Abstract
Hydrogen is an ideal energy carrier manufactured mainly by the natural gas steam reforming hydrogen production process. The concentrations of , , , and in this process are key variables related to product quality, which thus need to be controlled accurately in real-time. However, conventional measurement methods for these concentrations suffer from significant delays or huge acquisition and upkeep costs. Virtual sensors effectively compensate for these shortcomings. Unfortunately, previously developed virtual sensors have not fully considered the complex characteristics of the hydrogen production process. Therefore, a virtual sensor model, called “moving window-based dynamic variational Bayesian principal component analysis (MW-DVBPCA)” is developed for key gas concentration estimation. The MW-DVBPCA considers complicated characteristics of the hydrogen production process, involving dynamics, time variations, and transportation delays. Specifically, the dynamics are modeled by the finite impulse response paradigm, the transportation delays are automatically determined using the differential evolution algorithm, and the time variations are captured by the moving window method. Moreover, a comparative study of data-driven virtual sensors is carried out, which is sporadically discussed in the literature. Meanwhile, the performance of the developed MW-DVBPCA is verified by the real-life natural gas steam reforming hydrogen production process.
1. Introduction
Hydrogen is an ideal energy storage medium with zero carbon emissions, essential in energy systems’ low-carbon transformation [1]. Currently, over 90% of the world’s large-scale industrial hydrogen production process is the fossil energy reforming process, of which more than 50% is the natural gas steam reforming process [2,3]. The natural gas steam reforming hydrogen production process consists of feedstock purification, steam reforming, medium temperature conversion, and pressure swing adsorption. In this process, , , , and are primary process gases, and the concentrations of these gases are key variables (KVs) related to the product quality. Infrequent and inaccurate measurements of these KVs risk substantial production losses, poor control performance, and even hidden dangers to safety. Consequently, real-time measurements of these KVs are essential and desirable.
Currently, measurements of the hydrogen production process’ KVs are classified into offline laboratory analyses, hardware sensors, and virtual sensors. The offline laboratory analyses give accurate measurements of the KVs, but result in significant measurement delays [4]. The hardware sensors measure the KVs in real-time, but need colossal investment and maintenance costs [5,6]. Virtual sensors are actually predictive mathematical models which use explanatory variables (EVs, i.e., easily measurable variables like pressure and flow rate) as inputs and estimates of the KVs as outputs, having the benefits of no measurement delays and low costs [7,8]. Therefore, the virtual sensor effectively compensates for the shortcomings of the offline laboratory analysis and hardware sensor [9,10]. As a result, virtual sensors have been intensively studied and widely used in the hydrogen production process.
Virtual sensors can generally be grouped into first-principle-based and data-driven virtual sensors. The first-principle-based virtual sensor is established by analyzing and explaining the physicochemical mechanisms of the hydrogen production process. For example, Yang et al. established a predictive model of ammonia pyrolysis decomposition rate through theoretical derivation for the reaction in the hydrogen production process [11]. Huang et al. developed a mathematical model between the EVs and the conversion rate of methane by coupling conduction, convection, thermal radiation, and chemical reaction kinetics [12]. Zhou et al. simulated the chemical looping hydrogen production process by analyzing the process mechanisms [13]. However, due to the complex reaction dynamics, precise first-principle-based models of the hydrogen production process are challenging to obtain. Usually, laboratory-scale studies or ideal steady-state analyses are the main applications of these first-principle-based virtual sensors. On the contrary, a data-driven virtual sensor is constructed by process-measured data, and does not rely on accurate mechanisms [14,15]. Therefore, it is closer to reality, and better describes the actual operations of the hydrogen production process [16,17]. As a result, data-driven virtual sensors are widely applied in the hydrogen production process. For example, Tong et al. built the multi-layer perceptron (MLP) neural network to estimate the concentration in the hydrogen production process [18]. Zamaniyan et al. employed the MLP model to predict the concentration of and of the hydrogen production process [19]. Ögren et al. established deep neural networks (DNNs) to estimate the concentration of , , , and , which have large network layers [20]. Considering the challenges of artificial neural network models in model selection and parameter adjustment with limited data, small-data-oriented models have been applied to the hydrogen production process. Fang et al. used a support vector machine (SVM) to predict the hydrogen yield [21]. Zhao et al. proposed a predictive model based on the least squares SVM (LSSVM) employed in wind power hydrogen production [22].
Despite these achievements on virtual sensors for the KVs, the hydrogen production process is usually complicated because of practical operations. Firstly, due to the feedstock variations and external disturbances, the hydrogen production process shows strong dynamics [23]. Secondly, the hydrogen production process involves many series-wound devices (e.g., pre-reformers and pre-heaters), which requires significant time to deliver the energies and feedstocks to the reformer [24]. That means the EVs and the KVs are recorded simultaneously and are mismatched (i.e., there are transportation delays between the EVs and the KVs). Thirdly, the hydrogen production process exhibits time-varying properties because of the process drifts caused by mechanical abrasions, catalyst deactivation, or even climatic variations [25].
The above complex properties of the hydrogen production process make it challenging to develop high-precision virtual sensors for the KVs. As far as we know, the existing virtual sensors developed for the hydrogen production process do not account for these complicated characteristics. Moreover, the hydrogen production process has multiple KVs to estimate, and the existing virtual sensors constructed multiple independent single-output virtual sensors (one for each KV), ignoring the correlations between the KVs. To this end, we first develop a multi-output virtual sensor model called “dynamic variational Bayesian principal component analysis (DVBPCA)” for real-time prediction of the KVs in the hydrogen production process. As a further contribution, a moving window-based DVBPCA (MW-DVBPCA) is developed to improve estimation performance while considering the time variations of the hydrogen production process. The main contributions we make in the article are organized as follows.
- (1)
- The developed DVBPCA considers both process dynamics and transportation delays of energies and materials. Concretely, the finite impulse response (FIR) method is employed to model the dynamics of the hydrogen production process. And the transportation delays related to the EVs are automatically determined by differential evolution (DE). Moreover, the DVBPCA is able to make full use of the correlations between KVs for performance enhancement.
- (2)
- The moving window (MW) approach is employed for updating the DVBPCA with the latest online process information, which effectively captures the time-varying characteristics of the hydrogen production process in real-time.
- (3)
- A comparative study of data-driven virtual sensors is implemented for the hydrogen production process, which is sparsely mentioned in the predecessors’ research. Furthermore, the performance of the developed MW-DVBPCA is verified by the real-life natural gas steam reforming hydrogen production process.
This article is structured as follows. The variational inference (VI) is introduced in Section 2. Section 3 describes the developed DVBPCA and MW-DVBPCA in detail. In Section 4, the performance of the DVBPCA and MW-DVBPCA is evaluated using the operational data from the distributed control system (DCS) database of a real-life hydrogen production process. Finally, Section 5 concludes the article.
2. Variational Inference
The VI and Monte Carlo–Markov Chain are common methods to study posterior distributions over RVs in probabilistic models [26]. And the VI was used to learn the developed DVBPCA, considering its advantages in convergence diagnosis and computational efficiency.
Denote the random variables (RVs) with unknown posterior distribution as . The equation shown as Equation (1) decomposes the log of model evidence, as follows:
where means the Kullback–Leibler (KL) divergence between and , is training dataset, represents any form of probability distribution over , represents the actual posterior distribution over , and means the variational evidence lower bound (ELBO) of the log of model evidence as .
Therefore, the posterior distributions over can be found by maximizing the ELBO as shown in Equation (2), i.e.,
where represents the variational solution of .
Assume can factorize into the product , where . The general rule to find the variational distribution is obtained as Equation (3):
where is the expectation of a function of the RV with respect to the distribution over , means factors in except , and means constant terms.
3. Dynamic Variational Bayesian Principal Component Analysis Based on Moving Window
3.1. Time-Delayed Moving Average Model
Due to the flexibility of combining various regression models, the FIR paradigm is generally employed for capturing dynamics. Moreover, the KVs are measured at a lower frequency than the EVs in the hydrogen production process, which implies that the model structure based on autoregression from the FIR family is unsuitable. More importantly, as mentioned earlier, the transportation delays between the EVs and the KVs are unknown, and require consideration. Based on these considerations, a time-delayed moving average (MA) model structure is embedded in the virtual sensor, which is given by
where are the n-th measurements of the -dimensional KVs, is n-th measurement of the i-th EV, S is the number of the EVs, and refer to the transportation delay and the order of , respectively, and both are non-negative integers, and means the mathematical relationship between the EVs and KVs (but there may exist strong colinearities between the EVs of the model ). Denote and for conciseness.
3.2. Dynamic Variational Bayesian Principal Component Analysis
Variational Bayesian principal component analysis (VBPCA) is a widely used model to deal with the colinearities between the EVs, owing to its advantage in the automatic determination of appropriate model dimensionality [27]. Therefore, it is ideally suited as the model . In this article, name the VBPCA combined with the model structure shown in Equation (4) as the dynamic VBPCA (DVBPCA) due to the capability of capturing process dynamics. Moreover, the DVBPCA can handle the overfitting resulting from highly dimensional variable augmentation in Equation (4) through penalizing parameter values, which are detailed as follows.
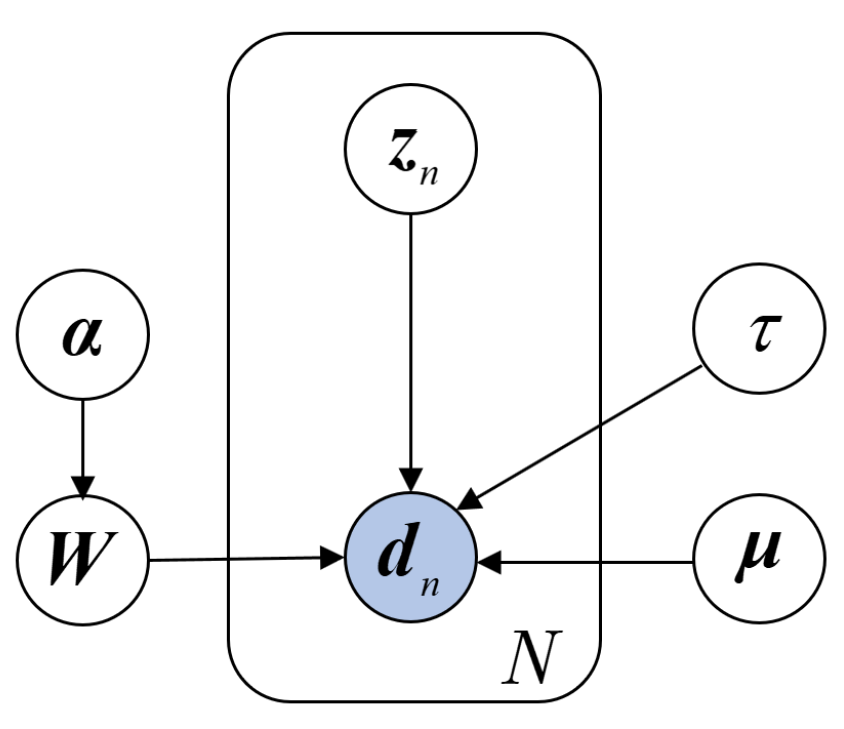
Denote the observed sequential dataset as , where means the n-th set of samples, and are inputs and outputs, respectively, and . Figure 1 graphically represents the DVBPCA. where, is the loading matrix of the inputs , is the loading matrix of the outputs , , are the M-dimensional hidden variables corresponding to the sample at time instant n, are the mean values of the inputs , are the mean values of the outputs , , is the accuracy parameter of the noise, and is the accuracy parameter set of the loading matrix. Moreover, denote each column of as , the transpose of each row of as , and . As illustrated in Equation (5), the observed data point is assumed to be generated by
where is the measurement noise.
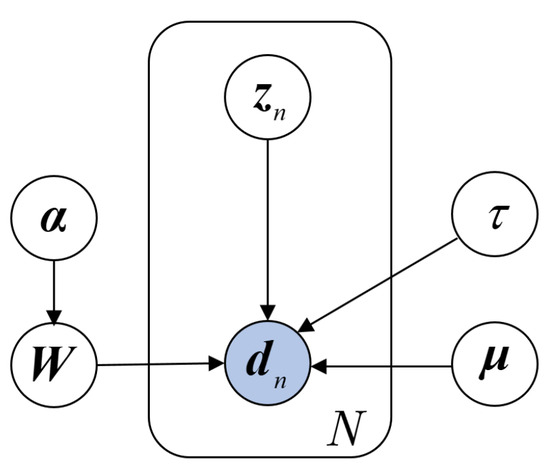
Figure 1.
Probability graph of the DVBPCA.
As shown in Equation (6), assign conjugate prior to the hidden variables
where represents the normal distribution probability density function, represents an M-dimensional column vector with element 0, and represents an M-dimensional unit matrix.
According to Figure 1, which shows that the samples are independently collected, the conditional distributions of the observed samples are designed as shown in Equations (7); that is,
where represents a K-dimensional unit matrix.
To conform with common sense and to simplify subsequent calculations, the distributions over all RVs are selected as conjugate priors as detailed in Equation (8)–(11); that is,
where represents a K-dimensional column vector with element 0, is the accuracy parameter of the mean, , , , are the hyper-parameters of the distributions over these RVs, and is the gamma distribution probability density function. Particularly, when little or no prior information is obtained for these priors, it is suggested to set noninformative priors for the RVs to minimize the effect on the posterior distribution. That is, the values of hyperparameters , , , and are set as small as possible so that the posteriors do not rely on the priors, but only on the data.
Remark 1.
To facilitate model training, rewrite Equation (8) as , where . Each inverse variance of the is controlled by the corresponding . Thus, if the posterior distribution of a particular is focused on larger values, the corresponding will converge to be tiny, effectively deactivating this particular direction in the latent space. Therefore, the effective dimensionality of the potential space is determined automatically.
According to Figure 1, the equation shown as Equation (12) represents the joint probability density function between training data and the RVs as follows:
The VI is employed to train the DVBPCA to obtain the posterior distributions of the RVs .
Assume the posterior distribution over , , can factorize into
According to Equation (2), the posterior distribution over is detailed as
where , , and is the expectation.
Similarly, by using the general rule given by Equation (2), we can find the variational posterior distributions over other RVs, as shown on the right side of Equation (13) one by one, which are given as follows.
The posterior distribution over is obtained as
where , and .
The posterior distribution over is obtained as
where , and .
The posterior distribution over is obtained as
where , and .
The posterior distribution over is obtained as
where , and .
The ELBO is calculated using the updated posterior distributions, i.e.,
The convergence of the training procedure can be diagnosed with ELBO. The termination criteria for the parameter learning process are defined as detailed in Equation (20), as follows:
where and are the values of ELBO at the -th and -th iterative steps, respectively, and is the threshold.
The main steps in training the DVBPCA model are summarized in Algorithm 1.
| Algorithm 1 Pseudocode for the DVBPCA. |
|
3.3. Moving Window-Based Dynamic Variational Bayesian Principal Component Analysis
The moving window (MW) method is used to trace time variations and reject disturbances [28]. It captures the latest process information by discarding the oldest sample after the latest sample is obtained and rebuilding a model with all data in the window. Specially, for the first local model, as mentioned above, set noninformation priors for the RVs. For subsequent local modeling, the prior distributions of the RVs in the MW-DVBPCA are updated one by one and replaced with the trained posterior distributions of the RVs at the previous moment. The MW-DVBPCA is detailed in this subsection.
Firstly, the training dataset (i.e., historical data) is preset in the MW, and the DVBPCA is trained on the training dataset to obtain the posterior distributions of the RVs . When the test samples (i.e., online samples) are acquired, the DVBPCA generated earlier is used to estimate the KVs, and the posterior distributions of RVs are used as the prior for the new DVBPCA model, which is elaborated as follows.
Let and denote the observations of inputs and outputs at certain online time instant , respectively, where is unknown. The hidden RVs are first introduced.
Since the outputs are unknown, the posterior distribution over is calculated with the observation of which, based on Equation (14), is given by the equation as shown in Equation (21) as follows:
where , and .
Then, the conditional distribution of given is obtained as
where and are the mean and covariance calculated from the posterior distribution , respectively, and and are the mean values and covariance matrix calculated from the posterior distribution , respectively.
Equation (22) can be transformed into
where represents the trace.
The mean vector and covariance matrix of Gaussian distribution in Equation (23) are obtained as illustrated in Equation (24) and Equation (25), respectively, as follows:
where .
By replacing the distribution of with its expectation, the probability distribution of the predicted KVs is approximated as
Therefore, based on Equation (26), the estimations of are given by
and the prediction uncertainty is quantified by the variance matrix of denoted by , which is given by Equation (28), i.e.,
Once the KVs predictions for the new sample are completed, the historical data window is slid down to include the latest measured sample set and to eliminate the oldest sample. The DVBPCA is then retrained according to the current window of the historical dataset for online prediction. This process repeats once new samples are obtained online.
3.4. Differential Evolutionary-Based Model Selection
The DE is an effective and simple intelligent optimization algorithm commonly used for solving NP-hard problems in real number fields [29]. Associated studies have demonstrated that DE has fast convergence performance as an excellent global optimization algorithm. Therefore, the DE is utilized for model selection (i.e., selecting the best parameter) of the DVBPCA and MW-DVBPCA, involving the dynamic orders and time delays given in Equation (4). Equation (29) shows the optimization problem, as follows:
where is the fitness function, and are the lower and upper bounds of the dynamic orders , respectively, and and are the lower and upper bounds of the delays , respectively.
Based on Equation (4), are non-negative integers. Therefore, the individuals generated by the DE need to be rounded. And the DE algorithm contains three core evolutionary operations, i.e., mutation, crossover and selection, which are introduced in detail as follows.
Initialization. Set the population size , dimension of individual , and the upper bounds and the lower bounds of the dynamic orders and time delays, where individuals in the population are randomly generated in integer field by Equation (30), i.e.,
Mutation. In the r-th generation, DE generates a mutation vector for the e-th individual, given by Equation (31); that is,
where , , and are individuals that randomly selected from population with , and F is the mutation rate.
Crossover. A trial individual vector is generated by the original individual vector or the mutation vector based on the crossover rate ranged in , which is shown in Equation (32), i.e.,
where is a random integer ranged in .
Selection. According to the fitness function , select the individual with a lower value as detailed in Equation (33) as follows:
Termination. The evolution continues until it reaches the given maximum generation or the change in the fitness value is small. Otherwise, the above three operators should be performed repeatedly.
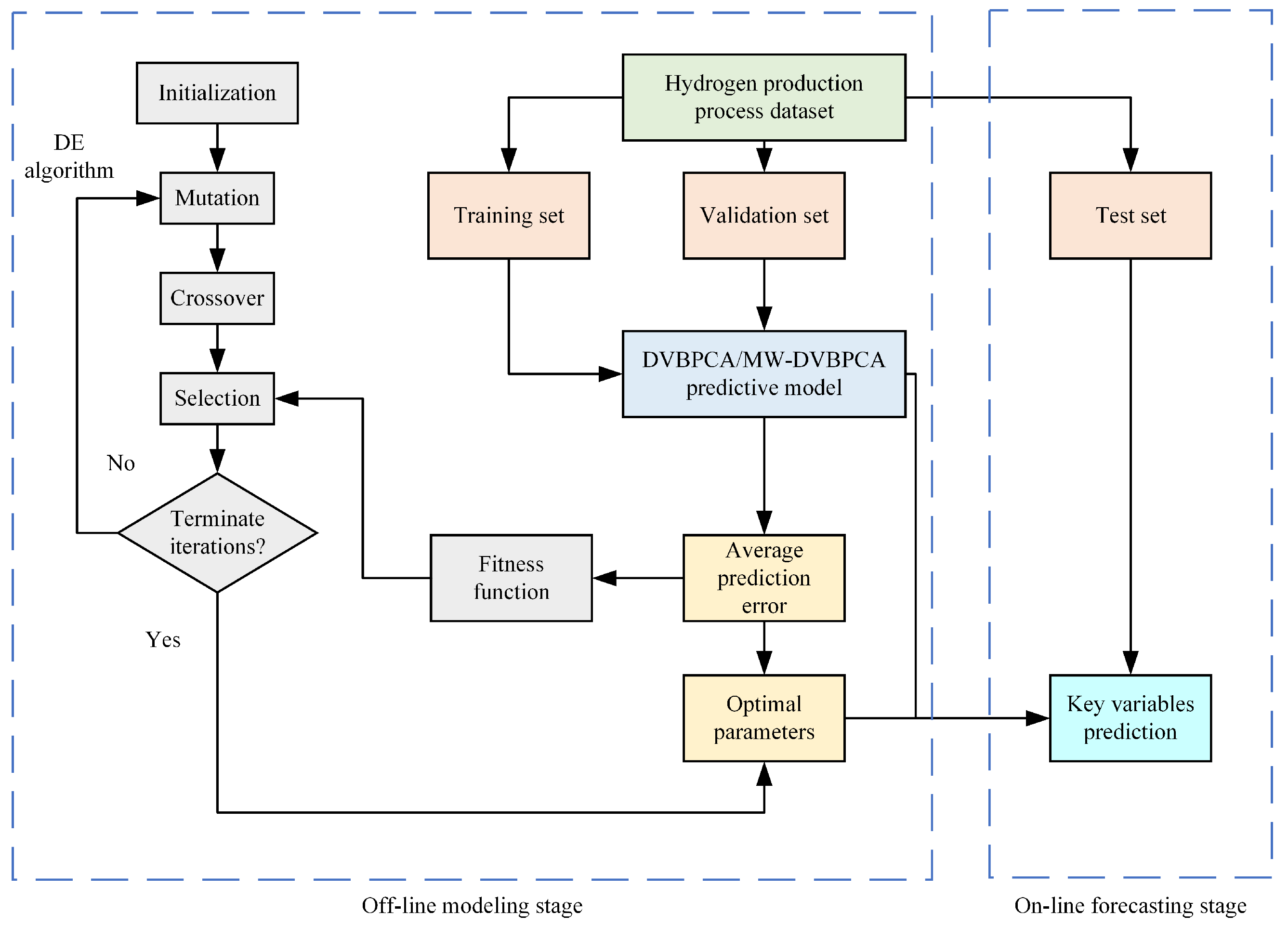
Figure 2 shows the flowchart of the DVBPCA and MW-DVBPCA combined with the DE for parameter optimization. Note that for the multi-output models, DVBPCA and MW-DVBPCA, the average prediction error of four KVs is set as the fitness function.
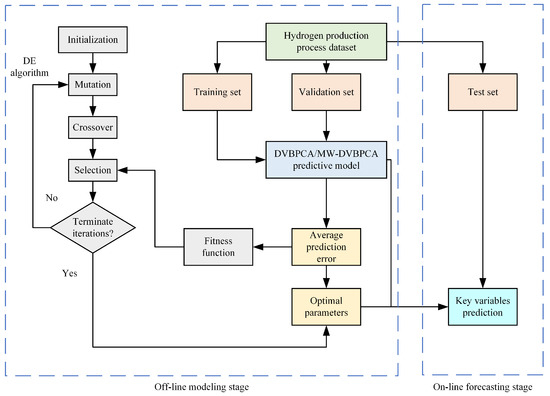
Figure 2.
The flowchart of the DVBPCA and MW-DVBPCA.
4. Case Studies and Comparisons
A comparative study of data-driven virtual sensors upon a real-life natural gas steam reforming hydrogen production process is provided in this section. Meanwhile, a case study is useful for understanding the hydrogen production processes and data features. The state-of-the-art virtual sensors and developed models (DVBPCA and MW-DVBPCA) are investigated, including partial least squares (PLS) [30], VBPCA, long short-term memory (LSTM) [31], echo state networks (ESN) [32], and dynamic PLS (DPLS) [33]. The PLS is a classic static model with the advantages of modeling data colinearities and simple data structure. The VBPCA is a static probabilistic model. Different from the PLS, the VBPCA determines the number of principal components automatically, which is also the basis of our developed models (DVBPCA and MW-DVBPCA). The LSTM and ESN are advanced dynamic neural network models that consider the dynamics. The DPLS is the improvement of the PLS based on the FIR paradigm, which also accounts for the dynamics of the hydrogen production process.
4.1. Natural Gas Steam Reforming Hydrogen Production Process
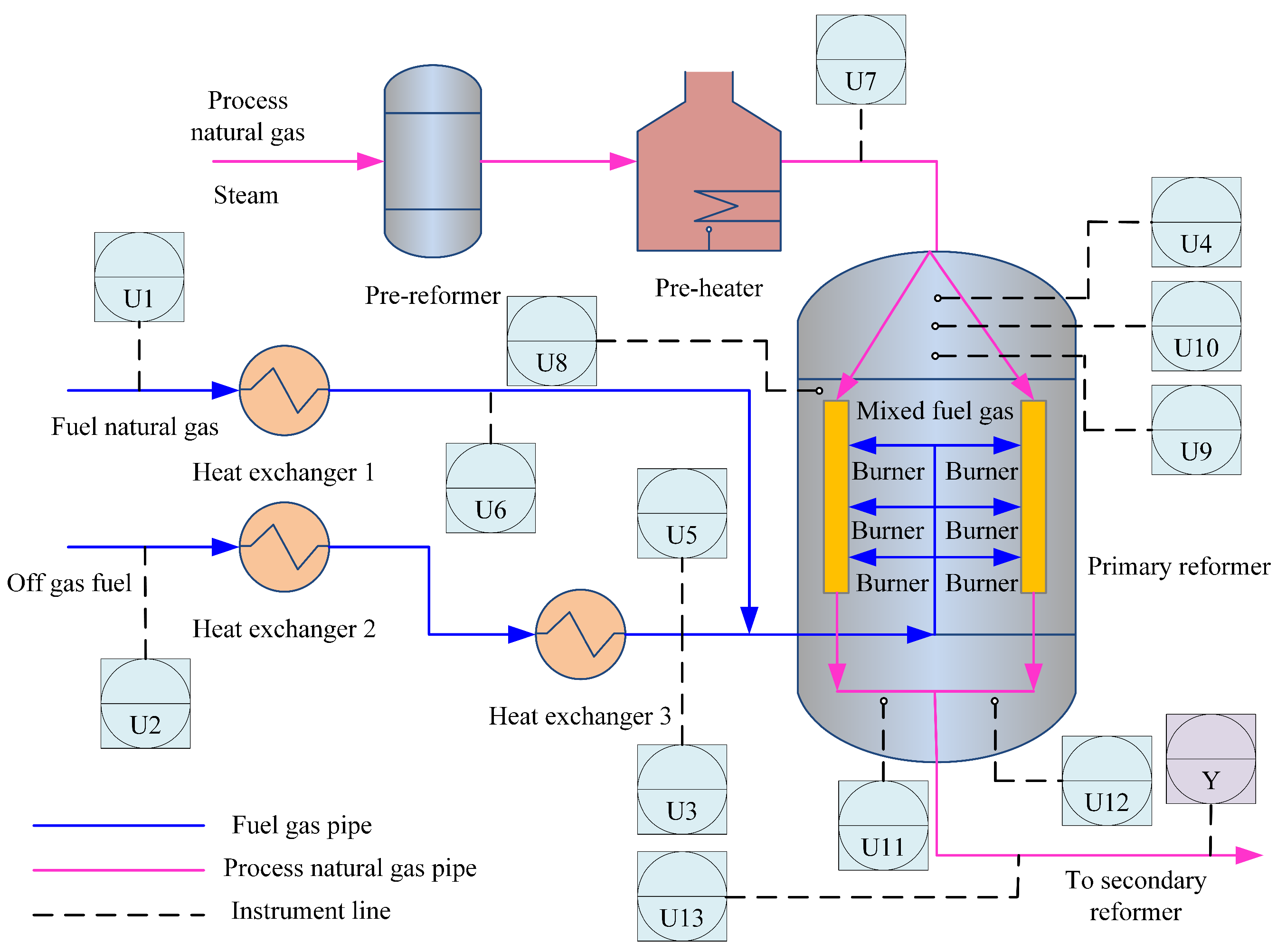
The natural gas steam reforming hydrogen production process is the largest industrial source of hydrogen, and it consists of four main processes: feedstock purification, steam reforming, medium temperature conversion, and pressure swing adsorption. Among these processes, steam reforming is the dominant reaction process, which is schematically shown in Figure 3 [34]. Processed gases are mixed with steam in the pre-reformer, where all hydrocarbons and some are converted to , and . The temperature then decreases, which is not conducive to promoting hydrogen generation. The pre-reformer output is heated in a pre-heater and then continuously fed to the primary reformer for complete reforming.
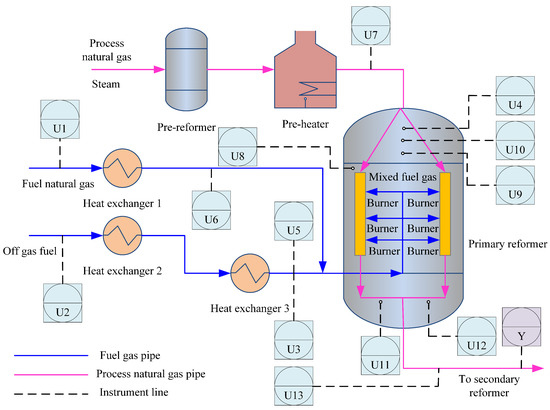
Figure 3.
The flowchart of steam reforming process.
The main chemical reactions of this process are shown as follows:
According to Equation (34), the exit gases of the hydrogen production process consist of , , , and , and the concentrations of these gases are KVs (as labeled “Y” in Figure 3) related to product quality. Therefore, these KVs need to be strictly monitored. In practice, offline laboratory analysis and hardware sensors are traditional methods for measuring the KVs, but have delays and high investment. Meanwhile, series-wound devices (such as pre-reformers and pre-heaters) introduce considerable transportation delays, which must be considered in virtual sensor modeling. Therefore, for giving real-time predictions of the KVs, a virtual sensor considering transportation delays is desirable.
4.2. Explanatory Variable Selection and Data Collection
A total of 13 EVs for the virtual sensor development are selected based on the first principles and the operation experience of the engineers. These EVs are easily measured variables, closely linked to the KVs and highly correlated with process variations, as shown by labels U1–U13 in Figure 3. The descriptions of these EVs are listed in Table 1.

Table 1.
EVs in the hydrogen production process.
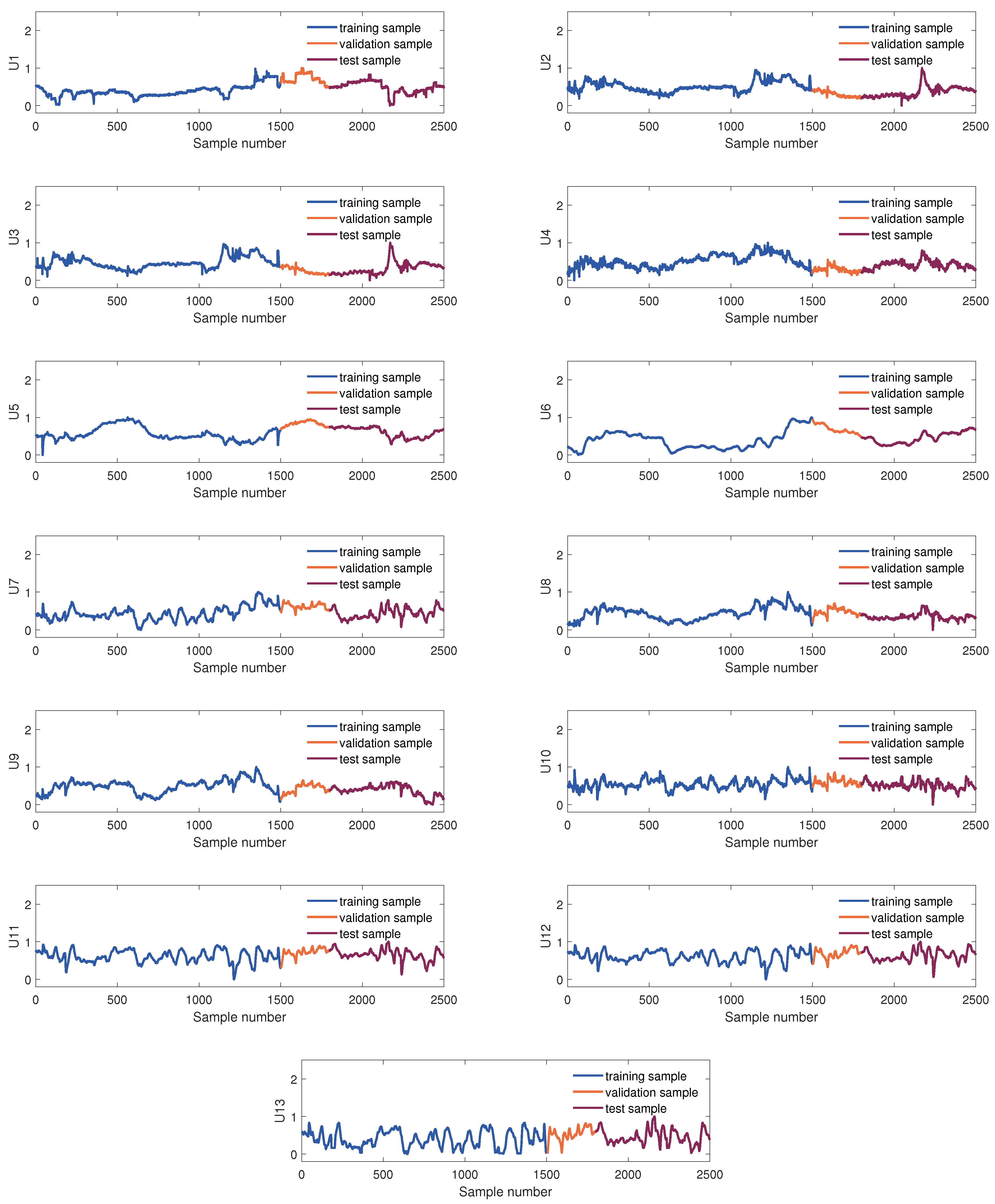
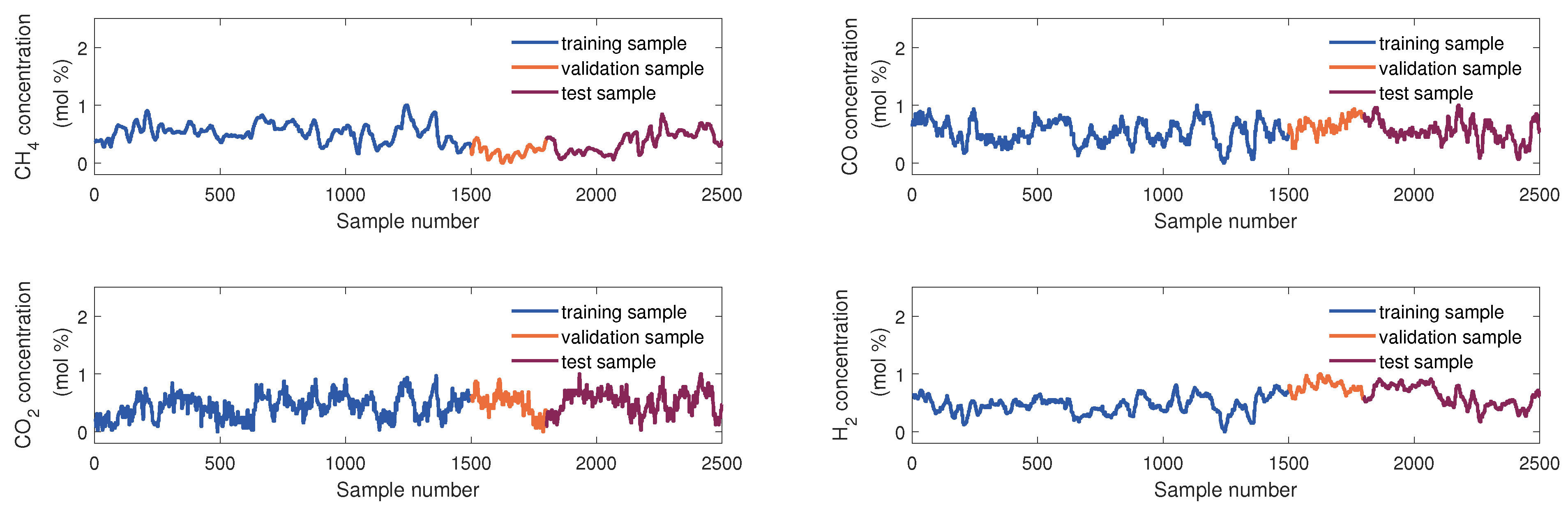
The samples used to develop the virtual sensor of the KVs were obtained from the DCS database. The KVs’ sampling rate is 10 min, and 2500 samples were collected. These were divided into three parts in order of collection time: the training set, the validation set, and the testing set, which consist of 1500 samples, 300 samples, and 700 samples, respectively. Figure 4 and Figure 5 show sample division and the changing trend of these EVs and four KVs, respectively. In this article, we use scaled dimensionless data for modeling.
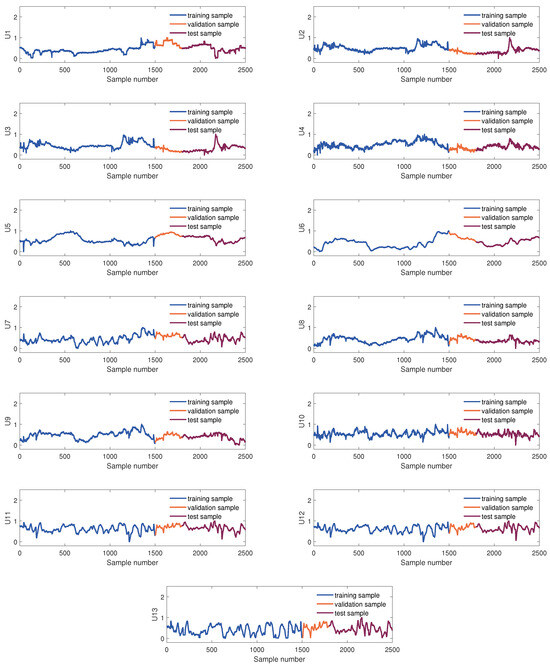
Figure 4.
The diagram of data partition of 13 EVs.
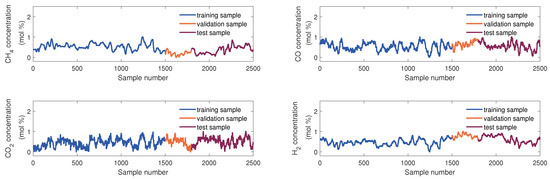
Figure 5.
The diagram of data partition of four KVs.
4.3. Evaluation Metrics
The root mean squares error (RMSE), the coefficient of determination (), and the mean absolute error (MAE) are chosen to quantify different models’ performance, which are defined as
where and are the estimated values and true values of the th testing sample, respectively, is the size of the testing dataset, and are the mean of the KVs in the testing dataset. The RMSE and MAE indexes characterize the average and largest prediction errors on the test set, respectively, and the index characterizes the correlation between the predicted and true values. Therefore, the smaller the RMSE and MAE or the bigger the , the higher the predictive accuracy.
4.4. Parameter Selection
All models’ optimal parameters need to be chosen to obtain different models’ best prediction performance. Select the DE algorithm to minimize the average RMSE (i.e., the mean of the RMSE of the four KVs) on the validation set for parameter optimization of different models. For the PLS, the number of principal components and the time delays are the parameters to be optimized. For the DPLS, the number of principal components, the time delays and the dynamic orders are the parameters to be optimized. For the VBPCA-based models, the time delays and the dynamic orders are the parameters to be optimized. For the LSTM and ESN, the time delays are the parameters to be optimized.
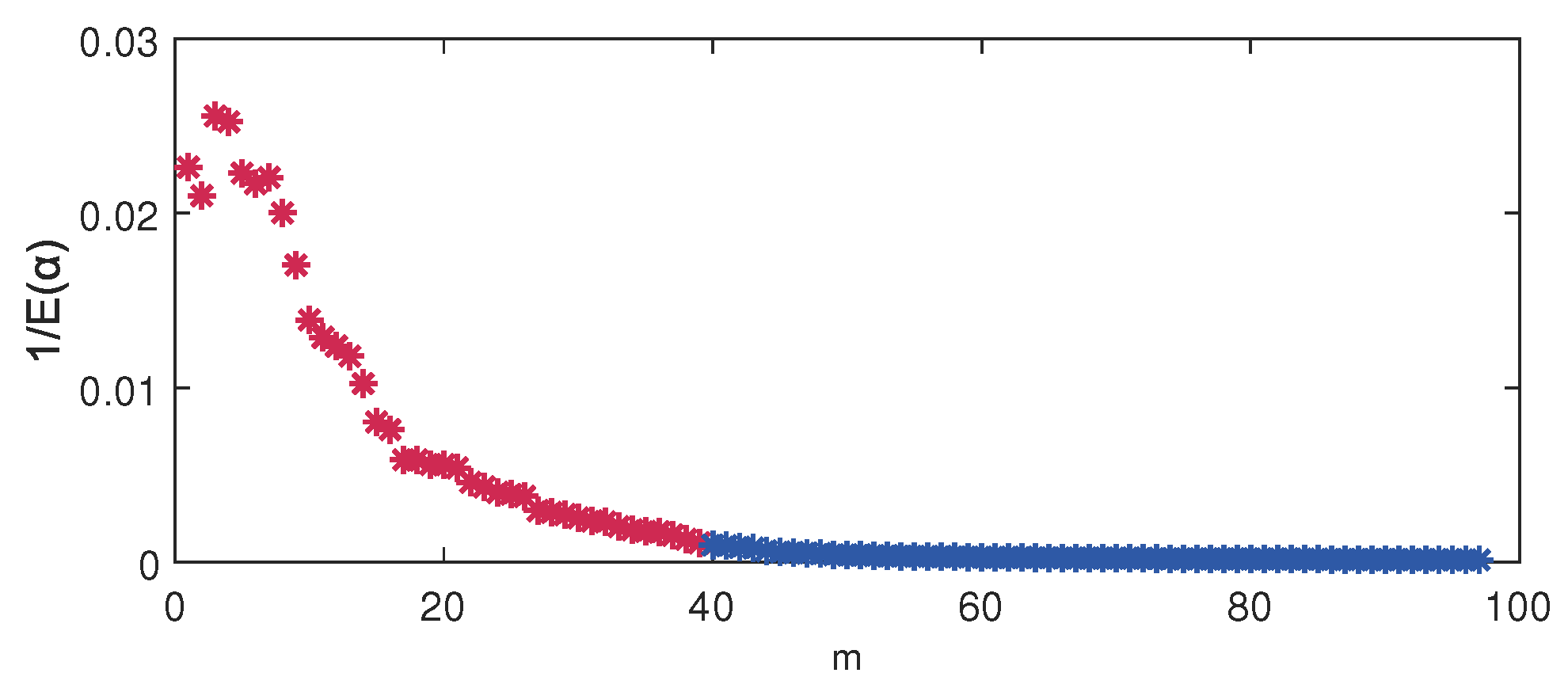
For the VBPCA-based models, the key issue of automatic parameter determination of the principal component number is whether each column of the loading matrix is either insignificant or significant, i.e., or , which can be controlled by according to Equation (8). Take DVBPCA for example, the fact that the variance of each can be quantified by for , which is displayed in Figure 6. The color distinction of the points in Figure 6 means the value of is either insignificant or significant by setting threshold, where red means significant and blue means insignificant. As shown in Figure 6, the appropriate dimensionality of the principal component subspace is selected as 39.
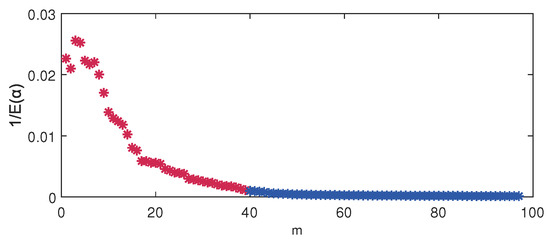
Figure 6.
Variance of each by DVBPCA.
For the ESN, set the input regulation scale to 0.1, set the reservoir size to 50, and set the spectral radius to 0.8. Considering that the ESN involves the random weights in the reservoir computing step, 20 modeling tests were performed. For each trial, the random weights are saved and fixed, and the DE algorithm is used to optimize the model delays further. Then, the best results from 20 tests are picked for model performance comparison. Note that the ESN is a single-output model; we therefore construct four ESN models, one for each KV. For the LSTM, based on the debugging experience, set the time step to 1, set the learning rate to 0.1, set the hidden layer to 1, and set the neuron number in the hidden layer to 100, which performs favorably empirically in each of the replicated experiments of this work.
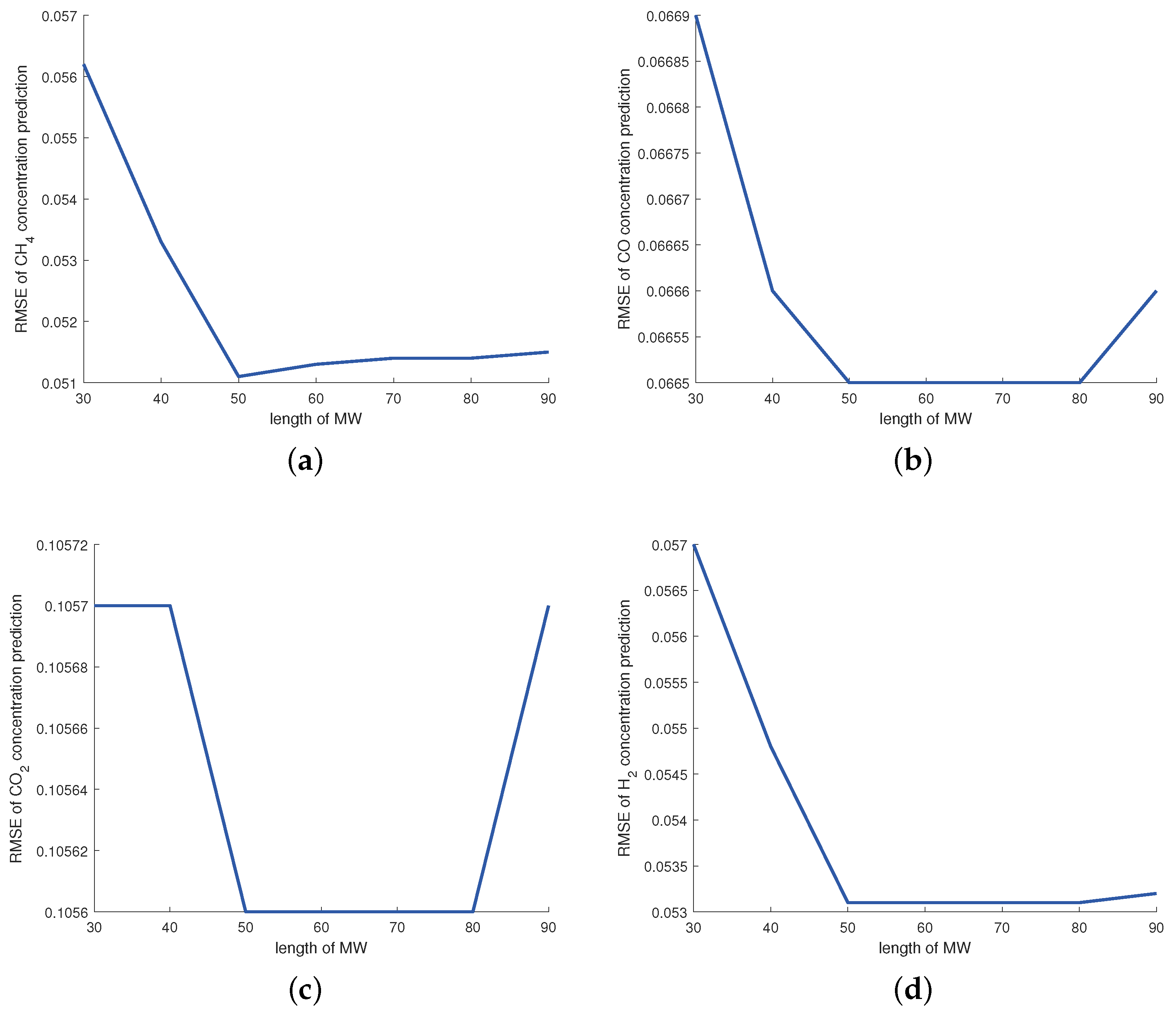
For the MW-DVBPCA, the impact of MW size is detailed in Figure 7. The MW size is in units of 10 min, i.e., setting the MW size to 50 means that the MW contains 500 min of data. As shown in Figure 7, for small MW sizes, the data in the window may not appropriately represent the relationship between process variables. In contrast, excessive MW size covers too much outdated sample data so that the MW-DVBPCA fails to track the process change adequately. Therefore, according to Figure 7, the MW size was selected as 50.
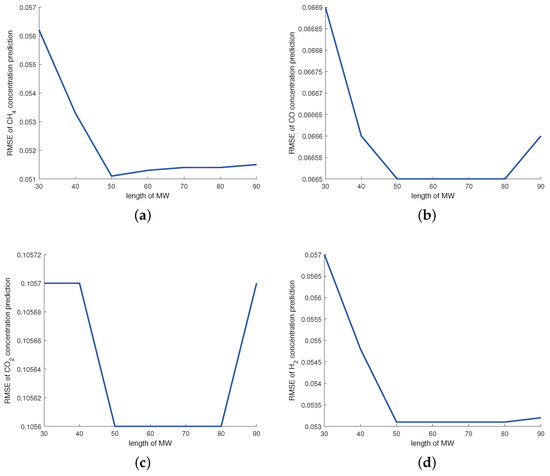
Figure 7.
Impact of MW size for: (a) concentration, (b) concentration, (c) concentration, and (d) concentration.
4.5. Results and Analysis
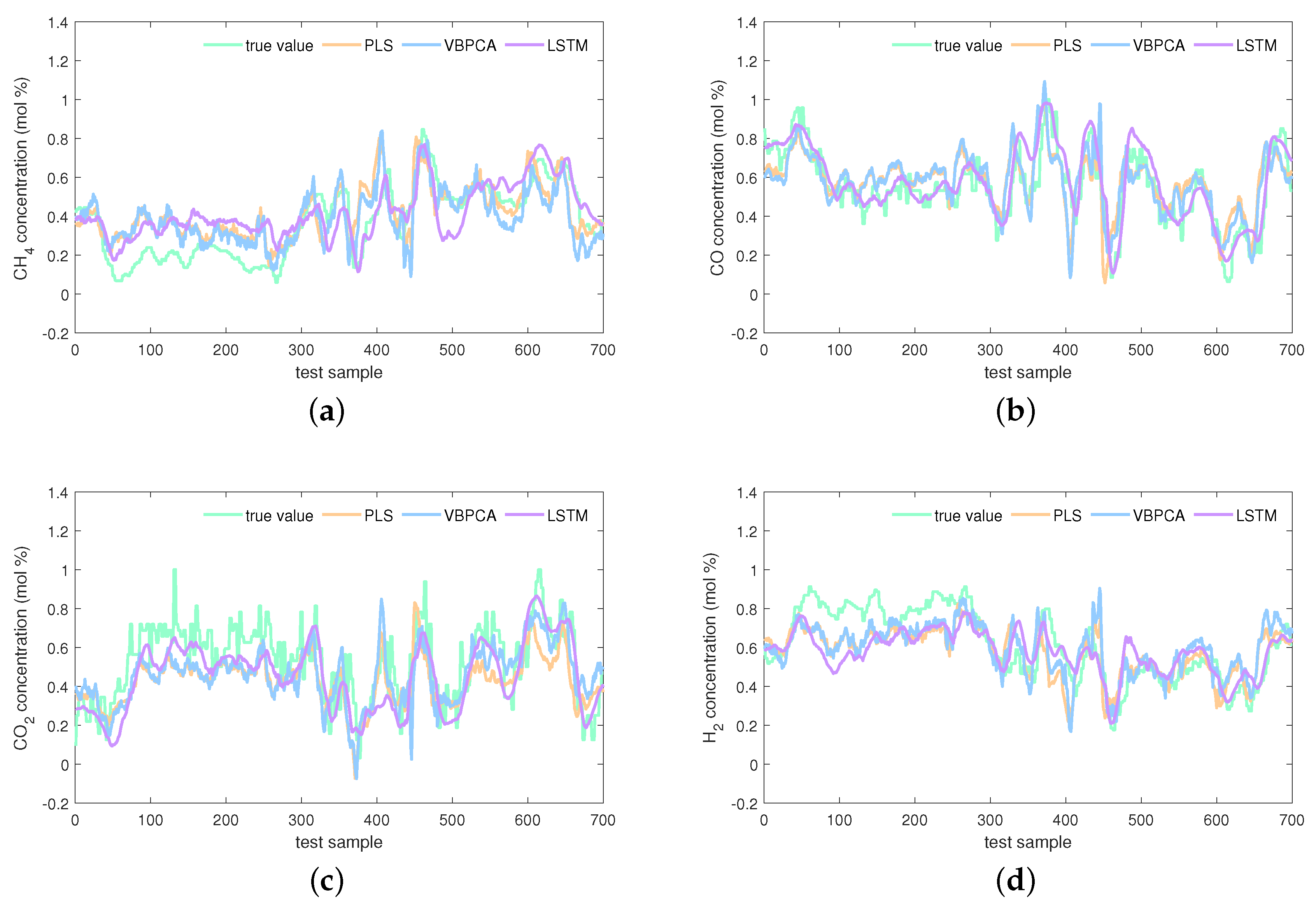
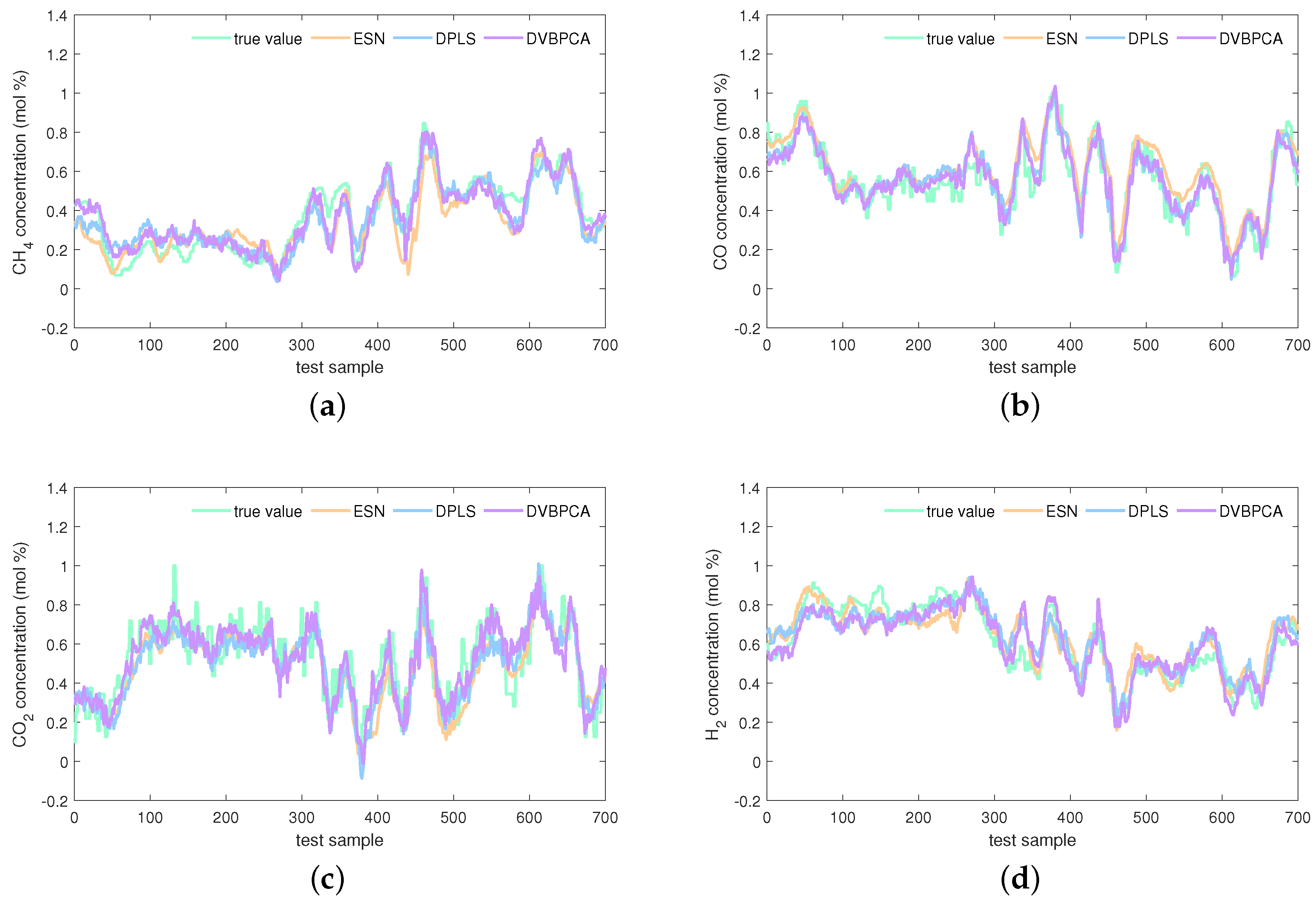
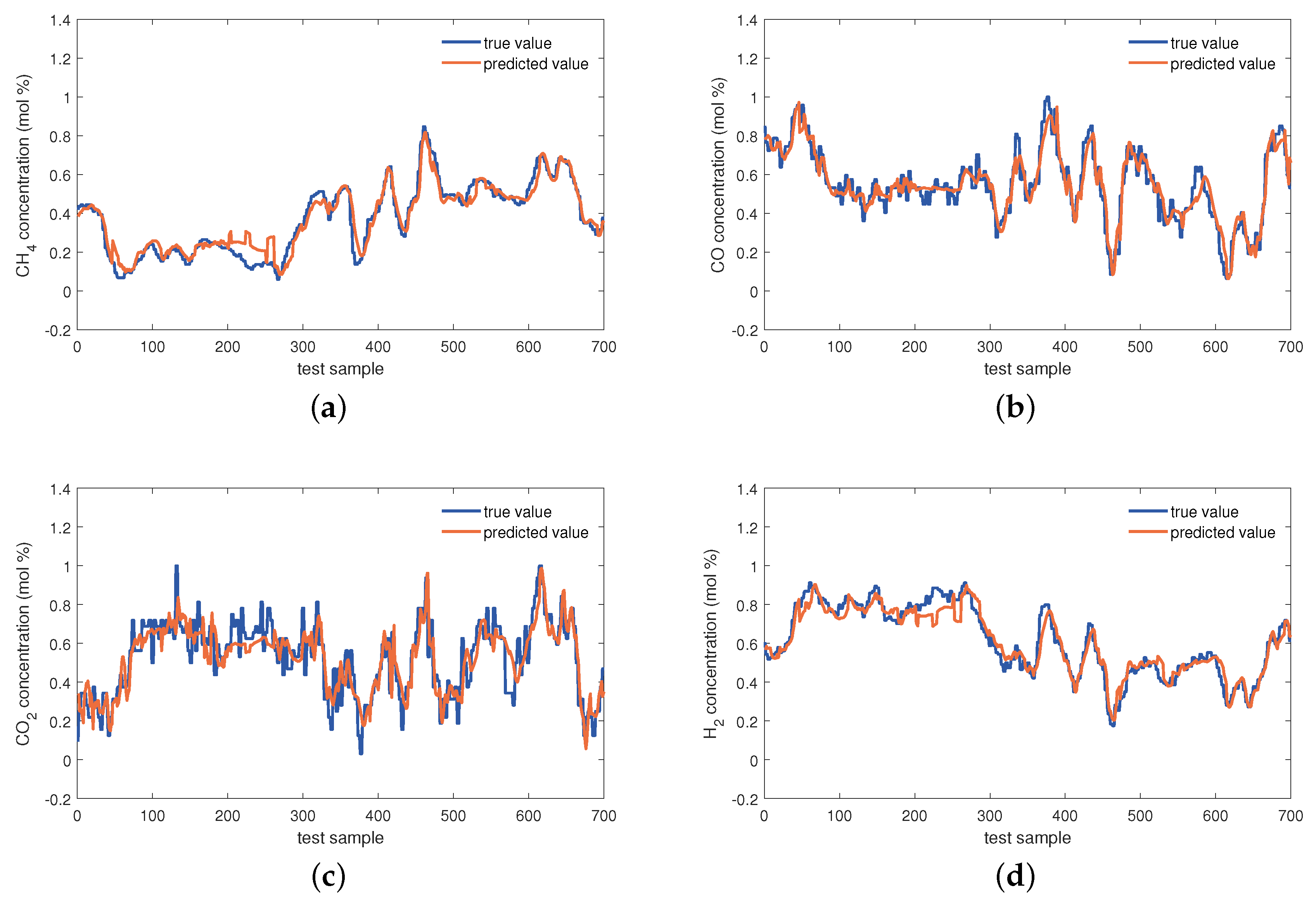
The estimations on the test set of the KVs obtained by the investigated seven virtual sensors are visualized in Figure 8, Figure 9 and Figure 10. In Figure 8, obviously, the PLS and VBPCA have the poor estimation performance. Because of the significant dynamics of the hydrogen production process, the estimation accuracy of the static models, PLS and VBPCA, is not as satisfactory as that of the other five dynamic models (such as around the 120-th sample of the concentration). Figure 9 shows that the estimated values of the DVBPCA tracks real values better than the other three models (such as around the 300-th sample of the concentration and around the 300-th sample of the concentration). That is because, on the one hand, the DVBPCA can deal with the colinearities between the EVs compared with the LSTM and ESN. On the other hand, the DVBPCA can tackle the overfitting results from high-order variable augmentation compared with the DPLS. Moreover, the ESN constructs four virtual sensors, one for each KV for estimation, but the DVBPCA is a multi-output model that considers the inherent relationships between the KVs. Figure 10 illustrate that the estimations of the four KVs by the MW-DVBPCA match the real values much better (particularly in the localized area of the concentration around the 440-th sample) than other models, revealing the importance of considering time variation properties in the virtual sensor modeling of the hydrogen production process. Moreover, although the overall predicted values do match well with the true ones when the proposed MW-DVBPCA method was used, some discrepancies can be observed between test sample number 200 and 300 for all the four KVs. The possible reasons for these differences in the predicted and true values are as follows. Firstly, the characteristics of the samples between test sample number 200 and 300 are changing rapidly, and model learning does not accommodate such changes in time. Secondly, the samples between test sample number 200 and 300 have nonlinearities, but the local model constructed by MW-DVBPCA is linear. Overall, it is recognized that the proposed models show noticeable advantages over the benchmark models.
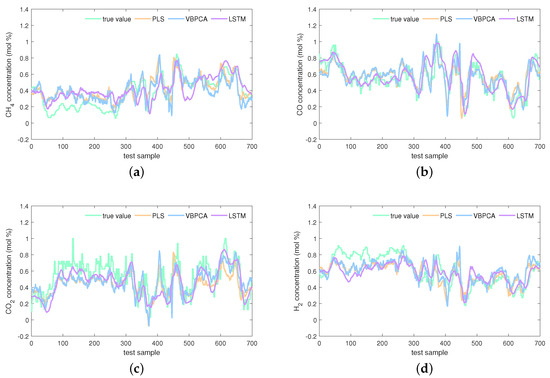
Figure 8.
Estimations of four KVs by the PLS, VBPCA, and LSTM: (a) concentration, (b) concentration, (c) concentration, and (d) concentration.
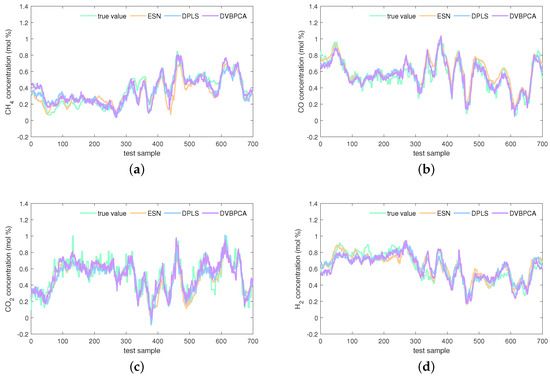
Figure 9.
Estimations of four KVs by the ESN, DPLS, and DVBPCA: (a) concentration, (b) concentration, (c) concentration, and (d) concentration.
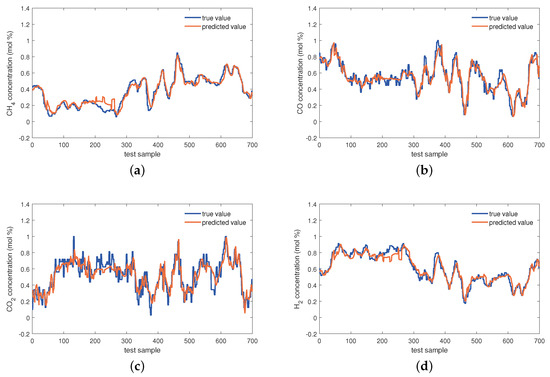
Figure 10.
Estimations of four KVs by the MW-DVBPCA: (a) concentration, (b) concentration, (c) concentration, and (d) concentration.
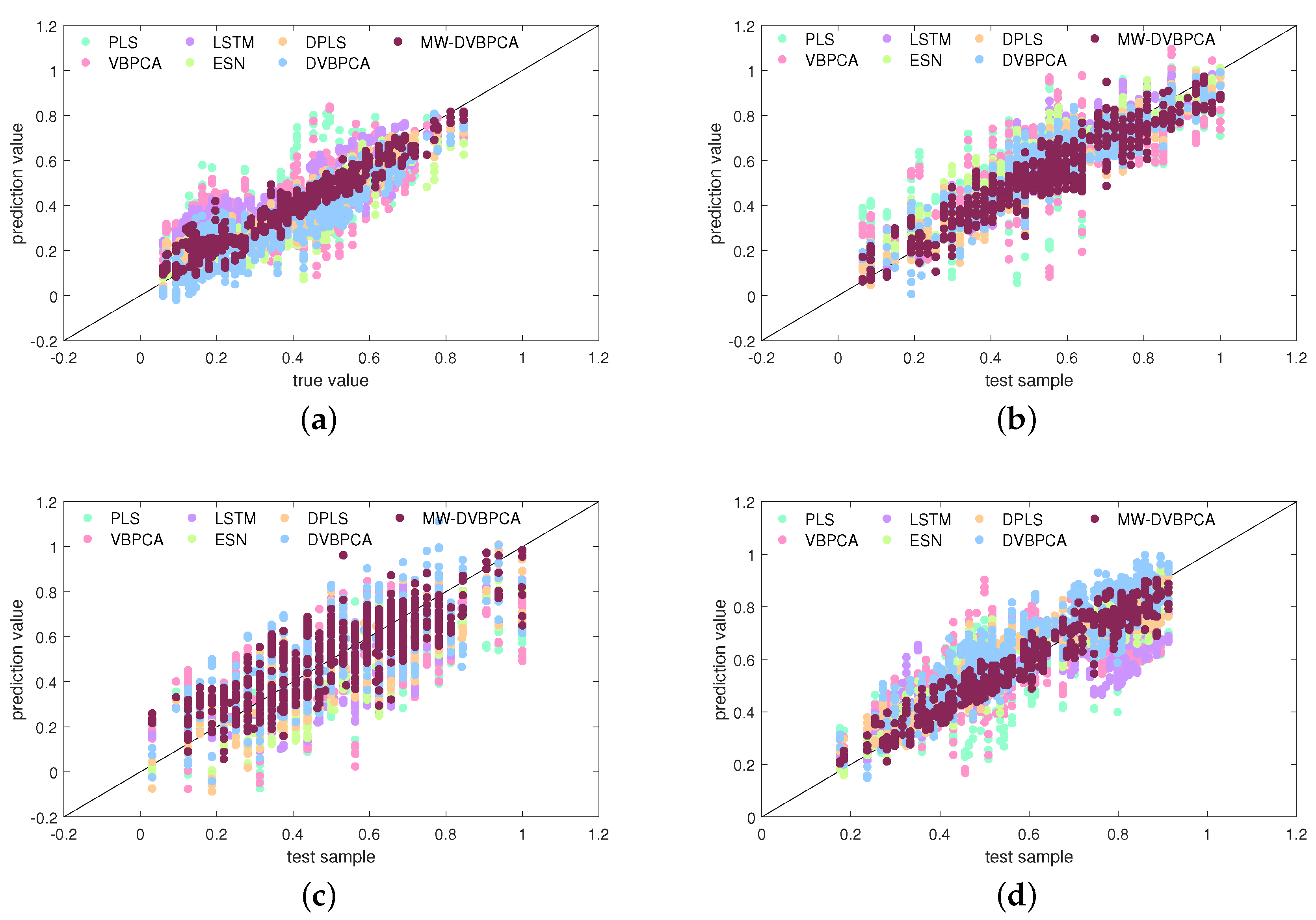
Figure 11 compares the seven models in terms of scatter plots. Based on Figure 11, a further comparison of the prediction of the data-driven models can be made. As shown in Figure 11a, the predictions of the PLS for component deviate obviously from the real values. Figure 11b,c shows that the VBPCA model improves the prediction accuracy of and concentrations somewhat compared to the PLS model. However, the overall prediction accuracy is still very low. Figure 11d reveals that all models have relatively poor prediction accuracy for the concentration, but the MW-DVBPCA presents a better result. As indicated in Figure 11, the scatters by MW-DVBPCA are more closely and clearly located around the diagonal line than those of other models, thus illustrating better performance.
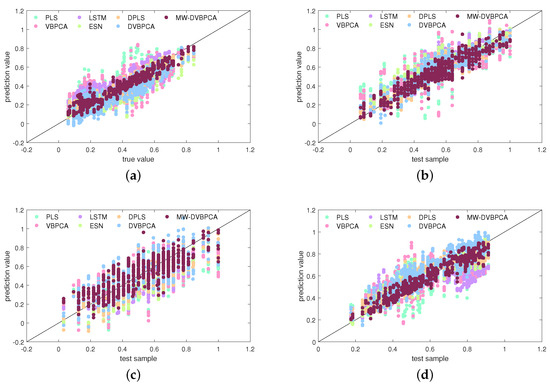
Figure 11.
Scatter plot comparisons between various models for: (a) concentration, (b) concentration, (c) concentration, and (d) concentration.
The estimation performance of all data-driven virtual sensors is quantitatively tabulated in Table 2 and Table 3. For a further comparison, Table 2 and Table 3 show the estimations of the data-driven virtual sensors not considering transportation delays. These models’ parameter selection is consistent with the corresponding model considering transportation delays. Overall, the estimation results in Table 2 and Table 3 provide an initial validation of the effectiveness of the data-driven virtual sensors. However, the performances of the different data-driven virtual sensors vary considerably. The performance of the models that consider delays is better than that of the corresponding models that do not, as shown in Table 2 and Table 3. Take the DVBPCA as an instance. The predictive performance based on the RMSE index of the four KVs by the model accounting for the time delays is improved by 18.6%, 13.0%, 2.3%, and 5.5%, respectively, compared to the model ignoring time delays. This is because the hydrogen production process has substantial time delays, and it has been proven that ignoring the delays could result in significantly deteriorated performance [29]. The values for two static models, i.e., the PLS and VBPCA, are as low as below 0.5; in contrast, the dynamic models, such as LSTM, ESN, and DPLS, show significantly better performance than the PLS and VBPCA, indicating the dynamic model better fits the data features of the actual hydrogen production process. Moreover, due to the capability of dealing with overfitting, the DVBPCA performs better than the DPLS. Concretely, compared to the DPLS, the RMSEs of the four KVs obtained by the DVBPCA are decreased by 13.4%, 1.8%, 3.2%, and 4.8%, respectively. Moreover, the MW-DVBPCA further improves the estimations of the four KVs. The s of the and concentrations reach as high as up to 0.9. Compared with the DVBPCA, the predictive performance on the four KVs by the MW-DVBPCA improves by 1.3%, 10.3%, 2.8%, and 33.4%, respectively, in terms of the MAE index.
Table 2.
Quantitative estimation results of various models for the concentrations of and .
Table 3.
Quantitative estimation results of various models for the concentrations of and .
Furthermore, to check whether the MW-DVBPCA’s performance is significantly different from that of other models, the Wilcoxon test is employed for statistical testing [35]. The Wilcoxon test is a non-parametric testing method which is used to examine whether there is significant difference in the median values of the squared estimation errors obtained by the two virtual sensors. In Wilcoxon’s test, the likelihood that the corresponding hypothesis will be accepted is measured by calculating the p-value. The smaller the value of p-value, the lower the probability that the corresponding hypothesis will be accepted. Typically, the hypothesis should be rejected if the p-value is less than the given significance level , the hypothesis should be rejected; that is, statistically the median values of two virtual sensors are different.
The Wilcoxon test results are given in Table 4, where , , , , , , and mean the median values of squared estimated errors obtained by the PLS, VBPCA, LSTM, ESN, DPLS, DVBPCA, and MW-DVBPCA, respectively. Additionally, set the significance level at 5%. As shown in Table 4, all hypothesized p-values are far below . Hence, all hypotheses are rejected. In other words, there is statistical significance in comparing the MW-DVBPCA with other virtual sensors in the hydrogen production process.
Table 4.
Results of the Wilcoxon test.
4.6. Computational Efficiency Analysis
Since this article is concerned with real-time estimation, examining the runtime of the model is desirable. The offline and online computational efficiency of the virtual sensors is evaluated using the average over 10 independent simulations, including the CPU time consumed offline for parameter optimization () and the CPU time consumed online (). All experiments were computed on a Core i5 (2.90 GHz × 2) with 8 GB RAM, Windows 10 and R2021a version of MATLAB.
Table 5 lists the time taken by each virtual sensor on parameter determination. As can be observed, the index for the DVBPCA model is much smaller than that for the LSTM, due to its more concise structure. The indices for other dynamic global models are almost the same as those for the DVBPCA, but other dynamic global models have lower accuracy than the DVBPCA given in Table 2 and Table 3. Note that the index for the MW-DVBPCA is much larger than that for the DVBPCA, which is because the MW-DVBPCA needs to rebuild the model each time it predicts a new valid sample. Fortunately, the parameter determination processes are carried out offline. In other words, this process hardly affects the online calculative efficiency of the MW-DVBPCA. The last column of Table 5 illustrates the online computation time of MW-DVBPCA. Consequently, the online computational efficiency of the developed models is not an issue. In practice, the indices for all virtual sensors are less than 0.1 s/sample, significantly faster than the minimum sampling period for the KVs in the hydrogen production process. The results show that all data-driven virtual sensors meet the time requirements for real-time estimation, including the developed DVBPCA and MW-DVBPCA.
Table 5.
Comparison of computational efficiency of various models (seconds).
5. Conclusions and Outlook
Considering the complicated properties of the hydrogen production process, we develop virtual sensors for the KVs of the hydrogen production process in this article. The MW-DVBPCA is developed to model complicated properties of the hydrogen production process, including dynamics, time variations, and transportation delays. To be specific, the FIR paradigm and MW technique are employed to extract process dynamics and to deal with time variations, respectively. The time delays are determined automatically by the DE. A comparative study of developed virtual sensors and other state-of-the-art virtual sensors is carried out. Meanwhile, the performance of MW-DVBPCA is demonstrated by the real-life natural gas steam reforming hydrogen production process.
From the industrial point of view, the online estimations of the KVs of the hydrogen production process need further research. Some future works are given to further improve the estimation performance of the KVs.
- Robust methods. The probabilistic model in this article is based on the traditional Gaussian distribution assumption, which is susceptible to outliers. Therefore, the training set must be cleaned to remove outliers. However, some outliers are indistinctive and challenging to detect and remove. To this end, finding a probability distribution insensitive to the noise and outliers can help improve the generalization performance of predictive models. Typically, Student’s t distribution with heavier tails is a candidate choice. As a result, designing a robust virtual sensor based on Student’s t distribution is worth investigating.
- Data-driven approaches fused with process knowledge. In fact, the states (or the hidden variables) of the system are influenced by variables characterizing materials and energies fed into the process. Conventional virtual sensors take all observed variables as inputs and the KVs as outputs, which makes it difficult to describe the true causality between variables of the hydrogen production process, weakening the interpretability and generalization abilities. A causal virtual sensor can better reflect the process mechanism and thus estimate the KVs more accurately. Therefore, equipping the MW-DVBPCA model with the causality of process variables of the hydrogen production process is desirable.
Author Contributions
Software, Y.Y. and Y.X.; Supervision, C.W. and W.S.; Writing—original draft, Y.Y. and Z.Z.; Writing—review & editing, Y.Y., C.W. and W.S. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China under Grants 62173344 and 62103364.
Data Availability Statement
Data are available for reasonable reasons by contacting the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Lee, C.; Li, S.; Chen, C.; Huang, Y.; Wang, Y. Real-time microscopic monitoring of flow, voltage and current in the proton exchange membrane water electrolyzer. Sensors 2018, 18, 867. [Google Scholar] [CrossRef] [PubMed]
- Ji, M.; Wang, J. Review and comparison of various hydrogen production methods based on costs and life cycle impact assessment indicators. Int. J. Hydrogen Energy 2021, 46, 38612–38635. [Google Scholar] [CrossRef]
- Chen, Y. Technical progress and development trend of hydrogen production from natural gas. Coal Chem. Ind. 2020, 43, 130–133. [Google Scholar]
- Yao, L.; Ge, Z. Deep learning of semisupervised process data with hierarchical extreme learning machine and soft sensor application. IEEE Trans. Ind. Electron. 2017, 65, 1490–1498. [Google Scholar] [CrossRef]
- Cao, Q.; Chen, S.; Zhang, D.; Xiang, W. Research on soft sensing modeling method of gas turbine’s difficult-to-measure parameters. J. Mech. Sci. Technol. 2022, 36, 4269–4277. [Google Scholar] [CrossRef]
- Dogan, A.; Birant, D. Machine learning and data mining in manufacturing. Expert Syst. Appl. 2021, 166, 114060. [Google Scholar] [CrossRef]
- Suthar, K.; Shah, D.; Wang, J.; He, Q.P. Next-generation virtual metrology for semiconductor manufacturing: A feature-based framework. Comput. Chem. Eng. 2019, 127, 140–149. [Google Scholar] [CrossRef]
- Liu, C.; Wang, K.; Wang, Y.; Xie, S.; Yang, C. Deep nonlinear dynamic feature extraction for quality prediction based on spatiotemporal neighborhood preserving SAE. IEEE Trans. Instrum. Meas. 2021, 70, 1–10. [Google Scholar] [CrossRef]
- Sadeghian, A.; Jan, N.M.; Wu, O.; Huang, B. Robust probabilistic principal component regression with switching mixture Gaussian noise for soft sensing. Chemom. Intell. Lab. Syst. 2022, 222, 104491. [Google Scholar] [CrossRef]
- Shao, W.; Ge, Z.; Song, Z. Semisupervised Bayesian Gaussian mixture models for non-Gaussian soft sensor. IEEE Trans. Cybern. 2019, 51, 3455–3468. [Google Scholar] [CrossRef]
- Yang, F.; Liang, Q.; Zhao, J.; Qiao, R. Hydrogen production from ammonia pyrolysis reforming and prediction model of ammonia decomposition rate. J. Ordnance Equip. Eng. 2022, 43, 277–280,285. [Google Scholar]
- Huang, X.; Zhao, B.; Zhang, H.; Zhang, R.; Wang, B.; Liu, H. Parameters research for hydrogen production of methane steam reforming under concentrated radiation. Chem. Eng. Oil Gas. 2021, 50, 58–65. [Google Scholar]
- Zhou, H.; Ma, Y.; Wang, K.; Li, H.; Meng, W.; Xie, J.; Li, G.; Zhang, D.; Wang, D.; Zhao, Y. Optimization and analysis of coal-to-methanol process by integrating chemical looping air separation and hydrogen technology. Chem. Ind. Eng. Prog. 2022, 41, 5332–5341. [Google Scholar]
- Yin, S.; Rodriguez-Andina, J.J.; Jiang, Y. Real-Time Monitoring and Control of Industrial Cyberphysical Systems: With Integrated Plant-Wide Monitoring and Control Framework. IEEE Ind. Electron. Mag. 2019, 13, 38–47. [Google Scholar] [CrossRef]
- Ye, Y.; Ren, J.; Wu, X.; Ou, G.; Jin, H. Data-driven soft-sensor modelling for air cooler system pH values based on a fast search pruned-extreme learning machine. Asia-Pac. J. Chem. Eng. 2017, 12, 186–195. [Google Scholar] [CrossRef]
- Yuan, X.; Qi, S.; Shardt, Y.A.; Wang, Y.; Yang, C.; Gui, W. Soft sensor model for dynamic processes based on multichannel convolutional neural network. Chemom. Intell. Lab. Syst. 2020, 203, 104050. [Google Scholar] [CrossRef]
- Wei, C.; Song, Z. Real-time forecasting of subsurface inclusion defects for continuous casting slabs: A data-driven comparative study. Sensors 2023, 23, 5415. [Google Scholar] [CrossRef]
- Tong, W.; Wei, B. Soft sensing modeling of methane content in conversion reaction based on GA-BP. Automat. Instrum. 2016, 31, 7–10. [Google Scholar]
- Zamaniyan, A.; Joda, F.; Behroozsarand, A.; Ebrahimi, H. Application of artificial neural networks (ANN) for modeling of industrial hydrogen plant. Int. J. Hydrogen Energy 2013, 38, 6289–6297. [Google Scholar] [CrossRef]
- Ögren, Y.; Tóth, P.; Garami, A.; Sepman, A.; Wiinikka, H. Development of a vision-based soft sensor for estimating equivalence ratio and major species concentration in entrained flow biomass gasification reactors. Appl. Energy 2018, 226, 450–460. [Google Scholar] [CrossRef]
- Fang, X.; Ding, Z.; Shu, X. Hydrogen yield prediction model of hydrogen production from low rank coal based on support vector machine optimized by genetic algorithm. J. China Coal Soc. 2010, 35, 205–209. [Google Scholar]
- Zhao, Y.; Song, H.; Guo, Y.; Zhao, L.; Sun, H. Super short term combined power prediction for wind power hydrogen production. Energy Rep. 2022, 8, 1387–1395. [Google Scholar] [CrossRef]
- Koc, R.; Kazantzis, N.K.; Ma, Y.H. A process dynamic modeling and control framework for performance assessment of Pd/alloy-based membrane reactors used in hydrogen production. Int. J. Hydrogen Energy 2011, 36, 4934–4951. [Google Scholar] [CrossRef]
- Pan, F.; Cheng, X.; Wu, X.; Wang, X.; Gong, J. Thermodynamic design and performance calculation of the thermochemical reformers. Energies 2019, 12, 3693. [Google Scholar] [CrossRef]
- Sharma, Y.C.; Kumar, A.; Prasad, R.; Upadhyay, S.N. Ethanol steam reforming for hydrogen production: Latest and effective catalyst modification strategies to minimize carbonaceous deactivation. Renew. Sustain. Energy Rev. 2017, 74, 89–103. [Google Scholar] [CrossRef]
- Blei, D.M.; Kucukelbir, A.; McAuliffe, J.D. Variational inference: A review for statisticians. J. Am. Stat. Assoc. 2017, 112, 859–877. [Google Scholar] [CrossRef]
- Oh, H.S.; Kim, D.G. Bayesian principal component analysis with mixture priors. J. Korean Stat. Soc. 2010, 39, 387–396. [Google Scholar] [CrossRef]
- Liu, Y.; Hu, N.; Wang, H.; Li, P. Soft chemical analyzer development using adaptive least-squares support vector regression with selective pruning and variable moving window size. Ind. Eng. Chem. Res. 2009, 48, 5731–5741. [Google Scholar] [CrossRef]
- Yao, L.; Ge, Z. Refining data-driven soft sensor modeling framework with variable time reconstruction. J. Process Control 2020, 87, 91–107. [Google Scholar] [CrossRef]
- Geladi, P.; Kowalski, B.R. Partial least-squares regression: A tutorial. Anal. Chim. Acta 1986, 185, 1–17. [Google Scholar] [CrossRef]
- Sherstinsky, A. Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network. Phys. D 2020, 404, 132306. [Google Scholar] [CrossRef]
- Chen, Q.; Zhang, A.; Huang, T.; He, Q.; Song, Y. Imbalanced dataset-based echo state networks for anomaly detection. Neural Comput. Appl. 2020, 32, 3685–3694. [Google Scholar] [CrossRef]
- Ricker, N.L. The use of biased least-squares estimators for parameters in discrete-time pulse-response models. Ind. Eng. Chem. Res. 1988, 27, 343–350. [Google Scholar] [CrossRef]
- Shao, W.; Ge, Z.; Yao, L.; Song, Z. Bayesian nonlinear Gaussian mixture regression and its application to virtual sensing for multimode industrial processes. IEEE Trans. Automat. Sci. Eng. 2019, 17, 871–885. [Google Scholar] [CrossRef]
- Rodríguez-Fdez, I.; Canosa, A.; Mucientes, M.; Bugarín, A. STAC: A web platform for the comparison of algorithms using statistical tests. In Proceedings of the 2015 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Istanbul, Turkey, 2–5 August 2015. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).