
Enhancing Cybersecurity in Healthcare: Evaluating Ensemble Learning Models for Intrusion Detection in the Internet of Medical Things


Abstract
1. Introduction
- We designed a scheme based on machine learning technology to enhance the classification of attacks versus normal operations.
- We applied feature selection methods to improve the IDS performance of IoMT network devices.
- We used ensemble learning techniques, including Stacking, Bagging, and Boosting.
- We evaluated the performance of our scheme in terms of accuracy, precision, recall, and F1-score.
- Our scheme outperformed recent studies utilizing the same dataset, specifically in Stacking and Bagging.
2. Background
2.1. Internet of Medical Things (IoMT) Connection Overview
2.1.1. Data Collection
2.1.2. Local Processing
2.1.3. Data Transmission
- Wi-Fi: many IoMT devices utilize local Wi-Fi networks to transmit data to healthcare providers or cloud servers.
- Bluetooth: wearable IoMT devices commonly utilize Bluetooth to transmit data to smartphones or gateways, which then forward the data to central systems.
- Cellular Networks: certain IoMT devices, particularly those for remote monitoring, integrate cellular connectivity to transmit data directly over mobile networks.
- Zigbee/Z-Wave: low-power wireless protocols such as Zigbee and Z-Wave are employed in some IoMT devices to facilitate short-range communication within healthcare facilities.
2.1.4. Data Aggregation and Storage
2.1.5. Data Processing and Analysis
- Real-Time Monitoring: continuously monitoring patient data to detect anomalies or critical events, triggering alerts for healthcare providers.
- Predictive Analytics: leveraging machine learning algorithms to anticipate potential health problems based on past and current data.
- Data Integration: combining data from multiple IoMT devices and other sources (e.g., electronic health records) to provide comprehensive insights into a patient’s health.
2.1.6. Communication and Feedback
- Alerts and Notifications: sending real-time alerts to healthcare providers when critical thresholds are crossed (e.g., a significant drop in blood oxygen levels).
- Reports and Dashboards: providing healthcare providers with detailed reports and dashboards to monitor patient health trends.
- Patient Feedback: sending notifications and recommendations to patients via mobile apps or other devices, encouraging them to take specific actions (e.g., medication reminders, and exercise prompts).
2.1.7. Secure Communication
- Encryption: encrypting data during transmission to protect it from interception and unauthorized access.
- Authentication: verifying the identity of devices and users to prevent unauthorized access to the network.
- Access Control: implementing strict access control policies to ensure that only authorized personnel can access sensitive patient data.
- Regular Updates: keeping device firmware and software up-to-date to protect against known vulnerabilities.
2.2. Challenges and Security Threats in IoMT
2.3. Challenges in IoMT
2.3.1. Interoperability
2.3.2. Data Management
2.3.3. Regulatory Compliance
2.3.4. Scalability
2.4. Security Threats in IoMT
2.4.1. Data Breaches
2.4.2. Malware and Ransomware
2.4.3. Device Hijacking
2.4.4. Insider Threats
2.4.5. Physical Attacks
2.5. The Role of IDS in IoMT Security
2.5.1. Anomaly Detection
2.5.2. Real-Time Alerts
2.5.3. Enhanced Visibility
3. Related Work
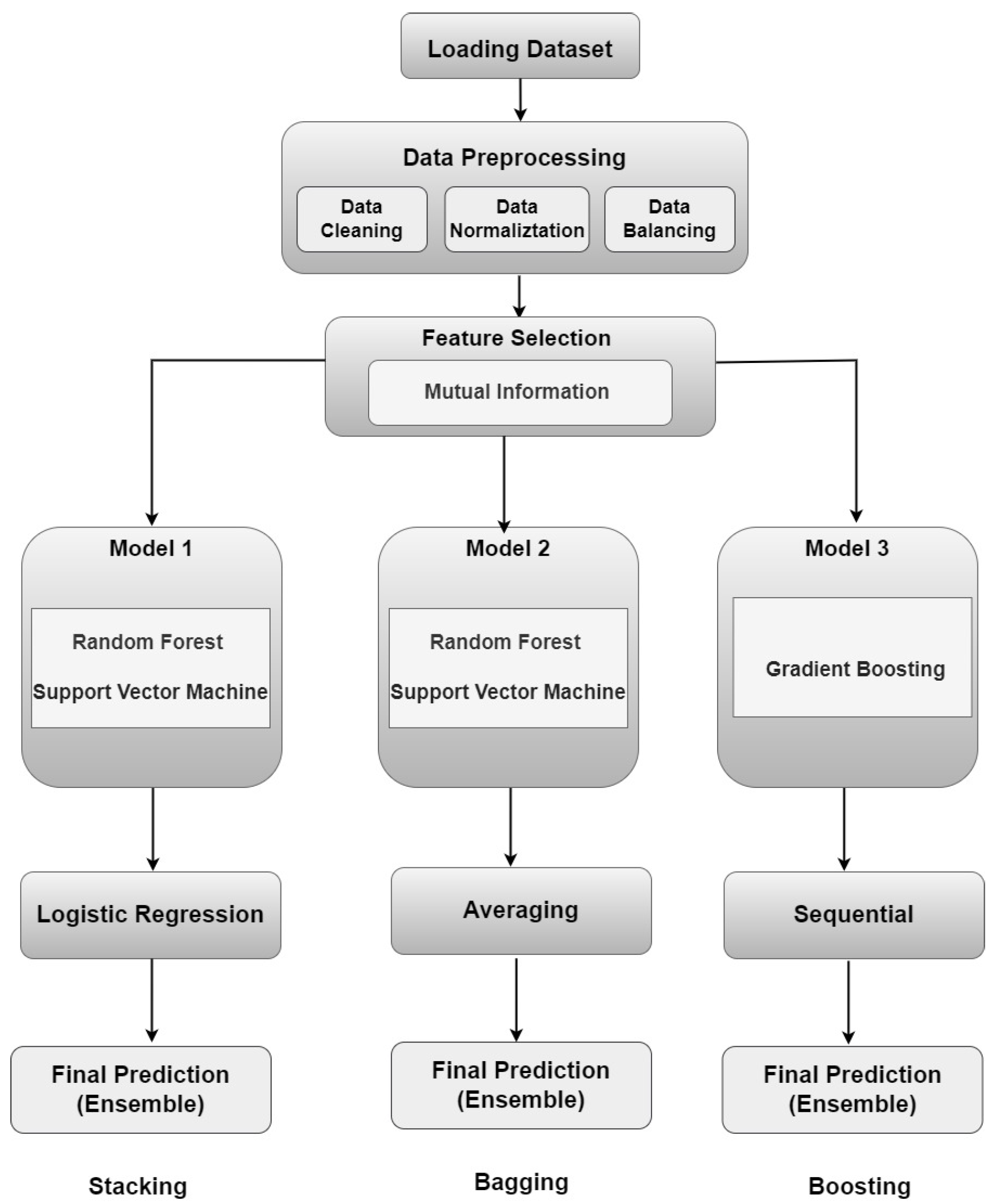
4. Methodology
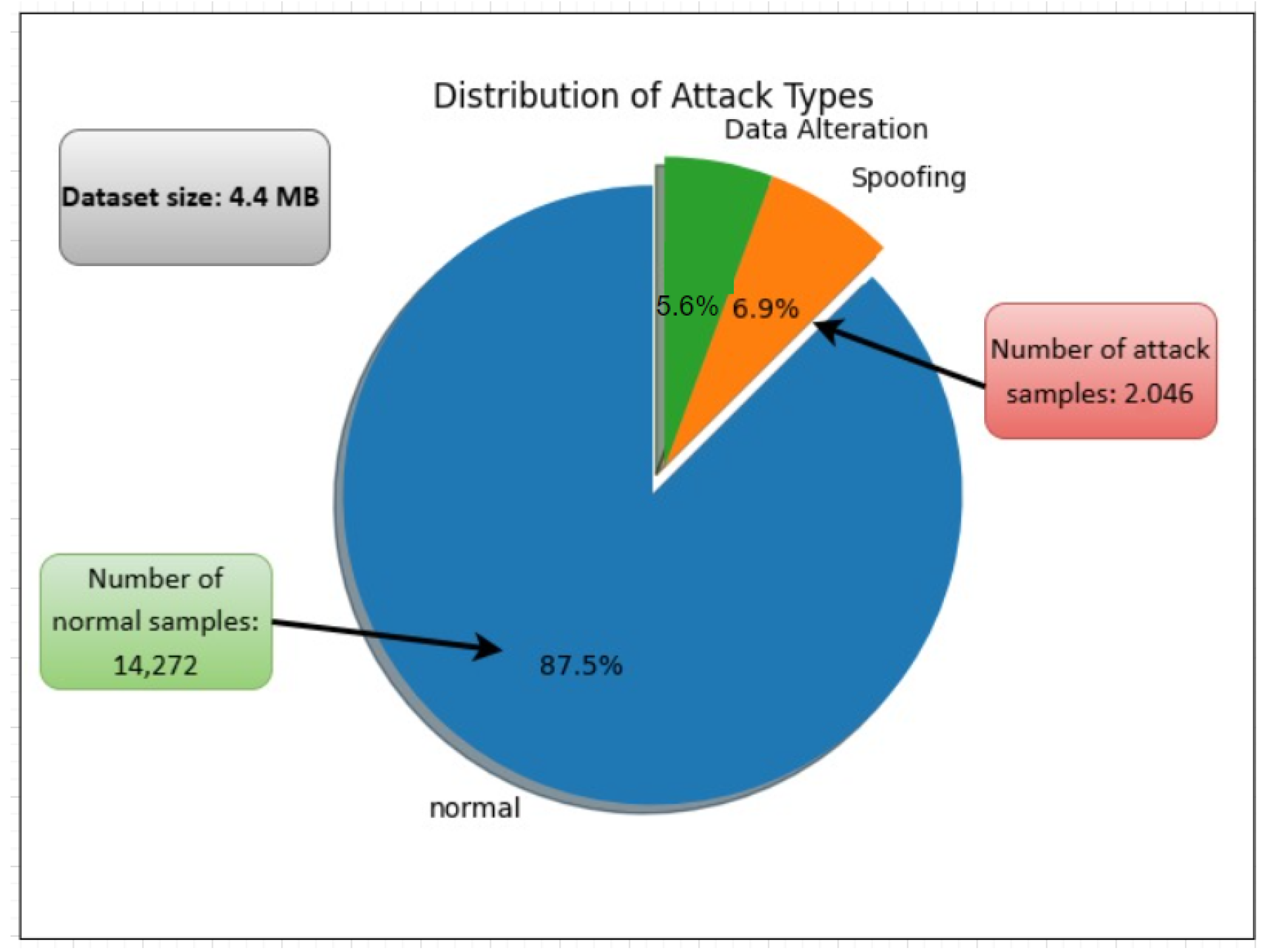
4.1. Dataset Description
4.2. Data Preprocessing
4.2.1. Data Cleaning
4.2.2. Data Normalization
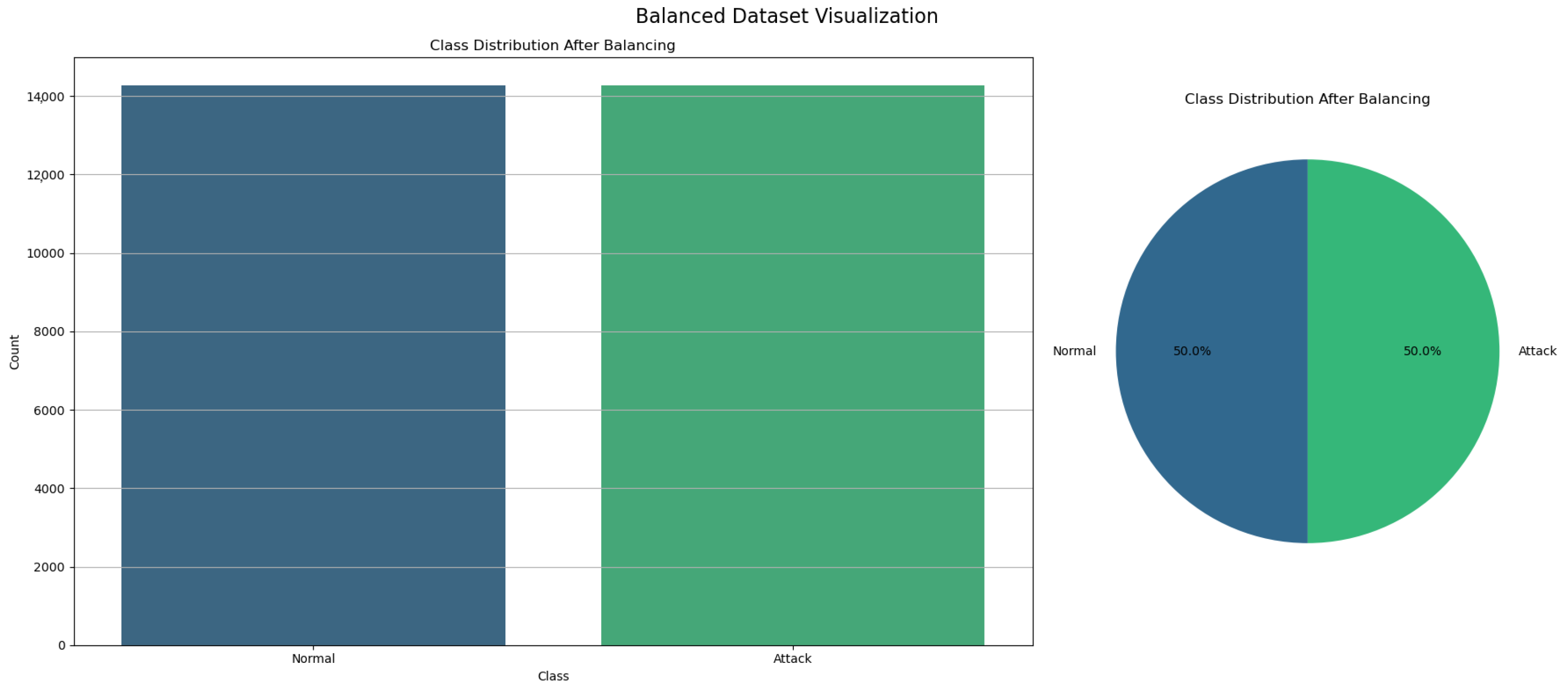
4.2.3. Data Balancing
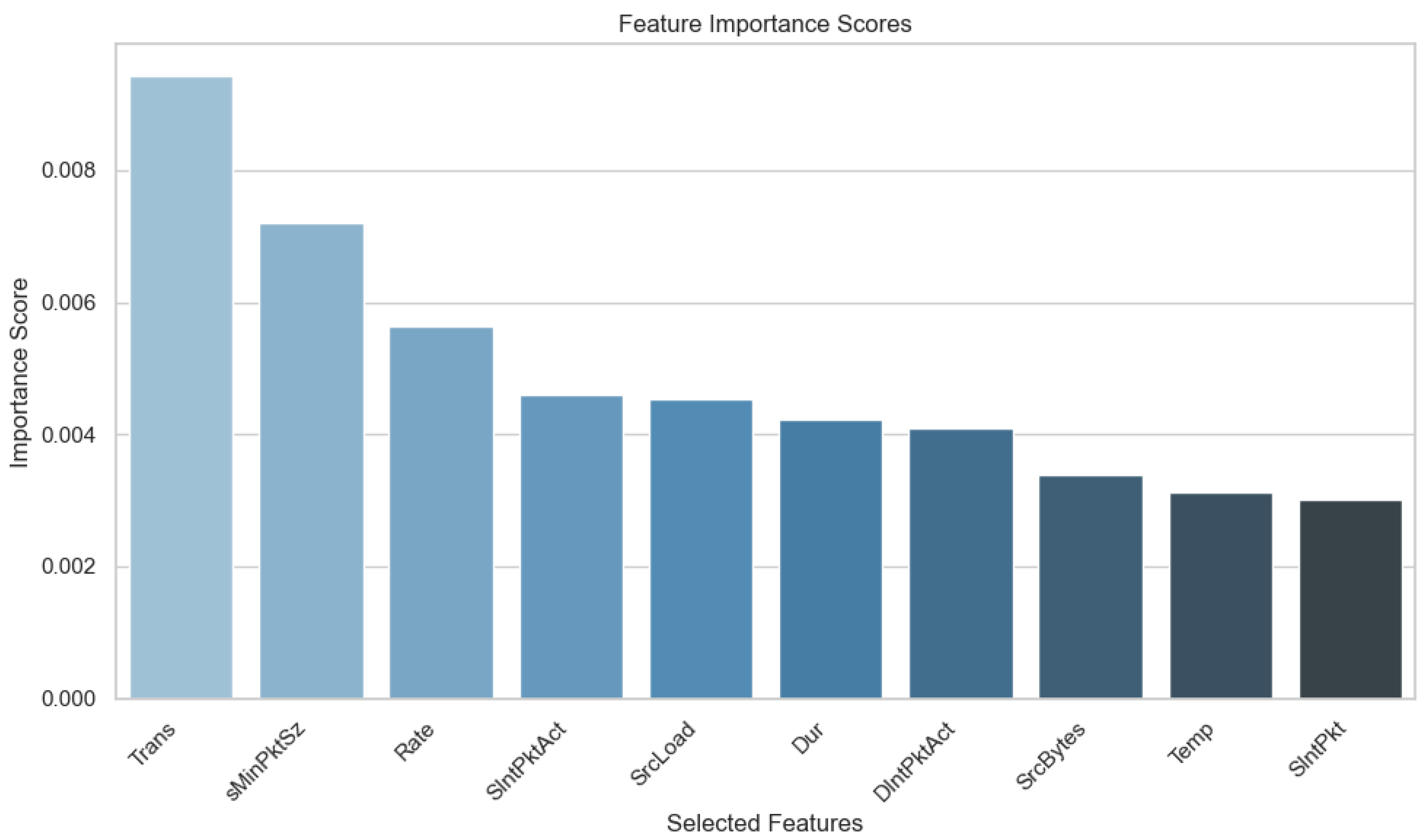
4.3. Data Selection
- X and Y are two random variables.
- is the joint probability mass (or density) function of X and Y.
- and are the marginal probability mass (or density) functions of X and Y, respectively.
4.4. Random Forest
4.5. Support Vector Machine
4.6. Ensemble Learning
4.6.1. Stacking
4.6.2. Boosting
4.6.3. Bagging
5. Results and Discussion
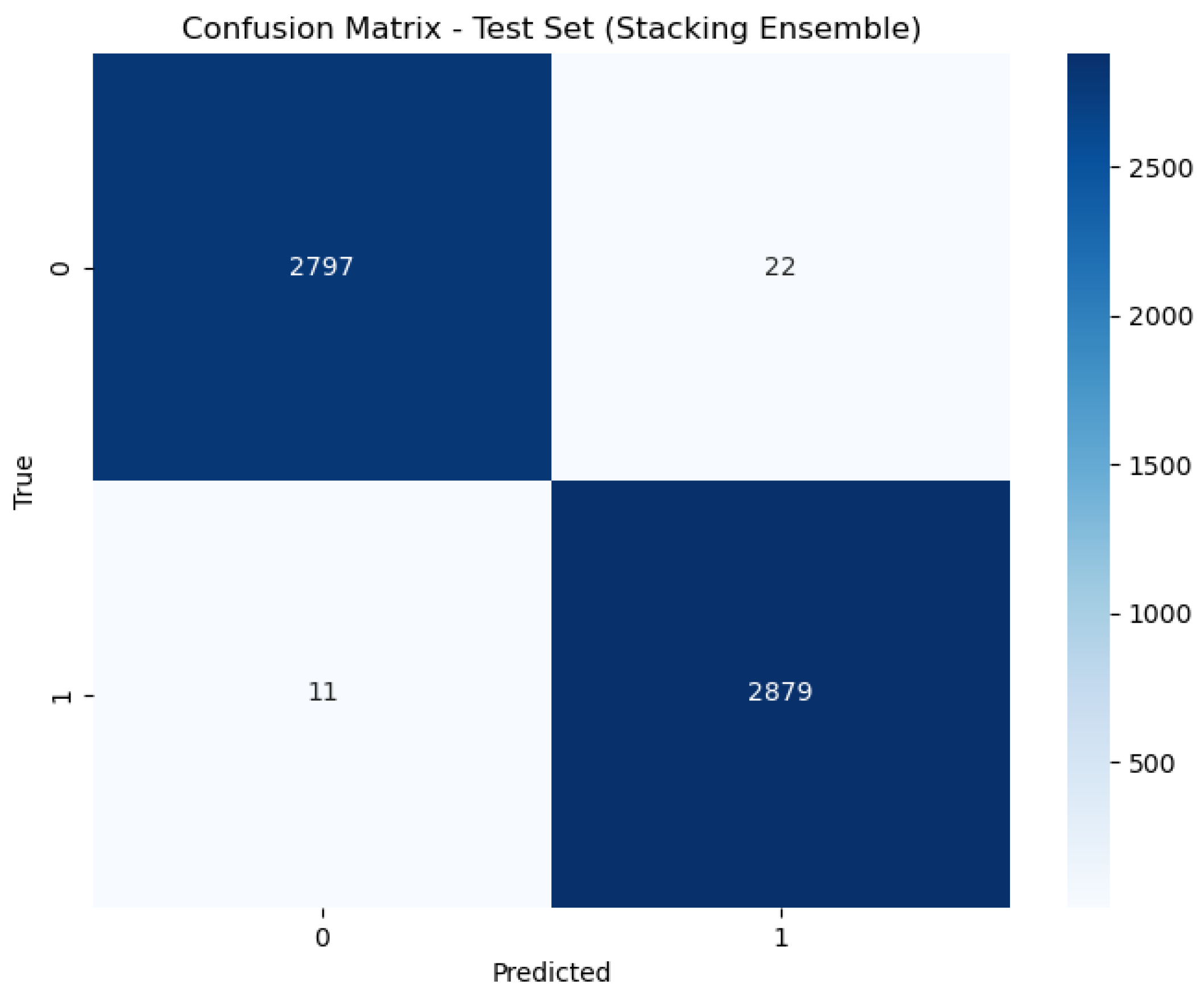
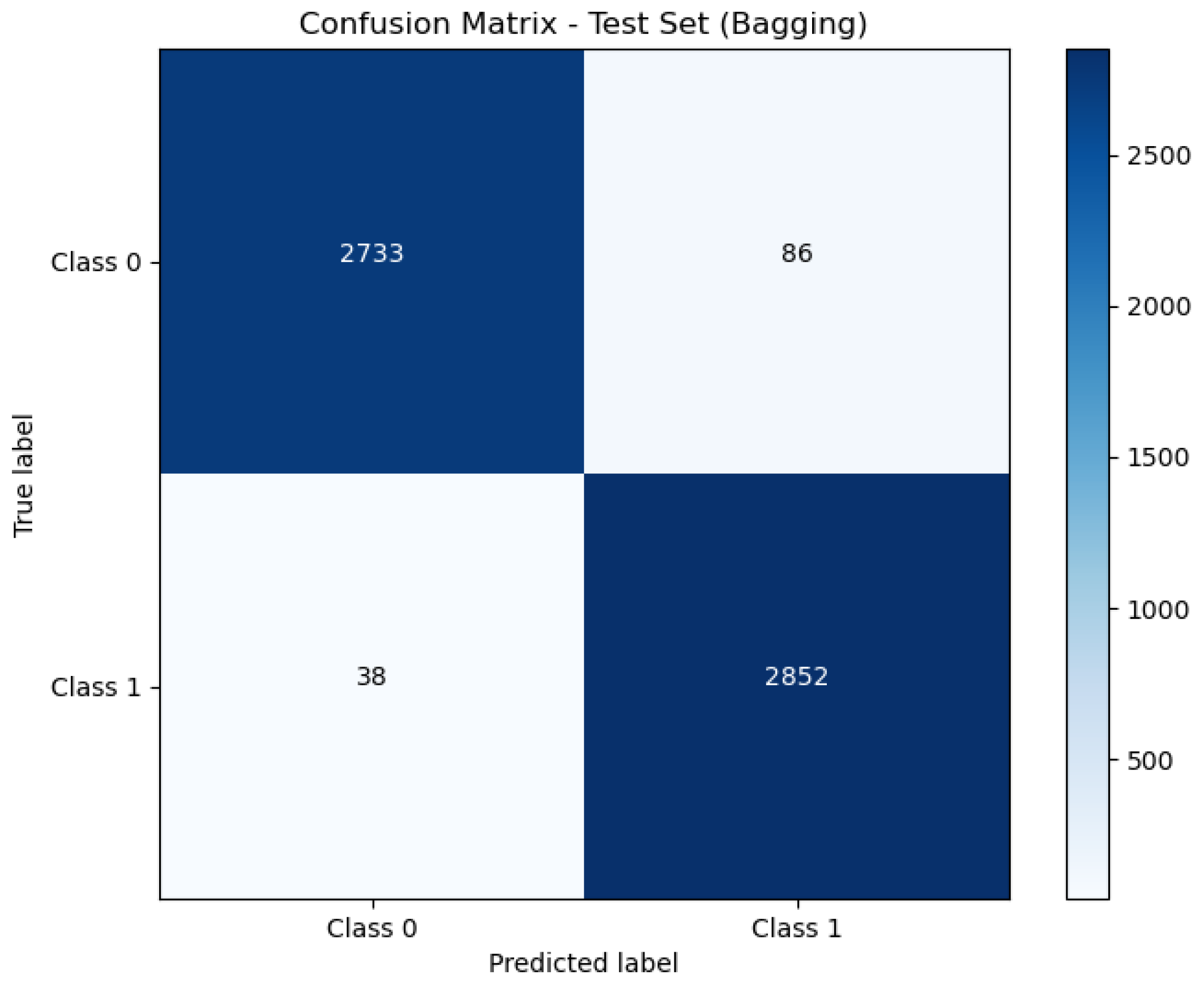
5.1. Accuracy
5.2. Precision
5.3. Recall
5.4. F1-Score
5.5. Limitation
5.6. Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Manickam, P.; Mariappan, S.A.; Murugesan, S.M.; Hansda, S.; Kaushik, A.; Shinde, R.; Thipperudraswamy, S. Artificial intelligence (AI) and internet of medical things (IoMT) assisted biomedical systems for intelligent healthcare. Biosensors 2022, 12, 562. [Google Scholar] [CrossRef] [PubMed]
- El-Rashidy, N.; El-Sappagh, S.; Islam, S.R.; El-Bakry, H.M.; Abdelrazek, S. Mobile health in remote patient monitoring for chronic diseases: Principles, trends, and challenges. Diagnostics 2021, 11, 607. [Google Scholar] [CrossRef] [PubMed]
- Alsharif, B.; Ilyas, M. Internet of things technologies in healthcare for people with hearing impairments. In IoT and Big Data Technologies for Health Care; Springer: Berlin, Germany, 2022; pp. 299–308. [Google Scholar]
- Levy-Loboda, T.; Sheetrit, E.; Liberty, I.F.; Haim, A.; Nissim, N. Personalized insulin dose manipulation attack and its detection using interval-based temporal patterns and machine learning algorithms. J. Biomed. Inform. 2022, 132, 104129. [Google Scholar] [CrossRef] [PubMed]
- Sharma, P.; Jain, S.; Gupta, S.; Chamola, V. Role of machine learning and deep learning in securing 5G-driven industrial IoT applications. Ad Hoc Netw. 2021, 123, 102685. [Google Scholar] [CrossRef]
- Osama, M.; Ateya, A.A.; Sayed, M.S.; Hammad, M.; Pławiak, P.; Abd El-Latif, A.A.; Elsayed, R.A. Internet of medical things and healthcare 4.0: Trends, requirements, challenges, and research directions. Sensors 2023, 23, 7435. [Google Scholar] [CrossRef]
- Koutras, D.; Stergiopoulos, G.; Dasaklis, T.; Kotzanikolaou, P.; Glynos, D.; Douligeris, C. Security in IoMT communications: A survey. Sensors 2020, 20, 4828. [Google Scholar] [CrossRef]
- Zikria, Y.B.; Afzal, M.K.; Kim, S.W. Internet of multimedia things (IoMT): Opportunities, challenges and solutions. Sensors 2020, 20, 2334. [Google Scholar] [CrossRef]
- Thota, C.; Sundarasekar, R.; Manogaran, G.; Varatharajan, R.; Priyan, M. Centralized fog computing security platform for IoT and cloud in healthcare system. In Fog Computing: Breakthroughs in Research and Practice; IGI Global: Hershey, PA, USA, 2018; pp. 365–378. [Google Scholar]
- Lindberg, B.; Nilsson, C.; Zotterman, D.; Söderberg, S.; Skär, L. Using information and communication technology in home care for communication between patients, family members, and healthcare professionals: A systematic review. Int. J. Telemed. Appl. 2013, 2013, 461829. [Google Scholar] [CrossRef]
- Dwivedi, R.; Mehrotra, D.; Chandra, S. Potential of Internet of Medical Things (IoMT) applications in building a smart healthcare system: A systematic review. J. Oral Biol. Craniofac. Res. 2022, 12, 302–318. [Google Scholar] [CrossRef]
- Alsolami, T.; Balhareth, G.; Ilyas, M. Survey for Security in IoT in e-Healthcare. In Proceedings of the 14th International Multi-Conference on Complexity, Informatics and Cybernetics: IMCIC 2023, Virtual Conference, 28–31 March 2023. [Google Scholar] [CrossRef]
- Rani, S.; Kataria, A.; Kumar, S.; Tiwari, P. Federated learning for secure IoMT-applications in smart healthcare systems: A comprehensive review. Knowl.-Based Syst. 2023, 274, 110658. [Google Scholar] [CrossRef]
- Sun, Y.; Lo, F.P.W.; Lo, B. Security and privacy for the internet of medical things enabled healthcare systems: A survey. IEEE Access 2019, 7, 183339–183355. [Google Scholar] [CrossRef]
- Tariq, U.; Ullah, I.; Yousuf Uddin, M.; Kwon, S.J. An effective self-configurable ransomware prevention technique for IOMT. Sensors 2022, 22, 8516. [Google Scholar] [CrossRef] [PubMed]
- Alsubaei, F.; Abuhussein, A.; Shandilya, V.; Shiva, S. IoMT-SAF: Internet of medical things security assessment framework. Internet Things 2019, 8, 100123. [Google Scholar] [CrossRef]
- Al-Garadi, M.A.; Mohamed, A.; Al-Ali, A.K.; Du, X.; Ali, I.; Guizani, M. A survey of machine and deep learning methods for internet of things (IoT) security. IEEE Commun. Surv. Tutor. 2020, 22, 1646–1685. [Google Scholar] [CrossRef]
- Alkanjr, B.; Alshammari, T. Iobt intrusion detection system using machine learning. In Proceedings of the 2023 IEEE 13th Annual Computing and Communication Workshop and Conference (CCWC), Virtual, 8–11 March 2023; pp. 0886–0892. [Google Scholar]
- Binbusayyis, A.; Alaskar, H.; Vaiyapuri, T.; Dinesh, M. An investigation and comparison of machine learning approaches for intrusion detection in IoMT network. J. Supercomput. 2022, 78, 17403–17422. [Google Scholar] [CrossRef]
- Nissar, G.; Khan, R.A.; Mushtaq, S.; Lone, S.A.; Moon, A.H. IoT in healthcare: A review of services, applications, key technologies, security concerns, and emerging trends. In Multimedia Tools and Applications; Springer: Berlin, Germany, 2024; pp. 1–62. [Google Scholar]
- Tauqeer, H.; Iqbal, M.M.; Ali, A.; Zaman, S.; Chaudhry, M.U. Cyberattacks detection in iomt using machine learning techniques. J. Comput. Biomed. Inform. 2022, 4, 13–20. [Google Scholar] [CrossRef]
- Alotaibi, Y.; Ilyas, M. Ensemble-learning framework for intrusion detection to enhance internet of things’ devices security. Sensors 2023, 23, 5568. [Google Scholar] [CrossRef]
- Alalhareth, M.; Hong, S.C. An improved mutual information feature selection technique for intrusion detection systems in the Internet of Medical Things. Sensors 2023, 23, 4971. [Google Scholar] [CrossRef]
- Aljuhani, A.; Alamri, A.; Kumar, P.; Jolfaei, A. An Intelligent and Explainable SaaS-Based Intrusion Detection System for Resource-Constrained IoMT. IEEE Internet Things J. 2023, 11, 25454–25463. [Google Scholar] [CrossRef]
- Gupta, K.; Sharma, D.K.; Gupta, K.D.; Kumar, A. A tree classifier based network intrusion detection model for Internet of Medical Things. Comput. Electr. Eng. 2022, 102, 108158. [Google Scholar] [CrossRef]
- Guembe, B.; Misra, S.; Azeta, A. Federated Bayesian optimization XGBoost model for cyberattack detection in internet of medical things. J. Parallel Distrib. Comput. 2024, 193, 104964. [Google Scholar] [CrossRef]
- Hady, A.A.; Ghubaish, A.; Salman, T.; Unal, D.; Jain, R. Intrusion Detection System for Healthcare Systems Using Medical and Network Data: A Comparison Study. IEEE Access 2020, 8, 106576–106584. [Google Scholar] [CrossRef]
- Faruqui, N.; Yousuf, M.A.; Whaiduzzaman, M.; Azad, A.; Alyami, S.A.; Liò, P.; Kabir, M.A.; Moni, M.A. SafetyMed: A novel IoMT intrusion detection system using CNN-LSTM hybridization. Electronics 2023, 12, 3541. [Google Scholar] [CrossRef]
- Alsharif, B.; Alanazi, M.; Ilyas, M. Machine Learning Technology to Recognize American Sign Language Alphabet. In Proceedings of the 2023 IEEE 20th International Conference on Smart Communities: Improving Quality of Life Using AI, Robotics and IoT (HONET), Boca Raton, FL, USA, 4–6 December 2023; pp. 173–178. [Google Scholar] [CrossRef]
- Anter, A.M.; Ali, M. Feature selection strategy based on hybrid crow search optimization algorithm integrated with chaos theory and fuzzy c-means algorithm for medical diagnosis problems. Soft Comput. 2020, 24, 1565–1584. [Google Scholar] [CrossRef]
- Mayo, M.; Chepulis, L.; Paul, R.G. Glycemic-aware metrics and oversampling techniques for predicting blood glucose levels using machine learning. PLoS ONE 2019, 14, e0225613. [Google Scholar] [CrossRef]
- Alsharif, B.; Altaher, A.S.; Altaher, A.; Ilyas, M.; Alalwany, E. Deep learning technology to recognize american sign language alphabet. Sensors 2023, 23, 7970. [Google Scholar] [CrossRef]
- Alalwany, E.; Mahgoub, I. Classification of normal and malicious traffic based on an ensemble of machine learning for a vehicle can-network. Sensors 2022, 22, 9195. [Google Scholar] [CrossRef]
- Alanazi, M.; Alsharif, B.; Altaher, A.S.; Altaher, A.; Ilyas, M. Multi-Dataset Human Activity Recognition: Leveraging Fusion for Enhanced Performance. In Proceedings of the 2023 IEEE 20th International Conference on Smart Communities: Improving Quality of Life Using AI, Robotics and IoT (HONET), Boca Raton, FL, USA, 4–6 December 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Alsharif, B.; Alanazi, M.; Altaher, A.S.; Altaher, A.; Ilyas, M. Deep Learning Technology to Recognize American Sign Language Alphabet Using Mulit-Focus Image Fusion Technique. In Proceedings of the 2023 IEEE 20th International Conference on Smart Communities: Improving Quality of Life Using AI, Robotics and IoT (HONET), Boca Raton, FL, USA, 4–6 December 2023; pp. 1–6. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Year | Dataset | Type of Attacks | Method | Accuracy |
|---|---|---|---|---|---|
| [21] | 2022 | WUSTL EHMS 2020 | Spoofing Data injection | Ensemble Learning, Stacking | 96.9% |
| [22] | 2023 | TON-IoT | Backdoor, DDoS, Injection, Password, Ransomware, Scanning, XSS | Ensemble Learning, Stacking Voting | 98.64% 96.63% |
| [23] | 2023 | WUSTL EHMS 2020 | Spoofing Data injection | Ensemble Learning, Stacking | 94.50% |
| [24] | 2023 | WUSTL EHMS 2020 | Spoofing Data injection | Ensemble Learning | 96.56% |
| [25] | 2022 | WUSTL EHMS 2020 | Spoofing Data injection | Ensemble Learning | 94.23% |
| [26] | 2024 | WUSTL EHMS 2020 | Spoofing Data injection | Federated Bayesian Optimization XGBoost | 96.00% |
| Our Research | 2024 | WUSTL EHMS 2020 | Spoofing Data injection | Ensemble Learning, Stacking Bagging Boosting | 98.88% 97.83% 88.68% |
| Metric | Description | Type |
|---|---|---|
| Trans | Aggregated packets count | Flow metric |
| sMinPktSz | Source minimum transmitted packet size | Flow metric |
| Rate | Number of packets per second | Flow metric |
| SIntPktAct | Source active inter packet arrival time | Flow metric |
| SrcLoad | Source load (bits per second) | Flow metric |
| Dur | Duration | Flow metric |
| DIntPktAct | Destination active inter packet arrival time | Flow metric |
| SrcBytes | Source bytes in the flow record | Flow metric |
| Temp | Temperature | Biometric |
| SIntPkt | Source inter packet arrival time | Flow metric |
| Algorithm | Hyperparameter |
|---|---|
| Stacking | param_grid_stacking = { ’rf_dist’: { ’n_estimators’: randint(50, 300), ’max_depth’: [None, 10, 20, 30], ’min_samples_split’: randint(2, 10), ’min_samples_leaf’: randint(1, 4), ’max_features’: [’auto’, ’sqrt’, ’log2’] } } |
| Bagging | param_grid_bagging = { ’rf_dist’: { ’n_estimators’: randint(50, 300), ’max_depth’: [None, 10, 20, 30], ’min_samples_split’: randint(2, 10), ’min_samples_leaf’: randint(1, 4), ’max_features’: [’auto’, ’sqrt’, ’log2’] } } |
| Boosting | param_grid_boosting = { ’n_estimators’: randint(50, 300), ’learning_rate’: uniform(0.01, 0.5), ’max_depth’: randint(3, 15), ’min_samples_split’: randint(2, 10), ’min_samples_leaf’: randint(1, 5) } |
| Algorithm | Accuracy | Precision | Recall | F1-Score | Training Time (per Sample) | Prediction Time (per Sample) |
|---|---|---|---|---|---|---|
| Stacking | 98.88% | 98.23% | 99.58% | 98.90% | 0.011487 s | 0.000010 s |
| Bagging | 97.83% | 97.07% | 98.69% | 97.87% | 0.001558 s | 0.000161 s |
| Boosting | 88.68% | 88.00% | 88.80% | 88.57% | 0.001582 s | 0.000310 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alsolami, T.; Alsharif, B.; Ilyas, M. Enhancing Cybersecurity in Healthcare: Evaluating Ensemble Learning Models for Intrusion Detection in the Internet of Medical Things. Sensors 2024, 24, 5937. https://doi.org/10.3390/s24185937
Alsolami T, Alsharif B, Ilyas M. Enhancing Cybersecurity in Healthcare: Evaluating Ensemble Learning Models for Intrusion Detection in the Internet of Medical Things. Sensors. 2024; 24(18):5937. https://doi.org/10.3390/s24185937
Chicago/Turabian StyleAlsolami, Theyab, Bader Alsharif, and Mohammad Ilyas. 2024. "Enhancing Cybersecurity in Healthcare: Evaluating Ensemble Learning Models for Intrusion Detection in the Internet of Medical Things" Sensors 24, no. 18: 5937. https://doi.org/10.3390/s24185937
APA StyleAlsolami, T., Alsharif, B., & Ilyas, M. (2024). Enhancing Cybersecurity in Healthcare: Evaluating Ensemble Learning Models for Intrusion Detection in the Internet of Medical Things. Sensors, 24(18), 5937. https://doi.org/10.3390/s24185937