Abstract
Bonding distance is defined by the projected distance on a substrate plane between two solder points of a bonding wire, which can directly affect the morphology of the bonding wire and the performance between internal components of the chip. For the inspection of the bonding distance, it is necessary to accurately recognize gold wires and solder points within the complex imagery of the chip. However, bonding wires at arbitrary angles and small-sized solder points are densely distributed across the complex background of bonding images. These characteristics pose challenges for conventional image detection and deep learning methods to effectively recognize and measure the bonding distances. In this paper, we present a novel method to measure bonding distance using a hierarchical measurement structure. First, we employ an image acquisition device to capture surface images of integrated circuits and use multi-layer convolution to coarsely locate the bonding region and remove redundant background. Second, we apply a multi-branch wire bonding inspection network for detecting bonding spots and segmenting gold wire. This network includes a fine location branch that utilizes low-level features to enhance detection accuracy for small bonding spots and a gold wire segmentation branch that incorporates an edge branch to effectively extract edge information. Finally, we use the bonding distance measurement module to develop four types of gold wire distribution models for bonding spot matching. Together, these modules create a fully automated method for measuring bonding distances in integrated circuits. The effectiveness of the proposed modules and overall framework has been validated through comprehensive experiments.
1. Introduction
In the microelectronics industry, wire bonding forms an essential electrical connection in integrated circuits. The primary factors affecting bonding performance include wire defects, weak bonding spots, and abnormal gold wire morphology. The geometry of gold wires influences high-frequency communication performance between chips. Therefore, in practical engineering, it is necessary to ensure that both the gold wires and bonding points are free from anomalies. Additionally, the geometry of the gold wires needs to be inspected, with bonding distance being a crucial metric for assessing gold wire geometry. As shown in Figure 1, the bonding distance refers to the horizontal distance from the bond spot to the lead of the package substrate during the wire bonding process. This is the actual span of the gold wire from the chip pad to the substrate pin, not including the bent or height portion of the gold wire. In wire bonding inspection, the bonding distance is one of the most important indices. Abnormal distance, which is a typical defect, can lead to a short circuit or broken circuit. Specifically, if the bonding distance exceeds the value intended in the design of the circuit, the bonding spot will be beyond the circuit boundary, resulting in a broken circuit. Conversely, if the bonding distance is too short, the adjacent gold wires may come into contact and cause a short circuit. Therefore, the measurement of a wire bonding distance is very essential in ensuring the production quality of integrated circuits. Nevertheless, existing key distance measurement methods have some limitations. First of all, gold wires are small in size and complex in structure. In addition, given the complex background of wire bondings, it is difficult to extract them and measure bonding distances throughout an integrated circuit.

Figure 1.
Example of an integrated circuit. (a) Zoomed-in view of wire bonding. The bonding distance is the projected distance between the centers of two bonding spots. (b) Image of an integrated circuit, with a resolution of . (c) Zoomed-in views of a bonding spot and a gold wire.
Methods currently in use for measuring and inspecting bonding distance include microscopy-based methods, two-dimensional (2D) image-based methods [1,2], and three-dimensional (3D) data-based methods [3]. Microscopy-based methods involve manual inspection of wire bondings one by one, which is a complex operation that requires a specialist worker. The second type of method involves inspecting the wire bonding based on a 2D image [1,2]. However, these approaches were designed for detecting wire bonding defects, such as breakage, loss, shifting, or sagging of the bonding, rather than for accurate bonding distance measurement. Although several state-of-the-art measurement methods [4,5] based on 2D image data have achieved good results recently in brake pad measurement and thread geometric error measurement, owing to the complex structure of gold wire bonding, simple dimensional measurement methods based on 2D images cannot be directly used for bonding distance measurement. The third type of approach involves measuring the bonding distance based on 3D point cloud data of the integrated circuit chips. Nonetheless, it is difficult to efficiently collect a 3D point cloud for gold wire bonding, as existing 3D scanning equipment cannot fully capture the necessary data for fine gold wire.
According to the above analysis, we believe that bonding distance measurement based on 2D images is practicable. In recent years, computer vision techniques [6,7,8,9], which represent an important research area in deep learning [10,11], have developed rapidly. Many computer-vision-based methods have been applied in various fields, including aero-engine blade defect detection [12], steel plate defect inspection [13], and visual measurements [14]. These methods all apply a fusion scheme to enhance feature learning ability and achieve state-of-the-art performance. Specifically, in wire bonding inspection, learning-based detection methods have achieved outstanding performance in solder spot detection, gold wire inspection, and other inspection tasks [15,16,17]. Therefore, the quality of wire bonding distance measurement could be improved by using learning-based methods to extract features of wire bonding.
However, because of the intricate structure and complex background of wire bonding, it is difficult to apply existing learning-based detection methods to accurately extract wire bonding, which in turn limits the accuracy of wire bonding distance measurements. For instance, the detailed information of small wire bonding objects is easily lost by classical convolutional neural network (CNN) detectors [18,19,20,21,22], as there are many pooling operations. Moreover, larger strides may also lead to information loss for small objects. In addition, a complex and redundant background increases the amount of computation and interferes with object detection.
To address these problems, we design a hierarchical inspection framework for the integrated circuit bonding distance inspection task. The proposed framework contains a multi-branch wire bonding inspection network and a bonding distance measurement module.
First, to remove noise and redundant background from integrated circuit images, we utilize a coarse location to extract the bonding region. Then, we develop the multi-branch wire bonding inspection network for bonding spot detection and gold wire segmentation on the extracted gold wire bonding regions of the images. Specifically, we use a learning-based fine location branch with a feature extraction module, a spatial correlation aware module, and a bidirectional feature fusion module. By establishing a feature extraction module based on dense blocks and dilated convolution operations, we can improve the extraction ability of bonding spots. In addition, we establish a spatial correlation aware module to extract high-level semantic information with a self-attention mechanism. As the gold wires and bonding spots have strong spatial correlations, this module can capture correlations among high-level feature entities. Moreover, we take advantage of the semantic information from the parallel segmentation branch to enhance the self-attention feature representation. Additionally, we employ a bidirectional feature extraction module in the fine location branch, which can effectively utilize low-level features to improve detection accuracy for small bonding spots, and a gold wire segmentation branch, including an edge branch, to extract edge information. The edge branch extracts the edge-related features of gold wire bonding via its gated convolution layer (GCL). Finally, we establish four types of gold wire distribution models to achieve bonding spot matching in the bonding distance measurement module (BDMM) with high accuracy. The centers of bonding spots are identified based on fitted circles, as all bonding spots have circular shapes. Therefore, we can confirm the bonding distance according to the identified center coordinates. Overall, the contributions of this study can be summarized as follows.
- We design a hierarchical measurement structure framework based on deep learning from 2D images to measure bonding distances in integrated circuits with high precision.
- We propose a novel multi-branch wire bonding inspection network (MWBINet) for wire bonding locations; each branch in the network provides auxiliary spatial correlation information for the others, which strongly enhances the feature representation, thereby solving the problem of limited target information when detecting very small targets.
- We propose the BDMM to implement bonding spot matching, thus achieving accurate bonding distance measurement.
Our experiments are exclusively based on integrated circuits without bonding point defects. This is due to the fact that the measurement of bonding distance is intended to identify potential short circuits or open circuits, which are vital for assessing the performance of the chip. If defects are present in the bonding points, the chip can be immediately classified as defective, eliminating the need for further measurement of the bond distance.
2. Related Work
2.1. Wire Bonding Inspection
As an essential electrical connection structure, wire bonding needs to be inspected during the production process of integrated circuits. Ko et al. [23] designed a system to measure the position of a wire during a wire bonding pull test, which can test the strength of wire efficiently. But this method is destructive and can only be used for sampling inspection. Feng et al. [1] proposed a method to monitor the quality of wire bonding by analyzing bonding voltage and current signals from an ultrasonic generator. However, these methods require contact and are difficult to operate, making them unsuitable for inspection during assembly-line production. Vision-based detection is an efficient non-contact detection method that has been widely studied with respect to its potential applications in the inspection of wire bonding. Perng et al. [2] proposed a system for wire bonding inspection that uses lighting to suppress the background from being extracted. This system could detect a variety of gold wire bonding defects in integrated circuit chips, such as broken, lost, shifted, or sagging bonding wires. However, this method is not suitable for use with complex wire bonding. Long et al. [15] developed a bonding joint inspection system based on image features and a support vector machine. Chen et al. [16] devised a data-driven method for wire bonding segmentation on X-ray images. In addition, they used CNNs to classify the segmentation results, with results superior to those obtained with traditional machine learning algorithms. Chan et al. [17] proposed a two-stage ball bonding detection method. First, the framework completes most of the ball bonding detection and classification tasks using CNNs and other methods. When the confidence level of the detection is below a certain threshold, experienced workers will perform manual inspection. Xie et al. [3] designed a learning-based algorithm to extract gold wire bonding structures from the an integrated circuit chip point cloud automatically. However, for complex integrated circuit chips, it is extremely difficult to obtain the required point cloud data. Overall, these vision-based detection methods perform well for wire bonding inspection, but they either require high-quality images or can only be adapted to a single scenario, such as bonding spot or gold wire detection. Moreover, these methods are not suitable for measuring bonding distances. To address the above issues, we establish a hierarchical measurement framework, including MWBINet and a BDMM, to simplify the distance measurement into bonding spot detection and gold wire segmentation using a visual detection method based on deep learning.
2.2. Learning-Based Object Detection
With the development of deep learning, object detection based on deep learning has become an important aspect of computer vision research [18,19,20,21,22,24]. CNN detectors, which are the most commonly used learning-based object detection algorithms, aim to find all objects of interest in an image and determine their categories and positions. Based on the steps used for object detection, these detectors can be divided into two main categories: two-stage object detectors and one-stage object detectors. The two-stage detectors use two steps consisting of region proposal and region-wise classification. A representative example of two-stage detectors is the “R-CNN family”, which includes R-CNN [18], Fast R-CNN [19], and Faster R-CNN [20]. The one-stage detector is a popular alternative, owing to its high efficiency and simplicity. The most popular one-stage detector is YOLO [21], which divides the image into many boxes using a grid and predicts bounding boxes for the object of interest in these boxes. Many improved methods have been developed based on the YOLO detector, such as YOLOv7 [25] and YOLOv8 [26], which have achieved good performance for object detection.
2.3. Learning-Based Semantic Segmentation
Similar to the learning-based object detection methods described above, state-of-the-art semantic segmentation approaches [10,11,27] are mainly based on CNNs. In an initial attempt to achieve semantic segmentation using CNNs, Jonathan Long [10] modified the contemporary classification network to the fully convolution network (FCN) for the semantic segmentation task. FCN performs end-to-end training and achieves pixel-level classification using intensive predictions. Yet, the segmentation accuracy of FCN is limited owing to the downsampling operation. In addition, FCN ignores potentially useful low-level feature information in previous feature maps. SegNet [28] is an encoder–decoder architecture based on modification of VGG16 [29] for semantic segmentation. This method introduces a maximum pooling index into the decoder, significantly improving the efficiency of segmentation. U-Net [11] introduces a skip connection into the backbone network, enabling the decoder to learn relevant features lost in the encoder by pooling at each stage. More recently, the DeepLab series [27,30,31,32] of algorithms proposed by Google researchers have shown outstanding performance. The DeepLabV1 [30] architecture mainly uses atrous convolution and a fully connected conditional random field (CRF). DeepLabV2 [32] adds atrous spatial pyramid pooling (ASPP), inspired by spatial pyramid pooling [33], using several atrous convolution modules with different rates to enhance the multi-scale recognition capability of the model. DeepLabV3 [31] reduces the resolution of feature maps by reconstructing networks based on DeepLabV2. The CRF module, which has been proved to be ineffective, was removed in DeepLabV3. DeepLabV3+ [27] introduces bilinear interpolation sampling in the decoder module, which improves the image semantic segmentation of the edge part.
3. Method
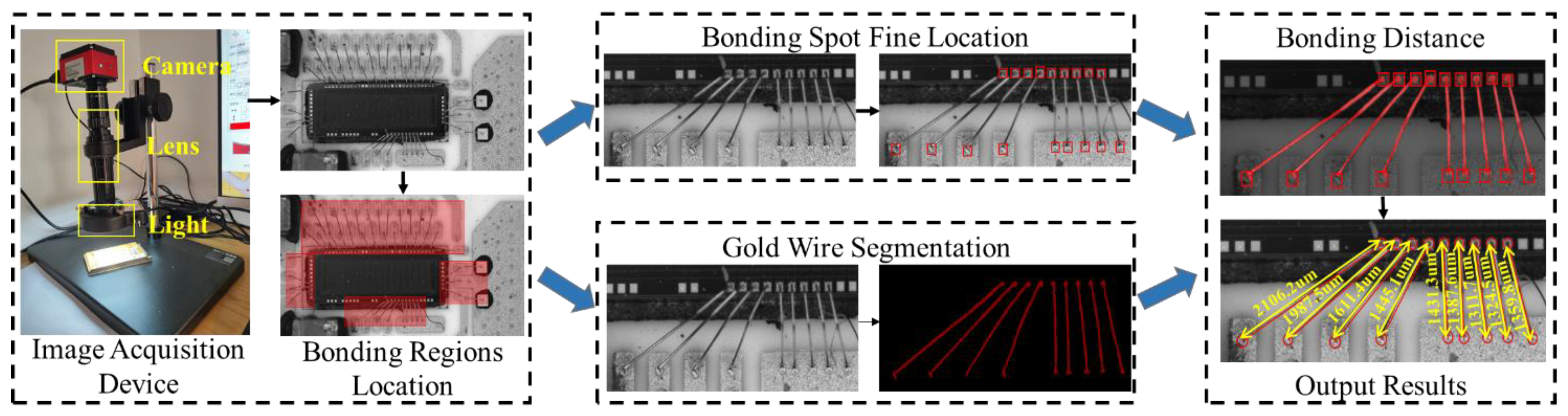
We implement wire bonding distance inspection based on hierarchical measurement structure, as shown in Figure 2. The structure contains an image acquisition device, bonding regions location module, bonding spot fine location module, and gold wire segmentation module.
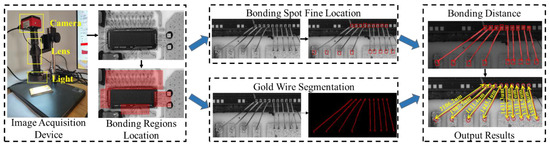
Figure 2.
Overview of our hierarchical measurement structure for the integrated circuit bonding distance inspection task. First, the bonding regions are coarsely located by several convolution layers. Second, the bonding regions are fed into two parallel modules for bonding spot detection and gold wire segmentation. Third, the detected bonding spots are matched using the gold wire segmentation information in the BDMM. Last, the bonding distance is measured by extracting the center of each bonding spot and calculating the distance corresponding to the center coordinates. The output comprises the bonding distances of all wire bondings in the image.
Among them, we design an image acquisition device to capture raw images from the surface of the integrated circuit with high resolution, which is the basic module used to achieve gold wire bonding defect inspection. There are three key components of this device: camera, high-magnification lens, and light, which are in charge of image collection, image zoom, and illumination supplement, respectively. Specifically, the camera model is HK830, manufactured by Jieshixin in Nanjing, China, and the output image resolution is . The model of the high-magnification lens is AO-HK830-5870, is also from Jieshixin, Nanjing, China. The height of the bracket is 355 mm, the focusing range is 65 mm, and the center range is 160 mm. Next, in this section, we first introduce the overall method, followed by a detailed description of the multi-branch wire bonding inspection network and the bonding distance measurement module.
3.1. Overview
As shown in Figure 1, gold wire bonding distance inspection is extremely challenging, as the gold wire is slender and the bonding spot is very small in the high-resolution images, which makes the location of the bonding difficult. In addition, the structure of the wire bonding is complex, which further increases the difficulty of the distance calculation. We design a hierarchical measurement structure that solves these problems.
First, we coarsely locate the bonding regions through several stacked convolutional layers. Since the gold wires on an integrated circuit board are usually clustered rather than discrete, we implement the coarse location to extract the bonding region. Thus, the features of the bonding spot and gold wires are amplified, and the accuracy of detection of the final location of the bonding is improved.
Subsequently, the extracted bonding region images are fed into the MWBINet with its fine location branch and wire segmentation branch to detect bonding spots and segment the gold wire. As the bonding spot is tiny and the gold wire is slender, it is difficult for general object detection methods [26,34,35] to locate them with high accuracy. To address this issue, we utilize spatial correlation information to improve the low positioning accuracy caused by the lack of pixel information. The two branches first extract low-level features via a shared backbone. Then, we separately employ the bidirectional feature fusion module and an edge module to extract the bonding spot and gold wire information. Given the spatial correlations between the bonding spots and gold wires, we utilize the semantic information in the segmentation branch as a semantic embedding to enhance the feature representation of the fine location branch.
Finally, we implement bonding spot center extraction and bonding spot matching for accurate bonding distance measurement.
3.2. Multi-Branch Wire Bonding Inspection Framework
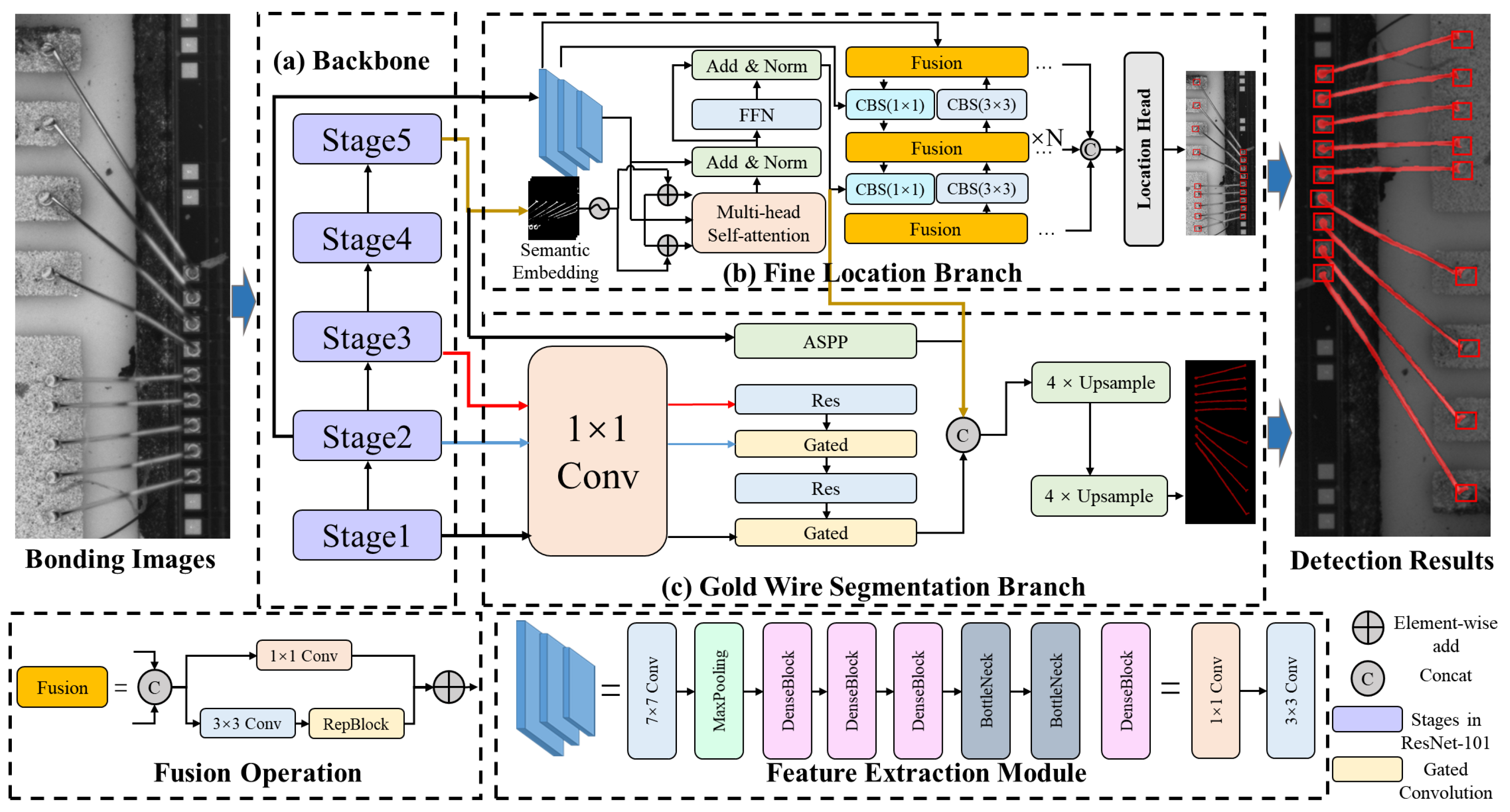
In the hierarchical measurement structure, we apply MWBINet to accomplish the wire bonding location task initially, as shown in Figure 3. The fine location branch and the wire segmentation branch are separately applied to locate the bonding spot and segment the gold wire.
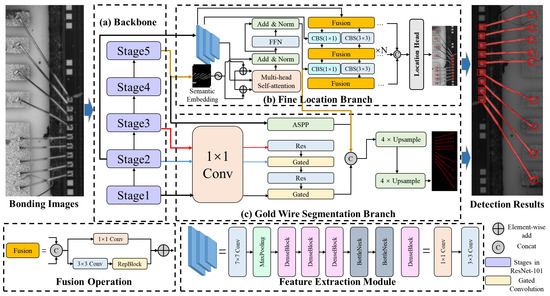
Figure 3.
Structure of MWBINet, containing the fine location branch and the wire segmentation branch. The two branches are used to extract the bonding spot and gold wire information. The fine location branch consists of the feature extraction module, spatial correlation sensing module, and the bidirectional feature fusion module. The gold wire segmentation branch contains an edge module and an ASPP module.
3.2.1. Fine Location Branch
After the process of coarse bonding region localization, the extracted bonding region images are fed into the fine location branch and gold wire segmentation branch for the detection of the bonding spots and gold wire. As shown in Figure 1, all the bonding spots of integrated circuits are of small size, and the gold wire is slender, which means that they provide few features to the location model. Therefore, we design a multi-branch structure to perform localization and segmentation tasks. The set of information obtained by the two branches complements each other, enhancing the feature representation of each branch. Compared with other detection or segmentation models, our structure utilizes the unique spatial relationships between the solder joints and the golden wire. This improves the precision of positioning and segmentation.
The two branches first pass through a shared backbone and then extract the features of the gold wire and solder joint, respectively, on two parallel branches. In the fine location branch, we utilize a feature extraction module, a spatial correlation aware module, and a bidirectional feature fusion module to accomplish bonding spot location.
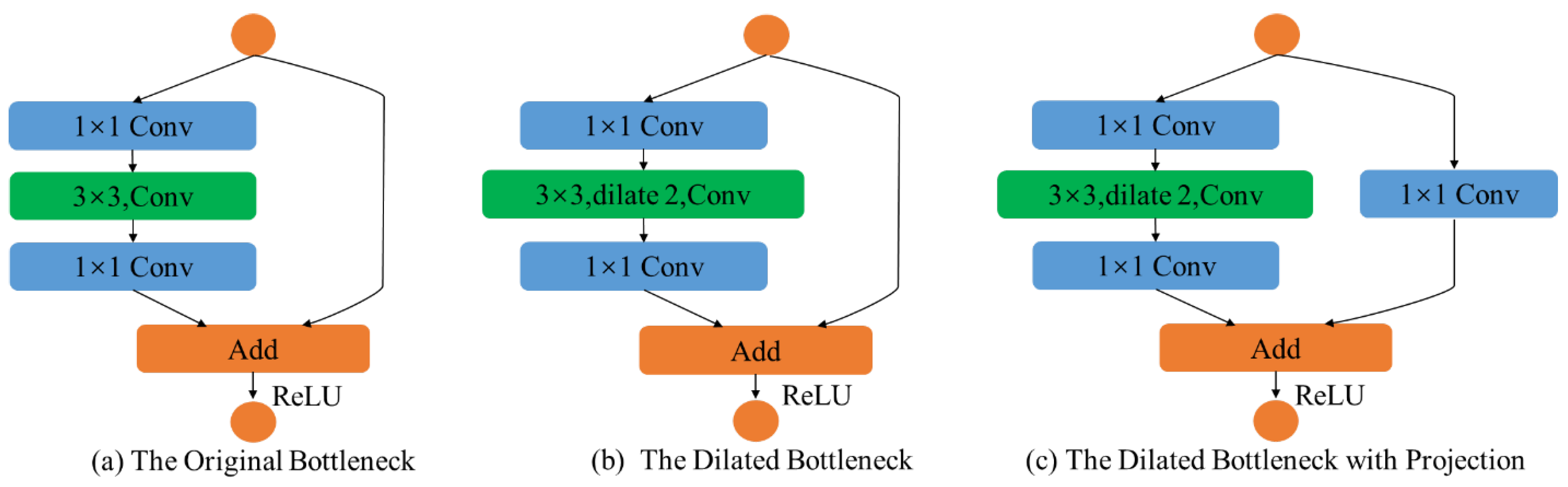
Our feature extraction module is composed of three stages, which consist of various convolution layers, dense blocks, and bottlenecks. The first stage is a convolution layer with a kernel of , followed by maxpooling layers and a dense block, containing alternations of convolutions and convolutions. The second stage contains two dense blocks. Since each layer of dense blocks is directly connected to the previous layer, the dense blocks can strengthen feature propagation and improve the utilization rate of feature maps. Meanwhile, since the convolution in the dense block can reduce the dimension of the feature map, relatively small numbers of parameters in dense blocks can reduce the computational complexity of training. Finally, the last stage contains two dilated bottlenecks and one dilated bottleneck with a convolution projection. The structure of the bottleneck is shown in Figure 4.
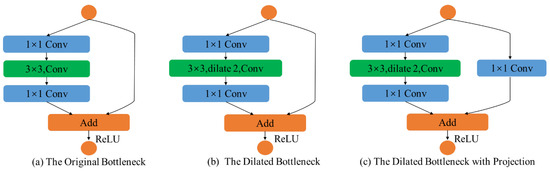
Figure 4.
Structure of the bottleneck. The orange circles indicate the input and output of the bottlenecks. (a) The original bottleneck, which consists of and convolutions. (b) The dilated bottleneck, which consists of and dilated convolutions. (c) The dilated bottleneck with a convolution projection.
The spatial correlation sensing module is a single-layer transformer module. Since high-level features contain rich semantic information, we utilize a self-attention mechanism to obtain global information. The spatial correlation perception module placed after the feature extraction module can capture the correlation between high-level feature entities. Furthermore, the transformer block fuses the semantic information from the last stage of the backbone of the segmentation branch. The features from the segmentation branch are applied as a semantic embedding, which is added element-wise to the Q and K matrices in the self-attention calculation. The semantic embedding matrix strongly enhances the feature representation of the Q and K matrices, such that the feature attention will focus more on the spatial correlation of the bonding spot and the gold wire. The calculation process can be represented as follows:
where Q, K, and V are the query, key, and value information extracted from the feature extraction module, respectively. E represents the semantic embedding from the segmentation branch.
To improve the accuracy of bonding spot detection, single-level features should be extended to multi-level features by the feature fusion method, as in FPN [36]. On the downside, FPN only uses one-way feature fusion without weight, which will lead to unbalanced feature fusion. To solve this problem, we employ a bidirectional feature fusion module to realize variable-weighted feature fusion and a bidirectional feature flow.
The bidirectional feature fusion module has two major characteristics: bidirectional connections and variable-weighted feature fusion. First, the bidirectional connections overcome the limitations of conventional top-down FPN, which is a one-way information flow, thereby obtaining more information from different feature maps. In this paper, we implement bidirectional feature fusion through the repeated fusion operation. The fusion operation is realized by RepBlock and the convolution layers. Second, variable-weighted feature fusion balances the features from different layers, as follows:
where represents the variable weight guaranteed, is a parameter to avoid a zero denominator, and represents a feature from the i-th layer.
3.2.2. Gold Wire Segmentation Branch
The gold wire segmentation branch functions in parallel with the bonding spot location branch. It aims to obtain an explicit and continuous gold wire edge with high segmentation precision. Its main components are an edge module and an ASPP [32] module. In addition, the bonding spot location branch provides spatial correlation information as auxiliary information to enhance the representation of gold wire features.
First, the input of the segmentation branch is , where I, W, and H represent the image and its width and height, respectively. We denote the output feature representation of the backbone as , where m is the stride of the backbone and C is the number of channels of the backbone network.
Parallel to the backbone network, the edge module contains several residual blocks and GCLs. The edge module takes the output of the backbone network’s first three stages as input. Specifically, as the edge module contains two GCLs, it can be divided into two layers. The feature map of the edge module is . In addition, the GCL ensures that the edge module only processes edge-relevant information. Finally, the ASPP module fuses features from different layers with different resolutions; this step has been widely used in semantic segmentation algorithms.
Our segmentation branch can also be regarded as an encoder–decoder structure. Specifically, the encoder module consists of the backbone network, the edge module, and the ASPP module. The outputs of the encoder module are regular feature maps from the ASPP module and low-level edge feature maps from the edge module. In the decoder module, we reconstruct the original segmentation map step by step. First, we upsample the regular feature maps based on a bilinear interpolation scheme. Then, the regular feature maps from ASPP are fused with the low-level edge feature maps from the edge module and the auxiliary feature from the fine location branch. Finally, we perform a 3 × 3 convolution and an upsampling on the feature map to produce the final segmentation output.
Gated Convolutional Layer. GCL is the core component of the segmentation branch, which extracts only edge-relevant information by filtering out other information from the regular feature maps of the backbone. Specifically, the operation of the GCL can be divided into two steps. First, we obtain an attention map from the feature maps and :
where and denote the feature maps of the backbone and edge modules, respectively; represents a convolutional layer; ‖ denotes feature concat; is the sigmoid function; and is the output attention map.
Next, we apply the element-wise product ⊙ on with attention map , followed by a residual connection. We define the GCL as:
where ⊙ represents the element-wise product, and is the output low-level edge feature map of the edge branch. Intuitively, denotes an attention map with more edge information. We have two GCLs that connect to the first three stages of the backbone.
Gold Wire Segmentation Loss (GWSL) Definition. In the segmentation branch, we jointly supervise segmentation and edge feature map prediction. Specifically, we design a GWSL function with four parts. The first two parts are the semantic segmentation loss () and the edge loss (). We use the standard cross-entropy (CE) loss and standard binary cross-entropy (BCE) loss on predicted semantic segmentation f and edge feature maps s, respectively. The definitions for and can be described as:
where and represent ground truth (GT) labels, and , are two balancing parameters; . Specifically, the balancing parameters are set to balance the influence of regular information and edge information in the detection process.
In addition, to prevent overfitting caused by foreground–background class imbalance, we propose two regularization loss functions, which constitute the other two parts of GWSL. We utilize the first regularization loss () to avoid GWSL offset due to mismatching between the GT edge and the predicted edge. The can be defined as:
where is a confidence value indicating whether a pixel belongs to the gold wire edge, is a similar value computed from the GT, and represents the set of predicted pixel coordinates.
Specifically, the value is computed as:
where G is the Gaussian filter, and is a label distribution of the prediction.
Moreover, we implement edge prediction to match semantic prediction, which also prevents overfitting:
where p and k represent the set of pixels and the set of labels, respectively; denotes the indicator function; denotes a threshold, which we set to 0.8 in the segmentation branch; and and denote two balancing parameters. Specifically, we set and in our experiments to optimize the performance of our segmentation branch.
3.3. Bonding Distance Measurement Module
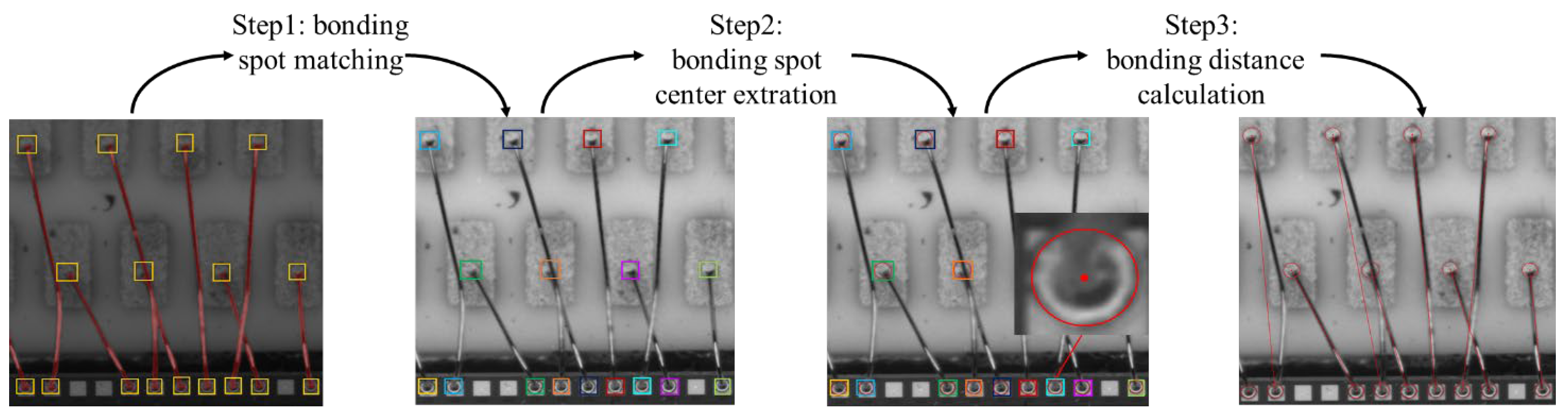
The bonding distance is defined as the projected distance between the centers of two corresponding bonding spots. Therefore, we need to find the corresponding bonding spots first. Nonetheless, given the complex distribution of gold wire bondings, it is difficult to directly calculate the bonding distance. To address this issue, we design a BDMM to gradually calculate the bonding distance based on bonding spot detection and gold wire segmentation results, as shown in Figure 5.
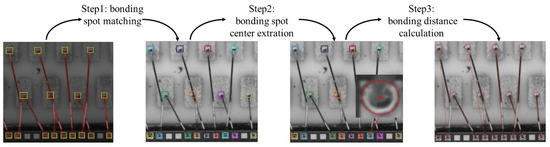
Figure 5.
Pipeline of the bonding distance measurement module, which consists of three steps: (1) bonding spot matching; (2) bonding spot center extraction; (3) bonding distance calculation. Different colors indicate different detection box for bonding spots.
Specifically, the bonding distance measurement has three main steps. First, the bonding spots are matched based on the gold wire segmentation results. Next, the center of each bonding spot is extracted using a RANSAC-based method. Finally, the bonding distance—that is, the distance between two corresponding boding spots—is confirmed based on the identified center coordinates.
Step 1 (bonding spot matching): For an integrated circuit image containing many detected bonding spots, we first need to match the corresponding two bonding spots connected by the gold wire. In fact, observation of the segmentation results for gold wire bonding shows that the distribution of the gold wire is very complicated. As a result, it is not possible to match bonding spots directly by nearby screening. As shown in Figure 6, based on the analysis of the segmentation results for gold wire, we establish four gold wire distribution models, representing straight-line, X, Y, and V shapes. Specifically, we first classify each segmented and connected region according to the gold wire distribution model. Furthermore, the bonding spots near the end of each segmented gold wire are searched and matched. We design different neighborhood search rules for different distribution types. Finally, the matched corresponding bonding spots are represented by the bounding box of the same color, as shown in Figure 5.

Figure 6.
Four gold wire bonding distribution models: (a) line shape, (b) X shape, (c) Y shape, (d) V shape.
Step 2 (bonding spot center extraction): Based on the definition of the gold wire bonding distance, we need to extract the bonding spot center. The areas of the detected bonding spots in the fine location branch are cropped into several small regions. As the bonding spot is not a standard circle, it cannot be fitted by Hough circle detection. Therefore, we use a RANSAC-based circle fitting method to extract the bonding spot circle, considering RANSAC-based method finds the center of the circle by randomly selecting a minimal subset of the data points and using the points to fit the circle. This method is not only suitable for extracting the center of ball bonding, but also suitable for extracting the center of wedge bonding.
Step 3 (bonding distance measurement): Having determined the relations of the bonding spots and all the bonding spot centers through the above two steps, we denote the centers of the corresponding bonding spots by and . The pixel distance of wire bonding is computed as follows:
where represents the pixel distance of the wire bonding; and represent the horizontal and vertical coordinates of in the image; and and represent the horizontal and vertical coordinates of in the image, respectively.
We calibrate the camera in advance to measure the physical distance of each pixel, so pixel distance can be easily converted into physical distance. Specifically, the internal parameter matrix, external parameter matrix, and distortion coefficients of the camera are solved using the Zhang Zhengyou plane calibration method. Then, we determine the proportional relationship between the object and the pixel by measuring the standard block. Therefore, the bonding distance can be calculated as:
where W represents the physical size of the standard measurement block, N represents the pixel size of the standard measurement block in the image, and K represents the equivalent pixel unit. Industrial cameras capture images at the same height, and the corresponding physical size per pixel does not change. Subsequent experiments have shown that this method can be used to measure the bonding distance efficiently and accurately.
4. Experiments and Results
4.1. Experimental Settings
We introduce three types of datasets, corresponding to the three types of detected objects: the bonding region, bonding spot, and gold wire. Raw images with high resolution are captured from the surface of the integrated circuit by the image acquisition device. First, the bonding region of the raw images is roughly marked for training of the bonding region location branch. After training, this branch can detect and extract the bonding regions and filter out the complex background. Next, the bonding spots and gold wires are extracted from the bonding region images for fine labeling manually. Finally, we divide the three annotated datasets into a training set, a validation set, and a testing set. Specifically, the image datasets are captured from 200 integrated circuits and include 1000 images. We use a series of image enhancement techniques to expand the 1000 images to 10,000 images, including rotation, translation, brightness adjustment, and adding random noise. All subsequent training was conducted based on these augmented 10,000 images. The proportions of the training set, validation set, and test set are , , and , respectively. Moreover, the bonding spot dataset and the gold wire dataset consist of the bonding region images extracted from the bonding region dataset.
During training, we use Pytorch and train the network on an NVIDIA GTX 3090 GPU from Jieshixin in Nanjing, China. The network is trained with the AdamW optimizer with a batch size of 16 and an initial learning rate of 0.001 decreased by 0.6 at every 20 epochs. The solver is a standard stochastic gradient descent with a momentum of 0.9.
4.2. Comparisons
Comparison of fine location branch with state-of-the-art methods. To validate the performance of the proposed fine location branch, we compare our method with state-of-the-art object detection methods, including RetinaNet [37], CenterNet [38], EfficientDet [35], Sparse-RCNN [34], RT-DETR [39], YOLOv8 [26], and Salience DETR [40], as shown in Table 1. The fine location branch achieves accuracy, precision, recall, and F-measure rates of 94.5%, 93.0%, 94.8%, and 93.9%, respectively. Notably, the accuracy of our method is 4.9% higher than that of Salience DETR and 16% higher than that of RT-DETR, indicating significant improvement. This enhancement is attributed to the limitations of models such as RetinaNet, CenterNet, Sparse-RCNN, YOLOv8, and Transformer models (e.g., Salience DETR and RT-DETR) in detecting small objects, as the multi-layer self-attention mechanism often leads to the loss of information about small objects. Additionally, EfficientDet shows performance declines in highly complex or dense scenes, such as integrated circuit bonding distance inspection, which involves numerous dense bounding spots.

Table 1.
Results of the detection of bonding spots from integrated circuit images.
Our proposed feature extraction module addresses these challenges by using dense blocks and dilated convolutions, enhancing the detection of small bonding spot targets. Furthermore, the bidirectional feature fusion module improves bonding spot detection by integrating information from different feature maps. Some detection results are shown in Figure 7.

Figure 7.
Some detection results for tiny bonding spots. Red boxes indicate the bonding region from the coarse location; green boxes indicate the bonding spots detected by the fine location branch.
Comparison of segmentation branch with state-of-the-art methods. Finally, we compare our gold wire segmentation branch with state-of-the-art segmentation methods, including FCN [20], U-Net [11], Seg-Net [28], PSP-Net [41], deeplabv3+ [27], SeaFormer [42], SAM [43], SSA [44], and Rein [45]. As shown in Figure 8, which provides a visualization of the results, in the gold wire segmentation by FCN, U-Net, Seg-Net, and PSP-net, the single gold wire segmentation is disconnected, resulting in a poor segmentation effect. DeepLabv3+ and our algorithm achieve complete segmentation of a single gold wire, but with the DeepLabv3+ algorithm, the segmentation width is quite different from the ground truth in some parts. The reason is that FCN, U-Net, Seg-Net, and PSP-Net, the early semantic segmentation networks, are not good at dealing with small targets like gold wires. The features of gold wires are easily lost during the downsampling and upsampling processes. Although DeepLabv3+ utilizes atrous convolution to enhance performance, the improvement is limited, and some small-sized features are still overlooked.

Figure 8.
Some segmentation results for gold wires. Red boxes indicate the bonding region from the coarse location; red masks indicate the gold wire.
As shown in Table 2, since our segmentation branch can process edge features separately via the edge branch to improve the segmentation accuracy for gold wire bonding, the results of our segmentation branch are superior to those of the other networks in terms of mean pixel accuracy (MPA) and MPA (86.2%) and mean intersection over union MIOU (87.3%). Specifically, our MIOU is 1.4% higher than the MIOU of the state-of-the-art Rein method and 2.5% higher than the well-known SAM. Figure 8 shows some examples of gold wire segmentation results obtained with our method.
Table 2.
Comparison of gold wire segmentation results from integrated circuit images.
4.3. Evaluation of Bonding Distance Measurement
The goal of this study is to measure bonding distances. Therefore, we verify the effectiveness of the whole framework on real integrated circuit components.
First, we calibrate the pixel equivalent unit based on the standard block. The size of the standard block was 1000 m, and we calculated the average pixel size of the standard block to be 232.76 pixels based on eight measurements. The pixel equivalent unit is computed as:
where W represents the physical size of the standard measure block, N represents the pixel size of the standard measure block in the image, and K represents the pixel equivalent unit.
Second, we compare our method with microscopy-based methods on 20 integrated circuit components. Specifically, the average processing time of our method for an image is 0.64 s. The average processing time of our method for an integrated circuit component is about 10 s, much shorter than that of microscopy-based methods. In addition, our method is automated and does not require manual operation.
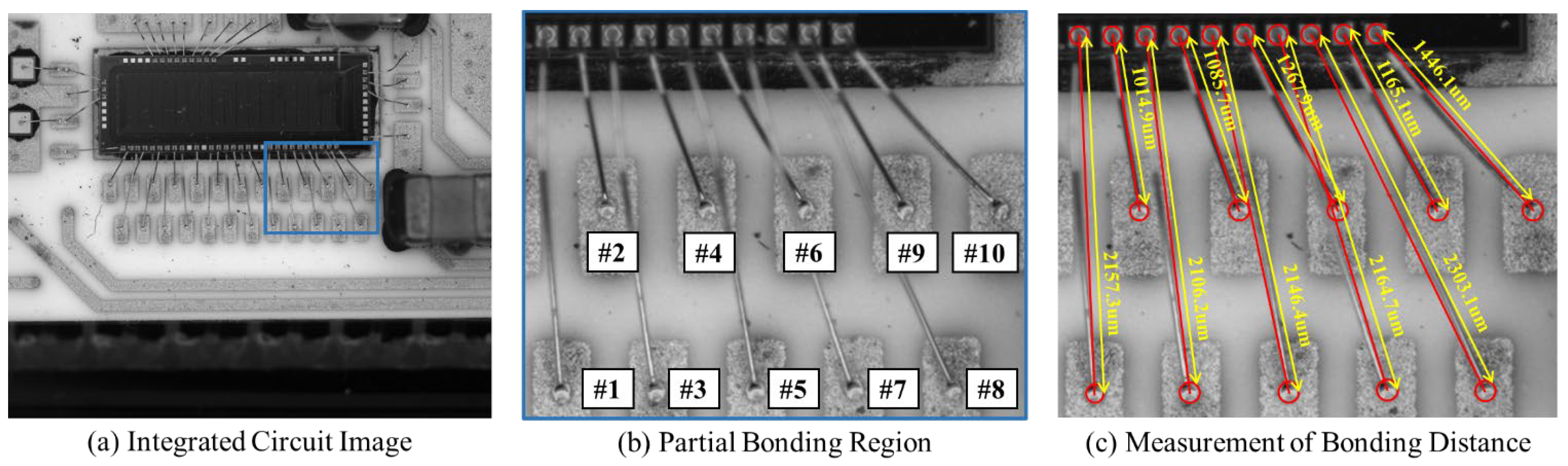
Finally, we verify the effectiveness of the BDMM on the integrated circuit shown in Figure 9. The bonding distance GT for the gold wires of this integrated circuit is measured using a microscope. We select ten wire bondings from the input integrated circuit image for the experiment. To improve the robustness of the measurement, we perform 20 measurements and took the average of these as the final bonding distance. Table 3 shows the bonding distance results for ten gold wire bondings, including GT bonding distance, mean value bonding distance, mean error, standard deviation, and maximum error. Our method achieves values of 8.3 m, 12.5 m, and 0.56% for mean error, maximum error, and relative error; the mean errors of the 20 measurements of the wire bonding distance were between and 11.3 m. These results demonstrate that the BDMM can achieve a high-precision bonding distance measurement.
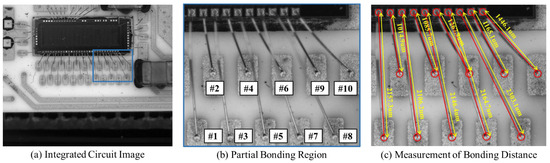
Figure 9.
An integrated circuit image was used to evaluate the bonding distance measurement method. (a) Integrated circuit image. (b) Partial bonding region. “#1–#10” denotes ten gold wires numbered from 1 to 10. (c) Measurement of bonding distance.
Table 3.
Bonding distance measurement results for real integrated circuits.
4.4. Ablation of Key Component Modules
The ablation results for each component module are presented in Table 4. It is evident that the absence of the coarse location branch significantly diminishes its performance, with precision decreasing by 11.2% and the mean error reaching 42.3%.
Table 4.
Ablation of key component modules.
In the segmentation branch, the omission of the semantic embedding and bidirectional feature fusion module resulted in suboptimal extraction of information related to the bonding spot and gold wire, owing to the neglect of the spatial correlation between them. As a result, the precision, recall, and F-measurement are decreased, with MPA and MIOU experiencing a slight decline. Specifically, the precision of MWBINet without semantic embedding was 90.1%, which is 2.9% lower than that of MWBINet with semantic embedding.
In the location branch, when the edge branch and GWSL were not utilized, overfitting caused by foreground–background class imbalance may occur. Thus, the performance of segmentation becomes less effective to a certain extent. The MPA and MIOU of MWBINet without the GSWL register show declines of 5.1% and 5.5%, respectively.
In conclusion, employing all five modules simultaneously enhances precision and maintains high MPA and low relative error. This integrated approach is pivotal for achieving accurate and efficient bonding distance measurements.
5. Conclusions and Future Work
In this paper, we systematically present a framework for measuring bonding distances in integrated circuit images. First, we use coarse localization to remove redundant information from the integrated circuit images. Next, we implement the fine localization branch and the gold wire segmentation branch to detect bonding spots and segment the gold wire. Finally, we apply a bonding distance measurement module to connect the corresponding bonding spots and calculate the bonding distance between them. Experimental results show that the proposed bonding distance measurement framework achieves a stable and efficient bonding distance measurement. In addition, our model can be applied in other industrial quality inspection tasks, such as pipe crack detection and metal surface scratch detection, evaluating the quality of the inspection object through distance measurement.
In the present work, we have not taken into account production defects in gold wire bonding other than abnormal bonding distances. If other manufacturing defects are present in gold wire bonding, measuring the bonding distance of the defective bonds will be meaningless; therefore, we must remove the gold wire bonds with other defects first. Unfortunately, due to the low frequency of production defects in gold wire bonding, we were unable to collect enough defect images for training. In the future, we will conduct bonding defect detection to expand the range of indicators in our bonding inspection and measurement framework, and we will continue to expand the application scenarios of our model.
Author Contributions
Conceptualization, Y.Z. (Yuan Zhang) and C.P.; methodology, Y.Z. (Yuan Zhang) and C.P.; software, Y.Z. (Yuan Zhang) and C.P.; validation, Y.Z. (Yanming Zhan), M.N. and L.H.; formal analysis, Y.Z. (Yanming Zhan), M.N. and L.H.; investigation, Y.Z. (Yuan Zhang) and C.P.; resources, Y.Z. (Yuan Zhang) and J.W.; data curation, Y.Z. (Yanming Zhan), M.N. and L.H.; writing—original draft preparation, Y.Z. (Yuan Zhang) and C.P.; writing—review and editing, Y.Z. (Yanming Zhan), M.N. and L.H.; visualization, M.N.; supervision, J.W.; project administration, Y.Z. (Yuan Zhang) and C.P. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (No. 92367301, No. 92267201, 52275493) and Sichuan Province Engineering Research Center for Broadband Microwave Circuit High Density Integration Open Fund.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data available on request due to restrictions. The data presented in this study are available on request from the corresponding author due to the commercial confidentiality involved.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Feng, W.; Chen, X.; Wang, C.; Shi, Y. Application research on the time–frequency analysis method in the quality detection of ultrasonic wire bonding. Int. J. Distrib. Sens. Netw. 2021, 17, 15501477211018346. [Google Scholar] [CrossRef]
- Perng, D.B.; Chou, C.C.; Lee, S.M. Design and development of a new machine vision wire bonding inspection system. Int. J. Adv. Manuf. Technol. 2007, 34, 323–334. [Google Scholar] [CrossRef]
- Xie, Q.; Long, K.; Lu, D.; Li, D.; Zhang, Y.; Wang, J. Integrated Circuit Gold Wire Bonding Measurement via 3D Point Cloud Deep Learning. IEEE Trans. Ind. Electron. 2021, 69, 11807–11815. [Google Scholar] [CrossRef]
- Xiang, R.; He, W.; Zhang, X.; Wang, D.; Shan, Y. Size measurement based on a two-camera machine vision system for the bayonets of automobile brake pads. Measurement 2018, 122, 106–116. [Google Scholar] [CrossRef]
- Min, J. Measurement method of screw thread geometric error based on machine vision. Meas. Control 2018, 51, 304–310. [Google Scholar] [CrossRef]
- Zhang, M.; Xing, X.; Wang, W. Smart Sensor-Based Monitoring Technology for Machinery Fault Detection. Sensors 2024, 24, 2470. [Google Scholar] [CrossRef]
- Kim, G.; Kim, S. A road defect detection system using smartphones. Sensors 2024, 24, 2099. [Google Scholar] [CrossRef]
- Egodawela, S.; Khodadadian Gostar, A.; Buddika, H.S.; Dammika, A.; Harischandra, N.; Navaratnam, S.; Mahmoodian, M. A Deep Learning Approach for Surface Crack Classification and Segmentation in Unmanned Aerial Vehicle Assisted Infrastructure Inspections. Sensors 2024, 24, 1936. [Google Scholar] [CrossRef] [PubMed]
- Jo, C.M.; Jang, W.K.; Seo, Y.H.; Kim, B.H. In Situ Surface Defect Detection in Polymer Tube Extrusion: AI-Based Real-Time Monitoring Approach. Sensors 2024, 24, 1791. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Li, D.; Li, Y.; Xie, Q.; Wu, Y.; Yu, Z.; Wang, J. Tiny Defect Detection in High-Resolution Aero-Engine Blade Images via a Coarse-to-Fine Framework. IEEE Trans. Instrum. Meas. 2021, 70, 1–12. [Google Scholar] [CrossRef]
- Zhou, X.; Fang, H.; Liu, Z.; Zheng, B.; Sun, Y.; Zhang, J.; Yan, C. Dense Attention-guided Cascaded Network for Salient Object Detection of Strip Steel Surface Defects. IEEE Trans. Instrum. Meas. 2021, 71, 5004914. [Google Scholar] [CrossRef]
- Li, X.; Yang, Y.; Ye, Y.; Ma, S.; Hu, T. An online visual measurement method for workpiece dimension based on deep learning. Measurement 2021, 185, 110032. [Google Scholar] [CrossRef]
- Long, Z.; Zhou, X.; Zhang, X.; Wang, R.; Wu, X. Recognition and classification of wire bonding joint via image feature and SVM model. IEEE Trans. Components Packag. Manuf. Technol. 2019, 9, 998–1006. [Google Scholar] [CrossRef]
- Chen, J.; Zhang, Z.; Wu, F. A data-driven method for enhancing the image-based automatic inspection of IC wire bonding defects. Int. J. Prod. Res. 2021, 59, 4779–4793. [Google Scholar] [CrossRef]
- Chan, K.Y.; Yiu, K.F.C.; Lam, H.K.; Wong, B.W. Ball bonding inspections using a conjoint framework with machine learning and human judgement. Appl. Soft Comput. 2021, 102, 107115. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Ko, K.W.; Kim, D.H.; Lee, J.; Lee, S. 3D Measurement System of Wire for Automatic Pull Test of Wire Bonding. J. Inst. Control Robot. Syst. 2015, 21, 1130–1135. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Terven, J.; Córdova-Esparza, D.M.; Romero-González, J.A. A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected CRFs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C.; et al. Sparse R-CNN: End-to-end object detection with learnable proposals. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14454–14463. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and efficient object detection. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint triplets for object detection. In Proceedings of the Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Lv, W.; Xu, S.; Zhao, Y.; Wang, G.; Wei, J.; Cui, C.; Du, Y.; Dang, Q.; Liu, Y. DETRs beat YOLOs on real-time object detection. arXiv 2023, arXiv:2304.08069. [Google Scholar]
- Hou, X.; Liu, M.; Zhang, S.; Wei, P.; Chen, B. Salience DETR: Enhancing Detection Transformer with Hierarchical Salience Filtering Refinement. arXiv 2024, arXiv:2403.16131. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Wan, Q.; Huang, Z.; Lu, J.; Yu, G.; Zhang, L. Seaformer: Squeeze-enhanced axial transformer for mobile semantic segmentation. arXiv 2023, arXiv:2301.13156. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment anything. In Proceedings of the Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 4015–4026. [Google Scholar]
- Ma, X.; Ni, Z.; Chen, X. Semantic and Spatial Adaptive Pixel-level Classifier for Semantic Segmentation. arXiv 2024, arXiv:2405.06525. [Google Scholar]
- Wei, Z.; Chen, L.; Jin, Y.; Ma, X.; Liu, T.; Lin, P.; Wang, B.; Chen, H.; Zheng, J. Stronger, fewer, & superior: Harnessing vision foundation models for domain generalized semantic segmentation. arXiv 2023, arXiv:2312.04265. [Google Scholar]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).