Abstract
Human trajectories can be tracked by the internal processing of a camera as an edge device. This work aims to match peoples’ trajectories obtained from cameras to sensor data such as acceleration and angular velocity, obtained from wearable devices. Since human trajectory and sensor data differ in modality, the matching method is not straightforward. Furthermore, complete trajectory information is unavailable; it is difficult to determine which fragments belong to whom. To solve this problem, we newly proposed the SyncScore model to find the similarity between a unit period trajectory and the corresponding sensor data. We also propose a Likelihood Fusion algorithm that systematically updates the similarity data and integrates it over time while keeping other trajectories in mind. We confirmed that the proposed method can match human trajectories and sensor data with an accuracy, a sensitivity, and an F1 of 0.725. Our models achieved decent results on the UEA dataset.
1. Introduction
The prevalence of surveillance cameras makes it possible to track individuals in various settings such as fitness gyms, classrooms, and nursing facilities. This data not only serves security purposes but also provides valuable insights for individuals wishing to review their own actions. It is possible to infer from the trajectory how many minutes a user spends on a particular fitness center machine, how long a certain group spends in a classroom discussion, or how long a user interacts with others in a care facility lounge. By matching an individual’s trajectories with other collected data, such as health data, trajectories can be used to determine strategies such as feedback to maximize the effectiveness of training, learning, and care interventions.
Data from wearable sensors alone can provide information on exercise duration and intensity, stationary time periods, GPS location, etc., and can be used for the purposes described above. Sleep duration and walking distance are also being measured by commercial wearable watches. This information contains important insights for maintaining good health. One thing that cannot be obtained from wearable sensor data alone is information on the trajectory of movement in a room or building. This information may be obtained from cameras installed in the room or the building, and can be used in a complementary manner to the wearable sensor data.
Figure 1 shows a hypothetical situation. Here, obtaining all the trajectories in the scene does not sufficiently reflect an individual’s actions. While all trajectories are available, each individual needs to know theirs. The trajectories for all individuals are obtained in a mixed state, and some are lost or misextracted. By identifying a specific person’s trajectory from others, it becomes possible to understand that person’s behavior. Furthermore, if the trajectories can be broken down individually, it will be possible to understand how people behave as a group. In this work, we focus on extracting the trajectory of the user we wish to analyze.

Figure 1.
A situation where a specific person wants to distinguish his/her trajectories from all other trajectories. An AI camera provides a mixture of all trajectories. By extracting the person’s trajectory from these trajectories, it is possible to analyze the person’s behavior. In particular, the person’s own trajectory provides a record of which room the person was moving in and how he/she was moving.
A naive idea is to track the faces in the video, but there are several problems with this. First of all, if a person turns one’s back to the camera, we cannot see that person’s face. In addition, if data management is based on privacy by design, a policy may be adopted to preserve only the trajectory and not the images themselves.
Another idea is to track people by their clothes, but this will be difficult when there is no diversity in the clothing of the people in a fitness gym or a care facility. In addition, no images will be saved because of privacy by design.
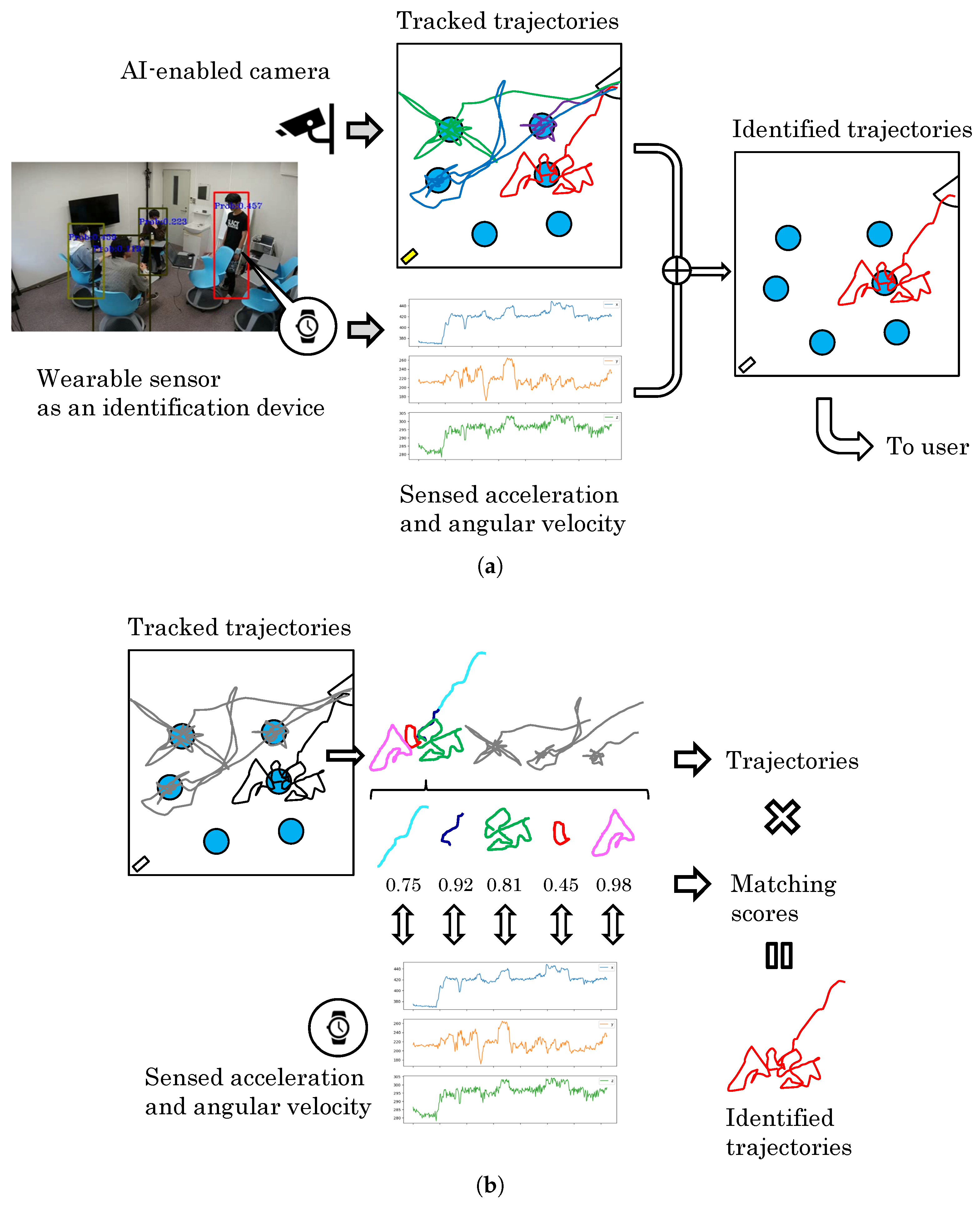
We propose a method of directly matching trajectory data with inertial data from a wearable watch. This method does not require any video saving as shown in Figure 2. From a privacy-by-design point of view, it is desirable to convert the trajectory data on the edge device. A new problem is that inertial data from the wearable watch may be added as a new condition, but this condition may not be a problem in many cases where the user wants to acquire his/her own trajectories while standing in front of a surveillance camera, or use his/her own trajectories for some kind of analysis.

Figure 2.
Overview of service and matching process. By matching the trajectories with the sensor signals of the wearable device, only the trajectory of the person who owns the wearable device is extracted. The owner of the device can extract his or her own trajectories from a large number of trajectories. The trajectories are observed as a mixture of the segmented trajectories. The proposed method computes a match score between the sensor signal and all corresponding segment trajectories, and aims to retrieve all corresponding trajectories. (a) Overview of the services envisioned. (b) Overview of the matching process.
However, to the best of the authors’ knowledge, no matching algorithm can solve such a problem. This work provides a new perspective and method for matching trajectories and sensor data, and provides a valuable basis for further research and applications in this area as well as a tool to support personalized services by enabling the analysis of individual behavior and the design of intelligent systems.
Although there are many related methods of image feature-based person re-identification [1,2,3], these methods aim to find the same person in different images. Person re-identification is achieved by extracting visual features such as clothing and facial features in one frame image and searching for a person with the same features in another frame image. In this work, instead of extracting features from individual frames, we aim to achieve personal recognition by calculating the likelihood of similarity between a person’s trajectory and simultaneously obtained sensor data. Deep neural networks can be used to calculate the similarity likelihood.
While actual attempts to match trajectories to sensor data provide uninterrupted sensor data, it is often the case that a person is not tracked continuously by the camera and is re-tracked after a few frames. As a result, a person’s trajectory will be fragmented. It is necessary to match sensor data even from such fragmented trajectories. We propose a method for matching both trajectory and sensor data at short intervals, and integrating the results into a whole sequence. We also propose a method for updating the matching likelihood by looking at the whole set of trajectories, based on the fact that, when multiple trajectories are observed, there will be at most one trajectory that corresponds to each of them.
In our proposed method, the matching likelihood is obtained from trajectory data and wearable sensor data. Both short-time trajectory data and sensor data are input into a deep neural network to obtain the matching likelihood. Next, the short-time trajectories are integrated to obtain the likelihood of the sensor data for a series of trajectories tracking the same person. Finally, the trajectory with the highest likelihood is selected to complete the matching of trajectory and sensor data.
The main challenge lies in the mismatch between the signals obtained from the wearable watch and the individual trajectories, which belong to different modalities. Additionally, occlusions can cause fragmentation in the individual trajectories, necessitating a method of collecting and integrating these fragmented trajectories using the information from the watch signal.
The contributions of this paper are as follows:
- We constructed a deep learning network-based SyncScore model (Section 3.2) to recognize the degree of matching between trajectory data and sensor data at each unit time period. A newly proposed Fusion Feature module (Section 3.2.1) and SecAttention module (Section 3.2.2) contribute to improve the matching accuracy.
- We developed a Likelihood Fusion algorithm (Section 3.3) that integrates the degree of matching between the trajectory data and sensor data for the entire trajectory by incrementally updating it while referring to the status of other trajectories. Update Rules (Section 3.3.1 and Section 3.3.2) contribute to integrating short-period likelihood into full-period likelihood.
- We created a dataset specifically designed for our research purposes (Section 4.1). With this dataset, we were able to evaluate the performance of our proposed method in specific scenarios and achieved satisfactory results.
- We experimented with some of the proposed modules on the UEA dataset and achieved excellent results (Section 4.2).
2. Related Work
Expansion on previous work and addressing limitations: Previous research has primarily focused on unimodal data, relying solely on image or video data. While significant progress has been made in related tasks, there is a lack of specific methods addressing the proposed task. Moreover, there is limited in-depth research on effectively utilizing and processing multi-channel data. The challenges associated with multi-channel tasks include the complexity of the data, the high dimensionality of the feature space, and the heterogeneity of the modalities.
To overcome these challenges, several aspects need to be considered:
- Data heterogeneity: Different modalities can produce diverse types of data, such as images, audio, text, or sensor readings. Developing a common representation and effectively integrating these heterogeneous modalities is a complex task.
- Feature extraction: Multi-channel tasks often require extracting features from multiple modalities, which can be time-consuming and computationally expensive. Selecting informative features that capture the essence of each modality is crucial for achieving accurate results.
- Alignment and synchronization: Modalities may not be perfectly aligned in time, leading to misalignment and reduced prediction accuracy. Synchronizing the modalities, especially in large datasets, presents a significant challenge.
By addressing these limitations and considering the complexities associated with multi-channel data, our proposed algorithm aims to provide an effective solution for selecting and obtaining individual trajectories with high precision while ensuring privacy. The algorithm utilizes the information from the wearable watch signals and integrates fragmented trajectories, ultimately enhancing the usability and privacy preservation of the data.
2.1. Person Identification by Appearance
Research work in the field of person identification, including deep learning-based face recognition, face embedding, face detection and alignment, person re-identification, and so forth, has proposed various innovative models and methods. Taigman et al. [4] proposed the DeepFace model, which achieved near-human-level facial verification performance through deep learning techniques. Their proposed model is trained on a large-scale facial image dataset to achieve efficient face verification by learning a compact representation of facial features.
Sun et al. [5] proposed a deep learning-based facial representation method to learn facial feature representations by predicting large-scale face categories. Their method utilizes deep neural networks to embed facial images into a high-dimensional feature space for face recognition and related tasks. We were inspired by this and concluded that we could also map our data into a high-dimensional feature space for further processing. Xiao et al. [6] proposed an end-to-end deep learning method for the task of person search. Their method combines person re-identification and object detection in a unified framework for accurate person search through federated learning. Wang et al. [7] proposed a pyramid space–time aggregation method for extracting feature representations of people in videos. This method divides the video into pyramid levels of multiple spatial and temporal scales, and obtains multi-scale feature representations by extracting features at each level and aggregating them. This pyramid structure can capture character feature information on different spatial and temporal scales, thereby improving the accuracy of character re-identification. Zhou et al. [3] proposed a full-scale feature learning method for person re-identification. Their method achieves more comprehensive person re-identification by learning global and local features. We were inspired to design a fusion of global features.
2.2. Multidimensional Time-Series Signal Processing
Our task involves processing multidimensional time series and designing models for multiple inputs. Our research in related fields shows that dealing with multidimensional time series is an important topic.
To solve this problem, we needed to consider some key factors. First, the processing of multidimensional time series needs to take into account the structure and characteristics of the data. Time-series data often has multiple dimensions, each of which may represent a different feature or variable. Therefore, we needed to choose appropriate methods to capture the association and temporal dependencies between different dimensions. Second, for models with multiple inputs, we needed to design appropriate architectures to handle different types of inputs. This involved fusing information from multiple input sources. Feature selection and dimensionality reduction were also important steps in dealing with these multidimensional time series.
Peng et al. [8] proposed a method based on wavelet transform and neural networks to forecast multidimensional time series. This method explores the application of wavelet transform in time-series feature extraction and combines it with neural network models. Hyndman et al. [9] introduced the method of using functional data analysis (FDA) to process multidimensional time-series data. This explores how multidimensional time series can be viewed as functional data and be modeled and analyzed using FDA techniques. Wang et al. [10] explored a method for multi-step time-series forecasting based on long short-term memory networks (LSTMs). Multi-step time-series forecasting refers to predicting the value of multiple time steps in the future through historical time-series data. LSTMs are a variant of recurrent neural networks (RNNs) and are particularly suited to processing sequential data. Wang et al. [11] gave an overview of the application of deep learning to time-series classification. This overview covers processing and feature extraction methods for multidimensional time-series, and summarizes the performance and challenges of deep learning models in time-series classification tasks. We were inspired by this and decided to design a deep learning model for our task. Pham et al. [12] proposed the temporally weighted spatiotemporal explainable model (TSEM), a neural network model for processing multivariate time-series data. This model combines temporal weighting and space–time interpretability mechanisms, aiming to provide interpretability of time-series forecasts to enhance model understandability and user trust.
Numerous studies are actively being conducted to estimate the user’s behavior and health status from IMU [13], GPS [14], and biosensors [15] attached to wearable watches and other devices. There is also work on platforms to utilize this information for the remote monitoring of patients [16]. Machine learning, including deep learning, is also used in these studies. While these studies provide rough information in terms of hours and minutes to promote health, we aim to estimate activity at a more detailed level, with the limitation that it is within a specific room that can be observed by an AI camera.
In recent years, Transformer models have shown remarkable results in various fields, which has been widely recognized.
Vaswani et al. [17] proposed the Transformer model, which introduced the self-attention mechanism into sequence modeling and replaced the traditional RNN structure. This model has achieved excellent performance on tasks such as machine translation. Huang et al. [18] proposed a Transformer-based time-series modeling method, which uses an autoregressive generative process to model time-series data. The method utilizes the Transformer model to model and predict temporal dependencies in sequences. Wu et al. [19] proposed a new method using the deep Transformer model for the important time-series forecasting task of influenza epidemic trend prediction. Traditional time-series forecasting methods may have difficulty capturing the long-term dependencies and nonlinear characteristics in time series, while the deep Transformer model has strong modeling ability and adaptability. Fawaz et al. [20] realized that time-series data have unique characteristics that require specialized methods for effective analysis. They proposed the InceptionTime model, which is based on the Inception architecture and aims to address the challenges of time-series classification. They applied AlexNet, a successful image classification architecture, to time-series classification tasks.
3. Methods
3.1. Sequences of Human Trajectory and Wearable Sensor Data
Suppose that a camera capable of AI processing provides the positions of several people in an image at time t. Since AI processing can extract a human region as a rectangle and can estimate the depth of the region, we define a human position as a 3D position that represents the center of the rectangle.
If the positions change little in adjacent frames, then a series of human trajectories can easily be connected. At time , if the Euclidean distance is the closest to the human position at time t and the distance is smaller than a certain threshold, then these positions are considered to be those of the same person. Since a human position may not be available due to occlusion or frameout, the trajectory is considered to cease and a new trajectory is considered to start when the closest distance is no longer available. A human trajectory may be confused with that of another person but, since this does not happen frequently, it is ignored in this paper. There are previous studies that determine the confusion of trajectories based on the characteristics of a person’s region [21,22].
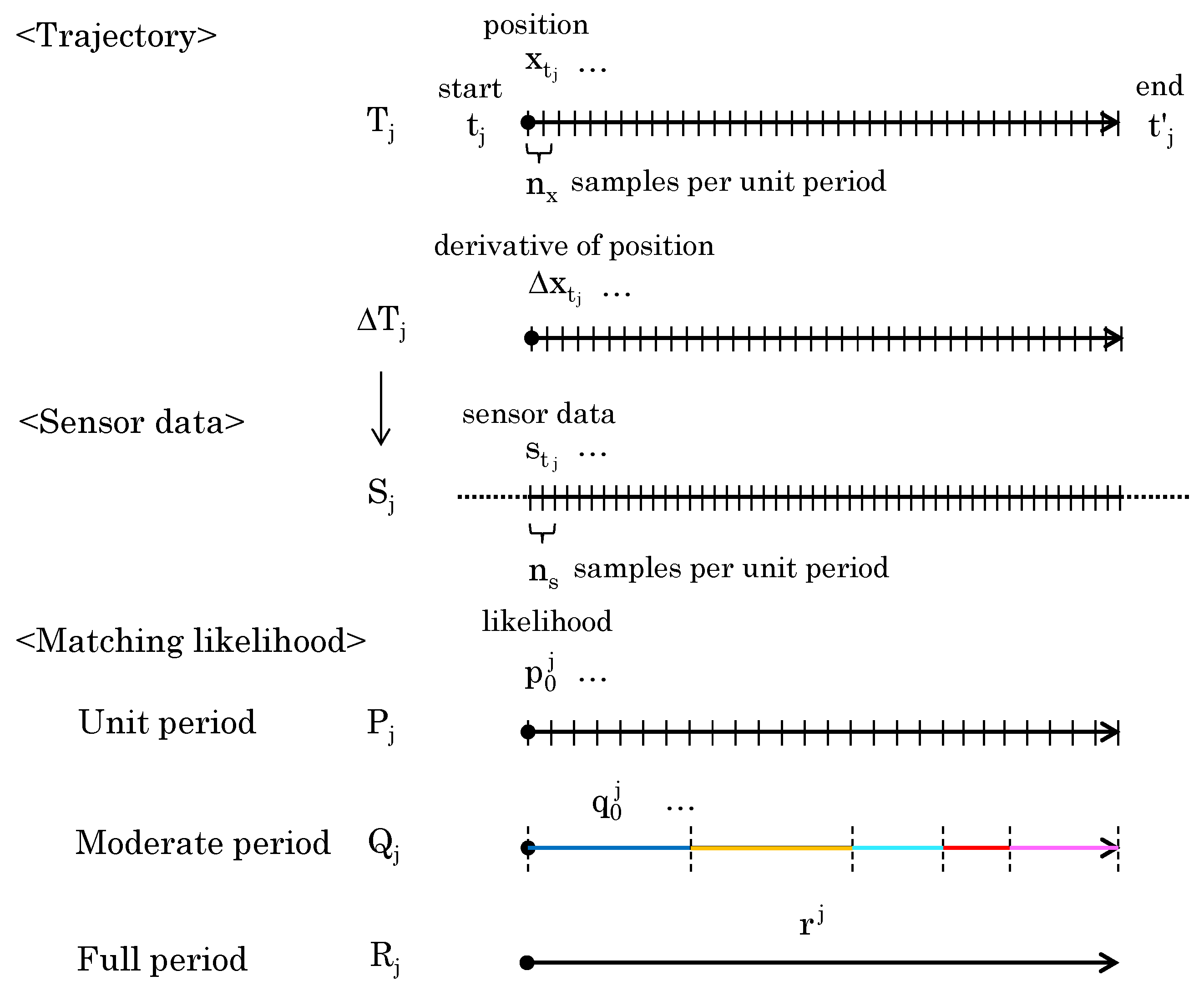
Figure 3 shows the definitions for the trajectory, sensor data, and the matching likelihood obtained from them. The human trajectory is defined as , , where and represent the first and last time of the trajectory, is the set of 3D positions, and is the 3D positions in the first frame. The 3D position is constituted by an object’s x and y coordinates within the image plane and its depth z indicating the distance from the viewpoint. represents the number of samples per unit period; here, “per unit period” is defined as one-second trajectory length and sensor data length, which is the input for the deep neural network.

Figure 3.
Sampling data and different period likelihood.
Since the absolute 3D position is not represented in the sensor data, the time derivative of the position is used instead of the 3D position. corresponds to the velocity at each time. If is the derivative of position at time , then the derivative of the human trajectory is , .
The wearable sensor data, on the other hand, is 9D data consisting of 3D acceleration, 3D angular velocity, 3D angular acceleration, and 3D magnetic field. For the acceleration and the angular velocity, the data are obtained in the sensor system. We are primarily interested in the rate of change of an object’s velocity and its rate of rotation, rather than the individual components of these vectors. Hence, through and , we convert acceleration and angular velocity into 1D data.
As a result, the wearable sensor data are treated as 5D data at each point in time, consisting of 3D angles, processed 1D acceleration, and 1D angular velocity. It can be assumed that data from wearable sensors, unlike trajectory data, are constantly obtained without the discontinuities that happen during video capture. The wearable sensor data that corresponds to is denoted as , , where represents the set of 5D wearable data, which serves as the input to our SyncScore. and are the 5D data at the first and last points in time. and represent the sampling frequency of the sensor and trajectory, respectively. is generally more than the number of frames in the trajectory () because the sampling frequency of the sensor data is generally higher than that of the camera-based human trajectory data.
For and , we can estimate the matching likelihood of the trajectory and data at each unit time. This is defined as . The likelihood is obtained by the deep neural networks (DNNs)—SyncScore described in Section 3.2. Finally, the likelihood obtained for the entire and is . Furthermore, as a likelihood with a granularity between and , the matching likelihood for a certain time period is expressed as . The method for time period division is explained in Section 3.3.
3.2. SyncScore Network for Unit Period Recognition
Assuming that data with the same timestamp can be extracted from and , we want to examine whether they are from the same person. There are several issues that need to be addressed:
- The start and end times are different in the trajectory and sensor data.
- The number of frames per unit time period is different in trajectory and sensor data due to different sampling rates.
- The lengths of the trajectories are different, so the dimension for network input is indeterminate.
- Even during periods when sensor data is available, trajectories will be partially unavailable, such as when the person is occluded from the camera.
To address these issues, we propose a deep learning network that extracts unit period data from trajectory and sensor data for comparison. If we can determine, per unit period, whether both datasets come from the same person, we will be able to investigate data across all time periods. Since we can obtain one sample per unit period, we can prepare the number of samples needed for deep learning.
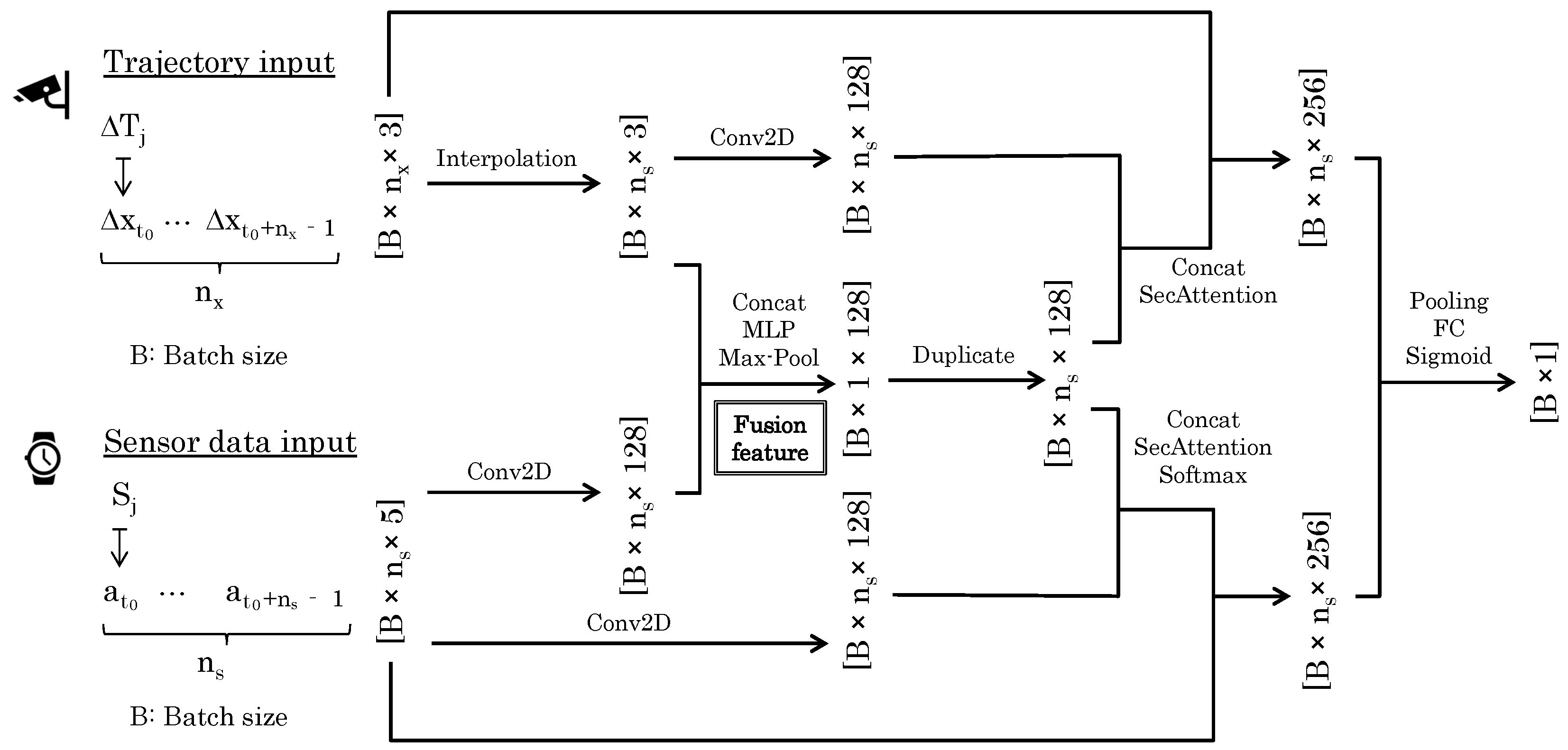
We defined the number of the samples per unit period as for the trajectory and for the sensor data. The input dimensions were then and , respectively. The output was a 1D likelihood that would tend to be one if both data originated from the same person, and zero otherwise. Within the batch size designated as B, we trained the network shown in Figure 4, which we named the SyncScore network.

Figure 4.
Structure of the SyncScore network.
The SyncScore network takes unit period trajectory and the corresponding sensor data as inputs and outputs the likelihood that they match. The training data can be obtained by having the target person wear the IMU sensor while recording the video simultaneously. Because we timestamped each piece of data during recording, we can align trajectory and sensor data through their corresponding timestamps. An annotator can easily tag the person wearing the sensor in the video by viewing footage. By training a network that outputs one when the sensor data and the trajectory of the target person are input and zero when the sensor data and the trajectory of another person are input, we will be able to determine the likelihood that the sensor data and the trajectory are from the same person when unknown data are input.
The SyncScore network is unique in several ways. First, the trajectory has a length , while the sensor data has a length ; we interpolate along the time dimension to match the length . This is achieved by interpolating additional data points between the existing points along each row. Specifically, the interpolated value v at a position in a row can be calculated using the following formula:
where and are the positions of the nearest known data points surrounding the interpolation point , and and are the values at these points. Next, a one-dimensional convolution process is performed on each of the trajectory and sensor data, and the concatenation of the two, or Fusion Feature, is synthesized. By aligning the two data sources, we created an integrated representation that captures the joint characteristics and facilitates a comprehensive analysis. This fusion approach enables us to consider the holistic aspects of the data and extract meaningful insights regarding their interplay.
It is necessary to match trajectory and sensor data at multiple time scales. Drawing inspiration from the InceptionTime model [20], we concatenated time-series data of different scale sizes and processed them as a single set of data. By doing so, we expected that matching results would not be compromised by short-term noise and that short-time features, which would be missed when considering only the long-term data, would also be considered.
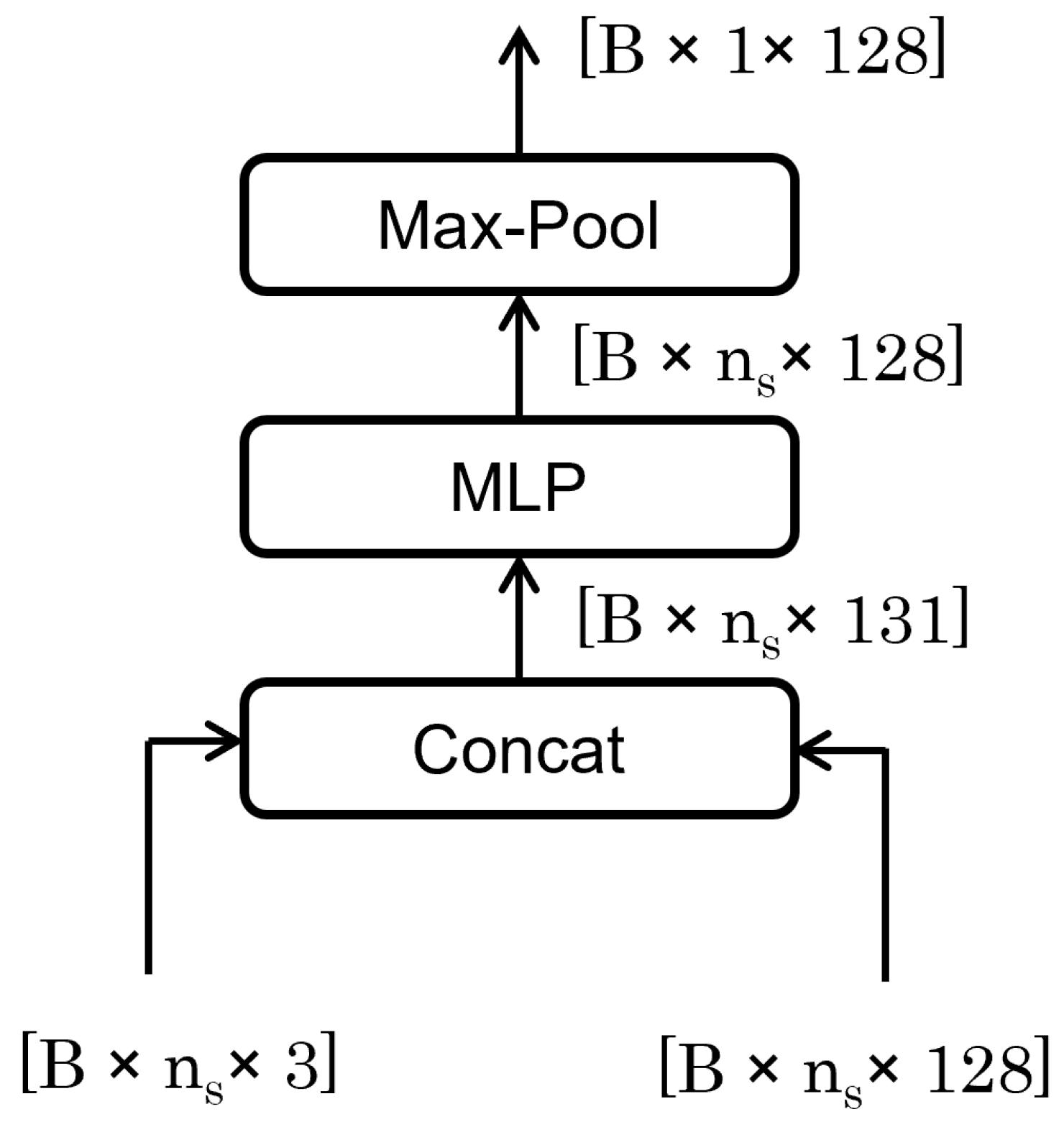
3.2.1. Fusion Feature
The Fusion Feature module, as shown in Figure 5, plays a pivotal role in the neural network by merging trajectory and sensor data to form a comprehensive feature set. This process involves concatenating features from both sources, enhancing the system’s state representation. Subsequent processing through a multilayer perceptron (MLP) and a max-pooling operation further refines these features by reducing dimensionality and emphasizing the most critical attributes. This streamlined approach not only reduces computational load but also mitigates the risk of overfitting, ensuring the module effectively captures essential global features for the task at hand, contingent on the integrity and synergy of the input data.
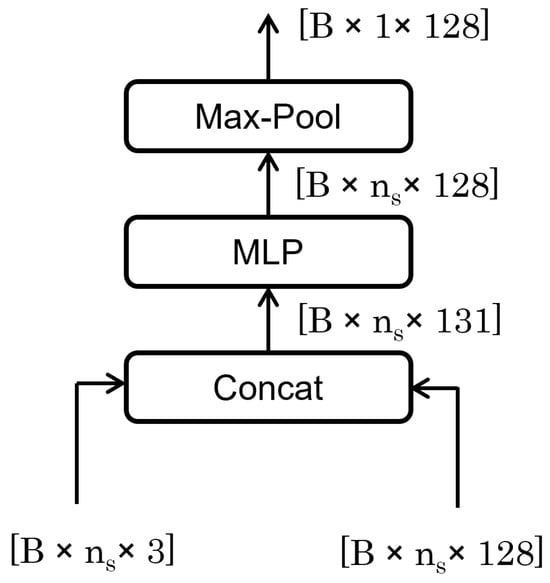
Figure 5.
Fusion Feature architecture.
3.2.2. SecAttention
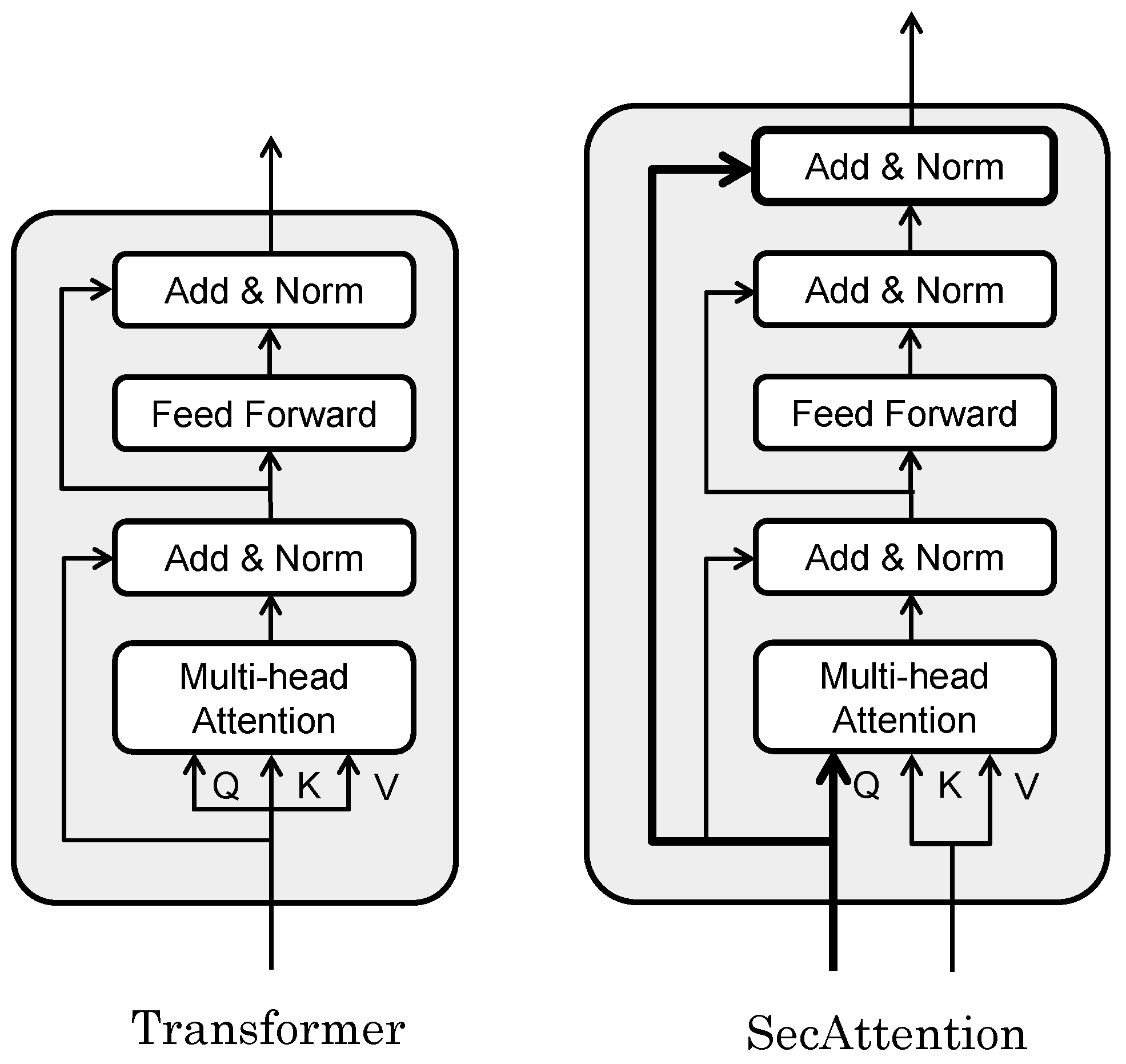
In this work, we used a modified Transformer to achieve high recognition accuracy for the target data. The Transformer [17], which has a self-attention mechanism, was successful at recognitioning series data. The self-attention mechanism can adaptively calculate the attention weight of each position according to the importance ascribed to different positions in the input data. By modeling and learning the relationships between locations, we can more accurately understand and capture key dependencies in the data.
Figure 6 shows the difference between the Transformer and our extended SecAttention. In the Transformer, the input to the block is normalized twice before output but, in our extended SecAttention, the input to the block is re-concatenated before normalization so that the input features leave the block in their original form. The input and output matrixes of the SecAttention module have the same dimensions but, by directly modeling the relationship between any two positions in the sequence, we can better capture the long-range dependencies in the sequence. The effect of this seemingly trivial improvement on the data is demonstrated numerically in the ablation study in the experimental section. Additionally, Transformer models typically employ the same input for linear transformations to derive queries, keys, and values. In contrast, our SecAttention model utilizes data transformed from features for its keys and values. For queries, we retained the original information and applied a linear transformation to it.
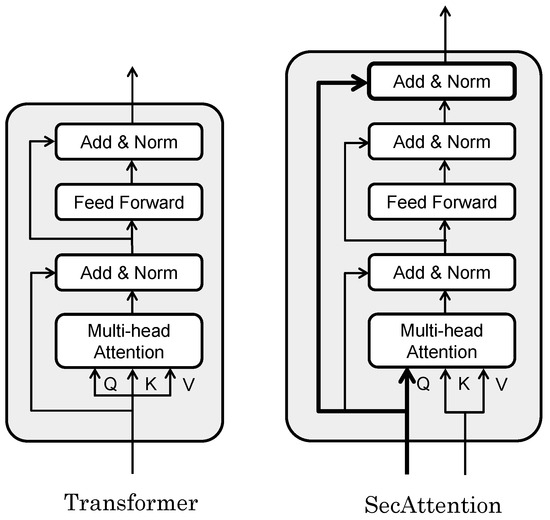
Figure 6.
SecAttention model extended from the Transformer model.
3.2.3. Loss Function
Binary Cross-Entropy (BCE) loss is a common loss function used in binary classification tasks. In the field of machine learning, especially when dealing with binary classification, BCE is used to measure the discrepancy between the model’s predicted probabilities and the actual labels. Its primary purpose is to minimize the entropy difference between predictions and actual values, thereby enhancing the accuracy of the model’s classification. The BCE loss can be calculated using the following formula:
where N is the number of samples. is the actual label of the i-th sample, which is either 0 or 1. is the model’s predicted probability of the i-th sample being of the positive class.
3.3. Likelihood Fusion Algorithm
The Likelihood Fusion algorithm is shown below. In the algorithm, the matching likelihoods obtained for each unit period are integrated step by step, and the desired likelihoods for the full period are obtained while referring to the status of other trajectories.
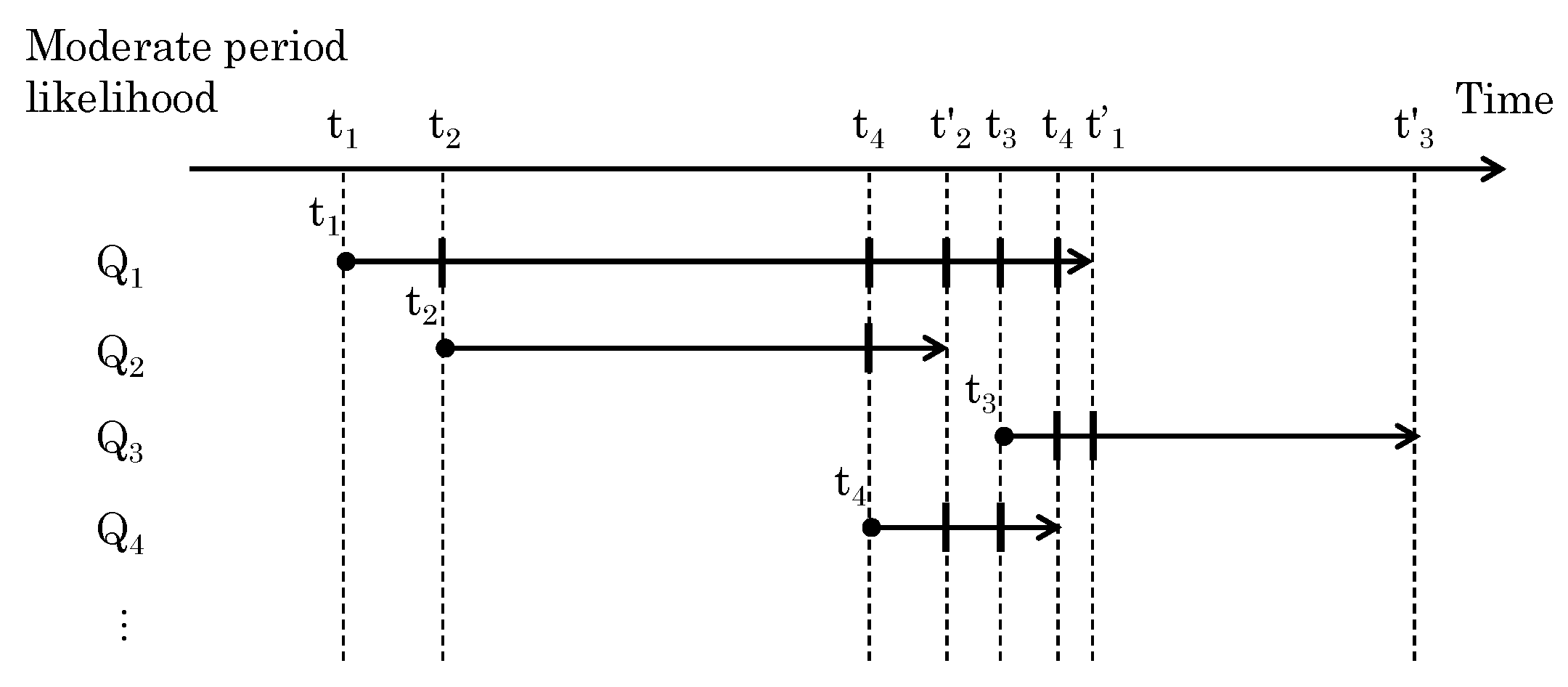
The in Figure 3 represents the matching likelihoods for the segmented periods in trajectory . The period is defined as a single time segment when multiple trajectories have a common time period, as shown in Figure 7. When trajectory starts at time and ends at time , then the start and end times of any given trajectory can be used to identify the time period in which multiple trajectories occur. For example, we can say that different pairs of segments share the same time period before and after the start of a given trajectory.

Figure 7.
Definition of moderate period by start and end times of all trajectories.
In each pair, a maximum of one segment corresponds to the sensor data. Additionally, trajectory partially does not correspond with the sensor data. Considering this, we updated the elements of before integrating into the likelihood .
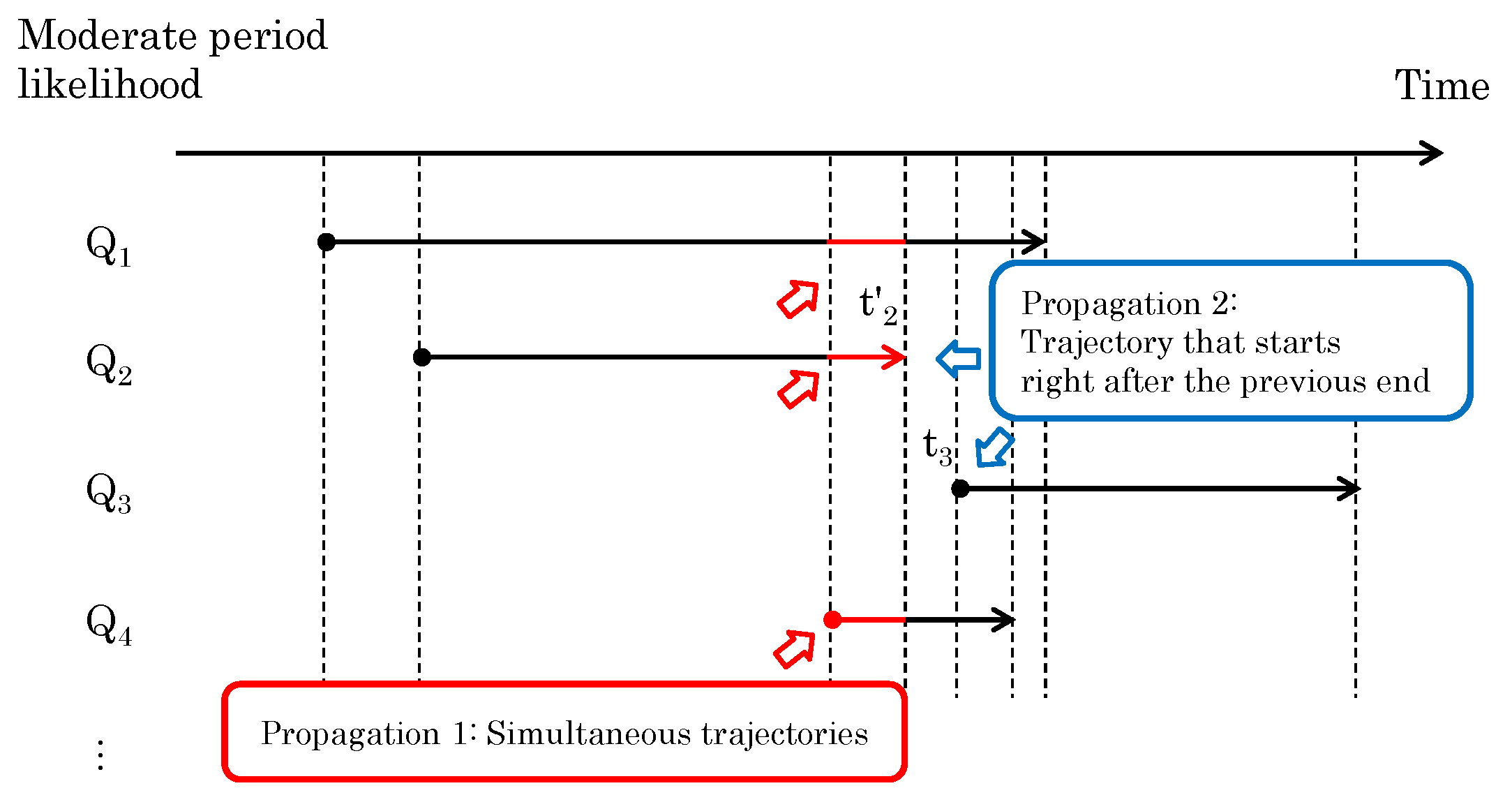
When multiple segments exist in the same time period, the one with the highest likelihood should be highlighted (Update Rule 1). When trajectories are segmented by a person’s occlusion, the segmented trajectories are treated differently. Therefore, if another trajectory with a high likelihood ends just before the start of one trajectory, the likelihood of the trajectory that begins immediately after it should be increased (Update Rule 2). The overview is shown in Figure 8, and the detailed methods are described below.

Figure 8.
The overview of Update Rules 1 and 2 for segmented likelihoods of trajectories.
3.3.1. Update Rule 1—Simultaneous Trajectories
For segmented trajectories observed at the same time, there is at most one trajectory that corresponds to the sensor data. If the moderate period likelihood for one trajectory is high, the other trajectories should be rejected. This can be well represented by the softmax function [23], which is often used as an activation function in DNNs, so we updated an arbitrary using the softmax function as the following equation.
We take the interval where the trajectory occurrence time overlaps in and perform softmax processing on the corresponding stamp.
3.3.2. Update Rule 2—Sequential Trajectories
During observation, it frequently happens that a person’s trajectory is fragmented for some reason. If there is a trajectory that ends just before another trajectory begins, we can expect that the two trajectories belong to the same person. To reflect this situation, if there is a trajectory that ends immediately before the start of another trajectory, we increase the likelihood of the first trajectory immediately after the start of the second trajectory.
Note that is the moderate-period likelihood obtained from the trajectory that ended just before started, and is a function that decreases with the length of , the time between the previous end and the immediate start. In the example shown in Figure 8, the value is applied to , which starts immediately after ends.
3.3.3. Integration of Moderate-Period Likelihood Q into Full-Period Likelihood R
To compute the full-period likelihood , consider integrating a set of moderate-period likelihoods . Each element of is obtained from different period lengths. When the likelihood of an element of longer period is high, the likelihood of the full period can also be considered high. Conversely, even if the moderate-period likelihood of the element is high, the likelihood may not indicate a trend for the entire dataset. Therefore, the period length should be reflected in the calculation of the full-period likelihood. As shown in Figure 9, the period length of moderate-period likelihood is directly used as a weight to obtain .
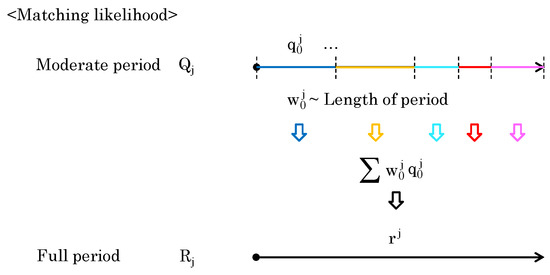
Figure 9.
Computation of by considering the lengths of the elements of .
After the likelihood is obtained for each trajectory , the trajectory with the largest likelihood is adopted in order according to the winner-takes-all rule. A trajectory that overlaps in time with the set of trajectories that have already been adopted is not adopted. Trajectories with likelihoods below a certain threshold are also not adopted. Trajectories of extremely short periods are excluded from the likelihood calculation at the initial stage and are also not adopted.
Through the combination of our proposed deep learning model and the processing method of the results as described above, we can obtain accurate matching results. In the experimental section, we present detailed experimental results and analysis.
4. Experiment
4.1. Original Dataset—Long and Short Datasets
4.1.1. Environment and Hyper-Parameters
The search ranges of hyper-parameters in our model are as follows: The learning rate of SyncScore is searched in , , and . The number of SecAttention N is searched in 1, 2, 3, and 4, and the number of heads in multi-attention is searched in 4 and 8. After tuning, we utilize the hyper-parameters with the best performance on the validation set as follows: The learning rate of SyncScore is . The number of layers of SecAttention is two and the number of heads is eight. All training uses the AdamW optimizer. The experiment use Binary Cross-Entropy (BCE) as the loss function. The parameters for all the baselines are tuned to attain the best performance or set as proposed by the authors. The experiments used Pytorch on Nvidia GeForce RTX 3090 (24 GB memory).
4.1.2. Long and Short Datasets and Evaluation Algorithm
In this experiment, we confirmed the accuracy of matching trajectories with sensor data. We could not find any existing datasets suitable for our experiments. Therefore, we first created a dataset specifically designed for our purposes and then conducted our experiments on it. (This empirical study was conducted with the approval of the Ethics Committee for Research Involving Humans at the Faculty of Engineering, University of Yamanashi.)
We prepared two datasets: a Long Dataset for trajectories and sensor data without video as a training model, and a Short Dataset of trajectories and sensor data with perfect tags by manually observing videos for observing the results (Table 1). The proportion of the two labels in the Long Dataset is 56% and 44%.

Table 1.
Information on two datasets: a Long Dataset without video, and a Short Dataset with video and manually added tags.
For the Long Dataset, we manually give the correct answer whether the person with a certain sensor Si matches each full period or not, so we can examine the accuracy of the match between and . For the Long Dataset, we compare the scores of the ablation study with and without the proposed Fusion Feature. An ablation study is also performed for SecAttention and the Transformer on which it is based. A case is True Positive (TP) when it is estimated to match and of the same person, and False Negative (FN) when it is estimated not to match and . A case is False Positive (FP) when a match is estimated for and of different persons, and True Negative (TN) when no match is estimated. When these are obtained for all combinations of and , Accuracy, Precision, Recall (Sensitivity), and F1 are obtained by the following equations, respectively.
From the Short Dataset, we can examine whether the proposed Likelihood Fusion Algorithm introduced in Section 3.3 contributes to integrating the trajectories and with an appropriate likelihood. The individual effectiveness of Update Rules 1 and 2 in the Likelihood Fusion Algorithm is also examined by ablation studies.
4.1.3. Data Acquisition
To obtain the data, we asked several subjects to wear wearable sensors and to move around the room. For the wearable sensor data, we utilized the WitMotion WT901SDLC sensor, which was worn on each person’s wrist to record movement. The sensor collected nine-axis data such as acceleration, angular velocity, angle, and timestamp. The sampling frequency of the sensor was set to 20 Hz. As for the human trajectory data, we employed a DepthAI camera Luxonis OAK-D-Pro along with the person-detection-retail-0013 model from the OpenVINO library to detect people and obtain their 3D coordinates. The process involved comparing each captured object box with the previous frame, concatenating the obtained points to form a trajectory, and manually annotating the trajectory.
For tagging data, we could have tagged the images but, for this experiment, we first used a simpler tagging method: we assigned a chair to each subject, visualized the trajectory in 3D, and identified the trajectories of each subject sitting in a certain chair and walking around the room before and after sitting in the chair. This method enabled the tagging of trajectories and sensor data for a long time period without the cumbersome task of video tagging. For the Long Dataset, we collected this data over 2.5 h and we employed a five-fold cross-validation approach for training the model.
To construct a more precise Short Dataset, we utilized camera videos to collect precisely corresponding data. When the videos could be viewed together, we could tag which person had the wearable sensor. Even after the trajectories collided, we could estimate which trajectory was made by the target person. With this method, it is necessary to match the images and trajectories at each period. Although it is possible to create a definite correct ground truth, the task of tagging becomes difficult. We used this dataset only for the test and did not use it for training and validation. The captured images were set to a resolution of 544 × 320 and sampled at a frequency of 7 Hz. There were ten videos in total, with two cameras simultaneously capturing five different situations from different positions. Four people in the video were wearing wearable sensors. So, we can say that there are 40 samples to observe the results. The average length of the videos was 52 s.
In our study, we classified the results in the same way as a typical classification task and validated them using metrics such as F1 score, accuracy, precision, and recall. Table 2 shows the performance metrics of the SyncScore network, which calculates the matching likelihood per unit period. Here, the process is performed at the unit period level P, before integrating to moderate period Q or full period R. Recognition is considered successful when the correct trajectory shows the highest likelihood compared to other trajectories at the same period. Since there are no models similar to our task for comparison, we compared the results when each method was removed by an ablation study.
Table 2.
Evaluation results in Long Dataset.
4.1.4. Long Dataset
In Figure 4 of Section 3.2, a Fusion Feature is created by concatenating the trajectory and sensor data. Even without creating this vector, the input and output of the network can be the same. In the experiment, we obtained the score when this vector was omitted. Also, since we could use Transformer instead of SecAttention, we also obtained the score in this case. As a result, it was confirmed that the score was best when both elements were included. From this, it can be said that both Fusion Feature and SecAttention are effective for recognizing our dataset.
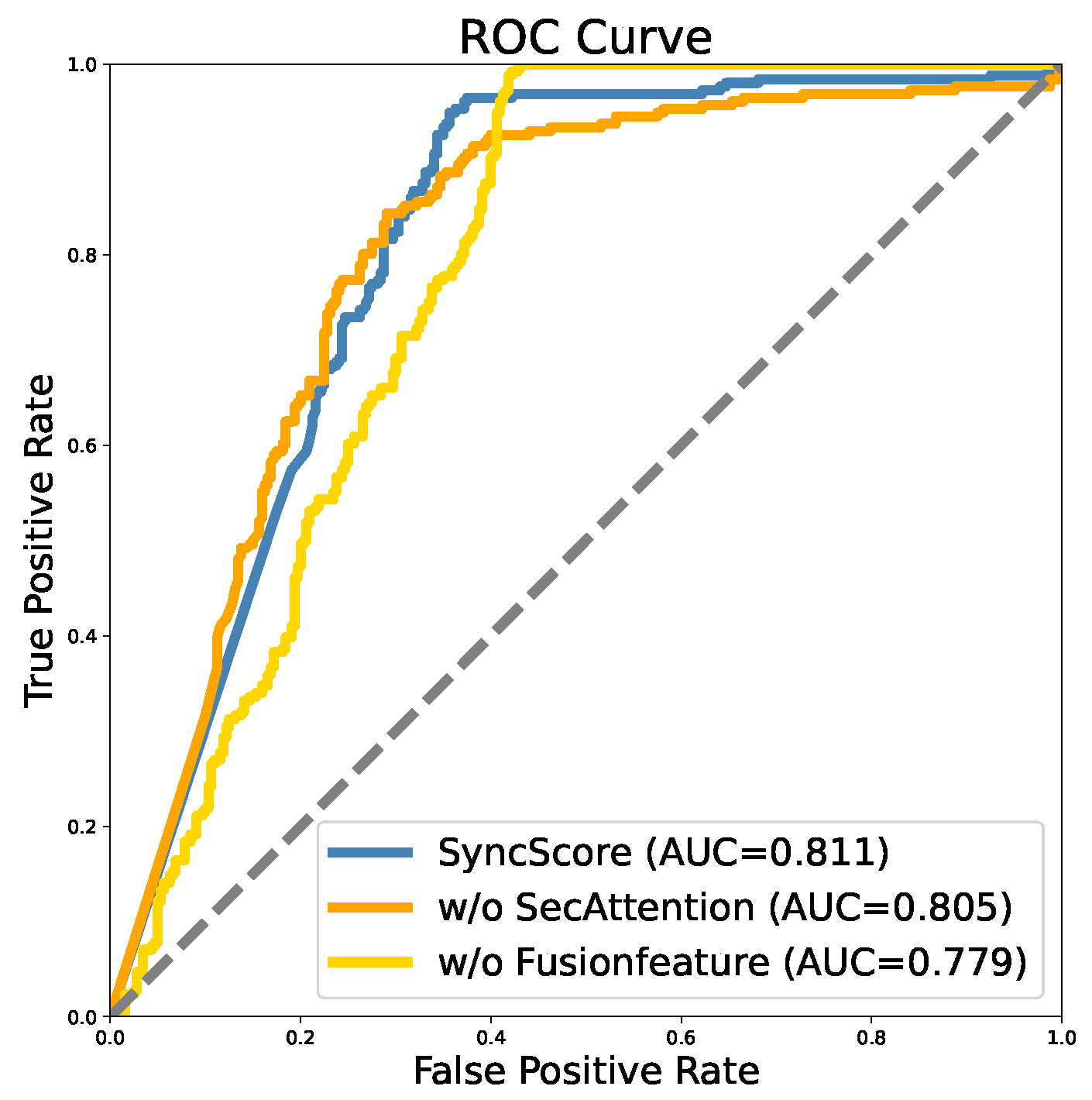
In Figure 10, the AUC value of the SyncScore model stands at 0.811, surpassing the values of 0.805 observed when excluding the SecAttention module and 0.779 when omitting the Fusion Feature module. This comparison underscores the superior performance of the SyncScore model in accurately classifying positive samples and distinguishing them from negative ones. The model excels not only in correctly identifying truly positive samples but also in minimizing misclassifications of negative samples as positive. The ROC curve of the SyncScore model is closer to the upper left corner, indicating that it performs better across the entire FPR range. This means that the SyncScore model can achieve a higher TPR at a lower FPR, thereby improving the overall performance of the model. The slope of the ROC curve is steep, which also shows that the recall metric performs well. Based on these, it is evident that the Fusion Feature and SecAttention exert a discernible impact on the overall performance of the model.

Figure 10.
Ablation results of ROC curve in Long Dataset.
In our study aimed at advancing the field of trajectory matching, we have strategically chosen to compare the Transformer model [17], along with its advancements in the form of Informer [24] and GTN (Gated Transformer Network) [25], to better understand their applicability and performance in this context. The decision to compare the Informer and GTN models to our work stems from their inherent capabilities in handling sequence and time-series data, which are fundamentally related to trajectory analysis. This involves the utilization of our novel deep learning model, SecAttention, an improvement based on the Transformer, tailored for trajectory matching.
The Transformer model, with its self-attention mechanism, serves as an excellent baseline for analyzing sequence data, prompting its inclusion in our comparative analysis. The Informer builds upon the Transformer by adding convolutional layers to better handle sequence dependencies, crucial for precise trajectory matching. Meanwhile, GTN brings a specialized approach to multivariate time series by blending a gating mechanism with self-attention, adeptly extracting key information for trajectory matching.
Given that our SecAttention model is an extension of the Transformer, focusing our comparative analysis on this component offers a direct evaluation of its enhancements. By replacing the SecAttention part of our SyncScore model with each comparison method in turn, we aim to assess their relative effectiveness strictly within the context of our model’s framework.
As detailed in Table 3, although our method slightly trails behind GTN in terms of precision, it excels in all other metrics, notably achieving the highest F1 score. This outcome underscores the efficacy of our approach in trajectory matching, highlighting the significance of our improvements over the foundational Transformer model.
Table 3.
Ablation results on trajectories in Long Dataset.
4.1.5. Short Dataset
Table 4 shows the results for the full period R. For all combinations of trajectories and sensor data in the dataset, the proposed method showed an accuracy of 0.725. Note that the scores for accuracy, precision, recall, and F1 are all the same because, when one trajectory is adopted, another is rejected, resulting in the same false negative and false positive values in most cases. When Update Rules 1 and 2, shown in Section 3.3, were not applied, this accuracy decreased. Although the accuracy of the proposed method cannot be deemed sufficiently high, we were able to demonstrate the effectiveness of each of Update Rules 1 and 2.
Table 4.
Evaluation results on videos in Short Dataset.
Table 5 shows the comparison results of applying different models in the Short Dataset. Transitioning from Transformer to Informer, and subsequently to GTN, fluctuations in accuracy were observed. Here, we adopted the update method of Rules 1 and 2. However, upon introducing SecAttention, a significant improvement in performance was noted. More importantly, after integrating SecAttention into the SyncScore model, the accuracy reached the highest point, indicating that the addition of SecAttention can significantly enhance the model’s ability to process time-series data. This result proves the effectiveness of SyncScore in improving the accuracy of trajectory-matching, especially in application scenarios with detailed temporal alignment.
Table 5.
Matching results of videos in Short Dataset.
Table 6, Table 7 and Table 8 and Figure 11, Figure 12 and Figure 13 show detailed results for the three test samples. These test samples do not have corresponding videos, and the correct trajectories are given only by clues to the seats. In each case, five subjects were observed, and a set of correct trajectories was defined.
Table 6.
Likelihood results of trajectory set for Sample 1. Bold set is the correct result.
Table 7.
Likelihood results of trajectory set for Sample 2.
Table 8.
Likelihood results of trajectory set for Sample 3.

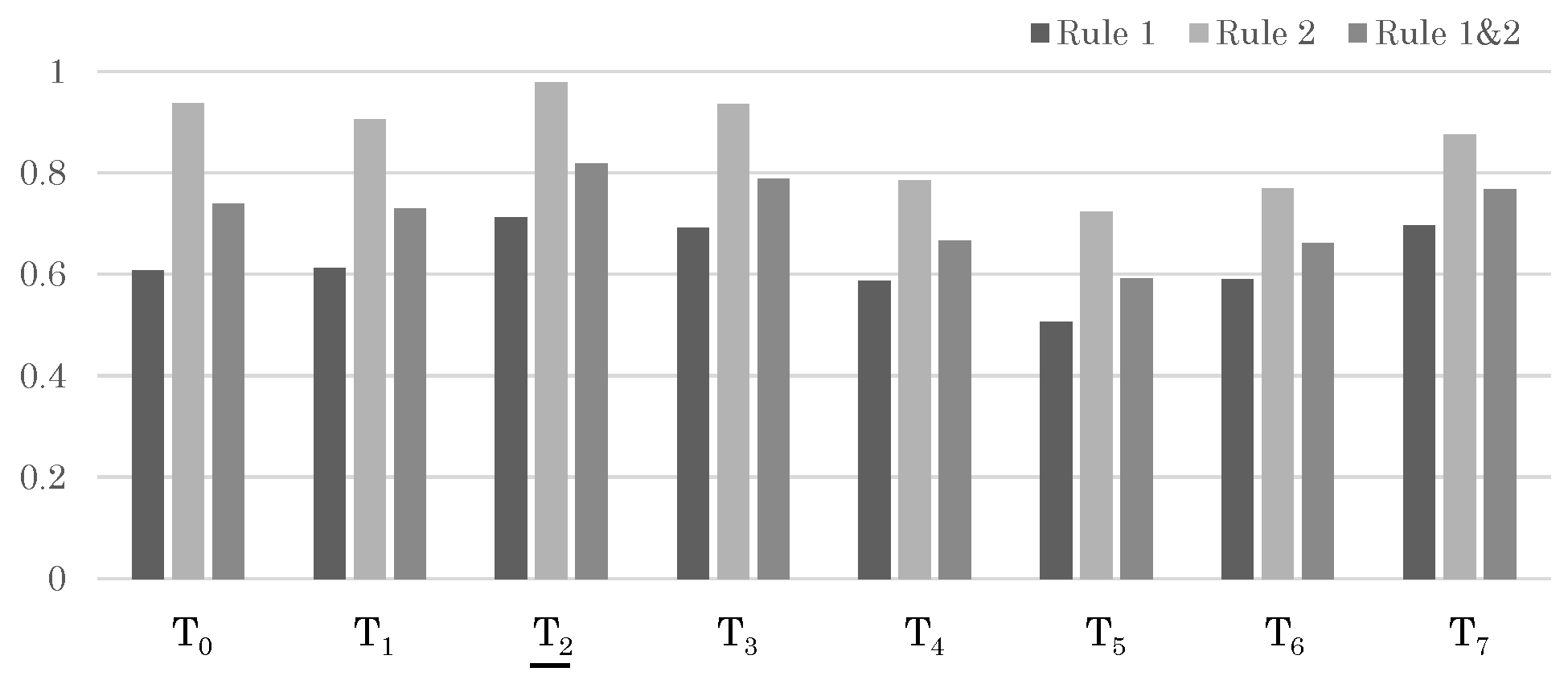
Figure 11.
Likelihood results for each trajectory in Sample 1. The trajectories that should be matched correctly are indicated with underlines.

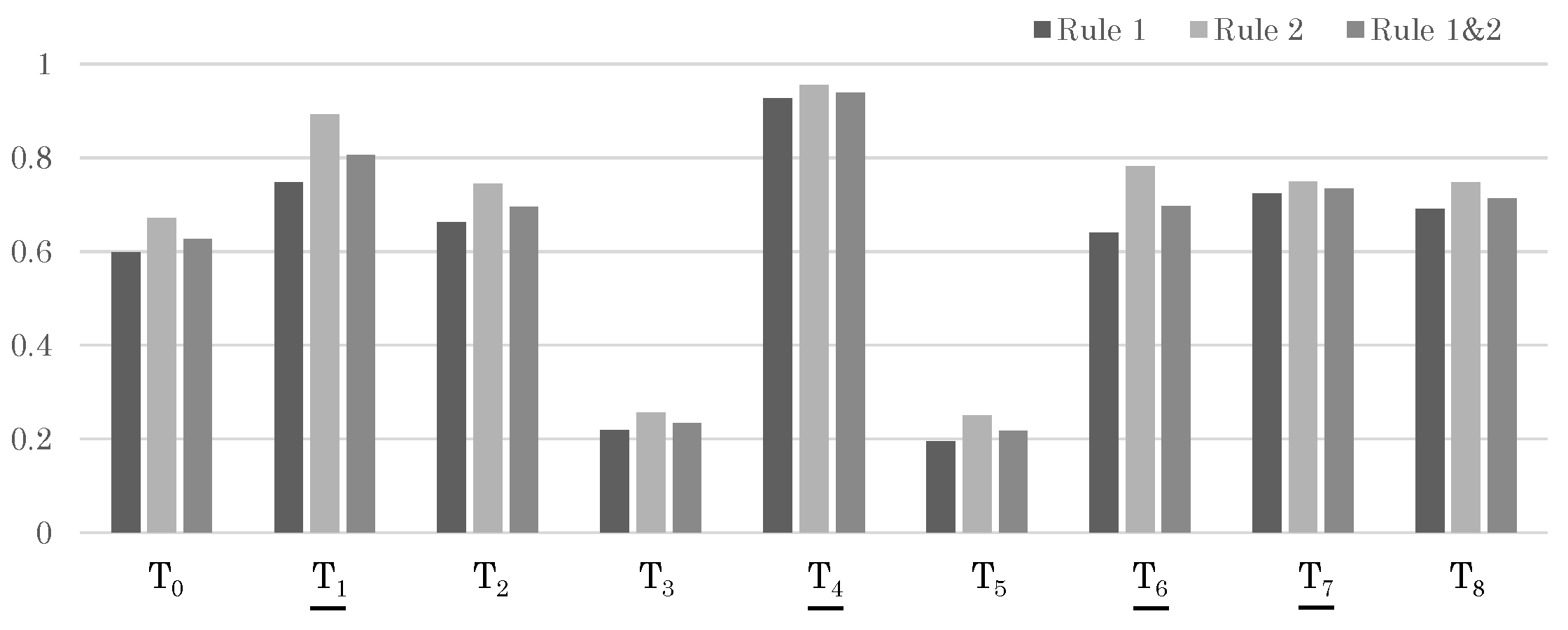
Figure 12.
Likelihood results for each trajectory in Sample 2. The trajectories that should be matched correctly are indicated with underlines.

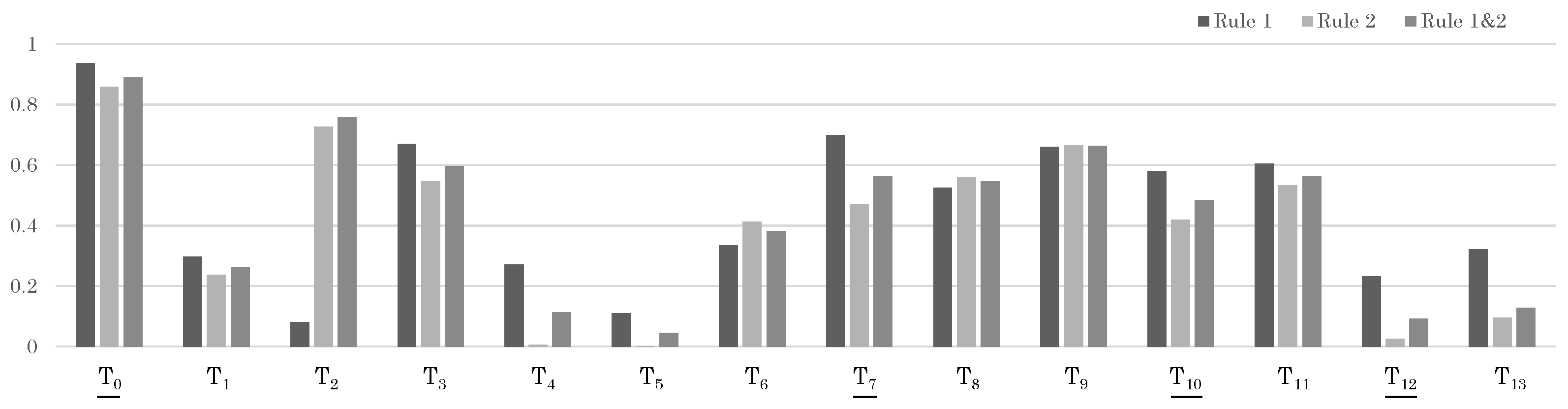
Figure 13.
Likelihood results for each trajectory in Sample 3. The trajectories that should be matched correctly are indicated with underlines.
For Test Sample 1, each person produced a set of trajectories, and the sensor data came from the wearable sensor of the target person in Trajectory Set 3. Therefore, if the likelihood of Trajectory Set 3 = was higher than that of other trajectory sets, it was considered a successful recognition. First, the likelihood at the moderate period Q is shown in Figure 11. At this point, even without applying the update rules, the correct trajectory shows the maximum likelihood. Furthermore, the likelihood for the full period R is shown in Figure 6. Here, again, the likelihood for the correct trajectory set, Trajectory Set 3, is the highest, indicating a successful recognition.
Table 7 and Figure 12 show similar results for a different test sample, Test Sample 2. In this sample, the correct Trajectory Set 2 is divided into and . Although each shows a high likelihood individually, there are also individual trajectories with even higher likelihoods. However, when viewed as a set of trajectories, the correct Trajectory Set 2 shows the highest likelihood, and we are finally able to obtain the correct result.
From Table 8 and Figure 13, it can be observed that the correct target set is Set 1. Although certain individual trajectories, such as , , and , may exhibit high likelihoods when considered in isolation, when we view these trajectories as a collective (namely Set 2), we find that, as a whole, this set demonstrates low likelihood. This analytical approach, considering combinations of trajectories rather than individual ones, can ultimately assist us in deriving the correct conclusions regarding Sample 3. We also note that the sole application of Rule 1 has led to misjudgment of the target, which is attributable to the incomplete considerations in the calculation under Rule 1. This inadvertently underscores the efficacy and importance of applying both Rule 1 and Rule 2 concurrently.
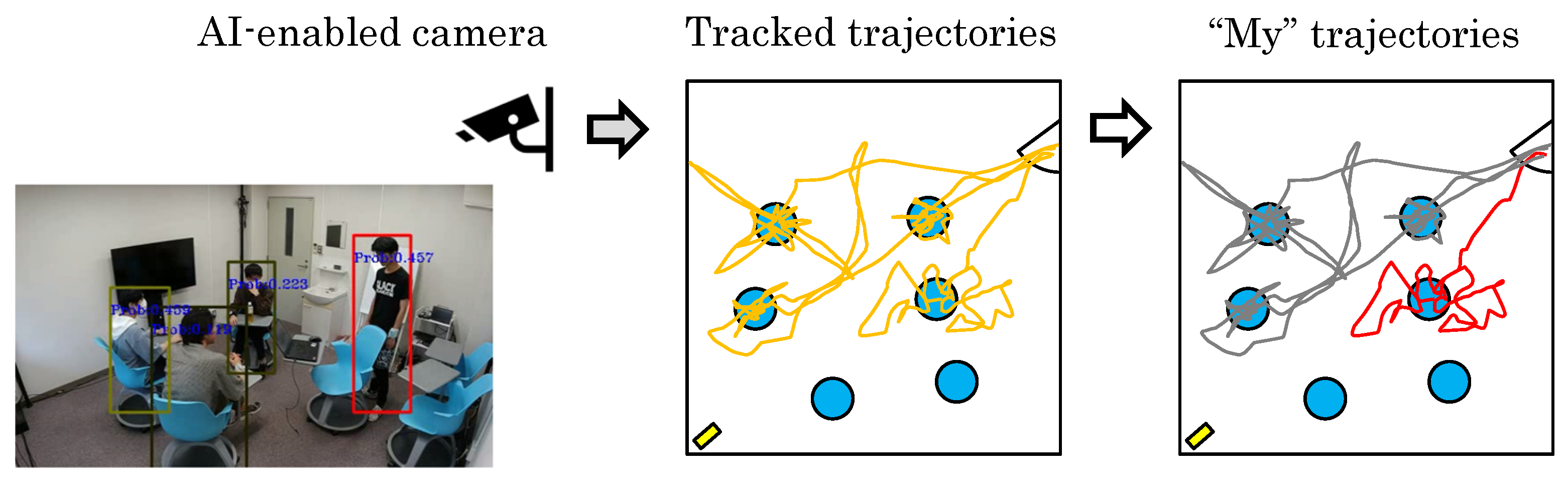
In Figure 14, we show a visualization of part of the experiment. The red box indicates the matching target of the data, and the color depth of the other boxes indicates the probability of the matching result. The darker the color, the lower the matching value, and vice versa. In each of the examples shown in the figure, the person wearing the wearable sensor was correctly estimated with Update Rules 1 and 2. Using one method alone produced one false result. The use of both update rules together comprehensively provided more accurate results. For the other people, different likelihoods were obtained depending on the movement of the trajectory. The correct person was extracted regardless of the position in the image or the depth position.

Figure 14.
Visualization of integration results. Each row is a different video visualization result: (left) target, (right-first) the result of Update Rule 2 processing, (right-middle) the result of Update Rule 1 processing, and (right-most) the result of the fusion of both update rules.
In some samples, we observe that results obtained from alternative trajectory sets closely resemble the correct ones. This occurrence is due to the similarity in behavioral patterns among multiple targets, resulting in a convergence of their likelihoods owing to analogous behavioral models.
From the above, it can be concluded that, for the aforementioned samples, the likelihood for individual trajectories is being calculated somewhat correctly and, furthermore, the integration of likelihoods works well.
4.2. UEA Dataset
The UEA Time Series Classification Dataset [26] is a publicly available dataset designed for time-series classification research, developed and maintained by the University of East Anglia (UEA). It consists of several time-series datasets covering various domains, including health monitoring (Atrial Fibrillation), motion recognition (Basic Motions), speech recognition (JapaneseVowels), and environmental sensing (ERing), among others. These datasets allow researchers to test and compare algorithm performance in different application scenarios.
The time series in the UEA dataset have different lengths, sampling frequencies, and data types, which provide diverse challenges and requirements for data processing. Although there are no pairs of data from wearable sensors and human trajectories in videos such as those addressed in this work, this is a dataset that has collected many synchronized pairs of time-sequential signals from different modalities. Each dataset is accompanied by well-defined class labels that facilitate the evaluation of classification tasks. This standardized labeling allows for direct performance comparison among different algorithms. To evaluate the recognition and integration algorithms proposed in this study, we performed experiments on this dataset and compared them with conventional methods.
In our experiments, we used the UEA dataset for comparison and the accuracy rate was used as an indicator for comparison. Since our model is a dual-input model, which is different from the data in the dataset, we use the same data as input for experiments. The methods involved included ShapeNet [27] for time-series classification, which uses a method combining neural network and shapelet; TapNet [28], which represents metric learning methods and small-sample learning; DTW [29], which represents distance-based methods, 1NNI, which stands for Independent Wrapping, where each dimension is calculated separately and then summed; and 1NND, which stands for Dependent Wrapping, for all Dimensions for DTW calculations. We also used clustering methods for classification, such as K-Means; and DSTP [30], GeoMAN [31], and STAM [32] for spatiotemporal data modeling and forecasting tasks. From the results in Table 9, it is observable that our method achieves the best win/tie results among all methods.
Table 9.
Accuracy for UEA.
In our experiments, we compared our proposed module with traditional time-series classification methods based on accuracy metrics. The results demonstrate a performance improvement of our module on the UEA Time Series Classification Dataset. Our module effectively captures the temporal correlations and feature representations in the time-series data compared to previous methods, resulting in enhanced classification accuracy and performance. These experimental findings further validate the effectiveness and generality of our proposed module, which is applicable to our specific task and to common single-input multidimensional time-series processing tasks. It presents a new approach and perspective for time-series data analysis and classification research.
5. Conclusions
In this paper, we propose a method for identifying human trajectories obtained from cameras and other devices by matching the trajectories to peoples’ wearable sensor data. People who were given sensor data from wearable devices were shown which trajectories corresponded to their own trajectories and could use that data to analyze their behavior independently. By checking the match between sensor data and trajectories, without using camera images as clues, a desirable system can be derived.
The problem with this method is that human trajectory data and sensor data have different modalities, and incomplete trajectory data are often obtained, making conventional matching methods inapplicable. To solve these problems, we proposed the SyncScore model to obtain the matching likelihood for short-term period data. We then used the Likelihood Fusion algorithm to gradually update the likelihood. We confirmed that the proposed methods gave high scores in our original dataset. We also confirmed that the proposed method provides better accuracy on the UEA dataset than the conventional method.
Our future work will include investigating how well the trajectories can be identified in large spaces with several people. One of the characteristics of AI cameras is their capability to obtain 3D trajectories by focusing the range to a certain distance. For this reason, it is possible that, in a large space, a person might be captured by a camera without their trajectory being found. Also, the presence of a large number of people will often occlude them from each other. In such cases, the trajectory would not score as highly as it would have in this work. An additional algorithm is required to deal with such incomplete trajectories. We believe that, even if the accuracy is not perfect, it can still be used. Since the results are given together with the likelihood, it is possible not to present the results to the user if the likelihood is not sufficient.
The time synchronization between the wearable sensor and the AI camera was assumed to be perfect in our experiment, but this was difficult to confirm. It is generally assumed that the AI camera is always connected to the network, but the time synchronization of the wearable sensor may be imperfect. It may be possible to synchronize the data by detecting the movements of the wearable sensors and detecting the targets’ trajectories before comparing the data. We would like to add a time synchronization algorithm using only data. This is a challenging problem in itself, because it requires solving the problem without knowing which person’s sensor data is being observed.
For completely unknown data that is not included in the current dataset, it is possible that sufficient accuracy may not be obtained if the camera capturing conditions or the behavior of the person in the video are very different.
The Nvidia GeForce RTX 3090 (24 GB) used in the experiments is sufficiently high-spec, but the processing time is about twice the length of the video, so it does not work in real time. The system does not acquire wearable sensor signals via the network currently, and we have to directly connect the cable to retrieve the signals after the experiment is over, which is also an issue in operation.
Author Contributions
Conceptualization, J.Y. and M.T.; methodology, J.Y. and M.T.; software, J.Y.; validation, J.Y.; formal analysis, J.Y.; investigation, J.Y., M.T. and X.W.; resources, M.T. and X.W.; data curation, J.Y. and M.T.; writing—original draft preparation, J.Y.; writing—review and editing, M.T. and X.W.; visualization, J.Y. and M.T.; supervision, M.T. and X.W.; project administration, M.T. and X.W.; funding acquisition, M.T. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by JST PRESTO Grant Number JPMJPR2135 and JSPS KAKENHI Grant Number JP21H00901.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; Hoi, S.C.H. Deep Learning for Person Re-Identification: A Survey and Outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 2872–2893. [Google Scholar] [CrossRef]
- Luo, H.; Gu, Y.; Liao, X.; Lai, S.; Jiang, W. Bag of Tricks and a Strong Baseline for Deep Person Re-Identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, CVPR Workshops 2019, Long Beach, CA, USA, 16–20 June 2019; Computer Vision Foundation/IEEE: New York, NY, USA, 2019; pp. 1487–1495. [Google Scholar] [CrossRef]
- Zhou, K.; Yang, Y.; Cavallaro, A.; Xiang, T. Omni-Scale Feature Learning for Person Re-Identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. DeepFace: Closing the Gap to Human-Level Performance in Face Verification. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar] [CrossRef]
- Sun, Y.; Wang, X.; Tang, X. Deep Learning Face Representation by Joint Identification-Verification. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Xiao, T.; Li, S.; Wang, B.; Lin, L.; Wang, X. End-to-End Deep Learning for Person Search. arXiv 2016, arXiv:1604.01850. [Google Scholar]
- Wang, Y.; Zhang, P.; Gao, S.; Geng, X.; Lu, H.; Wang, D. Pyramid Spatial-Temporal Aggregation for Video-based Person Re-Identification. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 12006–12015. [Google Scholar] [CrossRef]
- Peng, L.; Wang, L.; Xia, D.; Gao, Q. Effective energy consumption forecasting using empirical wavelet transform and long short-term memory. Energy 2022, 238, 121756. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Shang, H.L. Forecasting functional time series. J. Korean Stat. Soc. 2009, 38, 199–211. [Google Scholar] [CrossRef]
- Wang, Y.; Zhu, S.; Li, C. Research on Multistep Time Series Prediction Based on LSTM. In Proceedings of the 2019 3rd International Conference on Electronic Information Technology and Computer Engineering (EITCE), Xiamen, China, 18–20 October 2019; pp. 1155–1159. [Google Scholar] [CrossRef]
- Wang, Z.; Yan, W.; Oates, T. Time series classification from scratch with deep neural networks: A strong baseline. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 1578–1585. [Google Scholar] [CrossRef]
- Pham, A.D.; Kuestenmacher, A.; Ploeger, P.G. TSEM: Temporally-Weighted Spatiotemporal Explainable Neural Network for Multivariate Time Series. In Advances in Information and Communication; Arai, K., Ed.; Springer: Cham, Switzerland, 2023; pp. 183–204. [Google Scholar]
- Wang, B. Data Feature Extraction Method of Wearable Sensor Based on Convolutional Neural Network. J. Healthc. Eng. 2022, 2022, 1580134. [Google Scholar] [CrossRef] [PubMed]
- Allahbakhshi, H.; Conrow, L.; Naimi, B.; Weibel, R. Using Accelerometer and GPS Data for Real-Life Physical Activity Type Detection. Sensors 2020, 20, 588. [Google Scholar] [CrossRef] [PubMed]
- Kulkarni, M.B.; Rajagopal, S.; Prieto-Simón, B.; Pogue, B.W. Recent advances in smart wearable sensors for continuous human health monitoring. Talanta 2024, 272, 125817. [Google Scholar] [CrossRef] [PubMed]
- Waleed, M.; Kamal, T.; Um, T.W.; Hafeez, A.; Habib, B.; Skouby, K.E. Unlocking insights in iot-based patient monitoring: Methods for encompassing large-data challenges. Sensors 2023, 23, 6760. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Huang, L.; Mao, F.; Zhang, K.; Li, Z. Spatial-Temporal Convolutional Transformer Network for Multivariate Time Series Forecasting. Sensors 2022, 22, 841. [Google Scholar] [CrossRef] [PubMed]
- Wu, N.; Green, B.; Ben, X.; O’Banion, S. Deep Transformer Models for Time Series Forecasting: The Influenza Prevalence Case. arXiv 2020, arXiv:2001.08317. [Google Scholar]
- Ismail Fawaz, H.; Lucas, B.; Forestier, G.; Pelletier, C.; Schmidt, D.F.; Weber, J.; Webb, G.I.; Idoumghar, L.; Muller, P.A.; Petitjean, F. InceptionTime: Finding alexnet for time series classification. Data Min. Knowl. Discov. 2020, 34, 1936–1962. [Google Scholar] [CrossRef]
- Amirian, J.; Zhang, B.; Castro, F.V.; Baldelomar, J.J.; Hayet, J.B.; Pettré, J. OpenTraj: Assessing Prediction Complexity in Human Trajectories Datasets. In Proceedings of the Computer Vision—ACCV 2020; Springer: Cham, Switzerland, 2021; pp. 566–582. [Google Scholar]
- Zhang, L.; Liu, L.; Xia, Z.; Li, W.; Fan, Q. Sparse Trajectory Prediction Based on Multiple Entropy Measures. Entropy 2016, 18, 327. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 11106–11115. [Google Scholar]
- Liu, M.; Ren, S.; Ma, S.; Jiao, J.; Chen, Y.; Wang, Z.; Song, W. Gated transformer networks for multivariate time series classification. arXiv 2021, arXiv:2103.14438. [Google Scholar]
- Bagnall, A.; Dau, H.A.; Lines, J.; Flynn, M.; Large, J.; Bostrom, A.; Southam, P.; Keogh, E. The UEA multivariate time series classification archive, 2018. arXiv 2018, arXiv:1811.00075. [Google Scholar]
- Li, G.; Choi, B.; Xu, J.; Bhowmick, S.S.; Chun, K.P.; Wong, G.L.H. Shapenet: A shapelet-neural network approach for multivariate time series classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35. [Google Scholar]
- Zhang, X.; Gao, Y.; Lin, J.; Lu, C.T. Tapnet: Multivariate time series classification with attentional prototypical network. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34. [Google Scholar]
- Müller, M. Dynamic time warping. In Information Retrieval for Music and Motion; Springer: Heidelberg, Germany, 2007; pp. 69–84. [Google Scholar]
- Liu, Y.; Gong, C.; Yang, L.; Chen, Y. DSTP-RNN: A dual-stage two-phase attention-based recurrent neural network for long-term and multivariate time series prediction. Expert Syst. Appl. 2020, 143, 113082. [Google Scholar] [CrossRef]
- Liang, Y.; Ke, S.; Zhang, J.; Yi, X.; Zheng, Y. GeoMAN: Multi-Level Attention Networks for Geo-Sensory Time Series Prediction. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; AAAI Press: Menlo Park, CA, USA, 2018. IJCAI’18. pp. 3428–3434. [Google Scholar]
- Gangopadhyay, T.; Tan, S.Y.; Jiang, Z.; Meng, R.; Sarkar, S. Spatiotemporal Attention for Multivariate Time Series Prediction and Interpretation. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 3560–3564. [Google Scholar] [CrossRef]
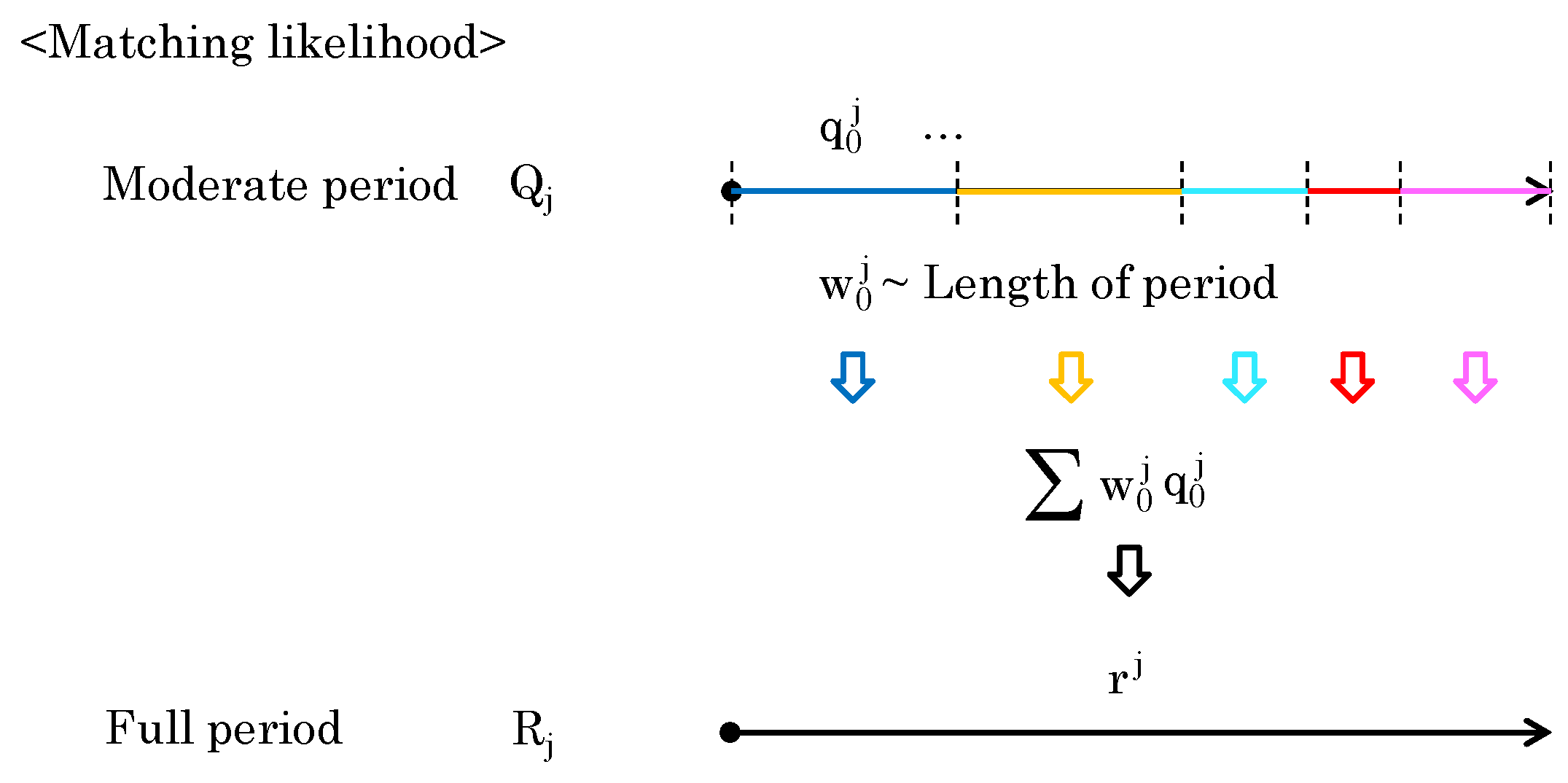

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).