A Pix2Pix Architecture for Complete Offline Handwritten Text Normalization


Abstract
1. Introduction
- The proposed model reduces the intra-personal variabilities present in the handwritten text of subjects. As far as we know, the complete handwriting text normalization problem with all its substages has not been addressed as a whole by any deep learning model. Moreover, the novelty of our proposal relies on the application of a Pix2Pix network for normalizing handwritten text while preserving the characters and the legibility of the word, rather than for generative purposes.
- The adjustment made to the original Pix2Pix architecture to tackle this particular problem. This adaptation involves a decrease in the number of layers of the U-Net generator and therefore the subsequent reduction in the number of parameters that is necessary to train the model.
- A comparison between the proposed solution and an ad hoc heuristic procedure.
2. Related Works
3. Materials and Methods
3.1. Handwriting Datasets Used
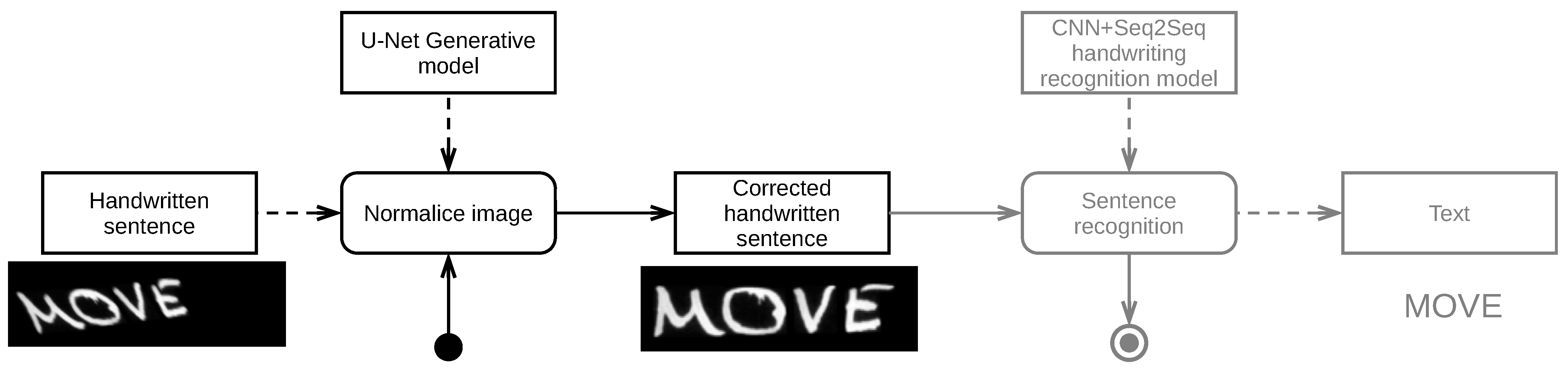
3.2. Normalization Scheme
| Algorithm 1 Heuristic normalization |
|
3.2.1. Image Inversion
3.2.2. Slant Correction
3.2.3. Baseline Detection and Slope Correction
3.2.4. Normalization of Ascenders and Descenders
3.2.5. Resizing
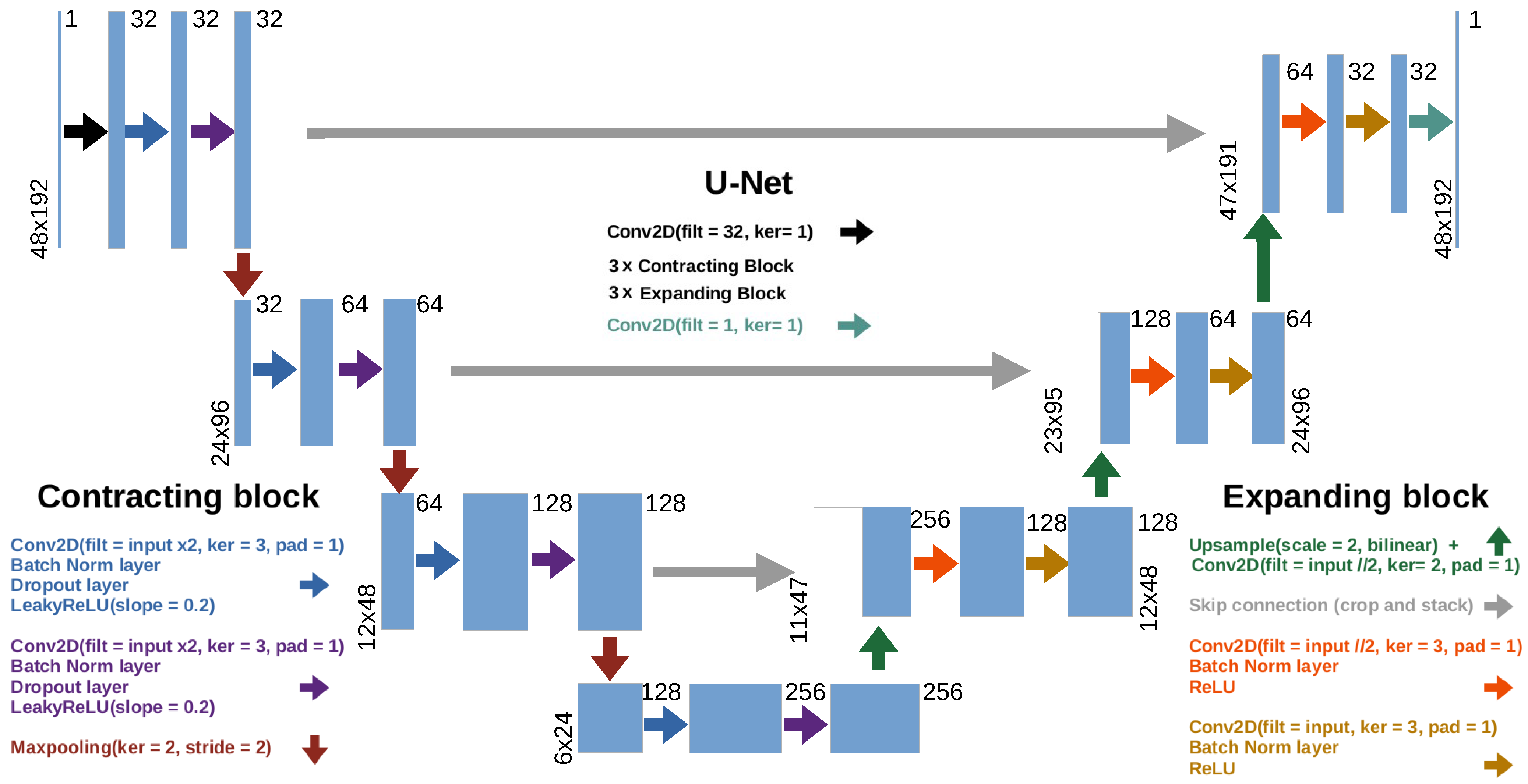
3.3. The Pix2Pix Architecture
3.3.1. The Pix2Pix Generator: U-Net
3.3.2. The Pix2Pix Discriminator: PatchGAN
3.3.3. Loss Function and L1 Distance
4. Experiments and Results
4.1. Summary of Experiments
- Identifying a value of for achieving good results on the test partition of each dataset, using the reference heuristic algorithm outputs as ground truth.
- Assessing whether our proposal restores images from the test partition of each dataset when subjected to distortions, similar to the results obtained by the reference heuristic algorithm.
- Estimating how our proposal and the reference heuristic algorithm approximate manual ad hoc normalization performed on a subset of the IAM test set.
- Conducting a preliminary comparison between the text recognition results obtained when using our Pix2Pix normalization approach as a step previous to recognition and those achieved using the reference heuristic normalization.
4.1.1. Experiment 1—Heuristic Replication Measurement
4.1.2. Experiment 2—Distorted Datasets
4.1.3. Experiment 3—Comparison with Manual Ad Hoc Normalization
4.1.4. Experiment 4—Examining Normalization Architecture in Deep Recognition
4.2. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Networks |
| DPI | Dots per Inch |
| DPP | Distance Per Pixel |
| GAN | Generative Adversarial Neural Networks |
| HTR | Handwritten Text Recognition |
| IAM dataset | IAM Handwriting Database |
| LSTM | Long Short-Term Memory |
| RANSAC | Random Sample Consensus |
| SSIM | Structural Similarity Index |
References
- España-Boquera, S.; Castro-Bleda, M.; Gorbe-Moya, J.; Zamora Martinez, F. Improving offline handwritten text recognition with hybrid HMM/ANN models. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 767–779. [Google Scholar] [CrossRef] [PubMed]
- Graves, A.; Liwicki, M.; Fernández, S.; Bertolami, R.; Bunke, H.; Schmidhuber, J. A novel connectionist system for unconstrained handwriting recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 855–868. [Google Scholar] [CrossRef] [PubMed]
- Vinciarelli, A.; Bengio, S.; Bunke, H. Offline recognition of unconstrained handwritten texts using HMMs and statistical language models. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 709–720. [Google Scholar] [PubMed]
- Pei, S.C.; Lin, C.N. Image normalization for pattern recognition. Image Vis. Comput. 1995, 13, 711–723. [Google Scholar] [CrossRef]
- Neji, H.; Ben Halima, M.; Nogueras-Iso, J.; Hamdani, T.M.; Lacasta, J.; Chabchoub, H.; Alimi, A.M. Doc-Attentive-GAN: Attentive GAN for historical document denoising. Multimed. Tools Appl. 2023, 83, 55509–55525. [Google Scholar] [CrossRef]
- Dutta, K.; Krishnan, P.; Mathew, M.; Jawahar, C. Improving CNN-RNN Hybrid Networks for Handwriting Recognition. In Proceedings of the 2018 16th International Conference on Frontiers in Handwriting Recognition (ICFHR), Niagara Falls, NY, USA, 5–8 August 2018; pp. 80–85. [Google Scholar]
- Ganeshaiah, K.P.; Hegde, V. Handwritten character recognition using optimization based skewed line segmentation method and multi-class support vector machine. Int. J. Adv. Technol. Eng. Explor. 2023, 10, 1476–1490. [Google Scholar] [CrossRef]
- Bera, S.K.; Chakrabarti, A.; Lahiri, S.; Barney Smith, E.H.; Sarkar, R. Normalization of unconstrained handwritten words in terms of Slope and Slant Correction. Pattern Recognit. Lett. 2019, 128, 488–495. [Google Scholar] [CrossRef]
- Nidhi; Ghosh, D.; Chaurasia, D.; Mondal, S.; Mahajan, A. Handwritten Documents Text Recognition with Novel Pre-processing and Deep Learning. In Proceedings of the 2021 Grace Hopper Celebration India, GHCI 2021, Bangalore, India, 19 February–12 March 2021. [Google Scholar] [CrossRef]
- Chu, S.C.; Yang, X.; Zhang, L.; Snásel, V.; Pan, J.S. Hybrid optimization algorithm for handwritten document enhancement. Comput. Mater. Contin. 2024, 78, 3763–3786. [Google Scholar] [CrossRef]
- Kass, D.; Vats, E. AttentionHTR: Handwritten Text Recognition Based on Attention Encoder-Decoder Networks. In Document Analysis Systems; Uchida, S., Barney, E., Eglin, V., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 507–522. [Google Scholar]
- Kang, L.; Toledo, J.I.; Riba, P.; Villegas, M.; Fornés, A.; Rusiñol, M. Convolve, Attend and Spell: An Attention-based Sequence-to-Sequence Model for Handwritten Word Recognition. In Pattern Recognition, Proceedings of the 40th German Conference, GCPR 2018, Stuttgart, Germany, 9–12 October 2018; Brox, T., Bruhn, A., Fritz, M., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 459–472. [Google Scholar]
- Michael, J.; Labahn, R.; Grüning, T.; Zöllner, J. Evaluating Sequence-to-Sequence Models for Handwritten Text Recognition. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, NSW, Australia, 20–25 September 2019; pp. 1286–1293. [Google Scholar]
- Sueiras, J.; Ruiz, V.; Sanchez, A.; Velez, J. Offline continuous handwriting recognition using seq2seq neural networks. Neurocomputing 2018, 289, 119–128. [Google Scholar] [CrossRef]
- Pesch, H.; Hamdani, M.; Forster, J.; Ney, H. Analysis of Preprocessing Techniques for Latin Handwriting Recognition. In Proceedings of the 2012 International Conference on Frontiers in Handwriting Recognition, Bari, Italy, 18–20 September 2012; pp. 280–284. [Google Scholar]
- Kozielski, M.; Forster, J.; Ney, H. Moment-Based Image Normalization for Handwritten Text Recognition. In Proceedings of the 2012 International Conference on Frontiers in Handwriting Recognition, Bari, Italy, 18–20 September 2012; pp. 256–261. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 3, 2672–2680. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Jabbar, A.; Li, X.; Omar, B. A Survey on Generative Adversarial Networks: Variants, Applications, and Training. ACM Comput. Surv. (CSUR) 2022, 54, 1–49. [Google Scholar] [CrossRef]
- Khamekhem Jemni, S.; Souibgui, M.; Kessentini, Y.; Fornés, A. Enhance to read better: A Multi-Task Adversarial Network for Handwritten Document Image Enhancement. Pattern Recognit. 2022, 123, 108370. [Google Scholar] [CrossRef]
- Souibgui, M.; Kessentini, Y. DE-GAN: A Conditional Generative Adversarial Network for Document Enhancement. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 1180–1191. [Google Scholar] [CrossRef]
- Calvo-Zaragoza, J.; Gallego, A.J. A selectional auto-encoder approach for document image binarization. Pattern Recognit. 2019, 86, 37–47. [Google Scholar] [CrossRef]
- Kang, S.; Iwana, B.; Uchida, S. Complex image processing with less data—Document image binarization by integrating multiple pre-trained U-Net modules. Pattern Recognit. 2021, 109, 107577. [Google Scholar] [CrossRef]
- Gonwirat, S.; Surinta, O. DeblurGAN-CNN: Effective Image Denoising and Recognition for Noisy Handwritten Characters. IEEE Access 2022, 10, 90133–90148. [Google Scholar] [CrossRef]
- Sauvola, J.; Pietikäinen, M. Adaptive document image binarization. Pattern Recognit. 2000, 33, 225–236. [Google Scholar] [CrossRef]
- Pal, U.; Chaudhuri, B. An improved document skew angle estimation technique. Pattern Recognit. Lett. 1996, 17, 899–904. [Google Scholar] [CrossRef]
- Kavallieratou, E.; Fakotakis, N.; Kokkinakis, G. Skew angle estimation for printed and handwritten documents using the Wigner–Ville distribution. Image Vis. Comput. 2002, 20, 813–824. [Google Scholar] [CrossRef]
- Pastor, M.; Toselli, A.; Vidal, E. Projection Profile Based Algorithm for Slant Removal. In Image Analysis and Recognition, Proceedings of the International Conference, ICIAR 2004, Porto, Portugal, 29 September–1 October 2004; Campilho, A., Kamel, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; pp. 183–190. [Google Scholar]
- Vinciarelli, A.; Luettin, J. A new normalization technique for cursive handwritten words. Pattern Recognit. Lett. 2001, 22, 1043–1050. [Google Scholar] [CrossRef]
- Gupta, J.D.; Chanda, B. An Efficient Slope and Slant Correction Technique for Off-Line Handwritten Text Word. In Proceedings of the 2014 Fourth International Conference of Emerging Applications of Information Technology, Kolkata, India, 19–21 December 2014; pp. 204–208. [Google Scholar]
- Sueiras, J. Continuous Offline Handwriting Recognition using Deep Learning Models. arXiv 2021, arXiv:2112.13328. [Google Scholar]
- Akbari, Y.; Al-Maadeed, S.; Adam, K. Binarization of Degraded Document Images Using Convolutional Neural Networks and Wavelet-Based Multichannel Images. IEEE Access 2020, 8, 153517–153534. [Google Scholar] [CrossRef]
- Sadri, N.; Desir, J.; Khallouli, W.; Shahab Uddin, M.; Kovacic, S.; Sousa-Poza, A.; Cannan, M.; Li, J. Image Enhancement for Improved OCR and Deck Segmentation in Shipbuilding Document Images. In Proceedings of the 2022 IEEE 13th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference, UEMCON 2022, New York, NY, USA, 26–29 October 2022; pp. 45–51. [Google Scholar]
- Khallouli, W.; Pamie-George, R.; Kovacic, S.; Sousa-Poza, A.; Canan, M.; Li, J. Leveraging Transfer Learning and GAN Models for OCR from Engineering Documents. In Proceedings of the 2022 IEEE World AI IoT Congress, AIIoT 2022, Seattle, WA, USA, 6–9 June 2022; pp. 15–21. [Google Scholar]
- Suh, S.; Kim, J.; Lukowicz, P.; Lee, Y. Two-stage generative adversarial networks for binarization of color document images. Pattern Recognit. 2022, 130, 108810. [Google Scholar] [CrossRef]
- Zhao, J.; Shi, C.; Jia, F.; Wang, Y.; Xiao, B. Document image binarization with cascaded generators of conditional generative adversarial networks. Pattern Recognit. 2019, 96, 106968. [Google Scholar] [CrossRef]
- Kumar, A.; Ghose, S.; Chowdhury, P.; Roy, P.; Pal, U. UdbNet: Unsupervised document binarization network via adversarial game. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 7817–7824. [Google Scholar]
- Davis, B.; Tensmeyer, C.; Price, B.; Wigington, C.; Morse, B.; Jain, R. Text and Style Conditioned GAN for Generation of Offline Handwriting Lines. In Proceedings of the 31st British Machine Vision Conference—BMVC 2020, Virtual, 7–10 September 2020; BMVA Press: Surrey, UK, 2020; pp. 1–13. [Google Scholar]
- Marti, U.V.; Bunke, H. The IAM-database: An English sentence database for offline handwriting recognition. Int. J. Doc. Anal. Recognit. 2003, 5, 39–46. [Google Scholar] [CrossRef]
- Causer, T.; Wallace, V. Building a volunteer community: Results and findings from Transcribe Bentham. Digit. Humanit. Q. 2012, 6. Available online: http://www.digitalhumanities.org/dhq/vol/6/2/000125/000125.html (accessed on 11 June 2024).
- Barreiro-Garrido, A.; Ruiz-Parrado, V.; Sanchez, A.; Velez, J.F. Handwritten Word Recognition on the Fundación-Osborne Dataset. In Bio-inspired Systems and Applications: From Robotics to Ambient Intelligence; Springer: Cham, Switzerland, 2022; pp. 298–307. [Google Scholar] [CrossRef]
- Chowdhury, A.; Vig, L. An efficient end-to-end neural model for handwritten text recognition. In Proceedings of the British Machine Vision Conference 2018—BMVC 2018, Newcastle, UK, 3–6 September 2018; pp. 1–13. [Google Scholar]
- Kim, G.; Govindaraju, V. A lexicon driven approach to handwritten word recognition for real-time applications. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 366–379. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015, Proceedings of the 18th International Conference, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Wang, Z.; Bovik, A.; Sheikh, H.; Simoncelli, E. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Yousef, M.; Bishop, T.E. OrigamiNet: Weakly-Supervised, Segmentation-Free, One-Step, Full Page Text Recognition by Learning to Unfold. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 14698–14707. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Normalization | DPP | SSIM |
|---|---|---|---|
| Pix2Pix | 0.052 | 0.700 | |
| IAM | Pix2Pix | 0.047 | 0.718 |
| Pix2Pix | 0.042 | 0.740 | |
| Pix2Pix | 0.051 | 0.470 | |
| Bentham | Pix2Pix | 0.048 | 0.498 |
| Pix2Pix | 0.045 | 0.529 | |
| Pix2Pix | 0.051 | 0.181 | |
| Osborne | Pix2Pix | 0.043 | 0.282 |
| Pix2Pix | 0.027 | 0.613 |
| Dataset | Normalization | DPP | SSIM |
|---|---|---|---|
| Distorted IAM | Pix2Pix | 0.036 | 0.758 |
| Pix2Pix | 0.031 | 0.784 | |
| Pix2Pix | 0.016 | 0.862 | |
| Heuristic method [14] | 0.046 | 0.772 | |
| Distorted Bentham | Pix2Pix | 0.032 | 0.737 |
| Pix2Pix | 0.033 | 0.747 | |
| Pix2Pix | 0.032 | 0.738 | |
| Heuristic method [14] | 0.049 | 0.643 | |
| Distorted Osborne | Pix2Pix | 0.025 | 0.854 |
| Pix2Pix | 0.025 | 0.858 | |
| Pix2Pix | 0.023 | 0.858 | |
| Heuristic method [14] | 0.030 | 0.806 |
| Normalization | DPP | SSIM |
|---|---|---|
| Pix2Pix | 0.089 | 0.556 |
| Pix2Pix | 0.081 | 0.582 |
| Pix2Pix | 0.073 | 0.595 |
| Heuristic method [14] | 0.102 | 0.545 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Barreiro-Garrido, A.; Ruiz-Parrado, V.; Moreno, A.B.; Velez, J.F. A Pix2Pix Architecture for Complete Offline Handwritten Text Normalization. Sensors 2024, 24, 3892. https://doi.org/10.3390/s24123892
Barreiro-Garrido A, Ruiz-Parrado V, Moreno AB, Velez JF. A Pix2Pix Architecture for Complete Offline Handwritten Text Normalization. Sensors. 2024; 24(12):3892. https://doi.org/10.3390/s24123892
Chicago/Turabian StyleBarreiro-Garrido, Alvaro, Victoria Ruiz-Parrado, A. Belen Moreno, and Jose F. Velez. 2024. "A Pix2Pix Architecture for Complete Offline Handwritten Text Normalization" Sensors 24, no. 12: 3892. https://doi.org/10.3390/s24123892
APA StyleBarreiro-Garrido, A., Ruiz-Parrado, V., Moreno, A. B., & Velez, J. F. (2024). A Pix2Pix Architecture for Complete Offline Handwritten Text Normalization. Sensors, 24(12), 3892. https://doi.org/10.3390/s24123892