
Integrating Spatial and Temporal Information for Violent Activity Detection from Video Using Deep Spiking Neural Networks




Abstract
1. Introduction
2. Related Work
2.1. Optical Flow
2.2. Benchmarks
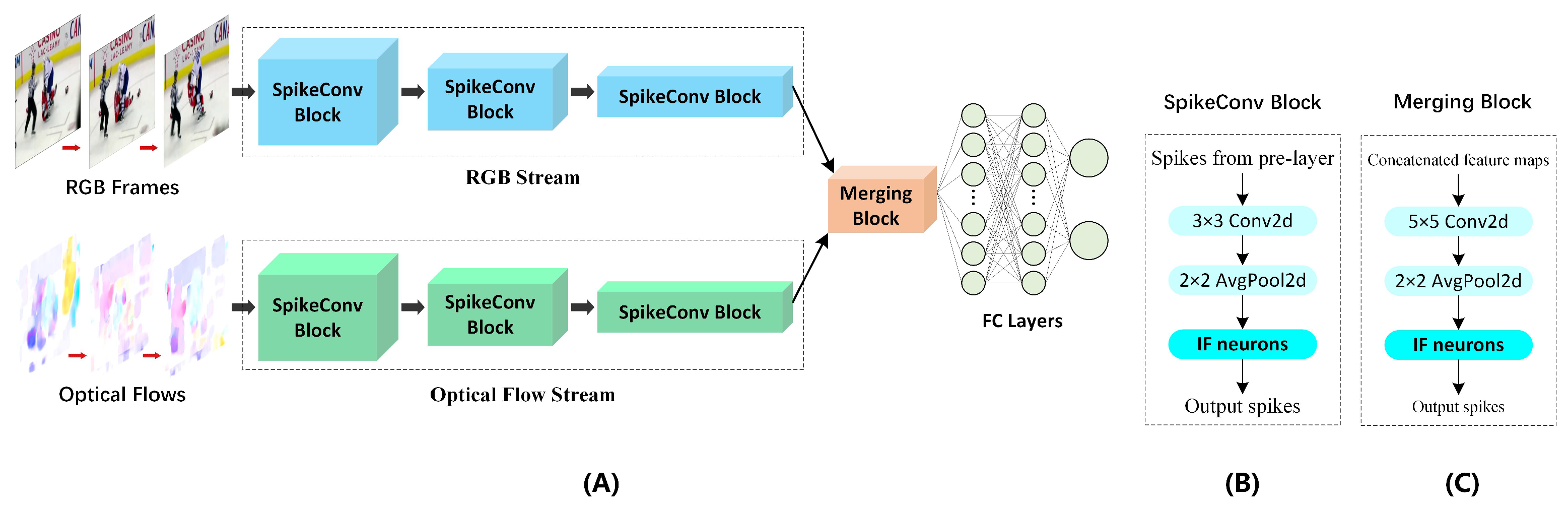
3. Proposed Method
3.1. IF Neuron-Based Gradient Descent Backpropagation Algorithm
3.2. SpikeConvFlowNet Architecture
3.3. Loss and Optimization
| Algorithm 1: Pseudocode for training in SpikeConvFlowNet. |
 |
3.4. Experiment Settings
4. Results
4.1. Datasets
4.2. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lim, M.C.; Jeffree, M.S.; Saupin, S.S.; Giloi, N.; Lukman, K.A. Workplace violence in healthcare settings: The risk factors, implications and collaborative preventive measures. Ann. Med. Surg. 2022, 78, 103727. [Google Scholar] [CrossRef] [PubMed]
- Ghareeb, N.S.; El-Shafei, D.A.; Eladl, A.M. Workplace violence among healthcare workers during COVID-19 pandemic in a Jordanian governmental hospital: The tip of the iceberg. Environ. Sci. Pollut. Res. 2021, 28, 61441–61449. [Google Scholar] [CrossRef] [PubMed]
- Subudhi, B.N.; Rout, D.K.; Ghosh, A. Big data analytics for video surveillance. Multimed. Tools Appl. 2019, 78, 26129–26162. [Google Scholar] [CrossRef]
- Chen, L.H.; Hsu, H.W.; Wang, L.Y.; Su, C.W. Violence detection in movies. In Proceedings of the 2011 Eighth International Conference Computer Graphics, Imaging and Visualization, Singapore, 17–19 August 2011; pp. 119–124. [Google Scholar]
- Rodríguez-Moreno, I.; Martínez-Otzeta, J.M.; Sierra, B.; Rodriguez, I.; Jauregi, E. Video activity recognition: State-of-the-art. Sensors 2019, 19, 3160. [Google Scholar] [CrossRef] [PubMed]
- Gao, Y.; Liu, H.; Sun, X.; Wang, C.; Liu, Y. Violence detection using oriented violent flows. Image Vis. Comput. 2016, 48, 37–41. [Google Scholar] [CrossRef]
- Bilinski, P.; Bremond, F. Human violence recognition and detection in surveillance videos. In Proceedings of the 13th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Colorado Springs, CO, USA, 23–26 August 2016; pp. 30–36. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks: Towards good practices for deep action recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 20–36. [Google Scholar]
- Zolfaghari, M.; Singh, K.; Brox, T. Eco: Efficient convolutional network for online video understanding. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 695–712. [Google Scholar]
- Zhou, P.; Ding, Q.; Luo, H.; Hou, X. Violent interaction detection in video based on deep learning. J. Phys. Conf. Ser. 2017, 844, 12–44. [Google Scholar] [CrossRef]
- Swathikiran, S.; Oswald, L. Learning to detect violent videos using convolutional long short-term memory. In Proceedings of the 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS) IEEE, Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Aayush, J.; Kumar, V.D. Deep NeuralNet For Violence Detection Using Motion Features From Dynamic Images. In Proceedings of the Third International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, 20–22 August 2020; pp. 826–831. [Google Scholar]
- Tian, C.; Zhang, X.; Lin, J.C.; Zuo, W.; Zhang, Y.; Lin, C. Generative adversarial networks for image super-resolution: A survey. arXiv 2022, arXiv:2204.13620. [Google Scholar]
- Tian, C.; Xu, Y.; Li, Z.; Zuo, W.; Fei, L.; Liu, H. Attention-guided CNN for image denoising. Neural Netw. 2020, 124, 117–129. [Google Scholar] [CrossRef]
- Jiang, B.; Yu, J.; Zhou, L.; Wu, K.; Yang, Y. Two-Pathway Transformer Network for Video Action Recognition. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 1089–1093. [Google Scholar]
- Chen, J.; Ho, C.M. MM-ViT: Multi-modal video transformer for compressed video action recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January; pp. 1910–1921.
- Taha, M.M.; Alsammak, A.K.; Zaky, A.B. InspectorNet: Transformer network for violence detection in animated cartoon. Eng. Res. J. Fac. Eng. (Shoubra) 2023, 52, 114–119. [Google Scholar] [CrossRef]
- Sarada, K.; Sanchari, S.; Swagath, V.; Anand, R. Dynamic spike bundling for energy-efficient spiking neural networks. In Proceedings of the IEEE/ACM International Symposium on Low Power Electronics and Design (ISLPED), Lausanne, Switzerland, 29–31 July 2019; pp. 1–6. [Google Scholar]
- Zhang, L.; Zhou, S.; Zhi, T.; Du, Z.; Chen, Y. TDSNN: From Deep Neural Networks to Deep Spike Neural Networks with Temporal-Coding. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 1319–1326. [Google Scholar]
- Lobov, S.A.; Chernyshov, A.V.; Krilova, N.P.; Shamshin, M.O.; Kazantsev, V.B. Competitive learning in a spiking neural network: Towards an intelligent pattern classifier. Sensors 2021, 20, 500. [Google Scholar] [CrossRef]
- Kheradpisheh, S.R.; Masquelier, T. Temporal Backpropagation for Spiking Neural Networks with One Spike per Neuron. Int. J. Neural Syst. 2020, 30, 205–227. [Google Scholar] [CrossRef]
- Bam, S.S.; Garrick, O. Slayer: Spike layer error reassignment in time. arXiv 2018, arXiv:1810.08646. [Google Scholar]
- Peter, O.; Efstratios, G.; Max, W. Temporally efficient deep learning with spikes. arXiv 2017, arXiv:1706.04159. [Google Scholar]
- Enmei, T.; Nikola, K.; Yang, J. Mapping temporal variables into the neucube for improved pattern recognition, predictive modeling, and understanding of stream data. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 1305–1317. [Google Scholar]
- Kasabov, N.K. Time-Space, Spiking Neural Networks and Brain-Inspired Artificial Intelligence; Springer: Heidelberg/Berlin, Germany, 2019; pp. 339–396. [Google Scholar]
- Clarence, T.; Marko, Š.; Nikola, K. Spiking Neural Networks: Background, Recent Development and the NeuCube Architecture. Neural Process. Lett. 2020, 52, 1675–1701. [Google Scholar]
- Tan, C.; Ceballos, G.; Kasabov, N.; Puthanmadam Subramaniyam, N. Fusionsense: Emotion classification using feature fusion of multimodal data and deep learning in a brain-inspired spiking neural network. Sensors 2020, 20, 5328. [Google Scholar] [CrossRef]
- Berlin, S.J.; John, M. Spiking neural network based on joint entropy of optical flow features for human action recognition. Vis. Comput. 2022, 38, 223–237. [Google Scholar] [CrossRef]
- Al-Shaban, Z.R.; Al-Otaibi, S.T.; Alqahtani, H.A. Occupational violence and staff safety in health-care: A cross-sectional study in a large public hospital. Risk Manag. Healthc. Policy 2021, 14, 1649–1657. [Google Scholar] [CrossRef]
- Kiran, K.; Sushant, P.; Pravin, D. Moving object tracking using optical flow and motion vector estimation. In Proceedings of the 2015 4th International Conference on Reliability, Infocom Technologies and Optimization (ICRITO) (Trends and Future Directions), Noida, India, 2–4 September 2015; pp. 1–6. [Google Scholar]
- Tu, Z.; Xie, W.; Zhang, D.; Poppe, R.; Veltkamp, R.C.; Li, B.; Yuan, J. A survey of variational and CNN-based optical flow techniques. Signal Process. Image Commun. 2019, 72, 9–24. [Google Scholar] [CrossRef]
- Anshuman, A.; Shivam, G.; Kumar, S.D. Review of optical flow technique for moving object detection. In Proceedings of the 2016 2nd International Conference on Contemporary Computing and Informatics (IC3I), Greater Noida, India, 14–17 December 2016; pp. 409–413. [Google Scholar]
- Shaul, O.; Aharon, B.; Shai, A. Extended lucas-kanade tracking. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 142–156. [Google Scholar]
- Shay, Z.; Lior, W. Interponet, a brain inspired neural network for optical flow dense interpolation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4563–4572. [Google Scholar]
- Li, D.; Wang, R. Context-LSTM: A robust classifier for video detection on UCF101. arXiv 2022, arXiv:2203.06610. [Google Scholar]
- Samadzadeh, A.; Far, F.S.T.; Javadi, A.; Nickabadi, A.; Chehreghani, M.H. Convolutional spiking neural networks for spatio-temporal feature extraction. arXiv 2021, arXiv:2003.12346. [Google Scholar] [CrossRef]
- Chankyu, L.; Shakib, S.S.; Priyadarshini, P.; Gopalakrishnan, S.; Kaushik, R. Enabling spike-based backpropagation for training deep neural network architectures. Front. Neurosci. 2020, 14, 119–142. [Google Scholar]
- Neftci, E.O.; Hesham, M.; Friedemann, Z. Surrogate gradient learning in spiking neural networks. IEEE Signal Process. Mag. 2019, 36, 51–63. [Google Scholar] [CrossRef]
- Jun, H.L.; Tobi, D.; Michael, P. Training deep spiking neural networks using backpropagation. Front. Neurosci. 2016, 10, 508–523. [Google Scholar]
- Yoshua, B.; Nicholas, L.; Aaron, C. Estimating or propagating gradients through stochastic neurons for conditional computation. arXiv 2013, arXiv:1308.3432. [Google Scholar]
- Panda, P.; Aketi, S.A.; Roy, K. Toward Scalable, Efficient, and Accurate Deep Spiking Neural Networks With Backward Residual Connections, Stochastic Softmax, and Hybridization. Front. Neurosci. 2020, 14, 653–681. [Google Scholar] [CrossRef]
- Samanwoy, G.D.; Hojjat, A. Third Generation Neural Networks: Spiking Neural Networks. In Advances in Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2009; pp. 167–178. [Google Scholar]
- Bermejo Nievas, E.; Deniz Suarez, O.; Bueno García, G.; Sukthankar, R. Violence detection in video using computer vision techniques. In Proceedings of the 14th International Conference on Computer Analysis of Images and Patterns, Seville, Spain, 29–31 August 2011. [Google Scholar]
- Tal, H.; Itcher, Y.; Kliper-Gross, O. Violent flows: Real-time detection of violent crowd behavior. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 1–6. [Google Scholar]
- Cheng, M.; Cai, K.; Li, M. RWF-2000: An Open Large Scale Video Database for Violence Detection. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 4183–4190. [Google Scholar]
- Evgin, G.; Akman, K.A. Comparative evaluations of cnn based networks for skin lesion classification. In Proceedings of the 14th International Conference on Computer Graphics, Visualization, Computer Vision and Image Processing, Zagreb, Croatia, 21–25 July 2020; pp. 1–6. [Google Scholar]
- Song, W.; Zhang, D.; Zhao, X.; Yu, J.; Zheng, R.; Wang, A. A Novel Violent Video Detection Scheme Based on Modified 3D Convolutional Neural Networks. IEEE Access 2019, 7, 39172–39179. [Google Scholar] [CrossRef]
- Joao, C.; Andrew, Z. Quo vadis, action recognition? a new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Hockey | Crowd | RWF | Params (M) |
|---|---|---|---|---|
| C3D | 96.5% | 84.4% | 82.8% | 94.8 |
| Context-LSTM | 99.2% | 93.8% | 92.3% | 1.7 |
| STS-ResNet | 98.9% | 91.2% | 88.3% | 11.7 |
| SpikeConvFlowNet | 98.4% | 90.2% | 88.5% | 0.178 |
| Method | Movies | Hockey | Crowd | RWF | Params (M) |
|---|---|---|---|---|---|
| 3D ConvNet | 99.97% | 99.6% | 94.3% | 81.7% * | 86.9 |
| ConvLSTM | 100% | 97.1% | 94.5% | 77.0% | 47.4 |
| C3D | 100% | 96.5% | 84.4% | 82.8% | 94.8 |
| I3D (Fusion) | 100% | 97.5% | 88.9% | 81.5% | 24.6 |
| Flow Gated Network | 100% | 98.0% | 88.8% | 87.2% | 0.27 |
| Context-LSTM * | 100% | 99.2% | 93.8% | 92.3% | 1.7 |
| STS-ResNet * | 100% | 98.9% | 91.2% | 88.3% | 11.7 |
| SpikeConvFlowNet | 100% | 98.4% | 90.2% | 88.5% | 0.178 |
| Method | HMDB51 | UCF101 |
|---|---|---|
| Context-LSTM | 80.1% * | 92.2% |
| STS-ResNet | 21.5% | 42.1% |
| SpikeConvFlowNet | 23.6% | 40.7% |
| Method | Training Time(h) | Inference Efficiency(fps) |
|---|---|---|
| Context-LSTM | 2.4 | 290.7 |
| STS-ResNet | 5.1 | 170.3 |
| SpikeConvFlowNet | 2.2 | 372.8 |
| Measures | Movies | Hockey | Crowd | RWF |
|---|---|---|---|---|
| 1.00 | 0.98 | 0.88 | 0.86 | |
| 1.00 | 0.99 | 0.91 | 0.92 | |
| 1.00 | 0.99 | 0.90 | 0.89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Yang, J.; Kasabov, N.K. Integrating Spatial and Temporal Information for Violent Activity Detection from Video Using Deep Spiking Neural Networks. Sensors 2023, 23, 4532. https://doi.org/10.3390/s23094532
Wang X, Yang J, Kasabov NK. Integrating Spatial and Temporal Information for Violent Activity Detection from Video Using Deep Spiking Neural Networks. Sensors. 2023; 23(9):4532. https://doi.org/10.3390/s23094532
Chicago/Turabian StyleWang, Xiang, Jie Yang, and Nikola K. Kasabov. 2023. "Integrating Spatial and Temporal Information for Violent Activity Detection from Video Using Deep Spiking Neural Networks" Sensors 23, no. 9: 4532. https://doi.org/10.3390/s23094532
APA StyleWang, X., Yang, J., & Kasabov, N. K. (2023). Integrating Spatial and Temporal Information for Violent Activity Detection from Video Using Deep Spiking Neural Networks. Sensors, 23(9), 4532. https://doi.org/10.3390/s23094532