
CVTrack: Combined Convolutional Neural Network and Vision Transformer Fusion Model for Visual Tracking


Abstract
:1. Introduction
- We propose an end-to-end object tracking architecture in parallel with the Siamese network and transformer, which only consists of two parts: a dual-branch parallel feature-extraction module and a prediction module. This architecture can effectively combine the local feature extraction capabilities of convolutional neural networks and the global modeling ability of the transformer while keeping the overall architecture simple without complex post-processing, enabling real-time running speed;
- By combining the features of two different network architectures, the CNN and the transformer, we propose a parallel dual-branch feature extractor that takes advantage of both CNN and transformer feature extraction. It not only obtains local features and global features simultaneously but also allows information exchange between the two branches, exchanging features at different resolutions of local features and global representation, maximally retaining the local features and global representation of the target, significantly improving the target recognizing ability of the tracker;
- We propose a way of information exchange and feature fusion, achieving two stages of information exchange and feature fusion. The first stage of information exchange is the feature extraction stage, where the local features and global features are exchanged between the two branches, i.e., between the CNN branch and the transformer branch. The second stage of feature fusion is the prediction stage, where the correlation information from the convolutional branch and the search area information from the transformer branch are fused. The fusion of the two stages provides the prediction module with richer feature information;
2. Related Work
2.1. Visual Object Tracking
2.2. Transformer
2.3. Local-Global Feature Extraction
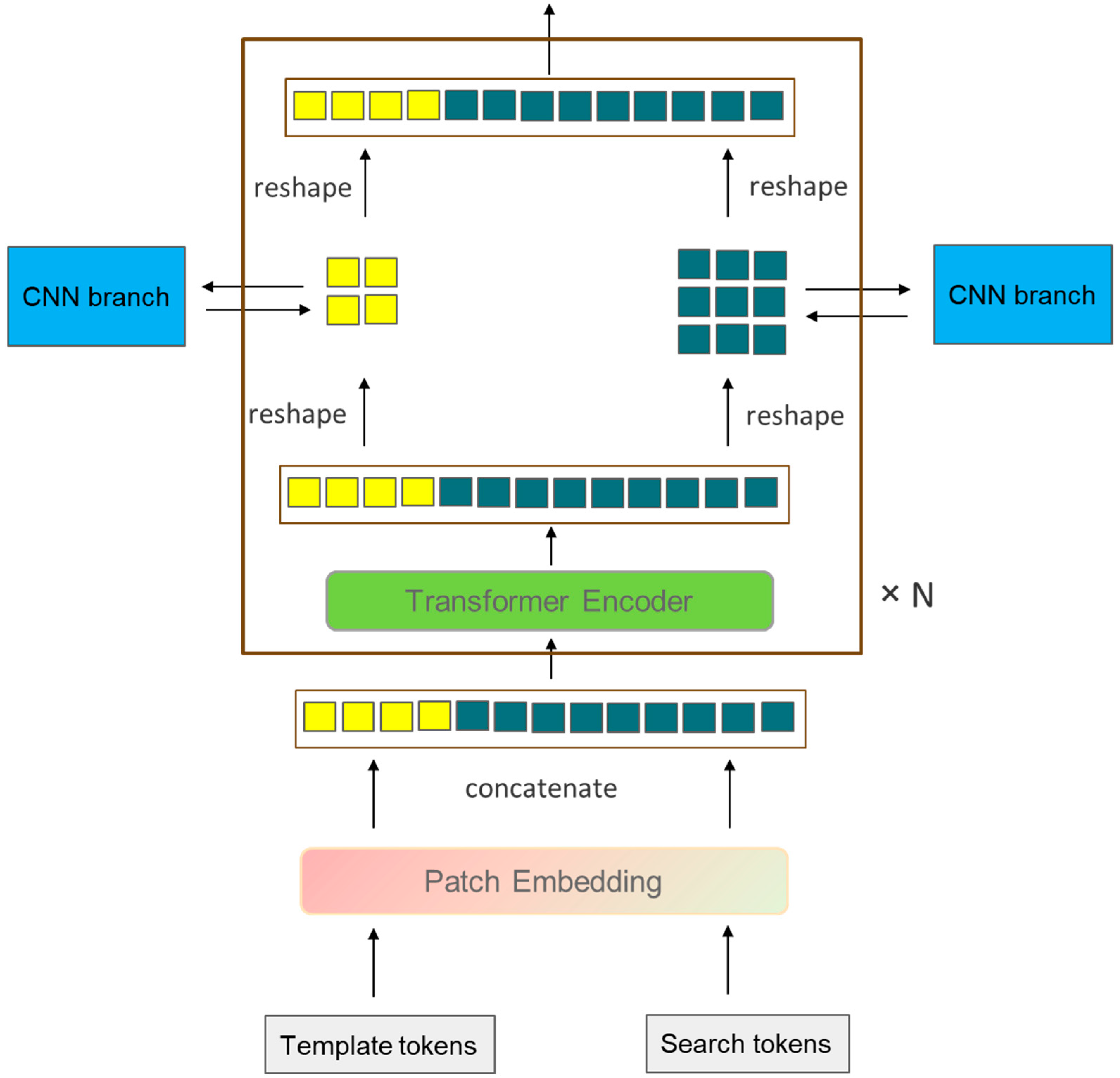
3. Method
3.1. Object Tracking Framework
3.2. Feature-Extraction Module
3.2.1. CNN Branch
3.2.2. Transformer Branch
3.3. Bidirectional Information Interaction Module
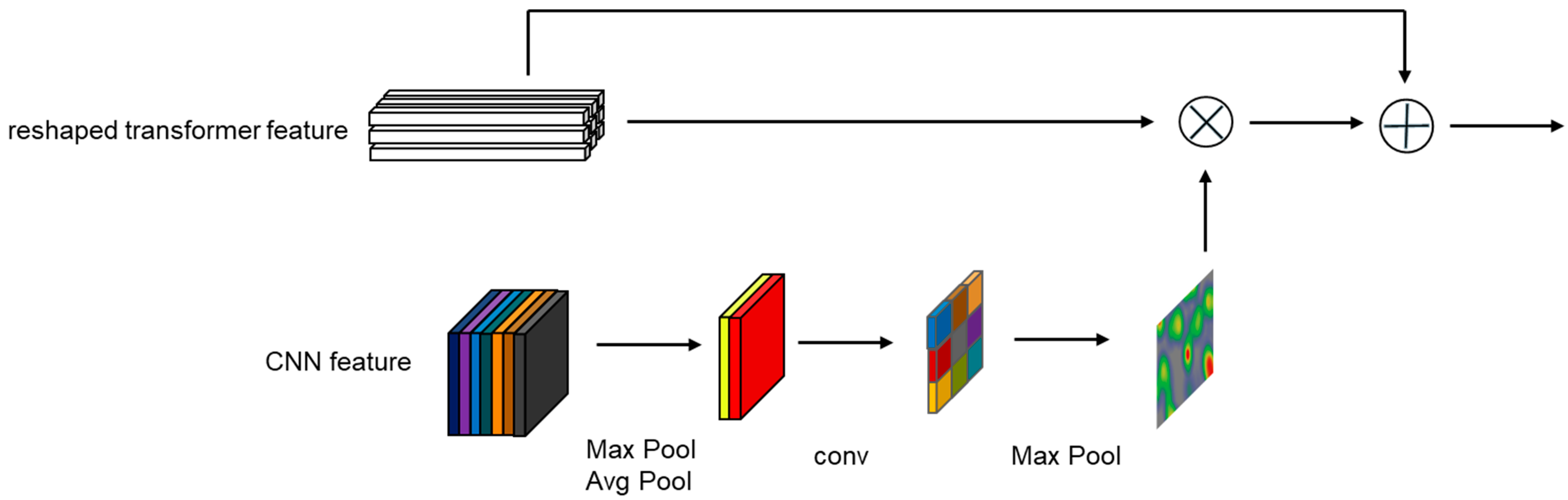
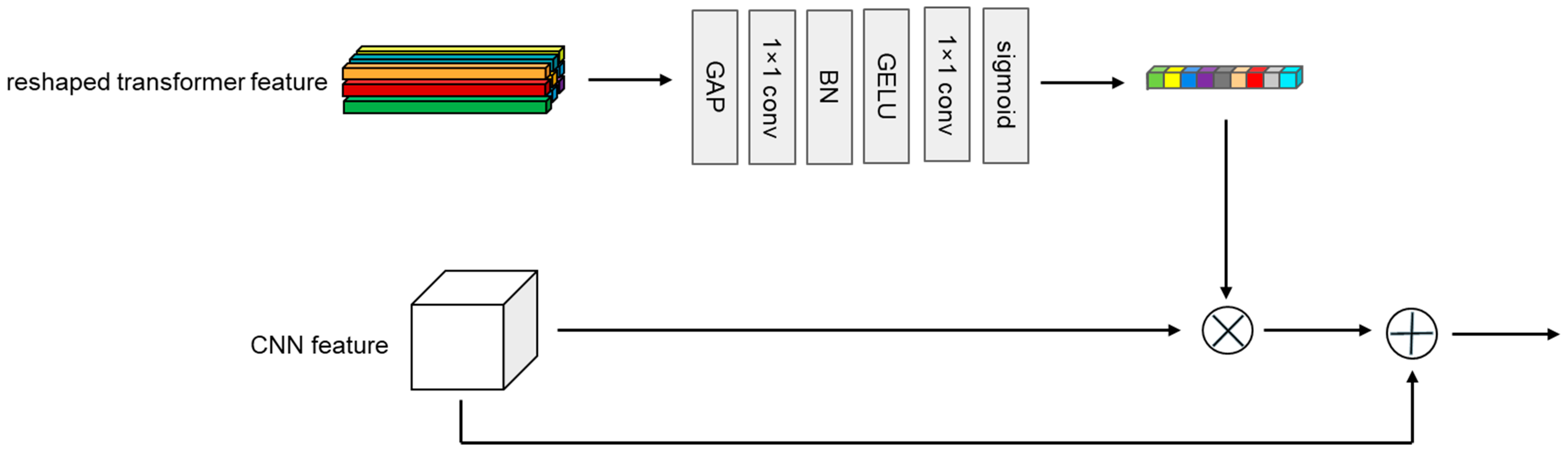
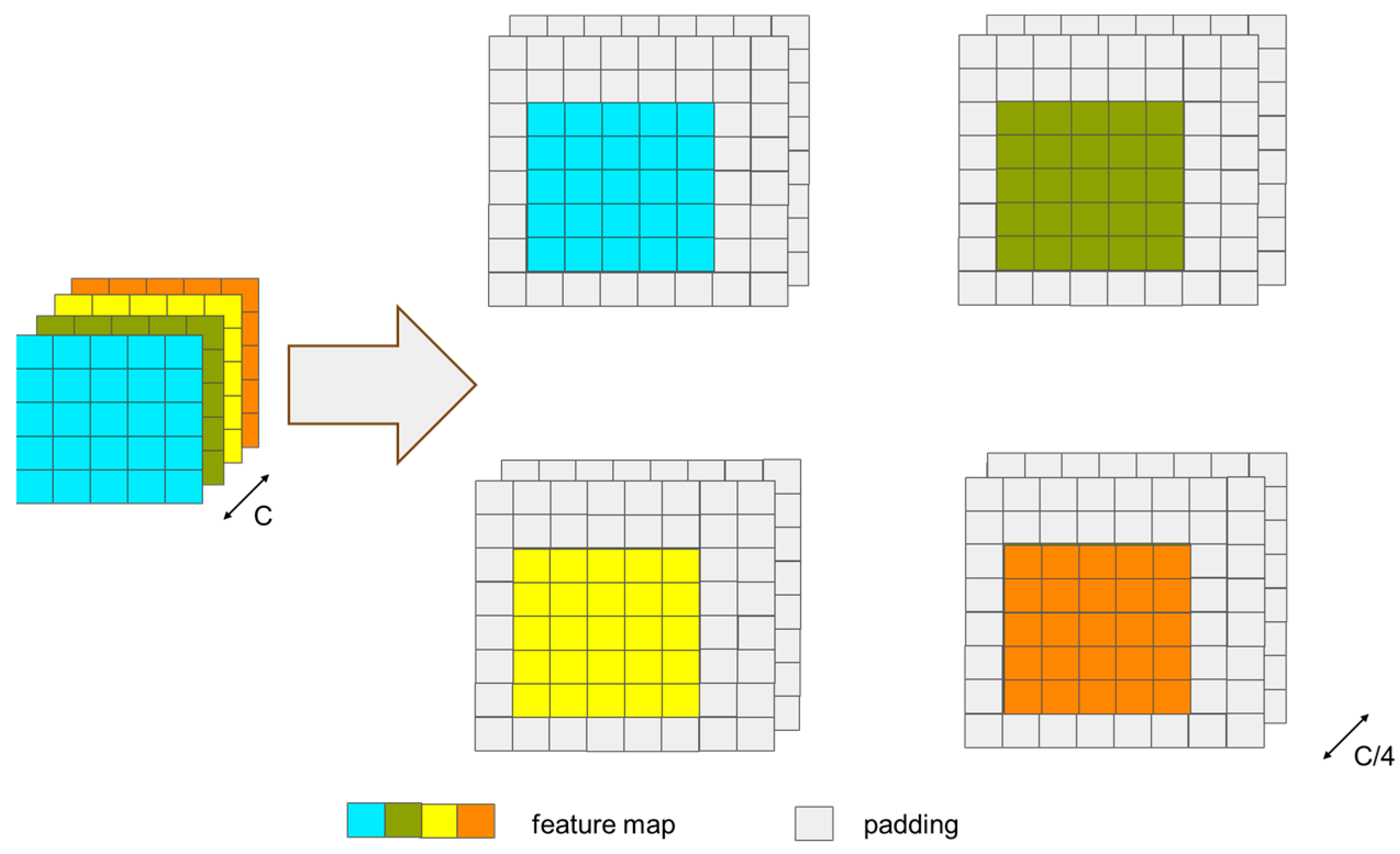
3.3.1. CNN→Transformer Channel
3.3.2. Transformer→CNN Channel
3.4. Feature Fusion
3.5. Prediction Module
3.5.1. Double-Head Predictor
3.5.2. Training Loss
4. Experiments
4.1. Training
4.2. Evaluation
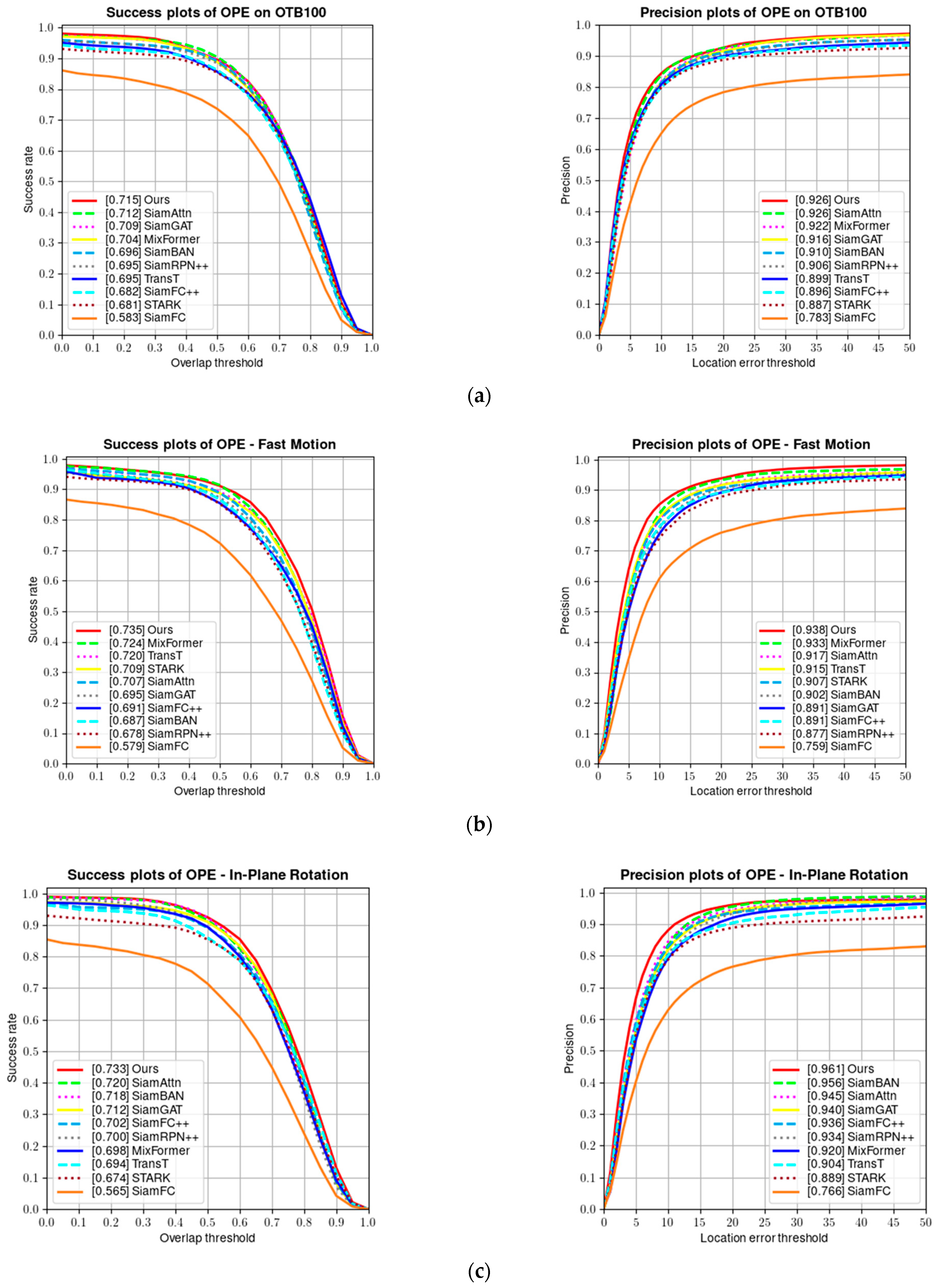
4.2.1. Results on OTB100 Benchmark
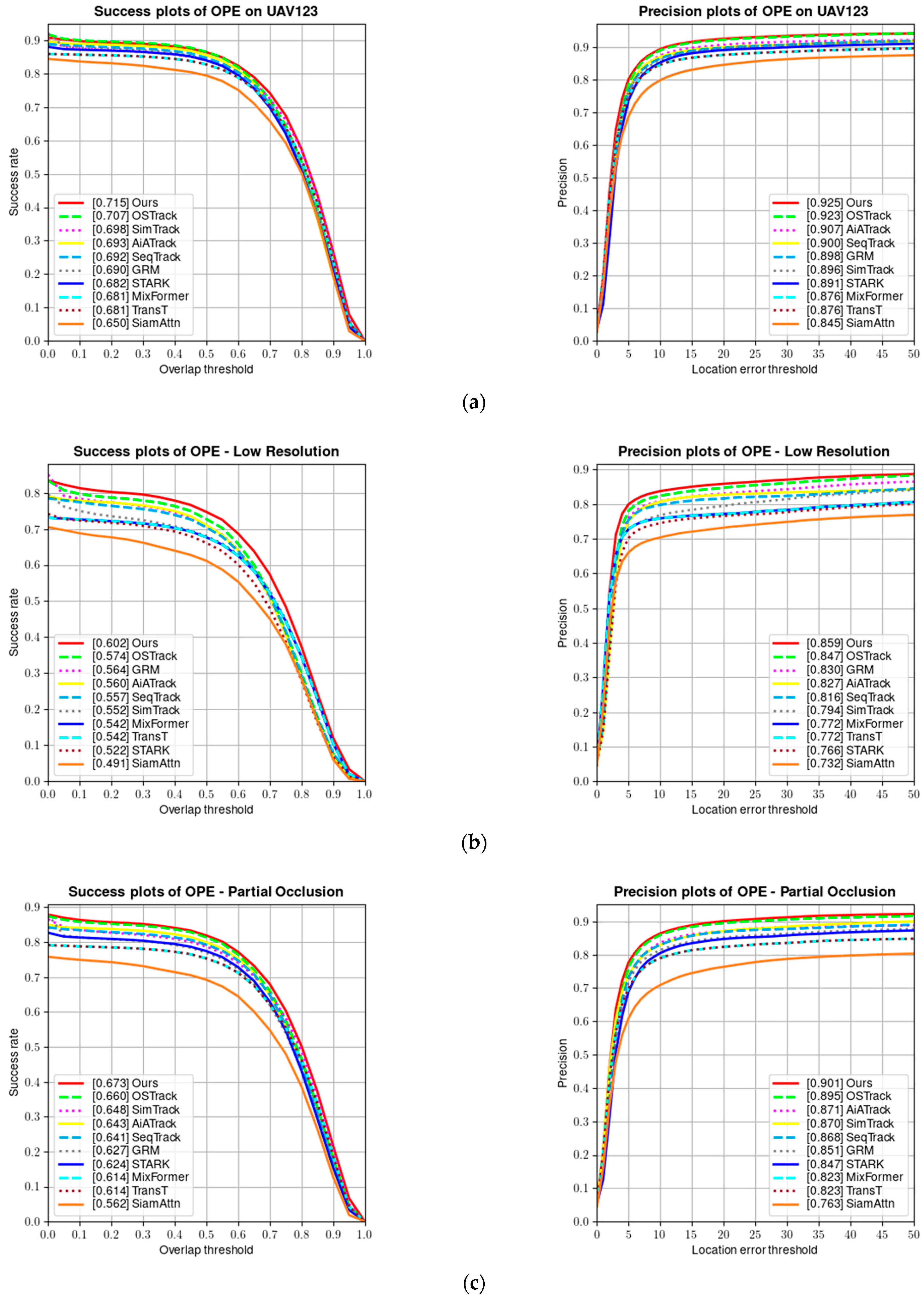
4.2.2. Results on UAV123 Benchmark
4.2.3. Results on LaSOT Benchmark
4.2.4. Results on TrackingNet Benchmark
4.3. Ablation Study
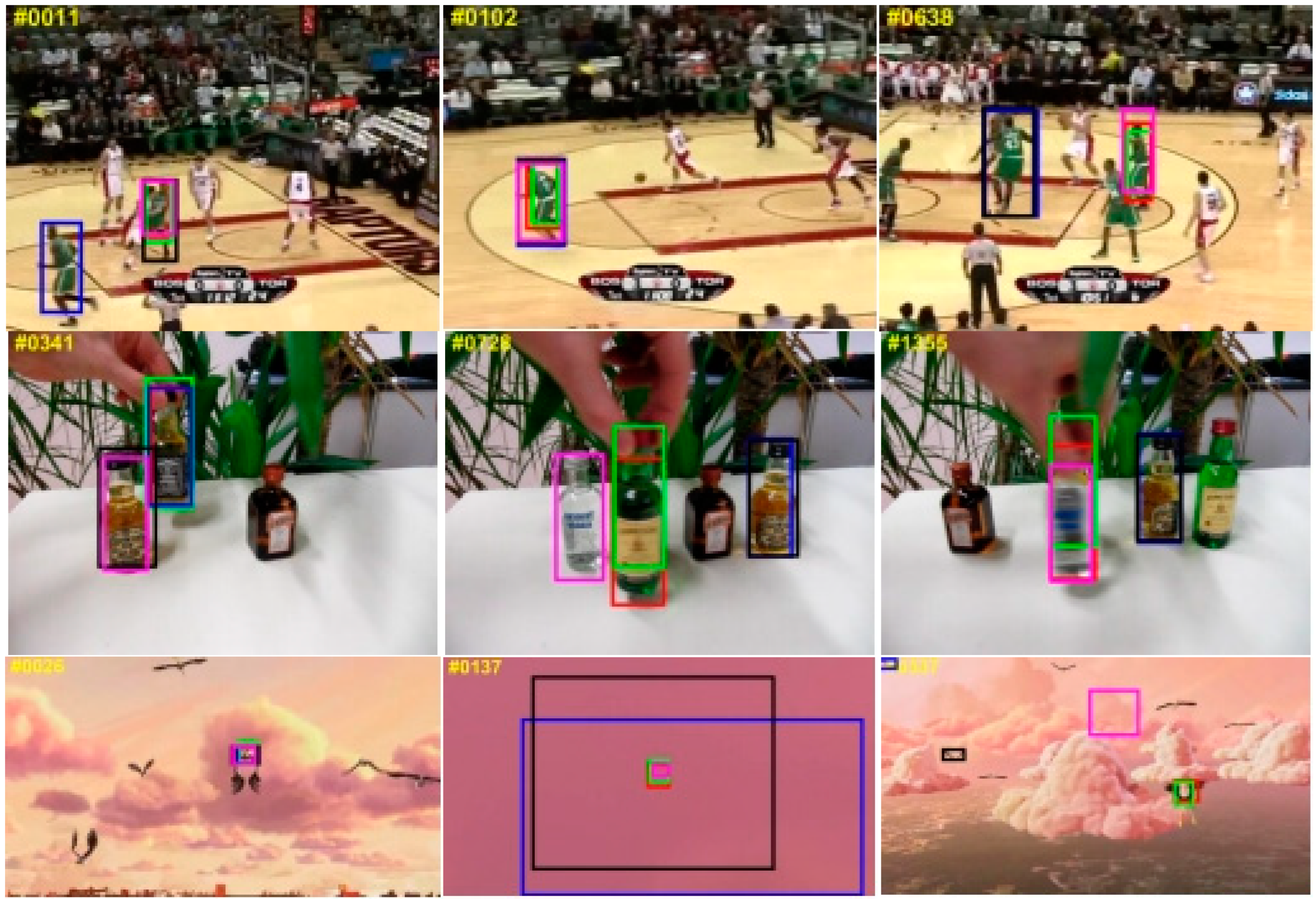
4.4. Qualitative Comparison
4.5. Failure Cases
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual Object Tracking Using Adaptive Correlation Filters. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. Exploiting the circulant structure of tracking-by-detection with kernels. Lect. Notes Comput. Sci. 2012, 7575, 702–715. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 583–596. [Google Scholar] [CrossRef] [PubMed]
- Kiani Galoogahi, H.; Fagg, A.; Lucey, S. Learning Background-aware Correlation Filters for Visual Tracking. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 19–22 October 2017; pp. 1135–1143. [Google Scholar]
- Mueller, M.; Smith, N.; Ghanem, B. Context-Aware Correlation Filter Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1387–1395. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. In Proceedings of the Computer Vision–ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–10 and 15–16 October 2016; pp. 850–865. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.H. Online object tracking: A benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2411–2418. [Google Scholar]
- Mueller, M.; Smith, N.; Ghanem, B. A benchmark and simulator for uav tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 445–461. [Google Scholar]
- Fan, H.; Lin, L.; Yang, F.; Chu, P.; Deng, G.; Yu, S.; Bai, H.; Xu, Y.; Liao, C.; Ling, H. Lasot: A high-quality benchmark for large-scale single object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5374–5383. [Google Scholar]
- Muller, M.; Bibi, A.; Giancola, S.; Alsubaihi, S.; Ghanem, B. Trackingnet: A large-scale dataset and benchmark for object tracking in the wild. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 300–317. [Google Scholar]
- Tao, R.; Gavves, E.; Smeulders, A.W.M. Siamese instance search for tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1420–1429. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High Performance Visual Tracking with Siamese Region Proposal Network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8971–8980. [Google Scholar]
- Zhang, Z.; Peng, H. Deeper and wider siamese networks for realtime visual tracking. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4591–4600. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. Siamrpn++: Evolution of siamese visual tracking with very deep networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4282–4291. [Google Scholar]
- Wang, Q.; Zhang, L.; Bertinetto, L.; Hu, W.; Torr, P.H. Fast Online Object Tracking and Segmentation: A Unifying Approach. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1328–1338. [Google Scholar]
- Chen, Z.; Zhong, B.; Li, G.; Zhang, S.; Ji, R. Siamese Box Adaptive Network for Visual Tracking. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 6667–6676. [Google Scholar]
- Zhang, Z.; Peng, H.; Fu, J.; Li, B.; Hu, W. Ocean: Object-aware anchor-free tracking. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 771–787. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Tian, Q. Centernet: Object detection with keypoint triplets. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Guo, D.; Wang, J.; Cui, Y.; Wang, Z.; Chen, S. SiamCAR: Siamese Fully Convolutional Classification and Regression for Visual Tracking. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 6268–6276. [Google Scholar]
- Xu, Y.; Wang, Z.; Li, Z.; Yuan, Y.; Yu, G. SiamFC++: Towards Robust and Accurate Visual Tracking with Target Estimation Guidelines. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12549–12556. [Google Scholar]
- Liao, B.; Wang, C.; Wang, Y.; Wang, Y.; Yin, J. Pg-net: Pixel to global matching network for visual tracking. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 429–444. [Google Scholar]
- Guo, D.; Shao, Y.; Cui, Y.; Wang, Z.; Zhang, L.; Shen, C. Graph attention tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9543–9552. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the NAACL-HLT, Minneapolis, MN, USA, 6–7 June 2019. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Wang, H.; Zhu, Y.; Adam, H.; Yuille, A.; Chen, L.-C. MaX-DeepLab: End-to-end panoptic segmentation with mask transformers. In Proceedings of the CVPR, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Chen, X.; Yan, B.; Zhu, J.; Wang, D.; Yang, X.; Lu, H. Transformer Tracking. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8122–8131. [Google Scholar]
- Zhao, M.; Okada, K.; Inaba, M. TrTr: Visual tracking with transformer. arXiv 2021, arXiv:2105.03817. [Google Scholar]
- Yan, B.; Peng, H.; Fu, J.; Wang, D.; Lu, H. Learning Spatio-Temporal Transformer for Visual Tracking. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 10428–10437. [Google Scholar]
- Xie, F.; Wang, C.; Wang, G.; Yang, W.; Zeng, W. Learning tracking representations via dual-branch fully transformer networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), 11–17 October 2021; pp. 2688–2697. [Google Scholar]
- Lin, L.; Fan, H.; Zhang, Z.; Xu, Y.; Ling, H. SwinTrack: A simple and strong baseline for transformer tracking. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; Curran Associates: Red Hook, NY, USA, 2022; Volume 35, pp. 16743–16754. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 9992–10002. [Google Scholar]
- Cui, Y.; Jiang, C.; Wang, L.; Wu, G. MixFormer: End-to-end tracking with iterative mixed attention. In Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 13598–13608. [Google Scholar]
- Chen, B.; Li, P.; Bai, L.; Qiao, L.; Shen, Q.; Li, B.; Gan, W.; Wu, W.; Ouyang, W. Backbone is all your need: A simplified architecture for visual object tracking. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 375–392. [Google Scholar]
- Ye, B.; Chang, H.; Ma, B.; Shan, S.; Chen, X. Joint feature learning and relation modeling for tracking: A one-stream framework. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 341–357. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 15979–15988. [Google Scholar]
- Peng, Z.; Huang, W.; Gu, S.; Xie, L.; Wang, Y.; Jiao, J.; Ye, Q. Conformer: Local features coupling global representations for visual recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 357–366. [Google Scholar]
- Chen, Y.; Dai, X.; Chen, D.; Liu, M.; Dong, X.; Yuan, L.; Liu, Z. Mobile-former: Bridging MobileNet and transformer. In Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 1–9. [Google Scholar]
- Chen, Q.; Wu, Q.; Wang, J.; Hu, Q.; Hu, T.; Ding, E.; Cheng, J.; Wang, J. MixFormer: Mixing features across windows and dimensions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5249–5259. [Google Scholar]
- Hong, Z.; Chen, Z.; Wang, C.; Mei, X.; Prokhorov, D.; Tao, D. MUlti-store Tracker (MUSTer): A cognitive psychology inspired approach to object tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 749–758. [Google Scholar]
- Zhao, L.; Zhao, Q.; Chen, Y.; Lv, P. Combined discriminative global and generative local models for visual tracking. J. Electron. Imaging 2016, 25, 023005. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Yuan, D.; Shu, X.; Liu, Q.; Zhang, X.; He, Z. Robust thermal infrared tracking via an adaptively multi-feature fusion model. Neural Comput. Appl. 2023, 35, 3423–3434. [Google Scholar] [CrossRef] [PubMed]
- Tao, H.; Duan, Q.; Lu, M.; Hu, Z. Learning Discriminative Feature Representation with Pixel-level Supervision for Forest Smoke Recognition. Pattern Recognit. 2023, 143, 109761. [Google Scholar] [CrossRef]
- Niu, A.; Zhu, Y.; Zhang, C.; Sun, J.; Wang, P.; Kweon, I.S.; Zhang, Y. Ms2net: Multi-scale and multi-stage feature fusion for blurred image super-resolution. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 5137–5150. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wang, N.; Zhou, W.; Wang, J.; Li, H. Transformer Meets Tracker: Exploiting Temporal Context for Robust Visual Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Kuala Lumpur, Malaysia, 19–25 June 2021. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Bender, G.; Kindermans, P.-J.; Zoph, B.; Vasudevan, V.; Le, Q. Understanding and simplifying one-shot architecture search. In Proceedings of the International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 10–15 June 2019; pp. 6105–6114. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Lan, J.-P.; Cheng, Z.-Q.; He, J.-Y.; Li, C.; Luo, B.; Bao, X.; Xiang, W.; Geng, Y.; Xie, X. Procontext: Exploring progressive context transformer for tracking. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Wu, S.; Wang, G.; Tang, P.; Chen, F.; Shi, L. Convolution with even-sized kernels and symmetric padding. Adv. Neural Inf. Process. Syst. 2019, 32, 1192–1203. [Google Scholar]
- Wu, Y.; Chen, Y.; Yuan, L.; Liu, Z.; Wang, L.; Li, H.; Fu, Y. Rethinking classification and localization for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10186–10195. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.Y.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Piscataway, NJ, USA, 16–20 June 2019; pp. 658–666. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Communications of the ACM; Association for Computing Machinery: New York, NY, USA, 2017; Volume 60, pp. 84–90. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019; pp. 1–9. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; Volume 8693, pp. 740–755. [Google Scholar]
- Huang, L.; Zhao, X.; Huang, K. Got-10k: A large high-diversity benchmark for generic object tracking in the wild. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1562–1577. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CNN Branch | Information Exchange Channel | Transformer Branch | ||||
|---|---|---|---|---|---|---|
| stage | Output size | structure | structure | Output size | ||
| c1 | S: 128 × 128 T: 64 × 64 | 7 × 7, 64 Stride = 2 | Patch Embedding | S: 256 × 768 T: 64 × 768 | ×1 | |
| S: 64 × 64 T: 32 × 32 | 3 × 3 max pooling, Stride = 2 | |||||
| c2 | S: 64 × 64 T: 32 × 32 | 1 × 1, 64 3 × 3, 256, C = 32 1 × 1, 64 | CNN→Trans | MHSA-12, 768 1 × 1, 3072 (MLP hidden size) 1 × 1, 768 | S: 256 × 768 T: 64 × 768 | ×3 |
| CNN←Trans | ||||||
| c3 | S: 32 × 32 T: 16 × 16 | 1 × 1, 128 3 × 3, 512, C = 32 1 × 1, 128 | CNN→Trans | MHSA-12, 768 1 × 1, 3072 (MLP hidden size) 1 × 1, 768 | S: 256 × 768 T: 64 × 768 | ×4 |
| CNN←Trans | ||||||
| c4 | S: 32 × 32 T: 16 × 16 | 1 × 1, 256 3 × 3, 1024, C = 32 1 × 1, 256 | CNN→Trans | MHSA-12, 768 1 × 1, 3072 (MLP hidden size) 1 × 1, 768 | S: 256 × 768 T: 64 × 768 | ×5 |
| CNN→Trans | ||||||
| S: 32 × 32 T: 16 × 16 | 1 × 1, 256 3 × 3, 1024, C = 32 1 × 1, 256 | ×1 | ||||
| 32 × 32 | depth-wise cross-correlated | Rearrange | S: 16 × 16 T: 8 × 8 | ×1 | ||
| fusion | 16 × 16 | 2 × 2 max pooling, Stride = 2 | Feature fusion | Extract search region | 16 × 16 | ×1 |
| Methods | Source | Backbone | AUC | Prec |
|---|---|---|---|---|
| SiamFC | ECCVW2016 | CNN | 58.3 | 78.3 |
| SiamRPN++ | CVPR2019 | CNN | 69.6 | 91.5 |
| SiamBAN | CVPR2020 | CNN | 69.6 | 91.0 |
| SiamR-CNN | CVPR2020 | CNN | 70.1 | 89.1 |
| SiamAttn | CVPR2020 | CNN | 71.2 | 92.6 |
| SiamGAT | CVPR2021 | CNN | 71.0 | 91.6 |
| TransT | CVPR2021 | CNN | 69.5 | 89.9 |
| STARK | ICCV2021 | CNN | 68.0 | 88.4 |
| SimTrack-B/16 | ECCV2022 | Transformer | 66.1 | 85.7 |
| Mixformer-L | CVPR2022 | Transformer | 70.4 | 92.2 |
| Ostrack-384 | ECCV2022 | Transformer | 68.1 | 88.7 |
| DropTrack | CVPR2023 | Transformer | 69.6 | 90.0 |
| CVTrack | Ours | CNN + Transformer | 71.5 | 92.6 |
| Methods | Template Size | Search Size | AUC | Prec |
|---|---|---|---|---|
| SiamFC | 127 × 127 | 255 × 255 | 48.5 | 69.3 |
| SiamRPN++ | 127 × 127 | 255 × 255 | 64.2 | 84.0 |
| SiamFC++_GoogLeNet | 127 × 127 | 303 × 303 | 62.3 | 81.0 |
| SiamBAN | 127 × 127 | 255 × 255 | 63.1 | 83.3 |
| SiamAttn | 127 × 127 | 255 × 255 | 65.0 | 84.5 |
| TransT | 128 × 128 | 256 × 256 | 68.1 | 87.6 |
| STARK | 128 × 128 | 320 × 320 | 68.5 | 89.5 |
| SimTrack-B/16 | 112 × 112 | 224 × 224 | 69.8 | 89.6 |
| SimTrack-B/14 | 112 × 112 | 224 × 224 | 71.2 | 91.6 |
| Mixformer | 128 × 128 | 320 × 320 | 68.7 | 89.5 |
| Mixformer-L | 128 × 128 | 320 × 320 | 69.5 | 91.0 |
| Ostrack-256 | 128 × 128 | 256 × 256 | 68.3 | 88.8 |
| Ostrack-384 | 192 × 192 | 384 × 384 | 70.7 | 92.3 |
| DropTrack | 192 × 192 | 384 × 384 | 70.9 | 92.4 |
| Ours | 128 × 128 | 256 × 256 | 71.4 | 92.5 |
| Methods | LaSOT | TrackingNet | ||||
|---|---|---|---|---|---|---|
| AUC | Norm.Prec | Prec | AUC | Norm.Prec | Prec | |
| SiamRPN++ | 49.6 | 56.9 | 49.1 | 73.3 | 80.0 | 60.4 |
| SiamBAN | 51.4 | 59.8 | 52.1 | — | — | — |
| SiamAttn | 56.0 | 64.8 | — | 75.2 | 81.7 | — |
| TransT | 64.9 | 73.8 | 69.0 | 81.4 | 86.7 | 80.3 |
| STARK | 67.1 | 76.9 | 72.2 | 82.0 | 86.9 | 79.1 |
| SimTrack | 69.3 | 78.5 | 74.0 | 82.3 | 86.5 | 80.2 |
| Mixformer | 70.0 | 79.9 | 76.3 | 83.9 | 88.9 | 83.1 |
| Ostrack | 71.1 | 81.1 | 77.6 | 83.9 | 88.5 | 83.2 |
| Ours | 70.7 | 80.1 | 76.1 | 83.4 | 88.0 | 83.4 |
| Methods | AUC-O | Prec-O | AUC-U | Prec-U | AUC-L | N.Prec-L | FPS |
|---|---|---|---|---|---|---|---|
| CVTrack | 71.5 | 92.6 | 71.5 | 91.9 | 70.7 | 80.1 | 43 |
| CVTrack-v1 | 69.1 | 90.9 | 63.4 | 84.9 | 63.7 | 72.5 | 71 |
| CVTrack-v2 | 68.3 | 89.8 | 68.6 | 90.0 | 69.0 | 78.4 | 58 |
| CVTrack-v3 | 70.3 | 91.6 | 70.2 | 91.1 | 70.1 | 79.0 | 47 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Song, Y.; Song, C.; Tian, H.; Zhang, S.; Sun, J. CVTrack: Combined Convolutional Neural Network and Vision Transformer Fusion Model for Visual Tracking. Sensors 2024, 24, 274. https://doi.org/10.3390/s24010274
Wang J, Song Y, Song C, Tian H, Zhang S, Sun J. CVTrack: Combined Convolutional Neural Network and Vision Transformer Fusion Model for Visual Tracking. Sensors. 2024; 24(1):274. https://doi.org/10.3390/s24010274
Chicago/Turabian StyleWang, Jian, Yueming Song, Ce Song, Haonan Tian, Shuai Zhang, and Jinghui Sun. 2024. "CVTrack: Combined Convolutional Neural Network and Vision Transformer Fusion Model for Visual Tracking" Sensors 24, no. 1: 274. https://doi.org/10.3390/s24010274