Abstract
Visually Impaired Persons (VIPs) have difficulty in recognizing vehicles used for navigation. Additionally, they may not be able to identify the bus to their desired destination. However, the bus bay in which the designated bus stops has not been analyzed in the existing literature. Thus, a guidance system for VIPs that identifies the correct bus for transportation is presented in this paper. Initially, speech data indicating the VIP’s destination are pre-processed and converted to text. Next, utilizing the Arctan Gradient-activated Recurrent Neural Network (ArcGRNN) model, the number of bays at the location is detected with the help of a Global Positioning System (GPS), input text, and bay location details. Then, the optimal bay is chosen from the detected bays by utilizing the Experienced Perturbed Bacteria Foraging Triangular Optimization Algorithm (EPBFTOA), and an image of the selected bay is captured and pre-processed. Next, the bus is identified utilizing a You Only Look Once (YOLO) series model. Utilizing the Sub-pixel Shuffling Convoluted Encoder–ArcGRNN Decoder (SSCEAD) framework, the text is detected and segmented for the buses identified in the image. From the segmented output, the text is extracted, based on the destination and route of the bus. Finally, regarding the similarity value with respect to the VIP’s destination, a decision is made utilizing the Multi-characteristic Non-linear S-Curve-Fuzzy Rule (MNC-FR). This decision informs the bus conductor about the VIP, such that the bus can be stopped appropriately to pick them up. During testing, the proposed system selected the optimal bay in 247,891 ms, which led to deciding the bus stop for the VIP with a fuzzification time of 34,197 ms. Thus, the proposed model exhibits superior performance over those utilized in prevailing works.
1. Introduction
The World Health Organization has stated that there are approximately 290 million VIPs worldwide. Self-navigation is a major issue for these individuals in society [1]. VIPs depend on others to accomplish daily tasks, due to their inability to recognize objects, and have difficulty in locating transport services and bus stations [2]. Primarily, research has focused on detecting obstacles to enable safer movement of VIPs. To inform VIPs about the type of obstacle, its distance from the person, and its position, these objects can be detected using deep learning techniques [3].
Through utilizing a transfer learning technique, various objects can be detected in real time [4]. However, to ensure the safety of VIPs, it is necessary to detect moving objects near them. Thus, to alert users, a voice-assisted smart stick has been designed using Radio Frequency Identification (RFID) technology and ultrasonic sensors [5]. Utilizing OpenStreetMap and the General Transit Feed Specification (GTFS), a multi-modal route planning system has been developed to guide VIPs [6]. After planning routes, the safer navigation of VIPs is ensured through the utilization of a Web-Based Application (WBA). The object information is forwarded to the MobileNet architecture by the WBA camera. Regarding objects, MobileNet produces audio messages via a speech module [7]. In this way, the user can recognize obstacles, including vehicles, shopping stores, and traffic signals, using a deep attention network [8].
To date, various wearable devices based on GPS have been developed to facilitate access to public transport [9,10]. VIPs can be informed about the current location and arrival of buses through an Application Interface (API) and learned database of the device [11]. Generally, bus detection systems are constructed with microcontrollers, RF modules, sensors, and Bluetooth [12]. Utilizing the BlindMobi app, bus travel in urban centers is made easier for VIPs [13]. A VIP at a bus station can be recognized by the corresponding bus driver via the user’s RFID tag [14]. The data from such a tag are forwarded to an RFID reader and alerts the bus driver about the person’s destination via voice messages [15]. However, no study in the existing literature has concentrated on guiding VIPs at a bus station which contains multiple bus lines. Thus, this study proposes an optimal bay selection method using the EPBFTOA approach, enabling VIPs to better access bus transport.
Problem Statement
The problems noticed in prevailing works are described below:
- -
- A bus station containing more than one bus line is not considered in most of the prevailing works, thus causing difficulty for VIPs in recognizing the relevant bus line.
- -
- The route information accessed from a single source is inefficient for VIPs who are making journeys.
- -
- The VIP still needs human guidance to identify bus routes and bus numbers, or they need to enquire of bus coordinators.
- -
- When there is a larger queue of buses at the bus station, it is difficult for VIPs to identify the correct bus, especially when the desired bus is farther away.
- -
- The conversion of the VIP’s voice data can be affected by the presence of background noise, resulting in the wrong information being attained.
- -
- In some existing works, computer vision has been used to capture the user’s surroundings for identification of buses. However, this approach is inefficient when nearby buses are not the appropriate transport for VIPs.
- -
- Main goal: The main goal of the proposed study is to detect and select the optimal bay, as per the visually impaired person’s query, in order to promote the accessibility of bus transport. Through selection of the optimal bay, the difficulties and obstacles faced by the VIP regarding the determination of the location of the desired bus in the bus station are mitigated. Thus, based on the recognition of the optimal bay, bus transportation becomes more efficient for the visually impaired. The major contributions or objectives of the proposed transportation system for the visually challenged are further mentioned.
The proposed work’s main objectives are as follows:
- -
- The optimal bay among the detected bus bays is selected using the EPBFTOA method, in order to recognize the appropriate bus line in the bus station.
- -
- To access the correct bus, information from multiple sources is obtained, including the GPS location, voice data, bus image, and bus route.
- -
- To minimize the need for human guidance, the VIP’s speech data are acquired using an Internet of Things (IoT) application via a mobile device to retrieve the details of the desired bus.
- -
- The VIPs face difficulty in reaching the correct bus among the large queue of buses. Thus, an RFID sensor is utilized to inform the respective bus drivers who should carry the VIP.
- -
- To retrieve correct information from the VIP, their voice data are pre-processed with the Mean Cross-Covariance Spectral Subtraction (MCC-SS) approach in order to remove background noise.
- -
- Utilizing the SSCEAD method, the text is segmented from the bus, and the Levenshtein Distance (LD) measure is used to determine the route similarity.
2. Literature Survey
Authors [16] proposed a technique named ‘My Vision’, which enables VIPs to identify bus route numbers. Through the Lucas–Kanade tracker of My Vision images, the arriving bus is captured. Next, the bus board area is acquired utilizing the Random Forest (RF) technique. Moreover, the route number is extracted utilizing the pattern-matching approach. In addition, the detection rate of the proposed method was enhanced, when compared to traditional techniques. However, the relationships among features could not be evaluated by RF, potentially resulting in the inaccurate detection of bus route numbers.
Authors [17] recommended a navigation system for VIPs in a multi-obstacle scenario. Through a query processor, the person’s query was accessed. The YOLO version 3 (YOLOv3) model is used to detect various obstacles, and the optimal path is selected utilizing the Environment-aware Bald Eagle Search algorithm. The performance was improved regarding latency and detection accuracy; however, the Actor–critic algorithm utilized for navigation decisions led to trade-offs, and the decisions made were not reliable.
Authors [18] established a wearable device for the safe traveling of VIPs. The bus is detected utilizing the YOLOv3 technique, and the bus board is segmented with a transfer learning technique. Next, the bus number obtained is transformed into a voice. The bus board detection accuracy was improved over prevailing techniques; however, smaller objects could not be recognized by the anchor box of YOLOv3, thus limiting the efficiency.
Authors [19] explored a device to assist in the navigation of blind persons. The user is informed to make a decision regarding the safer path through the use of a speech generation device. The Robot Operating System minimized the occurrence of distractions. Next, through a Fuzzy logic system, the safe directions are issued to the VIP. When compared to other approaches, the recommended device attained a lower collision rate; however, the Fuzzy rules were simply developed based on assumptions, and thus, an accurate decision was not produced.
Authors [20] suggested a smart glass system for the independent movement of blind persons at night-time. To detect the object accurately using the U2-Net model, the path image is pre-processed and represented as a tactile graph. Moreover, the text in the image is converted to speech. When compared to other networks, this model detected objects with higher accuracy and precision; however, the Tesseract model could not effectively extract text from low-quality and poorly lit images.
Authors [21] proposed a Commute Booster (CB) mobile application for the navigation support of blind persons. From the GTFS dataset, way-finding footage is obtained. Next, the Optimal Character Recognition (OCR) system is utilized to enable VIPs to identify the relevant path. When compared to prevailing techniques, the performance of the presented approach was improved, regarding precision, accuracy, and f1-score; however, the OCR could not process image data in different formats.
Authors [22] presented a lightweight bus detection approach for VIPs utilizing the YOLO network. To detect buses in real-time, the structure of YOLO is modified with a slim scale detection module. This model detected the bus with higher accuracy and precision; however, the bus detection performance was non-optimal, as the YOLO model was processed with fewer parameters.
Authors [23] proposed a framework named ‘Vision Navigator’ for the blind and VIPs utilizing a Recurrent Neural Network (RNN). To detect the presence of an object in the path, a stick utilizing the single-shot mechanism is created. Moreover, obstacles within shorter distances are detected via sensor-equipped lightweight shoes. The developed framework could detect obstacles with a high accuracy rate; however, the RNN did not learn complex data patterns due to the gradient vanishing problem, which degraded the framework’s efficiency.
Authors [24] established a mobile application for VIPs to identify bus stops. The bus stop signs were detected through a mobile camera with the All-Aboard Application (AAA) utilizing a neural network. The VIP can assess a bus stop within a distance of 30 to 50 m via AAA. Regarding the distance between actual bus stop locations and the indicated location, the performance was analyzed. However, for accurate detection, the application needed a large number of labeled data and high-quality images.
Authors [25] explored a wearable device to assist VIPs in navigation. The device was developed for use with a camera embedded on a smartphone or eyeglasses. Utilizing a Convolutional Neural Network (CNN), the object detection system was developed and deployed in the smart phone. The performance was evaluated regarding its efficiency and safety. However, its capacity for object detection was limited by the usage of a CNN, as it could not efficiently learn sequential data.
The related works are comparatively summarized in Table 1.

Table 1.
Comparative summary of related works.
3. Proposed Methodology
Using the MNC-FR and EPBFTOA methods, the proposed model comprises a transportation system that better enables VIPs to travel by bus. First, the bus bays are detected, and an image is captured from the optimal bay. Then, the text on buses is extracted from the captured image, in order to determine their destinations. Finally, a decision is made, and the VIP and bus conductor are consequently informed. Figure 1 depicts the proposed model’s architecture.
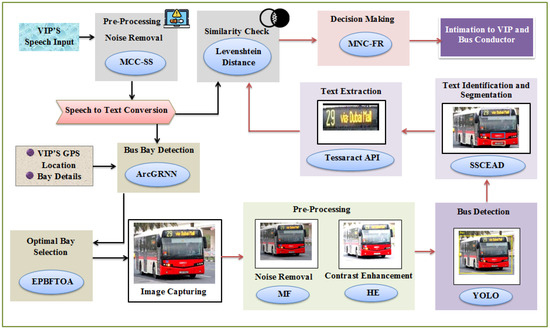
Figure 1.
Framework of the proposed model.
3.1. Speech Input
Initially, through utilizing an IoT application, the destination details of the VIP are gathered in the form of speech from their mobile device. Let the input speech be signified as
where the number of input words is denoted as . The input is then pre-processed as follows.
3.2. Speech Pre-Processing
Next, employing the MCC-SS method, the voice data are pre-processed to remove the background noise. To obtain a clean speech signal, Spectral Subtraction (SS) is used, which subtracts the noise spectrum present in the original audio. Nevertheless, fixed parameters that do not adapt to the noise level in the input are utilized as a subtraction factor. To mitigate this issue, the Mean Cross-Covariance (MCC), which analyzes each signal of the input, is employed to determine the subtraction parameter. The MCC-SS process is described as follows:
The cross-covariance between signals present in the speech input is computed as
where the mean value of is denoted as . The value , which is the obtained subtraction factor, is utilized to remove the input’s background noise. It is calculated as
where the pre-processed audio is signified as .
3.3. Speech-to-Text Conversion
The pre-processed speech is additionally converted into the text format, in order to obtain the VIP’s destination and detect the bus bay in the road traffic. The text format is also employed to check the similarity between the VIP’s bus destination and bus route. Let the text converted from speech be denoted as .
3.4. Bus Bay Detection
Utilizing ArcGRNN, the number of bus bays for the VIP is detected. The inputs employed for detecting the bus bays are as follows:
- -
- The VIP’s destination , in the form of text.
- -
- The VIP’s location , based on GPS.
- -
- Bay details concerning numerous locations, obtained from the cloud database.
An RNN, which can handle inputs of varying lengths and provides an output ranging from single- to multi-class classification, was utilized for bus bay detection. Even though the RNN can process memory and binary data, the vanishing and exploding gradient problems may occur during the backpropagation process. Therefore, to prevent this issue, the Arctan Gradient Activation Function (Arc-GAF), which automatically enlarges small inputs and blocks large inputs, was used as an activation function in the RNN. Figure 2 illustrates the framework of ArcGRNN.
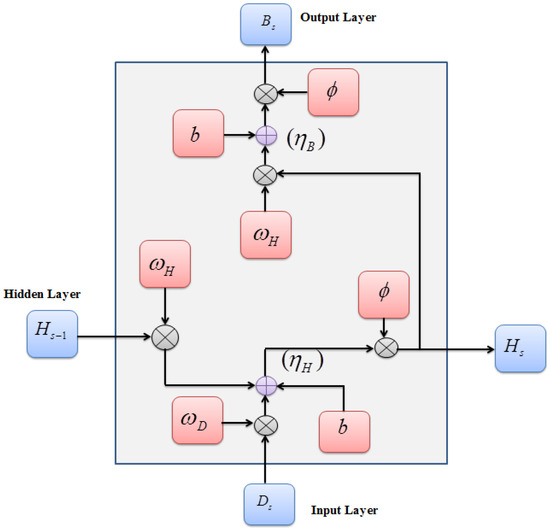
Figure 2.
Architecture of ArcGRNN.
The ArcGRNN process is described as follows:
- -
- Input Layer
The inputs required for the detection of bus bays are combined as follows:
where the VIP’s location is denoted as , which is employed to identify the number of bays present in the specified location. From the cloud database, the bay details of various locations are obtained. The input concerning time is passed to the hidden layer for further processing.
- -
- Hidden Layer
The hidden layer collects the information from the previous output and computes the input along with the activation function. The designed hidden layer’s input is given by
where the hidden layer’s previous output concerning time is signified as , are the weights of the input and hidden layers, respectively, and the bias value is denoted as .
Next, utilizing Arc-GAF, the computed value of the hidden state is activated. The Arc-GAF takes in the required input to avoid the gradient-related issues of RNNs. The Arc-GAF activation function is given by
where the parameters of the input are denoted as . Then, the hidden layer’s output is calculated as follows:
The output is further passed on to the output layer to obtain the final classification output.
- -
- Output layer
Regarding and the weight of the hidden layer, the output layer is computed as follows:
Utilizing , the value is activated to give the final output , as follows:
where are the detected bays for the respective VIP, and the number of detected bays is denoted as . The pseudocode for the ArcGRNN model is given below as Algorithm 1:
| Algorithm 1 Pseudocode for ArcGRNN |
| Input: VIP’s destination , location , bay details Output: Detected bay Begin Initialize parameters , For While input Calculate Hidden layer input Evaluate activation function Hidden layer output Vectorize output layer’s input Find final output End while End for Obtain detected bays End |
Next, optimal bays are chosen from the detected bus bays , as described below.
3.5. Optimal Bay Selection
Subsequently, utilizing EPBFTOA, the optimal bay is chosen from the detected bays . The optimal bay is the bay line of the bus station, which should be utilized by the VIP to catch the desired bus. In this context, for optimal bay selection, the Bacteria Foraging Optimization Algorithm (BFOA), which mimics the foraging strategy of bacteria to select the best value, is utilized. Nevertheless, BFOA may suffer from premature convergence, thereby affecting the outcome of the optimizer. To solve this issue, the Experienced Perturbed Adaptive Search (EPAS) mechanism with Triangular Mutation is utilized in BFOA, which computes health and reproduction parameters for the bacteria to overcome the abovementioned premature convergence problem.
The EPBFTOA is explained below:
- -
- Initialization
The detected bays , which are considered as bacteria, are the search agents. There are number of bacteria to search the nutrients (number of bays). The bacterium’s position is initialized as follows:
where is the bacteria’s position concerning the chemotaxis , is the reproduction value, and is the elimination dispersal step parameters.
- -
- Fitness
Concerning the minimum distance between bacteria and nutrients, the fitness value that is employed to obtain the optimal bay is computed. The fitness function is defined as
The EPBFTOA encompasses four foraging strategies; namely, chemotaxis, swarming, reproduction, and elimination and dispersal.
- -
- Chemotaxis
In this strategy, a bacterium chooses a favorable environment by swimming and tumbling. The bacterium’s movement concerning the swimming step and swimming direction is given by
where the number of swimming steps taken by the bacteria is signified as .
- -
- Swarming
The bacteria’s swarming behavior after chemotaxis is centered on the attraction and repulsion of the bacteria, defined by
where the depth and width regarding bacterial attraction are denoted as , and are the depth and width regarding bacterial repulsion.
The bacteria’s new position regarding swarming is given by
- -
- Reproduction
In this strategy, healthier bacteria are located to attain better optimization outcomes. Initially, centered on EPAS, the healthier bacteria are computed. Regarding the fitness function, the best bacteria are identified by the EPAS as follows:
where the mean and deviation of the healthier bacteria with random values are denoted as . Next, the reproduction value is obtained by Triangular Mutation, which gives the output concerning the best , the worst , and better bacteria, as follows:
where the mutation factors of the bacteria are signified as .
- -
- Elimination and Dispersal
After reproduction, the bacteria with lower probability dies and provide their optimal solution, with respect to their random dispersion and probability , as follows:
Thus, through using the EPBFTOA approach, the optimal bus bay value is obtained. The pseudocode for this optimizer is given below in Algorithm 2.
| Algorithm 2 Pseudocode for EPBFTOA |
| Input: Detected Bay Output: Optimal Bus Bay |
| Begin Initialize bacteria population , Iteration , Calculate fitness While For Move bacteria by chemotaxis Swarm bacteria Reproduce bacteria Eliminate and disperse If Optimal bus bay Else Original position End if End for End while Return optimal bus bay End |
After the selection of the optimal bay , the image is captured using the mobile device of the VIP. Then, the image is pre-processed as detailed below.
3.6. Image Capturing and Preprocessing
From the optimal bay , bus images are captured. These are then pre-processed for noise removal and contrast enhancement. Let the number of images captured via the mobile device of VIPs be represented as
In this way, unwanted artifacts are removed and the quality of the image is enhanced to make further processing more effective. The pre-processing of is described below.
3.6.1. Step 1: Noise Removal
Due to noises such as salt and pepper and speckle noise, the quality of the image is affected. Therefore, the Median Filter (MF)—which eliminates noisy pixels—is utilized for the removal of noise from the image , which is calculated as follows:
where the coordinates of pixels in the image are denoted as , and the noise-removed image, which is used for subsequent contrast enhancement, is denoted as .
3.6.2. Step 2: Contrast Enhancement
Histogram Equalization (HE), which adjusts the contrast using the image’s histogram, is used to make the image clearer for further processing. The HE is elaborated as follows:
Regarding histogram values such as the pixel value and number of pixels in the image , the probability of occurrence is given by
where the number of pixels regarding is denoted as , and the total grayscale value of is denoted as . Then, the cumulative distribution function is computed as:
Finally, the image’s contrast is improved as follows:
The contrast-enhanced image is the pre-processed image, and the bus present in this image is detected as explained below.
3.7. Bus Detection
Through employing a YOLO series model, buses are detected in the pre-processed image . The YOLO model splits the images into grids and detects objects concerning the bounding boxes of the grids. The YOLO model’s process is explained in the following.
Initially, the image is split into a grid pattern. These grids have a number of bounding boxes , which are signified as:
Each bounding box, with height , width , and coordinates is denoted as:
The bounding boxes might overlap each other, and therefore, the degree of overlap concerning bounding boxes is computed as:
Finally, utilizing and , the objects can be detected, which are given as:
A bus detected in the image is symbolized as and from this, the text is identified and segmented for further analysis.
3.8. Text Identification and Segmentation
Next, for identification of the destination of the bus, the text present in the detected bus image is identified and segmented. For this purpose, Encoder–Decoder (ED) processing is carried out. In this process, a CNN, which analyzes each input accurately, is utilized for encoding. To enhance the learning ability of the CNN, the Sub-pixel Shuffling Convolution (SSC) strategy is used in the convolution layer, thus expanding the receptive field of the CNN. A Bidirectional Long Short-Term Memory (BiLSTM) model is typically used as a decoder in the ED process; however, text identification becomes difficult, as BiLSTM models have high complexity. Thus, to enhance the text identification and segmentation effect, ArcGRNN is used as the decoder in this study. The SSCEAD process is elaborated further in the following.
- -
- Encoder
Utilizing the Sub-pixel Shuffling Convolution Encoder (SSCE), the text is first recognized in the image . Initially, the pixels of the input image are reshuffled in the convolutional layer of the CNN using SSC. Then, the encoder process is executed for the reshuffled image. The image that is obtained using SSC, with an up-sampling factor , is given as
Then, regarding the image and the Rectified Linear Unit (ReLU) activation function , the convolutional layer’s output is calculated as
where the coordinates of the image are , the weight value is denoted as , and the bias value of the image is signified as . The value is max-pooled and fully connected to give the encoded output :
where the text-detected image is denoted as . This image is then decoded as follows:
- -
- Decoder
In order to determine the destination of the bus, the text-identified image is decoded. The ArcGRNN decoder methodology, which processes the input concerning the prior information, enlarges the input size and blocks the large input (note that the process of the ArcGRNN technique is explained in Section 3.4). The image is processed via the hidden and output layers, along with Arc-GAF. The text-segmented image , which represents the bus destination, is the obtained output. Subsequently, the text is extracted from as detailed below.
3.9. Text Extraction
Next, regarding the bus destination image , the bus route is identified utilizing the Tesseract API, which is an OCR model. In this model, the text is extracted automatically from . Initially, the fixed pitch of the text present in the image is found. After that, the characters are split into words and are automatically recognized and extracted in text form for the fixed pitch. Let the extracted text be signified as , which is the destination of the bus in text form. Therefore, with respect to the bus route details obtained from the cloud database, the bus route is identified from . Subsequently, to make the decision command for transportation, the similarity between the VIP’s destination and the route and destination of the bus is checked.
3.10. Similarity Check
Next, the similarity analysis between the bus destination , bus route , and VIP’s destination is performed. For similarity analysis, the LD, which measures the similarity between two parameters, is used. First, the similarity between and is checked as follows. Let the length of be and length of be . Then, the similarity between and is calculated as
Equation (37) states that the similarity value becomes higher when the length of the destinations is similar. In addition, if there are changes in lengths, then the minimum conditions are followed to obtain the similarity score. If is high, this similarity value is used for decision-making. Otherwise, the similarity between and is checked further:
Here, the length of the words present in the bus route is denoted as . The similarity value is finally given for decision-making, as detailed below.
3.11. Decision-Making
Finally, regarding the similarity score between the VIP destination and the bus destination , as well as the similarity score between the bus route and the VIP destination , the decision is made to inform both the VIP and the bus conductor. In this context, the Fuzzy Rule (FR), which is used to analyze the input parameters efficiently, is utilized for decision-making. However, a probability measure that might make the output value zero is utilized in the Fuzzy logic approach. Therefore, a solution in decision-making may not be attained with the FR. Therefore, to mitigate this issue, a Multi-characteristic Index (MI) that gives non-zero output in Fuzzy logic is employed to compute the Fuzzy relationship. In addition, the Non-linear S-Curve (NC) membership function, which explains the certainty of the Fuzzy inputs, is used rather than the Fuzzy membership function. The MNC-FR approach is described further below.
- -
- Rule
Initially, based on the if–then condition, the rules are set for the decision-making as follows:
where the decision-making factor is denoted as and the non-decision factor is signified as . The rule states that the decision to inform the VIP and the bus conductor is made when the similarity scores are high; otherwise, no decision is made. The image capturing process continues until a high similarity is obtained.
- -
- Membership Function
The NC membership function is used to change the output value automatically, concerning the input data. To find the degree of relationship to the input parameter, the NC membership function is used. Therefore, is calculated as
where the scaling parameters of the input are denoted as , and the constant values are signified as . According to Equation (40), the membership function values are obtained in the range of 0 to 1 regarding the scaling parameter conditions.
- -
- Fuzzification
In this step, the input data are converted to Fuzzy data , such that the FR methodology can be used to enable further processing. Let the inputs and be combined and represented by . The fuzzification is then performed as follows:
- -
- Fuzzy Relationship
To make the final decision, the relationship between the Fuzzy data is determined. To calculate the Fuzzy relationship, the MI that gives the optimal decision accurately is used, which is given as
where the final decision obtained using the MNC-FR methodology is denoted as . These data are then converted back into crisp data.
- -
- Defuzzification
For the purpose of intimation, the data are converted into measurement data as follows:
Hence, the decision is made from to guide the VIP onto the designated bus through giving information to the VIP through an RFID signal. Simultaneously, it also informs the bus conductor when to stop the bus, taking the VIP’s current location into consideration. Therefore, an enhanced transportation system for the VIP to travel by bus can be designed through the utilization of the proposed methodology. In Section 4, the performance analysis of the proposed approach is detailed.
4. Results and Discussions
The performance of the proposed model was evaluated by comparing it with existing approaches. The proposed work was implemented using the PYTHON 3.11 software in order to analyze the performance.
4.1. Dataset Description
Bus identification was performed utilizing the data in a public bus transport dataset regarding Dubai Bus Transportation. The dataset contains the route ID, trip ID, stop ID, bus stop name, and number of boardings data. By utilizing the Geospatial Bus Route Analysis (GBRA) dataset, the bus route similarity based on the speech requirements of VIPs was determined. In the GBRA dataset, the Bus Route Transit (BRT) route details, non-BRT route details, route type, route description, and bus stop names are present. Moreover, the proposed model was validated utilizing the Microsoft Common Objects in Context (MS-COCO) dataset. This dataset consists of 328,000 images in more than 80 object categories. From all these datasets, the data were split with a ratio of 70:20:10 for training, testing, and validation of the proposed model, respectively.
Table 2 displays the obtained results for the captured bus images, noise-removed images, contrast-enhanced images, and text-segmented images using the proposed bus identification method.
Table 2.
Image outcomes of the proposed technique.
4.2. Performance Assessment
The proposed system’s performance was examined with respect to optimal bay selection, decision-making, text detection, and similarity between the bus route and voice data of the VIPs. Through comparing the proposed method with state-of-the-art algorithms including BFOA, Manta Ray Foraging Optimization (MRFO), African Vultures Optimization Algorithm (AVOA), and Bald Eagle Search Optimization (BESO), the time taken to select the optimal bay and fitness over iteration were evaluated.
Table 3 analyzes the time and fitness metrics of the proposed technique. In order to select the optimal bay, the proposed EPBFTOA took 247,891 ms, less than that of the prevailing techniques; in particular, for optimal bay selection, the BFOA, MRFO, AVOA, and BESO approaches took 389,124 ms, 596,757 ms, 804,628 ms, and 997,245 ms, respectively. The proposed algorithm selected the optimal bay within a minimum duration as the proposed algorithm compensates for the premature convergence problem in the selection process. When compared to the prevailing algorithms, the average fitness (9.068) attained by the proposed algorithm was lower, indicating the proposed EPBFTOA technique had enhanced performance in selecting the optimal bay.
Table 3.
Performance analysis of the proposed optimal bay selection method.
Figure 3 represents the performance of decision-making to reach the relevant bus for the VIP using the proposed MNC-FR technique. It can be observed that the MNC-FR technique performed fuzzification within 34,197 ms and de-fuzzification in 31,073 ms, and thus, generated the decision rule within 79,932 ms. When compared to prevailing techniques such as the FR, Trapezoidal Fuzzy Rule (Tp-FR), Triangular Fuzzy Rule (Tr-FR), and Decision Rule (DR), the decision time of the proposed technique was shorter. The proposed MNC-FR takes less time to determine the relevant bus as the similarity between the bus route and voice data is analyzed before generating a decision.
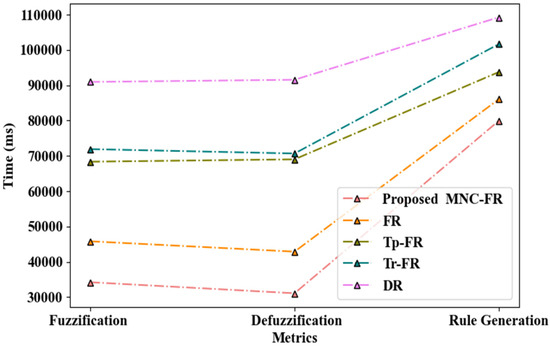
Figure 3.
Graphical representation of the proposed decision generation approach.
Figure 4 illustrates the proposed model’s performance in detecting the desired bus in comparison with the existing models. Regarding its accuracy, precision, recall, and f-measure, the proposed technique’s performance was analyzed in comparison with other techniques including the RNN, Long Short-Term Memory (LSTM), Deep Neural Network (DNN), and Artificial Neural Network (ANN) models. The proposed system detected bus bays with 96.932% accuracy, 95.872% precision, 96.328% recall, and 95.363% f-measure, which were all higher when compared to those of conventional network models. In particular, the average accuracy, precision, recall, and f-measure attained by the prevailing techniques were 92.743%, 92.294%, 92.891%, and 93.016%. The ArcGRNN model effectively detected the bay, as it was detected based on the GPS location and cloud database.
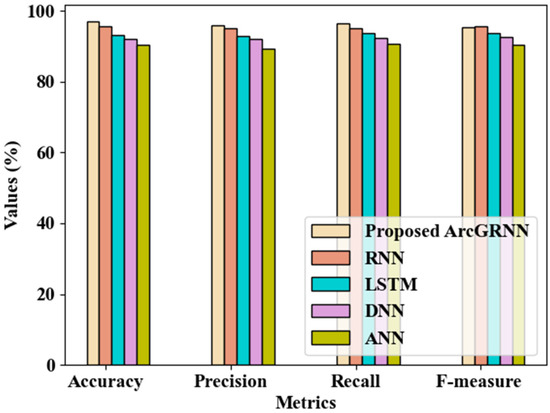
Figure 4.
Comparison of the proposed bus bay detection method with existing methods.
Table 4 details the bus bay detection performance with respect to specificity, sensitivity, and processing time. It can be observed that the proposed approach achieved 95.714% specificity and 96.328% sensitivity, which are higher compared to those of the prevailing networks. In particular, the detection performance of the proposed model was enhanced due to the mitigation of the gradient vanishing problem. Moreover, the proposed model carried out processing within a much shorter time (174,405 ms), when compared to the average time taken by the existing models (505,242 ms). This indicates that the bus bay is efficiently identified by the proposed network.
Table 4.
Performance of bus bay detection.
As specified in Figure 5, the bus bay detection performance was evaluated according to the False Positive Rate (FPR) and False Negative Rate (FNR). The ArcGRNN can properly detect the bus bay, as the person’s voice data are pre-processed and converted to text before detection. It can be seen that the proposed technique achieved an FPR and FNR of 0.0652% and 0.0529%, respectively, while the prevailing networks achieved an average FPR and FNR of 0.0820% and 0.0811%, respectively, higher than the proposed technique. This demonstrates that the performance of the proposed technique in terms of bus bay detection was improved, when compared to traditional approaches.
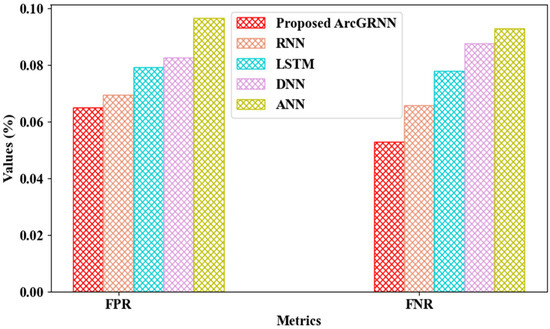
Figure 5.
Graphical analysis of FPR and FNR for bus bay detection.
In Table 5, the performance of the proposed method for bus bay detection is detailed, regarding the obtained Positive Predictive Value (PPV) and Negative Predictive Value (NPV). As the speech data are preprocessed for noise removal and converted to text prior to data training, the learning efficiency of the model is improved. Further, tackling the gradient vanishing issue through the use of the Arctan Gradient activation function aids in improving the detection performance, leading to a PPV of 96.74% and an NPV of 95.83%. For comparison, the existing RNN and LSTM attained PPVs of 94.20% and 93.41%, respectively. Furthermore, the existing DNN and ANN attained NPVs of 91.37% and 89.36%, respectively, which are lower than that of the proposed technique. Thus, the detection performance of the proposed method is better than those of the existing methods.
Table 5.
Bus bay detection analysis.
Figure 6 illustrates the performance of the proposed ArcGRNN, in terms of training time, in comparison to the traditional networks. It can be seen that the proposed model consumed a shorter time (of 43,148 ms) for training on the data, due to suppression of the overfitting problem through the use of the Arctan gradient activation function. Meanwhile, the RNN, LSTM, DNN, and ANN models had longer training times of 50,159 ms, 56,921 ms, 62,086 ms, and 67,935 ms, respectively. This is because these existing methods fail to focus on the overfitting or gradient vanishing problem during the backpropagation of data among the neuron layers. Hence, it was also verified that the proposed method is more efficient than the existing techniques.
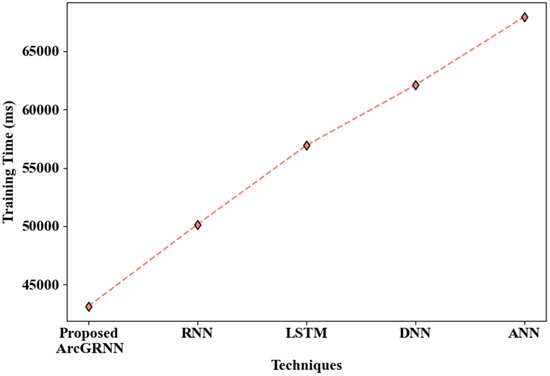
Figure 6.
Training time evaluation.
Figure 7 analyzes the proposed SSCEAD framework’s performance by weighing its similarity score against those of the models used in the comparison. It was found that the proposed technique attained a similarity score of 0.98973, which is higher than that of the prevailing text detection models. In particular, the Encoder–Decoder Network (EDN), General Adversarial Network (GAN), Hierarchical Attention Network (HAN), and CNN achieved similarity scores of 0.93565, 0.90721, 0.83862, and 0.77638, respectively, all lower than that attained by the proposed model. The learning capability of the proposed model was enhanced due to the use of SSC. Thus, the performance of SSCEAD in text detection provides an improvement over the other approaches.
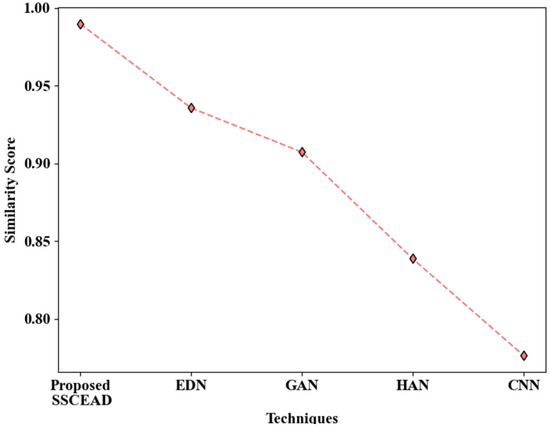
Figure 7.
Graphical depiction of similarity scores obtained by text detection approaches.
With respect to detection time, the performance of the proposed technique regarding text detection was also evaluated. Table 6 shows that the proposed SSCEAD technique took 160,738 ms to detect text, while the existing techniques took an average of 270,851 ms, longer than that of the proposed approach. The usage of the ArcGRNN model in text decoding helps in the rapid detection of text from images. Hence, when compared to the state-of-the-art approaches, the proposed technique could detect text in less time.
Table 6.
Performance comparison of text detection.
Figure 8 analyzes the presented SSCEAD technique for text identification regarding its accuracy, True Positive Rate (TPR), and True Negative Rate (TNR). The proposed model detected text with an accuracy of 97.19%, TPR of 96.55%, and TNR of 97.61%, which are all higher than the metrics obtained with the existing approaches. Among the prevailing techniques, the CNN displayed the lowest performance in text detection, with 89.25% accuracy, 86.56% TPR, and 89.02% TNR. The proposed technique efficiently recognizes text as the receptive field is expanded through pixel shuffling in the convolution kernel.
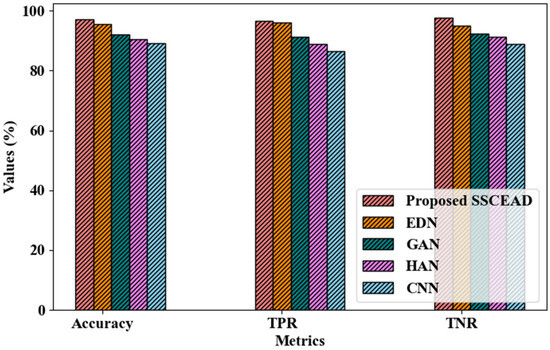
Figure 8.
Performance evaluation of the proposed SSCEAD.
4.3. Comparative Analysis with Related Works
In the framework of Suman et al. [23], who developed a stick using an RNN for VIPs, the obstacles on the path are analyzed for independent navigation. Utilizing this system, obstacles were detected with 91.6% accuracy; however, safer navigation after detecting obstacles was not considered. In this line, Bai et al. [25] presented a wearable travel aid device. To improve the perception of VIPs, this device was made using a CNN to be deployed on eyeglasses and smartphones. However, this device was not sufficient to enable travel from one place to another using a transport system. Hence, based on an improved YOLOv5 network, a bus detection model was proposed by Arifando et al. [22]. This model efficiently assists VIPs in detecting buses with 93.9% precision. Although the bus could be detected by the VIP, it only became efficient once they recognized the bus route name and number. Hence, Sujata Dash Subhendu Kumar Pani [18] detected the bus with the YOLOv3 network and segmented the bus board utilizing a transfer learning technique. Through the LSTM-based Tesseract tool, the route details were converted to text. This technique can detect buses with 90% accuracy and segment the bus board with 80% accuracy. However, to properly guide the VIP, recognizing the route number from the bus is necessary. Using RF and Haar-like filter-based approaches, the bus board area was identified. Next, the route number was recognized through the use of a pattern-matching approach. Tan et al. [16] assessed the bus route number with a detection rate of 56%. Nevertheless, none of these previous works have concentrated on the selection of an appropriate bus bay among the queue of buses in the bus station. Hence, the proposed method selects the optimal bus bay from the bus line utilizing multiple data sources. When identifying the relevant bus, the optimal bay could be selected within 247,891 ms. Moreover, the bus route number was shown to be segmented with 97.19% accuracy. This signifies that the proposed transportation system for VIPs outperforms the state-of-the-art techniques in this area.
Comparative Analysis with Similar Works Based on the MS-COCO Dataset
Next, the performance of the proposed system was assessed on the MS-COCO dataset, comparing it with related existing methods.
Table 7 shows a comparative analysis of the proposed system with respect to accuracy, precision, and f-measure. The proposed model exhibited a higher accuracy (96.93%), precision (95.87%), and f-measure (95.36%) for bus bay detection. Meanwhile, the existing ResNet 50 attained 61.50% precision, YOLO version 5 attained 94% f-measure, Neural Architecture Search (NAS) attained 86.30% precision, and Efficient Featurized Image Pyramid Network (EPIFNet) attained 31.60% precision. Further, the ANN attained 83% accuracy and 80% f-measure, which are both lower than those of the proposed system. The superior performance of the proposed method is due to its utilization of the Arctan Gradient Activation Function (Arc-GAF), which improves its learning ability through expanding smaller input data and converging against larger values. In this way, the vanishing or exploding of gradients during the backpropagation is suppressed. Therefore, the performance of the proposed network was found to be enhanced, when compared to the related object detection techniques.
Table 7.
Performance comparison on the MS-COCO dataset.
4.4. Practical Applicability of the Proposed System
In practice, the voice data of the VIP are collected through a voice assistance module that has an inbuilt microphone. Then, the collected data can be pre-processed using a device that is embedded with the proposed pre-processing approaches. Hence, the redundancy or noise in the voice data is removed, and the resulting clear signal is translated into text format using an installed text converter tool. Further, the retrieved text is sent as a message to the sensor device, which is installed in the wearable aid of the VIP. Then, according to the received text, the GPS location of the VIP and the bay details—namely, the bus bay and optimal bay—are intimated to the VIP. Simultaneously, the sensor captures an image of the destination bus in the bay via GPS. As per the proposed model, the text on the bus is detected, segmented, and extracted, and its similarity with the VIP’s voice data is assessed by the sensor. If the similarity is high, then the sensor transmits a message to the RFID tag, which is fixed in the bus. This informs the bus drivers and conductors about the VIP waiting at the bus station so that they can pick them up accordingly. In the case that the similarity level is very low, the process is iterated from recapturing of the VIP’s voice data. Therefore, the proposed model can be practically applied in the real world to assist VIPs in accurately boarding their desired bus.
4.5. Discussions and Limitations
From the simulated outcomes, the bus bay was exactly detected, and the optimal bay was selected with better performance by the proposed model, when compared to existing methods, as the inclusion of the Arctan gradient activation function in the traditional RNN allowed for effective processing of the input data. Thus, the bus bay was detected with higher accuracy, precision, and recall. Furthermore, introducing the EPAS into the proposed algorithm aids in selecting the optimal bay among the bus lines within a short time. The destination bus image is pre-processed, and the text in it is detected and segmented using the proposed SSCEAD, leading to higher accuracy and lower detection time. The learning efficiency of the CNN was also improved by expanding its receptive field using SSC, enabling more effective text detection. Subsequently, the similarity analysis between the extracted text and the pre-processed input voice aided in the decision to inform the bus coordinators. As various data sources and optimal bus bays were taken in to consideration to develop an effective transportation navigation system, the proposed model achieved better performance than those proposed in prevailing works in the related literature.
However, while applying the proposed framework in real-time, environmental factors can affect the transmission of data and may cause delays. Furthermore, the safety of the VIP after reaching and boarding the bus is not considered in this work. These are considered as limitations of this study. We will attempt to rectify these limitations in future work through the use of advanced deep learning techniques. In this regard, various obstacles—including the height of the bus stop from the ground, objects in the step, and environmental data—need to be analyzed to resolve some of the limitations of this study.
5. Conclusions
This study proposed an effective system to assist in the navigation of VIPs via bus transport, based on MNC-FR and EPBFTOA. The speech data of the VIP are first subjected to voice pre-processing, followed by text conversion. Then, to identify the desired bus and inform the VIP, optimal bay selection, image pre-processing, bus identification, text detection and segmentation, route similarity analysis, and decision-making processes are carried out. The superior performance of the proposed work was examined through comparing it with state-of-the-art techniques. The desired bus was accurately detected by the VIP using the proposed approach, due to selection of the optimal bay line. The obtained outcomes validated that the proposed model presents improved performance when compared to the existing techniques. Using the proposed technique, the optimal bay was selected within 247,891 ms, and the decision rule was generated within 79,932 ms. Moreover, to access the bus, the bus bay was detected with 96.932% accuracy, and text was identified with 97.19% accuracy. Thus, the proposed approach enables the development of an effective guidance system for blind and Visually Impaired People.
Future Scope
Although the bus was detected for the VIP using multiple data sources, we did not concentrate on the person’s safety when boarding the bus. Thus, this work will be extended in the future through determining the obstacles faced by VIPs while boarding the bus.
Author Contributions
All authors contributed equally. All authors have read and agreed to the published version of the manuscript.
Funding
The authors gratefully acknowledge the funding by the Deanship of Graduate Studies and Scientific Research, Jazan University, Saudi Arabia, through Project Number: GSSRD-24.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Choudhary, S.; Bhatia, V.; Ramkumar, K.R. IoT Based Navigation System for Visually Impaired People. In Proceedings of the ICRITO 2020—IEEE 8th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Direction), Noida, India, 13–14 October 2022; pp. 521–525. [Google Scholar] [CrossRef]
- Yadav, D.K.; Mookherji, S.; Gomes, J.; Patil, S. Intelligent Navigation System for the Visually Impaired—A Deep Learning Approach. In Proceedings of the 4th International Conference on Computing Methodologies and Communication, ICCMC, Erode, India, 11–13 March 2020; pp. 652–659. [Google Scholar] [CrossRef]
- Kuriakose, B.; Shrestha, R.; Sandnes, F.E. DeepNAVI: A deep learning based smartphone navigation assistant for people with visual impairments. Expert Syst. Appl. 2023, 212, 118720. [Google Scholar] [CrossRef]
- Khan, W.; Hussain, A.; Khan, B.M.; Crockett, K. Outdoor mobility aid for people with visual impairment: Obstacle detection and responsive framework for the scene perception during the outdoor mobility of people with visual impairment. Expert Syst. Appl. 2023, 228, 120464. [Google Scholar] [CrossRef]
- Poornima, J.; Vishnupriyan, J.; Vijayadhasan, G.K.; Ettappan, M. Voice assisted smart vision stick for visually impaired. Int. J. Control. Autom. 2020, 13, 512–519. [Google Scholar]
- Costa, C.; Paiva, S.; Gavalas, D. Multimodal Route Planning for Blind and Visually Impaired People; Lecture Notes in Intelligent Transportation and Infrastructure; Springer Nature: Cham, Switzerland, 2023; pp. 1017–1026. [Google Scholar] [CrossRef]
- Ashiq, F.; Asif, M.; Bin Ahmad, M.; Zafar, S.; Masood, K.; Mahmood, T.; Mahmood, M.T.; Lee, I.H. CNN-Based Object Recognition and Tracking System to Assist Visually Impaired People. IEEE Access 2022, 10, 14819–14834. [Google Scholar] [CrossRef]
- Yohannes, E.; Lin, P.; Lin, C.Y.; Shih, T.K. Robot Eye: Automatic Object Detection and Recognition Using Deep Attention Network to Assist Blind People. In Proceedings of the 2020 International Conference on Pervasive Artificial Intelligence, ICPAI, Taipei, Taiwan, 3–5 December 2020; pp. 152–157. [Google Scholar] [CrossRef]
- Gowda, M.C.P.; Hajare, R.; Pavan, P.S.S. Cognitive IoT System for visually impaired: Machine learning approach. Mater. Today Proc. 2021, 49, 529–535. [Google Scholar] [CrossRef]
- Martinez-Cruz, S.; Morales-Hernandez, L.A.; Perez-Soto, G.I.; Benitez-Rangel, J.P.; Camarillo-Gomez, K.A. An Outdoor Navigation Assistance System for Visually Impaired People in Public Transportation. IEEE Access 2021, 9, 130767–130777. [Google Scholar] [CrossRef]
- Akanda, M.R.R.; Khandaker, M.M.; Saha, T.; Haque, J.; Majumder, A.; Rakshit, A. Voice-controlled smart assistant and real-time vehicle detection for blind people. Lect. Notes Electr. Eng. 2020, 672, 287–297. [Google Scholar] [CrossRef]
- Agarwal, A.; Agarwal, K.; Agrawal, R.; Patra, A.K.; Mishra, A.K.; Nahak, N. Wireless bus identification system for visually impaired person. In Proceedings of the 1st Odisha International Conference on Electrical Power Engineering, Communication and Computing Technology, ODICON, Bhubaneswar, India, 8–9 January 2021; pp. 1–6. [Google Scholar] [CrossRef]
- de Andrade, H.G.V.; Borges, D.d.M.; Bernardes, L.H.C.; de Albuquerque, J.L.A.; da Silva-Filho, A.G. BlindMobi: A system for bus identification, based on Bluetooth Low Energy, for people with visual impairment. In Proceedings of the XXXVII Simpósio Brasileiro de Redes de Computadores e Sistemas Distribuídos, Gramado, Brazil, 6–10 May 2019; pp. 391–402. [Google Scholar] [CrossRef]
- Ramaswamy, T.; Vaishnavi, M.; Prasanna, S.S.; Archana, T. Bus identification for blind people using rfid. Int. Res. J. Mod. Eng. Technol. Sci. 2022, 4, 3478–3483. [Google Scholar]
- Kumar, K.A.; Sreekanth, P.; Reddy, P.R. Bus Identification Device for Blind People using Arduino. CVR J. Sci. Technol. 2019, 16, 48–52. [Google Scholar] [CrossRef]
- Tan, J.K.; Hamasaki, Y.; Zhou, Y.; Kazuma, I. A method of identifying a public bus route number employing MY VISION. J. Robot. Netw. Artif. Life 2021, 8, 224–228. [Google Scholar] [CrossRef]
- Mueen, A.; Awedh, M.; Zafar, B. Multi-obstacle aware smart navigation system for visually impaired people in fog connected IoT-cloud environment. Health Inform. J. 2022, 28, 14604582221112609. [Google Scholar] [CrossRef] [PubMed]
- Dash, S.; Pani, S.K.; Abraham, A.; Liang, Y. Advanced Soft Computing Techniques in Data Science, IoT and Cloud Computing. In Studies in Big Data; Springer International Publishing: Cham, Switzerland, 2021; Volume 89. [Google Scholar] [CrossRef]
- Bouteraa, Y. Design and development of a wearable assistive device integrating a fuzzy decision support system for blind and visually impaired people. Micromachines 2021, 12, 1082. [Google Scholar] [CrossRef] [PubMed]
- Mukhiddinov, M.; Cho, J. Smart glass system using deep learning for the blind and visually impaired. Electronics 2021, 10, 2756. [Google Scholar] [CrossRef]
- Feng, J.; Beheshti, M.; Philipson, M.; Ramsaywack, Y.; Porfiri, M.; Rizzo, J.R. Commute Booster: A Mobile Application for First/Last Mile and Middle Mile Navigation Support for People with Blindness and Low Vision. IEEE J. Transl. Eng. Health Med. 2023, 11, 523–535. [Google Scholar] [CrossRef]
- Arifando, R.; Eto, S.; Wada, C. Improved YOLOv5-Based Lightweight Object Detection Algorithm for People with Visual Impairment to Detect Buses. Appl. Sci. 2023, 13, 5802. [Google Scholar] [CrossRef]
- Suman, S.; Mishra, S.; Sahoo, K.S.; Nayyar, A. Vision Navigator: A Smart and Intelligent Obstacle Recognition Model for Visually Impaired Users. Mob. Inf. Syst. 2022, 2022, 9715891. [Google Scholar] [CrossRef]
- Pundlik, S.; Shivshanker, P.; Traut-Savino, T.; Luo, G. Field evaluation of a mobile app for assisting blind and visually impaired travelers to find bus stops. arXiv 2023, arXiv:2309.10940. [Google Scholar] [CrossRef]
- Bai, J.; Liu, Z.; Lin, Y.; Li, Y.; Lian, S.; Liu, D. Wearable travel aid for environment perception and navigation of visually impaired people. Electronics 2019, 8, 697. [Google Scholar] [CrossRef]
- Dubey, S.; Olimov, F.; Rafique, M.A.; Jeon, M. Improving small objects detection using transformer. J. Vis. Commun. Image Represent. 2022, 89, 103620. [Google Scholar] [CrossRef]
- Ancha, V.K.; Sibai, F.N.; Gonuguntla, V.; Vaddi, R. Utilizing YOLO Models for Real-World Scenarios: Assessing Novel Mixed Defect Detection Dataset in PCBs. IEEE Access 2024, 12, 100983–100990. [Google Scholar] [CrossRef]
- Said, Y.; Atri, M.; Albahar, M.A.; Ben Atitallah, A.; Alsariera, Y.A. Obstacle Detection System for Navigation Assistance of Visually Impaired People Based on Deep Learning Techniques. Sensors 2023, 23, 5262. [Google Scholar] [CrossRef] [PubMed]
- Quang, T.N.; Lee, S.; Song, B.C. Object detection using improved bi-directional feature pyramid network. Electronics 2021, 10, 746. [Google Scholar] [CrossRef]
- Naseer, A.; Almujally, N.A.; Alotaibi, S.S.; Alazeb, A.; Park, J. Efficient Object Segmentation and Recognition Using Multi-Layer Perceptron Networks. Comput. Mater. Contin. 2024, 78, 1381–1398. [Google Scholar] [CrossRef]
































Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).