



Research on Human Posture Estimation Algorithm Based on YOLO-Pose

Abstract
:1. Background
2. Introduction
2.1. Research Work by Relevant Scholars
2.2. Contribution of This Article
- (1)
- The Backbone section introduces a lightweight GhostNet module to complete the generation of redundant features with a more economical linear transformation, thus greatly reducing the computational cost of convolution to lower the number of parameters of the model and reduce the arithmetic demand, making it more suitable for deployment on UAVs.
- (2)
- The Neck part introduces the ACmix attention mechanism, which captures local features by convolution in the task of judgement and localization of the target by the model, so that it focuses on judging the human body’s bounding box convolution of local features to improve the detection speed.
- (3)
- The key points in the Head part and the decoupling information of key points are optimized through the coordinate attention mechanism in order to solve the problems of complex target background and poor target occlusion detection accuracy and to improve the positioning accuracy of key points.
- (4)
- The loss function and confidence function are improved to guarantee the robustness of the projection of the bounding box (BBox) for human pose estimation in complex scenes in order to improve the robustness of the model and prevent the occurrence of lagging, frame dropping, and video blurring problems [14].
3. Experimental Data
3.1. Research Object
3.2. Data Collection and Dataset
3.3. Details of the A800 Deep Learning GPU Computing Power Server
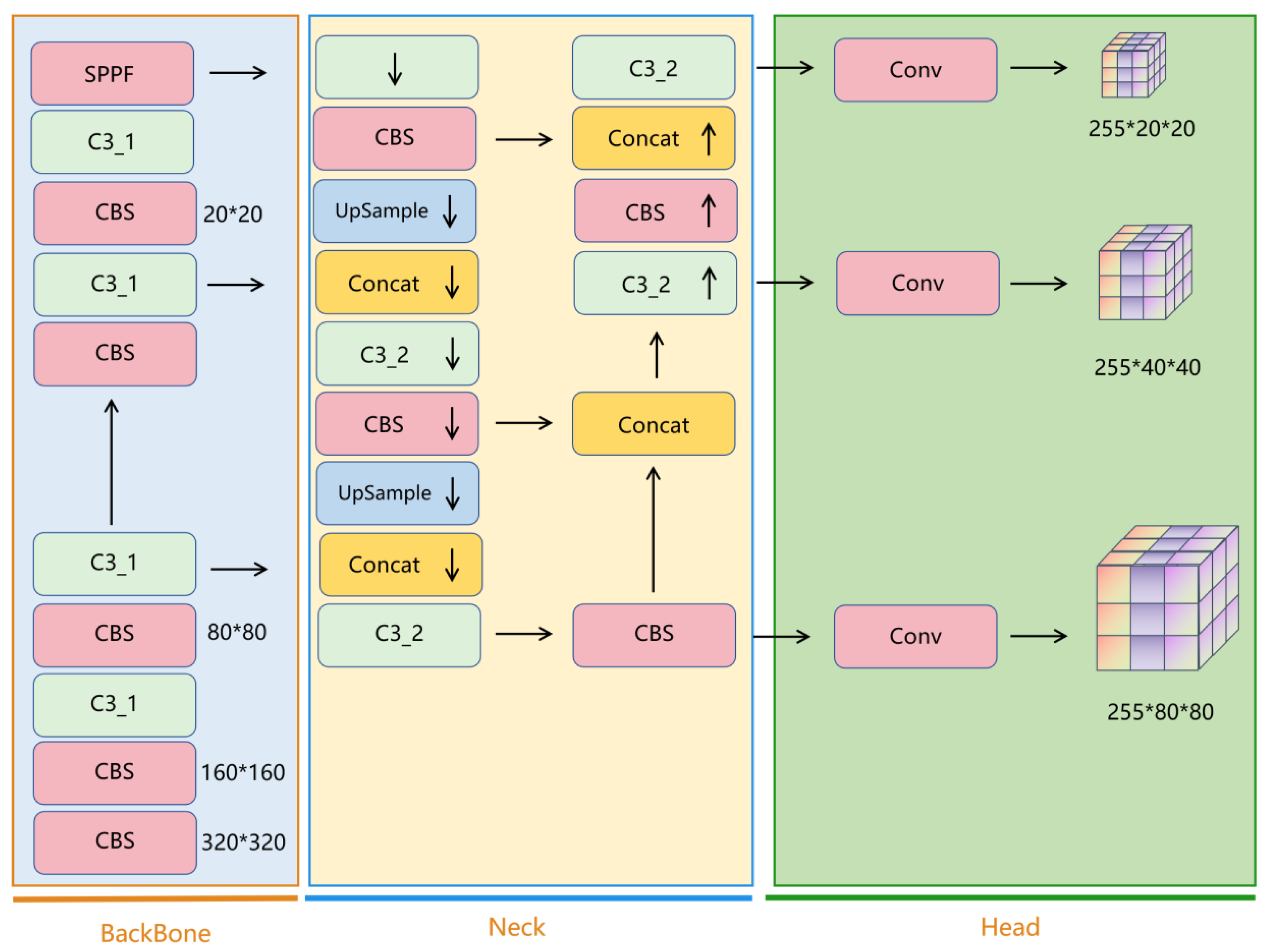
4. YOLO-Pose Human Posture Estimation Algorithm
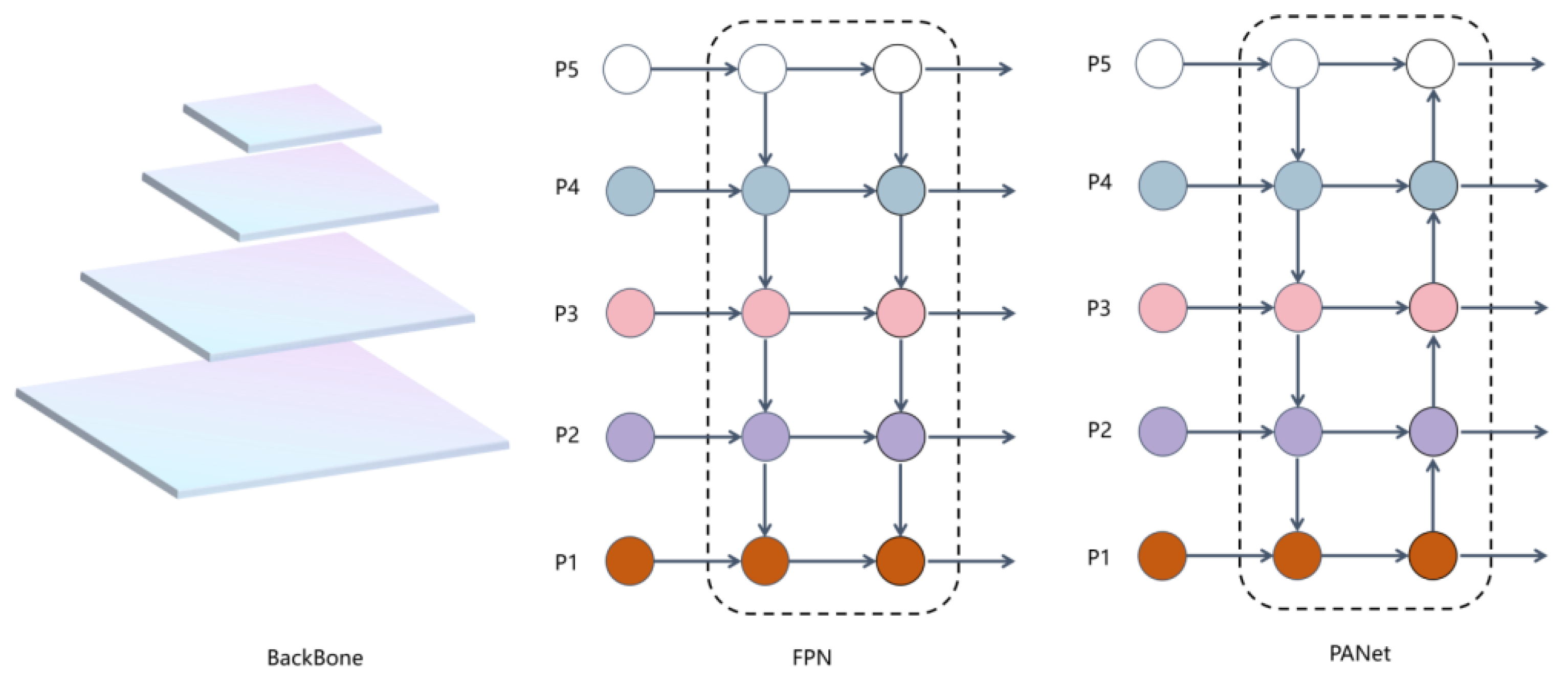
5. Improvement of YOLO-Pose Human Pose Estimation Algorithm
5.1. Backbone Section Introduces Lightweight GhostNet Module
5.2. Neck Partially Introduces the ACmix Attention Mechanism
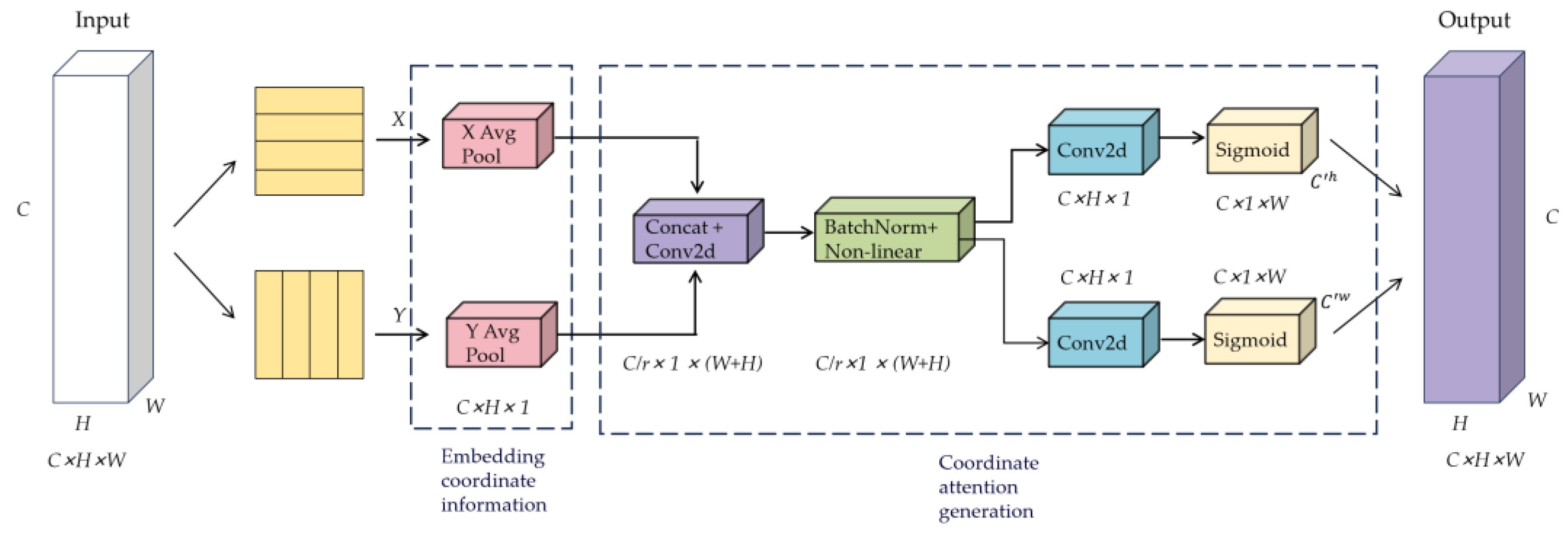
5.3. Optimizing the Head Section Key Points
5.4. Introduction of New Loss Function and Confidence Function
5.5. Improved YOLO-Pose Model
6. Experimental Methods and Results
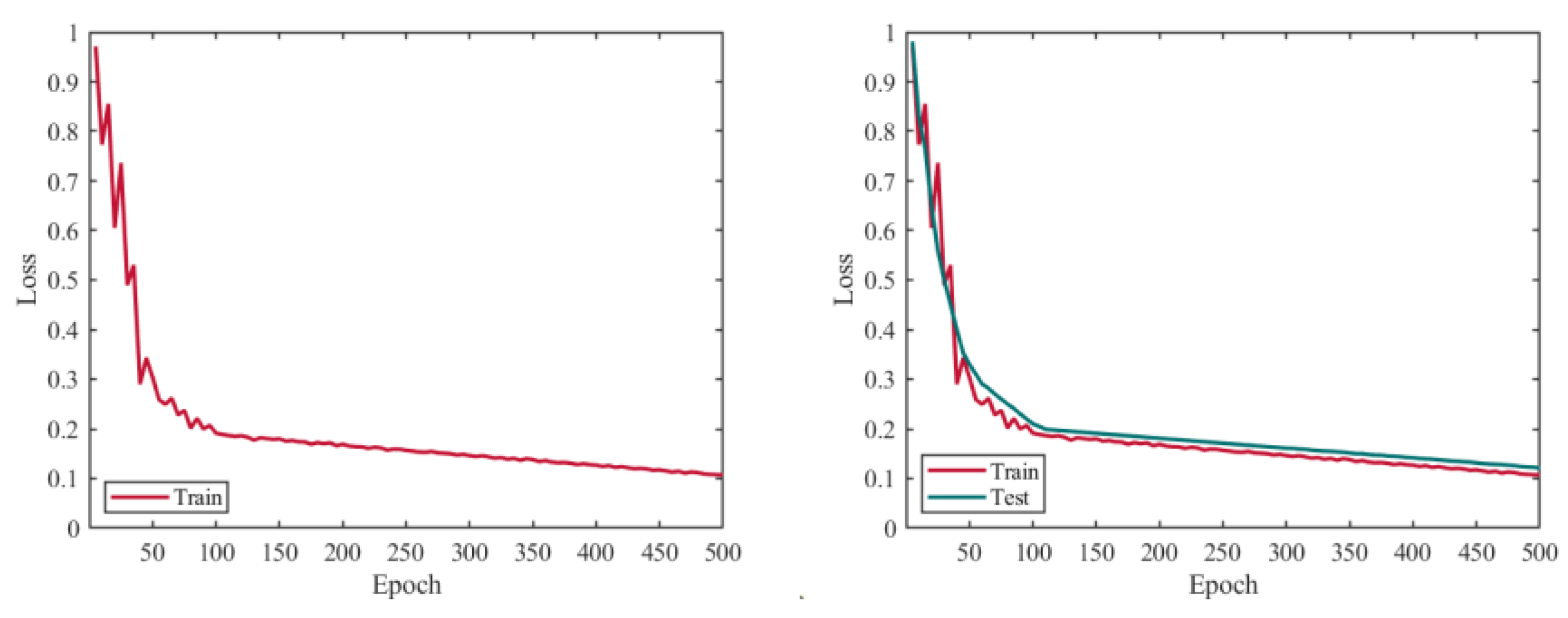
6.1. Network Training
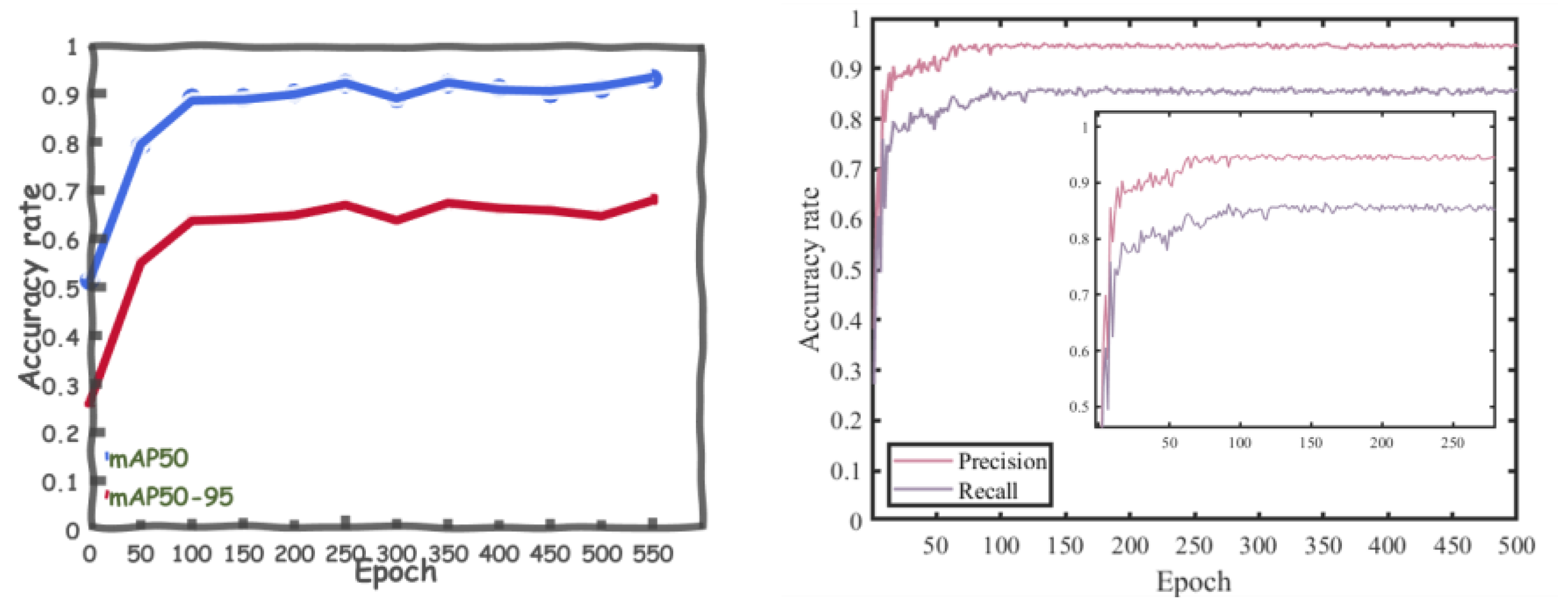
6.2. Evaluation Indicators
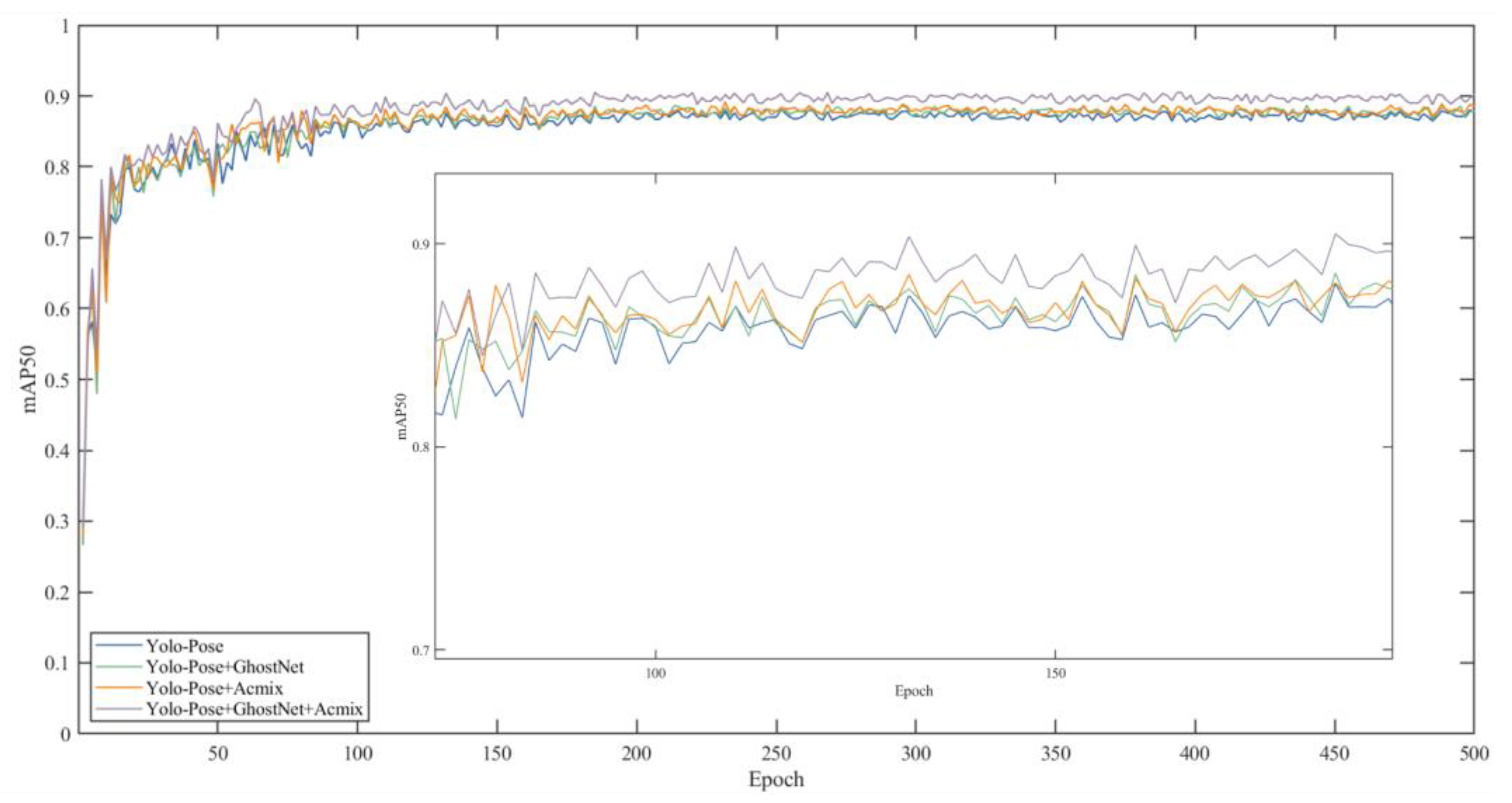
6.3. Ablation Experiment
6.4. Model Comparison
6.5. Detection Effect
7. Conclusions
- (1)
- Human pose estimation is a significant computer vision task; however, practical applications are often hindered by challenges such as low lighting conditions, dense target presence, severe edge occlusion, limited application scenarios, complex backgrounds, and poor recognition accuracy when targets are occluded. In this paper, we propose a YOLO-Pose model that leverages the lightweight and precision-enhanced features of the YOLOv5 object detection model, enabling its effective deployment on unmanned aerial vehicles (UAVs).
- (2)
- Additionally, we employ transfer learning techniques by utilizing pre-trained models trained on the ImageNet-1K and COCO datasets to train our local dataset. In the YOLO-Pose model, we integrate lightweight GhostNet modules into the Backbone section to reduce the model’s parameter count and computational requirements, making it more suitable for deployment on unmanned aerial vehicles (UAVs) to accomplish specific human pose detection tasks. In the Neck section, we introduce the ACmix attention mechanism to enhance detection speed during object judgment and localization. Furthermore, we optimize the Head section’s key points by incorporating coordinate attention mechanisms to improve key point localization accuracy. We also enhance the loss function and confidence function to enhance the model’s robustness.
- (3)
- The improved model demonstrates a reduction of 14.6 M parameters, an 8.47 ms decrease in detection time, a 5.24% improvement in mAP50, and a 5.05% improvement in mAP50-95. Notably, the parameter count and detection speed have been optimized by 30% and 39.5%, respectively, resulting in a detection speed of 19.9 ms per image. These enhancements enable the model to possess concise, user-friendly, and efficient features, making it suitable for monitoring students’ movement poses and assessing their body posture. The model provides valuable technical support by identifying and evaluating various types and levels of poor posture and offering low-cost and easily implementable intervention strategies for physical activities.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zheng, C.; Zhu, S.; Mendieta, M.; Yang, T.; Chen, C.; Ding, Z. 3d human pose estimation with spatial and temporal transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 11656–11665. [Google Scholar]
- Liu, Z.; Chen, H.; Feng, R.; Wu, S.; Ji, S.; Yang, B.; Wang, X. Deep dual consecutive network for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 525–534. [Google Scholar]
- Li, J.; Bian, S.; Zeng, A.; Wang, C.; Pang, B.; Liu, W.; Lu, C. Human pose regression with residual log-likelihood estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 11025–11034. [Google Scholar]
- Zhang, Y.; Zhu, T.; Ning, H.; Liu, Z. Classroom student posture recognition based on an improved high-resolution network. EURASIP J. Wirel. Commun. Netw. 2021, 2021, 140. [Google Scholar] [CrossRef]
- Li, W.; Liu, H.; Ding, R.; Liu, M.; Wang, P.; Yang, W. Exploiting temporal contexts with strided transformer for 3d human pose estimation. IEEE Trans. Multimed. 2022, 25, 1282–1293. [Google Scholar] [CrossRef]
- Liu, H.; Liu, T.; Chen, Y.; Zhang, Z.; Li, Y.F. EHPE: Skeleton cues-based gaussian coordinate encoding for efficient human pose estimation. IEEE Trans. Multimed. 2022, 1–12. [Google Scholar] [CrossRef]
- Yuan, C.; Zhang, P.; Yang, Q.; Wang, J. Fall detection and direction judgment based on posture estimation. Discret. Dyn. Nat. Soc. 2022, 2022, 8372291. [Google Scholar] [CrossRef]
- Lee, M.F.; Chen, Y.C.; Tsai, C.Y. Deep Learning-Based Human Body Posture Recognition and Tracking for Unmanned Aerial Vehicles. Processes 2022, 10, 2295. [Google Scholar] [CrossRef]
- Su, W.; Feng, J. Research on Methods of Physical Aided Education Based on Deep Learning. Sci. Program. 2022, 2022, 6447471. [Google Scholar] [CrossRef]
- Amadi, L.; Agam, G. PosturePose: Optimized Posture Analysis for Semi-Supervised Monocular 3D Human Pose Estimation. Sensors 2023, 23, 9749. [Google Scholar] [CrossRef]
- Manesco, J.R.R.; Berretti, S.; Marana, A.N. DUA: A Domain-Unified Approach for Cross-Dataset 3D Human Pose Estimation. Sensors 2023, 23, 7312. [Google Scholar] [CrossRef]
- Li, H.; Yao, H.; Hou, Y. HPnet: Hybrid Parallel Network for Human Pose Estimation. Sensors 2023, 23, 4425. [Google Scholar] [CrossRef]
- Mathew, M.P.; Mahesh, T.Y. Leaf-based disease detection in bell pepper plant using YOLO v5. Signal Image Video Process. 2022, 16, 841–847. [Google Scholar] [CrossRef]
- Niu, S.; Nie, Z.; Li, G.; Zhu, W. Early Drought Detection in Maize Using UAV Images and YOLOv8+. Drones 2024, 8, 170. [Google Scholar] [CrossRef]
- Yi, P.; Wang, Z.; Jiang, K.; Shao, Z.; Ma, J. Multi-temporal ultra dense memory network for video super-resolution. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 2503–2516. [Google Scholar] [CrossRef]
- Liu, C.; Yi, W.; Liu, M.; Wang, Y.; Hu, S.; Wu, M. A Lightweight Network Based on Improved YOLOv5s for Insulator Defect Detection. Electronics 2023, 12, 4292. [Google Scholar] [CrossRef]
- Ryu, S.; Yun, S.; Lee, S.; Jeong, I.C. Exploring the Possibility of Photoplethysmography-Based Human Activity Recognition Using Convolutional Neural Networks. Sensors 2024, 24, 1610. [Google Scholar] [CrossRef] [PubMed]
- Duan, X.; Lin, Y.; Li, L.; Zhang, F.; Li, S.; Liao, Y. Hierarchical Detection of Gastrodia elata Based on Improved YOLOX. Agronomy 2023, 13, 1477. [Google Scholar] [CrossRef]
- Wang, T.; Zheng, Y.; Ma, H.; Wang, C.; Liu, Y.; Li, X. An improved YOLOv5-based bird detection algorithm for transmission line. In Proceedings of the 2022 International Conference on Computer Engineering and Artificial Intelligence (ICCEAI), Shijiazhuang, China, 22–24 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 79–83. [Google Scholar]
- Lloyd, D.T.; Abela, A.; Farrugia, R.A.; Galea, A.; Valentino, G. Optically enhanced super-resolution of sea surface temperature using deep learning. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5000814. [Google Scholar] [CrossRef]
- Hou, J.; Zhou, H.; Hu, J.; Yu, H.; Hu, H. A Multi-Scale Convolution and Multi-Layer Fusion Network for Remote Sensing Forest Tree Species Recognition. Remote Sens. 2023, 15, 4732. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Zhang, X.; Sun, J. Object detection networks on convolutional feature maps. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1476–1481. [Google Scholar] [CrossRef] [PubMed]
- Lin, M.; Ji, R.; Wang, Y.; Zhang, Y.; Zhang, B.; Tian, Y.; Shao, L. Hrank: Filter pruning using high-rank feature map. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1529–1538. [Google Scholar]
- Gränzig, T.; Fassnacht, F.E.; Kleinschmit, B.; Förster, M. Mapping the fractional coverage of the invasive shrub Ulex europaeus with multi-temporal Sentinel-2 imagery utilizing UAV orthoimages and a new spatial optimization approach. Int. J. Appl. Earth Obs. Geoinformation 2021, 96, 102281. [Google Scholar] [CrossRef]
- Yin, D.; Wang, L.; Lu, Y.; Shi, C. Mangrove tree height growth monitoring from multi-temporal UAV-LiDAR. Remote Sens. Environ. 2024, 303, 114002. [Google Scholar] [CrossRef]
- Gunduz, M.Z.; Das, R. Smart Grid Security: An Effective Hybrid CNN-Based Approach for Detecting Energy Theft Using Consumption Patterns. Sensors 2024, 24, 1148. [Google Scholar] [CrossRef] [PubMed]
- Diwan, T.; Anirudh, G.; Tembhurne, J.V. Object detection using YOLO: Challenges, architectural successors, datasets and applications. Multimed. Tools Appl. 2023, 82, 9243–9275. [Google Scholar] [CrossRef]
- Yin, Y.; Li, H.; Fu, W. Faster-YOLO: An accurate and faster object detection method. Digit. Signal Process. 2020, 102, 102756. [Google Scholar] [CrossRef]
- Hsu, W.Y.; Lin, W.Y. Ratio-and-scale-aware YOLO for pedestrian detection. IEEE Trans. Image Process. 2020, 30, 934–947. [Google Scholar] [CrossRef] [PubMed]
- Terven, J.; Córdova-Esparza, D.M.; Romero-González, J.A. A comprehensive review of yolo architectures in computer vision: From yolov1 to yolov8 and yolo-nas. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Nghonda Tchinda, E.; Panoff, M.K.; Tchuinkou Kwadjo, D.; Bobda, C. Semi-Supervised Image Stitching from Unstructured Camera Arrays. Sensors 2023, 23, 9481. [Google Scholar] [CrossRef] [PubMed]
- Summerfield, G.I.; De Freitas, A.; van Marle-Koster, E.; Myburgh, H.C. Automated Cow Body Condition Scoring Using Multiple 3D Cameras and Convolutional Neural Networks. Sensors 2023, 23, 9051. [Google Scholar] [CrossRef] [PubMed]
- Souza, B.J.; Stefenon, S.F.; Singh, G.; Freire, R.Z. Hybrid-YOLO for classification of insulators defects in transmission lines based on UAV. Int. J. Electr. Power Energy Syst. 2023, 148, 108982. [Google Scholar] [CrossRef]
- Xu, F.; Liu, S.; Zhang, W. Research on power equipment troubleshooting based on improved AlexNet neural network. J. Meas. Eng. 2024, 12, 162–182. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Pan, X.; Ge, C.; Lu, R.; Song, S.; Chen, G.; Huang, Z.; Huang, G. On the integration of self-attention and convolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Su, P.; Han, H.; Liu, M.; Yang, T.; Liu, S. MOD-YOLO: Rethinking the YOLO architecture at the level of feature information and applying it to crack detection. Expert Syst. Appl. 2024, 237, 121346. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module1 | Module2 | Module3 | Module4 | mAP50/% | mAP50-95/% | Params/M | Detection Time/ms |
|---|---|---|---|---|---|---|---|
| — | — | — | — | 88.34 | 64.49 | 36.9 | 28.64 |
| √ | — | — | — | 88.62 | 63.45 | 26.88 | 23.84 |
| — | √ | — | — | 89.81 | 65.69 | 28.96 | 24.5 |
| — | — | √ | — | 88.59 | 66.98 | 30.11 | 26.6 |
| — | — | — | √ | 90.83 | 64.32 | 29.56 | 25.9 |
| √ | √ | √ | √ | 93.58 | 69.54 | 22.3 | 19.9 |
| mAP50/% | mAP50-95/% | Params/M | Detection Time/ms | |
|---|---|---|---|---|
| Faster R-CNN | 91.49 | 68.87 | 27.6 | 35.56 |
| SSD | 87.6 | 62.60 | 27.8 | 28.83 |
| YOLOv4 | 90.64 | 64.94 | 25.9 | 28.64 |
| YOLOv7 | 91.56 | 66.48 | 29.2 | 25.35 |
| YOLO-Pose | 93.58 | 69.54 | 22.3 | 19.99 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, J.; Niu, S.; Nie, Z.; Zhu, W. Research on Human Posture Estimation Algorithm Based on YOLO-Pose. Sensors 2024, 24, 3036. https://doi.org/10.3390/s24103036
Ding J, Niu S, Nie Z, Zhu W. Research on Human Posture Estimation Algorithm Based on YOLO-Pose. Sensors. 2024; 24(10):3036. https://doi.org/10.3390/s24103036
Chicago/Turabian StyleDing, Jing, Shanwei Niu, Zhigang Nie, and Wenyu Zhu. 2024. "Research on Human Posture Estimation Algorithm Based on YOLO-Pose" Sensors 24, no. 10: 3036. https://doi.org/10.3390/s24103036
APA StyleDing, J., Niu, S., Nie, Z., & Zhu, W. (2024). Research on Human Posture Estimation Algorithm Based on YOLO-Pose. Sensors, 24(10), 3036. https://doi.org/10.3390/s24103036