

Mobile Network Coverage Prediction Using Multi-Modal Model Based on Deep Neural Networks and Semantic Segmentation


Abstract
:1. Introduction
- Much of the work relies on additional information about the base station, such as height, transmission power, antenna gain, etc. Some of the work also needs the assistance of a path loss model. Both increase the complexity for coverage prediction on a large scale.
- Data augmentation such as translation and rotation are often needed to process satellite images. ResNet, VGG16, or a custom CNN are used to extract features from these images. These processes increase the complexity of the model.
- Most existing works only discuss the results of the model on the test set. Since the test set comes from random sampling of the dataset, the prediction of the test set is essentially close to interpolation based on neighboring positions, without considering the prediction effect of the model in an unknown area without measurement points.
- We designed the multi-modal model DNN-SS based on a DNN and semantic segmentation. The model does not rely on a path loss model or the height and transmission power of the base station, and only uses the latitude and longitude of a smartphone and base station combined with a satellite map of the measurement area to realize mobile network coverage prediction.
- We used a pre-trained semantic segmentation model based on OCRNet (Object-Contextual Representations for Semantic Segmentation) to process satellite images of the measurement area. Then, we used a DNN to extract the rich environmental features of each measurement point from the results after semantic segmentation, which improved prediction performance.
- We analyzed the possible fluctuation of data in large-scale measurements, and proposed a geospatial-temporal moving average filter algorithm to reduce the impact of outliers on the model.
- Unlike existing works that focus on random location prediction, this paper discusses two cases to evaluate the generalization ability of the model: 1. random locations with some measurement data; and 2. a test area without measurement data. The measurement experiments on campus show that DNN-SS is validated for two cases, a random location and a test area, respectively, which demonstrates good performance of the proposed method for mobile network coverage prediction.
2. Measurement and Dataset
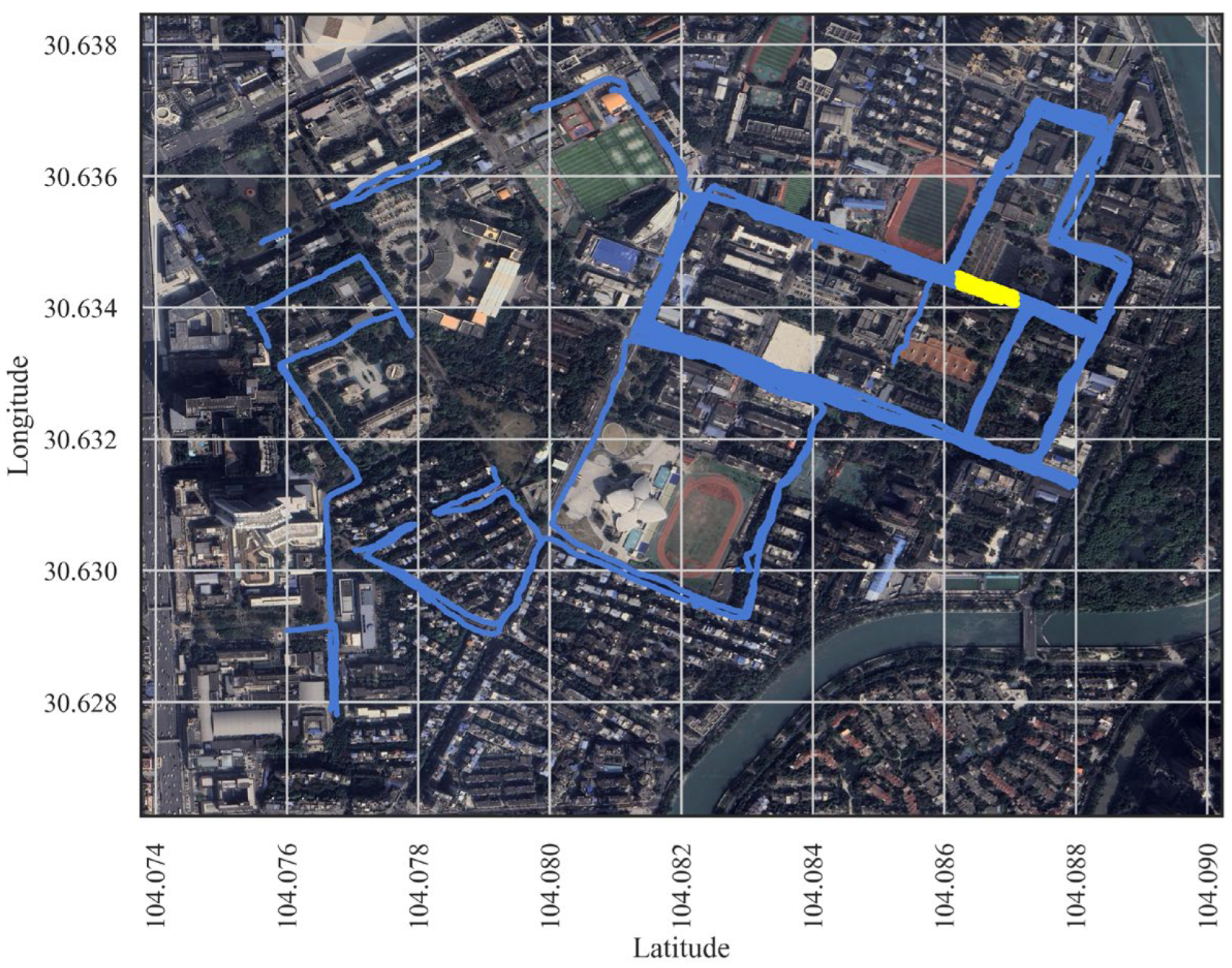
2.1. Environment of Measurement
2.2. Measurement Setup
2.3. Satellite Maps
2.4. Dataset
3. Methodology
3.1. System Architecture
3.2. Numerical Features
3.2.1. Geospatial-Temporal Moving Average Filter
| Algorithm 1. Geospatial-temporal moving average filter | |
| Inputs: | Dataset Draw, Distance, Interval |
| Output: | Dataset Dnew |
| 1 | Dnew ← {}; |
| 2 | for item ∈ Draw do |
| 3 | group ← {item}; |
| 4 | for d ∈ Draw do |
| 5 | if (item.distance – d.distance) ≤ Distance and (item.timstamp – d.timstamp) ≤ Interval then |
| 6 | group ← group ∪ {d}; |
| 7 | item.RSRP = Mean (group.RSRP) |
| 8 | Dnew ← Dnew ∪ {item}; |
| 9 | return Dnew |
3.2.2. Handcrafted Features
3.3. Environmental Features
3.3.1. Semantic Segmentation
3.3.2. Generation of the Environment Matrix
| Algorithm 2. Generate environment sub-matrix set | |
| Inputs: | Earea, D, box, height, width, size |
| Output: | E |
| 1 | E ← {}; |
| 2 | for item ∈ D do: |
| 3 | //get x and y coordinates of measurement point from latitude and longitude |
| 4 | x, y = ConvertLocation2Index (item.latitude, item.longitude, width, height, box); |
| 5 | //get a submatrix of measurement point from Earea according to x and y coordinates |
| 6 | Epoint = GetSubMatrixByIndex (Earea, x, y, size) |
| 7 | E ←E ∪ {Epoint}; |
| 8 | return E |
3.4. Prediction Network
3.5. Evaluation Metrics
4. Experimental Results
4.1. Training Setup
4.2. Prediction of Random Locations
4.3. Prediction of Test Area
4.4. Comparison of Models
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Taufique, A.; Jaber, M.; Imran, A.; Dawy, Z.; Yacoub, E. Planning Wireless Cellular Networks of Future: Outlook, Challenges and Opportunities. IEEE Access 2017, 5, 4821–4845. [Google Scholar] [CrossRef]
- Borralho, R.; Mohamed, A.; Quddus, A.U.; Vieira, P.; Tafazolli, R. A Survey on Coverage Enhancement in Cellular Networks: Challenges and Solutions for Future Deployments. IEEE Commun. Surv. Tutor. 2021, 23, 1302–1341. [Google Scholar] [CrossRef]
- Wang, J.; Wang, C.-X.; Huang, J.; Chen, Y. 6G THz Propagation Channel Characteristics and Modeling: Recent Developments and Future Challenges. IEEE Commun. Mag. 2024, 62, 56–62. [Google Scholar] [CrossRef]
- Hu, Y.; Zhang, R. A Spatiotemporal Approach for Secure Crowdsourced Radio Environment Map Construction. IEEE ACM Trans. Netw. 2020, 28, 1790–1803. [Google Scholar] [CrossRef]
- Li, K.; Li, C.; Yu, B.; Shen, Z.; Zhang, Q.; He, S.; Chen, J. Model and Transfer Spatial-Temporal Knowledge for Fine-Grained Radio Map Reconstruction. IEEE Trans. Cogn. Commun. Netw. 2022, 8, 828–841. [Google Scholar] [CrossRef]
- Zhang, Y.; Ma, L. Radio Map Crowdsourcing Update Method Using Sparse Representation and Low Rank Matrix Recovery for WLAN Indoor Positioning System. IEEE Wirel. Commun. Lett. 2021, 10, 1188–1191. [Google Scholar] [CrossRef]
- Erunkulu, O.O.; Zungeru, A.M.; Lebekwe, C.K.; Chuma, J.M. Cellular Communications Coverage Prediction Techniques: A Survey and Comparison. IEEE Access 2020, 8, 113052–113077. [Google Scholar] [CrossRef]
- He, D.; Guan, K.; Garcia-Loygorri, J.M.; Ai, B.; Wang, X.; Zheng, C.; Briso-Rodriguez, C.; Zhong, Z. Channel Characterization and Hybrid Modeling for Millimeter-Wave Communications in Metro Train. IEEE Trans. Veh. Technol. 2020, 69, 12408–12417. [Google Scholar] [CrossRef]
- Gao, Y.; Fujii, T. A Kriging-Based Radio Environment Map Construction and Channel Estimation System in Threatening Environments. IEEE Access 2023, 11, 38136–38148. [Google Scholar] [CrossRef]
- Zeng, S.; Chen, W.; Ji, Y.; Yan, L.; Zhao, X. Measurement and Calibration of EMF: A Study Using Phone and GBDT for Mobile Communication Signals. Radio Sci. 2024, 59, e2023RS007890. [Google Scholar] [CrossRef]
- Zhang, M.; Fan, Z.; Shibasaki, R.; Song, X. Domain Adversarial Graph Convolutional Network Based on RSSI and Crowdsensing for Indoor Localization. IEEE Internet Things 2023, 10, 13662–13672. [Google Scholar] [CrossRef]
- Bharti, A.; Adeogun, R.; Cai, X.; Fan, W.; Briol, F.-X.; Clavier, L.; Pedersen, T. Joint Modeling of Received Power, Mean Delay, and Delay Spread for Wideband Radio Channels. IEEE Trans. Antennas Propag. 2021, 69, 4871–4882. [Google Scholar] [CrossRef]
- Mohammadjafari, S.; Roginsky, S.; Kavurmacioglu, E.; Cevik, M.; Ethier, J.; Bener, A.B. Machine Learning-Based Radio Coverage Prediction in Urban Environments. IEEE Trans. Netw. Serv. Manag. 2020, 17, 2117–2130. [Google Scholar] [CrossRef]
- García, C.E.; Koo, I. Extremely Randomized Trees Regressor Scheme for Mobile Network Coverage Prediction and REM Construction. IEEE Access 2023, 11, 65170–65180. [Google Scholar] [CrossRef]
- Sani, U.S.; Malik, O.A.; Lai, D.T.C. Improving Path Loss Prediction Using Environmental Feature Extraction from Satellite Images: Hand-Crafted vs. Convolutional Neural Network. Appl. Sci. 2022, 12, 7685. [Google Scholar] [CrossRef]
- Wu, L.; He, D.; Ai, B.; Wang, J.; Qi, H.; Guan, K.; Zhong, Z. Artificial Neural Network Based Path Loss Prediction for Wireless Communication Network. IEEE Access 2020, 8, 199523–199538. [Google Scholar] [CrossRef]
- Juang, R.-T. Explainable Deep-Learning-Based Path Loss Prediction from Path Profiles in Urban Environments. Appl. Sci. 2021, 11, 6690. [Google Scholar] [CrossRef]
- Wang, X.; Guan, K.; He, D.; Zhang, Z.; Zhang, H.; Dou, J.; Zhong, Z. Super Resolution of Wireless Channel Characteristics: A Multi-Task Learning Model. IEEE Trans. Antennas Propag. 2023, 71, 8197–8209. [Google Scholar] [CrossRef]
- Ratnam, V.V.; Chen, H.; Pawar, S.; Zhang, B.; Zhang, C.J.; Kim, Y.-J.; Lee, S.; Cho, M.; Yoon, S.-R. FadeNet: Deep Learning-Based Mm-Wave Large-Scale Channel Fading Prediction and Its Applications. IEEE Access 2021, 9, 3278–3290. [Google Scholar] [CrossRef]
- Ahmadien, O.; Ates, H.F.; Baykas, T.; Gunturk, B.K. Predicting Path Loss Distribution of an Area From Satellite Images Using Deep Learning. IEEE Access 2020, 8, 64982–64991. [Google Scholar] [CrossRef]
- Waheed, M.T.; Fahmy, Y.; Khattab, A. DeepChannel: Robust Multimodal Outdoor Channel Model Prediction in LTE Networks Using Deep Learning. IEEE Access 2022, 10, 79289–79300. [Google Scholar] [CrossRef]
- Waheed, M.T.; Khattab, A.; Fahmy, Y. Highly Accurate Multi-Modal LTE Channel Prediction via Semantic Segmentation of Satellite Images. In Proceedings of the 2022 10th International Japan-Africa Conference on Electronics, Communications, and Computations (JAC-ECC), Alexandria, Egypt, 19–20 December 2022; pp. 90–93. [Google Scholar] [CrossRef]
- Thrane, J.; Zibar, D.; Christiansen, H.L. Model-Aided Deep Learning Method for Path Loss Prediction in Mobile Communication Systems at 2.6 GHz. IEEE Access 2020, 8, 7925–7936. [Google Scholar] [CrossRef]
- QGIS—The Leading Open Source Desktop GIS. Available online: https://www.qgis.org/ (accessed on 2 June 2024).
- Boussad, Y.; Mahfoudi, M.N.; Legout, A.; Lizzi, L.; Ferrero, F.; Dabbous, W. Evaluating Smartphone Accuracy for RSSI Measurements. IEEE Trans. Instrum. Meas. 2021, 70, 5501012. [Google Scholar] [CrossRef]
- GeographicLib Library. Available online: https://geographiclib.sourceforge.io/ (accessed on 2 June 2024).
- Wu, L.; He, D.; Guan, K.; Ai, B.; Briso-Rodriguez, C.; Shui, T.; Liu, C.; Zhu, L.; Shen, X. Received Power Prediction for Suburban Environment Based on Neural Network. In Proceedings of the 2020 International Conference on Information Networking (ICOIN), Barcelona, Spain, 7–10 January 2020; pp. 35–39. [Google Scholar] [CrossRef]
- Guo, Z.; Shengoku, H.; Wu, G.; Chen, Q.; Yuan, W.; Shi, X.; Shao, X.; Xu, Y.; Shibasaki, R. Semantic Segmentation for Urban Planning Maps Based on U-Net. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 6187–6190. [Google Scholar] [CrossRef]
- Yuan, Y.; Chen, X.; Chen, X.; Wang, J. Segmentation Transformer: Object-Contextual Representations for Semantic Segmentation. arXiv 2021, arXiv:1909.11065. [Google Scholar]
- Chaudhuri, B.; Demir, B.; Chaudhuri, S.; Bruzzone, L. Multilabel Remote Sensing Image Retrieval Using a Semisupervised Graph-Theoretic Method. IEEE Trans. Geosci. Remote Sens. 2018, 56, 1144–1158. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Type | Input Size | Output Size | Neurons | Activation | Normalization | Dropout |
|---|---|---|---|---|---|---|---|
| Network 1 | Dense Layer | 6 | 200 | 200 | ReLU | Batchnorm1d | |
| Dense Layer | 200 | 200 | 200 | ReLU | Batchnorm1d | 0.1 | |
| Dense Layer | 200 | 200 | 200 | ReLU | Batchnorm1d | 0.1 | |
| Dense Layer | 200 | 200 | 200 | ReLU | Batchnorm1d | 0.1 | |
| Dense Layer | 200 | 200 | 200 | ReLU | Batchnorm1d | 0.1 | |
| Dense Layer | 200 | 200 | 200 | ReLU | Batchnorm1d | 0.1 | |
| Dense Layer | 200 | 100 | 100 | Linear | |||
| Network 2 | Dense Layer | 256 × 256 | 200 | 200 | ReLU | Batchnorm1d | |
| Dense Layer | 200 | 200 | 200 | ReLU | Batchnorm1d | 0.1 | |
| Dense Layer | 200 | 200 | 200 | ReLU | Batchnorm1d | 0.1 | |
| Dense Layer | 200 | 200 | 200 | ReLU | Batchnorm1d | 0.1 | |
| Dense Layer | 200 | 200 | 200 | ReLU | Batchnorm1d | 0.1 | |
| Dense Layer | 200 | 200 | 200 | ReLU | Batchnorm1d | 0.1 | |
| Dense Layer | 200 | 100 | 100 | Linear | |||
| Network 3 | Desen Layer | 100 | 16 | 16 | ReLU | Batchnorm1d | |
| Desen Layer | 16 | 1 | 1 | Linear |
| Parameter | Value |
|---|---|
| Optimizer | Adam |
| Loss function | MSE |
| Learning rate | 0.001 |
| Weight decay | 0.01 |
| Dropout | 0.1 |
| Batch size | 128 |
| Epochs | 30 |
| Dataset | RMSE (dB) | MAE (dB) |
|---|---|---|
| Training set | 1.51 | 1.08 |
| Test set | 1.97 | 1.41 |
| Parameter | Real RSRP | Predicted RSRP |
|---|---|---|
| Mean (dB) | −77.65 | −77.74 |
| Median (dB) | −77 | −77.01 |
| STD (dB) | 7.94 | 7.82 |
| Coefficient of variation | −10.22 | −10.06 |
| Parameter | Real RSRP | Predicted RSRP |
|---|---|---|
| Mean (dB) | −75.84 | −76.33 |
| Median (dB) | −75.20 | −76.50 |
| STD (dB) | 4.36 | 3.95 |
| Coefficient of variation | −5.76 | −2.60 |
| Models | Receiver Parameters | Base Station Parameters | Satellite Images | Path Loss Model | Network Type |
|---|---|---|---|---|---|
| DNN-SS | Latitude, Longitude | Latitude, Longitude | Only one image for whole measurement area | DNN, OCRNet | |
| SS_DeepChannel | Latitude, Longitude, Height of the receiver | Latitude, Longitude, Heights of the transmitter, operation frequency | One image per measurement point | HataOkumara | DNN, UNet, CNN |
| Model-Aided DL | Latitude, Longitude | Latitude, Longitude, Heights of the transmitter, Transmission power | One image per measurement point | UMa_A, UMa_B | DNN, CNN |
| DeepChannel | Latitude, Longitude, Height of the receiver | Latitude, Longitude, Heights of the transmitter, operation frequency | One image per measurement point | HataOkumara | DNN, CNN |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, S.; Ji, Y.; Chen, W.; Yan, L.; Zhao, X. Mobile Network Coverage Prediction Using Multi-Modal Model Based on Deep Neural Networks and Semantic Segmentation. Sensors 2024, 24, 5178. https://doi.org/10.3390/s24165178
Zeng S, Ji Y, Chen W, Yan L, Zhao X. Mobile Network Coverage Prediction Using Multi-Modal Model Based on Deep Neural Networks and Semantic Segmentation. Sensors. 2024; 24(16):5178. https://doi.org/10.3390/s24165178
Chicago/Turabian StyleZeng, Sheng, Yuhang Ji, Weiwei Chen, Liping Yan, and Xiang Zhao. 2024. "Mobile Network Coverage Prediction Using Multi-Modal Model Based on Deep Neural Networks and Semantic Segmentation" Sensors 24, no. 16: 5178. https://doi.org/10.3390/s24165178