
Welding Seam Tracking and Inspection Robot Based on Improved YOLOv8s-Seg Model
Abstract
:1. Introduction
- (1)
- The complex characteristics of the weld surface are simulated by a data enhancement method. This avoids the over-fitting phenomenon of the model and improves the generalization and robustness of the model.
- (2)
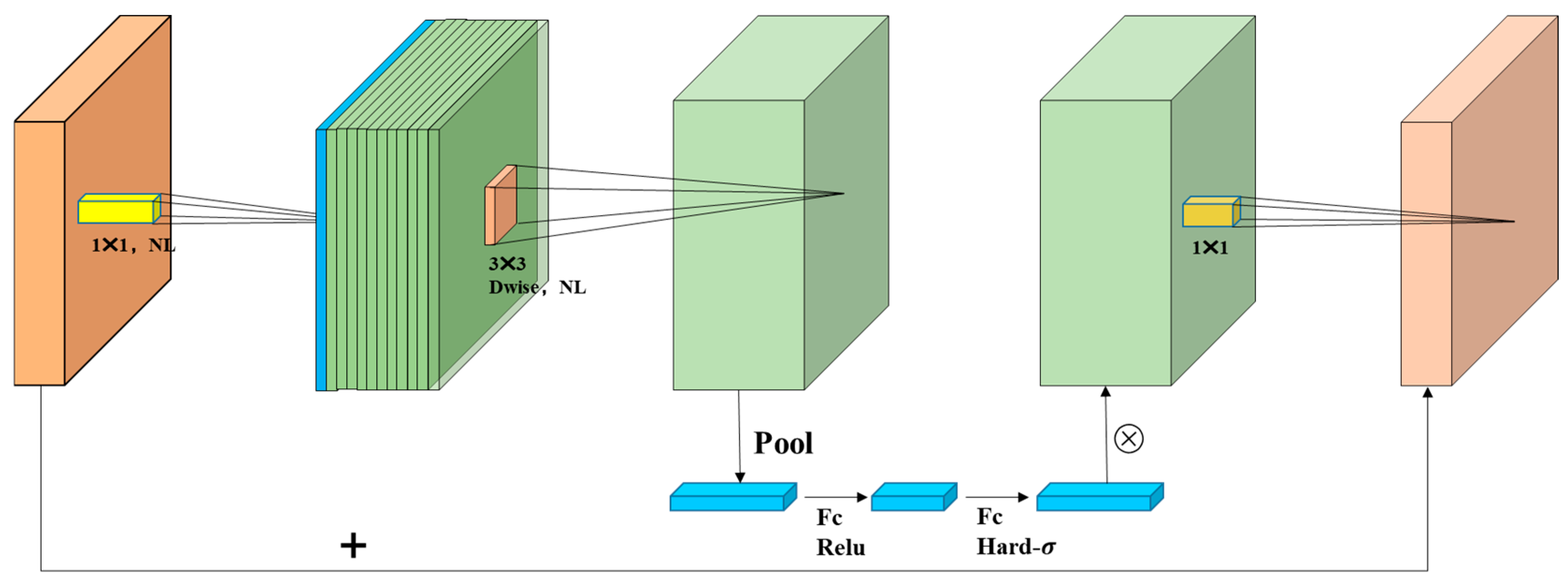
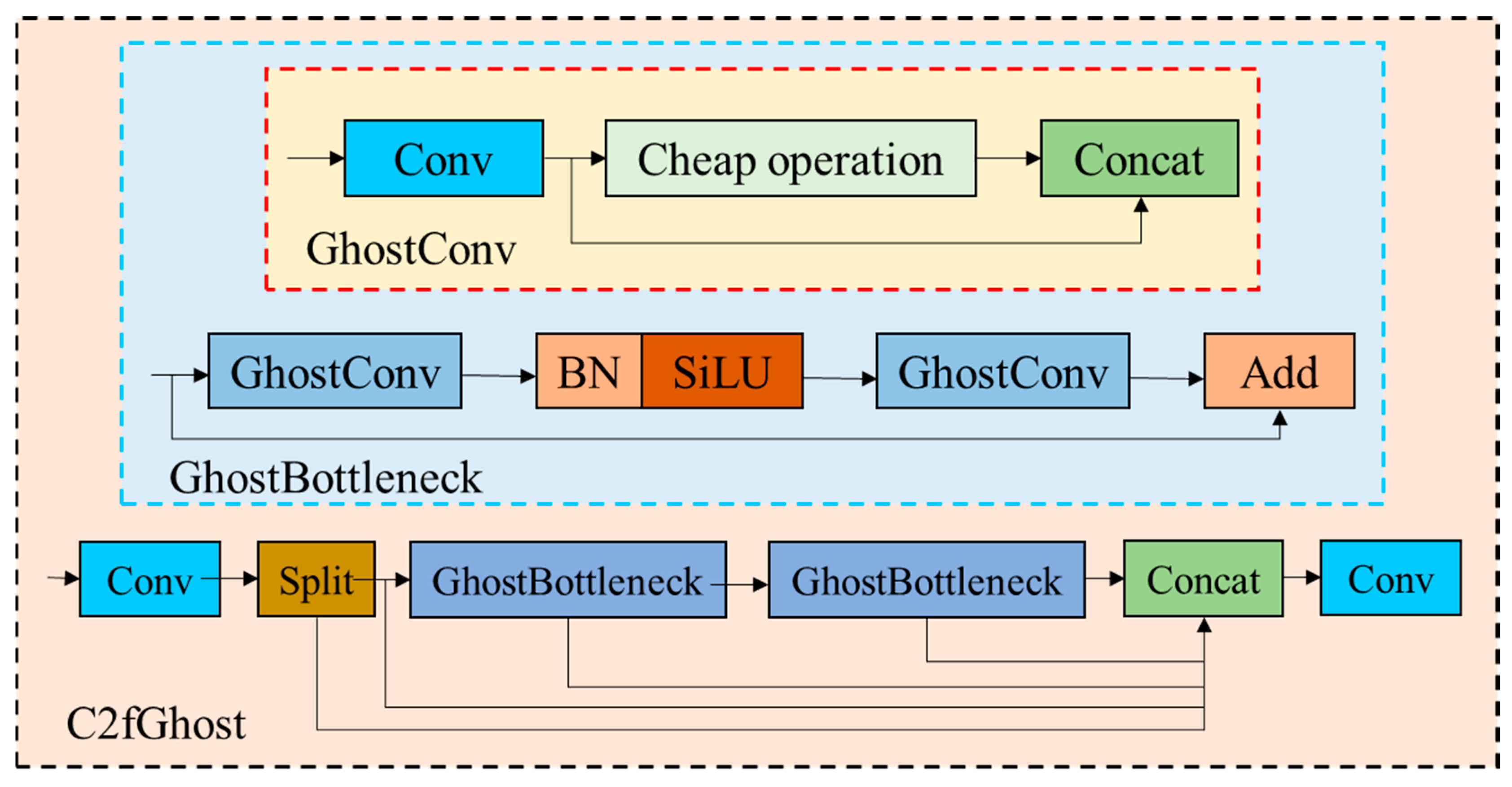
- The use of a MobileNetV3 light quantization backbone network to replace the original backbone network of YOLOv8s-seg, reconstruct C2f, and prune the number of output channels of the new module C2fGhost. Finally, the EMA is added to make the improved model more suitable for fast and high-precision detection tasks.
- (3)
- The improved model embeds the robot hardware device Jetson nano development board, and using TensorRT to accelerate model inference, the total inference time of each image is only 54 ms.
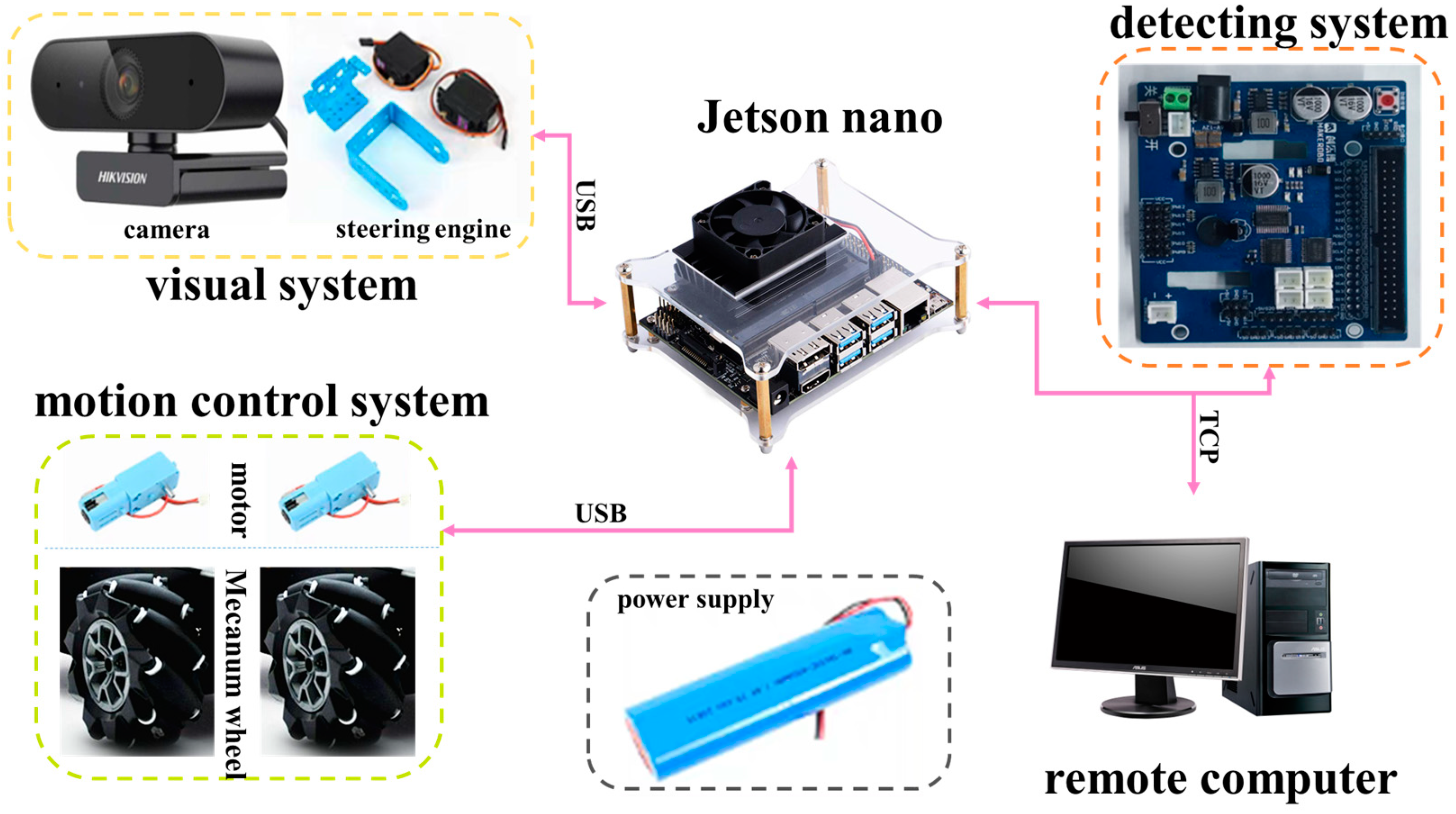
2. Robot Design
2.1. Robot Structure Design
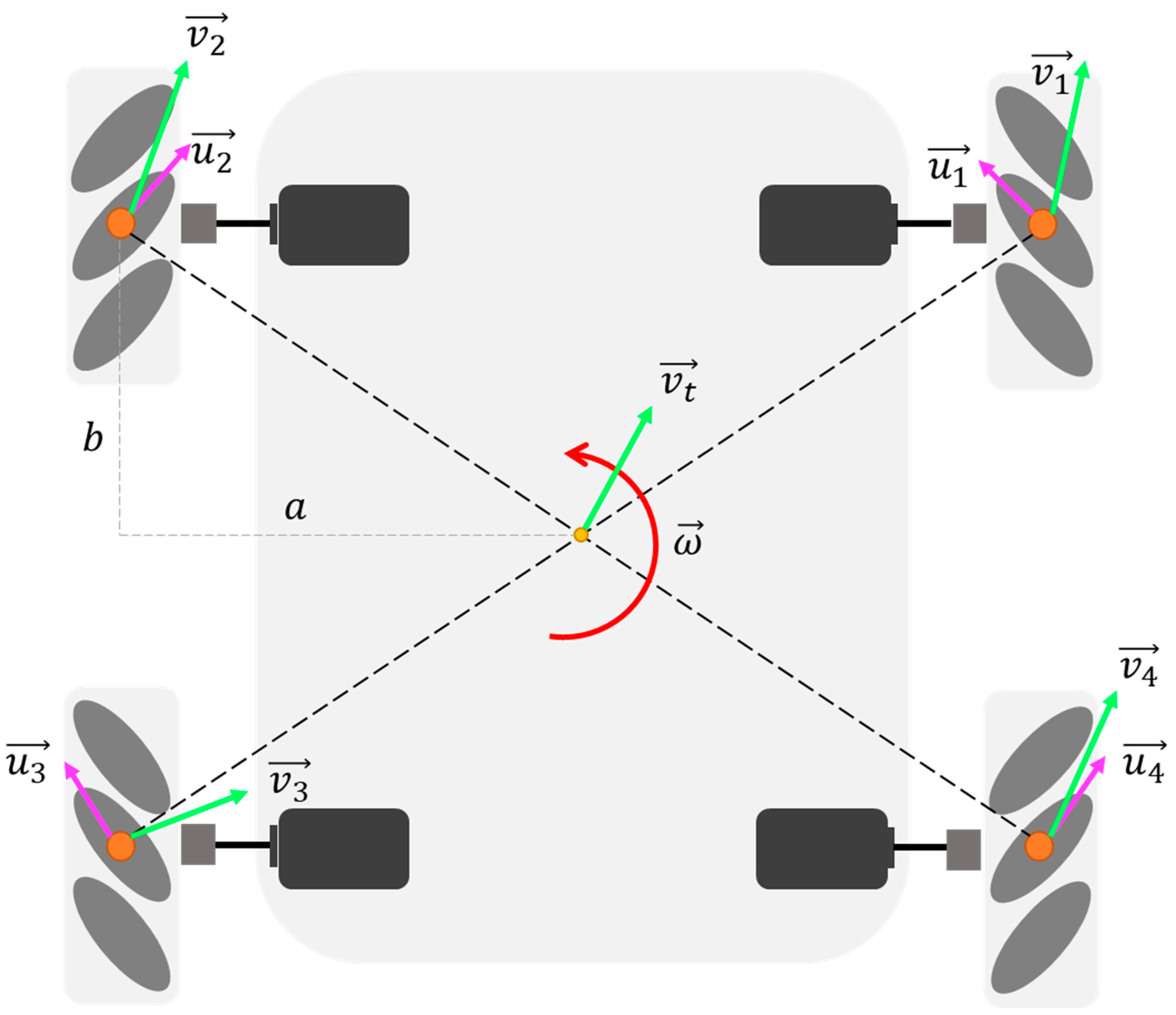
2.2. Robots Motion Control
2.3. Robot Kinematics Model
3. Weld Identification and Model Improvement
3.1. Construction of Weld Data Set
3.1.1. Initial Weld Data Set
3.1.2. Data Enhancement of Weld Image
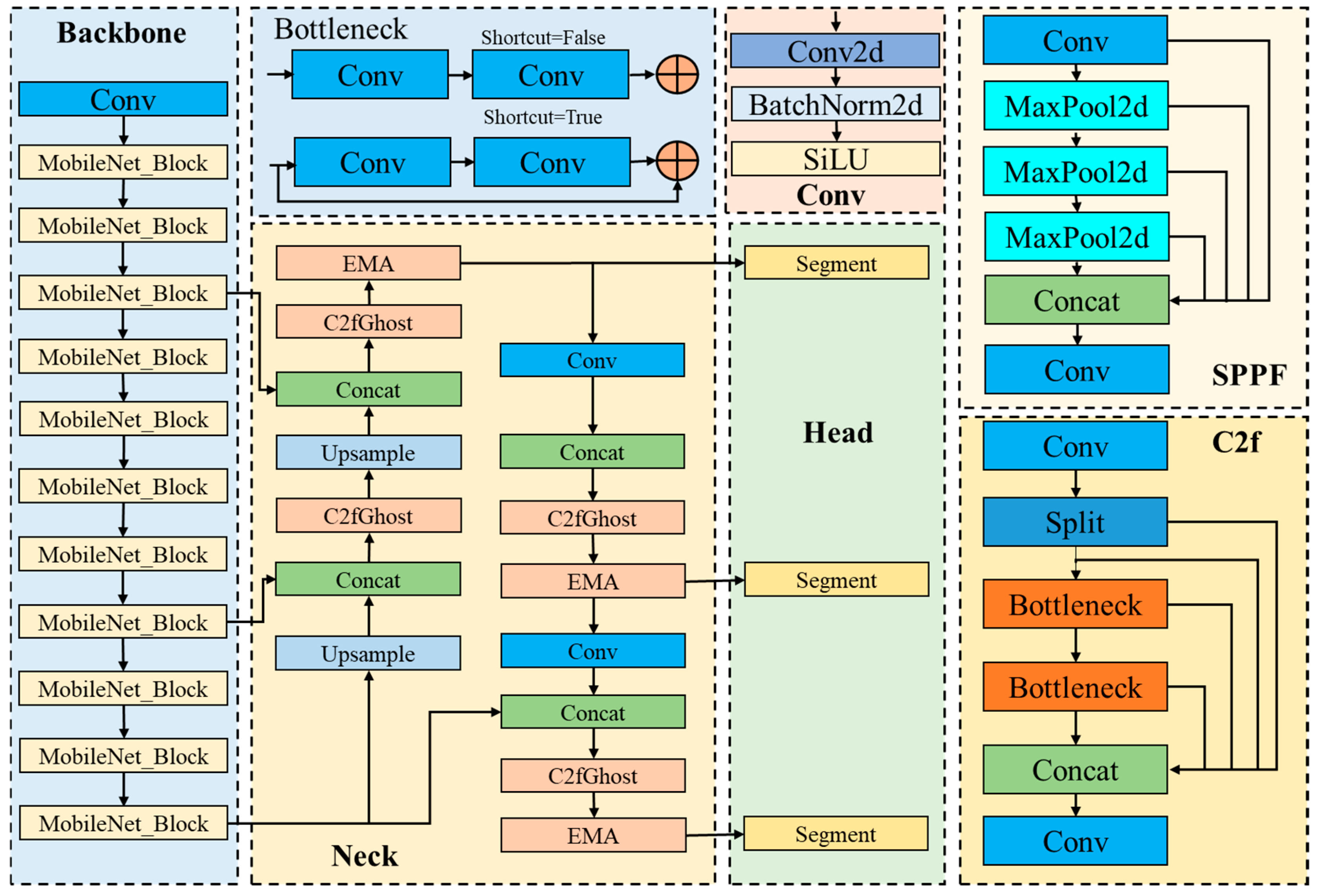
3.2. Weld Segmentation Model and Its Improvement
3.2.1. Weld Segmentation Model
3.2.2. Improve the Backbone Network
3.2.3. Improve the Neck Network
3.3. Weld Path Fitting Method
3.3.1. TensorRT Acceleration
3.3.2. Least Square Method Fitting Path
4. Experimental Results and Path Fitting Results
4.1. Experimental Environment
4.2. Experimental Results of Weld Segmentation
4.3. Path Fitting Results
4.4. Weld Path Planning Experiment
5. Discussion
5.1. Ablation Experiment
5.2. Light Quantization Model Comparison Experiment
5.3. Influence of Data Enhancement Strategy on Model Checking Performance
5.4. Performance Comparison of Different Segmentation Models
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Momčilović, N.; Ilić, N.; Kalajdžić, M.; Ivošević, Š.; Petrović, A. Effect of Corrosion-Induced Structural Degradation on the Ultimate Strength of a High-Tensile-Steel Ship Hull. J. Mar. Sci. Eng. 2024, 12, 745. [Google Scholar] [CrossRef]
- Li, K.; Xie, J.; Liu, Y.; Pan, Y.; Tan, Y. Development and characterization of anti-cracking epoxy asphalt for steel deck pavement. Constr. Build. Mater. 2024, 438, 137047. [Google Scholar] [CrossRef]
- Abdalla, A.M.; Hossain, S.; Nisfindy, O.B.; Azad, A.T.; Dawood, M.; Azad, A.K. Hydrogen production, storage, transportation and key challenges with applications: A review. Energy Convers. Manag. 2018, 165, 602–627. [Google Scholar] [CrossRef]
- Song, H.; Shin, H.; Shin, Y. Heat-treatment of clad steel plate for application of hull structure. Ocean Eng. 2016, 122, 278–287. [Google Scholar] [CrossRef]
- Ji, B.; Chen, D.-H.; Ma, L.; Jiang, Z.-S.; Shi, G.-G.; Lv, L.; Xu, H.-J.; Zhang, X. Research on stress spectrum of steel decks in suspension bridge considering measured traffic flow. J. Perform. Constr. Facil. 2012, 26, 65–75. [Google Scholar] [CrossRef]
- Qian, X.; Zhang, R.; Zhang, Q.; Yuan, M.; Zhao, Y. Cause analysis of the large-scale LPG explosion accident based on key investigation technology: A case study. ACS Omega 2021, 6, 20644–20656. [Google Scholar] [CrossRef] [PubMed]
- Uğurlu, Ö.; Kum, S.; Aydoğdu, Y.V. Analysis of occupational accidents encountered by deck cadets in maritime transportation. Marit. Policy Manag. 2017, 44, 304–322. [Google Scholar] [CrossRef]
- Biezma, M.V.; Schanack, F. Collapse of steel bridges. J. Perform. Constr. Facil. 2007, 21, 398–405. [Google Scholar] [CrossRef]
- Broberg, P. Imaging and Analysis Methods for Automated Weld Inspection. Ph.D. Thesis, Luleå Tekniska Universitet, Luleå, Sweden, 2014. [Google Scholar]
- Li, Y.; Hu, M.; Wang, T. Visual inspection of weld surface quality. J. Intell. Fuzzy Syst. 2020, 39, 5075–5084. [Google Scholar] [CrossRef]
- Li, J.; Li, B.; Dong, L.; Wang, X.; Tian, M. Weld seam identification and tracking of inspection robot based on deep learning network. Drones 2022, 6, 216. [Google Scholar] [CrossRef]
- Lei, T.; Rong, Y.; Wang, H.; Huang, Y.; Li, M. A review of vision-aided robotic welding. Comput. Ind. 2020, 123, 103326. [Google Scholar] [CrossRef]
- Shen, W.; Hu, T.; Zhang, C.; Ye, Y.; Li, Z. A welding task data model for intelligent process planning of robotic welding. Robot. Comput. Integr. Manuf. 2020, 64, 101934. [Google Scholar] [CrossRef]
- Banafian, N.; Fesharakifard, R.; Menhaj, M.B. Precise seam tracking in robotic welding by an improved image processing approach. Int. J. Adv. Manuf. Technol. 2021, 114, 251–270. [Google Scholar] [CrossRef]
- Yang, L.; Li, E.; Long, T.; Fan, J.; Liang, Z. A high-speed seam extraction method based on the novel structured-light sensor for arc welding robot: A review. IEEE Sens. J. 2018, 18, 8631–8641. [Google Scholar] [CrossRef]
- Gao, X.; Mo, L.; Xiao, Z.; Chen, X.; Katayama, S. Seam tracking based on Kalman filtering of micro-gap weld using magneto-optical image. Int. J. Adv. Manuf. Technol. 2016, 83, 21–32. [Google Scholar] [CrossRef]
- Ding, Y.; Sun, Z.; Chen, Q. Non-contacted permanent magnetic absorbed wall-climbing robot for ultrasonic weld inspection of spherical tank. In Proceedings of the MATEC Web of Conferences, Abu Dhabi, United Arab Emirates, 20–22 November 2018; p. 02013. [Google Scholar]
- Sogi, T.; Kawaguchi, Y.; Morisaki, H.; Ohkawa, K.; Kai, N.; Hayakawa, H. Inspection robot for spherical storage tanks. In Proceedings of the 2000 26th Annual Conference of the IEEE Industrial Electronics Society. IECON 2000. 2000 IEEE International Conference on Industrial Electronics, Control and Instrumentation. 21st Century Technologies, Nagoya, Japan, 22–28 October 2000; pp. 393–398. [Google Scholar]
- Jeon, K.-W.; Jung, E.-J.; Bae, J.-H.; Park, S.-H.; Kim, J.-J.; Chung, G.; Chung, H.-J.; Yi, H. Development of an In-Pipe Inspection Robot for Large-Diameter Water Pipes. Sensors 2024, 24, 3470. [Google Scholar] [CrossRef] [PubMed]
- Luo, G.; Luo, C.; Gao, S.; Xu, J.; Bao, X.; Jiang, Z.; Ma, Z. Research on a Wall-Climbing Cleaning and Inspection Robot for Offshore Cylindrical Steel Structures Based on Magnetic Adsorption Technology. Available at SSRN 4837249. [CrossRef]
- Zhu, M.; Zhang, B.; Zhou, C.; Zou, H.; Wang, X. Target Recognition of Multi source Machine Vision Pan tilt Integrated Inspection Robot for Power Inspection. IEEE Access 2024, 12, 45693–45708. [Google Scholar] [CrossRef]
- Leggieri, S.; Canali, C.; Caldwell, D.G. Design, modeling, and experimental analysis of the Crawler Unit for inspection in constrained space. Annu. Rev. Control 2024, 57, 100950. [Google Scholar] [CrossRef]
- Mendoza, N.; Haghshenas-Jaryani, M. Combined Soft Grasping and Crawling Locomotor Robot for Exterior Navigation of Tubular Structures. Machines 2024, 12, 157. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, H.; Liu, Y.; Wang, J.; Song, J. Influence on polygon effect with characteristic parameters of guide arc branch of the crawler robot. Int. J. Heavy Veh. Syst. 2024, 31, 32–48. [Google Scholar] [CrossRef]
- Yu, N.; Zhai, Y.; Yuan, Y.; Wang, Z. A bionic robot navigation algorithm based on cognitive mechanism of hippocampus. IEEE Trans. Autom. Sci. Eng. 2019, 16, 1640–1652. [Google Scholar] [CrossRef]
- Chen, G.; Wei, N.; Li, J.; Lu, H. Design and simulation analysis of a bionic ostrich robot. Biomech. Model. Mechanobiol. 2022, 21, 1781–1801. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C. Simulation analysis of bionic robot fish based on MFC materials. Math. Probl. Eng. 2019, 2019, 2720873. [Google Scholar] [CrossRef]
- He, B.; Wang, Z.; Li, M.; Wang, K.; Shen, R.; Hu, S. Wet adhesion inspired bionic climbing robot. IEEE Asme Trans. Mechatron. 2013, 19, 312–320. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, M.; Jiao, S.; Sun, L.; Li, M. Design and Optimization of the Wall Climbing Robot for Magnetic Particle Detection of Ship Welds. J. Mar. Sci. Eng. 2024, 12, 610. [Google Scholar] [CrossRef]
- Yang, P.; Sun, L.; Zhang, M. Design and analysis of a passive adaptive wall-climbing robot on variable curvature ship facades. Appl. Ocean Res. 2024, 143, 103879. [Google Scholar] [CrossRef]
- Hua, T. Design of Intelligent Detection System Based on Bionic Robot Snake. Curric. Teach. Methodol. 2021, 4, 64–66. [Google Scholar]
- Xu, F.; He, L.; Hou, Z.; Xiao, R.; Zuo, T.; Li, J.; Xu, Y.; Zhang, H. An automatic feature point extraction method based on laser vision for robotic multi-layer multi-pass weld seam tracking. Int. J. Adv. Manuf. Technol. 2024, 131, 5941–5960. [Google Scholar] [CrossRef]
- Ma, Y.; Fan, J.; Zhou, Z.; Zhao, S.; Jing, F.; Tan, M. WeldNet: A deep learning based method for weld seam type identification and initial point guidance. Expert Syst. Appl. 2024, 238, 121700. [Google Scholar] [CrossRef]
- Seo, B.W.; Jeong, Y.C.; Cho, Y.T. Machine learning for prediction of arc length for seam tracking in tandem welding. J. Weld. Join. 2020, 38, 241–247. [Google Scholar] [CrossRef]
- Cai, W.; Wang, J.; Zhou, Q.; Yang, Y.; Jiang, P. Equipment and machine learning in welding monitoring: A short review. In Proceedings of the 5th International Conference on mechatronics and robotics engineering, Rome, Italy, 16–18 February 2019; pp. 9–15. [Google Scholar]
- Ponweiser, W.; Ayromlou, M.; Vincze, M.; Beltran, C.; Madsen, O.; Gasteratos, A. RobVision: Vision based navigation for mobile robots. In Proceedings of the Conference Documentation International Conference on Multisensor Fusion and Integration for Intelligent Systems, Baden-Baden, Germany, 20–22 August 2001; pp. 109–114. [Google Scholar]
- Zhang, Y.; Guan, E.; Li, P.; Zhao, Y. An automated nondestructive testing system for the surface of pressure pipeline welds. J. Field Robot. 2023, 40, 1927–1944. [Google Scholar] [CrossRef]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Deng, L.; Lei, T.; Wu, C.; Liu, Y.; Cao, S.; Zhao, S. A weld seam feature real-time extraction method of three typical welds based on target detection. Measurement 2023, 207, 112424. [Google Scholar] [CrossRef]
- Jiao, L.T.; Guo, P.W.; Hong, B.; Feng, P. Vehicle wheel weld detection based on improved YOLO v4 algorithm. Кoмпьютерная Оптика 2022, 46, 271–279. [Google Scholar]
- Song, L.; Kang, J.; Zhang, Q.; Wang, S. A weld feature points detection method based on improved YOLO for welding robots in strong noise environment. Signal Image Video Process. 2023, 17, 1801–1809. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; proceedings, part III 18. pp. 234–241. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE international conference on computer vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Yu, R.; Kershaw, J.; Wang, P.; Zhang, Y. Real-time recognition of arc weld pool using image segmentation network. J. Manuf. Process. 2021, 72, 159–167. [Google Scholar] [CrossRef]
- Lu, J.; Yang, A.; Chen, X.; Xu, X.; Lv, R.; Zhao, Z. A Seam Tracking Method Based on an Image Segmentation Deep Convolutional Neural Network. Metals 2022, 12, 1365. [Google Scholar] [CrossRef]
- Tao, H.; Liu, J.; Yang, Z.; Wang, G.; Shang, J.; Qiu, H.; Gao, L. Revolutionizing flame detection: Novelization in flame detection through transferring distillation for knowledge to pruned model. Expert Syst. Appl. 2024, 249, 123787. [Google Scholar] [CrossRef]
- Available online: https://www.kaggle.com/datasets/engineeringubu/fsw-aa5083-aa5061 (accessed on 20 May 2023).
- Koonce, B.; Koonce, B. MobileNetV3. In Convolutional Neural Networks with Swift for Tensorflow: Image Recognition and Dataset Categorization; Apress Berkeley: New York, NY, USA, 2021; pp. 125–144. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient multi-scale attention module with cross-spatial learning. In Proceedings of the ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE international conference on computer vision, Las Condes, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Li, M.; Huang, J.; Xue, L.; Zhang, R. A guidance system for robotic welding based on an improved YOLOv5 algorithm with a RealSense depth camera. Sci. Rep. 2023, 13, 21299. [Google Scholar] [CrossRef]
- Zhang, C.; Chen, X.; Liu, P.; He, B.; Li, W.; Song, T. Automated detection and segmentation of tunnel defects and objects using YOLOv8-CM. Tunn. Undergr. Space Technol. 2024, 150, 105857. [Google Scholar] [CrossRef]
- Yue, X.; Qi, K.; Na, X.; Zhang, Y.; Liu, Y.; Liu, C. Improved YOLOv8-Seg network for instance segmentation of healthy and diseased tomato plants in the growth stage. Agriculture 2023, 13, 1643. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Weight Size | GFLOPs | mAp50 | Model FPS | Robot FPS | |
|---|---|---|---|---|---|
| YOLOv8s-seg | 22.7 | 42.4 | 97.3% | 51 | 1.7 |
| Ours | 4.88 | 17.7 | 97.8% | 57 | 18.5 |
| MobilenetV3 | C2fGhost | EMA | Weight Size | GFLOPs | mAp50 | F1 | |
|---|---|---|---|---|---|---|---|
| Model 1 | 22.7 | 42.4 | 97.3% | 97.2% | |||
| Model 2 | √ | 12.7 | 29.5 | 97.1% | 95.8% | ||
| Model 3 | √ | √ | 4.85 | 17.5 | 97.2% | 97.0% | |
| Model 4 | √ | √ | √ | 4.88 | 17.7 | 97.8% | 97.2% |
| Weight Size | GFLOPs | mAp50 | F1 | |
|---|---|---|---|---|
| N0 | 22.7 MB | 42.4 | 97.3% | 97.2% |
| N1 | 12.7 MB | 29.5 | 97.1% | 95.8% |
| N2 | 12.8 MB | 29.9 | 96.9% | 95.7% |
| N3 | 13.0 MB | 30.1 | 96.7% | 96.2% |
| N4 | 4.88 MB | 17.7 | 97.8% | 97.2% |
| Weight Size | GFLOPs | mAp50 | F1 | |
|---|---|---|---|---|
| With data enhancement | 4.88 MB | 17.7 | 97.5% | 97.2% |
| Without data enhancement | 4.83 MB | 17.7 | 82.9% | 78.3% |
| Weight Size | maP50 | GFLOPs | |
|---|---|---|---|
| YOLOv5s-seg | 14.4 MB | 95.0% | 25.7 |
| YOLOv5s-seg-CA | 17.2 MB | 95.6% | 28.6 |
| YOLOv8n-seg | 6.47 MB | 90.2% | 12 |
| YOLOv8n-seg-CM | 6.48 MB | 89.5% | 12.1 |
| YOLOv8s-seg | 22.7 MB | 97.3% | 42.4 |
| YOLOv8s-seg-RS | 30.7 MB | 89.3% | 54.6 |
| Ours | 4.88 MB | 97.8% | 17.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, M.; Liu, X.; Wang, K.; Liu, Z.; Dong, Q.; Wang, P.; Su, Y. Welding Seam Tracking and Inspection Robot Based on Improved YOLOv8s-Seg Model. Sensors 2024, 24, 4690. https://doi.org/10.3390/s24144690
Zhao M, Liu X, Wang K, Liu Z, Dong Q, Wang P, Su Y. Welding Seam Tracking and Inspection Robot Based on Improved YOLOv8s-Seg Model. Sensors. 2024; 24(14):4690. https://doi.org/10.3390/s24144690
Chicago/Turabian StyleZhao, Minghu, Xinru Liu, Kaihang Wang, Zishen Liu, Qi Dong, Pengfei Wang, and Yaoheng Su. 2024. "Welding Seam Tracking and Inspection Robot Based on Improved YOLOv8s-Seg Model" Sensors 24, no. 14: 4690. https://doi.org/10.3390/s24144690