3.1. Key Problem Description
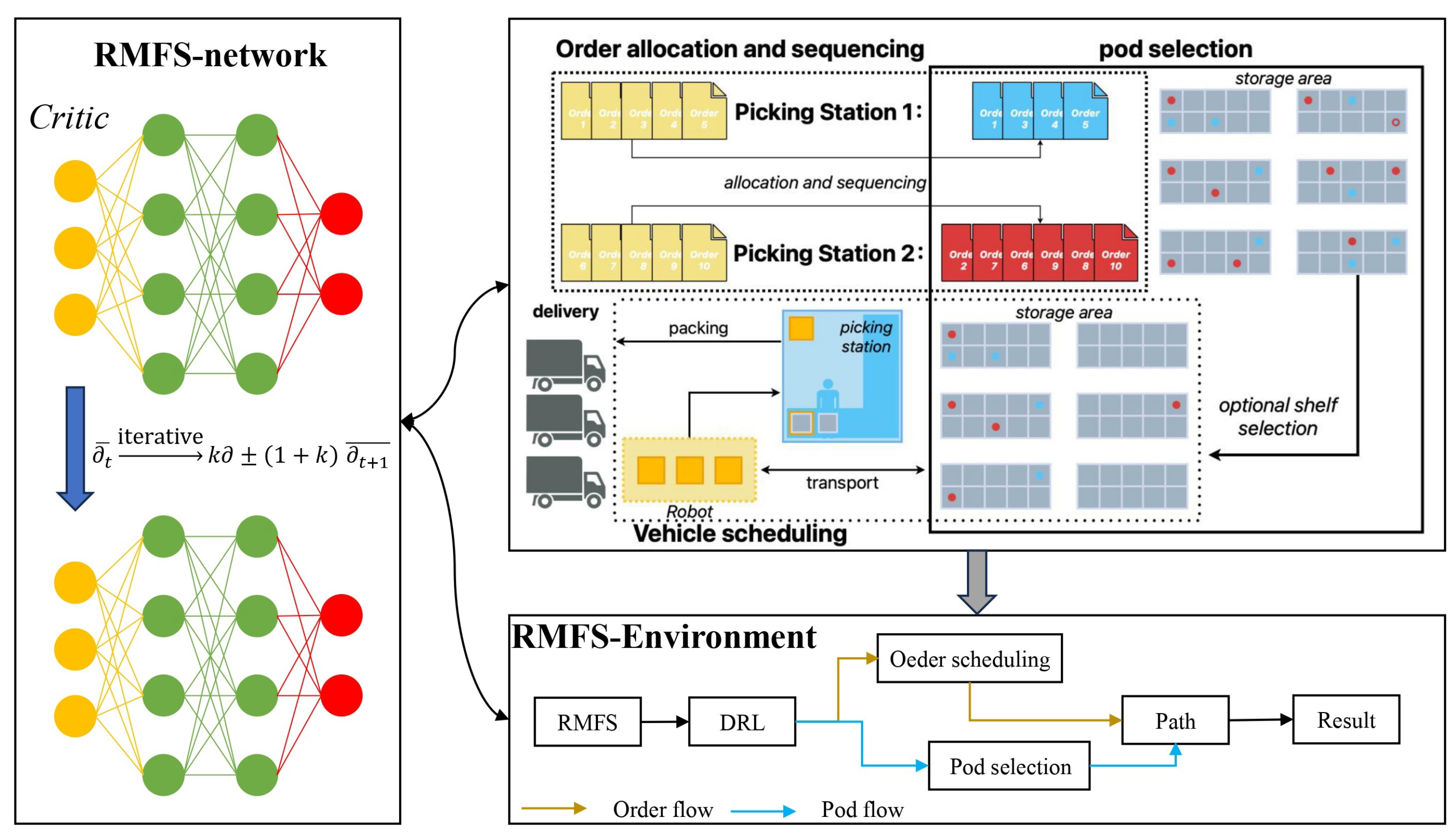
A Robotic Mobile Fulfillment System (RMFS) is a modern warehousing solution designed to enhance the efficiency of warehouse and logistics operations, especially tailored for e-commerce and online retail businesses. In an RMFS, Autonomous Mobile Robots (AMRs) autonomously navigate within the warehouse, locate the required inventory shelves or storage pods, and retrieve the entire shelf, to bring it to a picking station where human pickers carry out the picking and packaging tasks. An RMFS involves a series of interrelated decision problems, including order allocation, order sequencing, inventory pod selection, and robot scheduling [
38]. These decision problems are typically interdependent, and optimizing their relationships can significantly improve the performance of the RMFS. The following is a schematic diagram of the three stages involved:
First, regarding order scheduling, we address order allocation and sequencing, using a Genetic Algorithm to obtain the optimal order sequencing. This process includes steps such as population initialization, fitness calculation, selection, crossover, and mutation, to ultimately find the best order allocation and sequence. In an RMFS, optimizing the allocation and sequencing of orders is crucial for enhancing system performance. Imbalanced allocation of order lines can lead to under-utilization of picking stations, resulting in longer picking times. Simultaneously, rational order sequencing can increase the number of order lines processed per inventory pod, thereby improving system efficiency. In this paper, multiple orders are randomly generated and a Genetic Algorithm is employed, to find the optimal order allocation and sequencing. The algorithm design in this paper aims to balance the allocation of orders to picking stations while minimizing the movement of shelves. Due to the interconnections between various optimization problems, optimizing this particular problem ultimately reduces the operational time at picking stations, leading to improved system efficiency.
Second, regarding pod selection, we solve the shelf selection problem, using an Ant Colony Optimization Algorithm, with the objective of minimizing the total travel distance of shelves. Ants select shelves based on pheromone levels, where shorter paths deposit more pheromones, increasing the probability of choosing better shelves. The selection of inventory pods is equally critical for overall optimization. In an RMFS, a mixed-shelve storage strategy is commonly employed, where a specific SKU is distributed across various inventory pods, increasing consolidation opportunities. Typically, picking stations prefer pods that are closer to them, to reduce the total travel distance. However, when a pod can handle multiple orders, choosing that pod may also reduce the total travel distance. Therefore, in some situations, inventory pods located further from the picking station but offering more consolidation opportunities may be more suitable than pods with no consolidation, leading to a decrease in the average distance per picked order line. In summary, optimizing pod selection can also contribute to improving system efficiency.
Third, regarding vehicle scheduling, we solve the robot collaborative scheduling problem, using an Ant Colony Algorithm to determine specific robot scheduling schemes. Idle robots choose the next picking station task based on station completion times and pheromone levels. Better schedules that minimize total processing time have higher pheromone levels in future iterations. In the actual execution of an RMFS, fulfilling picking orders at the picking stations involves a sequence of movements by mobile robots. A robot typically remains at a stationary position until it receives a retrieval task. Subsequently, it moves from its current location to the designated pod location. Upon arrival, the robot can lift the entire inventory pod and transport it to the correct picking station. After the picking process is completed, the robot returns the inventory pod to its storage location and dwells there while waiting for its next task. These movements constitute the operational problem of vehicle scheduling in RMFSs. During multi-robot collaborative scheduling, there may be instances of inefficient waiting at locations like picking stations. Therefore, in some cases, allowing robots to briefly wait then process a pod with a longer processing time may reduce the overall order retrieval throughput time. Proper coordination of robot scheduling can further optimize the system’s efficiency. (The relevant assumptions are shown in
Table 1).
3.2. Mathematical Models
This paper constructs three mathematical models for the sequential optimization of multiple decision problems in Robotic Mobile Fulfillment Systems (RMFSs): the order allocation and sequencing model, the shelf selection model, and the robot collaborative scheduling model. The establishment of these three models was guided by different system efficiency optimization objectives, and heuristic algorithms were designed to solve the corresponding decision problems in a targeted manner. Ultimately, the application of this progressive approach, from mathematical modeling to algorithm design, is key to the gradual performance improvement and optimization of the entire complex collaborative system. The three models each play their part, finally promoting the system forward towards the intended goals of maximized throughput and minimized operating costs (
Figure 3).
Before expanding the description of the mathematical model, the meaning of the symbols is shown in the following table (
Table 2):
The first mathematical model is the order allocation and sequencing model. In this model, the total distance traveled by robots is closely linked to the total number of robot visits. Simultaneously, achieving a balanced distribution of order lines among picking stations is crucial for minimizing the overall task completion time. Therefore, the objective of this model is to minimize both the number of robot visits and the imbalance of order lines across picking stations. Our mathematical model for the proposed order allocation and sequencing problem is shown below. It is designed to ensure that the allocation of goods is as even as possible, thereby preventing scenarios where a single robot has to travel to multiple distant locations:
where
is whether an order
is allocated to a picking station
;
is an item from order line
k at picking station
s;
is the index of the selected pod
m at picking station
s;
is order number
i at picking station
s;
is the item number of order line
j from order
i at picking station
s;
is the number of order lines in order
i at picking station
s;
is the number of orders at picking station
s;
is the number of selected pods at picking station
p;
is the sequential order number of the last order line contained in the selected pod
m at picking station
s;
B is the integer variable minimum number of order lines allocated to the picking station;
is 1 when order
is allocated to station
or is 0 when otherwise.
The objective function (1) for this order allocation and sequencing model aims to minimize the number of visits made by inventory pods, thereby promoting consolidation and ensuring balanced workloads among picking stations.
In this model, both objectives—minimizing visits and balancing picking stations—are equally important, and their relative weights can be adjusted as needed.
Constraint (2): Ensures identical items from different orders are not assigned to the same picking station.
Constraint (3): Guarantees that the orders assigned to picking stations match the item requirements of the original orders.
Constraint (4): Mandates that all orders and order lines are assigned and completed at picking stations.
Constraint (5): Ensures selected pods align with the order lines.
Constraint (6): Serves as an initialization condition.
Constraint (7): Restricts certain decision variables to binary values.
The second mathematical model is the pod selection model. It is worth noting that the model takes as input the order allocation and sorting results computed by the previous mathematical model, thus significantly reducing the search space. However, this ordering approach may lead to sub-optimal solutions compared to integrating these two problems. The mathematical model, which, in practice, ultimately outputs the optimal pod allocation and ordering within each picking station, has the formulae and associated constraints shown below:
The relevant limitations of the mathematical model algorithm are as follows:
where
is the
k-th order line corresponding to goods at the
s-th picking station;
is the index of the
m-th selected pod at the
s-th picking station;
is the order number of the
i-th order at the
s-th picking station;
is the goods number corresponding to the
j-th order line in the
i-th order at the
s-th picking station;
is the number of order lines in the
i-th order at the
s-th picking station;
is the number of orders at the
s-th picking station;
is the quantity of pods selected by the
s-th picking station;
is the sequence number of the last included order line in the
m-th pod selected by the
s-th picking station.
The objective function (9) of this model aims to minimize the total distance traveled, which includes the distances from the inventory pods to the picking stations and between the pods. This is done to enhance consolidation opportunities. The constraints are similar to the mathematical model above: constraint (10) ensures that there are no duplicate goods assigned to the picking stations; constraint (11) ensures that the orders assigned to the picking stations correspond to the original orders’ goods requirements; constraint (12) requires that all orders and order lines are allocated to the picking stations and completed; constraint (13) ensures that the selected pods correspond to the order lines; constraint (14) serves as an initial condition; finally, constraint (8) ensures that certain decision variables can take binary values.
Lastly, the third mathematical model is the vehicle scheduling model. We present the mathematical modeling for the vehicle scheduling problem. Following the sequential approach, once we have solved the pod assignment problem from the previous section, we will obtain the optimal assignment and ordering of the shelves. These tasks will be used as inputs to the model in this section and assigned to the available mobile robots. In evaluating the accuracy of the model presented in this section, we schedule these tasks to the sorting stations, and these computations will dispatch the robots to load the goods under the fulfilled time conditions with high accuracy and time efficiency. The relevant mathematical formulae and constraints are shown below:
The relevant limitations of the mathematical model algorithm are as follows:
where
is the start time for the movement of the
r-th robot, selecting the
l-th shelf;
is the start time for the
s-th picking station, selecting the
m-th shelf;
is the shelf number corresponding to the
l-th task for the
r-th robot;
is the picking station number corresponding to the
l-th task for the
r-th robot;
is the number of mobile shelves assigned to the
r-th robot;
is the number of mobile shelves assigned to the
s-th picking station.
In the objective function (15), this paper minimizes the completion time of picking station activities. Constraints (16) and (17) are used to calculate the distance traveled by each robot when performing tasks. Constraint (18) ensures that the tasks allocated within a picking station are performed in order, while constraint (19) ensures that the tasks assigned to robots are also performed in order. Constraint (20) is an initial condition. Task start times should be greater than 0, and constraint (21) enforces this property.
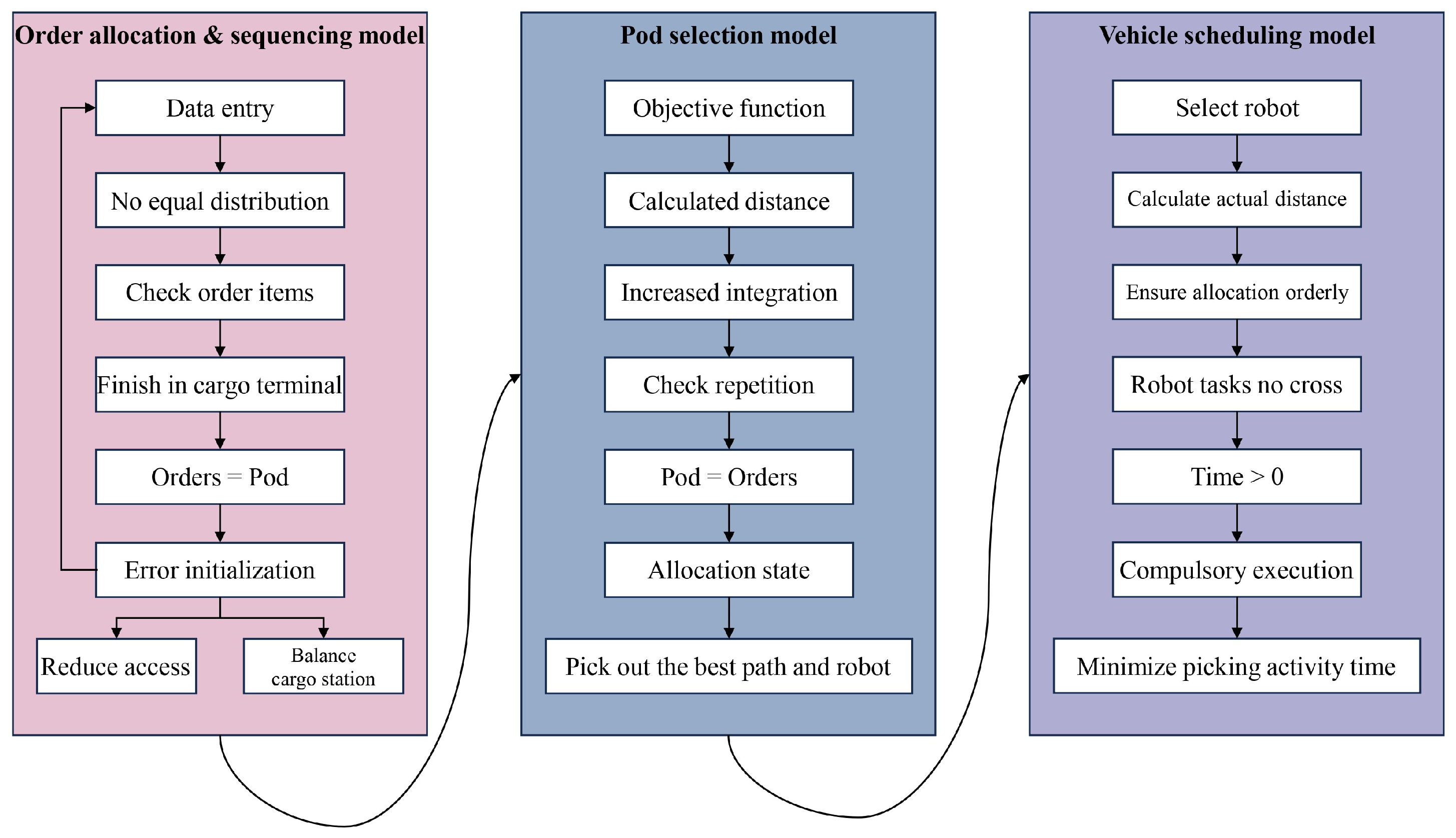
3.3. Algorithm
We use a Genetic Algorithm for solving the order allocation and sequencing problem by searching for the optimal solution through genetic operators, such as selection, crossover, and mutation [
39]. Then, an Ant Colony Algorithm is used to solve the shelf selection problem by simulating the behavior of ants dropping pheromones to find the shortest path. Also, the ACO algorithm can be used to solve the collaborative robot scheduling problem, where the ants make scheduling decisions according to pheromone levels. Finally, some basic optimization techniques, such as mathematical modeling, randomization methods, iterative search, etc., are also used. Various heuristic optimization algorithm techniques are used to solve combinatorial optimization problems in the RMFS (
Figure 4 shows the details).
The first problem to solve is the order allocation and sequencing problem, the solution specifically referring to the allocation of orders to different picking stations and their respective sequences. In this paper, a Genetic Algorithm is employed to solve the model described above. This includes major steps, such as initializing the population, calculating fitness, selection, crossover, mutation, and obtaining the optimal solution through iterations. In this section, we will focus on explaining how to design algorithms for these key steps.
(1) Population Initialization
In this paper, based on the constraints of the previous model, the pre-generated orders are randomly and non-repetitively assigned to each picking station, while the original order sequence is shuffled, to enhance consolidation opportunities. The pseudocode for generating a feasible solution in Algorithm 1 is as follows:
| Algorithm 1 Generate a Feasible Solution |
|
Using the above function, multiple initial feasible solutions can be obtained, to form the population needed in this paper.
(2) Calculate Fitness
Regarding fitness calculation, based on the model described earlier, the objective in this problem is to maintain balance among the picking stations and minimize the number of times inventory pods are moved. Calculating the imbalance among picking stations is relatively straightforward. It is important to note that when selecting an inventory pod, it should be capable of handling the current order lines as well as possible subsequent order lines. A smaller value for this objective function is more favorable, resulting in a higher fitness.
(3) Selection
For the selection step, this paper employs a roulette wheel selection method. Individuals with higher fitness values are less likely to be eliminated and have a lower probability of being chosen. Conversely, individuals with lower fitness values are more likely to be eliminated and have a higher probability of being selected. The selection step is primarily implemented in the main function and will not be discussed further here.
(4) Crossover
When an individual is selected, it may undergo a crossover operation. The design of this Algorithm 2 involves crossing the selected individual with the current best individual. Specifically, the order line sequence of a particular order in the selected individual is replaced with the order line sequence of the same order in the best individual. Clearly, this may improve the fitness of the selected individual. Through repeated iterations, we obtain better individuals. The crossover operation function is as follows:
(5) Crossover
When an individual is selected, it may undergo a crossover operation. The design of this Algorithm 3 involves crossing the selected individual with the current best individual. Specifically, the order line sequence of a particular order in the selected individual is replaced with the order line sequence of the same order in the best individual. Clearly, this may improve the fitness of the selected individual. Through repeated iterations, we obtain better individuals. The crossover operation function is as follows:
(6) Overview of Genetic Algorithm
Based on the aforementioned description, the entire Genetic Algorithm 4 iteration can be completed. This includes the main steps of initializing the population, calculating fitness, selection, crossover, and mutation. The result will be the optimal assignment and ordering of orders. The pseudocode for the Genetic Algorithm in this paper is as follows:
| Algorithm 4 Genetic Algorithm |
|
The second problem to solve is the pod selection problem. In the solution to the first problem, using the algorithm described above, we obtained the optimal assignment and ordering of orders. In the problem of pod selection, we will use this as input to solve for the optimal pod selection for each picking station. In this problem, for each order line within a picking station, there are three pods to choose from. If the picking station has n order lines, there are possible choices. This is clearly an NP-hard problem. Therefore, in this paper, we use an Ant Colony Algorithm to solve this decision problem.
(1) Ant Decision Description
In the Ant Colony Algorithm, a critical aspect is the decision-making process of the ants. In the problem of pod selection, decisions come into play when facing the choice of three pods corresponding to the current order line. Due to the potential for pod consolidation, it is challenging to directly determine which pod selection will have a global optimization effect. Therefore, this paper employs multiple ants that select pods based on the existing pheromone level, leaving behind new pheromone trails. When the total path is shorter, more pheromone is left and, as pheromone accumulates, the probability of choosing that pod also increases. With an increasing number of iterations, the algorithm’s solutions continuously improve, ultimately leading to the optimal solution.
(2) Initialization of Pheromones
To implement this algorithm, the first step is to initialize the pheromones. For each pod, the initialization of pheromones from itself to another pod is set to a constant value. Additionally, when a particular pod is the first one chosen, the pheromone encoding is set from that pod to itself. The pseudocode for initializing pheromones in Algorithm 5 is as follows:
| Algorithm 5 Initialize Pheromone |
|
(3) Updating Pheromones
Updating pheromones is a crucial part of the algorithm’s iterations. In this algorithm, the pheromones are continuously decaying with each iteration. At the same time, new pheromones are added, based on the total distance traveled by each ant. The pseudocode for updating pheromones in Algorithm 6 is as follows:
| Algorithm 6 Update Pheromone |
|
(4) Overview of Ant Colony Algorithm
Building upon the functions described above, the design of the entire Ant Colony Algorithm can be completed. In this algorithm, each ant selects a shelf based on the existing pheromone levels, using a roulette wheel selection method to choose the next shelf. Here is the pseudocode for the Ant Colony Algorithm 7 for this problem.
Furthermore, there is a relationship and potential for further integration between the two problems of order allocation and sequencing and of shelf selection. Using the algorithm described above for the order allocation and sequencing problems, it is possible to have multiple solutions with the same objective function value. To further optimize, a straightforward approach is to input these solutions with the same objective values into the algorithm presented in this section. While this is a feasible method, it would increase the algorithm’s time complexity. To integrate both problems effectively, the model can be modified into a multi-objective optimization model, where the solutions would represent order allocation and sequencing, ultimately providing the shelf allocation and sequencing for each picking station.
| Algorithm 7 Ant Colony Algorithm |
|
The third problem to solve is the vehicle scheduling problem. In the joint scheduling problem of robots, the algorithm described above uses the shelf allocation and sequencing as its input. There are two fundamental assumptions for this decision problem. First, when scheduling begins, it is evident that available robots should be deployed to fulfill the shelf requirements of picking stations. Second, it is not necessary to schedule robot transportation for the next shelf as soon as there is a vacancy at a picking station. This is because the number of robots is limited, and urgently handling the transportation of shelves for one picking station may lead to excessive waiting times at other picking stations. This paper employs an Ant Colony Algorithm to address this decision problem.
(1) Robot Decision Explanation
When a robot is in an idle state after completing a task, it is assigned to transport the next shelf to a picking station. However, the robot does not directly choose the next available picking station. Instead, it makes its decision based on the time required for each picking station to complete the current picking task and the existing pheromone levels. The probability of a picking station being chosen by a robot is higher when the completion time at that station is shorter and there is more residual pheromone. Additionally, when all picking tasks are completed, new pheromone is deposited, based on the total processing time. Clearly, decisions that lead to shorter total processing times will be favored in the subsequent iterations, resulting in a robot collaborative scheduling plan and minimizing the overall processing time.
(2) Initializing Pheromones
In this problem, the algorithm is designed for two picking stations. Whenever a robot becomes idle, it selects a task from one of the picking stations. When there are more than two picking stations, the initialization of pheromone levels is performed in a similar manner. The pseudocode for initializing pheromones in Algorithm 8 is as follows:
| Algorithm 8 Initialize Pheromone 2 |
|
(3) Updating Pheromones
Updating pheromones is a crucial part of the algorithm during iterations. Similar to the previous section, in this algorithm, pheromone levels decay with each iteration and new pheromones are added based on the total time taken by each ant. The updating method is similar to the one described earlier, and we will not go into detail here.
(4) Overview of Ant Colony Algorithm
In the algorithm presented in this section, the selection of robot–shelf pairs is also conducted using a roulette wheel method. The pseudocode for this section’s Ant Colony Algorithm 9 is as follows:
| Algorithm 9 Ant Colony Optimization 2 |
|
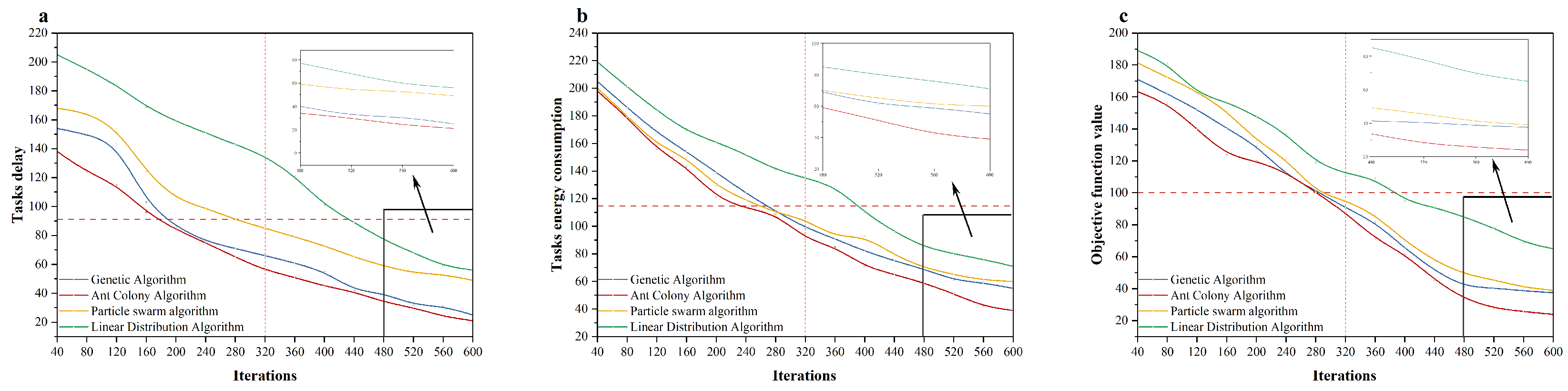
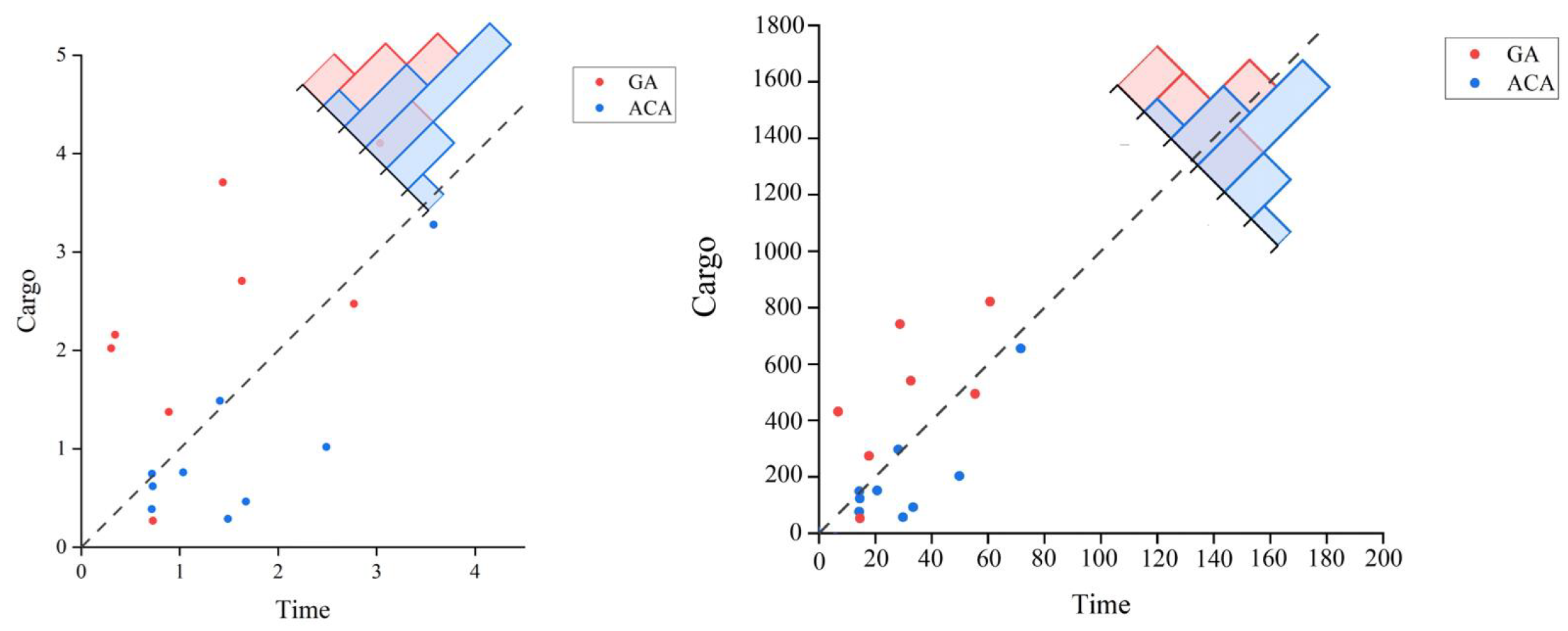
In order to evaluate the effectiveness of the Genetic Algorithm and the Ant Colony Algorithm, we added a Particle Swarm Algorithm and a Linear Assignment Algorithm to compare with our algorithms. The number of goods was set to 1000 and the number of robots was set to 10. (
Figure 5).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}