
Knowledge Distillation for Traversable Region Detection of LiDAR Scan in Off-Road Environments


Abstract
:1. Introduction
- We propose soft label knowledge distillation (SLKD) for off-road range view images. To the best of the authors’ knowledge, SLKD is the first method that distills knowledge for semantic segmentation of 3D point cloud range image in off-road view;
- We conduct experiments on the RELLIS-3D benchmark and demonstrated that SLKD achieves a significant improvement in mIoU performance when using the same computational costs;
- We evaluated the distillation performance with several student encoders, demonstrating the robustness of SLKD.
2. Related Works
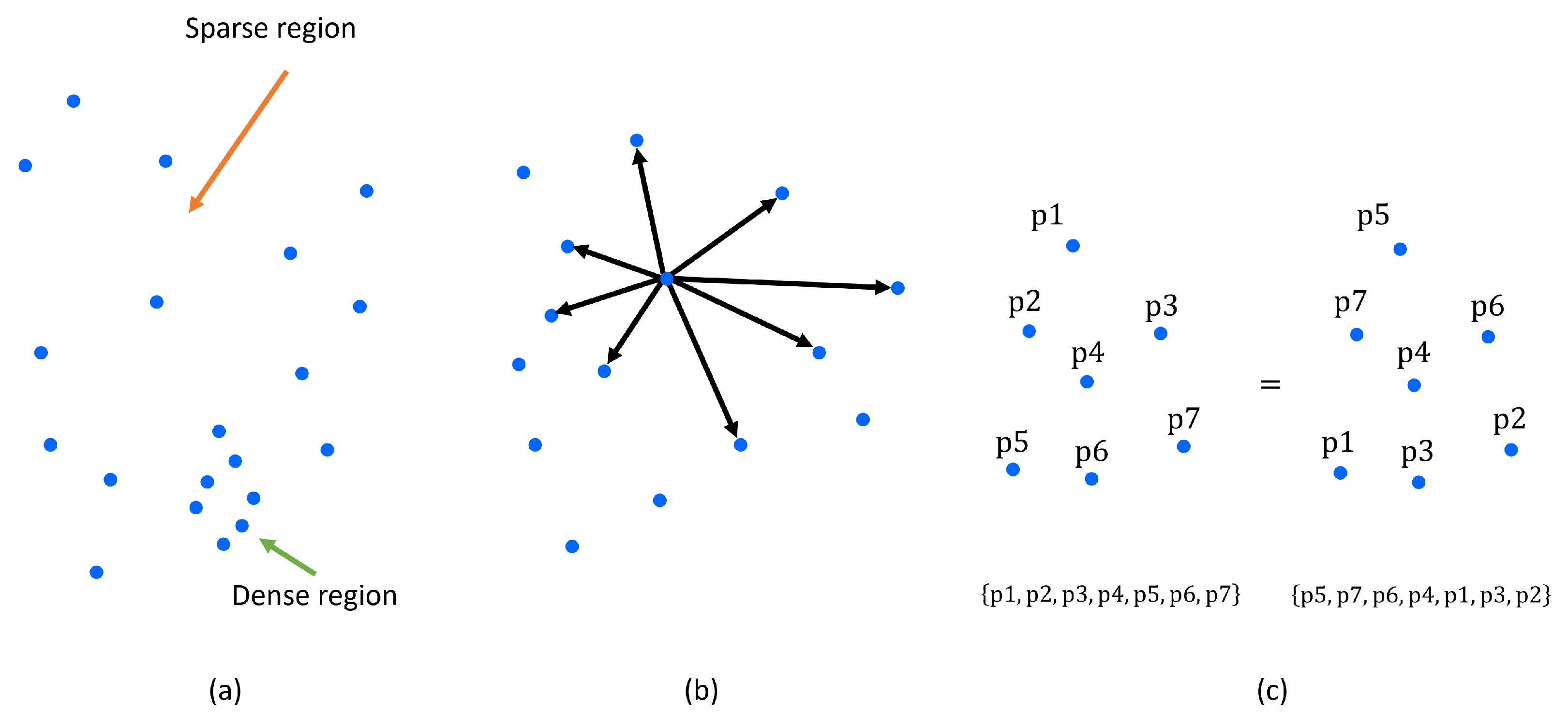
2.1. Point Cloud Processing
2.2. Traversable Region Detection
2.3. Knowledge Distillation
3. Method
3.1. RELLIS-3D
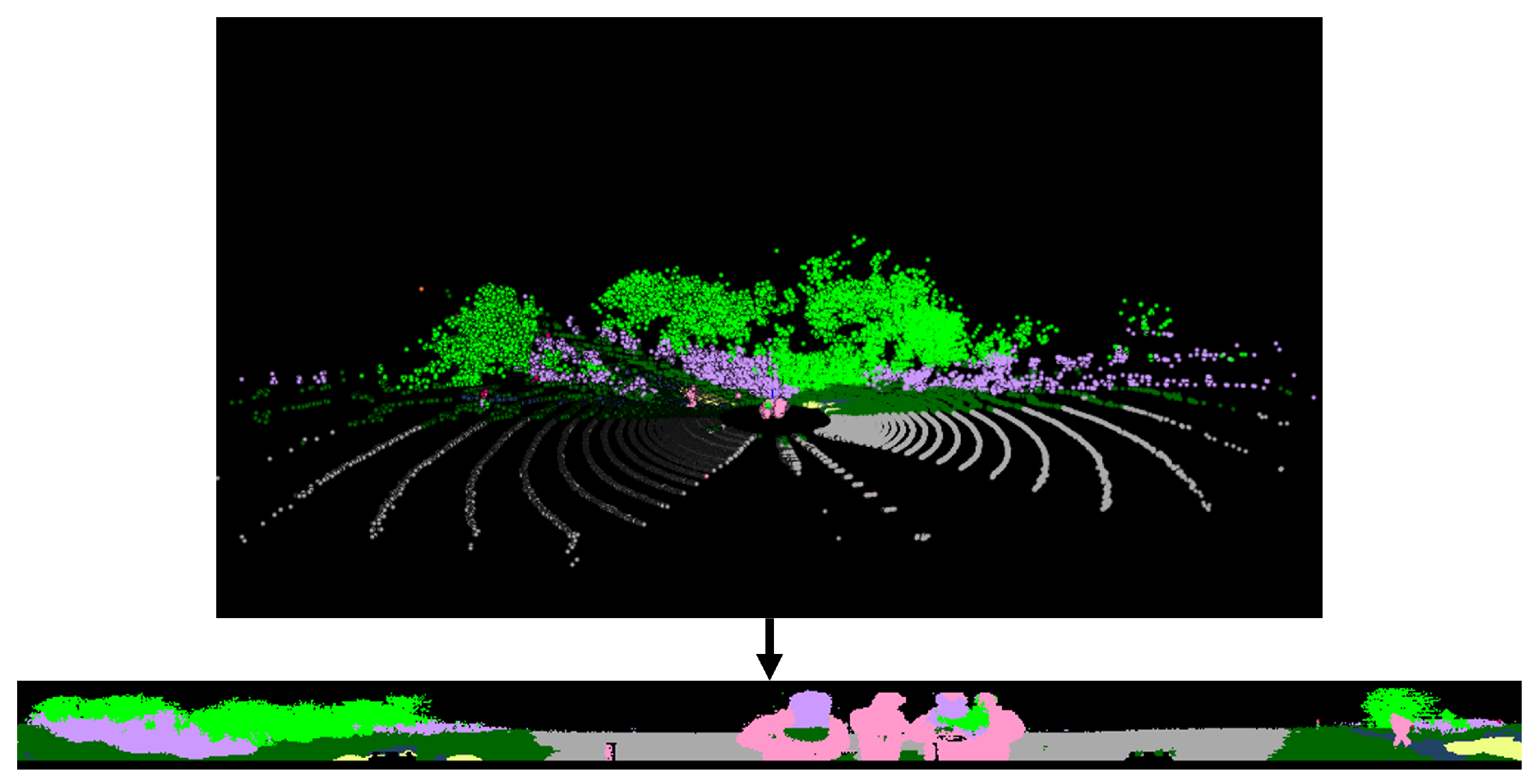
3.2. LiDAR Point Cloud Projection
3.3. Network Selection
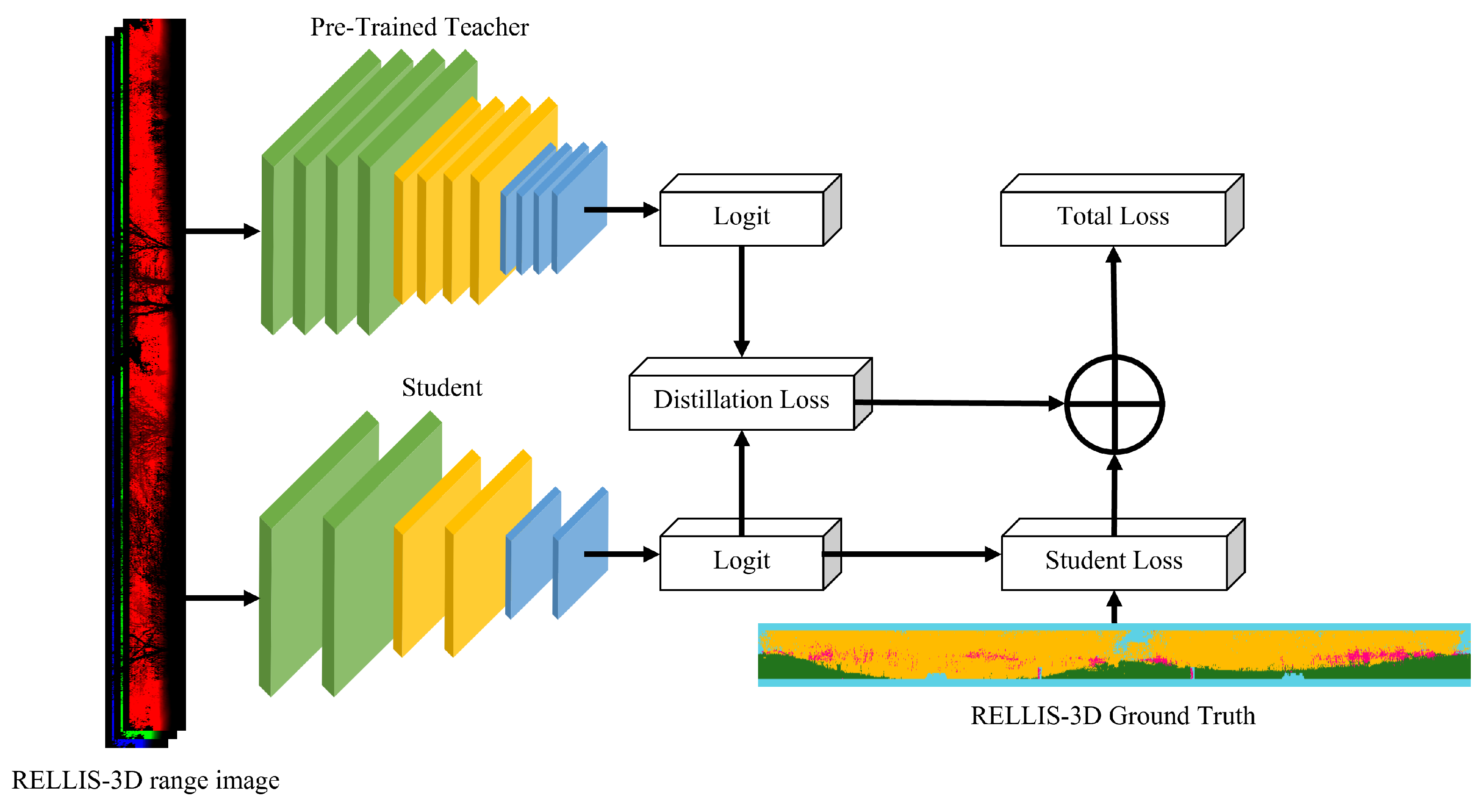
3.4. Soft-Label Knowledge Distillation (SLKD)
4. Results
4.1. Implementation Details
4.2. Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Grigorescu, S.; Trasnea, B.; Cocias, T.; Macesanu, G. A survey of deep learning techniques for autonomous driving. Field Rob. 2020, 37, 362–386. [Google Scholar] [CrossRef]
- Ni, J.; Chen, Y.; Chen, Y.; Zhu, J.; Ali, D.; Cao, W. A survey on theories and applications for self-driving cars based on deep learning methods. Appl. Sci 2020, 10, 2749. [Google Scholar] [CrossRef]
- Borges, P.; Peynot, T.; Liang, S.; Arain, B.; Wildie, M.; Minareci, M.; Lichman, S.; Samvedi, G.; Sa, I.; Hudson, N.; et al. A Survey on Terrain Traversability Analysis for Autonomous Ground Vehicles: Methods, Sensors, and Challenges. Field Rob. 2022, 2, 1567–1627. [Google Scholar] [CrossRef]
- Hawke, J.; Shen, R.; Gurau, C.; Sharma, S.; Reda, D.; Nikolov, N.; Mazur, P.; Micklethwaite, S.; Griffiths, N.; Shah, A.; et al. Urban Driving with Conditional Imitation Learning. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 251–257. [Google Scholar]
- Kirillov, A.; Wu, Y.; He, K.; Girshick, R. Pointrend: Image segmentation as rendering. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 9799–9808. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. BiSeNet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 325–341. [Google Scholar]
- Hambarde, P.; Murala, S. S2DNet: Depth Estimation from Single Image and Sparse Samples. IEEE Trans. Comput. Imaging 2020, 6, 806–817. [Google Scholar] [CrossRef]
- Milijas, R.; Markovic, L.; Ivanovic, A.; Petric, F.; Bogdan, S. A Comparison of LiDAR-based SLAM Systems for Control of Unmanned Aerial Vehicles. In Proceedings of the 2021 International Conference on Unmanned Aircraft Systems (ICUAS 2021), Athens, Greece, 15–18 June 2021; pp. 1148–1154. [Google Scholar]
- Shi, C.; Lai, G.; Yu, Y.; Bellone, M.; Lippiello, V. Real-Time Multi-Modal Active Vision for Object Detection on UAVs Equipped With Limited Field of View LiDAR and Camera. IEEE Robot. Autom. Lett. 2023, 8, 6571–6578. [Google Scholar] [CrossRef]
- Premebida, C.; Carreira, J.; Batista, J.; Nunes, U. Pedestrian detection combining RGB and dense LIDAR data. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; pp. 4112–4117. [Google Scholar]
- Milioto, A.; Vizzo, I.; Behley, J.; Stachniss, C. RangeNet ++: Fast and Accurate LiDAR Semantic Segmentation. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Macau, China, 3–8 November 2019; pp. 4213–4220. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. arXiv 2017, arXiv:1706.02413. [Google Scholar]
- Siam, M.; Gamal, M.; Abdel-Razek, M.; Yogamani, S.; Jagersand, M.; Zhang, H. A comparative study of real-time semantic segmentation for autonomous driving. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 587–597. [Google Scholar]
- Cherabier, I.; Hane, C.; Oswald, M.R.; Pollefeys, M. Multi-label semantic 3D reconstruction using voxel blocks. In Proceedings of the 2016 4th International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 601–610. [Google Scholar]
- Wu, B.; Wan, A.; Yue, X.; Keutzer, K. SqueezeSeg: Convolutional Neural Nets with Recurrent CRF for Real-Time Road-Object Segmentation from 3D LiDAR Point Cloud. In Proceedings of the IEEE International Conference on robotics and automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 1887–1893. [Google Scholar]
- Quaglia, G.; Visconte, C.; Scimmi, L.S.; Melchiorre, M.; Cavallone, P.; Pastorelli, S. Precision Agriculture. Encycl. Food Grains: Second. Ed. 2020, 9, 13. [Google Scholar]
- Szrek, J.; Zimroz, R.; Wodecki, J.; Michalak, A.; Góralczyk, M.; Worsa-Kozak, M. Application of the infrared thermography and unmanned ground vehicle for rescue action support in underground mine—the amicos project. Remote Sens. 2020, 13, 69. [Google Scholar] [CrossRef]
- Shi, S.; Wang, Q.; Xu, P.; Chu, X. Benchmarking state-of-the-art deep learning software tools. In Proceedings of the 2016 7th International Conference on Cloud Computing and Big Data (CCBD), Macau, China, 16–18 November 2016; pp. 99–104. [Google Scholar]
- Mishra, R.; Gupta, H.P.; Dutta, T. A Survey on Deep Neural Network Compression: Challenges, Overview, and Solutions. arXiv 2020, arXiv:2010.03954. [Google Scholar]
- Park, W.; Corp, K.; Kim, D.; Lu, Y. Relational Knowledge Distillation. In Proceedings of the the IEEE International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 3967–3976. [Google Scholar]
- Mirzadeh, S.I.; Farajtabar, M.; Li, A.; Levine, N.; Matsukawa, A.; Ghasemzadeh, H. Improved knowledge distillation via teacher assistant. In Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 5191–5198. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Yin Zhou, O.T. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection. In Proceedings of the the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4490–4499. [Google Scholar]
- Cortinhal, T.; Tzelepis, G.; Erdal Aksoy, E. SalsaNext: Fast, Uncertainty-Aware Semantic Segmentation of LiDAR Point Clouds. In Proceedings of the International Symposium on Visual Computing, San Diego, CA, USA, 5–7 October 2020; pp. 207–222. [Google Scholar]
- Aksoy, E.E.; Baci, S.; Cavdar, S. SalsaNet: Fast Road and Vehicle Segmentation in LiDAR Point Clouds for Autonomous Driving. In Proceedings of the IEEE intelligent vehicles symposium (IV), Melbourne, VIC, Australia, 7–11 September 2020; pp. 926–932. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention(MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Biasutti, P.; Lepetit, V.; Aujol, J.F.; Bredif, M.; Bugeau, A. LU-net: An efficient network for 3D LiDAR point cloud semantic segmentation based on end-to-end-learned 3D features and U-net. In Proceedings of the International Conference on Computer Vision Workshop(ICCVW), Seoul, Republic of Korea, 27–28 October 2019; pp. 942–950. [Google Scholar]
- Takikawa, T.; Acuna, D.; Jampani, V.; Fidler, S. Gated-SCNN: Gated shape CNNs for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 5228–5237. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding Marius. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Yan, X.; Gao, J.; Zheng, C.; Zheng, C.; Zhang, R.; Cui, S.; Li, Z. 2DPASS: 2D Priors Assisted Semantic Segmentation on LiDAR Point Clouds. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 677–695. [Google Scholar]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. SemanticKITTI. In Proceedings of the the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9297–9307. [Google Scholar]
- Zhou, H.; Zhu, X.; Song, X.; Ma, Y.; Wang, Z.; Li, H.; Lin, D. Cylinder3D: An Effective 3D Framework for Driving-scene LiDAR Semantic Segmentation. arXiv 2020, arXiv:2008.01550. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. Nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in Perception for Autonomous Driving: Waymo Open Dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2446–2454. [Google Scholar]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2636–2645. [Google Scholar]
- Jiang, P.; Osteen, P.; Wigness, M.; Saripalli, S. RELLIS-3D Dataset: Data, Benchmarks and Analysis. In Proceedings of the IEEE International Conference on Robotics and Automation, Xi’an, China, 30 May–5 June 2021; pp. 1110–1116. [Google Scholar]
- Wigness, M.; Eum, S.; Rogers, J.G.; Han, D.; Kwon, H. A RUGD Dataset for Autonomous Navigation and Visual Perception in Unstructured Outdoor Environments. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Macau, China, 4–8 November 2019; pp. 5000–5007. [Google Scholar]
- Valada, A.; Oliveira, G.L.; Brox, T.; Burgard, W. Deep Multispectral Semantic Scene Understanding of Forested Environments Using Multimodal Fusion. In Proceedings of the International Symposium on Experimental Robotics, Nagasaki, Japan, 3–8 October 2016; pp. 465–477. [Google Scholar]
- Yim, J. A gift from knowledge distillation: Fast optimization, network minimization and transfer learning. In Proceedings of the the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4133–4141. [Google Scholar]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge Distillation: A Survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Tung, F.; Mori, G. Similarity-Preserving Knowledge Distillation. In Proceedings of the the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1365–1374. [Google Scholar]
- Hou, Y.; Zhu, X.; Ma, Y.; Loy, C.C.; Li, Y. Point-to-Voxel Knowledge Distillation for LiDAR Semantic Segmentation. In Proceedings of the the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5229–5238. [Google Scholar]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. FitNets: Hints for thin deep nets. arXiv 2014, arXiv:1412.6550. [Google Scholar]
- Lin, H.I.; Nguyen, M.C. Boosting minority class prediction on imbalanced point cloud data. Appl. Sci. 2020, 10, 973. [Google Scholar] [CrossRef]
- Viswanath, K.; Singh, K.; Jiang, P.; Sujit, P.; Saripalli, S. Offseg: A semantic segmentation framework for off-road driving. In Proceedings of the IEEE International Conference on Automation Science and Engineering (CASE), Lyon, France, 23–27 August 2021; pp. 354–359. [Google Scholar]
- Kim, N.; An, J. Improved efficiency in determining off-road traversable through class integration. In Proceedings of the Korea Institue of Millitary Science and Technology (KIMST), Jeju, Republic of Korea, 15–16 June 2023; pp. 1769–1770. [Google Scholar]
- Bogoslavskyi, I.; Stachniss, C. Efficient online segmentation for sparse 3D laser scans. PFG J. Photogramm. Remote Sens. Geoinf. Sci. 2017, 85, 41–52. [Google Scholar] [CrossRef]
- Yuan, Y.; Chen, X.; Wang, J. Object-contextual representations for semantic segmentation. In Proceedings of the the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 173–190. [Google Scholar]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. Kpconv: Flexible and deformable convolution for point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6411–6420. [Google Scholar]
- Chen, C.; Chen, Q.; Xu, J.; Koltun, V. Learning to see in the dark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3291–3300. [Google Scholar]
- Kim, N.; An, J. Comparison of Deep Learning-based Semantic Segmentation Model for Offroad Self-driving. J. Korean Inst. Intell. Syst. 2023, 33, 423–429. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 8–22 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Wang, W.; Chu, G.; Chen, L.c.; Chen, B.; Tan, M. Searching for MobileNetV3. In Proceedings of the International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 1314–1324. [Google Scholar]
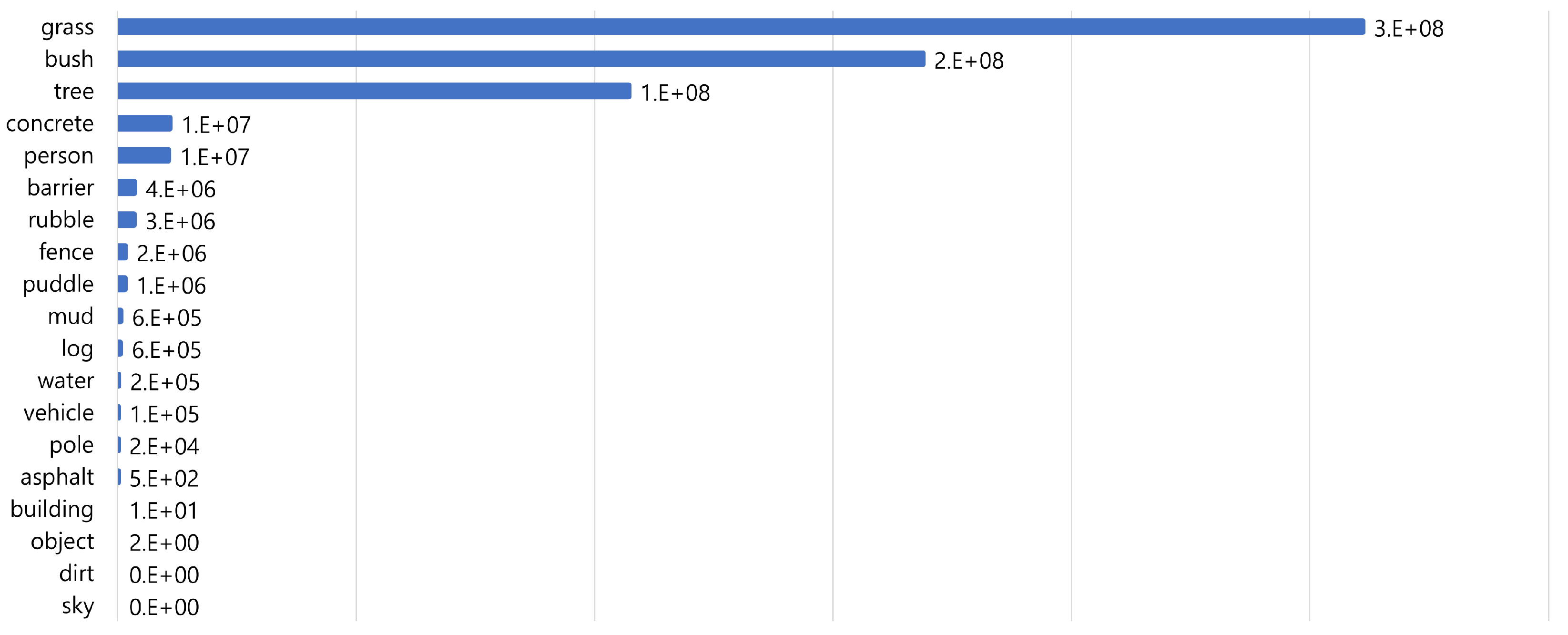




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Sub-Class |
|---|---|
| Sky | Sky |
| traversable region | Grass, Dirt, Asphalt, Concrete, Puddle, Mud |
| Non-traversable region | Bush, Void, Water, Deep Water |
| Obstacle | Vehicle, Barrier, Log, Pole, Object, Building, Person, Fence, Tree, Rubble |
| Model | Encoder | Sky | Traversable | Non-Traversable | Obstacle | mIoU |
|---|---|---|---|---|---|---|
| Teacher (GSCNN) | 95.76 | 44.50 | 45.20 | 53.45 | 59.73 | |
| MobileNet_v2 | 95.68 | 42.00 | 37.17 | 51.08 | 56.48 | |
| MobileNet_v2 (SLKD) | 95.55 | 42.63 | 37.93 | 53.04 | 57.28 | |
| MobileNet_v2_120d | 95.56 | 41.44 | 36.85 | 52.00 | 56.46 | |
| Student (DeepLabV3+) | MobileNet_v2_120d (SLKD) | 95.19 | 42.05 | 37.44 | 52.33 | 56.75 |
| MobileNet_v3_large | 94.59 | 38.23 | 34.01 | 50.60 | 54.37 | |
| MobileNet_v3_large (SLKD) | 95.56 | 40.20 | 34.37 | 52.67 | 55.70 | |
| MobileNet_v3_small | 94.95 | 42.28 | 36.78 | 51.01 | 56.25 | |
| MobileNet_v3_small (SLKD) | 94.45 | 39.20 | 29.49 | 54.42 | 54.39 |
| Model | Encoder | mIoU | GFLOPS | Parameter Size |
|---|---|---|---|---|
| Teacher (GSCNN) | 59.73 | 8493.46 | 137.27M | |
| MobileNet_v2 | 56.48 | 50.46 | 2.71M | |
| MobileNet_v2 (SLKD) | 57.28 | |||
| MobileNet_v2_120d | 56.46 | 84.99 | 5.04M | |
| Student (DeepLabV3+) | MobileNet_v2_120d (SLKD) | 56.75 | ||
| MobileNet_v3_large | 54.37 | 52.13 | 4.71M | |
| MobileNet_v3_large (SLKD) | 55.70 | |||
| MobileNet_v3_small | 56.25 | 32.88 | 2.16M | |
| MobileNet_v3_small (SLKD) | 54.39 |
| Model | Encoder | mIoU/GFLOPS |
|---|---|---|
| Teacher (GSCNN) | 0.007 | |
| MobileNet_v2 | 1.119 | |
| MobileNet_v2 (SLKD) | 1.135 (+0.016) | |
| MobileNet_v2_120d | 0.664 | |
| Student (DeepLabV3+) | MobileNet_v2_120d (SLKD) | 0.667 (+0.003) |
| MobileNet_v3_large | 1.042 | |
| MobileNet_v3_large (SLKD) | 1.068 (+0.026) | |
| MobileNet_v3_small | 1.170 | |
| MobileNet_v3_small (SLKD) | 1.654 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, N.; An, J. Knowledge Distillation for Traversable Region Detection of LiDAR Scan in Off-Road Environments. Sensors 2024, 24, 79. https://doi.org/10.3390/s24010079
Kim N, An J. Knowledge Distillation for Traversable Region Detection of LiDAR Scan in Off-Road Environments. Sensors. 2024; 24(1):79. https://doi.org/10.3390/s24010079
Chicago/Turabian StyleKim, Nahyeong, and Jhonghyun An. 2024. "Knowledge Distillation for Traversable Region Detection of LiDAR Scan in Off-Road Environments" Sensors 24, no. 1: 79. https://doi.org/10.3390/s24010079
APA StyleKim, N., & An, J. (2024). Knowledge Distillation for Traversable Region Detection of LiDAR Scan in Off-Road Environments. Sensors, 24(1), 79. https://doi.org/10.3390/s24010079