Abstract
Traffic flow prediction can provide important reference data for managers to maintain traffic order, and can also be based on personal travel plans for optimal route selection. On account of the development of sensors and data collection technology, large-scale road network historical data can be effectively used, but their high non-linearity makes it meaningful to establish effective prediction models. In this regard, this paper proposes a dual-stream cross AGFormer-GPT network with prompt engineering for traffic flow prediction, which integrates traffic occupancy and speed as two prompts into traffic flow in the form of cross-attention, and uniquely mines spatial correlation and temporal correlation information through the dual-stream cross structure, effectively combining the advantages of the adaptive graph neural network and large language model to improve prediction accuracy. The experimental results on two PeMS road network data sets have verified that the model has improved by about 1.2% in traffic prediction accuracy under different road networks.
1. Introduction
In the current society, with the high development of the economy and the strengthening of urbanization and population mobility, the complexity and challenge of the traffic system are becoming more and more prominent [1]. Effective and real-time traffic flow prediction is of great significance for alleviating traffic congestion, reducing traffic accidents, optimizing resource allocation, ensuring traffic safety, and formulating reasonable traffic planning policies. The traffic flow prediction algorithm, as the most critical research field in the context of intelligent transportation, has received great attention from scholars [2,3,4].
Recently, many traffic prediction models have been proposed by scholars. The deep neural network has the advantages of high precision, powerful non-linear relationship processing ability, strong generalization ability, ability to handle large-scale data, real-time prediction and response, and strong adaptability in traffic prediction, which makes deep neural networks a research hotspot in the field of traffic prediction [5]. For instance, Ref. [6] used stacked autoencoder (SAE) deep models to mine historical traffic information, which can effectively capture potential spatiotemporal dependencies. Ref. [7] combined LSTM and the attention mechanism from multiple scales to obtain important factors affecting traffic flow, thereby obtaining better prediction results. Ref. [8] proposed a DBN-SVR traffic prediction model, which has smaller errors than conventional DBN prediction models and other commonly used prediction models. As a variant of RNN, LSTMs can prevent long-term information forgetting and are widely proven to be effective predictive models. Ref. [9] used LSTM and CNN to separately capture the spatiotemporal dependence features and effectively integrate the input of traffic speed and flow using attention mechanisms, intuitively demonstrating the solvability of the DNN-BTF model. Ref. [10] divided road segments into different levels using ideal solution similarity ranking preference technology, and then used convolutional LSTM networks to spatiotemporally mine key road segments, which can accurately predict various states of key road segments. Ref. [11] proposed a CNN traffic prediction network capable of spatiotemporal analysis. This network analyzes the spatiotemporal correlation of progressiveness data before using CNN feature mining, which can select spatiotemporal features and improve the effectiveness of prediction algorithms. Ref. [12] proposed a new parallel processing framework combined with a distributed LSTM traffic prediction model, which improves the accuracy, efficiency, and scalability of predictions. Ref. [13] used hierarchical clustering to split traffic flow up into multiple parts, then calculated the spatial correlation through standard Euclidean space. Then, LSTM was used to mine the information of the most relevant sections of the predicted data, which has high prediction accuracy. Ref. [14] used a dual-branch gated convolutional network to extract the spatiotemporal dependence of historical traffic data, and designed an attention mechanism that only increases the width of the model to weight the hidden features, which ensures high prediction accuracy while increasing less computation time. Ref. [15] introduced the attention mechanism into the LSTM for traffic flow prediction. This helps the network model allocate different attention to different weight inputs, pay attention to key and essential information, and increase prediction accuracy. Ref. [16] combined LSTM networks with ensemble learning’s XBoost structure to forecast traffic flow, avoiding overfitting and improving the generalization of prediction models.
Traditional convolutional or recurrent neural network algorithms are only applicable to the feature extraction of Euclidean space data, and are not applicable to the graph data of non-Euclidean space generated by complex traffic networks. The graph neural network [17,18] can realize the information of neighbors of each node to mine their hidden features through various aggregation methods, and can well characterize the spatial topology of the traffic network, so it has a good prospect for the traffic network data mining task in non-Euclidean space. For example, [19] was the first to apply spatiotemporal graph convolution (STGCN) to traffic prediction, which uses graph convolution and gated convolution to mine hidden features with better accuracy compared to ordinary convolutions. Ref. [20], for the first time, integrated attention into the spatiotemporal graph neural network (ASTGCN). It mines the spatiotemporal correlation through three branches of different time attributes, and uses spatiotemporal attention to weight the hidden features of each layer in each branch, which further improves the prediction accuracy. Ref. [21] designed a special time–graph convolutional network (T-GCN) traffic prediction method, which combines the advantages of GCN and GRU to effectively capture the dynamic spatiotemporal correlation of traffic data, and the prediction effect is better than the advanced model proposed before. Ref. [22] designed a graph multiple attention network (GMAN) based on the encoder–decoder structure to predict the road network conditions of different duration. In this model, spatial attention and temporal attention mechanisms were combined by the gating mechanism to weight the spatiotemporal embedding features. Experiments on real data machines showed that it was effective in long-term prediction tasks. Ref. [23] designed a spatiotemporal synchronous graph convolutional network (STSGCN), which for the first time mined spatiotemporal correlation synchronously by establishing a local spatiotemporal graph of traffic, and significantly improved the prediction accuracy compared with the asynchronous mining of spatiotemporal correlation. Ref. [24] proposed a data-driven approach to generating “time graphs” to compensate for correlations that may not be reflected in spatial graphs with good performance for long-term prediction. Ref. [25] used a novel transformer network (STTN) to extract spatiotemporal dependencies of traffic feature, which effectively extends spatiotemporal relationships over long distances. Ref. [26] proposed a method of automatically obtaining the spatiotemporal state and spatiotemporal dependency in data using a multi-graph GAN. This method can obtain real-time traffic prediction results through GAN constraints. Ref. [27] fused the spatiotemporal characteristics of traffic flow through the spatiotemporal multi-graph convolutional network with cross attention, effectively reducing the prediction error. Ref. [28] designed a special spatiotemporal GCN mine global and local spatial relationships and integrated multi-granularity temporal dynamic relationships. In addition, it can fully utilize the semantic information of traffic data and achieve good predictive performance. Ref. [29] proposed a new model for learning the spatiotemporal relationships of traffic data, which can dynamically express temporal- and spatial-related features in a graphical manner, fully tapping into the inherent connections of time and space, and effectively improving accuracy. Ref. [30] designed an adaptive adjacency matrix calculation method combined with GCN to mine the dynamic spatial relationships of road information. Compared to using a fixed adjacency matrix local aggregation road network node hidden feature local method, it has better accuracy and adaptability. Ref. [31] proposed the spatiotemporal graph neural controlled differential equation (STG-NCDE) method for traffic prediction. In the process of converting dynamic graphs into time series, each point is converted into a sequence, and then ODE processing is performed on each sequence to effectively improve the accuracy. Ref. [32] used multiple transformer encoders to progressively predict future traffic conditions and adaptively select the optimal model. Ref. [33] enhanced DetectorNet with transformer, and excavated long and short time correlations and dynamic spatial correlation through multi-perspective spatiotemporal attention, and made accurate predictions. Ref. [34] used a temporal transformer network to mine the correlation between the recent and cycle time of traffic flow and generated the final predicted value in combination with a spatial transformer. Ref. [35] proposed a new model named Trafformer for traffic prediction, which unifies spatial and temporal information in one transformer-style model, which enables it to catch complex spatial–temporal dependencies. Ref. [36] fully considered the spatiotemporal heterogeneity when performing traffic prediction tasks, and used a causal spatiotemporal synchronous graph convolutional network to mine spatiotemporal correlations, achieving the best prediction results. Ref. [37] generated adjacency matrices through traffic flow matrices, and then combined attention mechanisms and graph convolutional networks to build a transformer encoder as a hidden feature extractor to mine spatiotemporal correlations, making the prediction model more effective.
Although these existing prediction models can be applied to irregular traffic network data, they still have shortcomings in extracting and utilizing the depth features of historical data, which mainly contain two parts: (1) In the feature extraction process, the influence of the interaction information between various observable traffic parameters on the prediction accuracy is ignored. (2) Traffic information spreads along two dimensions of space–time and space. Utilizing the effective spatiotemporal dependencies of historical traffic data remains a challenge. Regarding the above shortcomings, we designed a dual-stream cross AGFormer-GPT network with prompt engineering for traffic flow prediction. The uniqueness of this article lies in the following.
Firstly, our model designs a reminder engineering module that embeds historical traffic speeds and occupancy rates into a reminder sequence using cross attention. Then, the reminder sequence is effectively integrated into the historical traffic flow sequence, enabling more useful historical information to be utilized in subsequent spatiotemporal correlation mining and improving the prediction accuracy of the prediction model.
Secondly, our model introduces a dual stream crossover network that can simultaneously learn spatial and temporal information to improve performance. This dual flow method can avoid the sequential problem of extracting spatial and temporal correlations, and increase the non-linear fitting ability to better capture the complexity of traffic flow. It uses a fine-tuning GPT2 model to mine temporal correlations and an adaptive graph transformer network to mine spatial correlations, providing a thorough understanding of spatial and temporal dynamics.
Finally, our model is compared with several advanced prediction methods on two real data sets of PeMS. The experimental results show that the proposed method has better performance than others.
2. Preliminary
This section describes the symbolic representation of variables and the definition of related concepts in detail.
Spatial topology The spatial topology of the traffic network is a graph structure , where is the set of nodes, each representing the data sensor’s spatial position. N is the number of data sensors. E is the set of edges, and is the adjacency matrix of the graph structure G. Feature matrix. There are three kinds of observable traffic network information as the features of the nodes: traffic flow , traffic occupancy , and traffic speed . , , and represent the feature matrix composed of three information features of network nodes at time t.
Among them, traffic flow and traffic occupancy data can be obtained in real time by sensors installed on the road (such as a ring detector, video detector, etc.), providing real-time data support for the traffic management system. Traffic speed data can be obtained by sensors such as floating vehicle technology, GPS positioning technology, and microwave radar tachometer to provide real-time and accurate traffic speed information for traffic management departments.
The traffic flow prediction problem defined in this paper is described as follows. Learning a non-linear function (prediction model) calculating the traffic flow series for the next period,
where is the prediction horizon and is the history length of the input matrix.
3. Methodology
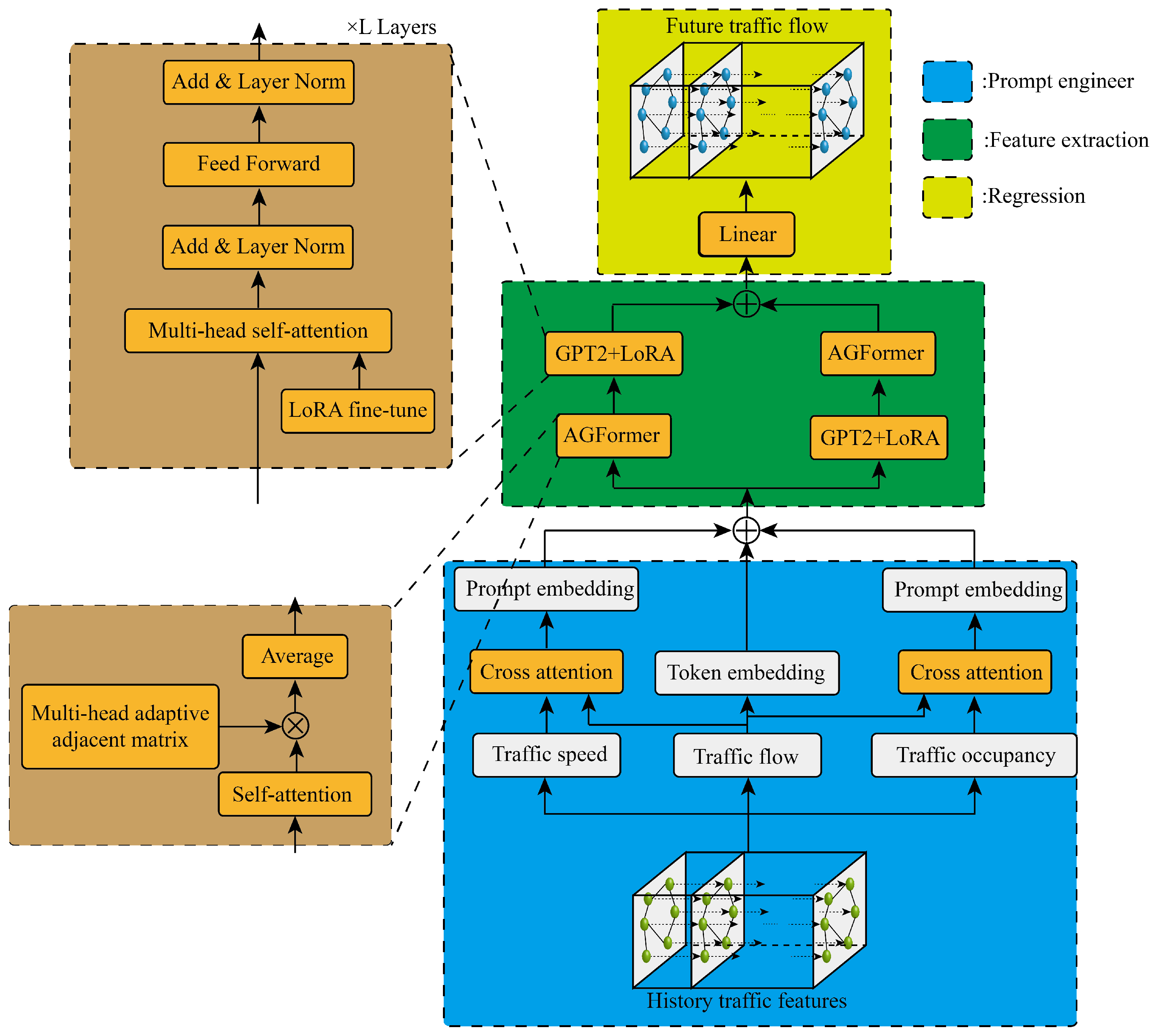
Figure 1 shows the specific structure of the dual-stream cross AGFormer-GPT network with prompt engineering proposed in this paper, which mainly includes three parts: prompt engineering, feature extraction and regression. The prompt engineering part can integrate historical traffic flow with other observable related parameters, the feature extraction part synchronously excavates spatiotemporal correlation through a dual-stream cross structure, and the regression part obtains the final predicted value through a linear layer. Next, we will provide a detailed description of the specific contents of the three parts.
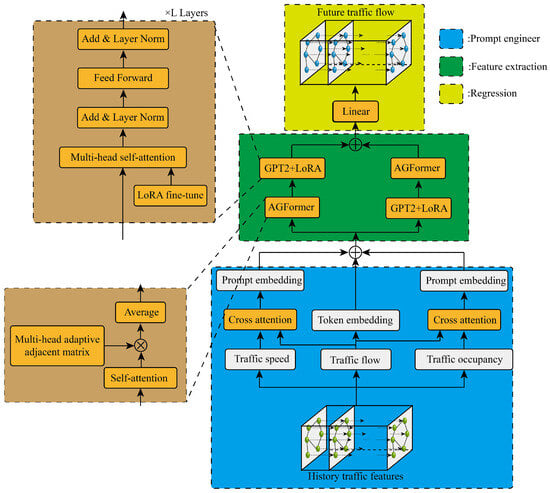
Figure 1.
The structure of the prediction model.
3.1. Prompt Engineer
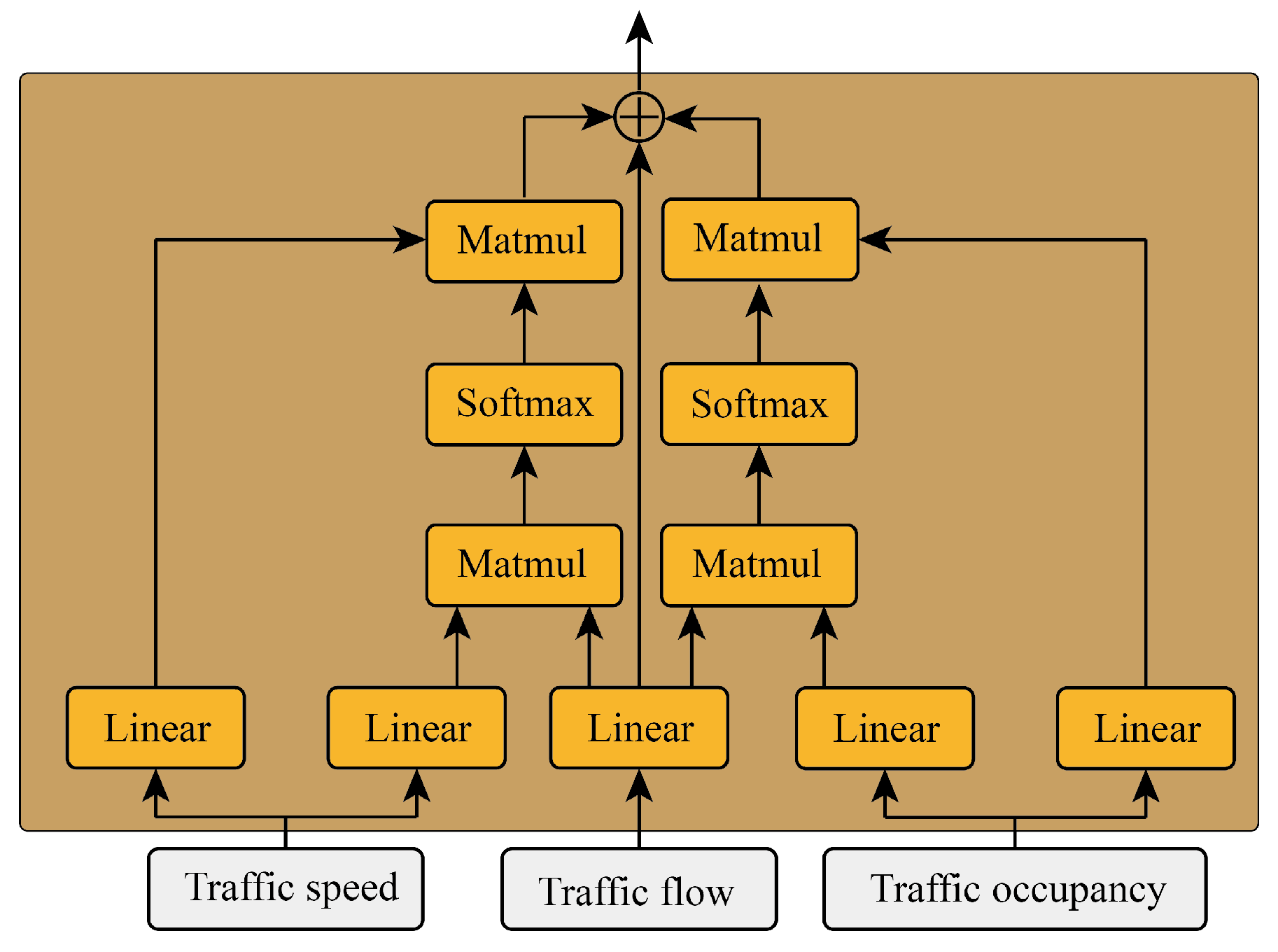
In traffic theory, traffic speed and traffic occupancy have a key impact on the change in traffic flow, and these two parameters are easy to observe. The suggested project proposed in this paper is to integrate the effective information of the two parameters of traffic speed and occupancy into traffic flow information through two cross-attention mechanisms, and the module is shown in Figure 2.
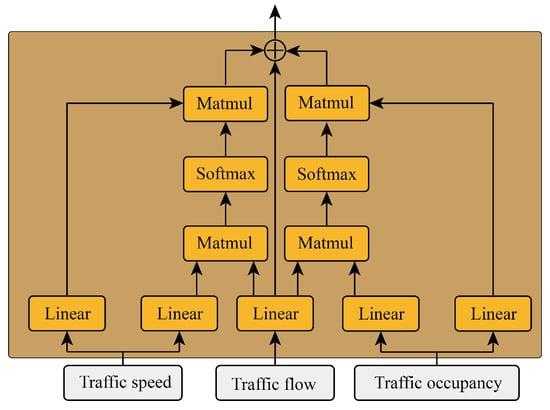
Figure 2.
The structure of the prompt engineer.
First, the query matrix of traffic flow is obtained through a linear layer:
where is the historical input features of traffic flow, is the linear layer weight for obtaining the traffic flow query matrix, and is the traffic flow query matrix.
Then two linear layers are used to obtain the key matrices and value matrices of traffic speed and traffic occupancy, respectively:
where and are the historical input features of traffic occupancy and traffic speed, respectively, and are the linear layer weights for obtaining the traffic speed and occupancy key matrices, and are the linear layer weights for obtaining the traffic speed and occupancy value matrices, and are the traffic speed and traffic occupancy key matrices, and and are the traffic speed and occupancy value matrices.
Then, the prompt values of traffic speed and occupancy are obtained by two cross-attention methods, respectively:
where and are prompt values of the traffic speed and traffic occupancy.
Finally, the two prompt values are added to the query value of the traffic flow to obtain the feature value with the prompt engineer:
3.2. Feature Extraction
In the feature extraction part, the dual-stream cross structure takes advantage of extracting the spatial–temporal correlation. In one stream branching line, the adaptive graph transformer (AGFormer) takes advantage of extracting the spatial correlation, then the GPT2 network is fine-tuned to extract the temporal correlation, while the other stream branching is reversed.
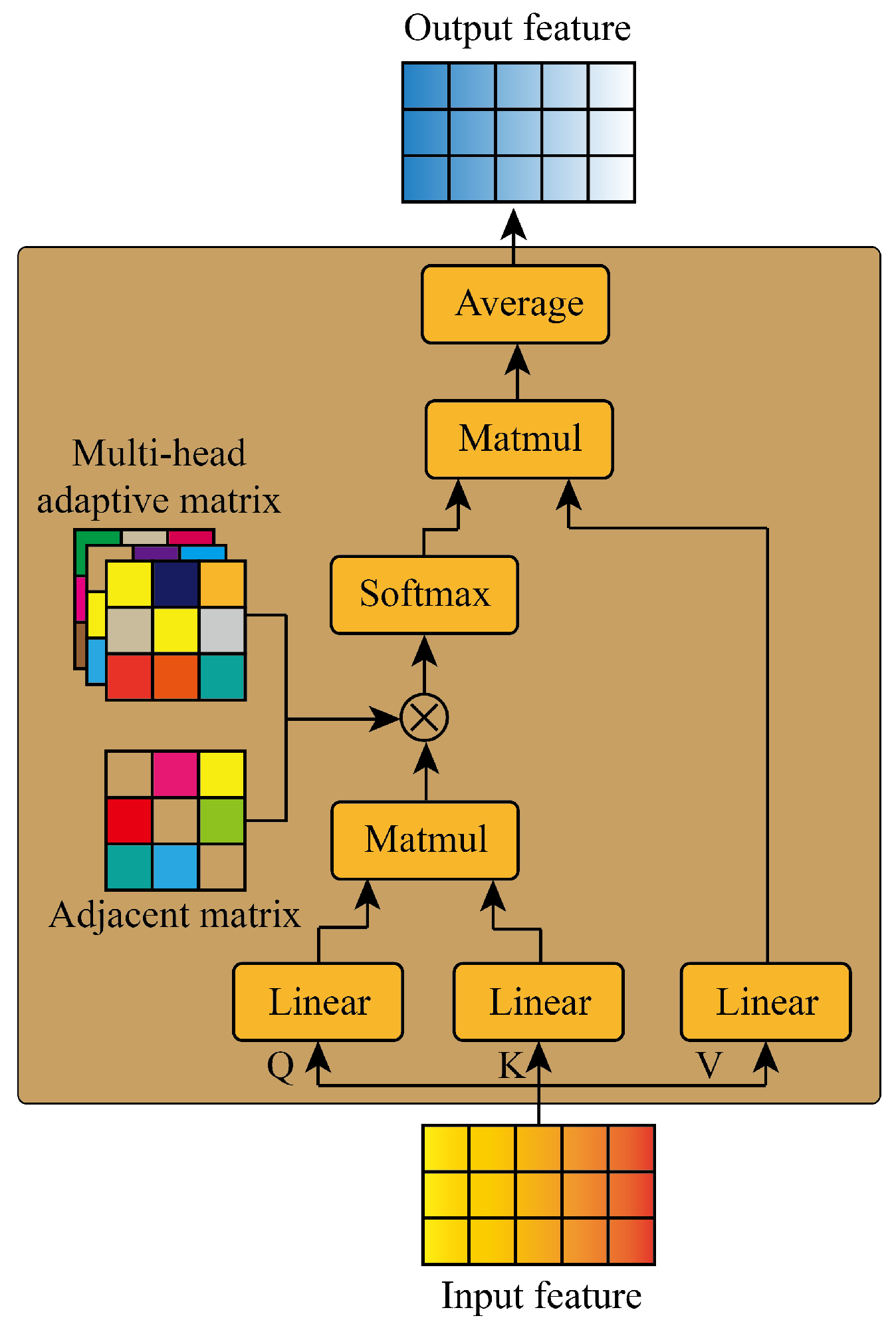
AGFormer is a network based on the graph self-attention structure as shown in Figure 3.
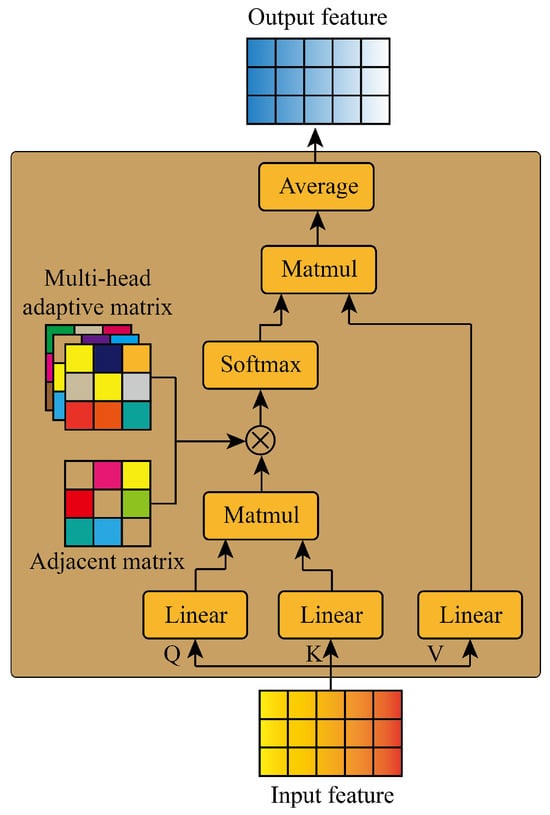
Figure 3.
The structure of AGFormer.
The query, key, and value matrices are first obtained through three linear layers:
Then, we obtain the attention coefficient with the adaptive graph structure by obtaining the dot product and the element-wise product:
where A is the adjacent matrix, is the ith head of the adaptive matrix, and is the ith head of the attention coefficient.
Finally, the output features are obtained through averaging:
where is the l output of the graph self-attention structure, and M is the number of the head.
GPT-2 is OpenAI’s second generation generative pre-trained model, introduced in 2019, which consists of multiple layers of transformer encoders, each consisting of multi-head self-attention mechanisms and feedforward neural networks [38]. This architecture allows the model to compute multiple attention weights in parallel to better capture dependencies between different locations and different semantics. By stacking multiple encoder layers, the GPT-2 model is capable of deep feature extraction and representation learning of the input sequence [39].
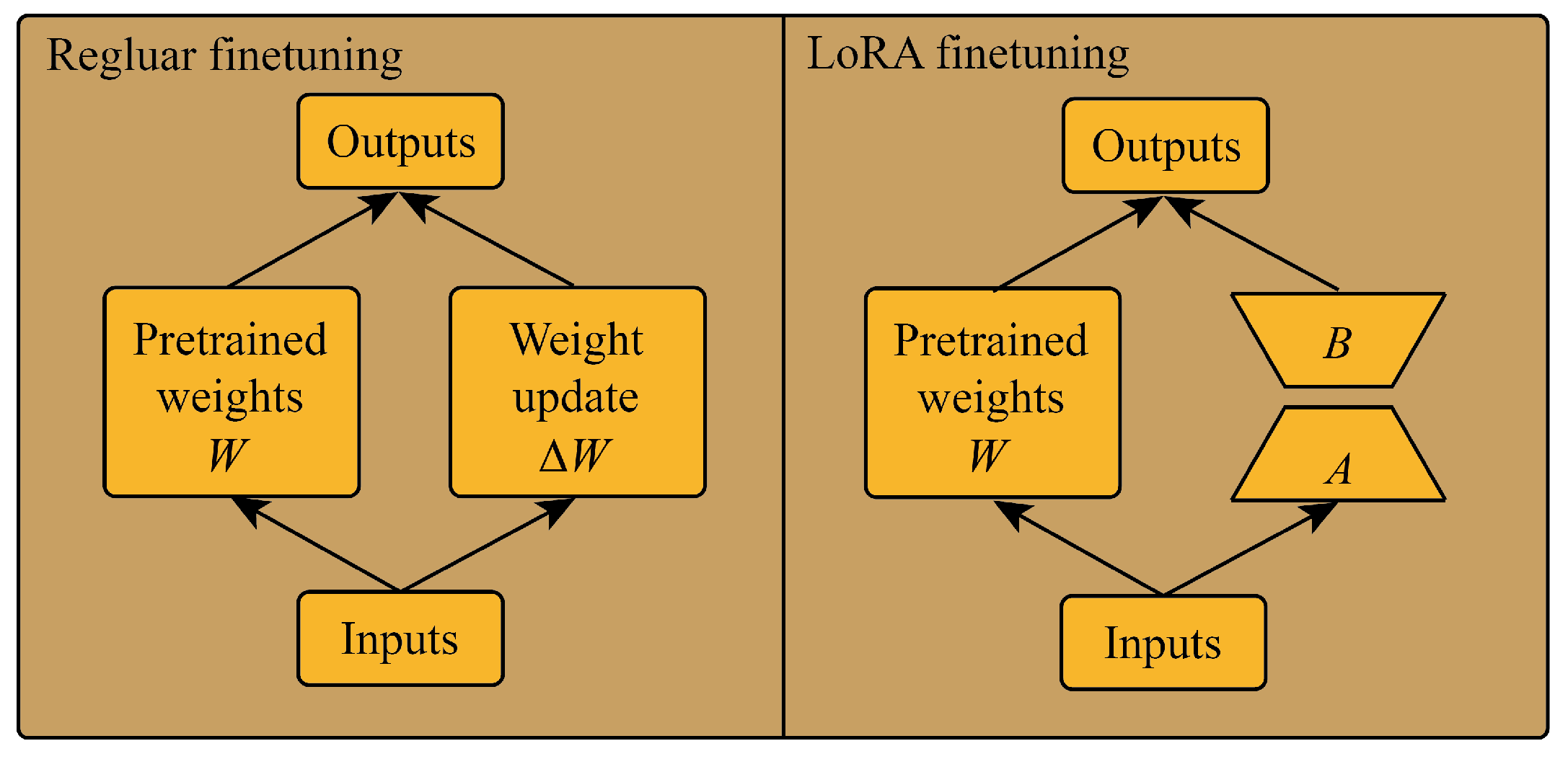
In order to enable the GPT2 model to mine the temporal correlation of historical traffic information, this paper uses a Low-Rank Adaptation (LoRA) [40] method to fine-tune. The implementation principle of LoRA is to freeze the pre-trained model weights and inject the trainable rank decomposition matrix into each weight in the transformer layer as shown in Figure 4.
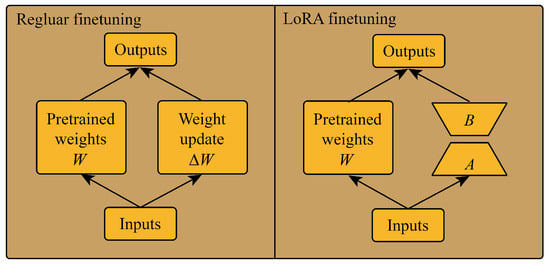
Figure 4.
Regular fine-tuning and LoRA fine-tuning.
Assuming that the update of the weights also has a lower “intrinsic rank” during the adaptation process, for a pre-trained weight matrix , we represent its updates through low rank decomposition:
where , , and . During the training process, 0 is frozen and does not receive gradient updates, while A and B contain trainable parameters.
3.3. Regression and Model Training
After obtaining the deeply hidden features through the dual-stream cross structure, the final prediction values are obtained through the regression module composed of a linear layer. The specific calculation process is as follows:
where is the final prediction value. is the weights of the linear layer.
In order to train the optimal parameters of the above model, the optimizer used for iteration is the Adam algorithm, and the loss function uses the root mean square error, which is calculated as follows:
where indicates the time size of each training batch, indicates the prediction value, and indicates the true value.
4. Experimental Analysis
The entire simulation experiment was completed on a computer with NVIDIA GeForce RTX 3090 (Nvidia, Santa Clara, CA, USA), and the model was built using the Pytorch 2.0.1 open source framework.
Two public data sets in PeMS are used for simulation in this paper [20]. PeMSD4—this data set contains 307 sensor network data for 59 days in the San Francisco Bay Area. PeMSD8—this data set contains 170 sensor network data in the SAN Bernardino area, which were collected over a period of 61 days. In this paper, the data of the last 12 days of the above two data sets are used as the test set, and all the remaining data are used as the training set.
4.1. Experimental Parameter Settings
Through several training test experiments, our model parameters with the best performance were selected, setting them as follows: (1) The length of input matrix is 60 min, and the length of the prediction horizon is 60 min. Since the interval between adjacent temporal points is 5 min, . (2) In the AGFormer module, the number of the head , and the number of the layer is 2. In the GPT2+LoRA module, the size of the rank , and the number of the layer is 6. (3) The batch size is 32, and the learning rate is 1 × .
In order to prove the superiority of the model we designed, we use the advanced seven baseline model based on the depth study to compare, which respectively are the LSTM, STGCN [19], ASTGCN [20], STSGCN [23], STFGNN [33], STTNs [25], and STGNCDE [31]. In addition, the LSTM model adopts a five-layer structure. The parameter structure of the other baseline models is set as described in the references.
4.2. Comparison of Prediction Performance
First, the prediction accuracy of each prediction model is compared. The mean absolute error (MAE), root mean square error (RMSE), and mean absolute percentage error (MAPE) are used as evaluation metrics:
where is the number of channels in the time dimension of the test set, and and are the predicted and true values. In general, the lower the , and , the higher the accuracy of the model.
Table 1 shows MAE, RMSE and MAPE using different prediction models on the two data sets. It can be seen that LSTM has the largest error because it can only mine the time dependence of historical information, and cannot mine the space dependence. STSGCN and STFGNN can simultaneously mine the time and space dependence of historical information, so STGCN and ASTGCN have smaller errors. STTNs and STGNCDE both model the space–time dependence through a new paradigm, so the error is smaller. Our model has the lowest MAE, RMSE and MAPE, indicating that the prediction accuracy of this method is better than other baseline models.

Table 1.
Three error indicators of different prediction models on two data sets.
To verify the accuracy of our model over time and space as a whole, the Pearson coefficient and Spearman coefficient are selected as the evaluation indexes of all prediction models. The Pearson coefficient measures the strength and direction of the linear relationship between two variables. Its value range is between −1 and 1: when it approaches 1, it indicates a strong positive correlation between variables; when it approaches −1, it indicates a strong negative correlation between variables; and when it approaches 0, it indicates that there is no linear correlation between variables. The specific calculation formula is:
The Spearman coefficient is a non-parametric statistical indicator used to measure the monotonic relationship between two variables. The Spearman coefficient ranges from −1 to 1, similar to the Pearson correlation coefficient. When it approaches 1, it indicates a strong positive correlation between variables; when it approaches −1, it indicates a strong negative correlation between variables; and when it approaches 0, it indicates that there is no monotonic relationship between variables. The specific calculation formula is:
Table 2 shows the results of the Pearson correlation coefficient and Spearman correlation coefficient of the eight forecasting models. It can be seen that the two correlation coefficients of our model are closer to 1 than those of the other forecasting models, which means that in terms of time as a whole, the prediction accuracy of the period is the best.
Table 2.
Correlation coefficient of different prediction models on two data sets.
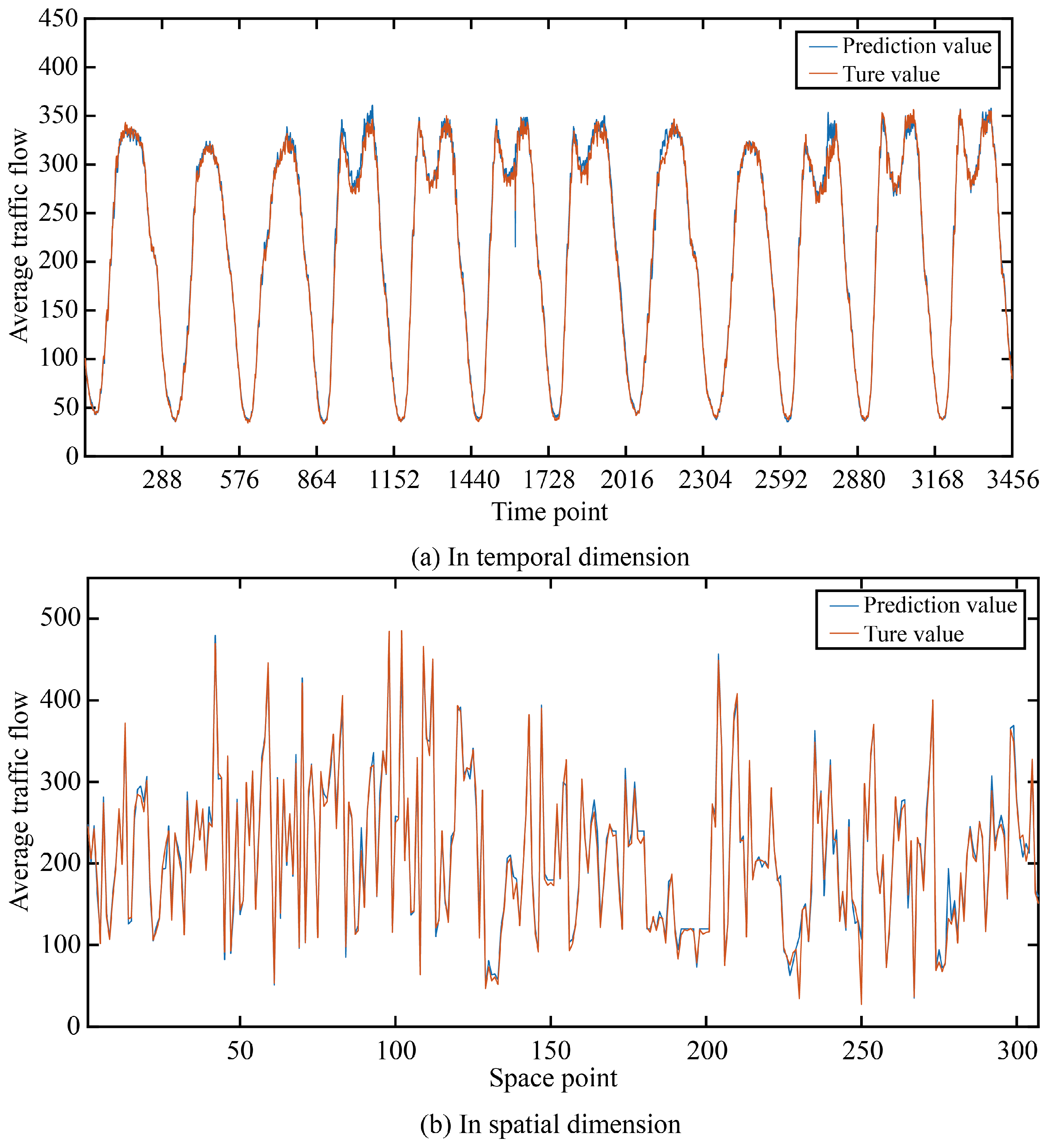
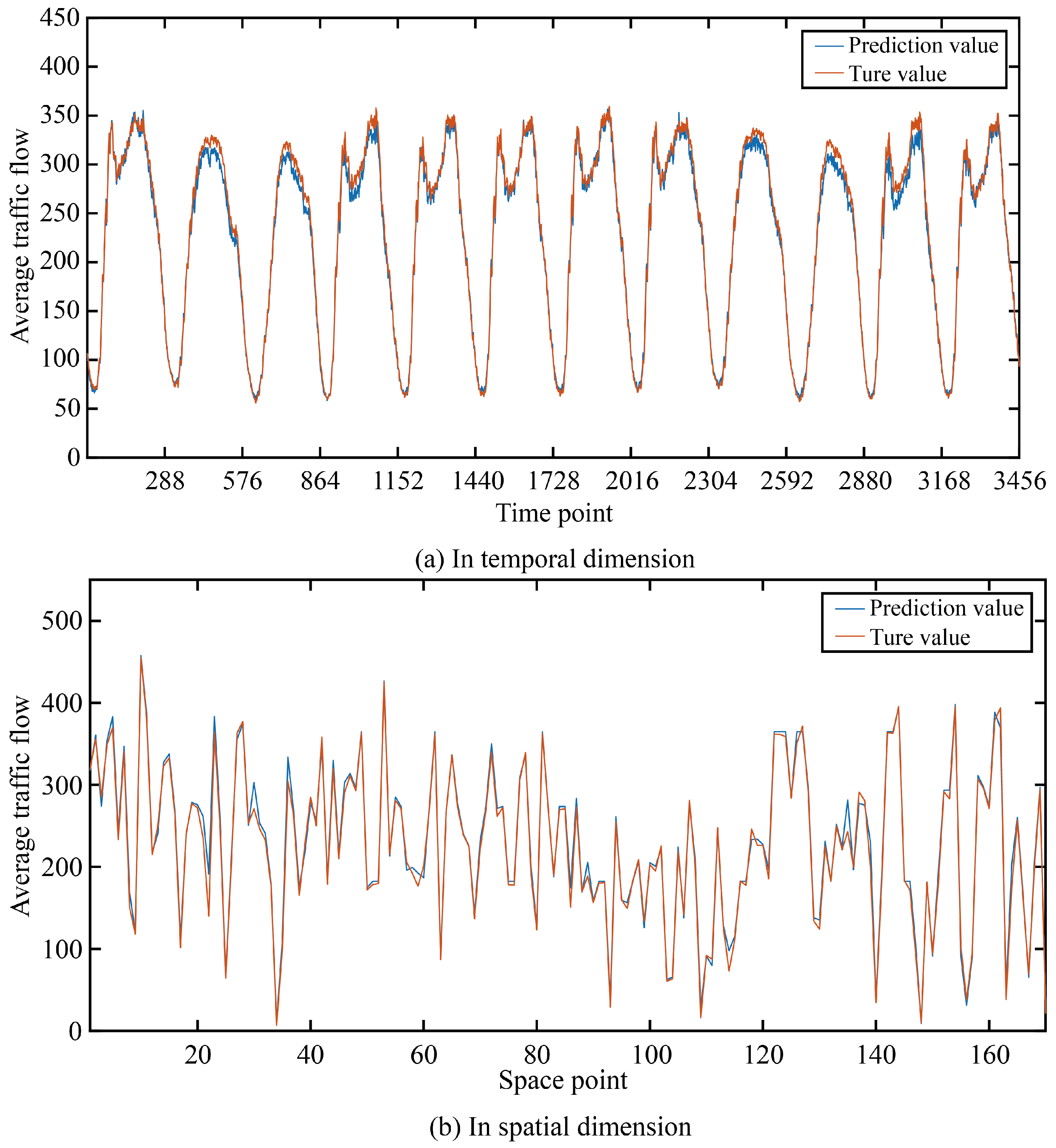
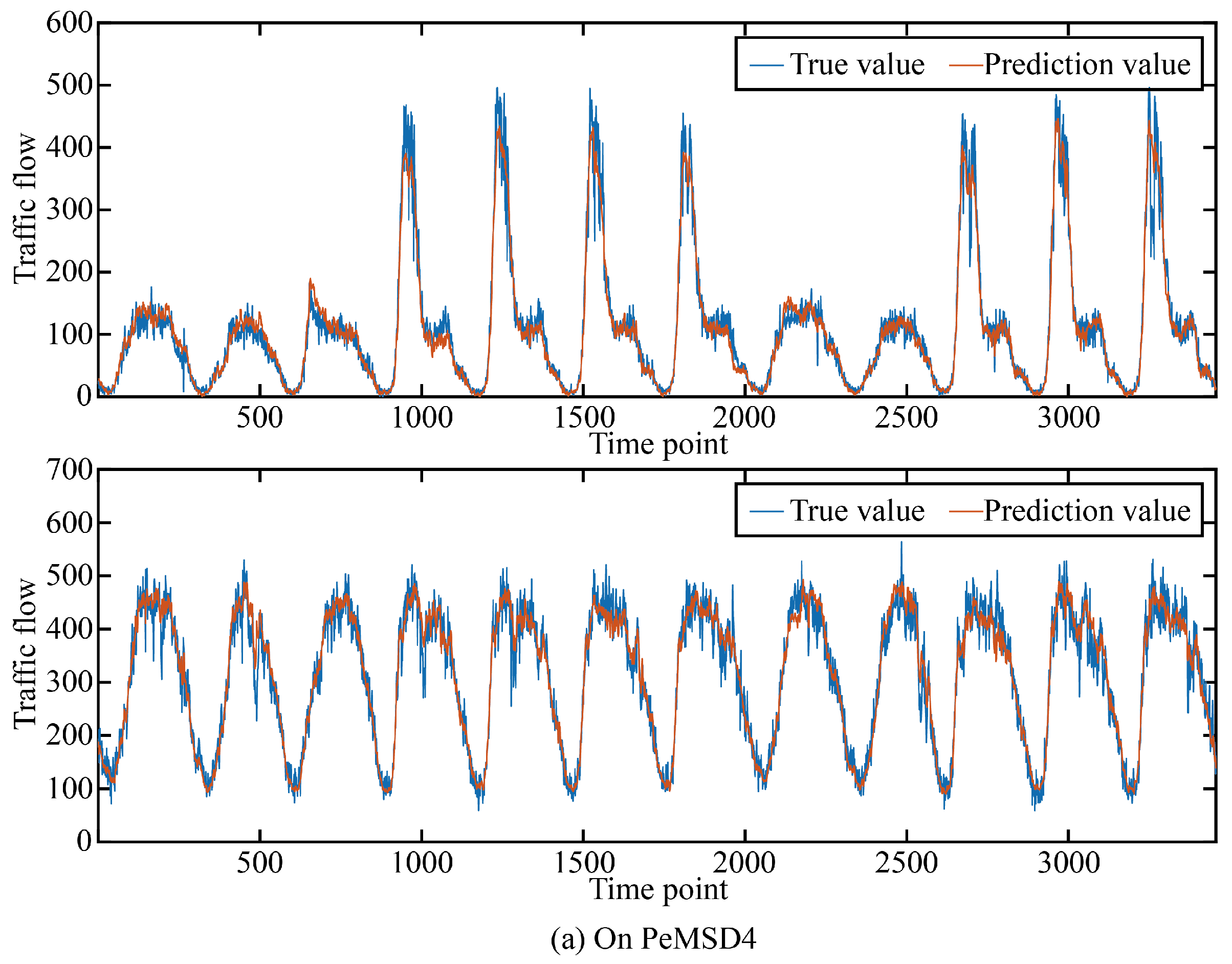
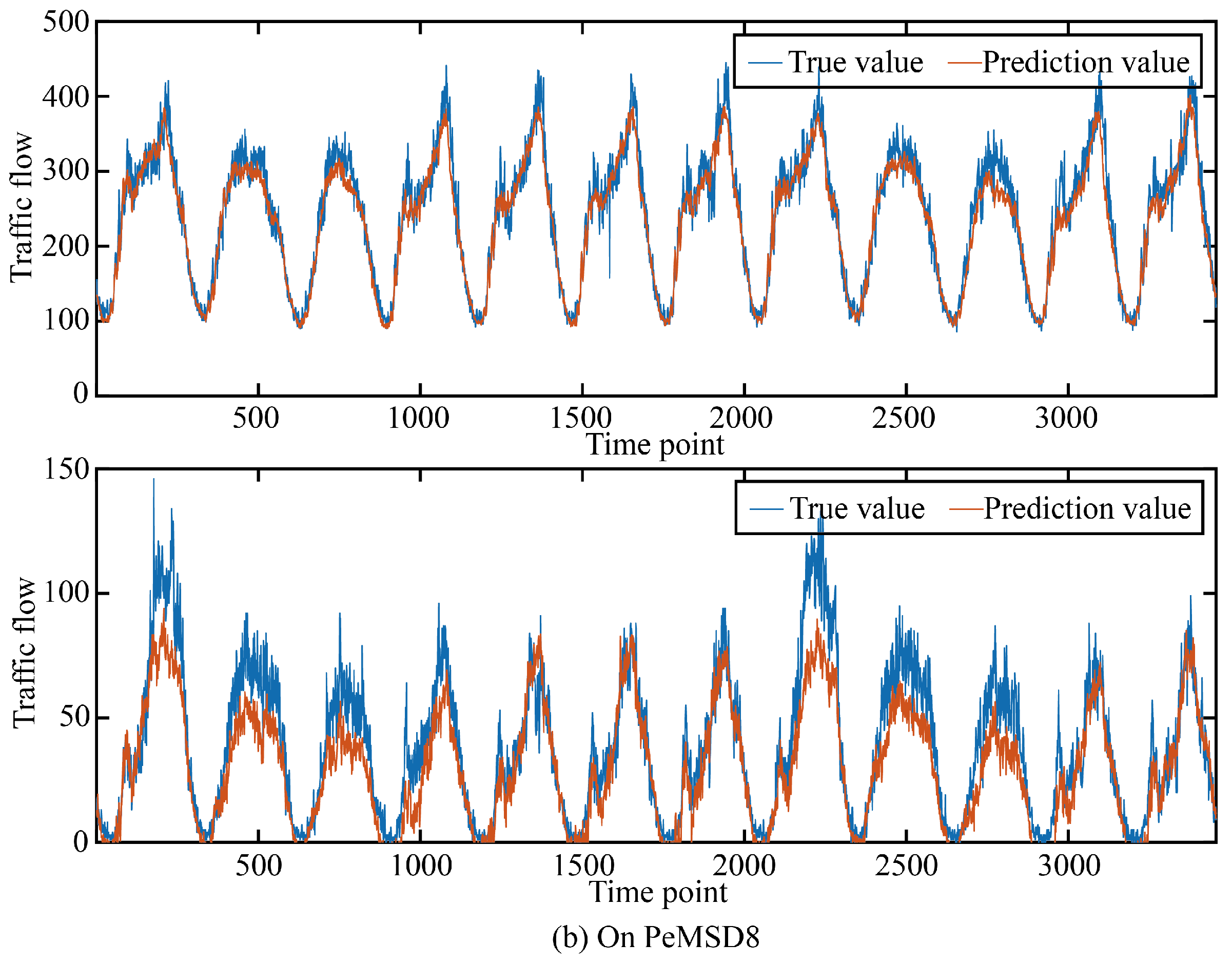
In order to more intuitively show the prediction accuracy of our model in the time dimension and space dimension, we visualized the real and predicted values on the two data sets as shown in Figure 5 and Figure 6.
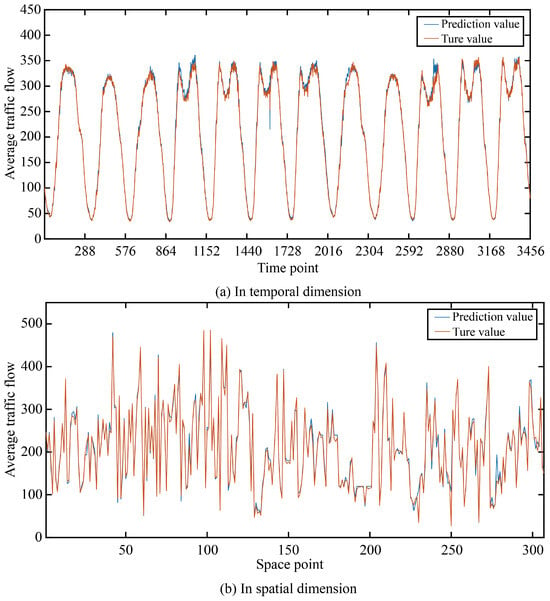
Figure 5.
The true value and prediction value on PeMSD4.
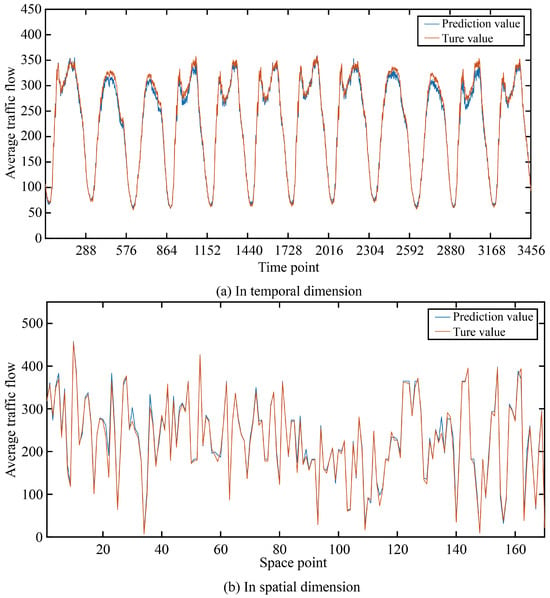
Figure 6.
The true value and prediction value on PeMSD8.
It can be seen that in the two data sets, the real value and the predicted value are very similar in both the time dimension and space dimension, and it can be seen that the accuracy at time points or space points with large average traffic flow is smaller than that at time points or space points with small average traffic flow.
4.3. Ablation Experiment
There are two key modules in our model that affect the predictive performance of the model, namely, the prompt engineering module and dual-stream structure.
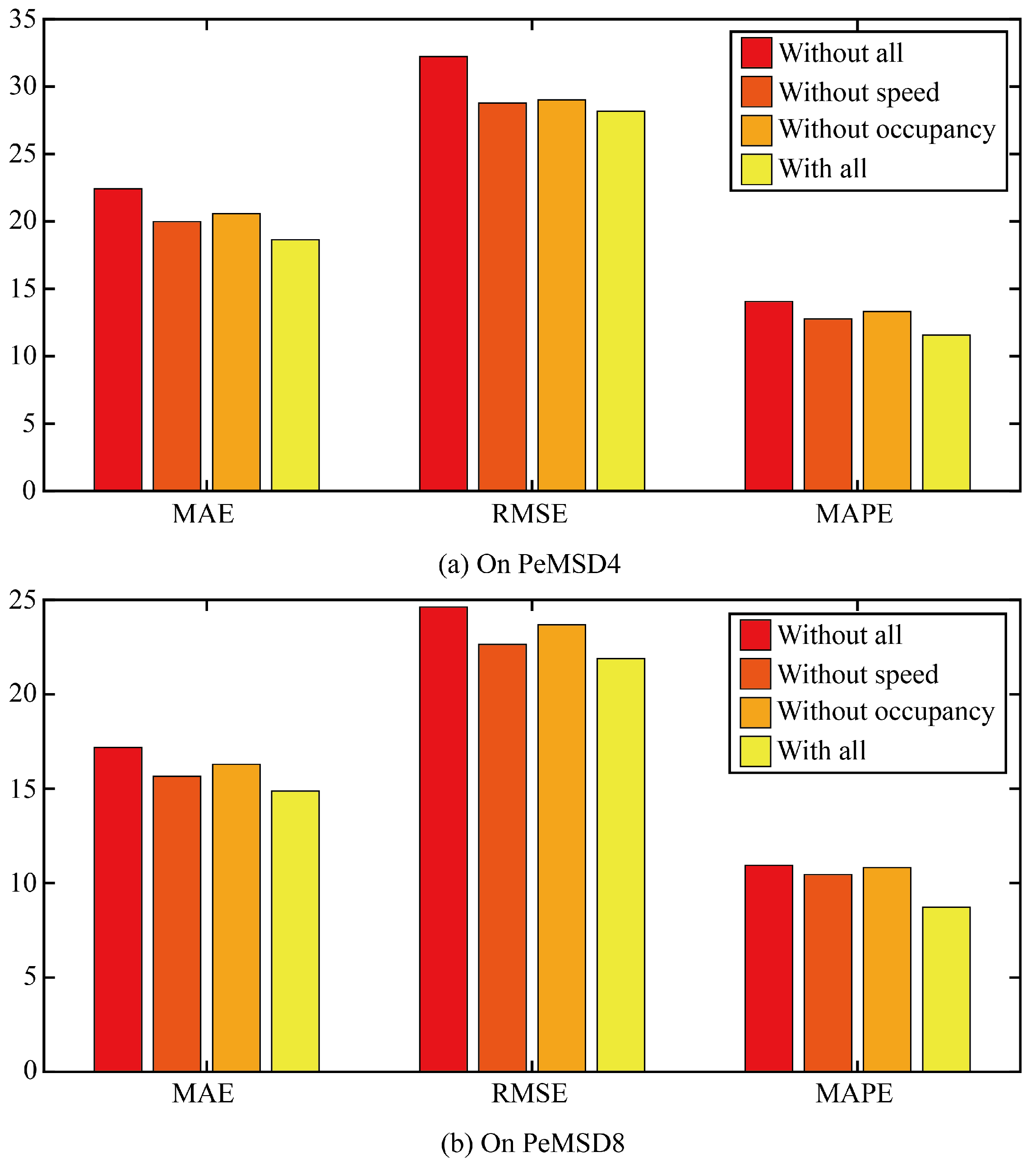
Firstly, ablation experiments are conducted to verify the impact of the tip engineering module on the performance of the prediction model. Three comparison models are designed. The first ablation model is based on the original model to remove all the suggestive features. The second ablation model is based on the original model to remove the suggestive features provided by the traffic speed. The third ablation model is based on the original model to remove the prompt features provided by the traffic occupancy.
The three error results of the three ablation models and the original model are shown in Figure 7. It can be seen that any ablation model can increase the error of the model, indicating that the prompt features of traffic speed and traffic occupancy can increase the prediction accuracy of the model, and the error of removing the traffic speed model is smaller than that of removing the traffic occupancy model. The effect of traffic occupancy on traffic flow is greater than that of traffic speed on traffic flow.
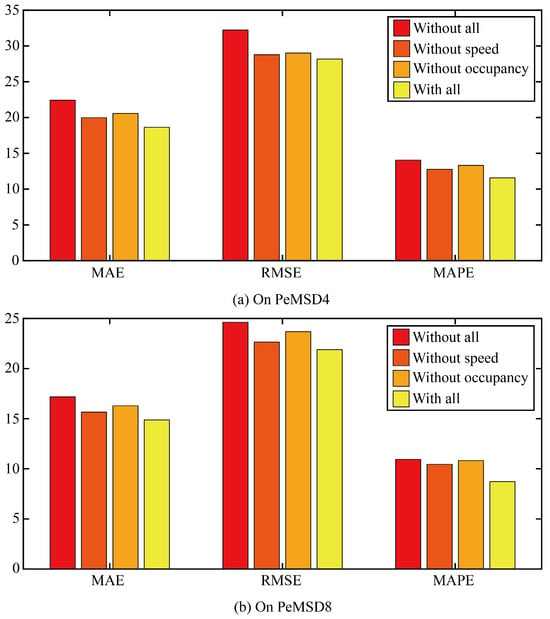
Figure 7.
The three error results of the three ablation models and the original model.
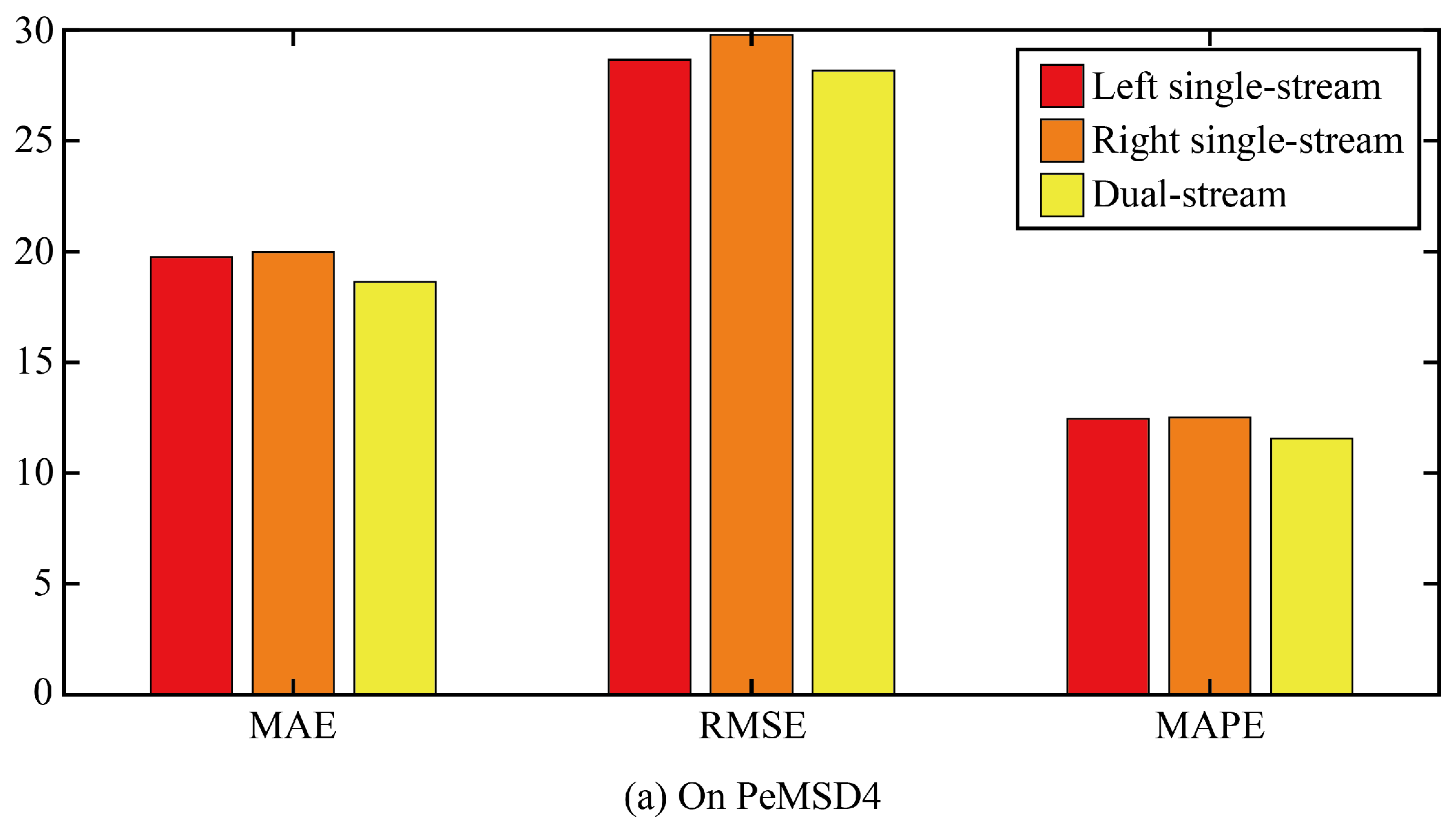
Then, this paper verifies the role of the dual-stream structure through ablation experiments. Two comparison models are designed. In the first ablation model, only the single-stream structure on the left of the original model was retained, that is, the spatial correlation was extracted by AGFomer and then the temporal correlation was extracted by GPT2. The second ablation model only retained the single-stream structure on the right of the original model, that is, GPT2 was first used to extract the temporal correlation, and then AGFomer was used to extract the spatial correlation.
The three error results of the three ablation models and the original model are shown in Figure 8. It can be seen that any ablation model can increase the error of the model, which indicates that the dual-stream structure is superior to the single-steam structure in improving the accuracy of the prediction model, and the error similarity of the two ablation models is relatively high, which indicates that the extraction order of the temporal correlation and spatial correlation has little influence on the prediction accuracy of the model.
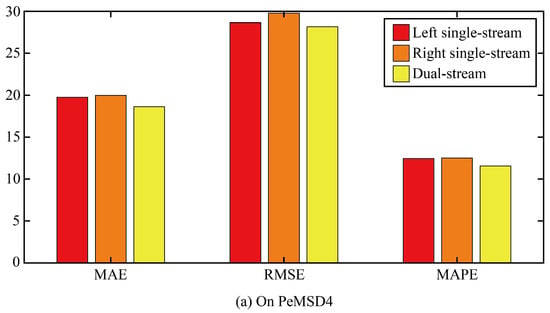
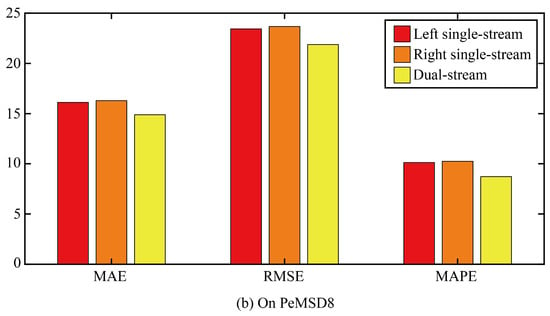
Figure 8.
The true value and prediction value on different space points.
4.4. Real Case Analysis
In this section, in order to verify the validity of our model more directly, we analyze the error of the real value and the calculated value from the aspect of the case study. We randomly select two spatial points from two data sets and visualize their predicted and true values as shown in Figure 9. We randomly select two space points from two data sets and visualize their predicted value and true value as shown in Figure 9. It can be seen that the predicted value of our model still maintains a small error under different conditions, but the error will be slightly larger when the fluctuation is large.
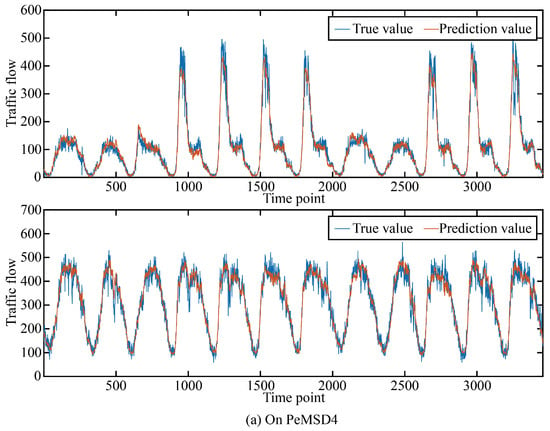
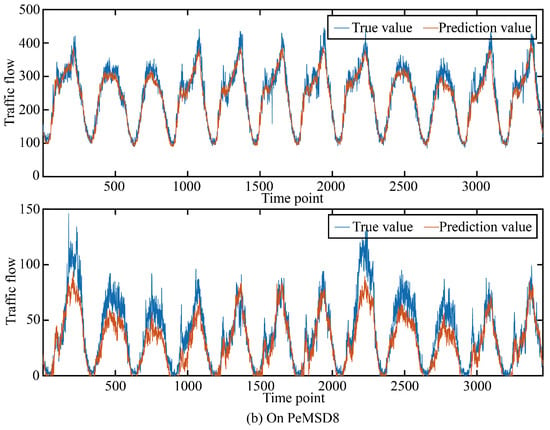
Figure 9.
The visualization of real cases.
5. Conclusions
In this paper, a dual-stream cross AGFormer-GPT network with prompt engineering is proposed for traffic flow prediction, which integrates traffic occupancy and traffic speed as prompt features into traffic flow through the form of cross-attention, and uses the dual-stream cross structure to uniquely mine spatial and temporal correlation information, effectively capturing the complex dynamics of traffic patterns. In terms of three types of errors, our model is decreased by 0.57, 2.94, and 1.21% compared to the most accurate comparison model on the PeMS04 data set, and by 0.58, 2.93, and 1.20% on the PeMS08 data set. In addition, we verify the importance of key modules through ablation experiments.
Author Contributions
Conceptualization, Y.S. (Yu Sun), Y.S. (Yajing Shi), Z.Z. and L.Q.; methodology, Y.S. (Yu Sun), Z.Z. and L.Q.; software, Y.S. (Yu Sun) and K.J.; validation, Y.S. (Yu Sun), Y.S. (Yajing Shi) and K.J.; formal analysis, Y.S. (Yu Sun) and Y.S. (Yajing Shi); investigation, Y.S. (Yu Sun), Y.S. (Yajing Shi) and K.J.; resources, Y.S. (Yu Sun), Y.S. (Yajing Shi), Z.Z. and L.Q.; data curation, Y.S. (Yu Sun) and Y.S. (Yajing Shi); writing—original draft preparation, Y.S. (Yu Sun) and Y.S. (Yajing Shi); writing—review and editing, Y.S. (Yu Sun), K.J., Z.Z. and L.Q.; visualization, Y.S. (Yu Sun), Y.S. (Yajing Shi) and K.J.; supervision, Y.S. (Yu Sun), Z.Z. and L.Q.; project administration, Y.S. (Yu Sun), Z.Z. and L.Q. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding. The APC was funded by the authors.
Data Availability Statement
Data set download URL: https://gitcode.com/wanhuaiyu/ASTGCN/tree/master/data.
Acknowledgments
We would like to express our sincere gratitude to Ling Yu, Cong-Xiang Sun, and Wen-Han Zhang for their support in providing equipment and computational resources for this research. We also thank the members of the Key Laboratory of Communication and Information Systems for their helpful discussions and suggestions throughout the research process. Additionally, we acknowledge all the anonymous supporters who have contributed to this work in various ways.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Xu, T.; Han, G.; Qi, X.; Du, J.; Lin, C.; Shu, L. A Hybrid machine learning model for demand prediction of edge-computing-based bike-sharing system using internet of things. IEEE Internet Things J. 2020, 7, 7345–7356. [Google Scholar] [CrossRef]
- Lv, Z.; Li, J.; Dong, C.; Xu, Z. DeepSTF: A deep spatial–temporal forecast model of taxi flow. Comput. J. 2021, 66, 565–580. [Google Scholar] [CrossRef]
- Zambrano-Martinez, J.L.; Calafate, C.T.; Soler, D.; Cano, J.-C.; Manzoni, P. Modeling and characterization of traffic flows in urban environments. Sensors 2020, 18, 2020. [Google Scholar] [CrossRef] [PubMed]
- Berlotti, M.; Grande, S.; Cavalieri, S. Proposal of a machine learning approach for traffic flow prediction. Sensors 2024, 24, 2348. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Shen, L.; Fan, W. A TSENet model for predicting cellular network traffic. Sensors 2024, 24, 1713. [Google Scholar] [CrossRef]
- Lv, Y.; Duan, Y.; Kang, W.; Li, Z.; Wang, F.Y. Traffic Flow Prediction With Big Data: A Deep Learning Approach. IEEE Trans. Intell. Transp. Syst. 2015, 16, 865–873. [Google Scholar] [CrossRef]
- Yang, B.; Sun, S.; Li, J.; Lin, X.; Tian, Y. Traffic flow prediction using LSTM with feature enhancement. Neurocomputing 2018, 332, 320–327. [Google Scholar] [CrossRef]
- Xu, H.; Jiang, C. Deep belief network-based support vector regression method for traffic flow forecasting. Neural Comput. Appl. 2020, 32, 2027–2036. [Google Scholar] [CrossRef]
- Wu, Y.; Tan, H.; Qin, L.; Ran, B.; Jiang, Z. A hybrid deep learning based traffic flow prediction method and its understanding. Transportation Research Part C Emerging Technologies. Transp. Res. Part Emerg. Technol. 2018, 90, 166–180. [Google Scholar] [CrossRef]
- Yang, G.; Wang, Y.; Yu, H.; Ren, Y.; Xie, J. Short-term traffic state prediction based on the spatiotemporal features of critical road sections. Sensors 2018, 18, 2287. [Google Scholar] [CrossRef]
- Zhang, W.; Yu, Y.; Qi, Y.; Shu, F.; Wang, Y. Short-term traffic flow prediction based on spatio-temporal analysis and CNN deep learning. Transp. Transp. Sci. 2019, 15, 1688–1711. [Google Scholar] [CrossRef]
- Xia, D.; Zhang, M.; Yan, X.; Bai, Y.; Zheng, Y.; Li, Y.; Li, H. A distributed WND-LSTM model on MapReduce for short-term traffic flow prediction. Neural Comput. Appl. 2021, 33, 2393–2410. [Google Scholar] [CrossRef]
- Zhao, L.; Wang, Q.; Jin, B.; Ye, C. Short-Term Traffic Flow Intensity Prediction Based on CHS-LSTM. Arab. J. Sci. Eng. 2020, 45, 10845–10857. [Google Scholar] [CrossRef]
- Zhang, Z.; Jiao, X. A deep network with analogous self-attention for short-term traffic flow prediction. IET Intell. Transp. Syst. 2021, 15, 902–915. [Google Scholar] [CrossRef]
- Fang, W.; Zhuo, W.; Yan, J.; Song, Y.; Jiang, D.; Zhou, T. Attention meets long short-term memory: A deep learning network for traffic flow forecasting. Phys. A 2022, 587, 126458. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, Q. Short-Term Traffic Flow Prediction Based on LSTM-XGBoost Combination Model. Comput. Model. Eng. Sci. 2020, 125, 95–109. [Google Scholar] [CrossRef]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering. Adv. Neural Inf. Process. Syst. 2016, 29, 3844–3852. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph Attention Networks. ICLR 2018, 1050, 10-48550. [Google Scholar]
- Yu, B.; Yin, H.; Zhu, Z. Spatio-temporal graph convolutional networks: A deep learning framework for traffic forecasting. arXiv 2018, arXiv:1709.04875. [Google Scholar]
- Guo, S.; Lin, Y.; Feng, N.; Song, C.; Wan, H. Attention Based Spatial-Temporal Graph Convolutional Networks for Traffic Flow Forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January 2019; pp. 922–929. [Google Scholar]
- Zhao, L.; Song, Y.; Zhang, C.; Liu, Y.; Wang, P.; Lin, T.; Deng, M.; Li, H. T-GCN: A temporal graph convolutional network for traffic prediction. IEEE Trans. Intell. Transp. Syst. 2019, 21, 3848–3858. [Google Scholar] [CrossRef]
- Zheng, C.; Fan, X.; Wang, C.; Qi, J. GMAN: A Graph Multi-Attention Network for Traffic Prediction. Assoc. Adv. Artif. Intell. 2020, 34, 1234–1241. [Google Scholar] [CrossRef]
- Song, C.; Lin, Y.; Guo, S.; Wan, H. Spatial-Temporal Synchronous Graph Convolutional Networks: A New Framework for Spatial-Temporal Network Data Forecasting. Assoc. Adv. Artif. Intell. 2020, 34, 914–921. [Google Scholar] [CrossRef]
- Li, M.; Zhu, Z. Spatial-Temporal Fusion Graph Neural Networks for Traffic Flow Forecasting. Assoc. Adv. Artif. Intell. 2021, 35, 4189–4196. [Google Scholar] [CrossRef]
- Xu, M.; Dai, W.; Liu, C.; Gao, X.; Lin, W.; Qi, G.J.; Xiong, H. Spatial-temporal transformer networks for traffic flow forecasting. arXiv 2020, arXiv:2001.02908. [Google Scholar]
- Wang, J.; Wang, W.; Liu, X.; Yu, W.; Li, X.; Sun, P. Traffic prediction based on auto spatiotemporal Multi-graph Adversarial Neural Network. Phys. A 2021, 11, 126736. [Google Scholar] [CrossRef]
- Yu, K.; Qin, X.; Jia, Z.; Du, Y.; Lin, M. Cross-Attention Fusion Based Spatial-Temporal Multi-Graph Convolutional Network for Traffic Flow Prediction. Sensors 2021, 21, 8468. [Google Scholar] [CrossRef]
- Zhang, X.; Xu, Y.; Shao, Y. Forecasting traffic flow with spatial–temporal convolutional graph attention networks. Neural Comput. Appl. 2022, 34, 15457–15479. [Google Scholar] [CrossRef]
- Li, Y.; Zhao, W.; Fan, H. A Spatio-Temporal Graph Neural Network Approach for Traffic Flow Prediction. Mathematics 2022, 10, 1754. [Google Scholar] [CrossRef]
- Hu, N.; Zhang, D.; Xie, K.; Liang, W.; Diao, C.; Li, K.-C. Multi-range bidirectional mask graph convolution based GRU networks for traffic prediction. J. Syst. Archit. 2022, 133, 102775. [Google Scholar] [CrossRef]
- Choi, J.; Choi, H.; Hwang, J.; Park, N. Graph Neural Controlled Differential Equations for Traffic Forecasting. Assoc. Adv. Artif. Intell. 2022, 36, 6367–6374. [Google Scholar] [CrossRef]
- Ye, X.; Fang, S.; Sun, F.; Zhang, C.; Xiang, S. Meta Graph Transformer: A Novel Framework for Spatial—Temporal Traffic Prediction. Neurocomputing 2022, 491, 544–563. [Google Scholar] [CrossRef]
- Li, H.; Zhang, S.; Li, X.; Su, L.; Huang, H.; Jin, D.; Chen, L.; Huang, J.; Yoo, J. DetectorNet: Transformer-enhanced Spatial Temporal Graph Neural Network for Traffic Prediction. In Proceedings of the 29th International Conference on Advances in Geographic Information Systems, Beijing, China, 2–5 November 2021; pp. 1–4. [Google Scholar]
- Liu, Q.; Li, J.; Lu, Z. ST-Tran: Spatial-Temporal Transformer for Cellular Traffic Prediction. IEEE Commun. Lett. Publ. IEEE Commun. Soc. 2021, 25, 3325–3329. [Google Scholar] [CrossRef]
- Jin, D.; Shi, J.; Wang, R.; Li, Y.; Huang, Y.; Yang, Y.B. Trafformer: Unify Time and Space in Traffc Prediction. Assoc. Adv. Artif. Intell. 2023, 37, 8114–8122. [Google Scholar] [CrossRef]
- Yu, X.; Bao, Y.; Shi, Q. STHSGCN: Spatial-temporal heterogeneous and synchronous graph convolution network for traffic flow prediction. Heliyon 2023, 9, 9. [Google Scholar] [CrossRef]
- Chen, J.; Zheng, L.; Hu, Y.; Wang, W.; Zhang, H.; Hu, X. Traffic flow matrix-based graph neural network with attention mechanism for traffic flow prediction. Inf. Fusion 2024, 104, 102146. [Google Scholar] [CrossRef]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. Openai Blog 2019, 1, 9. [Google Scholar]
- Jin, M.; Wang, S.; Ma, L.; Chu, Z.; Zhang, J.Y.; Shi, X.; Chen, P.; Liang, Y.; Li, Y.; Pan, S.; et al. Time-LLM: Time Series Forecasting by Reprogramming Large Language Models. arXiv 2023, arXiv:2310.01728. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. LoRA: Low-Rank Adaptation of Large Language Models. arXiv 2022, arXiv:2106.09685. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).