
Lightweight Scene Text Recognition Based on Transformer

Abstract
:1. Introduction
2. Related Work
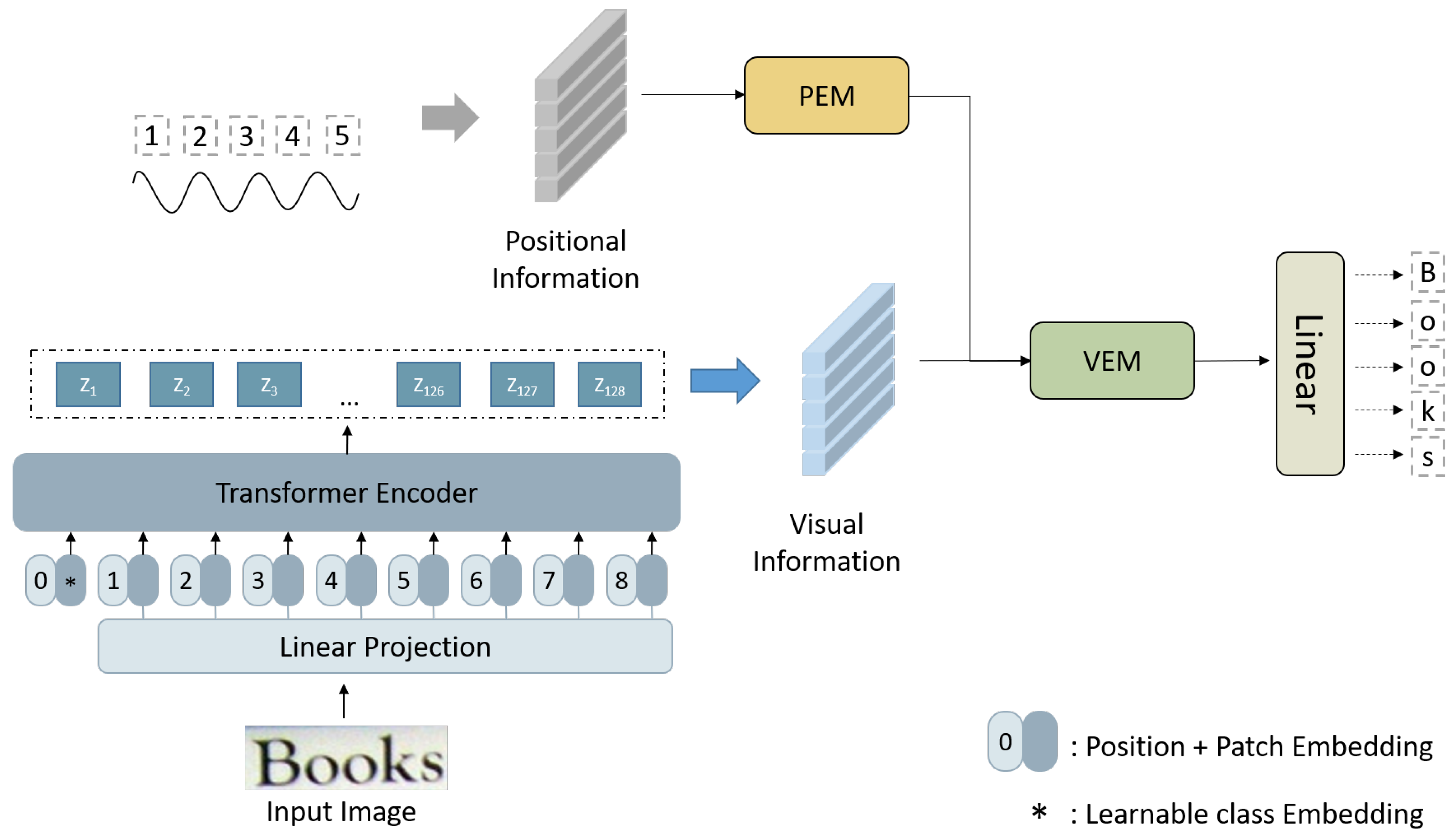
3. LSTR Model
3.1. Encoder
3.1.1. Backbone
3.1.2. Position Branch
3.2. Decoder
3.2.1. Position-Enhancement Module
3.2.2. Visual-Enhancement Module
4. Experimental Analysis
4.1. Datasets
- 1
- Synthetic datasets: Because of the high cost of labeling datasets, STR did not obtain sufficient datasets early on, so the synthetic datasets ST and MJ were widely used to train models.
- MJSynth (MJ): It is a dataset of synthetic text images generated by rendering text onto natural images using a variety of fonts, sizes, and colors. The dataset contains over 9 million images, each of which includes one or more instances of synthetic text. The text in the images is diverse, including different languages, scripts, and text styles. The dataset is primarily designed for training and evaluating OCR systems;
- SynthText (ST): It is another synthetic text dataset created by cropping the text from natural images and pasting it onto new backgrounds. The dataset was originally designed for scene text detection but has since been adapted for OCR. SynthText contains over 7 million synthetic images, each of which contains a single instance of text. The text in the images is mainly in English but includes examples of other languages. Unlike MJSynth, the text in SynthText is embedded in realistic scenes, such as street signs, shop windows, and posters.
- 2
- Real datasets: With the development of STR, more and more real datasets have been accumulated, and Bautista and others have integrated these datasets, namely ArT [38], Coco [39], LSVT [40], MLT19 [41], RCTW17 [42], OpenVINO [43], TextOCR [44], ReCTS [45] and Uber [46].
- ArT: A publicly available scene text recognition dataset that contains scene text images extracted from different works of art. The dataset consists of 9300 text images from various works of art and can be used for tasks such as character recognition, text detection, and text recognition;
- Coco: A widely used computer vision dataset that contains images and annotations for various tasks such as object detection, image segmentation, scene understanding, etc. The scene text recognition task in the COCO dataset refers to identifying text in the image and converting it to a computer-readable text format.
- LSVT: A large-scale scene text dataset from China that includes 100,000 images divided into training, validation, and test sets. The scene text in the dataset includes regular text, digits, letters, and Chinese characters.
- MLT19: A large-scale scene text dataset from multiple Asian countries that includes 10,000 images divided into training, validation, and test sets. The scene text in the dataset includes regular text, digits, letters, and Chinese characters.
- RCTW17: A scene text recognition dataset from China that includes 8940 images from street and outdoor scenes. The scene text in the dataset includes Chinese, English, and digits.
- OpenVINO: A scene text recognition dataset released by Intel that includes 23,000 images divided into training, validation, and test sets. The scene text in the dataset includes digits, letters, and Chinese characters.
- TextOCR: A scene text recognition dataset from India that includes 20,000 images from various scenes. The scene text in the dataset includes Indian languages, English, and digits.
- ReCTS: A scene text recognition dataset from the Hong Kong University of Science and Technology that includes 6000 images from street and outdoor scenes. The scene text in the dataset includes Chinese and English.
- Uber: A large-scale scene text dataset from Uber that includes 1 million images from different countries. The scene text in the dataset includes digits, letters, and Chinese characters.
- Regular datasets:
- IIIT5K [47]: This dataset contains 5000 text images extracted from Google image search. These images are high-resolution and undistorted, with little noise or background interference;
- SVT [48]: This dataset contains 804 outdoor street images collected from Google Street View. These images contain text in various fonts, sizes, and orientations, but with little interference and noise. This dataset is typically used to test OCR algorithm performance in recognizing text with diverse fonts, sizes, and orientations;
- CUTE80 [49]: It contains 80 curved text images and is primarily used to test the performance of OCR algorithms in curved text recognition tasks. Each image contains 3–5 words with varying fonts, sizes, colors, and some noise and interference. This dataset is commonly used to evaluate the performance of curved text recognition algorithms, particularly for the challenging curved text recognition tasks.
- Irregular datasets:
- ICDAR2015 (IC15) [50]: This dataset contains many blurred, rotated, low-resolution images, including 2077 and 1811 versions. We chose to use the 1811 version, which discards some extremely distorted images;
- SVTP [51]: This dataset contains 645 perspective text images extracted from Google Street View. These images contain text in various fonts, sizes, and orientations, but due to perspective distortion, the text lines may appear curved or distorted. This dataset is typically used to test OCR algorithm performance in processing perspective text images;
- ICDAR2013 (IC13) [47]: This dataset contains 288 curved text images where the text lines are arranged along curved paths. These images contain text in various fonts, sizes, and orientations, as well as some noise and interference. This dataset is typically used to test OCR algorithm performance in processing text images arranged along curved paths.
4.2. Experimental Setup
4.3. Evaluation Metrics
4.4. Comparison with Existing Technologies
4.5. Comparison with Lightweight Models
4.6. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mandavia, K.; Badelia, P.; Ghosh, S.; Chaudhuri, A. Optical Character Recognition Systems for Different Languages with Soft Computing; Springer: Cham, Switzerland, 2017; Volume 352, pp. 9–41. [Google Scholar]
- Nagy, G. Twenty years of document image analysis in PAMI. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 38–62. [Google Scholar] [CrossRef]
- Patel, C.; Shah, D.; Patel, A. Automatic number plate recognition system (anpr): A survey. Int. J. Comput. Appl. 2013, 69, 21–33. [Google Scholar] [CrossRef]
- Laroca., R.; Cardoso., E.V.; Lucio., D.R.; Estevam., V.; Menotti., D. On the Cross-dataset Generalization in License Plate Recognition. In Proceedings of the 17th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, Vienna, Austria, 6–8 February 2022; Volume 5, pp. 166–178. [Google Scholar] [CrossRef]
- Hwang, W.; Kim, S.; Seo, M.; Yim, J.; Park, S.; Park, S.; Lee, J.; Lee, B.; Lee, H. Post-OCR parsing: Building simple and robust parser via BIO tagging. In Proceedings of the Workshop on Document Intelligence at NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Limonova, E.; Bezmaternykh, P.; Nikolaev, D.; Arlazarov, V. Slant rectification in Russian passport OCR system using fast Hough transform. In Proceedings of the Ninth International Conference on Machine Vision (ICMV 2016), Nice, France, 18–20 November 2016; Volume 10341, pp. 127–131. [Google Scholar]
- Yao, C.; Bai, X.; Sang, N.; Zhou, X.; Zhou, S.; Cao, Z. Scene text detection via holistic, multi-channel prediction. arXiv 2016, arXiv:1606.09002. [Google Scholar]
- Liu, J.; Liu, X.; Sheng, J.; Liang, D.; Li, X.; Liu, Q. Pyramid mask text detector. arXiv 2019, arXiv:1903.11800. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Reading text in the wild with convolutional neural networks. Int. J. Comput. Vis. 2016, 116, 1–20. [Google Scholar] [CrossRef]
- Borisyuk, F.; Gordo, A.; Sivakumar, V. Rosetta: Large scale system for text detection and recognition in images. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 71–79. [Google Scholar]
- Luong, T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1412–1421. [Google Scholar] [CrossRef]
- Lee, C.Y.; Osindero, S. Recursive recurrent nets with attention modeling for ocr in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2231–2239. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the NIPS’17: Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Cheng, Z.; Bai, F.; Xu, Y.; Zheng, G.; Pu, S.; Zhou, S. Focusing attention: Towards accurate text recognition in natural images. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5076–5084. [Google Scholar]
- Zheng, T.; Chen, Z.; Fang, S.; Xie, H.; Jiang, Y.G. Cdistnet: Perceiving multi-domain character distance for robust text recognition. arXiv 2021, arXiv:2111.11011. [Google Scholar]
- Yue, X.; Kuang, Z.; Lin, C.; Sun, H.; Zhang, W. Robustscanner: Dynamically enhancing positional clues for robust text recognition. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 135–151. [Google Scholar]
- Atienza, R. Vision transformer for fast and efficient scene text recognition. In Proceedings of the Document Analysis and Recognition—ICDAR 2021: 16th International Conference, Lausanne, Switzerland, 5–10 September 2021; pp. 319–334. [Google Scholar]
- Neumann, L.; Matas, J. Real-time scene text localization and recognition. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3538–3545. [Google Scholar]
- Yao, C.; Bai, X.; Shi, B.; Liu, W. Strokelets: A learned multi-scale representation for scene text recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 4042–4049. [Google Scholar]
- Yang, X.; He, D.; Zhou, Z.; Kifer, D.; Giles, C.L. Learning to read irregular text with attention mechanisms. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; Volume 1, p. 3. [Google Scholar]
- Lee, C.Y.; Bhardwaj, A.; Di, W.; Jagadeesh, V.; Piramuthu, R. Region-based discriminative feature pooling for scene text recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 4050–4057. [Google Scholar]
- Cho, K.; van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar] [CrossRef]
- Bai, F.; Cheng, Z.; Niu, Y.; Pu, S.; Zhou, S. Edit probability for scene text recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1508–1516. [Google Scholar]
- Wan, Z.; Zhang, J.; Zhang, L.; Luo, J.; Yao, C. On vocabulary reliance in scene text recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11425–11434. [Google Scholar]
- Liao, M.; Zhang, J.; Wan, Z.; Xie, F.; Liang, J.; Lyu, P.; Yao, C.; Bai, X. Scene text recognition from two-dimensional perspective. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8714–8721. [Google Scholar]
- Wan, Z.; He, M.; Chen, H.; Bai, X.; Yao, C. Textscanner: Reading characters in order for robust scene text recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12120–12127. [Google Scholar]
- Liu, W.; Chen, C.; Wong, K.Y.K.; Su, Z.; Han, J. Star-net: A spatial attention residue network for scene text recognition. In Proceedings of the BMVC, York, UK, 19–22 September 2016; Volume 2, p. 7. [Google Scholar]
- Wan, Z.; Xie, F.; Liu, Y.; Bai, X.; Yao, C. 2D-CTC for scene text recognition. arXiv 2019, arXiv:1907.09705. [Google Scholar]
- Shi, B.; Bai, X.; Yao, C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 2298–2304. [Google Scholar] [CrossRef] [PubMed]
- Gao, Y.; Chen, Y.; Wang, J.; Lu, H. Reading scene text with attention convolutional sequence modeling. arXiv 2017, arXiv:1709.04303. [Google Scholar]
- Li, H.; Wang, P.; Shen, C.; Zhang, G. Show, attend and read: A simple and strong baseline for irregular text recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8610–8617. [Google Scholar]
- Wang, T.; Zhu, Y.; Jin, L.; Luo, C.; Chen, X.; Wu, Y.; Wang, Q.; Cai, M. Decoupled attention network for text recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12216–12224. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Virtual, 3–7 May 2021. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Synthetic data and artificial neural networks for natural scene text recognition. arXiv 2014, arXiv:1406.2227. [Google Scholar]
- Gupta, A.; Vedaldi, A.; Zisserman, A. Synthetic data for text localisation in natural images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2315–2324. [Google Scholar]
- Bautista, D.; Atienza, R. Scene text recognition with permuted autoregressive sequence models. In Proceedings of the Computer Vision—ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; pp. 178–196. [Google Scholar]
- Yin, F.; Liu, C.L.; Lu, S. A new artwork dataset for experiments in artwork retrieval and recognition. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 1220–1225. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Liu, Y.; Jin, L.; Zhang, S.; Zhang, Z. LSVT: Large scale vocabulary training for scene text recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8774–8781. [Google Scholar]
- Liu, Y.; Chen, H.; Shen, C.; He, T.; Jin, L.; Wang, L.; Zhang, Z. Multi-lingual scene text dataset and benchmarks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7602–7611. [Google Scholar]
- Yin, F.; Zhang, Y.; Liu, C.L.; Lu, S. ICDAR2017 competition on reading Chinese text in the wild (RCTW-17). In Proceedings of the 2018 13th IAPR International Workshop on Document Analysis Systems (DAS), Vienna, Austria, 24–27 April 2018; pp. 178–183. [Google Scholar]
- Krylov, I.; Nosov, S.; Sovrasov, V. Open images v5 text annotation and yet another mask text spotter. In Proceedings of the Asian Conference on Machine Learning, Virtually, 17–19 November 2021; pp. 379–389. [Google Scholar]
- Mishra, A.; Shekhar, R.; Jawahar, C. Scene text recognition using higher order language priors. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 222–235. [Google Scholar]
- Shen, C.; Liu, X.; Yang, Y.; Jin, L.; Zhang, Z.; Chen, H.; Liu, F.; Zhang, Y.; Wu, W.; Liu, Y.; et al. ReCTS: A Large-Scale Reusable Corpus for Text Spotting. IEEE Trans. Multimed. 2019, 21, 1468–1481. [Google Scholar]
- Schneider, J.; Puigcerver, J.; Cissé, M.; Ginev, D.; Gruenstein, A.; Gutherie, D.; Jayaraman, D.; Kassis, T.; Kazemzadeh, F.; Llados, J.; et al. U-BER: A Large-Scale Dataset for Street Scene Text Reading. arXiv 2019, arXiv:1911.03585. [Google Scholar]
- Mishra, A.; Alahari, K.; Jawahar, C.V. Top-Down and Bottom-Up Cues for Scene Text Recognition. In Proceedings of the 2012 International Conference on Frontiers in Handwriting Recognition, Bari, Italy, 18–20 September 2012; pp. 359–364. [Google Scholar] [CrossRef]
- Wang, K.; Babenko, B.; Belongie, S. End-to-End Scene Text Recognition. In Proceedings of the 2011 International Conference on Document Analysis and Recognition, Beijing, China, 18–21 September 2011; pp. 296–303. [Google Scholar] [CrossRef]
- Yin, X.Y.; Wang, X.; Zhang, P.; Wen, L.; Bai, X.; Lei, Z.; Li, S.Z. Robust Text Detection in Natural Images with Edge-Enhanced Maximally Stable Extremal Regions. In Proceedings of the 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 151–156. [Google Scholar] [CrossRef]
- Karatzas, D.; Gomez-Bigorda, L.; Nicolaou, A.; Ghosh, S.; Bagdanov, A.; Iwamura, M.; Matas, J.; Neumann, L.; Chandrasekhar, V.; Lu, S.; et al. ICDAR 2015 Competition on Robust Reading. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; pp. 1156–1160. [Google Scholar] [CrossRef]
- Quy Pham, T.; Kieu Nguyen, H.; Cheung, N.M. Recognizing text in perspective view of scene images based on unsupervised feature learning. Pattern Recognit. 2013, 46, 1834–1848. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Year | Train Data | IC13 | SVT | IIIT5k | IC15 | SVTP | CUTE80 | Avg |
|---|---|---|---|---|---|---|---|---|---|
| CRNN | 2017 | S | 89.4 | 80.1 | 81.8 | 65.3 | 65.9 | 61.5 | 74 |
| RARE | 2016 | S | 92.3 | 85.4 | 86 | 73.5 | 75.4 | 71 | 80.6 |
| TRBA | 2019 | S | 93.4 | 87.6 | 87.8 | 77.4 | 78.1 | 75.02 | 83.22 |
| SAR | 2019 | S | 91 | 84.5 | 91.5 | 69.2 | 76.4 | 83.5 | 82.68 |
| VisionLAN | 2021 | S | 95.7 | 91.7 | 95.8 | 83.7 | 86 | 88.5 | 90.23 |
| ViTSTR | 2021 | S | 93.2 | 87.7 | 88.4 | 78.5 | 81.8 | 81.3 | 85.15 |
| ABI | 2021 | S | 97.4 | 93.5 | 96.2 | 86 | 89.3 | 89.2 | 91.93 |
| cdist | 2021 | S | 94.6 | 93.8 | 96.5 | 86.2 | 89.7 | 89.58 | 91.73 |
| SVTR | 2022 | S | 97.2 | 91.7 | 96.3 | 86.6 | 88.4 | 95.1 | 92.55 |
| CornerTransformer | 2022 | S | 96.4 | 94.6 | 95.9 | 86.3 | 91.5 | 92 | 92.78 |
| baseline | - | S | 94.86 | 91.8 | 93.76 | 83.26 | 83.41 | 86.8 | 88.98 |
| LSTR | - | S | 96.96 | 94.12 | 95.6 | 87.41 | 88.83 | 88.83 | 91.95 |
| LSTR | - | S, R | 98.6 | 96.44 | 98.13 | 90.94 | 92.55 | 97.22 | 95.64 |
| Method | Year | Avg | Parameters () | Time (ms/Image) |
|---|---|---|---|---|
| CRNN | 2017 | 74 | 8.3 | 6.3 |
| RARE | 2016 | 80.6 | 10.8 | 18.8 |
| TRBA | 2019 | 83.22 | 49.6 | 22.8 |
| SAR | 2019 | 82.68 | 57.5 | 120.0 |
| VisionLAN | 2021 | 90.23 | 32.8 | 28.0 |
| ViTSTR | 2021 | 85.15 | 85.5 | 9.8 |
| ABI | 2021 | 91.93 | 36.7 | 50.6 |
| cdist | 2021 | 91.73 | 65.4 | 123.28 |
| SVTR | 2022 | 92.55 | 40.8 | 18.0 |
| CornerTransformer | 2022 | 92.78 | 85.7 | 294.9 |
| baseline | - | 88.98 | 5.4 | 13.6 |
| LSTR | - | 91.95 | 7.1 | 13.6 |
| LSTR * | - | 95.64 | 7.1 | 13.6 |
| Method | Year | IC13 | SVT | IIIT5k | IC15 | SVTP | CUTE80 | Avg | Parameters | Time | FLOPS |
|---|---|---|---|---|---|---|---|---|---|---|---|
| CRNN | 2017 | 89.4 | 80.1 | 81.8 | 65.3 | 65.9 | 61.5 | 74 | 8.3 | 6.3 | 1.4 |
| ViTSTR-tiny | 2021 | 90.8 | 93.2 | 83..7 | 72.0 | 74.5 | 65.0 | 79.1 | 5.4 | 9.3 | 1.3 |
| MGP-tiny | 2022 | 94.0 | 91.1 | 94.3 | 83.3 | 83.5 | 84.3 | 88.5 | 21.0 | 12.0 | 7.2 |
| LSTR | — | 96.96 | 94.12 | 95.6 | 87.41 | 88.83 | 88.83 | 91.95 | 7.1 | 13.6 | 5.7 |
| ViTSTR-small | 2021 | 91.7 | 87.3 | 86.6 | 77.9 | 81.4 | 77.9 | 83.8 | 21.5 | 9.5 | 4.6 |
| MGP-small | 2022 | 96.8 | 93.5 | 95.3 | 86.1 | 87.3 | 87.9 | 91.15 | 52.6 | 12.2 | 25.4 |
| ViTSTR-base | 2021 | 93.2 | 87.7 | 88.4 | 78.5 | 81.8 | 81.3 | 85.15 | 85.5 | 9.8 | 17.6 |
| MGP-base | 2022 | 97.3 | 94.7 | 96.4 | 87.2 | 91.0 | 90.3 | 92.81 | 148.0 | 12.3 | 94.7 |
| Method | Image Size (Patch) | IC13_857 | SVT | IIIT5k | IC15 | SVTP | CUTE80 | Avg |
|---|---|---|---|---|---|---|---|---|
| baseline | 32 × 128 (4 × 4) | 94.86 | 91.80 | 93.76 | 83.26 | 83.41 | 86.80 | 88.98 |
| baseline | 224 × 224 (16 × 16) | 95.79 | 90.10 | 94.10 | 82.71 | 83.56 | 83.68 | 88.32 |
| Method | IC13 | SVT | IIIT5k | IC15 | SVTP | CUTE80 | Avg |
|---|---|---|---|---|---|---|---|
| baseline | 94.86 | 91.80 | 93.76 | 83.26 | 83.41 | 86.80 | 88.98 |
| +VisAug | 95.21 | 91.65 | 94.36 | 83.43 | 85.27 | 85.76 | 89.28 |
| +posAug+VisAug | 96.96 | 94.12 | 95.60 | 87.41 | 88.83 | 88.83 | 91.95 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luan, X.; Zhang, J.; Xu, M.; Silamu, W.; Li, Y. Lightweight Scene Text Recognition Based on Transformer. Sensors 2023, 23, 4490. https://doi.org/10.3390/s23094490
Luan X, Zhang J, Xu M, Silamu W, Li Y. Lightweight Scene Text Recognition Based on Transformer. Sensors. 2023; 23(9):4490. https://doi.org/10.3390/s23094490
Chicago/Turabian StyleLuan, Xin, Jinwei Zhang, Miaomiao Xu, Wushouer Silamu, and Yanbing Li. 2023. "Lightweight Scene Text Recognition Based on Transformer" Sensors 23, no. 9: 4490. https://doi.org/10.3390/s23094490
APA StyleLuan, X., Zhang, J., Xu, M., Silamu, W., & Li, Y. (2023). Lightweight Scene Text Recognition Based on Transformer. Sensors, 23(9), 4490. https://doi.org/10.3390/s23094490