
Human Joint Angle Estimation Using Deep Learning-Based Three-Dimensional Human Pose Estimation for Application in a Real Environment

Abstract
:1. Introduction
2. Related Work
2.1. Skeleton Model
2.2. Volumetric Model
3. Methodology
3.1. Pose-Estimation Methods
3.2. Performance Comparison in Real-World Environments
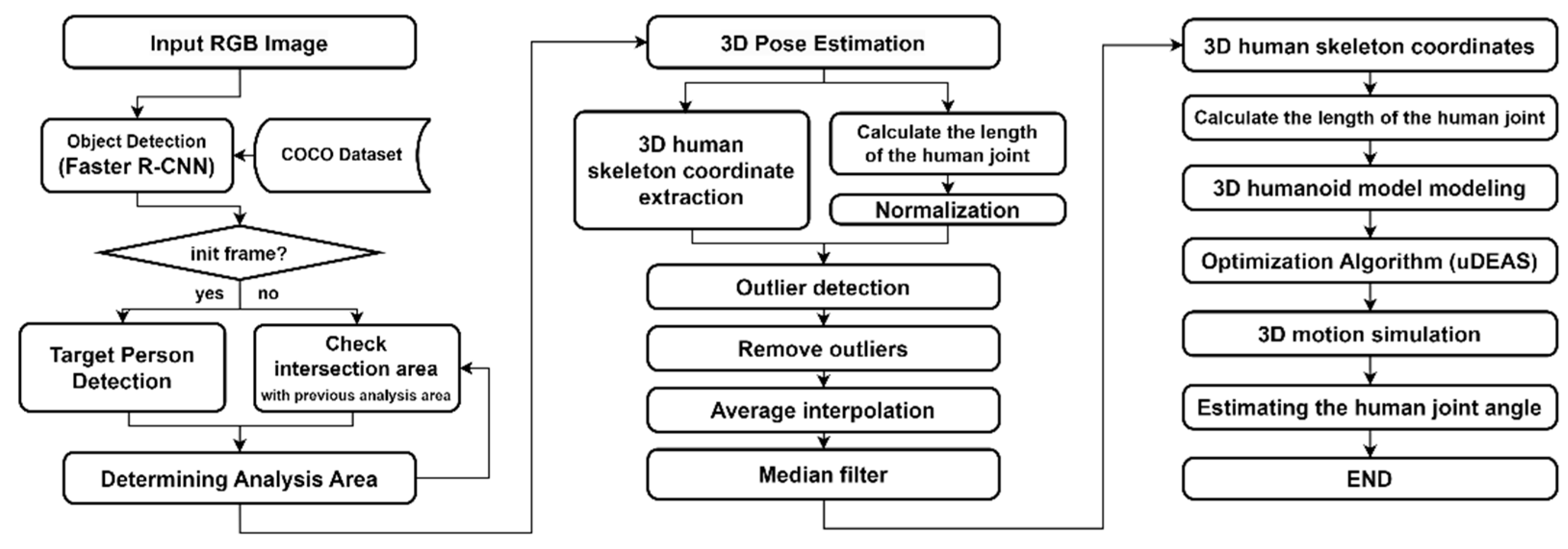
3.3. Improving Pose Recognition Performance
3.3.1. Improving Human Recognition Accuracy
- All BBs with confidence scores below a certain threshold were removed.where is the confidence score associated with BB .
- All detected BBs that were not identified as humans were removed.
- Finally, the ROI to be analyzed was determined. Among the remaining BBs, only the one with the largest area was retained, and the rest were removed.
- In the current frame, all BBs that were not identified as humans were removed;
- The intersection over union (IoU) between the BB recognized in the previous frame and BBs in the current frame was calculated. The IoU is a common measure used in object detection to assess the similarity between two sets. This is calculated as the ratio of the intersection area () of the recognized regions in the current () and previous () frames to their union areas, as expressed below:
- Finally, the BB with the highest sum of the confidence and IoU scores was adopted.
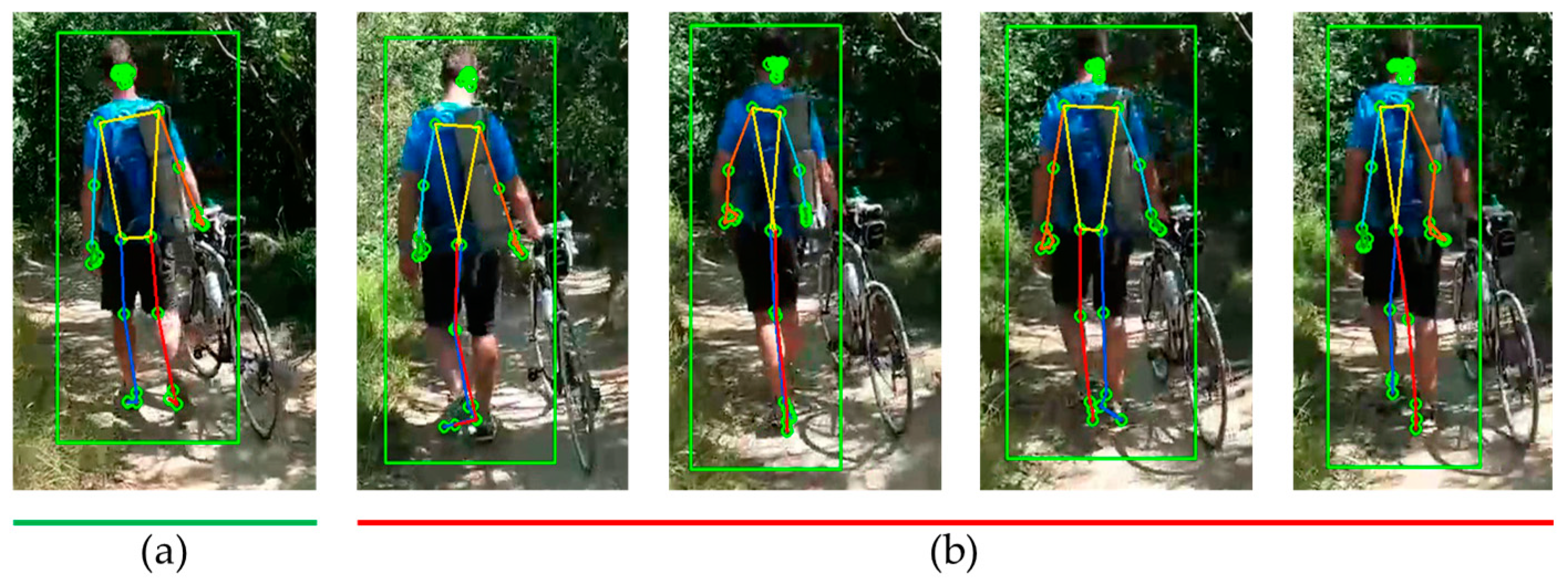
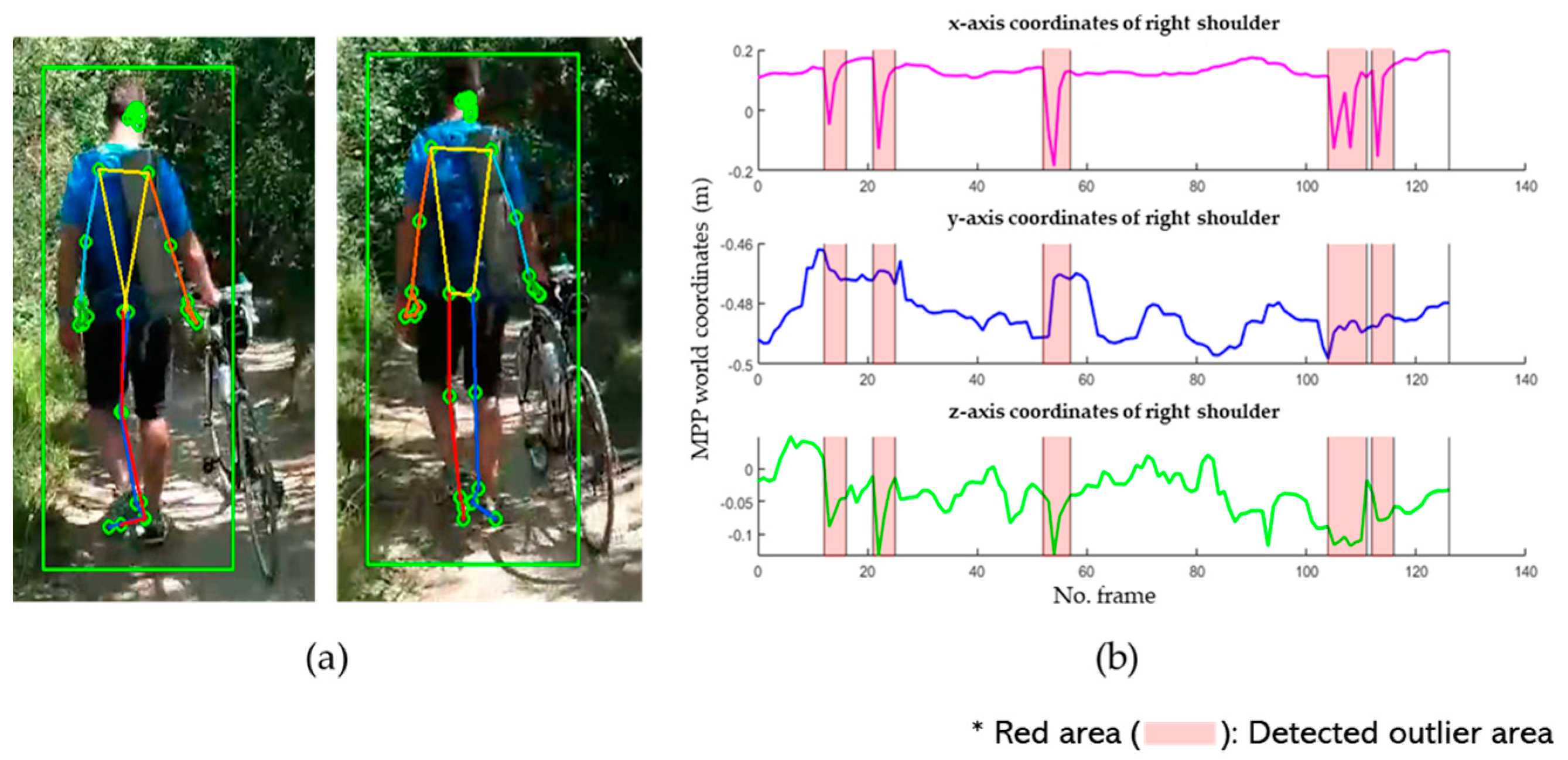
3.3.2. Detection of Outliers
3.3.3. Outlier Correction
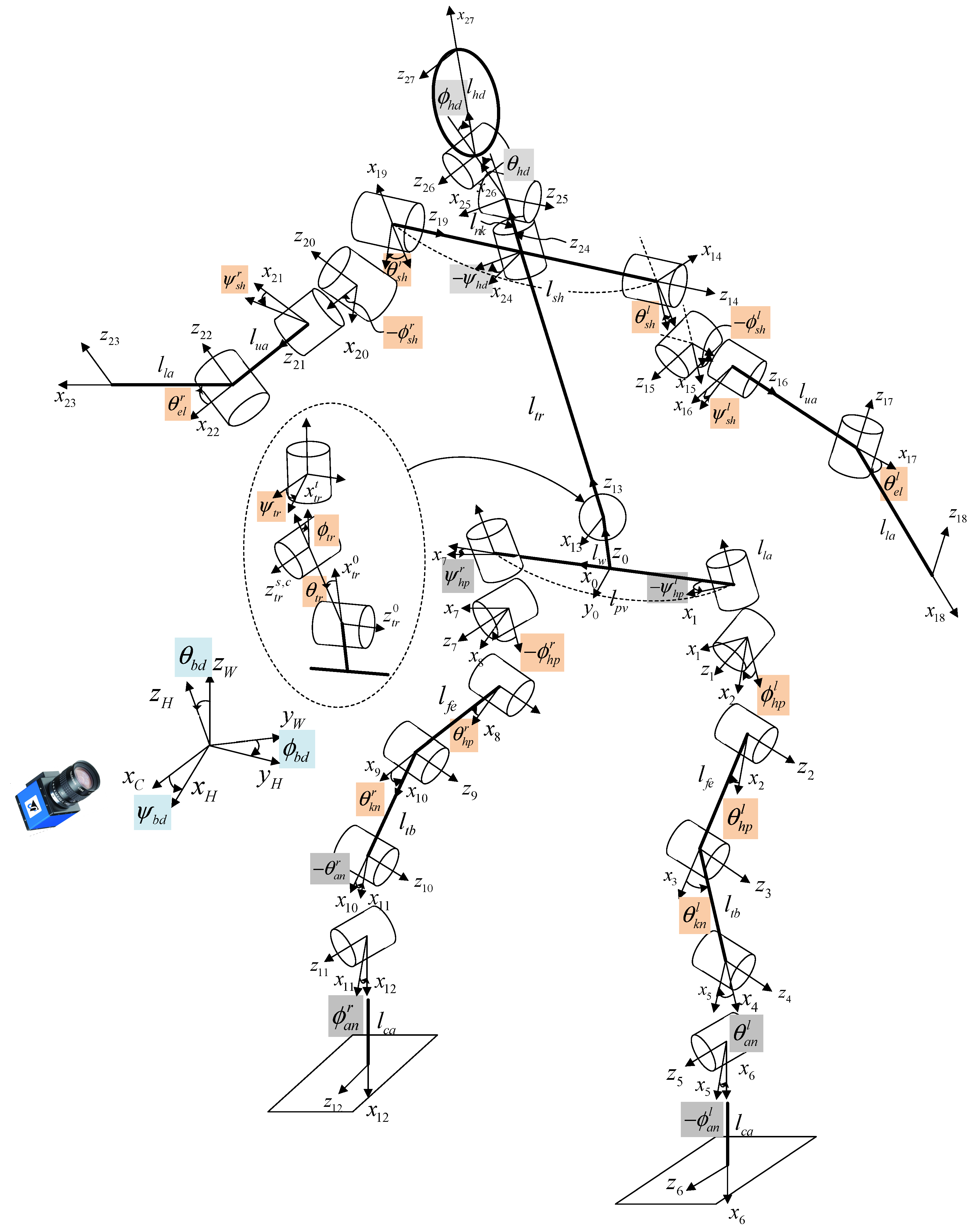
3.3.4. Joint Angle Estimation
3.4. Proposed Method
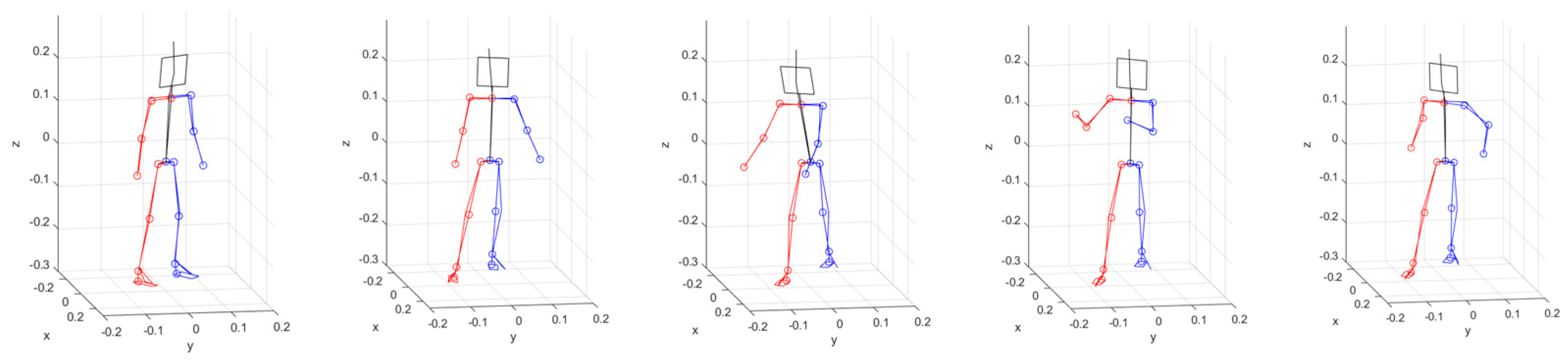
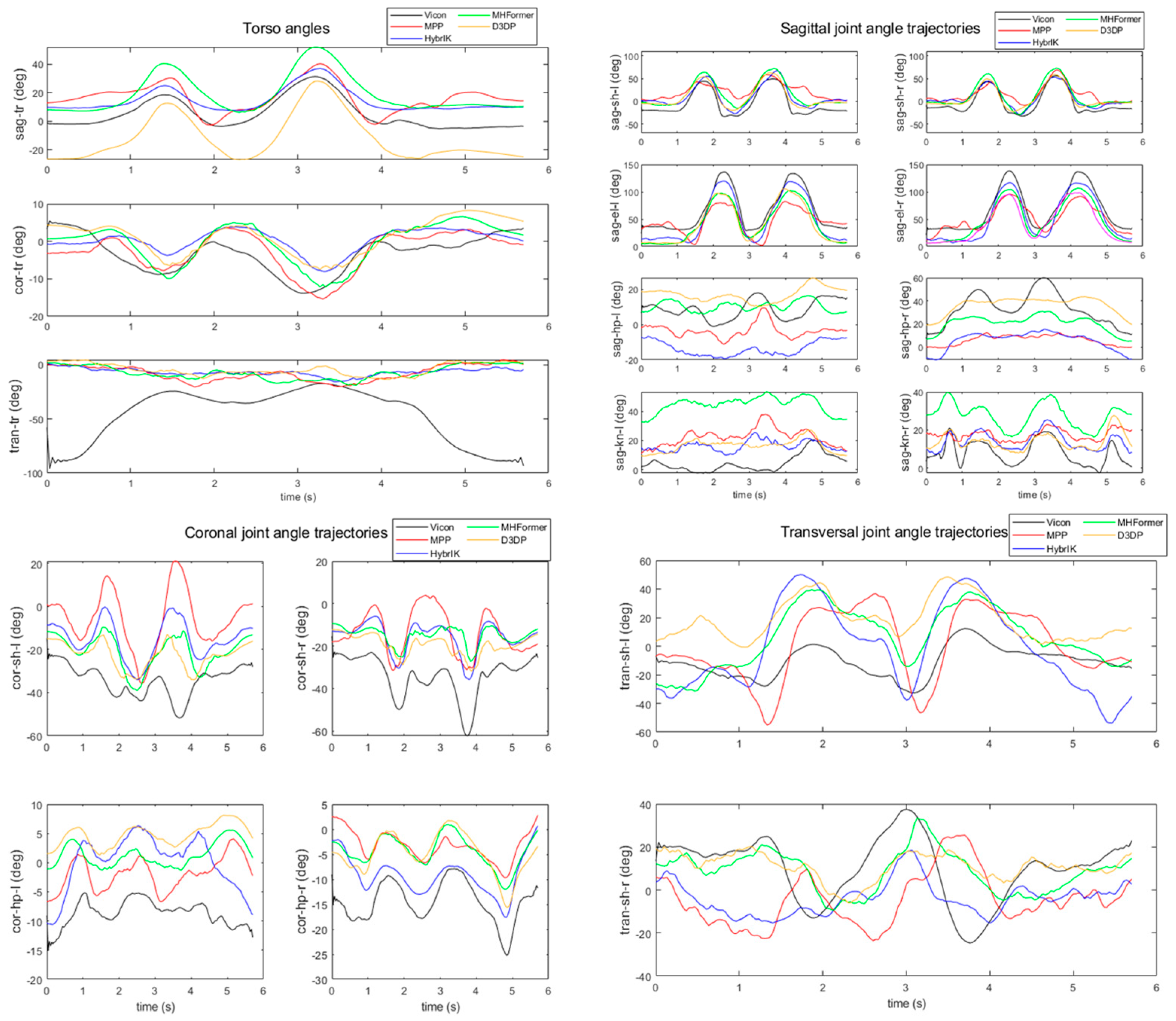
4. Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- 3D Motion Capture Market. Available online: https://www.futuremarketinsights.com/reports/3d-motion-capture-market (accessed on 19 February 2024).
- Yehya, N.A. Researchers Analyze Walking Patterns Using 3D Technology in Community Settings. Available online: https://health.ucdavis.edu/news/headlines/researchers-analyze-walking-patterns-using-3D-technology-in-community-settings-/2023/01 (accessed on 15 November 2023).
- Seel, T.; Raisch, J.; Schauer, T. IMU-based joint angle measurement for gait analysis. Sensors 2014, 14, 6891–6909. [Google Scholar] [CrossRef] [PubMed]
- Vithanage, S.S.; Ratnadiwakara, M.S.; Sandaruwan, D.; Arunathileka, S.; Weerasinghe, M.; Ranasinghe, C. Identifying muscle strength imbalances in athletes using motion analysis incorporated with sensory inputs. IJACSA 2020, 11, 811–818. [Google Scholar] [CrossRef]
- MediaPipe Pose. Available online: https://github.com/google/mediapipe/blob/master/docs/solutions/pose.md (accessed on 25 November 2023).
- Li, J.; Xu, C.; Chen, Z.; Bian, S.; Yang, L.; Lu, C. Hybrik: A hybrid analytical-neural inverse kinematics solution for 3d human pose and shape estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 3383–3393. [Google Scholar]
- Li, J.; Bian, S.; Liu, Q.; Tang, J.; Wang, F.; Lu, C. NIKI: Neural Inverse Kinematics with Invertible Neural Networks for 3D Human Pose and Shape Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12933–12942. [Google Scholar]
- Shan, W.; Liu, Z.; Zhang, X.; Wang, S.; Ma, S.; Gao, W. P-stmo: Pre-trained spatial temporal many-to-one model for 3d human pose estimation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 461–478. [Google Scholar]
- Wehrbein, T.; Rudolph, M.; Rosenhahn, B.; Wandt, B. Probabilistic monocular 3d human pose estimation with normalizing flows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 11199–11208. [Google Scholar]
- Li, W.; Liu, H.; Tang, H.; Wang, P.; Gool, L.V. MHFormer: Multi-Hypothesis Transformer for 3D Human Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13147–13156. [Google Scholar]
- Shan, W.; Liu, Z.; Zhang, X.; Wang, Z.; Han, K. Diffusion-Based 3D Human Pose Estimation with Multi-Hypothesis Aggregation. arXiv 2023, arXiv:2303.11579. [Google Scholar]
- Moon, G.; Lee, K.M. I2l-meshnet: Image-to-lixel prediction network for accurate 3d human pose and mesh estimation from a single RGB image. In Proceedings of the European Conference Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 752–768. [Google Scholar]
- Zhang, H.; Tian, Y.; Zhou, X.; Ouyang, W.; Liu, Y.; Wang, L.; Sun, Z. Pymaf: 3d human pose and shape regression with pyramidal mesh alignment feedback loop. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 11446–11456. [Google Scholar]
- Zhang, S.; Wang, C.; Dong, W.; Fan, B. A Survey on Depth Ambiguity of 3D Human Pose Estimation. Appl. Sci. 2022, 12, 10591. [Google Scholar] [CrossRef]
- Ronchi, M.R.; Perona, P. Benchmarking and error diagnosis in multi-instance pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 369–378. [Google Scholar]
- Kim, M.; Lee, S. Fusion Poser: 3D Human Pose Estimation Using Sparse IMUs and Head Trackers in Real Time. Sensors 2022, 22, 4846. [Google Scholar] [CrossRef] [PubMed]
- Hanyue, T.; Chunyu, W.; Wenjun, Z. VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Environment. arXiv 2020, arXiv:2004.06239. [Google Scholar]
- Zheng, C.; Wu, W.; Chen, C.; Yang, T.; Zhu, S.; Shen, J.; Kehtarnavaz, N.; Shah, M. Deep learning-based human pose estimation: A survey. ACM Comput. Surv. 2023, 56, 1–37. [Google Scholar] [CrossRef]
- Kim, J.-W.; Choi, Y.-L.; Jeong, S.-H.; Han, J. A Care Robot with Ethical Sensing System for Older Adults at Home. Sensors 2022, 22, 7515. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.-W.; Choi, J.-Y.; Ha, E.-J.; Choi, J.-H. Human pose estimation using MediaPipe Pose and optimization method based on a humanoid model. Appl. Sci. 2023, 13, 2700. [Google Scholar] [CrossRef]
- BlazePose: A 3D Pose Estimation Model. Available online: https://medium.com/axinc-ai/blazepose-a-3D-pose-estimation-model-d8689d06b7c4 (accessed on 20 November 2023).
- Elkess, G.; Elmoushy, S.; Atia, A. Karate first Kata performance analysis and evaluation with computer vision and machine learning. In Proceedings of the International Mobile, Intelligent, and Ubiquitous Computing Conference, Cairo, Egypt, 27–28 September 2023; pp. 1–6. [Google Scholar]
- Loper, M.; Mahmood, N.; Romero, J.; Pons-Moll, G.; Black, M.J. SMPL: A skinned multi-person linear model. ACM Trans. Graph. 2015, 34, 1–16. [Google Scholar] [CrossRef]
- Moon, G.; Lee, K.M. Pose2pose: 3D positional pose-guided 3d rotational pose prediction for expressive 3D human pose and mesh estimation. arXiv 2020, arXiv:2011.11534. [Google Scholar]
- FrankMocap: A Strong and Easy-to-Use Single View 3D Hand+Body Pose Estimator. Available online: https://github.com/facebookresearch/frankmocap (accessed on 26 June 2023).
- SMPL Expressive. Available online: https://smpl-x.is.tue.mpg.de/ (accessed on 28 September 2023).
- Fasterrcnn_resnet50_hpn. Available online: https://pytorch.org/vision/main/models/generated/torchvision.models.detection.fasterrcnn_resnet50_fpn.html (accessed on 25 September 2023).
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13 December 2015; pp. 1440–1448. [Google Scholar]
- Size Korea. Available online: https://sizekorea.kr/ (accessed on 10 December 2023).
- Kim, J.-W.; Kim, T.; Park, Y.; Kim, S.W. On load motor parameter identification using univariate dynamic encoding algorithm for searches (uDEAS). IEEE Trans. Energy Convers. 2008, 23, 804–813. [Google Scholar]
- Kim, J.-W.; Ahn, H.; Seo, H.C.; Lee, S.C. Optimization of Solar/Fuel Cell Hybrid Energy System Using the Combinatorial Dynamic Encoding Algorithm for Searches (cDEAS). Energies 2022, 15, 2779. [Google Scholar] [CrossRef]
- Denavit, J.; Hartenberg, R.S. A kinematic notation for lower-pair mechanisms based on matrices. J. Appl. Mech. 1955, 77, 215–221. [Google Scholar] [CrossRef]
- Vicon. Available online: https://www.vicon.com/ (accessed on 2 January 2024).
- HybrIK. Available online: https://github.com/Jeff-sjtu/HybrIK (accessed on 2 December 2023).
- MHFormer: Multi-Hypothesis Transformer for 3D Human Pose Estimation. Available online: https://github.com/Vegetebird/MHFormer (accessed on 7 February 2024).
- Diffusion-Based 3D Human Pose Estimation with Multi-Hypothesis Aggregation. Available online: https://github.com/paTRICK-swk/D3DP (accessed on 7 February 2024).

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Components | Specification |
|---|---|
| OS | Ubuntu 20.04 |
| CPU | 11th Gen Intel Core (TM) i7-11700 @ 2.50 GHz Title 3 (Intel, Santa Clara, CA, USA) |
| RAM | 32.0 GB |
| GPU | NVIDIA GeForce RTX 3060 (NVIDIA, Santa Clara, CA, USA) |
| Language | Python 3.8 |
| Motion | MPP [5] | HybrIK [34] | MHFormer [35] | D3DP [36] |
|---|---|---|---|---|
| Baseball | 10.60% | 6.55% | 6.17% | 5.59% |
| Cycling | 4.12% | 100% | 5.15% | 21.65% |
| Walking | 21.97% | 3.79% | 2.27% | 1.52% |
| Yoga | 2.38% | 2.38% | 2.86% | 1.90% |
| MPP [5] | HybrIK [34] | MHFormer [35] | D3DP [36] |
|---|---|---|---|
| 0.0409 | 0.3120 | 0.1946 | 0.1756 |
| Motion | Methods | Avg. MPJPE (m) | Torso MAJAE (3 Joints) | Sagittal MAJAE (8 Joints) | Coronal MAJAE (4 Joints) | Transversal MAJAE (2 Joints) | Avg. MAJAE | Improvement |
|---|---|---|---|---|---|---|---|---|
| 1 (standing rowing exercise) | MPP (orig.) | 0.0160 | 18.80 | 19.66 | 16.71 | 21.11 | 18.99 | 1.53% |
| MPP (mod.) | 0.0160 | 18.39 | 19.18 | 16.74 | 21.13 | 18.70 | ||
| HybrIK (orig.) | 0.0145 | 43.31 | 49.99 | 37.60 | 34.31 | 44.05 | 62.56% | |
| HybrIK (mod.) | 0.0045 | 18.04 | 16.81 | 12.82 | 20.24 | 16.49 | ||
| MHFormer (orig.) | 0.0349 | 18.91 | 20.86 | 13.02 | 14.66 | 17.94 | 2.20% | |
| MHFormer (mod.) | 0.0346 | 19.13 | 19.78 | 13.11 | 15.08 | 17.55 | ||
| D3DP (orig.) | 0.0348 | 22.82 | 16.72 | 11.91 | 19.71 | 17.02 | 5.40% | |
| D3DP (mod.) | 0.0332 | 21.44 | 15.08 | 12.27 | 19.79 | 16.10 | ||
| 2 (back and chest exercise) | MPP (orig.) | 0.0205 | 9.33 | 20.66 | 22.31 | 33.99 | 20.62 | 0.57% |
| MPP (mod.) | 0.0205 | 8.96 | 20.31 | 22.60 | 34.37 | 20.50 | ||
| HybrIK (orig.) | 0.0153 | 21.16 | 52.92 | 41.79 | 44.44 | 43.70 | 56.11% | |
| HybrIK (mod.) | 0.0064 | 10.15 | 18.33 | 19.77 | 34.96 | 19.18 | ||
| MHFormer (orig.) | 0.0258 | 10.65 | 19.89 | 19.83 | 25.66 | 18.92 | 1.35% | |
| MHFormer (mod.) | 0.0252 | 10.39 | 19.40 | 19.98 | 25.52 | 18.67 | ||
| D3DP (orig.) | 0.0350 | 12.85 | 16.27 | 18.96 | 18.78 | 16.59 | 7.27% | |
| D3DP (mod.) | 0.0265 | 8.42 | 15.42 | 18.98 | 18.51 | 15.39 | ||
| 3 (arm and leg exercise) | MPP (orig.) | 0.0209 | 7.17 | 17.65 | 16.47 | 24.76 | 16.36 | 5.74% |
| MPP (mod.) | 0.0198 | 7.24 | 16.24 | 15.64 | 23.98 | 15.42 | ||
| HybrIK (orig.) | 0.0163 | 24.57 | 50.72 | 37.60 | 36.04 | 41.29 | 64.87% | |
| HybrIK (mod.) | 0.0051 | 6.90 | 15.69 | 12.36 | 25.48 | 14.51 | ||
| MHFormer (orig.) | 0.0343 | 7.49 | 20.61 | 16.32 | 46.56 | 20.34 | 10.74% | |
| MHFormer (mod.) | 0.0336 | 7.51 | 17.90 | 14.66 | 42.13 | 18.16 | ||
| D3DP (orig.) | 0.0325 | 9.18 | 16.59 | 16.30 | 40.62 | 18.04 | 9.60% | |
| D3DP (mod.) | 0.0318 | 9.13 | 14.08 | 15.48 | 37.65 | 16.31 | ||
| Avg. MAJAE (orig.) | 17.19 | 26.88 | 22.40 | 30.05 | 24.49 | 18.99% | ||
| Avg. MAJAE (mod.) | 12.14 | 17.35 | 16.20 | 26.57 | 17.25 | |||
| Improvement | 29.35% | 35.44% | 27.68% | 11.59% | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, J.-Y.; Ha, E.; Son, M.; Jeon, J.-H.; Kim, J.-W. Human Joint Angle Estimation Using Deep Learning-Based Three-Dimensional Human Pose Estimation for Application in a Real Environment. Sensors 2024, 24, 3823. https://doi.org/10.3390/s24123823
Choi J-Y, Ha E, Son M, Jeon J-H, Kim J-W. Human Joint Angle Estimation Using Deep Learning-Based Three-Dimensional Human Pose Estimation for Application in a Real Environment. Sensors. 2024; 24(12):3823. https://doi.org/10.3390/s24123823
Chicago/Turabian StyleChoi, Jin-Young, Eunju Ha, Minji Son, Jean-Hong Jeon, and Jong-Wook Kim. 2024. "Human Joint Angle Estimation Using Deep Learning-Based Three-Dimensional Human Pose Estimation for Application in a Real Environment" Sensors 24, no. 12: 3823. https://doi.org/10.3390/s24123823