Abstract
Human-level driving is the ultimate goal of autonomous driving. As the top-level decision-making aspect of autonomous driving, behavior decision establishes short-term driving behavior strategies by evaluating road structures, adhering to traffic rules, and analyzing the intentions of other traffic participants. Existing behavior decisions are primarily implemented based on rule-based methods, exhibiting insufficient generalization capabilities when faced with new and unseen driving scenarios. In this paper, we propose a novel behavior decision method that leverages the inherent generalization and commonsense reasoning abilities of visual language models (VLMs) to learn and simulate the behavior decision process in human driving. We constructed a novel instruction-following dataset containing a large number of image–text instructions paired with corresponding driving behavior labels, to support the learning of the Drive Large Language and Vision Assistant (DriveLLaVA) and enhance the transparency and interpretability of the entire decision process. DriveLLaVA is fine-tuned on this dataset using the Low-Rank Adaptation (LoRA) approach, which efficiently optimizes the model parameter count and significantly reduces training costs. We conducted extensive experiments on a large-scale instruction-following dataset, and compared with state-of-the-art methods, DriveLLaVA demonstrated excellent behavior decision performance. DriveLLaVA is capable of handling various complex driving scenarios, showing strong robustness and generalization abilities.
1. Introduction
In recent years, autonomous driving has made significant progress and has rapidly become one of the most promising fields in modern technology, with the potential to transform global transportation systems [1,2]. The ultimate goal of autonomous driving is to achieve human-level driving. As a core challenge of autonomous driving systems, behavior decision-making focuses on devising behavior strategies for autonomous vehicles that are consistent with human driving processes, such as lane change and speed adjustment, to ensure that they can intelligently respond to complex and dynamic traffic environments.
The challenge of behavior decisions lies in the need to adapt to diverse driving scenarios and make reasonable driving strategies. In traditional autonomous driving systems, behavior decision-making is typically based on rule-based methods [3,4,5,6], which determine driving strategies through pre-designed explicit rules to handle various scenarios. These methods have a high degree of interpretability but may fail when encountering scenarios not covered by the rules or previously unseen extreme driving scenarios, especially long-tail edge cases [7,8] (i.e., irregular behavior of road users, atypical obstacles, and unusual environments).
To ensure that vehicles can handle a wide range of driving scenarios, learning-based methods [9,10,11,12,13,14,15,16] have become the mainstream approach in modern autonomous driving systems for behavior decisions. These methods are data-driven, using human driving data to train decision models. Despite demonstrating excellent performance, their operation resembles a “black box”, meaning the entire decision process lacks intuitive interpretability and is difficult for humans to understand, leading to widespread public distrust and legal concerns. Moreover, current rule-based and learning-based methods lack a certain degree of social intelligence [17,18,19,20]. They treat autonomous driving as a mechanical task, viewing the interaction between the vehicle and its surroundings as simple kinematic cooperation [21,22], while neglecting the social cognitive context that is crucial for understanding driving behavior.
The rapid development of Large Language Models (LLMs) brings hope for addressing these challenges. LLMs possess powerful generalization and commonsense reasoning abilities, enabling them to infer information from previously unseen scenarios. This potential can help autonomous vehicles handle long-tail edge cases. Since LLMs are pretrained on vast amounts of interdisciplinary data, including understanding social interactions and human behavior, they may bridge the social intelligence gap present in autonomous driving systems [23]. Furthermore, to achieve an understanding of visual information, Vision Language Models (VLMs) build on LLMs by mapping multimodal inputs from images, videos, and other spatial data into the text domain, enabling VLMs to process and comprehend these multimodal data as text.
This paper aims to employ VLMs for behavior decision tasks in autonomous driving. We reference human driving paradigms to identify three essential capabilities for VLMs: (1) Observation: The model can accurately perceive the surrounding environment and changes in specific driving scenarios. (2) Reasoning: Based on observational information, the model can use common sense and experience to reason and make decisions. (3) Explanation: The model’s reasoning and decision process can be clearly explained.
Based on these three characteristics, this paper proposes a novel Vision Language Model, DriveLLaVA, to learn and simulate the behavior decision process in human driving. DriveLLaVA uses multimodal perception information from the ego vehicle as prompt input to accurately plan future driving behavior. To ensure the consistency of DriveLLaVA’s reasoning outputs with human behavior decisions, we constructed a highly interpretable instruction-following dataset based on the nuScenes [24] dataset. This dataset contains a large number of image–text instructions paired with corresponding driving behavior labels for fine-tuning the model.
The main contributions of this paper are as follows:
- (1)
- We construct an instruction-following dataset containing a large number of interpretable image–text instructions and driving behavior labels. The image–text instructions provide multimodal perception information, including surrounding traffic participants’ observation information, ego vehicle motion information, and environmental visual information. The driving behavior labels detail the ego vehicle’s actual future driving behaviors and are represented as text-based meta-action sets. This novel dataset comprehensively reflects the behavior decision process in human driving.
- (2)
- We propose a novel Vision Language Model, DriveLLaVA, specifically for autonomous driving behavior decision tasks and fine-tuned on the constructed instruction-following dataset. During fine-tuning, adapter technology is employed to efficiently optimize model parameters, significantly reducing training costs. The proposed VLM can efficiently infer driving behavior strategies consistently with human behavior.
- (3)
- We evaluate this method on multiple experiments, and DriveLLaVA outperforms all baseline methods, demonstrating excellent behavior decision performance. Additionally, DriveLLaVA can handle various unseen complex driving scenarios through few-shot generalization, showing strong robustness and generalization abilities.
2. Related Work
2.1. Learning-Based Autonomous Driving Behavior Decision
As the top-level planning aspect of autonomous driving, behavior decision-making establishes short-term driving strategies by evaluating road structures, adhering to traffic rules, and interpreting the activities of other traffic participants. The primary output of the behavior decision task is a limited set of actions suitable for driving scenarios [25], including basic driving behavior strategies (such as car-following and lane-changing).
Currently, learning-based autonomous driving behavior decision-making mainly includes Imitation Learning (IL) methods and Deep Reinforcement Learning (DRL) methods. IL methods, which learn from expert demonstrations to replicate human-like driving behavior, have become a prominent technology in the field of autonomous driving behavior decision. Tian et al. [9] proposed a personalized end-to-end IL decision method that efficiently learns a Model Prediction Control (MPC)-based driver-specific lane-changing policy from a few driver demonstrations. Ozcelik et al. [10] employed Generative Adversarial Imitation Learning (GAIL) and Curriculum Learning (CL) to mimic expert behavior in highway scenarios, aiming to achieve driving behavior similar to human drivers. Bhattacharyya et al. [11] described the use of GAIL and its extensions, such as Parameter Sharing-GAIL (PS-GAIL), Reward-Augmented Imitation Learning (RAIL), and Burn-InfoGAIL, to simulate highway driving behavior, replicate human demonstrations and generate realistic, emergent behavior in traffic flows.
Furthermore, researchers have explored the application of DRL methods in autonomous driving behavior decisions, with DRL integration fostering a series of advances across various driving scenarios. Kamran et al. [12] proposed an efficient DRL-based decision process to provide high-level strategies and specify the operation mode of low-level planners in merging scenarios. Valiente et al. [13] extended the use of Deep Q-Network (DQN) to facilitate autonomous behavior navigation in diverse scenarios such as highways and roundabouts. Zhang et al. [14] developed a two-stage lane-changing behavior decision system, demonstrating a complex balance between rule-based and DRL methods, enhancing cooperation between vehicles and improving overall safety and efficiency in traffic scenarios. Toghid et al. [15] introduced Social Value Orientation (SVO) into the DRL paradigm, enabling AVs to form alliances, guide traffic, and actively influence the behavior of Human-driven Vehicles (HVs) in mixed autonomy environments. Wang et al. [16] improved and stabilized Adversarial Inverse Reinforcement Learning (AIRL) by adding semantic rewards, making it suitable for challenging behavior decision tasks in highly interactive autonomous driving environments. However, current learning-based methods also have inherent limitations. On the one hand, the entire behavior decision process resembles a “black box”, lacking intuitive interpretability and transparency. On the other hand, due to the neglect of the social cognitive context in the driving process, there is a gap in social intelligence.
This paper aims to employ VLM for autonomous driving behavior decision tasks using multimodal perception information from ego vehicles as input to accurately plan future high-level driving behavior. To enhance the interpretability of the entire decision process, this work designs future driving behavior as a text-based meta-action set, with each meta-action subdivided into a combination of direction and speed components. Additionally, VLM is pretrained on vast amounts of interdisciplinary data, possesses common knowledge of the human world, and can address the social intelligence gap present in current methods.
2.2. LLM/VLM in Autonomous Driving
Currently, LLMs have achieved rapid development, showing significant potential in simulating human intelligence. These models are trained on vast amounts of internet data to understand and generate human-like text, demonstrating outstanding performance in natural language processing. The most notable features of LLM are their emergent capabilities, such as In-Context Learning (ICL) [26], Instruction-Following [27], and chain-of-thought (CoT) reasoning [28]. GPT [26] was a pioneering work that proposed using the Generative Pretrained Transformer (GPT) to address text understanding and generation problems. Subsequent versions, GPT-3.5 and GPT-4 [29], have also demonstrated impressive conversational and reasoning abilities. Recently released LLMs, such as PaLM [30], Vicuna [31], LLaMA and LLaMA 2 [32,33], generate corresponding text feedback based on human-followed instructions to better leverage LLM’s instruction-following capabilities. Furthermore, to handle various input types beyond text, research on VLM has also gained extensive academic attention. These models combine LLM with visual encoders, enabling them to efficiently perform various tasks involving images, videos and audio data. Based on the strong weights of natural language models, some recently proposed VLM, such as CLIP [34], PaLM-E [35], VisualBERT [36], simVLM [37], and Flamingo [38], possess excellent cross-modal understanding capabilities by aligning on large-scale multimodal datasets. Typically, VLMs use Q-former or linear mapping to align image features with the embedding space of language models. Blip-2 [39] uses Q-former to project multimodal inputs into the text space, while LLaVA [40] and Qwen-VL [41] train a fully connected layer as a projector to align image features with text features.
In the field of autonomous driving, LLM/VLM have the potential to understand traffic scenarios, improve the driving decision process, and revolutionize interactions between humans and vehicles. Trained on large amounts of autonomous driving data, they can extract valuable information from various sources such as maps, text annotations, and traffic rules to enhance the navigation and planning of autonomous vehicles, adapting to ever-changing traffic scenarios. Fu et al. [42] used GPT-3.5 for explanation and interaction in simple simulated scenarios, initially validating the applicability of LLM in autonomous driving tasks. Mao et al. [43] redefined motion planning as a language modeling problem, utilizing GPT-3.5 to describe high-precision vehicle trajectory coordinates and internal reasoning processes in natural language. Tian et al. [44] introduced DriveVLM, which integrates a chain-of-thought module combination for autonomous driving scenario description and analysis, achieving hierarchical planning functions. Sima et al. [45] designed DriveLM by fine-tuning VLM on private datasets to predict high-level driving plans (e.g., move straight, turn left).
This paper proposes a novel VLM, DriveLLaVA, to learn and simulate the behavior decision process in real human driving. Leveraging the strong generalization and commonsense reasoning abilities of VLM, DriveLLaVA can handle challenging long-tail driving scenarios. Additionally, DriveLLaVA offers better decision transparency and human-like reasoning compared to current methods, primarily due to our novel instruction-following dataset based on the nuScenes dataset.
3. Problem Definition
In the real world, human drivers observe their surroundings and other traffic participants, predicting their future movements while driving a vehicle. Based on these observations and predictions, human drivers make timely judgments, plan driving behaviors, and execute corresponding actions to control the vehicle’s future motion. Inspired by human driving thinking, this paper proposes an innovative method that leverages VLM to learn and simulate the decision process in human driving. This method uses multi-modal perception information from the ego vehicle as prompt input, including surrounding traffic participants’ observation information, ego vehicle motion information, and environmental visual information, guiding the VLM to accurately plan the ego vehicle’s future driving behavior.
Behavior decision-making aims to accurately plan the vehicle’s future high-level driving behaviors, such as lane changes and speed adjustment. To achieve this task, we use surrounding traffic participants’ observation information , ego vehicle motion information , and front-view camera images as inputs to guide the VLM in outputting the future driving behavior of ego vehicle :
where represents the decision function. Observation information includes category name of surrounding traffic participants i, (e.g., vehicles, pedestrians, and animals), location at the current observation time , and predicted trajectory for the next timesteps, which is defined as
Ego vehicle motion information is a set containing current states and historical trajectory :
where current states cover location , , velocity , acceleration , yaw rate and steering angle of the ego vehicle at the current observation time , and historical trajectory records the motion trajectory over the past timesteps. The front-view camera images provide rich environmental visual information about road facilities, traffic signs, and more.
The future driving behavior can be expressed as a set of meta-actions for ego vehicle over the future timesteps:
where meta-action is defined as a combination of direction judgment and speed estimation :
resulting in 10 different meta-actions (stop is independent). Meta-action information can cover most driving scenarios and comprehensively simulate the vehicle’s behavior patterns in complex road environments.
The problem is defined as follows: by integrating multimodal perception information, including surrounding traffic participants’ observation information, ego vehicle motion information, and environmental visual information, DriveLLaVA based on VLM learns and simulates the behavior decision process of human drivers in real driving environments, planning the vehicle’s future high-level driving behavior. This method aims to improve the adaptability and safety of autonomous driving technology in complex traffic environments.
4. Dataset Generation
The purpose of dataset generation is to create an instruction-following dataset specifically for autonomous driving behavior decision tasks, based on real vehicle and surrounding traffic environment information. This dataset will be used for instruction fine-tuning of the VLM, enabling it to learn and simulate the behavior decision process in real human driving. We reviewed several existing autonomous driving datasets, including the KITTI, Argoverse, and Waymo Open Dataset:
- (1)
- KITTI: An early benchmark for autonomous driving research, providing 3D point clouds and high-resolution images suitable for tasks such as object detection and SLAM. However, its dataset is relatively small, with limited and homogeneous scenes, lacking diversity and complex driving environments.
- (2)
- Argoverse: Contains various sensor data and map information, suitable for perception and prediction tasks, but has a low sampling frequency and limited scene coverage.
- (3)
- Waymo Open Dataset: A large-scale dataset containing various sensor data, such as 360-degree point clouds and high-resolution images, suitable for multiple autonomous driving tasks. However, the data are complex and voluminous, requiring high processing and storage capabilities.
This work selects nuScenes as the base dataset, an open dataset specifically designed for autonomous driving research. The dataset contains approximately 1000 real driving scenes collected from six cities, including Boston and Singapore, providing a rich and diverse set of urban driving environments. The nuScenes dataset features high-frequency sampling, with each scene lasting 20 s and sampled at a frequency of 2 Hz, resulting in a sequence of multiple keyframe camera images. Each keyframe image not only provides high-definition visual information but also comes with comprehensive sensor data. These sensor data detail ego vehicle motion data (like state data, trajectory data, and direction data) and surrounding traffic participants’ observation data (like category, current location, and predicted trajectory).
Given that the input for DriveLLaVA is multimodal prompt instructions and the output is fixed-format reasoning labels, this work constructs an instruction-following dataset specifically for autonomous driving behavior decision tasks based on the nuScenes dataset. This dataset contains a large number of image–text instructions paired with corresponding driving behavior labels. Figure 1 shows the construction process of the instruction-following dataset. We designed a tool library that includes a set of functions to extract DriveLLaVA input and output information from multi-view camera images and sensor data of each keyframe in the driving scenes.
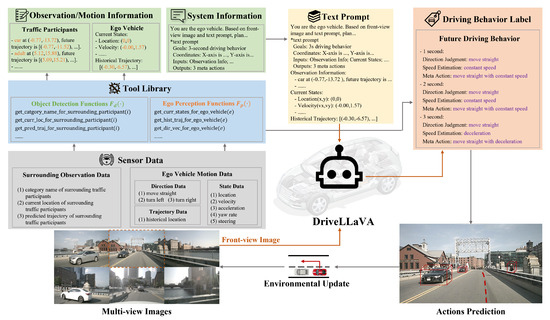
Figure 1.
Instruction—following dataset generation process.
To generate image–text instructions, first, object detection functions and ego perception functions in the tool library are used to extract specific sensor data. By processing these data, we obtained surrounding traffic participants’ observation information and ego vehicle motion information. Then, these data are encapsulated into a text prompt along with system information describing the background task. Finally, the front-view camera image of each keyframe in the driving scenes is selected and paired with the corresponding text prompt to generate image–text instructions, which are used to guide DriveLLaVA reasoning.
Similarly, to generate driving behavior labels, ego perception functions in the tool library are used to extract specific sensor data. By applying explicit rules to these data, we obtain the future driving behaviors that match each image–text instructions. These behaviors are then formatted into driving behavior labels and used to fine-tune the DriveLLaVA’s reasoning output.
4.1. Image–Text Instructions
To generate image–text instructions , all keyframe front-view camera images from various driving scenarios in the nuScenes dataset are first selected, providing rich environmental visual information. Next, the sensor data accompanying each frame are processed to obtain surrounding traffic participants’ observation information and ego vehicle motion information . Specifically, this method uses object detection functions from the tool library to extract surrounding traffic participants’ observation data from the sensor data , such as category name , current location , and predicted trajectory . For each surrounding traffic participant, a fixed sentence is designed to describe these attributes, which together constitute the observation information . Using ego perception functions from the tool library, this method extracts current state information of the ego vehicle from , including location , velocity , acceleration , yaw rate , and steering angle , as well as historical trajectory . These are embedded into the fixed text to generate ego vehicle motion information . Finally, system information for background description, including task objective and coordinate, is provided, integrating it with surrounding traffic participants observation information and ego vehicle motion information to form text prompt , as shown in the upper part of Figure 1. Each keyframe front-view camera image is paired with the corresponding text prompt , thus forming the image–text instruction .
4.2. Driving Behavior Labels
To enable the VLM to learn the outcomes of real human behavior decisions, this method generated driving behavior labels that match the image–text instructions . The specific process is shown in Algorithm 1. The driving behavior label set is initialized (line 1). Next, ego perception functions in the tool library are used to extract the adjacent speeds of the ego vehicle in the future timesteps from the sensor data . By evaluating their numerical relationships, the longitudinal behavior label (speed estimation) is determined. Firstly, if both adjacent speeds are below the specified speed threshold , is set to “stop”. Secondly, if the absolute difference between adjacent speeds is less than the speed threshold , is set to “constant speed”. Finally, the size relationship between adjacent speeds is assessed: if is greater than , is set to “acceleration”; if is less than , is set to “deceleration” (lines 3–13). The ego vehicle’s direction command vector is also extracted using and based on its value type, the lateral behavior label (direction judgment) is determined. When is [1, 0, 0], is set to “turn right”; when is [0, 1, 0], is set to “turn left”; and when is [0, 0, 1], is set to “move straight” (lines 14–21). After obtaining the longitudinal and lateral behavior labels, we combine them into meta-actions a (“stop” is independent) and add them to driving behavior set (lines 22–24).
| Algorithm 1 Driving behavior labeling algorithm |
|
Based on the above steps, this work constructs an instruction-following dataset containing approximately 24K image–text instructions and corresponding driving behavior label samples. ChatGPT-4 was used to refine these samples into more concise forms. Compared to other datasets, the instruction-following dataset constructed in this work has the following advantages. (a) Diverse and Complex Scenarios: It includes 24K driving images collected from a wide variety of urban driving environments. This diversity ensures the dataset covers numerous complex driving conditions, enhancing the robustness of the model’s decision capabilities. (b) Multimodal Input Prompts: It integrates high-resolution visual information with comprehensive sensor data, like multi-view camera images and text prompts. This multimodal information provides a richer context for training, allowing the model to make more informed and accurate driving decisions. (c) Rich image–text Instructions and Precise Driving Behavior Labels: The rich image–text instructions generated from front-view camera images and sensor data, along with the precise driving behavior labels created through the designed tool library, provide the model with a large number of training samples and help in better learning and simulating human driving behavior decision processes. An example of a sample from the instruction-following dataset is shown in Figure 2.

Figure 2.
Example of instruction−following dataset sample, including Front-view Image, System Message, Observation Message, Motion Message, and Behavior Label.
5. Methodology
5.1. Model Architecture
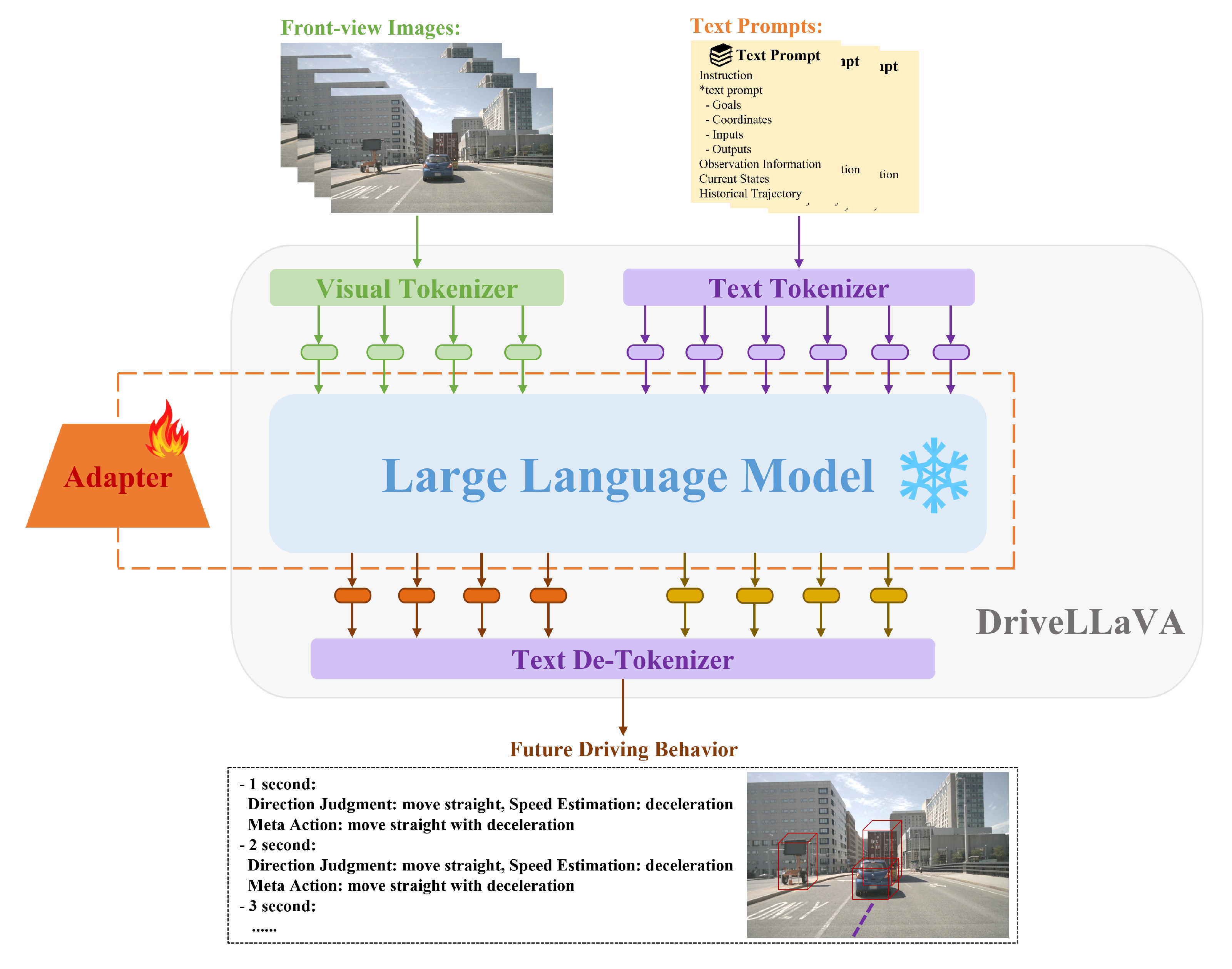
The DriveLLaVA model architecture is divided into three main parts, as shown in Figure 3: multimodal data encoding and alignment, lightweight fine-tuning with an adapter for the LLM base, and fixed-format decoding of future driving behavior.
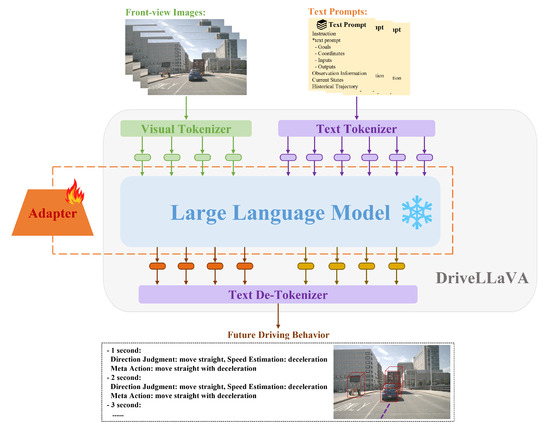
Figure 3.
Overall architecture of DriveLLaVA divided into three parts: Multimodal data encoding and alignment, lightweight fine-tuning of the LLM with adapter, and fixed-format decoding of future driving behavior.
Firstly, the multimodal data-encoding and alignment part is mainly responsible for converting visual images and text prompts into a format that the LLM can process. The text prompts are encoded through a text tokenizer, while the visual images are encoded through a visual tokenizer and aligned with the text embedding space. These two different modalities of data are converted into token sequences with unified embedding space dimensions and are input together into the LLM for processing.
Secondly, to ensure that the DriveLLaVA model can accurately adapt to the current task, adapter technology is used for lightweight fine-tuning of the LLM. This adapter fine-tuning approach enhances the LLM’s ability to understand and process the encoded and aligned multimodal data, allowing it to generate effective prediction tokens. Additionally, by optimizing the number of LLM parameters, this approach significantly reduces training costs while ensuring that the model maintains high performance and efficiency.
Finally, the predicted tokens generated by the LLM are decoded using a text de-tokenizer. In the decoding process, to improve the efficiency of data extraction, the predicted future driving behavior is designed in a fixed format: a text-based set of meta-actions, with each meta-action subdivided into a combination of direction and speed components.
5.1.1. Multimodal Data Encoding and Alignment
The input of DriveLLaVA is the multimodal information for each driving scene frame, namely the image–text instruction . First, the text prompt is converted into a series of text tokens using a text tokenizer :
Secondly, the front-view camera image is processed using a visual tokenizer. The visual tokenizer comprises an image encoder and an image-language connector . Following the work of [40], we adopt CLIP-ViT-L/336px as the image encoder, which has been pretrained on a large number of image–text pairs to extract the visual features of the input image :
where the first token of the visual features, , represents the global feature of the image, while the other 256 tokens, , correspond to the local features of various patches in the image. The global feature and all local features are concatenated to obtain the complete visual features of the input image :
where ⊕ denotes concatenation. We use a two-layer perceptron (MLP) as the image–language connector to map the complete visual features into the text embedding space:
where represents the image tokens, which have the same embedding space dimensions as the text tokens .
Finally, all the obtained tokens are concatenated, where , and processed as the input to the LLM.
5.1.2. Lightweight Fine-Tuning of the LLM with the Adapter
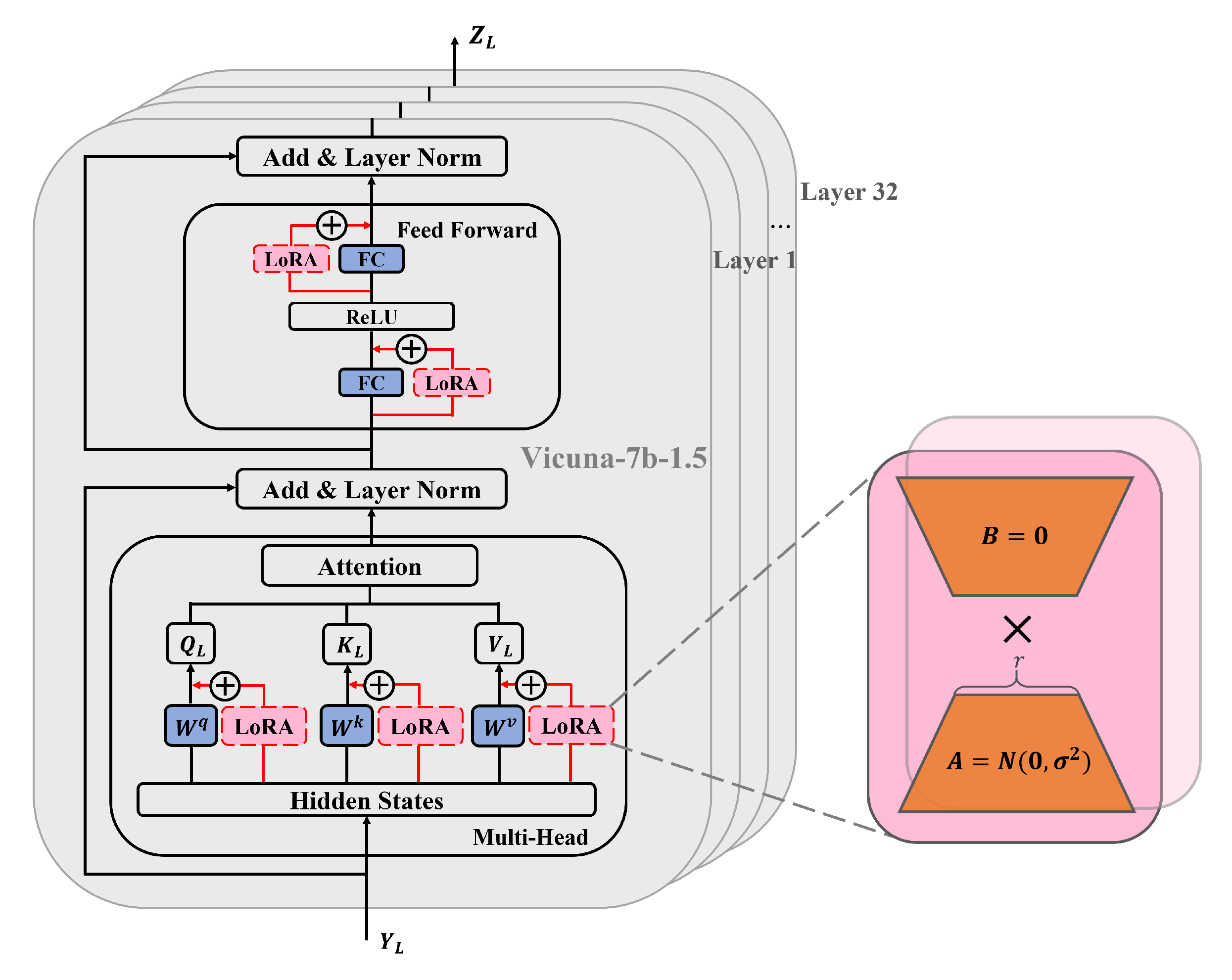
This work uses LoRA as an adapter for lightweight fine-tuning of the LLM. The core idea of LoRA fine-tuning approach is to achieve dynamic adjustment of model weights by adding low-rank matrices to the weight matrix of the pretrained model. This fine-tuning approach allows the effective adjustment of the model to a specific task by introducing only a small number of parameters while keeping the weight parameters of the pretrained model unchanged.
As shown in Figure 4, Vicuna-7b-1.5 is used as the LLM, which consists of 32 layers of transformers and has excellent instruction-following capabilities for language tasks. In this work, LoRA is added to the linear layers of each transformer in Vicuna-7b-1.5, including the Multi-Head Attention (MHA) and Feed-Forward Network (FFN) layers. First, the LLM input enters the Multi-Head Attention layer. In this layer, LoRA is added to each attention matrix, including query matrix , key matrix , and value matrix . LoRA is a bypass module that includes a down-projection matrix and an up-projection matrix. During training, the input and output dimensions of the Multi-Head Attention layer remain unchanged, and the linear transformation matrices of each attention matrix are frozen. Only the added down-projection matrix and up-projection matrix are trained, with initialized using a random Gaussian distribution and initialized using a zero matrix. Therefore, the calculation process of the entire Multi-Head Attention mechanism can be represented as follows:
where , and are the linear transformation matrices of query matrix , key matrix and value matrix for each attention head . , , and are the corresponding down-projection matrices. , and are the corresponding up-projection matrices, with . represents the output transformation matrix.
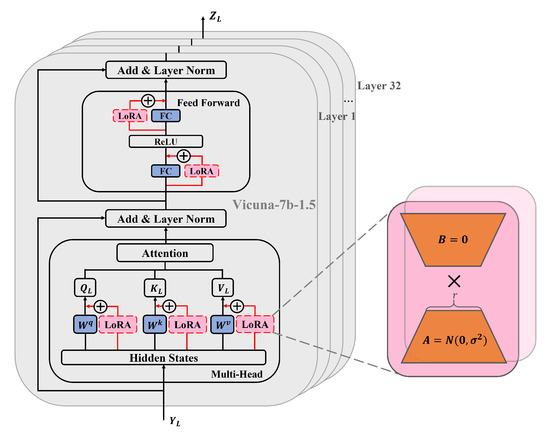
Figure 4.
Lightweight fine-tuning of the LLM with the adapter.
Furthermore, by performing a residual connection and layer normalization, we obtain :
then goes through the feed-forward network layer , which consists of two fully connected layers and a ReLU activation function. We add LoRA to both fully connected layers, and the training method is the same as mentioned above. The weight matrices of each fully connected layer are frozen, and only the down-projection matrix and up-projection matrix are trained. Then, by performing another residual connection and layer normalization, we obtain the output of a single transformer layer :
where is the weight matrix of the first fully connected layer and is the weight matrix of the second fully connected layer. and are the corresponding down-projection matrices. and are the corresponding up-projection matrices, with .
Finally, goes through layers of transformers, repeating the above process, to obtain the final prediction tokens of the LLM, which contain all the output information for the current task.
5.1.3. Fixed-Format Decoding of Future Driving Behavior
To facilitate extraction and subsequent processing, predicted future driving behavior is decoded into a fixed format. The specific decoding process is as follows:
After obtaining the prediction tokens generated by the LLM, the text de-tokenizer is used to decode them back into human language. During the decoding process, future driving behavior is designed as text-based meta-action set, with each meta-action subdivided into a combination of direction and speed components. This fixed-format decoding of driving behavior enhances the transparency and interpretability of the model throughout the decision process. The above decoding process can be represented as
where indicates that future driving behavior belongs to the text domain.
5.2. Model Fine-Tuning
To enable DriveLLaVA to understand and handle the current task, we perform instruction fine-tuning using the instruction-following dataset constructed in Section 4. Considering that the output of DriveLLaVA is only a text corpus, we use the cross-entropy loss to supervise the model’s output. The cross-entropy loss is defined as follows:
where represents the trainable parameters and represents all the driving behavior sequences before the current predicted meta-action .
Throughout the fine-tuning process, to significantly reduce training costs, we adopt the LoRA approach to efficiently optimize the number of model parameters. This means keeping the weights of the image encoder and the LLM frozen and updating only the weights of the image-language connector and LoRA by minimizing the cross-entropy loss. This allows DriveLLaVA to accurately infer future behavior strategies consistent with actual human driving decisions.
6. Experiment
This section evaluates the capabilities of DriveLLaVA through extensive experiments on an instruction-following dataset. First, the experimental setup and evaluation metrics are introduced. Next, this method is compared with other baseline methods, demonstrating its superior performance in behavior decisions. An ablation study is then conducted to verify the compatibility and optimization design of our method. Additionally, a comparative experiment between in-context learning and instruction fine-tuning is designed, proving the necessity of model fine-tuning. Finally, extensive qualitative analysis of behavior decision examples in various complex driving scenarios demonstrates DriveLLaVA’s robustness and generalization ability.
6.1. Experimental Setup
The entire instruction-following dataset is divided into a training set and a validation set. The training set is used to instruction fine-tune the model, and the model’s performance is evaluated on the validation set, which ensures a fair comparison with baseline methods. During the instruction fine-tuning phase, the AdamW optimizer is used to update the loss function, with the initial learning rate set to 2 × 10−5 and decayed to 0 using cosine annealing. The input image size is 336 × 336. Considering the large number of parameters in the entire model, the LoRA fine-tuning approach is used to optimize the number of model parameters and save training costs. The dimension of the down-projection matrix r is set to 128, and the target modules are set to all linear layers of the LLM backbone in the model. The model is trained for five epochs, with a batch size of three per GPU. The entire training process used 8 RTX 4090 (24 GB) GPUs.
To quantitatively evaluate the effectiveness of our method in behavior decision tasks, meta-action accuracy is used as the evaluation metric and further divides the overall accuracy into direction and speed components. By comparing the model’s inference results with the manually collected ground truth labels, we comprehensively reflect the accuracy of the decisions and their similarity to human driving behavior. Following common practice, our method evaluates the behavior decision results within a 3-s time horizon.
6.2. Dataset Analysis
Table 1 presents a comparison with the previous datasets designed for driving understanding with natural language. The instruction-following dataset constructed in this work can simultaneously include perception, reasoning, decision, and alignment, offering a more reasonable and comprehensive reflection of the behavior decision process in actual human driving. Moreover, the vast amount of image–text instructions and corresponding driving behavior labels generated from the rich camera images and sensor information in the nuScenes dataset also enhances the interpretability and transparency of the entire decision process.

Table 1.
Comparison of autonomous driving datasets for driving understanding.
6.3. Comparison with Baseline Methods
To demonstrate DriveLLaVA’s superior performance in behavior decision, this work compares it with advanced baseline methods, which encompass the rule-based method, the LM-based method, and the end-to-end IL method. They have shown satisfactory results in behavior decision tasks, providing a robust benchmark for comparing the performance of DriveLLaVA. These baseline methods include
- (1)
- InstructBLIP [51] and Apollo [52]: Behavior decision methods based on VLM and Finite State Machines (FSMs), achieving few-shot adaptation by providing input/decision pairs.
- (2)
- DriveVLM [44]: An autonomous driving system that enhances scene understanding and planning capabilities through VLM, integrating a unique combination of chain-of-thought (CoT) modules to achieve scene description, scene analysis, and hierarchical planning.
- (3)
- DriveMLM [53]: An autonomous driving behavior planning module built on LLM, using driving rules, user commands, and sensor data as inputs to make driving decisions and provide explanations.
- (4)
- DriveLM-Agent and DriveLM-Agent(GT) [45]: A decision module based on VLM, trained on internet-scale data, making decisions through Visual Question Answering (VQA) adaptation.
- (5)
- TransFuser++ [54]: An end-to-end autonomous driving system based on the IL method, tested on CARLA, with excellent route-following capabilities.
Table 2 shows a comparison of DriveLLaVA with baseline methods in terms of behavior decision performance. DriveLLaVA significantly outperformed baseline methods in meta-action accuracy metrics, demonstrating the accuracy of this approach in generating human-like driving behaviors. Specifically, DriveLLaVA achieves the highest meta-action accuracy at 78.97%, an 8.78% improvement over the second-best method, TranFuser++. Its accuracy levels in the direction and speed components are 90.99% and 82.42%, respectively, surpassing baseline methods and showcasing its decision capabilities across various directional and speed decisions. Moreover, in driving scenarios such as straight roads and intersections, DriveLLaVA consistently exhibits superior behavior decision ability, indicating its high efficiency and practicality in common driving scenarios. Compared to non-large model (LM)-based methods, such as Apollo and TransFuser++, DriveLLaVA leverages the general knowledge and understanding capabilities of VLM to plan behavior strategies that more closely resemble those of human drivers, especially in extreme driving scenarios, such as adverse weather, unexpected pedestrians, or obstacles, where meta-action accuracy is significantly improved.
Table 2.
Behavior decision performance.
Compared to LM-based methods, such as DriveVLM, DriveMLM and DriveLM-Agent, DriveLLaVA also has performance advantages. These methods heavily rely on intensive multi-turn QA pairs (QAs) and chain-of-thought reasoning, making their systems complex and time-consuming. In contrast, DriveLLaVA only uses the multi-modal perception information from the ego vehicle as input observations, relying on the powerful prior knowledge capability of VLM for behavior decisions, making it much simpler than these methods. Thus, DriveLLaVA’s exceptional meta-action accuracy underscores its prowess in behavior decision, substantially enhancing autonomous driving safety. The integration of multi-turn QAs holds potential for further performance enhancements.
6.4. Ablation Study
An ablation study was conducted to verify the compatibility and optimization design of this method. The ego vehicle’s driving behavior is represented as a set of meta-actions over multiple future timesteps. A series of ablation experiments were designed by varying the granularity of meta-actions, i.e., the number of meta-actions representing future driving behavior, to observe the performance differences of DriveLLaVA. Specifically, the ego vehicle’s future 3-s driving behavior was represented with 1 meta-action (3 s interval), 3 meta-actions (1 s interval), and 6 meta-actions (0.5 s interval), using meta-action accuracy as the evaluation metric. The results of the ablation experiment are provided in Table 3. It was observed that the model performs optimally when the meta-action granularity is set to 3. However, the model’s performance decreases when the granularity is set to 1 or 6. Nevertheless, these configurations generally perform similarly to baseline methods. Thus, the ablation study on meta-action granularity preliminarily verifies the compatibility and optimization design of this method.
Table 3.
Quantitative results of ablation study.
6.5. Instruction Fine-Tuning vs. In-Context Learning
In-Context Learning and instruction fine-tuning are two popular strategies for guiding VLM to perform specific tasks. Although the instruction fine-tuning strategy in this work performs excellently in behavior decision tasks, it raises the question of whether In-Context Learning could achieve comparable results. To this end, an In-Context Learning experiment was designed, where the prompts and expected outputs from the training set were used as new exemplar inputs to guide DriveLLaVA. The results were then compared with instruction fine-tuning.
As shown in Table 4, instruction fine-tuning significantly outperforms In-Context Learning in terms of meta-action accuracy. This is mainly because, in In-Context Learning, the model’s contextual observation window is very limited. In this work, due to the inherent sequence length limitation of DriveLLaVA, it can only accommodate up to two examples at a time. Therefore, in behavior decision, instruction fine-tuning performs noticeably better than In-Context Learning, demonstrating that the instruction fine-tuning strategy is indispensable in this work.
Table 4.
Instruction fine-tuning vs. In-Context Learning.
6.6. Visualization and Qualitative Analysis
To demonstrate the robustness and generalization ability of DriveLLaVA, Figure 5 provides a visual comparison of DriveLLaVA, GPT-DRIVER, and ChatGPT-4 on the task of behavior decision. These scenarios include extreme weather conditions (such as night and rainy days), construction zones, intersections, and unexpected situations during driving (such as pedestrians crossing a zebra crossing or encountering a barrier gate). As shown in the figure, DriveLLaVA accurately identifies key traffic participants and predicts their future actions in various complex driving scenarios. Based on these observations and predictions, it generates comprehensive and precise high-level driving behaviors, using a meta-action sequence to depict behavioral states every second. In contrast, GPT-DRIVER uses a single meta-action to describe the entire future 3-s driving behavior, which is less comprehensive and more error-prone. Meanwhile, the driving behavior descriptions by ChatGPT-4 are overly verbose and lack intuitiveness. Thus, this approach provides greater comprehensiveness and intuitiveness and is comparable to the current best, ChatGPT-4. For example, in Figure 5a, DriveLLaVA can promptly detect the black car ahead and the white car in the left lane about to merge into the current lane during a low-visibility nighttime roundabout driving scenario. It then generates a right turn and deceleration action to avoid collisions with these cars. As shown Figure 5d, while driving through a construction zone, DriveLLaVA can recognize all obstacles in the road (such as traffic cones) and construction trucks. It then generates a straight-ahead action, maintaining a steady speed to pass through the construction zone. As shown in Figure 5g, DriveLLaVA can promptly spot a pedestrian crossing the zebra crossing ahead and appropriately generate a stop action to yield to the pedestrian. Figure 6 shows the complete driving process inferred by DriveLLaVA for the next three seconds. In Figure 6a, the future driving behavior of the ego vehicle is depicted when it encounters a sudden lane change from the left lane into the straight lane, and then other vehicles pass each other. Figure 6b illustrates the ego vehicle’s left lane change behavior in a construction zone.


Figure 5.
Visualization examples of behavior decisions.

Figure 6.
Driving video of DriveLLaVA. Video (a) shows the driving behavior of the ego vehicle when encountering lane change and passing by other vehicles; Video (b) shows the lane change behavior of the ego vehicle in a construction zone.
Therefore, by quantitatively analyzing the results of DriveLLaVA in multiple experiments, the effectiveness and superior decision capabilities of this method are demonstrated. Through visualization and qualitative analysis of behavior decision examples of DriveLLaVA in various complex traffic driving scenarios, the robustness and generalization ability of DriveLLaVA are further illustrated.
7. Conclusions
This paper introduces DriveLLaVA, a novel VLM dedicated to autonomous driving behavior decision tasks. A novel instruction-following dataset is developed, containing a large number of interpretable image–text instructions and driving behavior labels, used for fine-tuning DriveLLaVA. During the fine-tuning process, the LoRA approach is employed to optimize model parameters and reduce training costs. DriveLLaVA can utilize multimodal perception information, including surrounding traffic participants’ observation information, ego vehicle motion information, and environmental visual information, to infer future behavior strategies consistent with human driving.
Through extensive experiments on the instruction-following dataset, DriveLLaVA demonstrated excellent performance, robustness, and generalization ability in behavior decisions, surpassing baseline methods. The implementation of DriveLLaVA offers research potential for the field of autonomous driving decisions. However, there are still some drawbacks and limitations. On the one hand, due to dataset limitations, our method only fine-tunes DriveLLaVA for the autonomous driving behavior decision task without a pretraining process for the model. Future work should first pretrain it using a larger-scale autonomous driving domain dataset to equip it with prior general knowledge about autonomous driving, followed by instruction fine-tuning for specific tasks. On the other hand, due to parameter limitations, VLM-based methods usually exhibit longer inference times compared to existing MLP-based methods, making it challenging to meet the real-time requirements of commercial driving applications. Future work should focus on distilling a smaller VLM or using a large VLM to guide a smaller VLM to optimize inference time.
Author Contributions
Author Contributions: Conceptualization, R.Z.; methodology, Q.Y.; software, J.L.; validation, Y.F.; formal analysis, Y.L.; investigation, F.G.; resources, F.G.; writing—original draft preparation, Q.Y.; writing—review and editing, R.Z.; visualization, F.G.; funding acquisition, R.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Science Foundation of China under Grant 52202495 and Grant 52202494.
Institutional Review Board Statement
Not applicable for studies not involving humans or animals.
Informed Consent Statement
This study does not involve humans.
Data Availability Statement
The data presented in this study are available upon request from the corresponding author.
Conflicts of Interest
On behalf of all the authors, the corresponding author states that there are no conflicts of interest.
References
- Liu, T.; Liao, Q.; Gan, L. The role of the hercules autonomous vehicle during the covid-19 pandemic: An autonomous logistic vehicle for contactless goods transportation. IEEE Robot. Autom. Mag. 2021, 28, 48–58. [Google Scholar] [CrossRef]
- Parekh, D.; Poddar, N.; Rajpurkar, A. A review on autonomous vehicles: Progress, methods and challenges. Electronics 2022, 11, 2162. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, X.; Li, L. A novel lane change decision-making model of autonomous vehicle based on support vector machine. IEEE Access 2019, 7, 26543–26550. [Google Scholar] [CrossRef]
- Ahmad, I.S.; Abubakar, S.; Gambo, F.L. A Rule-Based Expert System for Automobile Fault Diagnosis. Int. J. Perceptive Cogn. Comput. 2021, 7, 20–25. [Google Scholar]
- Claussmann, L.; O’Brien, M.; Glaser, S. Multi-criteria decision making for autonomous vehicles using fuzzy dempster-shafer reasoning. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; IEEE: New York, NY, USA, 2018; pp. 2195–2202. [Google Scholar]
- Michon, J.A. Explanatory pitfalls and rule-based driver models. Accid. Anal. Prev. 1989, 21, 341–353. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Lin, Y.-L.; Zheng, N.-N. Artificial intelligence test: A case study of intelligent vehicles. Artif. Intell. Rev. 2018, 50, 441–465. [Google Scholar] [CrossRef]
- Sun, C.; Deng, Z.; Chu, W. Acclimatizing the operational design domain for autonomous driving systems. IEEE Intell. Transp. Syst. Mag. 2021, 14, 10–24. [Google Scholar] [CrossRef]
- Tian, H.; Wei, C.; Jiang, C. Personalized lane change planning and control by imitation learning from drivers. IEEE Trans. Ind. Electron. 2022, 70, 3995–4006. [Google Scholar] [CrossRef]
- Ozcelik, M.B.; Agin, B.; Caldiran, O. Decision Making for Autonomous Driving in a Virtual Highway Environment based on Generative Adversarial Imitation Learning. In Proceedings of the 2023 Innovations in Intelligent Systems and Applications Conference (ASYU), Sivas, Türkiye, 11–13 October 2023; IEEE: New York, NY, USA, 2023; pp. 1–6. [Google Scholar]
- Bhattacharyya, R.; Wulfe, B.; Phillips, D.J. Modeling human driving behavior through generative adversarial imitation learning. IEEE Trans. Intell. Transp. Syst. 2022, 24, 2874–2887. [Google Scholar] [CrossRef]
- Kamran, D.; Ren, Y.; Lauer, M. High-level decisions from a safe maneuver catalog with reinforcement learning for safe and cooperative automated merging. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; IEEE: New York, NY, USA, 2021; pp. 804–811. [Google Scholar]
- Valiente, R.; Razzaghpour, M.; Toghi, B. Prediction-Aware and Reinforcement Learning-Based Altruistic Cooperative Driving. IEEE Trans. Intell. Transp. Syst. 2023, 25, 2450–2465. [Google Scholar] [CrossRef]
- Zhang, J.; Chang, C.; Zeng, X. Multi-agent DRL-based lane change with right-of-way collaboration awareness. IEEE Trans. Intell. Transp. Syst. 2022, 24, 854–869. [Google Scholar] [CrossRef]
- Toghi, B.; Valiente, R.; Sadigh, D. Social coordination and altruism in autonomous driving. IEEE Trans. Intell. Transp. Syst. 2022, 23, 24791–24804. [Google Scholar] [CrossRef]
- Wang, P.; Liu, D.; Chen, J. Decision making for autonomous driving via augmented adversarial inverse reinforcement learning. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; IEEE: New York, NY, USA, 2021; pp. 1036–1042. [Google Scholar]
- Wang, F.Y.; Carley, K.M.; Zeng, D. Social computing: From social informatics to social intelligence. IEEE Intell. Syst. 2007, 22, 79–83. [Google Scholar] [CrossRef]
- Wang, F.Y. Forward to the Past: CASTLab’s Cyber-Social-Physical Approach for ITS in 1999 [History and Perspectives]. IEEE Intell. Transp. Syst. Mag. 2023, 15, 171–175. [Google Scholar] [CrossRef]
- Li, B.; Cao, D.; Tang, S. Sharing traffic priorities via cyber–physical–social intelligence: A lane-free autonomous intersection management method in metaverse. IEEE Trans. Syst. Man Cybern. Syst. 2022, 53, 2025–2036. [Google Scholar] [CrossRef]
- Wang, F.Y. Parallel intelligence in metaverses: Welcome to Hanoi! IEEE Intell. Syst. 2022, 37, 16–20. [Google Scholar] [CrossRef]
- Karle, P.; Geisslinger, M.; Betz, J. Scenario understanding and motion prediction for autonomous vehicles—Review and comparison. IEEE Trans. Intell. Transp. Syst. 2022, 23, 16962–16982. [Google Scholar] [CrossRef]
- Chen, L.; Li, Y.; Huang, C. Milestones in autonomous driving and intelligent vehicles: Survey of surveys. IEEE Trans. Intell. Veh. 2022, 8, 1046–1056. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, X.; Wang, X. The ChatGPT after: Building knowledge factories for knowledge workers with knowledge automation. IEEE/CAA J. Autom. Sin. 2023, 10, 2041–2044. [Google Scholar] [CrossRef]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A Multimodal Dataset for Autonomous Driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
- Mozaffari, S.; Al-Jarrah, O.Y.; Dianati, M. Deep learning-based vehicle behavior prediction for autonomous driving applications: A review. IEEE Trans. Intell. Transp. Syst. 2020, 23, 33–47. [Google Scholar] [CrossRef]
- Ouyang, L.; Wu, J.; Jiang, X. Training language models to follow instructions with human feedback. Adv. Neural Inf. Process. Syst. 2022, 35, 27730–27744. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- OpenAI. GPT-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Chowdhery, A.; Narang, S.; Devlin, J. Palm: Scaling language modeling with pathways. J. Mach. Learn. Res. 2023, 24, 1–113. [Google Scholar]
- Zheng, L.; Chiang, W.L.; Sheng, Y. Judging llm-as-a-judge with mt-bench and chatbot arena. Adv. Neural Inf. Process. Syst. 2024, 36. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Touvron, H.; Martin, L.; Stone, K. Llama 2: Open foundation and fine-tuned chat models. arXiv 2023, arXiv:2307.09288. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; PMLR: New York, NY, USA, 2021; pp. 8748–8763. [Google Scholar]
- Driess, D.; Xia, F.; Sajjadi, M.S.M. Palm-e: An embodied multimodal language model. arXiv 2023, arXiv:2303.03378. [Google Scholar]
- Li, L.H.; Yatskar, M.; Yin, D.; Hsieh, C.J.; Chang, K.W. VisualBERT: A Simple and Performant Baseline for Vision and Language. arXiv 2019, arXiv:1908.03557. [Google Scholar]
- Wang, Z.; Yu, J.; Yu, A.W. Simvlm: Simple visual language model pretraining with weak supervision. arXiv 2021, arXiv:2108.10904. [Google Scholar]
- Alayrac, J.B.; Donahue, J.; Luc, P. Flamingo: A visual language model for few-shot learning. Adv. Neural Inf. Process. Syst. 2022, 35, 23716–23736. [Google Scholar]
- Li, J.; Li, D.; Savarese, S. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; PMLR: New York, NY, USA, 2023; pp. 19730–19742. [Google Scholar]
- Liu, H.; Li, C.; Li, Y. Improved baselines with visual instruction tuning. arXiv 2023, arXiv:2310.03744. [Google Scholar]
- Bai, J.; Bai, S.; Yang, S. Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv 2023, arXiv:2308.12966. [Google Scholar]
- Fu, D.; Li, X.; Wen, L. Drive like a human: Rethinking autonomous driving with large language models. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 1–6 January 2024; pp. 910–919. [Google Scholar]
- Mao, J.; Qian, Y.; Zhao, H. Gpt-driver: Learning to drive with gpt. arXiv 2023, arXiv:2310.01415. [Google Scholar]
- Tian, X.; Gu, J.; Li, B. DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models. arXiv 2024, arXiv:2402.12289. [Google Scholar]
- Sima, C.; Renz, K.; Chitta, K. Drivelm: Driving with graph visual question answering. arXiv 2023, arXiv:2312.14150. [Google Scholar]
- Wu, D.; Han, W.; Wang, T. Language Prompt for Autonomous Driving. arXiv 2023, arXiv:2309.04379. [Google Scholar]
- Qian, T.; Chen, J.; Zhuo, L. NuScenes-QA: A Multi-Modal Visual Question Answering Benchmark for Autonomous Driving Scenario. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 4542–4550. [Google Scholar]
- Sachdeva, E.; Agarwal, N.; Chundi, S. Rank2Tell: A Multimodal Driving Dataset for Joint Importance Ranking and Reasoning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 1–6 January 2024; pp. 7513–7522. [Google Scholar]
- Xu, Z.; Zhang, Y.; Xie, E. DriveGPT4: Interpretable End-to-End Autonomous Driving via Large Language Model. arXiv 2023, arXiv:2310.01412. [Google Scholar]
- Movva, R.; Balachandar, S.; Peng, K. Large Language Models Shape and Are Shaped by Society: A Survey of arXiv Publication Patterns. arXiv 2023, arXiv:2307.10700. [Google Scholar]
- Dai, W.; Li, J.; Li, D.; Tiong, A.M.H.; Zhao, J.; Wang, W.; Li, B.; Fung, P.N.; Hoi, S. InstructBLIP: Towards General-Purpose Vision-Language Models with Instruction Tuning. Adv. Neural Inf. Process. Syst. 2024, 36. [Google Scholar]
- Xu, K.; Xiao, X.; Miao, J.; Luo, Q. Data Driven Prediction Architecture for Autonomous Driving and Its Application on Apollo Platform. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; IEEE: New York, NY, USA, 2020; pp. 175–181. [Google Scholar]
- Wang, W.; Xie, J.; Hu, C.Y.; Zou, H.; Fan, J.; Tong, W.; Wen, Y.; Wu, S.; Deng, H.; Li, Z.; et al. DriveMLM: Aligning Multi-Modal Large Language Models with Behavioral Planning States for Autonomous Driving. arXiv 2023, arXiv:2312.09245. [Google Scholar]
- Jaeger, B.; Chitta, K.; Geiger, A. Hidden Biases of End-to-End Driving Models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 8240–8249. [Google Scholar]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).