ARAware: Assisting Visually Impaired People with Real-Time Critical Moving Object Identification


Abstract
:1. Introduction
- We provide an E2E camera-based CMO avoidance pipeline from video capture to message delivery, where the essential properties of the perception of the VIP in practice are comprehensively considered. Particularly, we design a deep learning-based moving object tracking capable of achieving real-time processing without missing critical information in the input video. Additionally, we develop a novel object–VIP collision prediction method based on the object’s moving direction for effective collision prediction. We also construct a 2D to 3D coordinate projection method for more accurate object–VIP distance estimation, which significantly improves the performance of object–VIP collision prediction, and thus CMO identification. The ARAware scheme is customizable and designed for future-proofing; according to the requirements of the VIP, other object detectors, trackers, and distance estimators can be integrated for higher accuracy or faster processing speed.
- We provide a systematic CMO risk level estimation scheme, derived from comprehensive empirical studies, that provides an indicator of the damage caused to the VIP via collisions of different types of objects moving at different speeds in practical settings. We classify the identified CMOs with different risk levels, and develop a novel prioritised CMO warning strategy, based on the CMOs risk levels and predicted collision times, to immediately warn about high-risk threats for the safety of the VIP, and to postpone the warning of low-risk threats until an acceptable deadline (sufficient for VIP to react) to reduce potential false alarms.
- We implement a real-world prototype of ARAware using commercially available devices (i.e., an RGB camera, a laptop, and bone conduction headphones), and validate its effectiveness and efficiency based on extensive real-world field trials. Experimental results demonstrate that, consuming 30 fps input video, ARAware manages to accurately identify CMOs with 97.26% overall mean Average Recall (mAR) and 88.20% overall mean Average Precision (mAP), precisely classify their risk levels with 100% overall mAR and 91.69% overall mAP, and achieve real-time processing with an average E2E processing speed of 32 fps. Furthermore, the ARAware warning emission strategy manages to effectively alert the VIP about identified CMOs with different risk levels, where high-risks are alerted immediately (e.g., cars moving at 60 km/h are alerted at least 6 s in advance), and, low-risks are not alerted until the deadline is reached (e.g., pedestrians moving at 3 km/h are alerted 5 s ahead, instead of 15.21 s in advance when they are first identified), which effectively reduces potential false alarms, considering that the accuracy of detecting proximate objects is higher than that of distant objects.
2. Related Work
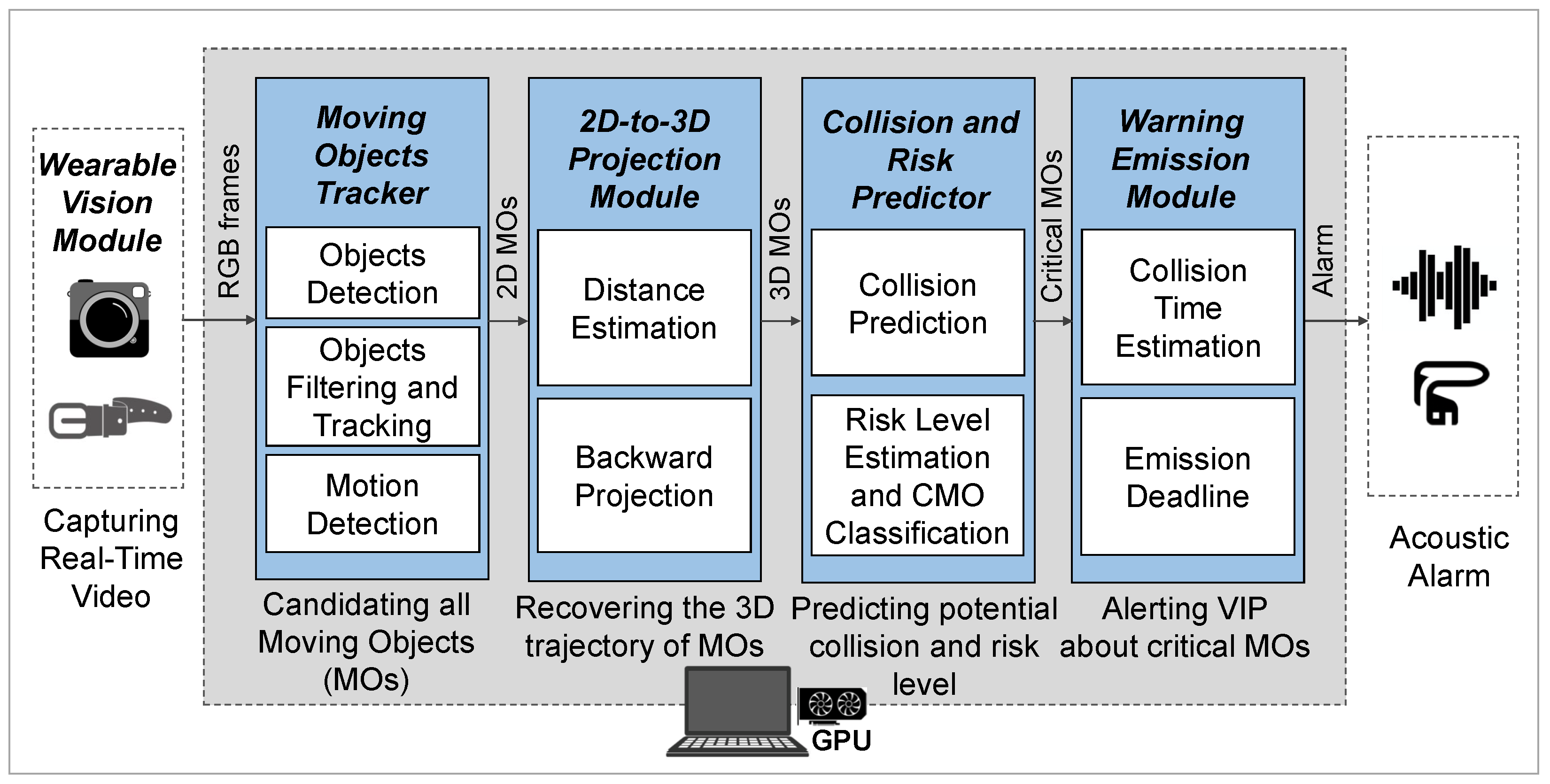
3. ARAware Schematic Design
3.1. The Wearable Vision Module
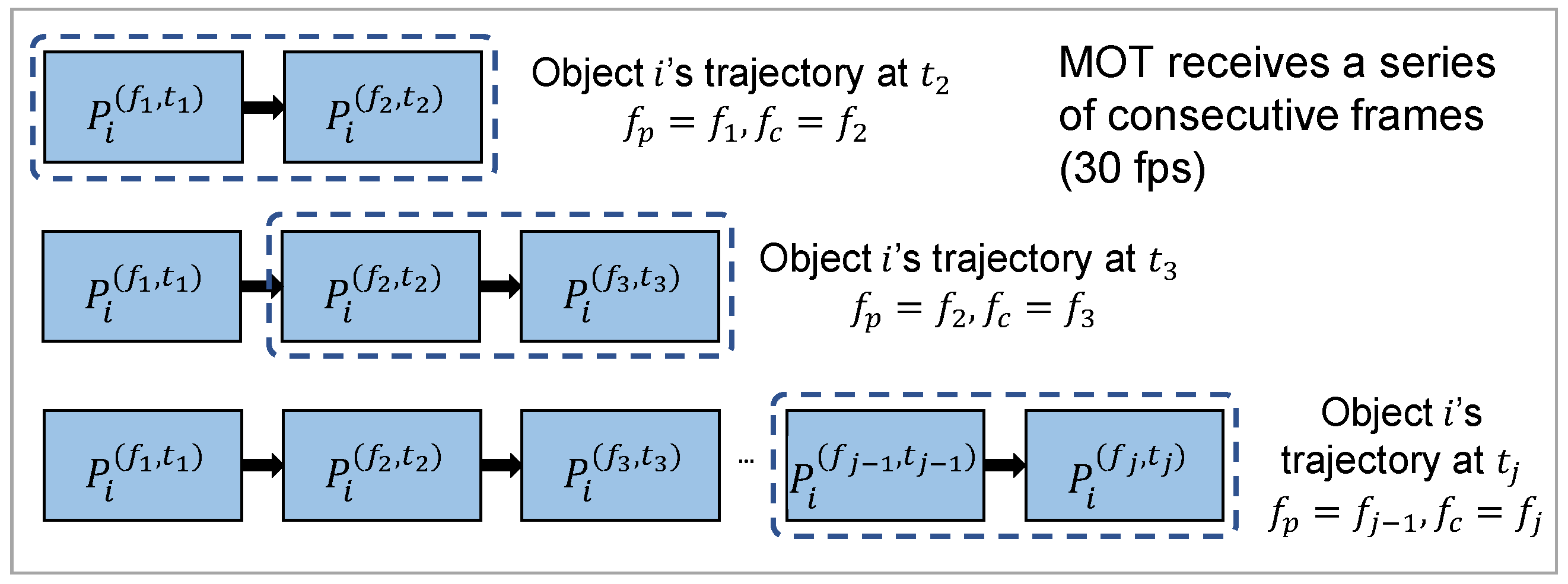
3.2. The Moving Object Tracker
3.2.1. Object Detection
3.2.2. Object Filtering and Tracking
3.2.3. Motion Detection
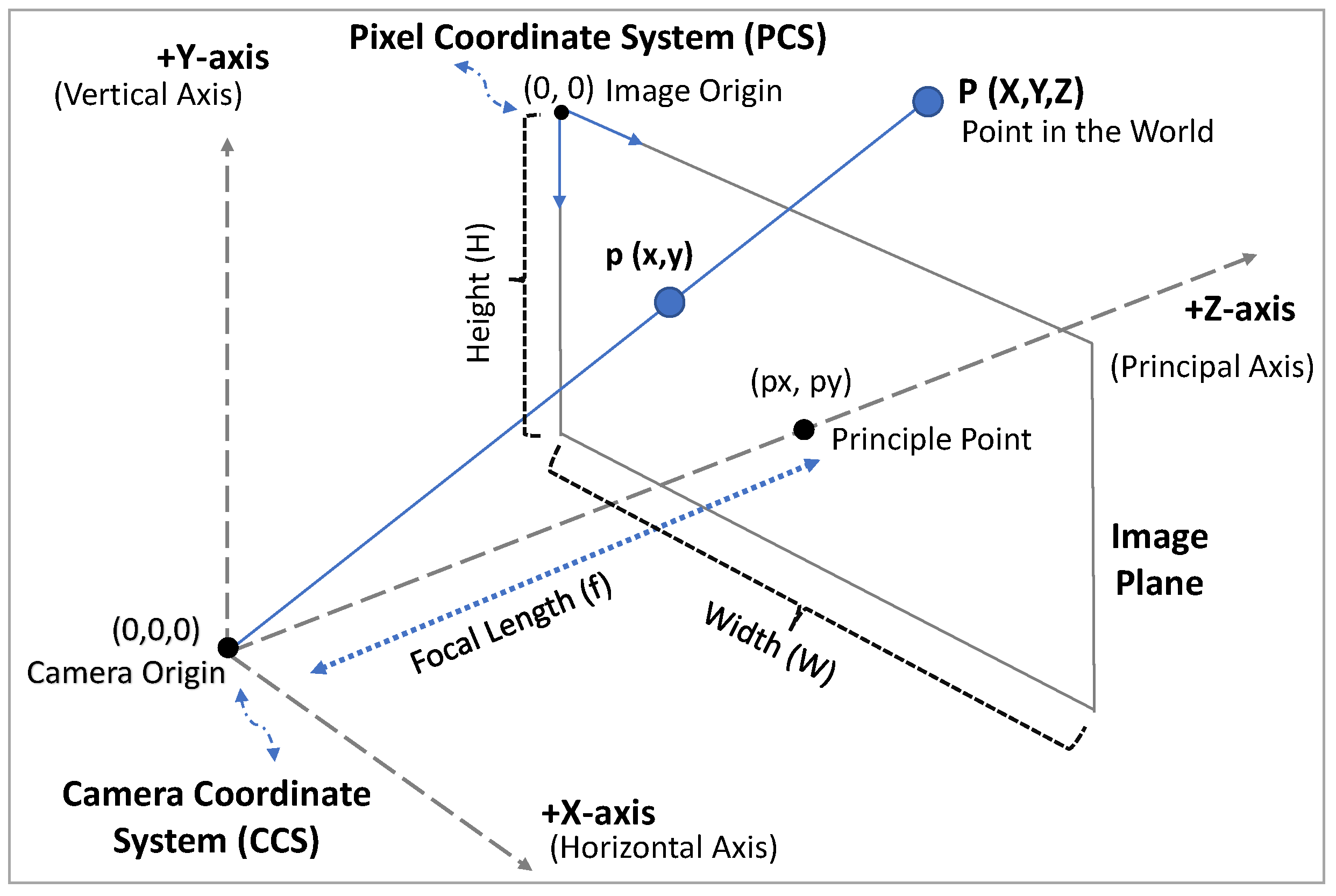
3.3. The 2D-to-3D Projection Module
3.3.1. Distance Estimation
- s: = 160 cm, = 170 cm, and = 400 cm;
- s: = 124 cm, = 65 cm, and = 190 cm;
- s: = 105 cm, = 40 cm, and = 175 cm;
- s: = 175 cm, = 55 cm, and = 30 cm.
3.3.2. Backward Transformation
3.4. The Collision and Risk Predictor
3.4.1. Collision Prediction
- The angle between and (see Appendix A for the derivations), which can be expressed as:where is the Euclidean distance between the VIP and the object at , which is calculated using Equations (4) and (6) as follows:where and are the X-axis and Z-axis coordinates of the VIP point B, while and are the X-axis and Z-axis coordinates of the object point O at . We ignore the Y-axis coordinates (i.e., and ) since we assume that the camera motion at the Y-axis is negligible, as it is vertical to the ground plane.
- The angle of the displacement vector from O to B, which is expressed as:
- The angle of the displacement vector from O to , which can be calculated as:
- s: = 0.9 m, = 3 m,
- s: = 0.45 m, = 1.75 m,
- s: = 0.35 m, = 1.25 m,
- s: = 0.25 m, = 0.75 m.
3.4.2. Risk Level Estimation and CMO Classification
3.5. The Warning Emission Module
- Prioritising warning messages of CMOs with different risk levels (i.e., scaled from 1 to 4, where 1 denotes the highest risk and 4 denotes the lowest risk).
- Reducing false alarms as much as possible to ensure scheme usability.
- ‘Front’: ∈ [−1 m, 1 m].
- ‘Right’: >1 m.
- ‘Left’: <−1 m.
- ‘Front’: ∈ [−0.5 m, 0.5 m].
- ‘Right’: > m.
- ‘Left’: < −0.5 m.
4. Implementation and Evaluation
4.1. ARAware Implementation
4.2. Evaluation Methodology
4.2.1. Experimental Dataset
- VMOT contains 96 short video clips with different lengths, totalling 28 min, collected in different private outdoor places (we chose such places to facilitate the setup of our experiments (e.g., as illustrated in Figure 5, identifying the radius of and and the critical zone on the ground with ropes) for an accurate and comprehensive performance evaluation of our CMO collision prediction method, as well as to ensure the researchers’, volunteers’, and the public’s safety) as shown in Figure 8.The video clips encompass different numbers of objects (up to five) from the target classes (car, motorbike, bicycle, pedestrian) located at various distances from the VIP (up to 20 m) and moving at slow speeds (<10 km/h). For all VMOT clips, we manually identified the ground truth (at the frame level) using the MATLAB Ground Truth Labeler (https://uk.mathworks.com/help/driving/ground-truth-labeling.html (accessed on 17 October 2023)). Objects moving inside the critical zone (marked by yellow ropes in Figure 8) were identified as CMOs, and those moving outside the critical zone were identified as non-CMOs. The total numbers of CMOs (i.e., ) and non-CMOs (i.e., ) are 539 and 217, respectively.
- VCRP contains 44 video clips with different lengths, totalling 15 min, collected in private outdoor environments similar to that in VMOT. Each clip specifically focused on one object (e.g., car, motorbike, bicycle, or pedestrian) initially positioned at different distances (up to 100 m) and moving at a uniform fixed speed (up to 60 km/h) towards the camera (i.e., a CMO). Note that our method can be applied to objects moving at varying speeds, and we made the CMO speed uniform during the video only for evaluation purposes, to facilitate the obtaining of accurate speed measurements (i.e., ground truth), as precise speed-measurement equipment was not available. For the object in each clip, both the initial object–VIP distance (i.e., ) and the object moving speed (i.e., ) were manually determined, thus known, and the object was tagged with a risk level label according to Figure 6 as the ground truth (i.e., severe, serious, minor, and minimal). Note that in labelling, cars and motorbikes are labelled using their speedometers. For bicycles and pedestrians, we measured the time taken to travel a predefined distance, and then we calculated the speed by dividing the distance by the time taken.
4.2.2. Evaluation Metrics
- mean Average Recall (mAR) indicating the capability of successfully identifying all objects in different classes (in terms of either object types or risk levels):where M is the number of video clips processed, K is the number of frames of video clip m, and and denote numbers of class i objects identified and missed in frame k, respectively.
- mean Average Precision (mAP) indicating the capability of correctly identifying objects in different classes:where denotes the number of non-class i objects falsely identified as class i objects in k. We used with a threshold to classify the correct and false identifications (i.e., and ).
- Multiple Object Tracking Accuracy (MOTA) [56] indicating the capability of correctly tracking objects in their trajectories:where is the number of object mismatches in a trajectory in k, and is the number of ground truth objects in k.
- Multiple Object Tracking Precision (MOTP) [56] indicating the capability of precisely localising objects in video frames:where denotes how well object j’s ground truth and tracked bounding boxes in k match with each other, and is the number of matched objects in k. We used with a 0.5 threshold to classify the matched ground truth and tracked bounding box pairs.
- Absolute Error () measuring the difference between the estimated and actual values of speed, distance and collision time:Note that the absolute value () is not considered in Equation (27) for more explicit representation, i.e., to show that with a negative value, an estimated value is less than an actual value and vice versa.
- End-to-End mean FPS (EmFPS) indicating the capability of achieving real-time CMO identification and classification:where denotes clip m’s total number of processed frames, and and are the end time and the start time of clip m’s end-to-end processing time, respectively.
5. Results and Discussions
5.1. MOT Validation
5.2. Validation of Distance and Speed Estimation
5.2.1. Distance Estimation
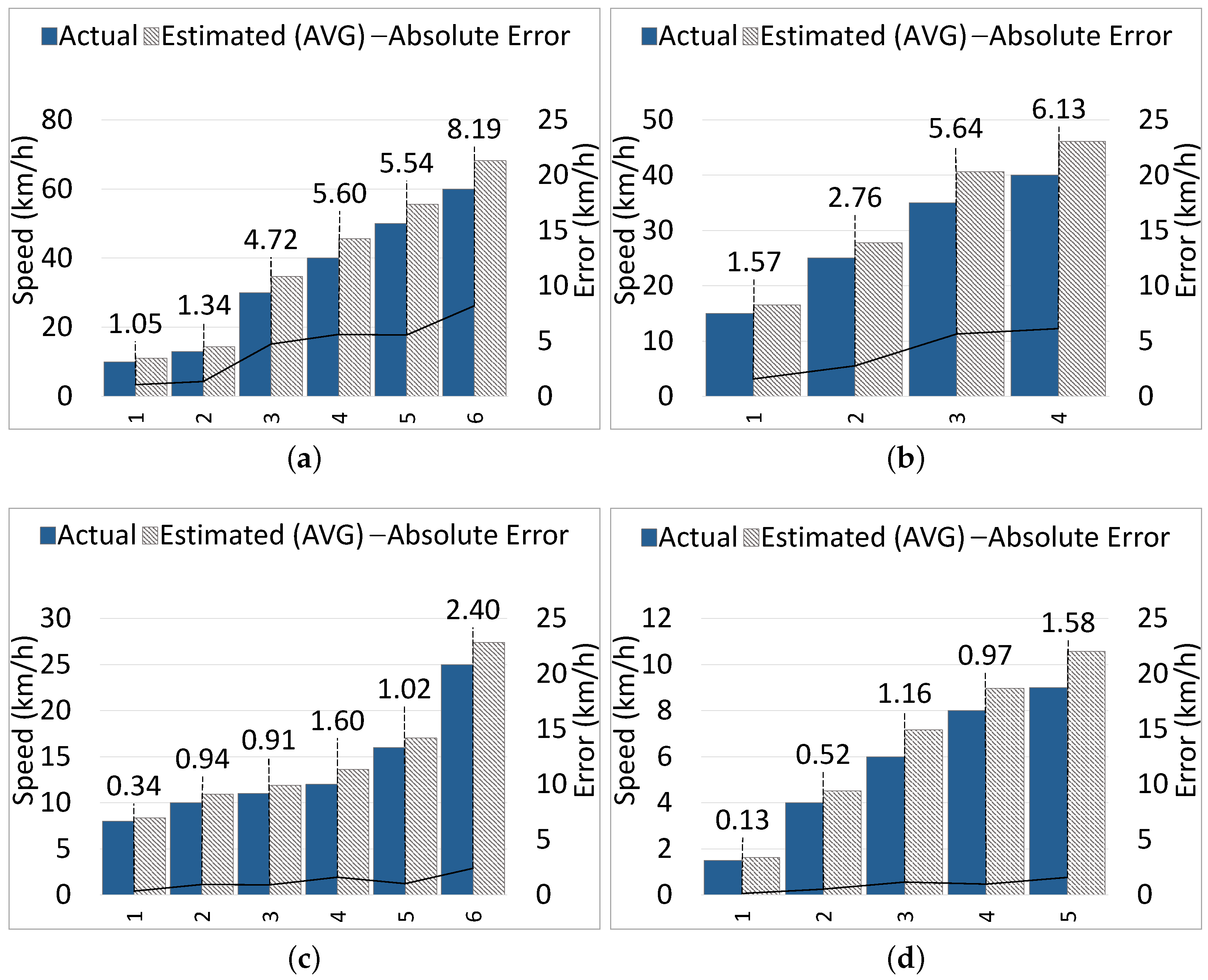
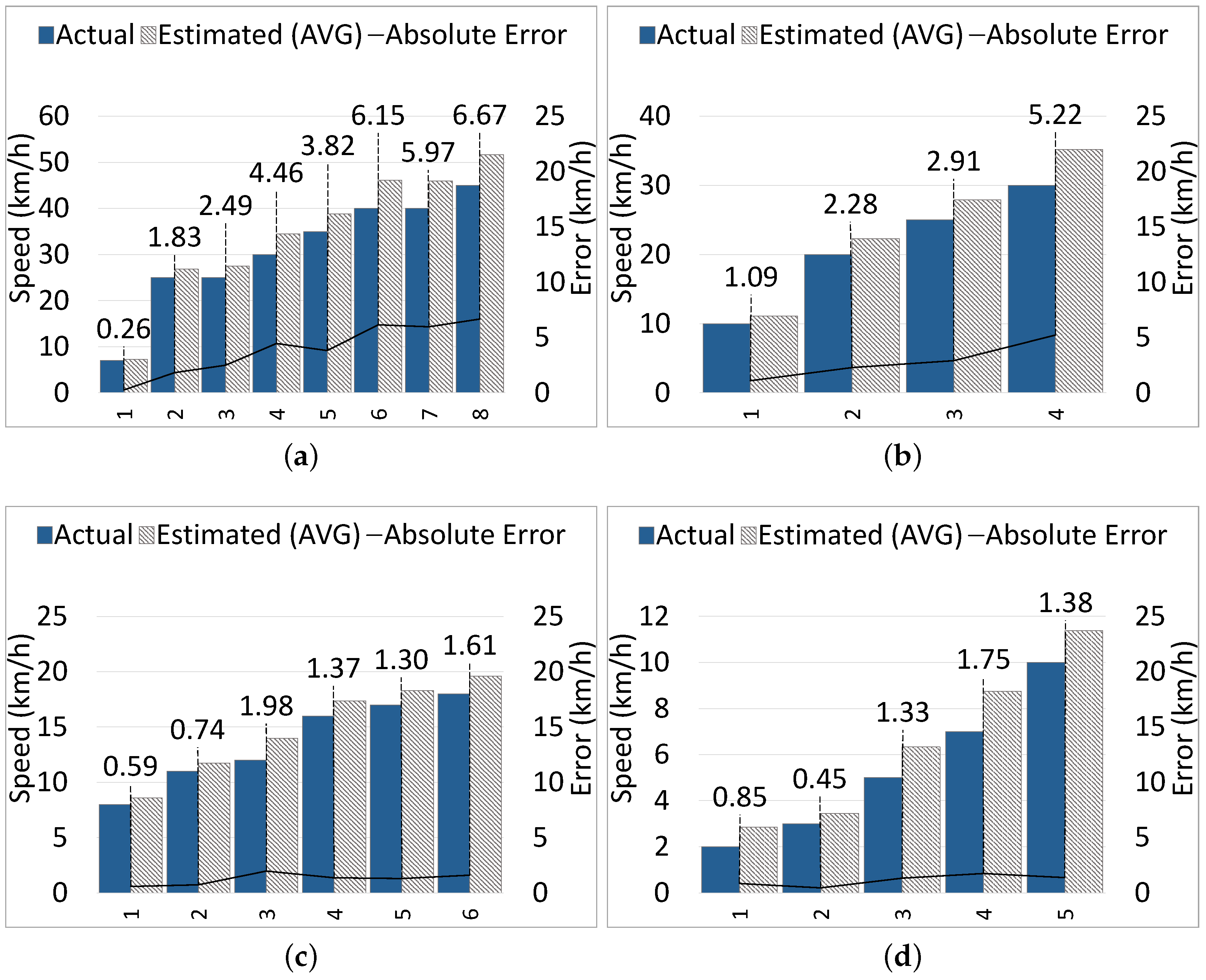
5.2.2. Speed Estimation
5.3. Performance of ARAware
5.3.1. CMO Identification
5.3.2. CMO Classification
5.3.3. Warning Notification
5.4. ARAware versus DEEP-SEE
6. Limitation of ARAware
6.1. Motion Detection
6.2. Prototype Endurance and Human-Machine Interface
6.3. Scalability
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| VIPs | Visually Impaired People |
| CMO | Critical Moving Object |
| WVM | Wearable Vision Module |
| MOT | Moving Object Tracker |
| PM | 2D-to-3D Projection Module |
| CRP | Collision and Risk Predictor |
| WEM | Warning Emission Module |
| CCS | Camera Coordinate System |
| PCS | Pixel Coordinate System |
Appendix A. Derivation of the Alpha Angle
References
- El-Taher, F.E.Z.; Miralles-Pechuán, L.; Courtney, J.; Millar, K.; Smith, C.; Mckeever, S. A survey on outdoor navigation applications for people with visual impairments. IEEE Access 2023, 11, 14647–14666. [Google Scholar] [CrossRef]
- Hafeez, F.; Sheikh, U.U.; Al-Shammari, S.; Hamid, M.; Khakwani, A.B.K.; Arfeen, Z.A. Comparative analysis of influencing factors on pedestrian road accidents. Bull. Electr. Eng. Inform. 2023, 12, 257–267. [Google Scholar] [CrossRef]
- Islam, M. An exploratory analysis of the effects of speed limits on pedestrian injury severities in vehicle-pedestrian crashes. J. Transp. Health 2023, 28, 101561. [Google Scholar] [CrossRef]
- University of Zurich. Bio-Inspired Cameras and AI Help Drivers Detect Pedestrians and Obstacles Faster. 2024. Available online: https://www.sciencedaily.com/releases/2024/05/240529144230.htm (accessed on 13 June 2024).
- Akamine, S.; Totoki, S.; Itami, T.; Yoneyama, J. Real-time obstacle detection in a darkroom using a monocular camera and a line laser. Artif. Life Robot. 2022, 27, 828–833. [Google Scholar] [CrossRef]
- Mala, N.S.; Thushara, S.S.; Subbiah, S. Navigation gadget for visually impaired based on IoT. In Proceedings of the 2017 2nd International Conference on Computing and Communications Technologies (ICCCT’17), Chennai, India, 23–24 February 2017; pp. 334–338. [Google Scholar]
- Beingolea, J.R.; Zea-Vargas, M.A.; Huallpa, R.; Vilca, X.; Bolivar, R.; Rendulich, J. Assistive devices: Technology development for the visually impaired. Designs 2021, 5, 75. [Google Scholar] [CrossRef]
- Kayukawa, S.; Higuchi, K.; Guerreiro, J.; Morishima, S.; Sato, Y.; Kitani, K.; Asakawa, C. Bbeep: A sonic collision avoidance system for blind travellers and nearby pedestrians. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; pp. 1–12. [Google Scholar]
- El-Taher, F.E.Z.; Taha, A.; Courtney, J.; Mckeever, S. A Systematic Review of Urban Navigation Systems for Visually Impaired People. Sensors 2021, 21, 3103. [Google Scholar] [CrossRef] [PubMed]
- Schieber, H.; Kleinbeck, C.; Pradel, C.; Theelke, L.; Roth, D. A mixed reality guidance system for blind and visually impaired people. In Proceedings of the 2022 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW), Christchurch, New Zealand, 12–16 March 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 726–727. [Google Scholar]
- Muhsin, Z.J.; Qahwaji, R.; Ghanchi, F.; Al-Taee, M. Review of substitutive assistive tools and technologies for people with visual impairments: Recent advancements and prospects. J. Multimodal User Interfaces 2024, 18, 135–156. [Google Scholar] [CrossRef]
- Rodrigo-Salazar, L.; González-Carrasco, I.; Garcia-Ramirez, A.R. An IoT-based contribution to improve mobility of the visually impaired in Smart Cities. Computing 2021, 103, 1233–1254. [Google Scholar] [CrossRef]
- Asiedu Asante, B.K.; Imamura, H. Towards Robust Obstacle Avoidance for the Visually Impaired Person Using Stereo Cameras. Technologies 2023, 11, 168. [Google Scholar] [CrossRef]
- Lin, B.; Lee, C.; Chiang, P. Simple smartphone-based guiding system for visually impaired people. Sensors 2017, 17, 1371. [Google Scholar] [CrossRef]
- Tapu, R.; Mocanu, B.; Zaharia, T. DEEP-SEE: Joint object detection, tracking and recognition with application to visually impaired navigational assistance. Sensors 2017, 17, 2473. [Google Scholar] [CrossRef]
- Ou, W.; Zhang, J.; Peng, K.; Yang, K.; Jaworek, G.; Müller, K.; Stiefelhagen, R. Indoor Navigation Assistance for Visually Impaired People via Dynamic SLAM and Panoptic Segmentation with an RGB-D Sensor. arXiv 2022, arXiv:2204.01154. [Google Scholar]
- Khoi, T.Q.; Quang, N.A.; Hieu, N.K. Object detection for drones on Raspberry Pi potentials and challenges. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1109, 012033. [Google Scholar] [CrossRef]
- Lee, J.; Hwang, K.i. YOLO with adaptive frame control for real-time object detection applications. Multimed. Tools Appl. 2022, 81, 36375–36396. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, X.; Kojima, M.; Huang, Q.; Arai, T. A wearable navigation device for visually impaired people based on the real-time semantic visual SLAM system. Sensors 2021, 21, 1536. [Google Scholar] [CrossRef] [PubMed]
- Shaik, T.B.; Mal, R. Algorithm to Assist Visually Impaired Person for Object Detection in Real Time. In Proceedings of the International Conference on Emerging Electronics and Automation, Assam, India, 16–18 December 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 147–157. [Google Scholar]
- Kang, M.; Chae, S.; Sun, J.; Yoo, J.; Ko, S. A novel obstacle detection method based on deformable grid for the visually impaired. IEEE Trans. Consum. Electron. 2015, 61, 376–383. [Google Scholar] [CrossRef]
- Kang, M.; Chae, S.; Sun, J.; Lee, S.; Ko, S. An enhanced obstacle avoidance method for the visually impaired using deformable grid. IEEE Trans. Consum. Electron. 2017, 63, 169–177. [Google Scholar] [CrossRef]
- Aladrén, A.; López-Nicolás, G.; Puig, L.; Guerrero, J.J. Navigation assistance for the visually impaired using RGB-D sensor with range expansion. IEEE Syst. J. 2016, 10, 922–932. [Google Scholar] [CrossRef]
- Lin, S.; Wang, K.; Yang, K.; Cheng, R. KrNet: A kinetic real-time convolutional neural network for navigational assistance. In Proceedings of the International Conference on Computers Helping People with Special Needs, Linz, Austria, 11–13 July 2018; pp. 55–62. [Google Scholar]
- Parikh, N.; Shah, I.; Vahora, S. Android smartphone based visual object recognition for visually impaired using deep learning. In Proceedings of the 2018 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 3–5 April 2018; pp. 420–425. [Google Scholar]
- Tapu, R.; Mocanu, B.; Bursuc, A.; Zaharia, T. A smartphone-based obstacle detection and classification system for assisting visually impaired people. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) Workshops, Sydney, Australia, 1–8 December 2013. [Google Scholar]
- Badrloo, S.; Varshosaz, M.; Pirasteh, S.; Li, J. Image-based obstacle detection methods for the safe navigation of unmanned vehicles: A review. Remote Sens. 2022, 14, 3824. [Google Scholar] [CrossRef]
- Dong, X.; Garratt, M.A.; Anavatti, S.G.; Abbass, H.A. Towards real-time monocular depth estimation for robotics: A survey. IEEE Trans. Intell. Transp. Syst. 2022, 23, 16940–16961. [Google Scholar] [CrossRef]
- Zereen, A.N.; Corraya, S. Detecting real time object along with the moving direction for visually impaired people. In Proceedings of the 2016 2nd International Conference on Electrical, Computer Telecommunication Engineering (ICECTE), Rajshahi, Bangladesh, 8–10 December 2016; pp. 1–4. [Google Scholar]
- Vaidya, S.; Shah, N.; Shah, N.; Shankarmani, R. Real-time object detection for visually challenged people. In Proceedings of the 2020 4th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 13–15 May 2020; pp. 311–316. [Google Scholar]
- Shadi, S.; Hadi, S.; Nazari, M.A.; Hardt, W. Outdoor navigation for visually impaired based on deep learning. In Proceedings of the CEUR Workshop Proceedinds, Otzenhausen, Germany, 8–12 September 2019; Volume 2514, pp. 97–406. [Google Scholar]
- Kumar, S.; Mishra, D.N.; Ganie, S.M.; Bharathikannan, R.; Vijayakanthan, K. Artificial Intelligence Solutions for the Visually Impaired: A Review. In Handbook of Research on AI and Knowledge Engineering for Real-Time Business Intelligence; IGI Global: Hershey, PA, USA, 2023; pp. 198–207. [Google Scholar]
- Rana, L.; Rehman, A.U.; Javaid, S.; Ali, T.M. A Novel Model-Driven Approach for Visual Impaired People Assistance OPTIC ALLY. In Proceedings of the 2022 Third International Conference on Latest trends in Electrical Engineering and Computing Technologies (INTELLECT), Karachi, Pakistan, 16–17 November 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–8. [Google Scholar]
- Saxena, A.; Schulte, J.; Ng, A.Y. Depth Estimation Using Monocular and Stereo Cues. In Proceedings of the IJCAI, Hyderabad, India, 6–12 January 2007; Volume 7, pp. 2197–2203. [Google Scholar]
- Duman, S.; Elewi, A.; Yetgin, Z. Design and implementation of an embedded real-time system for guiding visually impaired individuals. In Proceedings of the 2019 International Artificial Intelligence and Data Processing Symposium (IDAP), Malatya, Turkey, 21–22 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–5. [Google Scholar]
- Sohan, M.; Sai Ram, T.; Reddy, R.; Venkata, C. A Review on YOLOv8 and Its Advancements. In Proceedings of the International Conference on Data Intelligence and Cognitive Informatics, Tirunelveli, India, 18–20 November 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 529–545. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. YOLO by Ultralytics; Ultralytics Inc.: Frederick, MD, USA, 2023. [Google Scholar]
- Xiao, X.; Feng, X. Multi-object pedestrian tracking using improved YOLOv8 and OC-SORT. Sensors 2023, 23, 8439. [Google Scholar] [CrossRef] [PubMed]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 1–5. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Muhammad, A.; Zalizniak, V. Practical Scientific Computing; Woodhead Publishing: Sawston, UK, 2011. [Google Scholar]
- Haseeb, M.A.; Guan, J.; Ristic-Durrant, D.; Gräser, A. DisNet: A novel method for distance estimation from monocular camera. In Proceedings of the 10th Workshop on Planning, Perception and Navigation for Intelligent Vehicles (PPNIV18), IROS, Madrid, Spain, 1 October 2018; pp. 1–6. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Trucco, E.; Verri, A. Introductory Techniques for 3-D Computer Vision; Prentice Hall: Upper Saddle River, NJ, USA, 1998. [Google Scholar]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision, 2nd ed.; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Fiorini, P.; Shiller, Z. Motion planning in dynamic environments using velocity obstacles. Int. J. Robot. Res. 1998, 17, 760–772. [Google Scholar] [CrossRef]
- Clark-Carter, D.D.; Heyes, A.D.; Howarth, C.I. The efficiency and walking speed of visually impaired people. Ergonomics 1986, 29, 779–789. [Google Scholar] [CrossRef] [PubMed]
- Robineau, D.; Baden, P.; Dhani, A.; Dark, M.; Bhagat, A.; Mann, H. Reported Road Casualties Great Britain: 2017; Technical Report; Department for Transport: London, UK, 2018. [Google Scholar]
- Walz, F.; Hoefliger, M.; Fehlmann, W. Speed Limit Reduction from 60 to 50 km/h and Pedestrian Injuries; Technical Report; Institute of Forensic Medicine University of Zurich: Zürich, Switzerland, 1983. [Google Scholar]
- Richards, D.C. Relationship between Speed and Risk of Fatal Injury: Pedestrians and Car Occupants; Technical Report; Department for Transport: London, UK, 2010. [Google Scholar]
- Rebollo-Soria, M.C.; Arregui-Dalmases, C.; Sánchez-Molina, D.; Velázquez-Ameijide, J.; Galtés, I. Injury pattern in lethal motorbikes-pedestrian collisions, in the area of Barcelona, Spain. J. Forensic Leg. Med. 2016, 43, 80–84. [Google Scholar] [CrossRef] [PubMed]
- Short, A.; Grzebieta, R.; Arndt, N. Estimating bicyclist into pedestrian collision speed. Int. J. Crashworth. 2007, 12, 127–135. [Google Scholar] [CrossRef]
- Chandra, S.; Bharti, A.K. Speed distribution curves for pedestrians during walking and crossing. Procedia Soc. Behav. Sci. 2013, 104, 660–667. [Google Scholar] [CrossRef]
- Freer, C. Vehicle Speed Compliance Statistics, Great Britain: 2018; Technical Report; Department of Transport: London, UK, 2019. [Google Scholar]
- Nie, B.; Li, Q.; Gan, S.; Xing, B.; Huang, Y.; Li, S.E. Safety envelope of pedestrians upon motor vehicle conflicts identified via active avoidance behaviour. Sci. Rep. 2021, 11, 3996. [Google Scholar] [CrossRef] [PubMed]
- Bernardin, K.; Stiefelhagen, R. Evaluating multiple object tracking performance: The clear mot metrics. EURASIP J. Image Video Process. 2008, 2008, 246309. [Google Scholar] [CrossRef]
- Lin, T.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Shao, S.; Zhao, Z.; Li, B.; Xiao, T.; Yu, G.; Zhang, X.; Sun, J. Crowdhuman: A benchmark for detecting human in a crowd. arXiv 2018, arXiv:1805.00123. [Google Scholar]
- Wen, L.; Du, D.; Cai, Z.; Lei, Z.; Chang, M.C.; Qi, H.; Lim, J.; Yang, M.H.; Lyu, S. UA-DETRAC: A new benchmark and protocol for multi-object detection and tracking. Comput. Vis. Image Underst. 2020, 193, 102907. [Google Scholar] [CrossRef]
- Milan, A.; Leal-Taixé, L.; Reid, I.; Roth, S.; Schindler, K. MOT16: A benchmark for multi-object tracking. arXiv 2016, arXiv:1603.00831. [Google Scholar]
- Zhao, Y.; Yan, C.; Wang, Q. CPU tracking algorithm for lightweight vehicles based on deepsort. In Proceedings of the 2022 18th International Conference on Computational Intelligence and Security (CIS), Chengdu, China, 16–18 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 102–106. [Google Scholar]
- Held, D.; Thrun, S.; Savarese, S. Learning to track at 100 fps with deep regression networks. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 749–765. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Learning to compare image patches via convolutional neural networks. In Proceedings of the IEEE Conference on computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4353–4361. [Google Scholar]
- Yazdi, M.; Bouwmans, T. New trends on moving object detection in video images captured by a moving camera: A survey. Comput. Sci. Rev. 2018, 28, 157–177. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, J.; Wu, Q.; Qian, X.; Zhou, T.; Fu, H. Extended kernel correlation filter for abrupt motion tracking. KSII Trans. Internet Inf. Syst. 2017, 11, 4438–4460. [Google Scholar] [CrossRef]
- Kuen, J.; Lim, K.M.; Lee, C.P. Self-taught learning of a deep invariant representation for visual tracking via temporal slowness principle. Pattern Recognit. 2015, 48, 2964–2982. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Meers, S.; Ward, K. A substitute vision system for providing 3D perception and GPS navigation via electro-tactile stimulation. In Proceedings of the International Conference on Sensing Technology, Nurnberg, Germany, 10–11 May 2005. [Google Scholar]
- Tao, M.; Li, X.; Xie, R.; Ding, K. Pedestrian Identification and Tracking within Adaptive Collaboration Edge Computing. In Proceedings of the 2023 26th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Rio de Janeiro, Brazil, 24–26 May 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1124–1129. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Dataset | mAP50 | mAR |
|---|---|---|---|
| YOLOv8m | VMOT | 97.61% | 96.45% |
| YOLOv8m [37] | COCO [57] | 50.20% | - |
| YOLOv8n | VMOT | 93.68% | 90.15% |
| YOLOv8n [37] | COCO [57] | 37.30% | - |
| YOLOv8n [38] | CrowdHuman [58] | 82.00% | - |
| Model | Dataset | MOTA | MOTP |
|---|---|---|---|
| Deep SORT (YOLOv8m) | VMOT | 94.55% | 80.88% |
| Deep SORT (YOLOV5l) [61] | UA-DETRAC [59] | 84.40% | 77.40% |
| Deep SORT (Faster R-CNN) [39] | MOT16 [60] | 61.40% | 79.10% |
| Samp. | CMO | (km/h) | (km/h) | (km/h) | (m) | (m) | (m) | |
|---|---|---|---|---|---|---|---|---|
| 1 | Car | M | 7 | 7.26 | 0.13 | 5 | −0.06 | −0.01 |
| 2 | S | 10 | 11.05 | 3.13 | 10 | −0.46 | −0.05 | |
| 3 | S | 13 | 14.34 | 4.81 | 20 | −1.10 | −0.06 | |
| 4 | M | 25 | 26.83 | 2.09 | 20 | −1.61 | −0.08 | |
| 5 | M | 25 | 27.49 | 3.62 | 25 | −1.04 | −0.04 | |
| 6 | S | 30 | 34.72 | 3.56 | 25 | −0.50 | −0.02 | |
| 7 | M | 30 | 34.46 | 3.31 | 30 | −1.19 | −0.04 | |
| 8 | M | 35 | 38.82 | 1.44 | 45 | −0.63 | −0.01 | |
| 9 | S | 40 | 45.60 | 3.03 | 50 | −0.19 | −0.00 | |
| 10 | M | 40 | 46.15 | 3.33 | 60 | −1.03 | −0.02 | |
| 11 | M | 40 | 45.97 | 2.40 | 60 | −1.33 | −0.02 | |
| 12 | M | 45 | 51.67 | 2.74 | 70 | −2.28 | −0.03 | |
| 13 | S | 50 | 55.54 | 6.38 | 75 | −1.18 | −0.02 | |
| 14 | S | 60 | 68.19 | 2.86 | 100 | −0.75 | −0.01 | |
| 15 | Motorbike | M | 10 | 11.09 | 0.32 | 9 | −0.15 | −0.02 |
| 16 | S | 15 | 16.57 | 6.49 | 12 | −0.02 | −0.00 | |
| 17 | M | 20 | 22.28 | 2.11 | 17 | −0.84 | −0.05 | |
| 18 | S | 25 | 27.76 | 5.63 | 20 | −0.04 | −0.00 | |
| 19 | M | 25 | 27.91 | 3.57 | 20 | −0.25 | −0.01 | |
| 20 | M | 30 | 35.22 | 2.48 | 25 | −1.55 | −0.06 | |
| 21 | S | 35 | 40.64 | 3.57 | 30 | −1.20 | −0.04 | |
| 22 | S | 40 | 46.13 | 4.59 | 30 | −0.80 | −0.03 | |
| 23 | Bicycle | S | 8 | 8.34 | 3.50 | 5 | −0.14 | −0.03 |
| 24 | M | 8 | 8.59 | 0.82 | 5 | −0.02 | −0.00 | |
| 25 | S | 10 | 10.94 | 1.66 | 5 | −0.21 | −0.04 | |
| 26 | S | 11 | 11.91 | 2.34 | 5 | −0.26 | −0.05 | |
| 27 | M | 11 | 11.74 | 1.74 | 11 | −1.45 | −0.13 | |
| 28 | M | 12 | 13.98 | 0.65 | 14 | −0.75 | −0.05 | |
| 29 | S | 12 | 13.60 | 0.85 | 15 | −0.50 | −0.03 | |
| 30 | S | 16 | 17.02 | 4.09 | 15 | −1.18 | −0.08 | |
| 31 | M | 16 | 17.37 | 2.04 | 15 | −0.05 | −0.00 | |
| 32 | M | 17 | 18.30 | 4.22 | 16 | −1.50 | −0.09 | |
| 33 | M | 18 | 19.61 | 2.61 | 16 | −0.87 | −0.05 | |
| 34 | S | 25 | 27.40 | 3.59 | 23 | −0.25 | −0.01 | |
| 35 | Pedestrian | S | 1.5 | 1.63 | 0.08 | 5 | −0.42 | −0.08 |
| 36 | M | 2 | 2.85 | 0.15 | 9.15 | −1.94 | −0.21 | |
| 37 | M | 3 | 3.45 | 0.19 | 10 | −1.09 | −0.11 | |
| 38 | S | 4 | 4.52 | 0.97 | 11 | −0.16 | −0.01 | |
| 39 | M | 5 | 6.33 | 0.95 | 11 | −0.14 | −0.01 | |
| 40 | S | 6 | 7.16 | 1.23 | 14 | −1.24 | −0.09 | |
| 41 | M | 7 | 8.75 | 0.48 | 15 | −0.26 | −0.02 | |
| 42 | S | 8 | 8.97 | 1.97 | 16 | −1.33 | −0.08 | |
| 43 | S | 9 | 10.58 | 0.19 | 16 | −1.13 | −0.07 | |
| 44 | M | 10 | 11.38 | 0.81 | 50 | −1.99 | −0.04 |
| Component | Over. mAP | Over. mAR | EmFPS |
|---|---|---|---|
| CMO identification | 88.20% | 97.26% | 32 fps |
| CMO classification | 91.69% | 100% |
| CMO | TP | FP | FN | TN | mAP | mAR | ||
|---|---|---|---|---|---|---|---|---|
| Car | 182 | 65 | 174 | 19 | 8 | 46 | 91.61% | 95.62% |
| Motorbike | 112 | 31 | 108 | 19 | 4 | 12 | 88.96% | 96.62% |
| Bicycle | 77 | 35 | 75 | 17 | 2 | 18 | 86.44% | 96.97% |
| Pedestrian | 168 | 86 | 167 | 46 | 1 | 40 | 85.81% | 99.83% |
| Total | 539 | 217 | 524 | 101 | 15 | 116 | 88.20% | 97.26% |
| CMO | TP | FP | mAP | Over. mAP |
|---|---|---|---|---|
| Car | 422 | 4 | 99.32% | 91.69% |
| Motorbike | 105 | 7 | 96.01% | |
| Bicycle | 159 | 47 | 88.77% | |
| Pedestrian | 737 | 194 | 82.66% |
| CMO | (s) | (s) | ||||
|---|---|---|---|---|---|---|
| Car | Serious | 10 | 7.38 | 2 | 2 | Imm. |
| Moto.R | Serious | 5.40 | 2.70 | 2 | 1 | Imm. |
| Bic.R | Minor | 9.95 | 7.60 | 3 | 3 | s |
| Ped. | Minimal | 18.86 | 15.21 | 4 | 4 | s |
| CMO | (s) | (s) | (s) | (s) | ||
|---|---|---|---|---|---|---|
| Car | Severe | 6–14.41 | 5 | 6 | 11 | Imm. or |
| Serious | 14.99–51.55 | 5 | 4 | 9 | ||
| Moto.R | Severe | 4.50–7.20 | 5 | 6 | 11 | Imm. |
| Serious | 7.50–17.99 | 5 | 4 | 9 | Imm. or | |
| Bic.R | Serious | 7.20–17.99 | 5 | 4 | 9 | Imm. or |
| Minor | 20–22.52 | 5 | 2 | 7 | ||
| Ped. | Minor | 17.99–25.77 | 5 | 2 | 7 | |
| Minimal | 29.94–119.05 | 5 | 0 | 5 |
| Model | MOTA | MOTP | Aver. Processing Time |
|---|---|---|---|
| Deep SORT (YOLOv8) | 94.55% | 80.88% | 0.64 ms |
| DEEP-SEE [15] (YOLOv8) | 87.04% | 68.75% | 380 ms |
| Scheme | Over. mAP | Over. mAR | Aver. E2E Processing Time |
|---|---|---|---|
| ARAware | 88.20% | 97.26% | 31 ms |
| DEEP-SEE [15] | 77.32% | 54.64% | 430 ms |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Surougi, H.; Zhao, C.; McCann, J.A. ARAware: Assisting Visually Impaired People with Real-Time Critical Moving Object Identification. Sensors 2024, 24, 4282. https://doi.org/10.3390/s24134282
Surougi H, Zhao C, McCann JA. ARAware: Assisting Visually Impaired People with Real-Time Critical Moving Object Identification. Sensors. 2024; 24(13):4282. https://doi.org/10.3390/s24134282
Chicago/Turabian StyleSurougi, Hadeel, Cong Zhao, and Julie A. McCann. 2024. "ARAware: Assisting Visually Impaired People with Real-Time Critical Moving Object Identification" Sensors 24, no. 13: 4282. https://doi.org/10.3390/s24134282