Abstract
The efficient and accurate identification of traffic signs is crucial to the safety and reliability of active driving assistance and driverless vehicles. However, the accurate detection of traffic signs under extreme cases remains challenging. Aiming at the problems of missing detection and false detection in traffic sign recognition in fog traffic scenes, this paper proposes a recognition algorithm for traffic signs based on pix2pixHD+YOLOv5-T. Firstly, the defogging model is generated by training the pix2pixHD network to meet the advanced visual task. Secondly, in order to better match the defogging algorithm with the target detection algorithm, the algorithm YOLOv5-Transformer is proposed by introducing a transformer module into the backbone of YOLOv5. Finally, the defogging algorithm pix2pixHD is combined with the improved YOLOv5 detection algorithm to complete the recognition of traffic signs in foggy environments. Comparative experiments proved that the traffic sign recognition algorithm proposed in this paper can effectively reduce the impact of a foggy environment on traffic sign recognition. Compared with the YOLOv5-T and YOLOv5 algorithms in moderate fog environments, the overall improvement of this algorithm is achieved. The precision of traffic sign recognition of the algorithm in the fog traffic scene reached 78.5%, the recall rate was 72.2%, and mAP@0.5 was 82.8%.
1. Introduction
In recent years, the occurrence and frequency of haze have constantly been increasing, bringing severe threats to people’s daily lives [1]. Foggy weather is one of the most common adverse weather conditions as it reduces visibility; it is always a major hidden risk to traffic safety. Traffic signs contain important semantic information such as road conditions, driving environment, and speed limit warnings, which play a significant role in reducing the rate of road accidents, therefore, it is vital to recognize these signs quickly and accurately [2].
Detection algorithms for traffic signs are now primarily divided into two categories: detection algorithms based on traditional methods and detection algorithms based on deep learning. Traditional detection algorithms for traffic signs include the detection method based on color features and detection methods based on shape features. Among them, the former detects traffic signs according to color models such as RGB, HSV, and HSI, while the latter is also the subject of extensive research conducted by scholars. J. M. LIillo Castellano et al. [3] studied the segmentation region methods based on HSV color models to extract traffic sign information after segmenting the specified regions. C. Bahilmann et al. [4] considered the color and Haar features of images, and achieved traffic sign detection using AdaBoost algorithms. C. G. KIRAN et al. [5] first performed the color segmentation of images and combined segmented chunks with edge features, and then used a support vector machine (SVM) to achieve traffic sign classification. However, since the selective methods of traditional features are subjective and easily affected by complex environments, deep learning-based traffic sign detection methods are more advantageous. This algorithm learns features by training a large amount of data, which is more accurate than the traditional methods that use artificially designed features, and its precision is significantly improved.
Currently, mainstream object detection algorithms are categorized into two-stage object detection algorithms and single-stage object detection algorithms. The Faster R-CNN [6] is a classic representative of the two-stage algorithm, which adds a region proposal network (RPN) on the basis of a Fast R-CNN, realizes CNN feature sharing, and uses a convolutional neural network (CNN) to automatically generate a region proposal instead of the traditional generating method for a region proposal, which improves the speed of network computation [7]. In deep learning-based object detection algorithms, the two-stage detection algorithm has high accuracy but a slow speed of recognition, so this kind of algorithm usually needs to be optimized in traffic sign detection scenes. In [8], the authors proposed a Fast R-CNN based on a residual network for multi-task parallel detection and applied it to road environment perception; they succeeded in detecting multiple types of targets with a detection speed of more than 7 fps. In [9], the authors mentioned that an improved classifier based on the Fast R-CNN and the recognition precision on the TT-100K datasets was increased by 7.7%, and the detection speed was also greatly improved. Jinghao Cao et al. [10] added an attention mechanism module to the backbone of a Fast R-CNN and incorporated multi-scale fusion architecture to improve the detection precision of traffic signs.
The end-to-end single-stage model mainly includes you only look once (YOLO) [11], the single-shot multi-box detector (SSD) [12], etc. Sun Fuwen [13] improved the YOLOv3 model by proposing an enhanced version and using reduced down-sampling feature maps (four times four) to predict target information. The experimental results showed that when small-sized traffic signs are recognized, the mean average precision () of an improved YOLOv3 model is 3.7% higher than that of the original YOLOv3. In [14], the authors combined synthetic images with original images through data augmentation to expand the dataset distribution and improve the detection performance. The precision in YOLOv3 and YOLOv4 is 84.9% and 89.33%, respectively. J. Wang [15] used the attention fusion feature pyramid network (AF-FPN) to replace the original FPN in YOLOv5. He improved the detection performance of the YOLOv5 network for multi-scale targets while ensuring real-time detection. Yin Jinghan et al. [16] optimized the architecture of the YOLOv5 network, adopted reverse thinking, reduced the depth-aware feature pyramid network (FPN), and limited the maximum down-sampling multiples to solve the problem of small targets being difficult to recognize. This optimization enables the network to maintain high-precision recognition even in adverse weather conditions.
There are generally two methods for traffic sign detection in a foggy environment. The first is to process foggy images and then perform detection. Among them, the most common method for processing foggy images is the defogging algorithm. He et al. [17] proposed an image-defogging algorithm based on the dark channel prior (DCP) theory to optimize the transmission estimation and effectively avoid color-shifting artifacts in the bright areas of an image and the halo effect in the sudden transition of the depth of field. Cai et al. [18] at the South China University of Technology also designed the DehazeNet defogging algorithm based on CNN architecture. The occurrence of Pix2Pix [19] and Cycle GAN [20] enabled the conversion of one scene representation into another. Inspired by the above-mentioned generative adversarial network (GAN), the authors in [21,22,23] used priors, which are different from the defogging algorithm; they learned the difference between fog and sunny day images through the adversarial network and realized the conversion of foggy images to sunny day images. The above-mentioned defogging algorithms are mostly used in low-level vision tasks, and there is still much room for improvement when facing high-level vision tasks (such as traffic sign recognition). The second method for detecting traffic signs in a foggy environment is to improve the robustness of the target detection network in the foggy environment by optimizing the detection network structure. Pengfei Hu [24] combined an improved DCP algorithm with an optimized LeNet5 network to achieve traffic sign recognition in a foggy environment, with a significant performance improvement but it was not validated using fog datasets. Shubo Yu [25] compared the performance of HOG-SVM and improved the Faster RCNN in fog and found that HOG-SVM is limited in complex scenes, while the Faster RCNN improves accuracy and detection, but the validation set contained fewer real fog images. Binke Lang et al. [26] improved YOLOv5 detection for traffic signs in foggy environments by introducing the BIFPN and CA, but mAP@0.5 only increased by 0.2% and lacked verification in real fog scenes. In [16,24,25,26,27,28,29], the authors used an FPN as the backbone of a multi-level feature pyramid to better detect small targets and achieve good detection results even in complex environmental backgrounds. In addition to using a parallel pyramid network to improve feature extraction, [16] introduced a residual aggregation network. In [30], the authors extracted detailed features by building a residual aggregation module, using dense connections, and combining low-dimensional features to generate high-dimensional features. However, these methods could not fundamentally solve the impact of a foggy environment on the visibility of traffic signs.
Based on the aforementioned research, in traditional defogging algorithms, both image enhancement methods and image restoration methods lead to the loss of feature information of small targets in images; in deep learning-based defogging algorithms, the use of a neural network to estimate parameters such as atmospheric transmission also lead to estimation errors. GANs are used to remove fog and can circumvent the uncertainties of prior information, such as estimating atmospheric light intensity, but in the process of generating object-style images, there are still problems with the loss of local feature information and domain transfer. Improving the target detection algorithm usually involves changing the number and size of the convolutional network and adding an attention mechanism to improve the target detection algorithm’s ability to extract target features. However, increasing the receptive field by stacking convolution kernels makes it fundamentally difficult to solve the problem of information loss during feature extraction. Inspired by [31], this paper leverages the dynamic game characteristics of the discriminator and generator in the conditional generative adversarial network and applies the Pix2PixHD network to the task of defogging traffic sign images in foggy traffic scenes. In order to better match the defogging algorithm with the object detection algorithm, as well as improve the speed and accuracy of detection, the feature extraction module in YOLOv5 is improved. The transformer encoder module is integrated into the YOLOv5 detection model, which introduces a multi-head attention mechanism to establish connections between the parts of target images, thus reducing the influence of a foggy environment on traffic sign detection. At the same time, the iterations of the convolutional module are reduced, and the training efficiency of the model is enhanced so as to improve the detection speed of traffic signs. Finally, the defogging algorithm based on the Pix2PixHD network is combined with the improved YOLOv5 model for the recognition of traffic signs in foggy environments, and the effectiveness of the proposed method is verified using comparative experiments.
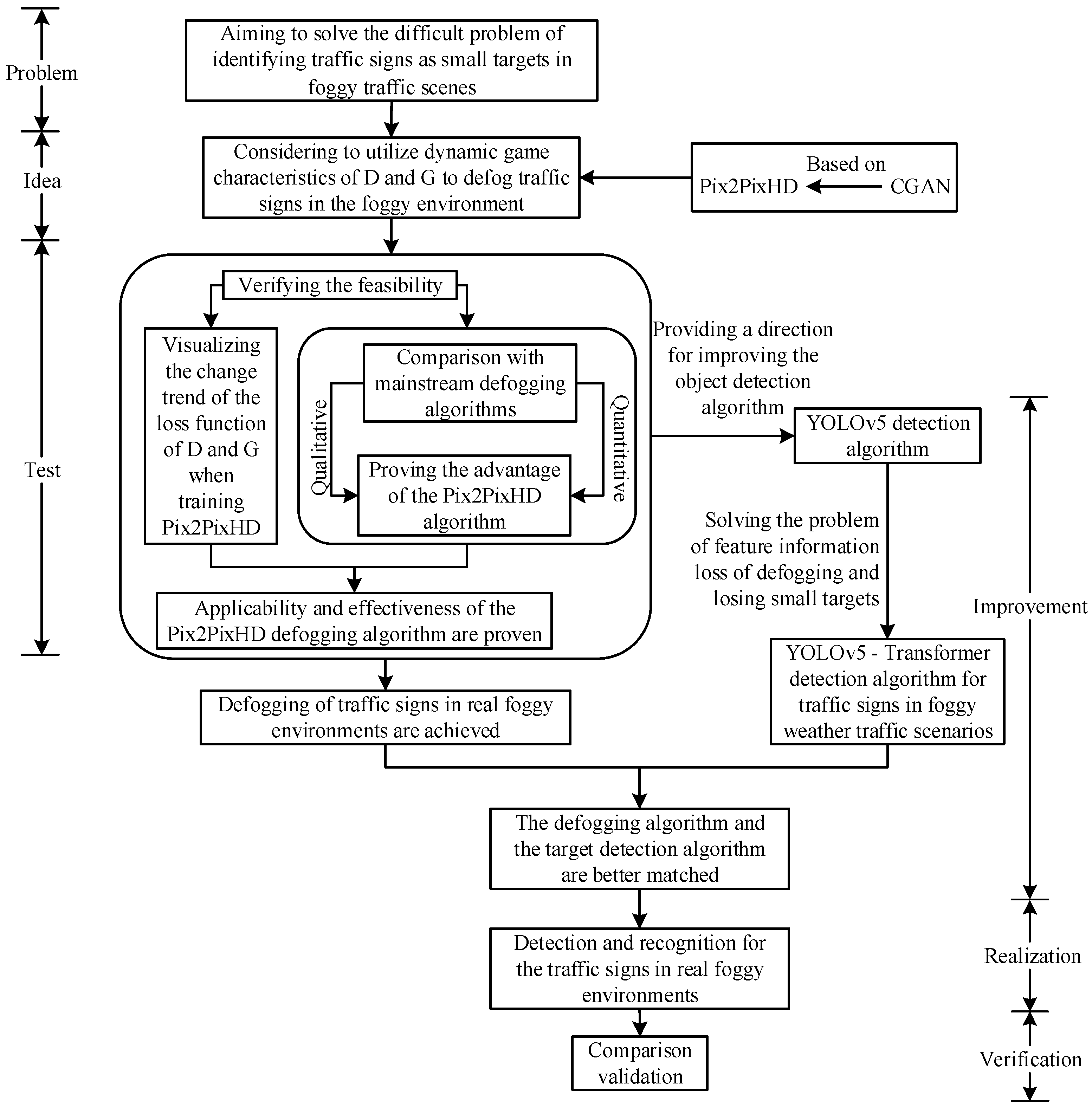
The contribution made in this paper mainly involves aiming to solve the difficult problem of identifying traffic signs as small targets in foggy traffic scenes. First, the conditional generation adversarial network Pix2PixHD is trained, the changing trend of its network loss function is visualized, and a qualitative and quantitative comparison with mainstream defogging algorithms is carried out, which proves the applicability and effectiveness of Pix2PixHD for defogging traffic sign images in foggy traffic scenes. Then, the defogging algorithm based on the Pix2PixHD network is used to defog traffic sign images in a foggy environment and then obtain the conversion of the foggy image to a clear image, which provides a basis for the selection of the defogging algorithm of the traffic sign images in the foggy traffic scene. It effectively avoids generating estimation errors in the atmospheric light intensity and transmission rate and the problem of dimension conversion. At the same time, it generates high-definition traffic sign images conducive to the recognition of the detection algorithm. Secondly, a transformer is used to improve both the shallow network and deep network in the feature extraction network of YOLOv5 Backbone, and the YOLOv5-T detection algorithms is proposed, which effectively improves the extraction ability of the network to the features of the traffic sign image. Finally, the image-defogging algorithm based on Pix2PixHD and the YOLOv5-T detection algorithm are combined to realize the identification of traffic signs in a foggy environment. The comparative experiments demonstrated that the method proposed in this paper is significantly better than other methods, especially in moderate fog datasets. The overall research idea of this paper is shown in Figure 1.
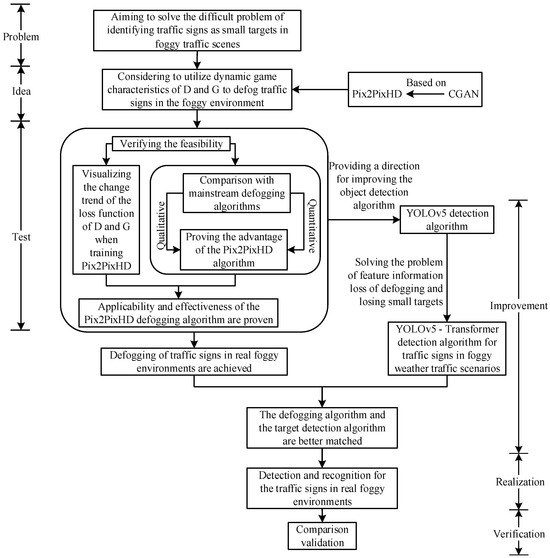
Figure 1.
Overall research idea.
2. Principle of the Defogging Algorithm Based on the Conditional Generative Adversarial Network
A conditional generative adversarial network (CGAN) is often used for scenarios such as semantic segmentation [31] and image enhancement. In this paper, the dynamic game characteristics of the discriminator and generator in a CGAN are utilized for the task of defogging traffic sign images in foggy traffic scenes.
2.1. Principle of the Conditional Generative Adversarial Network (CGAN)
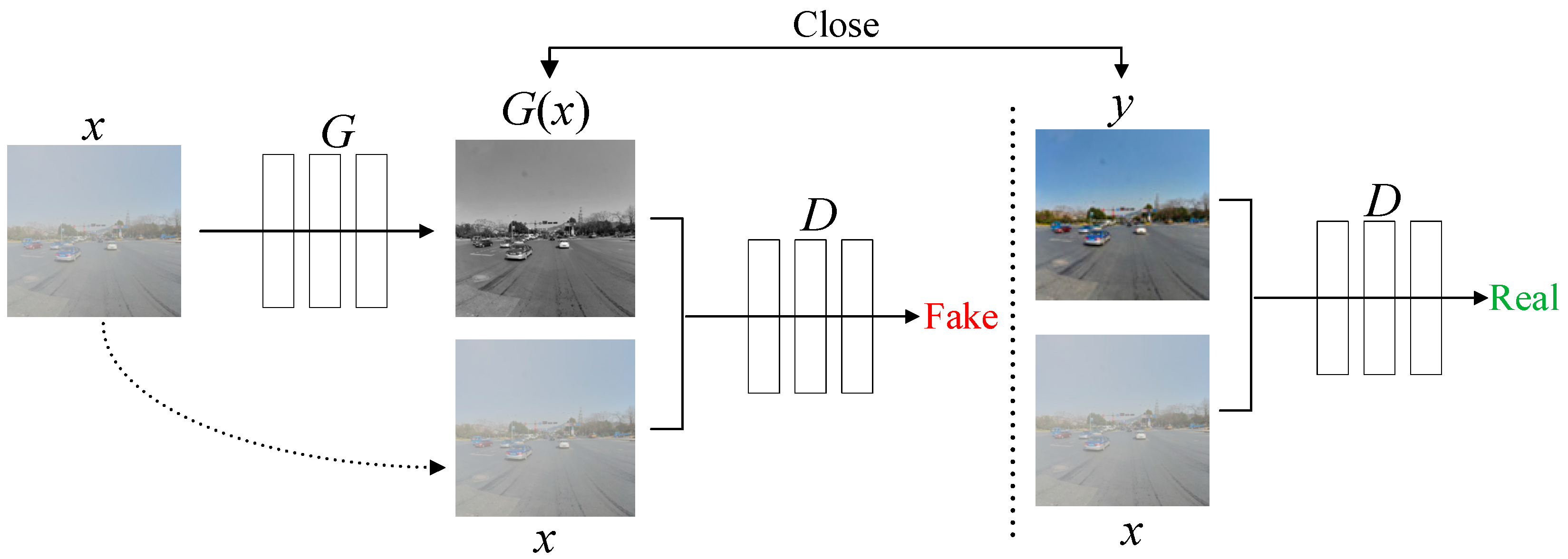
The CGAN is roughly similar to traditional GANs in structure, consisting of a generator (G) and a discriminator (D). A CGAN adds a constraint condition y to the GAN, as shown in Figure 2. The input foggy image x is fed into the generator, which continuously learns the feature distribution of sunny day images y to produce the generated image G(x). Based on the input actual paired images y and x, the discriminator judges G(x) and the input foggy image x whether they satisfy the requirements of the objective function. The training process of the CGAN involves a dynamic “zero-sum game” between G and D. The discriminator evaluates the adequacy of the generated image based on the input labeled image and then provides feedback to the generator through backpropagation. Through continuous iterations between G and D, G(x) gradually approaches the real image y. The ultimate goal of the model is to make D unable to distinguish between the authenticity of the generated data G(x).
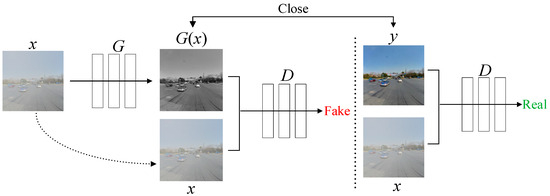
Figure 2.
Conditional generative adversarial network structure.
2.2. Pix2PixHD Network
2.2.1. Architecture of the Pix2PixHD Generator
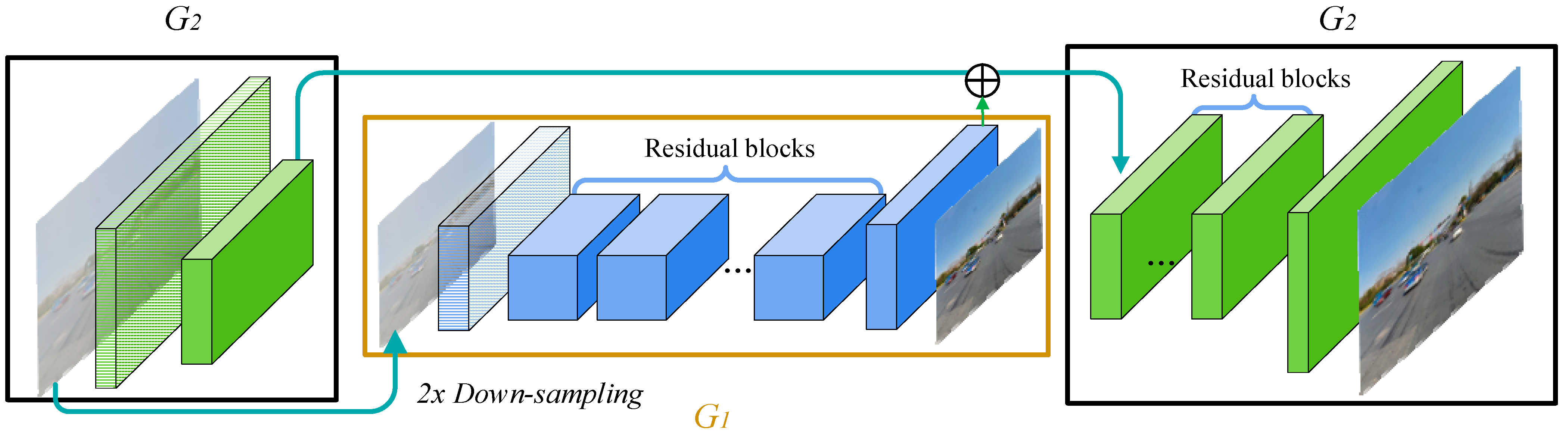
The Pix2PixHD model is an improvement based on the CGAN. Its core principle is the same as the principle of the CGAN, and its architecture can be seen as an integration of two CGANs with different sizes. As shown in Figure 3, the multi-scale generator of Pix2PixHD consists of two modules, G1 and G2, which are similar in structure. G1 represents the global generator network, with an input and output image size of 1024 × 512. G2 represents the local enhancer network, with an input and output image size of 2048 × 1024. Overall, another generator (G1) is embedded in a regular generator (G2). The global structural features extracted by G1 and the features extracted by the shallow layer of G2 are fused and input into the middle layer of G2 to generate high-quality images. During the training process, G1, with a smaller resolution, is first trained, and then G1 and G2 are trained together. The input fog image is double down-sampled via the convolution layer of generator G2, and then another generator, G1, is used to generate low-resolution images. The output generated by G1 and the image obtained from the down-sampling carry out element-wise adding, and then this combined result is fed into the subsequent network of G2 to generate high-resolution images. In the generator structure of Pix2PixHD, double down-sampling refers to reducing the width and height of the input image to half of its original size through a convolutional layer with a step size of two in order to extract the features of images on different scales and reduce the computational load for subsequent processing.
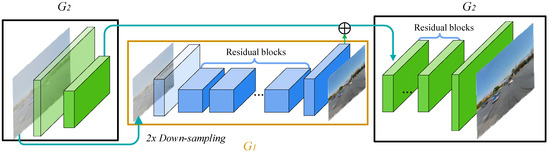
Figure 3.
Architecture of the Pix2PixHD generator.
2.2.2. Architecture of the Pix2PixHD Discriminator
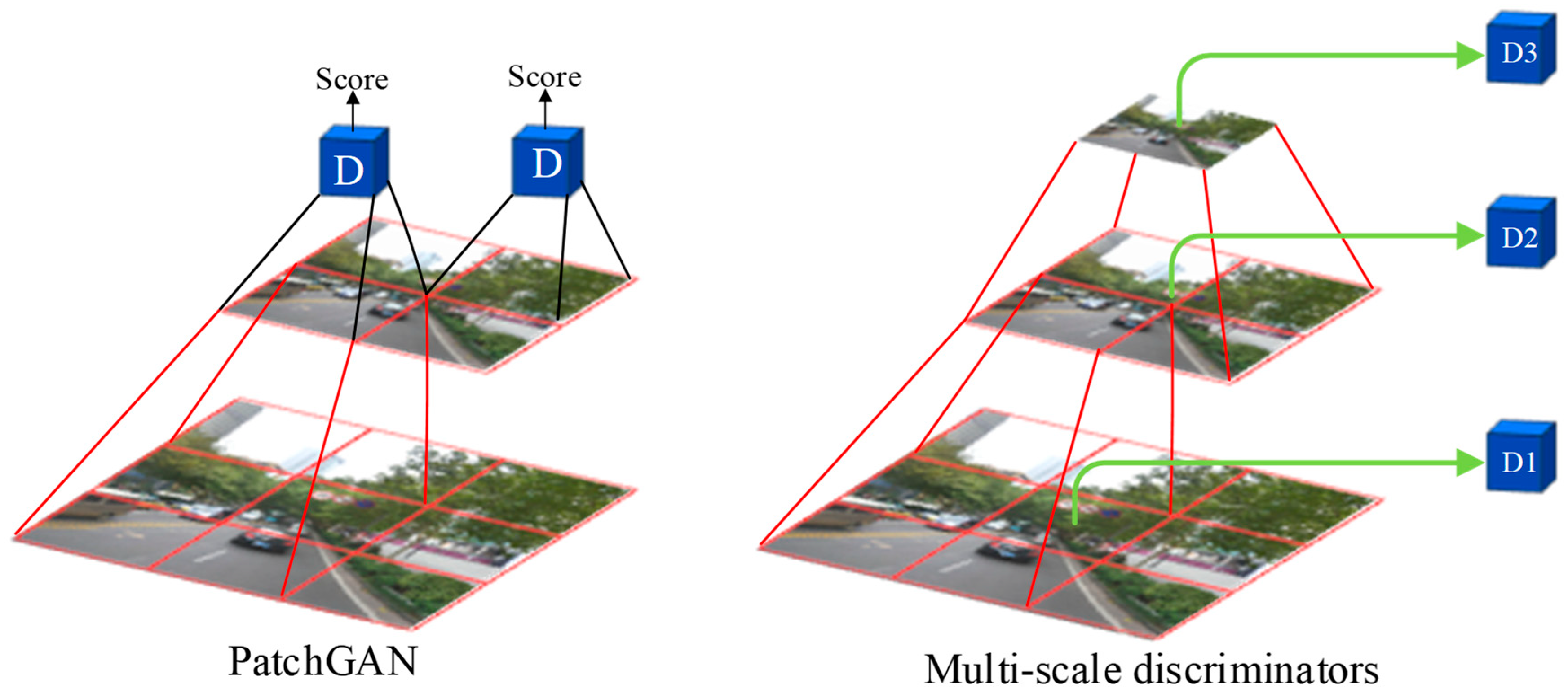
The Pix2PixHD discriminator is an improvement based on the Markovian discriminator (PatchGAN). The architecture of PatchGAN is illustrated in Figure 4. First, the discriminator utilizes a convolutional neural network (CNN) to divide the input images into multiple patches and perform continuous down-sampling. A patch of the feature map extracted using the high-level CNN corresponds to an area of the low-level feature map, representing a receptive field. Then, the discriminator is used to make a decision for each patch of the output layer image. Finally, the average loss of all patches on the entire image is taken as the final result.
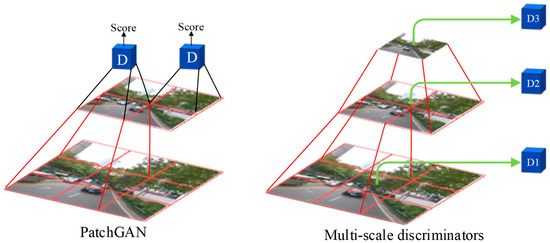
Figure 4.
Architecture of the Pix2PixHD discriminator.
To generate higher-resolution images, it is not enough for Pix2PixHD to improve the generator alone. The discriminator also needs to be optimized. First, the discriminator needs to have a large receptive field, so a deeper network is also needed. However, stacked convolutional layers can lead to overfitting and require significant memory usage. Based on PatchGAN, the multi-scale discriminator has been proposed, which employs three discriminators D1, D2, and D3 with the same network architecture but operating on different image scales. An image pyramid comprising three scales is constructed by down-sampling the real and synthetic high-resolution images by factors of 2 and 4. Specifically, D1 operating on the coarsest image (the one with the lowest resolution) has the largest receptive field, enabling it to understand the image more globally and provide feedback to the generator to produce globally consistent images. In contrast, D3 operating on the finest image (the one with the highest resolution) is responsible for guiding the generator to generate details. D2 lies between these two, offering an intermediate scale evaluation that focuses on both details and the overall integrity of the image. By adopting a multi-scale discriminator, Pix2PixHD is able to evaluate different aspects of the generated image better, thereby enhancing the fidelity and quality of the image generation.
3. Training Experiments Based on the Pix2PixHD Network
3.1. Building the Training Dataset
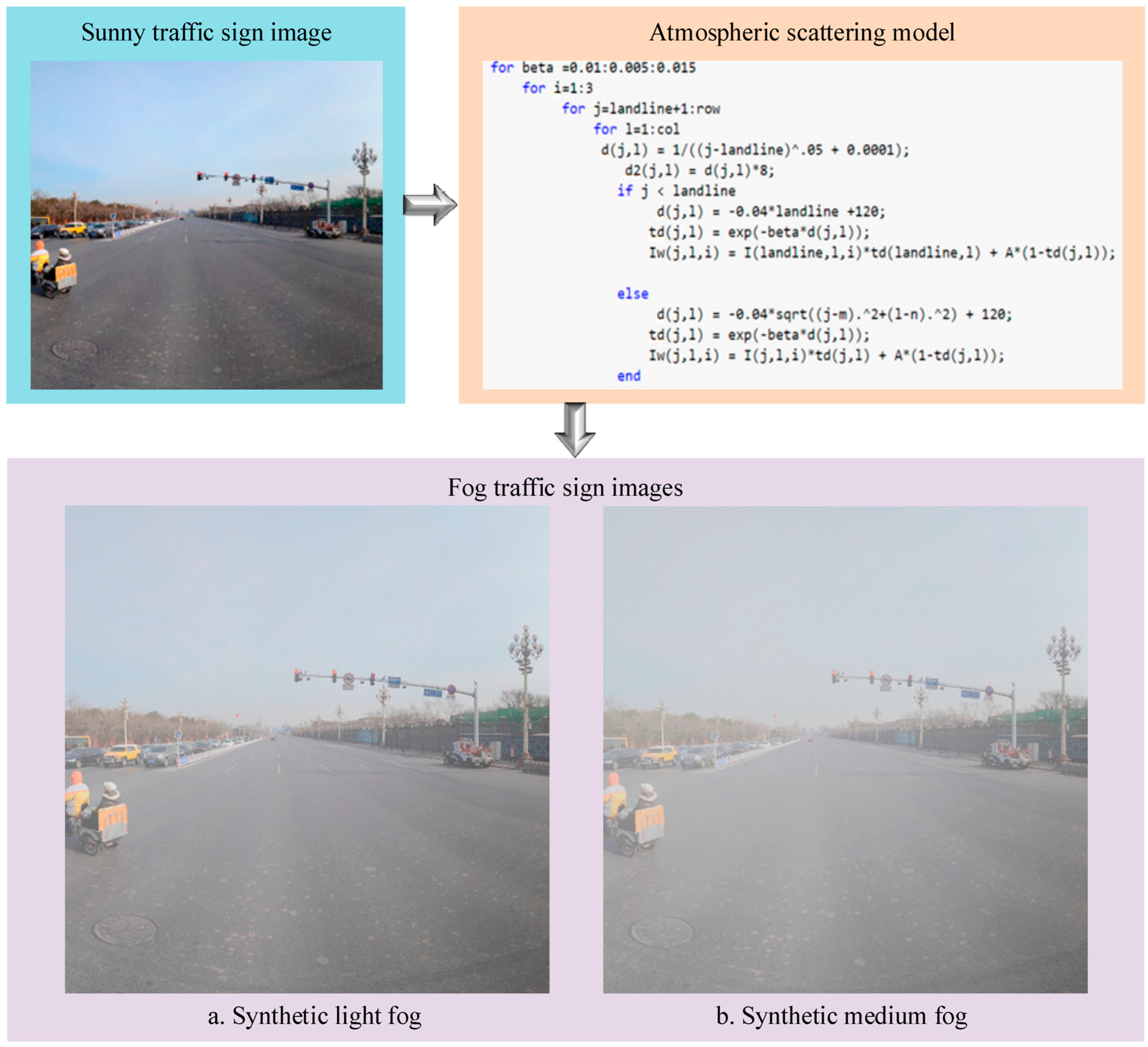
To utilize GANs for defogging traffic sign images in foggy environments, a large number of paired image samples are required for training. However, in reality, it is difficult to collect a large number of traffic sign images in a foggy environment as well as their corresponding sunny day images. Therefore, open-source datasets and captured foggy images were used to construct the dataset of this paper. The TT100K dataset [32] was used for the sunny day traffic sign dataset. This dataset was derived from a Chinese street view containing more than 300 cities with rich scenes and complete types of traffic signs. To expand the sample of the dataset, the sunny day images were fogged according to the real fog images.
To make the synthetic foggy traffic scenes as close as possible to real foggy scenes, MATLAB was used to simulate light fog and medium fog conditions based on the principle of the atmospheric scattering model [33]. Specifically, the atmospheric light value A was set to 0.8, and the scattering coefficient β was set to 0.04 and 0.08. The construction process of the synthetic foggy images is shown in Figure 5. Some images of the dataset constructed in this paper are shown in Figure 6.
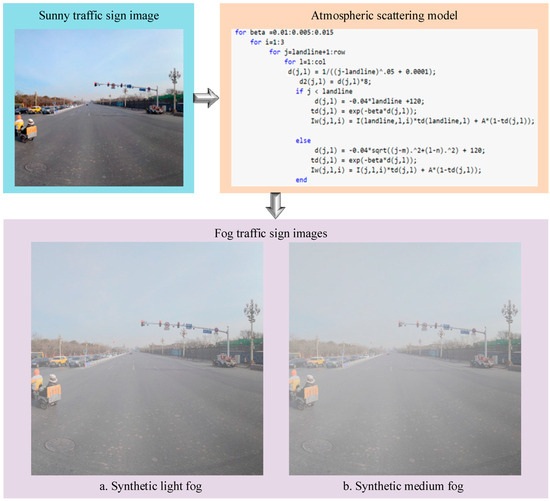
Figure 5.
The construction process of a synthetic foggy image.

Figure 6.
Image examples of the dataset constructed in this paper.
3.2. Training Parameter Configuration
The debugged Pix2PixHD model was trained by using Pytorch 1.10.0+cuda 11.3. The training batch size was set to 1, the initial learning rate was set to 0.0002, and the number of epochs was 300. The detailed parameters are presented in Table 1.

Table 1.
Training parameter settings.
3.3. Analysis of the Training Results
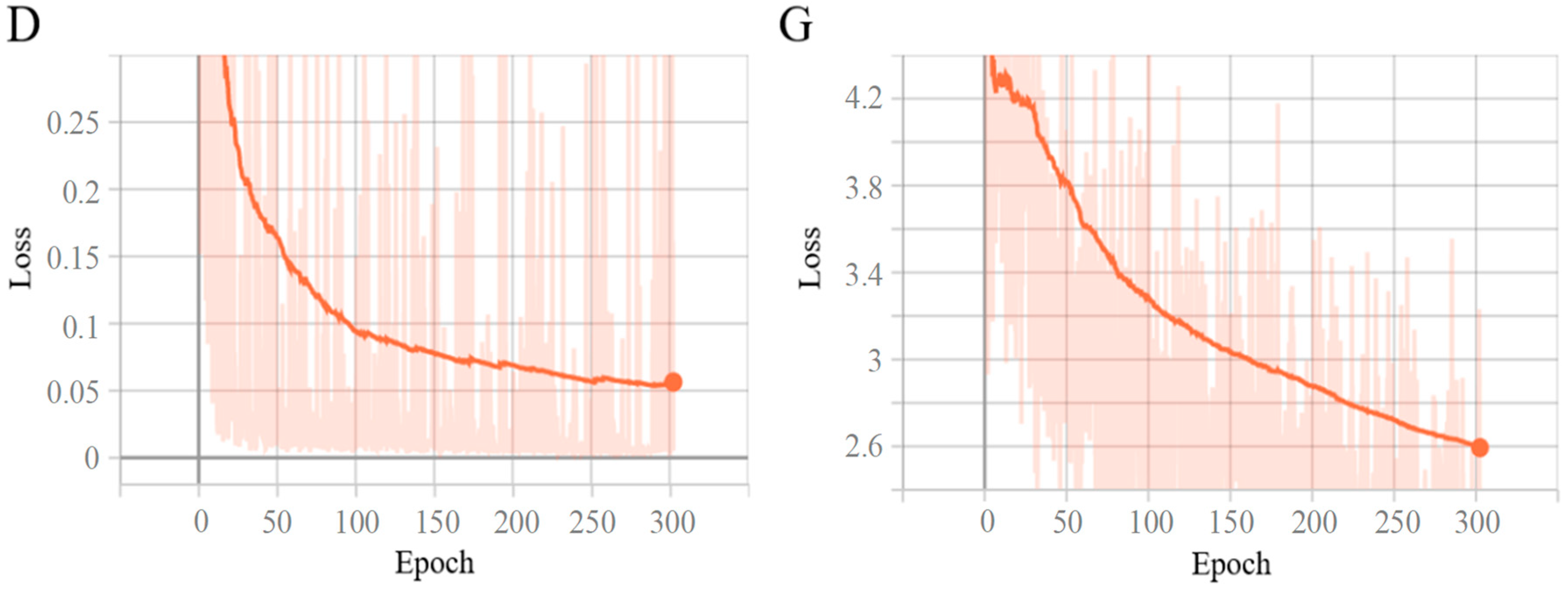
The loss function curve is a crucial indicator in the training of deep-learning models. It can reflect the changes and training results of the model during the training process. By observing the loss function, we can clearly understand the stability of the model training process, whether the model has achieved optimization, and the quality of the final model’s performance. The visualization tool TensorBoard was used to visualize the changing trend of the loss functions of the discriminator and generator during Pix2PixHD training. To fully prove the convergence of each loss function, we visualized all 300 epochs. As can be seen from Figure 7, although the loss function of both the discriminator and the generator had some oscillations, they show an overall downward trend. At the same time, the convergence rate was the fastest in the first 100 epochs, and after the 250th epoch, the value of the loss function hardly changed. This shows that the model continuously learned the characteristics of sunny days and foggy environments, and the performance of the model gradually stabilized after a period of training. Among them, D is the changing trend of the loss function of the discriminator, and G is the changing trend of the loss function of the generator.
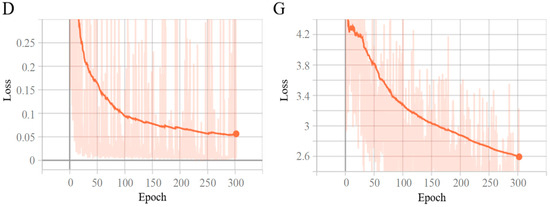
Figure 7.
The trends of the loss function during training.
3.4. Comparative Analysis of the Defogging Effect
To ensure the accurate and efficient recognition of traffic sign images in foggy traffic scenes, defogged images should not only guarantee the clarity of the global image but also require sufficient clarity of local targets. To verify whether the defogging algorithm based on the Pix2PixHD network used in this paper could meet this requirement, we introduced the CAP [34], DCP [35], Dehaze-Net [18], FFA-Net [36], GCA-Net [22], Cycle GAN [23], and AOD-Net [37] defogging algorithms for a comparative analysis from both qualitative and quantitative aspects.
3.4.1. Qualitative Analysis
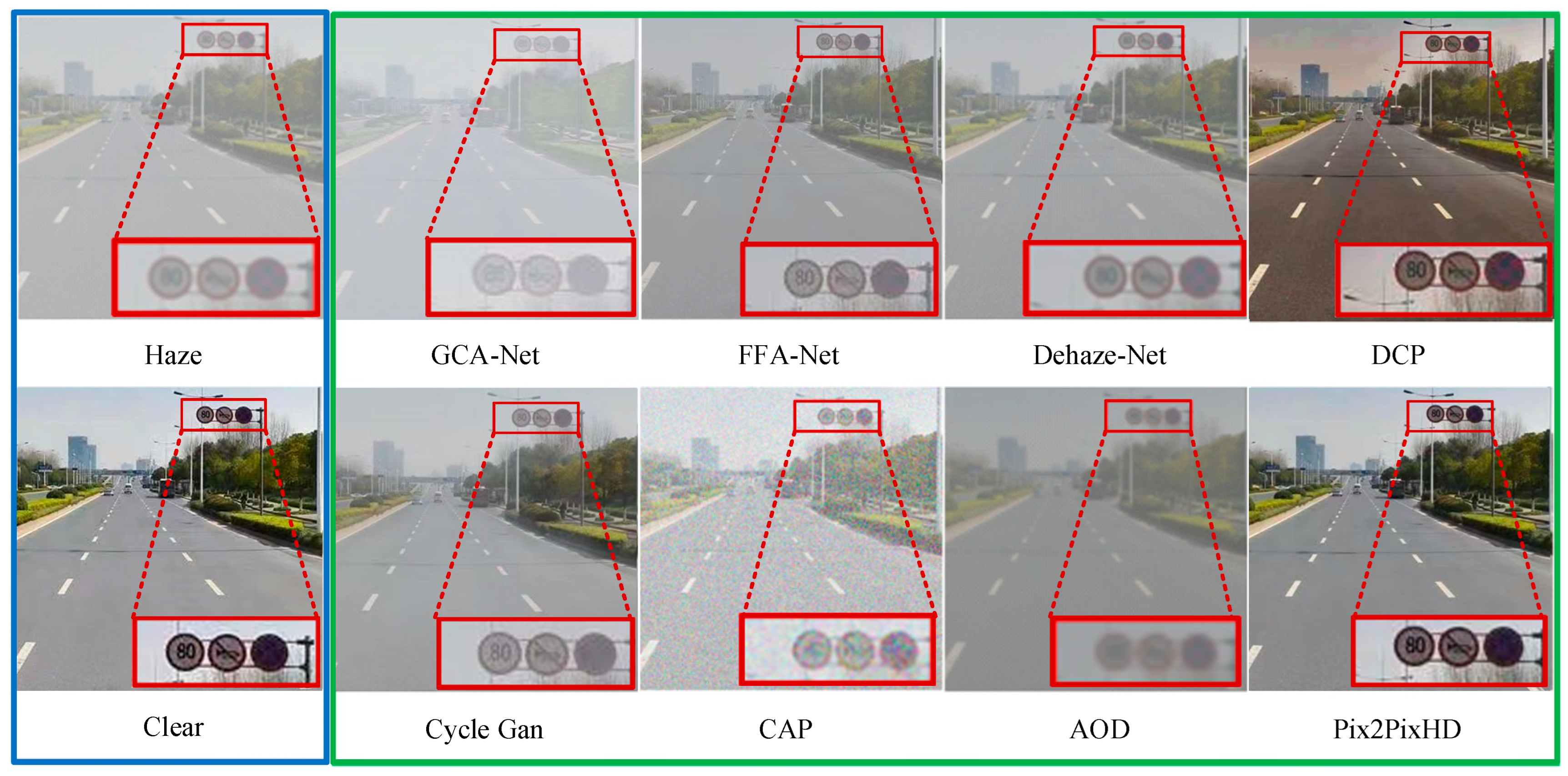
The defogging algorithm proposed in this paper was used to process traffic sign images in foggy traffic scenes, and a visualization comparison was made with other defogging algorithms. As shown in Figure 8, the blue wireframe shows the generated foggy images and the corresponding clear sky images; the green wireframe shows the defogging effect of the compared defogging algorithms and the defogging algorithm proposed in this paper on the foggy images; and the red wireframe shows the traffic sign that needs to be recognized. Through observation, it can be found that the traffic sign features in the image processed using the defogging algorithm presented in this paper are significantly enhanced, and the overall clarity of the image is also greatly improved. The traffic sign features are noticeable after defogging with the DCP method, but there is a noticeable distortion in the overall image. While the Cycle GAN achieves good global defogging, it suffers from severe loss of traffic sign feature information. After defogging with the FFA-Net, the clarity of large objects in the image is indeed improved, but small objects remain blurry. CAP adds other noise while defogging, making the image more blurred, indicating that this algorithm is not suitable for traffic scenes. The enhancement effect of the image feature of the other algorithms is not obvious. The above-mentioned comparison shows that the Pix2PixHD defogging algorithm is not only suitable for traffic scenes but also has great advantages in processing image details and is suitable for restoring traffic signs in a foggy environment.
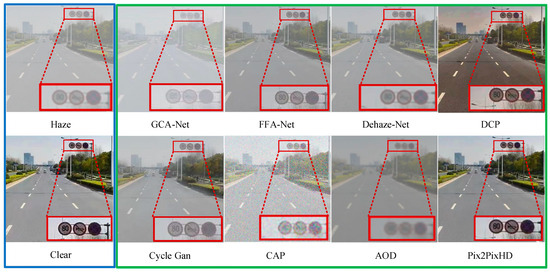
Figure 8.
Qualitative analysis and visualization of defogging images.
3.4.2. Quantitative Analysis
At present, there is no unified evaluation standard for the quality of image defogging. In this paper, two common image quality evaluation indexes, the peak signal-to-noise ratio (PSNR) and structural similarity (SSIM), were selected to evaluate the defogging quality. The PSNR is a commonly used indicator for the objective quantitative evaluation of image quality, which is used to evaluate the errors between the corresponding pixels of two images. The larger the PSNR value is, the better the image-defogging effect is. The SSIM is an indicator for measuring the similarity between two images, ranging from 0 to 1. The larger the SSIM value is, the higher the similarity is. When the two images are exactly the same, the SSIM is one. Compared with the PSNR, the SSIM is more consistent with the judgment of image quality from the perspective of human eyes. The traffic sign images in light fog and medium fog were tested separately. The highest index is marked in red font, and the lowest index is marked in blue font. The testing results are shown in Table 2 and Table 3.
Table 2.
Values of the SSIM and PSNR in light fog.
Table 3.
Values of the SSIM and PSNR in medium fog.
As shown in Table 2, in a light fog environment, the SSIM value of Dehaze-Net is 0.898, and the SSIM value of Pix2PixHD is 0.897, with a difference of only 0.001. However, the PSNR value of Pix2PixHD is 24.269, and the PSNR value of Dehaze-Net is 22.520. In a medium fog environment, the SSIM and PSNR values of Pix2PixHD are both the highest, being 0.975 and 26.465, respectively. The structural similarity is 0.04~0.7 higher than the other defogging algorithms.
Combined with the results of the qualitative analysis, although the SSIM and PSNR values of FFA-Net, Dehaze-Net, and DCP are also high, the visualization effects of these three defogging algorithms are average. This indicates that while these three defogging algorithms indeed reduced the influence of fog on images to a certain extent, they are not sufficient in reducing noise in the targets within the images in terms of overall style. Therefore, although the SSIM and PSNR values are not bad, the visualization effect is poor. During qualitative analysis, DCP and Cycle GAN exhibit different characteristics. The DCP algorithm performs well in restoring image details, but the overall color background is altered. On the other hand, Cycle GAN achieves good overall defogging effects but suffers from a significant loss of specific targets in the image, resulting in lower SSIM and PSNR values. Other defogging algorithms perform relatively poorly in both qualitative and quantitative analyses, indicating that these algorithms are not suitable for application in traffic scenes.
Based on the qualitative and quantitative comparative analysis results presented above, it is evident that the defogging algorithm based on the Pix2PixHD network demonstrates the best effect. The algorithm’s applicability and effectiveness for traffic signs in foggy traffic scenes are validated.
4. The Detection Algorithm for Traffic Signs Based on the Improved YOLOv5 Algorithm
4.1. Building the Dataset
The construction of the foggy traffic sign dataset was completed through image acquisition, image screening, and the labeling of traffic sign detection targets in the images. The sunny day dataset was selected from the TT100K dataset and the GTSDB dataset [38]. The foggy images were captured using a vehicle-mounted camera in urban driving scenes in Qingdao, including images of varying foggy conditions. In addition, to enhance the diversity of the data, foggy traffic sign images from other publicly available autonomous driving datasets on the internet, such as BDD100K [39], Oxford RobotCar Dataset [40], ApolloScape [41], were also utilized. These alternative datasets contained a total of 1000 foggy images. Furthermore, to meet the data requirements for model training, it was necessary to conduct statistics and screening on the number distribution of traffic signs in the dataset.
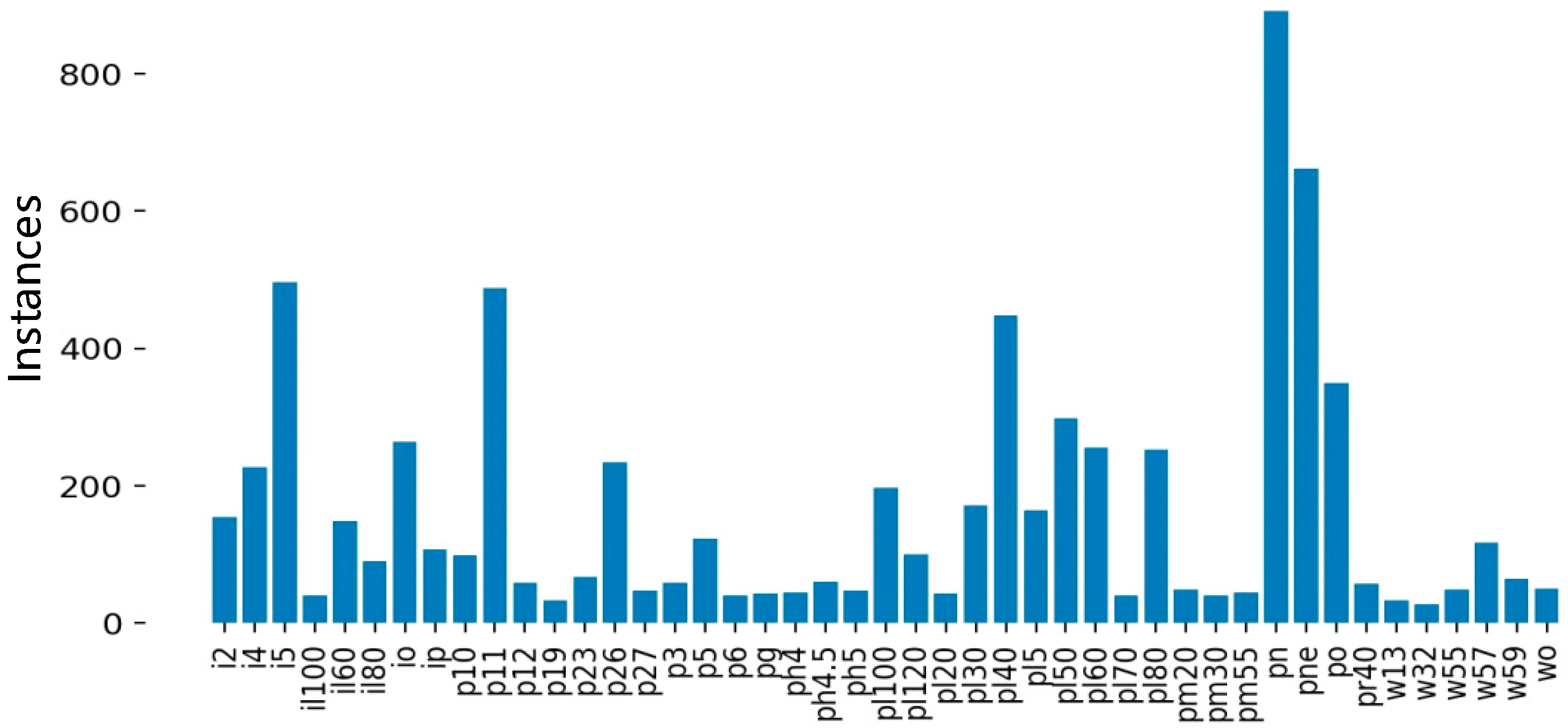
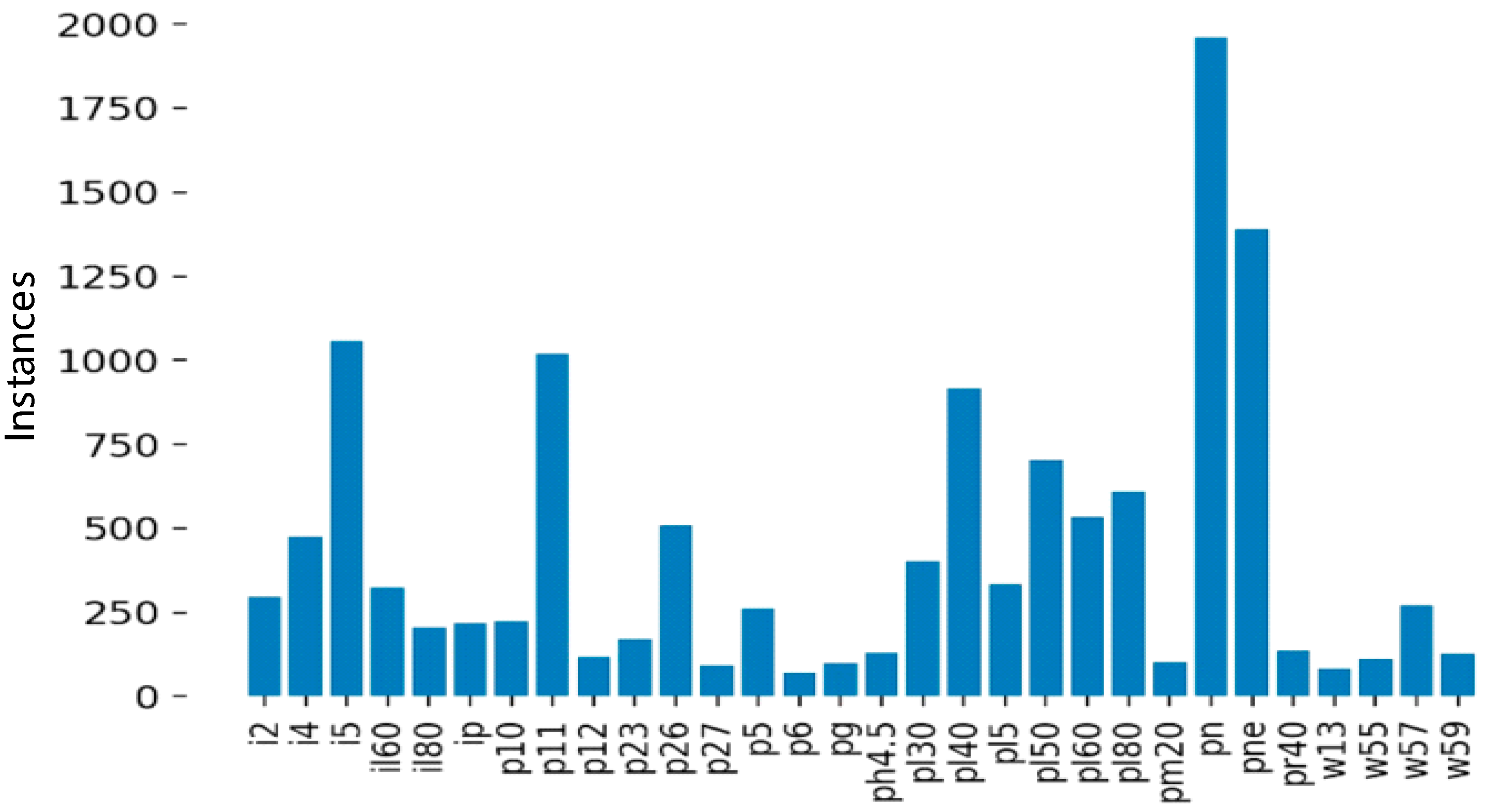
As shown in Figure 9, after data augmenting and screening, 45 types of traffic signs were collected. Among them, il100, p19, w32, etc., appeared less than 100 times and were not frequently used. Since a CNN cannot fully learn the characteristics of these traffic signs, it is necessary to further augment and screen the collected images. The screening results are shown in Figure 10.
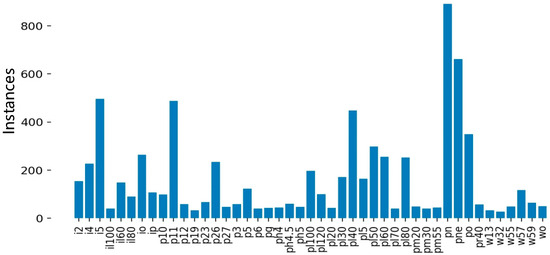
Figure 9.
Types of traffic signs and data volume distribution before screening.
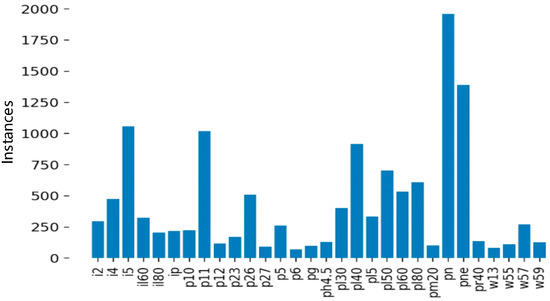
Figure 10.
Types of traffic signs and data volume distribution after screening.
Python was used to enhance the dataset of traffic sign images in this paper. Horizontal or vertical flipping, rotation, scaling, cropping, shearing, translation, contrast, color jitter, noise, and other operations were also used to simulate the overexposure, underexposure, and fog that traffic signs may experience in adverse weather conditions, thereby enhancing the robustness of the model in adverse weather conditions. The effect of traffic sign image augmentation is shown in Figure 11.

Figure 11.
Sample of traffic sign image augmentation.
Finally, based on the important semantic information and the distribution of traffic sign quantities, a total of 30 categories of traffic signs were selected from the constructed dataset, including directive signs, warning signs, and prohibitory signs, along with their corresponding annotations, as shown in Figure 12. In traffic signs, blue is predominantly used for mandatory signs, such as “Straight Ahead”; red is typically employed for prohibitory signs, like “No Entry”; while yellow is mainly utilized for warning signs, such as “Pedestrians Crossing”.

Figure 12.
Thirty types of traffic signs.
4.2. Traffic Sign Detection Based on YOLOv5
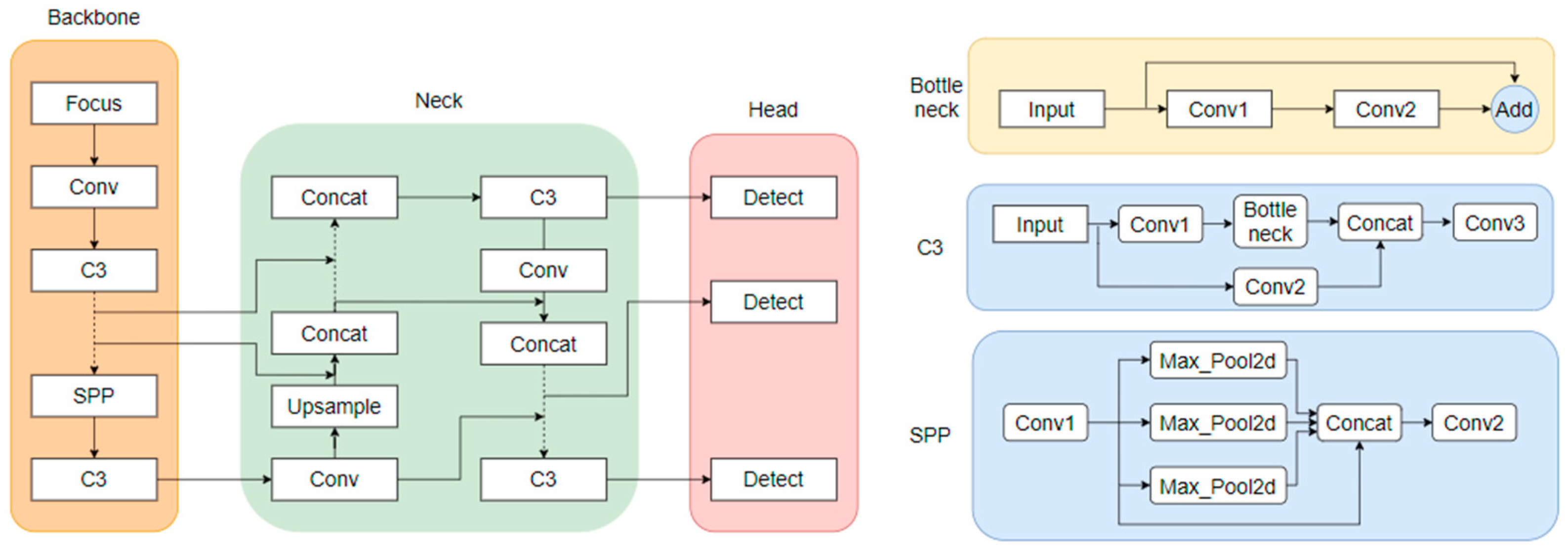
As shown in Figure 13, the architecture of the YOLOv5 model is divided into three parts: the backbone, neck, and head. The backbone is the main structure of YOLOv5, which contains a CNN composed of convolutional modules such as Focus, Conv, and C3, mainly used to perform image enhancement and normalization on the input images. Spatial pyramid pooling (SPP) [42] was used to integrate local and global features, thereby improving the ability to represent feature maps. The backbone was used to extract feature information of the target images and input them into the next network layers. The neck part contains a series of convolutional layers that mix and combine image features, the core of which is the feature pyramid network (FPN) and path aggregation network (PANet). These structures can complement the features of various types of targets and enhance information transmission. They can accurately retain spatial information, help to locate pixels to form masks properly, and finally pass the fused image features to the prediction layer. The head is the detection architecture of YOLOv5. Traditional neural networks input the highest-level features into the detection layer, which causes the serious information loss of small target features after layers of convolution, making the target difficult to recognize [43]. YOLOv5 inputs the features extracted with the convolutional layers of different depths into the detect module and sets three detection heads for large, medium, and small target images to overcome the disadvantage of small target information loss.
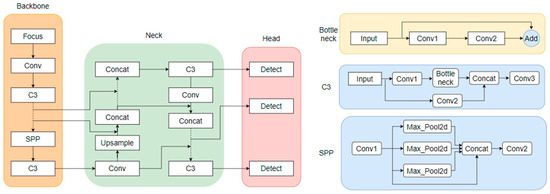
Figure 13.
YOLOv5 model architecture and main module structure.
On the basis of the dataset of 7000 images, the dataset was divided into a training set, a validation set, and a test set according to the ratio of 8:1:1. The training epoch value was 200. To highlight the influence of fog on traffic sign recognition, the trained YOLOv5 model was used to detect traffic signs in sunny and medium fog environments, and then the detection results were analyzed. The results are shown in Table 4. The foggy environments influence the recognition precision, recall, mAP@0.5, and mAP@0.5:0.95 of the model. In the medium foggy environment, the recall decreased by 15%, and mAP@0.5 and mAP@0.5:0.95 decreased by 14.2% and 13.6%, respectively.
Table 4.
Analysis of the model metrics at different visibility levels.
4.3. Improvement of the YOLOV5 Target Detection Algorithm
There are some challenges in traffic sign detection. First, there is the problem of data imbalance, which includes the distribution of traffic sign types in the dataset being unbalanced and the number of positive and negative samples being unbalanced when the algorithm generates candidate boxes. Second, when a convolutional network extracts features from traffic signs, excessive convolutional layers can lead to the loss of feature information. To solve the imbalance problem of traffic sign data, the focus module performs data augmentation on the input images to ensure that the entire model has sufficient data for training. However, the extraction of detailed semantic information in traffic signs requires stacking enough convolutional layers, which causes the feature information of the detection target to be lost as the convolutional modules are stacked. Although the introduction of residual connections can improve the extraction of feature information, the computational complexity of the entire model also increases accordingly. A transformer [44] does not need to stack convolution modules to obtain global information like CNNs continuously. Instead, it can directly obtain global information by dividing the image into several regions [45]. However, a traditional transformer needs to construct many patches, and embedding sequences that are too long consumes a lot of computing power when calculating attention. The Swin transformer [46] solves this problem by using the principles of windows and layers.
4.3.1. Principles of Transformer Architecture
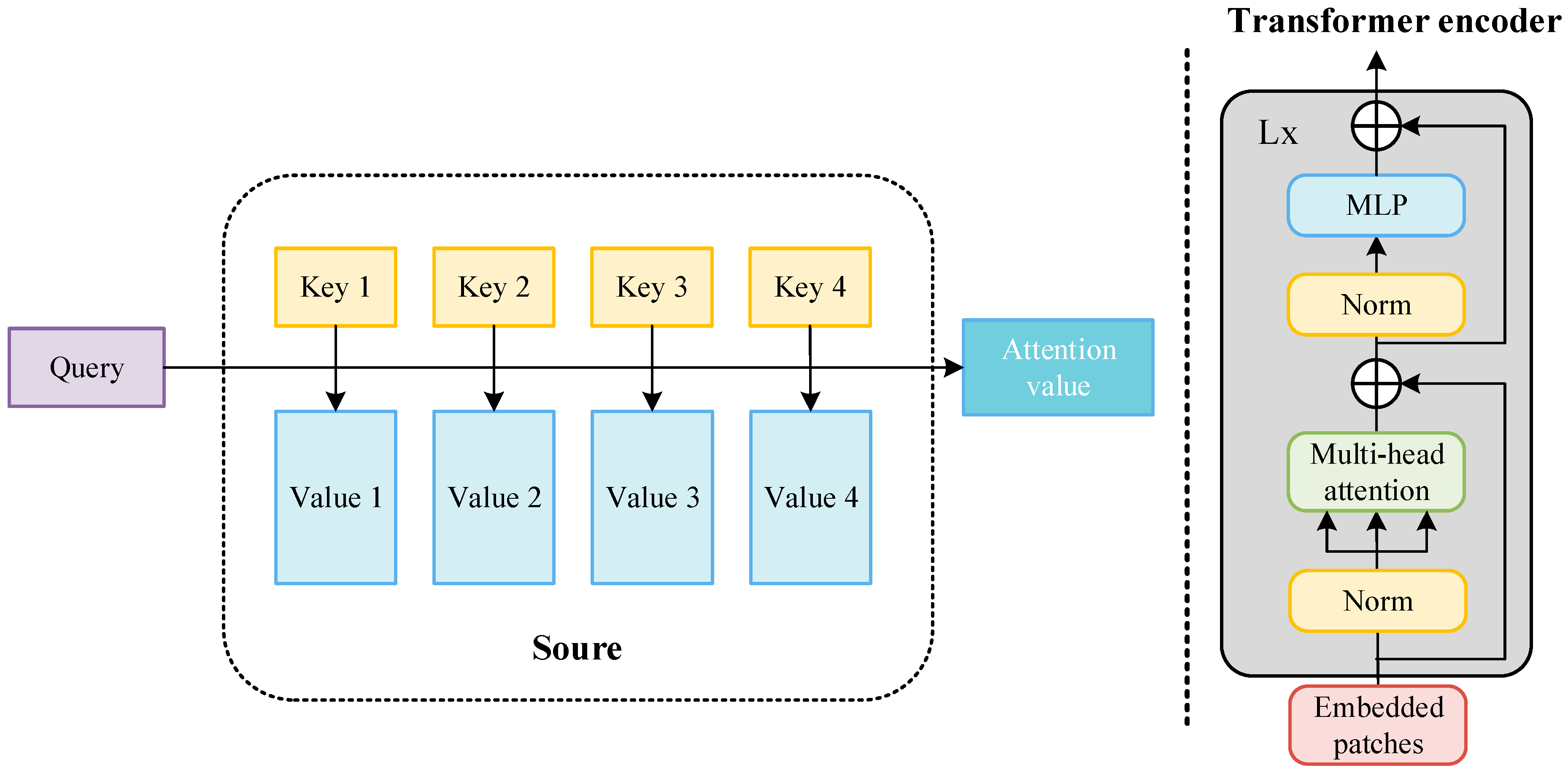
The transformer is a new neural network architecture based on the self-attention mechanism. As shown in Figure 14, the input image is converted into an embedding vector. , query (), key (), and value () represent the weight vector obtained after encoding. Query is used to inquire about information between other vectors, key is used to receive information about other input vectors, and value is the characteristic information of each input vector itself. The inner products of query and key are used to represent the correlation between the input vectors. To prevent the inner product from increasing with the increase in the dimension, the inner product of the two vectors (query and key) is divided by , normalized using the softmax function, and then the inner product is summed with value to obtain the attention value. In the attention value, the more relevant the target is to the detection target, the greater the proportion of its feature information. The attention value of each target in the target image is calculated in this way, and then weighted integration is performed to obtain the final weight of the self-attention mechanism. The attention value of each target in the target images is calculated in this way, and then weighted integration is performed to obtain the final weight of the self-attention mechanism, where is the sequence length and represent the dimensions of the vectors. For details, see Equation (1). The attention mechanism is the main module that constitutes the transformer. As shown in Figure 14, the transformer encoder inputs the image and extracts the image features. First, the image is divided into several regions (patches), and then each patch is encoded and embedded. After the embedded patches are normalized, they are inputted into the multi-head attention mechanism. The structure and workflow of the multi-head attention mechanism are the same as the above-mentioned attention mechanism, but this is a module in which the attention weights of different parameters are connected in parallel. It is then normalized and then enters the multi-layer perceptron (MLP). The entire structure also has two residual links to ensure the stable performance of the transformer module during multiple cycles.
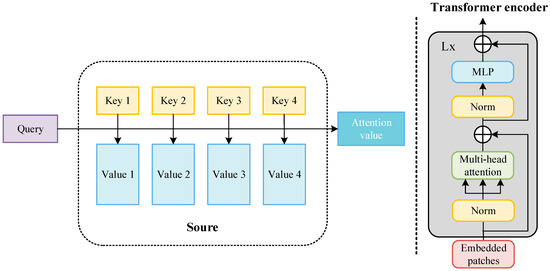
Figure 14.
Components of the transformer’s architecture.
4.3.2. Feature Extraction of Traffic Signs Using the YOLOv5 Backbone
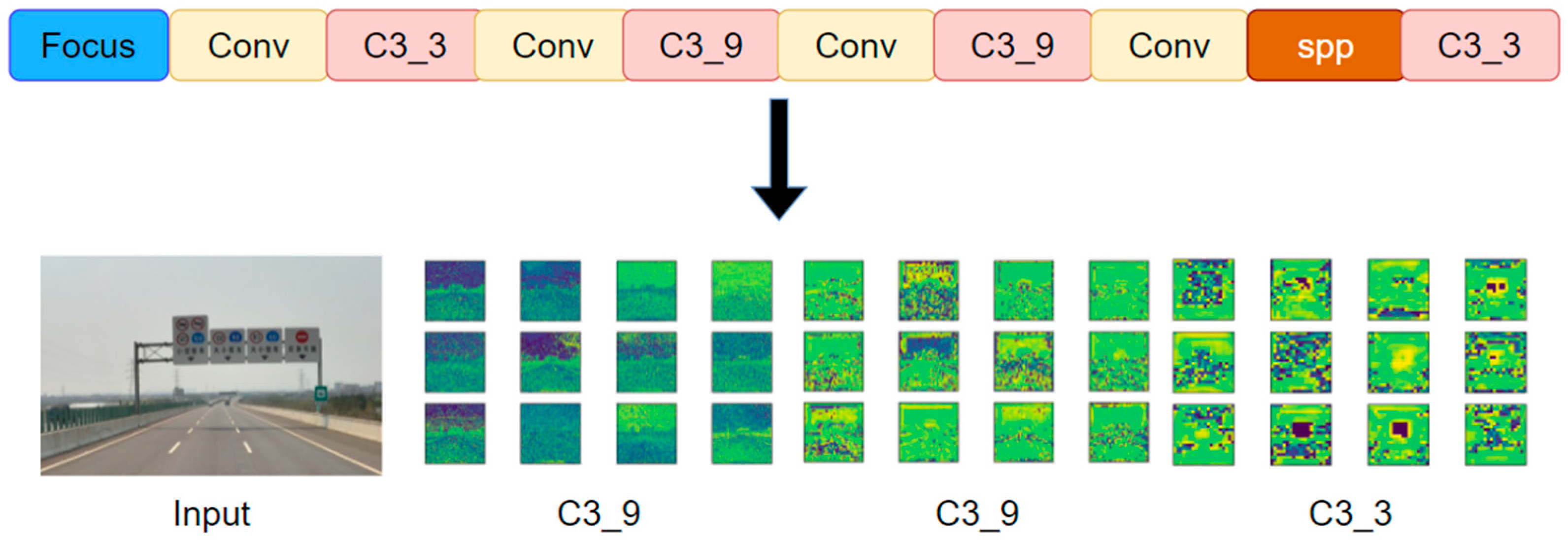
The main task of the YOLOv5 backbone is to extract features from the input images and input the extracted features to the next module for feature fusion and detection. Therefore, feature extraction plays a decisive role in the final detection result. As shown in Figure 15, the input images first pass through the focus module to complete data enhancement and then pass through a series of convolution modules to extract the feature map. Among them, the feature maps extracted by the first C3_9, the second C3_9, and the last C3_3 need to be input into the next module in YOLOv5. However, with the increase in convolution operations, the extracted features become more complex, and some feature information is lost. In adverse weather conditions such as fog, snow, and rain, the captured traffic images contain a lot of noise [47], which also interferes with feature extraction. As mentioned above, the main reason why the YOLOv5 model has a poor effect on traffic sign detection in a foggy environment is that the backbone of YOLOv5 cannot effectively extract target feature information.
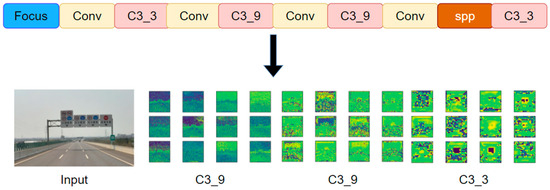
Figure 15.
Feature extraction of traffic signs using the YOLOv5 backbone.
4.3.3. Feature Extraction of Traffic Signs Using the Transformer
The transformer consists of a self-attention mechanism. Using a transformer encoder can enhance attention to small targets, improve the network receptive field, and reduce the computational and storage costs of low-resolution feature maps. The class activation mapping (CAM) method was introduced to visualize the process of extracting traffic sign features using a transformer and CNN and analyze the degree of attention paid to the same detection target with the model before and after the improvement. We can see that when using a transformer to extract features from traffic sign images, the attention mechanism can automatically match the detection target and reduce the degree of missed detection in target detection, which is something that conventional CNNs cannot do, as shown in Figure 16.

Figure 16.
Thermograph comparison of a transformer and CNN.
4.3.4. Improvement of the YOLOv5 Network
In the original YOLOv5, the input images are continuously convolved through the various convolution modules of the backbone to extract features, and the extracted features are passed to the neck of YOLOv5. The neck module mainly uses the PANet structure to generate a feature pyramid to enhance the model’s detection ability for targets of different scales so that it can recognize the same target of different sizes and scales. The feature pyramid fuses the high-level features extracted using the convolution module with the low-level features, thereby improving the effect of target detection.
Traffic sign detection in foggy environments is not only affected by small size, but also by the foggy environment. When passing through layers of convolutional modules, feature information is lost, especially the feature information extracted using the last convolutional module of the backbone. The feature information output from the last layer is used for small target detection, so traffic sign detection in a foggy environment becomes very difficult.
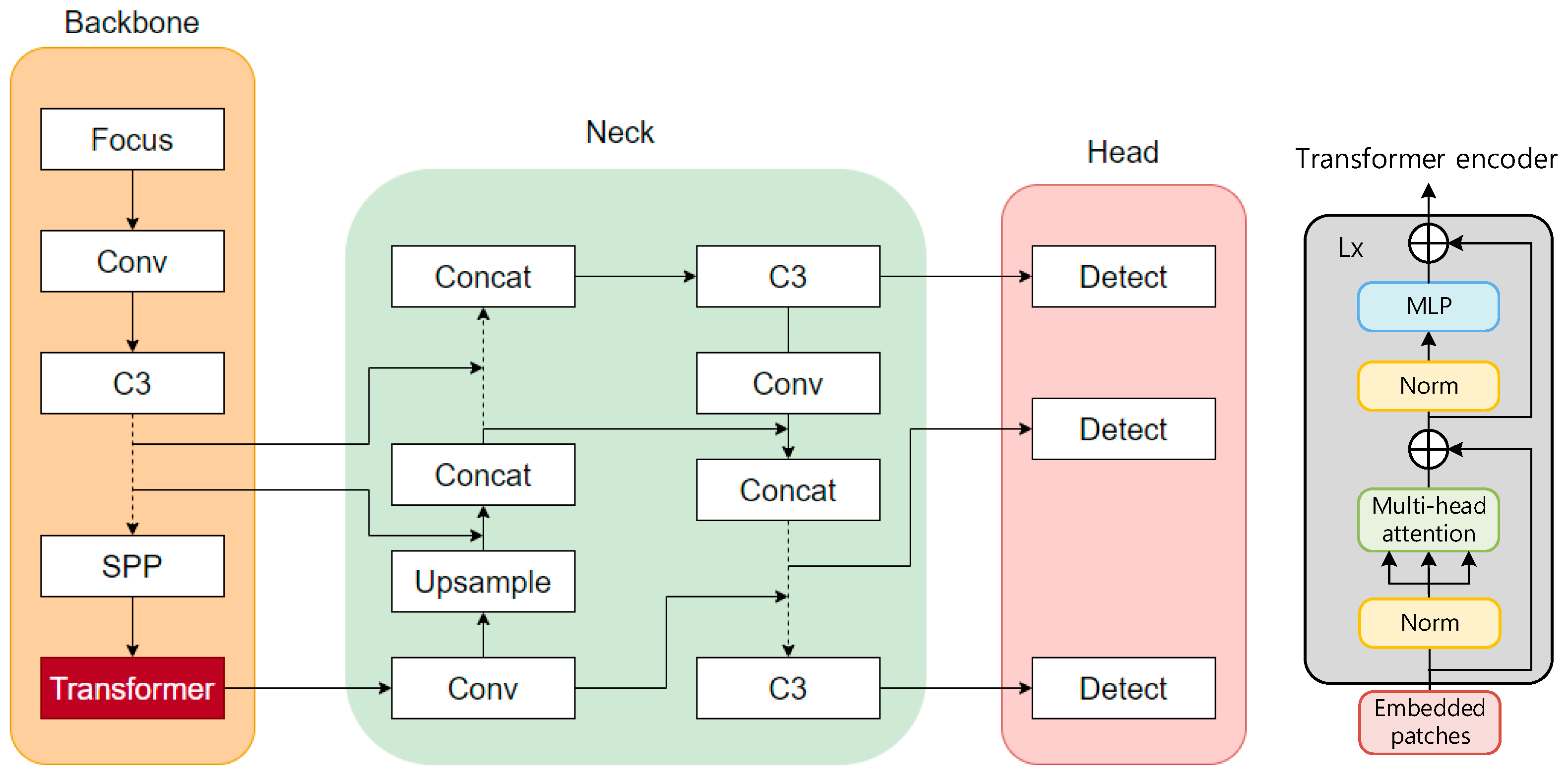
To improve target feature extraction, target detection algorithms either use a combination of attention mechanisms and convolutional layers or change the number of neural network layers and the size of convolutions [46]. The transformer module is a module composed of a self-attention mechanism, which has great advantages in image feature extraction. First, the transformer module has a more complex feature representation capability and can better extract image features. Second, the model structure of the transformer module has better scalability, which can more easily expand the depth and complexity of the network and capture more feature information in the input images. In addition, the transformer module has better long-distance dependency modeling capabilities, can better model complex targets or scenes, and improve network performance. In view of the limitations of the feature information extraction of traffic signs in a foggy environment, this paper used transformer encoder blocks to replace some convolution blocks and C3 in the original YOLOv5 and used a transformer encoder as an independent feature extraction module to complete feature extraction and pass the extracted features to the head for detection. Each transformer encoder block contains two sublayers: the first sublayer is a multi-head attention layer, and the second sublayer (MLP) is a fully connected layer, and residual connections are used between each sublayer. The transformer encoder block increases the ability to capture different local information, and can also use the self-attention mechanism to explore the potential of feature representation. To ensure the improvement of the performance of the entire network models, the authors referred to the residual network (PANet) [48] and used the PANet to fuse the features extracted using the convolution modules of each layer with the features extracted using the transformer encoder module. The improved model is YOLOv5-T, and the structure is shown in Figure 17. Compared with the original bottleneck blocks in CSPDarknet 53, the YOLOv5 model with the transformer encoder module added at the end of the backbone can capture global information and rich contextual information, and reduce the computational cost and storage cost of high-resolution feature maps.
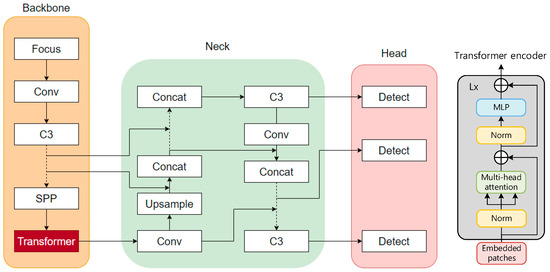
Figure 17.
Architecture of YOLOv5 after the improvement.
4.3.5. Analysis of the Training Results
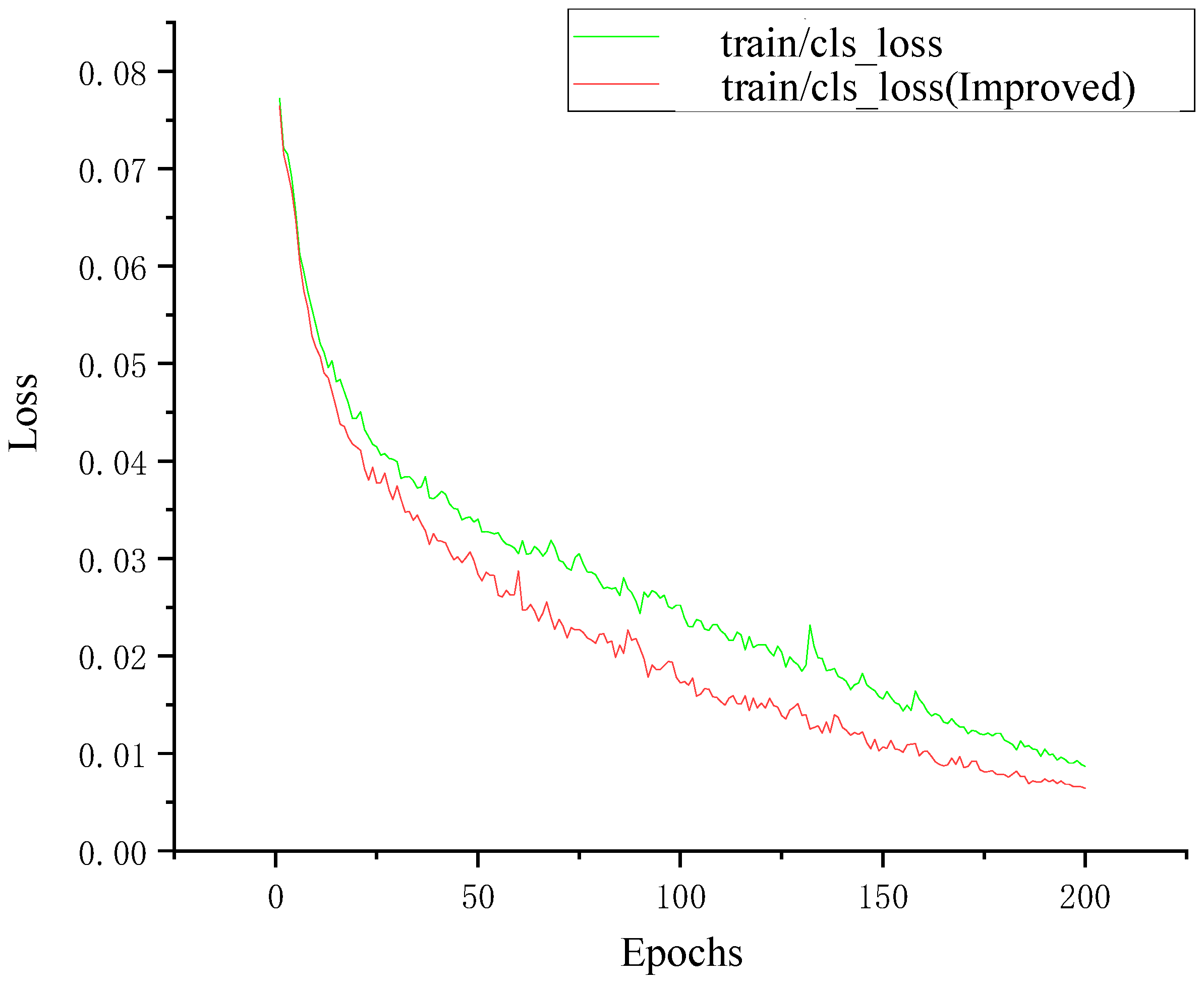
As shown in Figure 18, the loss values of both models are relatively large in the initial stage of training. As the number of training epochs increases, the loss values gradually decrease and eventually stabilize, which proves that both models converged after training. The loss value of the model YOLOv5-T after the introduction of the transformer encoder module converges faster than the original YOLOv5 model, and there are no large spikes. When the training reaches 200 epochs, the loss value reaches the lowest point, and the trained model performs well. When the improved model is used for training data, the loss function can achieve the same decrease effect in 100 epochs as that of the original model in 150 epochs, which fully proves that the use of the transformer encoder module requires fewer computing resources and has high computing efficiency to extract the feature information of the traffic sign.
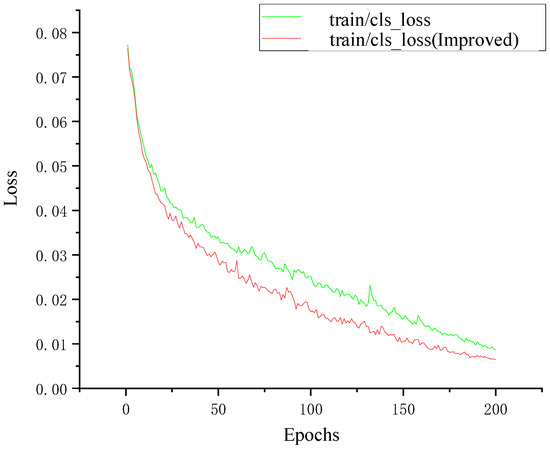
Figure 18.
Training loss before and after the improvement.
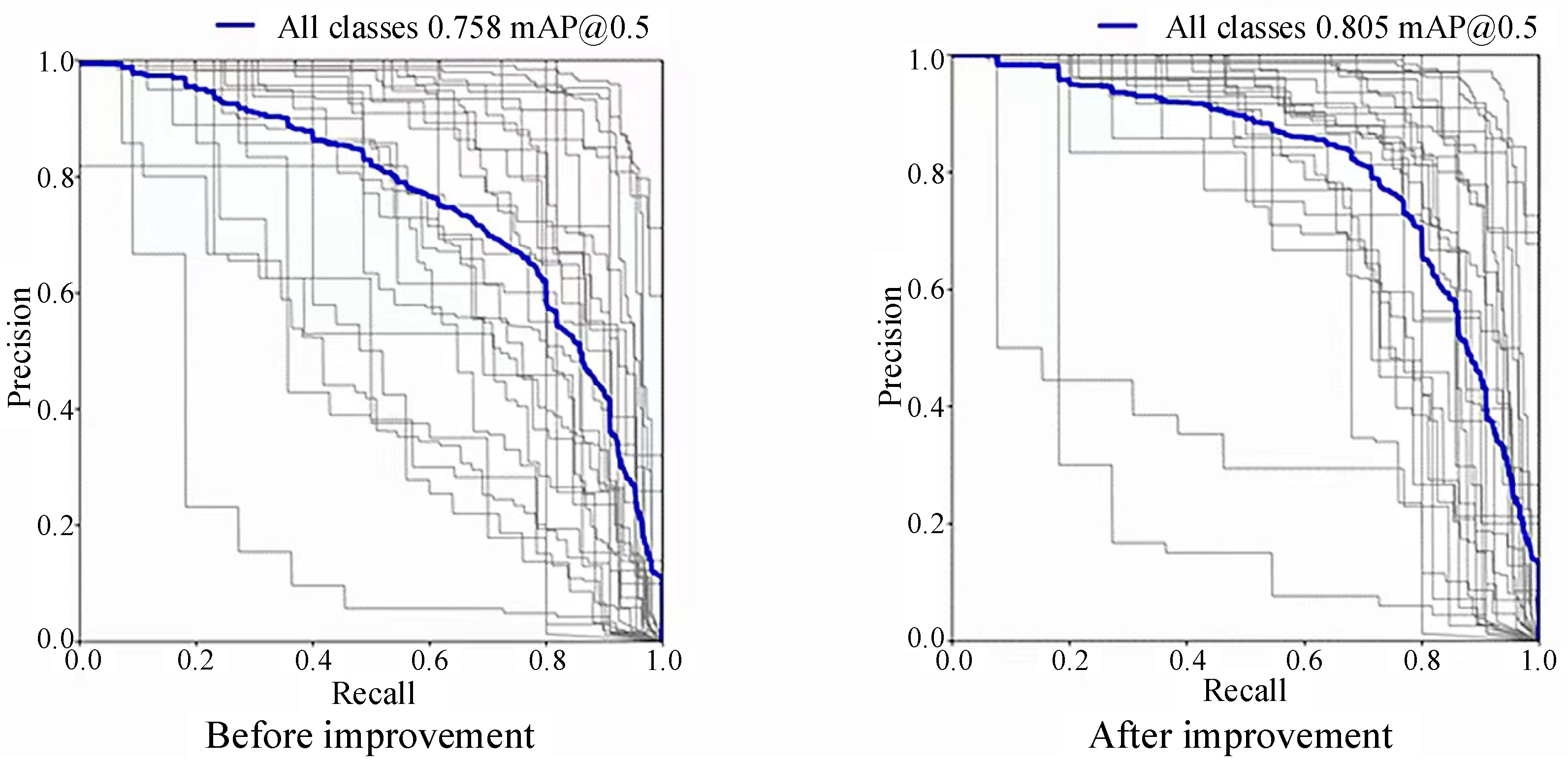
In the precision–recall curve, the vertical axis is precision, and the horizontal axis is recall. The blue curve represents the total P–R curve for all categories, and the black curve represents the P–R curve for each category. The black curve close to the upper right corner indicates that the precision and recall of the traffic sign of this category are close to one in training, and the training effect is good; the black curve close to the lower left corner indicates that the precision and recall of the traffic sign of this category are low, which is mainly because the number of training samples for this type of traffic sign is low. The area enclosed by each black curve represents the mAP@0.5 value of each type of traffic sign, and the area enclosed by the blue curve represents the total mAP@0.5 value of the 30 types of traffic signs. As shown in Figure 19, in the data trained with the YOLOv5-T model, most of the black curves are located above the blue curve near the upper right corner, while when the original YOLOv5 model is used to train the same dataset, we can see that the black curves are scattered on both sides of the blue curve, with more near the lower left corner. The total mAP@0.5 of the improved model training is 0.805, while the original model mAP@0.5 is 0.758. Thus, mAP@0.5 significantly improved.
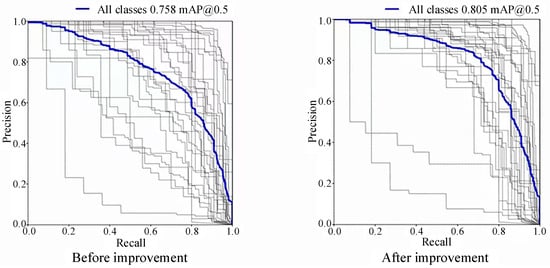
Figure 19.
The comparison of mAP@0.5.
5. Recognition of Traffic Signs in Foggy Environments and Contrastive Analysis of the Recognition Effect
5.1. Influence of Fog on the Image Recognition of Traffic Signs
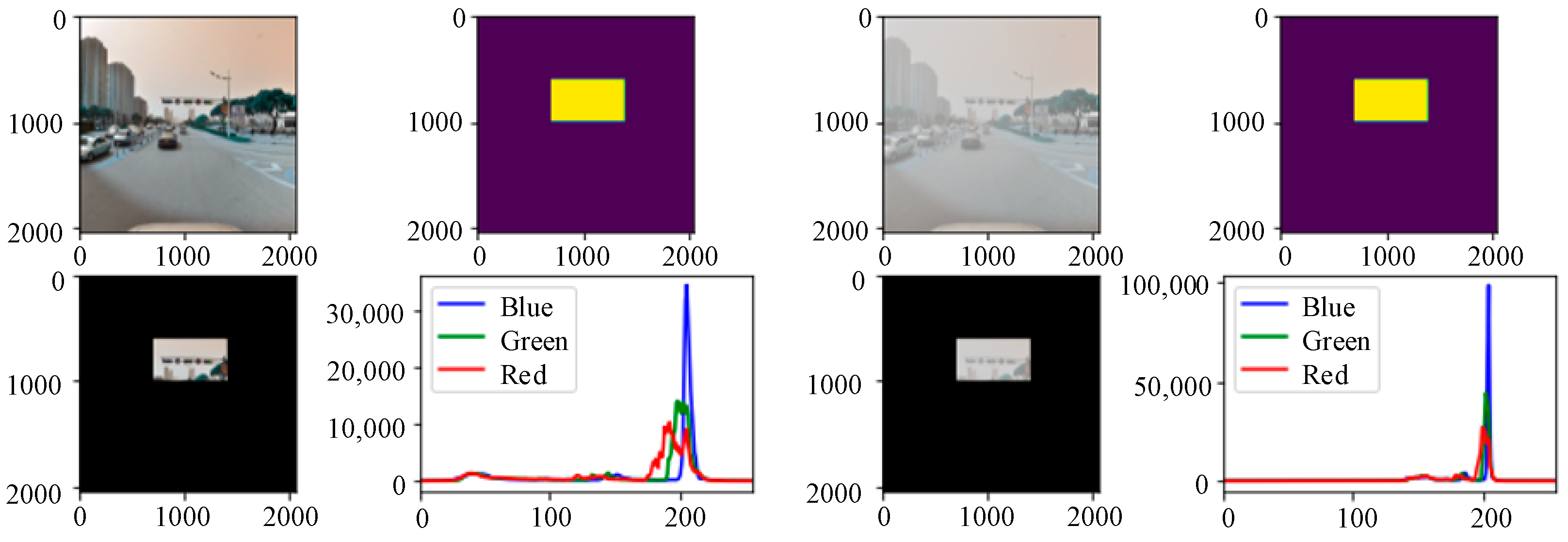
In foggy weather conditions, light is absorbed and refracted, resulting in the visibility of impaired visibility images. To analyze the specific influence of a foggy environment on the detection targets, a three-channel color histogram was used in this paper to count the pixel value distribution of traffic signs on sunny days and foggy environments. To reduce the influence of the background environment on the testing targets and consider the distance factors at the same time, the detection image was masked with the help of a Python script. As shown in Figure 20, in the same scene, the RGB three-channel histogram of the foggy images changed greatly. First, the actual pixel value of the image changed significantly. The peak values of the three colors of the foggy image increased significantly, which is twice the pixel value of the sunny image. Second, the peak distribution area of the red, green, and blue curves became smaller and concentrated together, and the brightness of the three peaks has an overall rightward shift trend. At the same time, the fluctuations of the red, green, and blue colors in the low brightness range changed from curves to straight lines. From the RGB histogram of the foggy images, it can be concluded that the overall brightness of the red, green, and blue colors in the image increased under the influence of foggy weather conditions, but the brightness distribution was concentrated. Colors with lower brightness disappear directly under the influence of fog. By combining these with the foggy scene images, we can see that the characteristics of foggy scene imaging are also expressed through the RGB three-channel histogram. Through the above analysis of the RGB histogram, we can see that there is the most obvious difference in color saturation between the sunny images and foggy images. In a sunny environment, due to sufficient light and bright colors, the color saturation of the image is relatively high, so the histogram distribution of its RGB three channels is relatively uniform. In a foggy environment, due to a large amount of water vapor and suspended matter that affect the penetration and propagation of light, the color saturation of the image decreases, the histogram distribution is relatively concentrated, and it presents a trend of being “thin and tall”. Compared with the sunny environment, the pixel values of the three channels of the detection targets in the foggy environment are concentrated at 200. This shows that the overall brightness of the images in the foggy environment improved, the pixel values in other intervals were reduced, and the distribution of the pixel values of each channel was unbalanced. Since traffic signs are composed of specific colors and shapes, the concentrated distribution of pixel values in each color channel in a foggy environment affects the detection of traffic signs.
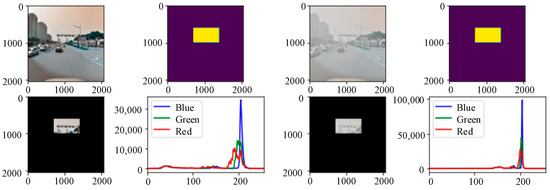
Figure 20.
Color histograms of the detected targets in different environments.
5.2. Comparative Analysis of the Visualization of Traffic Sign Recognition Based on a Defogging Algorithm
In actual road scenes, traffic signs are small targets compared to other detection targets, so missed detection, false detection, and low precision are common problems. In response to the aforementioned problems, the main task of this paper is to improve the precision and efficiency of traffic sign recognition in a foggy environment by combining the defogging algorithms based on the Pix2PixHD network with the improved YOLOv5 algorithm, reflecting the comprehensive advantages of the combination of the two in the recognition of small targets such as traffic signs in actual road scenes. To fully verify the advantages of the Pix2PixHD+YOLOv5-T algorithms proposed in this paper, a comparative analysis of the visualizations of the recognition effects of synthetic foggy images of traffic signs and real foggy images of traffic signs in actual road scenes was carried out.
Figure 21 shows the experimental results of the comparative analysis of synthetic foggy images of traffic sign recognition in actual road scenes. We can see from this figure that the most obvious difference is that there is a big difference in the degree of missed detection of traffic signs. By using GCA-Net+YOLOv5-T and AOD-Net+YOLOv5-T for traffic sign recognition, GCA-Net and AOD-Net remove a lot of the target information in traffic scene images, which ultimately makes it unable to recognize traffic signs. When CAP+YOLOv5-T is used for traffic sign recognition, CAP does not reduce the noise caused by foggy weather conditions but increases noise, which makes it difficult for YOLOv5-T to recognize traffic signs. When CycleGan+YOLOv5-T is used to detect traffic signs, although CycleGan has an obvious defogging effect, it causes a serious loss of target details. Therefore, the CycleGan+YOLOv5-T algorithm is not suitable for the recognition of small targets such as traffic signs. The three algorithms FFA-Net+YOLOv5-T, Dehaze-Net+YOLOv5-T, and DCP+YOLOv5-T succeed in detecting two traffic signs, which outperform YOLOv5-T used directly in the process of recognizing a foggy environment. The algorithm Pix2PixHD+YOLOv5-T in this paper can recognize all traffic signs in the images, and its detection efficiency is significantly better than the other algorithms; at the same time, its precision is also higher than the other algorithms.

Figure 21.
Recognition of traffic sign images in synthetic foggy environments.
Figure 22 shows the experimental results of a comparative analysis of traffic sign image recognition in real foggy weather conditions. We can see from this figure that the Dehaze-Net+YOLOv5-T and DCP+YOLOv5-T algorithms have difficulty recognizing traffic signs in images of real foggy scenes due to the severe distortion of image brightness, color, and contrast after defogging. Although the GCA-Net+YOLOv5-T and FFA-Net+YOLOv5-T algorithms recognized the short-distance traffic sign No p11 (no honking), they failed to recognize the smaller traffic sign i5 (keep right) in the distance. This algorithm can be used to recognize large and short-distance targets, while traffic signs on the road are not only affected by their own size but also by distance. Therefore, the GCA-Net+YOLOv5-T and FFA-Net+YOLOv5-T algorithms are difficult to apply to the recognition of traffic signs in real road scenes of foggy environments. The Cycle Gan+YOLOv5-T algorithm did not detect the small traffic sign i5 (keep right) in the distance. At the same time, the close traffic sign p11 (no honking) was misidentified as p26 (no trucks allowed), resulting in serious misdetection. The AOD-Net+YOLOv5-T and CAP+YOLOv5-T algorithms did not recognize the traffic signs in the image; therefore, they are difficult to apply in the traffic sign recognition of road scenes in real foggy environments. The Pix2PixHD+YOLOv5-T proposed in this paper could not only recognize short-distance traffic signs but could also recognize long-distance small-target traffic signs in a real foggy environment. From the above comparative experimental results, it is safe to say that this paper improves the precision and recall of traffic sign recognition in a foggy environment by combining the Pix2PixHD network defogging algorithm with the improved YOLOv5 detection algorithm. Whether in synthetic foggy scenes or real foggy scenes, it can more effectively complete the task of traffic sign recognition.

Figure 22.
Recognition of traffic sign images in a real foggy environment.
5.3. Comparative Analysis of Three Recognition Methods for Traffic Signs in Foggy Environments
To further prove the advantages of the algorithm proposed in this paper, traffic sign images on sunny days and on real fog days were used as testing sets to conduct further comparative analysis of the various algorithms in this paper. The comparative experimental results show that the Pix2PixHD+YOLOv5-T algorithm is better than YOLOv5 and YOLOv5-T for recognizing traffic signs in a real foggy environment. The specific results are listed in Table 5.
Table 5.
Comparison of the recognition effects of three recognition methods for traffic signs.
We can see from Table 5 that the recognition result is not very high compared with the other target recognition results. There are several reasons for this. First, the detection datasets of this paper contained 30 different kinds of traffic signs. They are not simply detected based on the shapes of the traffic signs, but the specific semantic information is recognized. Second, the recognition scenes are traffic scenes in a real foggy environment. The foggy environment and the complex environments of the road bring great difficulty to the recognition of traffic signs. Finally, the focus of this paper was to improve the performance of the target detection algorithms and study the applicability of the defogging algorithms for traffic signs in real road scenes, aiming to prove that the combined algorithms proposed in this paper could effectively improve the recognition performance of YOLOv5 on the datasets of traffic signs in foggy environments. According to the data in the table, when detecting foggy traffic signs, the overall performance index of Pix2PixHD+YOLOv5-T is improved compared with the YOLOv5-T and YOLOv5 models. Among them, its precision reaches 78.5%, the recall reaches 72.2%, and the mAP@0.5 is 82.8%. mAP@0.5 is 3.8% higher than YOLOv5-T for detecting foggy images and 11.4% higher than YOLOv5 for detecting foggy images. The transformer module can fully improve the comprehensive detection performance of YOLOv5, and Pix2PixHD has a good defogging effect in the face of a real foggy environment. The experiments show that the YOLOv5-T model in this paper can make full use of advantages of the defogging algorithm Pix2PixHD, and the combination of the Pix2PixHD and YOLOv5-T models can effectively improve the recognition performance of traffic signs in a foggy environment.
6. Conclusions
Due to the inherent characteristics of traffic signs such as color, shape, and size, as well as the complex and changeable actual road environments, traffic sign recognition in foggy environments is very challenging. This paper proposed the Pix2PixHD+ YOLOv5-T algorithms by combining the defogging algorithm based on the Pix2PixHD network with the improved YOLOv5 algorithm to recognize traffic signs in foggy traffic scenes. First, the visualization tool TensorBoard was used to visualize the changing trends of the loss functions of the discriminator and generator in Pix2PixHD training, and the Pix2PixHD defogging method was compared with the mainstream defogging algorithms in qualitative and quantitative ways, which proved the applicability and effectiveness of the Pix2PixHD network in defogging traffic sign images in foggy traffic scenes. Then, the defogging algorithm based on the Pix2PixHD network was used to complete image defogging and achieve the conversion of foggy images to clear images. At the same time, the analysis revealed that the defogging images would be accompanied by the loss of object feature information and the reduction in pixel values, which provides a direction for the improvement of the detection algorithm. With this idea, the YOLOv5 recognition algorithm was improved to enhance YOLOv5′s ability to extract image feature information. Then, an improved model, YOLOv5-Transformer, was proposed to improve the efficiency and performance of the feature extraction of traffic signs with small targets. Based on the above study, Pix2PixHD was combined with YOLOv5-T to realize traffic sign detection in foggy traffic scenes. Finally, a visual comparative analysis of traffic sign recognition based on defogging algorithms was carried out on synthetic fog datasets and real fog datasets, and a comparative analysis of three recognition algorithms of traffic signs was carried out on moderate fog datasets. The comparative analysis results showed that whether in synthetic fog datasets or real fog datasets, compared with other methods, the Pix2PixHD+YOLOv5-T algorithm proposed in this paper has a good effect on traffic sign recognition in a foggy environment. However, this paper also has certain limitations. Only 30 types of traffic signs were selected for detection, and the types of detection could be further expanded. In addition, the optimization of the model was only local optimization; that is, the whole network could detect traffic signs in a foggy environment by improving the quality and speed of extracting target features from the local network. This feature extraction network still has numerous convolutional modules, so the loss of target features cannot be ignored. Therefore, the next stage of research and improvement goals include expanding the detection types and optimizing the feature extraction network to further improve the recognition performance of traffic signs in foggy environments.
Author Contributions
Conceptualization, Z.L.; methodology, Z.L. and J.Z.; software, J.Z.; validation, J.Y.; formal analysis, Z.L. and J.Y.; resources, Z.L.; data curation, J.Z. and J.Y.; writing—original draft preparation, Z.L. and J.Z.; writing—review and editing, Z.L. and J.Y.; visualization, J.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Open Fund Project of the State Key Laboratory of Automotive Simulation and Control (ASCL), grant number 20210216.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors without undue reservation.
Acknowledgments
We appreciate Ruotong Wei and Wenjing Chen for their valuable discussions. We would like to thank all the reviewers for their help in shaping and refining the paper.
Conflicts of Interest
All of the authors declare that no conflicts of interest exist in the submission of this manuscript.
References
- Liu, Y.; Tian, J.; Zheng, W.; Yin, L. Spatial and Temporal Distribution Characteristics of Haze and Pollution Particles in China Based on Spatial Statistics. Urban Clim. 2022, 41, 101031. [Google Scholar] [CrossRef]
- Chen, X.X.; Ye, Y.; Yu, C.C.; Zhang, X. Deep learning-based traffic sign recognition in hazy weather. J. Chongqing Jiaotong Univ. (Nat. Sci. Ed.) 2020, 39, 1. [Google Scholar]
- Lillo-castellano, J.; Mora-jiménez, I.; Figuera-pozuelo, C.; Rojo-Álvarez, J. Traffic Sign Segmentation and Classification Using Statistical Learning Methods. Neurocomputing 2015, 153, 286–299. [Google Scholar] [CrossRef]
- Bahlmann, C.; Zhu, Y.; Ramesh, V.; Pellkofer, M.; Koehler, T. A System for Traffic Sign Detection, Tracking, and Recognition Using Color, Shape, and Motion Information. In Proceedings of the IEEE Proceedings. Intelligent Vehicles Symposium, Las Vegas, NV, USA, 6–8 June 2005; pp. 255–260. [Google Scholar]
- Kiran, C.; Prabhu, L.V.; Rajeev, K. Traffic Sign Detection and Pattern Recognition Using Support Vector Machine. In Proceedings of the IEEE 2009 Seventh International Conference on Advances in Pattern Recognition, Kolkata, India, 4–6 February 2009; pp. 87–90. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-time Object Detection with Region Proposal Networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef]
- Niranjan, D.; Vinaykarthik, B. Performance Analysis of Ssd and Faster RCNN Multi-class Object Detection Model for Autonomous Driving Vehicle Research Using Carla Simulator. In Proceedings of the IEEE 2021 Fourth International Conference on Electrical, Computer and Communication Technologies (ICECCT), Erode, India, 15–17 September 2021; pp. 1–6. [Google Scholar]
- Dai, X.; Hu, J.; Zhang, H.; Shitu, A.; Luo, C.; Osman, A.; Sfarra, S.; Duan, Y. Multi-task Faster R-CNN for Nighttime Pedestrian Detection and Distance Estimation. Infrared Phys. Technol. 2021, 115, 103694. [Google Scholar] [CrossRef]
- Li, W.; Na, X.; Su, P.; Zhang, Q. Traffic Sign Detection and Recognition Based on CNN-ELM. In Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2021; p. 012106. [Google Scholar]
- Cao, J.; Zhang, J.; Jin, X. A Traffic-sign Detection Algorithm Based on Improved Sparse R-CNN. IEEE Access 2021, 9, 122774–122788. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A. Ssd: Single Shot Multibox Detector. In Proceedings of the Computer Vision–ECCV 2016, 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Sun, F. Research on Traffic Sign Recognition Based on Deep Learning; Harbin Institute of Technology: Harbin, China, 2021. [Google Scholar]
- Dewi, C.; Chen, R.; Liu, Y.; Jiang, X.; Hartomo, K. YOLOv4 for Advanced Traffic Sign Recognition with Synthetic Training Data Generated by Various Gan. IEEE Access 2021, 9, 97228–97242. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Dong, Z.; Gao, M. Improved YOLOv5 Network for Real-time Multi-scale Traffic Sign Detection. Neural Comput. Appl. 2022, 35, 7853–7865. [Google Scholar] [CrossRef]
- Yin, J.; Qu, S.; Yao, Z.; Hu, X.; Qin, X.; Hua, P. Traffic Sign Recognition Model in Haze Weather Based on YOLOv5. J. Comput. Appl. 2022, 42, 2876. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single Image Haze Removal Using Dark Channel Prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. Dehazenet: An End-to-end System for Single Image Haze Removal. IEEE Trans. Image Process 2016, 25, 5187–5198. [Google Scholar] [CrossRef] [PubMed]
- Isola, P.; Zhu, J.; Zhou, T.; Efros, A. Image-to-image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Zhu, J.; Park, T.; Isola, P.; Efros, A. Unpaired Image-to-image Translation Using Cycle-consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Dong, Y.; Liu, Y.; Zhang, H.; Chen, S.; Qiao, Y. FD-GAN: Generative Adversarial Network with Fusion-discriminator for Single Image Dehazing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 10729–10736. [Google Scholar]
- Chen, D.; He, M.; Fan, Q.; Liao, J.; Zhang, L.; Hou, D.; Yuan, L.; Hua, G. Gated Context Aggregation Network for Image Dehazing and Deraining. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1375–1383. [Google Scholar]
- Engin, D.; Genç, A.; Kemal Ekenel, H. Cycle-dehaze: Enhanced Cyclegan for Single Image Dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 825–833. [Google Scholar]
- Hu, P. Detection and Recognition of traffic Signs under Haze Conditions; Xi’an University of Electronic Science and Technology: Xi’an, China, 2018. [Google Scholar]
- Yu, S. Research on Road Traffic Sign Recognition and Lane Line Detection in Haze Weather; Beijing Jiaotong University: Beijing, China, 2020. [Google Scholar]
- Lang, B.; Lv, B.; Wu, J.; Wu, R. A Traffic Sign Detection Model Based on CA-BIFPN. J. Shenzhen Univ. (Sci. Eng. Ed.) 2023, 40, 335–343. [Google Scholar]
- Ghiasi, G.; Lin, T.; Le, Q.V. NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7036–7045. [Google Scholar]
- Ocer, N.E.; Kaplan, G.; Erdem, F.; Kucuk Matci, D.; Avdan, U. Tree Extraction from Multi-scale UAV Images Using Mask R-CNN with FPN. Remote Sens. Lett. 2020, 11, 847–856. [Google Scholar] [CrossRef]
- Shin, S.; Han, H.; Lee, S.H. Improved YOLOv3 with Duplex FPN for Object Detection Based on Deep Learning. Int. J. Electr. Eng. Educ. 2021. [Google Scholar] [CrossRef]
- Liu, Y. Image Clarification Processing in Bad Weather Environments Based on Residual Aggregation Network. Command. Control Simul. 2020, 42, 46–52. [Google Scholar]
- Wang, T.; Liu, M.; Zhu, J.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution Image Synthesis and Semantic Manipulation with Conditional Gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8798–8807. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Song, R.; Liu, Z.; Wang, C. End-to-end dehazing of traffic sign images using reformulated atmospheric scattering model. J. Intell. Fuzzy Syst. 2021, 41, 6815–6830. [Google Scholar] [CrossRef]
- Zhu, Q.; Mai, J.; Shao, L. A Fast Single Image Haze Removal Algorithm Using Color Attenuation Prior. IEEE Trans. Image Process 2015, 24, 3522–3533. [Google Scholar]
- Sarkar, M.; Sarkar, P.R.; Mondal, U.; Nandi, D. Empirical Wavelet Transform-based Fog Removal Via Dark Channel Prior. IET Image Process 2020, 14, 1170–1179. [Google Scholar] [CrossRef]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-net: Feature Fusion Attention Network for Single Image Dehazing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 11908–11915. [Google Scholar]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. AOD-net: All-in-one Dehazing Network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4770–4778. [Google Scholar]
- Zhang, J.; Wang, W.; Lu, C.; Wang, J.; Sangaiah, A. Lightweight deep network for traffic sign classification. Ann. Telecommun. 2019, 75, 369–379. [Google Scholar] [CrossRef]
- Yu, F.; Xian, W.; Chen, Y.; Liu, F.; Liao, M.; Madhavan, V.; Darrell, T. Bdd100k: A diverse driving video database with scalable annotation tooling. arXiv 2018, arXiv:1805.04687. [Google Scholar]
- Maddern, W.; Pascoe, G.; Linegar, C.; Newman, P. 1 year, 1000 km: The Oxford robotcar dataset. Int. J. Robot. Res. 2017, 36, 3–15. [Google Scholar] [CrossRef]
- Huang, X.; Cheng, X.; Geng, Q.; Cao, B.; Zhou, D.; Wang, P.; Lin, Y.; Yang, R. The apolloscape dataset for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 954–960. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Network for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Jin, Y.; Fu, Y.; Wang, W.; Sun, J. Multi-feature Fusion and Enhancement Single Shot Detector for Traffic Sign Recognition. IEEE Access 2020, 8, 38931–38940. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Haque, W.A.; Arefin, S.; Shihavuddin, A.; Hasan, M. Deepthin: A Novel Lightweight Cnn Architecture for Traffic Sign Recognition Without Gpu Requirements. Expert Syst. Appl. 2021, 168, 114481. [Google Scholar] [CrossRef]
- Tai, Y.; Yang, J.; Liu, X. Image Super-resolution via Deep Recursive Residual Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3147–3155. [Google Scholar]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).