
Partial Transfer Learning Method Based on Inter-Class Feature Transfer for Rolling Bearing Fault Diagnosis

 and
and
Abstract
1. Introduction
2. Preliminaries
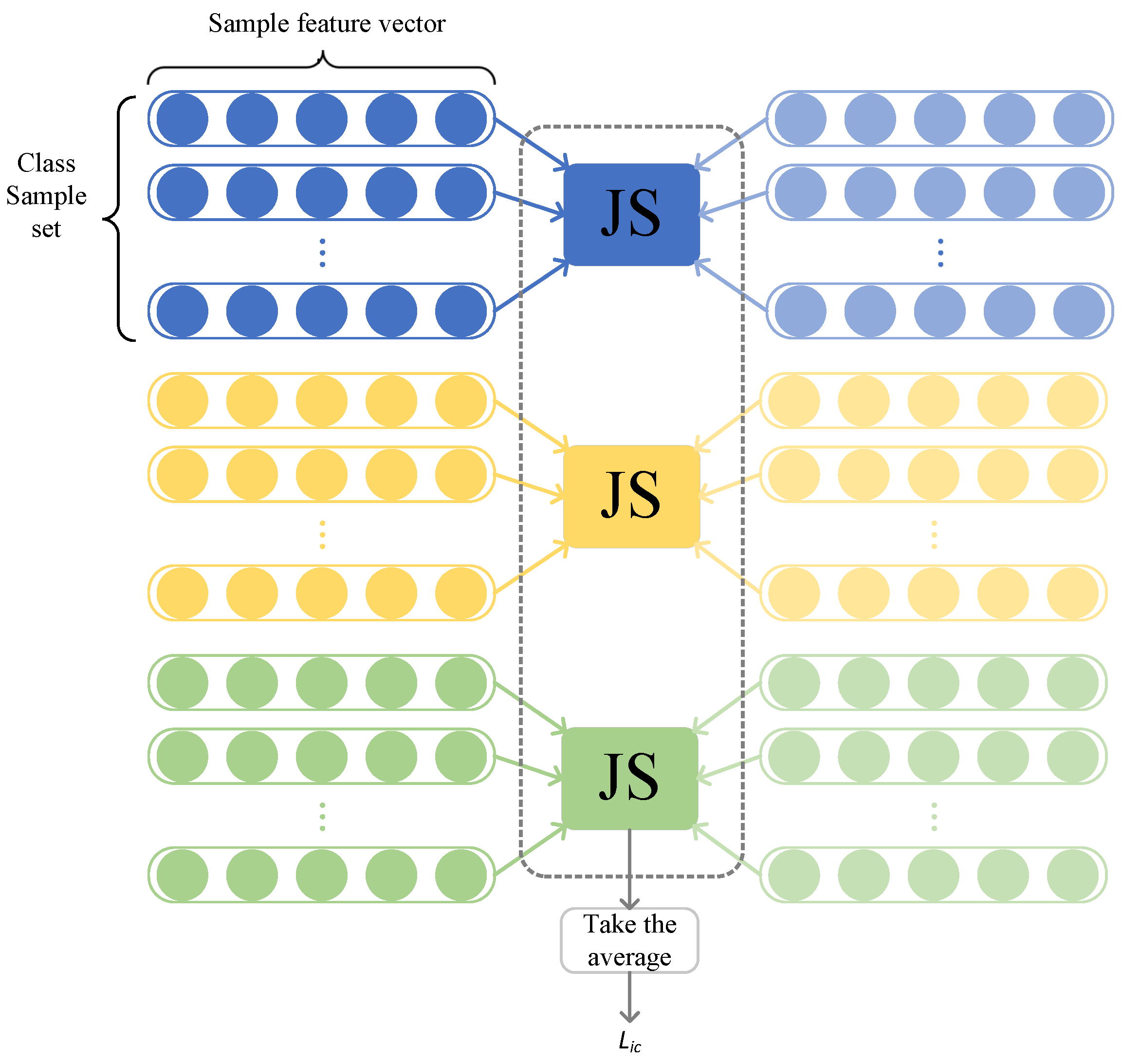
2.1. Jensen–Shannon Divergence
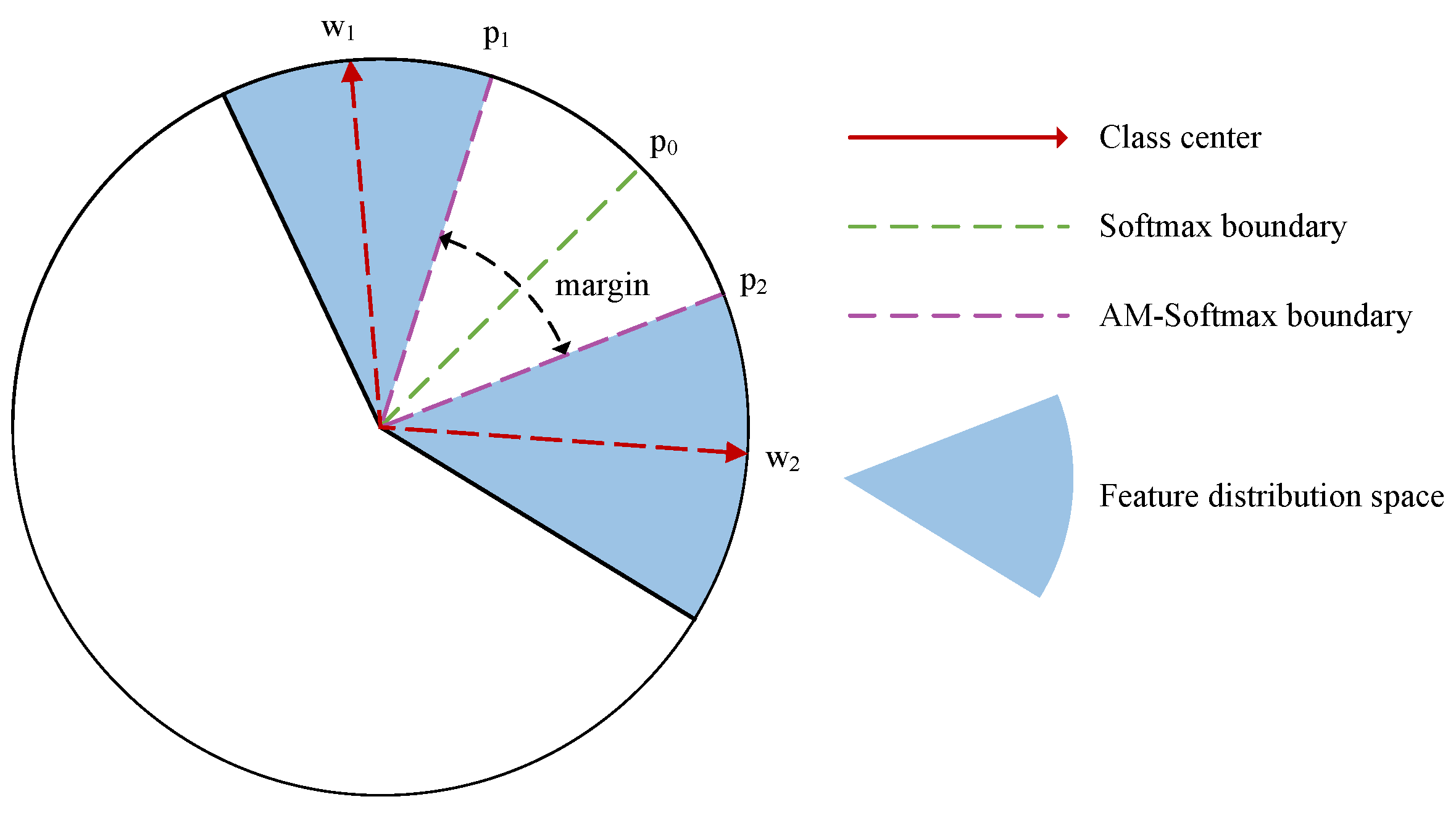
2.2. Additive Margin Softmax
3. Proposed Method
3.1. Problem Formulation
- The health status labels in the source domain are sufficient to cover all possible states in the target domain;
- Each class within the source domain has an ample amount of labeled samples;
- Each class within the target domain has an ample amount of labeled samples;
- There are differences between the source and target domains in terms of data distribution and label space.
3.2. Inter-Class Feature Transfer Module
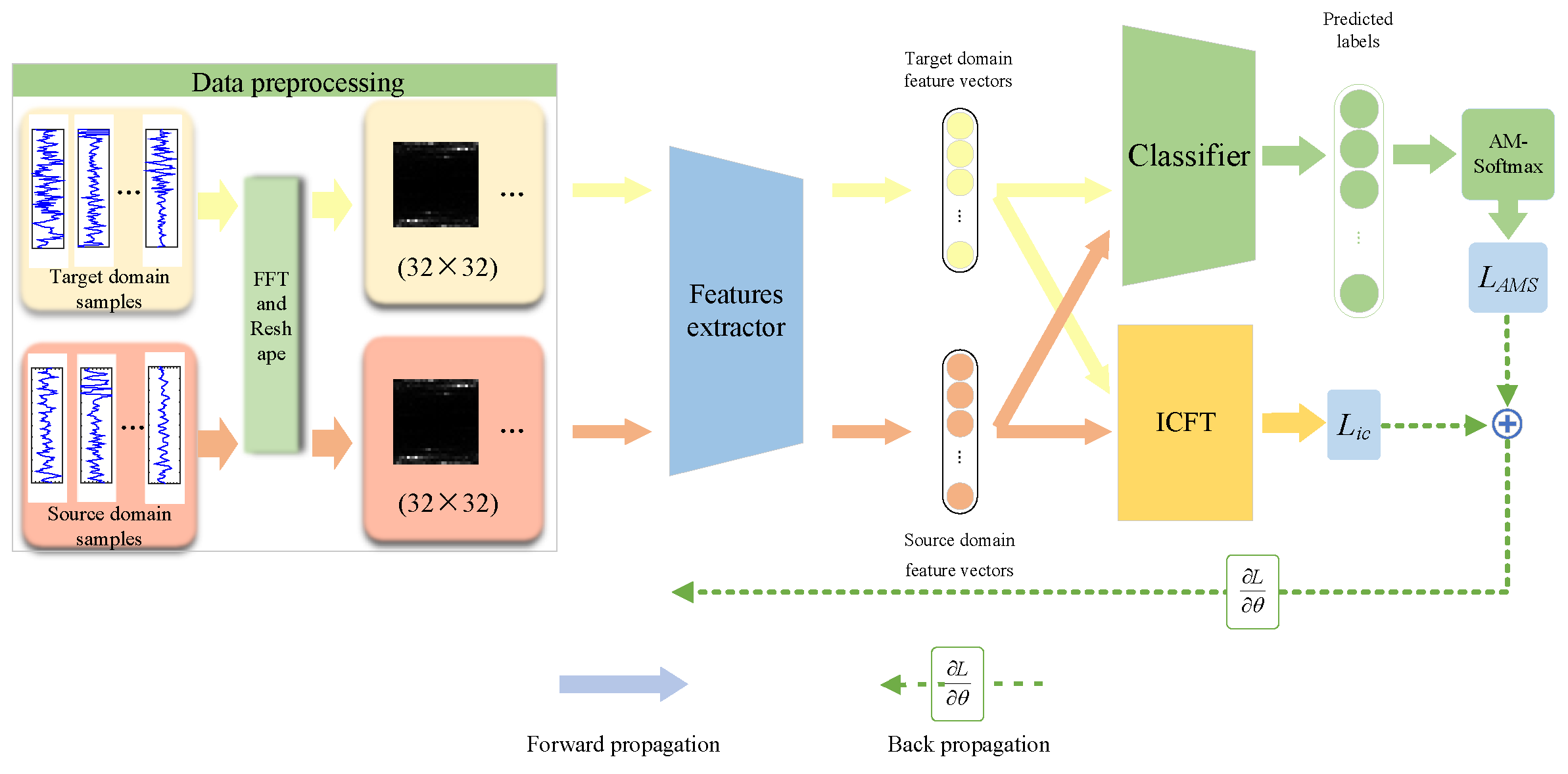
3.3. General Framework
3.4. Loss Function and Optimization
4. Experiment Results
4.1. Dataset Description
4.2. Results and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- de Las Morenas, J.; Moya-Fernández, F.; López-Gómez, J.A. The edge application of machine learning techniques for fault diagnosis in electrical machines. Sensors 2023, 23, 2649. [Google Scholar] [CrossRef]
- Purbowaskito, W.; Lan, C.y.; Fuh, K. The potentiality of integrating model-based residuals and machine-learning classifiers: An induction motor fault diagnosis case. IEEE Trans. Ind. Inform. 2023, 20, 2822–2832. [Google Scholar] [CrossRef]
- Song, Y.; Ma, Q.; Zhang, T.; Li, F.; Yu, Y. Research on fault diagnosis strategy of air-conditioning systems based on DPCA and machine learning. Processes 2023, 11, 1192. [Google Scholar] [CrossRef]
- Mian, T.; Choudhary, A.; Fatima, S. Multi-sensor fault diagnosis for misalignment and unbalance detection using machine learning. IEEE Trans. Ind. Appl. 2023, 59, 5749–5759. [Google Scholar] [CrossRef]
- Wang, H.; Zheng, J.; Xiang, J. Online bearing fault diagnosis using numerical simulation models and machine learning classifications. Reliab. Eng. Syst. Saf. 2023, 234, 109142. [Google Scholar] [CrossRef]
- Cui, L.; Dong, Z.; Xu, H.; Zhao, D. Triplet attention-enhanced residual tree-inspired decision network: A hierarchical fault diagnosis model for unbalanced bearing datasets. Adv. Eng. Inform. 2024, 59, 102322. [Google Scholar] [CrossRef]
- Wan, L.; Gong, K.; Zhang, G.; Yuan, X.; Li, C.; Deng, X. An efficient rolling bearing fault diagnosis method based on spark and improved random forest algorithm. IEEE Access 2021, 9, 37866–37882. [Google Scholar] [CrossRef]
- Sun, B.; Liu, X. Significance support vector machine for high-speed train bearing fault diagnosis. IEEE Sensors J. 2021, 23, 4638–4646. [Google Scholar] [CrossRef]
- Liang, X.; Yao, J.; Zhang, W.; Wang, Y. A novel fault diagnosis of a rolling bearing method based on variational mode decomposition and an artificial neural network. Appl. Sci. 2023, 13, 3413. [Google Scholar] [CrossRef]
- Zhu, J.; Hu, T.; Jiang, B.; Yang, X. Intelligent bearing fault diagnosis using PCA–DBN framework. Neural Comput. Appl. 2020, 32, 10773–10781. [Google Scholar] [CrossRef]
- Pei, X.; Zheng, X.; Wu, J. Intelligent bearing fault diagnosis based on Teager energy operator demodulation and multiscale compressed sensing deep autoencoder. Measurement 2021, 179, 109452. [Google Scholar] [CrossRef]
- Zou, P.; Hou, B.; Lei, J.; Zhang, Z. Bearing fault diagnosis method based on EEMD and LSTM. Int. J. Comput. Commun. Control 2020, 15. [Google Scholar] [CrossRef]
- Li, W.; Chen, J.; Li, J.; Xia, K. Derivative and enhanced discrete analytic wavelet algorithm for rolling bearing fault diagnosis. Microprocess. Microsyst. 2021, 82, 103872. [Google Scholar] [CrossRef]
- Chen, J.; Jiang, J.; Guo, X.; Tan, L. An Efficient CNN with Tunable Input-Size for Bearing Fault Diagnosis. Int. J. Comput. Intell. Syst. 2021, 14, 625–634. [Google Scholar] [CrossRef]
- Hu, Z.; Han, T.; Bian, J.; Wang, Z.; Cheng, L.; Zhang, W.; Kong, X. A deep feature extraction approach for bearing fault diagnosis based on multi-scale convolutional autoencoder and generative adversarial networks. Meas. Sci. Technol. 2022, 33, 065013. [Google Scholar] [CrossRef]
- Gu, K.; Zhang, Y.; Liu, X.; Li, H.; Ren, M. DWT-LSTM-based fault diagnosis of rolling bearings with multi-sensors. Electronics 2021, 10, 2076. [Google Scholar] [CrossRef]
- Csurka, G. Domain adaptation for visual applications: A comprehensive survey. arXiv 2017, arXiv:1702.05374. [Google Scholar]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M. Learning transferable features with deep adaptation networks. In Proceedings of the International Conference on Machine Learning (PMLR), Lille, France, 6–11 July 2015; pp. 97–105. [Google Scholar]
- Chen, X.; Yang, R.; Xue, Y.; Huang, M.; Ferrero, R.; Wang, Z. Deep transfer learning for bearing fault diagnosis: A systematic review since 2016. IEEE Trans. Instrum. Meas. 2023, 72, 1–21. [Google Scholar] [CrossRef]
- Qureshi, A.S.; Khan, A.; Zameer, A.; Usman, A. Wind power prediction using deep neural network based meta regression and transfer learning. Appl. Soft Comput. 2017, 58, 742–755. [Google Scholar] [CrossRef]
- Xiao, D.; Huang, Y.; Qin, C.; Liu, Z.; Li, Y.; Liu, C. Transfer learning with convolutional neural networks for small sample size problem in machinery fault diagnosis. Proc. Inst. Mech. Eng. Part C J. Mech. Eng. Sci. 2019, 233, 5131–5143. [Google Scholar] [CrossRef]
- Wang, K.; Wu, B. Power equipment fault diagnosis model based on deep transfer learning with balanced distribution adaptation. In Proceedings of the International Conference on Advanced Data Mining and Applications, Nanjing, China, 16–18 November 2018; pp. 178–188. [Google Scholar]
- Xie, Y.; Zhang, T. A transfer learning strategy for rotation machinery fault diagnosis based on cycle-consistent generative adversarial networks. In Proceedings of the IEEE 2018 Chinese Automation Congress (CAC), Xi’an, China, 30 November–2 December 2018; pp. 1309–1313. [Google Scholar]
- Cao, P.; Zhang, S.; Tang, J. Preprocessing-free gear fault diagnosis using small datasets with deep convolutional neural network-based transfer learning. IEEE Access 2018, 6, 26241–26253. [Google Scholar] [CrossRef]
- Chen, R.; Chen, S.; Yang, L.; Xu, X.; Dong, S.; Tang, L. Fault diagnosis of rolling bearings based on improved TrAdaBoost multi-classification algorithm. J. Vib. Shock 2019, 38, 36–41. [Google Scholar]
- Yang, B.; Lei, Y.; Jia, F.; Li, N.; Du, Z. A polynomial kernel induced distance metric to improve deep transfer learning for fault diagnosis of machines. IEEE Trans. Ind. Electron. 2019, 67, 9747–9757. [Google Scholar] [CrossRef]
- Han, T.; Liu, C.; Yang, W.; Jiang, D. A novel adversarial learning framework in deep convolutional neural network for intelligent diagnosis of mechanical faults. Knowl.-Based Syst. 2019, 165, 474–487. [Google Scholar] [CrossRef]
- Wang, F.; Cheng, J.; Liu, W.; Liu, H. Additive margin softmax for face verification. IEEE Signal Process. Lett. 2018, 25, 926–930. [Google Scholar] [CrossRef]
- Bao, H.; Yan, Z.; Ji, S.; Wang, J.; Jia, S.; Zhang, G.; Han, B. An enhanced sparse filtering method for transfer fault diagnosis using maximum classifier discrepancy. Meas. Sci. Technol. 2021, 32, 085105. [Google Scholar] [CrossRef]
- Jin, Y.; Wang, X.; Long, M.; Wang, J. Minimum class confusion for versatile domain adaptation. In Proceedings of the 16th European Conference of the Computer Vision (ECCV 2020), Glasgow, UK, 23–28 August 2020; pp. 464–480. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class Label | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| Fault Location | 0 | IF | IF | IF | BF | BF | BF | OF | OF | OF | |
| Dataset I Dataset II | Fault Size (mm) | N/A | 0.2 | 0.4 | 0.6 | 0.2 | 0.4 | 0.6 | 0.2 | 0.4 | 0.6 |
| Domain | Load | Available Labels (as Source Domain) | Available Labels (as Target Domain) | Sample Size (as Source Domain) | Sample Size (as Target Domain) | Test Sample Size | |
|---|---|---|---|---|---|---|---|
| Dataset I | A | 0 N | 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 | 0, 3, 7, 9 | 200 | 200 | 200 |
| B | 20 N | 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 | 0, 3, 7, 9 | 200 | 200 | 200 | |
| C | 40 N | 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 | 0, 3, 7, 9 | 200 | 200 | 200 | |
| D | 60 N | 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 | 0, 3, 7, 9 | 200 | 200 | 200 | |
| Dataset II | A | 1 kN | 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 | 0, 3, 7, 9 | 200 | 200 | 200 |
| B | 2 kN | 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 | 0, 3, 7, 9 | 200 | 200 | 200 | |
| C | 3 kN | 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 | 0, 3, 7, 9 | 200 | 200 | 200 |
| Method | Description |
|---|---|
| M1 | Only source domain data are used for training, and CE loss function is used in the training process |
| M2 | The CE loss function is used to train the data of source domain and target domain |
| M3 | CE + MMD |
| M4 | DANN + Labeled target domain sample, CE loss |
| M5 | IWAN + Labeled target domain sample, CE loss |
| M6 | PADA + Labeled target domain sample, CE loss |
| M7 | Minimum Class Confusion (MCC) [30] + Unlabeled target domain sample, CE loss |
| M8 | MCC + Labeled target domain sample, CE loss |
| A1 | Only AM-Softmax loss function is used |
| ICFT | The proposed complete method |
| Task | M1 | M2 | M3 | M4 | M5 | M6 | M7 | M8 | A1 | ICFT |
|---|---|---|---|---|---|---|---|---|---|---|
| A→B | 58.80 ± 2.93 | 73.40 ± 1.94 | 74.03 ± 1.53 | 53.23 ± 5.81 | 54.88 ± 2.79 | 47.31 ± 1.03 | 49.44 ± 2.42 | 58.33 ± 1.24 | 73.22 ± 1.77 | 77.09 ± 2.27 |
| A→C | 50.73 ± 2.95 | 68.38 ± 0.34 | 68.6 ± 0.31 | 48.57 ± 4.95 | 49.32 ± 2.10 | 45.61 ± 1.76 | 41.39 ± 1.94 | 49.44 ± 1.11 | 68.22 ± 0.86 | 69.85 ± 1.61 |
| A→D | 51.48 ± 2.39 | 65.27 ± 0.68 | 67.45 ± 0.93 | 47.01 ± 6.13 | 47.73 ± 3.94 | 45.41 ± 2.08 | 58.06 ± 1.94 | 62.5 ± 1.39 | 65.2 ± 0.91 | 67.77 ± 1.97 |
| B→A | 54.56 ± 2.87 | 69.02 ± 0.42 | 69.61 ± 0.50 | 47.32 ± 4.00 | 49.06 ± 4.33 | 48.86 ± 1.35 | 58.06 ± 2.30 | 66.11 ± 1.11 | 70.44 ± 2.36 | 70.53 ± 0.66 |
| B→C | 95.29 ± 2.13 | 99.88 ± 0.06 | 99.83 ± 0.10 | 81.81 ± 2.56 | 84.53 ± 3.09 | 76.99 ± 2.22 | 97.22 ± 2.15 | 99.44 ± 1.11 | 99.60 ± 0.26 | 99.86 ± 0.09 |
| B→D | 88.25 ± 2.70 | 99.07 ± 0.22 | 98.72 ± 0.17 | 74.56 ± 3.76 | 78.03 ± 3.91 | 62.51 ± 6.41 | 91.11 ± 1.11 | 99.44 ± 1.11 | 97.83 ± 1.66 | 98.51 ± 0.54 |
| C→A | 44.7 ± 1.98 | 66.67 ± 0.56 | 65.52 ± 0.37 | 38.15 ± 2.52 | 41.27 ± 4.77 | 43.71 ± 1.54 | 48.61 ± 2.85 | 62.78 ± 1.36 | 65.18 ± 1.26 | 67.13 ± 0.47 |
| C→B | 93.76 ± 2.33 | 99.02 ± 0.17 | 99.44 ± 0.16 | 83.08 ± 2.53 | 80.68 ± 4.17 | 52.31 ± 2.69 | 92.78 ± 2.54 | 95.00 ± 1.67 | 99.2 ± 0.27 | 99.71 ± 0.12 |
| C→D | 96.66 ± 0.88 | 99.80 ± 0.09 | 99.84 ± 0.04 | 84.35 ± 2.39 | 85.22 ± 2.51 | 64.12 ± 3.21 | 98.05 ± 1.78 | 100.00 ± 0.00 | 99.75 ± 0.09 | 99.82 ± 0.06 |
| D→A | 50.23 ± 2.09 | 63.87 ± 0.69 | 66.12 ± 1.01 | 39.38 ± 3.56 | 42.31 ± 4.76 | 42.39 ± 0.85 | 47.78 ± 1.11 | 62.22 ± 1.36 | 63.59 ± 1.51 | 66.85 ± 0.43 |
| D→B | 84.88 ± 3.71 | 96.77 ± 0.38 | 98.21 ± 0.35 | 73.81 ± 2.78 | 75.49 ± 2.93 | 52.52 ± 3.05 | 84.17 ± 3.05 | 90.28 ± 3.11 | 96.05 ± 0.99 | 98.74 ± 0.21 |
| D→C | 95.6 ± 1.16 | 98.78 ± 0.47 | 97.49 ± 0.34 | 83.65 ± 2.05 | 85.73 ± 3.98 | 66.24 ± 5.33 | 97.22 ± 0.00 | 97.22 ± 0.00 | 97.8 ± 0.82 | 98.71 ± 0.49 |
| Average | 72.08 | 83.33 | 83.74 | 62.91 | 64.52 | 54.00 | 71.99 | 78.56 | 83.00 | 84.55 |
| Task | M1 | M2 | M3 | M4 | M5 | M6 | M7 | M8 | A1 | ICFT |
|---|---|---|---|---|---|---|---|---|---|---|
| A→B | 79.02 ± 1.23 | 87.10 ± 0.61 | 88.30 ± 1.30 | 87.47 ± 0.26 | 66.26 ± 4.18 | 48.74 ± 2.99 | 84.16 ± 1.78 | 100.00 ± 0.00 | 87.59 ± 0.30 | 94.14 ± 3.70 |
| A→C | 82.96 ± 1.05 | 86.96 ± 0.49 | 84.62 ± 0.59 | 87.19 ± 2.45 | 58.88 ± 4.34 | 48.62 ± 1.29 | 78.61 ± 1.27 | 85.28 ± 1.27 | 90.10 ± 2.22 | 91.69 ± 3.16 |
| B→A | 88.85 ± 0.12 | 98.69 ± 0.19 | 97.41 ± 0.45 | 98.71 ± 0.34 | 75.74 ± 4.09 | 47.07 ± 1.32 | 83.33 ± 0.00 | 100.00 ± 0.00 | 98.65 ± 0.18 | 98.89 ± 0.31 |
| B→C | 97.61 ± 0.21 | 97.05 ± 0.24 | 91.82 ± 1.10 | 96.66 ± 0.63 | 83.47 ± 4.39 | 54.53 ± 1.62 | 94.72 ± 1.50 | 93.05 ± 1.385 | 97.02 ± 0.37 | 97.76 ± 0.82 |
| C→A | 87.67 ± 0.10 | 97.03 ± 0.22 | 94.44 ± 1.03 | 96.30 ± 1.15 | 67.03 ± 8.32 | 43.32 ± 1.90 | 73.61 ± 1.39 | 90.56 ± 1.36 | 97.54 ± 0.18 | 97.59 ± 0.40 |
| C→B | 97.77 ± 0.10 | 97.65 ± 0.18 | 95.93 ± 0.56 | 97.69 ± 0.52 | 80.08 ± 3.16 | 60.76 ± 3.91 | 93.33 ± 1.36 | 99.72 ± 0.83 | 97.31 ± 0.34 | 97.31 ± 0.36 |
| Average | 88.98 | 94.08 | 92.09 | 94.00 | 71.91 | 50.51 | 84.63 | 94.77 | 94.70 | 96.23 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Que, H.; Liu, X.; Jin, S.; Huo, Y.; Wu, C.; Ding, C.; Zhu, Z. Partial Transfer Learning Method Based on Inter-Class Feature Transfer for Rolling Bearing Fault Diagnosis. Sensors 2024, 24, 5165. https://doi.org/10.3390/s24165165
Que H, Liu X, Jin S, Huo Y, Wu C, Ding C, Zhu Z. Partial Transfer Learning Method Based on Inter-Class Feature Transfer for Rolling Bearing Fault Diagnosis. Sensors. 2024; 24(16):5165. https://doi.org/10.3390/s24165165
Chicago/Turabian StyleQue, Hongbo, Xuyan Liu, Siqin Jin, Yaoyan Huo, Chengpan Wu, Chuancang Ding, and Zhongkui Zhu. 2024. "Partial Transfer Learning Method Based on Inter-Class Feature Transfer for Rolling Bearing Fault Diagnosis" Sensors 24, no. 16: 5165. https://doi.org/10.3390/s24165165
APA StyleQue, H., Liu, X., Jin, S., Huo, Y., Wu, C., Ding, C., & Zhu, Z. (2024). Partial Transfer Learning Method Based on Inter-Class Feature Transfer for Rolling Bearing Fault Diagnosis. Sensors, 24(16), 5165. https://doi.org/10.3390/s24165165