

VA-LOAM: Visual Assist LiDAR Odometry and Mapping for Accurate Autonomous Navigation

Abstract
1. Introduction
- (1)
- Visual Information Integration: This study proposes a new method that utilizes visual information collected from vision sensors to enhance the precision of LiDAR Odometry. This approach reduces 3D–2D depth association errors and enables accurate pose estimation in LiDAR Odometry. By integrating vision sensor data with LiDAR data, this method achieves better performance compared to traditional LiDAR Odometry. The rich environmental information provided via vision sensors complements the limitations of LiDAR, maintaining high accuracy even in complex environments;
- (2)
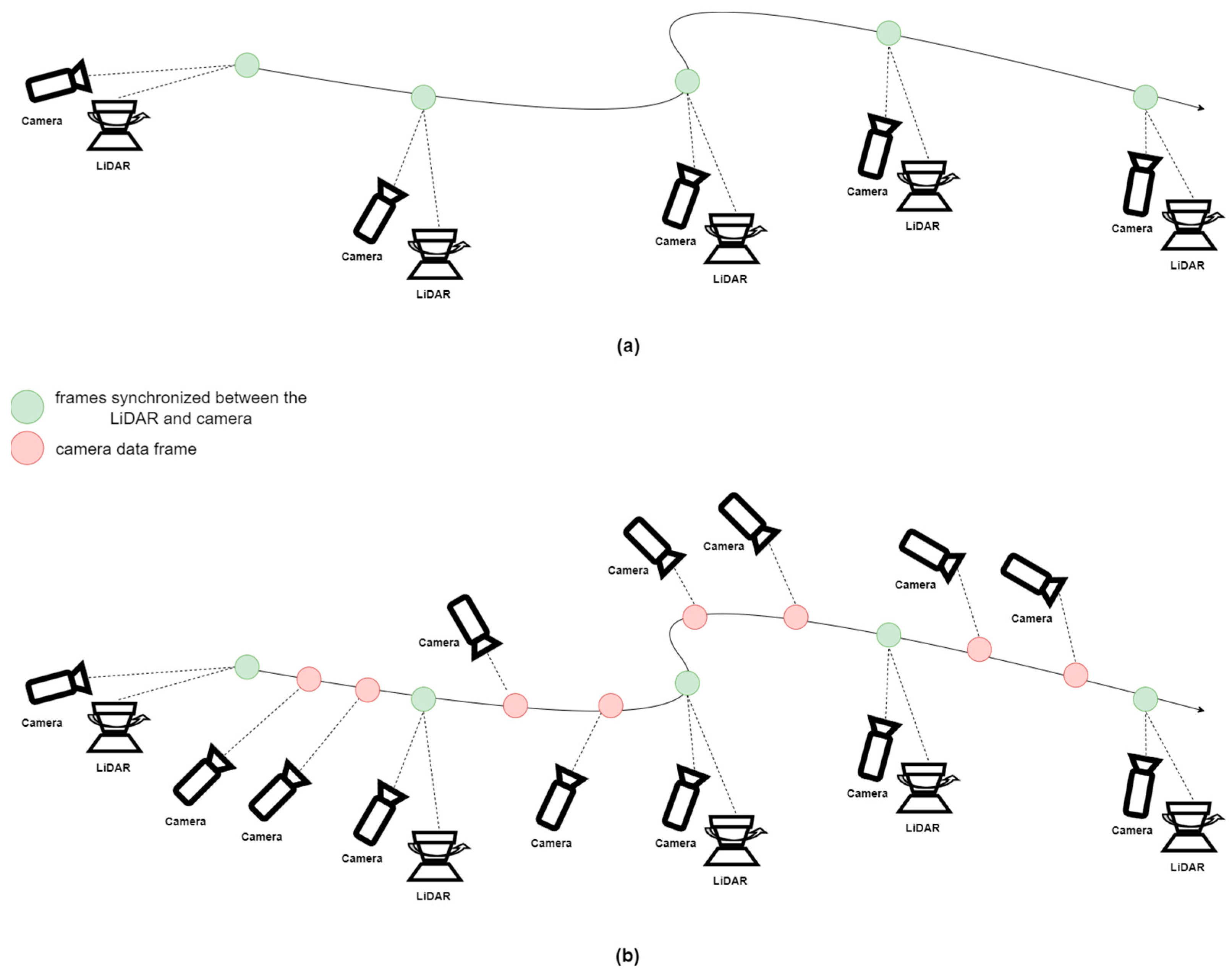
- Enhanced LiDAR Odometry through Vision Sensor Support: We have clarified that this contribution focuses on using LiDAR as the primary sensor while utilizing vision sensors as a supplementary aid. Traditional methods that fuse LiDAR and vision sensors often rely on the vision sensor as the main sensor, which can fail in environments where vision sensors are weak (e.g., dark conditions and reflective surfaces). Our method ensures that in typical environments vision sensors assist in matching LiDAR feature points, improving accuracy. However, in challenging conditions for vision sensors, the system can operate using only LiDAR, maintaining the performance of traditional LiDAR-based Odometry. This approach ensures stable and consistent performance across various environments by leveraging the strengths of LiDAR while mitigating the weaknesses of vision sensors;
- (3)
- Validation and Performance Improvement of VA-LOAM: This paper develops and validates the Visual Assist LiDAR Odometry and Mapping (VA-LOAM) method, which integrates visual information into existing LiDAR Odometry techniques. This method was tested using the publicly available KITTI dataset, demonstrating improved performance over existing LiDAR Odometry methods;
- (4)
- Open-Source Contribution: By making the source code of VA-LOAM publicly available, this work ensures the reproducibility and transparency of the research across the community, enhancing the accessibility of the technology. This fosters collaboration and innovation in research and development.
2. Related Work
- (1)
- Visual SLAM: Refs. [1,2,3,4,5,6,7,8] pertain to this method. LSD-SLAM [1] and SVO [2] match continuous images using photogrammetric consistency without preprocessing the sensor data. This approach is particularly useful in environments lacking distinct image features. Methods [3,4,5,6,7,8] extract local image feature points (edges, corner points, and lines) and track them to estimate their positional changes. By analyzing the camera’s motion and the feature points’ positional shifts, the distance to these points and the camera’s pose can be calculated. Additionally, image features are used to perform loop detection. ORB-SLAM [3] performs feature matching using fast features and brief descriptors. The pose is calculated based on matched feature points using the Perspective-n-Point (PnP) algorithm. VINS-Mono [4] is a tightly coupled sensor fusion method that uses visual sensors and IMUs. It performs visual–inertial odometry using tracked features from a monocular camera and pre-integrated IMU measurements. While accurate feature matching can be achieved through image descriptors, the process of estimating feature point depth involves significant errors. Research has been conducted using stereo cameras and RGB-D cameras to reduce these errors in depth estimation. TOMONO [5] and ENGEL [6] proposed methods using stereo cameras. TOMONO [5] introduced an edge point-based SLAM method using stereo cameras, which is particularly effective in non-textured environments where it detects edges and performs edge-based SLAM. ENGEL [6] improved SLAM accuracy by estimating pixel depth using a fixed-baseline stereo camera and motion from a multiview stereo. KERL [7] and SCHOPS [8] proposed RGB-D SLAM using entropy-based keyframe selection and loop closure detection;
- (2)
- LiDAR SLAM: Refs. [9,10,11,12,13,14] apply to this method. This technique uses point clouds containing three-dimensional points and intensities, employing feature extraction and matching to estimate position. LiDAR provides accurate 3D points, enabling precise pose estimation. However, a lack of sufficient descriptors can lead to matching errors. Methods [10,11,12,13,14] have evolved from LOAM [9]. F-LOAM [14] offers faster processing speeds and lower memory usage, enabling real-time SLAM on lower-performance devices. A-LOAM [11] enhances accuracy by incorporating loop closure functionality and reducing mapping errors caused by obstacles. LeGO-LOAM [10] proposes a lightweight, terrain-optimized method for ground vehicles, classifying and processing the terrain accordingly. ISC-LOAM [13] addresses the issue of insufficient descriptors in LiDAR by proposing an intensity-based scan context, which improves performance in loop closure detection. LIO-SAM [12] tightly integrates LiDAR sensors with Inertial Measurement Units (IMUs), using pre-integrated IMU-derived estimated motion as initial values for point cloud corrections and LiDAR Odometry optimization;
- (3)
- Visual-LiDAR SLAM: This technology is broadly classified into loosely coupled and tightly coupled approaches. The loosely coupled approach includes LiDAR-assisted Visual SLAM and Visual Assist LiDAR SLAM. LiDAR-assisted Visual SLAM [15,16,17,18] addresses one of the main issues in Visual SLAM—depth inaccuracies of image feature points—by correcting them with LiDAR data. While this greatly enhances the accuracy of feature points, the relatively low resolution of LiDAR data can lead to errors in 3D–2D mapping. To mitigate these issues, more precise data integration techniques are required. Visual Assist LiDAR SLAM utilizes LiDAR Odometry to estimate position and uses image data from the corresponding location to recognize the environment. It employs image feature points for loop closure detection, minimizing errors that may occur over time. The tightly coupled approach combines the advantages of LiDAR Odometry and Visual Odometry. In this method, rapid pose estimation from Visual-assisted Visual Odometry is refined through LiDAR Odometry. Although tightly coupled systems are robust, they require substantial computational resources;
3. Preliminaries
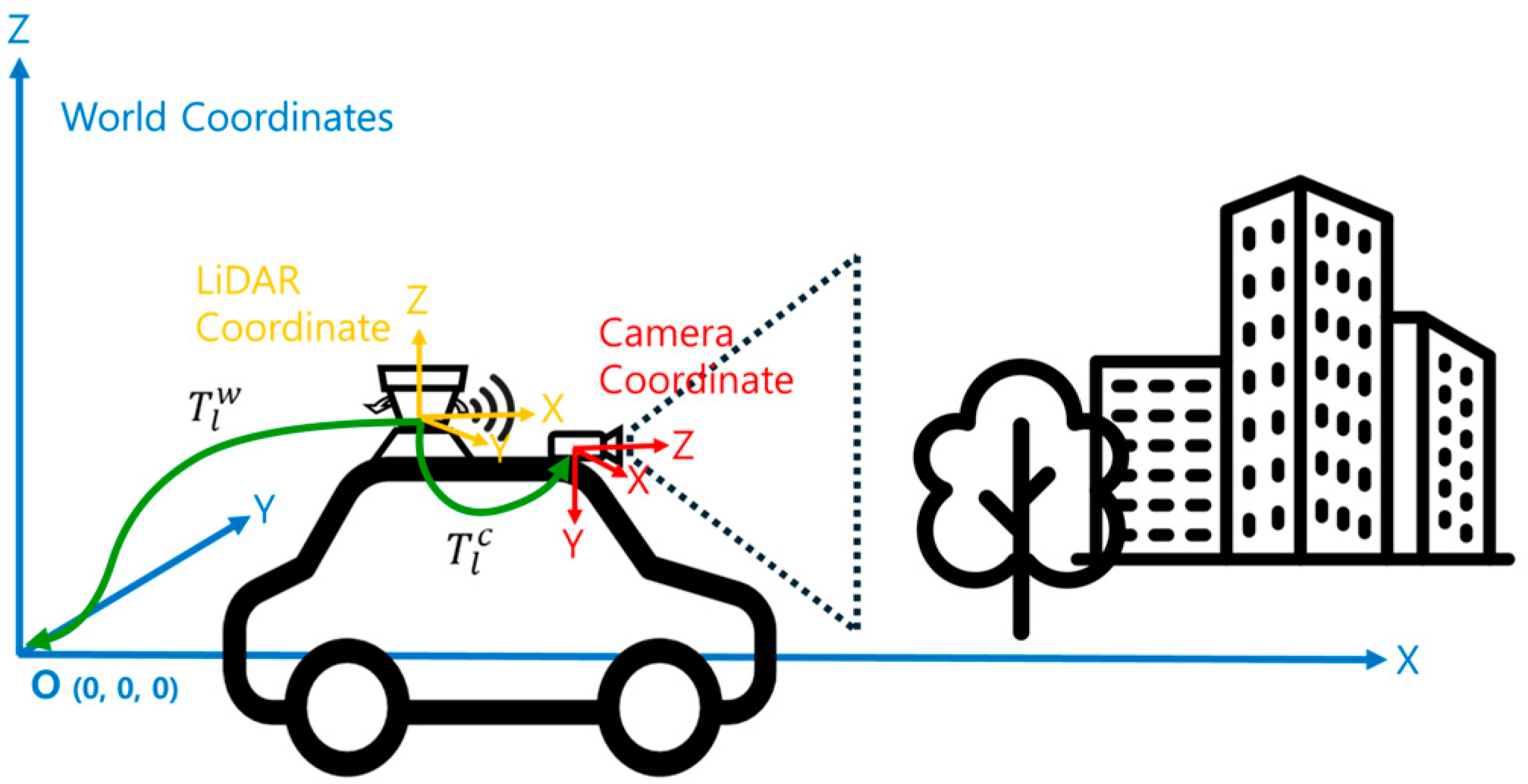
3.1. Coordinate Systems
3.2. Camera Projection Model
4. Proposed Methodology
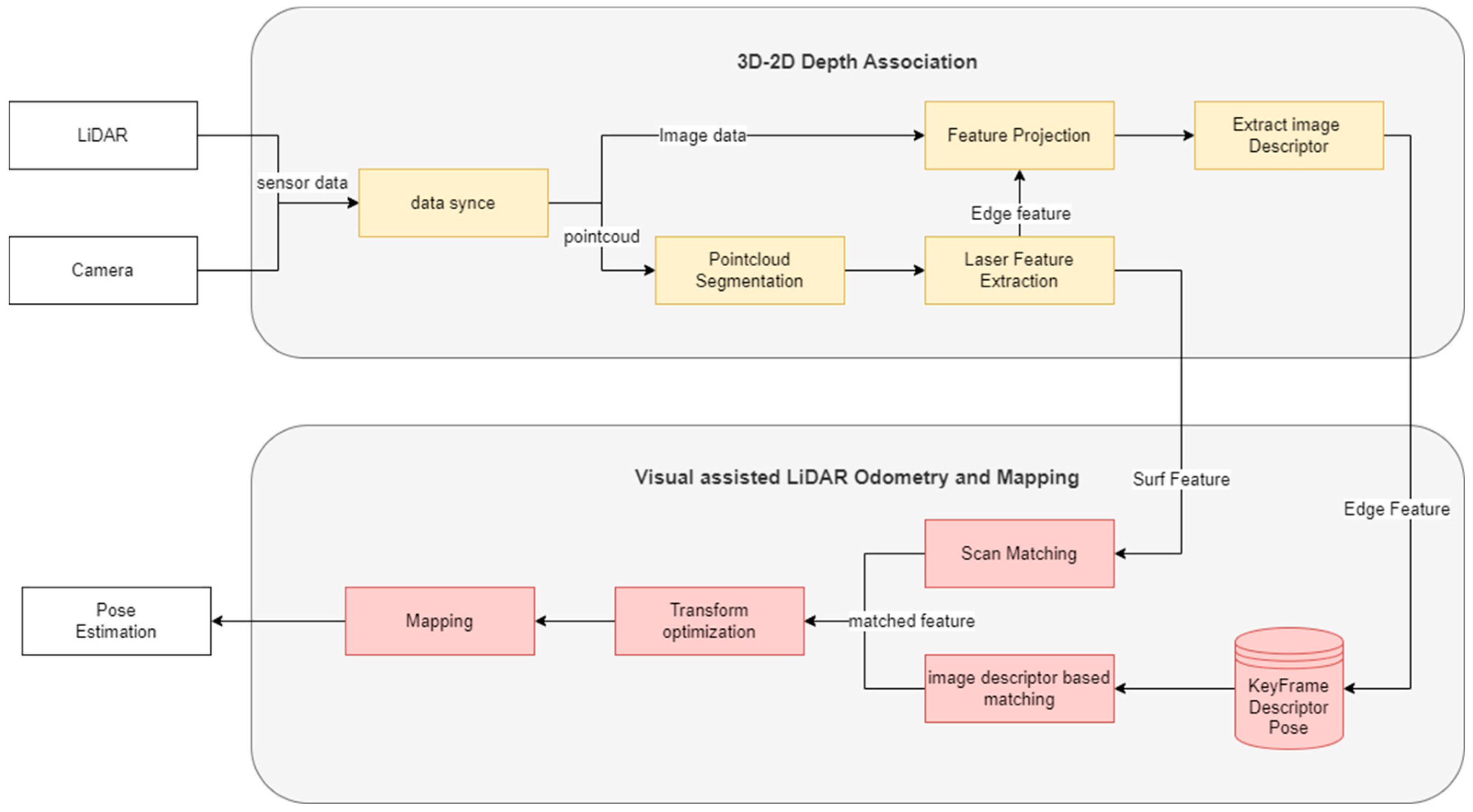
4.1. System Overview
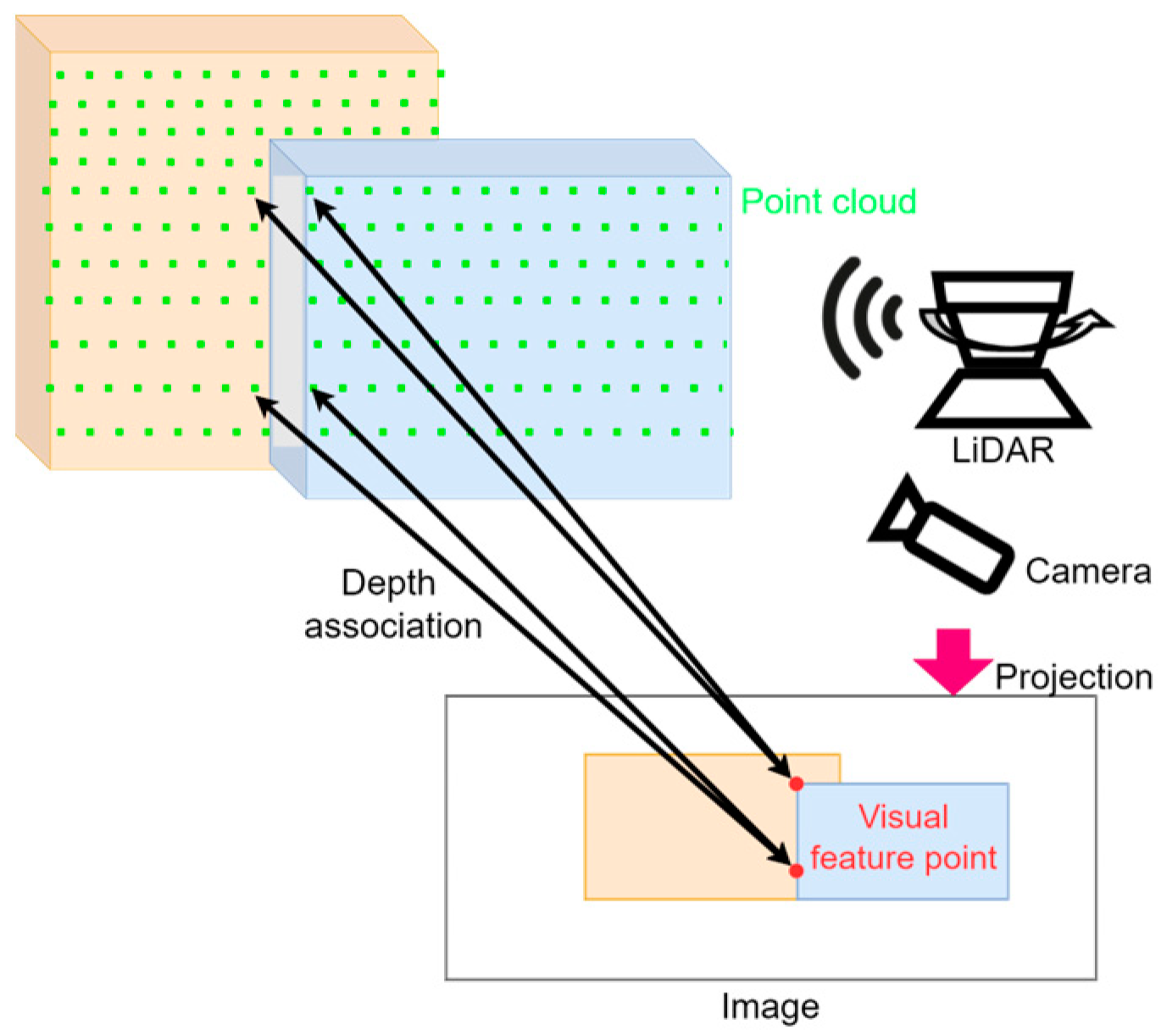
4.2. Point Cloud Preprocessing
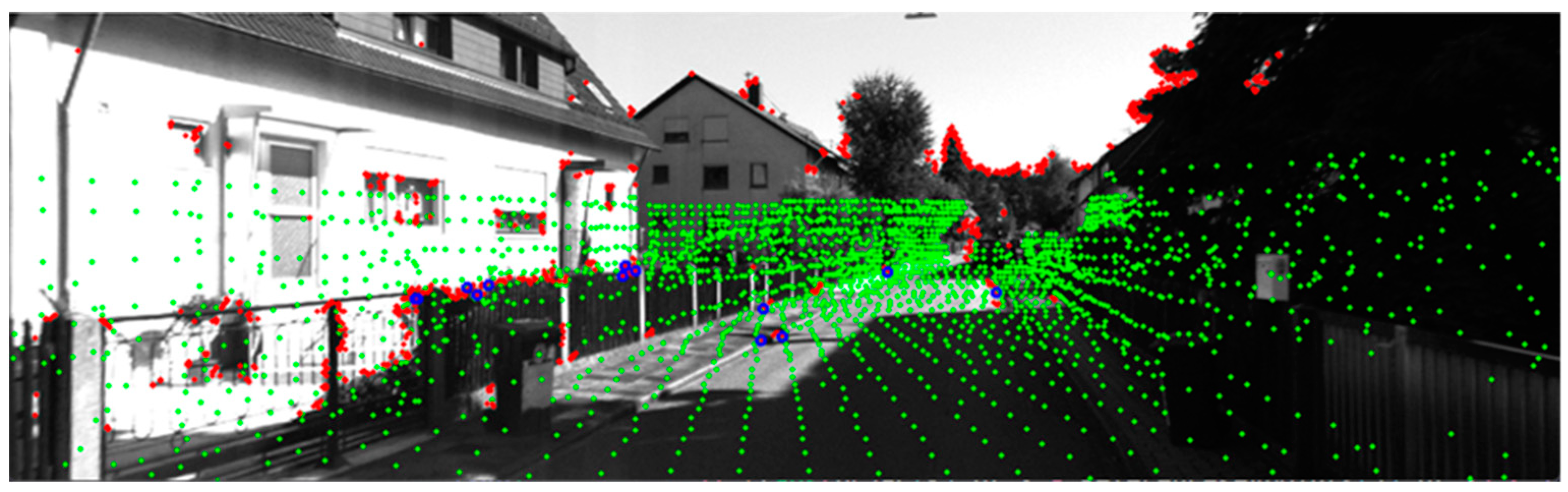
4.3. Visual Assist LiDAR Feature
4.4. Pose Estimation
5. Experimental Setup and Validation
5.1. Evaluation on Public Datasets
5.2. Performance of LiDAR Odometry and Mapping
5.3. Performance of Visual Assist LiDAR Odometry and Mapping
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-Scale Direct Monocular SLAM. In European Conference on Computer Vision; Springer International Publishing: Cham, Switzerland, 2014; pp. 834–849. [Google Scholar] [CrossRef]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast Semi-Direct Monocular Visual Odometry. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 15–22. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Montiel, J.M.M.; Tardós, J.D. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Qin, T.; Li, P.; Shen, S. VINS-Mono: A Robust and Versatile Monocular Visual-Inertial State Estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef]
- Tomono, M. Robust 3D SLAM with a Stereo Camera Based on an Edge-Point ICP Algorithm. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 4306–4311. [Google Scholar] [CrossRef]
- Engel, J.; Stückler, J.; Cremers, D. Large-Scale Direct SLAM with Stereo Cameras. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 1935–1942. [Google Scholar] [CrossRef]
- Kerl, C.; Sturm, J.; Cremers, D. Dense Visual SLAM for RGB-D Cameras. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 2100–2106. [Google Scholar] [CrossRef]
- Schöps, T.; Sattler, T.; Pollefeys, M. BAD SLAM: Bundle Adjusted Direct RGB-D SLAM. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 134–144. [Google Scholar] [CrossRef]
- Zhang, J.; Singh, S. LOAM: Lidar Odometry and Mapping in Real-Time. In Proceedings of the Robotics: Science and Systems, Berkeley, CA, USA, 12–16 July 2014; pp. 1–9. [Google Scholar] [CrossRef]
- Shan, T.; Englot, B. LEGO-LOAM: Lightweight and Ground-Optimized Lidar Odometry and Mapping on Variable Terrain. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 4758–4765. [Google Scholar] [CrossRef]
- Shen, T.; Li, X.; Wang, G.; Wei, B.; Hu, H. A-LOAM: Tightly Coupled Lidar-Odometry and Mapping for Autonomous Vehicles. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 8747–8754. [Google Scholar]
- Shan, T.; Englot, B.; Meyers, D.; Wang, W.; Ratti, C.; Rus, D. LIO-SAM: Tightly-Coupled Lidar Inertial Odometry via Smoothing and Mapping. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 5135–5142. [Google Scholar] [CrossRef]
- Wang, H.; Wang, C.; Xie, L. Intensity Scan Context: Coding Intensity and Geometry Relations for Loop Closure Detection. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 2095–2101. [Google Scholar]
- Wang, H.; Wang, C.; Chen, C.L.; Xie, L. F-LOAM: Fast Lidar Odometry and Mapping. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 4390–4396. [Google Scholar] [CrossRef]
- Zhang, J.; Singh, S. Visual-Lidar Odometry and Mapping: Low-Drift, Robust, and Fast. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 2174–2181. [Google Scholar] [CrossRef]
- Zhang, J.; Kaess, M.; Singh, S. A Real-Time Method for Depth Enhanced Visual Odometry. Auton. Robot. 2017, 41, 31–43. [Google Scholar] [CrossRef]
- Graeter, J.; Wilczynski, A.; Lauer, M. LIMO: Lidar-Monocular Visual Odometry. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 7872–7879. [Google Scholar] [CrossRef]
- Huang, S.S.; Ma, Z.Y.; Mu, T.J.; Fu, H.; Hu, S.M. Lidar-Monocular Visual Odometry Using Point and Line Features. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 1091–1097. [Google Scholar]
- Wong, C.-C.; Feng, H.-M.; Kuo, K.-L. Multi-Sensor Fusion Simultaneous Localization Mapping Based on Deep Reinforcement Learning and Multi-Model Adaptive Estimation. Sensors 2024, 24, 48. [Google Scholar] [CrossRef] [PubMed]
- Cai, Y.; Qian, W.; Dong, J.; Zhao, J.; Wang, K.; Shen, T. A LiDAR–Inertial SLAM Method Based on Virtual Inertial Navigation System. Electronics 2023, 12, 2639. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are We Ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar] [CrossRef]
- De Aguiar, A.S.; de Oliveira, M.A.; Pedrosa, E.F.; dos Santos, F.B. A Camera to LiDAR Calibration Approach through the Optimization of Atomic Transformations. Expert Syst. Appl. 2021, 176, 114894. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Descriptor | Advantages | Disadvantages |
|---|---|---|
| SIFT | Scale invariance, rotation invariance, robustness to illumination changes | Slow computation speed |
| SURF | Performance similar to SIFT Faster speed | Vulnerable to specific lighting conditions |
| ORB | Fast speed–Real-time processing Low computational cost | Slightly lower accuracy |
| BRISK | Shares characteristics with ORB Superior performance in texture-rich images | Vulnerable to specific deformations |
| AKAZE | Performance similar to SIFT Fast speed | Vulnerable to specific textures |
| Deep Learning-based Descriptors | High accuracy | Requires large amounts of training data and computation |
| Dataset | Seq No. | Data Name | Environment | Path Len. (m) |
|---|---|---|---|---|
| KITTI Odometry Set | 1 | 2011_09_30_drive_0016 | Country | 397 |
| 2 | 2011_09_30_drive_0018 | Urban | 2223 | |
| 3 | 2011_09_30_drive_0020 | Urban | 1239 | |
| 4 | 2011_09_30_drive_0027 | Urban | 695 | |
| 5 | 2011_09_30_drive_0033 | Urban + Country | 1717 | |
| 6 | 2011_09_30_drive_0034 | Urban + Country | 919 | |
| 7 | 2011_10_03_drive_0027 | Urban | 3714 | |
| 8 | 2011_10_03_drive_0034 | Urban + Country | 5075 | |
| 9 | 2011_10_03_drive_0042 | Highway | 4268 | |
| KITTI Raw Data Set | 1 | 2011_09_26_drive_0001 | Urban | 107 |
| 2 | 2011_09_26_drive_0005 | Urban | 69 | |
| 3 | 2011_09_26_drive_0009 | Urban | 332 | |
| 4 | 2011_09_26_drive_0011 | Urban | 114 |
| Dataset | Seq No. | F-LOAM [14] | A-LOAM [11] | LEGO-LOAM [10] | ISC-LOAM [13] | LIO-SAM [12] |
|---|---|---|---|---|---|---|
| KITTI Odometry Set | 1 | 2.67 | 5.00 | 3.65 | 2.67 | 5.78 |
| 2 | 10.89 | 113.08 | 9.53 | 10.90 | 10.25 | |
| 3 | 9.25 | 21.28 | 4.91 | 9.25 | 21.34 | |
| 4 | 1.85 | 5.94 | 1.63 | 1.85 | 1.55 | |
| 5 | 17.79 | 124.16 | 22.94 | 17.79 | 20.08 | |
| 6 | 8.67 | 61.02 | 17.85 | 8.67 | 12.05 | |
| 7 | 19.76 | 182.32 | 171.39 | 19.76 | fail | |
| 8 | 31.30 | 183.91 | 294.73 | 31.30 | 41.76 | |
| 9 | 145.49 | 261.86 | 373.20 | 145.49 | 167.86 | |
| KITTI Raw Data Set | 1 | 1.70 | 5.70 | 5.04 | 1.70 | 1.22 |
| 2 | 1.53 | 1.77 | 1.76 | 1.53 | 1.51 | |
| 3 | 5.86 | 6.15 | 13.4 | 5.86 | 7.05 | |
| 4 | 1.27 | 3.66 | 2.2 | 1.27 | 1.71 |
| Dataset | Seq No. | F-LOAM [14] | A-LOAM [11] | LEGO-LOAM [10] | ISC-LOAM [13] | LIO-SAM [12] |
|---|---|---|---|---|---|---|
| KITTI Odometry Set | 1 | 2.67 | 2.70 | 3.74 | 2.67 | 5.77 |
| 2 | 10.89 | 10.43 | 7.61 | 10.89 | 8.40 | |
| 3 | 9.25 | 8.46 | 4.92 | 9.25 | 19.02 | |
| 4 | 1.85 | 1.62 | 1.76 | 1.85 | 1.50 | |
| 5 | 17.79 | 18.71 | 22.93 | 17.79 | 20.15 | |
| 6 | 8.67 | 9.82 | 18.53 | 8.67 | 11.35 | |
| 7 | 19.76 | 20.77 | 158.65 | 19.76 | fail | |
| 8 | 31.30 | 101.64 | 275.88 | 31.30 | 39.79 | |
| 9 | 145.49 | 166.58 | 376.63 | 145.49 | 166.19 | |
| KITTI Raw Data Set | 1 | 1.70 | 5.70 | 5.04 | 1.70 | 1.22 |
| 2 | 1.53 | 1.77 | 1.76 | 1.53 | 1.51 | |
| 3 | 5.86 | 6.15 | 13.4 | 5.86 | 7.05 | |
| 4 | 1.27 | 3.66 | 2.2 | 1.27 | 1.71 |
| Dataset | Seq No. | LEGO-LOAM [10] | VA-LEGO-LOAM | ISC-LOAM [13] | VA-ISC-LOAM | LIO-SAM [12] | VA-LIO-SAM |
|---|---|---|---|---|---|---|---|
| KITTI Odometry Set | 1 | 3.65 | 3.22 | 2.67 | 2.89 | 5.78 | 5.74 |
| 2 | 9.53 | 8.74 | 10.90 | 8.53 | 10.25 | 9.49 | |
| 3 | 4.91 | 4.31 | 9.25 | 9.20 | 21.34 | 21.17 | |
| 4 | 1.63 | 1.58 | 1.85 | 2.22 | 1.55 | 1.43 | |
| 5 | 22.94 | 20.03 | 17.79 | 14.18 | 20.08 | 18.59 | |
| 6 | 17.85 | 17.92 | 8.67 | 9.35 | 12.05 | 12.29 | |
| 7 | 171.39 | 165.12 | 19.76 | 13.81 | fail | fail | |
| 8 | 294.73 | 230.55 | 31.30 | 24.13 | 41.76 | 34.35 | |
| 9 | 373.20 | 361.16 | 145.49 | 129.41 | 167.86 | 163.62 | |
| KITTI Raw Data Set | 1 | 5.04 | 4.91 | 1.70 | 0.36 | 1.22 | 1.22 |
| 2 | 1.76 | 1.68 | 1.53 | 1.50 | 1.51 | 1.50 | |
| 3 | 13.4 | 13.24 | 5.86 | 5.83 | 7.05 | 6.98 | |
| 4 | 2.2 | 2.05 | 1.27 | 1.15 | 1.71 | 1.71 |
| Dataset | Seq No. | LEGO-LOAM [10] | VA-LEGO-LOAM | ISC-LOAM [13] | VA-ISC-LOAM | LIO-SAM [12] | VA-LIO-SAM |
|---|---|---|---|---|---|---|---|
| KITTI Odometry Set | 1 | 3.74 | 3.74 | 2.67 | 2.89 | 5.77 | 5.74 |
| 2 | 7.61 | 7.54 | 10.89 | 8.39 | 8.40 | 7.97 | |
| 3 | 4.92 | 4.31 | 9.25 | 9.20 | 19.02 | 19.00 | |
| 4 | 1.76 | 1.66 | 1.85 | 2.22 | 1.50 | 1.42 | |
| 5 | 22.93 | 19.87 | 17.79 | 14.18 | 20.15 | 18.68 | |
| 6 | 18.53 | 18.69 | 8.67 | 9.35 | 11.35 | 12.17 | |
| 7 | 158.65 | 152.04 | 19.76 | 13.05 | fail | fail | |
| 8 | 275.88 | 214.67 | 31.30 | 23.82 | 39.79 | 33.15 | |
| 9 | 376.63 | 362.46 | 145.49 | 129.04 | 166.19 | 164.48 | |
| KITTI Raw Data Set | 1 | 5.04 | 4.91 | 1.70 | 0.36 | 1.22 | 1.22 |
| 2 | 1.76 | 1.68 | 1.53 | 1.50 | 1.51 | 1.50 | |
| 3 | 13.4 | 13.24 | 5.86 | 5.83 | 7.05 | 6.98 | |
| 4 | 2.2 | 2.05 | 1.27 | 1.15 | 1.71 | 1.71 |
| Dataset | Seq No. | Algorithm | Accuracy Improvement (%) | Algorithm | Accuracy Improvement (%) | Algorithm | Accuracy Improvement (%) |
|---|---|---|---|---|---|---|---|
| Dataset KITTI Odometry Set | 1 | VA-LEGO-LOAM | 11.79 | VA-ISC-LOAM | −8.24 | VA-LIO-SAM | 0.65 |
| 2 | 8.24 | 21.73 | 7.41 | ||||
| 3 | 12.22 | 0.63 | 0.78 | ||||
| 4 | 2.91 | −19.73 | 7.75 | ||||
| 5 | 12.68 | 20.28 | 7.46 | ||||
| 6 | −0.41 | −7.86 | −1.98 | ||||
| 7 | 3.66 | 30.11 | - | ||||
| 8 | 21.78 | 22.90 | 17.75 | ||||
| 9 | 3.23 | 11.05 | 2.52 | ||||
| KITTI Raw Data Set | 1 | VA-LEGO-LOAM | 2.58 | VA-ISC-LOAM | 78.82 | VA-LIO-SAM | 0.00 |
| 2 | 4.55 | 1.96 | 0.66 | ||||
| 3 | 1.19 | 0.51 | 0.99 | ||||
| 4 | 6.82 | 9.45 | 0.00 | ||||
| Avg | 7.02 | 12.43 | 3.67 | ||||
| Dataset | Seq No. | Algorithm | Accuracy Improvement (%) | Algorithm | Accuracy Improvement (%) | Algorithm | Accuracy Improvement (%) |
|---|---|---|---|---|---|---|---|
| Dataset KITTI Odometry Set | 1 | VA-LEGO-LOAM | 0.09 | VA-ISC-LOAM | −8.24 | VA-LIO-SAM | 0.55 |
| 2 | 0.88 | 23.01 | 5.11 | ||||
| 3 | 12.38 | 0.63 | 0.08 | ||||
| 4 | 5.60 | −19.73 | 5.42 | ||||
| 5 | 13.33 | 20.28 | 7.31 | ||||
| 6 | −0.84 | −7.86 | −7.17 | ||||
| 7 | 4.17 | 33.98 | - | ||||
| 8 | 22.19 | 23.90 | 16.69 | ||||
| 9 | 3.76 | 11.31 | 1.03 | ||||
| KITTI Raw Data Set | 1 | VA-LEGO-LOAM | 2.58 | VA-ISC-LOAM | 78.82 | VA-LIO-SAM | 0.00 |
| 2 | 4.55 | 1.96 | 0.66 | ||||
| 3 | 1.19 | 0.51 | 0.99 | ||||
| 4 | 6.82 | 9.45 | 0.00 | ||||
| Avg | 5.90 | 5.95 | 2.42 | ||||
| Dataset | Seq No. | Environment | VA-LEGO-LOAM | VA-ISC-LOAM | VA-LIO-SAM |
|---|---|---|---|---|---|
| KITTI Raw Data set | 1 | Only LiDAR (Traditional) | 5.042 | 1.698 | 1.221 |
| Daytime/Urban | 4.913 | 0.362 | 1.215 | ||
| Night-time/Urban | 4.922 | 0.365 | 1.218 | ||
| Image Sensor Fault | 5.042 | 1.698 | 1.215 | ||
| 2 | Only LiDAR (Traditional) | 1.76 | 1.529 | 1.507 | |
| Daytime/Urban | 1.684 | 1.496 | 1.503 | ||
| Night-time/Urban | 1.686 | 1.497 | 1.504 | ||
| Image Sensor Fault | 1.759 | 1.529 | 1.509 | ||
| 3 | Only LiDAR (Traditional) | 13.375 | 5.859 | 7.047 | |
| Daytime/Urban | 13.241 | 5.832 | 6.98 | ||
| Night-time/Urban | 13.297 | 5.868 | 7.379 | ||
| Image Sensor Fault | 13.375 | 5.859 | 6.99 | ||
| 4 | Only LiDAR (Traditional) | 2.203 | 1.266 | 1.71 | |
| Daytime/Urban | 2.053 | 1.149 | 1.705 | ||
| Night-time/Urban | 2.052 | 1.159 | 1.706 | ||
| Image Sensor Fault | 2.203 | 1.267 | 1.707 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jung, T.-K.; Jee, G.-I. VA-LOAM: Visual Assist LiDAR Odometry and Mapping for Accurate Autonomous Navigation. Sensors 2024, 24, 3831. https://doi.org/10.3390/s24123831
Jung T-K, Jee G-I. VA-LOAM: Visual Assist LiDAR Odometry and Mapping for Accurate Autonomous Navigation. Sensors. 2024; 24(12):3831. https://doi.org/10.3390/s24123831
Chicago/Turabian StyleJung, Tae-Ki, and Gyu-In Jee. 2024. "VA-LOAM: Visual Assist LiDAR Odometry and Mapping for Accurate Autonomous Navigation" Sensors 24, no. 12: 3831. https://doi.org/10.3390/s24123831
APA StyleJung, T.-K., & Jee, G.-I. (2024). VA-LOAM: Visual Assist LiDAR Odometry and Mapping for Accurate Autonomous Navigation. Sensors, 24(12), 3831. https://doi.org/10.3390/s24123831