
DOT-SLAM: A Stereo Visual Simultaneous Localization and Mapping (SLAM) System with Dynamic Object Tracking Based on Graph Optimization


Abstract
1. Introduction
- A graph optimization framework that is tightly coupled is introduced. This framework employs rigid body motion to establish reprojection errors for features associated with dynamic objects and performs joint optimization of the vehicle pose, dynamic object poses, local road plane, and visual feature points as optimization nodes.
- A method for initializing the pose of dynamic objects is introduced, utilizing local road plane constraints and non-holonomic constraints. This method significantly reduces uncertainty and enhances the accuracy of dynamic objects’ initial poses.
- A multi-scale depth estimation method for dynamic objects is presented. It starts with a coarse initial pose derived from the camera–road plane geometry, which then guides refined stereo matching to ascertain the 3D spatial locations of feature points on dynamic objects.
- A unified SLAM system is introduced that is capable of creating a globally consistent map of the static environment. The system’s performance is validated through one public dataset and real vehicle experiments, demonstrating superior localization accuracy compared to state VSLAM and VISLAM in highly dynamic scenes for the vehicle.
2. Related Work
2.1. Visual SLAM Systems in Dynamic Scenes
2.2. Coupled Visual SLAM and Dynamic Object Tracking
3. Preliminaries
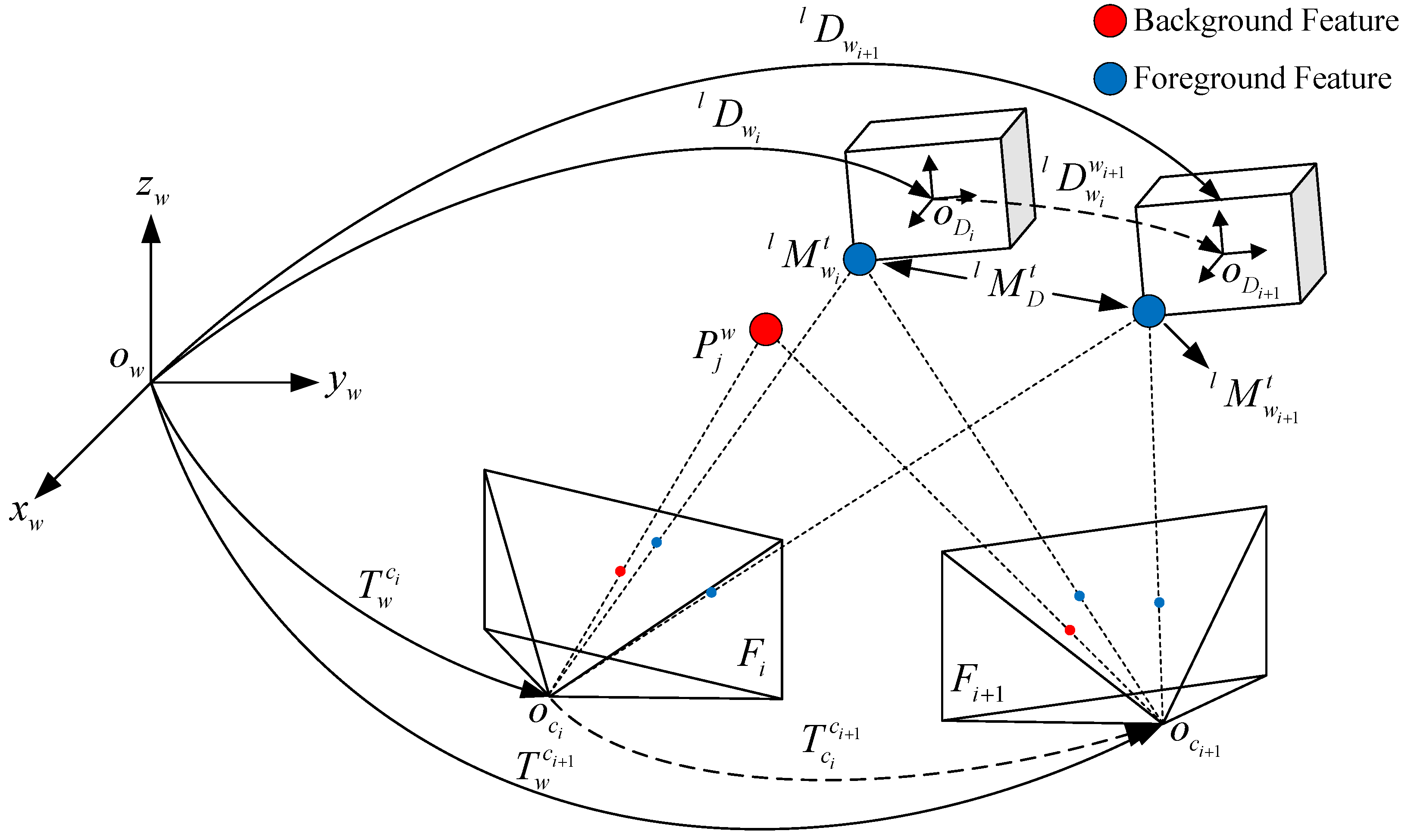
3.1. Notation
3.2. Pose Representations of Dynamic Objects and Features
4. Proposed System
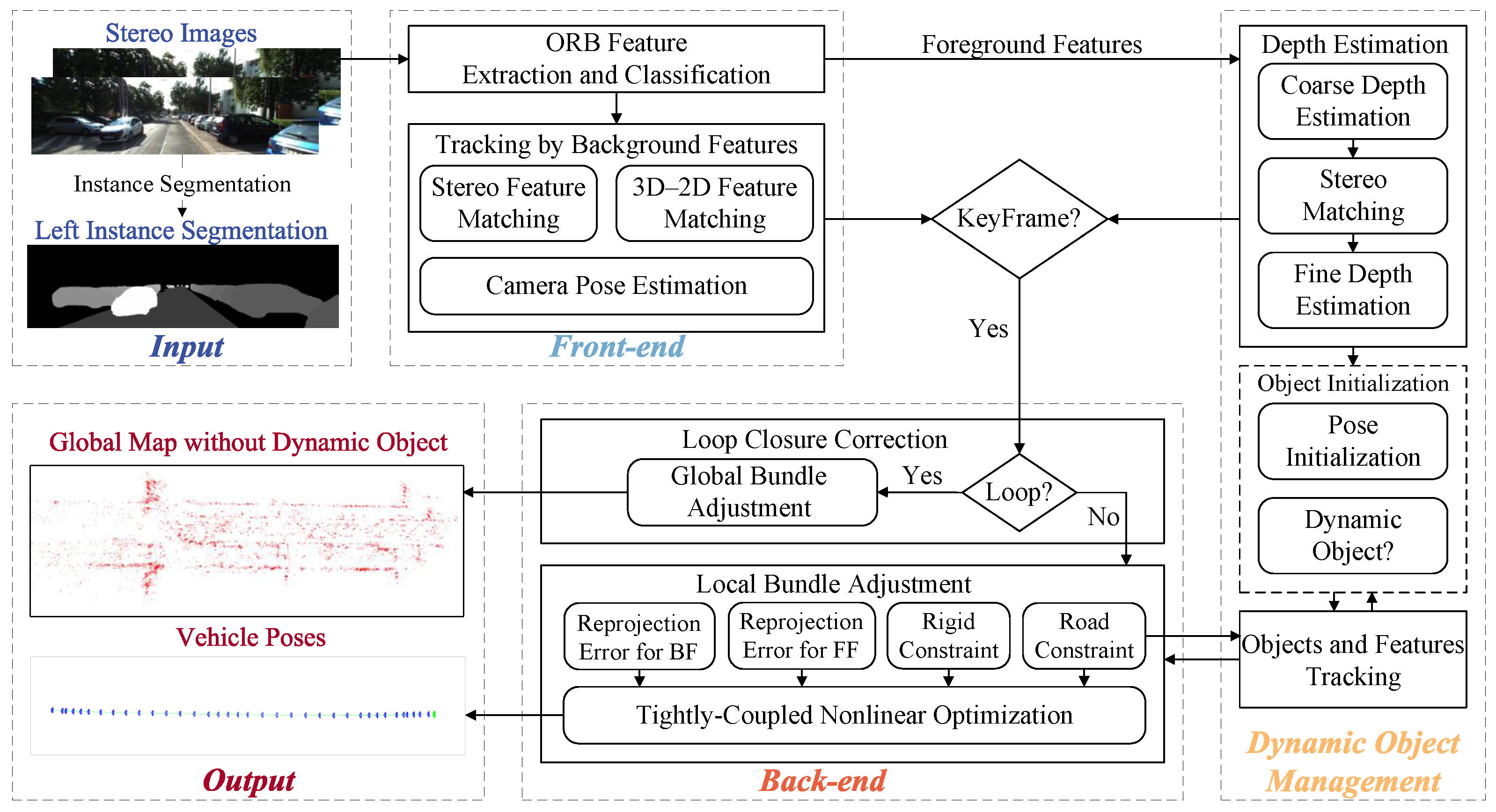
4.1. System Overview
4.2. Front-End
4.3. Dynamic Object Management
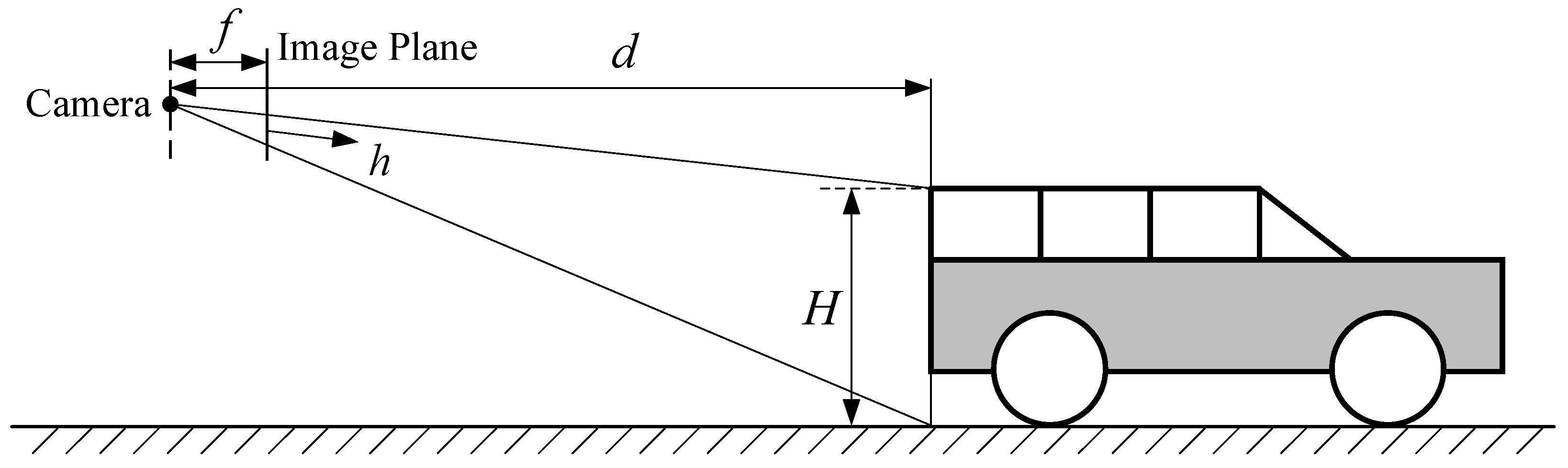
4.3.1. Depth Estimation
| Algorithm 1: Calculation of stereo disparity search range |
 |
4.3.2. Object and Feature Tracking
4.3.3. Object Initialization
4.4. Back-End
4.4.1. Local Bundle Adjustment
4.4.2. Loop Correction
5. Experiments
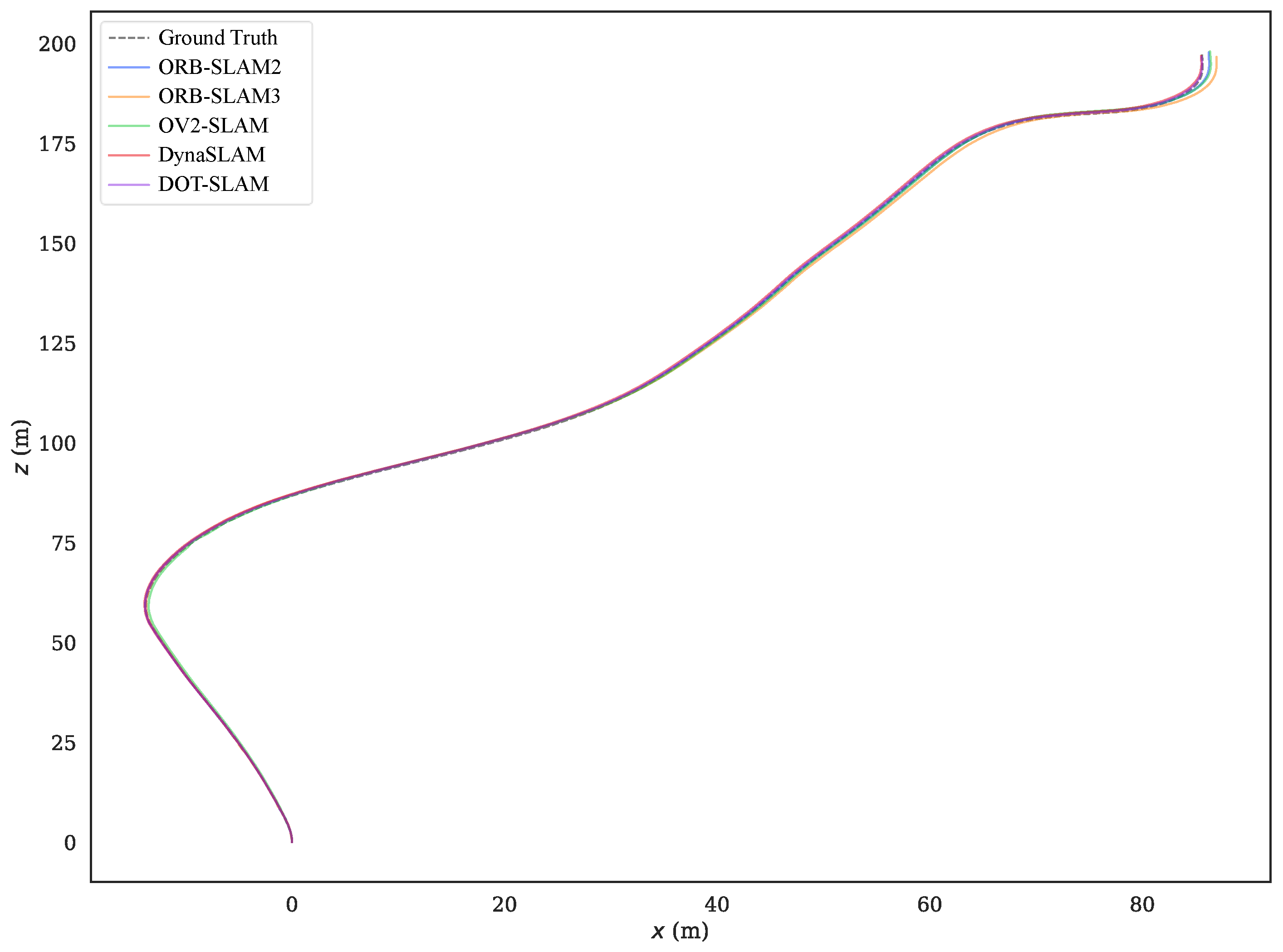
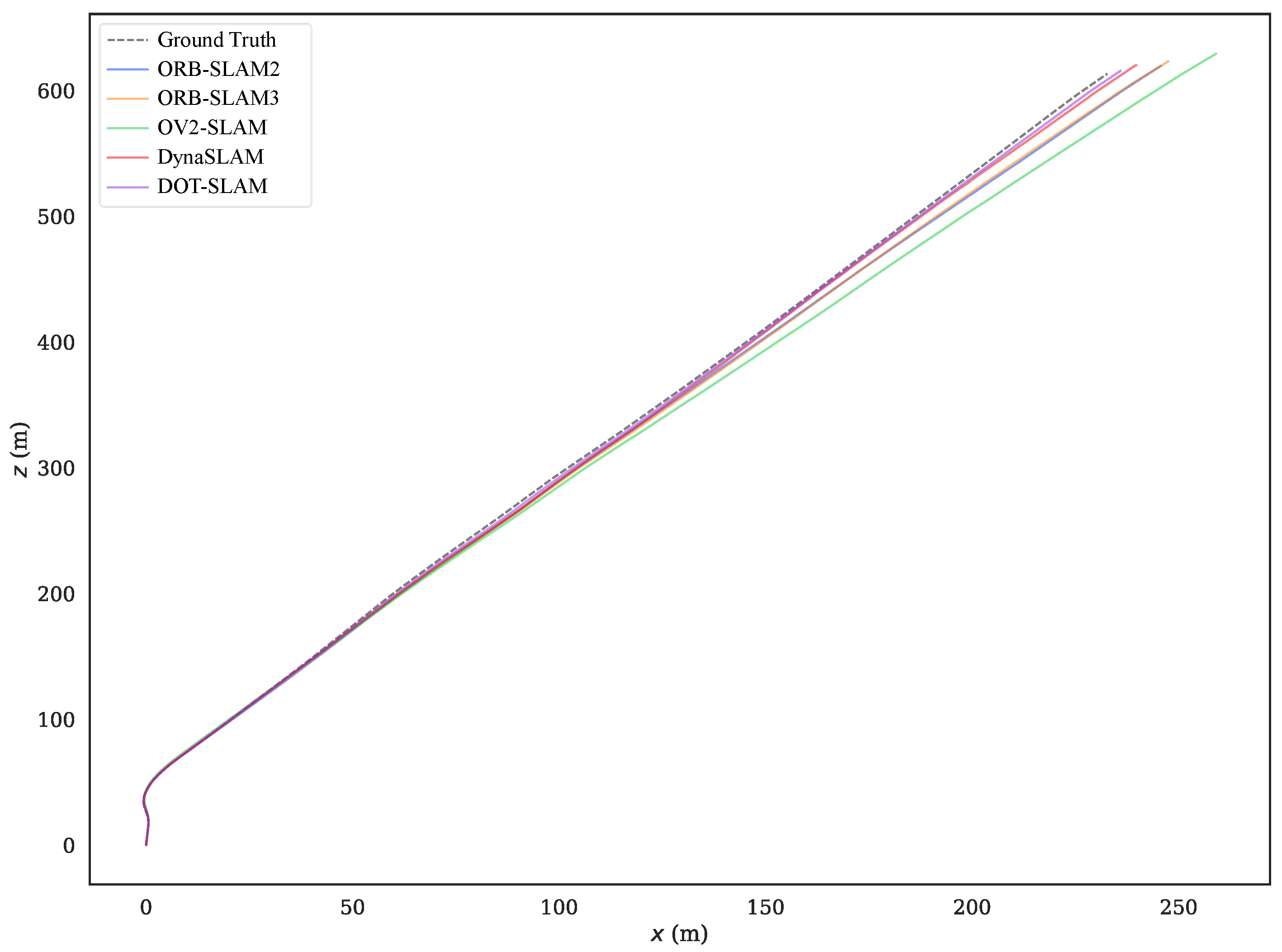
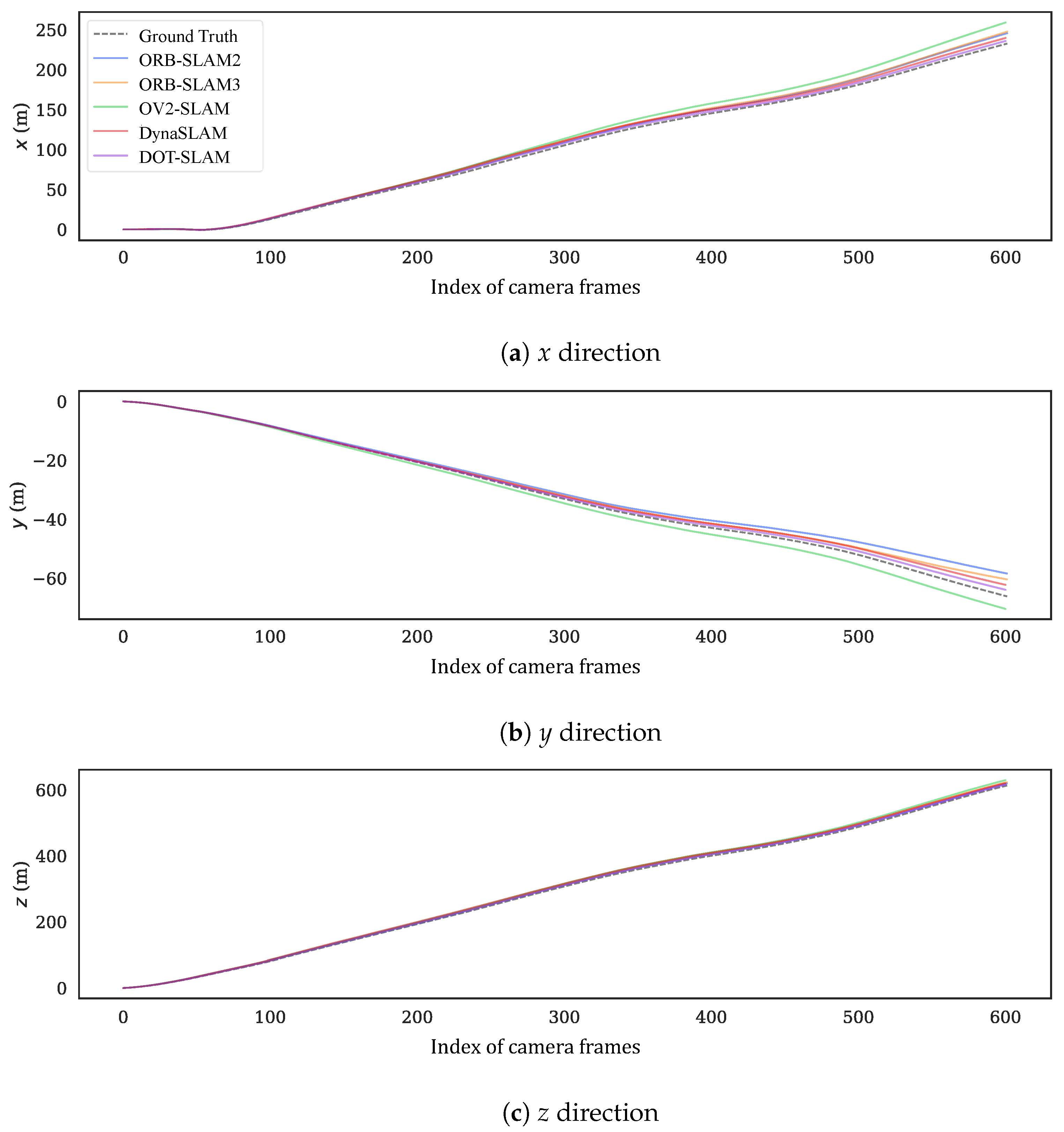
5.1. KITTI-360 Dataset
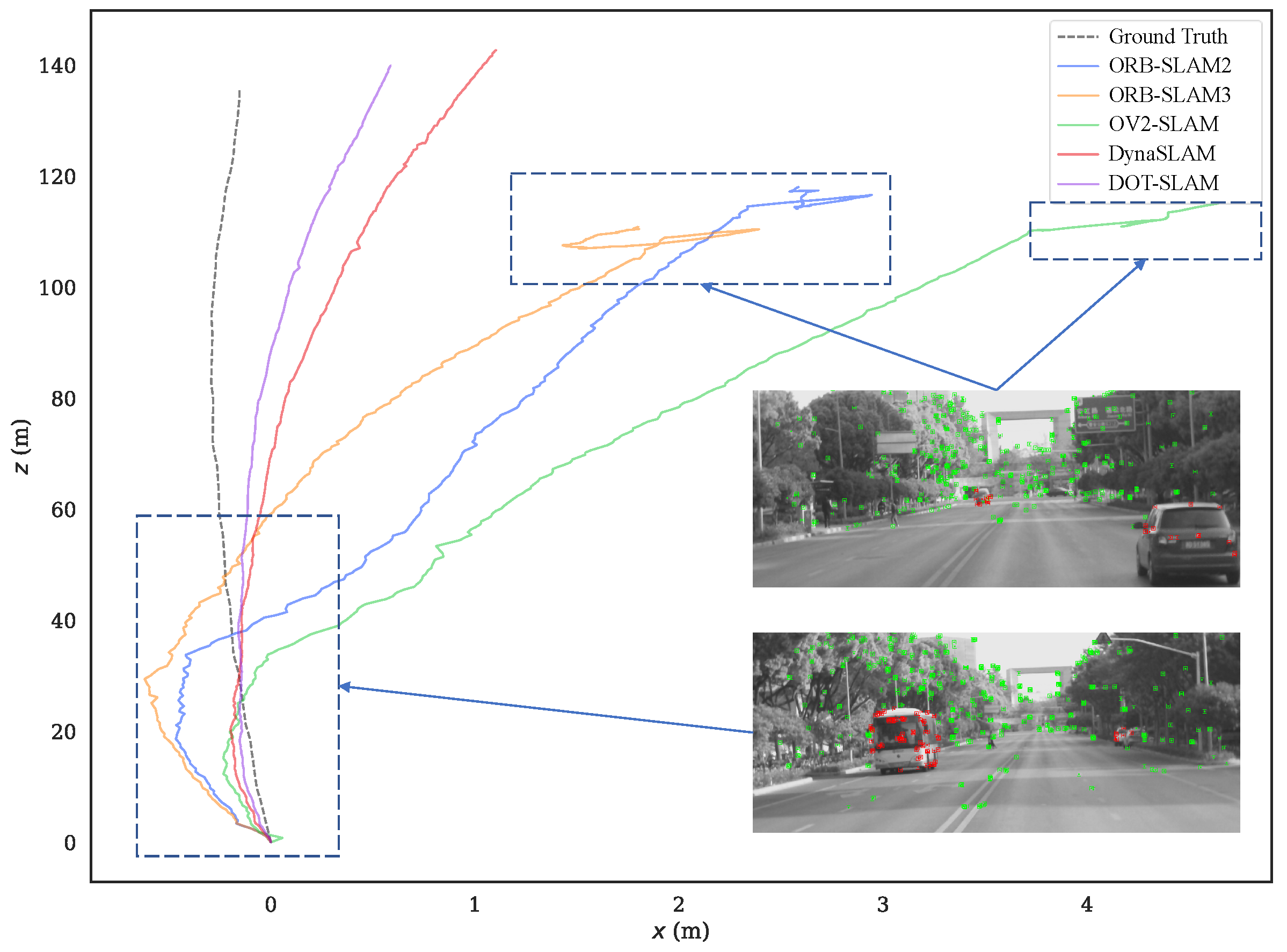
5.2. Real-World Experiments
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bala, J.A.; Adeshina, S.A.; Aibinu, A.M. Advances in Visual Simultaneous Localisation and Mapping Techniques for Autonomous Vehicles: A Review. Sensors 2022, 22, 8943. [Google Scholar] [CrossRef]
- Cheng, J.; Zhang, L.; Chen, Q.; Hu, X.; Cai, J. A Review of Visual SLAM Methods for Autonomous Driving Vehicles. Eng. Appl. Artif. Intell. 2022, 114, 104992. [Google Scholar] [CrossRef]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, Present, and Future of Simultaneous Localization and Mapping: Toward the Robust-Perception Age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.; Tardós, J.D. ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual–Inertial, and Multimap SLAM. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Ferrera, M.; Eudes, A.; Moras, J.; Sanfourche, M.; Le Besnerais, G. OV2SLAM: A Fully Online and Versatile Visual SLAM for Real-Time Applications. IEEE Robot. Autom. Lett. 2021, 6, 1399–1406. [Google Scholar] [CrossRef]
- Fan, Y.; Zhang, Q.; Tang, Y.; Liu, S.; Han, H. Blitz-SLAM: A Semantic SLAM in Dynamic Environments. Pattern Recognit. 2022, 121, 108225. [Google Scholar] [CrossRef]
- Klein, G.; Murray, D. Parallel Tracking and Mapping for Small AR Workspaces. In Proceedings of the 2007 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, Nara, Japan, 13–16 November 2007; pp. 225–234. [Google Scholar]
- Min, F.; Wu, Z.; Li, D.; Wang, G.; Liu, N. COEB-SLAM: A Robust VSLAM in Dynamic Environments Combined Object Detection, Epipolar Geometry Constraint, and Blur Filtering. IEEE Sens. J. 2023, 23, 26279–26291. [Google Scholar] [CrossRef]
- Wen, S.; Li, X.; Liu, X.; Li, J.; Tao, S.; Long, Y.; Qiu, T. Dynamic SLAM: A Visual SLAM in Outdoor Dynamic Scenes. IEEE Trans. Instrum. Meas. 2023, 72, 1–11. [Google Scholar] [CrossRef]
- Yan, L.; Hu, X.; Zhao, L.; Chen, Y.; Wei, P.; Xie, H. DGS-SLAM: A Fast and Robust RGBD SLAM in Dynamic Environments Combined by Geometric and Semantic Information. Remote Sens. 2022, 14, 795. [Google Scholar] [CrossRef]
- Yu, C.; Liu, Z.; Liu, X.-J.; Xie, F.; Yang, Y.; Wei, Q.; Fei, Q. DS-SLAM: A Semantic Visual SLAM towards Dynamic Environments. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1168–1174. [Google Scholar]
- Zhong, F.; Wang, S.; Zhang, Z.; Chen, C.; Wang, Y. Detect-SLAM: Making Object Detection and SLAM Mutually Beneficial. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1001–1010. [Google Scholar]
- Xiao, L.; Wang, J.; Qiu, X.; Rong, Z.; Zou, X. Dynamic-SLAM: Semantic Monocular Visual Localization and Mapping Based on Deep Learning in Dynamic Environment. Robot. Auton. Syst. 2019, 117, 1–16. [Google Scholar] [CrossRef]
- Yin, H.; Li, S.; Tao, Y.; Guo, J.; Huang, B. Dynam-SLAM: An Accurate, Robust Stereo Visual-Inertial SLAM Method in Dynamic Environments. IEEE Trans. Robot. 2023, 39, 289–308. [Google Scholar] [CrossRef]
- Huang, J.; Yang, S.; Zhao, Z.; Lai, Y.-K.; Hu, S.-M. ClusterSLAM: A SLAM Backend for Simultaneous Rigid Body Clustering and Motion Estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5875–5884. [Google Scholar]
- Huang, J.; Yang, S.; Mu, T.-J.; Hu, S.-M. ClusterVO: Clustering Moving Instances and Estimating Visual Odometry for Self and Surroundings. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2168–2177. [Google Scholar]
- Bescos, B.; Campos, C.; Tardós, J.D.; Neira, J. DynaSLAM II: Tightly-Coupled Multi-Object Tracking and SLAM. IEEE Robot. Autom. Lett. 2021, 6, 5191–5198. [Google Scholar] [CrossRef]
- Chang, Y.; Hu, J.; Xu, S. OTE-SLAM: An Object Tracking Enhanced Visual SLAM System for Dynamic Environments. Sensors 2023, 23, 7921. [Google Scholar] [CrossRef]
- Zhang, J.; Henein, M.; Mahony, R.; Ila, V. VDO-SLAM: A visual dynamic object-aware SLAM system. arXiv 2020, arXiv:2005.11052. [Google Scholar]
- Tian, X.; Zhu, Z.; Zhao, J.; Tian, G.; Ye, C. DL-SLOT: Tightly-Coupled Dynamic LiDAR SLAM and 3D Object Tracking Based on Collaborative Graph Optimization. IEEE Trans. Intell. Veh. 2024, 9, 1017–1027. [Google Scholar] [CrossRef]
- Kundu, A.; Krishna, K.M.; Sivaswamy, J. Moving Object Detection by Multi-View Geometric Techniques from a Single Camera Mounted Robot. In Proceedings of the 2009 IEEE/RSJ International Conference on Intelligent Robots and Systems, St. Louis, MO, USA, 11–15 October 2009; pp. 4306–4312. [Google Scholar]
- Zou, D.; Tan, P. CoSLAM: Collaborative Visual SLAM in Dynamic Environments. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 354–366. [Google Scholar] [CrossRef]
- Tan, W.; Liu, H.; Dong, Z.; Zhang, G.; Bao, H. Robust Monocular SLAM in Dynamic Environments. In Proceedings of the 2013 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Adelaide, SA, Australia, 1–4 October 2013; pp. 209–218. [Google Scholar]
- Dai, W.; Zhang, Y.; Li, P.; Fang, Z.; Scherer, S. RGB-D SLAM in Dynamic Environments Using Point Correlations. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 373–389. [Google Scholar] [CrossRef]
- Klappstein, J.; Vaudrey, T.; Rabe, C.; Wedel, A.; Klette, R. Moving Object Segmentation Using Optical Flow and Depth Information. In Proceedings of the Advances in Image and Video Technology, Tokyo, Japan, 13–16 January 2009; Wada, T., Huang, F., Lin, S., Eds.; Springer: Tokyo, Japan, 2009; pp. 611–623. [Google Scholar]
- Derome, M.; Plyer, A.; Sanfourche, M.; Besnerais, G.L. Moving Object Detection in Real-Time Using Stereo from a Mobile Platform. Unmanned Syst. 2015, 3, 253–266. [Google Scholar] [CrossRef]
- Song, S.; Lim, H.; Lee, A.J.; Myung, H. DynaVINS: A Visual-Inertial SLAM for Dynamic Environments. IEEE Robot. Autom. Lett. 2022, 7, 11523–11530. [Google Scholar] [CrossRef]
- Bescos, B.; Fácil, J.M.; Civera, J.; Neira, J. DynaSLAM: Tracking, Mapping, and Inpainting in Dynamic Scenes. IEEE Robot. Autom. Lett. 2018, 3, 4076–4083. [Google Scholar] [CrossRef]
- He, J.; Li, M.; Wang, Y.; Wang, H. OVD-SLAM: An Online Visual SLAM for Dynamic Environments. IEEE Sens. J. 2023, 23, 13210–13219. [Google Scholar] [CrossRef]
- Ballester, I.; Fontán, A.; Civera, J.; Strobl, K.H.; Triebel, R. DOT: Dynamic Object Tracking for Visual SLAM. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 11705–11711. [Google Scholar]
- Singh, G.; Wu, M.; Do, M.V.; Lam, S.-K. Fast Semantic-Aware Motion State Detection for Visual SLAM in Dynamic Environment. IEEE Trans. Intell. Transp. Syst. 2022, 23, 23014–23030. [Google Scholar] [CrossRef]
- Cvišić, I.; Marković, I.; Petrović, I. SOFT2: Stereo Visual Odometry for Road Vehicles Based on a Point-to-Epipolar-Line Metric. IEEE Trans. Robot. 2023, 39, 273–288. [Google Scholar] [CrossRef]
- Yuan, C.; Xu, Y.; Zhou, Q. PLDS-SLAM: Point and Line Features SLAM in Dynamic Environment. Remote Sens. 2023, 15, 1893. [Google Scholar] [CrossRef]
- Hong, C.; Zhong, M.; Jia, Z.; You, C.; Wang, Z. A Stereo Vision SLAM with Moving Vehicles Tracking in Outdoor Environment. Mach. Vis. Appl. 2023, 35, 5. [Google Scholar] [CrossRef]
- Zheng, Z.; Lin, S.; Yang, C. RLD-SLAM: A Robust Lightweight VI-SLAM for Dynamic Environments Leveraging Semantics and Motion Information. IEEE Trans. Ind. Electron. 2024, 1–11. [Google Scholar] [CrossRef]
- Song, B.; Yuan, X.; Ying, Z.; Yang, B.; Song, Y.; Zhou, F. DGM-VINS: Visual–Inertial SLAM for Complex Dynamic Environments With Joint Geometry Feature Extraction and Multiple Object Tracking. IEEE Trans. Instrum. Meas. 2023, 72, 1–11. [Google Scholar] [CrossRef]
- Zhang, M.; Chen, Y.; Li, M. Vision-Aided Localization For Ground Robots. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 2455–2461. [Google Scholar]
- Liu, C.; Chen, X.-F.; Bo, C.-J.; Wang, D. Long-Term Visual Tracking: Review and Experimental Comparison. Mach. Intell. Res. 2022, 19, 512–530. [Google Scholar] [CrossRef]
- Beghdadi, A.; Mallem, M. A Comprehensive Overview of Dynamic Visual SLAM and Deep Learning: Concepts, Methods and Challenges. Mach. Vis. Appl. 2023, 22, 54. [Google Scholar] [CrossRef]
- Li, P.; Qin, T.; Shen, S. Stereo Vision-Based Semantic 3D Object and Ego-Motion Tracking for Autonomous Driving. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2018; pp. 646–661. [Google Scholar]
- Yang, S.; Scherer, S. CubeSLAM: Monocular 3-D Object SLAM. IEEE Trans. Robot. 2019, 35, 925–938. [Google Scholar] [CrossRef]
- Zhang, H.; Uchiyama, H.; Ono, S.; Kawasaki, H. MOTSLAM: MOT-Assisted Monocular Dynamic SLAM Using Single-View Depth Estimation. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; pp. 4865–4872. [Google Scholar]
- Feng, S.; Li, X.; Xia, C.; Liao, J.; Zhou, Y.; Li, S.; Hua, X. VIMOT: A Tightly Coupled Estimator for Stereo Visual-Inertial Navigation and Multiobject Tracking. IEEE Trans. Instrum. Meas. 2023, 72, 1–14. [Google Scholar] [CrossRef]
- Li, X.; Liu, D.; Wu, J. CTO-SLAM: Contour Tracking for Object-Level Robust 4D SLAM. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 10323–10331. [Google Scholar]
- Geneva, P.; Eckenhoff, K.; Yang, Y.; Huang, G. LIPS: LiDAR-Inertial 3D Plane SLAM. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 123–130. [Google Scholar]
- Wang, X.; Zhang, R.; Kong, T.; Li, L.; Shen, C. SOLOv2: Dynamic and Fast Instance Segmentation. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–12 December 2020; Curran Associates, Inc.: Vancouver, BC, Canda, 2020; Volume 33, pp. 17721–17732. [Google Scholar]
- Wu, Z.; Wang, H.; An, H.; Zhu, Y.; Xu, R.; Lu, K. DPC-SLAM: Discrete Plane Constrained VSLAM for Intelligent Vehicle in Road Environment. In Proceedings of the 2023 IEEE 26th International Conference on Intelligent Transportation Systems (ITSC), Bilbao, Spain, 24–28 September 2023; pp. 1555–1562. [Google Scholar]
- Zhu, Y.; An, H.; Wang, H.; Xu, R.; Wu, M.; Lu, K. RC-SLAM: Road Constrained Stereo Visual SLAM System Based on Graph Optimization. Sensors 2024, 24, 536. [Google Scholar] [CrossRef] [PubMed]
- Jain, S.; Oosterlee, C.W. The Stochastic Grid Bundling Method: Efficient Pricing of Bermudan Options and Their Greeks. Appl. Math. Comput. 2015, 269, 412–431. [Google Scholar] [CrossRef]
- Zhu, Y.; Xu, R.; An, H.; Zhang, A.; Lu, K. Research on Automatic Emergency Braking System Development and Test Platform. In Proceedings of the 2022 Fifth International Conference on Connected and Autonomous Driving (MetroCAD), Detroit, MI, USA, 28–29 April 2022; pp. 1–6. [Google Scholar]
- Kümmerle, R.; Grisetti, G.; Strasdat, H.; Konolige, K.; Burgard, W. G2o: A General Framework for Graph Optimization. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 3607–3613. [Google Scholar]
- Galvez-López, D.; Tardos, J.D. Bags of Binary Words for Fast Place Recognition in Image Sequences. IEEE Trans. Robot. 2012, 28, 1188–1197. [Google Scholar] [CrossRef]
- Liao, Y.; Xie, J.; Geiger, A. KITTI-360: A Novel Dataset and Benchmarks for Urban Scene Understanding in 2D and 3D. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 3292–3310. [Google Scholar] [CrossRef]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A Benchmark for the Evaluation of RGB-D SLAM Systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are We Ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Arun, K.S.; Huang, T.S.; Blostein, S.D. Least-Squares Fitting of Two 3-D Point Sets. IEEE Trans. Pattern Anal. Mach. Intell. 1987, 9, 698–700. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Seq. | Start/Stop Frame | DOT-SLAM | Stereo ORB-SLAM2 | Stereo Inertial ORB-SLAM3 | Stereo OV2SLAM | DynaSLAM | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 00 | 9693/10,220 | 0.29 | 0.12 | 0.12 | 0.33 | 0.11 | 0.13 | 0.46 | 0.18 | 0.11 | 1.35 | 0.89 | 0.23 | 0.31 | 0.13 | 0.12 |
| 02 | 11,432/12,944 | 3.58 | 0.46 | 0.19 | 3.57 | 0.42 | 0.20 | 4.17 | 0.53 | 0.23 | 4.76 | 0.51 | 0.21 | 3.82 | 0.52 | 0.20 |
| 03 | 328/900 | 2.10 | 0.35 | 0.18 | 2.47 | 0.38 | 0.22 | 3.48 | 0.56 | 0.25 | 2.40 | 0.78 | 0.45 | 2.25 | 0.36 | 0.17 |
| 04 | 9975/10,220 | 1.13 | 0.33 | 0.12 | 1.21 | 0.37 | 0.15 | 1.23 | 0.45 | 0.15 | 5.59 | 0.85 | 0.20 | 1.11 | 0.35 | 0.14 |
| 05 | 4208/4588 | 0.42 | 0.32 | 0.20 | 0.58 | 0.31 | 0.35 | 0.72 | 0.42 | 0.35 | 1.45 | 1.07 | 0.36 | 0.48 | 0.32 | 0.25 |
| 06 | 8805/9537 | 2.49 | 0.52 | 0.23 | 2.60 | 0.57 | 0.19 | 2.84 | 0.59 | 0.18 | 5.39 | 0.67 | 0.63 | 2.61 | 0.53 | 0.18 |
| 07 | 3/1360 | 4.38 | 0.45 | 0.24 | 4.63 | 0.41 | 0.29 | 4.44 | 0.60 | 0.26 | 8.73 | 0.84 | 0.30 | 4.27 | 0.45 | 0.24 |
| 09 | 1847/4711 | 6.12 | 0.50 | 0.30 | 6.25 | 0.62 | 0.29 | 5.98 | 0.48 | 0.33 | 6.05 | 0.45 | 0.29 | 6.40 | 0.58 | 0.31 |
| 10 | 2611/3212 | 2.22 | 1.42 | 0.70 | 3.18 | 1.68 | 0.68 | 3.64 | 2.02 | 0.62 | 4.82 | 2.45 | 0.70 | 2.48 | 1.58 | 0.72 |
| Seq. | DOT-SLAM | Stereo ORB-SLAM2 | Stereo OV2-SLAM | Stereo Inertial ORB-SLAM3 | DynaSLAM | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 00 | 5.62 | 1.21 | 0.59 | 10.01 | 1.52 | 1.09 | 9.04 | 1.59 | 1.25 | 11.32 | 1.61 | 1.28 | 6.25 | 1.43 | 0.64 |
| 01 | 2.19 | 1.25 | 0.23 | 3.56 | 1.52 | 0.24 | 3.77 | 1.74 | 0.33 | 3.74 | 1.85 | 0.26 | 2.93 | 1.39 | 0.43 |
| 02 | 2.83 | 0.99 | 0.39 | 2.94 | 1.03 | 0.45 | 2.84 | 1.32 | 0.40 | 7.01 | 2.49 | 0.56 | 2.92 | 1.04 | 0.43 |
| 03 | 3.85 | 0.89 | 0.24 | 3.99 | 0.94 | 0.26 | 3.79 | 0.93 | 0.29 | 4.70 | 1.06 | 0.33 | 4.04 | 0.98 | 0.26 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, Y.; An, H.; Wang, H.; Xu, R.; Sun, Z.; Lu, K. DOT-SLAM: A Stereo Visual Simultaneous Localization and Mapping (SLAM) System with Dynamic Object Tracking Based on Graph Optimization. Sensors 2024, 24, 4676. https://doi.org/10.3390/s24144676
Zhu Y, An H, Wang H, Xu R, Sun Z, Lu K. DOT-SLAM: A Stereo Visual Simultaneous Localization and Mapping (SLAM) System with Dynamic Object Tracking Based on Graph Optimization. Sensors. 2024; 24(14):4676. https://doi.org/10.3390/s24144676
Chicago/Turabian StyleZhu, Yuan, Hao An, Huaide Wang, Ruidong Xu, Zhipeng Sun, and Ke Lu. 2024. "DOT-SLAM: A Stereo Visual Simultaneous Localization and Mapping (SLAM) System with Dynamic Object Tracking Based on Graph Optimization" Sensors 24, no. 14: 4676. https://doi.org/10.3390/s24144676
APA StyleZhu, Y., An, H., Wang, H., Xu, R., Sun, Z., & Lu, K. (2024). DOT-SLAM: A Stereo Visual Simultaneous Localization and Mapping (SLAM) System with Dynamic Object Tracking Based on Graph Optimization. Sensors, 24(14), 4676. https://doi.org/10.3390/s24144676