
Multiscale Deblurred Feature Extraction Network for Automatic Four-Rod Target Detection in MRTD Measuring Process of Thermal Imagers


Abstract
:1. Introduction
- (1)
- We contribute a dataset of 991 four-rod target photos and make it open-source.
- (2)
- We demonstrate the effectiveness of a multiscale deblurred feature extraction network (MDF-Net) in four-rod target detection.
- (3)
- We propose the GAM attention module and RepVGG module to lower the influence of the scale variability of the four-rod targets and the low pixel resolution of the photos.
1.1. Related Work
MRTD Measurement Development
1.2. Multiscale Detection Methods in Deep Learning
1.3. Four-Rod Target Detection in Infrared Thermal Imaging Systems
2. Proposed Method
2.1. Infrared Four-Rod Target Dataset
2.1.1. Experimental System Setup
2.1.2. Dataset Acquisition Process
- 1.
- Measure the temperature of our experiment chamber as T and maintain it to ensure the accuracy of the test results, put the infrared imager on the optical platform stably, adjust the temperature of the blackbody to T + 10 K and install a four-rod target with fixed spatial frequency on the radiation surface of the blackbody. The four-rod target can then be distinguished clearly on the thermal imager.
- 2.
- Gradually decrease the temperature of the blackbody by 0.1 K until the temperature difference between the target and the background become negative. Photos of the four-rod target are taken by the thermal imager at each temperature point. Data acquisition ends when the four-rod target can be distinguished clearly in negative temperature difference.
- 3.
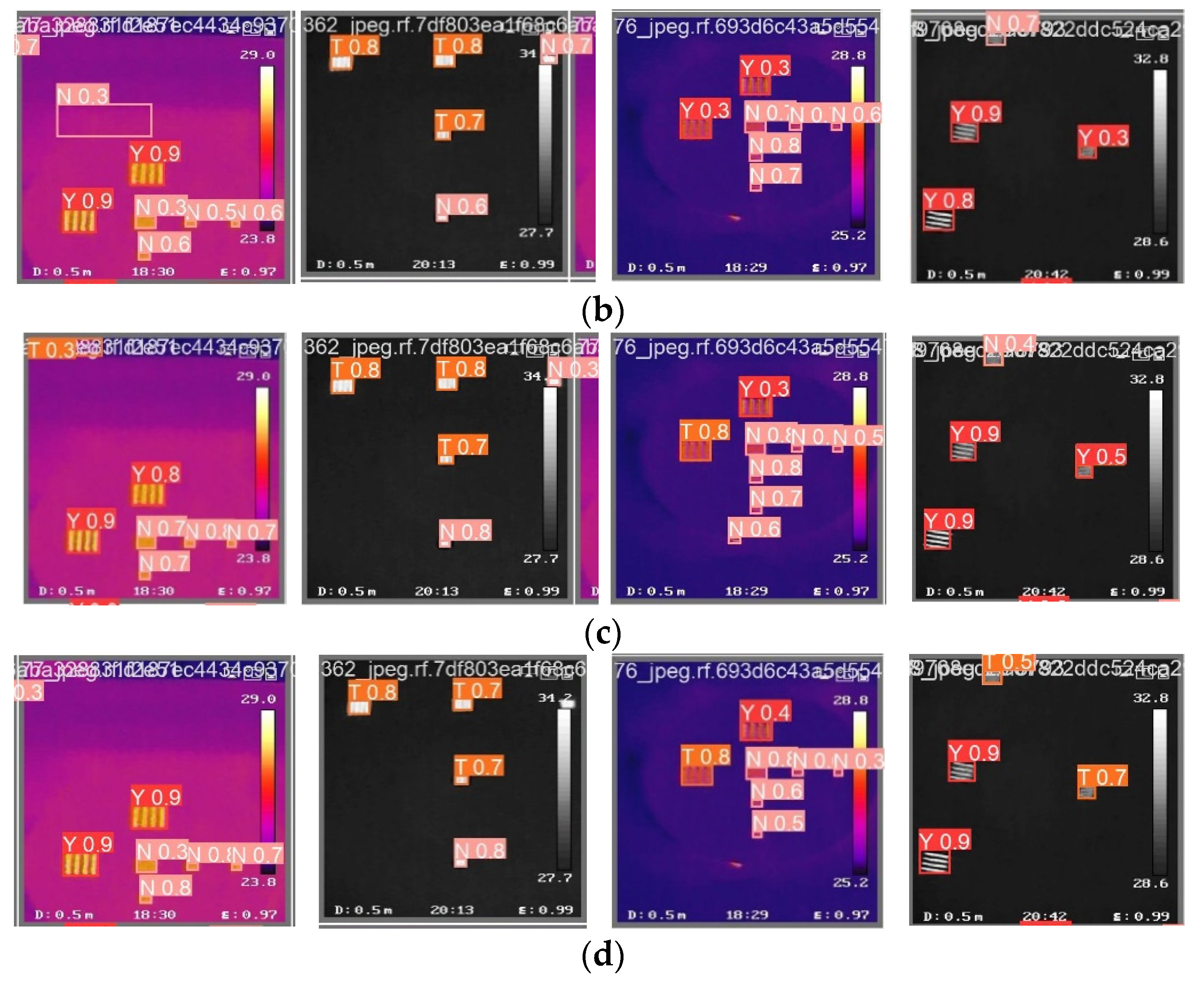
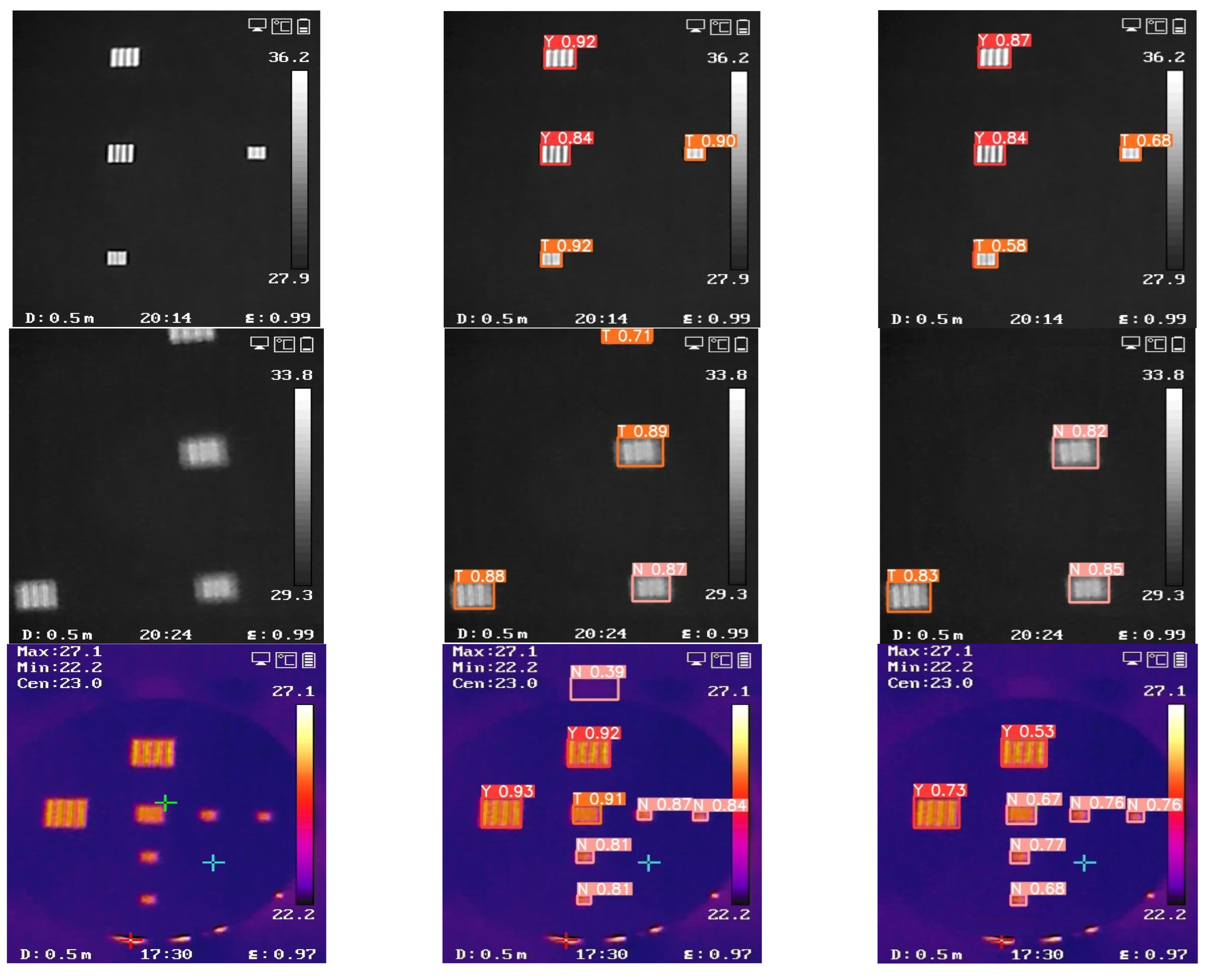
- Invite a group of testers to mark labels for the data; the category labels are divided into “Y”, “N” and “T”, which represent distinguishable targets, totally indistinguishable targets and targets on the margin of distinguishable and indistinguishable, respectively. Then, we finally obtain the GW-MRTD dataset.
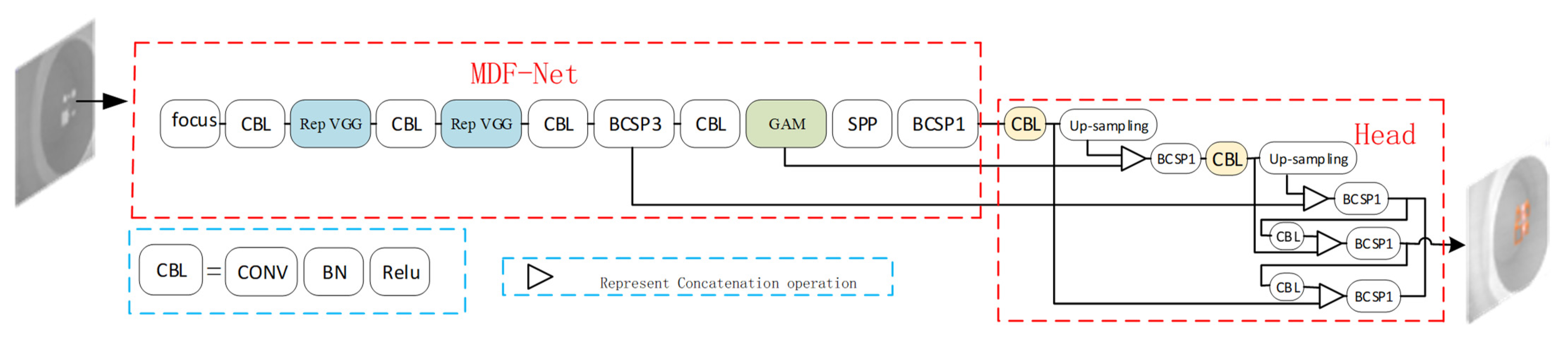
2.2. Proposed Neural Network
2.2.1. Overall Network Framework
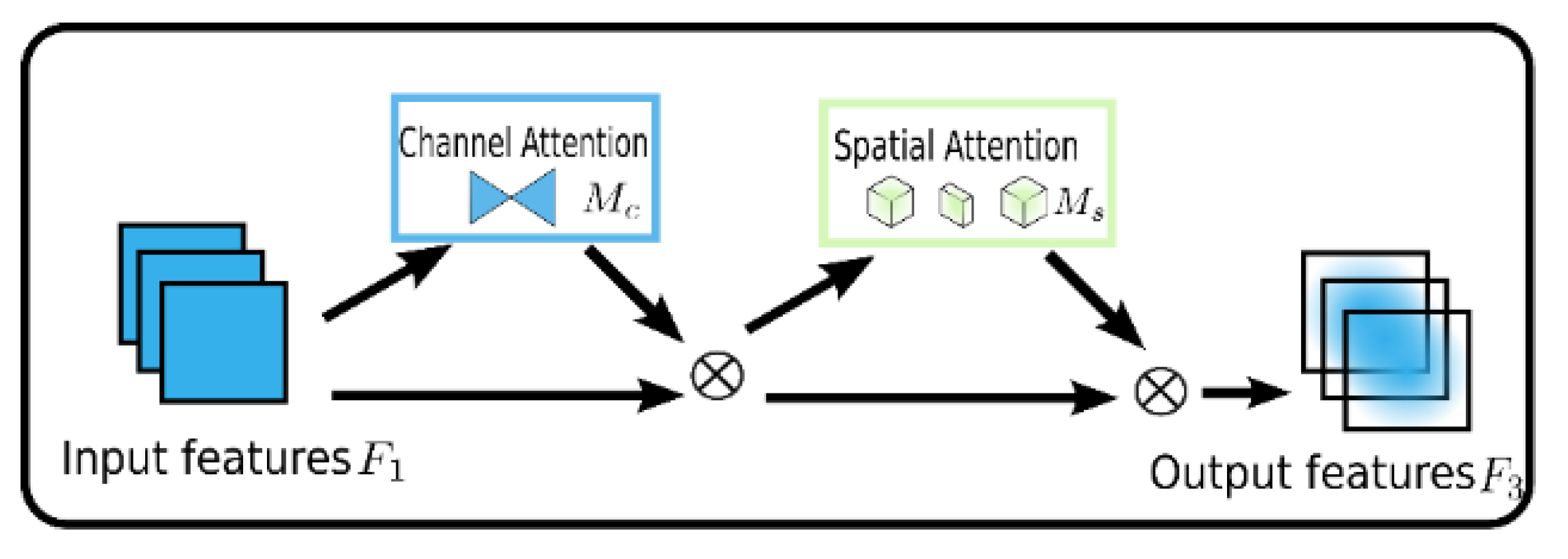
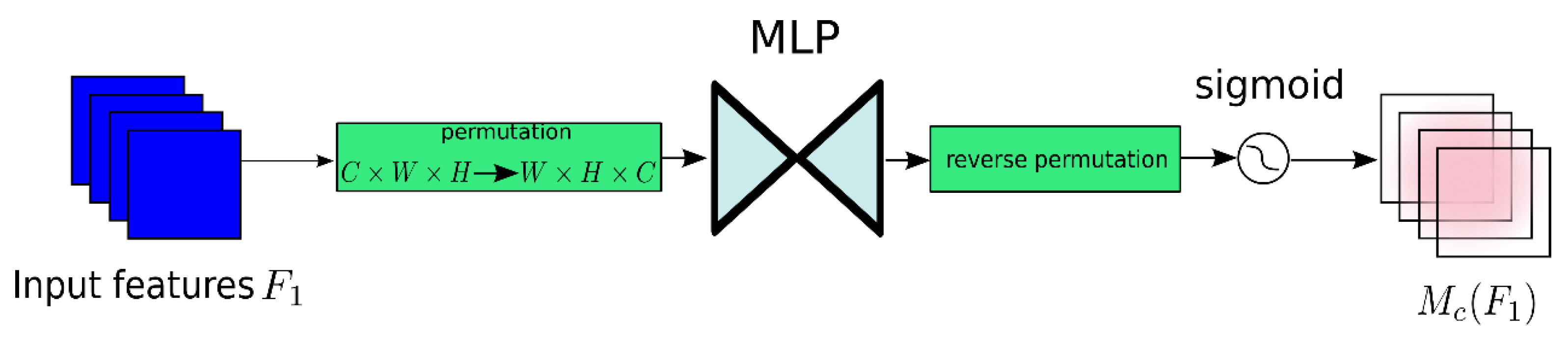
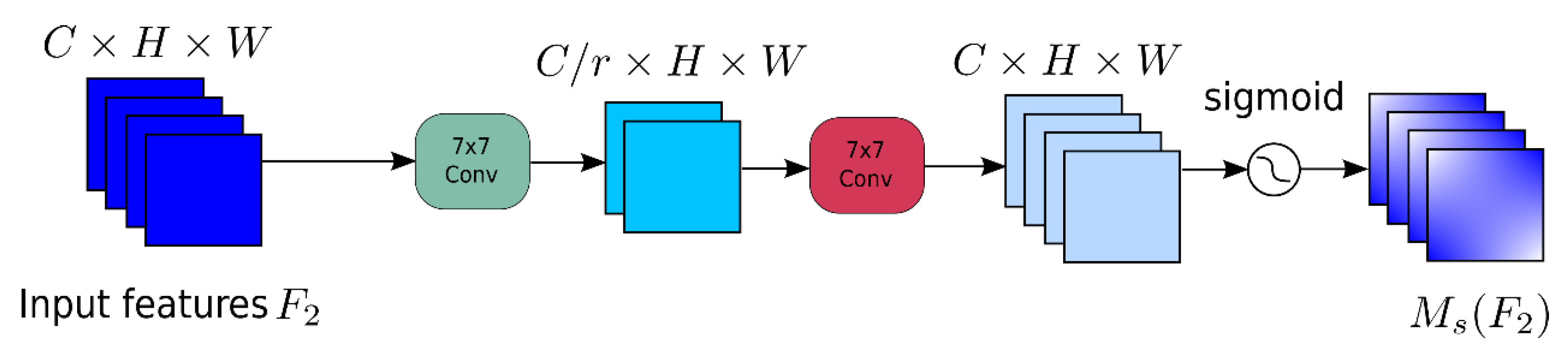
2.2.2. Global Attention Mechanism (GAM) Attention Module
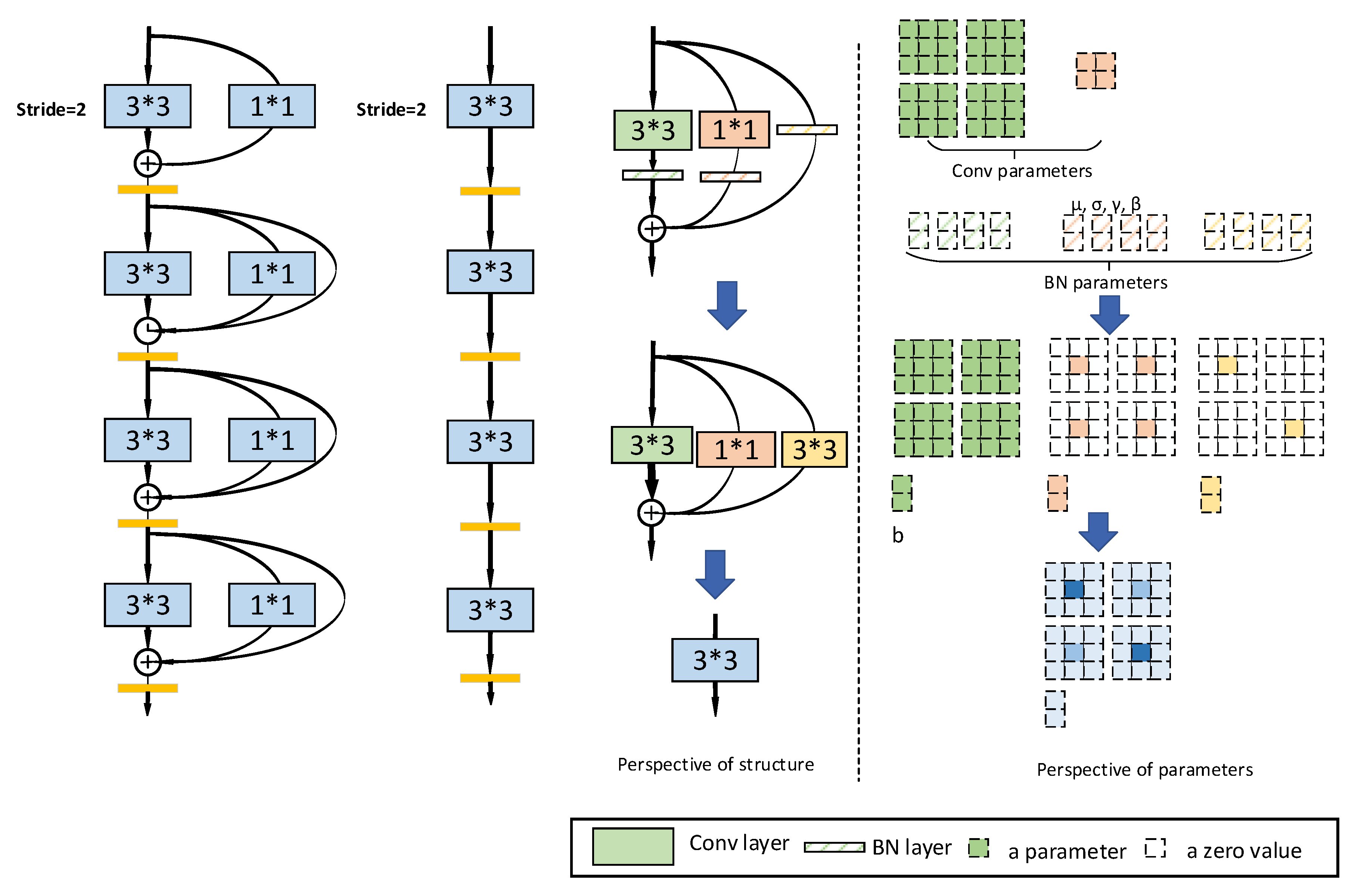
2.2.3. Rep VGG Module
3. Experiments and Discussion
- (1)
- Dataset: A dataset of 991 images with 1280 × 1280 pixels was used to train our detection model. The whole GW-MRTD dataset (991 images) can be divided into a training set (921 images), a valid set (50 images) and a test set (20 images). To begin with, we applied pre-processing to the original data, including auto-orient and stretching to a size of 640 × 640. To improve the generalization of the net and mitigate the overfitting, some data augmentations were adopted, such as cropping from 0% minimum zoom to 10% maximum zoom, noise up to 5% of pixels and mosaic. Next, we generated coco-formatted datasets for training using annotation tools. Finally, the backbone of the yolov5 framework was pretrained on the coco128 dataset and trained on our GW-MRTD dataset for 100 epochs.
- (2)
- Experimental configuration: We adopted Pytorch as the framework. An Intel Core i7-8700 CPU and an NVIDIA RTX3060 with 128 GB of memory made up the computer’s processor setup. Ubuntu 18.04 was used as the default operating system.
- (3)
- Detection criteria: Precision (P), recall (R) and achieved mean average precision (mAP) are three commonly used indices that are used to objectively evaluate the effectiveness of defect detection methods. P is the proportion of “true” samples among all “true” samples as determined by the system. R is the proportion of “true” samples among all true samples. mAP is the average of AP for each category, and AP reflects the detection accuracy of a particular category. We further fine-tuned the hyperparameters and finally set the batch size at 16 and the learning rate at 0.01. After the process, MAP_0.5 (mean average precision when IOU set at 0.5) was employed as the evaluation metric, which equals the average of all categories of the area under the precision–recall curve of a certain category.
3.1. Ablation Experiment
3.2. Comparison with Other Nets
4. Conclusions
- 1.
- The GAM module and the RepVGG module both play an important role in the detection of the four-rod target, increasing by a mAP at 2.7% and 3.4% separately.
- 2.
- The proposed MDF-Net based on YoloV5 achieved a mAP of 82.3% on the test photos of the four-rod target, indicating that the model proposed can identify and classify the four-rod target into “Y”,” N” and “T”. The research results suggest that training an artificial neural network to measure the MRTD automatically is promising.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sutherland, W.; Emerson, J.; Dalton, G.; Atad-Ettedgui, E.; Beard, S.; Bennett, R.; Bezawada, N.; Born, A.; Caldwell, M.; Clark, P. The visible and infrared survey telescope for astronomy (VISTA): Design, technical overview, and performance. Astron. Astrophys. 2015, 575, A25. [Google Scholar] [CrossRef]
- Jiang, L.; Ng, E.; Yeo, A.; Wu, S.; Pan, F.; Yau, W.; Chen, J.; Yang, Y. A perspective on medical infrared imaging. J. Med. Eng. Technol. 2005, 29, 257–267. [Google Scholar] [CrossRef] [PubMed]
- Hudson, R.; Hudson, J.W. The military applications of remote sensing by infrared. Proc. IEEE 1975, 63, 104–128. [Google Scholar] [CrossRef]
- Mo, Z.-X.; Chen, Y.-J. Research and prospects of the domestic infrared thermography technology. Laser Infrared 2014, 44, 1300–1305. [Google Scholar]
- Wang, Y.; Gu, Z.; Wang, S.; He, P. The temperature measurement technology of infrared thermal imaging and its applications review. In Proceedings of the 2017 13th IEEE International Conference on Electronic Measurement & Instruments (ICEMI), Yangzhou, China, 20–22 October 2017; pp. 401–406. [Google Scholar]
- Ring, E.; Ammer, K. Infrared thermal imaging in medicine. Physiol. Meas. 2012, 33, R33. [Google Scholar] [CrossRef] [PubMed]
- Lahiri, B.B.; Bagavathiappan, S.; Jayakumar, T.; Philip, J. Medical applications of infrared thermography: A review. Infrared Phys. Technol. 2012, 55, 221–235. [Google Scholar] [CrossRef] [PubMed]
- Cui, H.; Xu, Y.; Zeng, J.; Tang, Z. The methods in infrared thermal imaging diagnosis technology of power equipment. In Proceedings of the 2013 IEEE 4th International Conference on Electronics Information and Emergency Communication, Beijing, China, 15–17 November 2013; pp. 246–251. [Google Scholar]
- Kastberger, G.; Stachl, R. Infrared imaging technology and biological applications. Behav. Res. Methods Instrum. Comput. 2003, 35, 429–439. [Google Scholar] [CrossRef] [PubMed]
- Kolobrodov, V.; Mykytenko, V. Refinement of thermal imager minimum resolvable temperature difference calculating method. In Proceedings of the Twelfth International Conference on Correlation Optics, Chernivtsi, Ukraine, 14–18 September 2015; pp. 82–87. [Google Scholar]
- Church, J.S.; Hegadoren, P.; Paetkau, M.; Miller, C.; Regev-Shoshani, G.; Schaefer, A.; Schwartzkopf-Genswein, K. Influence of environmental factors on infrared eye temperature measurements in cattle. Res. Vet. Sci. 2014, 96, 220–226. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Zhang, X.-H.; Guo, H.-S. Research on Minimum Resolvable Temoerature Difference Automatic Test Method of the Thermal Imaging System. Infrared Technol. 2010, 32, 509. [Google Scholar] [CrossRef]
- Perić, D.; Livada, B. MRTD Measurements Role in Thermal Imager Quality Assessment. 2019. Available online: https://www.researchgate.net/profile/Branko-Livada/publication/334964614_MRTD_Measurements_Role_in_Thermal_Imager_Quality_Assessment/links/5d47d19e299bf1995b66419e/MRTD-Measurements-Role-in-Thermal-Imager-Quality-Assessment.pdf (accessed on 1 May 2023).
- van Rheenen, A.D.; Taule, P.; Thomassen, J.B.; Madsen, E.B. MRTD: Man versus machine. In Proceedings of the Infrared Imaging Systems: Design, Analysis, Modeling, and Testing XXIX, Orlando, FL, USA, 17–18 April 2018; pp. 52–63. [Google Scholar]
- Khare, S.; Singh, M.; Kaushik, B.K. Development and validation of a quantitative model for the subjective and objective minimum resolvable temperature difference of thermal imaging systems. Opt. Eng. 2019, 58, 104111. [Google Scholar] [CrossRef]
- Singh, M.; Khare, S.; Kaushik, B.K. Objective evaluation method for advance thermal imagers based on minimum resolvable temperature difference. J. Opt. 2020, 49, 94–101. [Google Scholar] [CrossRef]
- Singh, H.; Pant, M. Auto-minimum resolvable temperature difference method for thermal imagers. J. Opt. 2021, 50, 689–700. [Google Scholar] [CrossRef]
- Knežević, D.; Redjimi, A.; Mišković, K.; Vasiljević, D.; Nikolić, Z.; Babić, J. Minimum resolvable temperature difference model, simulation, measurement and analysis. Opt. Quantum Electron. 2016, 48, 1–7. [Google Scholar] [CrossRef]
- Chrzanowski, K.; Hong Viet, N. Virtual MRTD—An indirect method to measure MRTD of thermal imagers using computer simulation. Opt. Appl. 2020, 50, 671–688. [Google Scholar] [CrossRef]
- Irwin, A.; Grigor, J. An alternate method for performing MRTD measurements. In Proceedings of the Infrared Imaging Systems: Design, Analysis, Modeling, and Testing XXV, Baltimore, MD, USA, 6–8 May 2014; pp. 331–337. [Google Scholar]
- Wang, J.-h.; Jin, W.-q. Research and development on performance models of thermal imaging systems. In Proceedings of the International Symposium on Photoelectronic Detection and Imaging 2009: Advances in Infrared Imaging and Applications, Beijing, China, 17–19 June 2009; pp. 469–479. [Google Scholar]
- Bijl, P.; Hogervorst, M.A.; Valeton, J.M. TOD, NVTherm, and TRM3 model calculations: A comparison. In Proceedings of the Infrared and Passive Millimeter-Wave Imaging Systems: Design, Analysis, Modeling, and Testing, Orlando, FL, USA, 3–5 April 2002; pp. 51–62. [Google Scholar]
- Sun, J.; Ma, D. Intelligent MRTD testing for thermal imaging system using ANN. In Proceedings of the ICO20: Remote Sensing and Infrared Devices and Systems, Changchun, China, 21–26 August 2005; pp. 260–266. [Google Scholar]
- Xu, L.; Li, Q.; Lu, Y. Method of object MRTD-testing for thermal infrared imager. In Proceedings of the Optical Design and Testing VIII, Beijing, China, 11–13 October 2018; pp. 311–319. [Google Scholar]
- Rong, W.; Zhang, W.; He, W.; Chen, Q.; Gu, G.; Zhao, T.; Qiu, Z. A method of MRTD parameter measurement based on CNN neural network. In Proceedings of the 2019 International Conference on Optical Instruments and Technology: Optoelectronic Measurement Technology and Systems, Beijing, China, 26–28 October 2019; pp. 293–299. [Google Scholar]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. Proc. IEEE 2023, 11, 257–276. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Felzenszwalb, P.; McAllester, D.; Ramanan, D. A discriminatively trained, multiscale, deformable part model. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Malisiewicz, T.; Gupta, A.; Efros, A.A. Ensemble of exemplar-svms for object detection and beyond. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 89–96. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. Available online: https://proceedings.neurips.cc/paper/2015/file/14bfa6bb14875e45bba028a21ed38046-Paper.pdf (accessed on 18 April 2023). [CrossRef] [PubMed]
- Szegedy, C.; Toshev, A.; Erhan, D. Deep neural networks for object detection. Adv. Neural Inf. Process. Syst. 2013, 26. Available online: https://proceedings.neurips.cc/paper_files/paper/2013/file/f7cade80b7cc92b991cf4d2806d6bd78-Paper.pdf (accessed on 18 April 2023).
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Part I 14; pp. 21–37. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 9627–9636. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Tao, Y.; Li, B.; Okae, J. Concealed multiscale feature extraction network for automatic four-bar target detection in infrared imaging. Opt. Eng. 2022, 61, 063104. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| GAM | RepVGG | MAP_0.5 (%) |
|---|---|---|
| 0 | 0 | 73.7 |
| 0 | 1 | 78.9 |
| 1 | 0 | 79.6 |
| 1 | 1 | 82.3 |
| Nets | MAP_0.5 (%) | AP Y (%) | AP N (%) | AP T (%) |
|---|---|---|---|---|
| RCNN | 72.4 | 89.7 | 79.4 | 70.3 |
| YOLOV3 | 77.5 | 92.1 | 80.1 | 69.8 |
| YOLOV4 | 79.6 | 94.7 | 81.9 | 72.1 |
| YOLOV5 | 81.1 | 95.2 | 80.9 | 72.4 |
| Our method | 82.3 | 97.6 | 83.5 | 73.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, Z.; Guan, W.; Wu, H. Multiscale Deblurred Feature Extraction Network for Automatic Four-Rod Target Detection in MRTD Measuring Process of Thermal Imagers. Sensors 2023, 23, 4542. https://doi.org/10.3390/s23094542
Guo Z, Guan W, Wu H. Multiscale Deblurred Feature Extraction Network for Automatic Four-Rod Target Detection in MRTD Measuring Process of Thermal Imagers. Sensors. 2023; 23(9):4542. https://doi.org/10.3390/s23094542
Chicago/Turabian StyleGuo, Zhenggang, Wei Guan, and Haibin Wu. 2023. "Multiscale Deblurred Feature Extraction Network for Automatic Four-Rod Target Detection in MRTD Measuring Process of Thermal Imagers" Sensors 23, no. 9: 4542. https://doi.org/10.3390/s23094542