1. Introduction
Parkinson’s disease (PD) is the second most common neurodegenerative disorder worldwide, primarily resulting from the progressive loss of neurons in the substantia nigra of the midbrain, leading to a deficiency of dopamine produced by these neurons. This deficiency results in impaired motor functions and progressive non-motor symptoms such as cognitive impairments [
1]. Epidemiologically, the prevalence and incidence of Parkinson’s disease increase with age. According to a study by Willis et al. [
2], the incidence rates among North Americans are 108 to 212 per 100,000 for those aged 65 and above and 47 to 77 per 100,000 for those over 45. Similarly, research by Park et al. [
3] noted significant disparities in the South Korean population, where the incidence rate for individuals under 49 is 1.7 per 100,000, with a prevalence of 5.8, whereas those aged 50 and above have an incidence rate of 88.7 per 100,000 and a prevalence of 455.7. Parkinson’s disease poses substantial public health and economic burdens, particularly in countries experiencing population aging. In the United States, the annual cost attributed to PD is estimated at approximately USD 52 billion [
2]. In South Korea, the total medical insurance costs related to PD reached KRW 542.8 billion in 2020, marking a 25.3% increase from four years earlier [
4]. This financial burden extends not only to the nations but also to patients suffering from the disease and their families who bear the caregiving responsibilities.
One of the prominent symptoms among PD patients is speech and articulation disorders. Many experience hypokinetic dysarthria, characterized by reduced movement, resulting in rapid speech, diminished vocal loudness, monotone rhythm, and altered speech patterns [
5]. Cognitive impairments can further deteriorate patients’ speech capabilities, manifested through reduced sentence and vocabulary comprehension, attention deficits, and overall impaired language function [
5]. These issues could serve as biomarkers for screening the disease. Various studies have identified acoustic features such as tVSA, VAI, noise-to-harmonics ratio (NHR), jitter, and pitch from vowel phonation and demonstrated their diagnostic relevance [
6,
7,
8]. Similarly, features like the average articulation rate and syllable duration stability, short-term variability measured by Jitt and nPVI, rate slope, and relative amplitude of vowels and consonants in diadochokinetic (DDK) tasks have been effectively used as biomarkers [
9,
10,
11,
12]. Recent advances include applying machine learning models to these acoustic features or using deep learning for automated classification of PD, showing notable performance [
13,
14,
15].
However, in the field of AI learning for medical applications, including PD classification, there are issues related to data bias, which primarily stem from difficulties encountered during data collection [
16,
17,
18]. Specifically, when collecting voice data from PD patients, the challenges faced by those with cognitive impairments in performing multi-tasks, the essential requirement for patient consent, and the fragmented healthcare systems restrict researchers to a limited sample of patients. These challenges not only limit the amount of data collected but also hinder the collection of high-quality data, thereby increasing the bias and reducing the performance of deep learning models. Moreover, deep learning possesses inherent “black box” characteristics. Like in other industries, transparency and trust in decision-making are crucial in healthcare, as the performance of models and the understanding of how conclusions are reached can significantly impact patient health and treatment outcomes. Furthermore, the lack of interpretability is closely related to ethical considerations, which are of paramount importance to regulatory bodies like the FDA [
19]. Therefore, there has been a significant push in the medical field to develop interpretable forms of machine-learning models [
20].
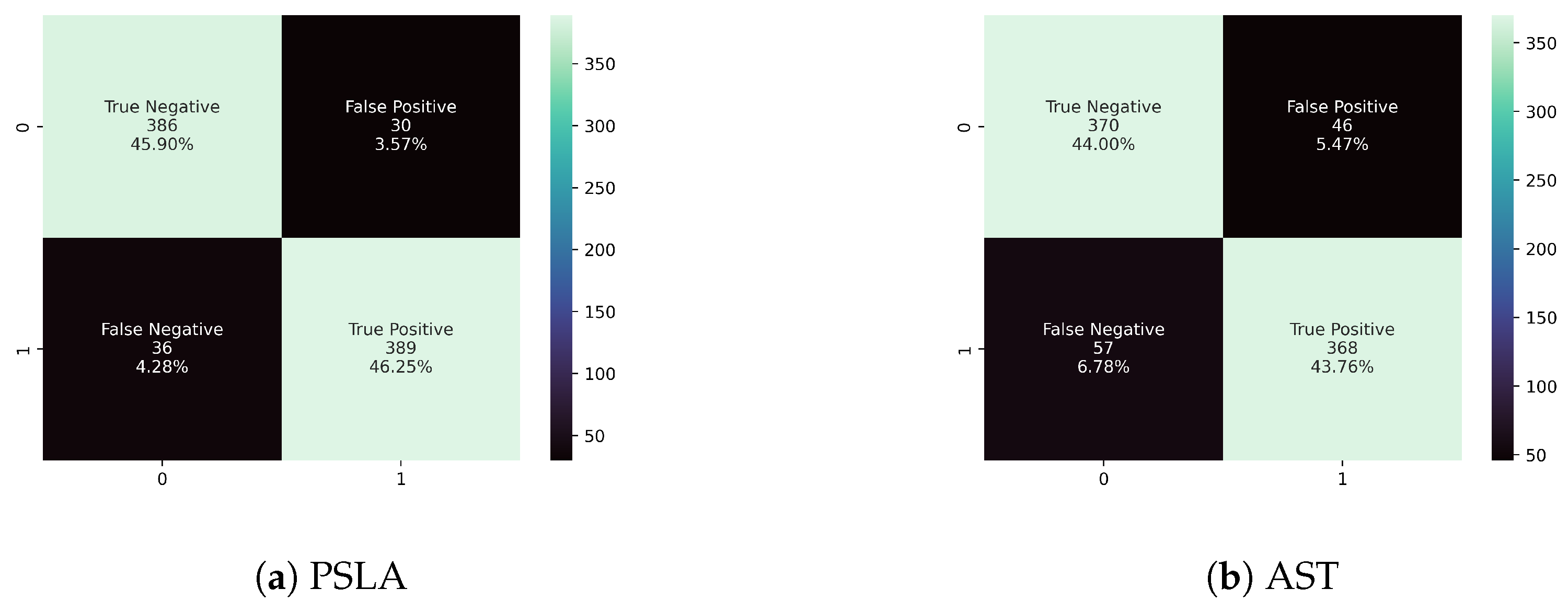
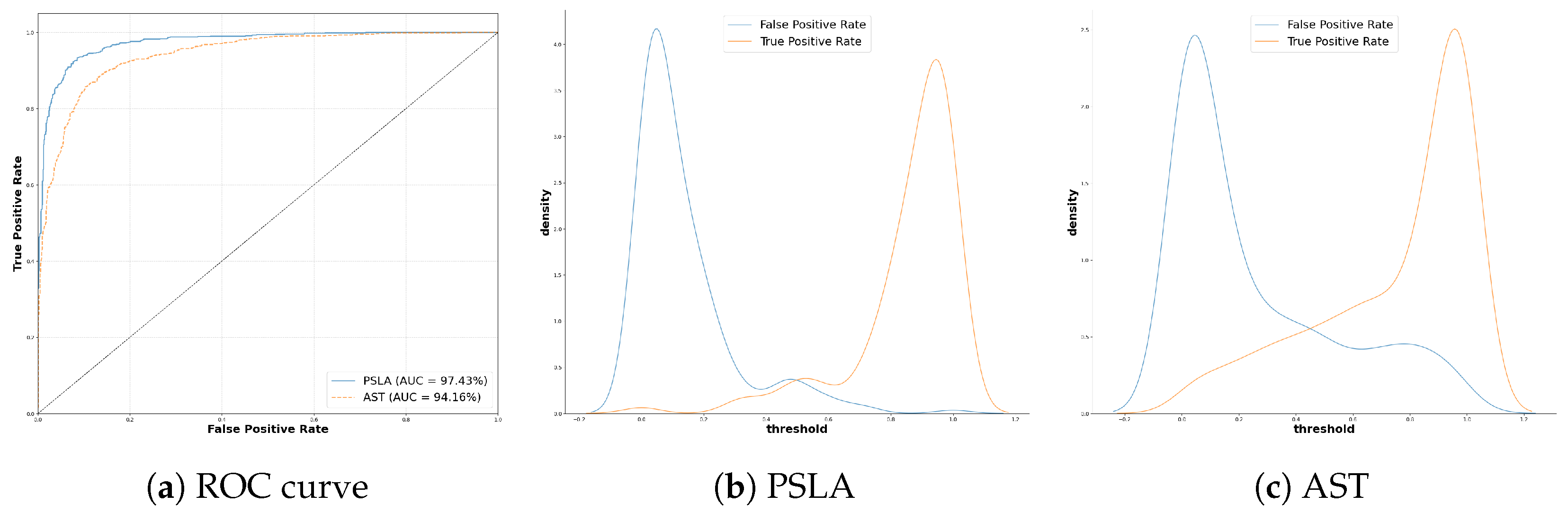
In this study, we aimed to identify distinguishing patterns between Parkinson’s patients and healthy controls using two prominent models in general voice classification: the transformer-based AST [
21] and the PSLA [
22] model, which incorporates CNNs and attention modules. Quantitative comparisons show that PSLA outperforms AST, with 92.15% accuracy and 97.43% AUC, compared to 87.75% accuracy and 94.16% AUC by AST. The study also explores the application of explainable AI (XAI) techniques such as class activation mapping (CAM) [
23], Gradient-weighted class activation mapping (Grad-CAM) [
24], and Eigen-CAM to address the challenges of the black-box problem by providing interpretability to deep learning predictions. Our qualitative analysis using the Eigen-CAM [
25] algorithm offers insights into the reasons behind the model’s predictions, further validating its reliability and effectiveness in distinguishing between the groups based on vocal characteristics, specifically capturing the narrow speech bandwidth and distinct articulation features of PD patients.
3. Methods
3.1. Data Preprocessing
The dataset employed in this study includes speech recordings from Korean individuals and is structured to distinguish between healthy controls and patients diagnosed with PD, following the Movement Disorders Society clinical diagnostic guidelines [
34]. The dataset comprises equal numbers of participants, 100 diagnosed with PD and 100 healthy individuals, engaged in various speech tasks that require sustained and repetitive speech patterns.
Consent was duly obtained from all participants, and the study protocol was rigorously reviewed and approved by the Institutional Ethical Review Board (IRB No.: 2108-235-1250). The control group demographics included 47 males and 53 females, with an average age of 65.8, while the PD group consisted of 49 males and 51 females, with an average age of 64.3 years. Participants with PD had an average disease duration of 6.9 years and an average Hoehn and Yahr stage of 1.9, indicating mild to moderate disease severity. Comprehensive demographic and clinical details are outlined in
Table 2.
This research involved three specific speech simulation tasks relevant to PD classification: the production of vowels, the production of consonants, and the DDK task. Each task was designed to capture the unique vocal patterns of the participants, which include both Parkinson’s patients and healthy controls.
The vowel task required participants to repeat the sequence of vowels ‘/a/, /e/, /i/, /o/, and /u/’ two times. In the consonant task, participants articulated a series of Korean phonemes such as /ga-ga-ga/, /na-na-na/, /da-da-da/, and /ha-ha-ha/ three times consecutively. The DDK task, commonly known as the ‘pa-ta-ka’ sequence, involved rapid pronunciation of the sequence for 10 s following a deep breath. Summary information related to voice tasks can be found in
Table 3 below.
Recordings were meticulously gathered using the “Voice Recorder Pro 3.7.1” app on an iPhone, within a carefully controlled environment to minimize background noise. All audio files were recorded at a frequency of 16,000 Hz and at a bitrate of 64 kbps. This methodical approach ensured the integrity and clarity of the speech data crucial for subsequent analysis. The duration of tasks varied, with the control group averaging 88.37 ± 20.79 s, and the Parkinson’s group slightly longer at 93.30 ± 19.30 s, reflecting subtle differences in speech dynamics between the groups.
The preprocessed speech is converted into log Mel filterbank features. These features, used as input images for the PSLA and AST models, are derived by compressing the frequency axis of the Mel-spectrogram into a log scale and then quantizing it into multiple stages of bins. The energy in each bin is calculated by aggregating the energy across the corresponding frequency bands. This feature map allows for the observation of energy changes in both the time domain and frequency domain, thus providing higher dimensional representation than one-dimensional raw audio data or two-dimensional waveform data. Such a representation facilitates more effective learning processes in machine learning [
35].
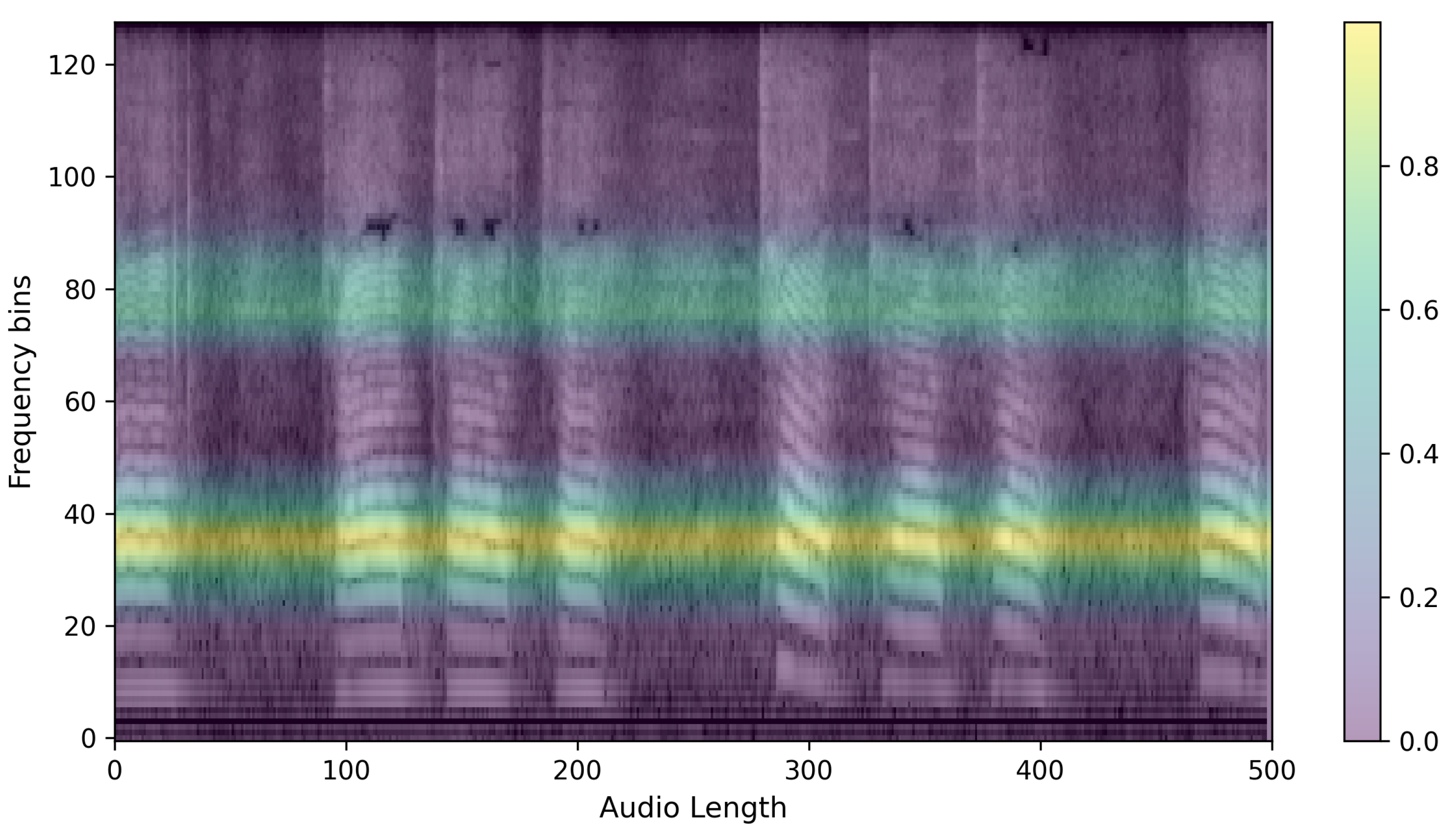
Furthermore, by compressively representing the frequency axis compared to the traditional Mel-spectrogram, the log Mel filterbank significantly enhances both spatial and temporal efficiency during neural network training. Specifically, the transformation of these features utilizes a 25 ms Hanning window with a 10ms overlap on the time axis (
x-axis), and on the frequency axis (
y-axis), the maximum frequency of 8000 Hz for a 16,000 Hz audio file is converted into the log Mel scale and then quantized into 128 bins. Below is an example of the extracted log Mel filterbank features, as shown in
Figure 1.
3.2. Model Training
In this study, we aimed to classify PD patients and healthy controls using the high-performance audio classification models AST and PSLA. For AST, the transformed 128-d log Mel filterbank features are divided into 16 × 16 patches with an overlap of 6 units. Each divided patch is linearly embedded into a vector of length 768, and to allow the model to learn data location and class information, a trainable position embedding layer of the same length is added to the patch embedding, with a [CLS] token appended. Since AST is designed for classification tasks, we used only the encoder of the transformer. We employed the standard architecture available in PyTorch for the transformer encoder, which consists of an embedding dimension of 768, 12 layers, and 12 multi-head attention modules.
Unlike the 3-channel image input of ViT, the log mel filterbank features consist of single-channel spectrograms. We averaged the weights corresponding to each of the three input channels in the ViT patch embedding layer to adapt them for the AST patch embedding layer and normalized the input audio spectrogram so that the dataset’s mean and standard deviation were 0 and 0.5, respectively. Finally, we employed knowledge distillation to learn the CNN’s inductive biases using the weights of DeiT [
36] pre-trained on ImageNet [
37]. The outcomes from DeiT include a [CLS] token and a [DIST] token, and in this study, we projected the average of these two tokens through an MLP layer to predict the most likely class. The structure of AST is shown in
Figure 2.
For PSLA, although it follows the same data normalization assumptions as AST, it does not undergo patch division but instead inputs the image directly into an EfficientNet [
38] pre-trained on ImageNet. Subsequent features extracted are then averaged pooled along the frequency axis, and a 4-head attention module is used to facilitate the model’s understanding of the feature map and to predict probabilities for each class. Specifically, the attention module transforms the channel dimension of the feature map to match the class size through two parallel 1 × 1 kernel convolution layers. After normalization is applied to one of the resulting feature maps and multiplied by the other, the final prediction is computed by applying a weighted average through learned weights for each head after average pooling along the time axis. The structure of PSLA is shown in
Figure 3.
During the model development phase, we programmed the algorithm to undergo 50 epochs for both the training and validation phases to ensure robust model training. The model that exhibited optimum performance during the validation phase was subsequently selected for further assessments on an independent test dataset. This systematic training strategy allowed for comprehensive model evaluation.
In the processing of each 5 s audio segment, a log mel filterbank was utilized with a configuration of 512 time samples and 128 frequency bins. The learning rate was set to 0.00001, and we adopted the Adam optimizer to facilitate better convergence during training. To further enhance the variability of the training data, we implemented data augmentation techniques such as frequency and time masking [
39]. Additionally, Mixup [
40] was applied at a ratio of 0.5 to augment the dataset diversity. Given the minor discrepancies in segment counts across classes, the balanced sampling feature of AST was considered but ultimately found unnecessary for this specific dataset.
For the PSLA model, training, validation, and testing were conducted on the same dataset splits as those used for AST. The primary encoder used in PSLA was the EfficientNet-B2, which was pretrained on ImageNet, and the model utilized four attention heads. The training involved 50 epochs to provide adequate learning time. The Adam optimizer was chosen to facilitate optimal convergence, with a learning rate set to 0.001.
Similar to AST, data augmentation techniques such as frequency and time masking were implemented to enhance the dataset’s complexity. Mixup was also applied with a probability of 0.5 to increase the diversity of the training examples. Also, like AST, balanced sampling was not employed in the PSLA model due to the minor variations in segment counts across classes.
3.3. XAI
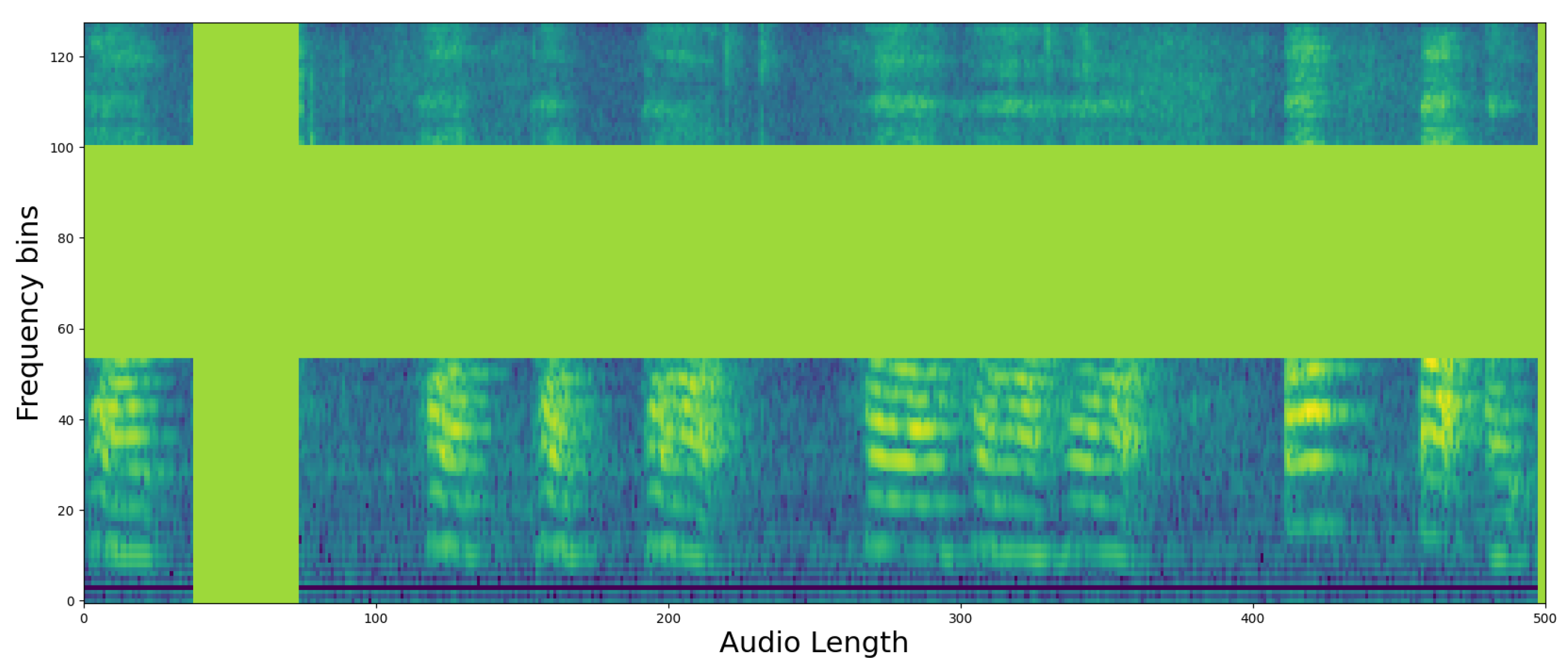
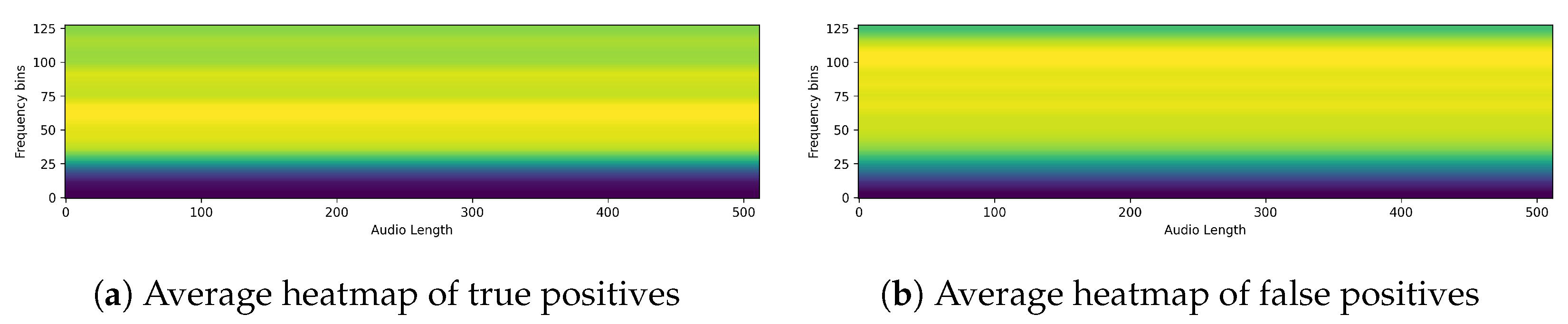
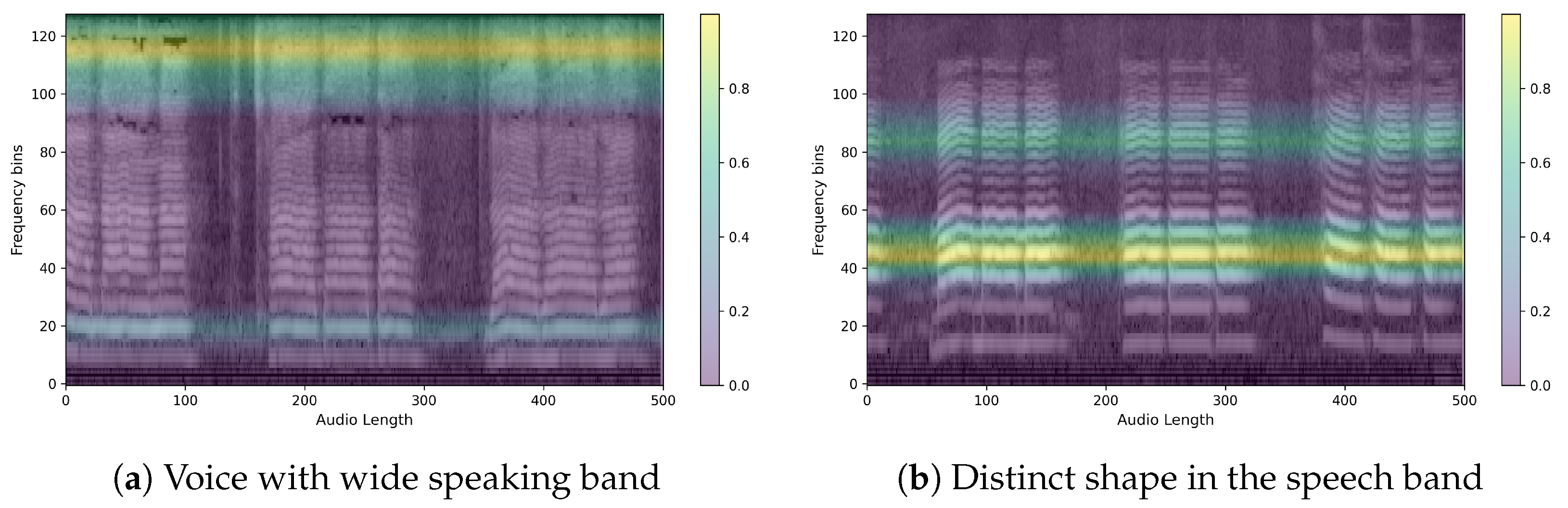
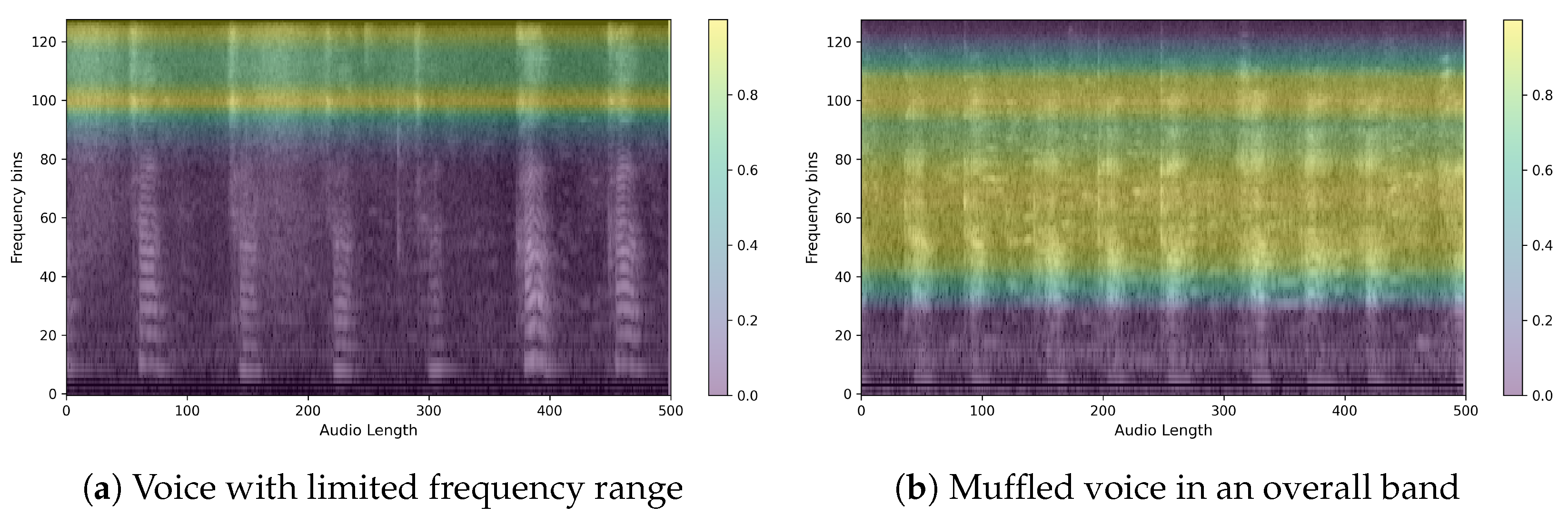
Finally, to evaluate the reasonableness of the model’s predictions, we compared the predicted results for each model by outputting them as heatmaps. Since our training data is in the form of images, we used CAM techniques commonly used in image prediction models and compared the predicted heatmaps using Grad-CAM, Grad-CAM++, and EigenCAM, as mentioned in
Section 2.2. Of the three XAI CAMs, we determined that EigenCAM had the highest explanatory power for the same output, so we ran our evaluation through EigenCAM. An example of a heatmap for a single piece of speech data is shown in
Figure 4. The figure shows a single spectrogram imaged by EigenCAM from the PSLA prediction model. The spectrogram of the speech data is represented in grayscale, and the heatmap is represented using the color map on the right. The higher the value, the more focused the model is in making predictions, and the lower the value, the more unfocused the model is. As can be seen in
Figure 4, for the PSLA model, the heatmap regions are formed along the frequency axis.
6. Conclusions
In this study, we demonstrated promising performance in predicting Parkinson’s disease (PD) using patients’ voice data. The model achieved an accuracy of 92.15% and an AUC of 97.43%. These results suggest that the model has favorable properties for predicting PD when speech data are transformed into 2D log Mel filterbank images. Additionally, we employed eXplainable AI (XAI) techniques, such as GradCAM, GradCAM++, and EigenCAM, to visualize which parts of the voice spectrogram the model focuses on. Our findings indicate that CAM techniques performed meaningfully from a qualitative perspective, especially when analyzing the same individual.
The obtained heatmaps revealed distinct features between PD and non-PD patients. For control predictions, there are neat high and low-frequency bands, with EigenCAM focusing on both. Conversely, PD predictions are characterized by a muffled waveform, particularly in the high-frequency band, where EigenCAM focuses the most. This confirms that the trained model accurately reflects the characteristics of PD patients, such as having a choppy waveform across all bands.
Meanwhile, we recognize the importance of analyzing individual speech tasks independently to enhance model performance and insights. Although the current study segmented speech data into 5 s intervals to capture sufficient acoustic information, we did not separate tasks for individual analysis. Future work will involve detailed experiments to process and analyze each type of speech task separately, followed by early and late fusion techniques to combine the results. This approach is expected to provide deeper insights into the specific contributions of each task to the overall performance of PD classification.
Moreover, an ablation study on model and data preprocessing was conducted, but experiments on the parameters of the mel-spectrogram and the input image were not performed. This suggests that there is room for further performance improvement along with the model development, which will be addressed in future research.
Future work will also focus on developing predictive models for various diseases beyond PD and analyzing how XAI can elucidate the features of each disease. By extending our methodology and analysis to different conditions, we aim to enhance the generalizability and applicability of our models in the medical field.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}