Abstract
The automatic detection of smoke by analyzing the video stream acquired by traditional surveillance cameras is becoming a more and more interesting problem for the scientific community thanks to the necessity to prevent fires at the very early stages. The adoption of a smart visual sensor, namely a computer vision algorithm running in real time, allows one to overcome the limitations of standard physical sensors. Nevertheless, this is a very challenging problem, due to the strong similarity of the smoke with other environmental elements like clouds, fog and dust. In addition to this challenge, data available for training deep neural networks is limited and not fully representative of real environments. Within this context, in this paper we propose a new method for smoke detection based on the combination of motion and appearance analysis with a modern convolutional neural network (CNN). Moreover, we propose a new dataset, called the MIVIA Smoke Detection Dataset (MIVIA-SDD), publicly available for research purposes; it consists of 129 videos covering about 28 h of recordings. The proposed hybrid method, trained and evaluated on the proposed dataset, demonstrated to be very effective by achieving a 94% smoke recognition rate and, at the same time, a substantially lower false positive rate if compared with fully deep learning-based approaches (14% vs. 100%). Therefore, the proposed combination of motion and appearance analysis with deep learning CNNs can be further investigated to improve the precision of fire detection approaches.
1. Introduction
Forest fires are becoming more frequent and fierce as highlighted in the EFFIS (European Forest Fire Information System) Annual Fire Reports [1]. Fires can cause enormous damage in terms of humans and animals deaths and loss of private property and public infrastructure [2]; for example, every year more than three thousand people are killed by fires in the US [3]. Human-based surveillance is not sufficient to guarantee a constant monitoring of the whole forested area of a country; therefore, the availability of effective and accurate systems to detect fires at the early stages is crucial to allow for prompt management, thus reducing the impact of a big fire. To this aim, smoke detection systems play a crucial role. Indeed, when the fire is not yet visible, the smoke generated in the preliminary phase of combustion can be detected even from long distances.
The detection of smoke is usually approached in two different ways [4]: (1) using physical sensors that measure particles, temperature and relative humidity [5,6,7,8] or (2) performing analysis on videos and images acquired by surveillance cameras (visual sensors) [9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24]. While sensors are commonly used to monitor small and limited areas like rooms, their use is unpractical for monitoring wide areas, such as high warehouses, or outdoor environments, such as landfill or forests. Indeed, in the first case, even if indoor, the number of sensors would be very high for guaranteeing full coverage; moreover, due to the position of the sensor on the ceiling, the alarm would be generated only where the fire has already reached large dimensions. Additionally, in outdoor environments, it is very difficult to install the sensors (for example, in a forest), so then the usage of cameras becomes the only viable solution. This is why in the last years we assisted the growing interest of the scientific community by designing accurate video analytic algorithms able to automatically detect the presence of smoke in real time using visual sensors-based computer vision technologies [25].
There are several factors that make automatic smoke detection through computer vision a very challenging task. The smoke may assume different shades of white, gray and black, and it may not have salient features (for example, it can be dense or sparse). Also, when the area to be monitored is outdoor, it can be easily confused with other elements such as fog or clouds, as evident in Figure 1; the contours of the smoke are very blurred and not highlighted compared to other objects.

Figure 1.
Examples of challenges in smoke detection, namely different colors and similarity to clouds, fog and dust.
For a long time before the advent of deep learning, the literature focused on methods based on handcrafted features, combined with different types of classifiers, such as SVM, KNN, Random Forest or neural networks. Some of the most common features used in the literature are based on motion [9,10,11]. In particular, in [9] the authors propose a method to find potential smoke regions through the Maximally Stable Extremal Region (MSER) detection algorithm. Once the potential smoke region is detected, it is tracked in the subsequent frames. At the same time, the motion vectors of the potential smoke regions are monitored to identify the distinctive upward movement and the expansion of the smoke. Differently, in [11] a cumulative motion model based on the integral image is proposed to quickly estimate the motion orientation of smoke. The collection of the motion vectors over the time is performed to compensate for the errors in the estimation of orientation. In [10], the authors use a condensed image, where static objects are horizontal lines, while shaking objects appear as dithering horizontal lines, in order to find smoke based on the uprising and uniform motion.
In general, motion-based methods assume that the smoke moves only upward; unfortunately this hypothesis does not fit all the cases occurring in the reality, since the presence of adverse weather conditions (such as rain or wind) cause a variation in the typical smoke movement properties, as shown in Figure 2. This causes a drop in accuracy, making these approaches not sufficiently robust when applied in the wild.

Figure 2.
Examples of smoke moving in different directions, namely, left (a), upward (b) and right (c).
Together with motion, other typical features adopted to increase the robustness are color [12,13], texture [14,15,16,17], energy and flickering [18].
In recent years, the disruptive accuracy achieved by convolutional neural networks (CNNs) on image analysis tasks has encouraged the proposal of deep learning-based approaches for smoke detection too [19,20,21,22,23,24]. In particular, in [19] the authors propose the first CNN for smoke recognition that operates directly on the raw RGB frame without the need of the feature extraction stage. A slightly modified version of AlexNet [26] is proposed in [20], to classify smoke against background. In [27], a custom CNN for classifying the entire image is employed. In [22], a joint detection framework based on Faster-RCNN for smoke localization and on a 3D CNN for smoke recognition is proposed. The authors have experimentally demonstrated that replacing the softmax layer with an SVM classifier significantly improves the performance of the system when the amount of training data is quite limited. A deep smoke segmentation network to infer high-quality segmentation masks from blurry smoke images is proposed in [24]. To overcome large variations in the texture, color and shape of smoke appearance, the network is divided into a coarse path and a fine path, which are two encoders-decoder FCNs with skip structures; the output of the two paths is then supplied as input to small networks providing the final outcome.
In [28,29] the authors formalize smoke recognition as a detection problem, by proposing neural networks that jointly locate and classify the smoke. Different typologies of detectors have been used, ranging from Yolov5 [30] to Detectron2 [31], and more recently to transformers [32].
However, it is quite complex, also for humans, to distinguish smoke from dust, fog, clouds or other similar environmental phenomena only looking at the appearance (color, shape or texture) on a single frame without taking into account the movement or the context (see Figure 1). For this reason, other recent papers propose to combine motion and appearance to improve the overall accuracy. In [23], the authors propose to combine two deep neural networks: the first to extract image-based features (smoke color, texture and sharp-edge detection), while the second is specialized on motion-based features (moving region of smoke, growing region and rising region detection); thus, the outcome of the two networks is then combined by an SVM. Differently, Aslan et al. [33] propose the use of a Deep Convolutional Generative Adversarial Network (DCGAN) trained in two stages to obtain a robust representation of sequences with and without smoke. In particular, the learning procedure includes the regular training of a DCGAN with real images and noise vectors, while the temporal evolution of smoke is taken into account through a pre-processing step that applies a motion-based transformation of the images. Finally, in [34] the authors propose a complex architecture that combines deep convolutional recurrent motion–space networks (RMSNs) and Recurrent Neural Networks (RNNs). The RMSNs are used to analyze motion and space context through a very basic CNN architecture, composed of six convolutional layers and a fully connected final stage; the outcome is then combined to feed the RNNs. In the classification stage, a temporal pooling layer that provides a summarized representation of the video sequence is the input of a softmax that predicts the presence of the smoke.
Although the approaches completely based on CNNs are able to achieve remarkable performance on the datasets on which they are trained and evaluated, they have a limited generalization capability in real-world scenarios. One of the reasons is the lack of datasets containing samples representative of all the situations that a smoke detection system is expected to address in the wild; this is true both for popular datasets like [35,36,37], that are based on video collected from real environments, and for those that are composed of synthetic samples [21,38]. Another reason is the complexity of the proposed models that combine motion and appearance; since CNNs can be easily found pre-trained, they can be effectively fine-tuned on new image analysis tasks through transfer learning using few samples. Completely new deep networks, especially if they have a complex architecture with thousands of parameters, require being trained from scratch on a huge amount of samples to avoid overfitting; they are typically specialized on the dataset used for the training and have limited capability to generalize on unseen situations. Therefore, considering the current context, it is clear that the proposal of new datasets is surely needed to extend the scenarios to be used to train such methods. Moreover, there is also the need to work with motion and appearance using more simple approaches that are able to inherit all the benefits of CNNs without adding too much complexity.
According to these considerations, in this paper we provide three main contributions to the state of the art: (i) the proposal of a hybrid method that combines the benefits of traditional motion-based and appearance-based approaches with the modern CNNs; (ii) a new dataset, namely the MIVIA Smoke Detection Dataset (MIVIA-SDD) that contains videos acquired in real environments; (iii) an experimental comparison over the MIVIA-SDD of well-known state-of-the-art CNNs (MobileNet [39], VGG-19 [40], ResNet-50 [41], Inception v3 [42] and Xception [43]). The proposed method firstly analyzes motion and appearance to identify promising regions of the image where the smoke is supposed to be; then, such regions are processed by a CNN to confirm the presence of smoke. The outcome of the CNN is not directly related to an alarm, but different patches are analyzed over time before notifying an alarm to the presence of smoke. This process allows it to achieve a high smoke recognition rate, but at the same time it significantly reduces the false positive rate.
The method has been tested and validated on the MIVIA-SDD, which we made publicly available, composed of 129 videos (59 positive and 70 negative), with about 28 h of videos acquired in real environments. In Table 1, we show the advantages of our dataset with respect to the others, in terms of number and duration of smoke videos. If we analyze the number of frames, we can note that our dataset is approximately 20 times larger than the datasets currently available in the scientific literature. In the experiments, we demonstrate that despite how using only CNNs does not provide a reliable smoke detection system, the addition of a proper pre-processing stage is able to achieve the same accuracy claimed by more complex state-of-the-art approaches.

Table 1.
Comparison of our proposed dataset (MIVIA-SDD) with the other datasets present in the literature. The main advantage of our dataset is the larger number of smoke videos and the longer total duration. Note that the total number of videos for Bilkent, FIRESENSE and CVPR KMU datasets also include fire videos (14, 11 and 22 videos, respectively).
The paper is organized as follows. In Section 2 we present and discuss the proposed method. The dataset MIVIA-SDD is then described in Section 3, with the addition of some visual examples. In Section 4 we detail the experimental setup and the results. Finally, in Section 5, we draw conclusions and propose further improvements.
2. Proposed Method
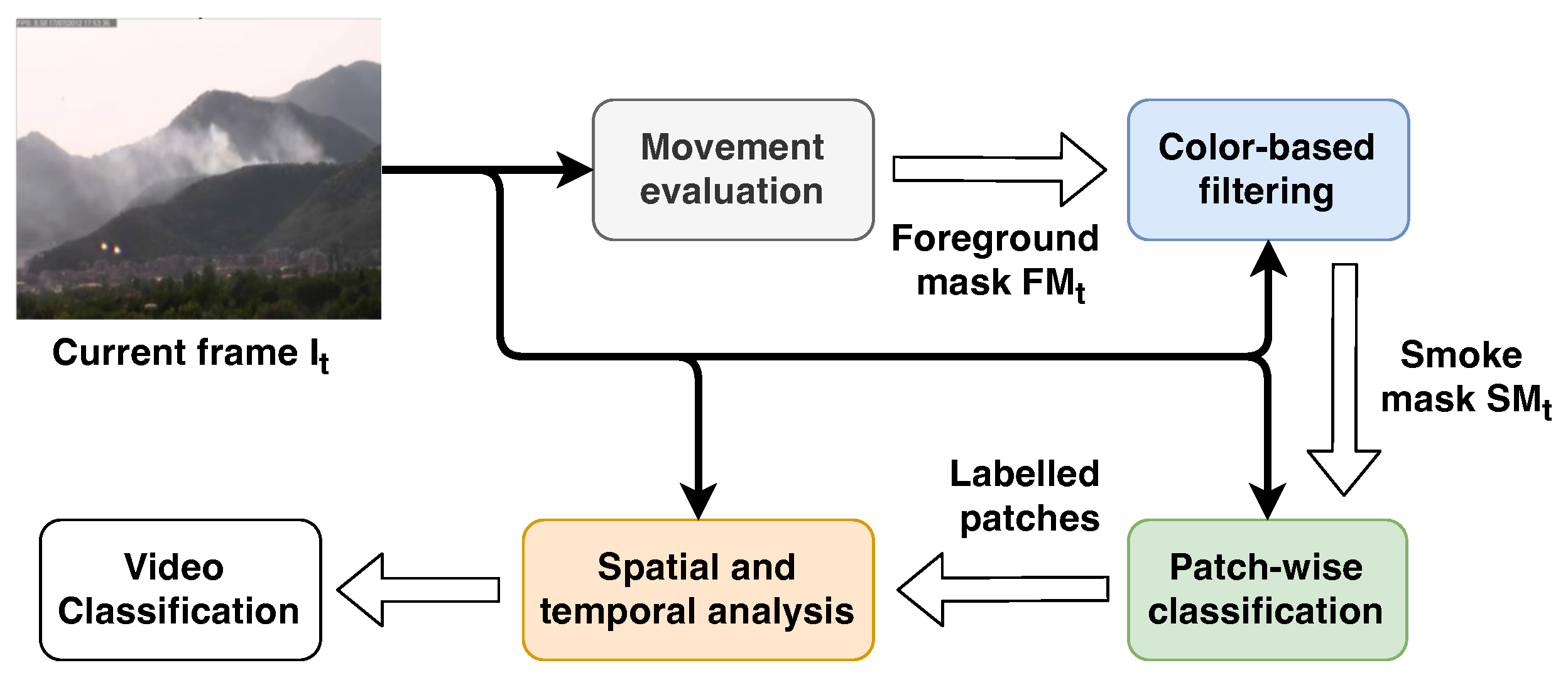
As introduced in Section 1, we propose a hybrid method combining traditional approaches, based mostly on the analysis of movement and color, and CNNs, with the addition of a video-wise evaluation. With this approach, we obtain an accurate detector that is robust in the most common environmental phenomena where fog, cloud and dust can be easily mistaken for smoke. An overview of the proposed method is shown in Figure 3.
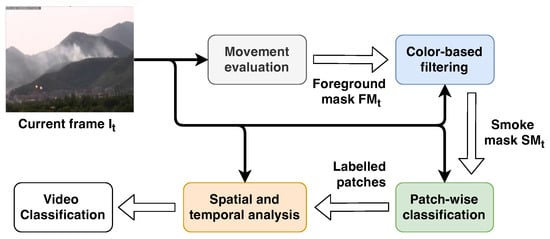
Figure 3.
Overview of the proposed method. The current frame () is spread to all the stages together with the outcome of each of them. The movement evaluation takes the current frame as input and produces an updated foreground mask to the color-based filtering module, which performs a further refinement of the binary mask by taking into account the appearance. The output of the latter is a binary mask, namely the smoke mask , used by the patch-wise classification stage to select the region of the image in which the smoke is expected to be. Finally, the outcome of the classification is provided to the last stage, spatial and temporal analysis, to evaluate the evolution of the smoke over the time and classify the video.
The first stage is the movement analysis, which is necessary to distinguish the smoke from the environment under the hypothesis that the former is the only moving object in the scene. This task is commonly performed through the evaluation of a background model representing the environment, updated frame by frame, that is subtracted from the frame under analysis so as to obtain only the pixels belonging to the moving objects, namely the foreground. Obviously, in most of the cases there could be other objects in movement like trees, animals and so on; therefore, we would like to pay attention only on the movement of the smoke. For this reason we use the color to provide a further refinement of the foreground by removing the pixels that do not respect the expected color range. The final foreground image is then converted into a binary image, named smoke mask, which is used to identify the promising regions to feed the CNN. The original frame is then divided in contiguous rectangular regions of pixels named patches; only those patches containing more than a given percentage of smoke candidate pixels are provided to the CNN to perform the patch-wise classification. This step determines whether the patch contains the smoke or not. Finally, the current frame is considered to contain smoke if at least one patch is classified as smoke by the CNN. In addition, since the smoke is expected to be not only in the current frame, but in a sequence of frames, a video classifier analyzes the label of a sequence of frames within a time window; if the number of frames containing smoke is higher than a given threshold, the video will be classified as a video with smoke.
According to the previous description, the overall smoke detection process consists of four stages: movement analysis, color-based filtering, patch-wise classification and spatial and temporal analysis. In the next sections we describe each of them in more detail in more detail; the values of the parameters used in our experiments and thoroughly described in the following are reported in Table 2.
Table 2.
Values of the parameters used in our experiments, empirically chosen after a comprehensive grid search on the validation set. A brief description of the parameters is reported, while more details can be found in the specific sections.
2.1. Movement Analysis
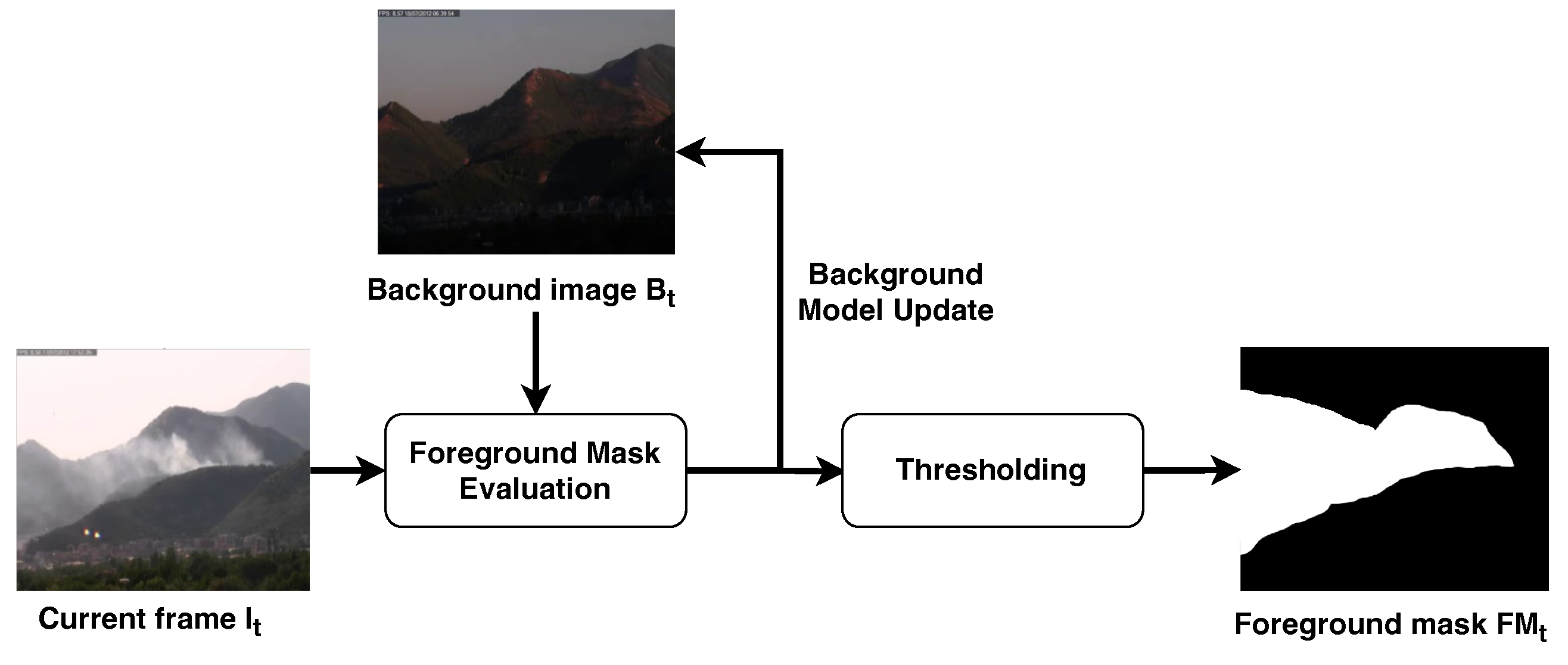
The analysis of moving objects, realized with the pipeline shown in Figure 4, is performed through background subtraction [44], which is an approach that is commonly used in video surveillance applications to separate the pixels belonging to objects of interest in the scene from those that are considered static and, thus, part of the environment.
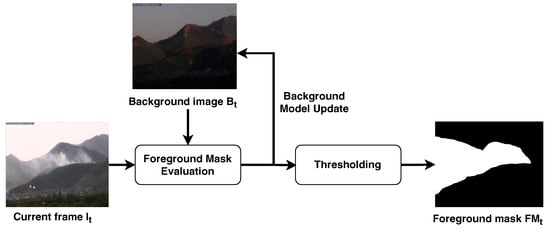
Figure 4.
Movement analysis stage. The current frame and background image are used to update the background image and compute the foreground image . The latter is then converted to a binary image through thresholding.
The first step of background subtraction is to build a background model to identify the pixels belonging to the background image, which we denote as ; note that is related to the discrete time instant t because it is not static, but it evolves over time and has to be updated frame-by-frame. To this purpose, in [45] the authors propose using a model based on a mobile weighted average reported in the following:
The background image at the current discrete time instant t is updated by taking into account both the current frame and the background image computed at the previous discrete time instant . Note that the update is performed pixel-by-pixel as highlighted by the notation , which refers to the pixel at the coordinate of the background image. The two terms and are weighted differently through factor that is also updated frame-by-frame according to the following rule:
The aim of such a time-dependent weight is to gradually incorporate a pixel in the background image as it remains static over time. The time required to absorb a pixel into the background is regulated by the term , namely the inter-frame time, which represents the time between two consecutive frames, together with the constant T, which approximates the maximum time to be waited before considering the pixel static.
Once the background image has been obtained, we can compute the foreground image as the absolute difference between the current frame and .
In particular, observing the evolution of the image over time, the effect obtained is that a static pixel vanishes from the foreground image in a time T. To this aim, a binary mask , named foreground mask, is built by thresholding as follows:
The effect of such a threshold is to consider as moving pixels only the ones whose intensity value are higher than the threshold . It is common to remove from the pixels that are going to vanish from , since the difference between that pixels in the current frame and in the background is not significant.
2.2. Color-Based Filtering
Color is as relevant as the movement to distinguish smoke from environmental phenomena. In fact, it can assume different colors and saturation on the base of the combustible material that is burning; therefore, it is important to have the possibility to manually set filtering criteria according to the smoke we are interested in detecting. In [46], the authors discuss a criterion to set the threshold of a color filter. Indeed, they have experimentally demonstrated that the RGB components of the smoke pixels are very close each other, independently from the specific shades of white, gray and black. Given a generic frame at the time instant t and where , and are the three components of the image on the Red, Green and Blue channels, we compute the color mask of the frame as formalized in Equation (5), by defining a single threshold configurable by the user in the range [0, 255].
Working on the RGB components is not the only criterion that can be adopted to detect the presence of smoke in the scene. In a recent survey on video smoke detection [47], it is highlighted how the presence of smoke can substantially affect the saturation and the brightness of the objects that are behind it. According to this observation, we also apply a saturation thresholding over the image in the color filtering stage. With as the saturation component and as the value component of the frame in the HSV color space, we compute the saturation mask as shown in Equation (6), by using and as saturation and value thresholds, respectively.
The smoke mask of the frame is the combination of the foreground mask computed in the motion analysis, the color mask and the saturation mask , as shown in Figure 5. The resulting smoke mask is used in the subsequent stages to select the regions of interest to be processed by the CNN:
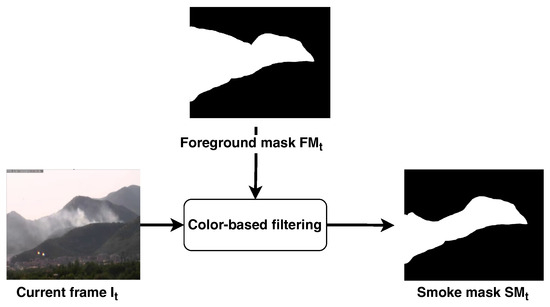
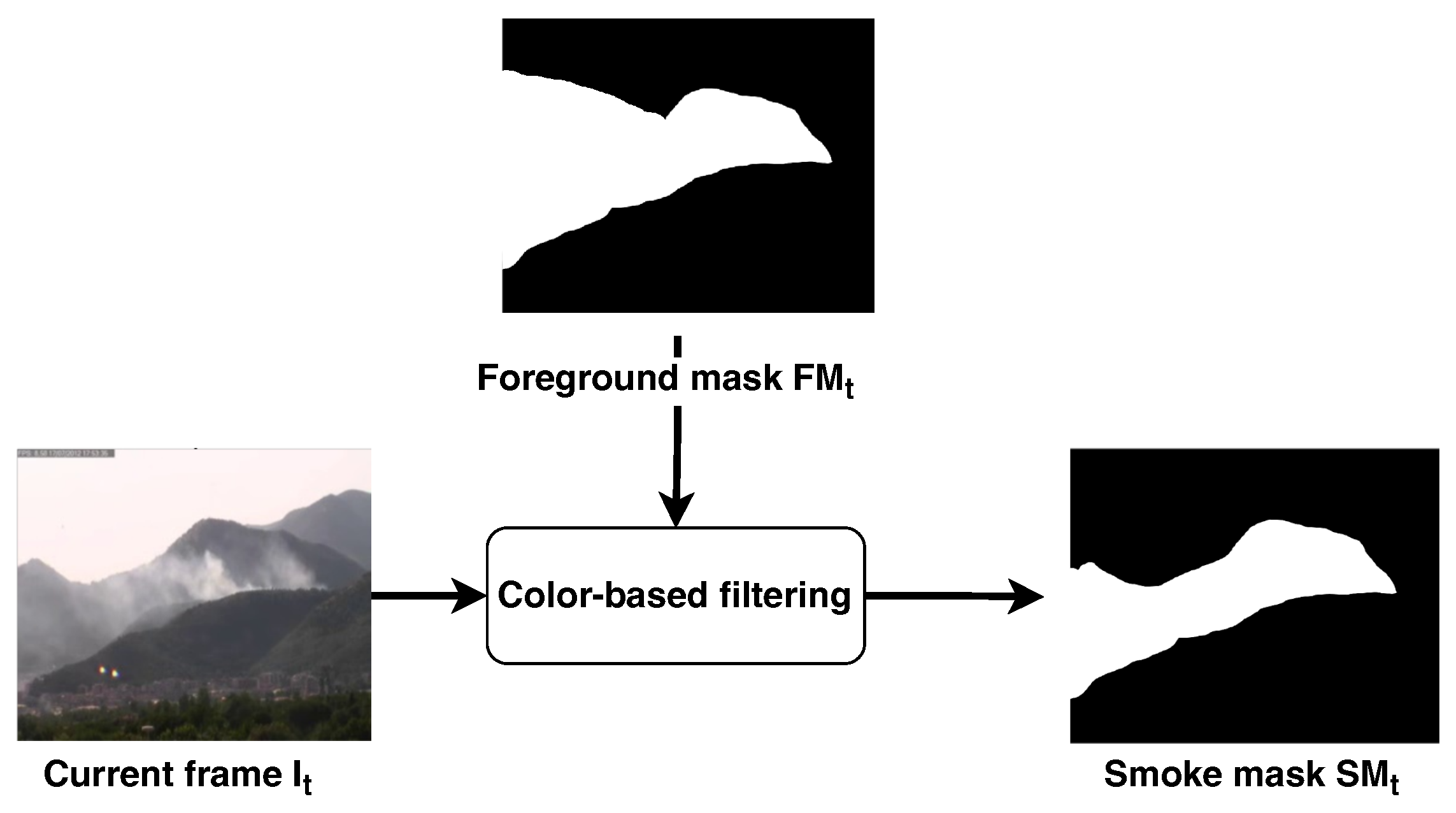
Figure 5.
Color filtering step. The foreground mask computed during the movement analysis is used to highlight the area of the current frame that has to be processed by the color filter. The output of this stage is a refined binary mask, namely the smoke mask, where the color criteria discussed in Section 2.2 have been applied.
2.3. Patch-Wise Classification
Smoke does not have a sharp outline [48]. Therefore, if we select the objects to be classified by the CNN using approaches based on connected component labeling that are widely adopted for the detection of objects of interest on a binary mask [47], we will obtain bounding boxes with wide variability in size and aspect ratio. This choice would complicate the training of CNNs, which have a fixed input image size, because we have to re-scale the image before providing it to classifier. To the best of our knowledge, this problem is not properly addressed in the literature.
In this paper, we propose to solve this problem by dividing the image through a grid, as shown in Figure 6. Therefore, we obtain a set of non-overlapped adjacent sub-images of the pixels area, namely patches. In this way, we can train and apply the smoke classifier on image patches that always have the same aspect ratio and we can dynamically adapt the size K of the patches according to the distance from the smoke. In more detail, the patch division is applied both on the current smoke mask and on the current frame ; each patch is identified by the coordinate over the image of its top-left pixel , in order to map directly a patch on the smoke mask with the corresponding one on the current frame, namely .
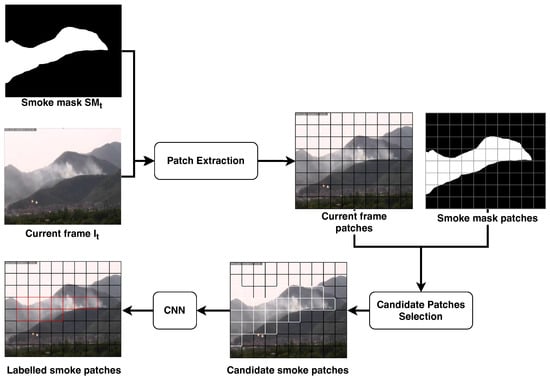
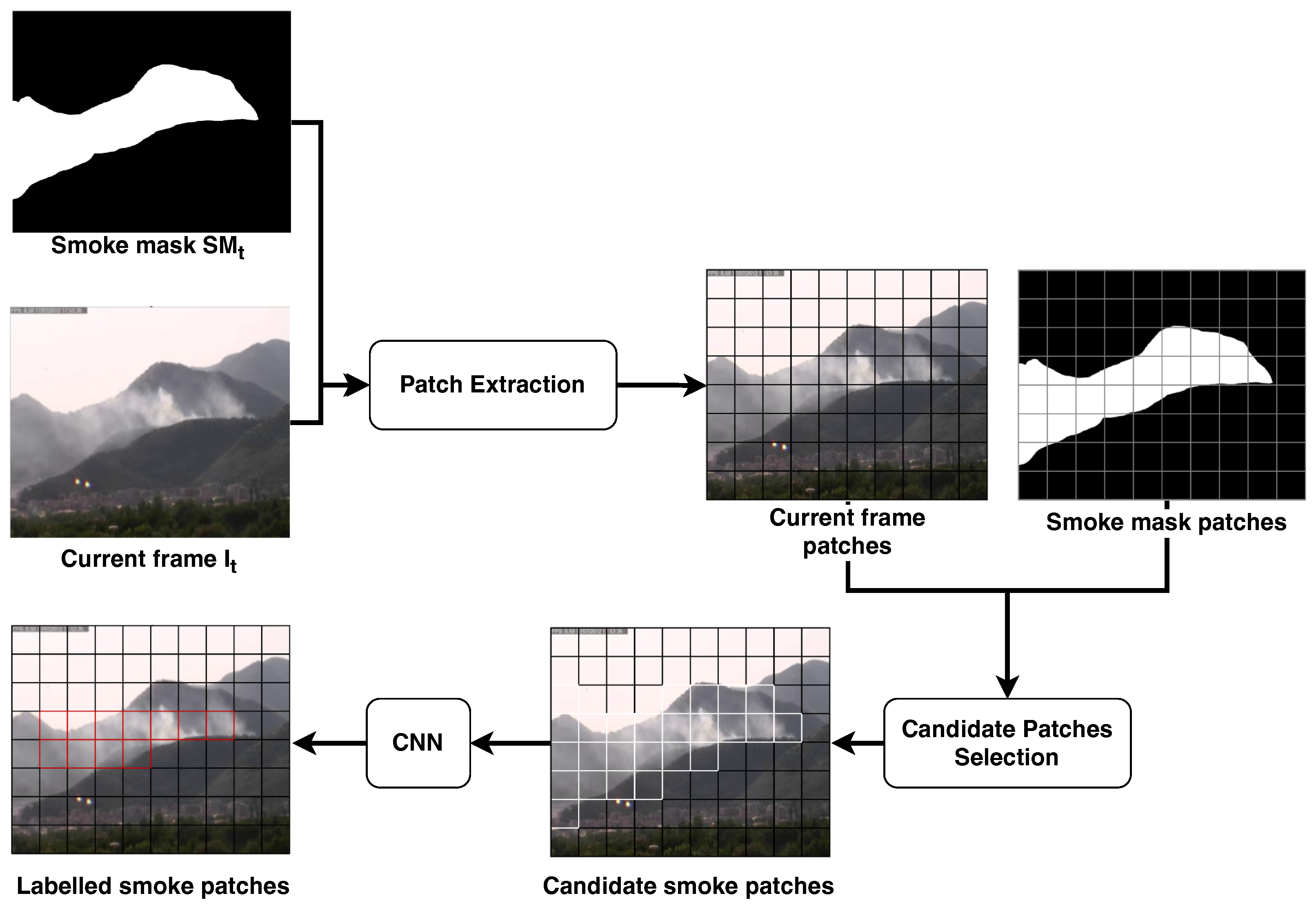
Figure 6.
Outline of the patch-wise classification described in Section 2.3. The current frame and the smoke mask are both divided in patches of pixels; during the candidate selection, only the patches containing a percentage of white pixels higher than are provided to the CNN to be confirmed as smoke patches. The output of this stage is the set of all the patches with the corresponding label: smoke or no-smoke.
The patch division is applied over the smoke mask first, in order to evaluate the patches that may contain smoke according to the motion and color filtering. The purpose is to select from the smoke mask the patches having a percentage of foreground pixels higher than a given threshold , thus extract the corresponding patches from the current frame and provide them to the patch classifier. In Equation (8), we compute the percentage of non-zero pixels with respect to the total number of pixels in the patch .
For each patch we evaluate if the percentage is higher than a given threshold :
If the patch is not promising (), it is automatically classified as background and then no further investigations are required; vice-versa, if (), the corresponding patch of the current frame is provided as input to the smoke classifier. It is important to point out that this preliminary filtering of the promising patches allows one to reduce the number of classifications required for each frame and, consequently, to speed up the overall frame processing.
As discussed in Section 1, in this paper we experimentally compared the following state-of-the-art convolutional neural networks to perform patch classification: MobileNetV2 [39], VGG-19 [40], ResNet-50 [41], Inception v3 [42] and Xception [43]. Details about the experimental results are reported in Section 4.
2.4. Spatial and Temporal Analysis
Although the classifier is able to guarantee a satisfying accuracy on the analysis of the patches, having a few of them classified as smoke is not sufficient to fire an alarm. Indeed, we will demonstrate in Section 4.2 that even with the most accurate classifier it is not possible to avoid false positives. Therefore, in order to make the system more stable while working on a video stream acquired from a surveillance camera, we decided to also explicitly exploit the temporal information, by adding a further layer that performs spatial and temporal analysis of the patches (see Figure 7).
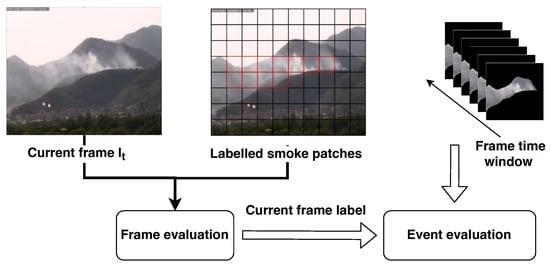
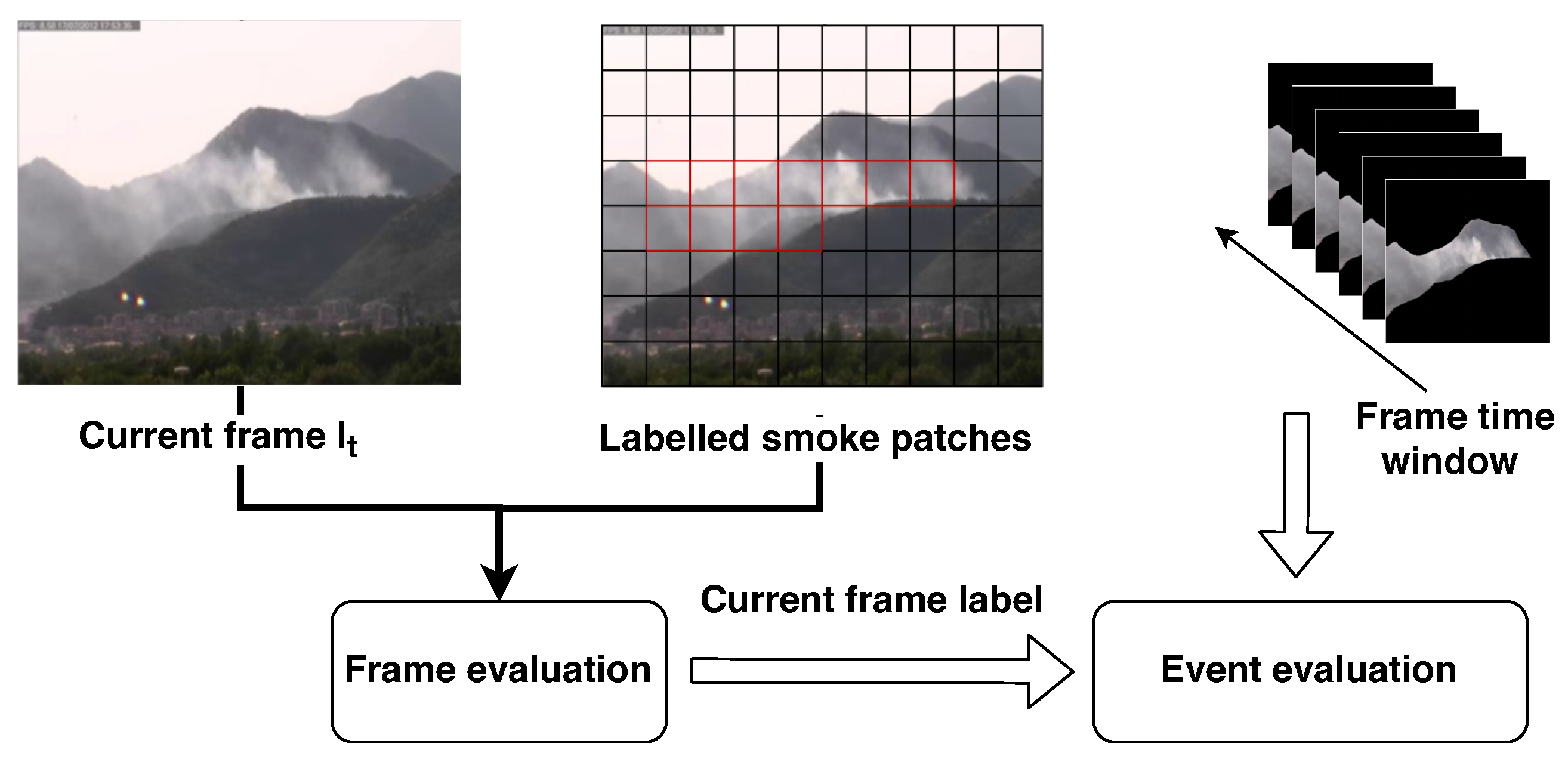
Figure 7.
Overview of the spatial and temporal analysis stage discussed in Section 2.4. The current frame together with its classified patches are analyzed to classify the entire frame . The output of the frame-based classification is provided to the video classifier that collects in an internal buffer a set of consecutive frames contained in a configured time window. If more than of consecutive frames are classified as smoke, the whole time window is considered to contain smoke and an alarm is raised.
This analysis is performed in two steps:
- Frame-based evaluation: A frame is considered positive if it contains at least one patch classified as smoke. This can be considered a kind of spatial aggregation.
- Event-based evaluation: A smoke event is generated if in a time window composed of k consecutive frames, at least of them are classified as smoke.
Note that in our experiments, we consider a video as smoke if at least an event is generated. We will refer to this as video-based classification.
3. Dataset
As mentioned in the introduction, one of the contributions of this paper is a new dataset for smoke detection in videos, namely the MIVIA Smoke Detection Dataset. It is one of the datasets with pixel-level groundtruth, so it can be used also for smoke segmentation.
MIVIA-SDD is designed to benchmark both smoke and fire detectors and has been acquired in the wild: a camera has been mounted in the MIVIA Lab of the University of Salerno, Italy, framing the mountain in front of the lab. Totally, the dataset is composed of 129 videos, with 28 h of footage and a resolution of pixels; each video is about 15 min long and contains 7500 frames on average. MIVIA-SDD contains both positive videos, i.e., those with smoke and fire, and negative videos, in which there are only background elements without smoke or fire.
Table 3 contains details about the number of videos in the dataset and its partition in training, validation and test sets. All the negative video samples are in the test set to evaluate the false positive rate of the proposed system. The dataset has been realized considering environmental elements that can be easily confused as smoke or fire together with challenging environmental conditions, such as red houses in a wide valley, mountains at sunset, sun reflections in the camera and clouds moving in the sky. Some positive video examples of the MIVIA-SDD are reported in Figure 8, while negative examples are reported in Figure 9. The dataset is made publicly available in our website (https://mivia.unisa.it/datasets/video-analysis-datasets/smoke-detection-dataset/ accessed on 1 July 2024).
Table 3.
Training, validation and test set of the MIVIA Smoke Detection Dataset.

Figure 8.
Examples of positive videos from the MIVIA-SDD, with smoke on the mountains with more light (a) and less light (b,c).

Figure 9.
Examples of negative videos from the MIVIA-SDD, without fire in progress, but with clouds (a), red shades (b) and red houses (c).
Concerning the ground truth, a common approach is to provide it in terms of labeled videos (by assigning a label smoke or non-smoke to the whole video), frames (by assigning a label smoke or non-smoke to the single frame) or bounding boxes (by drawing the minimum bounding box around the smoke, frame by frame). Furthermore, as shown in the example in Figure 10, the bounding box for its nature can not be considered representative of the smoke, since it also contains a huge amount of non-smoke pixels. Even if this is a quite common approach for detection problems, it is not the best possible approach when dealing with smoke, given its specific shape. For this reason, we have manually annotated one frame per second by drawing the polygon around the smoke, then the intermediate frames have been automatically annotated through interpolation. It is important to note that such kind of annotation allows for use of the dataset for training both smoke detectors and CNNs for smoke segmentation.

Figure 10.
Comparison between bounding box (a) and polygon labeling (b). The image on the left shows an example of bounding box while the one on the right depicts a polygon annotation example. It is clear that polygon labeling is more appropriate and can better capture the smoke shape without including non-smoke areas.
4. Experimental Analysis
In this section, we present the experimental protocol and results. Benchmarking the proposed multi-stage system only on the base of its outcome on videos does not allow us to properly evaluate the performance of all the stages involved in the classification process. Therefore, the adopted protocol allows us to take into account separately the capability of a fully deep learning-based approach and the improvement obtained by the combination with the color/motion-based approach. In detail, we have considered three aspects, performing specific experiments for each of them:
- Patch-based: the aim of the analysis at this level is to evaluate the accuracy of the considered CNNs as patch-wise classifiers. All the models have been trained on a dataset of patches randomly extracted from the videos belonging to the training set and tested on those extracted from the test set.
- Frame-based: a frame-by-frame analysis on frames extracted from test set videos allows us to evaluate the entire pipeline discussed in Section 2, consisting of movement evaluation, color-based filtering and patch classification (frame classification).
- Video-based: this last level evaluates the pipeline with the addition of the spatial and temporal analysis (video classification) when classifying the entire video.
4.1. Performance Metrics
For all the three kinds of analysis (patch-, frame- and video-based) we consider three performance metrics, namely: accuracy (A) (see Equation (10)), recognition rate (RR) (see Equation (11)) and false positive rate (FPR) (see Equation (12)).
All the three metrics are based on the following measures: true positives (TPs) is the number of correct smoke classifications, false negatives (FNs) is the number of smoke samples wrongly classified as background, false positives (FPs) is the number of negative samples wrongly classified as smoke and true negatives (TNs) is the number of correctly classified background samples.
Furthermore, for the video-based evaluation we also compute other two metrics:
- False Positive Videos (FPVs): number of negative videos where at least one temporal window is classified as smoke.
- False Positive Events (FPEs): number of false positive events raised in the negative videos (i.e., the number of temporal windows classified as smoke).
4.2. Experimental Results
As introduced in Section 2, we have considered different widely used CNN architectures: MobileNet, VGG-19, ResNet-50, Inception v3 and Xception. We chose these neural networks since they cover most of the architectures widely used in recent years.
The networks are pre-trained on ImageNet, a very large dateset for object detection tasks; then, they have been fine-tuned to classify smoke patches with transfer learning by using the 6,406,047 patches extracted from the videos of the training set and validated on 1,348,275 patches of the validation set. As for the learning procedure, since the task is a binary classification we have considered a binary cross-entropy loss function; the training of the CNNs has been performed using RMSprop with an initial learning rate of , a batch size of 128 and an early stopping mechanism that aborts the training if the accuracy on the validation set does not improve for 5 epochs. Finally, the model has been tested over the 4,551,303 patches extracted from the test set videos.
In Table 4, we show the results of the three analyses; in particular accuracy, recognition rate and false positive rate are reported for patch-based and frame-based analyses, while false positive videos and false positive events are used for the video-based one.
Table 4.
Results obtained on the MIVIA-SDD test set in terms of accuracy (A), recognition rate (RR), false positive rate (FPR), false positive videos (FPVs) and false positive events (FPEs). The best results are highlighted in bold.
We can note that Inception v3 is the model obtaining the best overall accuracy for the patch-based evaluation (), namely the best trade-off between recognition rate () and false positive rate (). VGG-19 () and Xception () reach higher recognition rates, but at the cost of higher false positive rates ( and ). MobileNet and ResNet-50 achieve the worst results both in terms of recognition rate and false positive rate.
For the frame-based evaluation, the results are substantially more balanced, probably due to the fact that the adoption of movement evaluation and color-based filtering allows for selecting the most promising smoke regions. We can note, for this reason, a reduction in both the recognition and the false positive rates. This high sensitivity implies a lower average accuracy and a lower FPR with respect to patch-based analysis. Inception v3 is still the CNN obtaining the best false positive rate (), paying with the worst recognition rate () but retaining the top-2 accuracy (). In this case, Xception achieves the best accuracy (), namely the top-1 compromise between recognition rate () and false positive rate (). ResNet-50, VGG-19 and MobileNet achieve very similar results ( vs. vs. accuracy).
For the video-based evaluation, which is in principle the main analysis of our experimentation, the recognition rate and the false positive rate are higher on average. This is due to the fact that the time persistence of a single patch can trigger a smoke alarm, even if the negative effects are limited by the movement evaluation and the color-based filtering. Inception v3 confirms its superiority against the other networks in terms of false positive rate (), which in turn corresponds to the highest accuracy () with the same recognition rate of Xception, ResNet-50 and VGG-19 (). In addition, the lowest false positive videos (10 in total, 3 less than Xception, ResNet-50 and VGG-19 and 5 less than Xception) and false positive events (192 in total, 14 less than the top-2 result) confirm the higher effectiveness of Inception v3 with respect to the other networks for video-based smoke detection.
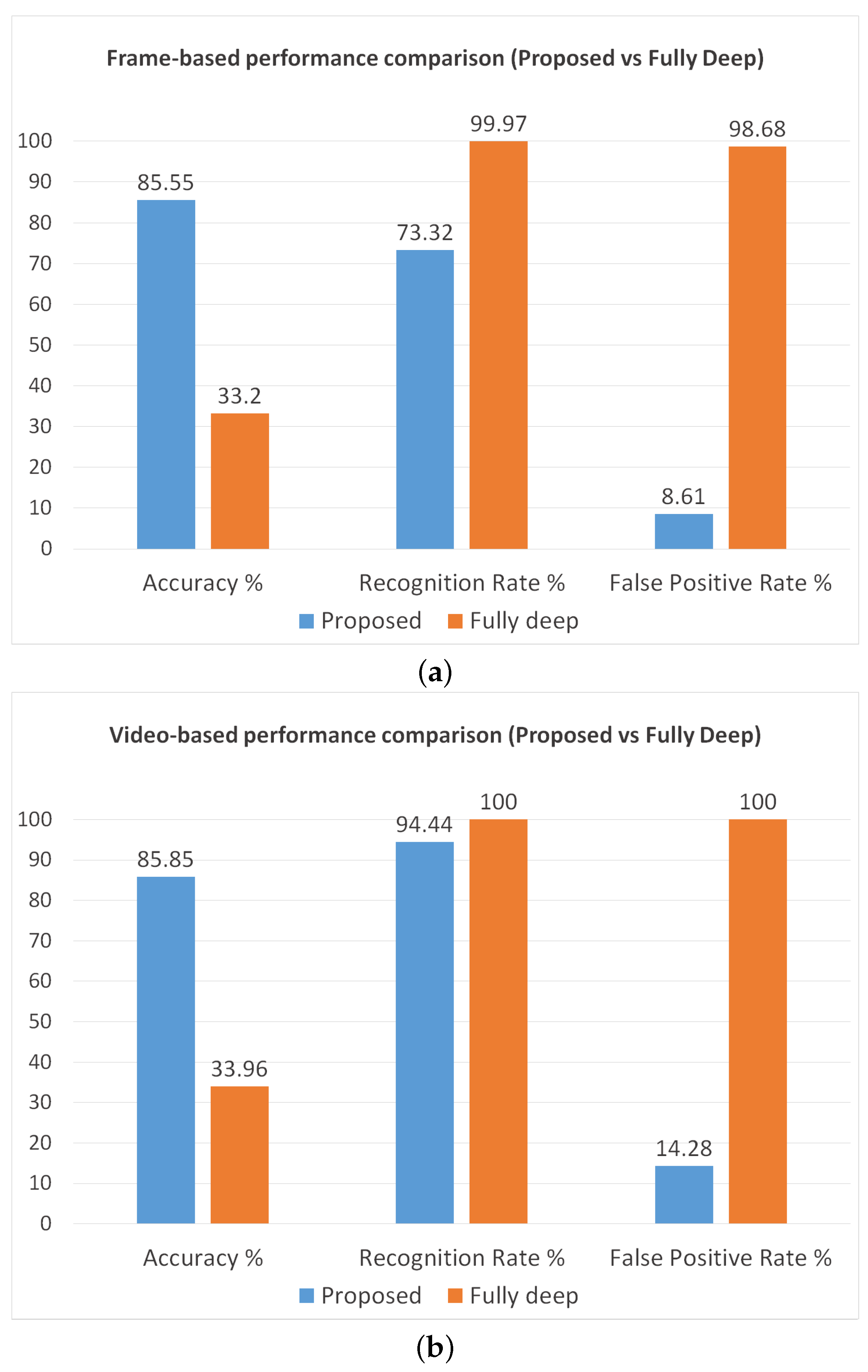
Furthermore, we also perform another analysis to observe the reduction in the false positive rate due to the application of movement evaluation and color-based filtering. As reference we use Inception v3, since it demonstrated the best performance in the previous experiments. The achieved results are reported in Figure 11 and confirm our hypotheses. Indeed, we can note that the system based on the fully deep approach obtains a very high recognition rate ( frame-based, video-based), but in turn also the false positive rate becomes much higher ( frame-based, video-based), making the system unusable in real-world conditions.
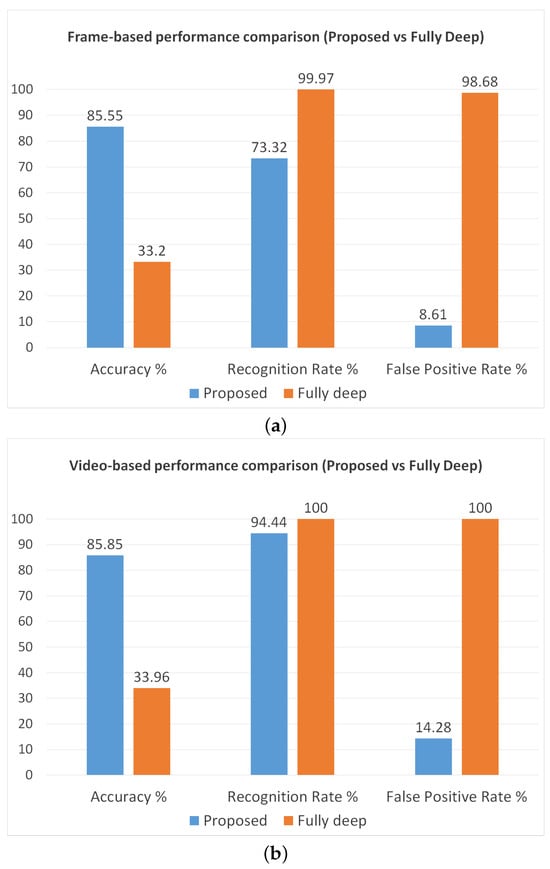
Figure 11.
Performance comparison between our proposed method and the fully deep approach. The chart on the top (a) shows the frame-based performance, while the other (b) represents the video-based performance.
This result is quite unexpected by considering the high patch-based accuracy (); however, the capability of the network to recognize the patches does not imply a remarkable frame-based and video-based performance. In principle, around of the patches may be always misclassified by the CNN, so obtaining very high frame-based and video-based FPR. Therefore, such an experimental result confirms that the movement evaluation and the color-based filtering are essential steps for our method.
In conclusion, considering the not negligible number of false positive videos and events, it is worth investigating the causes. After a qualitative analysis, we notice that there are some specific negative videos that are more problematic in terms of false alarms. In fact, MobileNet, VGG-19 and ResNet-50 generate false positive events in the same 13 videos; some examples are reported in Figure 12. The majority of false alarms are raised due to the moving clouds in the sky (especially when they are grayish, otherwise they are filtered out by the color rule) and due to brightness changes in the videos and sudden reflections of the sun on the mountains (e.g., when a cloud goes away the sun suddenly lights up the scene and these changes are detected by the movement evaluation). This evidence suggests that, even combining movement and color rules with deep learning techniques, we are not able to cut down the false positive rate below a certain threshold.

Figure 12.
Examples of false positives detected by the algorithm on smoke-like objects, namely fog (a) and headlights (b).
5. Conclusions
In this work, we proposed a novel method for video-based smoke detection. It is a hybrid approach combining traditional image processing techniques like movement evaluation and color-based filtering with modern CNNs for smoke recognition. In addition, we proposed a novel challenging dataset, MIVIA-SDD, which was realized by collecting 129 videos in the wild, for 28 h in total; we used it to assess and evaluate the performance of the proposed method. The experimental results show that our system achieves a remarkable recognition rate of more than , keeping the false positive rate lower than the fully deep approach ( vs. ). However, the experimental analysis points out that, despite how we adopted various countermeasures available in the state of the art, there is still room for improving the capability to reduce the false positive rate.
Furthermore, by making our smoke detection dataset publicly available, we hope to promote future research in this field.
Author Contributions
All the authors contributed equally to conceptualization, methodology, software, validation, formal analysis, writing—original draft preparation, writing—review and editing for this work. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The dataset is available under request at the following link: https://mivia.unisa.it/datasets/video-analysis-datasets/smoke-detection-dataset/ accessed on 1 July 2024.
Acknowledgments
This research has been partially supported by A.I. Tech s.r.l. (www.aitech.vision).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- EFFIS Annual Fire Reports. 2020. Available online: https://effis.jrc.ec.europa.eu/reports-and-publications/annual-fire-reports (accessed on 1 July 2024).
- Di Lascio, R.; Greco, A.; Saggese, A.; Vento, M. Improving Fire Detection Reliability by a Combination of Videoanalytics. In Proceedings of the Image Analysis and Recognition; Campilho, A., Kamel, M., Eds.; Springer: Cham, Switerland, 2014; pp. 477–484. [Google Scholar]
- U.S. Fire Deaths, Fire Death Rates, and Risk of Dying in a Fire. 2020. Available online: https://www.usfa.fema.gov/statistics/deaths-injuries/states.html (accessed on 1 July 2024).
- Gaur, A.; Singh, A.; Kumar, A.; Kumar, A.; Kapoor, K. Video flame and smoke based fire detection algorithms: A literature review. Fire Technol. 2020, 56, 1943–1980. [Google Scholar] [CrossRef]
- Wang, S.; Xiao, X.; Deng, T.; Chen, A.; Zhu, M. A Sauter mean diameter sensor for fire smoke detection. Sens. Actuators B Chem. 2019, 281, 920–932. [Google Scholar] [CrossRef]
- Solórzano, A.; Fonollosa, J.; Fernández, L.; Eichmann, J.; Marco, S. Fire detection using a gas sensor array with sensor fusion algorithms. In Proceedings of the 2017 ISOCS/IEEE International Symposium on Olfaction and Electronic Nose (ISOEN), Montreal, QC, Canada, 28–31 May 2017; pp. 1–3. [Google Scholar]
- Mtz-Enriquez, A.; Padmasree, K.; Oliva, A.; Gomez-Solis, C.; Coutino-Gonzalez, E.; Garcia, C.; Esparza, D.; Oliva, J. Tailoring the detection sensitivity of graphene based flexible smoke sensors by decorating with ceramic microparticles. Sens. Actuators B Chem. 2020, 305, 127466. [Google Scholar] [CrossRef]
- Hwang, W.Y.; Lee, H.J.; Jin, J.; Ryou, H.S.; Choi, C.K.; Hong, S.H.; Lee, S.H. Computational design of a smoke detector with high sensitivity considering three-dimensional flow characteristics. Case Stud. Therm. Eng. 2024, 53, 103896. [Google Scholar] [CrossRef]
- Zhou, Z.; Shi, Y.; Gao, Z.; Li, S. Wildfire smoke detection based on local extremal region segmentation and surveillance. Fire Saf. J. 2016, 85, 50–58. [Google Scholar] [CrossRef]
- Luo, S.; Yan, C.; Wu, K.; Zheng, J. Smoke detection based on condensed image. Fire Saf. J. 2015, 75, 23–35. [Google Scholar] [CrossRef]
- Yuan, F. A fast accumulative motion orientation model based on integral image for video smoke detection. Pattern Recognit. Lett. 2008, 29, 925–932. [Google Scholar] [CrossRef]
- Yuan, C.; Liu, Z.; Zhang, Y. Learning-based smoke detection for unmanned aerial vehicles applied to forest fire surveillance. J. Intell. Robot. Syst. 2019, 93, 337–349. [Google Scholar] [CrossRef]
- Zhao, Y. Candidate smoke region segmentation of fire video based on rough set theory. J. Electr. Comput. Eng. 2015, 2015. [Google Scholar] [CrossRef]
- Lin, G.; Zhang, Y.; Zhang, Q.; Jia, Y.; Xu, G.; Wang, J. Smoke detection in video sequences based on dynamic texture using volume local binary patterns. Trans. Internet Inf. Syst. 2017, 11, 5522–5536. [Google Scholar]
- Yuan, F. Video-based smoke detection with histogram sequence of LBP and LBPV pyramids. Fire Saf. J. 2011, 46, 132–139. [Google Scholar] [CrossRef]
- Dimitropoulos, K.; Barmpoutis, P.; Grammalidis, N. Higher order linear dynamical systems for smoke detection in video surveillance applications. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 1143–1154. [Google Scholar] [CrossRef]
- Yuan, F.; Shi, J.; Xia, X.; Yang, Y.; Fang, Y.; Wang, R. Sub Oriented Histograms of Local Binary Patterns for Smoke Detection and Texture Classification. Ksii Trans. Internet Inf. Syst. 2016, 10, 1807–1823. [Google Scholar]
- Xu, Z.; Xu, J. Automatic fire smoke detection based on image visual features. In Proceedings of the 2007 International Conference on Computational Intelligence and Security Workshops (CISW 2007), Harbin, China, 15–19 December 2007; pp. 316–319. [Google Scholar]
- Frizzi, S.; Kaabi, R.; Bouchouicha, M.; Ginoux, J.M.; Moreau, E.; Fnaiech, F. Convolutional neural network for video fire and smoke detection. In Proceedings of the IECON 2016-42nd Annual Conference of the IEEE Industrial Electronics Society, Florence, Italy, 24–27 October 2016; pp. 877–882. [Google Scholar]
- Tao, C.; Zhang, J.; Wang, P. Smoke detection based on deep convolutional neural networks. In Proceedings of the 2016 International Conference on Industrial Informatics-Computing Technology, Intelligent Technology, Industrial Information Integration (ICIICII), Wuhan, China, 3–4 December 2016; pp. 150–153. [Google Scholar]
- Xu, G.; Zhang, Y.; Zhang, Q.; Lin, G.; Wang, J. Deep domain adaptation based video smoke detection using synthetic smoke images. Fire Saf. J. 2017, 93, 53–59. [Google Scholar] [CrossRef]
- Lin, G.; Zhang, Y.; Xu, G.; Zhang, Q. Smoke detection on video sequences using 3D convolutional neural networks. Fire Technol. 2019, 55, 1827–1847. [Google Scholar] [CrossRef]
- Pundir, A.S.; Raman, B. Dual Deep Learning Model for Image Based Smoke Detection. Fire Technol. 2019, 55, 2419–2442. [Google Scholar] [CrossRef]
- Yuan, F.; Zhang, L.; Xia, X.; Wan, B.; Huang, Q.; Li, X. Deep smoke segmentation. Neurocomputing 2019, 357, 248–260. [Google Scholar] [CrossRef]
- Gragnaniello, D.; Greco, A.; Sansone, C.; Vento, B. Onfire contest 2023: Real-time fire detection on the edge. In Proceedings of the International Conference on Image Analysis and Processing; Springer: Berlin/Heidelberg, Germany, 2023; pp. 273–281. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 25 2012, 1097–1105. [Google Scholar] [CrossRef]
- Senthilnayaki, B.; Devi, M.A.; Roseline, S.A.; Dharanyadevi, P. Deep Learning-Based Fire and Smoke Detection System. In Proceedings of the 2024 Second International Conference on Emerging Trends in Information Technology and Engineering (ICETITE), Vellore, India, 22–23 February 2024; pp. 1–6. [Google Scholar] [CrossRef]
- de Venâncio, P.V.A.; Lisboa, A.C.; Barbosa, A.V. An automatic fire detection system based on deep convolutional neural networks for low-power, resource-constrained devices. Neural Comput. Appl. 2022, 34, 15349–15368. [Google Scholar] [CrossRef]
- Huo, Y.; Zhang, Q.; Zhang, Y.; Zhu, J.; Wang, J. 3DVSD: An end-to-end 3D convolutional object detection network for video smoke detection. Fire Saf. J. 2022, 134, 103690. [Google Scholar] [CrossRef]
- Wu, Z.; Xue, R.; Li, H. Real-Time Video Fire Detection via Modified YOLOv5 Network Model. Fire Technol. 2022, 58, 2377–2403. [Google Scholar] [CrossRef]
- Abdusalomov, A.B.; Islam, B.M.S.; Nasimov, R.; Mukhiddinov, M.; Whangbo, T.K. An improved forest fire detection method based on the detectron2 model and a deep learning approach. Sensors 2023, 23, 1512. [Google Scholar] [CrossRef]
- Mardani, K.; Vretos, N.; Daras, P. Transformer-based fire detection in videos. Sensors 2023, 23, 3035. [Google Scholar] [CrossRef]
- Aslan, S.; Güdükbay, U.; Töreyin, B.U.; Çetin, A.E. Early wildfire smoke detection based on motion-based geometric image transformation and deep convolutional generative adversarial networks. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8315–8319. [Google Scholar]
- Yin, M.; Lang, C.; Li, Z.; Feng, S.; Wang, T. Recurrent convolutional network for video-based smoke detection. Multimed. Tools Appl. 2019, 78, 237–256. [Google Scholar] [CrossRef]
- Töreyin, B.U.; Dedeoğlu, Y.; Cetin, A.E. Wavelet based real-time smoke detection in video. In Proceedings of the 2005 13th European Signal Processing Conference, Antalya, Turkey, 4–8 September 2005; pp. 1–4. [Google Scholar]
- Ko, B.C.; Ham, S.J.; Nam, J.Y. Modeling and formalization of fuzzy finite automata for detection of irregular fire flames. IEEE Trans. Circuits Syst. Video Technol. 2011, 21, 1903–1912. [Google Scholar] [CrossRef]
- Dimitropoulos, K.; Barmpoutis, P.; Grammalidis, N. Spatio-temporal flame modeling and dynamic texture analysis for automatic video-based fire detection. IEEE Trans. Circuits Syst. Video Technol. 2014, 25, 339–351. [Google Scholar] [CrossRef]
- Xu, G.; Zhang, Q.; Liu, D.; Lin, G.; Wang, J.; Zhang, Y. Adversarial adaptation from synthesis to reality in fast detector for smoke detection. IEEE Access 2019, 7, 29471–29483. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Piccardi, M. Background subtraction techniques: A review. In Proceedings of the 2004 IEEE International Conference on Systems, Man and Cybernetics (IEEE Cat. No. 04CH37583), The Hague, The Netherlands, 10–13 October 2004; Volume 4, pp. 3099–3104. [Google Scholar]
- Carletti, V.; Foggia, P.; Greco, A.; Saggese, A.; Vento, M. Automatic detection of long term parked cars. In Proceedings of the 2015 12th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Karlsruhe, Germany, 25–28 August 2015; pp. 1–6. [Google Scholar]
- Ha, C.; Jeon, G.; Jeong, J. Vision-based smoke detection algorithm for early fire recognition in digital video recording system. In Proceedings of the 2011 Seventh International Conference on Signal Image Technology & Internet-Based Systems, Dijon, France, 28 Novermber–1 December 2011; pp. 209–212. [Google Scholar]
- Matlani, P.; Shrivastava, M. A survey on video smoke detection. In Information and Communication Technology for Sustainable Development; Springer: Berlin/Heidelberg, Germany, 2018; pp. 211–222. [Google Scholar]
- Kim, D.; Wang, Y.F. Smoke detection in video. In Proceedings of the 2009 WRI World Congress on Computer Science and Information Engineering, Los Angeles, CA, USA, 31 March–2 April 2009; Volume 5, pp. 759–763. [Google Scholar]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).