
Enhanced Hybrid Vision Transformer with Multi-Scale Feature Integration and Patch Dropping for Facial Expression Recognition

Abstract
1. Introduction
- We propose a lightweight facial expression recognition method based on a hybrid vision transformer. This method integrates an improved efficient multi-scale attention module, enabling the model to capture multi-scale expression image features and enhance the model’s utilization efficiency of key information through cross-dimensional expression feature aggregation. This effectively addresses the occlusion FER problem.
- We designed a simple and effective patch dropping module, which simulates the non-uniform distribution characteristic of human visual attention, guiding the model to focus on the most discriminative features and reducing the influence of irrelevant features.
- We conducted extensive experiments on the RAF-DB dataset and the FER2013 dataset. The experimental results demonstrate that our proposed method outperforms mainstream CNN-based FER methods, achieving excellent performance. It is worth noting that our model has only 3.64 MB parameters, which is smaller than most lightweight models and significantly smaller than other transformer-based models.
2. Related Work
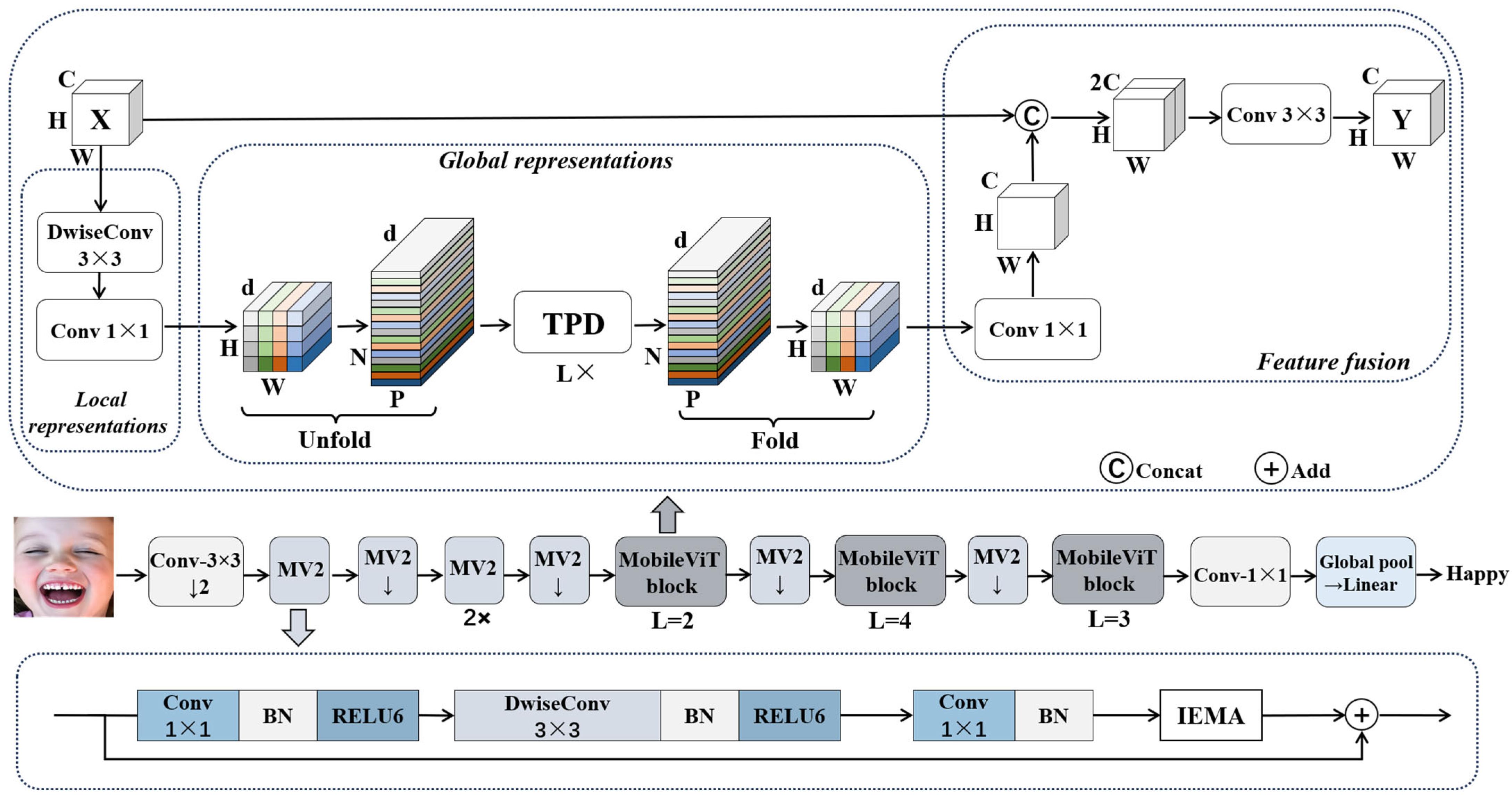
3. Method
3.1. The Proposed Architecture
3.2. The Improved Efficient Multi-Scale Attention Module
3.3. Patch Dropping Module
- Randomization of Local Features: By randomly dropping patches, the model is encouraged to explore different regions in the feature map, thereby enhancing sensitivity to local features.
- Enhancement of Model Generalization: As the model encounters different combinations of patches during training, it helps the model learn more generalized feature representations, reducing reliance on specific features.
- Facilitation of Multi-Scale Feature Learning: Patch dropping encourages the model to focus on features at both large and small scales, as randomly dropping patches may compel the model to extract more information from the remaining patches.
- Synergy with Multi-Head Self-Attention Mechanism (MSA): MSA allows the model to consider the relationships between multiple patches simultaneously. Even if certain patches are dropped, MSA can still help the model maintain an understanding of the entire feature map. This synergy enables the model to maintain strong facial expression recognition capabilities even in the absence of local information.
4. Experimental Results
4.1. Preparation for Experiment
4.2. Ablation Experiments
4.3. Comparison with Other Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alharbi, M.; Huang, S. A Survey of Incorporating Affective Computing for Human-System co-Adaptation. In Proceedings of the 2nd World Symposium on Software Engineering, Xiamen, China, 28–30 September 2020; pp. 72–79. [Google Scholar]
- Li, S.; Deng, W. Deep facial expression recognition: A survey. IEEE Trans. Affect. Comput. 2020, 13, 1195–1215. [Google Scholar] [CrossRef]
- Xie, S.; Hu, H.; Wu, Y. Deep multi-path convolutional neural network joint with salient region attention for facial expression recognition. Pattern Recognit. 2019, 92, 177–191. [Google Scholar] [CrossRef]
- Pan, X. Fusing HOG and convolutional neural network spatial–temporal features for video-based facial expression recognition. IET Image Process. 2020, 14, 176–182. [Google Scholar] [CrossRef]
- Wang, K.; Peng, X.; Yang, J.; Meng, D.; Qiao, Y. Region attention networks for pose and occlusion robust facial expression recognition. IEEE Trans. Image Process. 2020, 29, 4057–4069. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Zeng, J.; Shan, S.; Chen, X. Occlusion aware facial expression recognition using CNN with attention mechanism. IEEE Trans. Image Process. 2018, 28, 2439–2450. [Google Scholar] [CrossRef]
- Li, Y.; Lu, G.; Li, J.; Zhang, Z.; Zhang, D. Facial expression recognition in the wild using multi-level features and attention mechanisms. IEEE Trans. Affect. Comput. 2020, 14, 451–462. [Google Scholar] [CrossRef]
- Li, Y.; Zeng, J.; Shan, S.; Chen, X. Patch-Gated CNN for Occlusion-Aware Facial Expression Recognition. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2209–2214. [Google Scholar]
- Fan, Y.; Li, V.O.; Lam, J.C. Facial expression recognition with deeply-supervised attention network. IEEE Trans. Affect. Comput. 2020, 13, 1057–1071. [Google Scholar] [CrossRef]
- Li, J.; Jin, K.; Zhou, D.; Kubota, N.; Ju, Z. Attention mechanism-based CNN for facial expression recognition. Neurocomputing 2020, 411, 340–350. [Google Scholar] [CrossRef]
- Mehta, S.; Rastegari, M. Mobilevit: Light-weight, general-purpose, and mobile-friendly vision transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]
- Liu, C.; Wechsler, H. Gabor feature based classification using the enhanced fisher linear discriminant model for face recognition. IEEE Trans. Image Process. 2002, 11, 467–476. [Google Scholar]
- Shan, C.; Gong, S.; McOwan, P.W. Facial expression recognition based on local binary patterns: A comprehensive study. Image Vis. Comput. 2009, 27, 803–816. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Cai, J.; Meng, Z.; Khan, A.S.; Li, Z.; O’Reilly, J.; Tong, Y. Island Loss for Learning Discriminative Features in Facial Expression Recognition. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 302–309. [Google Scholar]
- Pan, B.; Wang, S.; Xia, B. Occluded Facial Expression Recognition Enhanced through Privileged Information. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 566–573. [Google Scholar]
- Li, S.; Deng, W. A deeper look at facial expression dataset bias. IEEE Trans. Affect. Comput. 2020, 13, 881–893. [Google Scholar] [CrossRef]
- Yao, L.; He, S.; Su, K.; Shao, Q. Facial expression recognition based on spatial and channel attention mechanisms. Wirel. Pers. Commun. 2022, 125, 1483–1500. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–23 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for Mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the European Conference on computer Vision (ECCV) 2018, Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Nan, Y.; Ju, J.; Hua, Q.; Zhang, H.; Wang, B. A-MobileNet: An approach of facial expression recognition. Alex. Eng. J. 2022, 61, 4435–4444. [Google Scholar] [CrossRef]
- Han, B.; Hu, M.; Wang, X.; Ren, F. A triple-structure network model based upon MobileNet V1 and multi-loss function for facial expression recognition. Symmetry 2022, 14, 2055. [Google Scholar] [CrossRef]
- Zhang, L.Q.; Liu, Z.T.; Jiang, C.S. An Improved SimAM Based CNN for Facial Expression Recognition. In Proceedings of the 2022 41st Chinese Control Conference (CCC), Hefei, China, 25–27 July 2022; pp. 6510–6514. [Google Scholar]
- Zhou, J.; Zhang, X.; Lin, Y.; Liu, Y. Facial expression recognition using frequency multiplication network with uniform rectangular features. J. Vis. Commun. Image Represent. 2021, 75, 103018. [Google Scholar] [CrossRef]
- Cotter, S.F. MobiExpressNet: A Deep Learning Network for Face Expression Recognition on Smart Phones. In Proceedings of the 2020 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 4–6 January 2020; pp. 1–4. [Google Scholar]
- Goodfellow, I.J.; Erhan, D.; Carrier, P.L.; Courville, A.; Mirza, M.; Hamner, B.; Cukierski, W.; Tang, Y.; Thaler, D.; Lee, D.H.; et al. Challenges in Representation Learning: A Report on Three Machine Learning Contests. In Proceedings of the Neural Information Processing: 20th International Conference, ICONIP 2013, Daegu, Republic of Korea, 3–7 November 2013; Proceedings, Part III 20. Springer: Berlin/Heidelberg, Germany, 2013; pp. 117–124. [Google Scholar]
- Li, S.; Deng, W.; Du, J. Reliable Crowdsourcing and Deep Locality-Preserving Learning for Expression Recognition in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2852–2861. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Ghosh, S.; Dhall, A.; Sebe, N. Automatic Group Affect Analysis in Images via Visual Attribute and Feature Networks. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 1967–1971. [Google Scholar]
- Hua, C.H.; Huynh-The, T.; Seo, H.; Lee, S. Convolutional Network with Densely Backward Attention for Facial Expression recognition. In Proceedings of the 2020 14th International Conference on Ubiquitous Information Management and Communication (IMCOM), Taichung, Taiwan, 3–5 January 2020; pp. 1–6. [Google Scholar]
- Shan, L.; Deng, W. Reliable crowdsourcing and deep locality-preserving learning for unconstrained facial expression recognition. IEEE Trans. Image Process. 2018, 28, 356–370. [Google Scholar]
- Jiang, P.; Liu, G.; Wang, Q.; Wu, J. Accurate and reliable facial expression recognition using advanced softmax loss with fixed weights. IEEE Signal Process. Lett. 2020, 27, 725–729. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Bousaid, R.; El Hajji, M.; Es-Saady, Y. Facial Emotions Recognition Using Vit and Transfer Learning. In Proceedings of the 2022 5th International Conference on Advanced Communication Technologies and Networking (CommNet), Marrakech, Morocco, 12–14 December 2022; pp. 1–6. [Google Scholar]
- Ma, F.; Sun, B.; Li, S. Facial expression recognition with visual transformers and attentional selective fusion. IEEE Trans. Affect. Comput. 2021, 14, 1236–1248. [Google Scholar] [CrossRef]
- Huang, Q.; Huang, C.; Wang, X.; Jiang, F. Facial expression recognition with grid-wise attention and visual transformer. Inf. Sci. 2021, 580, 35–54. [Google Scholar] [CrossRef]
- Momeny, M.; Neshat, A.A.; Jahanbakhshi, A.; Mahmoudi, M.; Ampatzidis, Y.; Radeva, P. Grading and fraud detection of saffron via learning-to-augment incorporated Inception-v4 CNN. Food Control 2023, 147, 109554. [Google Scholar] [CrossRef]
- Shao, J.; Cheng, Q. E-FCNN for tiny facial expression recognition. Appl. Intell. 2021, 51, 549–559. [Google Scholar] [CrossRef]
- Mollahosseini, A.; Chan, D.; Mahoor, M.H. Going Deeper in Facial Expression Recognition Using Deep Neural Networks. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–10. [Google Scholar]
- Chen, C.F.; Panda, R.; Fan, Q. Regionvit: Regional-to-local attention for vision transformers. arXiv 2021, arXiv:2106.02689. [Google Scholar]
- Yuan, L.; Chen, Y.; Wang, T.; Yu, W.; Shi, Y.; Jiang, Z.H.; Tay, F.E.; Feng, J.; Yan, S. Tokens-to-Token vit: Training Vision Transformers from Scratch on Imagenet. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 558–567. [Google Scholar]
- Zhou, D.; Kang, B.; Jin, X.; Yang, L.; Lian, X.; Jiang, Z.; Hou, Q.; Feng, J. Deepvit: Towards deeper vision transformer. arXiv 2021, arXiv:2103.11886. [Google Scholar]
- Chen, C.F.R.; Fan, Q.; Panda, R. Crossvit: Cross-Attention Multi-Scale Vision Transformer for Image Classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 357–366. [Google Scholar]
- Han, Q.; Fan, Z.; Dai, Q.; Sun, L.; Cheng, M.M.; Liu, J.; Wang, J. On the connection between local attention and dynamic depth-wise convolution. arXiv 2021, arXiv:2106.04263. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Zhou, J.; Wang, P.; Wang, F.; Liu, Q.; Li, H.; Jin, R. Elsa: Enhanced local self-attention for vision transformer. arXiv 2021, arXiv:2112.12786. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Angry | Disgust | Fear | Happy | Neutral | Sad | Suprise |
|---|---|---|---|---|---|---|---|
| RAF-DB | 867 | 877 | 355 | 5957 | 3204 | 2460 | 1619 |
| FER2013 | 4953 | 547 | 5121 | 8989 | 6198 | 6077 | 4002 |
| The Improved Efficient Multi-Scale Attention Module | Patch Dropping Module | Accuracy (%) | Parameters (MB) | |
|---|---|---|---|---|
| RAF-DB | FER2013 | |||
| 84.63 | 68.27 | 3.64 | ||
| √ | 85.61 | 69.16 | 3.64 | |
| √ | 85.25 | 69.49 | 3.64 | |
| √ | √ | 86.51 | 69.84 | 3.64 |
| Model | RAF-DB (%) | FER2013 (%) | Parameter (MB) |
|---|---|---|---|
| ResNet18 [32] | 84.10 | 70.09 | 11.69 |
| ResNet50 [32] | 86.01 | 71.26 | 25.56 |
| VGG16 [33] | 81.68 | 68.89 | 14.75 |
| VGG19 [33] | 81.17 | 68.53 | 20.06 |
| AlexNet [34] | 55.60 | 67.51 | 60.92 |
| Ours | 86.51 | 69.84 | 3.64 |
| Model | Accuracy (%) | Parameters (MB) |
|---|---|---|
| Capsule-based Net [35] | 77.78 | - |
| DBA-Net(DenseNet-161) [36] | 79.37 | 42.9 |
| PG-CNN [8] | 82.27 | - |
| DLP-CNN [37] | 84.13 | - |
| Mean+ASL+L2SL [38] | 84.69 | - |
| gACNN [6] | 85.07 | >134.29 |
| Mini-Xception | 76.26 | - |
| MobileNetV1 [20] | 81.62 | 3.2 |
| MobileNetV2 [21 | 67.77 | 2.3 |
| MobileNetV3-small [22] | 68.29 | 1.5 |
| ViT [39] | 83.44 | 86 |
| Vit-TL [40] | 84.25 | >86 |
| CVT [41] | 82.27 | 51.80 |
| FER-VT [42] | 84.31 | - |
| Ours | 86.51 | 3.64 |
| Model | Accuracy (%) | Parameters (MB) |
|---|---|---|
| Inception V4 [43] | 66.80 | - |
| E-FCNN [44] | 66.17 | - |
| DCN [45] | 69.30 | - |
| MobileNetV2 [21] | 67.90 | 2.3 |
| MobileNetV3-small [22] | 67.50 | 1.5 |
| Region ViT [46] | 56.03 | 40.8 |
| Tokens-to-Token ViT [47] | 61.28 | 21.5 |
| Deep ViT [48] | 43.45 | 55 |
| CrossViT [49] | 50.27 | 43.3 |
| Ours | 69.84 | 3.64 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, N.; Huang, Y.; Wang, Z.; Fan, Z.; Li, X.; Xiao, Z. Enhanced Hybrid Vision Transformer with Multi-Scale Feature Integration and Patch Dropping for Facial Expression Recognition. Sensors 2024, 24, 4153. https://doi.org/10.3390/s24134153
Li N, Huang Y, Wang Z, Fan Z, Li X, Xiao Z. Enhanced Hybrid Vision Transformer with Multi-Scale Feature Integration and Patch Dropping for Facial Expression Recognition. Sensors. 2024; 24(13):4153. https://doi.org/10.3390/s24134153
Chicago/Turabian StyleLi, Nianfeng, Yongyuan Huang, Zhenyan Wang, Ziyao Fan, Xinyuan Li, and Zhiguo Xiao. 2024. "Enhanced Hybrid Vision Transformer with Multi-Scale Feature Integration and Patch Dropping for Facial Expression Recognition" Sensors 24, no. 13: 4153. https://doi.org/10.3390/s24134153
APA StyleLi, N., Huang, Y., Wang, Z., Fan, Z., Li, X., & Xiao, Z. (2024). Enhanced Hybrid Vision Transformer with Multi-Scale Feature Integration and Patch Dropping for Facial Expression Recognition. Sensors, 24(13), 4153. https://doi.org/10.3390/s24134153