
TransNeural: An Enhanced-Transformer-Based Performance Pre-Validation Model for Split Learning Tasks

Abstract
:1. Introduction
- A mathematical model for SL training latency and convergence is established, which jointly considers unknown non-i.i.d. data distributions, device participate sequence, inaccurate CSI, and deviations in occupied computing resources. These are crucial factors for SL training performance, but are often overlooked in existing SL studies.
- To close the gap in SL-target DTN pre-validation environment, we propose a TransNeural algorithm to estimate SL training latency and convergence under given resource allocation strategies. This algorithm combines the transformer and neural network to model data similarities between devices, establish complex relationships between SL performance and network factors such as data distributions, wireless and computing resources, dataset sizes, and training iterations, and learn the reporting deviation characteristics of different devices.
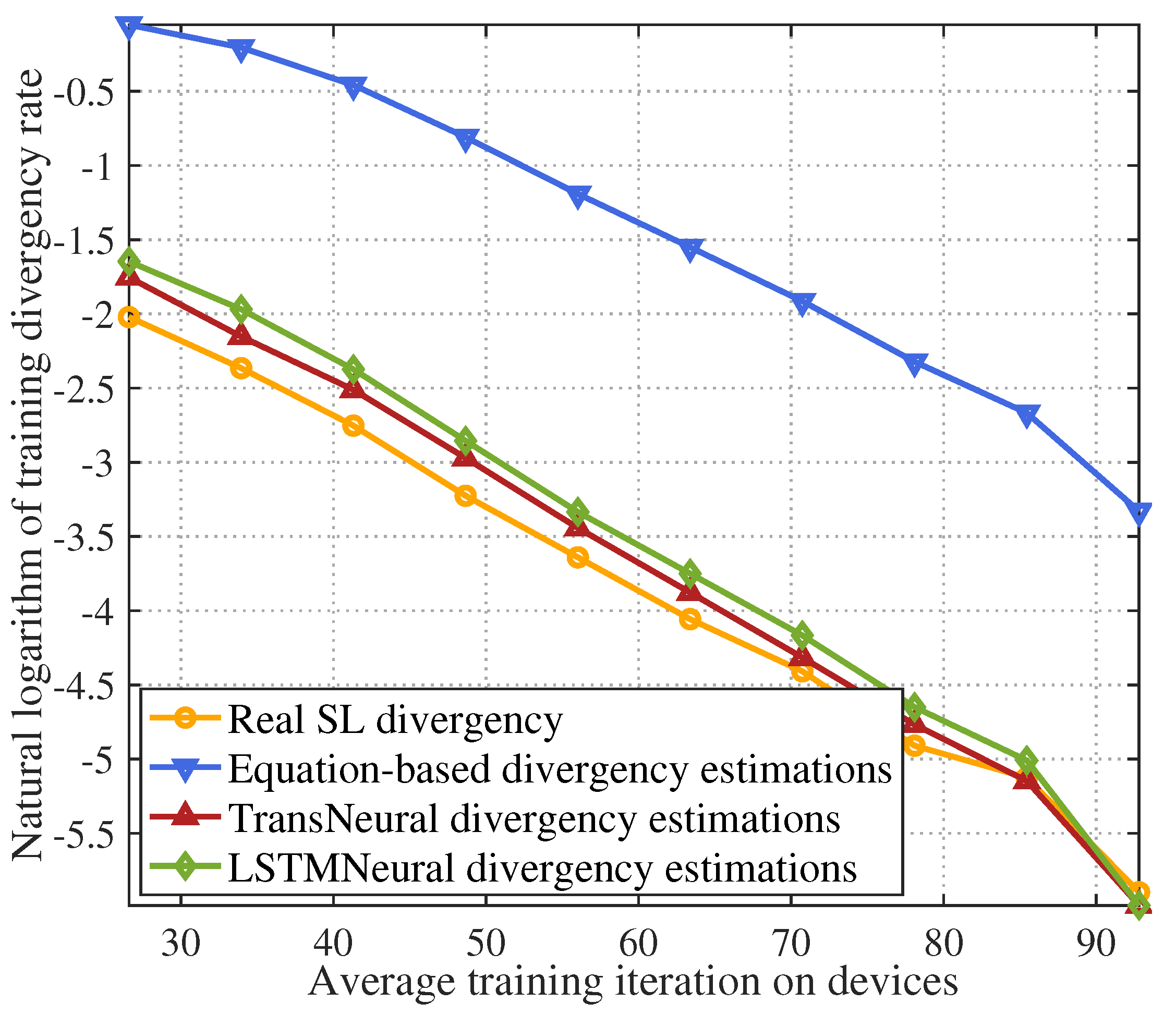
- Simulations show that the proposed TransNeural algorithm improves latency estimation accuracy by compared to traditional equation-based algorithms and enhances convergence estimation accuracy by .
2. System Description
2.1. System Model
2.2. Communication Model
2.3. Split Learning Process
2.4. Digital Twin Network
3. Transformer-Based Pre-Validation Model for DTN
3.1. Problem Analysis for SL Convergence Estimation
3.2. Problem Analysis for SL Latency Estimation
3.3. Proposed Transformer-Based Pre-Validation Model
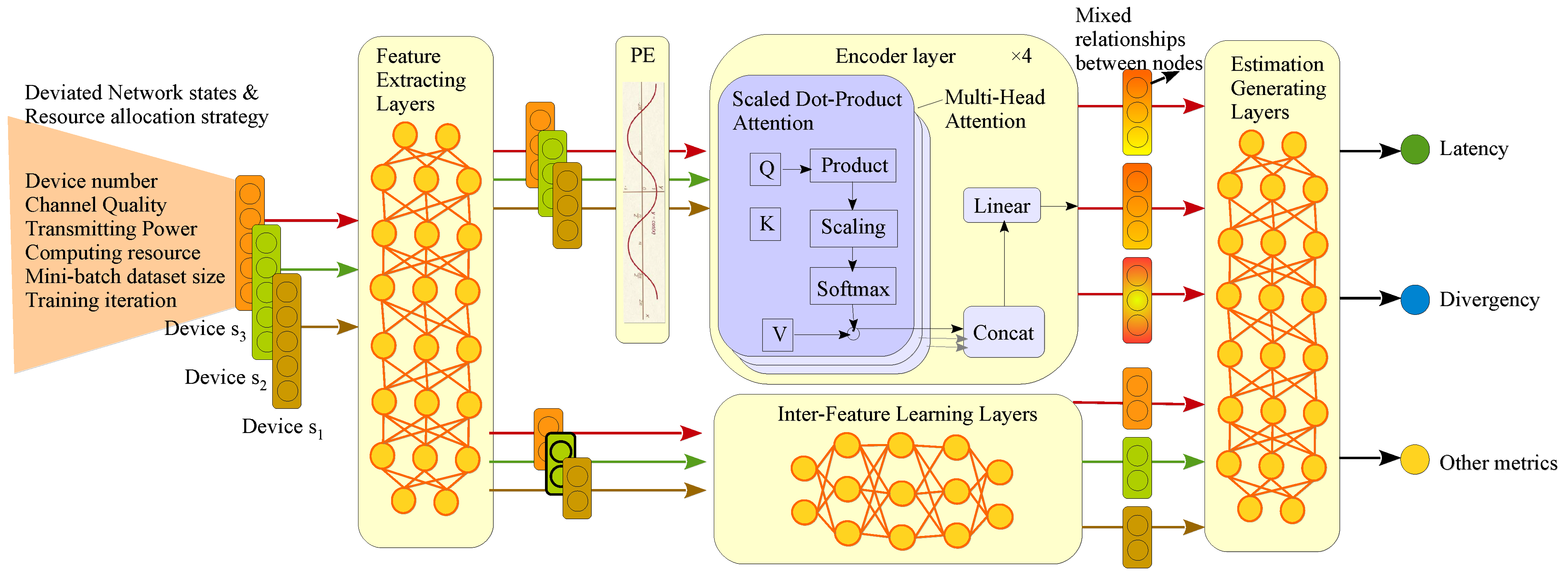
3.3.1. Overall Architecture
3.3.2. Feature Extracting Layers
3.3.3. Positional Encoding Layer
3.3.4. Encoder Layers
3.3.5. Inter-Feature Learning Layers
3.3.6. Estimation Generating Layer
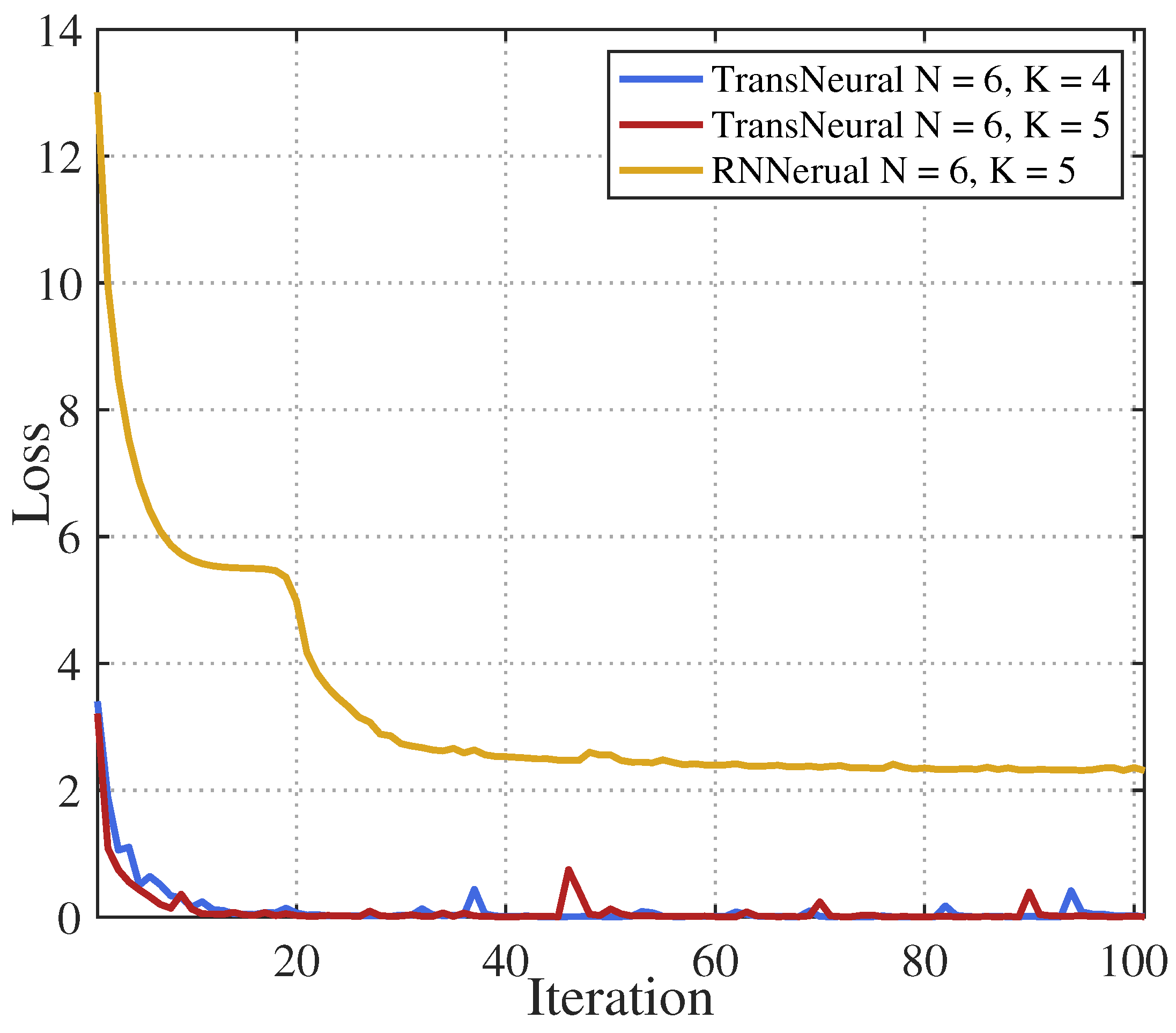
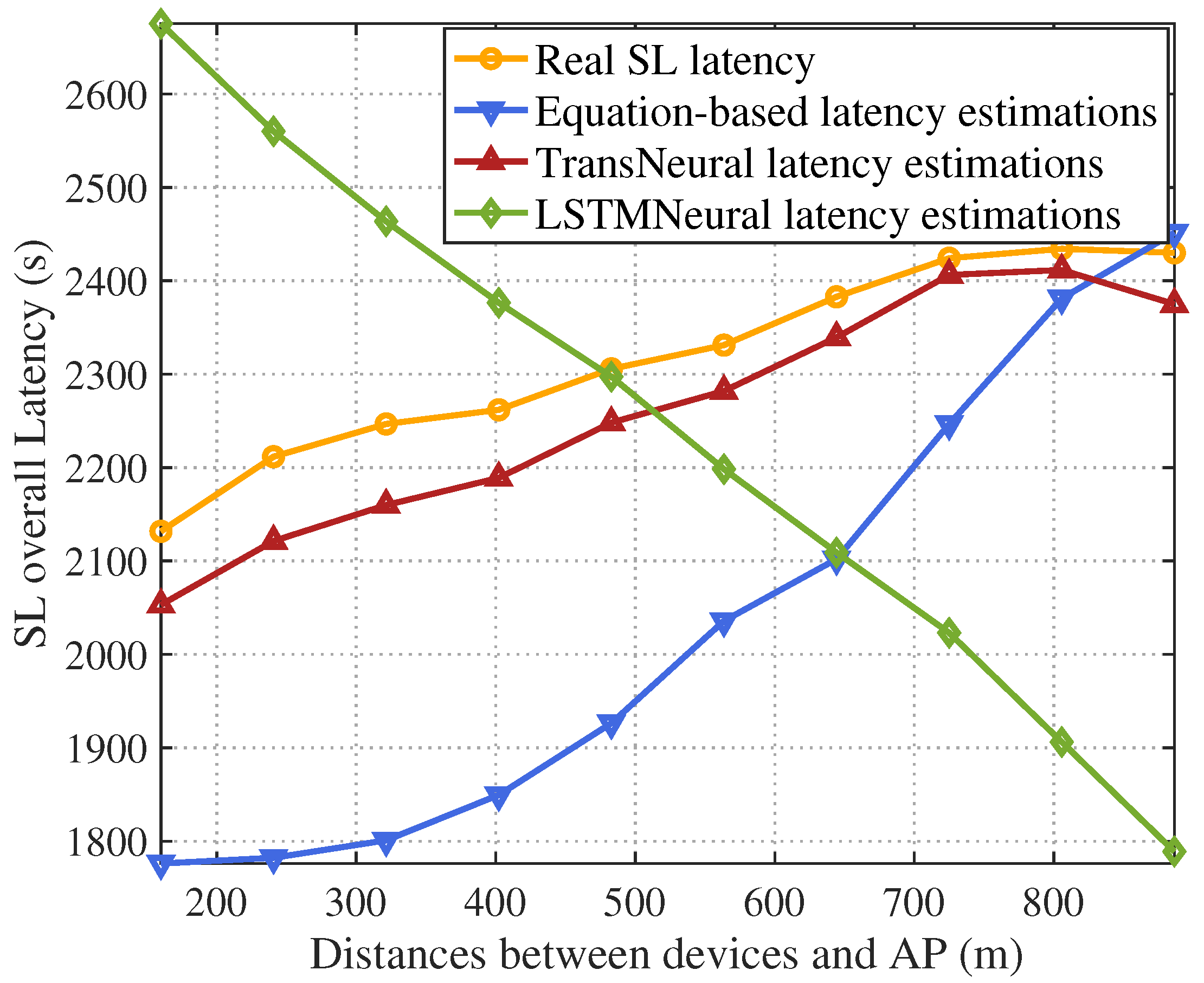
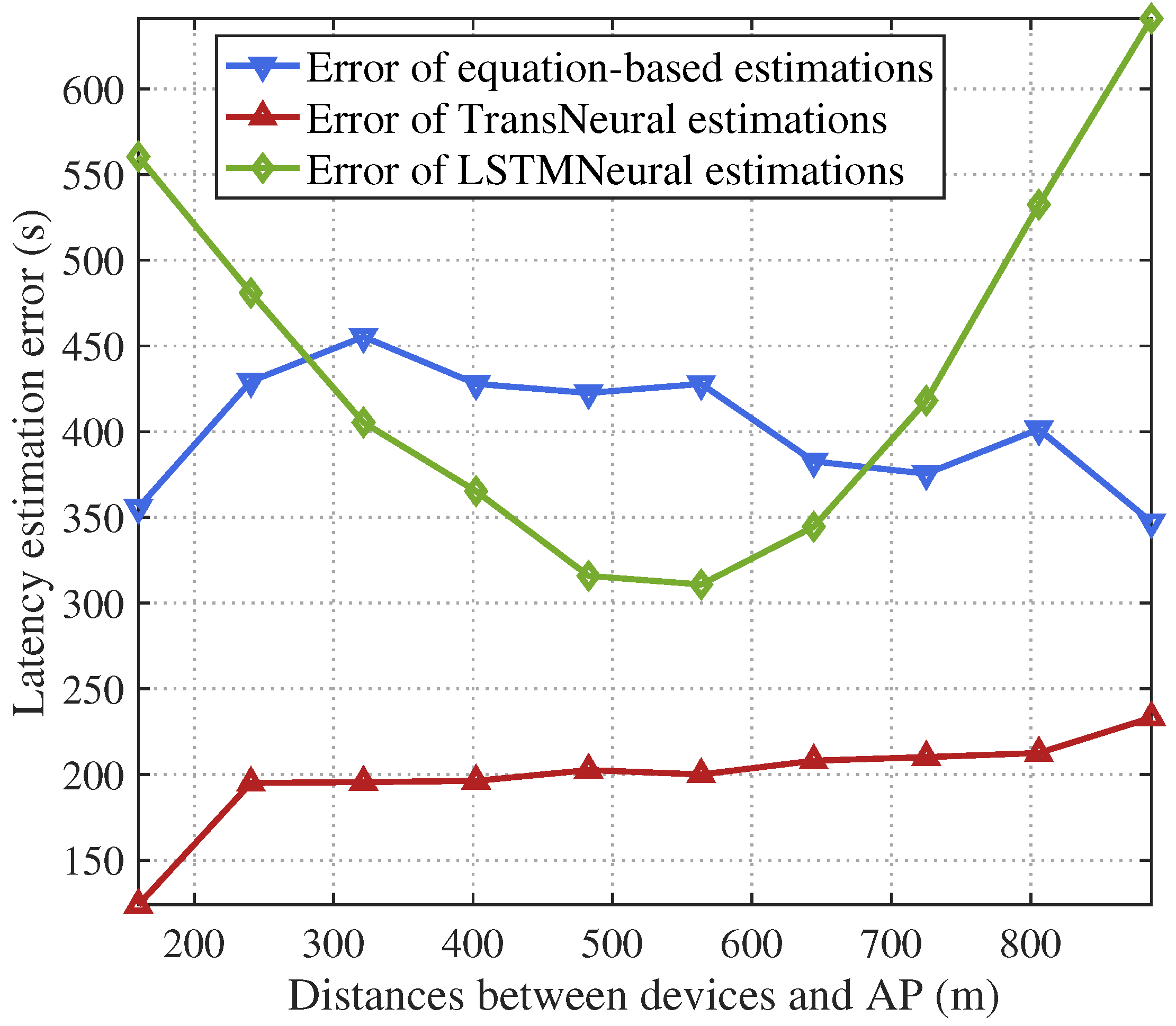
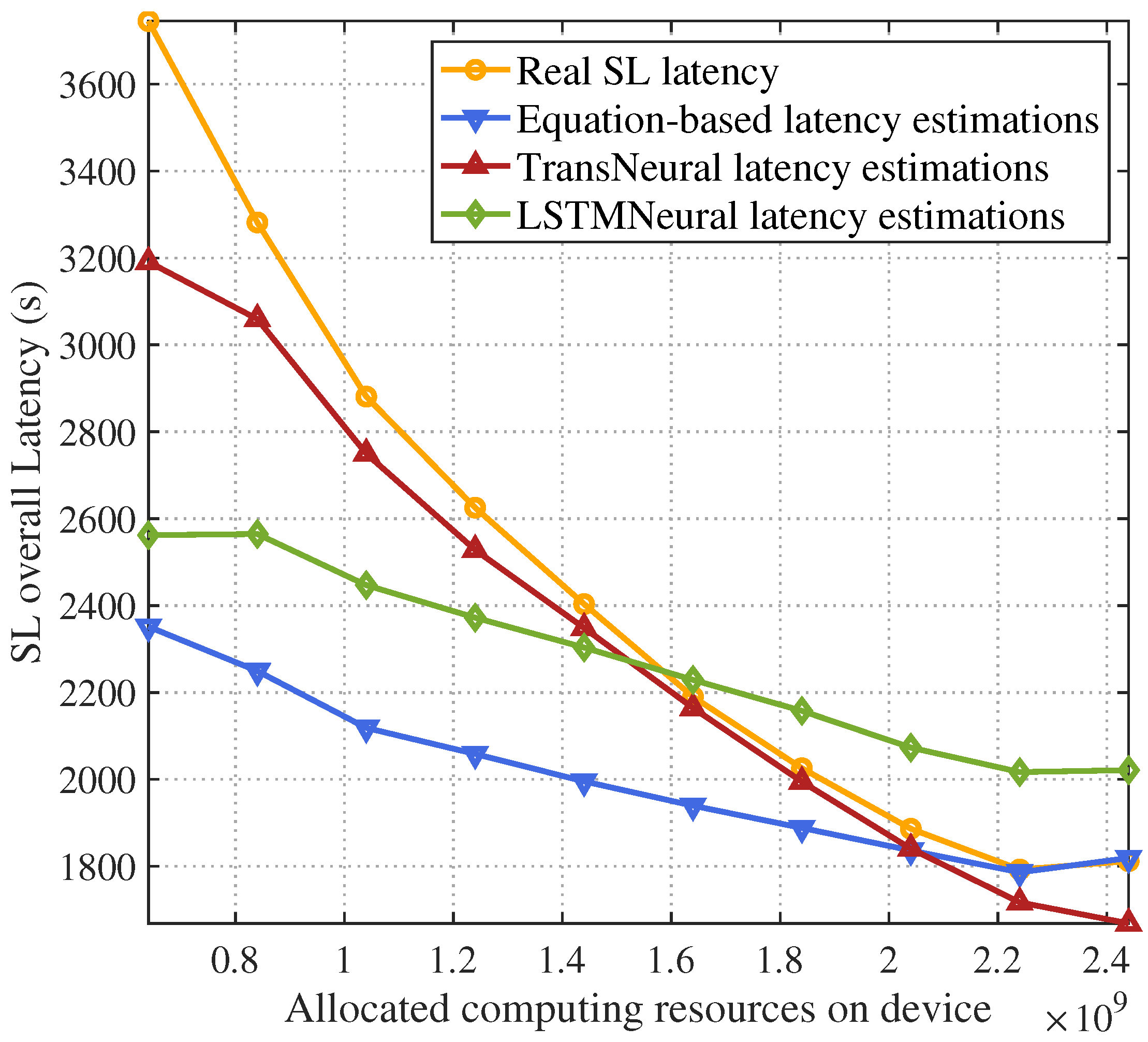
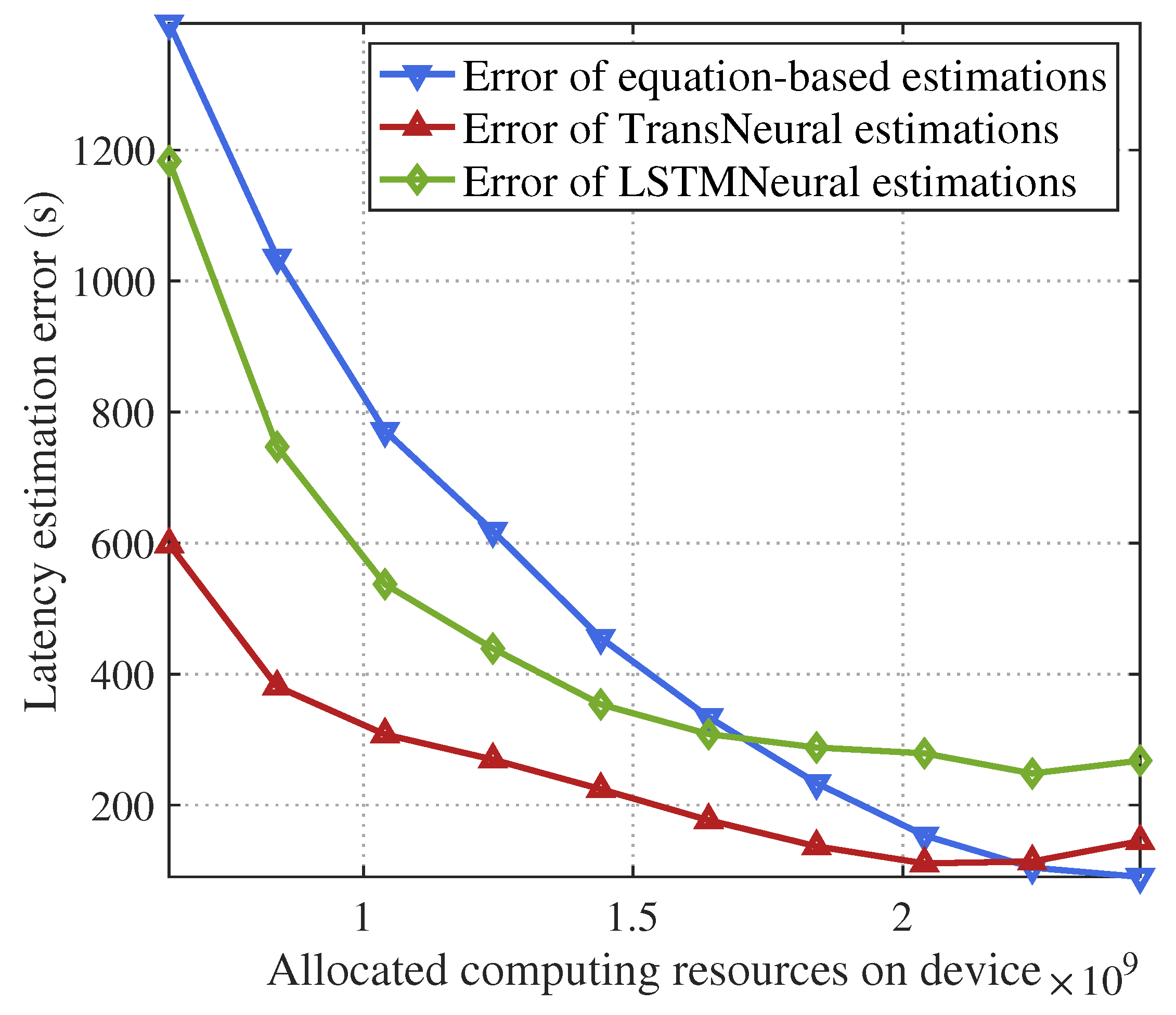
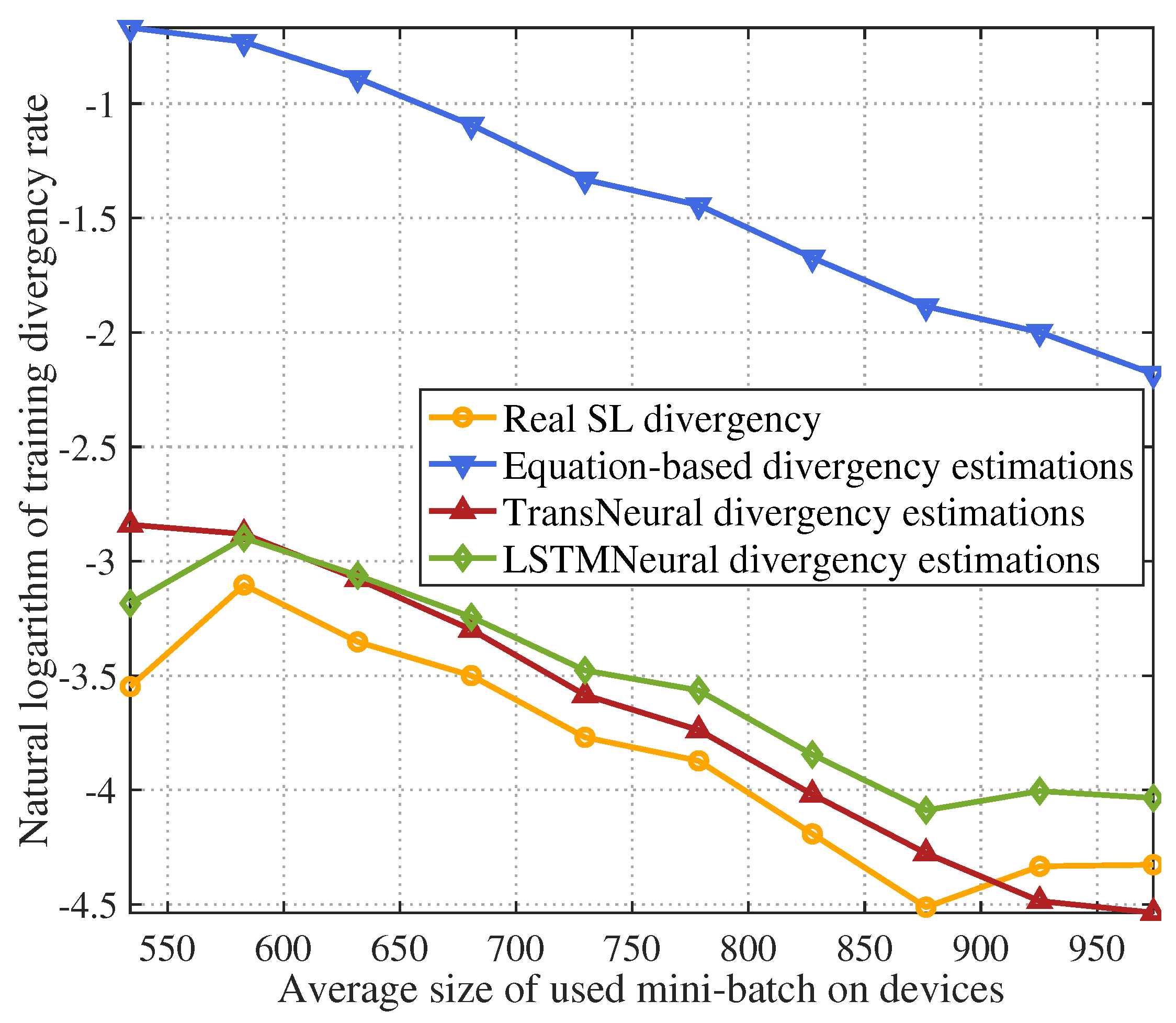
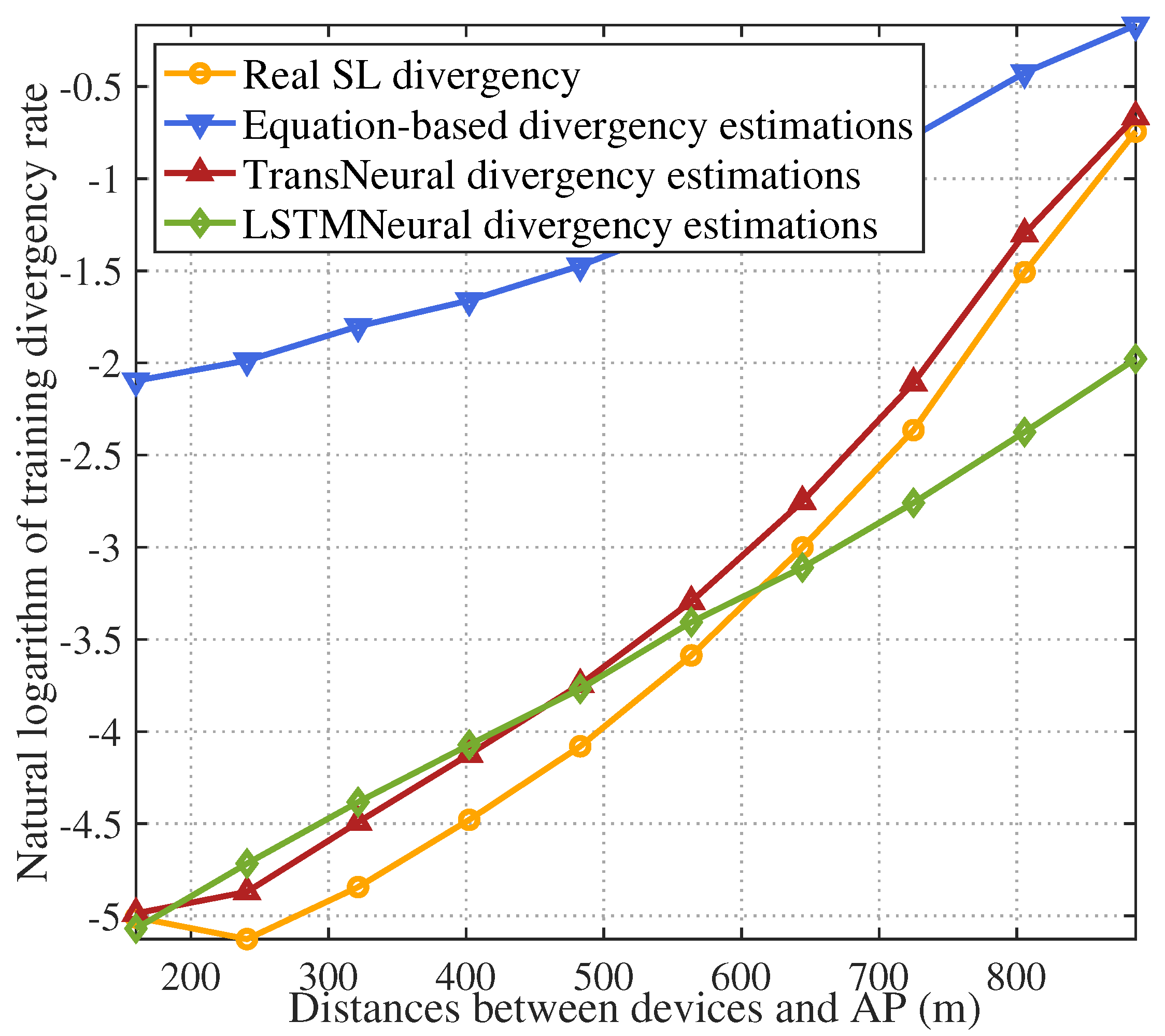
4. Simulation
- Equation-based algorithm: this algorithm estimates latency and divergency based on the equations in Section 3.1 and Section 3.2.
- LSTMNeural algorithm: We merge the long short-term memory (LSTM) and neural network to form a LSTMNeural algorithm. That is, in the architecture of proposed TransNeural algorithm, the PE layer and encoder layer are replaced by an LSTM. The input dimension of the LSTM is 16. The architecture of its hidden layer is .
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- An, K.; Sun, Y.; Lin, Z.; Zhu, Y.; Ni, W.; Al-Dhahir, N.; Wong, K.K.; Niyato, D. Exploiting Multi-Layer Refracting RIS-Assisted Receiver for HAP-SWIPT Networks. IEEE Trans. Wirel. Commun. 2024, 1. [Google Scholar] [CrossRef]
- Lin, Z.; Lin, M.; de Cola, T.; Wang, J.B.; Zhu, W.P.; Cheng, J. Supporting IoT With Rate-Splitting Multiple Access in Satellite and Aerial-Integrated Networks. IEEE Internet Things J. 2021, 8, 11123–11134. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, C.; Lan, S.; Zhu, L.; Zhang, Y. End-Edge-Cloud Collaborative Computing for Deep Learning: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2024, 1. [Google Scholar] [CrossRef]
- Wen, J.; Zhang, Z.; Lan, Y.; Cui, Z.; Cai, J.; Zhang, W. A survey on federated learning: Challenges and applications. Int. J. Mach. Learn. Cybern. 2023, 14, 513–535. [Google Scholar] [CrossRef] [PubMed]
- Shen, X.; Liu, Y.; Liu, H.; Hong, J.; Duan, B.; Huang, Z.; Mao, Y.; Wu, Y.; Wu, D. A Split-and-Privatize Framework for Large Language Model Fine-Tuning. arXiv 2023, arXiv:2312.15603. [Google Scholar]
- Lin, Z.; Qu, G.; Chen, X.; Huang, K. Split Learning in 6G Edge Networks. IEEE Wirel. Commun. 2024, 31, 170–176. [Google Scholar] [CrossRef]
- Satpathy, S.; Khalaf, O.; Kumar Shukla, D.; Chowdhary, M.; Algburi, S. A collective review of Terahertz technology integrated with a newly proposed split learningbased algorithm for healthcare system. Int. J. Comput. Digit. Syst. 2024, 15, 1–9. [Google Scholar]
- Wu, W.; Li, M.; Qu, K.; Zhou, C.; Shen, X.; Zhuang, W.; Li, X.; Shi, W. Split Learning Over Wireless Networks: Parallel Design and Resource Management. IEEE J. Sel. Areas Commun. 2023, 41, 1051–1066. [Google Scholar] [CrossRef]
- Lin, Z.; Zhu, G.; Deng, Y.; Chen, X.; Gao, Y.; Huang, K.; Fang, Y. Efficient Parallel Split Learning over Resource-constrained Wireless Edge Networks. IEEE Trans. Mob. Comput. 2024, 1–16. [Google Scholar] [CrossRef]
- Khan, L.U.; Saad, W.; Niyato, D.; Han, Z.; Hong, C.S. Digital-Twin-Enabled 6G: Vision, Architectural Trends, and Future Directions. IEEE Commun. Mag. 2022, 60, 74–80. [Google Scholar] [CrossRef]
- Kuruvatti, N.P.; Habibi, M.A.; Partani, S.; Han, B.; Fellan, A.; Schotten, H.D. Empowering 6G Communication Systems With Digital Twin Technology: A Comprehensive Survey. IEEE Access 2022, 10, 112158–112186. [Google Scholar] [CrossRef]
- Almasan, P.; Galmés, M.F.; Paillisse, J.; Suárez-Varela, J.; Perino, D.; López, D.R.; Perales, A.A.P.; Harvey, P.; Ciavaglia, L.; Wong, L.; et al. Digital Twin Network: Opportunities and Challenges. arXiv 2022, arXiv:2201.01144. [Google Scholar]
- Lai, J.; Chen, Z.; Zhu, J.; Ma, W.; Gan, L.; Xie, S.; Li, G. Deep learning based traffic prediction method for digital twin network. Cogn. Comput. 2023, 15, 1748–1766. [Google Scholar] [CrossRef] [PubMed]
- He, J.; Xiang, T.; Wang, Y.; Ruan, H.; Zhang, X. A Reinforcement Learning Handover Parameter Adaptation Method Based on LSTM-Aided Digital Twin for UDN. Sensors 2023, 23, 2191. [Google Scholar] [CrossRef] [PubMed]
- Ferriol-Galmés, M.; Suárez-Varela, J.; Paillissé, J.; Shi, X.; Xiao, S.; Cheng, X.; Barlet-Ros, P.; Cabellos-Aparicio, A. Building a Digital Twin for network optimization using Graph Neural Networks. Comput. Netw. 2022, 217, 109329. [Google Scholar] [CrossRef]
- Wang, H.; Wu, Y.; Min, G.; Miao, W. A Graph Neural Network-Based Digital Twin for Network Slicing Management. IEEE Trans. Ind. Inform. 2022, 18, 1367–1376. [Google Scholar] [CrossRef]
- Tam, D.S.H.; Liu, Y.; Xu, H.; Xie, S.; Lau, W.C. PERT-GNN: Latency Prediction for Microservice-based Cloud-Native Applications via Graph Neural Networks. In Proceedings of the KDD ’23: 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 6–10 August 2023; pp. 2155–2165. [Google Scholar] [CrossRef]
- Wang, H.; Xiao, P.; Li, X. Channel Parameter Estimation of mmWave MIMO System in Urban Traffic Scene: A Training Channel-Based Method. IEEE Trans. Intell. Transp. Syst. 2024, 25, 754–762. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Popovski, P.; Trillingsgaard, K.F.; Simeone, O.; Durisi, G. 5G wireless network slicing for eMBB, URLLC, and mMTC: A communication-theoretic view. IEEE Access 2018, 6, 55765–55779. [Google Scholar] [CrossRef]
- Hou, Z.; She, C.; Li, Y.; Zhuo, L.; Vucetic, B. Prediction and Communication Co-Design for Ultra-Reliable and Low-Latency Communications. IEEE Trans. Wirel. Commun. 2020, 19, 1196–1209. [Google Scholar] [CrossRef]
- Schiessl, S.; Gross, J.; Skoglund, M.; Caire, G. Delay Performance of the Multiuser MISO Downlink under Imperfect CSI and Finite Length Coding. IEEE J. Sel. Areas Commun. 2019, 37, 765–779. [Google Scholar] [CrossRef]
- Kang, M.; Li, X.; Ji, H.; Zhang, H. Digital twin-based framework for wireless multimodal interactions over long distance. Int. J. Commun. Syst. 2023, 36, e5603. [Google Scholar] [CrossRef]
- 3GPP 5G. Physical Layer Procedures for Data (Release 16); Technical Report, 3GPP TS 36.214; ETSI: Sophia Antipolis, France, 2020. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| Dataset on the n-th device, size of dataset on the n-th device | |
| DTN notation, network management module, network strategy module, pre-validation environment and network database in DTN | |
| Reported and real available computing resources, expected and real computing resources allocating strategy | |
| Expected transmission rate in downlink and uplink; Real transmission rate in downlink and uplink | |
| Outage probability, computing divergence, final divergence on the -th device | |
| Data correlation matrix, training iteration | |
| Bit-size of lower and upper layers in target model, bit-size of middle parameter in forward and backward propagation |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| G cycles/s | 100 G cycles/s | ||
| B | 10 MHz | K | 64 |
| W | 88 W | ||
| 1 Mbits | 1 Mbits | ||
| 100 M cycles | 100 M cycles | ||
| 1 M cycles | 1 M cycles | ||
| 1 Gbits |
| Latency Estimation (s) | Accuracy | |
|---|---|---|
| Actual SL latency | / | |
| TransNeural algorithm | ||
| LSTMNeural algorithm | ||
| Equation-based algorithm | ||
| Convergence Estimation | Accuracy | |
| Actual SL convergence | / | |
| TransNeural algorithm | ||
| LSTMNeural algorithm | ||
| Equation-based algorithm |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, G.; Kang, M.; Zhu, Y.; Zheng, Q.; Zhu, M.; Li, N. TransNeural: An Enhanced-Transformer-Based Performance Pre-Validation Model for Split Learning Tasks. Sensors 2024, 24, 5148. https://doi.org/10.3390/s24165148
Liu G, Kang M, Zhu Y, Zheng Q, Zhu M, Li N. TransNeural: An Enhanced-Transformer-Based Performance Pre-Validation Model for Split Learning Tasks. Sensors. 2024; 24(16):5148. https://doi.org/10.3390/s24165148
Chicago/Turabian StyleLiu, Guangyi, Mancong Kang, Yanhong Zhu, Qingbi Zheng, Maosheng Zhu, and Na Li. 2024. "TransNeural: An Enhanced-Transformer-Based Performance Pre-Validation Model for Split Learning Tasks" Sensors 24, no. 16: 5148. https://doi.org/10.3390/s24165148