Abstract
Feature selection (FS) represents an essential step for many machine learning-based predictive maintenance (PdM) applications, including various industrial processes, components, and monitoring tasks. The selected features not only serve as inputs to the learning models but also can influence further decisions and analysis, e.g., sensor selection and understandability of the PdM system. Hence, before deploying the PdM system, it is crucial to examine the reproducibility and robustness of the selected features under variations in the input data. This is particularly critical for real-world datasets with a low sample-to-dimension ratio (SDR). However, to the best of our knowledge, stability of the FS methods under data variations has not been considered yet in the field of PdM. This paper addresses this issue with an application to tool condition monitoring in milling, where classifiers based on support vector machines and random forest were employed. We used a five-fold cross-validation to evaluate three popular filter-based FS methods, namely Fisher score, minimum redundancy maximum relevance (mRMR), and ReliefF, in terms of both stability and macro-F1. Further, for each method, we investigated the impact of the homogeneous FS ensemble on both performance indicators. To gain broad insights, we used four (2:2) milling datasets obtained from our experiments and NASA’s repository, which differ in the operating conditions, sensors, SDR, number of classes, etc. For each dataset, the study was conducted for two individual sensors and their fusion. Among the conclusions: (1) Different FS methods can yield comparable macro-F1 yet considerably different FS stability values. (2) Fisher score (single and/or ensemble) is superior in most of the cases. (3) mRMR’s stability is overall the lowest, the most variable over different settings (e.g., sensor(s), subset cardinality), and the one that benefits the most from the ensemble.
1. Introduction
Maintaining the proper operation of industrial systems is crucial to meet the productivity and reliability requirements [1]. To this end, different maintenance strategies exist, among which the predictive maintenance (PdM) is particularly receiving a lot of interest from both industry and academia [2]. PdM is based on assessing the health condition of the monitored system so that a timely maintenance plan can be made accordingly. This is unlike other strategies where maintenance is performed only after the occurrence of failure (i.e., run-to-failure maintenance) or regularly based on a predefined schedule (i.e., preventive maintenance) [3]. PdM allows for preventing failures while maximizing the utilization of the industrial components as well as minimizing the downtime and maintenance costs [1].
The PdM mainly includes diagnosis tasks (e.g., fault identification, health state recognition) and prognosis tasks (e.g., prediction of the remaining useful life) [2]. The specific PdM application addressed in this paper is the classification-based tool condition monitoring (TCM) in milling, i.e., health diagnosis, where different data classes correspond to different health conditions of the tool. Milling is a popular machining process in which a rotating cutting tool is used to remove material from the workpiece in such a way that the desired geometry of the surface is attained. The tool, inevitably, wears gradually due to the joint effect of the heat and force generated during the milling process. The quality of the finished surface is directly affected by the tool wear. In addition, when the tool wear exceeds a certain level, a tool breakage occurs. Therefore, TCM is essential for ensuring good quality products and for replacing the tool in a timely manner [1,4].
The advances in collecting, storing, and processing large amounts of data are key enablers of data-driven PdM solutions [2,3,5]. Data-driven solutions include statistical methods, stochastic models, and machine learning (ML) methods. ML can perform complex tasks that might not be handled by other data-driven solutions. This is due to the ML advanced learning algorithms that can capture complex relations from data [2]. A general framework of ML-based PdM in the offline phase is depicted in Figure 1, and it encompasses the following steps [3,6]:

Figure 1.
A general framework of the machine learning-based predictive maintenance in the offline phase.
- Acquiring raw sensor signals representing the process at hand, e.g., tool wear progression during machining.
- Preprocessing the sensor signals, e.g., for reducing noise.
- Extracting features from the sensor signals.
- Reducing the data dimensionality (feature reduction), mainly through feature transformation or feature selection.
- Building a learning model that can eventually be deployed in the online phase to assess the system health.
Feature extraction allows for reaching meaningful information about the underlying process. However, it is quite intricate, if not impossible, to theoretically determine the optimal sensory features for the problem at hand. This is mainly due to the complexity and dynamics of the industrial processes being monitored and the presence of diverse factors affecting the importance of a given feature, including the operating conditions [4,7,8], position of sensors, signal-to-noise ratio of the acquired signals [8], the window size of feature extraction [9], etc. Therefore, in order to ensure that sufficient information is derived, many features are initially extracted from the sensor signals in the time, frequency, and/or time-frequency domain. However, some of these features might be irrelevant and redundant [6], and the number of extracted features might be too large, causing the overfitting problem [8,10]. Hence, the role of the subsequent step, i.e., dimensionality reduction, is to provide a feature vector of a lower dimension while keeping the most representative information from the original features.
Dimensionality reduction is essential for model building as it enhances the generalizability of the model and reduces the storage and computation requirements. To this end, two major techniques exist, namely feature transformation and feature selection. In the former, the original feature space is mapped into another lower-dimensional space, and thus, completely new features are constructed, whereas in the latter, no transformation is performed, but rather, a subset of the most relevant features is selected from the entire feature set. Since feature selection preserves the physical meaning of the features, it outperforms the feature transformation with respect to the interpretability [11]. The focus of this paper is on feature selection (FS).
FS methods can be categorized based on the involvement of the learning algorithm into: filter, wrapper, and embedded methods.
- Filter methods function independently of any learning algorithm. They rely solely on the intrinsic properties of the features, e.g., their correlation with the output, variance, etc. Filter methods are characterized by being fast and computationally efficient, which is particularly beneficial for high-dimensional datasets. However, they usually lead to a lower classification accuracy compared to the other two categories [12].
- Wrapper methods utilize a specific learning method along with a search strategy that searches the space of possible feature subsets. Each drawn feature subset is evaluated based on the employed learning model’s performance, e.g., predictive accuracy, which is assessed using a validation set or cross-validation. As a result, wrappers suffer from the intensive computations needed, as each iteration involves training and testing the model from scratch [10]. Another disadvantage of wrappers is the risk of overfitting. Additionally, the selected features are specific to the learning algorithm employed [13].
- Embedded methods employ a learning algorithm that inherently assesses the feature importance as part of the model training, e.g., random forest. Therefore, these methods are computationally more efficient than the wrappers [12]. Similarly to wrappers, the embedded methods suffer from the bias of their output by the particular learning algorithm employed [13].
Only filter-based FS methods are considered in the experiments conducted in this paper, as they are less computationally expensive than the other two categories and also produce generic solutions due to their independence of the learning algorithm.
The output of a given FS method can take one of the three following forms, with N being the total number of the evaluated features [12]:
- Weights (scores), where weights are assigned to the N features based on their importance, as perceived by the employed FS method.
- Ranks, where the most important feature is usually ranked first, whereas the least important one is ranked Nth.
- A subset of features selected from the original N-feature set.
Before training the model, a subset of selected features is eventually derived from the weights or ranks. The weights of features are sorted to produce a ranked list of features, and this list can be cut by specifying a specific number of features or a threshold (usually a percentage of the selected features) to generate a subset of the most important features [14].
FS methods have been extensively employed, investigated, and developed in the field of PdM, including a wide range of industrial processes, e.g., machining [4], industrial components, e.g., machining tools [4], gears [15], bearings [16], as well as PdM tasks, e.g., diagnosis [5] and prognosis [17]. Regarding the evaluation of FS methods, the majority of these works only consider the predictive power of the FS, expressed as the predictive performance of the learning model whose input are the features selected by the FS method, e.g., accuracy or similar measures [4]. Some works also consider other performance indicators such as the run time of the FS algorithm [18], among others. However, to the best of our knowledge, the stability of FS has not been considered in any of the works existing in the field of PdM. The stability of a given FS method reflects the ability of this method to select a consistent subset of features under small perturbations (variations) in the input data. Such data variations can be at the instance level and/or feature level [12]. The focus of this paper is on the instance-level data perturbations, i.e., when the variations are caused by adding or removing some data samples that come from the same process generating the data [12,19,20]. The stability of FS started to gain a lot of attention in many domain areas, especially where the data tend to have a high number of features but a small number of observations, e.g., in text mining and bioinformatics [12,21]. It has recently been addressed with various applications, e.g., sensor array optimization in electronic nose [22], and with different kinds of data, e.g., text, image, video, electrocardiogram (ECG) signal, voice recording [21]. However, it is still neglected in the area of PdM. Therefore, the main aim of this paper is to fill this research gap, both theoretically and experimentally. We argue that the stability of FS is an important aspect to be considered in the various PdM applications for many reasons, summarized as follows.
- The data used for PdM purposes are mostly time-series sensory signals that represent complex, dynamic industrial processes. These signals are usually non-stationary and contaminated with different kinds of noise. As such, estimating the stability of the FS outcome under changes in the dataset can reflect the extent to which the selected sensory features are generic and robust.
- The reproducibility of results is a crucial aspect to increase the confidence in the obtained outcome and the underlying implementation. Before the actual implementation of the PdM system, many elements should be determined in the offline phase, among which FS is of high significance as it selects the features that will be fed to the learning algorithm. Thus, the FS method that selects extremely different features for slightly different data samples may decrease the confidence in the total implementation, even if, in some cases, different subsets of features might build different models of equal accuracies.
- In the context of PdM, the selected features can be used by the domain experts to explore possible relations between some events, e.g., faults and health states, and the selected features. This is beneficial to reach a better understanding of the monitored system, which in turn can promote the PdM system. For such knowledge discovery and understandability purposes, stability of FS is of high importance.
- Many of the datasets acquired from real-world industrial processes contain only a small number of training observations. This is mainly due to the high requirements associated with acquiring large datasets in terms of cost, storage, and time [23]. Moreover, multisensor fusion is increasingly employed for PdM, leading to a larger pool of candidate features compared to the case of a single sensor. As such, it is not unlikely for the PdM dataset to suffer from a low sample-to-dimension ratio (SDR) (i.e., the ratio between the number of observations and number of features), in which case examining the FS stability would be particularly crucial.
- It is common in the literature to assess the candidate sensors based on the relevance of the features extracted from their signals, as performed in [4,24,25]. Such an assessment is especially important when there is a constraint on the number of the sensors to be used. In addition, the selected features in the offline phase will determine which signal analysis to be used in the online phase, e.g., fast Fourier transform, wavelet transform, etc. Thus, the FS stability can also affect the confidence in selecting the sensor(s) and signal analysis methods.
When it comes to facing FS stability issues, the trend in the literature seems to be toward developing techniques that can improve the stability of any FS method rather than establishing new FS methods that are stable. This is to be expected since there are already multitude of well-established FS methods and also given the fact that there is no single FS that is considered the best for all the applications. A recent technique that has been shown to increase the FS stability is the FS homogeneous ensemble. It was first introduced in [12] and is based on combining the outputs of identical FS methods that were fed with different data samples taken from the same dataset. This technique can be applied on all the FS types and algorithms, and it has been studied in various areas, e.g., bioinformatics, biomedicine [12], text mining [21], etc. To the best of our knowledge, it has also not been studied yet in the field of PdM.
Stability and homogeneous ensemble of FS are two recent research areas that have been studied in many fields but not yet in the PdM. This paper aims to fill this research gap with an application to TCM in milling. Our contributions in this paper can be summarized as follows:
- Presenting a brief review of the existing performance indicators of FS methods in the PdM field.
- Introducing the stability of FS as an important performance indicator to be considered in the field of PdM, which is, to the best of our knowledge, still neglected in this research area. Our motivation was driven by the reasons described above.
- Presenting a brief review of the existing measures of FS stability while highlighting their pros and cons with respect to this study.
- Investigating the impact of incorporating the homogeneous FS ensemble into the general framework of PdM. We experimented with different ensemble sizes and examined the impact of the FS ensemble on both the FS stability and predictive performance. Hence, this paper also contributes to the research area of FS ensemble, by exploring the potential of this technique for PdM.
- Conducting a performance comparison of three well-known, filter-based FS methods, namely Fisher score, maximum relevance minimum redundancy (mRMR), and ReliefF, in terms of both the stability and predictive performance. This comparison is performed for both the single and ensemble versions of these methods and for different numbers of selected features.
- The experimental study was performed for individual sensors and sensor fusion.
- As mentioned previously, the PdM application addressed in this paper is classification-based TCM in milling. We used four milling datasets obtained from two sources: (1) milling experiments we conducted and (2) NASA’s data repository [26]. Our data and NASA’s data were generated under different experimental setups (different machines, milling tools, sensors, data acquisition systems (DAS), operating conditions, etc.). Further, they differ in the main data characteristics in terms of the number of classes and observations. Our aim of using such diverse milling datasets is to conduct a comprehensive, non-biased study with respect to the experimental cases and data characteristics.
The remainder of this paper can be summarized as follows. In Section 2, related works are reviewed. In Section 3, the methodologies used in this paper are presented, including the FS methods, the FS stability and its measures, and the homogeneous FS ensemble. In Section 4, the overall FS scheme implemented for both the single and ensemble versions of FS methods is described. Section 5 contains the implementation details concerning the datasets, experimental setups, data processes, results, and discussion. Finally, in Section 6, the conclusion and future work are presented.
2. Related Works
FS represents an integral part of many of the PdM frameworks existing in the literature. In many of these frameworks, traditional FS methods that were originally developed in the area of ML have been employed and investigated. For example, Fisher’s discriminant ratio [27], t-test [7], genetic algorithm [28], recursive feature elimination [29], and random forest [24] were used for TCM in different machining processes. In [30], mRMR was employed for machinery fault diagnosis. In addition, a performance comparison of different FS methods was conducted in some works. In [16], a comparison between sequential forward selection, sequential floating forward selection, and genetic algorithm was performed for fault diagnosis of bearing. In [17], three metaheuristic optimization FSs, namely Dragonfly, Harris hawk, and genetic algorithms, were compared for tool wear prediction. In [31], FS techniques based on decision trees, neural fuzzy systems, scatter matrix, and a cross-correlation were compared for TCM in milling. Aside from the well-known FS methods, some application-specific FS schemes were proposed in the field of PdM to meet particular needs and scenarios, e.g., an FS scheme was proposed in [4] to tackle the challenges related to anomaly detection of milling tools when the data belong to different operating conditions. In [5], an FS scheme was proposed to reduce the detrimental effect of the data outliers on the accuracy of fault diagnosis. Other general FS techniques were also developed in the PdM area with the aim of improving the diagnosis accuracy, as in [15,18].
To evaluate the effectiveness of the FS schemes proposed in the literature, their performance is usually compared with popular FS methods [4,15,25,32], with other related works [5], and/or with the case when no FS is performed (i.e., all the features are used) [5,8,15,25,33,34]. The major performance indicator used to evaluate a given FS or to compare different FSs is the predictive performance of the learning model, e.g., accuracy, which was built using the features selected by the corresponding FS method [4,15,16,17,18,25,32,33,34,35,36,37]. Other performance indicators of FS, not yet commonly used, include run time of the FS algorithm [18,34,37], training time of the learning model trained by the selected features [33,34], the computation complexity of FS in terms of the number of parameters to be adjusted in the FS algorithm [32], and the number of selected features [32,34,36]. However, as mentioned previously, to the best of our knowledge, stability of FS has not been considered in the field of PdM, including the various industrial processes, components, and monitoring tasks existing in this field. Table 1 summarizes the most common FS performance indicators used for PdM based on the existing literature.

Table 1.
The most common performance indicators of the feature selection methods in the existing literature of predictive maintenance.
A recent topic that has been studied in conjunction with the stability of FS is the homogeneous ensemble of FS [12,21,38,39,40]. It has been studied in many domain areas, mainly with the aim of improving the FS stability. Based on the existing works in the literature, there seems to be no general conclusion regarding the impact of homogeneous FS ensemble, as the ensemble performance is dependent on many factors, e.g., domain, dataset, FS method, aggregation method, etc. A broad study was conducted in [21], where the ensemble was tested in many domains, data sizes, and different FS types. It was found in [21] that the less stable the method is, the more it can benefit from the ensemble. Another common conclusion in the literature is that the homogeneous ensemble can increase the FS stability while maintaining (or even with slightly increasing) the classification performance [12,21]. However, there are examples where the FS homogeneous ensemble led to an improvement in the classification performance, but coupled with a decrease in the FS stability, e.g., the t-test ensemble with the cancer diagnosis microarrays datasets tested in [39]. Other examples exist when the increased stability caused by the homogeneous ensemble comes at the expense of decreasing the classification performance, e.g., the ensemble of random forest caused a decrease in the classification accuracy by an average of 10% compared to the single version for the biomarker discovery datasets tested in [12]. To the best of our knowledge, the homogeneous ensemble of FS has also not been explored yet in the field of PdM.
Stability and homogeneous ensemble of FS are two recent research areas that have been studied in many domain areas but not in the PdM. This paper aims to fill this research gap with an application to TCM in milling.
3. Methodologies
3.1. The Feature Selection Methods Studied in This Paper
As mentioned in Section 1, three filter-based FS methods are studied in this paper, namely Fisher score, mRMR, and ReliefF. These filters are supervised, i.e., the target classes are fed to the FS algorithm along with the observations, where each observation is represented by the features . These methods assign weights (scores) to the features, which can be further converted into ranks, and a subset (see the forms of FS output explained in Section 1). These particular methods were selected in this paper due to the fact that they are well-known, widely-used FS methods and that they are distinct from each other in terms of the general characteristics, as shown in Table 2. More specifically,
Table 2.
The main characteristics of the filter-based feature selection methods studied in this paper.
- The metric used for feature assessment in Fisher score, mRMR, and ReliefF is statistical, information-based, and instance-based, respectively.
- Regarding whether or not the assessment of a given feature is influenced by the other features, Fisher score is univariate, i.e., each feature is assessed independently of the others, whereas both mRMR and ReliefF are multivariate, i.e., the inter-dependency among features is considered.
- Regarding feature redundancy, only mRMR, among the three studied FSs, considers the redundancy among features.
More details about these methods are described as follows.
Fisher score: It is a simple-yet-effective FS method [41]. Each feature is evaluated individually based on its discriminant ability, , expressed as in (1) [42].
where is the number of observations in class c. The number of classes is C. and are the mean and variance of samples in class c corresponding to the feature , respectively. denotes the mean of all the samples of feature . Fisher score reflects the feature’s ability to globally maximize the between-class scatter (the numerator in (1)) and minimize the within-class scatter (the denominator in (1)). The major disadvantage of the Fisher score is that the relations between the features are not considered [42].
mRMR: It uses two mutual information-based criteria to score the features, namely relevance and redundancy. The most important features are considered to be the ones that are highly relevant to the class while being most dissimilar to the other features. The score given to the feature represents the mutual information quotient , as given in (2) [43].
where the numerator and denominator of (2) represent the relevance and redundancy of the feature , respectively. is the mutual information between the feature and the target class Y, whereas represents the mutual information between the features and . S is the feature set.
ReliefF: A major advantage of the feature assessment performed by ReliefF is that the local dependencies between features are harnessed without loss of the global view [44]. The basic idea is to evaluate the features based on the extent to which their values discern the closely spaced observations. This assessment is performed iteratively. In each iteration, an observation is randomly drawn from the observation space. The k nearest neighbors of this observation are determined from the same class as well as from each of the other classes. The score of each feature is updated based on the difference of the feature values between the concerned observation and the nearest neighbors. The score, , decreases if the feature values are different within the same class and increases if the feature values differ for the neighbors of the other classes, as shown in (3).
where m is the number of iterations. is the observation drawn in the iteration i. and are neighboring observations to from the same class () and a different class, respectively. is the prior probability of the class c, and is usually determined from the training samples fed to the ReliefF algorithm. The Equation (3) corresponds to the case where all the K nearest neighbors have the same influence (as indicated by the factor ()), which is the version used in our implementation [44]. is the value difference of the feature between two observations, and is given by (4).
where and are the values of feature for the observations and , respectively. and are the maximum and minimum values of the feature , respectively.
Recall that the data classes in our work represent different health conditions of the milling tool, and the importance score given to a certain sensory feature will reflect its discriminative power for tool health diagnosis as perceived by the respective FS method.
3.2. Stability of Feature Selection and the Measure Adopted in This Paper
The stability of a given FS method reflects the sensitivity of its outcome to small perturbations (variations) in the input data [45]. As mentioned previously, this paper focuses on the data perturbations at the instance level. Thus, stability reflects the consistency of the selected features when different subsamples from the same data-generating process are input to the FS algorithm [19,20], i.e., it is indicative of the reproducibility of the selected features [21,46].
The stability of FS was a neglected issue and is considered a research area of recent interest [21]. Various measures have been proposed in the literature to quantify the FS stability, most of which are essentially similarity measures, e.g., Pearson, Jaccard measures [45]. The input to the stability measure is the FS’s different outputs generated under different data versions of the original dataset. To quantify the stability, a pairwise similarity is first computed for different outputs, and then the overall estimated stability would be the average of the resulting similarities [45]. Let X be a dataset with M instances (observations) and N features, m is the number of perturbed versions of X. To quantify stability under instance perturbations, the m versions are usually created by resampling techniques, such as bootstrapping or cross-validation [14]. The total stability () is given as in (5) [12].
where and are the two outputs of FS corresponding to the ith and jth data versions, respectively. is the similarity value between and computed based on the stability measure used.
Different stability measures exist for different types of FS output (weights, ranks, or subset) [12,45,47]. Nevertheless, some measures can be used for many output forms, e.g., Pearson’s correlation coefficient [45]. The Pearson’s correlation coefficient and the Spearman rank correlation coefficient are widely used for feature weighting and feature ranking, respectively [12,14,47]. As for the feature subsets, a variety of measures exist in the literature, most of which are basically increasing functions of the cardinality of the pairwise intersections, i.e., the higher the number of overlapping features between the feature subsets, the higher the stability is [20,45]. Examples of such measures include Jaccard’s, Hamming’s, and Kuncheva’s measures [45]. A thorough review on different stability measures can be found in [47].
The FS methods studied in this paper produce feature weightings that can be further converted into ranks and feature subsets. Thus, all the aforementioned types of stability measures can be applied. However, different types of measures represent the stability from different perspectives, and thus, provide different information. Weighting-/ranking-based measures estimate the stability from a global point of view as they take the weights/ranks of all the features into account. On the other hand, subset-based measures focus only on the subset of selected features, giving a finer view concerning the most important features [14]. Thus, the selection of the type(s) of stability measure should be driven by what insights are sought for the respective study. Since the main purpose of FS in this paper is to select the features that will be input to the classifier, we only focus on the subset-based stability measures.
As mentioned previously, most of the existing subset-based measures mainly rely on finding the features that the compared subsets have in common. Some of these measures suffer from specific drawbacks that result in constraints and/or invalid interpretations of the estimated stability in certain scenarios. For example, some measures, e.g., Kuncheva’s measure, require the compared feature subsets to be of the same cardinality [45]. Clearly, this constraint might not be met by the wrapper FS methods, for example. Other measures do not consider the so-called “similarity by chance” (the case when the stability corresponding to a random feature selection is dependent on the number of selected features) [48]. The usual trend for such measures is that the larger the subsets of selected features, the more features they have in common, as is the case with the Jaccard’s measure [45]. However, such a higher feature overlap is not linked to a higher stability in feature selection, but rather to a higher “chance”. To account for this issue, corrections are usually added to the stability measure so that the stability is zero for a random feature selection regardless of the number of selected features [45]. In addition, most of the existing measures assume that the different features are independent of one another [46] and, thus, regard features with different identifiers, e.g., , as different regardless of whether they are highly correlated or not [20]. This drawback might lead, in the presence of highly correlated features, to having a seemingly low estimated stability when different yet similar features exist across the different output feature subsets [20,46]. The existing stability measures that consider the similarity among features are few, and a review on them can be found in [48]. Hence, in order to have a reliable quantification of the FS stability, it is critical to select a suitable measure for the respective study. For example, the issues related to having subsets with different cardinalities are not relevant to our work since we deal with ranking-based FSs, i.e., we can control that the number of the eventually selected features is constant over all the compared subsets. Based on the properties of the existing stability measures in the literature, and driven by what we consider desirable properties for our work, we adopted the stability measure proposed in [20], called SMA, for the following main reasons:
- It takes into account the issue of “similarity by chance” that was described above.
- It takes into account the correlation between the features belonging to different subsets. Thus, two features of different identifiers are considered similar if the correlation between them is high (compared to a predefined correlation threshold). This property is significant for PdM applications where the features extracted from the sensor signals might be highly correlated.
- In the SMA measure [20], the correlation-based similarity between features is assessed based on the absolute value of inter-feature correlation, which is unlike other existing measures that take the direction of correlation into account, such as the nPOGR measure proposed in [46]. The absolute value is relevant to our work since it represents the correlation strength (irrespectively of whether the correlation direction is positive or negative), which is the aspect of interest when examining the redundancy among features [4].
The aforementioned reasons represent the main properties that motivated us to adopt the SMA measure in this paper. However, it is worth mentioning that this measure also has other properties that were not mentioned above, e.g., it does not require the compared feature subsets to be of the same cardinality, which makes it applicable with all the FS algorithms including those that immediately generate a feature subset whose size might not necessarily be the same across different input samples. More properties and proofs of this measure can be found in detail in [20,48]. The SMA stability measure is given in (6) [20].
where is the number of overlapping features between the two feature subsets and . denotes an upper bound for and is set in this paper to , as in [20]. is the adjustment function added to the stability measure to account for similarity between features from different subsets. Four different variants of this adjustment were proposed and investigated in [20]. They differ in the function used, but are similar in terms of the theoretical properties and the experimentally-attained stability values, as shown in [20]. Therefore, as recommended in [20], we will use the variant with the shortest execution time, which is called , and is calculated as in (7).
where is computed as in (8):
Hence, represents the number of features that are included in but not in and has a similarity exceeding the threshold with at least one feature included in but not in . Similarity is assessed in this paper based on the absolute value of Pearson’s correlation coefficient, as it will be shown in Section 5.5.
As for in (6), it represents the expected value corresponding to a random feature selection. Since this value is data-dependent, there is no general equation to calculate it. However, it can be estimated by repeating the following Monte Carlo procedure L times: (1) Performing a random feature selection, with each feature having an equal probability, to generate two feature subsets whose cardinalities are the same as the corresponding subsets and , respectively. (2) Calculating the corresponding score . Then, would be the average of the L scores. In this paper, L is set to 10,000 as in [20,46]. Estimating will be performed for each pair of subsets .
3.3. Homogeneous Ensemble of Feature Selection
The rationale of FS ensemble is similar to that of the ensemble learning. Ensemble learning was originally developed to enhance the performance of classification and regression tasks by combining the outputs of many individual models [12]. The diversity of these models is a crucial aspect of ensemble learning, and it can be induced at the algorithm level and/or the data level [21]. The ensemble concept has gained an increasing interest in the area of FS, mainly with the aim of increasing the stability of FS methods and the predictive performance [49].
The FS ensemble consists of two main components: individual feature selectors, also referred to as base selectors [21,49], and an aggregator. Each base selector generates a single output based on the input data and the type of the base selector (the applied FS method). Then, the aggregator combines the individual outputs to form one final output of the ensemble [12]. Many methods exist for both the base selectors and aggregators. Based on how the diversity is formed in the ensemble, the ensemble has two main categories: homogeneous and heterogeneous ensembles. In the former, the base selectors are all of the same type. However, the input data fed to them represent different versions of the original training data. On the other hand, the base selectors in the heterogeneous ensemble use the same input data, but they apply different FS methods on that data [21,49]. In this paper, only homogeneous ensemble is considered as it was experimentally shown to improve the stability of FS in many works, e.g., [12,21].
Different components and parameters should be considered when designing the homogeneous FS ensemble. First, instance perturbations are generated to attain the diversity needed for this ensemble category. To this end, sampling techniques are usually used, e.g., cross-validation [50], bootstrapping [12,38]. In this paper, bootstrapping is used to create B bootstrap samples with each one having T instances drawn, with replacement, from the training set; T is the number of instances in the training set. Thus, the employed FS will be applied to each one of these B bootstrap samples, resulting in B different outputs. The ensemble size, i.e., B, is a crucial design parameter. Hence, different values of this parameter will be tested in this paper, as it will be shown in Section 5.6.2. The resultant outputs will be eventually combined by an aggregator to produce the final output. The common aggregators existing in the literature combine rankings or subsets [12,49]. Rank-based aggregators are used in this paper. There exist several rank-based aggregators that range in complexity from aggregators with very simple functions, e.g., mean, median, etc., to more complex ones, e.g., the aggregator proposed in [38] that assigns bootstrap-dependent weights to the individual ranks of each feature based on the test accuracy of a classifier trained on the respective bootstrap sample. However, the sophisticated aggregators are more computationally expensive, without necessarily increasing the FS stability or the predictive accuracy [21]. Therefore, we will use a simple aggregator with a mean-based function as it was shown to perform well in many studies [21]. As such, the final rank of a given feature will be the mean of its individual B ranks, i.e., the final rank of feature is . The final feature ranking of the ensemble would be an ascendingly sorted list of the feature ranks; the lower the feature’s rank, the higher the feature’s importance.
4. The Feature Selection Scheme Implemented in This Paper
For each of the three FS methods explained in Section 3.1, two versions are implemented, namely the single version and the homogeneous ensemble version (as described in Section 3.3).
As mentioned previously, redundancy among features are not taken into account by both Fisher score and ReliefF. However, redundant features, even if relevant to the class, increase the data dimensionality without necessarily enhancing, or even degrading, the representation of the process at hand. It was experimentally shown in [4] that, for a constant number of 5 features, an increase in the assessment accuracy of the milling tool was gained by simply replacing more-important yet redundant features with less-important but non-redundant ones. Additionally, it was shown in [51] that a more accurate fault diagnosis was achieved when redundant features are removed from a specific feature subset. Similarly to [4,51,52], we applied the following iterative procedure to eliminate redundant features, in which redundancy among features was examined using the Pearson’s correlation coefficient: In the first iteration, the top ranked feature eliminates the less important features with which it exhibits a correlation whose absolute value exceeds a threshold. In the next iteration, the same process is performed after determining the top ranked feature among the features remaining from the previous iteration, and so on until no feature is remaining. The Pearson’s correlation coefficient (absolute value), , between two features is given as in (9).
where and are the feature samples corresponding to the features and , respectively. and are the mean values of feature samples for and , respectively.
The range of is [0, 1]. In this paper, the condition for eliminating redundant features is . A threshold value that is too high might not effectively remove redundant features. On the other hand, a threshold value that is too low might also lead to removing significant features. A common trade-off choice of this threshold is 0.9, as in [52,53,54,55,56], which is also the Th value used in this paper. This step of eliminating redundant features will be implemented for each of the studied FS methods. It should be noted that, even for mRMR which takes the redundancy among features into account, this step will not affect the feature preference perceived by this method, since mRMR considers the more-relevant, dissimilar features more important than the less-relevant, redundant ones.
Figure 2 illustrates the overall FS scheme implemented in this paper for both the single and ensemble versions of each FS method.
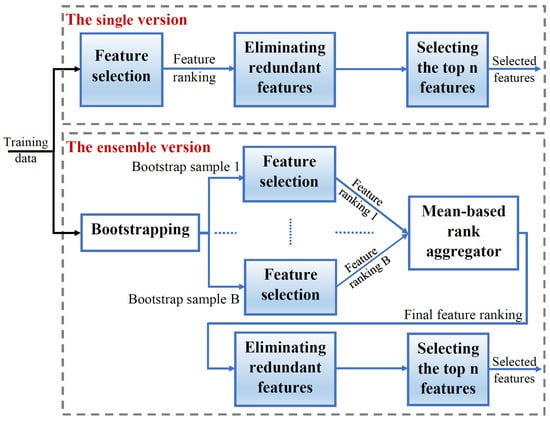
Figure 2.
The overall feature selection scheme implemented in this paper for both the single and homogeneous ensemble versions of the FS method (Fisher score, mRMR, or ReliefF). The training set represented by the feature vectors is directly passed to the FS algorithm in the single version, whereas in the ensemble version, it undergoes the bootstrapping technique so that B different data versions are generated from the training set. The B bootstrap samples are fed to the same FS algorithm, resulting in B feature rankings. These rankings are combined using a mean-based aggregator to generate the final feature ranking of the ensemble. The next steps are the same as those applied in the single version, where redundant features are removed and the top n remaining features are selected.
In the FS scheme, the training set represented by the feature vectors will be fed to the single version of a given FS method. However, for the ensemble version, the bootstrapping technique is applied on the training set to generate B bootstrap samples. Then, the respective FS method will be applied on each bootstrap sample to generate a corresponding feature ranking. As discussed in Section 3.3, we use a mean-based rank aggregator that averages the B individuals ranks generated for each feature. The resulting feature ranking will represent the ensemble feature ranking. For both the single and ensemble versions, the final feature ranking will be used to eliminate the redundant, less important features. Finally, the selected features will be the top n features among the remaining ones.
5. Implementation Details
This section presents all the details related to the datasets used, the workflow implemented, including preprocessing, feature extraction, FS (single and ensemble), and classification-based TCM, as well as the different evaluations performed, and finally the results and discussions. A five-fold cross-validation was used for the different evaluations performed in this section. The MATLAB R2020b software was used to perform the different experiments on the data.
5.1. Experimental Datasets
Four real milling datasets are used in this paper. Two of them, called DS1 and DS2 hereafter, are generated from our experiments, whereas the other two, called DS3 and DS4 hereafter, are from the NASA’s data repository [26]. Each of these four datasets contains run-to-failure data of the milling tool, i.e., the dataset covers the different stages of tool wear progression, starting from when the tool is completely new, through the different degradation states, and finally to the failure state. These datasets differ in many aspects, e.g., DAS, sensors, operating conditions, data size, etc. However, the main difference between the two datasets under each setup, i.e., (DS1, DS2) and (DS3, DS4), is the operating conditions of the milling process. The sensors and operating conditions of the four datasets are shown in Table 3. The detailed experimental setups will be described in the following two subsections.
Table 3.
The sensor(s) and main operating conditions of the datasets used in this paper.
5.1.1. Experimental Setup and Preprocesses of Our Milling Datasets (DS1 and DS2)
The milling machine used in our experiments is a five-axis milling center from Metrom GmbH that is equipped with an Andronic 2060 CNC control. We used solid carbide milling cutters with a diameter of 8 mm, cutting material of VHM, a tooth number of 2, and a cutting edge length/total length of 19 mm/63 mm. A workpiece of steel was used. The workpiece surface was machined line-by-line with the cutter. The milling performed is dry milling. For each collected run-to-failure dataset, the milling was performed under a distinct set of operating conditions defined mainly by the rotation speed, depth of cut, and feed rate (See Table 3). We used a radial depth of cut of 3.6 mm for all the experiments. Two types of milling processes were performed, namely up milling, in which the cutter rotates against the feed direction, and down milling, in which the cutter rotates along the feed direction. For each dataset, these two types were used alternately, i.e., the milling type changes with every cutting line. A microphone (model: SPU0410LR5H-QB) and an accelerometer (model: ADXL1005) were used to collect the sound and vibration signals, respectively. Five classes were used to label the data. To this end, several factors were taken into account for labeling, mainly the quality of the finished workpiece surface; the characteristics of the chips generated during milling, specifically, their color and shape; as well as the experience of the machine operator (also guided by the sound and vibration generated during milling). The first two factors, i.e., surface quality and chip characteristics, are largely influenced by the tool wear. As the tool wear increases, the surface quality degrades, the chip no longer rolls in as much, and the cutting temperature also increases due to the increased friction, which affects the chip color. Figure 3 illustrates the main setup of our milling experiments, including the CNC machine used, the sensors mounted inside the milling center, a snapshot of the milling process, the up and down milling processes, and the finished surface quality as well as the chips generated during milling corresponding to the five classes.

Figure 3.
Our experimental setup. (a) CNC machine. (b) Up milling and down milling processes and the cutting paths on the workpiece. (c) The sensors and cutter inside the milling center. (d) Snapshot of the milling process. (e) The finished surface quality and the chips generated with the five classes of the tool health.
The sensor signals were amplified by an amplifier and then fed to a Red Pitaya board that served as a data acquisition system in our setup. The sampling frequency for each of the sensors was about 1.95 MHz. The acquired sensor signals were then transferred to a PC where they were stored for further analysis. The signals of each sensor were stored in packages of 16,381 samples each, where the frequency of the packages is about 10 Hz. The following preprocesses were performed on each of the sensor signals: (1) Filtering using a median filter which was selected due to its capabilities of removing high-frequency noise without affecting the useful information. (2) As in [1,24], the parts of signals corresponding to the following events of the milling process were eliminated: the aircut (when the tool is in the air) and the entry/exit cuts which correspond to when the tool first engages/disengages in/out of the workpiece. (3) The original sampling frequency of 1.95 MHz was reduced to about 400 KHz, where the latter frequency, given the frequency ranges of the sensors used and the monitoring signals, is sufficient according to the Nyquist–Shannon sampling theorem which states that the sampling frequency should be at least twice as high as the maximum frequency contained in the sampled signal. In our case, the sampling frequency of 400 KHz is about 7 times higher than the maximum frequency of interest contained in the observed signals. Figure 4 illustrates an example of the microphone signal before filtering (Figure 4a) and after filtering (Figure 4b) for different machining lines. It can be noticed from the figure that, before filtering the signal, events such as when the tool is in the air cannot be clearly recognized. The signal parts corresponding to the aircuts are those parts whose amplitude is considerably lower than the other parts corresponding to the actual milling.
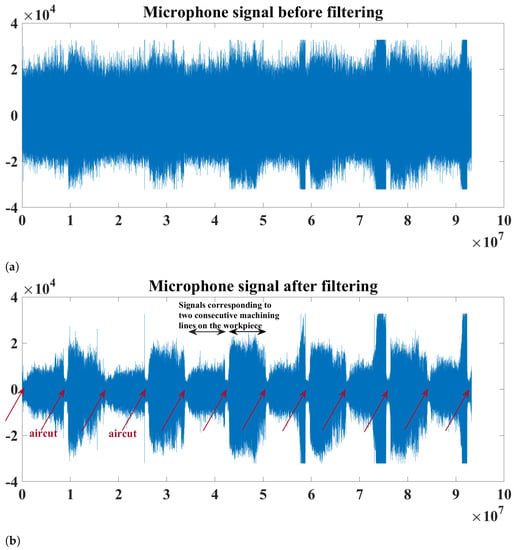
Figure 4.
An example of the microphone signal during our milling experiments in the time domain: (a) before filtering and (b) after filtering. Some events, e.g., aircuts, cannot be recognized clearly before filtering.
5.1.2. Experimental Setup and Preprocesses of the NASA Milling Datasets
The publicly available NASA milling data [26] contains 16 run-to-failure datasets with 6 sensors. For this paper, we only used two datasets, namely case 9 and case 10. We only used two sensors, namely the AC current sensor of the spindle motor and the acoustic emission (AE) sensor mounted on the machining table. Each run of the machine is provided with sensor signals, with each signal containing 9000 samples obtained at a sampling frequency of 250 Hz. The data are labeled with a flank wear value (VB) that was measured after each run. As in [1], we divided the dataset into three classes based on their VB values as follows: VB < 0.2 mm, 0.2 mm ≤ VB ≤ 0.4 mm, and VB > 0.4 mm. We performed the following preprocesses on the NASA datasets: (1) Eliminating the aircut and entry/exit cuts, as described previously in our setup. (2) Segmenting the signal corresponding to the milling part of each run into 4 non-overlapping segments of 1024 samples each.
5.2. Feature Extraction
For feature extraction, we applied signal analysis methods that are quite similar to those used in [4]. The methods and the corresponding features are described as follows.
- Time-domain statistical analysis was used to calculate the following 8 statistical features: mean, variance, skewness, kurtosis, impulse factor, crest factor, root mean square (RMS), and range [4,6].
- A multi-resolution analysis was performed using a non-decimated discrete wavelet transform. For this, the following mother wavelet functions were used: db1 and db3. As in [4], with each of the mother wavelets, a six-level decomposition of the data segment was performed, resulting in six details (D1, D2, …, D6) and one approximation (A6). From each of these coefficients, the following statistical features were extracted: mean, variance, skewness, and kurtosis, constituting a total of 28 features. Since 2 mother wavelet functions were used, a total of 56 wavelet-based features were generated.
- Time-frequency analysis was performed to calculate the mean peak frequency. The mean peak frequency is the average of the peak frequencies determined at different time instances of the data segment, with each peak frequency being the frequency with the maximum power at the corresponding instance [4]. In [4], this feature was extracted from the scalogram generated by the continuous wavelet transform. However, in this paper, we extracted this feature from the spectrogram generated by the short-time Fourier transform (STFT) since this latter transform is less computationally expensive than the continuous wavelet transform.
As such, 65 (8 + 56 + 1) features were extracted out of each sensory segment, as depicted in Figure 5. After the feature extraction, each segment representing one observation, will be represented by the corresponding extracted features, rather than by raw sensor signals. As such, for an individual sensor, the 65 features corresponding to that sensor will be used for feature selection, whereas for the sensor fusion, the concatenated feature vectors from two sensors, i.e., a 130-feature vector, will be used. Table 4 shows the main characteristics of the four datasets used in this paper in terms of the number of classes, observations, and extracted features, as well as the SDR. SDR is a common measure used to reflect the difficulty of the task performed by the FS methods [12,21], with SDR 1 being considered too challenging [21]. In this paper, SDR is only computed on the training set, since it is the data portion that the FS method will see. Since the same number of features were extracted for all the datasets, the SDR variation over the datasets is caused by merely the difference in the number of observations. As it can be noticed from the table, there is a considerable difference in SDR values between (DS1 and DS2) on the one hand, and (DS3 and DS4) on the other. For sensor fusion, for example, SDR for the datasets DS1–DS4 is 78.03, 96.40, 0.22, and 0.25, respectively. Such a huge difference allows for gaining diversified insights into the behavior of the FS methods and classifiers, as it will be shown later.
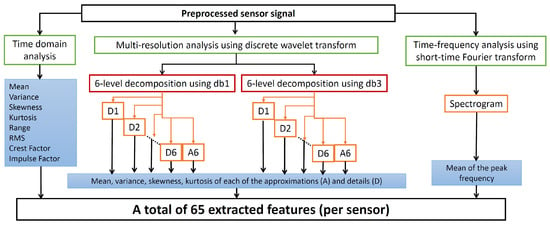
Figure 5.
The methods used to extract sensory features in this paper.
Table 4.
The description of the datasets used in this paper.
5.3. Feature Selection
Before performing the feature selection, the extracted features are normalized based on the training samples that will be input to the FS. For this purpose, the z-score is used in this paper as in (10).
where and are the original and normalized values of the sample j corresponding to the feature . and are the mean and standard deviation of the feature ’s samples, respectively.
As mentioned previously, Fisher score, mRMR, and ReliefF are applied for all the experiments performed in this paper. Regarding the parameters related to the implementation of ReliefF, the number of the nearest neighbors, k in (3), was set to 10. Additionally, all the observations input to the ReliefF algorithm were used for computing the feature weights, and all the k nearest neighbors contribute equally to the weight updates [44].
It is noteworthy that, for a given dataset, the Fisher score of a specific feature related to a specific sensor will be the same for both the cases of the individual sensor and the sensor fusion. This is unlike the scores given by mRMR and ReliefF, i.e., the scores given by these methods to the feature will vary between the single sensor and sensor fusion cases. This is due to the fact that the latter two methods are multivariate, and hence, scoring the feature will be influenced by the other input features.
5.4. Classification-Based Tool Condition Monitoring
As mentioned previously, TCM is modeled in this paper as a multi-class classification problem. We employed support vector machines (SVM) and random forest (RF) as classifiers for the following main reasons:
- SVM is one of the most popular classifiers that have shown a promising performance for TCM, e.g., in [1,24,28,29,33,37].
- RF is considered the most popular method of creating a decision forest—a model ensemble whose base learners are decision trees. It has been widely and satisfactorily used for diagnosis tasks of different industrial components, e.g., bearings [57], and it recently started gaining interest for TCM, e.g., in [58,59]. However, it is still not extensively investigated with different FS methods for classification-based TCM.
Recall that in this paper, a five-class classification was performed for DS1 and DS2, and a three-class classification for DS3 and DS4. The one-versus-one approach was employed to constitute the multi-class SVM-based classifier consisting of binary classifiers, where C is the number of classes. Hence, the SVM classifier consists of 10 and 3 binary classifiers for the 5-class and 3-class classification problems, respectively. For each experimental case, we used the two following non-linear kernels: the polynomial kernel of order 2 (the quadratic kernel) and the radial basis function (RBF) kernel. The penalty parameter was fixed to 1 in all the experiments.
Regarding the RF implementation, the RF model consists of 50 classification trees, the minimal leaf size is set to 1, and the number of the randomly selected features for each decision split is the square root of the total number of input features.
5.5. Performance Indicators of FS Methods
As mentioned previously, the FS methods studied in this paper will be evaluated based on their stability and the predictive performance of the classifier trained with the features selected by the respective FS method. Given the classification-based TCM performed in this paper, the stability of a given FS method will reflect the sensitivity of the selected features, i.e., those considered by the method to be the most informative for distinguishing between the different health conditions, to variations in the training observations (drawn from the corresponding run-to-failure data). As discussed in Section 1, FS stability is a significant performance indicator to be considered prior the deployment of the PdM system. However, it should not solely be used to select the best FS method. Assessing the predictive power of the selected features is also critical to ensure that they allow building an accurate classification model that can eventually serve as the diagnosis model.
Regarding the stability, the SMA measure is adopted as discussed in Section 3.2. Recall that this measure considers two features to be alike if they are either identical, i.e., , or different, i.e., , but highly correlated in reference to a predefined correlation threshold. As mentioned previously, the similarity of two features in (8) was computed using the absolute value of the Pearson’s correlation coefficient, which is the same similarity measure we used to examine redundancy among features (See Section 4). in (8) was set to 0.9, which is also the same threshold we adopted to examine redundancy among features. As for evaluating the predictive performance, we will use the macro-F1 of the classifiers. Macro-F1 is calculated by averaging the individual F1-scores corresponding to the individual classes, as in (14) [60]. F1-score for class c is given in (13), and it represents the harmonic mean of the recall (given in (11)) and precision (given in (12)).
where TP and TN represent the number of test observations that were classified correctly as positive and negative, respectively. FP and FN represent the number of test observations that were wrongly classified as positive and negative, respectively. C is the number of classes.
A five-fold cross-validation was implemented. As such, for a given dataset, each of the five folds will be used once as the test set for the classifier, while the remaining four folds will constitute the training set used for the feature selection and training the classifier. For a given FS method (whether a single or ensemble version), the overall stability of FS and the macro-F1 of the classifier will be calculated as follows.
- The overall stability is estimated by the SMA measure, as in (6), where the input to this measure is the five feature subsets selected based on the five training sets. Thus, m in (6) is 5, and the computed 10 pairwise similarities are averaged to obtain the overall stability. It is noteworthy that, since we used 5-fold cross-validation, the percentage of overlapping observations for each pair of training sets is roughly 75%.
- The overall macro-F1 is calculated by averaging the five macro-F1 values corresponding to the five test sets, with each value being calculated as in (14).
5.6. Experimental Results and Discussions
In this section, many evaluations of the studied FS methods will be performed over all the datasets and sensor configurations and can be summarized as follows:
- The macro-F1 of the FS single versions is evaluated over all the possible numbers of selected features. Based on the results, only specific subset cardinalities will be selected for the next experiments.
- For each of the subset cardinalities specified in step 1, the stability of each FS method is evaluated for both its single and ensemble versions. Five ensemble sizes are tested for the ensemble versions. The ensemble size that achieves the highest stability will be determined for each experimental case to represent the corresponding ensemble version. Finally, a global stability profile will be presented for the single and ensemble versions for all the datasets.
- The FS single and ensemble versions are evaluated in terms of the stability and macro-F1 for the subset cardinalities specified in step 1 and the ensemble sizes being as determined in step 2.
- Based on the comprehensive results of step 3, we specify only one cardinality of feature subset for each combination of dataset/sensor(s), where the FS single and ensemble versions will be evaluated based on the harmonic mean of the stability and macro-F1. Based on the results, the superior FS method (in its superior version, i.e., single or ensemble) will be determined for each combination.
5.6.1. Evaluation of FS Methods (Only Single Versions) in Terms of Macro-F1 over All the Possible Numbers of Selected Features
As mentioned previously, feature rankings can be generated from the FS methods studied in this paper. Thus, to generate a feature subset out of each ranking, a threshold or a specific number of features, n, should be determined to select the top features. The optimum number of selected features, with respect to the predictive performance, is influenced by many factors, including the number of training observations, the complexity of the dataset and the task at hand [4], the FS method [21], etc. In light of that, we first conducted exhaustive experiments in which a classification model was built and tested for each of all the possible feature subsets consisting of the top n features, starting from and up to the total number of features remaining after eliminating redundant features. Our aim of these experiments is to reveal the trend of the macro-F1 variation over the number of selected features, and accordingly, select only some cardinalities of interest for the further experiments. Moreover, such experiments allow for comparing the number of features required by the different FS methods to achieve the highest predictive performance for a specific classifier, as it will be shown later.
Figure 6 shows the macro-F1 variation of the SVM classifiers over the number of selected features across all the datasets and sensor configurations. It can be vividly seen that the trends of macro-F1 variation corresponding to the datasets DS1 and DS2 for all the sensor configurations are more or less similar. Additionally, the trends with DS3 and DS4 are quite alike. However, the trend with both DS1 and DS2 differs largely from that with DS3 and DS4. Regarding DS1 and DS2, the macro-F1 increases with the addition of features, indicating an improvement in the classification performance of the models with more features added until a certain number of features is reached, where the macro-F1 does not change or slightly degrades with adding further features thereafter. For DS3 and DS4, however, the trend tends to be more complex, as the macro-F1 reaches its peak value with only a few features (mostly 1–3 features) and thereafter fluctuates with adding further features, with an overall decreasing trend. This can be attributed to the fact that the number of training observations for DS3 and DS4 is low (see Table 4), and thus, the risk of overfitting increases with adding more features, which adversely affects the classification performance on the test data. Moreover, the limited training samples increase the sensitivity of the learning to the information presented by new features, which can explain the fluctuation.
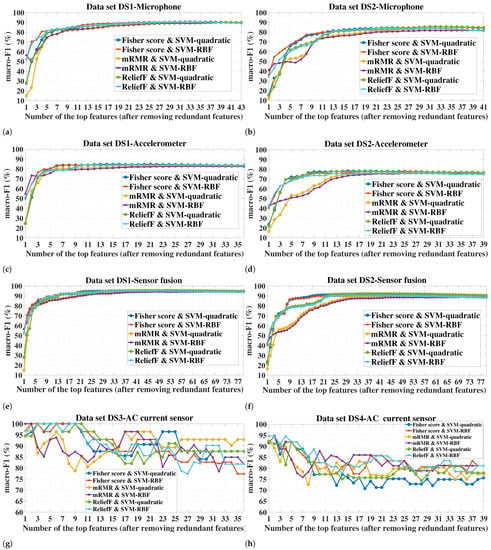
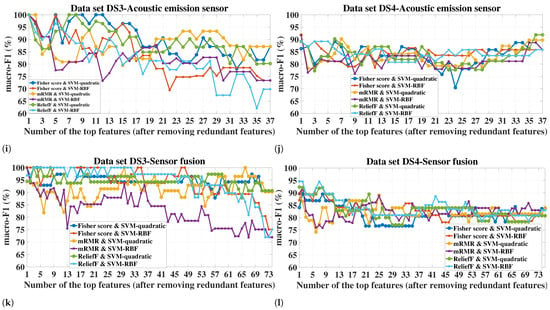
Figure 6.
Macro-F1 (the average using 5-fold cross-validation) of the SVM classifiers as a function of the number of the top ranked features selected after removing the redundant features for different sensor configurations. (a–f) Datasets DS1 and DS2, (g–l) Datasets DS3 and DS4. The top features are added incrementally (one feature at a time), and a corresponding classification model is built and tested for each resulting feature subset. The aim of these experiments is to reveal the trend of the macro-F1 variation over the different cardinalities of feature subset, which in turn helps to select some cardianlities of interest for the further experiments and to show the number of features required by each FS method to achieve the highest performance for a specific classifier. For DS1 and DS2, adding more features improves the generalizability of the classification models until a certain number of features is reached, where the performance converges thereafter. The trend for DS3 and DS4 is different, as the macro-F1 reaches its peak value with only a few features (mostly 1–3 features) and thereafter fluctuates by adding further features with an overall decreasing trend. This can be attributed to the fact that the number of training observations for DS3 and DS4 is low, which increases the risk of overfitting with adding more features. The highest macro-F1 achieved for each case is given in Table 5.
As it can be seen from Figure 7 corresponding to the sensor fusion case, the trend of the macro-F1 variation obtained with the RF classifier strongly resembles that obtained with the SVM classifiers for the respective dataset and FS method. The only significant difference in the trend is related to the small datasets DS3 and DS4 where RF showed a higher robustness to increasing the dimensionality compared to the SVM classifiers. For briefness, we only included the sensor fusion results in Figure 7 as the resemblance in the macro-F1 variation trend between the SVM and RF classifiers was also observed for the individual sensors.
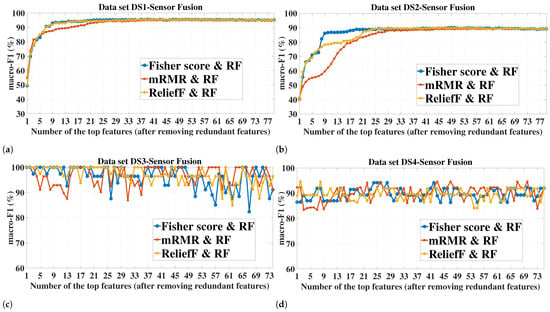
Figure 7.
Macro-F1 (the average using 5-fold cross-validation) of the random forest classifier as a function of the number of the top ranked features selected after removing the redundant features, for the sensor fusion. (a–d) Datasets DS1–DS4. The highest macro-F1 achieved for each case is given in Table 5.
For a given classifier, the number of features required to achieve a certain value of macro-F1 is dependent on the FS method. On the other hand, the superior FS method seems to be dependent on the number of features. For example, for all the sensor configurations in DS1 and DS2, mRMR led to the highest macro-F1 of both SVM-RBF and RF when only one feature was used. However, mRMR did not remain the superior when higher numbers of features were added (see Figure 6a–f and Figure 7a,b).
Regarding the performance comparison between the two SVM kernels, the superior kernel is largely dependent on the number of features. For example, for datasets DS1 and DS2, the RBF kernel tends to considerably outperform the quadratic kernel for all the FS methods when the number of features is low (around 4 features), e.g., for the case of the DS1-sensor fusion-one feature (Figure 6e), the difference in macro-F1 between the kernels reached 24.65%, 41.41%, 24.32%, for Fisher score, mRMR, and ReliefF, respectively. However, this difference diminishes rapidly with adding more features, and after a certain number of features, the quadratic kernel is mostly the superior of these two datasets.
Table 5 shows the maximum macro-F1 achieved by each FS method, along with the corresponding number of features. It should be noted that, for a given combination of dataset/sensor(s)-FS, the same macro-F1 value might be achieved with different numbers of selected features. For such cases, only the lowest number of features is recorded in Table 5. The table also shows the macro-F1 achieved when no FS was applied, i.e., all the features extracted from the sensor(s) were used to build and test the models. This latter case serves as a baseline for the FS methods to reflect the utility of applying the feature selection. An effective FS scheme should improve or at least not significantly degrade the classification performance compared to the case where no FS is applied. It can be seen from the table that this is fulfilled for all the datasets/sensor(s). In most of the experimental cases, the highest macro-F1 can be achieved with at least one of the three FS methods, which emphasizes the role of FS in improving the health assessment of the milling tool while simultaneously reducing the storage and computation requirements. This is especially true for the small datasets, such as DS3 and DS4, which increase the risk of overfitting when the feature dimension is relatively large. For example, all the FS methods in DS3-AC current achieved a macro-F1 of 100% with only 1–3 features for both SVM kernels, whereas all the 65 features (no FS) achieved 89.33% and 90.22% for the quadratic and RBF kernels, respectively. Concerning the cases where using all the features led to a higher classification performance compared to when FS was applied, the difference in the macro-F1 is mostly marginal and can be neglected given the higher number of features required, e.g., for the case corresponding to the accelerometer-quadratic kernel, a total of 65 features led to a macro-F1 of 85.65% and 78.31% for datasets DS1 and DS2, respectively, whereas for the same case, 84.74% and 78.27% were achieved by the Fisher score with only 21 and 15 features, respectively (i.e., a reduction by 44 and 50 features with a macro-F1 reduction by only 0.91% and 0.04%, respectively). For a given dataset, sensor(s), and classifier, the maximum achieved macro-F1 as well as the corresponding number of features are dependent on the FS method. It is always desirable to obtain a high predictive performance with the lowest number of features possible. For DS1 and DS2, the maximum F1-macro achieved by Fisher score and ReliefF is higher than that of mRMR for all the cases of the SVM classifiers and most of the cases of the RF classifier, and the number of required features is always lower than that of mRMR. However, mRMR with datasets DS3 and DS4 showed a comparable performance, and in some cases better (e.g., case of DS4-AE for both SVM-RBF and RF), compared to the other two FS methods.
Table 5.
The highest macro-F1 value (%) and the corresponding number of selected features across the different datasets and sensor(s). When the maximum macro-F1 for a given FS method is obtained by more than one cardinality of feature subset, only the lowest cardinality is recorded in the table. These results are mainly based on Figure 6 and Figure 7.
Among the tested classifiers, RF achieved the highest macro-F1 with all the FS methods and sensor(s) for DS1, whereas SVM-quadratic was the superior for DS2. All the classifiers achieved a maximum macro-F1 value of 100% in all the cases of DS3, whereas for DS4, the superior classifier varies with the cases.
As for the sensor(s) used, the classification performance was better with sensor fusion compared to the individual sensors for DS1 and DS2. Taking SVM-quadratic as an example, the maximum macro-F1 that can be reached by sensor fusion is higher than that of the microphone by an average (over the three FS methods) of 4.93% and 6.5% for DS1 and DS2, respectively. The improvement gained by sensor fusion is even higher when compared to the accelerometer. However, for DS3 and DS4, the sensor fusion mostly led to an identical macro-F1 (and even lower with some cases of SVM) compared to the individual sensors. This represents an example of when adding more sensors might lead to more hardware and computation requirements without necessarily improving the performance.
Based on the macro-F1 values observed for the different datasets and sensor configurations in Figure 6 and Figure 7, and Table 5, the number of selected features, n, that will be considered for the next experiments is as follows:
- For datasets DS1 and DS2, we consider the value set of {10, 20, 30} for each of the individual sensors and {10, 20, 30, 40, 50} for the sensor fusion.
- For datasets DS3 and DS4, we consider the value set of {1, 2, 3} for each of the individual sensors and {1, 2, 3, 4, 5} for the sensor fusion.
5.6.2. Stability of the FS Methods (Single Versions and Ensemble Versions with Different Sizes) for Different Numbers of Selected Features
In this subsection, the stability of the studied FS methods will be examined for the numbers of selected features specified in Section 5.6.1. This will be performed for both the single and ensemble versions of FS methods. For each fold of the five-fold cross-validation, the corresponding training set will be fed to the single version and ensemble versions of a given FS method as illustrated in Figure 2. Recall that B is the number of bootstrap samples (the ensemble size). B is a significant design parameter of the ensemble. The experiments conducted in many different domains in [21] showed that a value of 50 for B is sufficient to increase the FS stability, and that higher numbers led to little or no improvement. Similarly, 30 and 40 bootstrap samples were shown to be sufficient in [12,39], respectively. Hence, in this paper, we will not consider more than 50 bootstrap samples. We tested five B values: 10, 20, 30, 40, and 50. Figure 8 shows the stability of the studied FS methods for both the single versions as well as the ensemble versions with different ensemble sizes for different feature subsets cardinalities. The following can be noticed from Figure 8:
Figure 8.
Stability (%) of the FS methods (single and ensemble versions) for different numbers of selected features and different sensor configurations. Different ensemble sizes (Ensemble-B) are tested, where B is the number of bootstrap samples used to construct the homogeneous ensemble of each FS method. (a–f) Datasets DS1 and DS2, (g–l) Datasets DS3 and DS4.
- Different FS methods can largely differ in their stability, e.g., in the case of DS2-sensor fusion-20 features, the stability values of the single versions of Fisher score, mRMR, and ReliefF are 97.05%, 58.69%, and 91.88%, respectively, i.e., a noticeable difference between the Fisher score and ReliefF on the one hand, and mRMR on the other hand. Such a difference reflects the interaction between the data and the inherent functioning of the different FS methods and it promotes the role of the stability as a decisive performance indicator when it comes to selecting the best FS method for a PdM task.
- Concerning the FS single versions, mRMR has the lowest stability in all the datasets and sensor configurations, except for some feature cardinalities related to cases of DS3 and DS4, where it showed a similar stability to the other two methods (see Figure 8g–h).
- Concerning the FS ensemble versions, the stability of mRMR is the one most influenced by the ensemble technique. This manifests itself in the stability variation over the single version and the ensemble versions of the different sizes. On the other hand, the stability of Fisher score is the least influenced by the ensemble.
- Applying the ensemble technique can improve the stability of a given FS method, especially with mRMR in DS1 and DS2. However, there are also cases where the stability dropped with the ensemble, such as for mRMR in the case of DS4-AC current sensor-1 feature (see Figure 8h) and ReliefF in the case of DS1-Microphone-10 features (see Figure 8a).
- The stability can significantly vary over different ensemble sizes, as mostly seen with mRMR, e.g., in the case of DS4-sensor fusion-4 features, the mRMR ensemble with 10 and 30 bootstrap samples improves the stability over that of the single version by 5.98% and 50.69%, respectively. This emphasizes the importance of selecting the ensemble size experimentally so that the most benefit can be obtained when there is an improvement potential with the ensemble.
- The only negative stability values were obtained by the mRMR ensemble: −6.74% and −0.84% in the case of DS3-sensor fusion-10 bootstrap samples for one and two features, respectively (see Figure 8k), and −0.38% in the case of DS4-AE-10 bootstraps-1 feature (see Figure 8j). Obtaining a negative value for the adopted stability measure indicates that the stability is worse than that of a random feature selection for the corresponding case.
- Generally speaking, the stability of a given FS (whether single or ensemble) is influenced by the dataset, sensor(s), and the number of selected features.
For the next experiments and analysis, only the ensemble size that achieved the highest stability will be considered for the corresponding experimental case. The best ensemble sizes based on Figure 8 are given in Table 6. When the highest stability is achieved by different ensemble sizes, the largest ensemble size is recorded in the table since it will be more representative of the ensemble version.
Table 6.
The FS ensemble size (the number of bootstrap samples) that yielded the highest stability among the sizes experimented (10, 20, 30, 40, and 50); if the highest stability is achieved by more than one size, the largest size is recorded. The entries of this table is based on the results shown in Figure 8.
In order to provide a global stability profile of the FS methods, revealing their overall stability performance for each dataset as well as the extent to which their stability can vary with different settings, Figure 9 shows a statistical summary represented by a box plot of the stability values achieved by the respective method across the different sensor configurations and subset cardinalities studied for the corresponding dataset. In each boxplot, the horizontal, red line represents the median. Additionally, the longer the box plot and the whiskers, the larger the stability variability, and vice versa. Recall that, as far as the sample size is concerned, DS1 and DS2 do not pose a challenge to the FS stability, as opposed to DS3 and DS4, which have very small training samples (see Table 4). Starting with DS1 and DS2, it can be seen that Fisher score (both single and ensemble) achieved the highest overall median stability (96.27% and 100% for DS1 and DS2, respectively) and showed the most consistent stability performance over the different sensor(s) and numbers of features studied under each dataset, which increases the confidence in considering the Fisher score the most globally stable method for these two datasets irrespectively of the underlying settings. On the other hand, mRMR showed clearly the lowest stability as well as the largest stability variability over the different cases for DS1 and DS2. This indicates that its stability in selecting the features relevant to TCM can vary largely with different sensor(s) and numbers of features for the same dataset. However, applying the ensemble technique significantly improved the overall stability of mRMR and also reduced its stability variability. Moreover, since the overall stability of Fisher score and ReliefF was already high in their single versions and did not get influenced much by the ensemble, the stability difference between the mRMR ensemble and those of the other two methods diminished noticeably, making mRMR more competitive under its ensemble version. As for DS3 and DS4, Fisher score and ReliefF showed the highest median stability, respectively. However, the stability variability of all the FS methods is larger compared to DS1 and DS2, especially mRMR, showing a larger dependence on the specific settings. This holds true even when the ensemble brought improvements. Further, a large overlapping between the stability values of the different methods can be observed. This all indicates that there is no global winner with respect to stability for these two datasets, and the best method should be determined based on the specific case. The behavior of the FS methods observed with these two datasets can be largely attributed to the small data size.
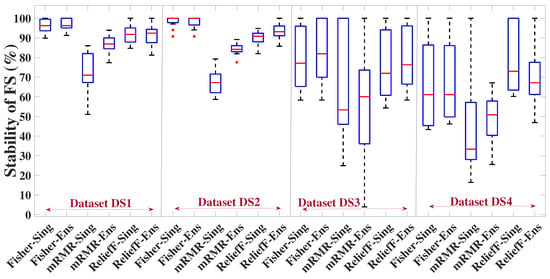
Figure 9.
Distribution of stability values achieved by the single and ensemble FS versions over the different sensor configurations and subset cardinalities for each dataset. Fisher score was the most stable method for DS1–DS3, whereas ReliefF was the superior for DS4. The stability of mRMR is the lowest, the most variable, and the one that benefits the most from the ensemble technique.
Figure 9 is meaningful to show the overall stability behavior of the different FS methods. However, when it comes to selecting the best FS method for a PdM system, a case-specific evaluation should be considered, i.e., with respect to the specific dataset, sensor(s) and number of features used in the PdM system. Moreover, as mentioned previously, stability should not be considered solely for evaluating the FS methods but along with the predictive power. This is what will be shown in the next subsection.
5.6.3. Comparison of the Studied FS Methods (Single and Ensemble Versions) in Terms of Both Stability and Macro-F1 for Different Numbers of Selected Features
Table 7 and Table 8 show the results of stability and macro-F1 of the FS methods for the datasets (DS1 and DS2) and (DS3 and DS4), respectively. Among the single (or ensemble) versions of the FS methods, the bold value, for a specific performance indicator, indicates the superior method for the corresponding combination of dataset, sensor configuration, classifier, and feature subset cardinality, whereas the underlined values indicate which of the single and ensemble versions of a specific FS is better for the corresponding case. Some general observations based on these two tables are that, for a specific performance indicator, there is no single FS method that is superior for all the cases. Moreover, the superior FS method might vary depending on whether the single or ensemble FS versions are compared, owing to the varying influence of the ensemble technique on the different FS methods for the same experimental case. Similarly, regarding the performance of given FS method, neither the single version nor the ensemble is always superior.
Table 7.
Macro-F1 and stability results of the studied FS methods (single and ensemble versions) for the datasets DS1 and DS2. The ensemble sizes are as defined in Table 6.
Table 8.
Macro-F1 and stability results of the studied FS methods (single and ensemble versions) for the datasets DS3 and DS4. The ensemble sizes are as defined in Table 6.
Starting with the single FS versions in Table 7, Fisher score was the most stable FS method in almost all the sensor configurations and subset cardinalities for DS1 and DS2. More specifically, it was the superior for the cases related to the accelerometer (6 out of 6 cases), sensor fusion (10 out of 10 cases), and microphone (4 out of 6 cases). Indeed, the stability of Fisher score reached 100% in many cases, which is the upper bound value for the adopted stability measure. As for macro-F1, Fisher score was also mostly the superior, whereas mRMR was overall ranked the last with respect to the two performance indicators. The performance difference between the FS methods tends to be more noticeable with regard to the stability than to the macro-F1. For example, in the case of DS1-sensor fusion-10 features, the stability of both Fisher score and ReliefF was 100%, while it was 51.06% for mRMR (a stability difference of 48.94%). However, for the same case, the macro-F1 difference between mRMR and the other two FS methods did not exceed 3.44%, 4.51%, and 4.79% for the SVM-quadratic, SVM-RBF, and RF, respectively. Moreover, for a specific classifier, the difference in macro-F1 between the different FS methods is more significant when the number of features is lower, which reflects the difference in the predictive power of the top features selected by each method.
For DS1, all the single FS versions achieved a higher FS stability (or comparable) with the accelerometer than with the microphone. However, for DS2, the ReliefF stability with the microphone was always higher than that obtained with the accelerometer, e.g., by 10.57% when 20 features were used. As for mRMR in DS2, the superior sensor with respect to the stability of its features is dependent on the feature cardinality. For a given FS method, the stability variation over different sensors can indicate the interaction between the functioning of the FS method on the one hand and the robustness of the sensor’s signals and its features on the other hand. Compared to the stability with the individual sensors, the stability of FS methods with the sensor fusion is higher or lower or somewhere in between. However, regarding macro-F1, sensor fusion is always better than using one sensor alone for DS1 and DS2.
As for the impact of the ensemble, it can be noticed from Table 7 that the stability with the ensemble version is mostly higher or comparable to that of the single version, with few exceptions, e.g., the case DS1-accelerometer-20 features where the ReliefF stability dropped by 8.32% with the ensemble. It can be noticed that mRMR is the method most benefiting from the ensemble in terms of stability. The stability improvement with the mRMR ensemble reached as high as 26.35% (in DS1-sensor fusion-10 features). The stability of Fisher score is the least affected by applying the ensemble, and overall it remained the same. The impact of the ensemble on the macro-F1 also varies with different FS methods. The ensemble version led to more or less the same macro-F1 as that of the single version in all the cases of DS1 and DS2 with Fisher score and DS1 with ReliefF. However, there are cases with ReliefF and mRMR in which the stability improvement brought by the ensemble was at the expense of the macro-F1, as in the case of DS2-sensor fusion-30 features for mRMR (a macro-F1 degradation by 5.2%, 4.48%, and 5.83% for the quadratic SVM, RBF SVM, and RF, respectively) and other cases where the ensemble achieved an improvement in both the stability and macro-F1, e.g., for ReliefF in DS2-sensor fusion-20 features, where the ensemble increased the stability by 5.17% and the macro-F1 by around 3% for both SVM kernels and by 2.32% for RF and for mRMR in DS2-sensor fusion-10 features, where the ensemble increased the stability by 18.67% and the macro-F1 by an average of 17.64% over all the classifiers. The biggest macro-F1 improvement/degradation brought by the ensemble reached 3.25%/2.71% for ReliefF and 18.92%/6.53% for mRMR. Overall, the biggest ensemble impact was seen with mRMR.
Thus, for DS1 and DS2, Fisher score (both single and ensemble versions) was almost always superior in terms of both the stability and predictive performance. Even in the few cases where it was not superior, it showed a high and comparable performance. Hence, it can be considered globally the best method to select stable and predictive features for TCM with these datasets.
As for Table 8 showing the results for the datasets DS3 and DS4 which have small training samples, it can also be seen that different FS methods can differ significantly in terms of stability. This is especially apparent with the AE and sensor fusion of DS4 where the stability of ReliefF was considerably higher than that of the other methods, e.g., in DS4-AE-2 features, the stability of ReliefF single version is 100% whereas that of Fisher score and mRMR is 58.24% and 28.08%, respectively. While the features selected by all the FS methods were powerful enough to achieve a high diagnosis performance with these two datasets, their stabilities suffered in some cases. This indicates that the small size can have a more negative impact on the FS stability than on the model generalizability. Similarly to DS1 and DS2, the single version of mRMR with DS3 and DS4 mostly ranks the last among the three methods in terms of stability. The only case where the mRMR stability dominated that of the other two FS methods, including DS1 and DS2, is the case DS3-AC current-2 features in which the mRMR stability was 100%, while the stability of Fisher score and ReliefF were 77.14% and 54.35%, respectively. The single versions of Fisher score and mRMR achieved with the AC current sensor an identical or higher stability compared to the AE sensor. As for ReliefF, its stability tends to be higher with the AE sensor. Among the numbers of features tested for DS3 and DS4, all the three FS methods seem to be more stable when only the top feature is selected.
Regarding the ensemble versions, the stability of Fisher score is more influenced by the ensemble technique with DS3 and DS4 compared to DS1 and DS2. This can be largely linked to the statistical nature of the Fisher score that benefits from the large sample size of DS1 and DS2, which enabled the Fisher score to have a high stability, both in its single and ensemble versions. The ensemble of Fisher score maintained or improved the stability and macro-F1 in all the cases of DS3. The same holds true for ReliefF, with the exception being DS3-sensor fusion-5 features where the ensemble degrades the performance of ReliefF. Additionally, the ensemble degraded the stability of ReliefF with some cases in DS4, i.e., for 2–3 features of AE and 1–2 features of sensor fusion, where the stability of the single version was 100% in three of them. As for mRMR, when only one or two features are selected, the ensemble had a detrimental impact on mRMR in terms of stability and/or macro-F1 for almost all the sensor configurations concerning DS3 and DS4. However, for some cases of higher numbers of features, the ensemble can still be beneficial to mRMR, e.g., in the case DS4-sensor fusion-4 features, the ensemble increased the mRMR stability by 50.69% and the macro-F1 of SVM-quadratic, SVM-RBF, and RF by 13.02%, 8.11%, and 7.89%, respectively. Indeed, for 4–5 features of DS4-sensor fusion, the ensemble was mostly beneficial to all the FS methods in terms of both stability and macro-F1. It can be noticed that, for some cases, the ensemble allows for a more solid choice of the best FS method given a specific classifier. For example, in DS3-sensor fusion-3 features, both the single and ensemble versions of Fisher score and ReliefF yielded a macro-F1 of 100% for both SVM kernels. Regarding stability for the same case, the single version of Fisher score was the best with a stability of 76.67%. However, the stability of ReliefF ensemble (84.42%) exceeds all the other stabilities of both the single and ensemble versions of the other methods. Clearly, the ReliefF ensemble would be superior for this case with respect to both stability and macro-F1.
Recall that the main difference between the datasets under each pair of (DS1, DS2) and (DS3, DS4) is the operating conditions. The varying results over each two datasets are largely linked to the milling operating conditions that affect the sensory features.
5.6.4. Comparison of the Studied FS Methods (Single and Ensemble Versions) in Terms of the Harmonic Mean of their Stability and Macro-F1
After studying the FS stability and predictive performance separately, it is worth having an overall expression that jointly reflects both performance indicators. To this end, we adopted the approach used in [12] in which the harmonic mean of the stability and classification performance is calculated. Given the performance indicators used in our paper, i.e., stability (SMA) and macro-F1, the harmonic mean (HM) is given as in (15), which corresponds to when both performance indicators are equally important.
As it was shown in the previous experiments and analysis, the evaluation was performed for different numbers of features to gain broad insights. However, for the actual implementation of PdM system, a specific feature subset should be selected. Since the ultimate goal is to achieve an accurate tool condition monitoring, the feature subset cardinality at which all the FS methods led to a reasonable (maximum or nearly maximum) macro-F1 is selected for the corresponding case. Therefore, to simplify the final evaluation, we will select only one feature subset cardinality, n, for each pair of dataset/sensor configuration. For datasets DS1 and DS2, n was set to be 30, 20, and 40 for the microphone, accelerometer, and sensor fusion, respectively, whereas it was set to 2 for all the sensor configurations of DS3 and DS4. Even though a macro-F1 of 100% was achieved with only one feature in some cases of DS3 and DS4, we consider that using only one feature (regardless of the sensor) might limit the robustness of the monitoring system. Thus, we consider two features for these datasets.
Table 9 shows the HM results for the FS methods across all the datasets and for the subset cardinalities specified above. The superior FS method for each combination of dataset/sensor(s)-classifier, as well as the overall impact of the ensemble can also be found in this table. For all the sensor configurations of DS1, Fisher score (in its single and/or ensemble version) was the superior. The same holds true for DS2, with the exception being DS2-microphone where the ReliefF ensemble was the best. Both Fisher score and mRMR achieved an HM of 100% in DS3-AC current. ReliefF was superior for the AE sensors for both DS3 and DS4. Overall, based on all the four datasets, sensor(s), and classifiers, Fisher score exhibited the superior performance in most of the cases (24 out of 36 cases).
Table 9.
Harmonic mean (HM) of stability and macro-F1 for the FS methods (single and ensemble versions) across the datasets and sensor(s).
It is noteworthy that the methodology presented in this work to evaluate the FS methods, including the main experimental design, stability measure, ensembles, etc., can also be applied with other PdM applications, i.e., diagnosis tasks of other industrial components, prognosis tasks, etc., as well as other FS types, i.e., wrapper and embedded FS methods.
6. Conclusions and Future Works
Feature selection (FS) represents an integral part of many predictive maintenance frameworks. The main aim of this paper is to shed light on the significance of examining the stability of FS for the PdM applications and to investigate the potential of the FS homogeneous ensemble in this field. The FS stability reflects the extent to which the selected features are generic and robust for the monitoring task, and it influences the confidence in the implemented PdM system, including the built model and selected sensor(s), etc. The specific PdM application addressed in this paper is classification-based tool condition monitoring in milling. We used four milling datasets: two datasets generated from milling experiments that we conducted (called DS1 and DS2) as well as two datasets from NASA’s repository (called DS3 and DS4). These datasets differ in many aspects, including the milling machine, operating conditions, sensor(s), data acquisition system, sample-to-dimension ratios (SDR), number of classes, etc. Such diversified datasets helped to reveal the behavior of the FS methods with different data characteristics and experimental milling settings. We conducted a comprehensive performance comparison between three widely-used filter-based FS methods, namely Fisher score, mRMR, and ReliefF in terms of stability and predictive performance (expressed by macro-F1 in this paper). This evaluation covers both the single and ensemble versions of these methods. For each dataset, the comparison was performed over different sensor configurations (namely two individual sensors and their fusion) and different numbers of selected features.
The tool condition monitoring was modeled as a five-class classification for our datasets DS1 and DS2, and a three-class classification for DS3 and DS4. We used three classifiers: support vector machine with two tested kernels, namely the quadratic and RBF kernels, as well as the random forest. Based on the experimental results, the conclusions of this paper can be summarized as follows:
- The difference in macro-F1 between different FS methods might be marginal, while the stability difference is quite significant. Such cases promote the role of FS stability as a decisive performance indicator when it comes to selecting the best FS method for a specific monitoring task.
- Given run-to-failure measurements of a milling tool, the sensor configuration, and the number of selected features can affect the FS stability to an extent that depends on the robustness of the FS method itself. Both Fisher score and ReliefF showed a considerably higher consistency (lesser variability) in their stability performance over different settings, compared to mRMR. Further, under the small datasets, the stability of all the FS methods showed a larger dependence on the underlying settings compared to the large datasets.
- Regarding the large datasets of our experiments, DS1 and DS2, the results over the different combinations of sensor configurations, operating conditions, and feature subset cardinalities showed that Fisher score (single and ensemble versions) was the superior FS method in terms of both the stability and predictive performance in almost all the individual cases. Even in the few cases where it was not superior, it showed a high and very comparable performance to the superior one (mostly ReliefF). Thus, Fisher score can be considered a global FS solution for these datasets. As for the small datasets studied in this paper, the results did not suggest a globally superior method, as it varies with the different cases, with the superior one mostly being Fisher score or ReliefF. Further, when a final feature subset cardinality was chosen (at which all the FS methods yielded a reasonable macro-F1) for each dataset/sensor configuration, Fisher score (single and/or ensemble) showed the highest harmonic mean of stability and macro-F1 in most of the cases (24 out of 36 cases). Thus, based on the overall results, we recommend that Fisher score is considered among the top-candidate FS methods to select both stable and predictive features for diagnosis tasks.
- The impact of the homogeneous ensemble generally depends on the FS method, data at hand, and number of selected features. The ensemble technique had overall little impact on Fisher score in the large milling datasets; however, it improves its stability and predictive power in many cases of the small datasets. For all the datasets, mRMR is the method that benefits the most from the ensemble in terms of stability. Especially in the large datasets DS1 and DS2, the mRMR ensemble considerably outperformed the single version in terms of the overall stability and the stability consistency over different settings and in some cases also in the predictive power. This indicates that the ensemble can still be quite beneficial for some FS methods even if the SDR of the data is too high (SDRs for the single sensor/sensor fusion of DS1 and DS2 are 156.06/78.03 and 192.80/96.40, respectively); most of the existing works in other fields focus only on the ensemble benefits with the datasets of SDR<<1. However, it should be noted that there are also cases where the ensemble degrades the stability and/or predictive power. Thus, its trade-off performance should be inspected for the particular case of interest.
- The stability of all the FS methods suffered in some cases under the small datasets and in some cases even after applying the ensemble. This emphasizes the necessity of examining the FS stability and investigating more solutions to increase the FS stability for small datasets since, when it comes to facing the challenges of small datasets, the researches existing in the current PdM literature focus only on how to increase the generalizability of the predictive models.
The Future research directions are as follows:
- The performance comparison presented in this work included only filter-based FS methods, which is a limitation that can be addressed in future work by also evaluating wrappers and embedded methods, e.g., those used in [15,17,24].
- As shown in the results, different factors can affect the stability of a given FS method for PdM applications, e.g., size of dataset, sensors, operating conditions, etc. To gain a more in-depth understanding of the stability behavior with the monitoring data, it is interesting to experimentally determine the most dominating factor among them all. Since the real-world datasets carry the combined effect of the different factors, each factor (e.g., size, operating conditions, etc.) should be changed individually under the same dataset while keeping the other factors constant to isolate their impact (e.g., changing only the size by subsampling the original data with different ratios for the datasets whose size was originally large or creating augmented data and adding them incrementally to the original samples of the datasets whose original size is small) and the resulting variation in stability can be observed.
- Studying the impact of the window size of feature extraction on the joint performance of the FS stability and predictive performance as well as on the ensemble performance in PdM applications.
Author Contributions
Conceptualization, M.A. and P.L.; methodology, M.A.; software, M.A.; validation, M.A. and P.L.; data curation of the datasets DS1 and DS2, J.P.S. and T.M.; writing—original draft preparation, M.A.; writing—review and editing, M.A. and P.L.; supervision, P.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work has been funded by the Federal Ministry of Education and Research of Germany (BMBF) within the iCampus Cottbus project, grant number 16ES1128K. Responsible for the content of this publication are the authors.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The first two datasets used in this paper are available upon request from the corresponding author. The last two datasets are publicly available (See Reference [26]).
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| CNC | Computer Numerical Control |
| DAS | Data Acquisition System |
| ECG | Electrocardiogram |
| FN | False Negative |
| FP | False Positive |
| FS | Feature Selection |
| HM | Harmonic Mean |
| MIQ | Mutual Information Quotient |
| mRMR | Minimum Redundancy Maximum Relevance |
| PdM | Predictive Maintenance |
| RF | Random Forest |
| RMS | Root Mean Square |
| SDR | Sample-to-Dimension Ratio |
| STFT | Short-Time Fourier Transform |
| SVM | Support Vector Machine |
| TCM | Tool Condition Monitoring |
| TN | True Negative |
| TP | True Positive |
References
- Lee, W.J.; Wu, H.; Yun, H.; Kim, H.; Jun, M.B.; Sutherland, J.W. Predictive maintenance of machine tool systems using artificial intelligence techniques applied to machine condition data. Procedia Cirp 2019, 80, 506–511. [Google Scholar] [CrossRef]
- Jimenez, J.J.M.; Schwartz, S.; Vingerhoeds, R.; Grabot, B.; Salaün, M. Towards multi-model approaches to predictive maintenance: A systematic literature survey on diagnostics and prognostics. J. Manuf. Syst. 2020, 56, 539–557. [Google Scholar] [CrossRef]
- Zhang, W.; Yang, D.; Wang, H. Data-driven methods for predictive maintenance of industrial equipment: A survey. IEEE Syst. J. 2019, 13, 2213–2227. [Google Scholar] [CrossRef]
- Assafo, M.; Langendörfer, P. A TOPSIS-Assisted Feature Selection Scheme and SOM-Based Anomaly Detection for Milling Tools Under Different Operating Conditions. IEEE Access 2021, 9, 90011–90028. [Google Scholar] [CrossRef]
- Kang, M.; Islam, M.R.; Kim, J.; Kim, J.; Pecht, M. A Hybrid Feature Selection Scheme for Reducing Diagnostic Performance Deterioration Caused by Outliers in Data-Driven Diagnostics. IEEE Trans. Ind. Electron. 2016, 63, 3299–3310. [Google Scholar] [CrossRef]
- Rauber, T.W.; Boldt, F.D.; Varejão, F.M. Heterogeneous Feature Models and Feature Selection Applied to Bearing Fault Diagnosis. IEEE Trans. Ind. Electron. 2015, 62, 637–646. [Google Scholar] [CrossRef]
- Brito, L.C.; da Silva, M.B.; Duarte, M.A.V. Identification of cutting tool wear condition in turning using self-organizing map trained with imbalanced data. J. Intell. Manuf. 2021, 32, 127–140. [Google Scholar] [CrossRef]
- Yu, J. A hybrid feature selection scheme and self-organizing map model for machine health assessment. Appl. Soft Comput. 2011, 11, 4041–4054. [Google Scholar] [CrossRef]
- Casusol, A.J.; Zegarra, F.C.; Vargas-Machuca, J.; Coronado, A.M. Optimal window size for the extraction of features for tool wear estimation. In Proceedings of the 2021 IEEE XXVIII International Conference on Electronics, Electrical Engineering and Computing (INTERCON), Lima, Peru, 5–7 August 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Tang, J.; Alelyani, S.; Liu, H. Feature selection for classification: A review. In Data Classification: Algorithms and Applications; CRC Press: Boca Raton, FL, USA, 2014; p. 37. [Google Scholar]
- Saeys, Y.; Abeel, T.; van de Peer, Y. Robust Feature Selection Using Ensemble Feature Selection Techniques. In Machine Learning and Knowledge Discovery in Databases. ECML PKDD 2008. Lecture Notes in Computer Science; Daelemans, W., Goethals, B., Morik, K., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; Volume 5212, pp. 313–325. [Google Scholar]
- Saeys, Y.; Inza, I.; Larranaga, P. A review of feature selection techniques in bioinformatics. Bioinformatics 2007, 23, 2507–2517. [Google Scholar] [CrossRef]
- Kalousis, A.; Prados, J.; Hilario, M. Stability of feature selection algorithms. In Proceedings of the Fifth IEEE International Conference on Data Mining (ICDM’05), Houston, TX, USA, 27–30 November 2005; p. 8. [Google Scholar]
- Athisayam, A.; Kondal, M. Fault feature selection for the identification of compound gear-bearing faults using firefly algorithm. Int. J. Adv. Manuf. Technol. 2023, 125, 1777–1788. [Google Scholar] [CrossRef]
- Islam, M.R.; Islam, M.M.M.; Kim, J. Feature selection techniques for increasing reliability of fault diagnosis of bearings. In Proceedings of the 2016 9th International Conference on Electrical and Computer Engineering (ICECE), Dhaka, Bangladesh, 20–22 December 2016; pp. 396–399. [Google Scholar]
- Shah, M.; Borade, H.; Sanghavi, V.; Purohit, A.; Wankhede, V.; Vakharia, V. Enhancing Tool Wear Prediction Accuracy Using Walsh–Hadamard Transform, DCGAN and Dragonfly Algorithm-Based Feature Selection. Sensors 2023, 23, 3833. [Google Scholar] [CrossRef]
- Liu, C.; Jiang, D.; Yang, W. Global geometric similarity scheme for feature selection in fault diagnosis. Expert Syst. Appl. 2014, 41, 3585–3595. [Google Scholar] [CrossRef]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Bommert, A.; Rahnenführer, J. Adjusted Measures for Feature Selection Stability for Data Sets with Similar Features. In Machine Learning, Optimization, and Data Science. LOD 2020. Lecture Notes in Computer Scienc; Springer: Cham, Switzerland, 2020; Volume 12565, pp. 203–214. [Google Scholar]
- Pes, B. Ensemble feature selection for high-dimensional data: A stability analysis across multiple domains. Neural Comput. Appl. 2020, 32, 5951–5973. [Google Scholar] [CrossRef]
- Wijaya, D.R.; Afianti, F. Stability Assessment of Feature Selection Algorithms on Homogeneous Datasets: A Study for Sensor Array Optimization Problem. IEEE Access 2020, 8, 33944–33953. [Google Scholar] [CrossRef]
- Zhou, Y.; Zhi, G.; Chen, W.; Qian, Q.; He, D.; Sun, B.; Sun, W. A new tool wear condition monitoring method based on deep learning under small samples. Measurement 2022, 189, 110622. [Google Scholar] [CrossRef]
- Abubakr, M.; Hassan, M.A.; Krolczyk, G.M.; Khanna, N.; Hegab, H. Sensors selection for tool failure detection during machining processes: A simple accurate classification model. CIRP J. Manuf. Sci. Technol. 2021, 32, 108–119. [Google Scholar] [CrossRef]
- Li, D.; Zhou, Y.; Hu, G.; Spanos, C.J. Optimal Sensor Configuration and Feature Selection for AHU Fault Detection and Diagnosis. IEEE Trans. Ind. Inform. 2017, 13, 1369–1380. [Google Scholar] [CrossRef]
- Agogino, A.; Goebel, K. Milling Data Set. BEST Lab, UC Berkeley. NASA Ames Prognostics Data Repository. Moffett Field, CA, USA. 2007. Available online: https://ti.arc.nasa.gov/project/prognostic-datarepository (accessed on 27 September 2022).
- Xie, Z.; Li, J.; Lu, Y. Feature selection and a method to improve the performance of tool condition monitoring. Int. J. Adv. Manuf. Technol. 2019, 100, 3197–3206. [Google Scholar] [CrossRef]
- Liao, X.; Zhou, G.; Zhang, Z.; Lu, J.; Ma, J. Tool wear state recognition based on GWO–SVM with feature selection of genetic algorithm. Int. J. Adv. Manuf. Technol. 2019, 104, 1051–1063. [Google Scholar] [CrossRef]
- Gomes, M.C.; Brito, L.C.; da Silva, M.B.; Duarte, M.A.V. Tool wear monitoring in micromilling using support vector machine with vibration and sound sensors. Precis. Eng. 2021, 67, 137–151. [Google Scholar] [CrossRef]
- Hu, Q.; Si, X.S.; Qin, A.S.; Lv, Y.R.; Zhang, Q.H. Machinery fault diagnosis scheme using redefined dimensionless indicators and mRMR feature selection. IEEE Access 2020, 8, 40313–40326. [Google Scholar] [CrossRef]
- Goebel, K.; Yan, W. Feature selection for tool wear diagnosis using soft computing techniques. In ASME International Mechanical Engineering Congress and Exposition; American Society of Mechanical Engineers: Orlando, FL, USA, 2000; Volume 19166, pp. 157–163. [Google Scholar]
- Tran, M.Q.; Elsisi, M.; Liu, M.K. Effective feature selection with fuzzy entropy and similarity classifier for chatter vibration diagnosis. Measurement 2021, 184, 109962. [Google Scholar] [CrossRef]
- Sun, J.; Hong, G.S.; Rahman, M.; Wong, Y.S. Identification of feature set for effective tool condition monitoring by acoustic emission sensing. Int. J. Prod. Res. 2004, 42, 901–918. [Google Scholar] [CrossRef]
- Yang, H.; Tieng, H.; Chen, S. Automatic feature selection and failure diagnosis for bearing faults. In Proceedings of the SICE Annual Conference 2011, Tokyo, Japan, 13–18 September 2011; pp. 235–239. [Google Scholar]
- Zhu, K.P.; Hong, G.S.; Wong, Y.S. A comparative study of feature selection for hidden Markov model-based micro-milling tool wear monitoring. Mach. Sci. Technol. 2008, 12, 348–369. [Google Scholar] [CrossRef]
- Cao, Y.; Sun, Y.; Xie, G.; Li, P. A Sound-Based Fault Diagnosis Method for Railway Point Machines Based on Two-Stage Feature Selection Strategy and Ensemble Classifier. IEEE Trans. Intell. Transp. Syst. 2022, 23, 12074–12083. [Google Scholar] [CrossRef]
- Liao, T.W. Feature extraction and selection from acoustic emission signals with an application in grinding wheel condition monitoring. Eng. Appl. Artif. Intell. 2010, 23, 74–84. [Google Scholar] [CrossRef]
- Abeel, T.; Helleputte, T.; van de Peer, Y.; Dupont, P.; Saeys, Y. Robust biomarker identification for cancer diagnosis with ensemble feature selection methods. Bioinformatics 2010, 26, 392–398. [Google Scholar] [CrossRef]
- Brahim, A.B.; Limam, M. Ensemble feature selection for high dimensional data: A new method and a comparative study. Adv. Data Anal. Classif. 2018, 12, 937–952. [Google Scholar] [CrossRef]
- Alhamidi, M.R.; Jatmiko, W. Optimal feature aggregation and combination for two-dimensional ensemble feature selection. Information 2020, 1, 38. [Google Scholar] [CrossRef]
- Sun, L.; Wang, T.; Ding, W.; Xu, J.; Lin, Y. Feature selection using Fisher score and multilabel neighborhood rough sets for multilabel classification. Inf. Sci. 2021, 578, 887–912. [Google Scholar] [CrossRef]
- Gan, M.; Li, Z. Iteratively local fisher score for feature selection. Appl. Intell. 2021, 51, 6167–6181. [Google Scholar] [CrossRef]
- Ding, C.; Peng, H. Minimum redundancy feature selection from microarray gene expression data. J. Bioinform. Comput. Biol. 2005, 3, 185–205. [Google Scholar] [CrossRef]
- Robnik-Šikonja, M.; Kononenko, I. Theoretical and empirical analysis of ReliefF and RReliefF. Mach. Learn. 2003, 53, 23–69. [Google Scholar] [CrossRef]
- Nogueira, S.; Brown, G. Measuring the stability of feature selection. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Cham, Switzerland, 2016; pp. 442–457. [Google Scholar]
- Zhang, M.; Zhang, L.; Zou, J.; Yao, C.; Xiao, H.; Liu, Q.; Wang, J.; Wang, D.; Wang, C.; Guo, Z. Evaluating reproducibility of differential expression discoveries in microarray studies by considering correlated molecular changes. Bioinformatics 2009, 25, 1662–1668. [Google Scholar] [CrossRef]
- Khaire, U.M.; Dhanalakshmi, R. Stability of feature selection algorithm: A review. J. King Saud Univ. Comput. Inf. Sci. 2019, 34, 1060–1073. [Google Scholar] [CrossRef]
- Bommert, A. Integration of Feature Selection Stability in Model Fitting. Ph.D. Thesis, TU Dortmund University, Dortmund, Germany, 2020. [Google Scholar]
- Bolón-Canedo, V.; Alonso-Betanzos, A. Ensembles for feature selection: A review and future trends. Inf. Fusion 2019, 52, 1–12. [Google Scholar] [CrossRef]
- Bellapu, R.P.; Tirumala, R.; Kurukundu, R.N. Evaluation of Homogeneous and Heterogeneous Distributed Ensemble Feature Selection Approaches for Classification of Rice Plant Diseases. In Proceedings of the 2021 5th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 6–8 May 2021; pp. 1086–1094. [Google Scholar] [CrossRef]
- Mo, W.; Kari, T.; Wang, H.; Luan, L.; Gao, W. Power Transformer Fault Diagnosis Using Support Vector Machine and Particle Swarm Optimization. In Proceedings of the 2017 10th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 9–10 December 2017; pp. 511–515. [Google Scholar] [CrossRef]
- Jemielniak, K.; Urbański, T.; Kossakowska, J.; Bombiński, S. Tool condition monitoring based on numerous signal features. Int. J. Adv. Manuf. Technol. 2012, 59, 73–81. [Google Scholar] [CrossRef]
- Traini, E.; Bruno, G.; D’antonio, G.; Lombardi, F. Machine learning framework for predictive maintenance in milling. IFAC-PapersOnLine 2019, 52, 177–182. [Google Scholar] [CrossRef]
- Gómez, Á.L.P.; Maimó, L.F.; Celdrán, A.H.; Clemente, F.J.G. Madics: A methodology for anomaly detection in industrial control systems. Symmetry 2020, 12, 1583. [Google Scholar] [CrossRef]
- Guo, Y.; Li, G.; Chen, H.; Wang, J.; Guo, M.; Sun, S.; Hu, W. Optimized neural network-based fault diagnosis strategy for VRF system in heating mode using data mining. Appl. Therm. Eng. 2017, 125, 1402–1413. [Google Scholar] [CrossRef]
- Calabrese, F.; Regattieri, A.; Bortolini, M.; Galizia, F.G.; Visentini, L. Feature-based multi-class classification and novelty detection for fault diagnosis of industrial machinery. Appl. Sci. 2021, 11, 9580. [Google Scholar] [CrossRef]
- Wan, L.; Gong, K.; Zhang, G.; Yuan, X.; Li, C.; Deng, X. An Efficient Rolling Bearing Fault Diagnosis Method Based on Spark and Improved Random Forest Algorithm. IEEE Access 2021, 9, 37866–37882. [Google Scholar] [CrossRef]
- Nasir, V.; Dibaji, S.; Alaswad, K.; Cool, J. Tool wear monitoring by ensemble learning and sensor fusion using power, sound, vibration, and AE signals. Manuf. Lett. 2021, 30, 32–38. [Google Scholar] [CrossRef]
- Balachandar, K.; Jegadeeshwaran, R. Friction stir welding tool condition monitoring using vibration signals and Random forest algorithm–A Machine learning approach. Mater. Today Proc. 2021, 46, 1174–1180. [Google Scholar] [CrossRef]
- Uysal, A.K. An improved global feature selection scheme for text classification. Expert Syst. Appl. 2016, 43, 82–92. [Google Scholar] [CrossRef]











Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).