




The Role of Selected Speech Signal Characteristics in Discriminating Unipolar and Bipolar Disorders



Abstract
1. Introduction
- Pharmacotherapy—the mood is controlled (i.e., stabilized), and symptoms are alleviated with the help of an adapted and difficult-to-define combination of at least one of the following: antidepressants, antipsychotics, mood stabilizers, and other drugs, e.g., anxiolytics, hypnotics.
- Psychotherapy—patients are trained to manage symptoms and find practical ways to prevent episodes through behavioral and lifestyle choices such as routine sleep, social activity, and appropriate stress management.
- Psychoeducation—patients and their relatives and close friends are taught about the intricacies of unipolar and bipolar disorders, the causes of episode recurrences, and how to deal with the disease.
2. Related Research
2.1. Speech-Based Depression Recognition
2.1.1. Datasets
2.1.2. Depression Recognition Methods
- Voice quality features, e.g., jitter and shimmer [36].
2.2. Speech-Based Mania Recognition
2.2.1. Datasets
2.2.2. Mania Recognition Methods
- Prosodies such as pitch, intensity (energy), rate of speech, and pause duration [49];
3. Methodology
3.1. Experimental Specification
- Patient voice data related to the daily recordings of the voice samples.
- Sleep data (i.e., Mi Fit band or sleep survey).
- Data on physical activity (e.g., number of steps).
- Other behavioral data (e.g., number of phone calls made).
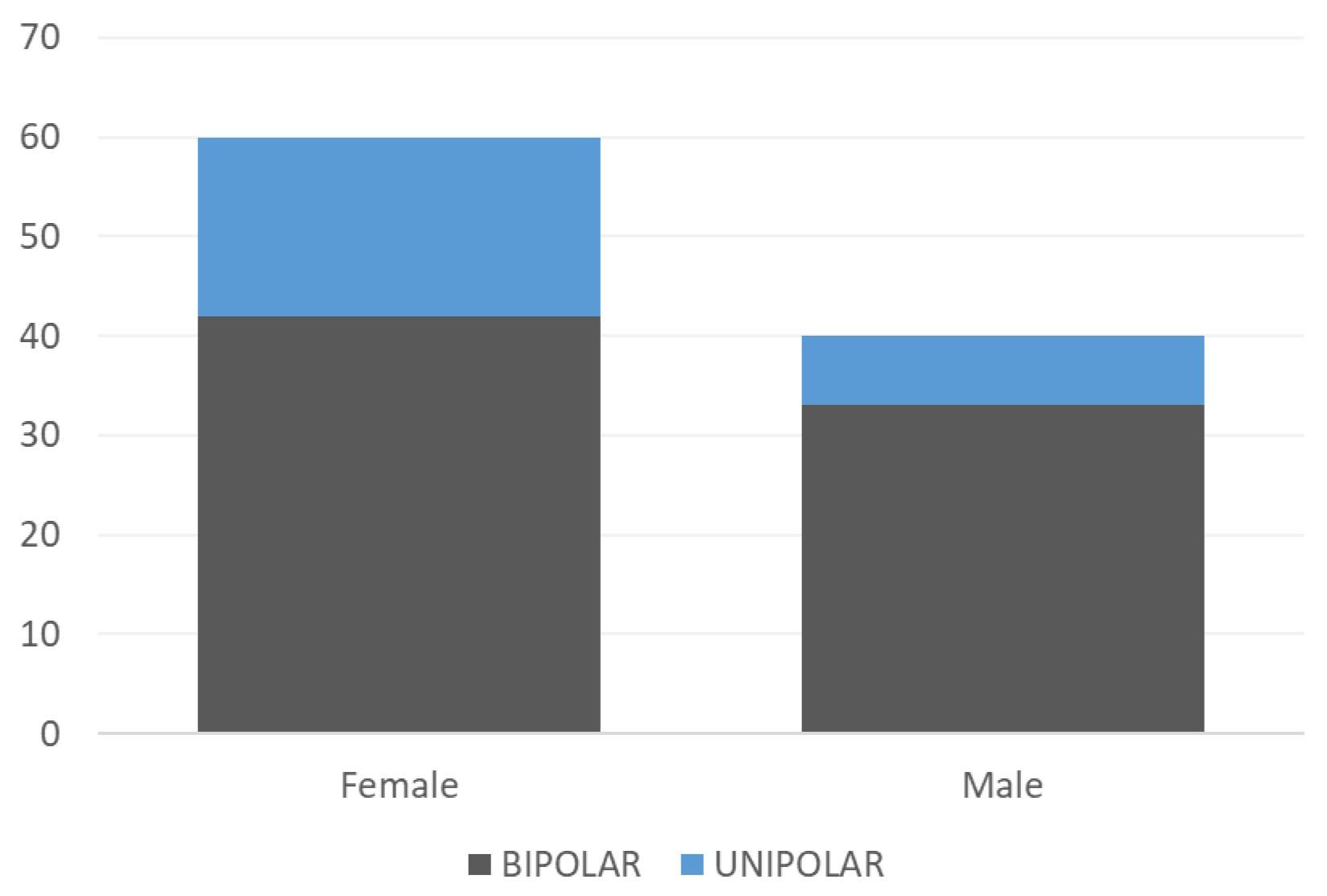
- The observational part of the clinical trial involved the observation of 100 patients (60 women, 40 men);
- A total of 546 changes in patients’ condition were observed during this period;
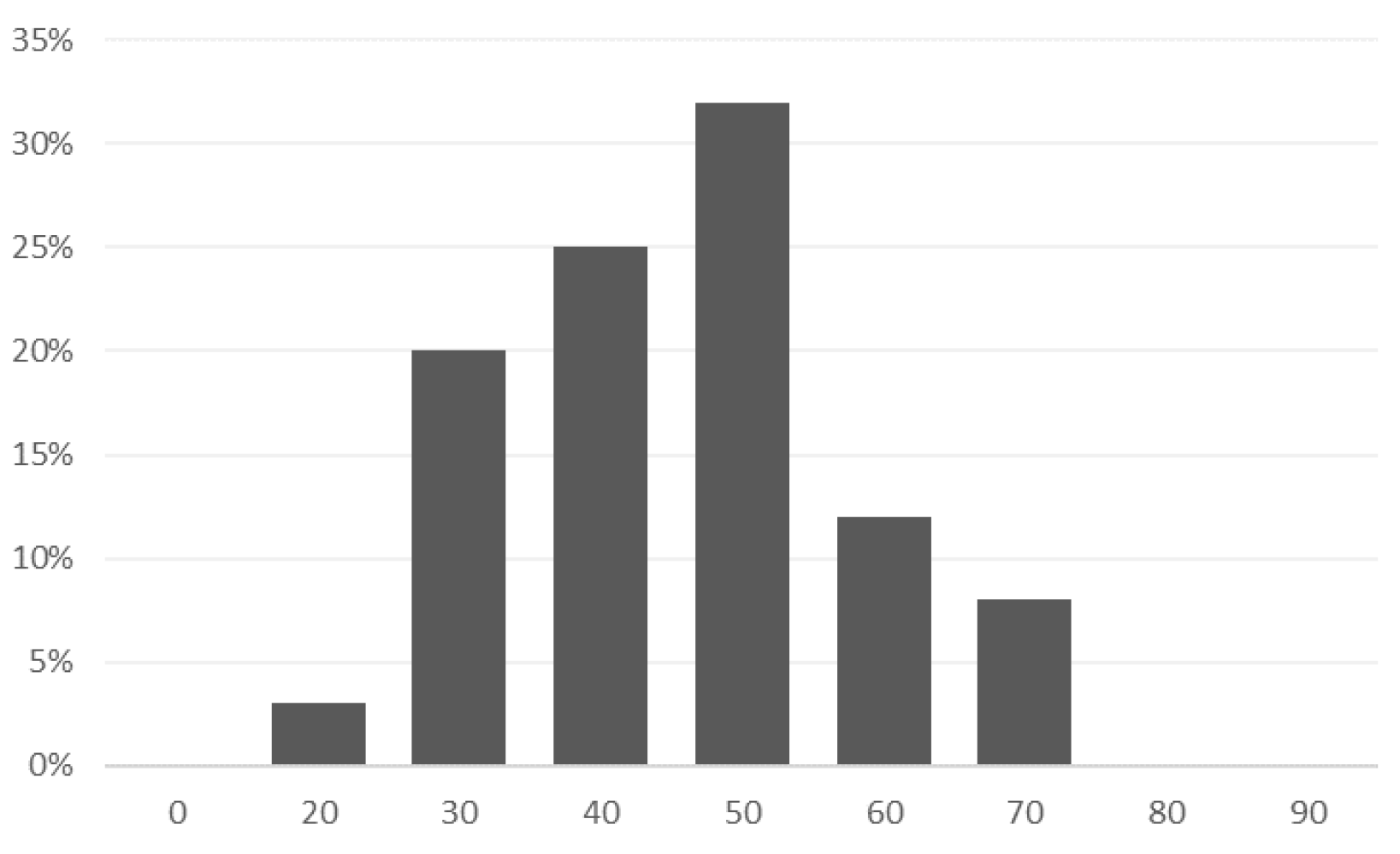
- The average age of the patients in the study was 41 years; most of them were single (48), married (37), divorced (13), or widowed (2);
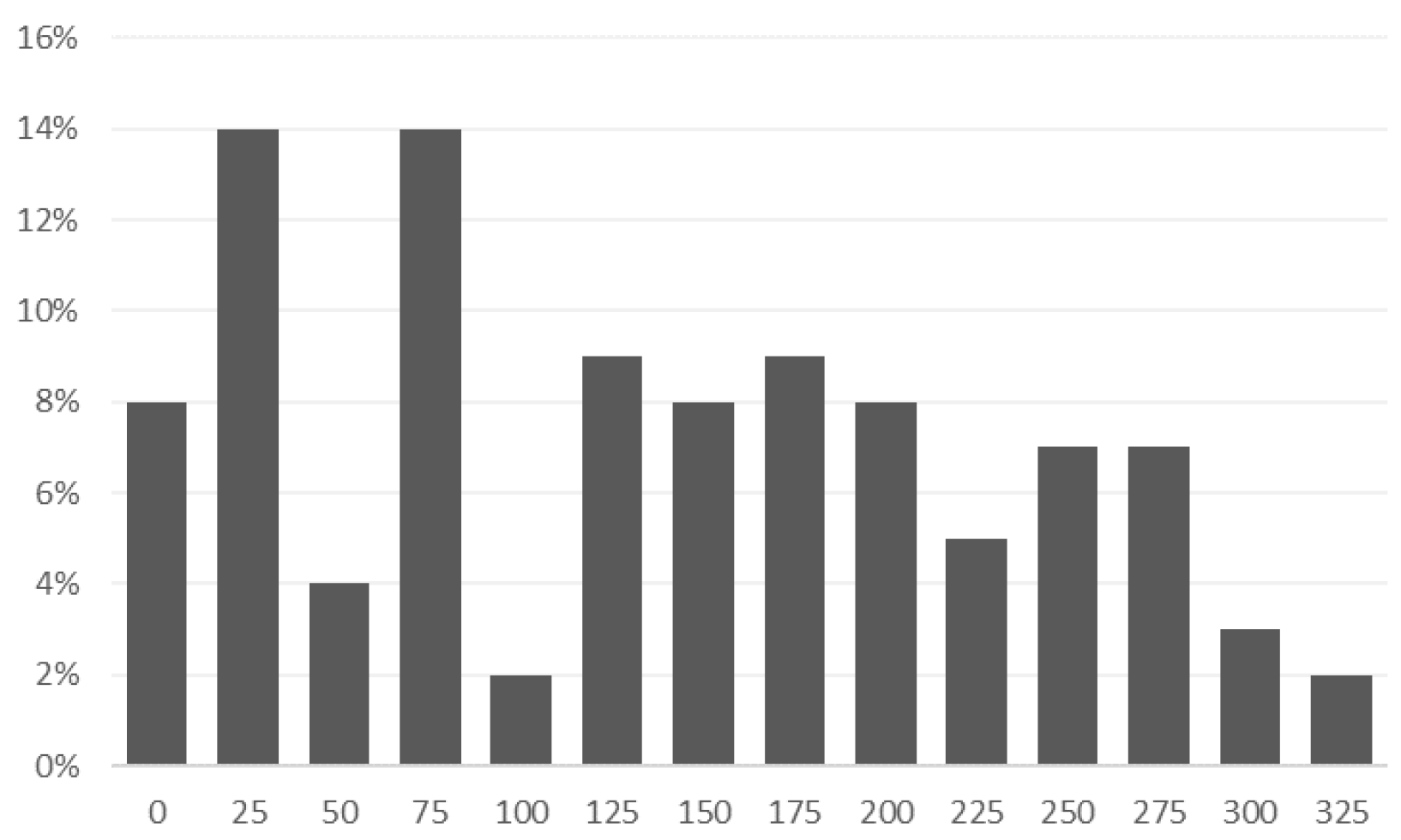
- On average, each patient had 124 recordings of voice samples.
3.2. Speech Signal
3.2.1. Fundamental Frequency (F0), Pitch
3.2.2. Short-Time Energy
3.2.3. Zero Crossing Rate (ZCR)
3.2.4. Pauses
3.2.5. Jitter and Shimmer
3.2.6. LPC and Formants
3.2.7. MFCC
4. Results
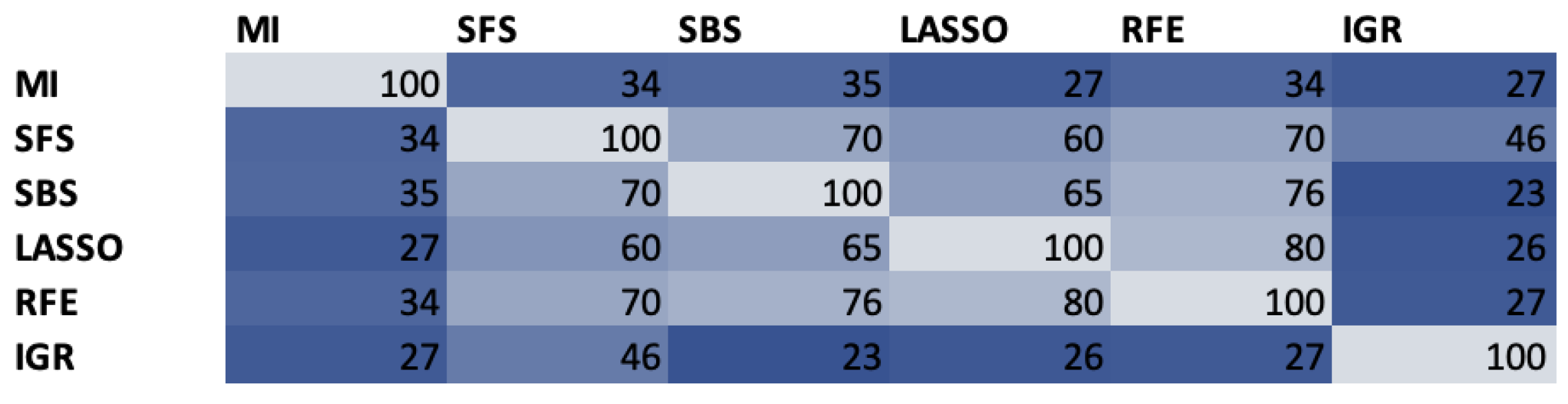
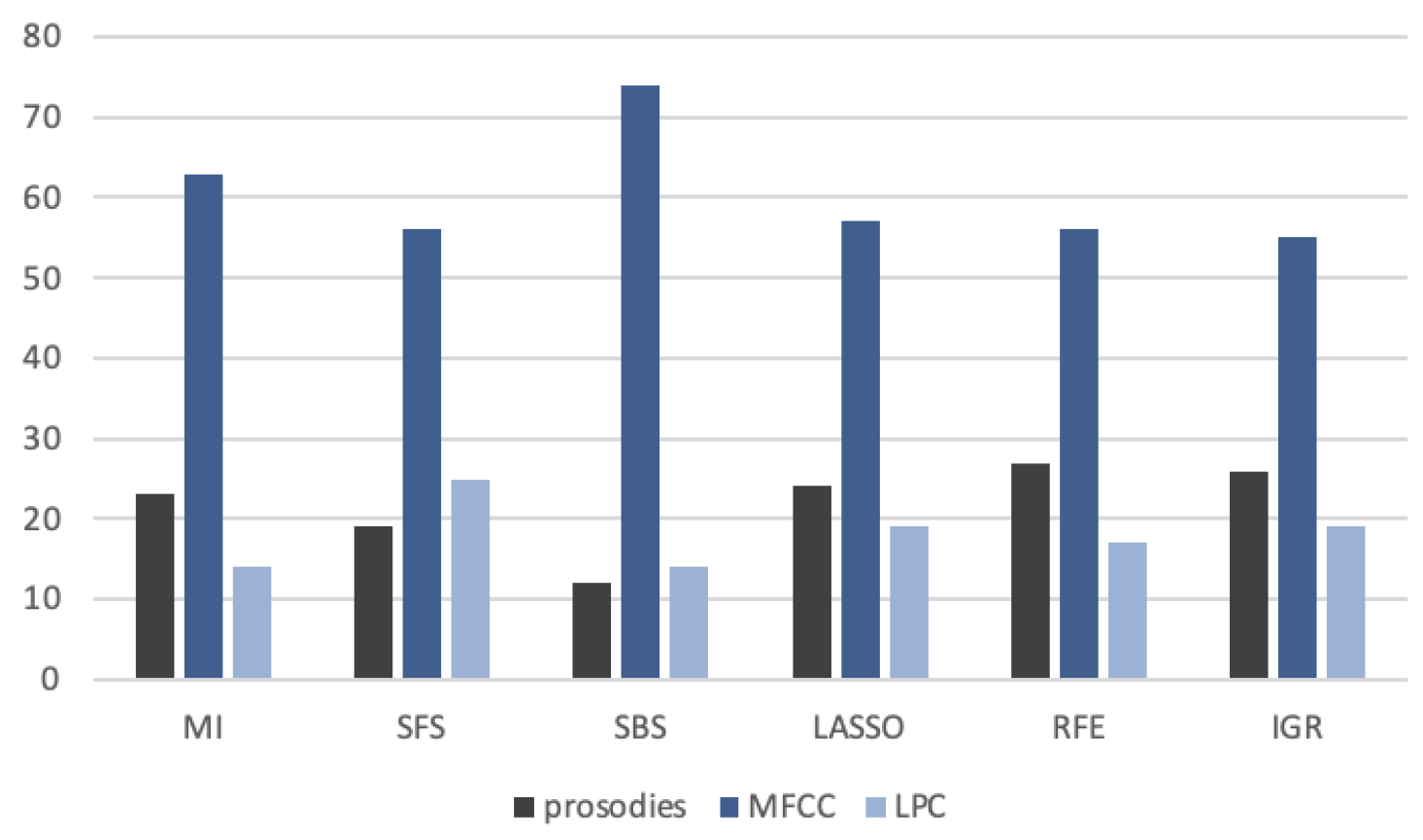
4.1. Feature Selection
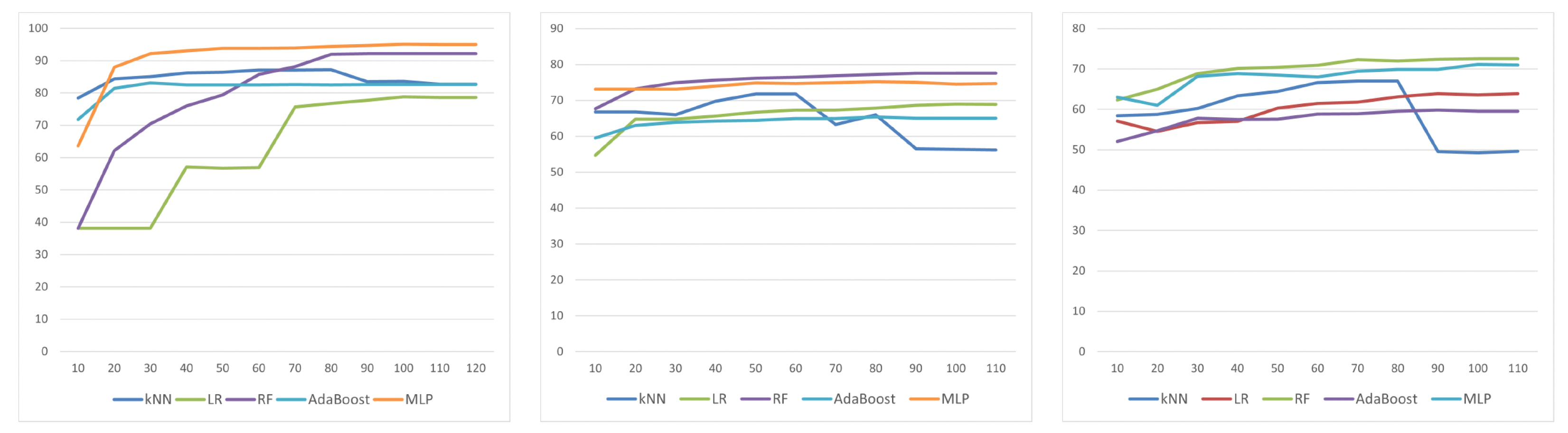
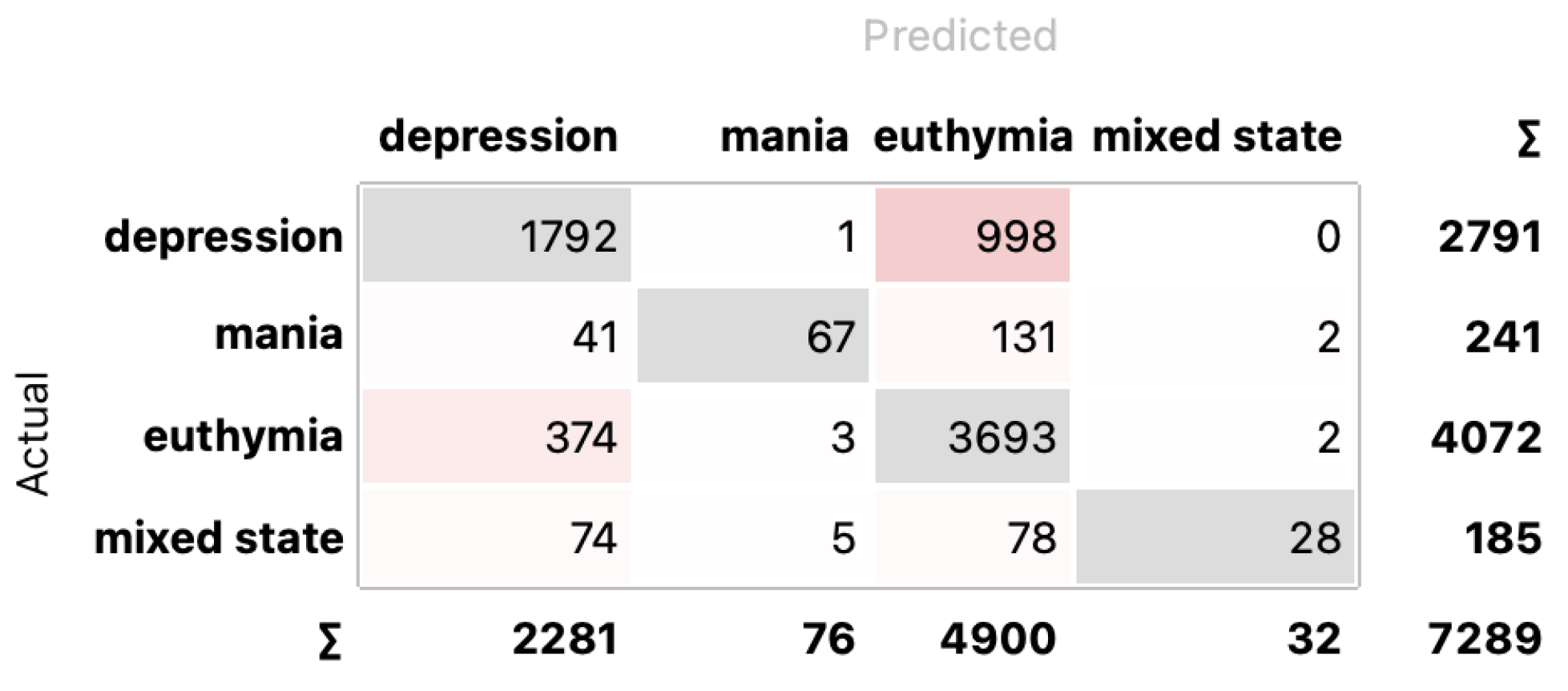
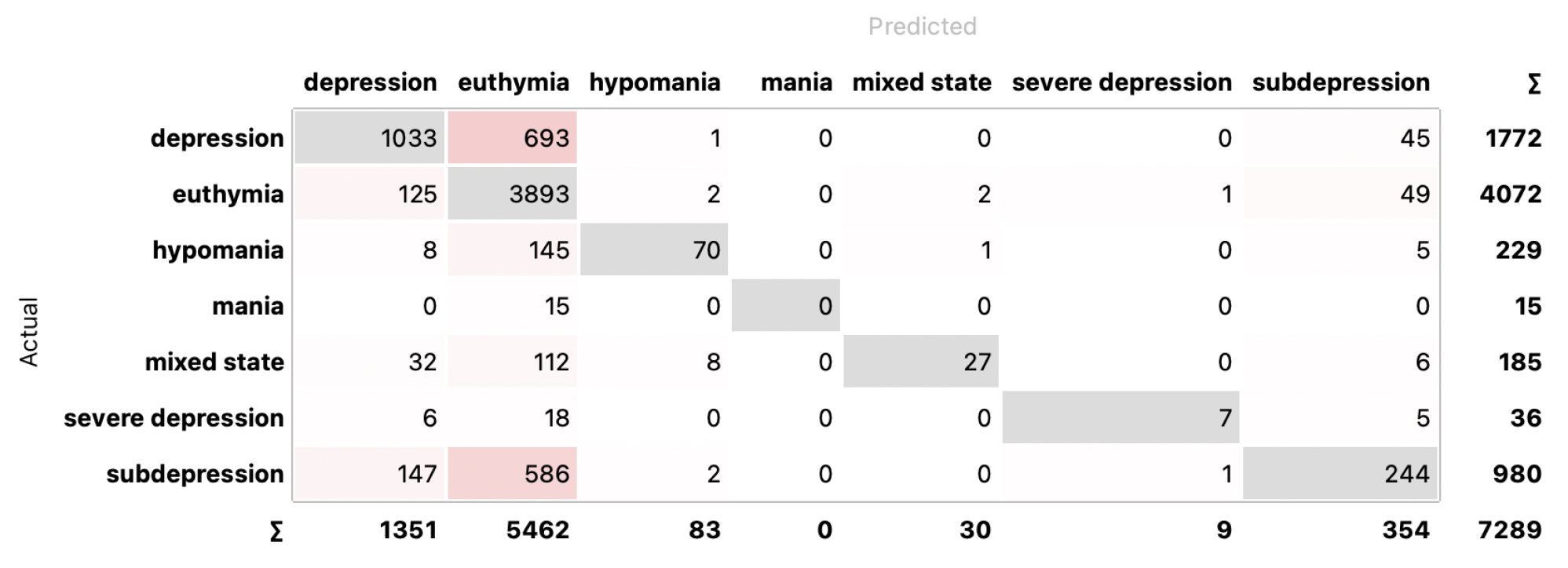
4.2. Classification
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kessler, R.C.; Chiu, W.T.; Demler, O.; Walters, E.E. Prevalence, severity, and comorbidity of 12-month DSM-IV disorders in the National Comorbidity Survey Replication. Arch. Gen. Psychiatry 2005, 62, 617–627. [Google Scholar] [CrossRef] [PubMed]
- Anker, S.D.; Morley, J.E.; von Haehling, S. Welcome to the ICD-10 code for sarcopenia. J. Cachexia Sarcopenia Muscle 2016, 7, 512–514. [Google Scholar] [PubMed]
- OECD; European Union. Health at a Glance: Europe 2018: State of Health in the EU Cycle; OECD: Paris, France, 2018. [Google Scholar]
- OECD; European Union. Health at a Glance: Europe 2020; OECD: Paris, France, 2020; p. 237. [Google Scholar] [CrossRef]
- Kessing, L.V.; Andersen, P.K. Predictive effects of previous episodes on the risk of recurrence in depressive and bipolar disorders. Curr. Psychos. Ther. Rep. 2005, 3, 123–130. [Google Scholar]
- Park, D.Y.; Do, D.; Chang, L.; Shah, S.; Yuen, L.D.; Hooshmand, F.; Wang, P.W.; Miller, S.; Ketter, T.A. Episode accumulation associated with hastened recurrence and delayed recovery in bipolar disorder. J. Affect. Disord. 2018, 227, 657–664. [Google Scholar] [CrossRef] [PubMed]
- Vieta, E.; Berk, M.; Schulze, T.; Carvalho, A.; Suppes, T.; Calabrese, J.; Gao, K.; Miskowiak, K.; Grande, I. Bipolar disorders. Nat. Rev. Dis. Prim. 2018, 4, 18008. [Google Scholar] [CrossRef] [PubMed]
- Halfin, A. Depression: The benefits of early and appropriate treatment. Am. J. Manag. Care 2007, 13, S92. [Google Scholar] [PubMed]
- Popova, E.; Benabarre, A.; Cruz, N.; Asenjo, M.A.; Vieta, E. Long-term mental health resource utilisation and cost of care following group psychoeducation or unstructured group support for bipolar disorders: A cost-benefit analysis. J. Clin. Psychiatry 2009, 70, 378–386. [Google Scholar]
- Sachs, G.S. Bipolar mood disorder: Practical strategies for acute and maintenance phase treatment. J. Clin. Psychopharmacol. 1996, 16, 32S–47S. [Google Scholar] [CrossRef] [PubMed]
- Nicholas, J.; Larsen, M.E.; Proudfoot, J.; Christensen, H. Mobile apps for bipolar disorder: A systematic review of features and content quality. J. Med. Internet Res. 2015, 17, e4581. [Google Scholar] [CrossRef]
- Ekman, P. Facial Action Coding System (FACS). A Human Face; Oxford University Press: Oxford, UK, 2002. [Google Scholar]
- Pease, A.; McIntosh, J.; Cullen, P. Body Language; Camel; Malor Books: Los Altos, CA, USA, 1981. [Google Scholar]
- Izdebski, K. Emotions in the Human Voice, Volume 3: Culture and Perception; Plural Publishing: San Diego, CA, USA, 2008; Volume 3. [Google Scholar]
- Kim, J.; André, E. Emotion recognition based on physiological changes in music listening. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 2067–2083. [Google Scholar] [CrossRef]
- de Melo, W.C.; Granger, E.; Hadid, A. Combining global and local convolutional 3d networks for detecting depression from facial expressions. In Proceedings of the 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), Lille, France, 14–18 May 2019; pp. 1–8. [Google Scholar]
- Li, W.; Wang, Q.; Liu, X.; Yu, Y. Simple action for depression detection: Using kinect-recorded human kinematic skeletal data. BMC Psychiatry 2021, 21, 205. [Google Scholar] [CrossRef] [PubMed]
- Yasin, S.; Hussain, S.A.; Aslan, S.; Raza, I.; Muzammel, M.; Othmani, A. EEG based Major Depressive disorder and Bipolar disorder detection using Neural Networks: A review. Comput. Methods Programs Biomed. 2021, 202, 106007. [Google Scholar] [CrossRef] [PubMed]
- Zangani, C.; Casetta, C.; Saunders, A.S.; Donati, F.; Maggioni, E.; D’Agostino, A. Sleep abnormalities across different clinical stages of Bipolar Disorder: A review of EEG studies. Neurosci. Biobehav. Rev. 2020, 118, 247–257. [Google Scholar] [CrossRef] [PubMed]
- Abaei, N.; Al Osman, H. A Hybrid Model for Bipolar Disorder Classification from Visual Information. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, Barcelona, Spain, 4–8 May 2020; Volume 2020, pp. 4107–4111. [Google Scholar]
- Wang, Y.; Lyu, H.L.; Tian, X.H.; Lang, B.; Wang, X.Y.; St Clair, D.; Wu, R.; Zhao, J. The similar eye movement dysfunction between major depressive disorder, bipolar depression and bipolar mania. World J. Biol. Psychiatry 2022, 23, 689–702. [Google Scholar] [CrossRef] [PubMed]
- Valstar, M.; Schuller, B.; Smith, K.; Almaev, T.; Eyben, F.; Krajewski, J.; Cowie, R.; Pantic, M. Avec 2014: 3d dimensional affect and depression recognition challenge. In Proceedings of the 4th International Workshop on Audio/Visual Emotion Challenge, Orlando, FL, USA, 7 November 2014; pp. 3–10. [Google Scholar]
- Gratch, J.; Artstein, R.; Lucas, G.; Stratou, G.; Scherer, S.; Nazarian, A.; Wood, R.; Boberg, J.; DeVault, D.; Marsella, S.; et al. The Distress Analysis Interview Corpus of Human and Computer Interviews; Technical Report; University of Southern California: Los Angeles, CA, USA, 2014. [Google Scholar]
- Ringeval, F.; Schuller, B.; Valstar, M.; Cummins, N.; Cowie, R.; Tavabi, L.; Schmitt, M.; Alisamir, S.; Amiriparian, S.; Messner, E.M.; et al. AVEC 2019 workshop and challenge: State-of-mind, detecting depression with AI, and cross-cultural affect recognition. In Proceedings of the 9th International on Audio/Visual Emotion Challenge and Workshop, Nice, France, 21 October 2019; pp. 3–12. [Google Scholar]
- Liu, Z.; Wang, D.; Zhang, L.; Hu, B. A novel decision tree for depression recognition in speech. arXiv 2020, arXiv:2002.12759. [Google Scholar]
- Cohn, J.F.; Kruez, T.S.; Matthews, I.; Yang, Y.; Nguyen, M.H.; Padilla, M.T.; Zhou, F.; De la Torre, F. Detecting depression from facial actions and vocal prosody. In Proceedings of the 2009 3rd International Conference on Affective Computing and Intelligent Interaction and Workshops, Amsterdam, The Netherlands, 10–12 September 2009; pp. 1–7. [Google Scholar]
- Yang, Y.; Fairbairn, C.; Cohn, J.F. Detecting depression severity from vocal prosody. IEEE Trans. Affect. Comput. 2012, 4, 142–150. [Google Scholar] [CrossRef] [PubMed]
- Mundt, J.C.; Vogel, A.P.; Feltner, D.E.; Lenderking, W.R. Vocal acoustic biomarkers of depression severity and treatment response. Biol. Psychiatry 2012, 72, 580–587. [Google Scholar] [CrossRef] [PubMed]
- Rejaibi, E.; Komaty, A.; Meriaudeau, F.; Agrebi, S.; Othmani, A. MFCC-based recurrent neural network for automatic clinical depression recognition and assessment from speech. Biomed. Signal Process. Control. 2022, 71, 103107. [Google Scholar] [CrossRef]
- Cummins, N.; Epps, J.; Breakspear, M.; Goecke, R. An investigation of depressed speech detection: Features and normalization. In Proceedings of the 12th Annual Conference of the International Speech Communication Association, Florence, Italy, 27–31 August 2011. [Google Scholar]
- Taguchi, T.; Tachikawa, H.; Nemoto, K.; Suzuki, M.; Nagano, T.; Tachibana, R.; Nishimura, M.; Arai, T. Major depressive disorder discrimination using vocal acoustic features. J. Affect. Disord. 2018, 225, 214–220. [Google Scholar] [CrossRef]
- Lopez-Otero, P.; Docio-Fernandez, L.; Garcia-Mateo, C. Assessing speaker independence on a speech-based depression level estimation system. Pattern Recognit. Lett. 2015, 68, 343–350. [Google Scholar] [CrossRef]
- Ringeval, F.; Schuller, B.; Valstar, M.; Gratch, J.; Cowie, R.; Scherer, S.; Mozgai, S.; Cummins, N.; Schmitt, M.; Pantic, M. Avec 2017: Real-life depression, and affect recognition workshop and challenge. In Proceedings of the 7th Annual Workshop on Audio/visual Emotion Challenge, Mountain View, CA, USA, 23 October 2017; pp. 3–9. [Google Scholar]
- Cummins, N.; Vlasenko, B.; Sagha, H.; Schuller, B. Enhancing speech-based depression detection through gender dependent vowel-level formant features. In Proceedings of the Conference on Artificial Intelligence in Medicine in Europe, Vienna, Austria, 21–24 June 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 209–214. [Google Scholar]
- Moore, E.; Clements, M.; Peifer, J.; Weisser, L. Comparing objective feature statistics of speech for classifying clinical depression. In Proceedings of the The 26th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, San Francisco, CA, USA, 1–5 September 2004; Volume 1, pp. 17–20. [Google Scholar]
- Alghowinem, S.; Goecke, R.; Wagner, M.; Epps, J.; Breakspear, M.; Parker, G. Detecting depression: A comparison between spontaneous and read speech. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 7547–7551. [Google Scholar]
- Jiang, H.; Hu, B.; Liu, Z.; Wang, G.; Zhang, L.; Li, X.; Kang, H. Detecting depression using an ensemble logistic regression model based on multiple speech features. Comput. Math. Methods Med. 2018, 2018, 6508319. [Google Scholar] [CrossRef]
- Sturim, D.; Torres-Carrasquillo, P.A.; Quatieri, T.F.; Malyska, N.; McCree, A. Automatic detection of depression in speech using gaussian mixture modeling with factor analysis. In Proceedings of the Twelfth Annual Conference of the International Speech Communication Association, Florence, Italy, 27–31 August 2011. [Google Scholar]
- Wu, P.; Wang, R.; Lin, H.; Zhang, F.; Tu, J.; Sun, M. Automatic depression recognition by intelligent speech signal processing: A systematic survey. CAAI Trans. Intell. Technol. 2022, 8, 701–711. [Google Scholar] [CrossRef]
- Muzammel, M.; Salam, H.; Hoffmann, Y.; Chetouani, M.; Othmani, A. AudVowelConsNet: A phoneme-level based deep CNN architecture for clinical depression diagnosis. Mach. Learn. Appl. 2020, 2, 100005. [Google Scholar] [CrossRef]
- Zhao, Y.; Xie, Y.; Liang, R.; Zhang, L.; Zhao, L.; Liu, C. Detecting Depression from Speech through an Attentive LSTM Network. IEICE Trans. Inf. Syst. 2021, 104, 2019–2023. [Google Scholar] [CrossRef]
- Harati, S.; Crowell, A.; Mayberg, H.; Nemati, S. Depression severity classification from speech emotion. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 5763–5766. [Google Scholar]
- Çiftçi, E.; Kaya, H.; Güleç, H.; Salah, A.A. The turkish audio-visual bipolar disorder corpus. In Proceedings of the 2018 First Asian Conference on Affective Computing and Intelligent Interaction (ACII Asia), Beijing, China, 20–22 May 2018; pp. 1–6. [Google Scholar]
- Ringeval, F.; Schuller, B.; Valstar, M.; Cowie, R.; Kaya, H.; Schmitt, M.; Amiriparian, S.; Cummins, N.; Lalanne, D.; Michaud, A.; et al. AVEC 2018 workshop and challenge: Bipolar disorder and cross-cultural affect recognition. In Proceedings of the 2018 on Audio/Visual Emotion Challenge and Workshop, Seoul, Republic of Korea, 22 October 2018; pp. 3–13. [Google Scholar]
- Zhang, J.; Pan, Z.; Gui, C.; Xue, T.; Lin, Y.; Zhu, J.; Cui, D. Analysis on speech signal features of manic patients. J. Psychiatr. Res. 2018, 98, 59–63. [Google Scholar] [CrossRef] [PubMed]
- McInnis, M.; Ryan, K.; Assari, S.; Evans, S.; Gideon, J.; Khorram, S.; Provost, E. Predicting individual outcomes for rapid intervention (priori). In Bipolar Disorders; Wiley: Hoboken, NJ, USA, 2017; Volume 19, p. 29. [Google Scholar]
- Pan, Z.; Gui, C.; Zhang, J.; Zhu, J.; Cui, D. Detecting manic state of bipolar disorder based on support vector machine and gaussian mixture model using spontaneous speech. Psychiatry Investig. 2018, 15, 695. [Google Scholar] [CrossRef] [PubMed]
- Faurholt-Jepsen, M.; Rohani, D.A.; Busk, J.; Vinberg, M.; Bardram, J.E.; Kessing, L.V. Voice analyses using smartphone-based data in patients with bipolar disorder, unaffected relatives and healthy control individuals, and during different affective states. Int. J. Bipolar Disord. 2021, 9, 38. [Google Scholar] [CrossRef] [PubMed]
- Farrús, M.; Codina-Filbà, J.; Escudero, J. Acoustic and prosodic information for home monitoring of bipolar disorder. Health Inform. J. 2021, 27, 1460458220972755. [Google Scholar] [CrossRef] [PubMed]
- Bedi, G.; Carrillo, F.; Cecchi, G.A.; Slezak, D.F.; Sigman, M.; Mota, N.B.; Ribeiro, S.; Javitt, D.C.; Copelli, M.; Corcoran, C.M. Automated analysis of free speech predicts psychosis onset in high-risk youths. NPJ Schizophr. 2015, 1, 1–7. [Google Scholar] [CrossRef]
- Faurholt-Jepsen, M.; Busk, J.; Frost, M.; Vinberg, M.; Christensen, E.M.; Winther, O.; Bardram, J.E.; Kessing, L.V. Voice analysis as an objective state marker in bipolar disorder. Transl. Psychiatry 2016, 6, e856. [Google Scholar] [CrossRef]
- Muaremi, A.; Gravenhorst, F.; Grünerbl, A.; Arnrich, B.; Tröster, G. Assessing bipolar episodes using speech cues derived from phone calls. In Proceedings of the Pervasive Computing Paradigms for Mental Health: 4th International Symposium, MindCare 2014, Tokyo, Japan, 8–9 May 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 103–114. [Google Scholar]
- Picard, R.W. Affective Computing; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Williams, C.E.; Stevens, K.N. Emotions and speech: Some acoustical correlates. J. Acoust. Soc. Am. 1972, 52, 1238–1250. [Google Scholar] [CrossRef] [PubMed]
- Nakatsu, R.; Nicholson, J.; Tosa, N. Emotion recognition and its application to computer agents with spontaneous interactive capabilities. In Proceedings of the 7th ACM International Conference on Multimedia (Part 1), Orlando, FL, USA, 30 October–5 November 1999; pp. 343–351. [Google Scholar]
- Li, S.; Jain, A. Fundamental Frequency, Pitch, F0. In Encyclopedia of Biometrics; Springer: Boston, MA, USA, 2009. [Google Scholar]
- Jalil, M.; Butt, F.A.; Malik, A. Short-time energy, magnitude, zero crossing rate and autocorrelation measurement for discriminating voiced and unvoiced segments of speech signals. In Proceedings of the 2013 The International Conference On Technological Advances in Electrical, Electronics and Computer Engineering (TAEECE), Konya, Turkey, 9–11 May 2013; pp. 208–212. [Google Scholar]
- Ying, S.; Zhang, X. A study of zero-crossings with peak-amplitudes in speech emotion classification. In Proceedings of the 2010 First International Conference on Pervasive Computing, Signal Processing and Applications, Harbin, China, 17–19 September 2010; pp. 328–331. [Google Scholar]
- Teixeira, J.P.; Gonçalves, A. Algorithm for jitter and shimmer measurement in pathologic voices. Procedia Comput. Sci. 2016, 100, 271–279. [Google Scholar] [CrossRef]
- Gupta, H.; Gupta, D. LPC and LPCC method of feature extraction in Speech Recognition System. In Proceedings of the 2016 6th International Conference-Cloud System and Big Data Engineering (Confluence), Noida, India, 14–15 January 2016; pp. 498–502. [Google Scholar]
- Han, W.; Chan, C.F.; Choy, C.S.; Pun, K.P. An efficient MFCC extraction method in speech recognition. In Proceedings of the 2006 IEEE International Symposium on Circuits and Systems (ISCAS), Kos, Greece, 21–24 May 2006; p. 4. [Google Scholar]
- Bogdanov, D.; Wack, N.; Gómez Gutiérrez, E.; Gulati, S.; Boyer, H.; Mayor, O.; Roma Trepat, G.; Salamon, J.; Zapata González, J.R.; Serra, X.; et al. Essentia: An audio analysis library for music information retrieval. Proceedings 14th Conference of the International Society for Music Information Retrieval (ISMIR), Curitiba, Brazil, 4–8 November 2013; Britto, A., Gouyon, F., Dixon, S., Eds.; International Society for Music Information Retrieval (ISMIR): Montreal, QC, Canada, 2013; pp. 493–498. [Google Scholar]
- Reeves, S.J.; Zhe, Z. Sequential algorithms for observation selection. IEEE Trans. Signal Process. 1999, 47, 123–132. [Google Scholar] [CrossRef]
- Chen, X.W.; Jeong, J.C. Enhanced recursive feature elimination. In Proceedings of the Sixth International Conference on Machine Learning and Applications (ICMLA 2007), Cincinnati, OH, USA, 13–15 December 2007; pp. 429–435. [Google Scholar]
- Vergara, J.R.; Estévez, P.A. A review of feature selection methods based on mutual information. Neural Comput. Appl. 2014, 24, 175–186. [Google Scholar] [CrossRef]
- Mohammad, A.H. Comparing two feature selections methods (information gain and gain ratio) on three different classification algorithms using arabic dataset. J. Theor. Appl. Inf. Technol. 2018, 96, 1561–1569. [Google Scholar]
- Fonti, V.; Belitser, E. Feature Selection Using Lasso; Vrije Universiteit Amsterdam: Amsterdam, The Netherlands, 2017; Volume 30, pp. 1–25. [Google Scholar]
- Parmar, A.; Katariya, R.; Patel, V. A review on random forest: An ensemble classifier. In Proceedings of the International Conference on Intelligent Data Communication Technologies and Internet of Things (ICICI), Coimbatore, India, 7–8 August 2018; Springer: Berlin/Heidelberg, Germany, 2019; pp. 758–763. [Google Scholar]
- Yan, Z.; Xu, C. Combining KNN algorithm and other classifiers. In Proceedings of the 9th IEEE International Conference on Cognitive Informatics (ICCI’10), Beijing, China, 7–9 July 2010; pp. 800–805. [Google Scholar]
- Liao, X.; Xue, Y.; Carin, L. Logistic regression with an auxiliary data source. In Proceedings of the 22nd International Conference on Machine Learning, Bonn, Germany, 7–11 August 2005; pp. 505–512. [Google Scholar]
- Morariu, D.; Crețulescu, R.; Breazu, M. The weka multilayer perceptron classifier. Int. J. Adv. Stat. It&C Econ. Life Sci. 2017, 7. Available online: https://magazines.ulbsibiu.ro/ijasitels/index.php/IJASITELS/article/view/17 (accessed on 13 April 2024).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | # of Subjects | # of Clips | Recording Method |
|---|---|---|---|
| AVEC2014 [22] | 84 patients | 300 | reading aloud/questions responding |
| DAIC-WOZ [23] | 189 patients | 189 | Wizard-of-Oz and automated agent |
| E-DAIC [24] | 351 patients | 275 | Wizard-of-Oz and automated agent |
| MODMA [25] | 23 depressed 29 control | 1508 | interviewing, reading, and picture description |
| CGI# | MI | SFS | SBS | LASSO | RFE | IGR |
|---|---|---|---|---|---|---|
| 7 | 71.7/67.7 | 72.6/68.5 | 72.6/68.5 | 73.4/73.1 | 72.7/68.3 | 72.2/68.4 |
| 4 | 77.1/75.3 | 76.3/74.2 | 76.9/74.8 | 77.1/75.3 | 75.9/73.9 | 75.9/73.9 |
| 2 | 93.1/93.1 | 92.8/92.8 | 92.4 /92.4 | 92.6/92.6 | 93.0/93.0 | 91.5/91.5 |
| CGI# | MI | SFS | SBS | LASSO | RFE | IGR |
|---|---|---|---|---|---|---|
| 7 | 66.2/65.4 | 64.7/64.2 | 66.6/65.9 | 57.3/58.4 | 65.2/64.5 | 67.1/65.5 |
| 4 | 68.2/67.6 | 66.2/65.8 | 69.2/68.7 | 63.8/63.3 | 70.1/68.7 | 71.8/69.5 |
| 2 | 89.7/89.7 | 86.8/86.8 | 87.4/87.4 | 88.0/88.0 | 88.6/88.6 | 87.3/87.3 |
| CGI# | MI | SFS | SBS | LASSO | RFE | IGR |
|---|---|---|---|---|---|---|
| 7 | 57.8/57.6 | 57.7/57.3 | 57.5/57.3 | 57.3/58.4 | 57.6/57.4 | 59.5/59.3 |
| 4 | 66.3/64.5 | 64.8/64.7 | 64.2/64.2 | 64.6/64.5 | 64.4/64.3 | 65.4/64.6 |
| 2 | 83.1/83.1 | 81.8/81.8 | 82.6/82.6 | 81.4 /81.4 | 81.6/81.6 | 82.8/82.8 |
| CGI# | MI | SFS | SBS | LASSO | RFE | IGR |
|---|---|---|---|---|---|---|
| 7 | 65.6/64.9 | 62.9/62.7 | 69.2/59.9 | 62.3/62.4 | 63.6/63.3 | 63.8/63.4 |
| 4 | 66.8/66.2 | 68.5/67.8 | 67.1 /66.5 | 68.5/67.8 | 69.0/68.2 | 70.3/69.2 |
| 2 | 76.4/76.4 | 72.6/72.5 | 73.9/73.9 | 73.8 /73.5 | 74.7/74.4 | 78.8/78.8 |
| CGI# | MI | SFS | SBS | LASSO | RFE | IGR |
|---|---|---|---|---|---|---|
| 7 | 70.5/66.6 | 68.7/65.1 | 70.0/66.4 | 70.0/65.8 | 69.6/65.8 | 71.6/67.6 |
| 4 | 75.5/73.4 | 75.0/73.8 | 73.6/73.6 | 74.9/72.8 | 75.7/73.8 | 75.0/72.8 |
| 2 | 95.0/95.0 | 95.0/95.0 | 93.8/93.8 | 94.0 /94.0 | 94.8/94.8 | 95.0/95.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kamińska, D.; Kamińska, O.; Sochacka, M.; Sokół-Szawłowska, M. The Role of Selected Speech Signal Characteristics in Discriminating Unipolar and Bipolar Disorders. Sensors 2024, 24, 4721. https://doi.org/10.3390/s24144721
Kamińska D, Kamińska O, Sochacka M, Sokół-Szawłowska M. The Role of Selected Speech Signal Characteristics in Discriminating Unipolar and Bipolar Disorders. Sensors. 2024; 24(14):4721. https://doi.org/10.3390/s24144721
Chicago/Turabian StyleKamińska, Dorota, Olga Kamińska, Małgorzata Sochacka, and Marlena Sokół-Szawłowska. 2024. "The Role of Selected Speech Signal Characteristics in Discriminating Unipolar and Bipolar Disorders" Sensors 24, no. 14: 4721. https://doi.org/10.3390/s24144721
APA StyleKamińska, D., Kamińska, O., Sochacka, M., & Sokół-Szawłowska, M. (2024). The Role of Selected Speech Signal Characteristics in Discriminating Unipolar and Bipolar Disorders. Sensors, 24(14), 4721. https://doi.org/10.3390/s24144721