
Listen to the Brain–Auditory Sound Source Localization in Neuromorphic Computing Architectures

Abstract
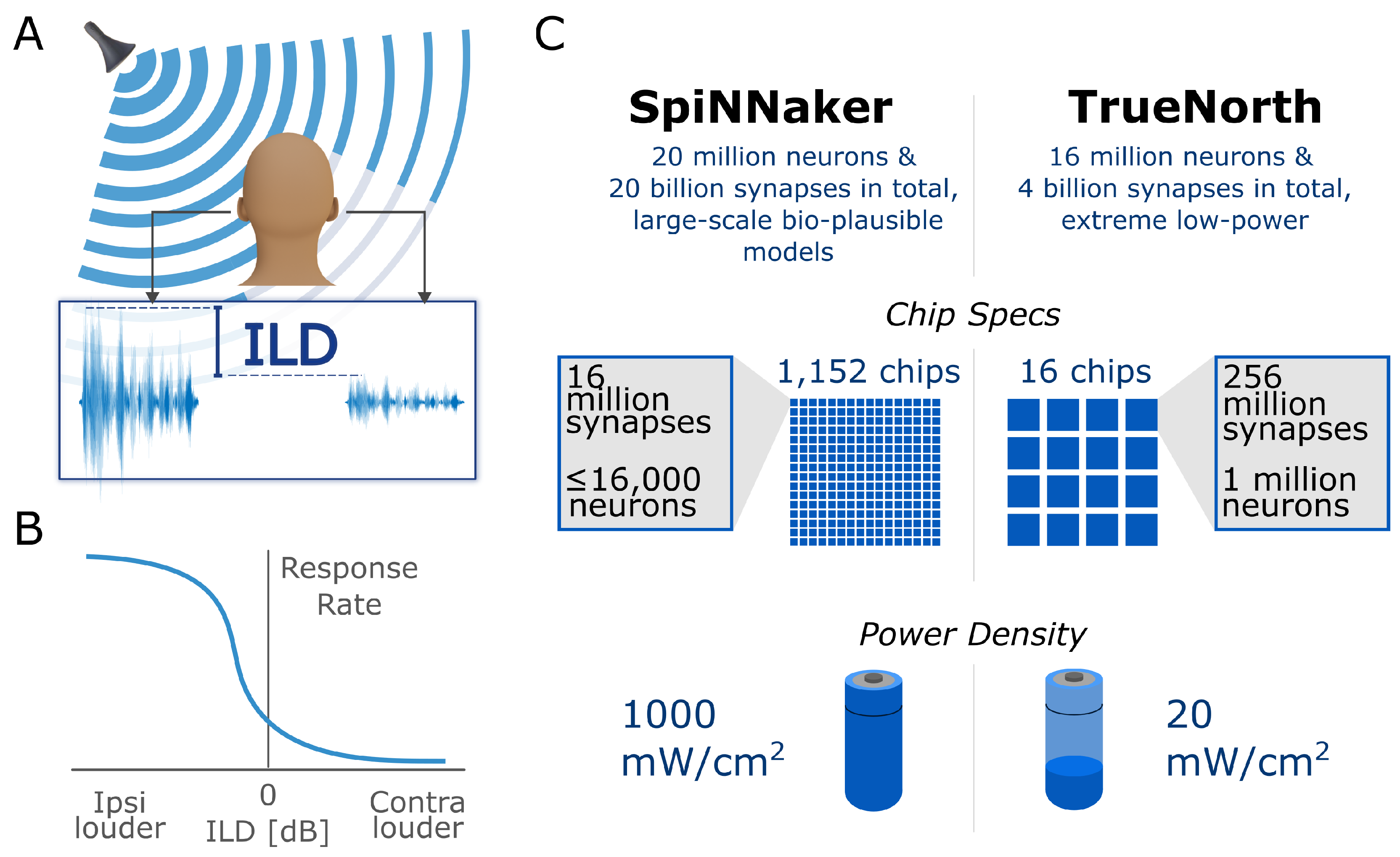
:1. Introduction
1.1. Motivation
1.2. Related Works
1.3. Summary
2. Materials and Methods
2.1. Generic Neuron Model to Build Complex Network Function
2.2. Generic Mapping Approach to Neuromorphic Hardware
2.3. Mapping the Auditory Sound Source Localization Model
2.3.1. The Auditory Sound Source Localization Model
2.3.2. Application of the Mapping Procedure
2.4. Experiments for Model Comparison
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rayleigh, L. XII. On our perception of sound direction. Lond. Edinb. Dublin Philos. Mag. J. Sci. 1907, 13, 214–232. [Google Scholar] [CrossRef]
- Brand, A.; Behrend, O.; Marquardt, T.; McAlpine, D.; Grothe, B. Precise inhibition is essential for microsecond interaural time difference coding. Nature 2002, 417, 543–547. [Google Scholar] [CrossRef] [PubMed]
- Grothe, B.; Pecka, M.; McAlpine, D. Mechanisms of Sound Localization in Mammals. Physiol. Rev. 2010, 90, 983–1012. [Google Scholar] [CrossRef]
- Yin, T.C.T. Neural Mechanisms of Encoding Binaural Localization Cues in the Auditory Brainstem. In Integrative Functions in the Mammalian Auditory Pathway; Oertel, D., Fay, R.R., Popper, A.N., Eds.; Springer: New York, NY, USA, 2002; pp. 99–159. [Google Scholar] [CrossRef]
- Merolla, P.A.; Arthur, J.V.; Alvarez-Icaza, R.; Cassidy, A.S.; Sawada, J.; Akopyan, F.; Jackson, B.L.; Imam, N.; Guo, C.; Nakamura, Y.; et al. A million spiking-neuron integrated circuit with a scalable communication network and interface. Science 2014, 345, 668–673. [Google Scholar] [CrossRef] [PubMed]
- Furber, S. Large-scale neuromorphic computing systems. J. Neural Eng. 2016, 13, 051001. [Google Scholar] [CrossRef] [PubMed]
- Roy, K.; Jaiswal, A.; Panda, P. Towards spike-based machine intelligence with neuromorphic computing. Nature 2019, 575, 607–617. [Google Scholar] [CrossRef] [PubMed]
- Schuman, C.D.; Potok, T.E.; Patton, R.M.; Birdwell, J.D.; Dean, M.E.; Rose, G.S.; Plank, J.S. A Survey of Neuromorphic Computing and Neural Networks in Hardware. arXiv 2017. [Google Scholar] [CrossRef]
- Young, A.R.; Dean, M.E.; Plank, J.S.; Rose, G.S. A Review of Spiking Neuromorphic Hardware Communication Systems. IEEE Access 2019, 7, 135606–135620. [Google Scholar] [CrossRef]
- Knight, J.C.; Nowotny, T. GPUs Outperform Current HPC and Neuromorphic Solutions in Terms of Speed and Energy When Simulating a Highly-Connected Cortical Model. Front. Neurosci. 2018, 12, 941. [Google Scholar] [CrossRef]
- Rhodes, O.; Peres, L.; Rowley, A.G.; Gait, A.; Plana, L.A.; Brenninkmeijer, C.; Furber, S.B. Real-time cortical simulation on neuromorphic hardware. Philos. Trans. R. Soc. A 2020, 378, 20190160. [Google Scholar] [CrossRef]
- Davies, M.; Wild, A.; Orchard, G.; Sandamirskaya, Y.; Guerra, G.A.F.; Joshi, P.; Plank, P.; Risbud, S.R. Advancing Neuromorphic Computing With Loihi: A Survey of Results and Outlook. Proc. IEEE 2021, 109, 911–934. [Google Scholar] [CrossRef]
- Hsu, J. IBM’s new brain [News]. IEEE Spectr. 2014, 51, 17–19. [Google Scholar] [CrossRef]
- Desai, D.; Mehendale, N. A review on sound source localization systems. Arch. Comput. Methods Eng. 2022, 29, 4631–4642. [Google Scholar] [CrossRef]
- Rascon, C.; Meza, I. Localization of sound sources in robotics: A review. Robot. Auton. Syst. 2017, 96, 184–210. [Google Scholar] [CrossRef]
- Lazzaro, J.; Mead, C.A. A Silicon Model Of Auditory Localization. Neural Comput. 1989, 1, 47–57. [Google Scholar] [CrossRef]
- Glackin, B.; Wall, J.; McGinnity, T.; Maguire, L.; McDaid, L. A Spiking Neural Network Model of the Medial Superior Olive Using Spike Timing Dependent Plasticity for Sound Localization. Front. Comput. Neurosci. 2010, 4, 18. [Google Scholar] [CrossRef]
- Xu, Y.; Afshar, S.; Singh, R.K.; Hamilton, T.J.; Wang, R.; van Schaik, A. A Machine Hearing System for Binaural Sound Localization based on Instantaneous Correlation. In Proceedings of the 2018 IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Escudero, E.C.; Peña, F.P.; Vicente, R.P.; Jimenez-Fernandez, A.; Moreno, G.J.; Morgado-Estevez, A. Real-time neuro-inspired sound source localization and tracking architecture applied to a robotic platform. Neurocomputing 2018, 283, 129–139. [Google Scholar] [CrossRef]
- Schoepe, T.; Gutierrez-Galan, D.; Dominguez-Morales, J.P.; Greatorex, H.; Chicca, E.; Linares-Barranco, A. Event-Based Sound Source Localization in Neuromorphic Systems. TechRxiv 2022. [Google Scholar] [CrossRef]
- Oess, T.; Löhr, M.; Jarvers, C.; Schmid, D.; Neumann, H. A Bio-Inspired Model of Sound Source Localization on Neuromorphic Hardware. In Proceedings of the 2020 2nd IEEE International Conference on Artificial Intelligence Circuits and Systems (AICAS), Genova, Italy, 31 August–2 September 2020; pp. 103–107. [Google Scholar] [CrossRef]
- Wang, W.; Pedretti, G.; Milo, V.; Carboni, R.; Calderoni, A.; Ramaswamy, N.; Spinelli, A.S.; Ielmini, D. Learning of spatiotemporal patterns in a spiking neural network with resistive switching synapses. Sci. Adv. 2018, 4, eaat4752. [Google Scholar] [CrossRef]
- Moro, F.; Hardy, E.; Fain, B.; Dalgaty, T.; Clémençon, P.; De Prà, A.; Esmanhotto, E.; Castellani, N.; Blard, F.; Gardien, F.; et al. Neuromorphic object localization using resistive memories and ultrasonic transducers. Nat. Commun. 2022, 13, 3506. [Google Scholar] [CrossRef]
- Dayan, P.; Abbott, L.F. Theoretical Neuroscience: Computational and Mathematical Modeling of Neural Systems; The MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Izhikevich, E.M. Dynamical Systems in Neuroscience: The Geometry of Excitability and Bursting; The MIT Press: Cambridge, MA, USA, 2006. [Google Scholar] [CrossRef]
- Gerstner, W.; Kistler, W.M.; Naud, R.; Paninski, L. Neuronal Dynamics: From Single Neurons to Networks and Models of Cognition; Cambridge University Press: Cambridge, MA, USA, 2014. [Google Scholar] [CrossRef]
- Cassidy, A.S.; Merolla, P.; Arthur, J.V.; Esser, S.K.; Jackson, B.; Alvarez-Icaza, R.; Datta, P.; Sawada, J.; Wong, T.M.; Feldman, V.; et al. Cognitive computing building block: A versatile and efficient digital neuron model for neurosynaptic cores. In Proceedings of the 2013 International Joint Conference on Neural Networks (IJCNN), Dallas, TX, USA, 4–9 August 2013; pp. 1–10. [Google Scholar] [CrossRef]
- Furber, S.; Temple, S.; Brown, A. High-performance computing for systems of spiking neurons. In Proceedings of the AISB’06 workshop on GC5: Architecture of Brain and Mind, Bristol, UK, 3–4 April 2006; Volume 2, pp. 29–36. [Google Scholar]
- Furber, S.B.; Galluppi, F.; Temple, S.; Plana, L.A. The SpiNNaker Project. Proc. IEEE 2014, 102, 652–665. [Google Scholar] [CrossRef]
- Brosch, T.; Neumann, H. Computing with a Canonical Neural Circuits Model with Pool Normalization and Modulating Feedback. Neural Comput. 2014, 26, 2735–2789. [Google Scholar] [CrossRef] [PubMed]
- Oess, T.; Ernst, M.O.; Neumann, H. Computational principles of neural adaptation for binaural signal integration. PLoS Comput. Biol. 2020, 16, e1008020. [Google Scholar] [CrossRef] [PubMed]
- Löhr, M.P.R.; Neumann, H. Contrast Detection in Event-Streams from Dynamic Vision Sensors with Fixational Eye Movements. In Proceedings of the 2018 IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Gewaltig, M.O.; Diesmann, M. NEST (NEural Simulation Tool). Scholarpedia 2007, 2, 1430. [Google Scholar] [CrossRef]
- Löhr, M.P.R.; Schmid, D.; Neumann, H. Motion Integration and Disambiguation by Spiking V1-MT-MSTl Feedforward-Feedback Interaction. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–9. [Google Scholar] [CrossRef]
- Brette, R.; Gerstner, W. Adaptive Exponential Integrate-and-Fire Model as an Effective Description of Neuronal Activity. J. Neurophysiol. 2005, 94, 3637–3642. [Google Scholar] [CrossRef]
- Roth, A.; van Rossum, M.C.W. Modeling Synapses. In Computational Modeling Methods for Neuroscientists; The MIT Press: Cambridge, MA, USA, 2009. [Google Scholar] [CrossRef]
- Davison, A.; Brüderle, D.; Eppler, J.; Kremkow, J.; Muller, E.; Pecevski, D.; Perrinet, L.; Yger, P. PyNN: A common interface for neuronal network simulators. Front. Neuroinform. 2009, 2, 11. [Google Scholar] [CrossRef] [PubMed]
- Carandini, M.; Heeger, D.J. Normalization as a canonical neural computation. Nat. Rev. Neurosci. 2012, 13, 51–62. [Google Scholar] [CrossRef] [PubMed]
- Tsotsos, J.K.; Rodríguez-Sánchez, A.J.; Rothenstein, A.L.; Simine, E. The different stages of visual recognition need different attentional binding strategies. Brain Res. 2008, 1225, 119–132. [Google Scholar] [CrossRef]
- Layher, G.; Brosch, T.; Neumann, H. Towards a mesoscopic-level canonical circuit definition for visual cortical processing. In Proceedings of the First International Workshop on Computational Models of the Visual Cortex: Hierarchies Layers, Sparsity, Saliency and Attention, New York, NY, USA, 3–5 December 2015. [Google Scholar] [CrossRef]
- Shinn-Cunningham, B.G.; Santarelli, S.; Kopco, N. Tori of confusion: Binaural localization cues for sources within reach of a listener. J. Acoust. Soc. Am. 2000, 107, 1627–1636. [Google Scholar] [CrossRef]
- He, W.; Motlicek, P.; Odobez, J.M. Deep Neural Networks for Multiple Speaker Detection and Localization. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 74–79. [Google Scholar] [CrossRef]
- Davies, M.; Srinivasa, N.; Lin, T.H.; Chinya, G.; Cao, Y.; Choday, S.H.; Dimou, G.; Joshi, P.; Imam, N.; Jain, S.; et al. Loihi: A Neuromorphic Manycore Processor with On-Chip Learning. IEEE Micro 2018, 38, 82–99. [Google Scholar] [CrossRef]
- Pehle, C.; Billaudelle, S.; Cramer, B.; Kaiser, J.; Schreiber, K.; Stradmann, Y.; Weis, J.; Leibfried, A.; Müller, E.; Schemmel, J. The BrainScaleS-2 Accelerated Neuromorphic System With Hybrid Plasticity. Front. Neurosci. 2022, 16, 795876. [Google Scholar] [CrossRef] [PubMed]
- Orchard, G.; Frady, E.P.; Rubin, D.B.D.; Sanborn, S.; Shrestha, S.B.; Sommer, F.T.; Davies, M. Efficient Neuromorphic Signal Processing with Loihi 2. In Proceedings of the 2021 IEEE Workshop on Signal Processing Systems (SiPS), Coimbra, Portugal, 19–21 October 2021; pp. 254–259. [Google Scholar] [CrossRef]
- Mayr, C.; Hoeppner, S.; Furber, S. SpiNNaker 2: A 10 Million Core Processor System for Brain Simulation and Machine Learning. arXiv 2019. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Auditory Cue | Hardware | Input Data |
|---|---|---|---|
| Lazzaro et al. [16] | ITD | IC | On-chip, click stimuli |
| Glackin et al. [17] | ITD | FPGA | Ear canal measurements, sound-dampened chamber |
| Xu et al. [18] | ITD | FPGA | Real-world, reverberant |
| Escudero et al. [19] | ILD | FPGA | Real-world, pure tones |
| Schoepe et al. [20] | ITD | FPGA+SpiNNaker | Real-world, pure tones and human speech |
| Ours | ILD | SpiNNaker or TrueNorth [21] | Synthetic, or real-world sounds in sound-dampened chamber |
| Wang et al. [22] | ITD | RRAM | Proof-of-concept laboratory setup |
| Moro et al. [23] | ITD | RRAM | Proof-of-concept laboratory setup |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schmid, D.; Oess, T.; Neumann, H. Listen to the Brain–Auditory Sound Source Localization in Neuromorphic Computing Architectures. Sensors 2023, 23, 4451. https://doi.org/10.3390/s23094451
Schmid D, Oess T, Neumann H. Listen to the Brain–Auditory Sound Source Localization in Neuromorphic Computing Architectures. Sensors. 2023; 23(9):4451. https://doi.org/10.3390/s23094451
Chicago/Turabian StyleSchmid, Daniel, Timo Oess, and Heiko Neumann. 2023. "Listen to the Brain–Auditory Sound Source Localization in Neuromorphic Computing Architectures" Sensors 23, no. 9: 4451. https://doi.org/10.3390/s23094451
APA StyleSchmid, D., Oess, T., & Neumann, H. (2023). Listen to the Brain–Auditory Sound Source Localization in Neuromorphic Computing Architectures. Sensors, 23(9), 4451. https://doi.org/10.3390/s23094451