
LiteFer: An Approach Based on MobileViT Expression Recognition


Abstract
1. Introduction
2. Related Work
2.1. Attention Mechanisms
2.2. Depth-Separable Convolution
2.3. ViT
3. Modeling Framework
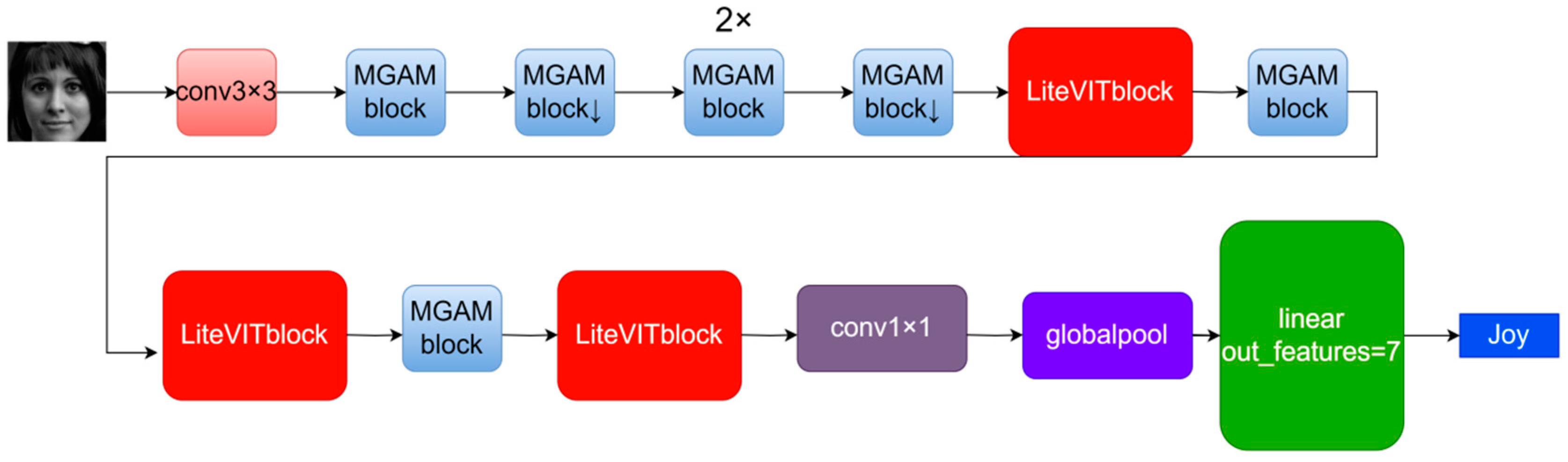
3.1. Overall Structure
3.1.1. Design of the LiteFer
3.1.2. Model Hierarchy
3.1.3. Output Layer
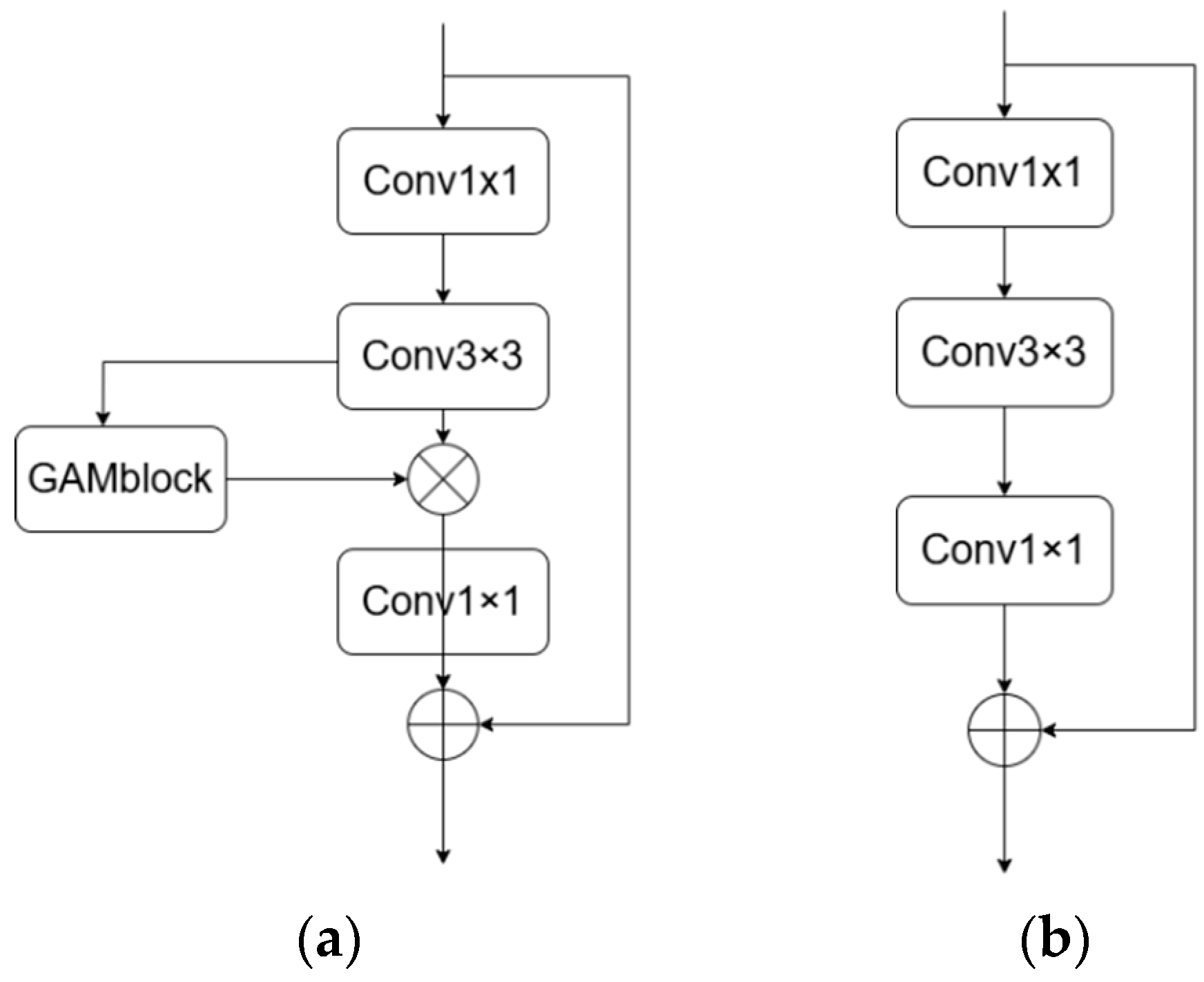
3.2. MGAMblock
3.2.1. General Structure of MGAMblock
3.2.2. GAM Attention Mechanism
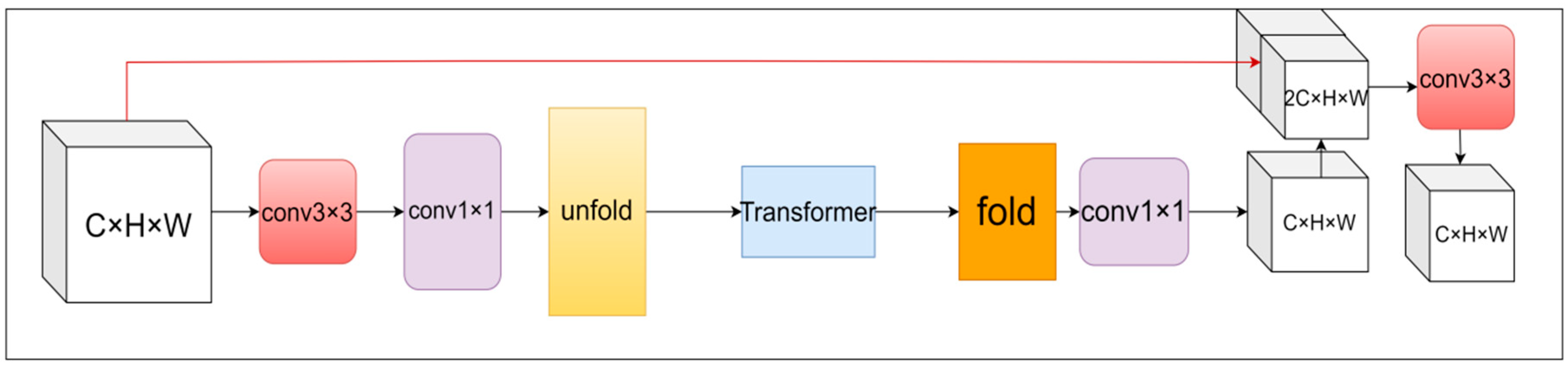
3.3. LiteViT Block
3.3.1. LiteViT Block Overall Structure
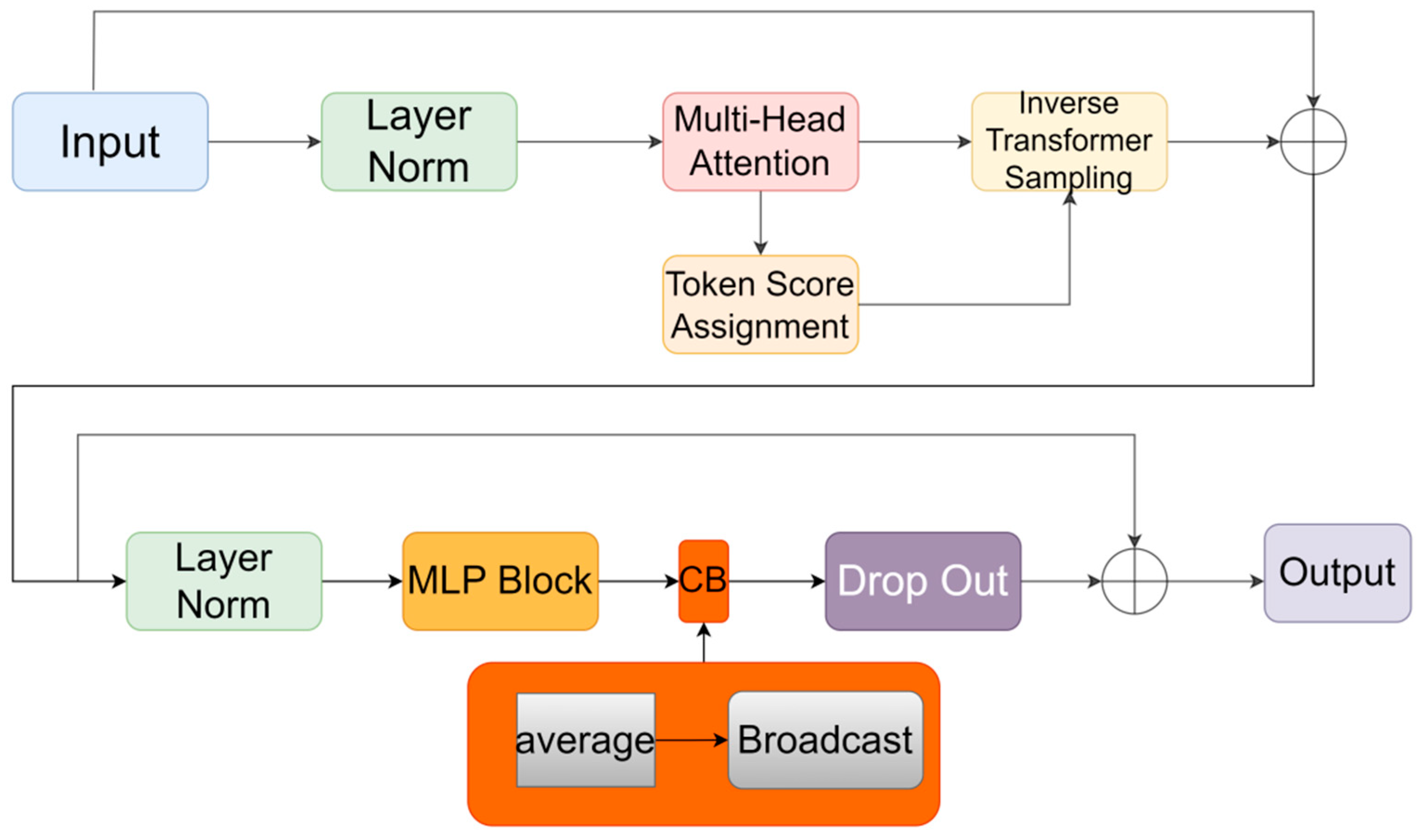
3.3.2. ATS Module
- (1)
- Token Scoring.
- (2)
- Token Sampling.
3.3.3. CB Module
3.4. LiteFer Details Table

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Size | Output Stride | Repetition | Output Channels |
|---|---|---|---|---|
| Image | 224 × 224 | 1 | ||
| Conv3 × 3 ↓ | 1 | |||
| MGAM block | 112 × 112 | 2 | 1 | 16 |
| MGAM block ↓ | 1 | |||
| MGAM block | 56 × 56 | 2 | 2 | 24 |
| MGAM block ↓ | 1 | |||
| LiteViT | 28 × 28 | 2 | 1 | 48 |
| MGAM block ↓ | 1 | |||
| LiteViT | 14 × 14 | 2 | 1 | 64 |
| MGAM block ↓ | 1 | |||
| LiteViT | 7 × 7 | 2 | 1 | 80 |
| Conv1 × 1 | 1 | 320 | ||
| Global pool | 1 × 1 | 2 | 1 | 1000 |
| Linear |
4. Experimental Setup
4.1. Environment Setup
4.2. Introduction of Dataset
4.3. Performance Comparison
4.4. Ablation Experiment
- MobileNet Combined With the ViT Approach: This hybrid architecture enhances the model’s ability to learn local and global features simultaneously. By combining MobileNet’s capabilities for local learning with ViT’s expertise in global feature modeling, the model effectively focuses on a wider range of facial key regions while capturing subtle facial nuances.
- GAM Attention Mechanism Module: The inclusion of the GAM module guarantees that the feature maps extracted by the MGAM module contain essential information without substantially increasing the parameter count. This mechanism allows the model to focus on crucial facial features, leading to improved recognition performance. Data augmentation techniques help address the problem of dataset imbalance, resulting in more robust training outcomes. Additionally, the integration of ATS adaptive sampling in ViT significantly reduces FLOPs, thereby accelerating the model’s training speed without compromising performance.
- CB Module Integration: Adding the CB module at the end of the MLP in LiteViT enhances the performance of ViT without introducing additional parameters. This module helps in enhancing feature representation, leading to improved recognition accuracy.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Correction Statement
References
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 1, pp. 886–893. [Google Scholar]
- Gabor, D. Theory of communication. J. Inst. Electr. Eng. 1946, 93, 429–441. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Harwood, D. A comparative study of texture measures with classification based on featured distributions. Pattern Recognit. 1996, 29, 51–59. [Google Scholar] [CrossRef]
- Pham, L.; Vu, T.H.; Tran, T.A. Facial Expression Recognition Using Residual Masking Network. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 4513–4519. [Google Scholar] [CrossRef]
- Yao, A.; Cai, D.; Hu, P.; Wang, S.; Sha, L.; Chen, Y. Holonet: Towards robust emotion recognition in the wild. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 472–478. [Google Scholar]
- Lu, X.; Zhang, H.; Zhang, Q.; Han, X. A Lightweight Network for Expression Recognition Based on Adaptive Mixed Residual Connections. In Proceedings of the 2022 5th International Conference on Pattern Recognition and Artificial Intelligence (PRAI), Chengdu, China, 19–21 August 2022; pp. 311–315. [Google Scholar]
- Zhou, Y.; Guo, L.; Jin, L. Quaternion Orthogonal Transformer for Facial Expression Recognition in the Wild. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Liu, S.; Xu, Y.; Wan, T.; Kui, X. A Dual-Branch Adaptive Distribution Fusion Framework for Real-World Facial Expression Recognition. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; IEEE: Piscataway, NJ, USA, 2023. [Google Scholar]
- Dinh, H.-H.; Do, H.-Q.; Doan, T.-T.; Le, C.; Bach, N.X.; Phuong, T.M.; Vu, V.-V. FGW-FER: Lightweight Facial Expression Recognition with Attention. KSII Trans. Internet Inf. Syst. 2023, 17, 2505–2528. [Google Scholar] [CrossRef]
- Liu, Y.; Shao, Z.; Hoffmann, N. Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions. arXiv 2021, arXiv:2112.05561v1[cs.CV]. [Google Scholar]
- Fayyaz, M.; Koohpayegani, S.A.; Jafari, F.R.; Sengupta, S.; Joze, H.R.V.; Sommerlade, E.; Pirsiavash, H.; Gall, J. Adaptive Token Sampling For Efficient Vision Transformers. arXiv 2022, arXiv:2111.15667v3. [Google Scholar]
- Hyeon-Woo, N.; Yu-Ji, K.; Heo, B.; Han, D.; Oh, S.J.; Oh, T.H. Scratching Visual Transformer’s Back with Uniform Attention. arXiv 2022, arXiv:2210.08457. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations (ICLR), Vienna, Austria, 4 May 2021. [Google Scholar]
- Mehta, S.; Rastegari, M. MobileViT: Light-weight general-purpose and mobile-friendly vision transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Elfwing, S.; Uchibe, E.; Doya, K. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural Netw. 2018, 107, 3–11. [Google Scholar] [CrossRef] [PubMed]
- Langner, O.; Dotsch, R.; Bijlstra, G.; Wigboldus, D.H.; Hawk, S.T.; van Knippenberg, A. Presentation and validation of the Radboud Faces Database. Cogn. Emot. 2010, 24, 1377–1388. [Google Scholar] [CrossRef]
- Barsoum, E.; Zhang, C.; Canton Ferrer, C.; Zhang, Z. Training deep networks for facial expression recognition with crowd-sourced label distribution. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 279–283. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wang, K.; Peng, X.; Yang, J.; Meng, D.; Qiao, Y. Region attention networks for pose and occlusion robust facial expression recognition. IEEE Trans. Image Process. 2020, 29, 4057–4069. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Zhang, Y.; Zhang, Y.; Wang, Y.; Song, Z. A Dual-Direction Attention Mixed Feature Network for Facial Expression Recognition. Electronics 2023, 12, 3595. [Google Scholar] [CrossRef]
- Zhao, G.; Yang, H.; Yu, M. Expression Recognition Method Based on a Lightweight Convolutional Neural Network. IEEE Access 2020, 8, 38528–38537. [Google Scholar] [CrossRef]
- Xue, F.; Wang, Q.; Guo, G. Transfer: Learning relation-aware facial expression representations with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3601–3610. [Google Scholar]
- Kim, J.; Kang, J.-K.; Kim, Y. A Resource Efficient Integer-Arithmetic-Only FPGA-Based CNN Accelerator for Real-Time Facial Emotion Recognition. IEEE Access 2021, 9, 104367–104381. [Google Scholar] [CrossRef]
- Wen, Z.; Lin, W.; Wang, T.; Xu, G. Distract your attention: Multi-head cross attention network for facial expression recognition. Biomimetics 2023, 8, 199. [Google Scholar] [CrossRef] [PubMed]



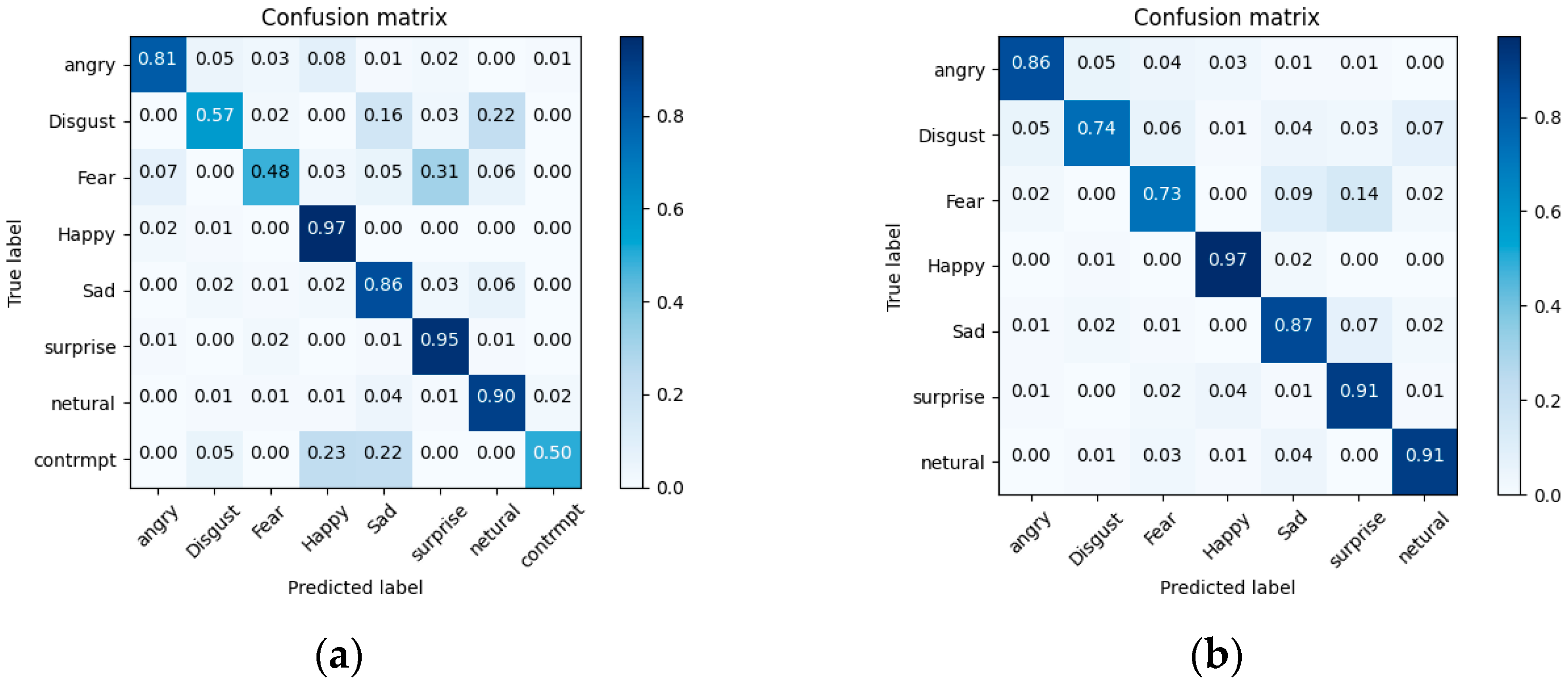
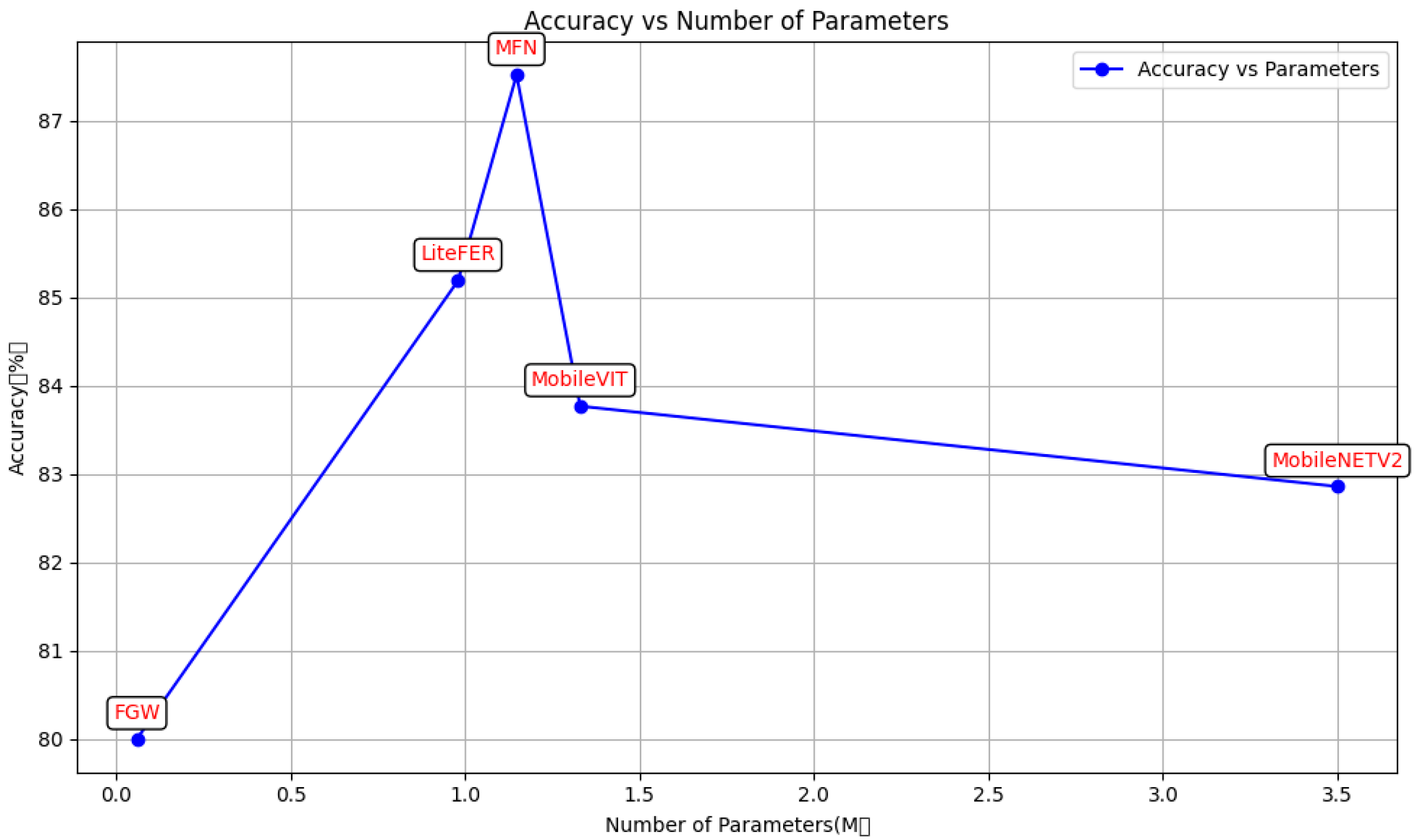

| Methods | Parameters | FLOPs | FERPlus | RAFDB | |
|---|---|---|---|---|---|
| 1 | Resnet-18 [23] | 11.18 M | 1.82 G | 84.78% | 84.67% |
| 2 | MoblieNetV2 | 3.50 M | 324.4 M | - | 82.86% |
| 3 | MobileViT | 1.33 M | 261.6 M | - | 83.77% |
| 4 | RAN [24] | 11.2 M | 14.5 G | 89.16% | 86.90% |
| 5 | MFN [25] | 1.148 M | 230.34 M | - | 87.52% |
| 6 | DenseNet [26] | 0.17 M | 0.17 B | 84.28% | - |
| 7 | TransFER [27] | 65.2 M | - | 90.83% | 90.11% |
| 8 | LLTQ [28] | 0.39 M | 28 M | 86.58% | |
| 9 | Ada-DF [8] | - | - | - | 90.04% |
| 10 | DAN [29] | 19.72 M | 2.23 G | 89.70% | |
| 11 | FGW | 0.06 M | - | 79.36% | 80.75% |
| 12 | LiteFer | 0.98 M | 218.3 M | 86.64% | 85.19% |
| GAM | ECA | ATS | CB | Parameters | FLOPs | RAFDB | FERPlus | |
|---|---|---|---|---|---|---|---|---|
| 1 | √ | 0.96 M | 254.5 M | 84.3% | 84.9% | |||
| 2 | √ | 0.98 M | 278.6 M | 84.9% | 86.4% | |||
| 3 | √ | √ | 0.98 M | 278.6 M | 85.2% | 86.8% | ||
| 4 | √ | √ | √ | 0.98 M | 218.3 M | 85.2% | 86.6% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, X.; Lan, Z.; Wang, N.; Li, J.; Wang, Y.; Meng, Y. LiteFer: An Approach Based on MobileViT Expression Recognition. Sensors 2024, 24, 5868. https://doi.org/10.3390/s24185868
Yang X, Lan Z, Wang N, Li J, Wang Y, Meng Y. LiteFer: An Approach Based on MobileViT Expression Recognition. Sensors. 2024; 24(18):5868. https://doi.org/10.3390/s24185868
Chicago/Turabian StyleYang, Xincheng, Zhenping Lan, Nan Wang, Jiansong Li, Yuheng Wang, and Yuwei Meng. 2024. "LiteFer: An Approach Based on MobileViT Expression Recognition" Sensors 24, no. 18: 5868. https://doi.org/10.3390/s24185868
APA StyleYang, X., Lan, Z., Wang, N., Li, J., Wang, Y., & Meng, Y. (2024). LiteFer: An Approach Based on MobileViT Expression Recognition. Sensors, 24(18), 5868. https://doi.org/10.3390/s24185868