


Leveraging Deep Learning for Time-Series Extrinsic Regression in Predicting the Photometric Metallicity of Fundamental-Mode RR Lyrae Stars

Abstract
1. Introduction
2. Background and Related Works
2.1. Time-Series Classification
2.2. Time-Series Clustering
2.3. Time-Series Regression
3. Photometric Data and Data Preprocessing
A TSER model is represented as a function → , where denotes a set of time series. The objective of time-series extrinsic regression is to derive a regression model from a dataset, , where each represents a time series and represents a continuous scalar value.
dex; mag;
- Phase Folding: In phase folding, observations of a variable star’s brightness over time are transformed into a phase-folded light curve. This involves folding the observations based on the star’s known or estimated period. The period is the duration of one complete cycle of variability, such as the time it takes for a star to pulsate or undergo other periodic changes. By folding the observations, multiple cycles of variability are aligned so that they overlap, simplifying the analysis of the star’s variability pattern. This technique allows astronomers to better understand the periodic behavior of variable stars and to compare observations more effectively.
- Phase Alignment: Alignment refers to the process of adjusting or aligning multiple observations of a variable star’s light curve to a common reference point. This is particularly important when studying stars with irregular or asymmetric variability patterns. By aligning observations, astronomers can more accurately compare the shape, timing, and amplitude of variations in the star’s brightness. This helps in identifying patterns, detecting periodicity, and studying the underlying physical mechanisms driving the variability. Therefore, RRab-type stars have a sawtooth-shaped light curve, which is indeed asymmetric, with a rapid rise and a slow decline. For these types of star, the phase alignment mentioned is particularly important.
4. Metodology
4.1. Model Selection and Optimization
4.2. Choosing the Right Neural Network Architecture for Time-Series Data
4.3. Network Architectures
4.3.1. Fully Convolutional Network
4.3.2. Inceptiontime
4.3.3. Residual Network
4.3.4. Long Short-Term Memory and Bi-Directional Long Short-Term Memory
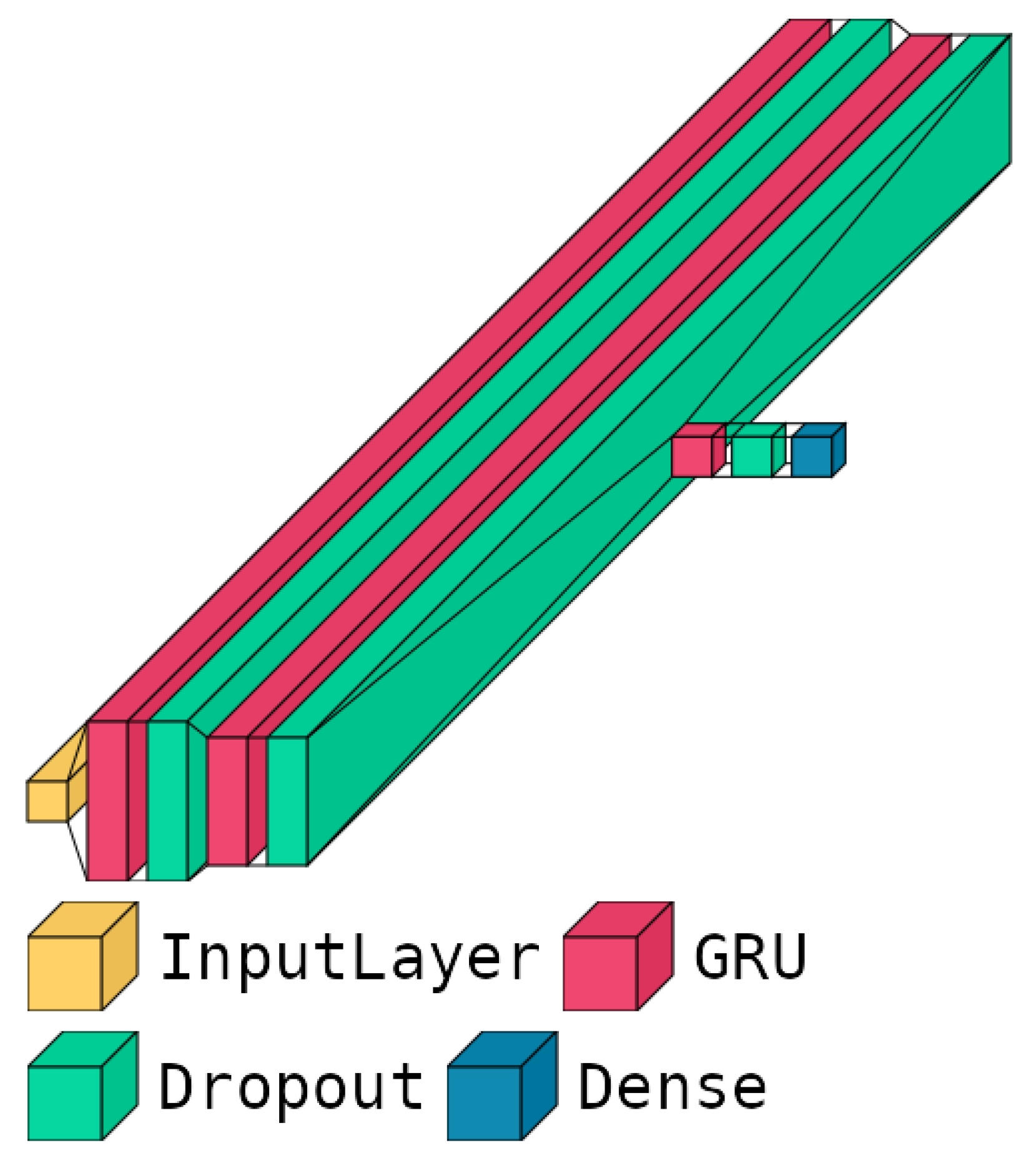
4.3.5. Gated Recurrent Unit and Bi-Directional Gated Recurrent Unit
4.3.6. Convolutional GRU and Convolutional LSTM
5. Results and Discussion
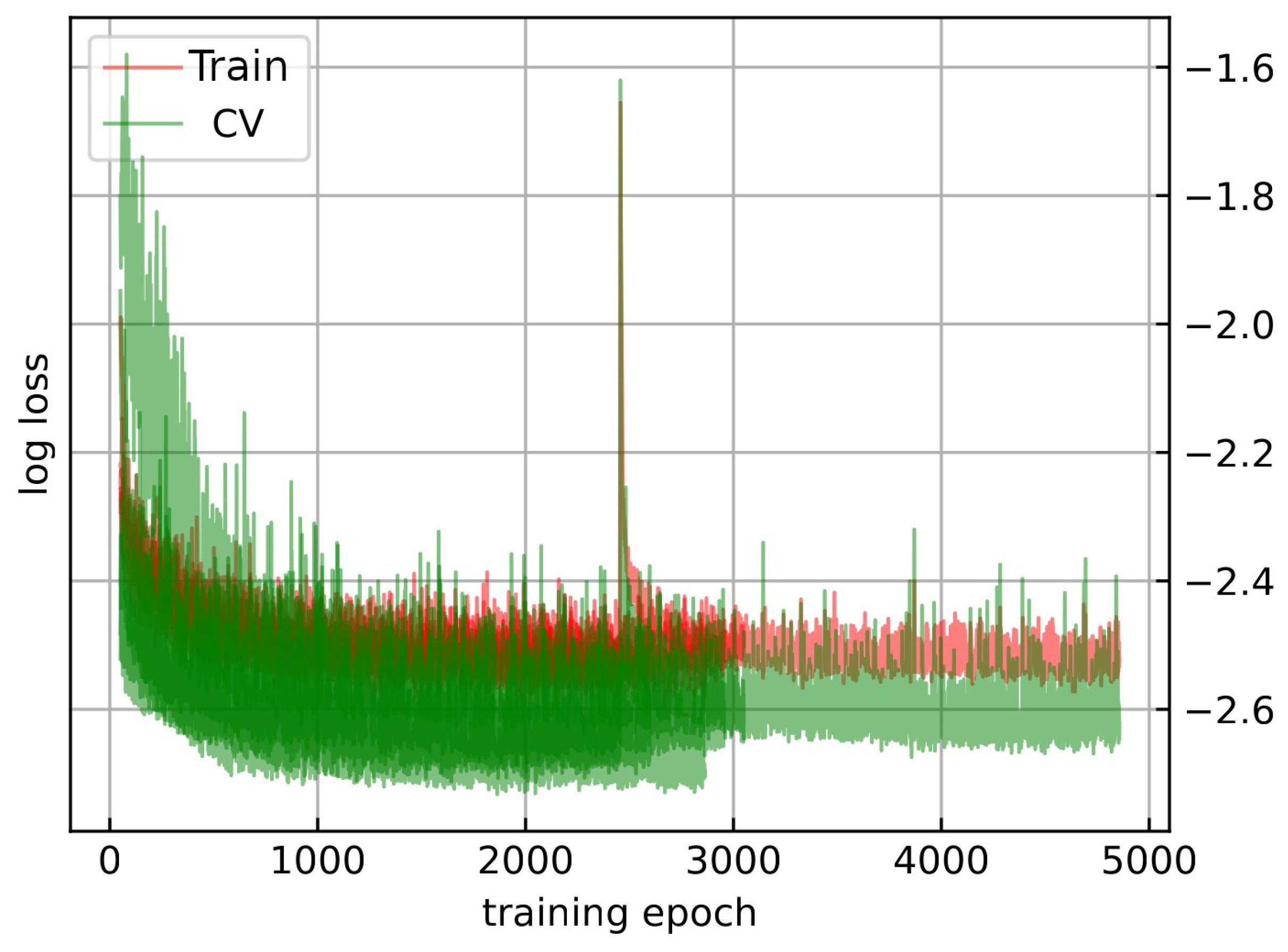
5.1. Experiment Setup
5.2. Results of the Experiments
5.3. Performance Comparison of Predictive Models
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ESA | European Space Agency |
| HDS | High Dispersion Spectroscopy |
| BP and RP | Blue Photometer and Red Photometer |
| TSER | Time-Series Extrinsic Regression |
| TSC | Time-Series Classification |
| BJD | Barycentric Julian Day |
| RNN | Recurrent Neural Networks |
| CNN | Convolutional Neural Networks |
| dTCN | dilated Temporal Convolutional Neural Networks |
| tCNN | temporal Convolutional Neural Networks |
| LSTM and BiLSTM | Long Short-Term Memory and Bi-Directional Long Short-Term Memory |
| GRU and BiGRU | Gated Recurrent Unit and Bi-Directional Gated Recurrent Unit |
| FCN | Fully Convolutional Network |
| ReLU | Rectified Linear Unit |
| ResNet | Residual Network |
| SOM | Self-Organizing Maps |
| RF | Random Forest |
| MSE | Mean Squared Error |
| RMSE and wRMSE | Root Mean Squared Error and weighted Root Mean Squared Error |
| MAE and wMAE | Mean Absolute Squared Error and weighted Mean Absolute Squared Error |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Raw Catalog | ||||||||||||||||||
| FCN | ResNet | Inception | LSTM | BiLSTM | GRU | BiGRU | ConvLSTM | ConvGRU | ||||||||||
| Metrics | training | validation | training | validation | training | validation | training | validation | training | validation | training | validation | training | validation | training | validation | training | validation |
| 0.8898 ± 0.3673 | 0.7188 ± 0.3520 | 0.954 ± 0.3957 | 0.7863 ± 0.3874 | 0.966 ± 0.3173 | 0.7888 ± 0.3073 | −0.0326 ± 0.3657 | −0.0326 ± 0.4035 | 0.9323 ± 0.0085 | 0.9230 ± 0.0099 | 0.9358 ± 0.3389 | 0.9247 ± 0.3267 | 0.9407 ± 0.0039 | 0.9294 ± 0.0078 | 0.1636 ± 0.3057 | 0.1570 ± 0.3838 | 0.9225 ± 0.0114 | 0.8980 ± 0.0162 | |
| wrmse | 0.1042 ± 0.0896 | 0.1664 ± 0.0858 | 0.0673 ± 0.0980 | 0.1451 ± 0.0959 | 0.0579 ± 0.0787 | 0.1442 ± 0.0762 | 0.3168 ± 0.0903 | 0.3168 ± 0.0994 | 0.0811 ± 0.0051 | 0.0865 ± 0.0059 | 0.0790 ± 0.0828 | 0.0856 ± 0.0798 | 0.0759 ± 0.0026 | 0.0828 ± 0.0048 | 0.2851 ± 0.0746 | 0.2862 ± 0.0935 | 0.0868 ± 0.0066 | 0.0996 ± 0.0090 |
| wmae | 0.0786 ± 0.0664 | 0.1297 ± 0.0636 | 0.0443 ± 0.0729 | 0.1132 ± 0.0713 | 0.037 ± 0.0585 | 0.1135 ± 0.0566 | 0.2367 ± 0.0671 | 0.2367 ± 0.0739 | 0.0619 ± 0.0038 | 0.0658 ± 0.0044 | 0.0602 ± 0.0614 | 0.0640 ± 0.0592 | 0.0578 ± 0.0019 | 0.0621 ± 0.0032 | 0.2006 ± 0.0554 | 0.2031 ± 0.0693 | 0.0671 ± 0.0052 | 0.0751 ± 0.0068 |
| rmse | 0.1049 ± 0.0896 | 0.1669 ± 0.0858 | 0.0676 ± 0.0980 | 0.1455 ± 0.0959 | 0.0584 ± 0.0787 | 0.1447 ± 0.0762 | 0.3189 ± 0.0903 | 0.3189 ± 0.0994 | 0.0814 ± 0.0051 | 0.0868 ± 0.0059 | 0.0792 ± 0.0828 | 0.0858 ± 0.0798 | 0.0762 ± 0.0026 | 0.0831 ± 0.0048 | 0.2869 ± 0.0746 | 0.2883 ± 0.0935 | 0.0871 ± 0.0066 | 0.0998 ± 0.0090 |
| mae | 0.0792 ± 0.0664 | 0.1302 ± 0.0636 | 0.0446 ± 0.0729 | 0.1135 ± 0.0713 | 0.0374 ± 0.0585 | 0.1139 ± 0.0566 | 0.2384 ± 0.0671 | 0.2384 ± 0.0739 | 0.0622 ± 0.0038 | 0.0661 ± 0.0044 | 0.0604 ± 0.0614 | 0.0642 ± 0.0592 | 0.0581 ± 0.0019 | 0.0624 ± 0.0032 | 0.2021 ± 0.0554 | 0.2048 ± 0.0693 | 0.0674 ± 0.0052 | 0.0754 ± 0.0068 |
| Pre-processed catalog without mean magnitude | ||||||||||||||||||
| 0.9303 ± 0.0073 | 0.9250 ± 0.0056 | 0.9400 ± 0.0070 | 0.9247 ± 0.0063 | 0.9449 ± 0.0070 | 0.9328 ± 0.0064 | 0.9343 ± 0.0067 | 0.9254 ± 0.0063 | 0.9333 ± 0.0047 | 0.9258 ± 0.0047 | 0.9382 ± 0.0069 | 0.9328 ± 0.0063 | 0.9329 ± 0.0038 | 0.9273 ± 0.0046 | 0.9439 ± 0.0071 | 0.9232 ± 0.0058 | 0.9437 ± 0.0069 | 0.9273 ± 0.0053 | |
| wrmse | 0.0823 ± 0.0046 | 0.0854 ± 0.0036 | 0.0764 ± 0.0044 | 0.0856 ± 0.0039 | 0.0732 ± 0.0044 | 0.0808 ± 0.0041 | 0.0799 ± 0.0042 | 0.0851 ± 0.0040 | 0.0805 ± 0.0029 | 0.0850 ± 0.0030 | 0.0775 ± 0.0043 | 0.0808 ± 0.0040 | 0.0808 ± 0.0023 | 0.0841 ± 0.0031 | 0.0738 ± 0.0045 | 0.0864 ± 0.0037 | 0.0739 ± 0.0043 | 0.0841 ± 0.0034 |
| wmae | 0.0600 ± 0.0032 | 0.0618 ± 0.0027 | 0.0561 ± 0.0033 | 0.0614 ± 0.0030 | 0.0539 ± 0.0032 | 0.0582 ± 0.0031 | 0.0594 ± 0.0031 | 0.0622 ± 0.0030 | 0.0590 ± 0.0023 | 0.0614 ± 0.0025 | 0.0569 ± 0.0031 | 0.0587 ± 0.0030 | 0.0595 ± 0.0017 | 0.0613 ± 0.0025 | 0.0547 ± 0.0032 | 0.0635 ± 0.0028 | 0.0548 ± 0.0032 | 0.0610 ± 0.0026 |
| rmse | 0.0824 ± 0.0046 | 0.0855 ± 0.0036 | 0.0767 ± 0.0044 | 0.0857 ± 0.0039 | 0.0735 ± 0.0044 | 0.0811 ± 0.0041 | 0.0802 ± 0.0042 | 0.0854 ± 0.0040 | 0.0807 ± 0.0029 | 0.0852 ± 0.0030 | 0.0778 ± 0.0043 | 0.0812 ± 0.0040 | 0.0810 ± 0.0023 | 0.0843 ± 0.0031 | 0.0742 ± 0.0045 | 0.0868 ± 0.0037 | 0.0742 ± 0.0043 | 0.0842 ± 0.0034 |
| mae | 0.0602 ± 0.0032 | 0.0620 ± 0.0027 | 0.0564 ± 0.0033 | 0.0617 ± 0.0030 | 0.0542 ± 0.0032 | 0.0585 ± 0.0031 | 0.0597 ± 0.0031 | 0.0624 ± 0.0030 | 0.0593 ± 0.0023 | 0.0617 ± 0.0025 | 0.0572 ± 0.0031 | 0.0591 ± 0.0030 | 0.0597 ± 0.0017 | 0.0615 ± 0.0025 | 0.0550 ± 0.0032 | 0.0638 ± 0.0028 | 0.0551 ± 0.0032 | 0.0613 ± 0.0026 |
| Pre-processed catalog | ||||||||||||||||||
| 0.9375 ± 0.0024 | 0.9317 ± 0.0048 | 0.9506 ± 0.0028 | 0.9303 ± 0.0042 | 0.9508 ± 0.0042 | 0.9392 ± 0.0027 | 0.9358 ± 0.0022 | 0.9301 ± 0.0032 | 0.9396 ± 0.0021 | 0.9333 ± 0.0073 | 0.9447 ± 0.0026 | 0.9401 ± 0.0031 | 0.9420 ± 0.0021 | 0.9368 ± 0.0027 | 0.9400 ± 0.0053 | 0.9271 ± 0.0051 | 0.9410 ± 0.0044 | 0.9325 ± 0.0042 | |
| wrmse | 0.0780 ± 0.0015 | 0.0815 ± 0.0031 | 0.0693 ± 0.0020 | 0.0823 ± 0.0027 | 0.0691 ± 0.0029 | 0.0769 ± 0.0019 | 0.0790 ± 0.0014 | 0.0824 ± 0.0018 | 0.0767 ± 0.0013 | 0.0805 ± 0.0047 | 0.0733 ± 0.0018 | 0.0763 ± 0.0018 | 0.0751 ± 0.0013 | 0.0784 ± 0.0017 | 0.0764 ± 0.0035 | 0.0842 ± 0.0031 | 0.0757 ± 0.0030 | 0.0810 ± 0.0025 |
| wmae | 0.0570 ± 0.0010 | 0.0585 ± 0.0018 | 0.0522 ± 0.0014 | 0.0601 ± 0.0020 | 0.0520 ± 0.0021 | 0.0564 ± 0.0014 | 0.0597 ± 0.0007 | 0.0612 ± 0.0012 | 0.0574 ± 0.0011 | 0.0594 ± 0.0034 | 0.0547 ± 0.0018 | 0.0563 ± 0.0011 | 0.0560 ± 0.0010 | 0.0575 ± 0.0018 | 0.0581 ± 0.0027 | 0.0630 ± 0.0025 | 0.0571 ± 0.0025 | 0.0597 ± 0.0022 |
| rmse | 0.0780 ± 0.0015 | 0.0815 ± 0.0031 | 0.0695 ± 0.0020 | 0.0823 ± 0.0027 | 0.0693 ± 0.0029 | 0.0769 ± 0.0019 | 0.0792 ± 0.0014 | 0.0825 ± 0.0018 | 0.0769 ± 0.0013 | 0.0807 ± 0.0047 | 0.0735 ± 0.0018 | 0.0765 ± 0.0018 | 0.0753 ± 0.0013 | 0.0785 ± 0.0017 | 0.0767 ± 0.0035 | 0.0844 ± 0.0031 | 0.0759 ± 0.0030 | 0.0811 ± 0.0025 |
| mae | 0.0571 ± 0.0010 | 0.0587 ± 0.0018 | 0.0525 ± 0.0014 | 0.0603 ± 0.0020 | 0.0523 ± 0.0021 | 0.0567 ± 0.0014 | 0.0600 ± 0.0007 | 0.0615 ± 0.0012 | 0.0577 ± 0.0011 | 0.0597 ± 0.0034 | 0.0549 ± 0.0018 | 0.0565 ± 0.0011 | 0.0562 ± 0.0010 | 0.0578 ± 0.0018 | 0.0584 ± 0.0027 | 0.0633 ± 0.0025 | 0.0573 ± 0.0025 | 0.0599 ± 0.0022 |
References
- Smith, H.A. RR Lyrae Stars; Cambridge University Press: Cambridge, UK, 2004; Volume 27. [Google Scholar]
- Tanakul, N.; Sarajedini, A. RR Lyrae variables in M31 and its satellites: An analysis of the galaxy’s population. Mon. Not. R. Astron. Soc. 2018, 478, 4590–4601. [Google Scholar] [CrossRef]
- Clementini, G.; Ripepi, V.; Molinaro, R.; Garofalo, A.; Muraveva, T.; Rimoldini, L.; Guy, L.P.; Fombelle, G.J.D.; Nienartowicz, K.; Marchal, O.; et al. Gaia Data Release 2: Specific characterisation and validation of all-sky Cepheids and RR Lyrae stars. Astron. Astrophys. 2019, 622, A60. [Google Scholar] [CrossRef]
- Dékány, I.; Grebel, E.K. Near-infrared Search for Fundamental-mode RR Lyrae Stars toward the Inner Bulge by Deep Learning. Astrophys. J. 2020, 898, 46. [Google Scholar] [CrossRef]
- Bhardwaj, A. RR Lyrae and Type II Cepheid Variables in Globular Clusters: Optical and Infrared Properties. Universe 2022, 8, 122. [Google Scholar] [CrossRef]
- Jurcsik, J.; Kovács, G. Determination of [Fe/H] from the light curves of RR Lyrae stars. Astron. Astrophys. 1996, 312, 111–120. [Google Scholar]
- Layden, A.C. The metallicities and kinematics of RR Lyrae variables, 1: New observations of local stars. Astron. J. 1994, 108, 1016–1041. [Google Scholar] [CrossRef]
- Smolec, R. Metallicity dependence of the Blazhko effect. arXiv 2005, arXiv:astro-ph/0503614. [Google Scholar] [CrossRef]
- Ngeow, C.C.; Yu, P.C.; Bellm, E.; Yang, T.C.; Chang, C.K.; Miller, A.; Laher, R.; Surace, J.; Ip, W.H. The palomar transient factory and RR Lyrae: The metallicity-light curve relatino based on ab-type RR Lyrae in kepler field. Astrophys. J. Suppl. Ser. 2016, 227, 30. [Google Scholar] [CrossRef]
- Skowron, D.; Soszyński, I.; Udalski, A.; Szymański, M.; Pietrukowicz, P.; Poleski, R.; Wyrzykowski, Ł.; Ulaczyk, K.; Kozłowski, S.; Skowron, J.; et al. OGLE-ing the Magellanic System: Photometric Metallicity from Fundamental Mode RR Lyrae Stars. arXiv 2016, arXiv:1608.00013. [Google Scholar] [CrossRef]
- Mullen, J.P.; Marengo, M.; Martínez-Vázquez, C.E.; Neeley, J.R.; Bono, G.; Dall’Ora, M.; Chaboyer, B.; Thévenin, F.; Braga, V.F.; Crestani, J.; et al. Metallicity of Galactic RR Lyrae from Optical and Infrared Light Curves. I. Period–Fourier–Metallicity Relations for Fundamental-mode RR Lyrae. Astrophys. J. 2021, 912, 144. [Google Scholar] [CrossRef]
- Crestani, J.; Fabrizio, M.; Braga, V.F.; Sneden, C.; Preston, G.; Ferraro, I.; Iannicola, G.; Bono, G.; Alves-Brito, A.; Nonino, M.; et al. On the Use of Field RR Lyrae as Galactic Probes. II. A New ΔS Calibration to Estimate Their Metallicity*. Astrophys. J. 2021, 908, 20. [Google Scholar] [CrossRef]
- Gilligan, C.K.; Chaboyer, B.; Marengo, M.; Mullen, J.P.; Bono, G.; Braga, V.F.; Crestani, J.; Dall’Ora, M.; Fiorentino, G.; Monelli, M.; et al. Metallicities from high-resolution spectra of 49 RR Lyrae variables. Mon. Not. R. Astron. Soc. 2021, 503, 4719–4733. [Google Scholar] [CrossRef]
- Vallenari, A.; Brown, A.G.; Prusti, T.; De Bruijne, J.H.; Arenou, F.; Babusiaux, C.; Biermann, M.; Creevey, O.L.; Ducourant, C.; Evans, D.W.; et al. Gaia data release 3-summary of the content and survey properties. Astron. Astrophys. 2023, 674, A1. [Google Scholar]
- Clementini, G.; Ripepi, V.; Garofalo, A.; Molinaro, R.; Muraveva, T.; Leccia, S.; Rimoldini, L.; Holl, B.; de Fombelle, G.J.; Sartoretti, P.; et al. Gaia Data Release 3-Specific processing and validation of all-sky RR Lyrae and Cepheid stars: The RR Lyrae sample. Astron. Astrophys. 2023, 674, A18. [Google Scholar] [CrossRef]
- Naul, B.; Bloom, J.S.; Pérez, F.; Walt, S.V.D. A recurrent neural network for classification of unevenly sampled variable stars. Nat. Astron. 2018, 2, 151–155. [Google Scholar] [CrossRef]
- Aguirre, C.; Pichara, K.; Becker, I. Deep multi-survey classification of variable stars. Mon. Not. R. Astron. Soc. 2019, 482, 5078–5092. [Google Scholar] [CrossRef]
- Jamal, S.; Bloom, J.S. On Neural Architectures for Astronomical Time-series Classification with Application to Variable Stars. Astrophys. J. Suppl. Ser. 2020, 250, 30. [Google Scholar] [CrossRef]
- Kang, Z.; Zhang, Y.; Zhang, J.; Li, C.; Kong, M.; Zhao, Y.; Wu, X.B. Periodic Variable Star Classification with Deep Learning: Handling Data Imbalance in an Ensemble Augmentation Way. Publ. Astron. Soc. Pac. 2023, 135, 094501. [Google Scholar] [CrossRef]
- Allam, T.; Peloton, J.; McEwen, J.D. The Tiny Time-series Transformer: Low-latency High-throughput Classification of Astronomical Transients using Deep Model Compression. arXiv 2023, arXiv:2303.08951. [Google Scholar] [CrossRef]
- Rebbapragada, U.; Protopapas, P.; Brodley, C.E.; Alcock, C. Finding anomalous periodic time series: An application to catalogs of periodic variable stars. Mach. Learn. 2009, 74, 281–313. [Google Scholar] [CrossRef]
- Armstrong, D.J.; Kirk, J.; Lam, K.W.; McCormac, J.; Osborn, H.P.; Spake, J.; Walker, S.; Brown, D.J.; Kristiansen, M.H.; Pollacco, D.; et al. K2 variable catalogue -II. Machine learning classification of variable stars and eclipsing binaries in K2 fields 0–4. Mon. Not. R. Astron. Soc. 2016, 456, 2260–2272. [Google Scholar] [CrossRef]
- Mackenzie, C.; Pichara, K.; Protopapas, P. Clustering-based feature learning on variable stars. Astrophys. J. 2016, 820, 138. [Google Scholar] [CrossRef]
- Valenzuela, L.; Pichara, K. Unsupervised classification of variable stars. Mon. Not. R. Astron. Soc. 2018, 474, 3259–3272. [Google Scholar] [CrossRef]
- Sanders, J.L.; Matsunaga, N. Hunting for C-rich long-period variable stars in the Milky Way’s bar-bulge using unsupervised classification of Gaia BP/RP spectra. Mon. Not. R. Astron. Soc. 2023, 521, 2745–2764. [Google Scholar] [CrossRef]
- Surana, S.; Wadadekar, Y.; Bait, O.; Bhosale, H. Predicting star formation properties of galaxies using deep learning. Mon. Not. R. Astron. Soc. 2021, 493, 4808–4815. [Google Scholar] [CrossRef]
- Noughani, N.G.; Kotulla, R. Chasing Down Variables from a Decade-Long Dataset. American Astronomical Society meeting 235, id. 110.09. Bulletin of the American Astronomical Society. 2020. [Google Scholar]
- R., M.F.; Corral, L.J.; Fierro-Santillán, C.R.; Navarro, S.G. O-type Stars Stellar Parameter Estimation Using Recurrent Neural Networks. arXiv 2022, arXiv:2210.12791. [Google Scholar]
- Dékány, I.; Grebel, E.K. Photometric Metallicity Prediction of Fundamental-mode RR Lyrae Stars in the Gaia Optical and K s Infrared Wave Bands by Deep Learning. Astrophys. J. Suppl. Ser. 2022, 261, 33. [Google Scholar] [CrossRef]
- Dékány, I.; Grebel, E.K.; Pojmański, G. Metallicity Estimation of RR Lyrae Stars From Their I-Band Light Curves. Astrophys. J. 2021, 920, 33. [Google Scholar] [CrossRef]
- Tan, C.W.; Bergmeir, C.; Petitjean, F.; Webb, G.I. Time series extrinsic regression: Predicting numeric values from time series data. Data Min. Knowl. Discov. 2021, 35, 1032–1060. [Google Scholar] [CrossRef] [PubMed]
- Muraveva, T.; Giannetti, A.; Clementini, G.; Garofalo, A.; Monti, L. Metallicity of RR Lyrae stars from the Gaia Data Release 3 catalogue computed with Machine Learning algorithms. arXiv 2024, arXiv:2407.05815. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; PMLR: New York, NY, USA, 2015; pp. 448–456. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Ismail Fawaz, H.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.A. Deep learning for time series classification: A review. Data Min. Knowl. Discov. 2019, 33, 917–963. [Google Scholar] [CrossRef]
- Ismail Fawaz, H.; Lucas, B.; Forestier, G.; Pelletier, C.; Schmidt, D.F.; Weber, J.; Webb, G.I.; Idoumghar, L.; Muller, P.A.; Petitjean, F. Inceptiontime: Finding alexnet for time series classification. Data Min. Knowl. Discov. 2020, 34, 1936–1962. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the difficulty of training recurrent neural networks. In Proceedings of the International Conference on Machine Learning, Scottsdale, AZ, USA, 29 April–1 May 2013; PMLR: New York, NY, USA; pp. 1310–1318. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar] [CrossRef]
- Karim, F.; Majumdar, S.; Darabi, H.; Chen, S. LSTM fully convolutional networks for time series classification. IEEE Access 2017, 6, 1662–1669. [Google Scholar] [CrossRef]
- Yu, Z.; Liu, G.; Liu, Q.; Deng, J. Spatio-temporal convolutional features with nested LSTM for facial expression recognition. Neurocomputing 2018, 317, 50–57. [Google Scholar] [CrossRef]
- Majd, M.; Safabakhsh, R. Correlational convolutional LSTM for human action recognition. Neurocomputing 2020, 396, 224–229. [Google Scholar] [CrossRef]
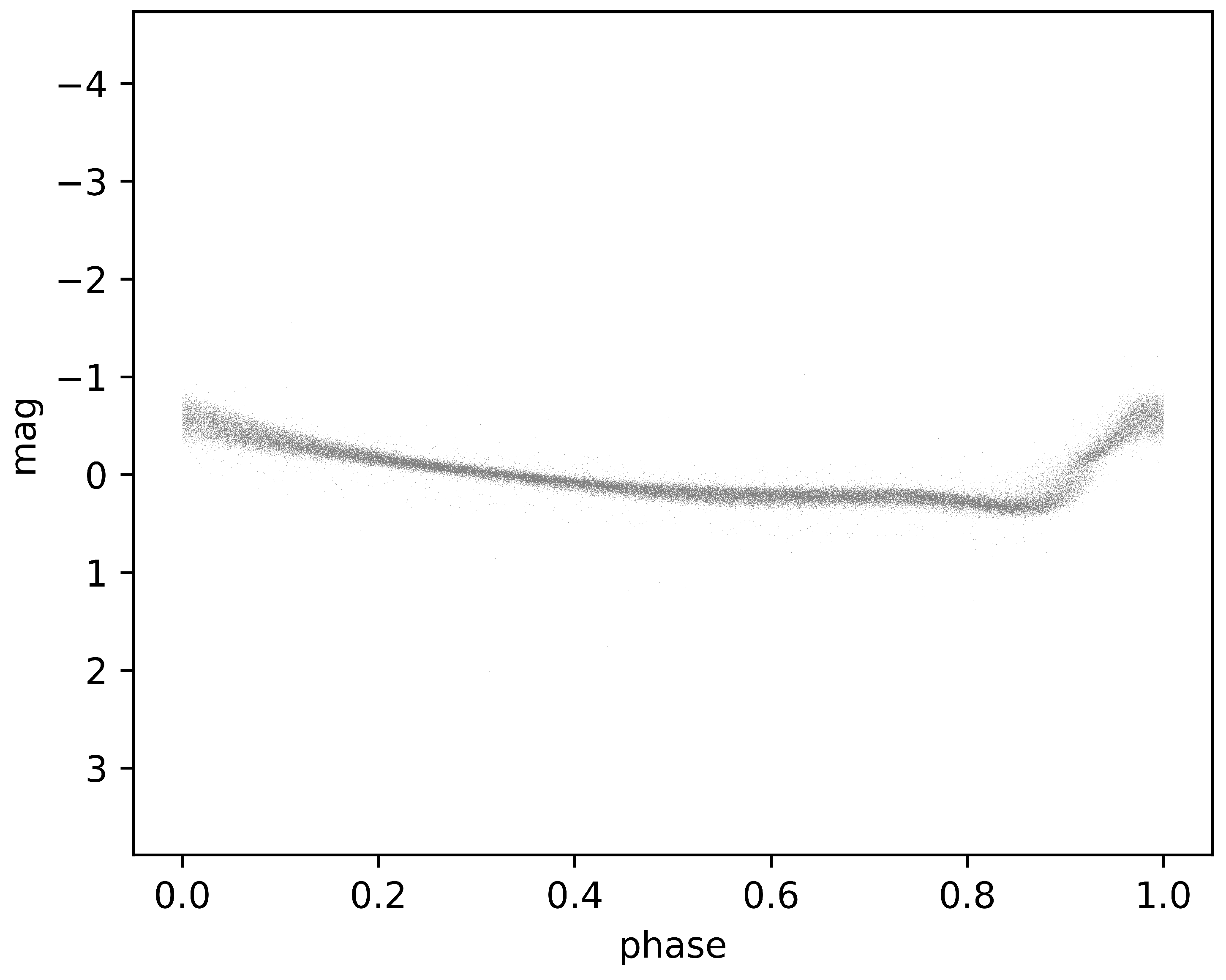
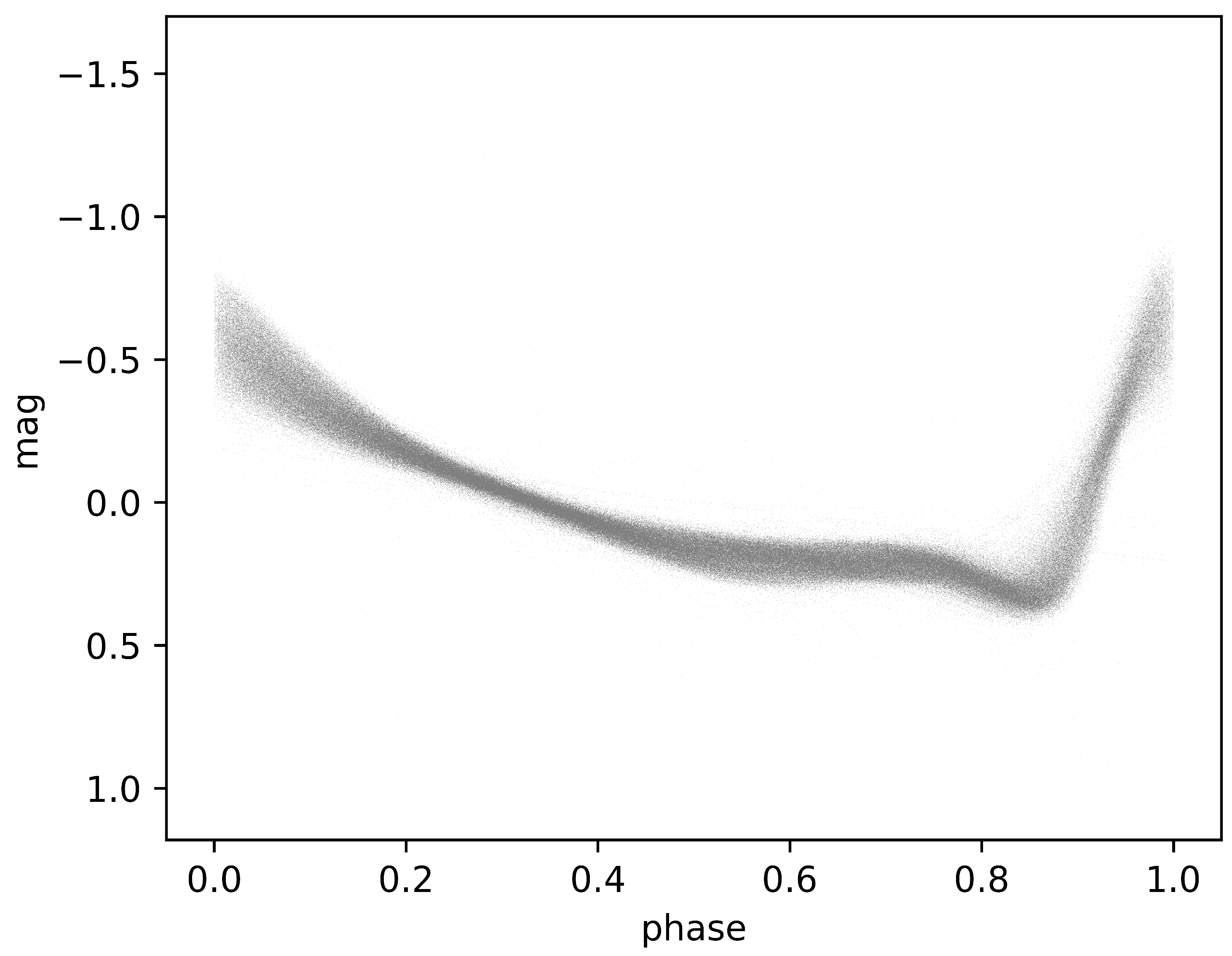


| id | Source_id | Period | AmpG | #Epochs | [Fe/H] | [Fe/H] |
|---|---|---|---|---|---|---|
| 0 | 5978423987417346304 | 0.415071 | 0.61029154 | 53 | −0.144963 | 0.398111 |
| 1 | 5358310424375618304 | 0.407642 | 0.6174223 | 56 | −0.223005 | 0.391468 |
| 2 | 5341271082206872704 | 0.327778 | 0.7399841 | 53 | 0.087612 | 0.382031 |
| 3 | 5844089608021904768 | 0.459576 | 0.47177884 | 54 | −0.380516 | 0.396500 |
| 4 | 5992931321712867200 | 0.390948 | 0.76943225 | 63 | −0.256892 | 0.391830 |
| ... | ... | ... | ... | ... | ... | ... |
| 5997 | 5917421845281955584 | 0.532958 | 0.9153245 | 52 | −1.507490 | 0.379151 |
| 5998 | 4659766188753815552 | 0.413777 | 0.9984105 | 245 | −0.758832 | 0.373709 |
| 5999 | 5868263951719014528 | 0.365109 | 1.0959375 | 66 | −0.300124 | 0.380579 |
| 6000 | 5963340573264428928 | 0.452752 | 1.0733474 | 64 | −1.079237 | 0.369655 |
| 6001 | 5796804423258834560 | 0.510323 | 1.0356201 | 57 | −1.553741 | 0.372771 |
| Layers | Hyperparameters | Parameters |
|---|---|---|
| input_1 | ... | 0 |
| gru_1 | 20 units | 1440 |
| dropout_1 | = 0.2 | 0 |
| gru_2 | 16 units | 1824 |
| dropout_2 | = 0.2 | 0 |
| gru_3 | 8 units | 624 |
| dropout_3 | = 0.1 | 0 |
| dense | ... | 9 |
| Metrics | Proposed Best Model (GRU) | Dekány Best Model (BiLSTM) | |
|---|---|---|---|
| Dataset (number of RR Lyrae stars) | 6002 | 4458 | |
| R2 regression performance | training | 0.9447 | 0.96 |
| validation | 0.9401 | 0.93 | |
| wRMSE | training | 0.0733 | 0.10 |
| validation | 0.0763 | 0.13 | |
| wMAE | training | 0.0547 | 0.07 |
| validation | 0.0563 | 0.10 | |
| RMSE | training | 0.0735 | 0.15 |
| validation | 0.0765 | 0.18 | |
| MAE | training | 0.0549 | 0.12 |
| validation | 0.0565 | 0.13 | |
| Architecture | GRU (3 layers) | BiLSTM (2 layers) | |
| Regularization | L1, L2 | L1 | |
| Dropout | Yes | Yes |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Monti, L.; Muraveva, T.; Clementini, G.; Garofalo, A. Leveraging Deep Learning for Time-Series Extrinsic Regression in Predicting the Photometric Metallicity of Fundamental-Mode RR Lyrae Stars. Sensors 2024, 24, 5203. https://doi.org/10.3390/s24165203
Monti L, Muraveva T, Clementini G, Garofalo A. Leveraging Deep Learning for Time-Series Extrinsic Regression in Predicting the Photometric Metallicity of Fundamental-Mode RR Lyrae Stars. Sensors. 2024; 24(16):5203. https://doi.org/10.3390/s24165203
Chicago/Turabian StyleMonti, Lorenzo, Tatiana Muraveva, Gisella Clementini, and Alessia Garofalo. 2024. "Leveraging Deep Learning for Time-Series Extrinsic Regression in Predicting the Photometric Metallicity of Fundamental-Mode RR Lyrae Stars" Sensors 24, no. 16: 5203. https://doi.org/10.3390/s24165203
APA StyleMonti, L., Muraveva, T., Clementini, G., & Garofalo, A. (2024). Leveraging Deep Learning for Time-Series Extrinsic Regression in Predicting the Photometric Metallicity of Fundamental-Mode RR Lyrae Stars. Sensors, 24(16), 5203. https://doi.org/10.3390/s24165203