
Multi-Sensor Fusion Simultaneous Localization Mapping Based on Deep Reinforcement Learning and Multi-Model Adaptive Estimation

Abstract
:1. Introduction
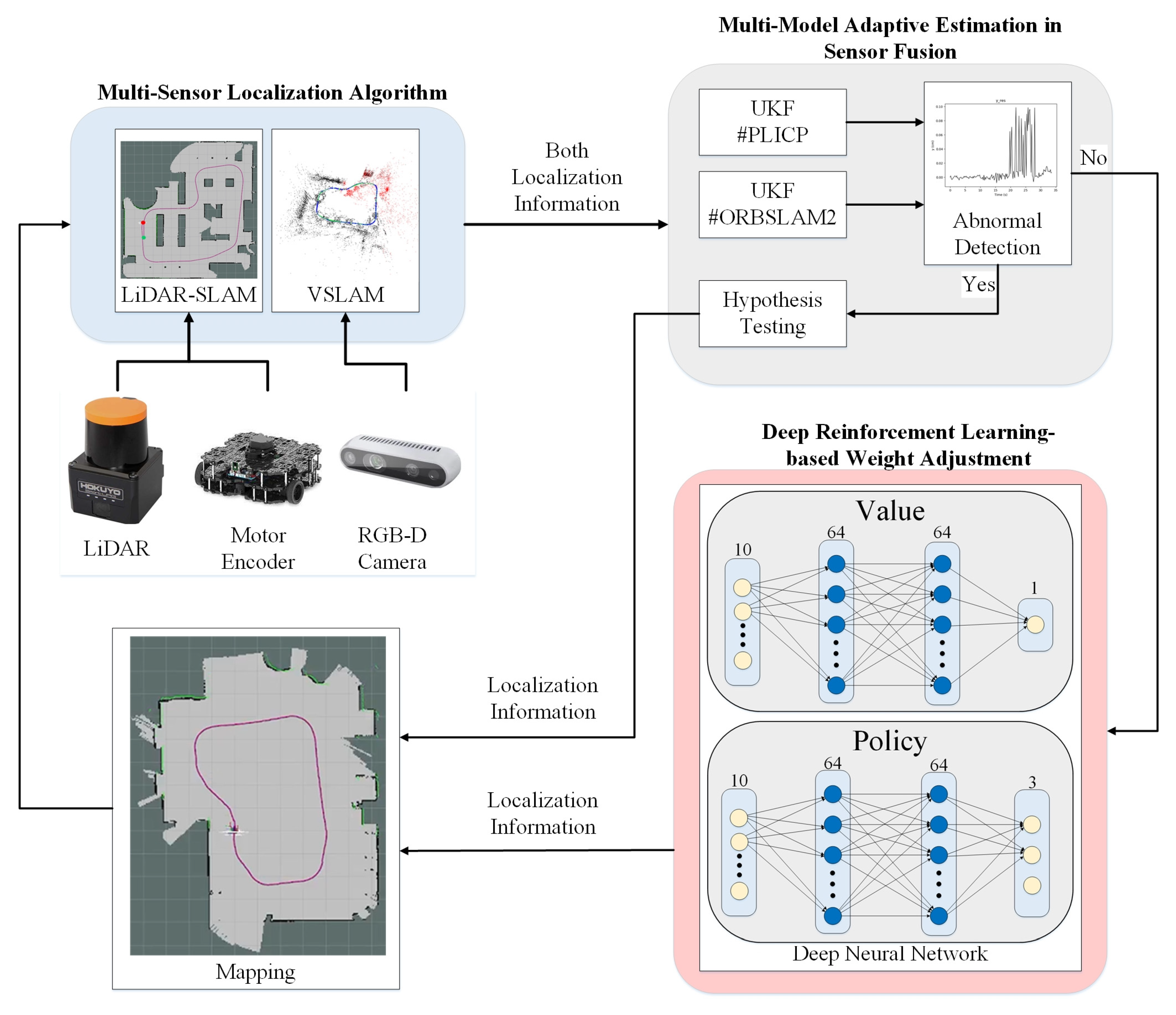
2. Multi-Sensor Fusion-Based System Structure
2.1. Multi-Sensor Localization Algorithms
2.2. Multi-Model Adaptive Estimation in Sensor Fusion
2.2.1. Unscented Kamman Filter (UKF)
- is the skewness of the last moment of state noise.
- is the skewness of the last moment of observed noise.
- is the state mean value;
- is the weight of the mean of the ith Sigma point;
- is the weight of the covariance of the ith Sigma point;
- is the set of predicted Sigma states.
- is the covariance of the state values from time k − 1 to time k;
- is the covariance of the state values from time k − 1 to time k over the observations;
- is the KF gain coefficient;
- is the residual value of the model.
2.2.2. Hypothesis Testing
2.2.3. Multi-Model Adaptive Estimates
2.3. Deep Reinforcement Learning-Based Weight Adjustment
2.3.1. The Amount of Variation Localized in the Interval
- is the change of ORBSLAM2 at time t;
- is the actual change of mobile robot at time t;
- is the change of PLICP at time t.
2.3.2. Outside the Interval of Variation
3. Experiment Result in Mobile Robot Localization
3.1. Simulation Scenes
3.2. Simulation Test
4. Conclusions
- (1)
- The localization algorithm proposed in this paper includes the concept of fault detection by setting a threshold value through the discrepancy of the residual values and also referring to the speed of the current mobile robot. It can detect the possible failure conditions of different sensors in real time and then calculate the confidence value of the current prediction of the two localization algorithms through hypothesis checking after detecting the failure. At the same time, it intervenes to adjust the weight of the current changes in the positioning of the sensor. Experimental results show that its proposed method can effectively detect anomalous values and immediately rule out anomalous localization. Thus, the robustness of the sensory fusion localization method for multi-model adaptive estimation is improved.
- (2)
- In this paper, deep reinforcement learning is used to complete the weight adjustment, and the input two-sensor localization algorithm is trained with the predicted variations and residual values. The trained system accepts inputs related to the localization algorithm and predicts the weights to be adjusted for different environmental information. The results show that a more robust weight adjustment mechanism can be established and achieve superior positioning accuracy in different environments.
- (3)
- Since this PLICP method can easily lead to the problem of minimal area under the environment of high-point cloud continuous smoothness, this paper used odometry information to improve the design of PLICP in calculating the displacement change and rotation change as the initial values of the first conversion relationship. This can effectively solve the problem of the minimal area by reducing the number of iterations and computing power. This method can also increase the information in the odometry, which can enhance the correlation between the sensor fusion.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gerkey, B. Gmapping. 2013. Available online: http://wiki.ros.org (accessed on 6 September 2019).
- Kohlbrecher, S.; Meyer, J.; Graber, T.; Petersen, K.; Klingauf, U.; Stryk, O. Hector Open Source Modules for Autonomous Mapping and Navigation with Rescue Robots. In Proceedings of the Robot Soccer World Cup 2013, Eindhoven, The Netherlands, 24–30 June 2013; pp. 24–30. [Google Scholar]
- Artal, R.M.; Montiel, J.M.M.; Tardós, J.D. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-Scale Direct Monocular SLAM. In Proceedings of the European Conference on Computer Vision 2014, Zurich, Switzerland, 6–12 September 2014; pp. 834–849. [Google Scholar]
- Lemus, R.; Díaz, S.; Gutiérrez, C.; Rodríguez, D.; Escobar, F. SLAM-R Algorithm of Simultaneous Localization and Mapping Using RFID for Obstacle Location and Recognition. J. Appl. Res. Technol. 2014, 12, 551–559. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.; Tardós, J.D. ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual-Inertial, and Multimap SLAM. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Wei, W.; Shirinzadeh, B.; Nowell, R.; Ghafarian, M.; Ammar, M.M.A.; Shen, T. Enhancing Solid State LiDAR Mapping with a 2D Spinning LiDAR in Urban Scenario SLAM on Ground Vehicles. Sensors 2021, 21, 1773. [Google Scholar] [CrossRef] [PubMed]
- Debeunne, C.; Damien, V. A Review of Visual-LiDAR Fusion based Simultaneous Localization and Mapping. Sensors 2020, 20, 2068. [Google Scholar] [CrossRef]
- Chan, S.H.; Wu, P.T.; Fu, L.C. Robust 2D Indoor Localization through Laser SLAM and Visual SLAM Fusion. In Proceedings of the 2018 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Miyazaki, Japan, 7–10 October 2018; pp. 1263–1268. [Google Scholar] [CrossRef]
- Liu, Z.; Li, Z.; Liu, A.; Sun, Y.; Jing, S. Fusion of Binocular Vision, 2D LiDAR and IMU for Outdoor Localization and Indoor Planar Mapping. Meas. Sci. Technol. 2022, 34, 025203. [Google Scholar] [CrossRef]
- Zhao, F.; Chen, C.; He, W.; Ge, S.S. A filtering approach based on MMAE for a SINS/CNS integrated navigation system. IEEE/CAA J. Autom. Sin. 2018, 5, 1113–1120. [Google Scholar] [CrossRef]
- Yan, Q.Z.; Sun, M.X. Suboptimal learning control for nonlinear systems with both parametric and nonparametric uncertainties. Acta Autom. Sin. 2015, 41, 1659–1668. [Google Scholar] [CrossRef]
- He, W.; Zhang, S.; Ge, S.S. Adaptive boundary control of a nonlinear flexible string system. IEEE Trans. Control Syst. Technol. 2014, 22, 1088–1093. [Google Scholar] [CrossRef]
- Huang, M.; Wang, X.; Wang, Z.L. Multiple model adaptive control for a class of nonlinear multi-variable systems with zero-order proximity boundedness. Acta Autom. Sin. 2014, 40, 2057–2065. [Google Scholar]
- Fang, J.C.; Ning, X.L. Autonomous Celestial Navigation Method for Deep Space Detector; Northwestern Polytechnical University Press: Xi’an, China, 2010. [Google Scholar]
- Magill, D. Optimal adaptive estimation of sampled stochastic processes. IEEE Trans. Autom. Control 1965, 10, 434–439. [Google Scholar] [CrossRef]
- Ducard, G. Fault-Tolerant Flight Control and Guidance Systems: Practical Methods for Small Unmanned Aerial Vehicles; National Defense Industry Press: Arlington, Virginia; Springer: London, UK, 2009. [Google Scholar] [CrossRef]
- Teng, B.; Jia, Q.; Song, J.; Yang, T.; Wu, W. Fault diagnosis of aircraft servo mechanism based on multi-model UKF. In Proceedings of the 2021 IEEE 5th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 12–14 March 2021; pp. 1766–1770. [Google Scholar] [CrossRef]
- Nam, D.V.; Gon-Woo, K. Learning Type-2 Fuzzy Logic for Factor Graph Based-Robust Pose Estimation with Multi-Sensor Fusion. IEEE Trans. Intell. Transp. Syst. 2023, 24, 3809–3821. [Google Scholar] [CrossRef]
- Wang, M.; Tayebi, A. Observers design for inertial navigation systems: A brief tutorial. In Proceedings of the 2020 59th IEEE Conference on Decision and Control (CDC), Jeju, Republic of Korea, 14–18 December 2020; pp. 1320–1327. [Google Scholar] [CrossRef]
- Lynen, S.; Achtelik, M.W.; Weiss, S.; Chli, M.; Siegwart, R. A robust and modular multi-sensor fusion approach applied to MAV navigation. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 3923–3929. [Google Scholar] [CrossRef]
- Shen, S.; Mulgaonkar, Y.; Michael, N.; Kumar, V. Multi-sensor fusion for robust autonomous flight in indoor and outdoor environments with a rotorcraft MAV. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 4974–4981. [Google Scholar] [CrossRef]
- Totani, M.; Sato, N.; Morita, Y. Step climbing method for crawler type rescue robot using reinforcement learning with Proximal Policy Optimization. In Proceedings of the 2019 12th International Workshop on Robot Motion and Control (RoMoCo), Poznan, Poland, 8–10 July 2019; pp. 154–159. [Google Scholar] [CrossRef]
- Zhang, X.; Jiang, X.; Li, N.; Yang, Z.; Xiong, Z.; Zhang, J. Eco-driving for Intelligent Electric Vehicles at Signalized Intersection: A Proximal Policy Optimization Approach. In Proceedings of the 6th International Conference on Information Science, Computer Technology and Transportation (ISCTT 2021), Xishuangbanna, China, 26–28 November 2021; pp. 1–7. [Google Scholar]
- Alhadhrami, E.; Seghrouchni, A.E.F.; Barbaresco, F.; Zitar, R.A. Drones Tracking Adaptation Using Reinforcement Learning: Proximal Policy optimization. In Proceedings of the 2023 24th International Radar Symposium (IRS), Berlin, Germany, 24–26 May 2023; pp. 1–10. [Google Scholar] [CrossRef]
- Xu, J.; Yan, X.; Peng, C.; Wu, X.; Gu, L.; Niu, Y. UAV Local Path Planning Based on Improved Proximal Policy Optimization Algorithm. In Proceedings of the ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Besl, P.J.; McKay, N.D. A Method for Registration of 3D Shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 239–256. [Google Scholar] [CrossRef]
- Mohammadzade, H.; Hatzinakos, D. Iterative Closest Normal Point for 3D Face Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 381–397. [Google Scholar] [CrossRef] [PubMed]
- Naus, K.; Marchel, Ł. Use of a Weighted ICP Algorithm to Precisely Determine USV Movement Parameters. Appl. Sci. 2019, 9, 3530. [Google Scholar] [CrossRef]
- Censi, A. An ICP Variant Using a Point-to-Line Metric. In Proceedings of the 2008 IEEE International Conference on Robotics and Automation, Pasadena, CA, USA, 19–23 May 2008; pp. 19–25. [Google Scholar] [CrossRef]
- Li, Y.; Huang, D.; Qi, J.; Chen, S.; Sun, H.; Liu, H.; Jia, H. Feature Point Registration Model of Farmland Surface and Its Application Based on a Monocular Camera. Sensors 2020, 20, 3799. [Google Scholar] [CrossRef] [PubMed]
- Mur-Artal, R.; Tardos, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Hanlon, P.D.; Maybeck, P.S. Multiple-Model Adaptive Estimation Using a Residual Correlation Kalman Filter Bank. IEEE Trans. Aerosp. Electron. Syst. 2000, 36, 393–406. [Google Scholar] [CrossRef]
- Julier, S.J.; Uhlmann, J.K. Unscented Filtering and Nonlinear Estimation. Proc. IEEE 2004, 92, 401–422. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar] [CrossRef]
- Aws-Robomaker-Bookstore-World. Available online: https://github.com/aws-robotics/aws-robomaker-bookstore-world.git (accessed on 6 March 2023).
- Aws-Robomaker-Small-Warehouse-World. Available online: https://github.com/aws-robotics/aws-robomaker-small-warehouse-world.git (accessed on 6 March 2023).
- Dong, L.; Zou, W.; Li, X.; Shu, W.; Wang, Z. Collaborative localization method using analytical and iterative solutions for microseismic/acoustic emission sources in the rockmass structure for underground mining. Eng. Fract. Mech. 2019, 210, 95–112. [Google Scholar] [CrossRef]
- Ko, D.; Choi, S.-H.; Ahn, S.; Choi, Y.-H. Robust Indoor Localization Methods Using Random Forest-Based Filter against MAC Spoofing Attack. Sensors 2020, 20, 6756. [Google Scholar] [CrossRef] [PubMed]

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Table of Error Types | ) | ||
|---|---|---|---|
| True | False | ||
| Decision about Null Hypothesis () | Accept | Correct Decision | Type II Error |
| Reject | Type I Error | Correct Decision | |
| Times | ORBSLAM2 [30] | PLICP [29] | Half Weight | Ours |
|---|---|---|---|---|
| 1 | 0.5319 | 0.2914 | 0.2013 | 0.1907 |
| 2 | 0.4274 | 0.0337 | 0.1061 | 0.0898 |
| 3 | 0.5503 | 0.3183 | 0.1495 | 0.1155 |
| 4 | 0.3403 | 0.0929 | 0.1215 | 0.1250 |
| 5 | 0.4524 | 0.0861 | 0.1282 | 0.0975 |
| 6 | 0.4037 | 0.1001 | 0.1697 | 0.1784 |
| 7 | 1.0574 | 0.2076 | 0.2355 | 0.1595 |
| 8 | 0.3671 | 0.1263 | 0.1310 | 0.1137 |
| 9 | 0.2511 | 0.2744 | 0.1343 | 0.1279 |
| 10 | 0.4908 | 0.0487 | 0.1738 | 0.1529 |
| Times | ORBSLAM2 [31] | PLICP [29] | Half Weight | Ours |
|---|---|---|---|---|
| 1 | 0.4723 | 0.4089 | 0.3818 | 0.3795 |
| 2 | 1.4706 | 0.3065 | 0.3075 | 0.2403 |
| 3 | 0.6790 | 0.4268 | 0.2963 | 0.2849 |
| 4 | 0.4001 | 0.5688 | 0.4135 | 0.3681 |
| 5 | 0.7822 | 0.4013 | 0.3086 | 0.4308 |
| 6 | 1.1127 | 0.9989 | 1.0556 | 0.9582 |
| 7 | 0.6071 | 0.2317 | 0.1992 | 0.1807 |
| 8 | 0.3400 | 0.3325 | 0.2515 | 0.2136 |
| 9 | 2.5652 | 0.2875 | 0.7886 | 0.7007 |
| 10 | 0.2584 | 0.0692 | 0.1267 | 0.1109 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wong, C.-C.; Feng, H.-M.; Kuo, K.-L. Multi-Sensor Fusion Simultaneous Localization Mapping Based on Deep Reinforcement Learning and Multi-Model Adaptive Estimation. Sensors 2024, 24, 48. https://doi.org/10.3390/s24010048
Wong C-C, Feng H-M, Kuo K-L. Multi-Sensor Fusion Simultaneous Localization Mapping Based on Deep Reinforcement Learning and Multi-Model Adaptive Estimation. Sensors. 2024; 24(1):48. https://doi.org/10.3390/s24010048
Chicago/Turabian StyleWong, Ching-Chang, Hsuan-Ming Feng, and Kun-Lung Kuo. 2024. "Multi-Sensor Fusion Simultaneous Localization Mapping Based on Deep Reinforcement Learning and Multi-Model Adaptive Estimation" Sensors 24, no. 1: 48. https://doi.org/10.3390/s24010048