
Intelligent Fault Diagnosis Method Based on Cross-Device Secondary Transfer Learning of Efficient Gated Recurrent Unit Network


Abstract
1. Introduction
- A method for intelligent fault diagnosis based on EGRUN cross-device second transfer learning is proposed. The EGRUN model, consisting of core structures such as MB, FMB, and GRU, is constructed, with continuous wavelet time-frequency maps used as inputs, thereby improving the model’s feature extraction capabilities and diagnostic accuracy.
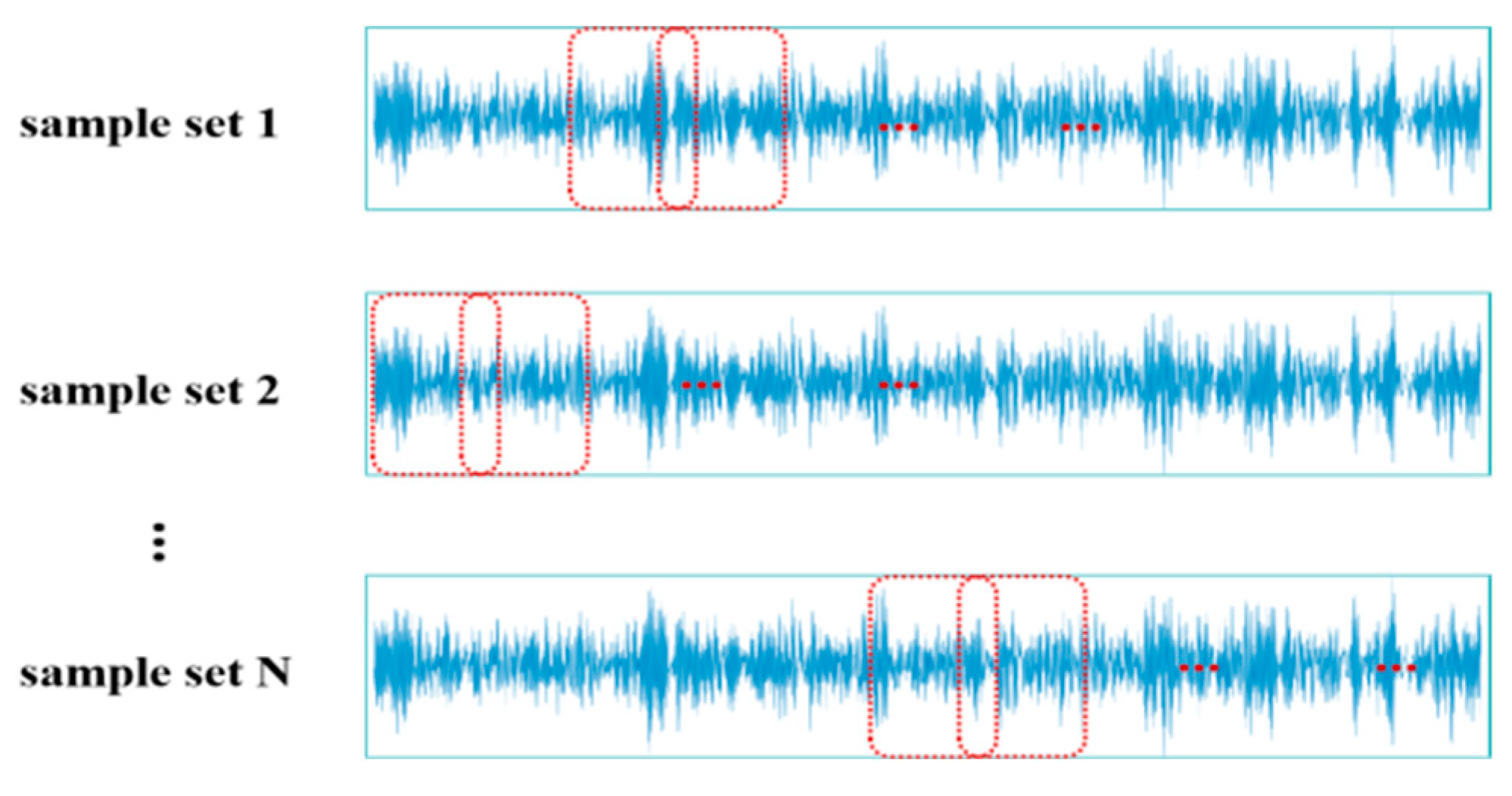
- Through data augmentation and secondary transfer-learning strategies using random overlapping sampling techniques, existing data are fully utilized, allowing the model to better learn mechanical equipment fault features, effectively improving the model’s fault recognition accuracy and generalization capabilities.
2. Transfer-Learning Explanation
3. EGRUN Diagnostic Scheme
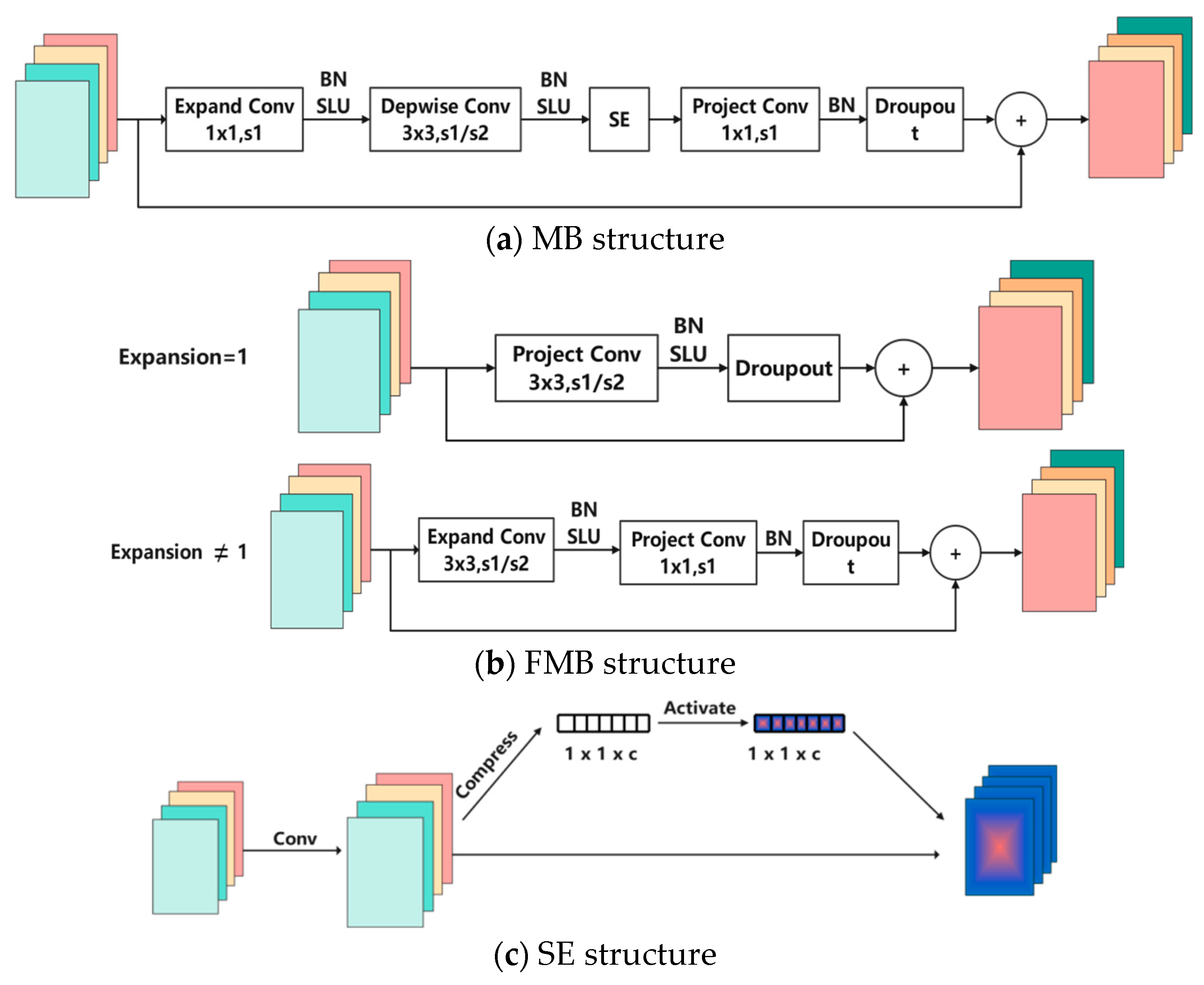
3.1. Description of Network Structure
- MBConv Structure
- 2.
- Fused-MBConv Structure
- 3.
- Stochastic Depth Dropout (SD-Dropout) Mechanism
- 4.
- SE Channel Attention Mechanism
- 5.
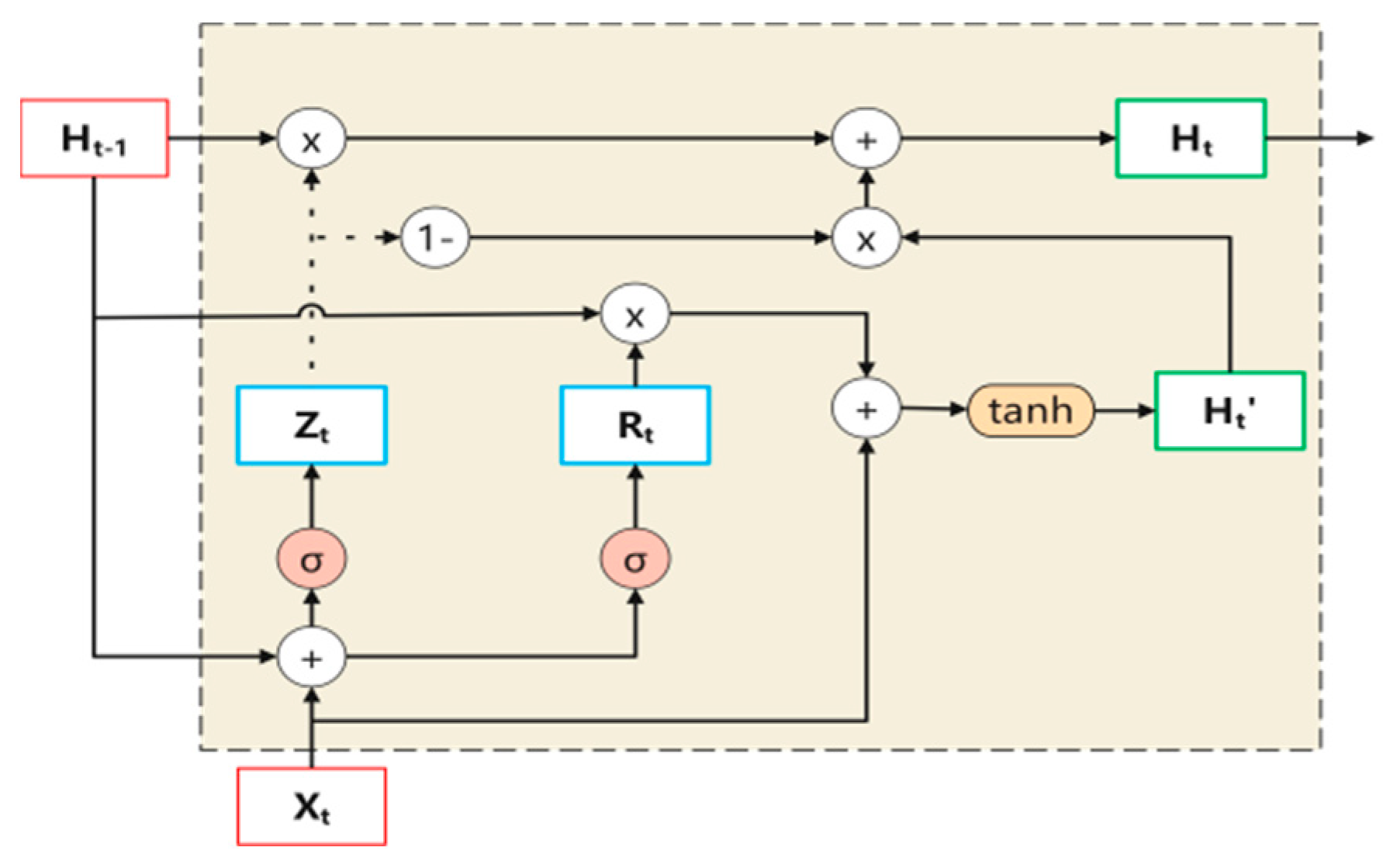
- Gate Recurrent Unit Structure
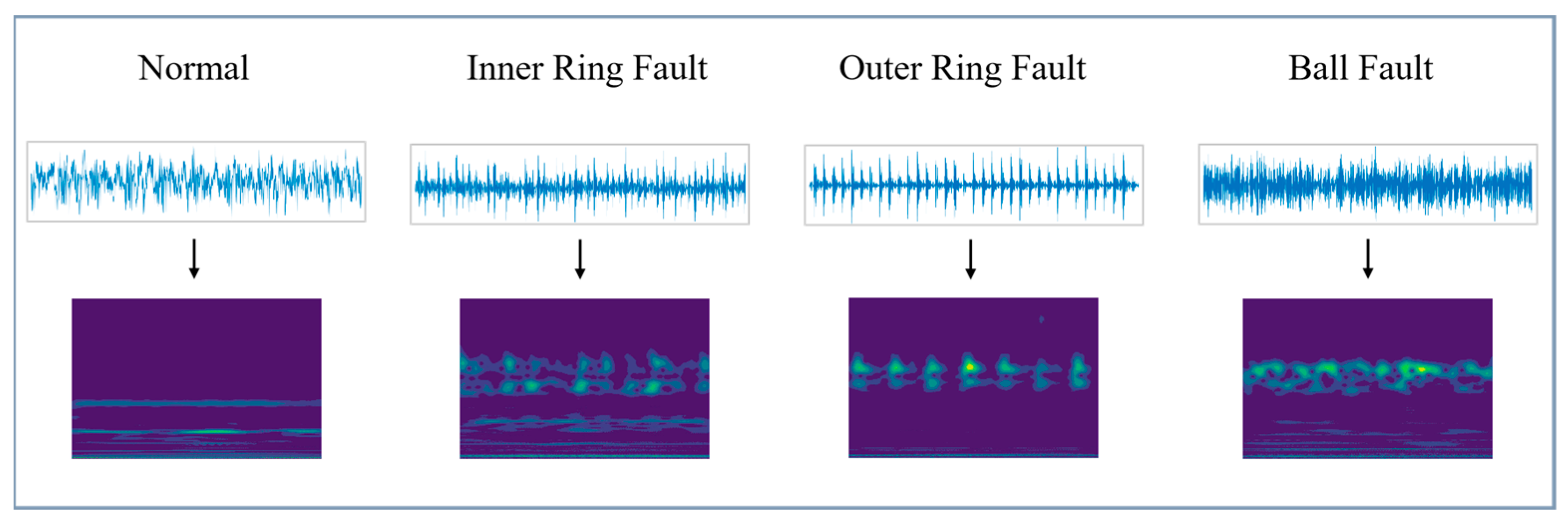
3.2. Continuous Wavelet Transform
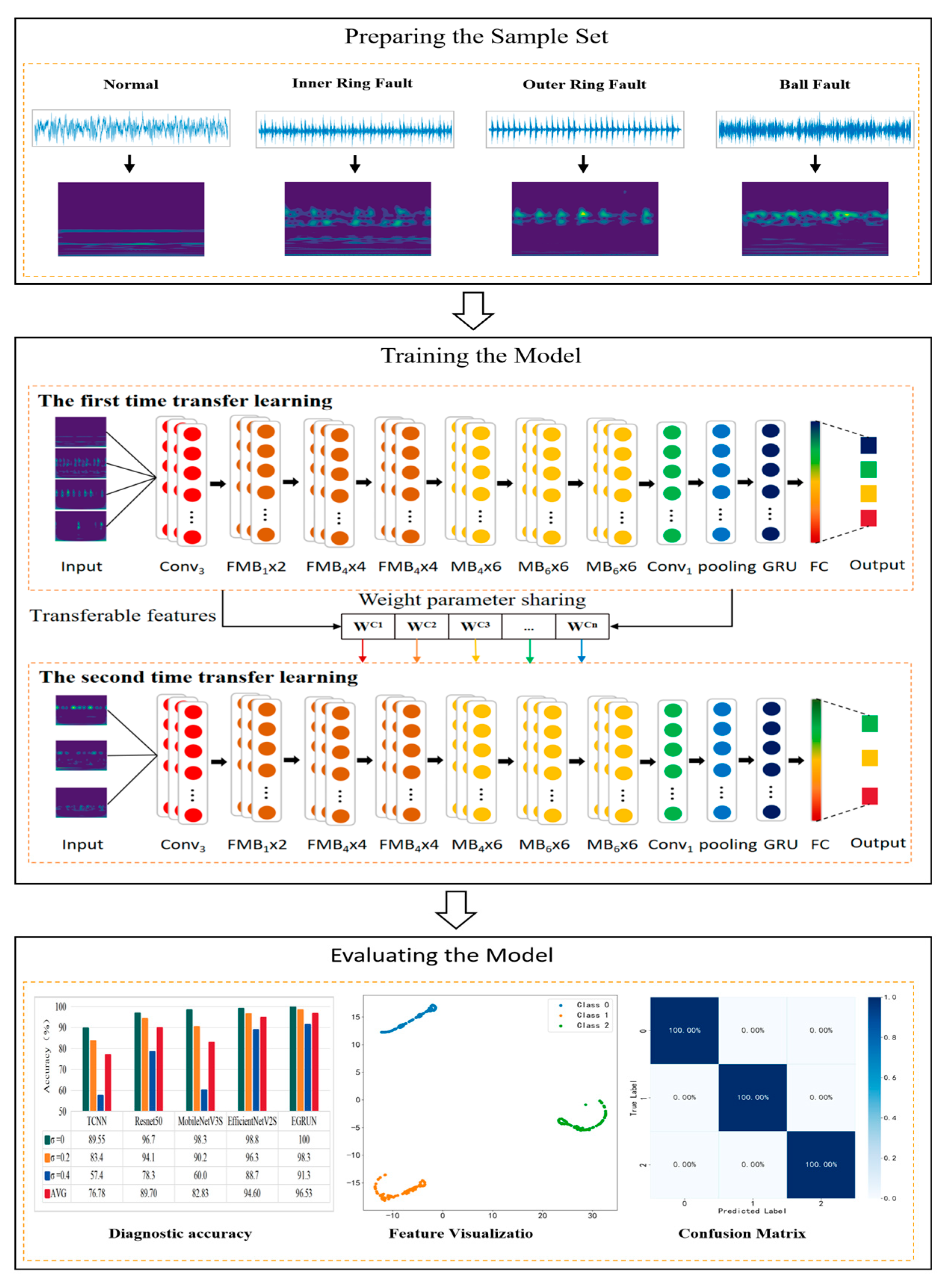
3.3. Network Fault Diagnosis Process
- (1)
- Preparing the Sample Set
- (2)
- Training the Model
- (3)
- Evaluating the Model
4. Fault Diagnosis Experimental Verification and Analysis
4.1. Data Description
- (1)
- Dataset I
- (2)
- Dataset II
4.2. Description of Comparative Methods
- (1)
- ResNet50 Proposed by He et al. [33], ResNet50 is an important network in deep learning. It utilizes a residual learning framework, which simplifies the training of very deep networks by learning residual functions for layers rather than learning unknown functions.
- (2)
- MobileNetV3S Introduced by Howard et al. [34], MobileNetV3S is a lightweight convolutional neural network architecture designed to address real-time image recognition and processing on mobile devices.
- (3)
- EfficientNetV2S Proposed by Tan et al. [35], EfficientNetV2S is an efficient convolutional neural network architecture. It balances the depth, width, and resolution of the network using compound scaling methods to achieve better performance and efficiency.
- (4)
- Traditional Convolutional Neural Network (TCNN) is one of the classic networks in deep learning, playing a crucial role in the diversification and deepening development of subsequent deep-learning technologies, laying a solid foundation. The network structure is designed as a double convolutional layer network with specific parameters: the input size is (32,32); the number of convolutional kernels in the first convolutional layer is 8, with a size of (3,3) and a stride of 1; the number of convolutional kernels in the second convolutional layer is 16, with a size of (3,3) and a stride of 1; max-pooling is used for pooling, with a pooling kernel size of (2,2); and the final output layer performs the classification task using the Softmax function.
4.3. Diagnosis Results and Analysis
- (1)
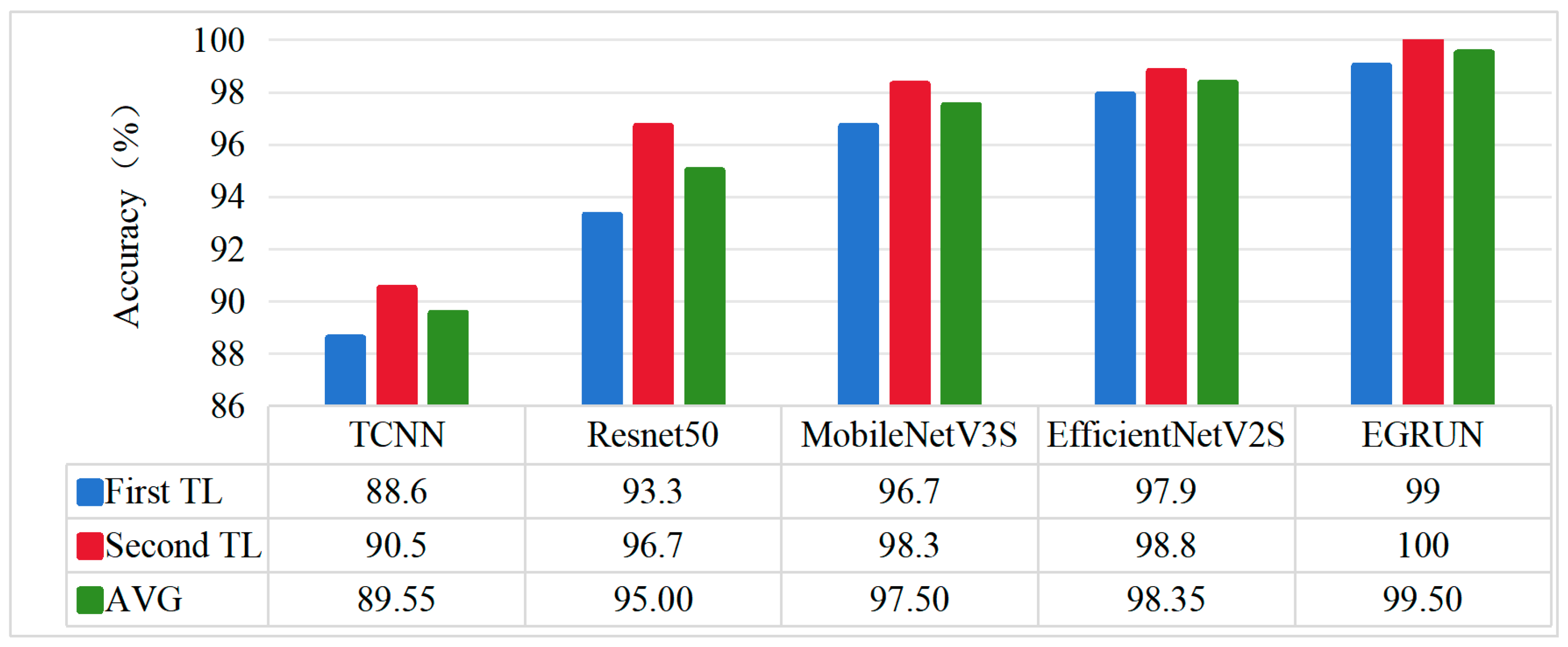
- Comparison of results on different transfer tasks.
- Analysis of Transfer-Learning Results for Each Model
- (2)
- Robustness Analysis
- Data Noising Process
- Performance of Models under Noising Conditions
- (3)
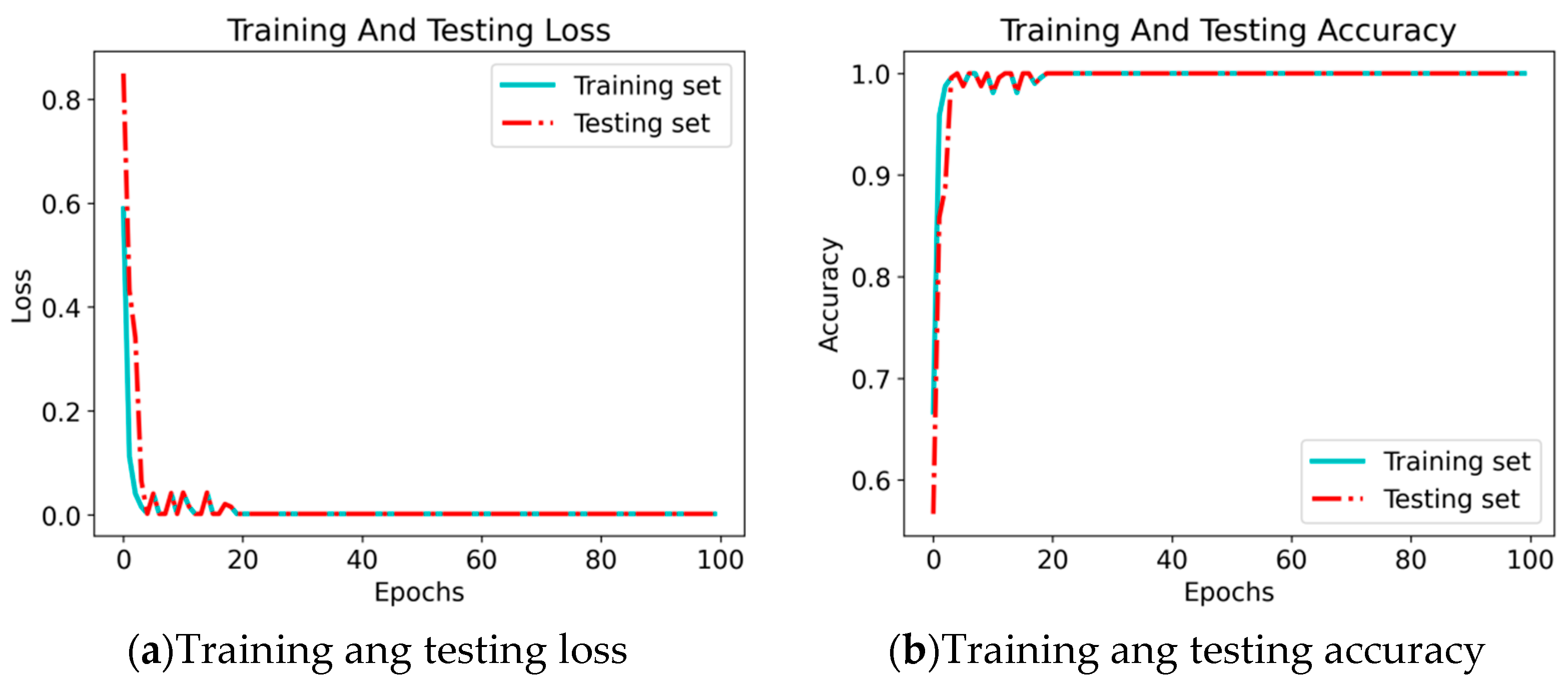
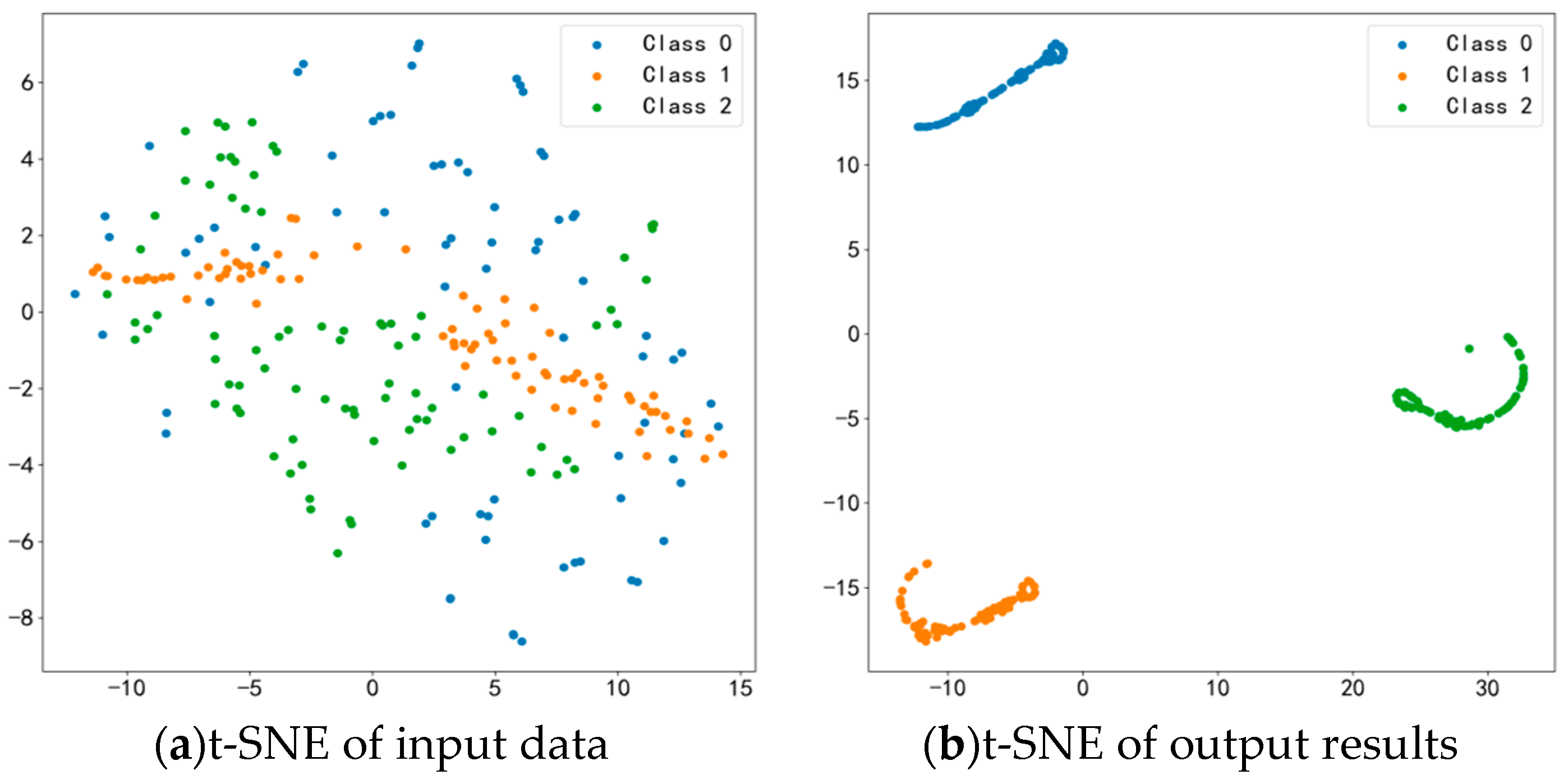
- Visualization Analysis (After Second Transfer Learning of the Model)
- Analysis of Loss Function Values and Diagnostic Accuracy
- t-SNE Result Analysis
- Confusion Matrix Result Analysis
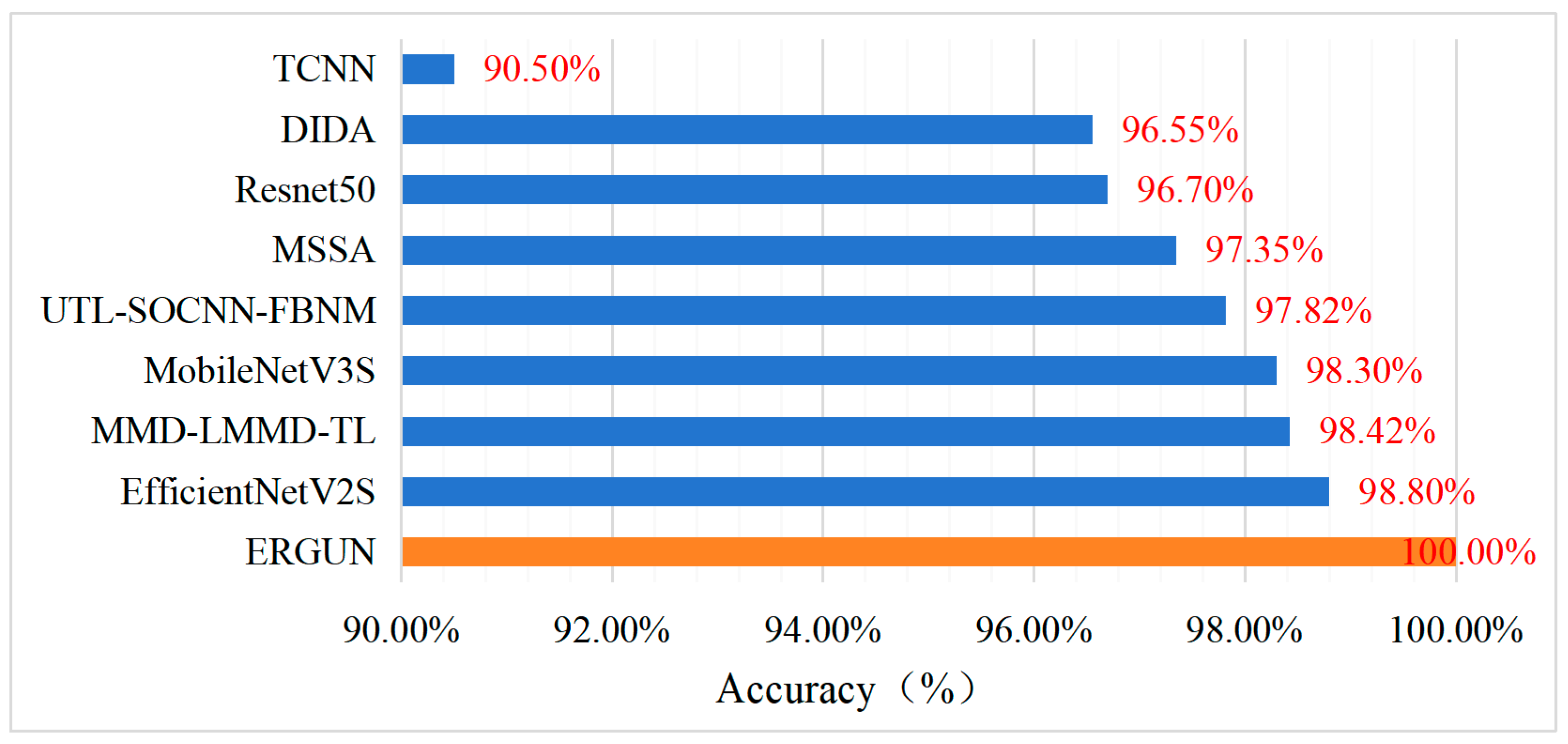
4.4. Comparison with State-of-the-Art Models in Terms of Diagnostic Accuracy
5. Conclusions
- (1)
- The EGRUN model, which combines the MBConv, Fused-MBConv, and GRU core structures, was designed. By using CWT images as input, the model’s feature extraction and diagnostic accuracy were significantly enhanced.
- (2)
- Data augmentation and secondary transfer learning were conducted using random overlapping sampling techniques, enabling the model to learn fault features more effectively and significantly improving the diagnostic performance on target domain samples.
- (3)
- Experimental validation demonstrated that compared to eight advanced deep-transfer-learning algorithms, the proposed method exhibited superior feature learning capability, fault classification accuracy, and generalization performance. With a diagnostic accuracy of 100%, it demonstrated the potential for practical applications.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Miao, Y.; Shi, H.; Li, C. Application of Harmonic Characteristic Mode Decomposition Method in Bearing Fault Diagnosis. J. Mech. Eng. 2023, 59, 234–244. [Google Scholar]
- Jing, L. Machine Informatics: Discipline Support for Mechanical Product Intelligence. J. Mech. Eng. 2021, 57, 11–20. [Google Scholar]
- Wang, G.; He, Z.; Chen, X. Research on the Basis of Mechanical Fault Diagnosis: Where to Go. J. Mech. Eng. 2013, 49, 63–72. [Google Scholar] [CrossRef]
- Li, X.; Fu, C.; Lei, Y. Equipment Collaborative Intelligent Fault Diagnosis Federated Transfer Learning Method Ensuring Data Privacy. J. Mech. Eng. 2023, 59, 1–9. [Google Scholar]
- Michau, G.; Fink, O. Unsupervised Transfer Learning for Anomaly Detection: Application to Complementary Operating Condition Transfer. Knowl.-Based Syst. 2021, 216, 106816. [Google Scholar] [CrossRef]
- Lei, Y.; Yang, B.; Du, Z. Deep Transfer Diagnosis Method for Mechanical Equipment Faults under Big Data. J. Mech. Eng. 2019, 55, 1–8. [Google Scholar]
- Shao, H.; Xiao, Y.; Yan, S. Improved Unsupervised Domain Adaptation Bearing Fault Diagnosis Driven by Simulation Data. J. Mech. Eng. 2023, 59, 76–85. [Google Scholar]
- Lei, Y.; Jia, F.; Kong, D. Opportunities and Challenges of Mechanical Intelligent Fault Diagnosis under Big Data. J. Mech. Eng. 2018, 54, 94–104. [Google Scholar] [CrossRef]
- Yu, W.; Zhao, C.; Huang, B. MoniNet with concurrent analytics of temporal and spatial information for fault detection in industrial processes. IEEE Trans. Cybern. 2021, 52, 8340–8351. [Google Scholar] [CrossRef]
- Xue, F.; Zhang, W.; Xue, F.; Li, D.; Xie, S.; Fleischer, J. A novel intelligent fault diagnosis method of rolling bearing based on two-stream feature fusion convolutional neural network. Measurement 2021, 176, 109226. [Google Scholar] [CrossRef]
- Yu, W.; Lv, P. An end-to-end intelligent fault diagnosis application for rolling bearing based on MobileNet. IEEE Access 2021, 9, 41925–41933. [Google Scholar] [CrossRef]
- Chen, Z.; Zhong, Q.; Huang, R. Mechanical Intelligent Fault Diagnosis Based on Enhanced Transfer Convolutional Neural Network. J. Mech. Eng. 2021, 57, 96–105. [Google Scholar]
- Hoang, D.T.; Kang, H.J. A Survey on Deep Learning Based Bearing Fault Diagnosis. Neurocomputing 2019, 335, 327–335. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, S.; Wang, B.; Habetler, T.G. Deep Learning Algorithms for Bearing Fault Diagnostics—A Comprehensive Review. IEEE Access 2020, 8, 29857–29881. [Google Scholar] [CrossRef]
- Wang, R.; Jiang, H.; Zhu, K. A Deep Feature Enhanced Reinforcement Learning Method for Rolling Bearing Fault Diagnosis. Adv. Eng. Inform. 2022, 54, 101750. [Google Scholar] [CrossRef]
- Bai, L.; He, M.; Chen, B. Cross-Condition Fault Diagnosis Method Based on Domain Generalization D3QN[J/OL]. J. Mech. Eng. 2024, 1–14. [Google Scholar]
- Chen, H.; Luo, H.; Huang, B.; Jiang, B.; Kaynak, O. Transfer Learning-Motivated Intelligent Fault Diagnosis Designs: A Survey, Insights, and Perspectives. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 2969–2983. [Google Scholar] [CrossRef]
- Chen, X.; Yang, R.; Xue, Y.; Huang, M.; Ferrero, R.; Wang, Z. Deep Transfer Learning for Bearing Fault Diagnosis: A Systematic Review since 2016. IEEE Trans. Instrum. Meas. 2023, 72, 1–21. [Google Scholar] [CrossRef]
- Long, M.; Zhu, H.; Wang, J.; Jordan, M.I. Deep Transfer Learning with Joint Adaptation Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 3470–3479. [Google Scholar]
- Zhu, J.; Chen, N.; Shen, C. A New Multiple Source Domain Adaptation Fault Diagnosis Method between Different Rotating Machines. IEEE Trans. Ind. Inform. 2020, 17, 4788–4797. [Google Scholar] [CrossRef]
- Yu, S.; Liu, Z.; Zhao, C. Domain Adaptive Intelligent Diagnosis Method Driven by Dynamic Simulation Data. China Mech. Eng. 2023, 34, 2832–2841. [Google Scholar]
- Han, T.; Liu, C.; Yang, W.; Jiang, D. A Novel Adversarial Learning Framework in Deep Convolutional Neural Network for Intelligent Diagnosis of Mechanical Faults. Knowl.-Based Syst. 2019, 165, 474–487. [Google Scholar] [CrossRef]
- Li, J.; Huang, R.; He, G.; Liao, Y.; Wang, Z.; Li, W. A Two-Stage Transfer Adversarial Network for Intelligent Fault Diagnosis of Rotating Machinery with Multiple New Faults. IEEE/ASME Trans. Mechatron. 2020, 26, 1591–1601. [Google Scholar] [CrossRef]
- Jiao, J.; Zhao, M.; Lin, J.; Liang, K.; Ding, C. A Mixed Adversarial Adaptation Network for Intelligent Fault Diagnosis. J. Intell. Manuf. 2022, 33, 2207–2222. [Google Scholar] [CrossRef]
- Chen, Z.; Gryllias, K.; Li, W. Intelligent Fault Diagnosis for Rotary Machinery Using Transferable Convolutional Neural Network. IEEE Trans. Ind. Inform. 2019, 16, 339–349. [Google Scholar] [CrossRef]
- Li, X.; Jiang, H.; Wang, R.; Niu, M. Rolling Bearing Fault Diagnosis Using Optimal Ensemble Deep Transfer Network. Knowl.-Based Syst. 2021, 213, 106695. [Google Scholar] [CrossRef]
- Zhao, J.; Yang, S.; Li, Q. A Residual Attention Transfer Learning Method and Its Application in Rolling Bearing Fault Diagnosis. China Mech. Eng. 2023, 34, 332–343. [Google Scholar]
- Li, W.; Huang, R.; Li, J.; Liao, Y.; Chen, Z.; He, G.; Yan, R.; Gryllias, K. A perspective survey on deep transfer learning for fault diagnosis in industrial scenarios: Theories, applications and challenges. Mech. Syst. Signal Process. 2022, 167, 108487. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Ni, Q.; Ji, J.C.; Feng, K.; Zhang, Y.; Lin, D.; Zheng, J. Data-Driven Bearing Health Management Using a Novel Multi-Scale Fused Feature and Gated Recurrent Unit. Reliab. Eng. Syst. Saf. 2024, 242, 109753. [Google Scholar] [CrossRef]
- Rafiee, J.; Rafiee, M.A.; Tse, P.W. Application of mother wavelet functions for automatic gear and bearing fault diagnosis. Expert Syst. Appl. 2010, 37, 4568–4579. [Google Scholar] [CrossRef]
- Yan, R.; Gao, R.X.; Chen, X. Wavelets for fault diagnosis of rotary machines: A review with applications. Signal Process. 2014, 96, 1–15. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, B.; Wang, W.; Chen, L.-C.; Tan, M.; Chu, G.; Vasudevan, V.; Zhu, Y. Searching for MobileNetV3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Tan, M.; Le, Q. EfficientNetV2: Smaller Models and Faster Training. In Proceedings of the International Conference on Machine Learning. PMLR, Long Beach, CA, USA, 10–15 June 2019; pp. 10096–10106. [Google Scholar]
- Huang, M.; Yin, J.; Yan, S.; Xue, P. A Fault Diagnosis Method of Bearings Based on Deep Transfer Learning. Simul. Model. Pract. Theory 2023, 122, 102659. [Google Scholar] [CrossRef]
- Zheng, B.; Huang, J.; Ma, X.; Zhang, X.; Zhang, Q. An Unsupervised Transfer Learning Method Based on SOCNN and FBNN and Its Application on Bearing Fault Diagnosis. Mech. Syst. Signal Process. 2024, 208, 111047. [Google Scholar] [CrossRef]
- Tian, J.; Han, D.; Li, M.; Shi, P. A Multi-Source Information Transfer Learning Method with Subdomain Adaptation for Cross-Domain Fault Diagnosis. Knowl.-Based Syst. 2022, 243, 108466. [Google Scholar] [CrossRef]
- Ding, Y.; Jia, M.; Zhuang, J.; Cao, Y.; Zhao, X.; Lee, C.-G. Deep Imbalanced Domain Adaptation for Transfer Learning Fault Diagnosis of Bearings under Multiple Working Conditions. Reliab. Eng. Syst. Saf. 2023, 230, 108890. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Operator | Layers | Stride | Channels |
|---|---|---|---|---|
| 1 | Input | 1 | - | 3 |
| 2 | Conv3x3 | 1 | 2 | 24 |
| 3 | Fused-MBConv1, k3x3 | 2 | 1 | 24 |
| 4 | Fused-MBConv4, k3x3 | 4 | 2 | 48 |
| 5 | Fused-MBConv4, k3x3 | 4 | 2 | 64 |
| 6 | MBConv4, k3x3, SE0.25 | 6 | 2 | 128 |
| 7 | MBConv6, k3x3, SE0.25 | 9 | 1 | 160 |
| 8 | MBConv6, k3x3, SE0.25 | 15 | 2 | 256 |
| 9 | Conv1x1 & Pooling | 1 | - | 1280 |
| 10 | GRU | 1 | - | 128 |
| 11 | Flatten & FC | 1 | - | 128 |
| 12 | Output | 1 | - | 10/3 |
| Label | Status | Fault Sizes (mm) | Training Set | Testing Set | Sample Lengths |
|---|---|---|---|---|---|
| 0 | B007 | 0.1778 | 80 | 20 | 1024 |
| 1 | B014 | 0.3556 | 80 | 20 | 1024 |
| 2 | B021 | 0.5334 | 80 | 20 | 1024 |
| 3 | IR007 | 0.1778 | 80 | 20 | 1024 |
| 4 | IR014 | 0.3556 | 80 | 20 | 1024 |
| 5 | IR021 | 0.5334 | 80 | 20 | 1024 |
| 6 | OR007 | 0.1778 | 80 | 20 | 1024 |
| 7 | OR014 | 0.3556 | 80 | 20 | 1024 |
| 8 | OR021 | 0.5334 | 80 | 20 | 1024 |
| 9 | Normal | — | 80 | 20 | 1024 |
| Label | Load/RPM | Status | Training Set | Testing Set |
|---|---|---|---|---|
| 0 | 0 HP, 1500 r/min | Bearing fault | 80 | 20 |
| 1 | 0 HP, 1500 r/min | Rotor fault | 80 | 20 |
| 2 | 0 HP, 1500 r/min | Normal | 80 | 20 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mo, C.; Huang, K. Intelligent Fault Diagnosis Method Based on Cross-Device Secondary Transfer Learning of Efficient Gated Recurrent Unit Network. Sensors 2024, 24, 4070. https://doi.org/10.3390/s24134070
Mo C, Huang K. Intelligent Fault Diagnosis Method Based on Cross-Device Secondary Transfer Learning of Efficient Gated Recurrent Unit Network. Sensors. 2024; 24(13):4070. https://doi.org/10.3390/s24134070
Chicago/Turabian StyleMo, Chaoquan, and Ke Huang. 2024. "Intelligent Fault Diagnosis Method Based on Cross-Device Secondary Transfer Learning of Efficient Gated Recurrent Unit Network" Sensors 24, no. 13: 4070. https://doi.org/10.3390/s24134070
APA StyleMo, C., & Huang, K. (2024). Intelligent Fault Diagnosis Method Based on Cross-Device Secondary Transfer Learning of Efficient Gated Recurrent Unit Network. Sensors, 24(13), 4070. https://doi.org/10.3390/s24134070