Abstract
‘Akizuki’ pear (Pyrus pyrifolia Nakai) corky disease is a physiological disease that strongly affects the fruit quality of ‘Akizuki’ pear and its economic value. In this study, Raman spectroscopy was employed to develop an early diagnosis model by integrating support vector machine (SVM), random forest (RF), gradient boosting decision tree (GBDT), extreme gradient boosting (XGBoost), and convolutional neural network (CNN) modeling techniques. The effects of various pretreatment methods and combinations of methods on modeling results were studied. The relative optimal index formula was utilized to identify the SG and SG+WT as the most effective preprocessing methods. Following the optimal preprocessing method, the performance of the majority of the models was markedly enhanced through the process of model reconditioning, among which XGBoost achieved 80% accuracy under SG+WT pretreatment, and F1 and kappa both performed best. The results show that RF, GBDT, and XGBoost are more sensitive to the pretreatment method, whereas SVM and CNN are more dependent on internal parameter tuning. The results of this study indicate that the early detection of Raman spectroscopy represents a novel approach for the nondestructive identification of asymptomatic ‘Akizuki’ pear corky disease, which is of paramount importance for the realization of large-scale detection across orchards.
1. Introduction
‘Akizuki’ pear (Pyrus pyrifolia Nakai) is a medium- and late-ripening brown pear that was introduced to Japan [1]. It is known for its juicy and sweet, fine and crisp flesh, unique fragrance, storage resistance, and high quality. Since its introduction, it has been favored by cultivators and consumers and has promising market prospects [2]. However, pear cork disease severely affects the quality of ‘Akizuki’ pear fruit and its commercial economic value, restricting the development of this variety in recent years. Akizuki pear cork disease is a physiological disease that occurs mainly during the fruit expansion period. Several studies have revealed that Ca deficiency is the main cause of pear corky disease [3]. Other mineral elements, such as B, K, and Mg, can also lead to corky disease [4]. Liu reported [5] that the accumulation of lignin in plants leads to the development of corkiness in fruits. For the nutritional level, Cui reported [6] that the cellulose content and starch content in diseased fruits were significantly greater than those in normal fruits, indicating that the cellulose content may be related to the development of corky disease. The disease characteristics of ‘Akizuki’ pear corky disease are divided into two types [7]: the diseased type and the asymptomatic type. The diseased type has obvious brown concave round spots on the surface of the diseased fruit, which the naked eye can observe (Figure 1B,b), whereas the asymptomatic type has no obvious concavity on the surface of the fruit, which may only have subtle dark spots (Figure 1C), while the diseased type is difficult to observe quickly by the naked eye. However, when the fruit is peeled, the flesh has ulcerated brown spots, and the flesh tissue is cork-bound (Figure 1c). At present, the detection of internal diseases is based mainly on manual picking, but this method is laborious, time intensive, labor intensive, and destructive. Thus, enhancing the ‘Akizuki’ pear’s detection and grading technology and ensuring the precision of its quality grading are vital for improving industry competitiveness in the market.


Figure 1.
Internal and external comparisons of healthy, diseased, and asymptomatic samples: (A) healthy sample surface, (a) inside; (B) diseased sample surface, (b) inside; (C) asymptomatic sample surface (c) inside.
The physical and chemical index detection method is the most accurate and widely used method for fruit detection and grading. However, its operation method is cumbersome and expensive, and it can cause damage to fruit. Therefore, it is more suitable for sampling and not suitable for large-scale fruit detection. Nondestructive testing is the main direction of development for rapid and large-scale detection of fruit. In recent years, research on nondestructive testing technology has focused mainly on machine vision, spectral technology, electronic noses, and ultrasonic measurements [8]. Spectral technology, which includes visible/near-infrared spectroscopy, X-ray, laser Doppler, Raman spectroscopy, and terahertz spectroscopy, is used to detect fruit quality-related information by reflecting, semitransmitting, or fully transmitting through the fruit [9].
Raman spectra are scattering spectra based on the Indian scientist C.V. Raman scattering effect discovered by Raman [10]. When an electromagnetic wave of a certain wavelength is applied to a molecule of the substance under study, it causes a jump in the corresponding energy level of the molecule, producing a molecular absorption spectrum. Raman spectroscopy is an analytical method used to study the scattering of compound molecules by light irradiation, the relationship between the energy level difference between scattered light and incident light, and the vibration frequency and rotation frequency of the compound. This technique provides detailed information on the chemical structure, phase, and morphology, as well as the crystallinity and molecular interactions of the sample. It is widely used in the fields of chemistry, physics, biology, and medicine. Raman spectroscopy has been used primarily in agriculture for testing agricultural product quality [11], detecting crop diseases [12], and identifying pesticide residues [13]. Raman spectroscopy allows for qualitative, structural, and quantitative analyses of fruits and vegetables. For example, it has been used to diagnose Huanglong disease in orange and grapefruit trees [14]; asymptomatic grape Esca disease [15]; rice salt stress; nitrogen, phosphorus, and potassium deficiency [16]; tomato yellow leaf Trichoderma virus (Tylcsv); and tomato spot wilt virus (Tswv) [17]. These experiments provide a theory and rationale for the early detection of ‘Akizuki’ pear corky disease. Raman spectroscopy has several advantages, including nondestructiveness, short detection time, low sample volume, and no need for pretreatment [18].
In recent years, with the rapid development of artificial intelligence technology, machine learning (ML), as one of its core branches, has gradually become an indispensable and effective tool in analytical science. ML has long been used to classify Raman spectral data, using algorithms to extract features from large amounts of data, build models, and then apply those models to make predictions or classifications of new data. Compared with traditional methods, the combination of machine learning algorithms and Raman spectroscopy has significant advantages in terms of data processing and analysis ability, model construction and prediction ability, expansion of application areas, adaptability and flexibility. These advantages make the combination of machine learning algorithms, and Raman spectroscopy have a wide range of application prospects and important scientific value in a variety of fields, such as analytical science, food safety, and biomedicine. In the field of food safety applications, the molecular structure information of food samples is obtained via Raman spectroscopy and combined with machine learning algorithms for rapid identification and classification, which can effectively detect harmful substances or adulterated ingredients in food. For example, Zhang et al. [19] and Yan et al. [20] used Raman spectroscopy in combination with ML to achieve accurate classification and analysis of foodborne pathogens, and Zhao et al. [21] compared ML with the principal component analysis (PCA) model, which is more efficient and accurate for the rapid identification of the type of edible oils and adulteration ML. In the field of medicine, Raman spectroscopy combined with machine learning is used for rapid analysis of drugs and improved identification of various diseases [22]. In summary, the combination of Raman spectroscopy and machine learning has significant advantages and broad prospects for development. In the future, with the continuous progress of technology and the continuous expansion of application fields, this combination will play an important role in more fields and promote the innovation and development of related technologies.
The spectral data are affected by many factors in the acquisition process, such as cosmic rays, the fluorescent background, and the dark current of the detector. These factors may lead to noise and interference in the spectral data, which may affect the accurate extraction of the chemical structure, phase and morphology information of the samples. Therefore, before Raman spectroscopy analysis, spectral data must be preprocessed to eliminate these interfering factors as much as possible to ensure the analytical accuracy and modeling stability of the collected data. While a single data preprocessing method often has difficulty in achieving the desired processing effect due to its limitations, the joint use of preprocessing methods has emerged to combine them and play a complementary role [23]. Therefore, six preprocessing methods and three combinations were chosen to preprocess the original spectral data. Then, their impact on modeling accuracy was examined to determine the most suitable spectral preprocessing method.
This study investigated the feasibility of Raman spectroscopy for the nondestructive detection of corky disease in ‘Akizuki’ pears. A Raman spectrometer was used to collect the Raman spectrum. By the Savitzky-Golay (SG), wavelet transform (WT), first derivative (FD), second derivative (SD), standard normal variable (SNV), multiple scattering correction (MSC), and three combination methods (SG+MSC, SG+SNV, and SG+WT), the original spectrum was preprocessed to remove the interference background. Five modeling methods, namely, support vector (SVM), random forest (RF), gradient lifting decision tree (GBDT), extreme gradient enhancement (XGBoost), and convolutional neural network (CNN), were used to establish a classification model for ‘Akizuki’ pear cork disease, and the most suitable classification model for the disease was selected. Ultimately, the performance of the model was optimized by adjusting the parameters of the most effective preprocessing model.
2. Materials and Methods
2.1. Material Preparation
In September 2023, a test was conducted at the ‘Akizuki’ pear demonstration base in Peach and Pear World Agricultural Fruit City, Shushan District, Hefei City, Anhui Province. The test samples consisted of 30 healthy fruits, 30 fruits with symptomatic disease, and 30 fruits with asymptomatic disease—all of which were selected under the guidance of experienced local fruit farmers. After being transported to the laboratory at the Biotechnology Building of Anhui Agricultural University, the samples were cleaned, wiped, and numbered for future use.
2.2. Spectral Data Acquisition
2.2.1. Instrumentation
The ultraminiature Raman spectroscopy identifier ‘ATR1600’, produced by AuPuTianCheng (Xiamen, Fujian, China) Optoelectronics Co., Ltd., was used to collect Raman spectral data in this experiment. The instrument has a spectral laser wavelength of 785 ± 0.5 nm, a wavelength range of 200–3000 cm−1, and a spectral resolution of 18 cm−1. To collect the spectral data, the ‘ATR1600′ application on a mobile phone is connected to the instrument via Bluetooth, and the mobile phone app is used, as shown in Figure 2.

Figure 2.
Ultra Miniature Raman Spectrometer “ATR1600” by OPTOTECNICA.
2.2.2. Data Collection
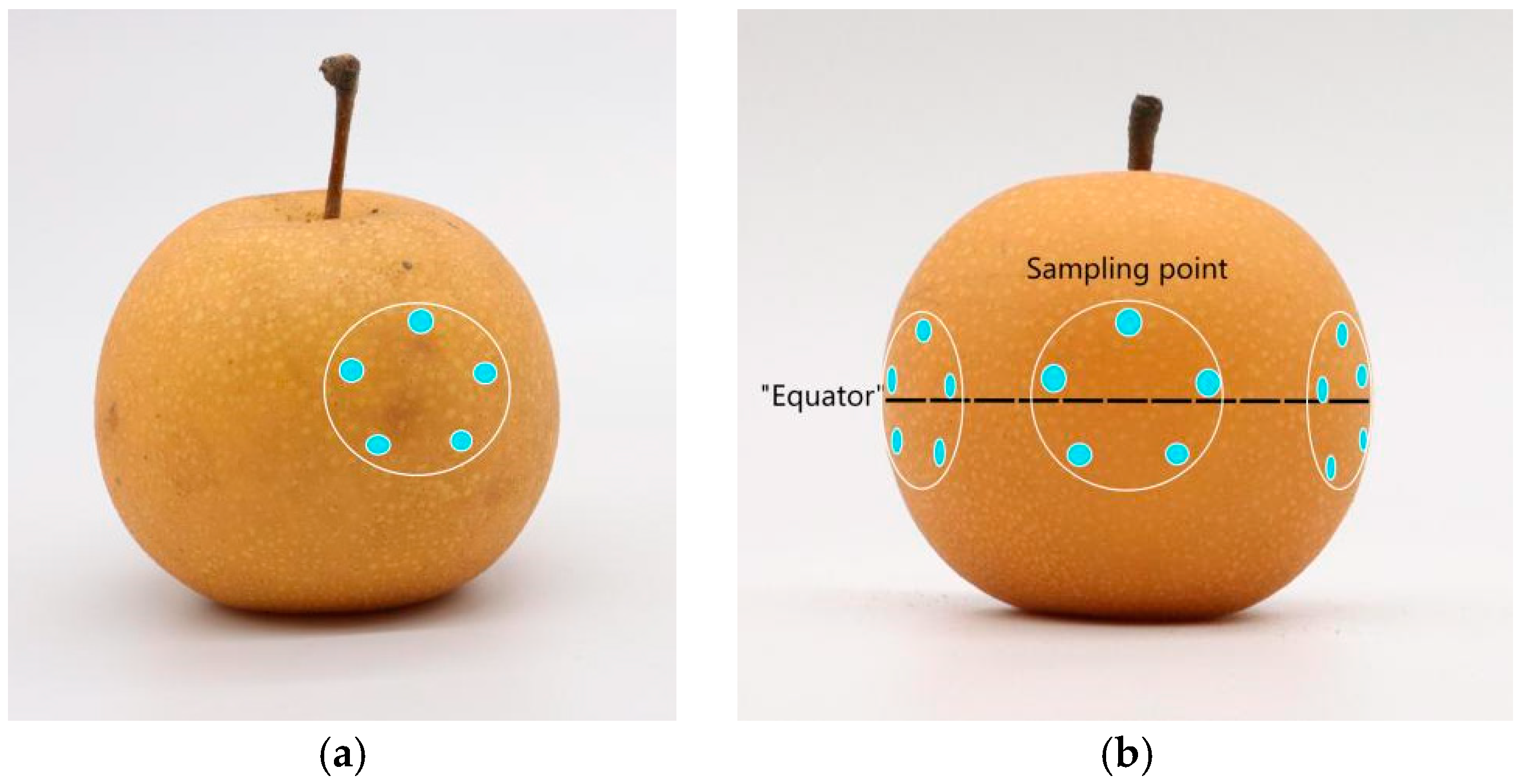
Raman spectral data were collected separately for different types of ‘Akizuki’ pear fruits. To reduce interference from other factors, the temperature of the room was maintained at approximately 20 °C, and the humidity was kept constant during spectral collection. First, for diseased fruits, the sampling area was selected directly by the location of the surface spots (Figure 3a), whereas for pear fruits without surface spots, the sampling area was selected at 120° intervals near the equator line of the pear equator with similar sizes (Figure 3b). A five-point sampling method was adopted in each sampling area, and the average value was taken as the scanning result. The pear fruits were then peeled to screen diseased pears without obvious spots on the surface but with brown spots of ulcer disease on the inside as asymptomatic data.
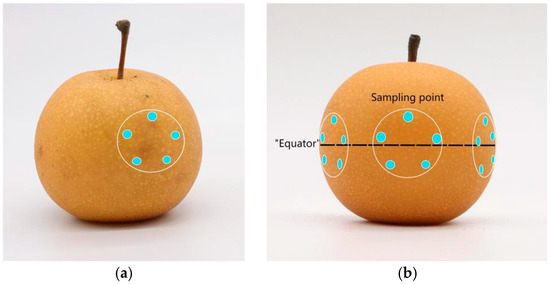
Figure 3.
Five-point sampling method for pear fruit: (a) sampling method for diseased fruit; (b) sampling method for disease-free spot fruit on the surface.
2.3. Spectral Data Preprocessing
The laboratory data are susceptible to environmental, sample, and equipment factors and other natural and unnatural factors. This can result in a spectral curve model that contains interference and disordered data, which can affect the accuracy and stability of the curve. Therefore, selecting an appropriate preprocessing method is crucial for ensuring the accuracy and stability of subsequent spectral curve establishment and modeling. Therefore, six preprocessing methods and three combinations, including multiple scattering correction (MSC), standard normal variable (SNV), first-order derivative (FD), second-order derivative (SD), Savitzky-Golay smoothed filtering function (SG), and wavelet transform (WT), SG+SNV, SG+MSC, and SG+WT, were used in the present study.
Scattering correction mainly includes MSC and SNV, which are employed to eliminate the influence caused by irregular particle size and distribution, eliminate interference and deviation caused by the scattering effect, and improve the quality and stability of spectral data [24]. The MSC aims to mathematically remove the spectral variability caused by the physical characteristics of the sample, such as the size of the particles. Unlike the MSC, the SNV corrects each spectrum individually. Instead of using a reference spectrum, SNV calculates the standard deviation for each wavelength and uses it to normalize the raw spectral data. Derivative processing is a common technique used in spectral analysis to extract spectral features and reduce the effects of baseline shifts and overlapping peaks. FD indicates changes in the slope of the spectrum and can reveal peaks and troughs. The SD shows changes in spectral curvature and is useful for precise feature extraction and noise amplification [25]. SG is a smoothing technique that reduces noise in spectral data while preserving signal features. This algorithm fits a polynomial function within a window around the data points, preserving peak heights and widths [26]. The WT is able to effectively remove noise and extract useful signals through its localization analysis property and denoising by the wavelet thresholding method, which has unique advantages in spectral denoising [27]. Among the three preprocessing combinations of the SG+MSC, SG+SNV and SG+WT algorithms, the SG and WT smoothing algorithms can eliminate noise burrs in the spectra, whereas the MSC and SNV algorithms can correct the spectral intensity variations. Together, these processing steps improve the quality of the spectral data and provide a more reliable database for subsequent analysis.
2.4. Relative Optimal Preprocessing Method Sorting Method
To select the optimal preprocessing method among the nine preprocessing methods of the ‘Akizuki’ pear corky disease prediction model, this paper refers to the relative optimality index formula in Equation (1) to calculate the difference between different preprocessing methods.
In Formula (1), ROIndexj is the relative optimal index, j represents the preprocessing method, and i is the model type. When model i is preprocessed as j, its accuracy is ranked as RAij in the list; when model i is preprocessed as j, its kappa values are ranked as RKij. The ranking is in ascending mode. To ensure the degree of universality of the preprocessing method, the ROIndexj formula adds the ranking of each model in the precision list and the kappa list when the preprocessing is j. This results in a ranking list that takes into account both the model accuracy and the classification consistency level. The relative best pretreatment technique can be chosen with clarity through data comparison [28].
2.5. Modeling Approach
2.5.1. Data Sampling
Selecting representative sample data and differentiating data are crucial steps in spectral data processing. These steps reduce the modeling effort and increase model stability and accuracy. The KS method is a commonly used algorithm for data sampling and sample set selection, particularly in spectroscopy and chemical analysis for model construction and calibration. The algorithm’s primary objective is to select representative samples from a dataset for constructing models, calibrating instruments, or performing analyses. This method reduces the dataset size and improves model efficiency while maintaining dataset diversity [29]. Following the KS method, the total number of samples was 345 (Healthy 0: 87; Asymptomatic 1: 90; Diseased 2: 168), train:test = 7:3 (241:104), where train: 0:1:2 = 65:62:114 Test: 0:1:2 = 22:28:54, as shown in Table 1.

Table 1.
Statistics for the ‘Akizuki’ pear sample.
2.5.2. Modeling Methods
With the growth and development of artificial intelligence in recent years, machine learning has manifested great advantages, which greatly accelerate the speed of experimental analysis and computation by effectively learning from a large amount of prelabeled data and then generating reasonable predictions for new datasets, making it an effective tool for analyzing Raman spectral data [30]. The support vector (SVM), random forest (RF), extreme gradient boosting (XGBoost), gradient-boosted decision tree (GBDT), and convolutional neural network (CNN) methods are the comparative modeling methods employed in this study.
SVM is a boundary-based supervised learning method that is widely applied to classification and regression analysis. In spectral data analysis, SVM correctly divides the training dataset with the most efficient geometric intervals by finding a hyperplane that can classify the data into different classes by choosing appropriate support vectors [31]. By projecting the samples to a high-dimensional feature space via the kernel, the SVM can create the ideal separation hyperplane when the samples are indistinguishable. The performance of the SVM model is significantly influenced by the selection of the kernel function, kernel parameters, and penalty parameters. Different parameters and kernel functions may lead to completely different results.
Integrated modeling is an important approach within the domain of machine learning and is a machine learning model that integrates the prediction results of multiple weak classifiers or weak regressors by combining them via a strategy to obtain a more powerful and robust prediction performance [32]. RF is a typical application of the bagging algorithm in integrated learning and one of the most popular algorithms in the current field of machine learning. Multiple decision trees are used to train and predict samples, and their predictions (regression problem) or majority voting (classification problem) are averaged to obtain the final prediction [33]. RF excels at handling high-dimensional data, easily performs parallel processing, works well with large sample training, and is robustly detect missing data and nonlinear relationships, but is prone to overfitting in noisy datasets.
GBDT is an iterative approach for training multiple weak classifiers (decision trees) and then combining them into one strong classifier. In GBDT, each decision tree is a correction for the prediction error of the current model, and in this way, the prediction performance of the model is gradually improved [34]. GBDT performs well in all kinds of machine learning tasks because of its efficient running speed and excellent prediction performance, especially when dealing with regression problems and some complex classification problems. XGBoost is based on GBDT to construct new decision trees in the negative gradient direction of the loss function. The generation process of each decision tree is an optimization problem, and constructing the decision tree by iteratively choosing the best split point is a successful execution of GBDT. In contrast to GBDT, XGBoost controls model complexity and guards against overfitting by adding regularization elements to the loss function. Given that calculating the derivative of the loss function is difficult, XGBoost utilizes not only the first derivative of the loss function but also the second derivative (Hessian matrix) to speed up convergence and improve the accuracy of the model.
Deep learning represents a branch of machine learning research that uses neural networks and relies on training data to increase accuracy. Compared with traditional machine learning methods, deep learning has excellent learning ability and low generalization error. The CNN is an exemplary deep learning algorithm that contains convolutional computations and has the deep structure of a feedforward neural network. The basic layer is the core layer of the CNN, and its principal function is to perform convolutional operations on the input 2D image to extract the characteristics of the picture. Pooling layers are used to reduce the spatial size of the data, minimize the number of parameters and computations in the network, and prevent overfitting. On the other hand, the fully connected layer is located at the end of the CNN and classifies the feature vector outputs from the pooling layer, mapping them to the probabilities of each category. It automatically extracts features from the data by simulating the human brain’s processing of visual information, using structures such as convolutional and pooling layers to achieve tasks such as classification and recognition [35].
2.6. Evaluation Metrics
The output of machine learning algorithms needs to be evaluated and analyzed, and this analysis must be interpreted correctly, so evaluation metrics are critical to understanding the performance of the model. For classification problems, binary classification models are generally evaluated via a confusion matrix. The actual values of the confusion matrix of the binary classifier (as shown in Table 2) are labeled “true” (1) and “false” (0), and the predicted values are labeled “positive” (1) and “negative” (0). The expressions TP, TN, FP, and FN in the confusion matrix provide the probability estimate for the classification model, where TP (true positive) refers to the case where the positive category is accurately predicted by the model to be positive; FP (false positive) refers to a situation in which the model incorrectly predicts a negative category to be positive; FN (false negative) refers to a situation in which the model incorrectly predicts a positive category to be negative; and TN (true negative) refers to the situation where the model correctly predicts a negative category as a negative category [36].
Table 2.
Confusion matrix for the binary classification problem.
The following four metrics provide a comprehensive picture of the performance of the classification model, including accuracy, accuracy, recall, and F1 score.
The most intuitive categorical metric is accuracy, which indicates the proportion of total samples correctly predicted by the model. The percentage of samples that the model correctly predicts to fall into the positive category out of all samples that the model predicts to fall into the positive category is known as precision. The precision and recall harmonic average is the F1 score and is a composite representation of them. The kappa coefficient is a measure of statistical consistency used to evaluate the consistency of the results of two or more evaluators on the same set of samples or to evaluate the consistency of the model’s predicted and actual classification results in a classification problem, where P0 represents the total accuracy of the module, and PE represents the random accuracy of the model. The range of the kappa values is −1–1. A score of −1 denotes total disagreement. A value of 0 denotes random agreement, i.e., there is no systematic correlation between the predicted and actual results, as in a random guess. A value of 1 indicates a perfect prediction, i.e., the predicted results are in perfect agreement with the actual results. Table 3 shows the corresponding kappa values for categorical agreement at different intervals [37].
Table 3.
Consistency levels of classifications that match the kappa coefficient.
3. Results and Discussion
3.1. Dataset Statistics
The variation in the peak values of the spectral curve is the result of the combined effects of multiple factors, including the chemical composition, physical state of the sample, and conditions of spectral detection. By analyzing the spectral curve, we can obtain important information about the sample’s composition, structure, and properties. Raman spectroscopy was established by collecting data from the surface of the ‘Akizuki’ pear. The cell wall of the pear epidermis is a thick-walled structure that exists outside of plant cells, and it is closely related to the growth, development, and life functions of the cells. ‘Akizuki’ pear corky disease causes changes in the physicochemical properties of pear epidermal cells, and several papers have shown that pear corky disease leads to a significant increase in the content of lignin and cellulose in the cell wall [5,6]. Lignin and cellulose are important components of the cell wall, and they work together to maintain the structural stability and function of the cell wall. Therefore, the resolution of the Raman characteristic region of cellulose and lignin is crucial for analyzing and verifying the altered physicochemical properties of the corky disease in ‘Akizuki’ pears.
According to a review of the literature, the Raman spectral band at 300–500 nm is the main characteristic peak of cellulose, and the main contributions are the 331 nm, 344 nm, 381 nm, 437 nm, 459 nm, and 520 nm Raman bands at the C-C-C, C-O-C, O-C-C, and O-C-O backbone bending vibrations of cellulose; the C-C-H and O-C-H bending vibrations; and the C-C and C-O skeleton stretching vibrations, mainly the pyran ring outer and bending vibrations. The characteristic peak of lignin in Raman spectroscopy is at approximately 1600 nm, which is attributed primarily to the symmetric stretching vibration of the aromatic ring at 1597 nm, the C=C stretching vibration at 1621 nm, and the C=O stretching vibration at 1662 nm [38,39,40].
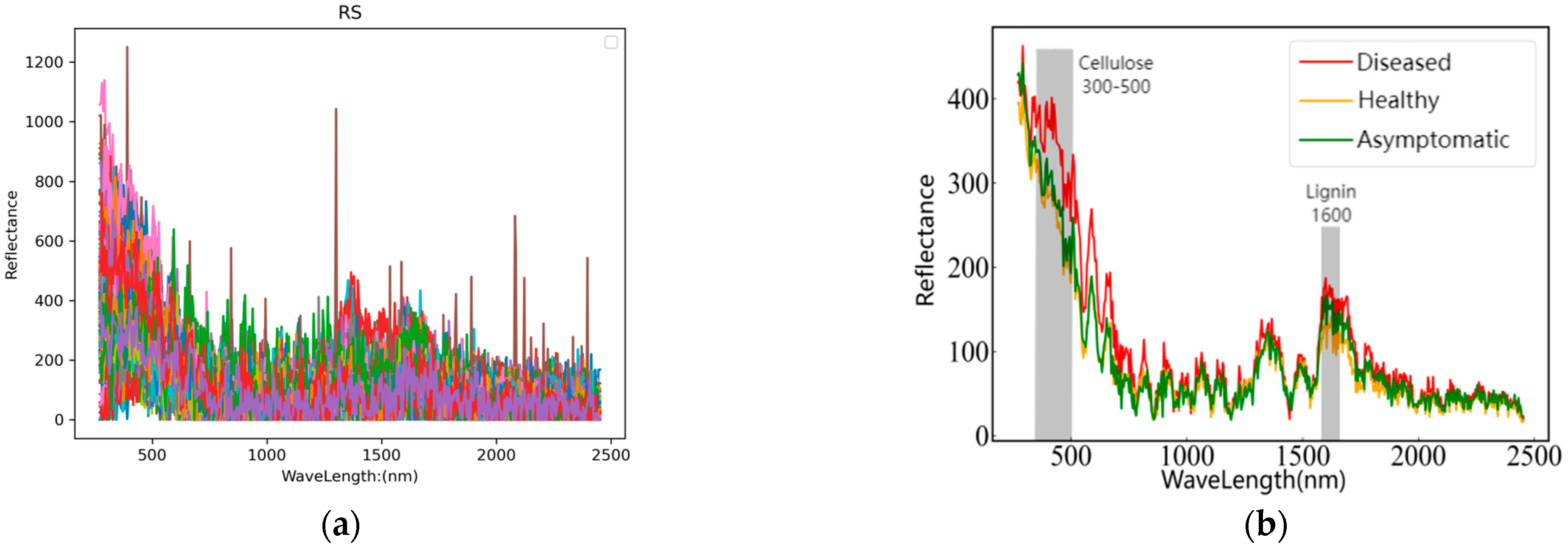
In the experiment, Raman spectra were collected in the range of 0–2500 nm. The original spectral images of diseased, asymptomatic, and healthy fruits are shown in Figure 4a, while the average Raman spectra of the three types of fruits are presented in Figure 4b. As illustrated in Figure 4b, the spectral curves of diseased, asymptomatic, and healthy fruits exhibit considerable overlap within the wavelength ranges of 950–1500 nm and 1800–2500 nm. However, significant distinctions are observed in the spectral profiles between diseased and both asymptomatic and healthy fruits within the range of 300–650 nm; notably, no substantial differences exist between asymptomatic and healthy fruits. Furthermore, pronounced variations in the spectral curves among diseased, asymptomatic, and healthy fruits are evident within the range of 1600–1700 nm. Therefore, the changes in the Raman characteristic peaks of these samples are generally consistent with conclusions drawn in other studies.
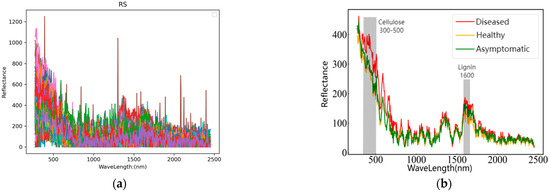
Figure 4.
(a) Original spectrogram; (b) Aaverage spectrogram.
Figure 4b also shows that the trends of the three spectral curves are becoming consistent, but the reflectances in each band are generally in the order of disease > asymptomatic > healthy. The disease curve shows a significant difference in the Raman characteristic peak range of cellulose and lignin compared with the healthy curve, whereas the asymptomatic samples, although not significantly different, still present some distinctions. This is because asymptomatic fruits are less severely affected than diseased fruits. However, even if the surface of the pear fruit shows no symptoms, the internal damage from cork disease still leads to an increase in lignin and cellulose, which differs from healthy pear fruits. These findings verify the conclusions of Cui et al. [6] that the lignin and cellulose contents in the fruit affected by ‘Akizuki’ pear corky disease are greater than those in healthy fruit. This also provides a basis for the feasibility of analyzing through Raman spectroscopy and establishing accurate classification models.
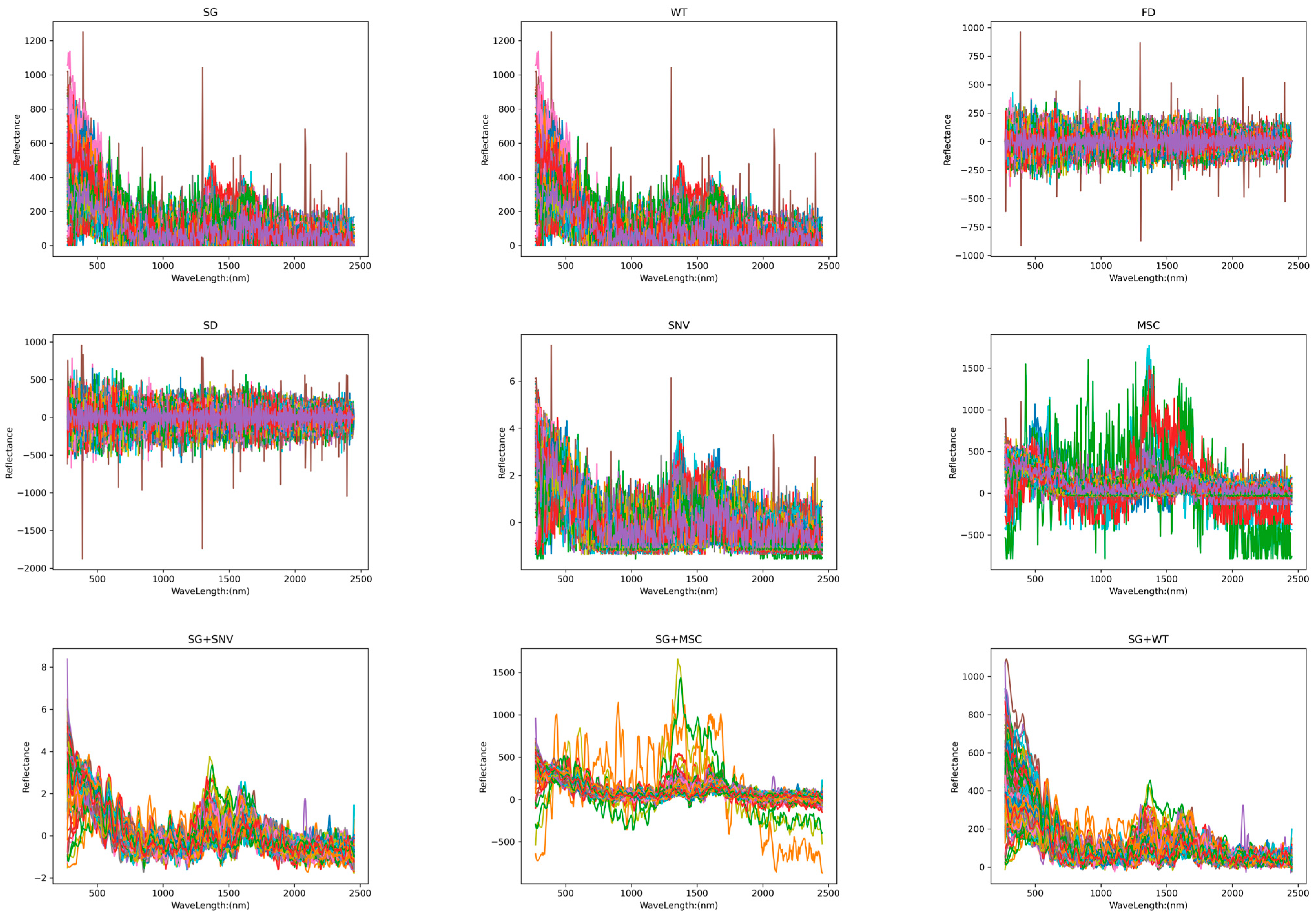
An essential component of spectral analysis is spectral preprocessing. We can acquire more precise and trustworthy spectrum data via this approach, which offers strong support for further examinations and uses. Different preprocessing techniques affect spectral pictures differently. Figure 5 shows Raman images from nine preprocessing methods. The spectral wavelength (nm) and absorbance (AU) were used as the x- and y-axes, respectively.
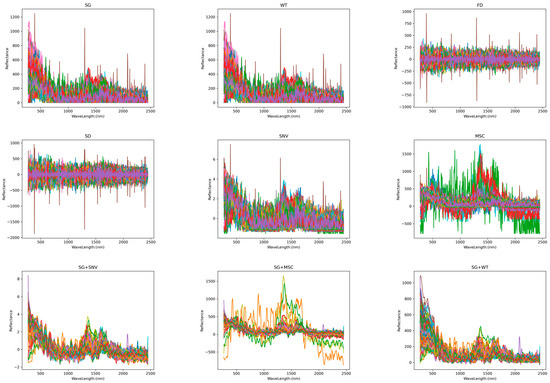
Figure 5.
Raman spectra after different pretreatment transformations.
Figure 5 shows that the MSC corrects the scattering effect in the spectral image to make the spectral data closer to the real chemical information. In the processed image, the spectral lines are more consistent, and the scattering-related spectral differences are corrected. The SNV makes the spectral image more homogeneous by standardizing each spectrum and eliminating multiplicative noise and intensity variations. In the processed image, the intensity differences in the spectra are eliminated, and the spectral lines are normalized to the same scale for easy comparison and further analysis. FD highlights changes in the position of absorption or emission peaks in a spectral image, emphasizing the slope of the spectral curve. The processed image shows more edge information, and the position of the peaks becomes more pronounced, but this may result in a weakening of the relative change in peak intensity. SD converges with the function of FD, but its processed image amplifies the noise and loses more information about the peak intensities. SG filtering and WT are mainly used to remove high-frequency noise from spectral images to make the spectral curve smoother. The processed image has less noise and a smoother spectral curve, but it slightly changes the position and shape of the peaks.
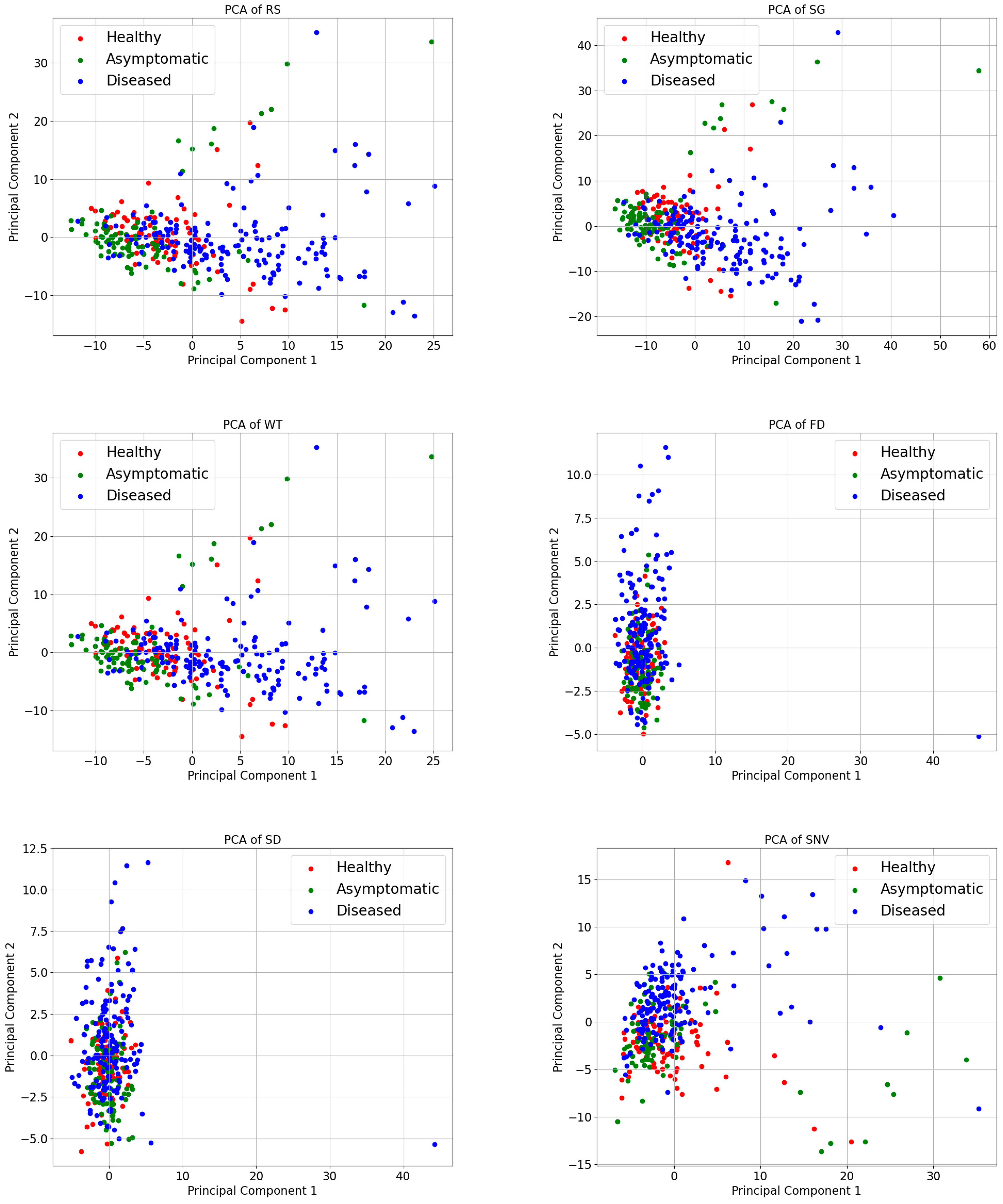
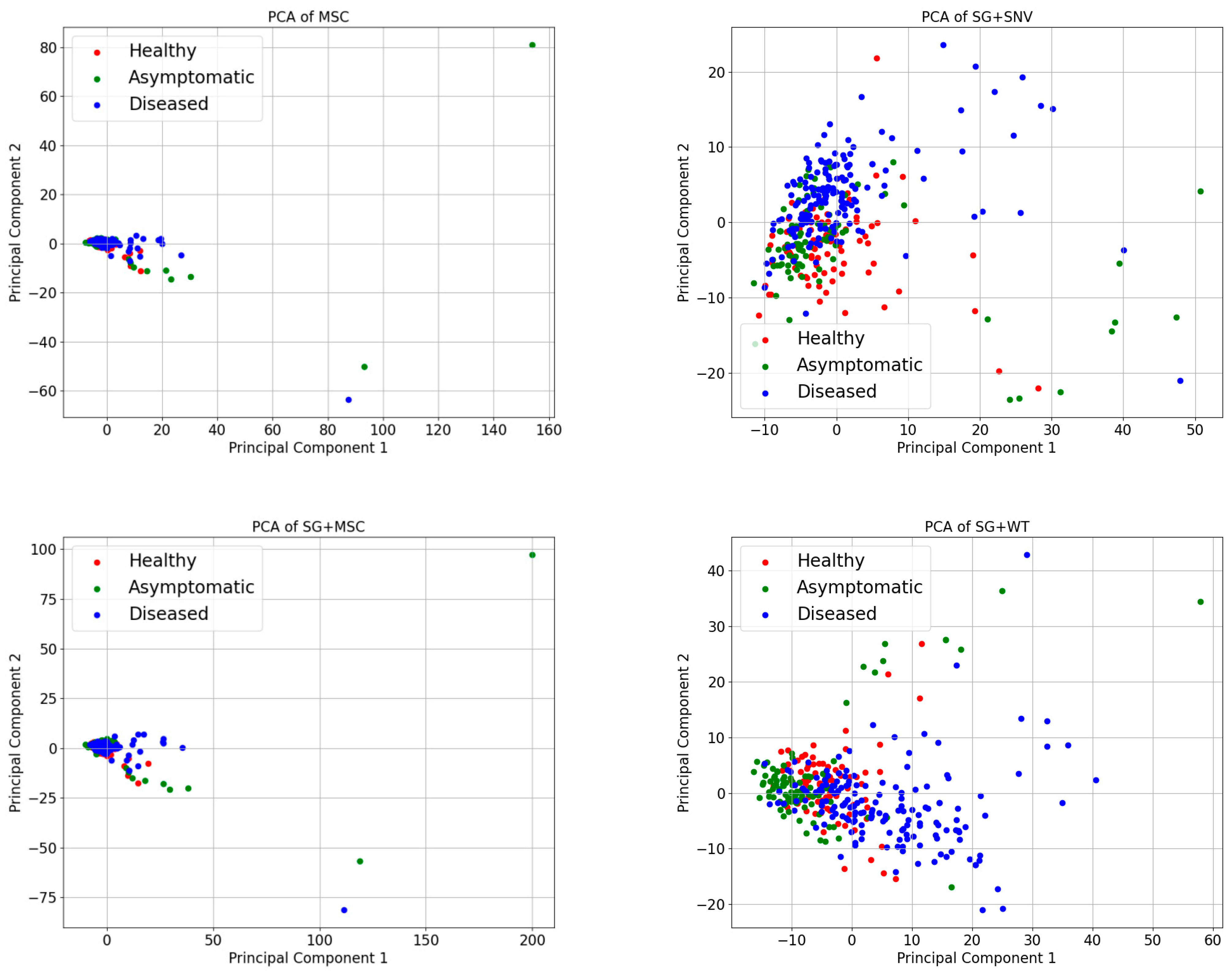
The spectral curves obtained by preprocessing, although each has its own characteristics, cannot be compared more intuitively in terms of their effects on the sample data. Therefore, in this study, principal component analysis (PCA) was used to process the results of different preprocessing methods. Reducing the dimensionality of the data while maintaining the most crucial information in the dataset is the primary objective of PCA [41]. The benefits include simplifying the dataset, removing noise and redundancy, and increasing the efficiency and effectiveness of subsequent processing steps. PCA projects the original data onto a new set of axes through a linear transformation. These axes represent the main elements of the information and are arranged in order of variance from largest to smallest. In PCA, data are visualized by selecting the data’s first two main components that contain more information than the two axes, horizontal and vertical. Figure 6 displays the sample distribution under various pretreatments, with H representing a healthy sample, K representing an asymptomatic sample, and Z representing a diseased sample.
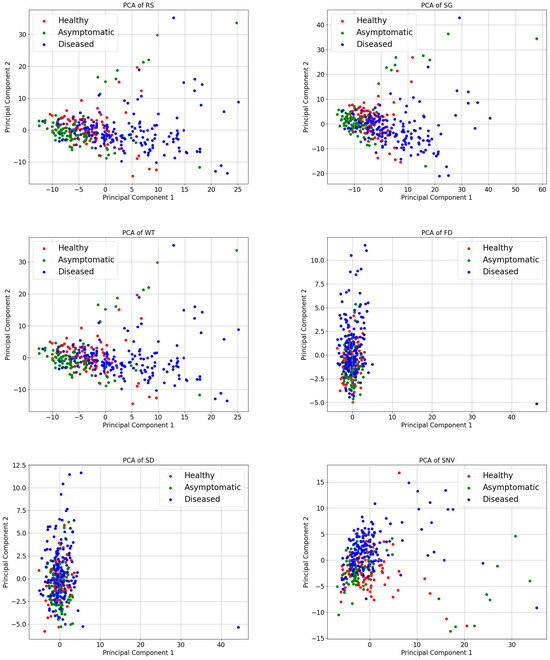
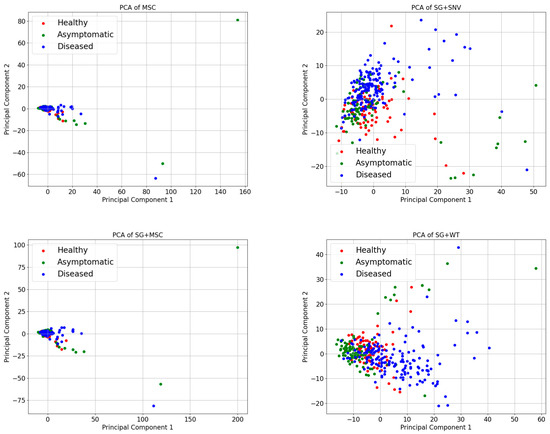
Figure 6.
PCA visualization of spectra under different pretreatment methods.
Figure 6 illustrates that the sample points of the healthy, asymptomatic, and diseased samples show a certain degree of differentiation between the different categories of samples in the PCA space, although there is a majority degree of overlap. However, the two-dimensional plane’s point distribution of the 345 samples significantly changed following the application of several preprocessing procedures to the original spectral data. A comparative analysis of the two-dimensional distribution maps of 24 samples revealed that WT, SG, and RS presented a high degree of similarity, which was also proven by their corresponding spectral maps. Similarly, the effects of SNV and SG+SNV, MSC and SG+MSC, and FD and SD on the Raman spectra also significantly differ.
3.2. Model Optimal Preprocessing Analysis and Comparison
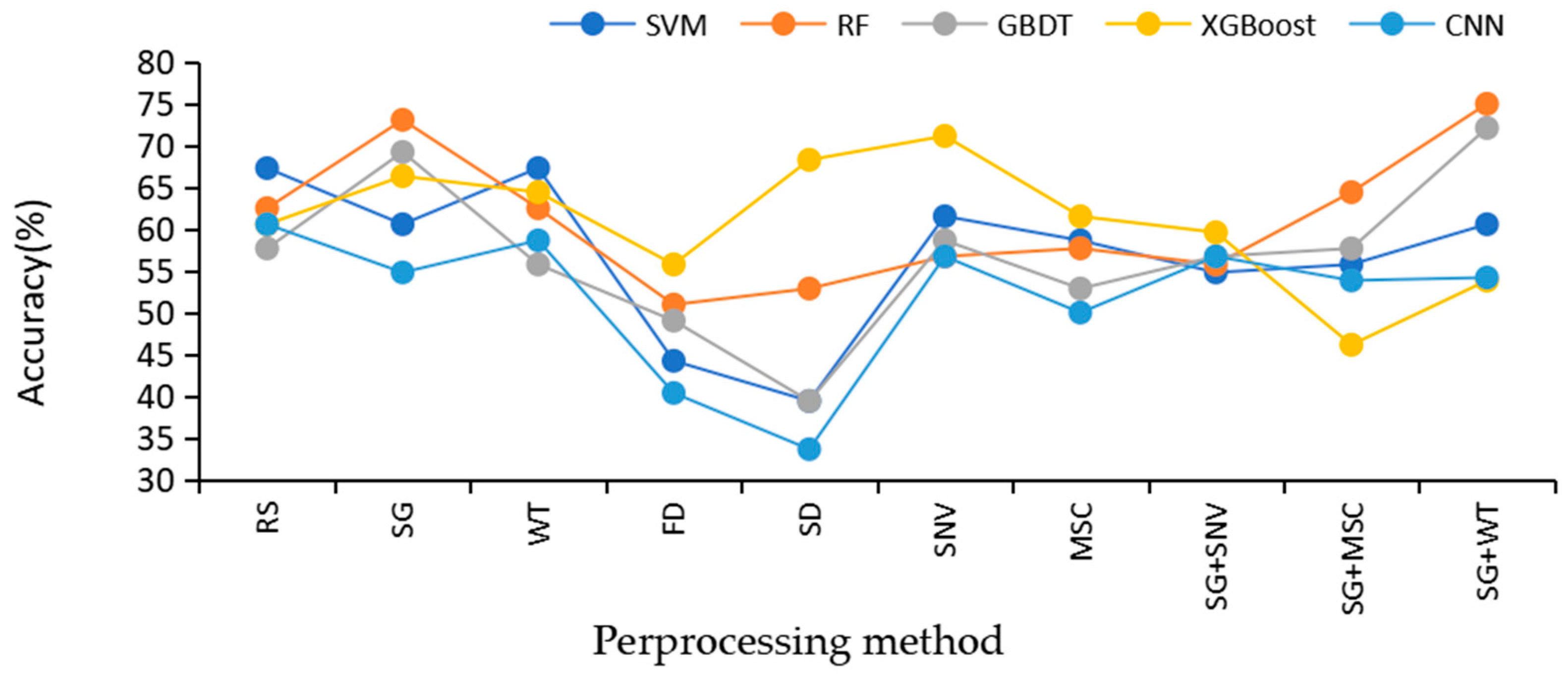
In this study, five classification algorithms under nine Raman spectrum preprocessing methods are compared to find the best algorithm. The accuracies of SVM, RF, GBDT, XGBoost, and CNN on the test set under nine different preprocessing methods are displayed in Figure 7.
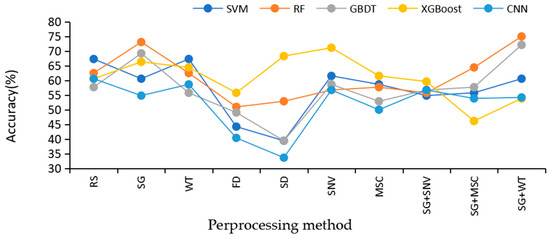
Figure 7.
The model was accurate under nine different pretreatment methods.
The comparative analysis in Figure 7 clearly reveals the key role of the preprocessing method in improving the accuracy of the models. The five models without preprocessing have similar performance and low overall accuracy on the original data, especially SVM and CNN, which instead decrease in accuracy after preprocessing. This is most likely attributed to the improper parameter configuration, resulting in the key features in the original data being inappropriately filtered or lost during preprocessing, which in turn reduces the match with the model. In contrast, the GBDT and RF models showed a significant increase in accuracy after SG+WT preprocessing, indicating that appropriate preprocessing methods can effectively mitigate the noise and undesirable factors in the raw data, thus enhancing the predictive ability of the models.
Specifically, for the choice of preprocessing methods, although SNV can eliminate the magnitude differences between spectra and enhance data comparability, its normalization process may be accompanied by partial loss of spectral information. SG filtering, on the other hand, smooths the data by means of local polynomial fitting, which reduces the noise while keeping the shape and features of the spectral signals better, showing the advantage of retaining the spectral information. On the other hand, WT is known for its excellent noise identification and removal ability, which can retain useful spectral information while eliminating noise that is not useful for classification or analysis.
The combined use of SG and WT becomes an efficient preprocessing strategy for spectral data. First, SG filtering performs preliminary smoothing of the spectral data to initially reduce the interference of noise; subsequently, the WT further refines the processing to identify and remove the remaining noise while ensuring that the key features in the spectral data are retained. This combination of methods not only effectively suppresses noise but also maximizes the retention of detailed information in the spectral data, which is particularly important for Raman spectral analysis that relies on high-resolution spectral features. Therefore, choosing an appropriate combination of preprocessing methods is crucial for improving the accuracy and reliability of the model in spectral data analysis.
Distinct preprocessing methods have different effects on different model performances, and evaluating model preprocessing methods only by a single evaluation index is not comprehensive enough. Thus, using the relative optimal index formula (2) as a basis, this study computed the accuracy and kappa values of each model under various pretreatment methods, and the results were derived by adding the descending ranking of their respective values. In the end, the best pretreatment method for this experiment was determined to be the one with the lowest optimum index. In Table 4, RA denotes the accuracy ranking, and RK denotes the kappa-based ranking of the classification consistency level.
Table 4.
The accuracy and kappa coefficient of each model under different preprocessing methods.
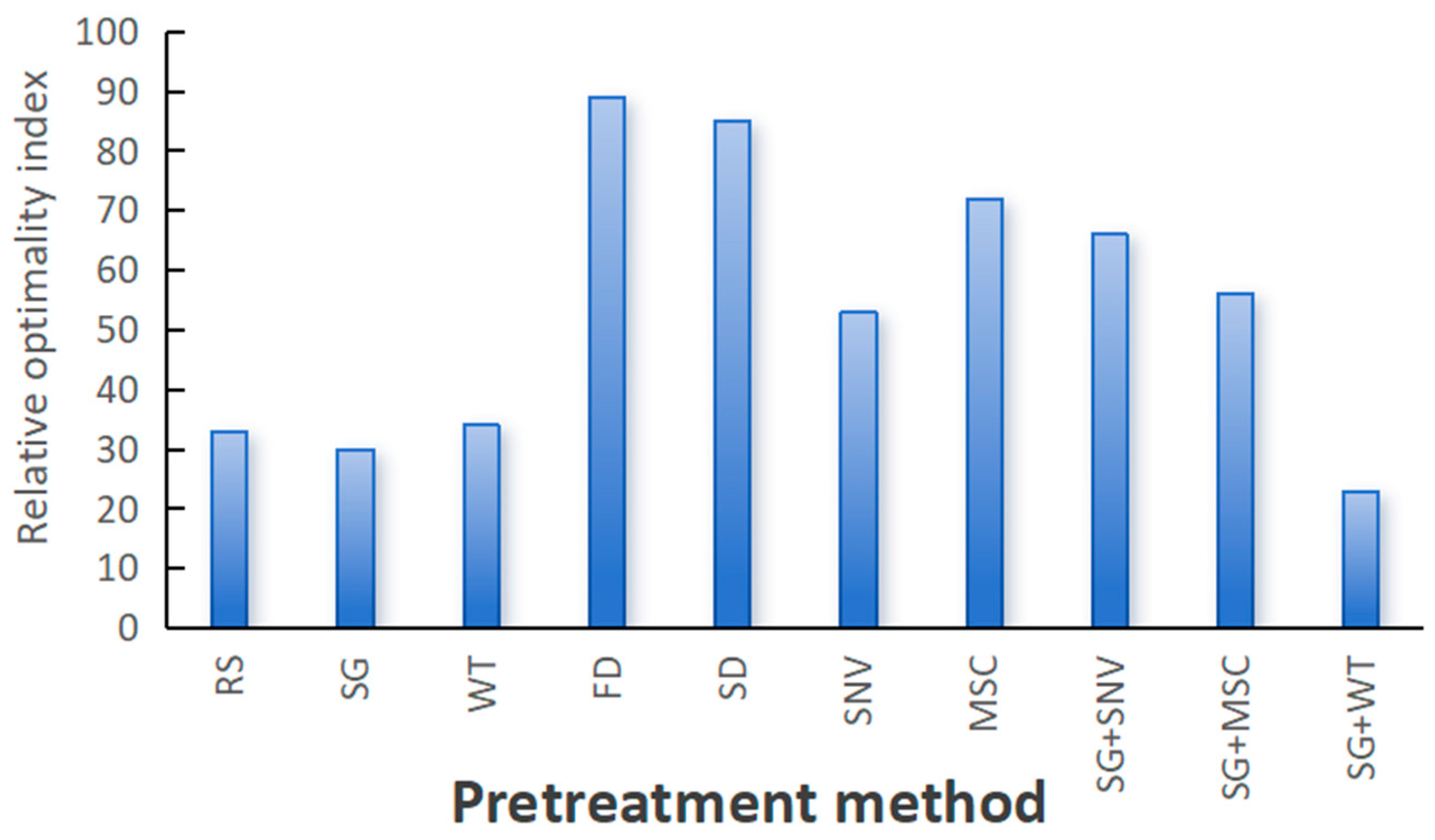
The ROIndex of each preprocessing method is summed by the values in Table 4. The ROIndex values of the nine pretreatment methods are displayed in Figure 8.
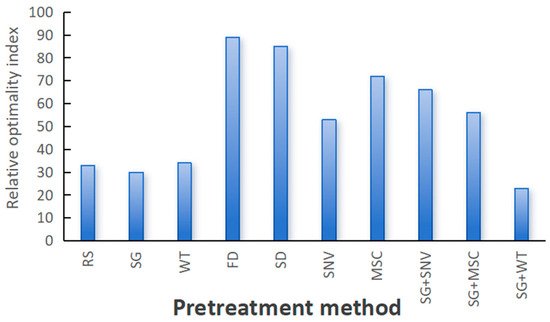
Figure 8.
The relative optimization index of the preprocessing method.
Figure 8 illustrates the preprocessing methods on the horizontal axis and their relative optimality indices on the vertical axis. This bar chart clearly shows the performance of different preprocessing methods on the relative optimality index. The figure shows that the FD and SD methods yield the highest values, indicating that these methods strongly influence the original spectral information and are the worst-performing preprocessing methods. In contrast, the SG and SG+WT methods demonstrate the most favorable performance, with relative optimality indices lower than those of RS (original data). This analysis serves as a crucial point of reference for selecting suitable preprocessing methods for data preparation. Moreover, the performance of other preprocessing methods also provides reference information, which helps to comprehensively evaluate the effectiveness of different preprocessing methods.
Among all the preprocessing methods, SG and SG+WT are the best preprocessing methods. As shown in Table 5, when the SG and SG+WT preprocessing methods were used instead of RS, the model performance changed greatly. The accuracy and kappa coefficient of the RF, GBDT, and XGBoost models were greatly enhanced, whereas those of the SVM and CNN models slightly decreased.
Table 5.
Model accuracy and kappa coefficient under the optimal preprocessing method.
3.3. Optimization of the Optimal Preprocessing Method for the ‘Akizuki’ Pear Model
In SVM model tuning, the primary parameters that require adjustment include the following key terms: kernel (kernel function), C (penalty coefficient), and gamma (kernel function coefficients). The kernel is used to map the input data into a high-dimensional space, thereby determining the best hyperplane within that space for classification purposes. The linear kernel function (Linear), polynomial kernel function (Poly) and radial basis function Kernel (RBF) are examples of frequently used kernel functions. The choice of a suitable kernel function is crucial for achieving optimal performance in classification problems, as different kernel functions are better suited to different data distributions. The penalty coefficient, C, balances the weights assigned to the classification interval margin and misclassified samples in the objective function. A larger C-value indicates that the model is more focused on fitting each sample, which may lead to overfitting. Conversely, a smaller C-value indicates that the model is more focused on interval boundaries, which can lead to underfitting. Gamma determines the shape and range of the kernel function. The larger the value of gamma is, the smaller the effect of individual samples on the whole classification hyperplane; conversely, the smaller the value of gamma is, the more complex the model.
All the integrated models select “max_depth” and “n_estimators” as the debugging objects. Insufficient n_estimators can result in underfitting, whereas excessive n_estimators may increase the number of computations and are prone to overfitting. The max_depth parameter restricts the depth of the tree, preventing overfitting and improving the model’s generalization ability. It also controls the complexity of the tree, allowing for the capture of more complex patterns. However, a deeper tree may also lead to overfitting. GBDT will also choose the “subsample”, which increases the diversity of the model by randomly selecting some samples instead of all to train each tree, thus improving the model’s performance. In addition, “min_samples_split” limits the conditions under which nodes continue to be partitioned, and “min_samples_leaf” limits the minimum number of samples required for leaf nodes. Higher values of both parameters prevent overfitting but may result in underfitting. To prevent overfitting, XGBoost selects the minimum sum of child node weights, which is referred to as “min_child_weight”.
In the process of CNN model tuning, the main parameters that need to be adjusted are the “batch size” and “epochs”. The number of samples used in each update of the model parameters is determined by the batch size, which needs to be selected according to the specific hardware conditions and the size of the dataset to choose the appropriate batch size. The number of times the model runs through the training set is indicated by the number of epochs. The number of iterations can be increased to improve the model’s performance. However, overfitting can occur when too many iterations are used.
Table 6 lists the precision and kappa coefficient of various models following parameter optimization under the optimal preprocessing methodology. As shown in Table 6, the preprocessing and parameter debugging procedures resulted in enhanced accuracy for the various models. After preprocessing and parameter debugging, SVM, CNN, RF, AdaBoost, GBDT, and XGBoost yield accuracies of approximately 0.74. Among these models, XGBoost following SG+WT processing and RF following SG processing are identified as the best in the context of this experimental model.
Table 6.
Model parameter values, accuracy of the optimized model and kappa values.
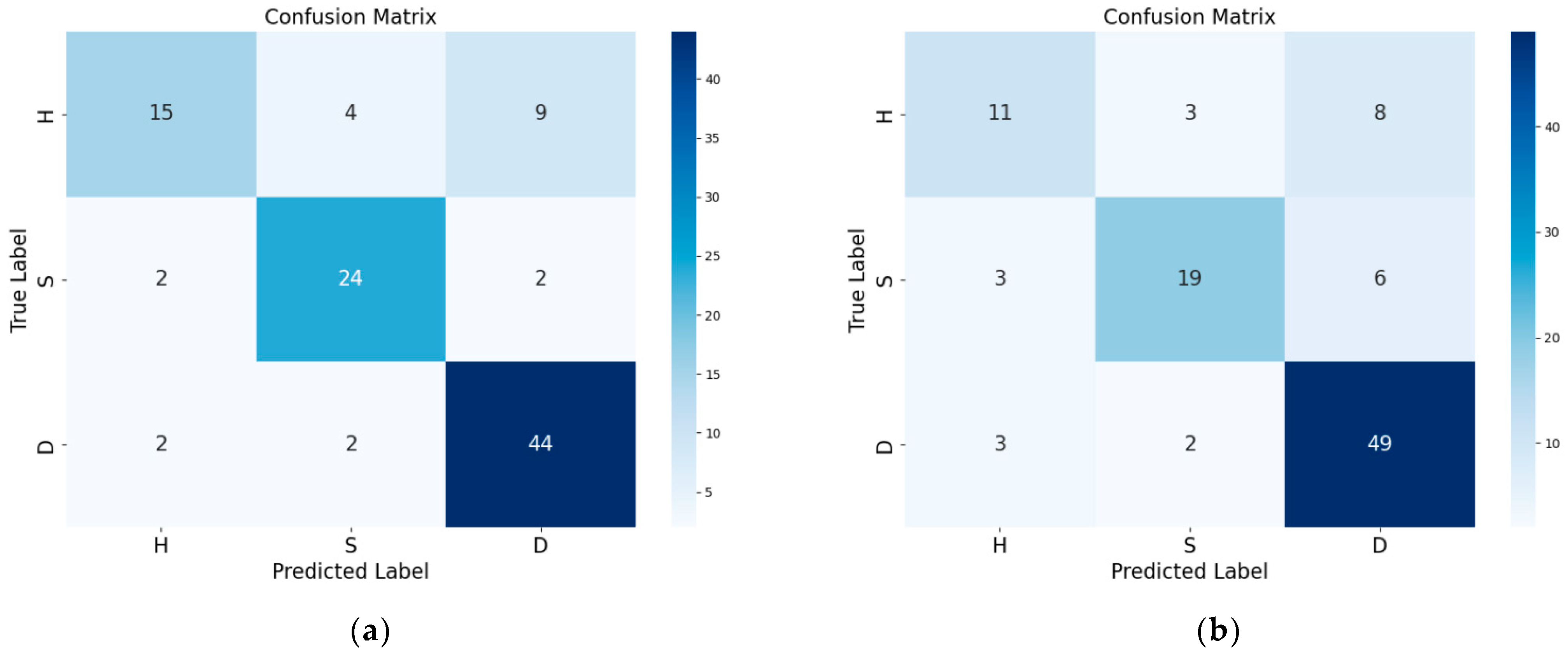
To provide a clearer demonstration of the model’s prediction performance for various sample categories, we utilize the confusion matrix to better illustrate the XGBoost and RF classifications. Figure 9 displays the confusion matrix of the two models.
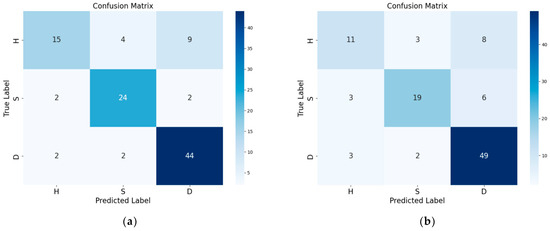
Figure 9.
Confusion matrix of the optimal model: (a) RF using the pretreatment technique of SG; (b) XGBoost using the pretreatment technique of SG+WT.
As shown in Figure 9, XGBoost and the RF model predicted a total of 104 samples. Among them, the RF model successfully predicted 79 samples and misclassified 6 healthy samples, 5 asymptomatic samples, and 14 diseased samples. XGBoost successfully predicted 83 samples and misclassified 4 healthy samples, 6 asymptomatic samples, and 11 diseased samples. Although there were some discrepancies in the predictive accuracy of the RF and SG+WT models when different categories of samples were classified, both models demonstrated satisfactory performance.
For the detection of corky disease in the ‘Akizuki’ pear, our team members used different methods to establish a corky disease identification model. In Zhang Hanhan’s study [32], a micro near-infrared spectrometer was employed, and multiple preprocessing methods were used to process the spectral data. When only the NIR spectra were used for modeling, most of the accuracies were approximately 60–70%, and the model performance was poor. Following preprocessing, each model’s performance was significantly enhanced. The Autokeras model, which was preprocessed via SG, exhibited the highest accuracy of 90%. In this study, a Raman spectrometer was used to collect the spectral data, followed by preprocessing and model reconditioning. Finally, the highest accuracy of 80% is achieved through SG+WT preprocessing for XGBoost modeling.
However, the accuracy of this model is still significantly lower than that of Zhang Hanhan’s research, and the accuracy is not high. As shown in Figure 9, the model demonstrates a higher error probability in predicting healthy samples than in predicting asymptomatic and diseased samples. This discrepancy may be attributed to the inadequate number of healthy samples utilized and the similarity of the surface symptoms between the asymptomatic and healthy samples. Therefore, if the model is improved further, expanding the sample size of the training set to increase the accuracy of the model would be beneficial.
3.4. Effects of Model Parameters and Preprocessing Methods on Model Performance
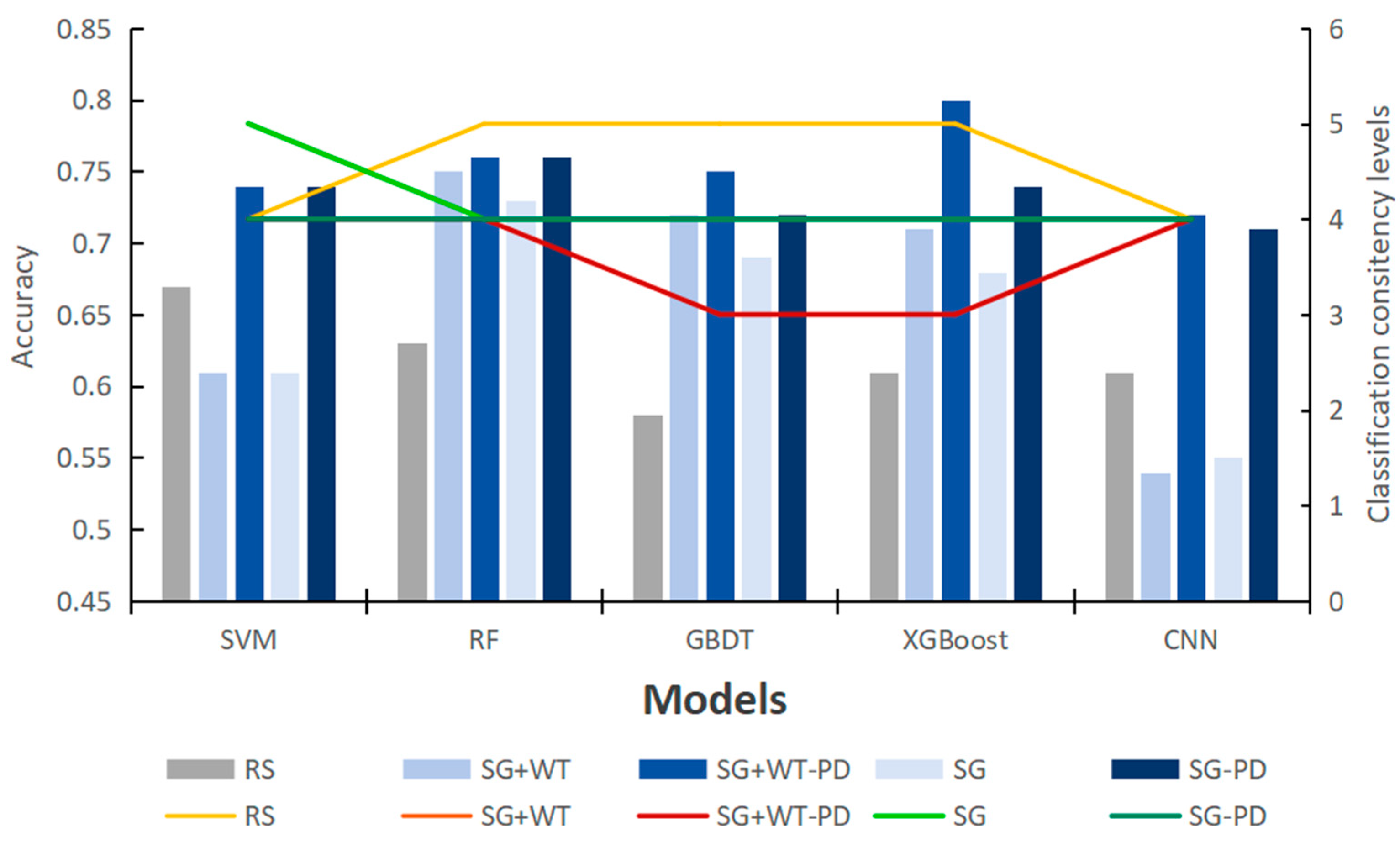
As shown in Figure 10, the accuracy of the SVM and CNN models decreases after preprocessing compared with the original data. However, after model tuning, the level of classification consistency is slightly improved, but the classification accuracy is significantly improved. However, preprocessing has a positive effect on the performance of the RF, GBDT and XGBoost models; their classification accuracy and classification consistency level are significantly improved, classification consistency is improved by one to two orders of magnitude, and accuracy is improved from 0.63 (RF), 0.58 (GBDT) and 0.63 (XGBoost) to between 0.68 and 0.80. However, after parameter tuning, their performance improvement is very weak compared with that of the SVM and CNN.
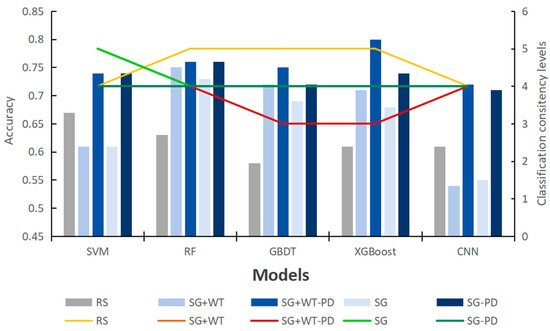
Figure 10.
Comparison of model accuracy and classification consistency before and after parameter adjustment.
Integrated learning models, SVMs, and CNNs exhibit significant differences in model performance and sensitivity to preprocessing methods, which is largely attributed to their unique workings and model structures. Integrated learning models improve the overall model accuracy and stability by combining the prediction results from multiple base learners. Its performance is highly dependent on the diversity and quality of the dataset, as the base learner needs to be trained and predicted on different subsets of data. Effective data preprocessing can significantly improve the distribution and feature relevance of the data, thus enhancing the generalization ability of the integrated learning model. However, if the preprocessing step is not performed properly, it may destroy the original information of the data or introduce noise, which in turn affects the performance of the model.
The SVM is a classifier that is based on interval maximization. However, in most cases, data points belonging to different categories are not clearly separated (it is also clear through Figure 5 of this paper that there is no significant difference in the distributions of healthy, asymptomatic, and diseased samples under different preprocessing methods). The SVM algorithm solves the problem of linear indivisibility in low-dimensional space by mapping the data to a high-dimensional space through the kernel function [42]. Therefore, the performance of SVM largely depends on its parameter settings, and by optimizing these parameters (e.g., regularization parameter C and kernel function parameter), SVM can be used to achieve better classification results on the training set, thus improving the classification accuracy of the model.
A CNN, on the other hand, is a deep learning model that automatically extracts high-level features from data through multilayer convolution and pooling operations. The performance of a CNN is affected by internal parameters such as the network architecture, optimizer selection, and learning rate [43]. In the field of deep learning, especially when the amount of training data is sufficient, excessive preprocessing may introduce the risk of overfitting or underfitting, as preprocessing may alter the original distribution of the data or eliminate subtle features useful for model classification. Lee et al. [44] classified Raman spectra obtained from extracellular vesicles (EVs), compared CNN modeling with raw data with baseline-corrected preprocessed data, and reported that the performance of the preprocessed model degraded, with the accuracy decreasing from 95.22% to 90.89%. The study attributes this to the fact that SNR small spectral features may be eliminated by background correction, which is retained in the raw data, and that this subtle information allows the CNN model to understand more details of the input signal, resulting in higher classification accuracy. Many of the preprocessing steps have a degree of arbitrariness, and the preprocessing may alter the original distribution or characteristics of the data, making it difficult for the model to capture valid information. Some preprocessing steps may destroy correlations or structural information between data, resulting in degraded model performance. The parameters or structure of the model may need to be adjusted to the preprocessed data but fail to do so in a timely or correct manner. These factors may also contribute to the degradation of model accuracy after preprocessing of SVM performance.
Therefore, when selecting preprocessing methods, trade-offs need to be made on the basis of the characteristics of the data and the needs of the model. For integrated learning models, preprocessing methods that can enhance the diversity and accuracy of the dataset should be prioritized; for SVMs, their parameters need to be carefully adjusted, and appropriate preprocessing steps should be considered to improve the data distribution; for deep learning models such as CNNs, preprocessing steps need to be carefully selected to avoid introducing the risk of overfitting or underfitting.
Overall, finding the optimal preprocessing methods and parameters is an iterative and comparative process, which may need to be combined with evaluation methods such as cross-validation to optimize model performance. Moreover, owing to the complexity of the spectral data acquisition environment and the weakness of the Raman effect, different experimental conditions and methods may lead to differences in the results; thus, the preprocessing methods and model parameters need to be flexibly adjusted according to the specific situation in practical applications.
4. Conclusions
This study successfully constructed a classification model for cork disease in ‘Akizuki’ pears using Raman spectroscopy data and explored the impact of preprocessing and model parameter selection on model performance. Through preprocessing and parameter tuning, the XGBoost model performed the best, achieving an accuracy, F1 score, and kappa coefficient of 0.80, 1.00, and 0.68, respectively, validating the effectiveness of Raman spectroscopy in detecting corky diseases. Among them, SG and SG+WT are the optimal preprocessing methods in this study, significantly enhancing model performance. The RF, GBDT, and XGBoost models are particularly sensitive to preprocessing, with accuracy improvements exceeding 10% through preprocessing. In contrast, the SVM and CNN models rely more on the selection of internal parameters, with accuracy improving by approximately 15% after parameter adjustments. Therefore, in practical applications, choosing appropriate optimization strategies based on the characteristics of the models is necessary.
These results indicate that the use of Raman technology for nondestructive testing of ‘Akizuki’ pear corky disease is feasible, providing a new approach for nondestructive testing. The focus of future work will be on further optimizing preprocessing and modeling methods to increase the accuracy and stability of the models, thereby providing strong support for the quality improvement and market competitiveness of the ‘Akizuki’ pear industry.
Author Contributions
Conceptualization, Y.Y. and H.Z.; methodology, L.L. (Li Liu) and X.J.; software, W.Y.; validation, X.Z., L.L. (Li Liu), and Z.Y.; formal analysis, X.T. and X.J.; investigation, J.X.; resources, L.L. (Lun Liu); data curation, W.H.; writing—original draft preparation, Y.Y. and W.Y.; writing—review and editing, L.L. (Li Liu); X.J. and H.Z.; visualization, B.J.; supervision, L.L. (Li Liu); project administration, L.L. (Li Liu); funding acquisition, L.L. (Li Liu). All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Modern Agriculture Industry Technology System Construction Special Project (CARS-28-14) and the Anhui Agricultural University Talent Project (rc322213).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in the study are included in the article, further inquiries can be directed to the corresponding author/s.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Li, D. New Japanese pear variety Akizuki. China Fruits 2005, 1, 54–64. [Google Scholar]
- Yu, X. Production technology of ‘Akizuki’ pear and high quality export fruit. Yantai Fruits 2010, 20, 21–22. [Google Scholar]
- Richardson, D.G.; Alani, A.M. Cork spot of d′anjou pear fruit relative to critical calcium concentration and other minerals. Acta Hortic. 1982, 124, 895–905. [Google Scholar]
- Facteau, T.J.; Cahn, H.; Mielke, E.A. Mineral concentrations in individual d′anjou pear fruit withand without cork spot. Food Qual. 2010, 23, 513–519. [Google Scholar] [CrossRef]
- Liu, J.; Cheng, Y.; Zhang, S.; He, Z.; Zhang, H. Study on Relationship between Browning Suberization Fruit and Mineral Nutrition of Early Crisp Pear. J. Fruit Resour. 2018, 2, 1–4. [Google Scholar]
- Cui, Z.; Jiao, Q.; Wang, R.; Ma, C. Investigation and analysis of relationship between mineral elements alteration and cork spot physiological disorder of Chinese pear ‘Chili’(Pyrus bretschneideri Rehd). Sci. Hortic. 2020, 260, 108883. [Google Scholar] [CrossRef]
- Zhang, X.; Cui, Z. Review of fruit cork spot disorder of Asian pear (Pyrus spp.). Front. Plant Sci. 2023, 14, 1211451. [Google Scholar] [CrossRef] [PubMed]
- Lorente, D.; Aleixos, N.; Gómez-Sanchis, J.; Cubero, S.; García-Navarrete, O.L.; Blasco, J. Recent Advances and Applications of Hyperspectral Imaging for Fruit and Vegetable Quality Assessment. Food Bioproc. Tech. 2012, 5, 1121–1142. [Google Scholar] [CrossRef]
- Xu, S.; Lu, H.; Qu, G.; Wang, C.; Liang, X. Research Progress and Application Status of FruitQuality Nondestructive Detection Technology. Guangdong Agric. Sci. 2020, 47, 229–236. [Google Scholar]
- Raman, C.V.; Krishnan, K.S. A new type of secondary radiation. Nature 1928, 121, 501–502. [Google Scholar] [CrossRef]
- Park, M.; Somborn, A.; Schlehuber, D.; Keuter, V.; Deerberg, G. Raman spectroscopy in crop quality assessment: Focusing on sensing secondary metabolites: A review. Hortic. Res. 2023, 10, uhad074. [Google Scholar] [CrossRef] [PubMed]
- Weng, S.; Hu, X.; Wang, J.; Tang, L.; Zhang, S.; Zhang, L.; Huang, L.; Xin, Z. Advanced application of Raman spectroscopy and surface-enhanced Raman spectroscopy in plant disease diagnostics: A review. J. Agric. Food Chem. 2021, 69, 2950–2964. [Google Scholar] [CrossRef] [PubMed]
- Xu, M.-L.; Gao, Y.; Han, X.-X.; Zhao, B. Detection of pesticide residues in food using surface-enhanced Raman spectroscopy: A review. J. Agric. Food Chem. 2017, 65, 6719–6726. [Google Scholar] [CrossRef] [PubMed]
- Sanchez, L.; Pant, S.; Mandadi, K.; Kurouski, D. Raman spectroscopy vs. quantitative polymerase chain reaction in early stage huanglongbing diagnostics. Sci. Rep. 2020, 10, 10101. [Google Scholar] [CrossRef]
- Baratto, C.; Ambrosio, G.; Faglia, G.; Turina, M. Early detection of esca disease in asymptomatic vines by Raman Spectroscopy. IEEE Sens. J. 2022, 22, 23286–23292. [Google Scholar] [CrossRef]
- Sanchez, L.; Ermolenkov, A.; Biswas, S.; Kurouski, D. Raman spectroscopy enables noninvasive and confirmatory diagnostics of salinity stresses, nitrogen, phosphorus, and potassium deficiencies in rice. Front. Plant Sci. 2020, 11, 573321. [Google Scholar] [CrossRef]
- Mandrile, L.; Rotunno, S.; Miozzi, L. Nondestructive Raman spectroscopy as a tool for early detection and discrimination of the infection of tomato plants by two economically important viruses. Anal. Chem. 2019, 91, 9025–9031. [Google Scholar] [CrossRef]
- Farber, C.; Mahnke, M.; Sanchez, L.; Kurouski, D. Advanced spectroscopic techniques for plant disease diagnostics. A review. TrAC-Trends Anal. Chem. 2019, 118, 43–49. [Google Scholar] [CrossRef]
- Zhang, B.; Rahman, M.A.; Liu, J.; Huang, J.; Yang, Q. Real-time detection and analysis of foodborne pathogens via machine learning based fiber-optic Raman sensor. Measurement 2023, 217, 113121. [Google Scholar] [CrossRef]
- Yan, S.; Wang, S.; Qiu, J.; Li, M.; Li, D.; Xu, D.; Li, D.; Liu, Q. Raman spectroscopy combined with machine learning for rapid detection of food-borne pathogens at the single-cell level. Talanta 2021, 226, 122195. [Google Scholar] [CrossRef]
- Zhao, H.; Zhan, Y.; Xu, Z.; Nduwamungu, J.J.; Zhou, Y.; Powers, R.; Xu, C. The application of machine-learning and Raman spectroscopy for the rapid detection of edible oils type and adulteration. Food Chem. 2022, 373, 131471. [Google Scholar] [CrossRef] [PubMed]
- Ralbovsky, N.M.; Lednev, I.K. Toward development of a novel universal medical diagnostic method: Raman spectroscopy and machine learning. Chem. Soc. Rev. 2020, 49, 7428–7453. [Google Scholar] [CrossRef] [PubMed]
- Sun, J.-H.; Zang, W.; Shi, J.-Q.; Li, Y. Selection and Application of Spectral Data Preprocessing Strategy. Acta Meteoro Sin. 2023, 44, 1284–1292. [Google Scholar]
- Bian, X.; Wang, Z.; Liu, W. Study on the selection of spectral preprocessing methods. Spectrosc. Spec. Anal. 2019, 39, 2800–2806. [Google Scholar]
- Zhao, N.; Wu, Z.; Cheng, Y.; Shi, X.; Qiao, Y. MDL and RMSEP assessment of spectral pretreatments by adding different noises in calibration/validation datasets. Spectrochim. Acta A 2016, 163, 20–27. [Google Scholar] [CrossRef] [PubMed]
- Jiao, Y.; Li, Z.; Chen, X.; Fei, S. Preprocessing methods for near-infrared spectrum calibration. J. Chemom. 2020, 34, e3306. [Google Scholar] [CrossRef]
- Wahab, M.F.; O’Haver, T.C. Wavelet transforms in separation science for denoising and peak overlap detection. J. Sep. Sc. 2020, 43, 1998–2010. [Google Scholar] [CrossRef]
- Zhang, J.; Liu, L.; Chen, Y.; Rao, Y.; Zhang, X.; Jin, X. The nondestructive model of Near-Infrared Spectroscopy with different pretreatment transformation for predicting “Dangshan” pear woolliness disease. Agronomy 2023, 13, 1420. [Google Scholar] [CrossRef]
- Kennard, R.W.; Stone, L.A. Computer aided design of experiments. Technometrics 1969, 11, 137–148. [Google Scholar] [CrossRef]
- Qi, Y.; Hu, D.; Jiang, Y.; Wu, Z.; Zheng, M.; Chen, E.X.; Liang, Y.; Sadi, M.A.; Zhang, K.; Chen, Y.P. Recent progresses in machine learning assisted Raman spectroscopy. Adv. Opt. Mater. 2023, 11, 2203104. [Google Scholar] [CrossRef]
- Wang, S.; Chuan, S.F.; Yu, L.; Yang, L. MATLAB Neural Networks 43 Case Studies; Beihang University Press: Beijing, China, 2013. [Google Scholar]
- Liu, L.; Zhang, H.; Wu, L.; Gu, S.; Xu, J.; Jia, B.; Ye, Z.; Hen, W.; Jin, X. An early asymptomatic diagnosis method for cork spot disorder in ‘Akizuki’ pear (Pyrus pyrifolia Nakai) using micro near infrared spectroscopy. Food Chem. X 2023, 19, 100851. [Google Scholar] [CrossRef] [PubMed]
- Wang, X. Research on forestland classification based on random forest algorithm. For. Sci. Technol. 2021, 46, 34–37. [Google Scholar]
- Li, T.; Wang, J.; Tu, M.; Zhang, Y.; Yan, Y. Enhancing link prediction using gradient boosting features. In Proceedings of the Intelligent Computing Theories and Application: 12th International Conference, ICIC 2016, Lanzhou, China, 2–5 August 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 81–92, Part II 12. [Google Scholar]
- Hu, J.; Zou, Y.; Sun, B.; Yu, X.; Shang, Z.; Huang, J.; Shang Zhong, J.; Liang, P. Raman spectrum classification based on transfer learning by a convolutional neural network: Application to pesticide detection. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2022, 265, 120366. [Google Scholar] [CrossRef] [PubMed]
- Vujović, Ž. Classification model evaluation metrics. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 599–606. [Google Scholar] [CrossRef]
- Foody, G.M. Explaining the unsuitability of the kappa coefficient in the assessment and comparison of the accuracy of thematic maps obtained by image classification. Remote Sens. Environ. 2020, 239, 111630. [Google Scholar] [CrossRef]
- Pan, T.-T.; Pu, H.; Sun, D.-W. Insights into the changes in chemical compositions of the cell wall of pear fruit infected by Alternaria alternata with confocal Raman microspectroscopy. Postharvest Biol. Technol. 2017, 132, 119–129. [Google Scholar] [CrossRef]
- Fang, S.; Zhao, Y.; Wang, Y.; Li, J.; Zhu, F.; Yu, K. Surface-enhanced Raman scattering spectroscopy combined with chemical imaging analysis for detecting apple Valsa canker at an early stage. Front. Plant Sci. 2022, 13, 802761. [Google Scholar] [CrossRef]
- Beć, K.B.; Grabska, J.; Bonn, G.K.; Popp, M.; Huck, C.W. Principles and applications of vibrational spectroscopic imaging in plant science: A review. Front. Plant Sci. 2020, 11, 1226. [Google Scholar] [CrossRef]
- Beattie, J.R.; Esmonde-White, F.W.L. Exploration of principal component analysis: Deriving principal component analysis visually using spectra. Appl. Spectrosc. 2021, 75, 361–375. [Google Scholar] [CrossRef]
- Aljarah, I.; Al-Zoubi, A.M.; Faris, H.; Hassonah, M.A.; Mirjalili, S.; Saadeh, H. Simultaneous feature selection and support vector machine optimization using the grasshopper optimization algorithm. Cogn. Comput. 2018, 10, 478–495. [Google Scholar] [CrossRef]
- Poojary, R.; Pai, A. Comparative study of model optimization techniques in fine-tuned CNN models. In Proceedings of the 2019 International Conference on Electrical and Computing Technologies and Applications (ICECTA), Ras Al Khaimah, United Arab Emirates, 19–21 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–4. [Google Scholar]
- Lee, W.; Lenferink, A.T.; Otto, C.; Offerhaus, H.L. Classifying Raman spectra of extracellular vesicles based on convolutional neural networks for prostate cancer detection. J. Raman Spectrosc. 2020, 51, 293–300. [Google Scholar] [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).