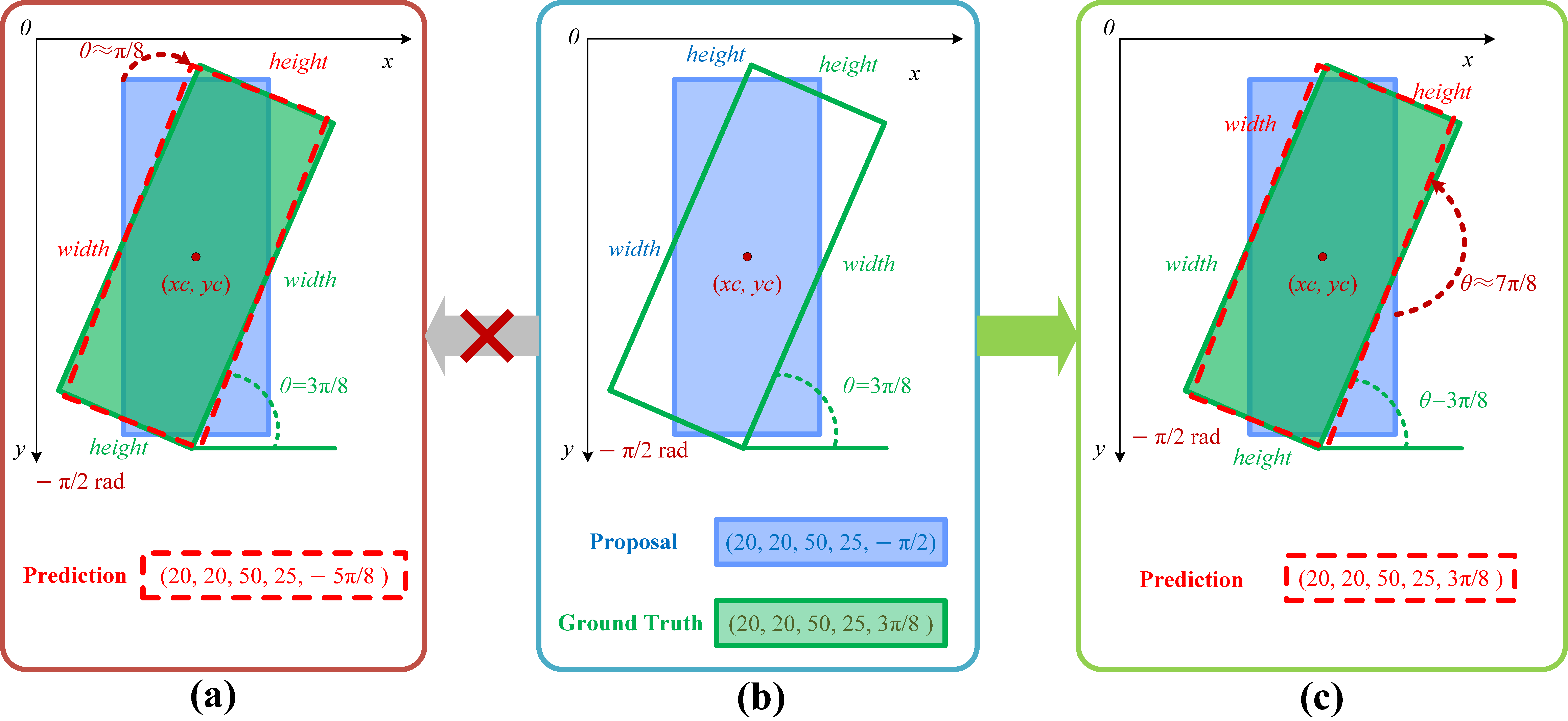
A persistent issue in the design of regression losses for rotated object detection is the inconsistency between model training metrics and final evaluation metrics. This inconsistency acts as a bottleneck, necessitating the design of a loss function specifically tailored for rotated object detection. Such a loss function must consider the unique characteristics of this task, especially in terms of the Intersection over Union (IoU), to enhance the model’s sensitivity to changes in angles.
To address this challenge, we introduce a novel regression loss, named the EAS loss. This loss function takes into account the IoU value between the predicted bounding box and the ground truth. The EAS loss effectively mitigates the inconsistency between training and evaluation metrics, enabling the model to accurately regress angles, particularly when the predicted box is close to the ground truth.
2.2.1. EAS Loss Design
To enhance the sensitivity to small angle deviations and improve metric consistency, a natural idea is to use IoU when regressing the angle
. In this case, the loss calculation is defined as in Equation (
2):
However, this introduces a new problem: when the centroid of the predicted box is far from the centroid of the ground truth box, the IoU value will be very small, leading to slow angle regression by the model. Assuming the aspect ratio of the box is 1:6, as shown in
Figure 7, even when the centroid of the predicted box and the ground truth box coincide, the slope of the
value becomes flat when the angle difference
exceeds 60°. This reduces the regression efficiency of the model for larger angle differences.
To address this, we introduce an IoU factor into the angle regression loss
calculation, as shown in Equation (
3):
Here,
adopts the calculation method of the Smooth L1 loss, leading to the ideal EAS loss calculation Equation (
4):
Here,
, and
and
are adjustable variables. When
and
, the relationship between
and the angle difference
is depicted in
Figure 8.
When the centroids of the predicted box and the ground truth box do not coincide, the EAS loss, incorporating the IoU factor in the angle regression loss component, prevents ineffective rotations of the predicted box. When the centroids of the predicted box and the ground truth box do coincide, the IoU factor allows the model to quickly and accurately learn to generate more precise predicted boxes as the predicted and ground truth angles approach each other. This makes it an ideal angle regression loss function.
The next issue is how to calculate the IoU value. Here, the IoU between the rotated bounding boxes is termed SkewIoU to distinguish it from horizontal IoU. The definition of SkewIoU is the same as IoU, as shown in Equation (
5):
where
P and
G are two rotated bounding boxes. To compute their intersection and union areas accurately, skewed bounding boxes are treated as polygons, and the convex polygon intersection calculation method [
5] is employed to precisely calculate SkewIoU. This process involves sorting and combining the coordinates of the vertices and intersection points of the rotated boxes, followed by the application of the triangulation method to calculate the area of the intersection region. The overall computation is relatively complex, with sorting and triangulation being the primary time-consuming factors. In practical applications, libraries such as OpenCV and Shapely are often employed to calculate SkewIoU. The specific implementation and optimizations in these libraries can impact performance, but the fundamental principles of computational complexity remain unchanged.
In general object detection, the IoU loss has long been a focus for effectively mitigating the inconsistency between evaluation metrics (dominated by IoU) and regression loss calculation methods. However, in rotated object detection, due to the computationally expensive nature of SkewIoU calculation, it is primarily used for validation and evaluation and has not been widely adopted in loss functions.
2.2.2. Gaussian Transformation for Approximate IoU Calculation
Recent studies, such as PIoU [
32], projection IoU [
33], GWD [
34], and KLD [
35], have explored methods to simulate the approximate SkewIoU loss. Among these, GWD and KLD introduced a Gaussian modeling approach, simplifying the complex SkewIoU calculation into a more efficient process. However, their methods involve nonlinear transformations and hyperparameters in the final loss function design using Gaussian distribution distance metrics, making them not fundamentally SkewIoU. KFIoU [
36] is a loss function based on the approximation of SkewIoU and center-point distance, but its performance in the proposed model in this paper is not ideal. As shown in
Table 1, after incorporating the KFIoU loss, the model’s AP50, AP75, and mAP all experienced varying degrees of decline. In the original paper, KFIoU achieved satisfactory results with backbone networks like ResNet-152 with large parameter sizes. In contrast, the model in this paper utilizes the ReResNet-50 backbone network with relatively fewer computational parameters, which might be one of the reasons for the performance degradation.
Despite KFIoU’s poor performance in ReBiDet, a simpler and more efficient method for approximating SkewIoU is worth considering. This method converts two rotated bounding boxes into Gaussian distributions, representing the overlapping region with a simpler mathematical formula and calculating the area of the minimum enclosing rectangle of this region. This approach significantly simplifies the original geometric computation while maintaining a high approximation to the exact IoU value [
36]. This method adheres to the SkewIoU calculation process, is mathematically rigorous, and does not introduce additional hyperparameters. Although the accuracy of the SkewIoU values obtained is relatively low, precise SkewIoU calculation is not strictly necessary in loss functions; minor errors are tolerable as long as the trend of the approximated SkewIoU matches the true value. Below are the basic steps and derivations for approximating SkewIoU using the Gaussian transformation method [
36]:
Transforming Rotated Rectangular Boxes into Gaussian Distributions. To begin, the rotated rectangular boxes are transformed into Gaussian distributions
. Each rectangular box is represented by two parameters: the covariance matrix
and the center coordinates
. For a rotated rectangular box
,
, and the covariance matrix is calculated as shown in Equation (
6):
where
. The final form of the covariance matrix
is given in Equation (
7):
The transformed Gaussian distribution is illustrated in
Figure 9.
Calculating Overlapping Area of Two Gaussian Distributions. The overlapping area of two Gaussian distributions is computed by multiplying the Gaussian distributions of the predicted box
P and the true target box
G using the Kalman filter’s multiplication rule. Specifically, the predicted box’s Gaussian distribution
is treated as the predicted value, and the true target box’s Gaussian distribution
is treated as the observed value. This yields the approximate Gaussian distribution
for the overlapping region
I, as shown in Equation (
8):
Here,
does not have a probability sum of 1 and is not a standard Gaussian distribution. The coefficient
can be expressed by Equation (
9):
When
,
can be approximated as a constant. Since the EAS loss is computed separately for the centroids of the bounding boxes, we can consider the scenario where the centroids of the predicted box
P and the ground truth box
G coincide, i.e.,
. In this case, the parameters
and
of the Gaussian distribution
for the overlap region
I are calculated using Equation (
10):
where
. When the central points of the predicted box
P and the true target box
G are close to overlapping (
), the center point
of the Gaussian distribution for the overlap region
I coincides with the central points of the predicted box
P and the true target box
G, as shown in
Figure 10. The covariance matrix
of the overlapping area
I can be approximated using Equation (
11):
It can be observed that the covariance
of the overlapping area
I is influenced by the covariance
and
of the Gaussian distributions of the predicted box
P and the true target box
G.
Calculating Areas of Externally Circumscribed Rectangles. The areas of the minimum enclosing rectangles for the predicted box
P, the ground truth box
G, and the overlap region
I are calculated using their respective Gaussian distributions. Since the dimensions of the predicted box
P and the ground truth box
G are known,
and
can be directly calculated. The area
can be conveniently derived from the covariance matrix
, as shown in Equation (
12):
Calculating the Approximate SkewIoU. The approximate SkewIoU (
) is calculated as follows:
However,
is not the exact area of the overlap of the predicted box
P and the true target box
G. Since
is not a standard Gaussian distribution and
is treated as a constant in the calculation, Xue Yang et al. derived that the upper bound of
is
[
36]. Using this upper bound, a linear transformation is applied to expand its value range to [0, 1], resulting in the approximate SkewIoU:
This approximation method for
demonstrates high consistency with the true
while being an ideal method for practical applications [
36]. Despite the complexity of the derivation, the implementation is straightforward in the EAS loss function, where
is used as a factor for angle regression without introducing additional hyperparameters and not participating in the backpropagation process.
The EAS loss function is given by:
where
, and
and
are adjustable parameters.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}