Abstract
Malicious social bots pose a serious threat to social network security by spreading false information and guiding bad opinions in social networks. The singularity and scarcity of single organization data and the high cost of labeling social bots have given rise to the construction of federated models that combine federated learning with social bot detection. In this paper, we first combine the federated learning framework with the Relational Graph Convolutional Neural Network (RGCN) model to achieve federated social bot detection. A class-level cross entropy loss function is applied in the local model training to mitigate the effects of the class imbalance problem in local data. To address the data heterogeneity issue from multiple participants, we optimize the classical federated learning algorithm by applying knowledge distillation methods. Specifically, we adjust the client-side and server-side models separately: training a global generator to generate pseudo-samples based on the local data distribution knowledge to correct the optimization direction of client-side classification models, and integrating client-side classification models’ knowledge on the server side to guide the training of the global classification model. We conduct extensive experiments on widely used datasets, and the results demonstrate the effectiveness of our approach in social bot detection in heterogeneous data scenarios. Compared to baseline methods, our approach achieves a nearly 3–10% improvement in detection accuracy when the data heterogeneity is larger. Additionally, our method achieves the specified accuracy with minimal communication rounds.
1. Introduction
The application of online social networks is becoming increasingly widespread, with the number of users on platforms like Twitter, Facebook, Instagram, and Weibo continuously growing. Social networks have become important tools for users to communicate, entertain, and obtain information. Alongside this, a new type of account controlled by automated programs has emerged on these social platforms [1]: social bots. Social bots can be categorized into malicious and benign accounts. Some benign social bots are designed to automatically aggregate content from various sources and provide services to regular users. However, over time, malicious social bots with nefarious purposes have emerged. These malicious social bot accounts strive to disguise themselves as real human accounts, creating artificial popularity, spreading false information [2], and guiding negative public opinion [3] on social platforms. Evidence of social bots manipulating public opinion for political purposes has been found in events such as Brexit and the 2016 US presidential election [4]. In summary, malicious social bots engage in a range of behaviors that disrupt the social network’s order, posing a significant threat to the social network’s security. Therefore, there is an urgent need for suitable and effective methods for social bot detection to foster a healthy social network environment. In our current research, we examine the differences between social bots and humans, but have not yet provided a detailed classification of social bots.
Existing social bot detection methods focus on the feature information of social accounts, including the user account features, user tweet features, and user relationship features. Graph representation learning methods based on graph neural networks are important approaches for fusing relationship features among users. We notice that most recent social bot detection works are conducted based on isolated data parties. However, utilizing account information from individual data parties for model training has several limitations: (1) the limited number and feature space of social accounts held by a single data party restricts the improvement of model performance [5]; (2) domain-specific bots across different data parties often exhibit similar characteristics [6], and sharing data facilitates the discovery of these common features; (3) labeling social bots is a challenging task, which means a high cost for each data island dedicated to building social bot detection models. Therefore, sharing the data from multiple parties for joint model training can leverage the advantages of a larger user base and richer user feature information, while alleviating the problem of difficult data labeling.
Data privacy is a primary challenge in implementing the data fusion of multi-party account information [7]. Under the premise of complying with relevant regulations and protecting data privacy, data owners often do not share data directly. The key problem lies in how to achieve the joint model training by integrating the multi-party data while ensuring that data privacy is not compromised. Federated learning has emerged as an important method to deal with the related problems.
Additionally, the heterogeneity among multiple data parties, known as the non-Independently and Identically Distributed (non-IID) problem, can significantly impact the performance of federated learning models [8]. For instance, when multiple data owners share their data for training a federated social bot detection model, there are substantial differences in the composition and distribution of social accounts among each participant (e.g., the number of human and social bot accounts present different distributions across multiple platforms). In such cases, utilizing the traditional federated learning methods for direct parameter averaging to obtain a global model can lead to severe biases in the global model, thereby affecting the performance of individual participant models. Consequently, even though federated learning facilitates the integration of multi-party data to some extent, the resulting global model may not positively impact the performance of all participant models. Some existing works [9,10] have improved upon the traditional federated averaging method by applying knowledge distillation. They distill the logit knowledge of client models to the server, resulting in significant improvements compared to existing federated learning algorithms when dealing with data heterogeneity issues among the clients.
Some recent research has focused on federal social bot detection. However, reference [5] fails to acknowledge the significance of the interaction between social accounts in enhancing the detection performance, while reference [6] overlooks the heterogeneity of the data distribution in federated learning. These shortcomings render these methods inadequate for real-world federated social bot detection scenarios. Our approach makes corresponding improvements to address these limitations. In this paper, we combine federated learning with the Relational Graph Convolutional Neural Network (RGCN) [11] graph representation learning method to construct a federated social bot detection model. We apply a class-level cross-entropy loss function to address the class imbalance problem between social bots and human accounts. The knowledge distillation method is applied to optimize and adjust for the data heterogeneity issue among multiple participants. Specifically, our social bot detection model is firstly divided into a feature extraction model based on the graph representation method and a classification model. The method of knowledge distillation is applied to train the global generator and global classification model. The global generator generates pseudo samples with global data knowledge to guide the training of the local classification model, making the decision boundary of the local model closer to the decision boundary of the model trained on global data; the global classification model integrates the logit knowledge of the clients’ local classification models, mitigating the impact of data heterogeneity among clients on model performance. The main contributions of this paper are as follows:
- We construct a naive Federated RGCN framework for social bot detection in a multi-party data fusion scenario;
- We define a class-level cross-entropy loss function. and applied it to the training process of local models, mitigating the impact of class imbalance issues during client model training;
- By applying the knowledge distillation method, we make adjustments at both the server and client sides, effectively alleviating the impact of data distribution heterogeneity among clients on the performance of the federated learning model.
2. Related Work
2.1. Social Bot Detection
The detection of bot accounts in social media began as early as 2010 [12]. Early social bot detection work primarily involved feature engineering methods, applying the traditional machine learning techniques to classify social accounts. Varol et al. [13] evaluated the classification models using over a thousand features extracted from users’ public data and metadata, including friends, tweets, network patterns, activity time series, and sentiment. Yang et al. [14] achieved an efficient analysis using minimal account metadata and extended it to real-time processing of the entire public tweet stream on Twitter. Kantepe et al. [15] extracted a plethora of features based on the account profiles, tweets, and temporal behavior, and classified accounts using machine learning classifiers.
With the widespread application of deep neural network models, several social bot detection frameworks based on deep neural networks have emerged. Kudugunta et al. [16] detected bots at the tweet level using the content and metadata, employing a deep neural network detection model based on the Long Short-Term Memory (LSTM) architecture. Wei et al. [17] applied a bidirectional LSTM (BiLSTM) network to extract semantic features from tweets. Stanton et al. [18] applied generative adversarial networks for spam detection, relying on limited labeled and unlabeled data to detect spam, thus avoiding labeling costs and inaccuracies. SATAR [19] combines a user’s tweet semantic information, attribute information, and neighbor information for the generalization, simultaneous training on a large number of self-supervised users, and fine-tuning for specific bot detection scenarios to adapt to the evolution of social bots. Hayawi et al. [20] utilized Long Short-Term Memory (LSTM) networks and dense layers to handle a hybrid input model. Arin et al. [21] employed three LSTM models and a fully connected layer to capture the complex behavioral activities of accounts, while exploring three learning schemes to train components connected across different levels.
With the application of graph neural networks for node representation and node classification tasks, many works have emerged that utilize graph models for social bot detection. Alhosseini et al. [22] firstly implemented social bot detection based on graph models by applying the GCN method to obtain the user representation and achieve the classification of the social accounts. BotRGCN [23] applied the relational graph convolutional neural network model to achieve social bot classification, obtaining better detection results. HGT [24] uses relational graph transformers to simulate the heterogeneous influence among users to learn user representations and uses semantic attention networks to aggregate information.
2.2. Federated Learning
The continuous development of big data technology has led to the emergence of an increasing number of data silos. Federated learning is an important approach to deal with the data silo problem nowadays. The concept of federated learning was first introduced by McMahan et al. in 2017 [25], with the FedAVG algorithm as the basis. It is a distributed machine learning method that allows data to remain on local clients for model training, eliminating the need for centralized data transmission to a server for centralized learning. The server only needs to aggregate the information learned by the clients to complete the global model update. Currently, federated learning has been widely applied in various fields, such as the medical field [26], the financial field [27], the recommendation field [28], and so on.
The non-IID problem is an important challenge in federated learning that needs to be addressed [29]. In federated learning, multiple participants often have different data characteristics. If a naive federated averaging method is used to simply aggregate the model parameters obtained from the local training of each participant, it often leads to the model falling into a local optimum [30], resulting in an ineffective global model. Our work focuses on the label-based distribution imbalance problem in social bot detection within federated learning, where multiple data contributors have similar data characteristics, but the label distribution of the data are highly imbalanced, leading to inconsistencies between the local optimum and global optima.
Existing optimization methods for the non-IID problem in federated learning can be considered from two perspectives: model-based and data-based. Model-based optimization methods can be further divided into adjustments for server aggregation methods and adjustments for client parameter updates. Adjustments for the server aggregation methods can involve adding weights to the parameters of each client, while adjustments for the client parameter updates include adding regularization terms to the local model updates to reduce the distance between the local and global models, thus addressing the non-IID problem. For example, FedNova [31] improves the model aggregation of FedAvg by normalizing and scaling the local updates of each participant based on their local training epochs before updating the global model. FedProx [32], based on FedAvg, adjusts the client parameter updates by adding a regularization term that constrains the optimization distance between the local and global models. SCAFFOLD [30] uses control variates to correct the client drift in local updates while ensuring faster convergence. FedDyn [33] and MOON [34] constrain the direction of the local model updates by comparing the similarity between model representations, thereby maintaining the consistency between local and global optimization objectives.
The data-based optimization methods can leverage data generation techniques to generate data that makes the data among different participants closer to being identically distributed, thus alleviating the performance loss of the global model caused by data heterogeneity between the clients. FedDistill [35] is a data-free knowledge distillation method, where the participants share the average of label-based logit vectors. FedGAN [36] trains a generative adversarial network (GAN) to handle non-IID data challenges in an efficient communication manner, but inevitably introduces bias. FedGen [37] and FedFTG [38] utilize generator models to simulate the global data distribution for performance improvement.
2.3. Federated Social Bot Detection
Most existing works on social bot detection are based on data from a single organization, with few considering the fusion of multi-party data to train powerful models and alleviate the difficulties of labeling social bots for each organization. DA-MRG [6] made the first attempt at federated social bot detection, where the method locally trains a domain-aware multi-relation graph model for social bot detection. Data were divided into multiple participants based on the data size, and the classic FedAvg algorithm was used to aggregate the parameters among the participants to obtain a global detection model. FedACK [5] also focused on the combination of federated learning and social bot detection by extracting features from the user metadata and tweet text for social bot detection. When constructing the federated learning models, it considered the impact of data heterogeneity among multiple participants and proposes a federated adversarial contrastive knowledge distillation method to address the issue of data heterogeneity. These methods do not simultaneously consider an effective social bot detection framework and the heterogeneity of data among multiple participants in federated social bot detection frameworks. To address the aforementioned limitations, we propose a knowledge distillation-based federated graph social bot detection method, achieving more efficient federated social bot detection.
3. Materials and Methods
3.1. Problem Definition
Given a social network account U, we define the basic account information as P, tweet information as T, and the relationship information as N. Our goal is to learn a bot detection function that makes the predicted label close to the true label y, maximizing the prediction accuracy of the model. For the construction of the federated social bot detection model, we consider the traditional federated learning framework based on the server–client scheme, assuming that there exists a server and K clients jointly participating in the training of the federated social bot model. Each client holds a private dataset , and each client’s dataset contains individual user information, then the final optimization objective of the problem is defined as:
L is a loss function parameterized by the model parameters to evaluate the performance of each client’s prediction model on its private dataset .
3.2. FedKG Social Bot Detection Framework
The overall framework of FedKG is shown in Figure 1. Below, we will introduce the overall model from two components: the local social bot detection framework and the knowledge distillation-optimized federated learning process.
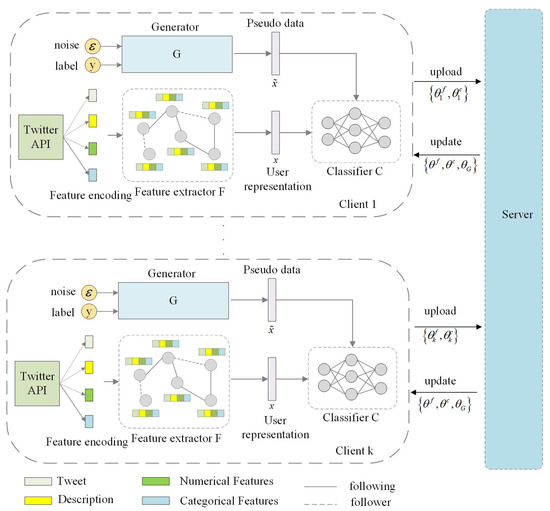
Figure 1.
Overview of our proposed FedKG framework.
3.2.1. Social Bot Detection Model Based on RGCN Graph Representation Approach
Each client’s local social bot detection model consists of two components: a feature extractor for extracting user feature representations and a classifier for classification, parameterized by and , respectively, and the feature extractor F and classifier C are trained in stages during the model training process. The details of each component of the local model are specified below.
- User feature coding
Firstly, the user tweet information, user description information and user account information are encoded to obtain the initial feature representation of the user. We used a similar encoding approach to BotRGCN [23] to encode user features. For the semantic information in the user’s tweets and descriptions, a pre-trained RoBERTa model [39] is applied for encoding, resulting in representations and ; for the user’s numerical features, z-score regularization is applied to obtain the representations ; for the user’s categorical features, one-hot encoding is applied to obtain the representations. These feature representations are then concatenated to form the overall feature representation vector of the user, which serves as the initial feature representation of the user.
- Feature extractor for user feature representation
The feature extractor is a module that performs the feature extraction on users based on the graph representation learning methods. A social network graph is firstly constructed. In online social networks, the neighbor information of users provides key information for a more accurate analysis of users, resulting in more accurate user feature representations. Therefore, a social network graph is constructed based on the neighbor relationships, and a graph neural network model is applied for feature extraction. Users in the social network are treated as nodes, forming a node set V, and the neighbor relationships between users are treated as edges, forming an edge set E. There are various types of relationships between users, such as follows, retweeting, and commenting. In this work, the focus is on the mutual following relationships between users. Considering that the following and follower relationships contain different information, the edge set contains two types of edges: one representing the following relationship between users, and the other representing the follower relationship between users. Thus, a heterogeneous graph is constructed to simulate real-world social networks. We apply the RGCN model as a graph neural network model to learn the low-dimensional feature representations of users. Firstly, we apply a linear layer to transform the initial feature representations of users into the initial representation vectors of nodes in the graph:
where and are learnable parameters. After that, L layer R-GCN is applied to learn the user embedding representation vector.
where is the adjacency matrix, R denotes the set of relationship types between users, and denotes the set of neighbors of a user with relationship type r. After L layers of R-GCN, we obtain the user feature representations . At this point, the final feature representation of each user is obtained by the feature extractor.
- Classifier for user classification
The classifier is used to further transform the user feature representation into the final classification result output. After obtaining the user feature representation through the feature extraction model, we further apply a Multilayer Perceptron (MLP) network to transform the user representation:
where and are the learnable parameters, and is the user feature representation. After that, a softmax layer is applied to transform the transformed user feature representation into a probability distribution:
where and are learnable parameters.
- Learning and optimization
We optimize the feature extractor F and classifier C with different loss functions during model training. Social bot detection is typically formulated as a binary classification problem. In general, the loss function is defined as the cross-entropy loss function to optimize the model parameters. For example, the loss of the feature extractor and the classifier are defined as follows:
where and are the loss functions of feature extractor F and classifier C, respectively, V is the set of all sample nodes, is the true label of the node , and is the probability that the node is predicted as a positive class by the model.
Considering that, in the social bot detection task, the class imbalance between human and social bot accounts will greatly affect the effectiveness of the training model, the traditional sample-level cross-entropy loss function calculates the loss for each sample and then takes the average. However, if the number of samples in each class is small, their impact on the average loss can be diluted. The optimization algorithm may be biased towards samples from the majority class, resulting in insufficient training of minority class samples. Thus, inspired by DAGAD [40], we modify the traditional sample-level cross-entropy loss function to a class-level cross-entropy loss function to alleviate the issue of local class imbalance for the local model. Specifically, we calculate the loss separately for each class, and then assign the same weight to these losses for summation. In this case, the losses for each class are treated equally, so even if the number of samples in a certain class is small, its loss value still has a greater impact on the model training. The equation is defined as follows:
where is the class-level cross-entropy loss function, and represent the sets of minority class sample nodes and majority class sample nodes, respectively, is the true label of the node, and is the probability that the node is predicted to be a positive class by the model. Correspondingly, the loss functions of the feature extractor and classifier are modified to class-level cross-entropy loss functions, i.e., and . The above describes the complete process of the basic social bot detection model for each client.
3.2.2. Knowledge Distillation-Optimized Federated Learning Framework
The overall process of the naive federal learning framework is as follows: the server first initializes the global model parameters and distributes the global model parameters to each client; each client trains its local model based on the local private data , including the training of the local feature extraction model and the local classification model; after the client’s local training is finished, it sends the updated model parameters to the server for the preliminary average aggregation:
where is the new global model parameters for the next round, K is the number of participating clients, is the number of samples of client k, and N is the sum of the number of samples across all clients. This completes one global iteration, and this iteration is repeated many times to obtain the optimal global model.
The data heterogeneity among multiple participants in federated learning has a non-negligible impact on the performance of federated learning. Therefore, in this work, we apply knowledge distillation methods to optimize the federated learning algorithm.
We train a global generator G on the server side, aiming to learn the global data distribution. The parameters of the global generator G are shared among all clients, as shown in Figure 1. Applying standard Gaussian noise , given target labels y, the global generator generates pseudo-samples (i.e., user feature representations). These pseudo-samples incorporate data information from all clients. By applying these pseudo-samples to further guide the training of the local classification model, the decision boundary learned by the client model can be closer to the decision boundary of all the global data. This approach mitigates the impact of data heterogeneity among clients and improves the performance of client detection models.
Therefore, the final loss function of the client’s classification model C is modified on the basis of the class-level cross-entropy loss function as follows:
where is the class-level cross-entropy loss of the classifier part calculated by client k based on the local real data, is the difference loss between the probabilities obtained from the real samples and the pseudo samples through the classification model, is the number of training samples of the client k, is the Kullback–Leibler divergence, is the classification model of client k, and is the softmax function. By minimizing Equation (9), we allow the probability distribution obtained from the real samples approach the probability distribution obtained from the pseudo-samples. This allows the pseudo-samples, which contain knowledge of the global data distribution, to influence the decision boundary of the client’s local classification model.
The global generator G is trained on the server using the knowledge distillation method to integrate the data distribution knowledge among global clients. The logits knowledge from the client models serves as the teacher model’s knowledge, while the server’s global generator serves as the student model. Equation (10) is defined to measure the difference in probability distributions between the logit outputs of the client models and the logit outputs of the server model:
where K is the number of participating clients, is the weight of the samples in client k with label y to the samples in all global data with label y, is the classification model of client k, C is the global classification model, and is the softmax function. We train the global generator by maximizing Equation (10) to generate pseudo-samples that are beneficial for model training. In addition, a diversity loss is introduced in order to ensure the diversity of samples generated by the generator and to avoid model collapse:
where and are pseudo-samples.
Then, the overall loss of the global generator is:
In order to further solve the problem of data heterogeneity among clients, after training the global generator, the server side also applies the knowledge distillation strategy to adjust the global average classifier model, and the loss function of the global classification model training is defined as:
By minimizing Equation (13), the global classification model can further integrate the knowledge from the client classification models, improving the generalization of the global model and enhancing communication efficiency.
4. Experiments and Analysis
4.1. Experimental Setup
4.1.1. Datasets
We conduct experiments on the Twibot-20 [41] dataset to evaluate our method. The Twibot-20 dataset is a widely used benchmark dataset for social bot detection tasks. It contains a total of 229,573 users. Among them, only 11,826 accounts are labeled, including 5237 human accounts and 6589 bot accounts. It provides the users’ semantic information, account information, and following and follower relationships information among users, supporting the construction of models based on the graph representation learning methods. The user account information used contains numerical features and categorical features, and the specific feature names and feature descriptions are shown in Table 1 and Table 2, respectively.

Table 1.
Users’ numerical features.
Table 2.
Users’ categorical features.
4.1.2. Baselines
We combine the federated learning framework with the classical RGCN method and apply the knowledge distillation method to optimize the classical federated learning algorithm to address the problem of data heterogeneity among clients. Therefore, the baselines we apply include a detection model trained only locally (named Local), and federated learning methods FedAvg [25], FedProx [32], and FedDistill [35] that address the data heterogeneity problem. We evaluate the performance of these methods under different degrees of data heterogeneity.
- Local: A detection model trained only on local private data, without any information exchange between participants;
- FedAvg: A basic federated learning algorithm, with parameter sharing between the client and the server, and the server performs weighted averaging of client parameters based on their sample quantities;
- FedProx: A federated learning method that introduces a regularization term in the loss function on the clients to reduce the distance between local and global models;
- FedDistill: A data-free federated knowledge distillation method where the clients share the average of the label-based logit vectors. Since there is no parameter sharing, the performance of FedDistill decreases significantly. To ensure fairness, we modified the original method to share logit averages based on shared model parameters as a baseline comparison method;
- FedACK: A federated social bot detection method that proposes a GAN-based federated adversarial comparison knowledge distillation mechanism. The relationship information between users is not considered in the social bot detection model, and the detection performance has a large gap with the detection of graph model-based methods; we modify its framework by replacing its local social bot detection model with our local detection framework as a baseline comparison method.
4.1.3. Data Heterogeneity
In the experimental validation, we divide the Twibot-20 dataset into multiple parts to simulate multiple participants in federated learning. For data distribution heterogeneity for different participants, we apply the Dirichlet distribution Dir() for non-IID partitioning of data to simulate the heterogeneity among different participants in the real world, following a previous work [42], where the parameter reflects the degree of the data heterogeneity, and a smaller indicates a higher degree of data heterogeneity among clients.
4.1.4. Implementation Details
The feature extractor utilizes a two-layer RGCN, while the classifier employs a three-layer MLP. The global generator model is an MLP with two linear layers, and the hidden layer dimension is 16. The basic parameters for model training are as follows: batch size is 64, learning rate is 0.01, optimizer is Adam optimizer, and the number of global communication rounds is set to 100.
Regarding the evaluation metrics, our study evaluates the model performance based on the average accuracy of each client model on the test set in each iteration. The experimental results below report the highest average accuracy achieved during the iterations.
4.2. Performance Comparison
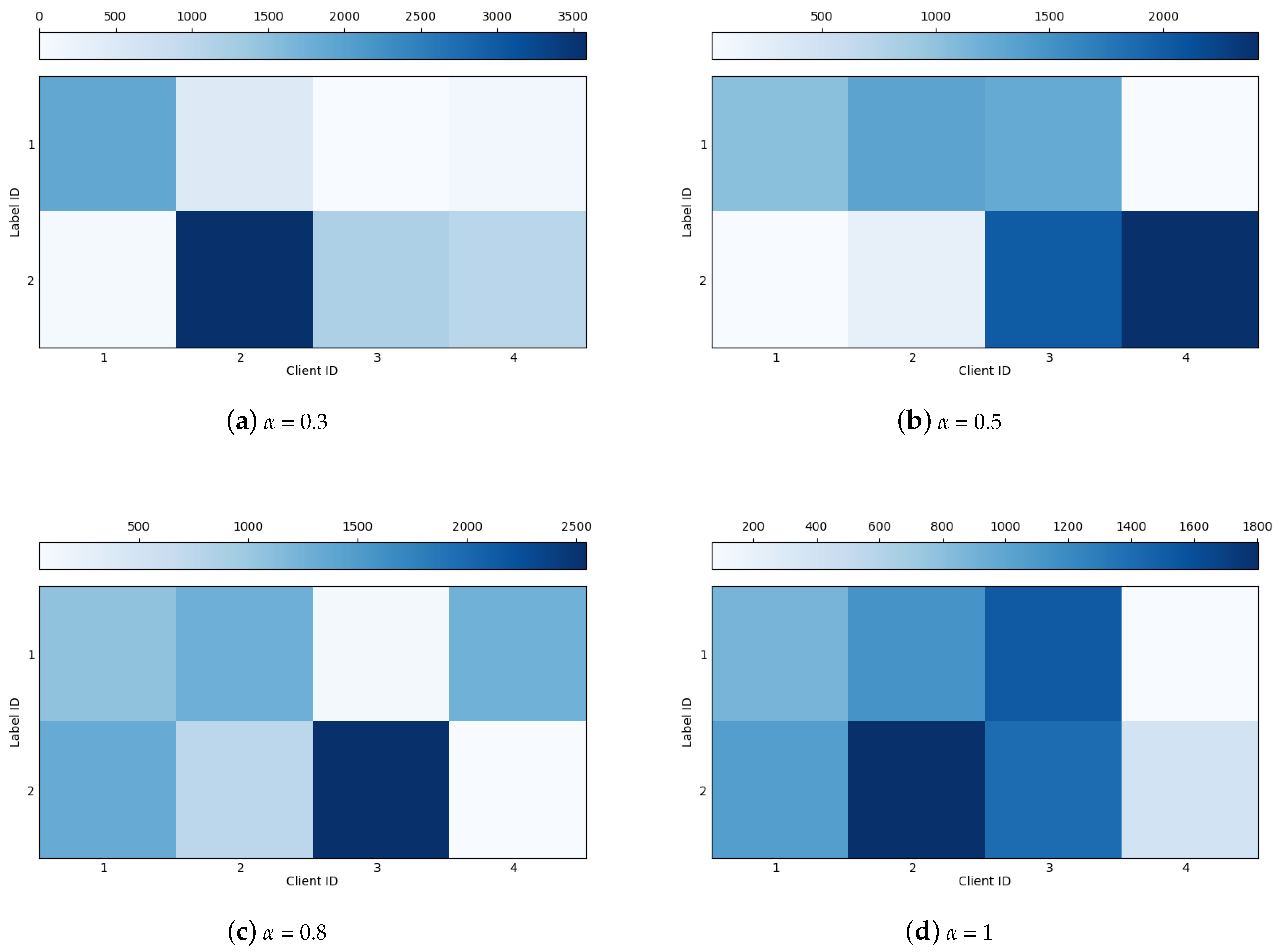
We first set the number of clients to four and the number of local training epochs to five. We set the heterogeneity level hyperparameter to {1, 0.8, 0.5, 0.3} to compare the performance of different methods under different heterogeneity degrees of data distribution. As shown in Figure 2, we visualize the number of human and bot samples at different , and we can see that as decreases, the distribution differences in the number of categories among different participants gradually become larger, which represents a major challenge for the construction of traditional federated learning models. Table 3 presents the detection performance of different methods under different degrees of data heterogeneity. It can be observed that our method, FedKG, consistently achieves the highest accuracy at higher degrees of heterogeneity. Specifically, at an of 0.8, our method has a 3% improvement over the second-highest method, and at an of 0.5, it has a nearly 10% improvement. Compared to the local training approach, where the clients only utilize their local data for training, the federated learning methods that involve data sharing show significant improvements in performance. At low level of data heterogeneity ( = 1), all of the various federated learning methods achieve relatively high accuracy rates; at higher levels of data heterogeneity, our method demonstrates a clear advantage.
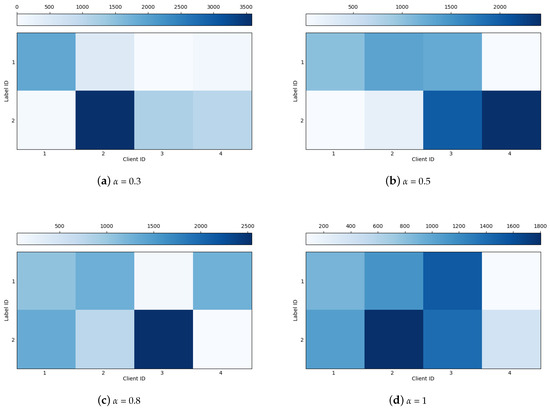
Figure 2.
Visualization of data heterogeneity among participants. A darker color means more training samples that a client has for the corresponding label.
Table 3.
Comparison of the test accuracy of different methods under different ; a smaller indicates higher heterogeneity. The bolded value indicates the highest value, and the underlined value indicates the second-highest value.
We also conducted an ablation experiment by replacing the class-level cross-entropy loss function with the ordinary sample-level cross-entropy loss, resulting in a variant method called FedKG-C. The experimental results show that after replacing the class-level cross-entropy loss function, the performance of FedKG-C decreases compared to the previous FedKG method under different degrees of data heterogeneity, which indicates that the class-level cross-entropy loss function plays a crucial role in addressing the imbalance issue in social bot detection. Furthermore, it can be observed from the experimental results that the variant method still outperforms other baseline methods when the data heterogeneity is low. This suggests that our method, applying the knowledge distillation method of tuning at both the client and server side, can effectively alleviate the impact of the data heterogeneity problem on the performance of federated learning algorithms, resulting in improved results.
4.3. Communication Efficiency Comparison
Table 4 demonstrates the number of rounds required for all algorithms to achieve the specified accuracy under different degrees of data heterogeneity when the number of clients is set to four and the number of local training epochs is set to five. The table shows that under different degrees of heterogeneity, our FedKG method achieves the corresponding accuracy with the minimum number of grounds, showing a clear advantage in terms of efficiency. The reason behind this is that during each ground of FedKG’s federated learning, the knowledge distillation approach is applied. The global generator is trained with the logit information from each client as the teacher knowledge, and pseudo samples with global data distribution are generated to guide the training of the client’s classification model. Additionally, after averaging the server parameters, further training of the global classification model is performed using the client’s classification model logit as knowledge. This method of separate tuning between clients and the server allows for rapid and efficient fusion of knowledge across clients, resulting in a significant improvement in communication efficiency.
Table 4.
The round number required for different methods under different to achieve the specified accuracy.
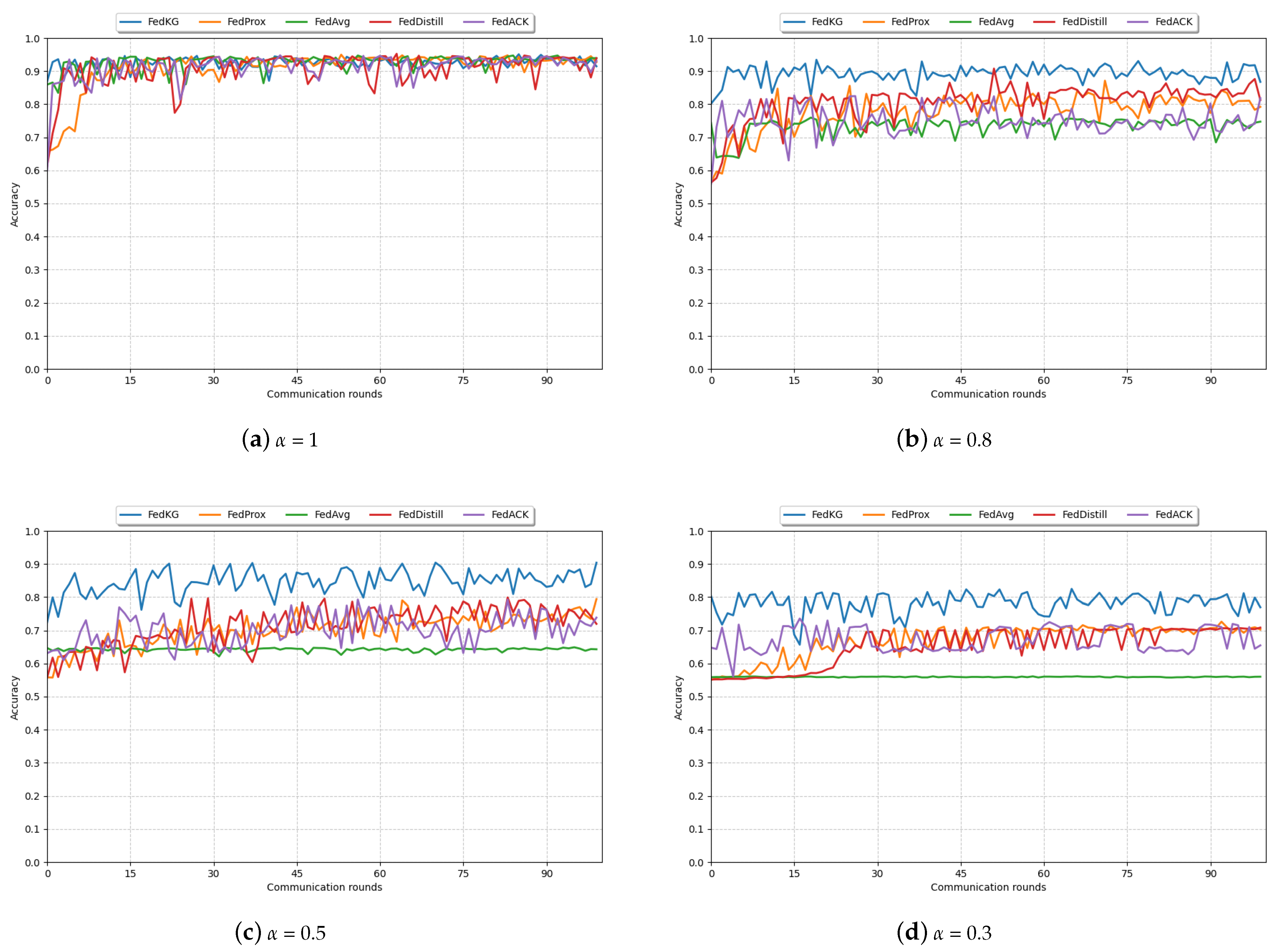
Figure 3 shows the model learning curves at 100 global communication rounds for different methods. It can be observed that our method, FedKG, achieves the specified accuracy with the fewest number of communication rounds and maintains relative stability throughout the global iteration process, demonstrating the best performance. The learning curves of both FedProx and FedDistill methods show an increasing and then relatively stable trend. However, FedProx, which addresses the data heterogeneity among clients by adding a regularization term on the client side, requires multiple communication rounds between the server and clients, resulting in poor performance in terms of communication efficiency.
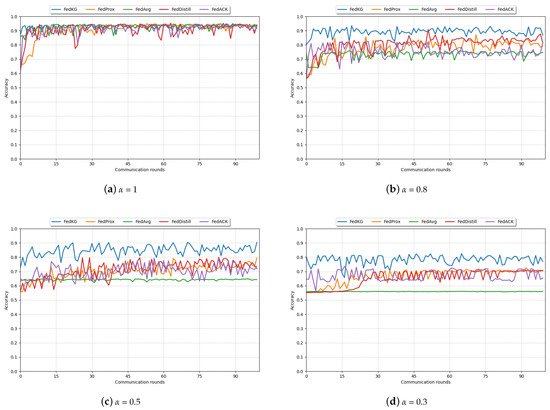
Figure 3.
Learning curves of different methods in 100 communication rounds under different .
4.4. Impact of Local Epochs
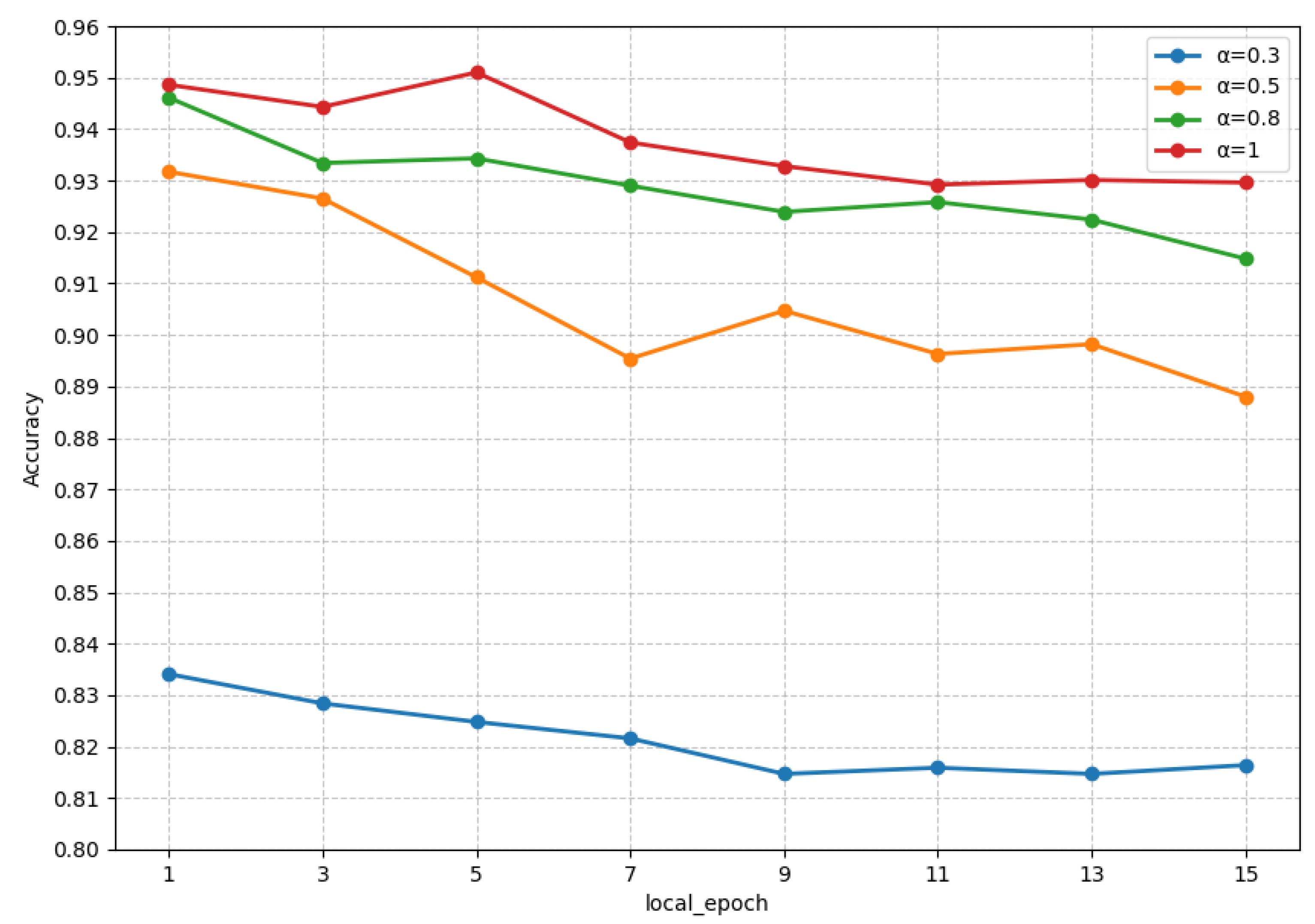
In order to explore the impact of the number of local training epochs on the model’s performance, we conducted experiments on the FedKG method, keeping the number of clients fixed at four and varying the number of local training iterations from 1 to 15. We observed the model performance under data heterogeneity levels, and the experimental results are shown in Figure 4.
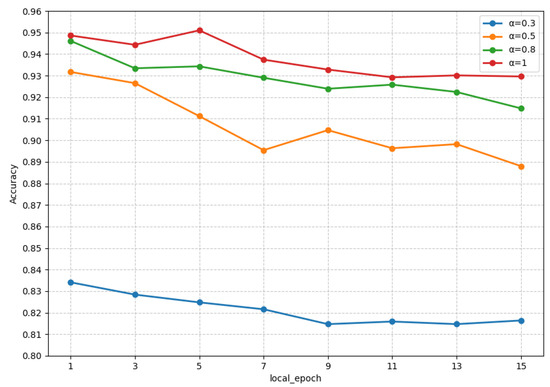
Figure 4.
Accuracy of FedKG with different local epochs under different .
From the figure, it can be observed that the model performance generally decreases as the number of local training epochs increases, regardless of the degree of data heterogeneity. This indicates that multiple local training epochs on local clients during the federated model training tend to lead the model towards the local optima which, in turn, results in a decline in the performance of the global model. Therefore, it is crucial to set an appropriate number of local training iterations in federated learning to achieve the best model performance.
4.5. Impact of the Number of Clients
We also conducted experiments by varying the number of clients to explore the impact of the number of participants on the model performance in the federated social bot detection problem in cross-organizational scenarios. Table 5 presents the accuracy of the FedKG method under different numbers of clients when the data heterogeneity level between clients is 0.3, 0.5, 0.8 and 1, respectively. It can be observed that the model achieves the highest accuracy when the number of clients is 2, regardless of the data heterogeneity level. With the increase in the number of clients, the accuracy of the model performance under different degrees of heterogeneity shows a decreasing trend. Moreover, this effect becomes more pronounced when the heterogeneity level is higher. This indicates that, as the number of participants increases, the challenge of data heterogeneity among multiple participants poses a more severe challenge to the performance of federated learning models.
Table 5.
Accuracy of FedKG with different number of clients with different .
5. Discussion
In this section, we discuss some limitations of the present study, further analysis of the experimental results, and future research directions. Firstly, due to the difficulty of obtaining and labeling data in multiple real social platforms, we heterogeneously partition the existing Twibot-20 dataset to simulate multiple data islands in the real world. This partly reflects the effectiveness of our method in training joint models with shared multi-party data. In the future, we will strive to collect data from multiple social platforms to train and verify the model in actual scenarios. Furthermore, in Section 4.5, we discuss the impact of participant numbers on model performance. The results indicate that the model achieves its highest accuracy when the number of clients is two. According to the results presented in Table 5, it is reasonable to infer that with the increase in the number of participants, the data heterogeneity among multiple participants will pose more serious challenges to the performance of the federated learning model. However, this does not necessarily imply that a fixed number of two participants should be employed when developing a federated social bot detection model in real-world scenarios. The determination of the number of participants is also related to factors such as the individual participant data volume, and warrants further comparison and analysis. Finally, we only consider the data heterogeneity issue among different participants and define same model architecture among clients, neglecting the need for different models among participants. In the future, we will pay more attention to the personalized federated learning method and further improve the federated learning algorithm under the premise of model heterogeneity among participants. For example, parameter decoupling can be adopted, where each client retains a portion of the model parameters for the local training without sharing them with the server. This enables each client to learn personalized representations, thereby achieving model heterogeneity across clients.
6. Conclusions
The presence of malicious social bots poses a serious threat to social network security. The singularity and scarcity of individual data, coupled with the high cost of labeling social bots, have led to the development of a joint model combining federated learning and social bot detection. We combine the federated learning framework with RGCN model to achieve federated social bot detection. To alleviate the impact of class imbalance in local data, a class-level cross-entropy loss function is applied during local model training. We apply the knowledge distillation method to address the issue of data heterogeneity. Extensive experimental results on benchmark datasets demonstrate the effectiveness of our method in social bot detection, outperforming baseline federated learning methods. In the future, we will further explore the combination of federated knowledge distillation and social bot detection tasks, focusing on the personalization issues in federated learning, and strive to build an efficient framework for federated social bot detection in real scenarios with model heterogeneity among clients.
Author Contributions
Conceptualization, X.W. and K.C.; methodology, X.W. and K.C.; software, K.C. and Z.W.; validation, K.C.; formal analysis, K.C.; investigation, K.C. and K.W.; resources, K.C.; data curation, K.C. and J.Z.; writing—original draft preparation, K.C.; writing—review and editing, K.C. and X.W.; visualization, K.C. and K.W.; supervision, X.W. and J.Z.; project administration, X.W. and K.Z.; funding acquisition, X.W. and K.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Beijing Natural Science Foundation, grant number 4202002.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Restrictions apply to the availability of these data. Data were obtained from Shangbin Feng and are available https://github.com/BunsenFeng/TwiBot-20 (accessed on 7 March 2023) with the permission of Shangbin Feng.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Abokhodair, N.; Yoo, D.; McDonald, D.W. Dissecting a social botnet: Growth, content and influence in Twitter. In Proceedings of the 18th ACM Conference on Computer Supported Cooperative Work & Social Computing, Vancouver, BC, Canada, 14–18 March 2015; pp. 839–851. [Google Scholar]
- Ferrara, E.; Wang, W.Q.; Varol, O.; Flammini, A.; Galstyan, A. Predicting online extremism, content adopters, and interaction reciprocity. In Proceedings of the Social Informatics, 8th International Conference, SocInfo 2016, Bellevue, WA, USA, 11–14 November 2016; Part II 8. Springer: Berlin/Heidelberg, Germany, 2016; pp. 22–39. [Google Scholar]
- Berger, J.; Morgan, J. Defining and Describing the Population of ISIS Supporters on Twitter. 2015. Available online: http://www.Brookings.Edu/research/papers/2015/03/isis-Twitter (accessed on 1 December 2022).
- Cresci, S. A decade of social bot detection. Commun. ACM 2020, 63, 72–83. [Google Scholar] [CrossRef]
- Yang, Y.; Yang, R.; Peng, H.; Li, Y.; Li, T.; Liao, Y.; Zhou, P. FedACK: Federated Adversarial Contrastive Knowledge Distillation for Cross-Lingual and Cross-Model Social Bot Detection. In Proceedings of the ACM Web Conference 2023, Austin, TX, USA, 30 April–4 May 2023; pp. 1314–1323. [Google Scholar]
- Peng, H.; Zhang, Y.; Sun, H.; Bai, X.; Li, Y.; Wang, S. Domain-Aware Federated Social Bot Detection with Multi-Relational Graph Neural Networks. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; IEEE: New York, NY, USA, 2022; pp. 1–8. [Google Scholar]
- McMahan, H.; Moore, E.; Ramage, D.; Arcas, B. Federated learning of deep networks using model averaging. arXiv 2016, arXiv:1602.05629. [Google Scholar]
- Zhao, Y.; Li, M.; Lai, L.; Suda, N.; Civin, D.; Chandra, V. Federated learning with non-iid data. arXiv 2018, arXiv:1806.00582. [Google Scholar] [CrossRef]
- Jeong, E.; Oh, S.; Kim, H.; Park, J.; Bennis, M.; Kim, S.L. Communication-efficient on-device machine learning: Federated distillation and augmentation under non-iid private data. arXiv 2018, arXiv:1811.11479. [Google Scholar]
- Lin, T.; Kong, L.; Stich, S.U.; Jaggi, M. Ensemble distillation for robust model fusion in federated learning. Adv. Neural Inf. Process. Syst. 2020, 33, 2351–2363. [Google Scholar]
- Schlichtkrull, M.; Kipf, T.N.; Bloem, P.; Van Den Berg, R.; Titov, I.; Welling, M. Modeling relational data with graph convolutional networks. In Proceedings of the Semantic Web: 15th International Conference, ESWC 2018, Heraklion, Crete, Greece, 3–7 June 2018; Proceedings 15. Springer: Berlin/Heidelberg, Germany, 2018; pp. 593–607. [Google Scholar]
- Yardi, S.; Romero, D.; Schoenebeck, G. Detecting spam in a twitter network. First Monday 2010, 15, 1–4. [Google Scholar] [CrossRef]
- Varol, O.; Ferrara, E.; Davis, C.; Menczer, F.; Flammini, A. Online human-bot interactions: Detection, estimation, and characterization. In Proceedings of the International AAAI Conference on Web and Social Media, Montreal, QC, Canada, 15–18 May 2017; Volume 11, pp. 280–289. [Google Scholar]
- Yang, K.C.; Varol, O.; Hui, P.M.; Menczer, F. Scalable and generalizable social bot detection through data selection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 1096–1103. [Google Scholar]
- Kantepe, M.; Ganiz, M.C. Preprocessing framework for Twitter bot detection. In Proceedings of the 2017 International Conference on Computer Science and Engineering (UBMK), Antalya, Turkey, 5–8 October 2017; IEEE: New York, NY, USA, 2017; pp. 630–634. [Google Scholar]
- Kudugunta, S.; Ferrara, E. Deep neural networks for bot detection. Inf. Sci. 2018, 467, 312–322. [Google Scholar] [CrossRef]
- Wei, F.; Nguyen, U.T. Twitter bot detection using bidirectional long short-term memory neural networks and word embeddings. In Proceedings of the 2019 First IEEE International Conference on Trust, Privacy and Security in Intelligent Systems and Applications (TPS-ISA), Los Angeles, CA, USA, 12–14 December 2019; IEEE: New York, NY, USA, 2019; pp. 101–109. [Google Scholar]
- Stanton, G.; Irissappane, A.A. GANs for semi-supervised opinion spam detection. arXiv 2019, arXiv:1903.08289. [Google Scholar]
- Feng, S.; Wan, H.; Wang, N.; Li, J.; Luo, M. Satar: A self-supervised approach to twitter account representation learning and its application in bot detection. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Online, 1–5 November 2021; pp. 3808–3817. [Google Scholar]
- Hayawi, K.; Mathew, S.; Venugopal, N.; Masud, M.M.; Ho, P.H. DeeProBot: A hybrid deep neural network model for social bot detection based on user profile data. Soc. Netw. Anal. Min. 2022, 12, 43. [Google Scholar] [CrossRef] [PubMed]
- Arin, E.; Kutlu, M. Deep learning based social bot detection on twitter. IEEE Trans. Inf. Forensics Secur. 2023, 18, 1763–1772. [Google Scholar] [CrossRef]
- Ali Alhosseini, S.; Bin Tareaf, R.; Najafi, P.; Meinel, C. Detect me if you can: Spam bot detection using inductive representation learning. In Proceedings of the Companion Proceedings of the 2019 World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 148–153. [Google Scholar]
- Feng, S.; Wan, H.; Wang, N.; Luo, M. BotRGCN: Twitter bot detection with relational graph convolutional networks. In Proceedings of the 2021 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, The Hague, The Netherlands, 7–10 December 2021; pp. 236–239. [Google Scholar]
- Feng, S.; Tan, Z.; Li, R.; Luo, M. Heterogeneity-aware twitter bot detection with relational graph transformers. Proc. AAAI Conf. Artif. Intell. 2022, 36, 3977–3985. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, PMLR, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Sheller, M.J.; Edwards, B.; Reina, G.A.; Martin, J.; Pati, S.; Kotrotsou, A.; Milchenko, M.; Xu, W.; Marcus, D.; Colen, R.R.; et al. Federated learning in medicine: Facilitating multi-institutional collaborations without sharing patient data. Sci. Rep. 2020, 10, 12598. [Google Scholar] [CrossRef] [PubMed]
- Aggarwal, D.; Zhou, J.; Jain, A.K. Fedface: Collaborative learning of face recognition model. In Proceedings of the 2021 IEEE International Joint Conference on Biometrics (IJCB), Shenzhen, China, 4–7 August 2021; IEEE: New York, NY, USA, 2021; pp. 1–8. [Google Scholar]
- Zhou, P.; Wang, K.; Guo, L.; Gong, S.; Zheng, B. A privacy-preserving distributed contextual federated online learning framework with big data support in social recommender systems. IEEE Trans. Knowl. Data Eng. 2019, 33, 824–838. [Google Scholar] [CrossRef]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and open problems in federated learning. Found. Trends Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Karimireddy, S.P.; Kale, S.; Mohri, M.; Reddi, S.; Stich, S.; Suresh, A.T. Scaffold: Stochastic controlled averaging for federated learning. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 5132–5143. [Google Scholar]
- Wang, J.; Liu, Q.; Liang, H.; Joshi, G.; Poor, H.V. Tackling the objective inconsistency problem in heterogeneous federated optimization. Adv. Neural Inf. Process. Syst. 2020, 33, 7611–7623. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]
- Acar, D.A.E.; Zhao, Y.; Navarro, R.M.; Mattina, M.; Whatmough, P.N.; Saligrama, V. Federated learning based on dynamic regularization. arXiv 2021, arXiv:2111.04263. [Google Scholar]
- Li, Q.; He, B.; Song, D. Model-contrastive federated learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 10713–10722. [Google Scholar]
- Seo, H.; Park, J.; Oh, S.; Bennis, M.; Kim, S.L. 16 federated knowledge distillation. In Machine Learning and Wireless Communications; Cambridge University Press: Cambridge, UK, 2022; p. 457. [Google Scholar]
- Rasouli, M.; Sun, T.; Rajagopal, R. Fedgan: Federated generative adversarial networks for distributed data. arXiv 2020, arXiv:2006.07228. [Google Scholar]
- Zhu, Z.; Hong, J.; Zhou, J. Data-free knowledge distillation for heterogeneous federated learning. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 12878–12889. [Google Scholar]
- Zhang, L.; Shen, L.; Ding, L.; Tao, D.; Duan, L.Y. Fine-tuning global model via data-free knowledge distillation for non-iid federated learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10174–10183. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Liu, F.; Ma, X.; Wu, J.; Yang, J.; Xue, S.; Beheshti, A.; Zhou, C.; Peng, H.; Sheng, Q.Z.; Aggarwal, C.C. Dagad: Data augmentation for graph anomaly detection. In Proceedings of the 2022 IEEE International Conference on Data Mining (ICDM), Orlando, FL, USA, 28 November–1 December 2022; IEEE: New York, NY, USA, 2022; pp. 259–268. [Google Scholar]
- Feng, S.; Wan, H.; Wang, N.; Li, J.; Luo, M. Twibot-20: A comprehensive twitter bot detection benchmark. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Online, 1–5 November 2021; pp. 4485–4494. [Google Scholar]
- Li, Q.; Diao, Y.; Chen, Q.; He, B. Federated learning on non-iid data silos: An experimental study. In Proceedings of the 2022 IEEE 38th International Conference on Data Engineering (ICDE), Kuala Lumpur, Malaysia, 9–12 May 2022; IEEE: New York, NY, USA, 2022; pp. 965–978. [Google Scholar]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).