the labeled samples is selected from among them and the label is queried. “QBC”, “GS” indicates that only the QBC or the GS strategy is used, respectively, and only one sample is queried. The “QBC Group” indicates the querying of a group of samples in an epoch using the QBC strategy, in which case the query is faster. The experimental results show that the strategy combining QBC and GS, which considers informativeness, representativeness, and diversity, has the best prediction effect.
RBF, cosine, Matern, and RQ are the four kernel functions in the DKL framework, and the tables show that the cosine kernel has a poor prediction performance. The CMP process is a nonlinear, multi-batch complex production process, and there is no significant correlation between the data features, which is a key factor limiting the performance of the cosine kernel. In comparison, RBF has a better fitting effect. For different application scenarios, the kernel functions and related hyperparameters need to be flexibly selected based on domain knowledge in order to achieve the maximum performance of the model.
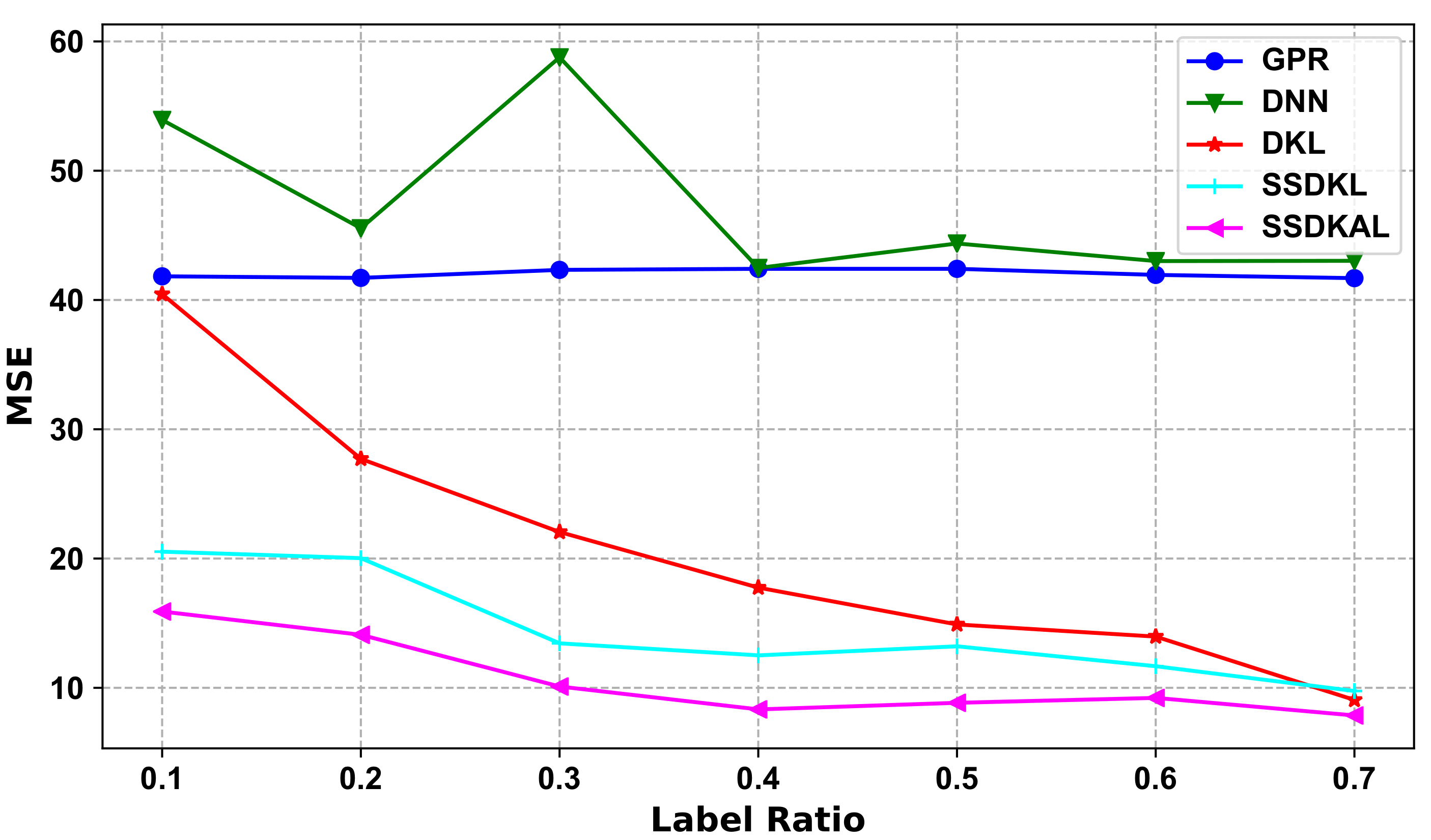
4.6. Effects of the SSDKAL Method
Table 11 presents the results of existing methods for MRR prediction and compares them with the proposed SSDKAL method. The data shown are the MSE. The ratio of labeled samples for the SSDKAL method is 0.7. SSDKAL achieves good prediction results without using all the labeled samples. In the feature extraction stage, SSDKAL takes into account the unequal length and multi-phase characteristics of the CMP process and extracts detailed process features through phase partition, phase matching, and phase feature extraction. DKL obtains the phase features through deep neural networks and further mines the depth features and the deep associations between variables. SSR adds the uncertainty of unlabeled samples to the loss function. The AL sample selection strategy compensates for the lack of representativeness and diversity of samples in SSR and makes full use of unlabeled sample information.
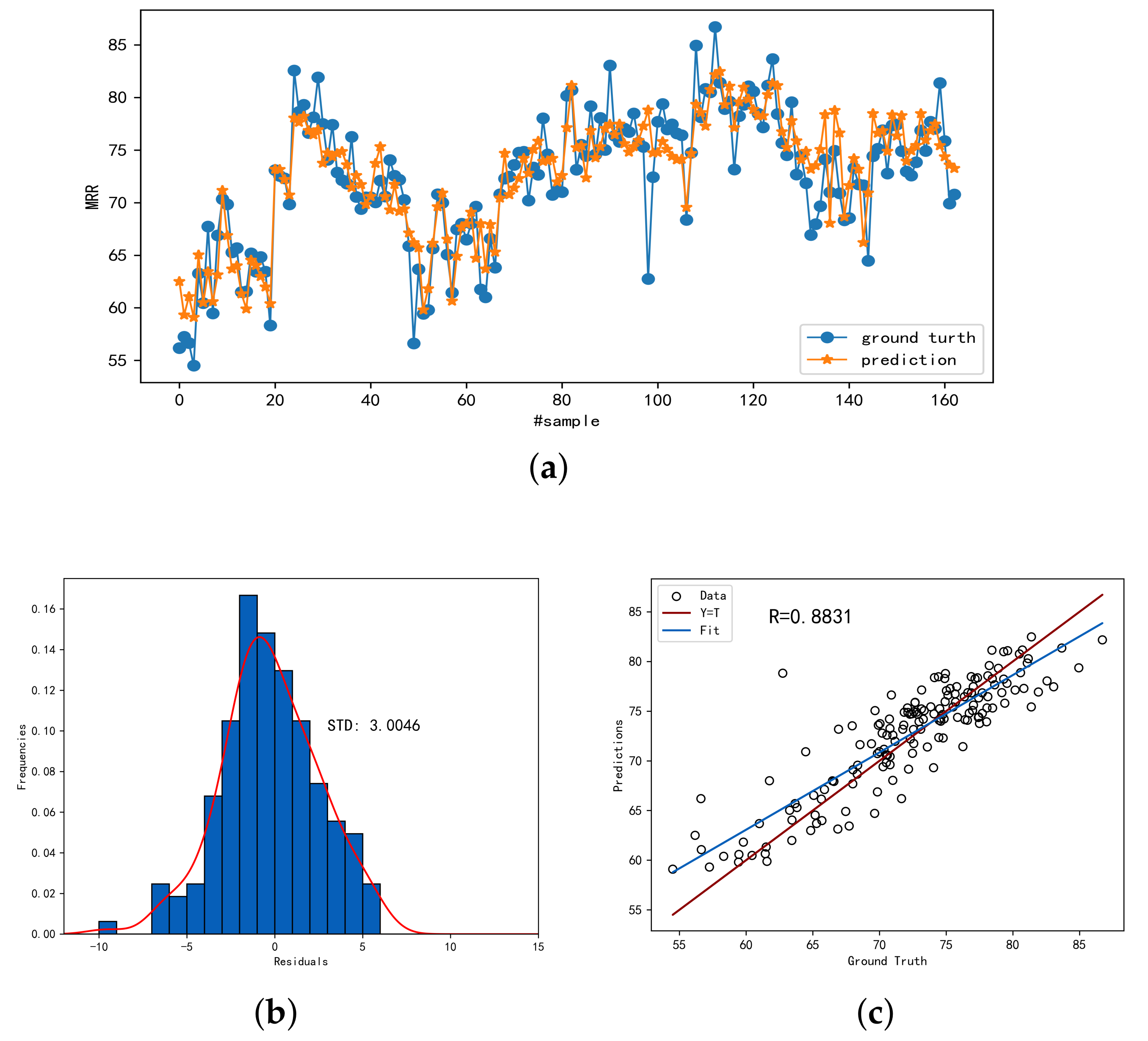
Figure 5 demonstrates the prediction accuracy of SSDKAL for a labeled sample ratio of 0.7.
Figure 5a shows the predicted values compared with the actual values,
Figure 5b shows the distribution of the residuals, and
Figure 5c shows the linear analysis of the predicted and actual values. It can be seen that SSDKAL can predict the MRR more accurately.
4.7. Limitations
The proposed method, SSDKAL, still has some limitations and drawbacks. Firstly, due to the small number of samples, the query samples for AL are still affected by the problem of insufficient representativeness and diversity. Since the query samples have an incomplete coverage of the overall distribution of the samples, the model’s estimation of the sample distribution is biased, which affects the prediction accuracy. Secondly, in the SSDKAL model, the deep kernel mapping of the Gaussian DKL model uses fully connected layers, which is insufficient for the extraction and mining of the depth features of the sample data. Finally, the AL sample selection strategy is based on the data features of the samples. However, the CMP process is complex, and the utilization of information from the process data is incomplete if knowledge obtained a priori, such as the process mechanism, is completely absent.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}