
FF3D: A Rapid and Accurate 3D Fruit Detector for Robotic Harvesting

Abstract
:1. Introduction
- Proposition and development of a new occlusion-aware 3D fruit detection network.
- Proposition and development of a new anisotropic Gaussian-based next-best view estimation for multi-view detection.
- Demonstration and quantitative analysis of different 3D detection methods in a manually labeled dataset and in a simulated environment.
2. Related Works
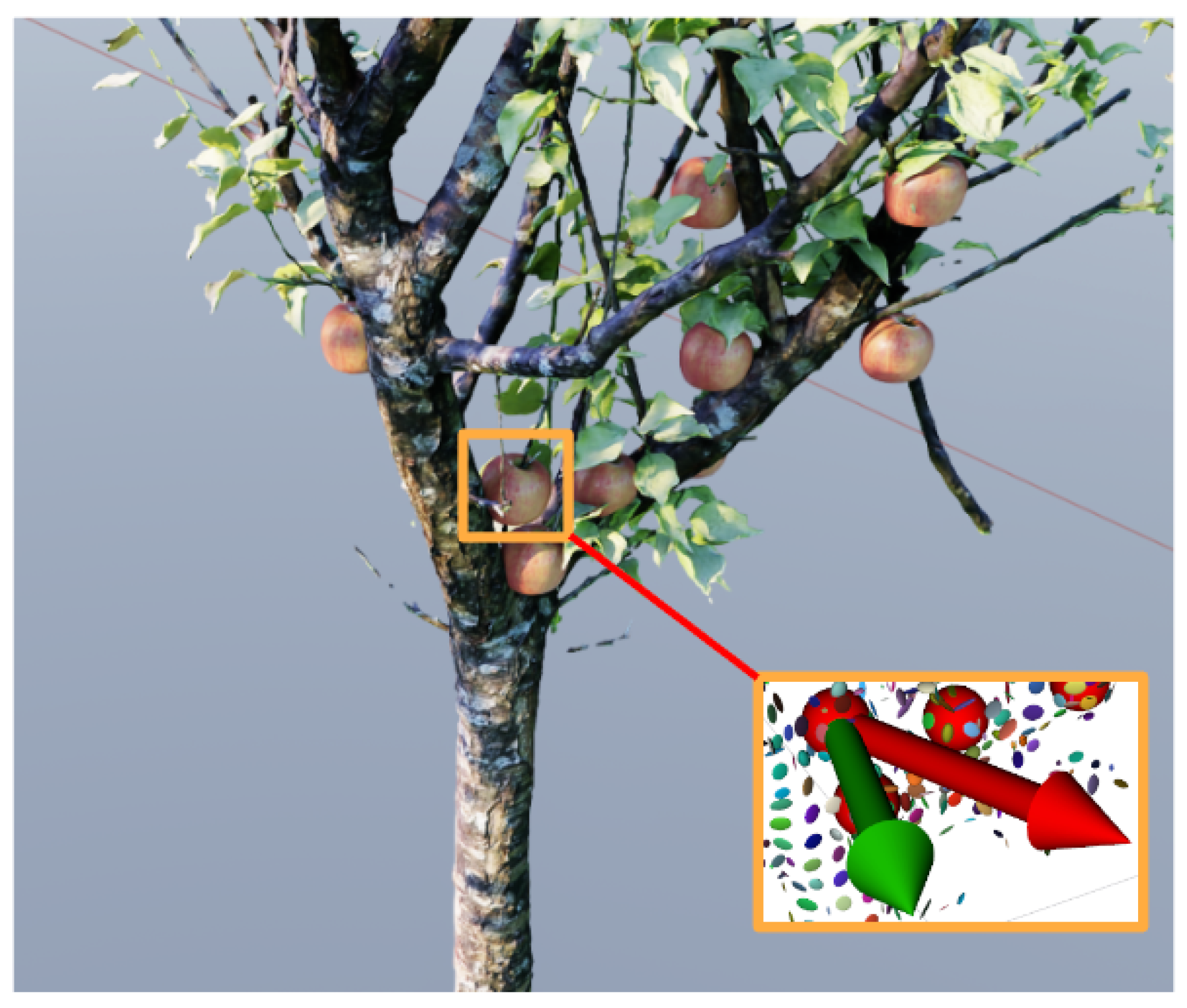
3. Problem Statement
4. Materials and Methods
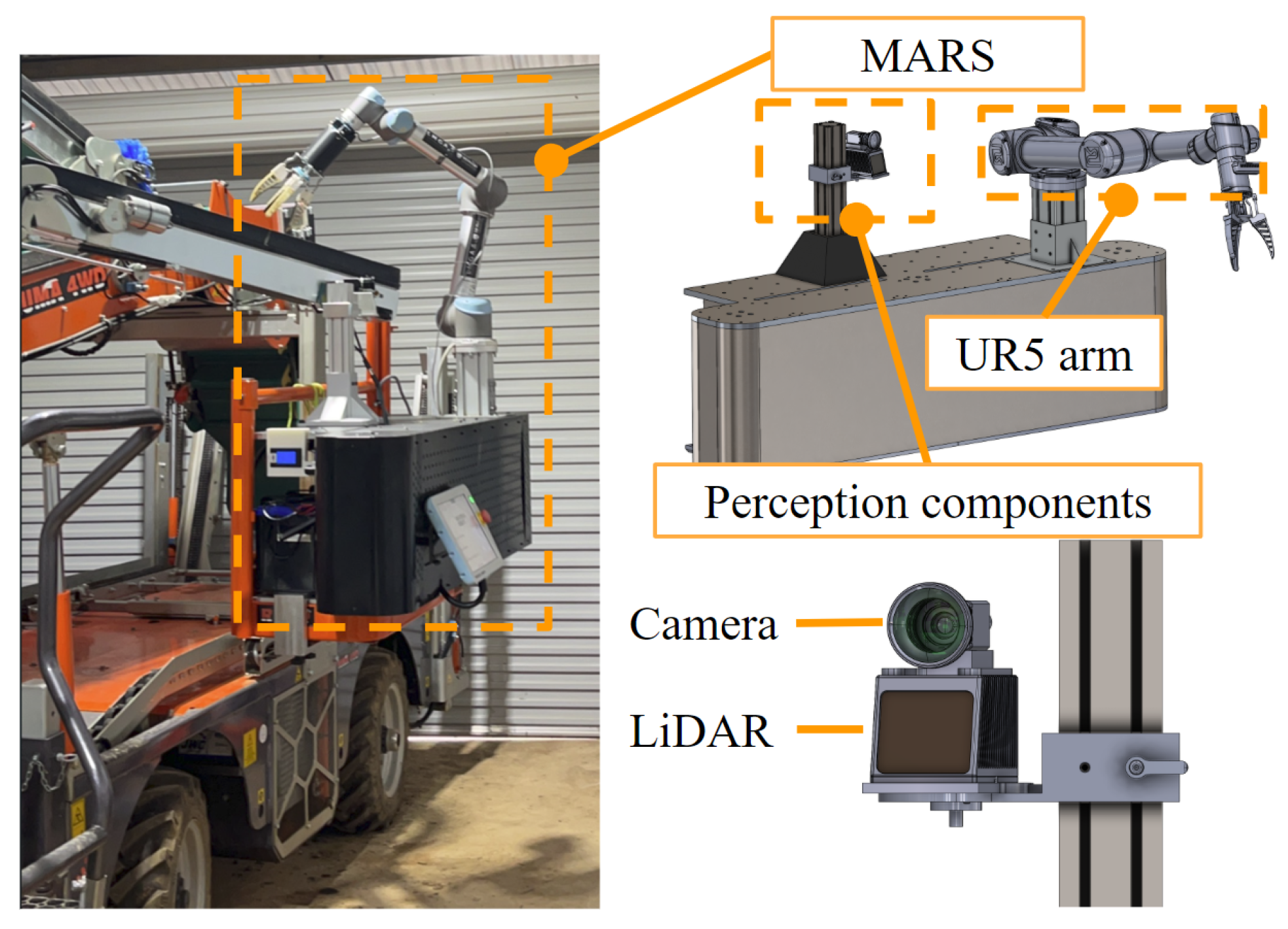
4.1. System Framework
4.2. Network Architecture
4.2.1. Encoder
4.2.2. Decoder
4.2.3. Detection Head
4.3. Nbv Estimation
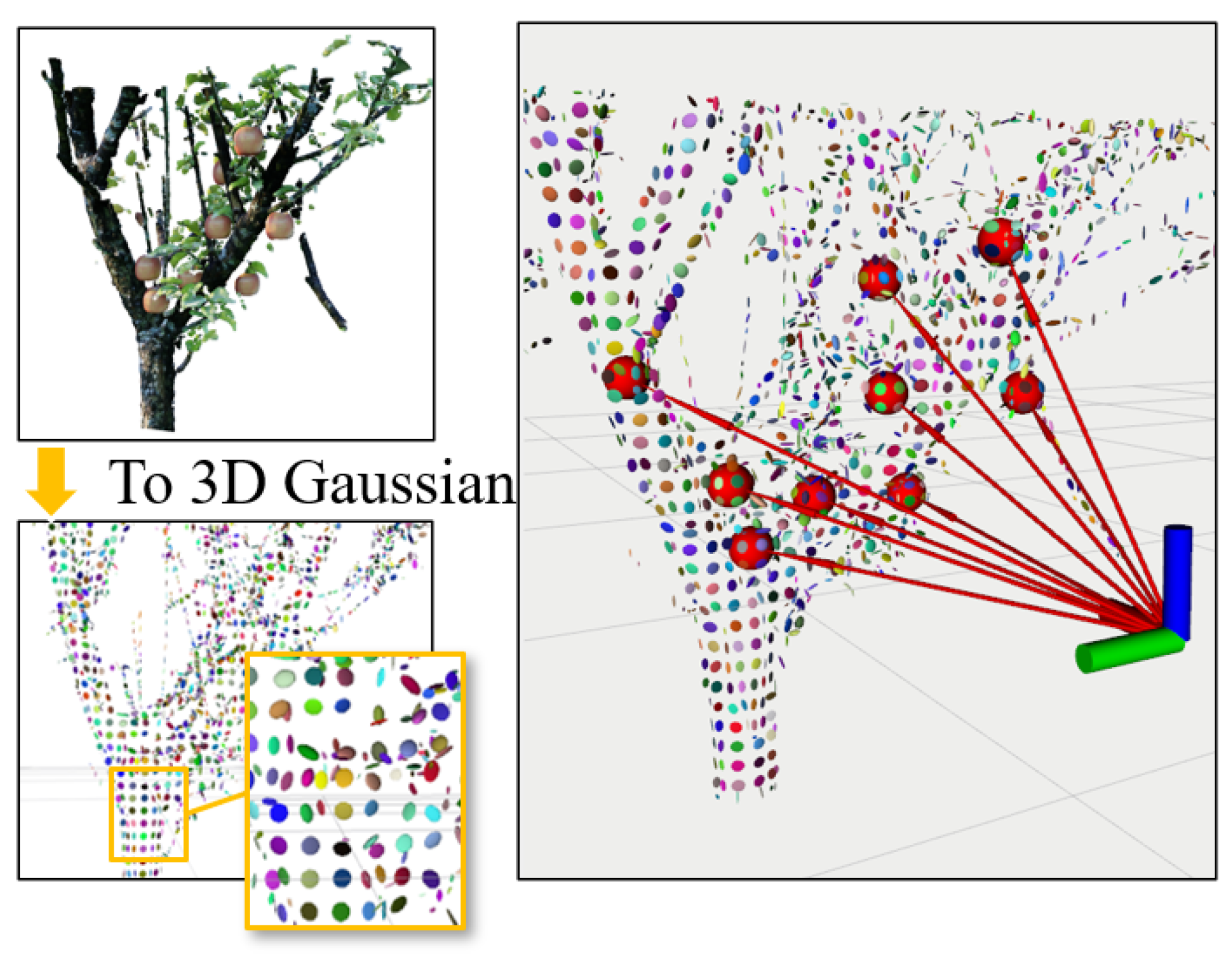
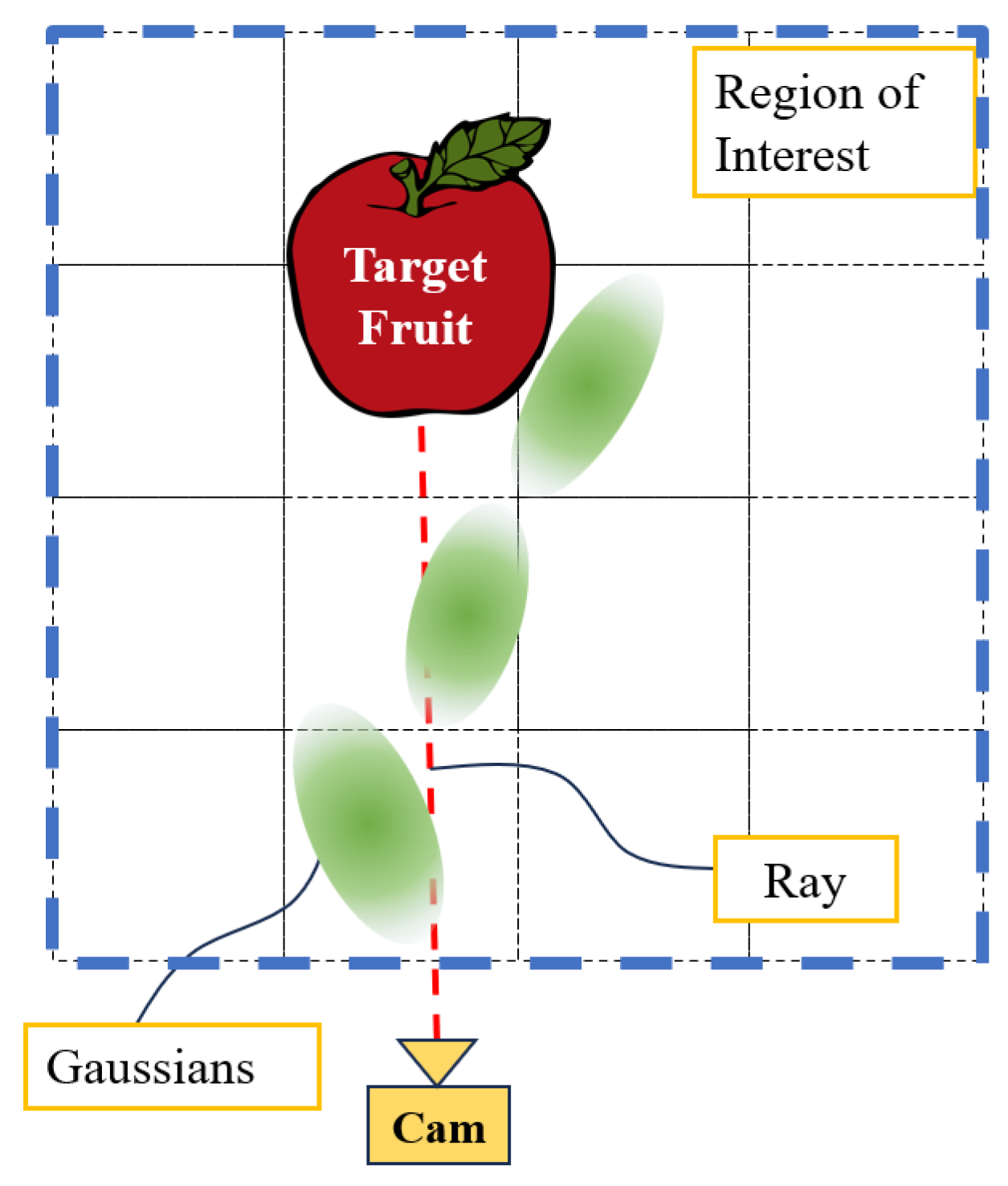
4.3.1. 3D Gaussian Obstacle Estimation
4.3.2. Occlusion Level of Single Target Fruit
4.3.3. Optimization
| Algorithm 1 NBV |
| Input: Last scan’s Network outputs . Last scan’s camera pose . Under optimized fruits set from previous scans. Output: Optimized fruit set and NBV V.
|
5. Implementation Details
5.1. Data Acquisition
5.2. Data Labeling
5.3. Dataset Structure
5.4. Data Augmentation
5.5. IG Calculation
6. Results
6.1. Experiment Setup
6.2. Evaluation Metrics
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Cambridge, MA, USA, 20–23 June 1995; pp. 1440–1448. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Kang, H.; Zhou, H.; Wang, X.; Chen, C. Real-time fruit recognition and grasping estimation for robotic apple harvesting. Sensors 2020, 20, 5670. [Google Scholar] [CrossRef]
- Gené-Mola, J.; Sanz-Cortiella, R.; Rosell-Polo, J.R.; Morros, J.R.; Ruiz-Hidalgo, J.; Vilaplana, V.; Gregorio, E. Fruit detection and 3D location using instance segmentation neural networks and structure-from-motion photogrammetry. Comput. Electron. Agric. 2020, 169, 105165. [Google Scholar] [CrossRef]
- Liu, G.; Nouaze, J.C.; Touko Mbouembe, P.L.; Kim, J.H. YOLO-tomato: A robust algorithm for tomato detection based on YOLOv3. Sensors 2020, 20, 2145. [Google Scholar] [CrossRef] [PubMed]
- Gong, L.; Wang, W.; Wang, T.; Liu, C. Robotic harvesting of the occluded fruits with a precise shape and position reconstruction approach. J. Field Robot. 2022, 39, 69–84. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- Yoshida, T.; Onishi, Y.; Kawahara, T.; Fukao, T. Automated harvesting by a dual-arm fruit harvesting robot. Robomech J. 2022, 9, 19. [Google Scholar] [CrossRef]
- Yin, H.; Sun, Q.; Ren, X.; Guo, J.; Yang, Y.; Wei, Y.; Huang, B.; Chai, X.; Zhong, M. Development, integration, and field evaluation of an autonomous citrus-harvesting robot. J. Field Robot. 2023, 40, 1363–1387. [Google Scholar] [CrossRef]
- Vrochidou, E.; Tziridis, K.; Nikolaou, A.; Kalampokas, T.; Papakostas, G.A.; Pachidis, T.P.; Mamalis, S.; Koundouras, S.; Kaburlasos, V.G. An autonomous grape-harvester robot: Integrated system architecture. Electronics 2021, 10, 1056. [Google Scholar] [CrossRef]
- Zhang, K.; Lammers, K.; Chu, P.; Li, Z.; Lu, R. System design and control of an apple harvesting robot. Mechatronics 2021, 79, 102644. [Google Scholar] [CrossRef]
- Zheng, C.; Chen, P.; Pang, J.; Yang, X.; Chen, C.; Tu, S.; Xue, Y. A mango picking vision algorithm on instance segmentation and key point detection from RGB images in an open orchard. Biosyst. Eng. 2021, 206, 32–54. [Google Scholar] [CrossRef]
- Lehnert, C.; McCool, C.; Sa, I.; Perez, T. Performance improvements of a sweet pepper harvesting robot in protected cropping environments. J. Field Robot. 2020, 37, 1197–1223. [Google Scholar] [CrossRef]
- Rukhovich, D.; Vorontsova, A.; Konushin, A. Fcaf3d: Fully convolutional anchor-free 3d object detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 477–493. [Google Scholar] [CrossRef]
- Kerbl, B.; Kopanas, G.; Leimkühler, T.; Drettakis, G. 3D Gaussian Splatting for Real-Time Radiance Field Rendering. ACM Trans. Graph. 2023, 42, 1–14. [Google Scholar] [CrossRef]
- Zhou, H.; Wang, X.; Au, W.; Kang, H.; Chen, C. Intelligent robots for fruit harvesting: Recent developments and future challenges. Precis. Agric. 2022, 23, 1856–1907. [Google Scholar] [CrossRef]
- Tang, Y.; Chen, M.; Wang, C.; Luo, L.; Li, J.; Lian, G.; Zou, X. Recognition and localization methods for vision-based fruit picking robots: A review. Front. Plant Sci. 2020, 11, 510. [Google Scholar] [CrossRef] [PubMed]
- Koirala, A.; Walsh, K.B.; Wang, Z.; McCarthy, C. Deep learning–Method overview and review of use for fruit detection and yield estimation. Comput. Electron. Agric. 2019, 162, 219–234. [Google Scholar] [CrossRef]
- Lin, G.; Tang, Y.; Zou, X.; Xiong, J.; Fang, Y. Color-, depth-, and shape-based 3D fruit detection. Precis. Agric. 2020, 21, 1–17. [Google Scholar] [CrossRef]
- Kang, H.; Wang, X.; Chen, C. Accurate fruit localisation using high resolution LiDAR-camera fusion and instance segmentation. Comput. Electron. Agric. 2022, 203, 107450. [Google Scholar] [CrossRef]
- Yu, T.; Hu, C.; Xie, Y.; Liu, J.; Li, P. Mature pomegranate fruit detection and location combining improved F-PointNet with 3D point cloud clustering in orchard. Comput. Electron. Agric. 2022, 200, 107233. [Google Scholar] [CrossRef]
- Kok, E.; Wang, X.; Chen, C. Obscured tree branches segmentation and 3D reconstruction using deep learning and geometrical constraints. Comput. Electron. Agric. 2023, 210, 107884. [Google Scholar] [CrossRef]
- Tian, Y.; Yang, G.; Wang, Z.; Wang, H.; Li, E.; Liang, Z. Apple detection during different growth stages in orchards using the improved YOLO-V3 model. Comput. Electron. Agric. 2019, 157, 417–426. [Google Scholar] [CrossRef]
- Fu, L.; Gao, F.; Wu, J.; Li, R.; Karkee, M.; Zhang, Q. Application of consumer RGB-D cameras for fruit detection and localization in field: A critical review. Comput. Electron. Agric. 2020, 177, 105687. [Google Scholar] [CrossRef]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum pointnets for 3D object detection from rgb-d data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 918–927. [Google Scholar] [CrossRef]
- Sukkar, F.; Best, G.; Yoo, C.; Fitch, R. Multi-robot region-of-interest reconstruction with Dec-MCTS. In Proceedings of the 2019 International conference on robotics and automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 9101–9107. [Google Scholar] [CrossRef]
- Menon, R.; Zaenker, T.; Dengler, N.; Bennewitz, M. NBV-SC: Next best view planning based on shape completion for fruit mapping and reconstruction. In Proceedings of the 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Detroit, MI, USA, 1–5 October 2023; pp. 4197–4203. [Google Scholar] [CrossRef]
- Wu, Y.; Wang, Y.; Zhang, S.; Ogai, H. Deep 3D object detection networks using LiDAR data: A review. IEEE Sens. J. 2020, 21, 1152–1171. [Google Scholar] [CrossRef]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar] [CrossRef]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar] [CrossRef]
- Qi, C.R.; Litany, O.; He, K.; Guibas, L.J. Deep hough voting for 3D object detection in point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9277–9286. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, Z.; Cao, Y.; Hu, H.; Tong, X. Group-free 3D object detection via transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2949–2958. [Google Scholar] [CrossRef]
- Choy, C.; Gwak, J.; Savarese, S. 4D spatio-temporal convnets: Minkowski convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3075–3084. [Google Scholar] [CrossRef]
- Gwak, J.; Choy, C.; Savarese, S. Generative sparse detection networks for 3d single-shot object detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part IV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 297–313. [Google Scholar] [CrossRef]
- Lin, C.; Tian, D.; Duan, X.; Zhou, J.; Zhao, D.; Cao, D. 3D-DFM: Anchor-Free Multimodal 3-D Object Detection With Dynamic Fusion Module for Autonomous Driving. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 10812–10822. [Google Scholar] [CrossRef] [PubMed]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar] [CrossRef]
- De la Escalera, A.; Armingol, J.M. Automatic chessboard detection for intrinsic and extrinsic camera parameter calibration. Sensors 2010, 10, 2027–2044. [Google Scholar] [CrossRef] [PubMed]
- CloudCompare Development Team. CloudCompare (Version 2.13.1) [GPL Software]. 2024. Available online: http://www.cloudcompare.org/ (accessed on 20 February 2024).
- Song, S.; Lichtenberg, S.P.; Xiao, J. SUN RGB-D: A RGB-D scene understanding benchmark suite. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 567–576. [Google Scholar] [CrossRef]
- Hahner, M.; Dai, D.; Liniger, A.; Gool, L.V. Quantifying Data Augmentation for LiDAR based 3D Object Detection. arXiv 2020, arXiv:2004.01643. [Google Scholar]
- NVIDIA. Isaac Sim User Guide; NVIDIA Corporation: Santa Clara, CA, USA, 2023. [Google Scholar]
- Tang, J.; Zhou, H.; Chen, X.; Hu, T.; Ding, E.; Wang, J.; Zeng, G. Delicate Textured Mesh Recovery from NeRF via Adaptive Surface Refinement. arXiv 2023, arXiv:2303.02091. [Google Scholar]
- Robotics, O. ROS Noetic Ninjemys, 2020. Version 1.15.11. Available online: https://www.ros.org/noetic/ (accessed on 20 February 2024).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | AP@25% | AP@50% | AR@25% | AR@50% | Time (ms) |
|---|---|---|---|---|---|
| ImVoteNet | 0.499 | 0.238 | 0.781 | 0.568 | 28.076 |
| GroupFree3D | 0.540 | 0.288 | 0.832 | 0.597 | 31.428 |
| TR3D | 0.591 | 0.302 | 0.838 | 0.586 | 13.647 |
| FCAF3D | 0.743 | 0.557 | 0.917 | 0.762 | 13.269 |
| FF3D (ours) | 0.763 | 0.602 | 0.923 | 0.789 | 14.871 |
| H, Kang. et al. [22] | 0.572 | 0.379 | 0.817 | 0.570 | 6.500 |
| Trial | Mean Position Error (mm) | Mean Diameter Error (mm) |
|---|---|---|
| 1 | 5.3690 | 1.6218 |
| 2 | 6.1716 | 1.7870 |
| 3 | 5.5280 | 1.9342 |
| 4 | 5.3637 | 1.6682 |
| 5 | 5.1914 | 1.8015 |
| 6 | 5.7238 | 1.7097 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, T.; Wang, X.; Hu, K.; Zhou, H.; Kang, H.; Chen, C. FF3D: A Rapid and Accurate 3D Fruit Detector for Robotic Harvesting. Sensors 2024, 24, 3858. https://doi.org/10.3390/s24123858
Liu T, Wang X, Hu K, Zhou H, Kang H, Chen C. FF3D: A Rapid and Accurate 3D Fruit Detector for Robotic Harvesting. Sensors. 2024; 24(12):3858. https://doi.org/10.3390/s24123858
Chicago/Turabian StyleLiu, Tianhao, Xing Wang, Kewei Hu, Hugh Zhou, Hanwen Kang, and Chao Chen. 2024. "FF3D: A Rapid and Accurate 3D Fruit Detector for Robotic Harvesting" Sensors 24, no. 12: 3858. https://doi.org/10.3390/s24123858