Abstract
Collaboration among road agents, such as connected autonomous vehicles and roadside units, enhances driving performance by enabling the exchange of valuable information. However, existing collaboration methods predominantly focus on perception tasks and rely on single-frame static information sharing, which limits the effective exchange of temporal data and hinders broader applications of collaboration. To address this challenge, we propose CoPnP, a novel collaborative joint perception and prediction system, whose core innovation is to realize multi-frame spatial–temporal information sharing. To achieve effective and communication-efficient information sharing, two novel designs are proposed: (1) a task-oriented spatial–temporal information-refinement model, which filters redundant and noisy multi-frame features into concise representations; (2) a spatial–temporal importance-aware feature-fusion model, which comprehensively fuses features from various agents. The proposed CoPnP expands the benefits of collaboration among road agents to the joint perception and prediction task. The experimental results demonstrate that CoPnP outperforms existing state-of-the-art collaboration methods, achieving a significant performance-communication trade-off and yielding up to 11.51%/10.34% Intersection over union and 12.31%/10.96% video panoptic quality gains over single-agent PnP on the OPV2V/V2XSet datasets.
1. Introduction
Autonomous driving is an important technology to improve the efficiency and safety of the transportation system, which has made great progress in recent decades due to the development of sensor technology [1,2] and intelligent algorithms [3,4]. However, the limited capability of a single vehicle restricts its further development. For example, vehicles can not pay enough attention to the region being occluded and at a distance because of the limitation of perception capability, resulting in safety risks. To solve this problem, autonomous driving with the help of collaboration among road agents, e.g., connected and autonomous vehicles (CAVs) and roadside units (RSUs), has arisen and attracted much attention from the research community. With vehicle-to-everything (V2X) communication, CAVs can share messages with neighboring CAVs or RSUs to enhance the capability to achieve good driving performance beyond the limitation of single-vehicle driving, breaking the limitation of single-vehicle.
Collaborative perception [5] is proposed to exchange the processed sensor information among road agents. It helps vehicles achieve perception beyond the line-of-sight and range-of-view, overcoming the occlusion issue and long-range issue of single-agent perception. Shan et al. [6] and Schiegg et al. [7] have demonstrated the effectiveness of the collaboration. To achieve more efficient collaboration, some works [8,9,10] propose efficient collaboration strategies to save communication costs and increase perception accuracy. To make the collaboration more robust, some works [11,12,13] consider collaboration in non-ideal scenarios, such as interruption and delay of V2X communication and pose error of localization among different agents. These works promote the practical application of collaborative perception in the real world.
However, there are two limitations restricting further application of the collaboration. (1) Most research on collaboration among road agents primarily focuses on perception only, without extending the investigation to subsequent autonomous driving processes. This limitation hinders further application of CAV collaboration. Moreover, considering only collaborative perception can lead to cascade error accumulation across sequential modules, posing risks to the performance and safety of autonomous driving systems. (2) Existing collaboration methods are based on single-frame static information sharing and do not account for temporal information sharing. This limitation hinders the completion of tasks requiring temporal information, such as tracking and prediction. When performing such temporal information-required tasks, collaboration must be conducted at each timestep, resulting in redundant communication loads and noise from irrelevant information.
The purpose of this work is to address the above issues, that is, to find an efficient way to share temporal information in a multi-agent collaboration system and expand the benefits of collaboration to more tasks in autonomous driving. To achieve this, we propose CoPnP, a novel collaborative joint perception and prediction system leveraging effective and communication-efficient spatial–temporal information sharing. In the proposed CoPnP system, we design a task-oriented spatial–temporal information-refinement model, which refines the redundant and noisy multi-frame features to comprehensive spatial–temporal features. The refinement model utilizes a spatial–temporal pyramid network and task-oriented explicit supervision to extract the most relevant spatial–temporal features for the PnP task. Additionally, we propose a spatial–temporal importance-aware feature-fusion model that comprehensively fuses the spatial–temporal features from different agents according to the importance of each feature cell.
The proposed CoPnP system has three key novelties:
- It extends the static single-frame information sharing to a multi-frame spatial–temporal information sharing framework. This allows agents to exchange comprehensive spatial–temporal information with minimal communication overhead in a single round of collaboration. Thereby, the collaborative message is enhanced and the system can support tasks that require temporal information.
- The system fully considers the spatial–temporal importance to the PnP task, ensuring that the most critical information is retained during information sharing, which makes the collaboration effective and efficient.
- The system simultaneously outputs the perception and prediction results decoded from a common fused spatial–temporal feature. This approach directly benefits prediction and mitigates the accumulation of cascade error.
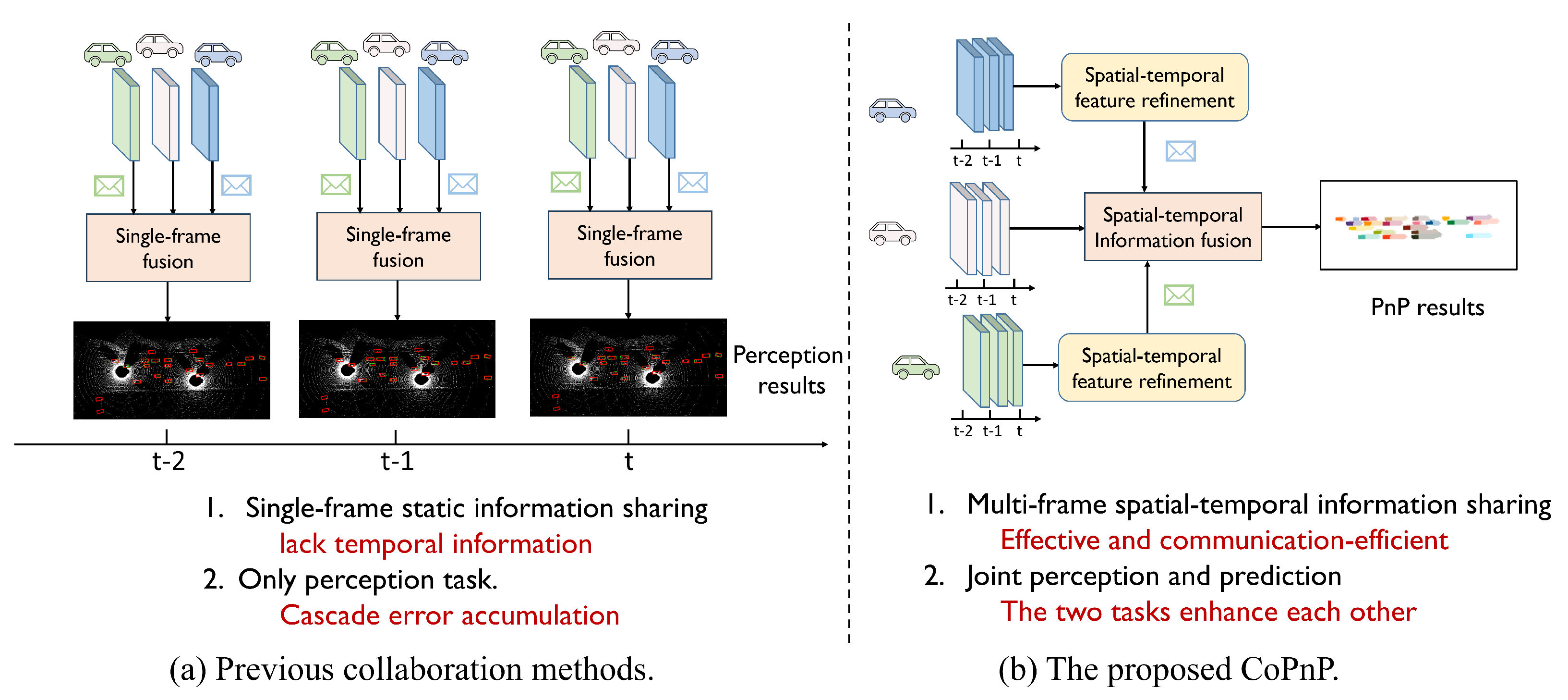
Figure 1 compares the proposed CoPnP with previous collaboration methods.
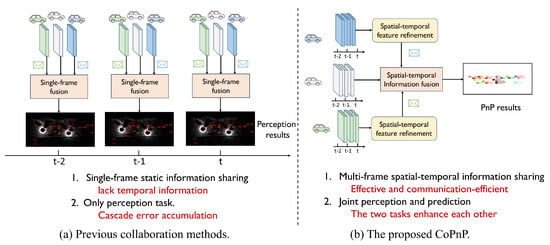
Figure 1.
Previous collaboration methods vs. Our proposed CoPnP. Previous methods are based on single–frame static information sharing and only support the perception task. The proposed CoPnP achieves multi-frame spatial–temporal information sharing and benefits more tasks that need temporal information.
To validate the proposed method for collaborative perception and prediction, we generate PnP labels for two public large-scale collaborative perception datasets, OPV2V [14] and V2XSet [15], and conduct experiments on these two datasets. The OPV2V dataset provides V2V scenarios in diverse traffic scenes, e.g., suburb midblock, urban roads and intersections, and the V2XSet dataset provides vehicle-to-vehicle (V2V) and vehicle-to-infrastructure (V2I) scenarios of 5 different roadway types. The experimental results demonstrate that the proposed CoPnP can outperform existing collaboration methods on the PnP task with a brilliant performance-communication volume trade-off, which can generalize to diverse scenarios and be robust to a certain degree of pose error. CoPnP has a performance gain up to 11.51%/10.34% IoU and 12.31%/10.96% VPQ over single-agent PnP on datasets OPV2V/V2XSet.
The contributions of this paper can be summarized as follows:
- (1)
- We propose CoPnP, a novel collaborative joint perception and Prediction system for autonomous driving, which extends the static single-frame information sharing in previous work to multi-frame spatial–temporal information sharing, expanding the benefits and promoting the application of collaboration among road agents.
- (2)
- To achieve effective and communication-efficient information sharing, we propose two novel designs in the CoPnP system: a task-oriented spatial–temporal information refine model to refine the collaborative messages and a spatial–temporal importance-aware feature-fusion model to comprehensively fuse the spatial–temporal features.
- (3)
- We generate PnP labels for two public large-scale collaborative perception datasets, OPV2V and V2XSet, and conduct experiments on these two datasets to validate the proposed CoPnP. The experimental results show that the proposed CoPnP outperforms existing state-of-the-art collaboration methods on the PnP task with a brilliant performance-communication trade-off and has a performance gain up to 11.51%/10.34% IoU and 12.31%/10.96% VPQ on datasets OPV2V/V2XSet.
The rest of this paper is organized as follows. Section 2 introduces related works. Then, Section 3 formulates the problem and introduces the proposed CoPnP system in detail. Section 4 discusses the experiments and analyzes the results to validate the proposed method. Finally, Section 5 concludes the main contributions of this work and gives some future research directions.
2. Related Works
This section introduces the related works, which are divided into two subsections. Section 2.1 introduces existing collaborative perception methods and Section 2.2 introduces the development of joint perception and prediction.
2.1. Collaborative Perception
Collaborative perception [5,7,16], which shares perception messages among agents, can overcome the occlusion and long-range issues of individual perception so that agents can achieve good perception performance beyond the line of sight and perception range. Existing methods of collaborative perception can be divided into three basic modes: early collaboration [17], which shares raw observation data, intermediate collaboration [8,15,18], which shares the processed intermediate perception features, and late collaboration, which shares perception results. Some works use mixed collaboration modes, such as DiscoNet [9], leveraging early collaboration as a teacher to guide the learning of a student adopting intermediate collaboration and Arnold et al. [19] conducting late collaboration when the visibility is with high quality and otherwise early collaboration. Both simulated [14,20] and real-world [21,22] datasets are collected to validate the collaborative perception methods.
To promote the application of collaboration perception in real-world scenarios, some works study collaborative perception facing challenging issues. Where2comm [10] proposes to share important features according to spatial confidence for a better trade-off between perception performance and communication volume. SyncNet [12] and CoBEVFlow [23] alleviate the effect of V2X communication delay by estimation from a sequence of features. V2X-INCOP [11] proposes an interruption-aware collaborative perception system that leverages historical information to recover the missing messages. Lu et al. [13] and Vadivelu et al. [24] propose pose-correction methods to make the collaboration perception system robust to pose errors.
Most previous works on collaborative perception only consider single-frame information sharing, which only exchanges static information of one single frame in one round of collaboration, and focuses on the perception task. This hinders collaborative messages carrying more comprehensive spatial–temporal information and prevents the effect of collaboration from benefiting more tasks that need temporal information. In this work, we study how to achieve effective and communication-efficient spatial–temporal information sharing and expand the benefit of collaboration to the PnP task.
2.2. Joint Perception and Prediction
Perception and prediction are two important modules of autonomous driving to improve safety [25] and reliability [26,27]. Traditional methods [28,29,30] conduct these two tasks in a cascade manner which first estimates the object detection and tracking results and predicts the object trajectory. This manner depends on the quality of the intermediate results, tends to result in error accumulation, and is unaware of the unknown objects. Some work [31,32] has proposed to conduct perception and prediction in a unified framework for joint reasoning, improving accuracy, robustness, and inference time. Recently, occupancy-based PnP methods [33,34,35], which directly predict semantic occupancy flow to simplify the comprehension of the dynamic scene, have attracted much attention.
Existing works on joint perception and prediction mainly focus on improving single-agent PnP performance and seldom consider the effect of collaboration on PnP performance. In this work, we study how to leverage collaboration among agents to promote the PnP performance on the basis of single-agent PnP.
3. Methods: Collaborative Joint Perception and Prediction System
In this section, we introduce the proposed collaborative joint perception and prediction (CoPnP) system. First, we give a problem statement of the addressed task, collaborative joint BEV occupancy perception and prediction. Next, we present the pipeline of CoPnP in detail, which mainly includes: BEV feature extraction, task-oriented spatial–temporal information refinement, message compression, sharing, and decompression, feature transformation, spatial–temporal importance-aware feature fusion, and feature decoding. Finally, we introduce the training loss function of the system. Table 1 provides an explanation of the notations and abbreviations in this paper.

Table 1.
Explanation of notations and the abbreviations for the proper nouns.
3.1. Problem Statement
We first introduce the fundamental definition and goals of the task of collaborative joint BEV occupancy perception and prediction. In a collaboration system, there are some agents located in different regions. To achieve collaboration, they collect observations of their surrounding environment and exchange relevant messages. With the received messages and their own observations, agents need to generate perception results of the current timestep and prediction results for future timesteps.
In this work, we consider that the system takes lidar point clouds collected by different agents at consecutive timesteps as input, including the current timestep and the previous T timesteps, and output segmentation maps and occupancy flow in BEV representation for the current perception and prediction for the future timesteps.
3.2. System
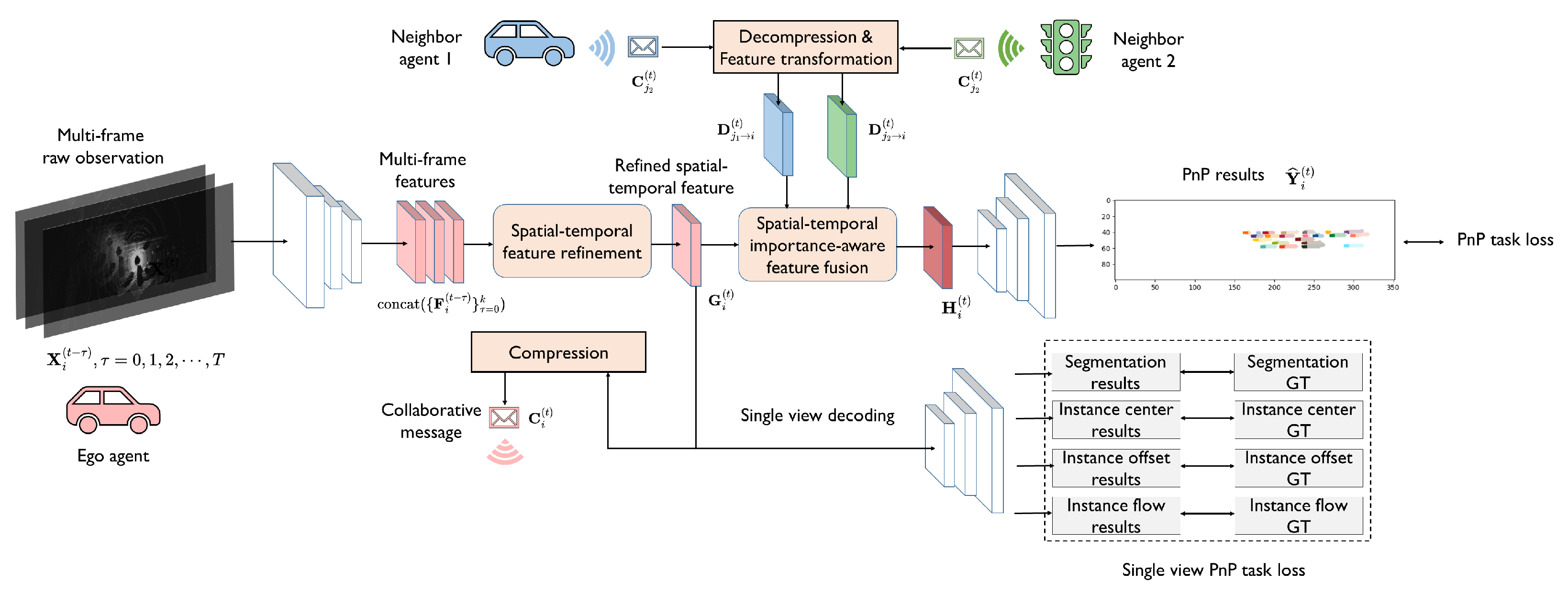
System overview. We propose a collaborative joint perception and prediction (CoPnP) system to solve the collaborative joint BEV occupancy perception and prediction task. The overall architecture of the system is shown in Figure 2. In the proposed CoPnP system, each agent collects observations of its surrounding environment at consecutive timesteps, and extracts the features of the raw observation at each timestep. Then we propose a task-oriented spatial–temporal information-refinement model to produce effective and communication-efficient collaborative messages for collaborative PnP. Subsequently, the collaborative messages are compressed by a compression model and then shared among neighbor agents. After message sharing, each agent decompresses the received messages and fuses them comprehensively with a novel spatial–temporal importance-aware feature-fusion model. Finally, we decode the fused features with a four-head decoder to obtain the final perception and prediction results. Next, we will introduce each component in the proposed CoPnP system in detail.
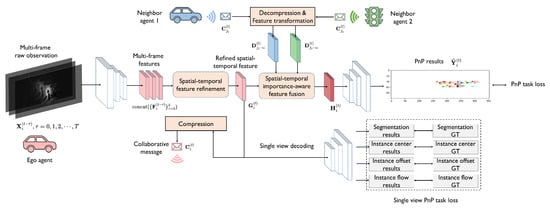
Figure 2.
The overall architecture of CoPnP. Given multi-frame extracted features at consecutive timesteps, a spatial–temporal information-refinement model is applied to filter out redundant data and obtain refined spatial–temporal information. Then, a spatial–temporal importance-aware feature-fusion model is used to fuse features from different agents, amplifying important information and suppressing irrelevant information. Finally, the PnP results are generated by a four-head decoder.
BEV feature extraction. We consider N agents in a collaboration system. Each agent collects the raw observations, i.e., the point cloud, of its surrounding environment at consecutive timesteps, where . When , it indicates the current timestep, otherwise it indicates the past timestep.
Given the collected point clouds at multiple timesteps from multiple agents, we leverage the backbone of pointpillars [36] as an encoder denoted by to extract the feature of each point cloud in BEV space, , that is,
Collaborative messages: task-oriented spatial–temporal information refinement. After feature encoding, each agent has a temporal sequence of features. If we directly transmit these features as collaborative messages, it will carry some redundant information. Specifically, the multi-frame features often contain repetitive or non-essential information, due to irrelevant environmental details and temporal correlations across consecutive frames. This redundancy costs many communication resources and introduces noise for collaborative PnP. To produce effective and communication-efficient collaborative messages, the key is to extract the most suitable spatial–temporal features for the PnP task from the multi-frame features and filter out redundant information. To achieve this goal, we propose a task-oriented spatial–temporal information-refinement model.
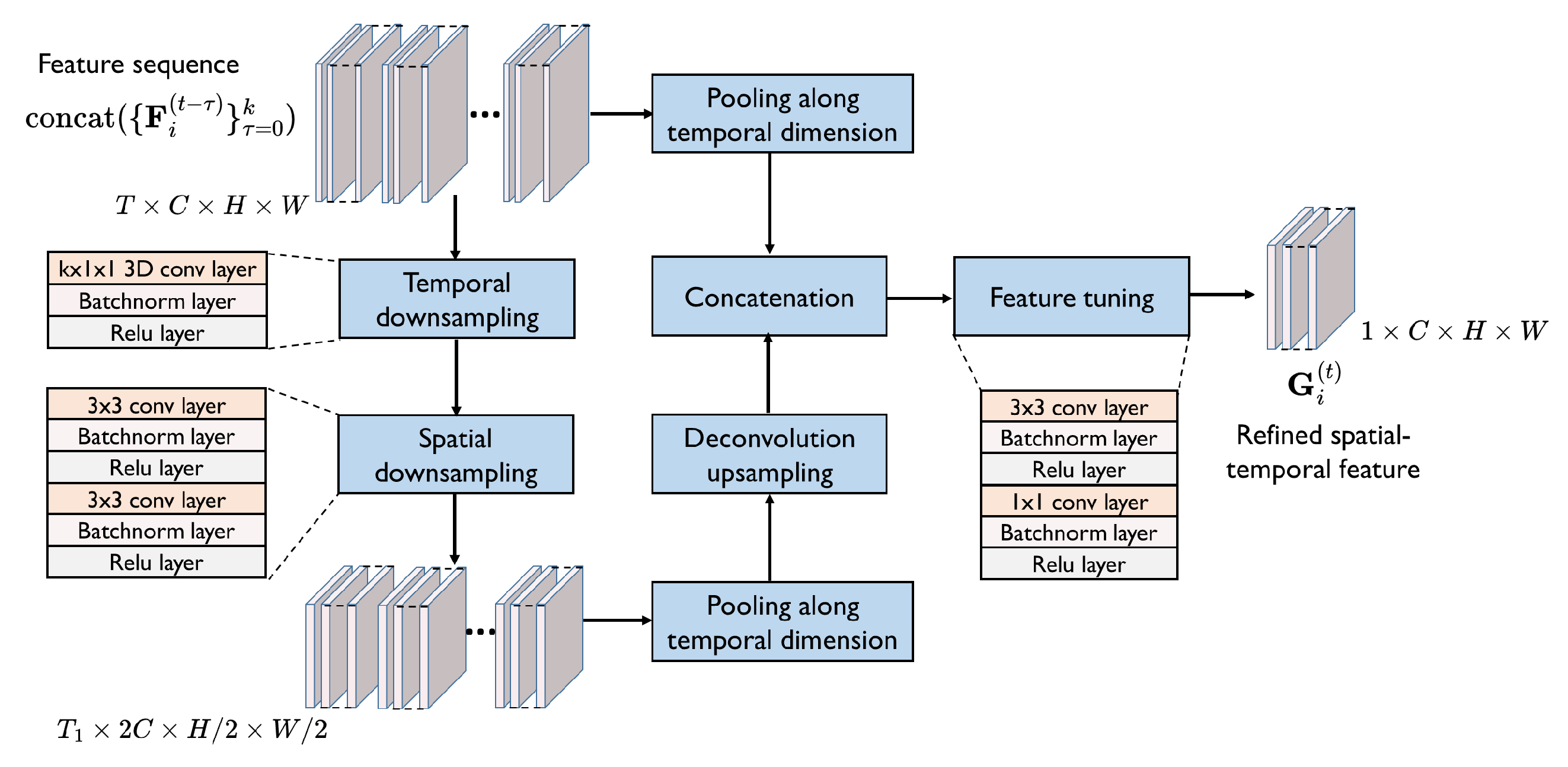
The main architecture of the refinement model is shown in Figure 3, which extracts multi-scale spatial–temporal features of multi-frame point cloud features. Given the multi-frame features , we concatenate them to a feature sequence as input of the model, that is, . We then use a 3D convolution layer with the kernel size of and two 2D convolution layers to downsample the feature sequence along both the temporal dimension and spatial dimension to obtain spatial–temporal features with two different resolutions. Each convolution layer is followed by a batch normalization layer and a relu function. Subsequently, we conduct a pooling function on the spatial–temporal features along the temporal dimension. Next, we concatenate the higher-resolution features with the upsampled lower-resolution features. That is, a skip connection is applied to fuse the features with different resolutions. Finally, we use two convolution layers to tune the features and generate the multi-scale spatial–temporal features of multi-frame point cloud features, i.e., the refined spatial–temporal feature. The refined spatial–temporal feature of agent at the timestep t, denoted by , is obtained as follows,
where represents the proposed refinement model. As a model extracting temporal features for prediction, the refinement model can effectively capture multi-scale spatial–temporal features. The model inputs all historical information together to avoid cascade errors and has a better prediction for short sequences.
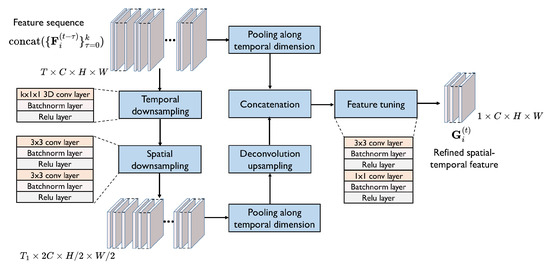
Figure 3.
Spatial–temporal information-refinement model. The model refines the feature sequence extracted from multi-frame point clouds to a multi-scale spatial–temporal feature in the following process. The input sequence is first downsampled along both the temporal dimension and spatial dimension. Then the features with two different resolutions are fused by a skip connection. Finally, the refined spatial–temporal feature is obtained by feature tuning.
To make the model extract the most suitable features for PnP, we give the refinement model more strong and explicit supervision. Concretely, the multi-scale spatial–temporal features produced by each agent will be not only shared among agents for collaboration but also be decoded to PnP results in the single-agent view supervised by a single-view PnP loss. The ground truth of these results is composed of the semantic segmentation and instance flow, which depicts whether it is foreground and whether it is dynamic at a spatial location and a timestep. The single-view PnP loss can give the refinement model explicit supervision about spatial importance and temporal importance so that the model can realize it and extract the most important information for the PnP task.
The proposed task-oriented spatial–temporal information-refinement model has two advantages: (1) since the single-view feature is also decoded to perception and prediction results and supervised by PnP task loss, the most important information for perception and prediction can be captured and shared among agents; (2) through the refinement model, the size of the collaborative messages to be transmitted is reduced from to , which is communication-efficient because it is not affected by the length of temporal information and is easy to compress.
Thus, carries the most important information for PnP with less communication resources consumption, so is effective and communication-efficient and can serve as the collaborative messages.
Collaborative messages compression, sharing, decompression. After the information refinement, each agent leverages a compression model to compress the refined features to save more communication resources. Concretely, the compression model uses a convolutional layer followed by a batch normalization layer to downsample the channel dimension from C to , that is,
Subsequently, each agent transmits the compressed features as well as its poses in 3D space to its neighbor agents and receives the corresponding messages. Then, each agent decompresses the received messages with a decompression model , which uses a convolutional layer followed by a batch normalization layer to upsample the channel dimension from to C, that is,
where is the decompressed feature of collaborative message from agent at timestep t.
Feature transformation. Next, each agent transforms the features from different agents into its ego coordinate system based on the poses of each agent, that is,
where is the transformation principle based on the poses of both agents and is the transformed feature. After this coordinate transformation, all features from neighbor agents are aligned within the same coordinate system of agent .
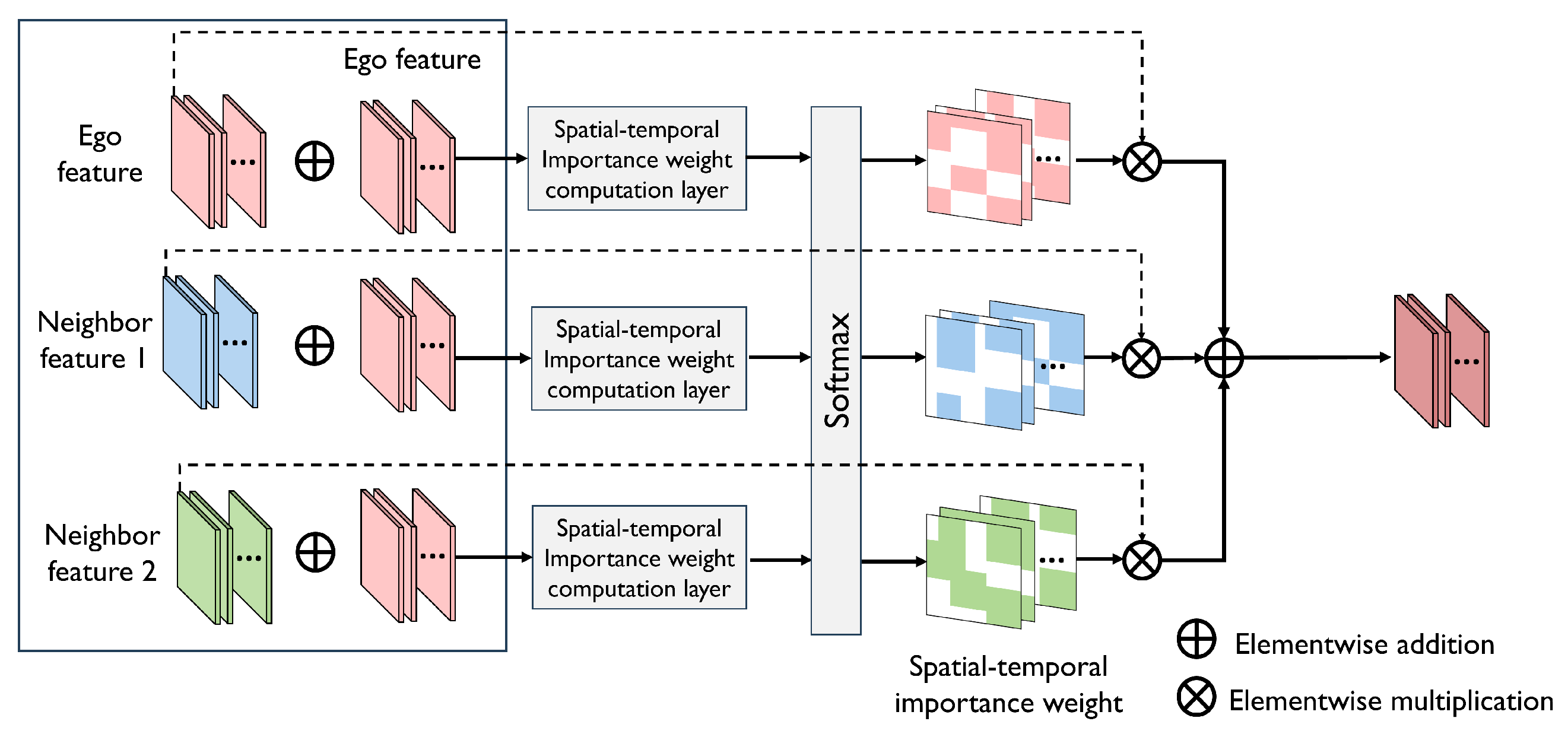
Spatial–temporal importance-aware feature fusion. Since different agents have different observations, the importance of the information located at the same spatial and temporal region from different agents is also different. When fusing such information, we should well consider the spatial and temporal importance to amplify the important information and suppress irrelevant information. To achieve comprehensive feature fusion, we propose a spatial–temporal importance (STI)-aware feature-fusion model, which first computes the importance weight of each spatial and temporal cell of the feature and then fuses features based on this weight. See Figure 4.
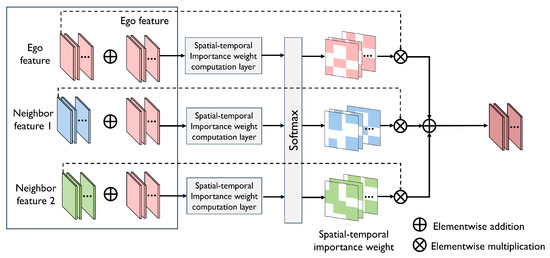
Figure 4.
STI-aware feature-fusion model. The model computes the spatial–temporal importance of the feature from different agents to the ego agent, and fuses features according to the computed importance to generate a feature carrying the most important spatial–temporal information for PnP of the ego agent.
Given the refined feature from ego agent and the decompressed features from neighbor agents, the STI-aware model first element-wise adds and each and then feeds them into two consecutive convolutional layers to produce a weight feature depicting the spatial–temporal importance of each cell in to , whose size is the same as and . Following this, a softmax function is applied to normalize the weight features to generate the final weights. The process is denoted as follows:
where is the normalized spatial–temporal weight of agent ’s feature. With the computed spatial–temporal importance weight, we employ weighted averaging to and , to achieve the feature fusion considering spatial–temporal importance, that is,
where is the fused feature. In this way, the STI-aware feature-fusion model simultaneously captures the spatial importance and temporal importance of each cell of the feature maps from different agents so that the most important information to the PnP task can be fused into the final fusion feature.
Feature decoding. Given the fused feature, we apply a multi-head decoder for the PnP task denoted by to produce the final PnP results. This decoder has four heads that produce the estimation of semantic segmentation, instance centerness, instance offset, and instance flow, respectively. Each head outputs the corresponding results at timesteps from t to . The semantic segmentation head outputs the results with the size of , which is the probability that indicates that each pixel is occupied or not by objects. H and W are the height and width of the output results, respectively. The instance centerness head outputs the results with a size of , which is the probability that indicates that each pixel is an instance center. The instance offset head output results with a size of , which is a two-dimensional vector pointing to the instance center. The instance flow head outputs the results with a size of , a two-dimensional displacement vector indicating the moving distance of the dynamic objects. The PnP results for agent at timestep t, , can be formulated as follows:
where .
3.3. Training Loss
The loss function supervising the training of the proposed CoPnP is composed of a PnP loss and a single-view PnP loss . The two PnP losses are both composed of four losses supervising the four decoding heads for PnP at the current timestep and the future timesteps, that is, a segmentation loss , an instance centerness loss , an instance offset loss , and an instance flow loss . The segmentation loss is a pixel-wise cross-entropy loss. The instance centerness loss is an L2 loss and the instance offset loss and the instance flow loss are both L1 losses. The loss of the future timesteps will be exponentially discounted by a parameter . The total loss can be formulated as follows:
4. Evaluation
In this section, we first introduce the evaluation datasets, metrics, and implementation of the proposed CoPnP. Then, we show the experimental results and corresponding analysis.
4.1. Dataset
In this work, we validate our proposed CoPnP system on the task of LiDAR-based joint BEV occupancy perception and prediction. We conduct the experiments on two public collaborative perception datasets, covering V2V, V2I, and V2X scenarios.
OPV2V dataset. OPV2V [14] is a V2V collaborative perception dataset simulated by CARLA and OpenCDA [37]. It includes 11,464 frames of 3D point clouds and 232,913 annotated 3D boxes. Each frame contains 2∼7 vehicles as collaboration agents. Frames totaling 6374/2920/2170 are selected as training/validation/testing samples, respectively. The perception range is m, 140 m], m, 40 m ].
V2XSet dataset. V2XSet [15] is a V2X collaborative perception dataset simulated by CARLA and OpenCDA. The scenes of V2XSet cover 5 different roadway types and 8 towns in CARLA and the agent type includes both AVs and infrastructures. It contains 11,447 frames of 3D point clouds split 6694/1920/2833 frames into train/validation/test sets, respectively. The perception range is m, 140 m], m, 40 m].
PnP label generation. OPV2V and V2XSet datasets only provide perception labels, i.e., 3D bounding boxes, and no labels for the PnP task. Fortunately, the data are collected and annotated regularly so that we can generate the corresponding PnP labels from the consecutive regularly collected detection annotations following the proposed approach in [33]. We project the 3D bounding boxes into the BEV plane to create an occupancy grid to obtain the segmentation label and then compute the corresponding instance center, offset and future ego-motion.
4.2. Metrics and Implementation
Metrics. We use two metrics, intersection over union (IoU) and video panoptic quality (VPQ), for evaluating PnP performance following previous PnP works. IoU is used to measure the quality of segmentation results at each timestep. VPQ is used to measure how consistently the instances are detected over time. The VPQ is defined as:
where H is the sequence length and , , and represent the sets of true positives, false positives, and false negatives, respectively.
To validate the communication efficiency, we compute the communication volume of each method by summarizing the float number that needs to be transmitted by an agent during one round of collaboration.
Implementation. We set and , that is, CoPnP takes observations at the past 2 timesteps and the current timestep as input and outputs perception results at the current timestep and prediction results at the future 4 timesteps. To enrich the evaluation scenario, we set the interval between two consecutive timesteps to 0.3 s and 0.5 s, which means the PnP performance of the future 1.2 s and 2 s will be evaluated. For the point cloud feature encoding, we set the width, length, and height of a voxel to be and the height, width, and channel of the encoded feature map , and , respectively. We set the compression ratio of the compression model . For the training loss, we set the coefficient of the single-view loss , discount coefficient , and initial learning rate to be 0.002. We optimize the model using the Adam [38] optimizer. The model is trained on an NVIDIA GeForce RTX A6000 GPU.
4.3. Quantitative Evaluation
Baselines and existing methods. As CoPnP is the first work to address the problem of collaborative joint PnP, we compare the proposed CoPnP with some designed baselines and models that integrate existing state-of-the-art collaboration methods with the PnP heads of CoPnP. The baseline methods are introduced as follows.
Single-agent PnP gives PnP results based on the single-agent observation with a Motionnet-like [39] model.
Detection boxes fusion + Kalman filter conducts late fusion of perception results and exchanges the detected box at each past timestep and current timestep, then uses a basic Kalman filter for object tracking and predicting the future state of each object box.
V2VNet [8] takes multi-frame point clouds as input and generates an intermediate feature map, and then aggregates the intermediate features with a graph neural network. Finally, it uses the PnP decoder to generate PnP results.
F-Cooper [18], DiscoNet [9], and Where2comm [10] conduct intermediate feature fusion based on max fusion, a distilled collaboration graph, and feature selection according to spatial confidence, respectively. To compare CoPnP with them on the PnP task, we first use these methods to conduct single-frame collaboration at each timestep and then generate PnP results with the same decoder as our proposed methods.
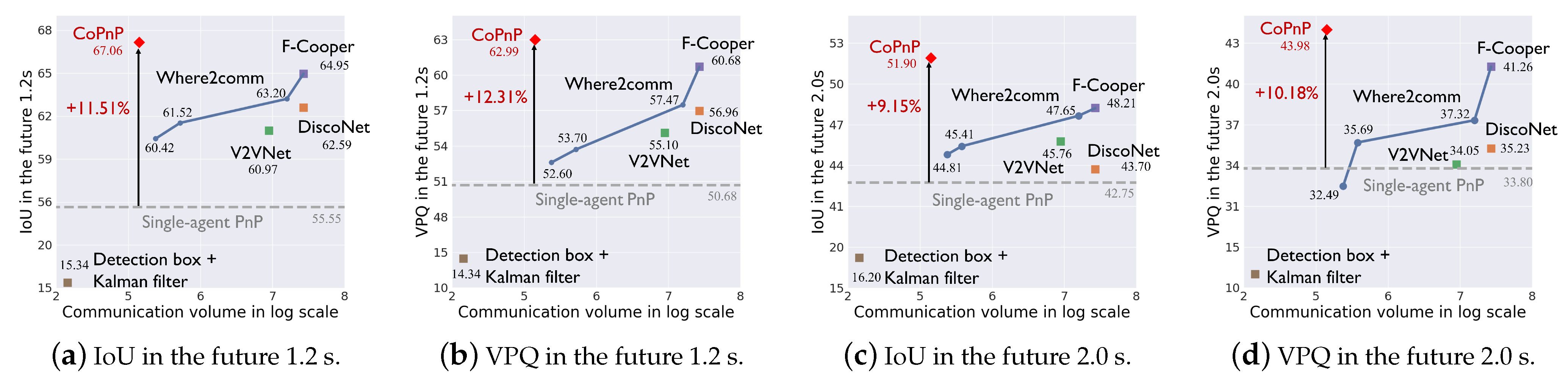
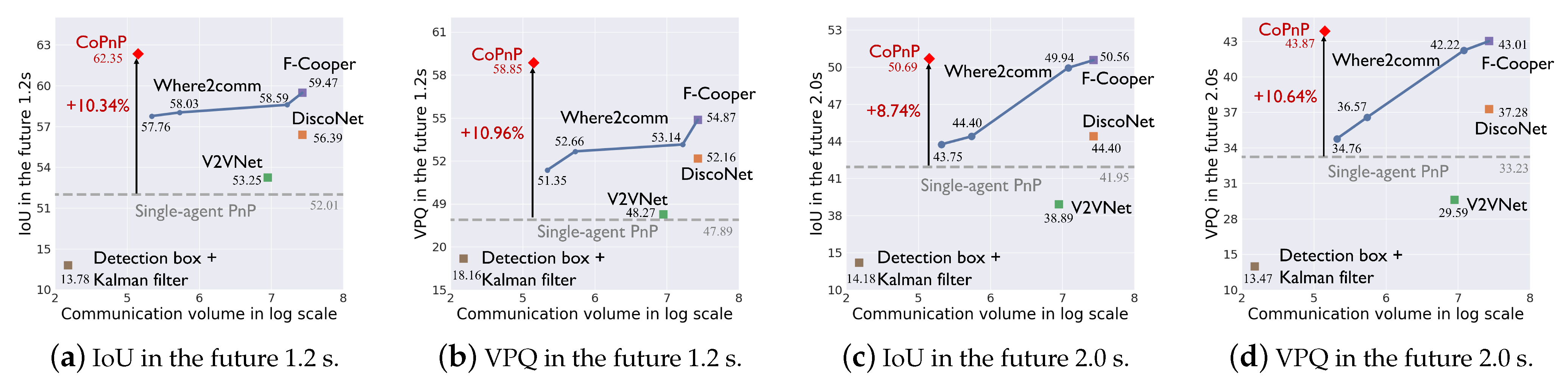
Benchmark comparison. Figure 5 and Figure 6 show the PnP performance (IoU and VPQ) of each method and corresponding communication volume on datasets OPV2V and V2XSet, respectively. The horizontal axis represents communication volume in the log scale and the vertical axis represents the PnP performance. Each scatter point represents the result of a method and the grey dashed line represents the performance of single-agent PnP. For Where2comm [10], we test its performance with four different communication volumes and with four thresholds of its confidence map, .
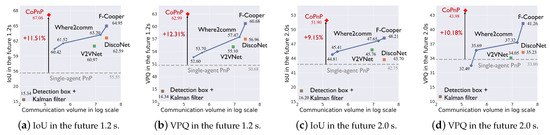
Figure 5.
PnP performance with communication volume on the OPV2V dataset.
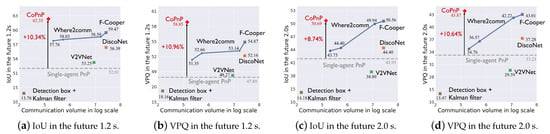
Figure 6.
PnP performance with communication volume on the V2XSet dataset.
From the results, we can see the following. (1) Most collaboration methods can outperform the single-agent PnP, reflecting the effectiveness of the collaboration. Detection boxes fusion + Kalman filter fails because the box matching among agents and timesteps raises many errors and generates a lot of false positives. (2) The proposed CoPnP outperforms all the baseline methods in the future 1.2s and 2.0s on the two datasets, achieving 67.06/62.35 IoU, 62.99/58.85 VPQ in the future 1.2s, and 51.90/50.69 IoU, 43.98/43.87 VPQ in the future 2.0 s on the datasets OPV2V/V2XSet. Compared with single-agent PnP achieving 55.55/52.01 IoU, 50.68/47.89 VPQ in the future 1.2 s, and 42.75/41.95 IoU, 33.80/33.23 VPQ in the future 2.0 s on datasets OPV2V/V2XSet, the proposed CoPnP has a gain over single-agent PnP up to 11.51% IoU and 12.31% VPQ on the OPV2V dataset and 10.34% IoU and 10.96% VPQ on the V2XSet dataset. (3) The proposed CoPnP achieves the best performance-communication volume trade-off, whose performance exceeds existing state-of-the-art collaboration methods with 192 times less communication volume. The above results demonstrate that the proposed CoPnP can achieve communication-efficient and high-performance PnP.
Perception only. To validate the perception performance of the proposed method, we test the perception-only results measured by segmentation IoU at the current timestep. Table 2 shows the perception results on the OPV2V and V2XSet datasets. The superscript * indicates that the temporal information (information at the past timesteps) is involved. From the results, we can see that: (1) with temporal information, F-Cooper and DiscoNet can obtain 2.86/3.31 and 5.12/6.46 perception performance gain on datasets OPV2V/V2XSet, respectively, suggesting exchanging temporal information significantly benefits the perception task; (2) CoPnP outperforms the collaborative perception methods based on single-frame collaboration, which makes full use of spatial–temporal information to improve perception performance.
Table 2.
Perception only results. The superscript * indicates the temporal information is involved. The Bold indicates the best results.
4.4. Qualitative Evaluation
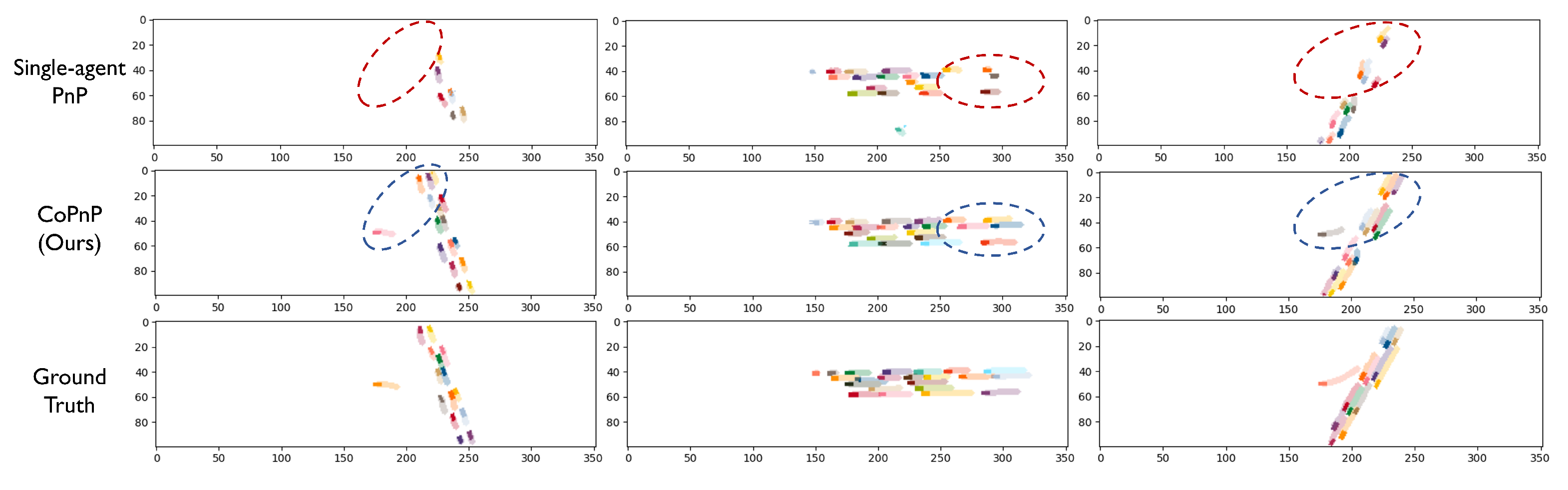
Figure 7 shows the visualization examples of the PnP results of the proposed CoPnP on the datasets OPV2V and V2XSet. Each column represents an example and the three rows represent the PnP results of single-agent PnP, our proposed CoPnP, and ground truth, respectively. We assign different colors for different vehicles for distinction. The darker color represents the current perception results and the lighter color represents the prediction result in the future. From the visualization examples, we can see that single-agent PnP fails in the occluded or long-range region in the red circle, while the proposed CoPnP can achieve accurate PnP results leveraging the collaboration among agents, which validates the effectiveness of our proposed method.
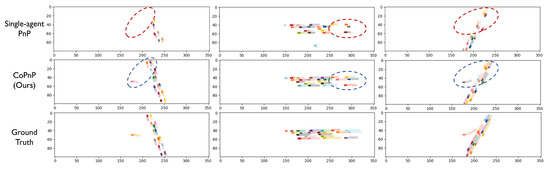
Figure 7.
Visualization of PnP results (occupancy flow) on datasets OPV2V and V2XSet. Each column represents an example and the three rows represent the PnP results of single-agent PnP, our proposed CoPnP, and ground truth, respectively. We assign different colors for different vehicles for distinction. The darker color represents the current perception results and the lighter color represents the prediction result in the future. The proposed CoPnP can achieve accurate PnP in the region where single-agent PnP suffers from missing perception and poor prediction performance due to long range and occlusion.
4.5. Ablation Study
We conduct an ablation study to validate the effectiveness of the two main designs of CoPnP, the task-oriented spatial–temporal information-refinement model, denoted as STIR, and the STI-aware feature-fusion model denoted as STI-aware fusion. To validate the effectiveness of STIR, we compare it with a vanilla collaboration model based on single-frame collaboration, which conducts single-frame intermediate collaboration with maxfusion and generates results with the Motionnet-like model and PnP decoder mentioned above. To validate the effectiveness of STI-aware fusion, we compare it with maxfusion and discofusion [9].
Table 3 shows the results of the ablation study, which are evaluated by the PnP performance in the future 1.2 s and the communication volume. STIR + maxfusion leverages the proposed STIR model to refine the spatial–temporal features of multi-frame information, and fuses features with maxfusion. STIR + Discofusion replaces the maxfusion with discofusion, which fuses features according to spatial attention. STIR + STI-aware fusion fuses the features with the proposed STI-aware feature-fusion model. The final row shows the result of the proposed CoPnP, which conducts feature compression and decompression with a 64 compression ratio.
Table 3.
Ablation study results. STIR represents the proposed task-oriented spatial–temporal information-refinement model. The Bold indicates the best results.
From the results, we can see the following. (1) STIR can reduce two-thirds of the communication volume and achieve 65.04/60.16 IoU and 61.20/55.45 VPQ on the datasets OPV2V/V2XSet, outperforming the vanilla model by 0.09/0.69 IoU and 0.52/0.58 VPQ on the datasets OPV2V/V2XSet. This suggests that the STIR model can effectively extract the spatial–temporal features of multi-frame information and filter the redundant information. (2) The STIR + STI-aware feature-fusion model achieves 67.16/62.68 IoU and 63.08/59.14 VPQ on the datasets OPV2V/V2XSet, outperforming maxfusion by 2.12/2.52 IoU and 1.88/3.69 VPQ, and outperforming discofusion by 0.72/1.45 IoU and 0.79/2.09 VPQ on the datasets OPV2V/V2XSet. This demonstrates the effectiveness of STI-aware fusion, which considers both the spatial and temporal importance of each cell of the spatial-temporal feature map, while maxfusion equally considers all cells and the discofusion only considers the spatial importance. (3) The last row shows that the proposed CoPnP exhibited only a slight degradation in performance with a further 64 times compression in communication volume, achieving 67.06/62.35 IoU and 62.99/58.85 VPQ on the datasets OPV2V/V2XSet. This indicates that the information sharing in CoPnP is effective and communication-efficient, which achieves an excellent trade-off between performance and communication volume.
4.6. Discussion of the Generalization and Robustness
We discuss the generalization and robustness of the proposed CoPnP based on the experiment results.
Generalization to different scenarios. The OPV2V dataset includes V2V scenarios in diverse traffic and CAV configurations, such as suburb midblock and urban roads. The V2XSet dataset includes V2V and V2I scenarios covering five roadway types, such as entrance ramps and intersections. The results in Figure 5 and Figure 6 show that CoPnP achieves 67.06/62.35 IoU, 62.99/58.85 VPQ in the future 1.2 s, and 51.90/50.69 IoU, 43.98/43.87 VPQ in the future 2.0 s on the datasets OPV2V/V2XSet and outperforms other collaboration methods, suggesting CoPnP can be generalized to diverse scenarios.
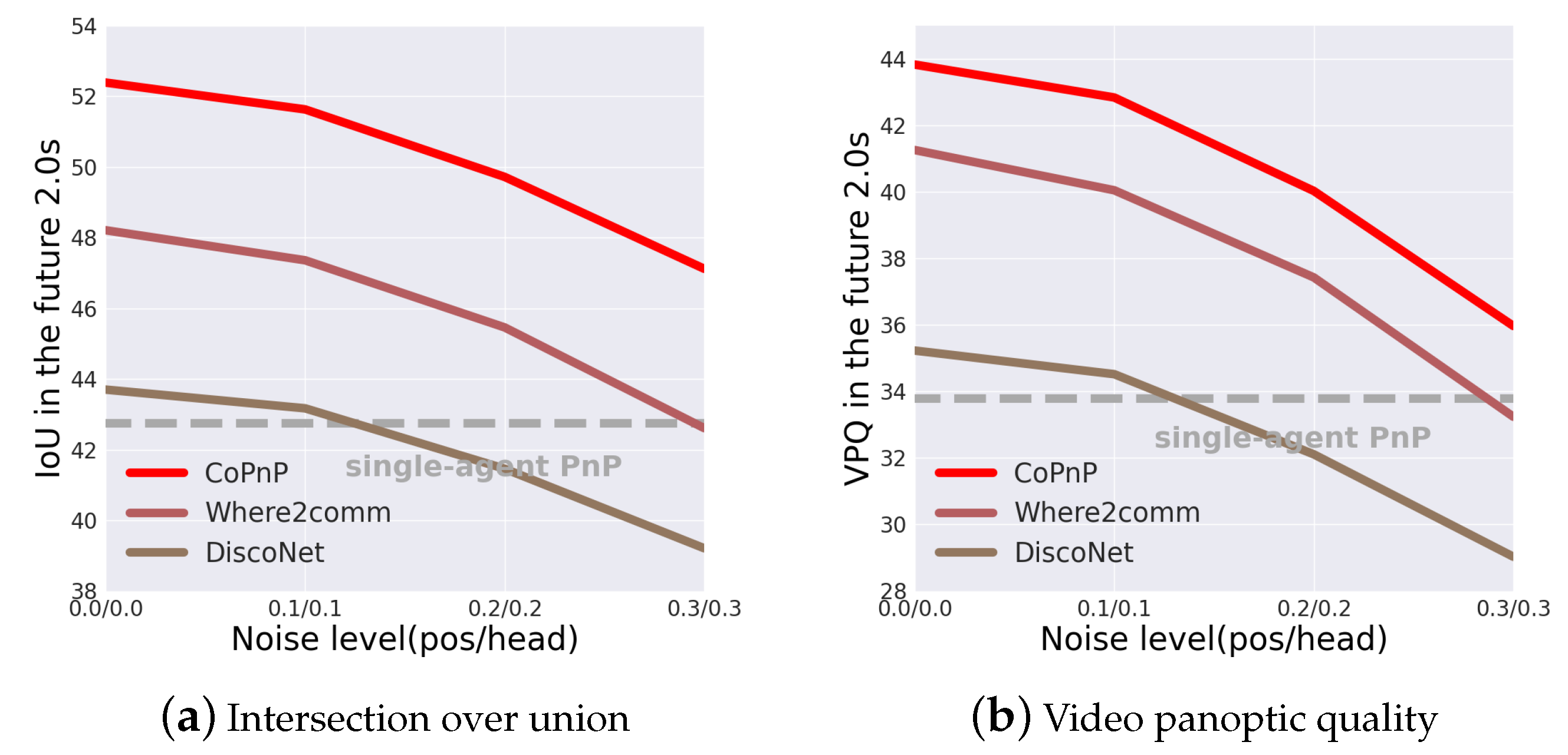
Robustness to pose error. Correct pose information plays a significant role in fusing information from different agents. However, localization errors are common in the real world. To validate the robustness to pose error of the proposed CoPnP, we test the PnP performance with varying levels of pose error. We use Gaussian noise on the center and yaw angle of the 6DoF pose to simulate the localization error. Figure 8 shows the PnP performance in the future 2.0 s of three collaboration methods with pose error on the OPV2V dataset. From the results, we can see that CoPnP can achieve 52.39/43.83, 51.63/42.84, 49.72/40.03, and 47.12/35.97 IoU/VPQ at pose noise level with 0.0/0.0, 0.1/0.1, 0.2/0.2, 0.3/0.3 standard deviation, respectively, and outperforms the baseline methods. The proposed CoPnP maintains significant gains over single-agent PnP with pose error when the standard deviation of the Gaussian noise is less than 0.3, which demonstrates the proposed CoPnP is robust to a certain degree of pose error.
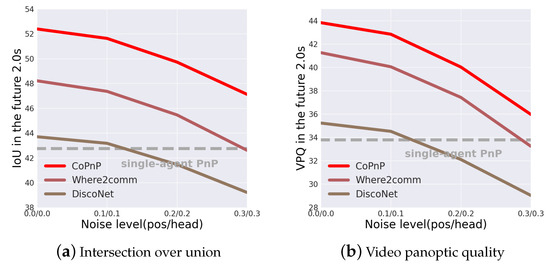
Figure 8.
PnP performance with different localization noise on the OPV2V dataset. The horizontal axis represents the localization noise level and the vertical axis represents the IoU and VPQ of the PnP results. The localization noise level is measured by the positional and heading error in Gaussian distribution with zero mean and varying standard deviation.
5. Conclusions
This work proposes a collaborative joint perception and prediction (CoPnP) system for autonomous driving, which significantly improves the PnP performance beyond single-agent through efficient spatial–temporal information sharing. Two novel designs are proposed in the CoPnP system, the task-oriented spatial–temporal information-refinement model and the spatial–temporal importance-aware feature-fusion model, which achieve comprehensive spatial–temporal feature refinement and fusion across collaboration agents. Experimental results demonstrate that CoPnP outperforms existing state-of-the-art collaboration methods with a brilliant performance-communication trade-off and has a performance gain up to 11.51%/10.34% IoU and 12.31%/10.96% VPQ over single-agent PnP on datasets OPV2V/V2XSet. This system promotes the application of collaboration among road agents in the real world.
In further research, more autonomous driving modules, such as planning and action controlling, can be considered in a unified framework, which can promote collaboration among road agents directly benefiting the entire process of autonomous driving, resulting in collaborative end-to-end autonomous driving.
Author Contributions
Conceptualization, S.R. and S.C.; methodology, S.R. and S.C.; software, S.R.; validation, S.R. and S.C.; formal analysis, S.R. and S.C.; investigation, S.R. and S.C.; resources, S.C. and W.Z.; data curation, S.R. and S.C.; writing—original draft preparation, S.R.; writing—review and editing, S.R., S.C. and W.Z.; visualization, S.R.; supervision, S.C. and W.Z.; project administration, S.R., S.C. and W.Z.; funding acquisition, S.C. and W.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research is partially funded by National Key R&D Program of China under Grant 2021ZD0112801, NSFC under Grant 62171276 and the Science and Technology Commission of Shanghai Municipal under Grant 21511100900 and 22DZ2229005.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The OPV2V dataset is available at https://mobility-lab.seas.ucla.edu/opv2v/ (accessed on 24 September 2024). The V2XSet dataset is available at https://github.com/DerrickXuNu/v2x-vit (accessed on 24 September 2024).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Li, Y.; Ibanez-Guzman, J. Lidar for Autonomous Driving: The Principles, Challenges, and Trends for Automotive Lidar and Perception Systems. IEEE Signal Process. Mag. 2020, 37, 50–61. [Google Scholar] [CrossRef]
- Zhou, T.; Yang, M.; Jiang, K.; Wong, H.; Yang, D. MMW Radar-Based Technologies in Autonomous Driving: A Review. Sensors 2020, 20, 7283. [Google Scholar] [CrossRef] [PubMed]
- Shi, S.; Wang, X.; Li, H. PointRCNN: 3D Object Proposal Generation and Detection From Point Cloud. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 770–779. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; Chen, S.; Zhang, W. Collaborative perception for autonomous driving: Current status and future trend. In Proceedings of the 2021 5th Chinese Conference on Swarm Intelligence and Cooperative Control; Springer: Singapore, 2022; pp. 682–692. [Google Scholar]
- Shan, M.; Narula, K.; Wong, Y.F.; Worrall, S.; Khan, M.; Alexander, P.; Nebot, E. Demonstrations of cooperative perception: Safety and robustness in connected and automated vehicle operations. Sensors 2020, 21, 200. [Google Scholar] [CrossRef] [PubMed]
- Schiegg, F.A.; Llatser, I.; Bischoff, D.; Volk, G. Collective perception: A safety perspective. Sensors 2020, 21, 159. [Google Scholar] [CrossRef] [PubMed]
- Wang, T.H.; Manivasagam, S.; Liang, M.; Yang, B.; Zeng, W.; Urtasun, R. V2VNet: Vehicle-to-vehicle communication for joint perception and prediction. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 605–621. [Google Scholar]
- Li, Y.; Ren, S.; Wu, P.; Chen, S.; Feng, C.; Zhang, W. Learning distilled collaboration graph for multi-agent perception. Adv. Neural Inf. Process. Syst. 2021, 34, 29541–29552. [Google Scholar]
- Hu, Y.; Fang, S.; Lei, Z.; Yiqi, Z.; Chen, S. Where2comm: Communication-Efficient Collaborative Perception via Spatial Confidence Maps. In Proceedings of the Thirty-Sixth Conference on Neural Information Processing Systems (Neurips), New Orleans, LA, USA, 28 November–9 December 2022. [Google Scholar]
- Ren, S.; Lei, Z.; Wang, Z.; Dianati, M.; Wang, Y.; Chen, S.; Zhang, W. Interruption-Aware Cooperative Perception for V2X Communication-Aided Autonomous Driving. IEEE Trans. Intell. Veh. 2024, 9, 4698–4714. [Google Scholar] [CrossRef]
- Lei, Z.; Ren, S.; Hu, Y.; Zhang, W.; Chen, S. Latency-aware collaborative perception. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 316–332. [Google Scholar]
- Lu, Y.; Li, Q.; Liu, B.; Dianati, M.; Feng, C.; Chen, S.; Wang, Y. Robust Collaborative 3D Object Detection in Presence of Pose Errors. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation, London, UK, 29 May–2 June 2023. [Google Scholar]
- Xu, R.; Xiang, H.; Xia, X.; Han, X.; Li, J.; Ma, J. OPV2V: An Open Benchmark Dataset and Fusion Pipeline for Perception with Vehicle-to-Vehicle Communication. In Proceedings of the 2022 IEEE International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022. [Google Scholar]
- Xu, R.; Xiang, H.; Tu, Z.; Xia, X.; Yang, M.H.; Ma, J. V2X-ViT: Vehicle-to-Everything Cooperative Perception with Vision Transformer. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Ngo, H.; Fang, H.; Wang, H. Cooperative Perception with V2V Communication for Autonomous Vehicles. IEEE Trans. Veh. Technol. 2023, 72, 11122–11131. [Google Scholar] [CrossRef]
- Chen, Q.; Tang, S.; Yang, Q.; Fu, S. Cooper: Cooperative perception for connected autonomous vehicles based on 3d point clouds. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems, Dallas, TX, USA, 7–10 July 2019; pp. 514–524. [Google Scholar]
- Chen, Q.; Ma, X.; Tang, S.; Guo, J.; Yang, Q.; Fu, S. F-cooper: Feature based cooperative perception for autonomous vehicle edge computing system using 3D point clouds. In Proceedings of the 4th ACM/IEEE Symposium on Edge Computing, Washington, DC, USA, 7–9 November 2019; pp. 88–100. [Google Scholar]
- Arnold, E.; Mozaffari, S.; Dianati, M. Fast and robust registration of partially overlapping point clouds. IEEE Robot. Autom. Lett. 2021, 7, 1502–1509. [Google Scholar] [CrossRef]
- Li, Y.; Ma, D.; An, Z.; Wang, Z.; Zhong, Y.; Chen, S.; Feng, C. V2X-Sim: Multi-Agent Collaborative Perception Dataset and Benchmark for Autonomous Driving. IEEE Robot. Autom. Lett. 2022, 7, 10914–10921. [Google Scholar] [CrossRef]
- Yu, H.; Luo, Y.; Shu, M.; Huo, Y.; Yang, Z.; Shi, Y.; Guo, Z.; Li, H.; Hu, X.; Yuan, J.; et al. DAIR-V2X: A Large-Scale Dataset for Vehicle-Infrastructure Cooperative 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 21361–21370. [Google Scholar]
- Xu, R.; Xia, X.; Li, J.; Li, H.; Zhang, S.; Tu, Z.; Meng, Z.; Xiang, H.; Dong, X.; Song, R.; et al. V2v4real: A real-world large-scale dataset for vehicle-to-vehicle cooperative perception. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 13712–13722. [Google Scholar]
- Wei, S.; Wei, Y.; Hu, Y.; Lu, Y.; Zhong, Y.; Chen, S.; Zhang, Y. Asynchrony-Robust Collaborative Perception via Bird’s Eye View Flow. In Proceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS 2023), New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Vadivelu, N.; Ren, M.; Tu, J.; Wang, J.; Urtasun, R. Learning to communicate and correct pose errors. In Proceedings of the Conference on Robot Learning, London, UK, 8–11 November 2021; pp. 1195–1210. [Google Scholar]
- Sun, C.; Zhang, R.; Lu, Y.; Cui, Y.; Deng, Z.; Cao, D.; Khajepour, A. Toward Ensuring Safety for Autonomous Driving Perception: Standardization Progress, Research Advances, and Perspectives. IEEE Trans. Intell. Transp. Syst. 2024, 25, 3286–3304. [Google Scholar] [CrossRef]
- Hell, F.; Hinz, G.; Liu, F.; Goyal, S.; Pei, K.; Lytvynenko, T.; Knoll, A.; Yiqiang, C. Monitoring perception reliability in autonomous driving: Distributional shift detection for estimating the impact of input data on prediction accuracy. In Proceedings of the 5th ACM Computer Science in Cars Symposium, Ingolstadt, Germany, 30 November 2021; pp. 1–9. [Google Scholar]
- Berk, M.; Schubert, O.; Kroll, H.M.; Buschardt, B.; Straub, D. Exploiting Redundancy for Reliability Analysis of Sensor Perception in Automated Driving Vehicles. IEEE Trans. Intell. Transp. Syst. 2020, 21, 5073–5085. [Google Scholar] [CrossRef]
- Casas, S.; Luo, W.; Urtasun, R. Intentnet: Learning to predict intention from raw sensor data. In Proceedings of the Conference on Robot Learning, Zürich, Switzerland, 29–31 October 2018; pp. 947–956. [Google Scholar]
- Luo, W.; Yang, B.; Urtasun, R. Fast and Furious: Real Time End-to-End 3D Detection, Tracking and Motion Forecasting with a Single Convolutional Net. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Liang, M.; Yang, B.; Zeng, W.; Chen, Y.; Hu, R.; Casas, S.; Urtasun, R. Pnpnet: End-to-end perception and prediction with tracking in the loop. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11553–11562. [Google Scholar]
- Li, L.L.; Yang, B.; Liang, M.; Zeng, W.; Ren, M.; Segal, S.; Urtasun, R. End-to-end contextual perception and prediction with interaction transformer. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 5784–5791. [Google Scholar]
- Wong, K.; Wang, S.; Ren, M.; Liang, M.; Urtasun, R. Identifying Unknown Instances for Autonomous Driving. In Proceedings of the Conference on Robot Learning, Virtual, 16–18 November 2020; Kaelbling, L.P., Kragic, D., Sugiura, K., Eds.; Proceedings of Machine Learning Research. PMLR: London, UK, 2020; Volume 100, pp. 384–393. [Google Scholar]
- Hu, A.; Murez, Z.; Mohan, N.; Dudas, S.; Hawke, J.; Badrinarayanan, V.; Cipolla, R.; Kendall, A. Fiery: Future instance prediction in bird’s-eye view from surround monocular cameras. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 15273–15282. [Google Scholar]
- Hu, S.; Chen, L.; Wu, P.; Li, H.; Yan, J.; Tao, D. St-p3: End-to-end vision-based autonomous driving via spatial-temporal feature learning. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 533–549. [Google Scholar]
- Zhang, Y.; Zhu, Z.; Zheng, W.; Huang, J.; Huang, G.; Zhou, J.; Lu, J. Beverse: Unified perception and prediction in birds-eye-view for vision-centric autonomous driving. arXiv 2022, arXiv:2205.09743. [Google Scholar]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]
- Xu, R.; Xiang, H.; Han, X.; Xia, X.; Meng, Z.; Chen, C.J.; Correa-Jullian, C.; Ma, J. The OpenCDA Open-Source Ecosystem for Cooperative Driving Automation Research. IEEE Trans. Intell. Veh. 2023, 8, 2698–2711. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Wu, P.; Chen, S.; Metaxas, D.N. Motionnet: Joint perception and motion prediction for autonomous driving based on bird’s eye view maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11385–11395. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).