
Improved Small Object Detection Algorithm CRL-YOLOv5

Abstract
:1. Introduction
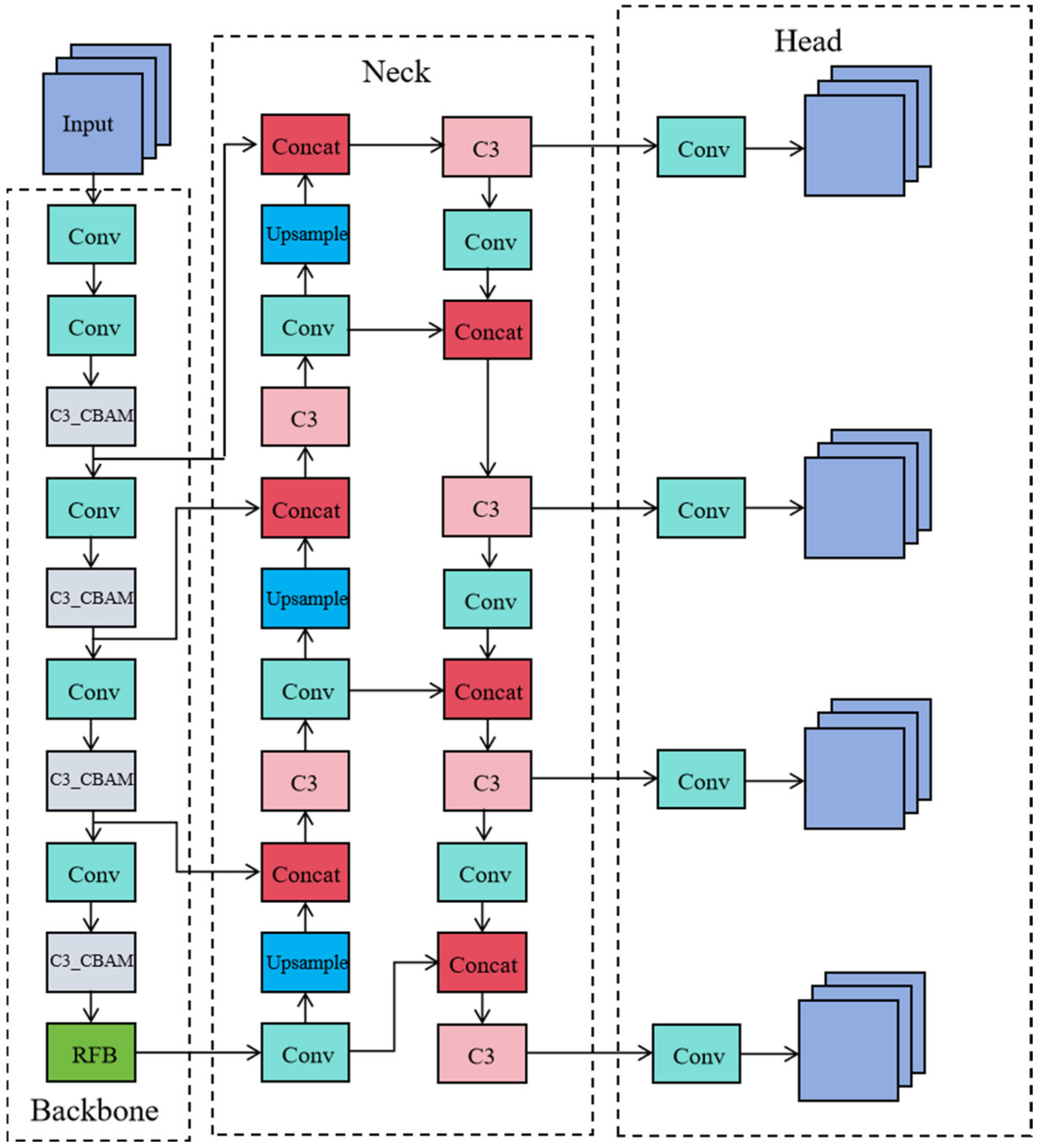
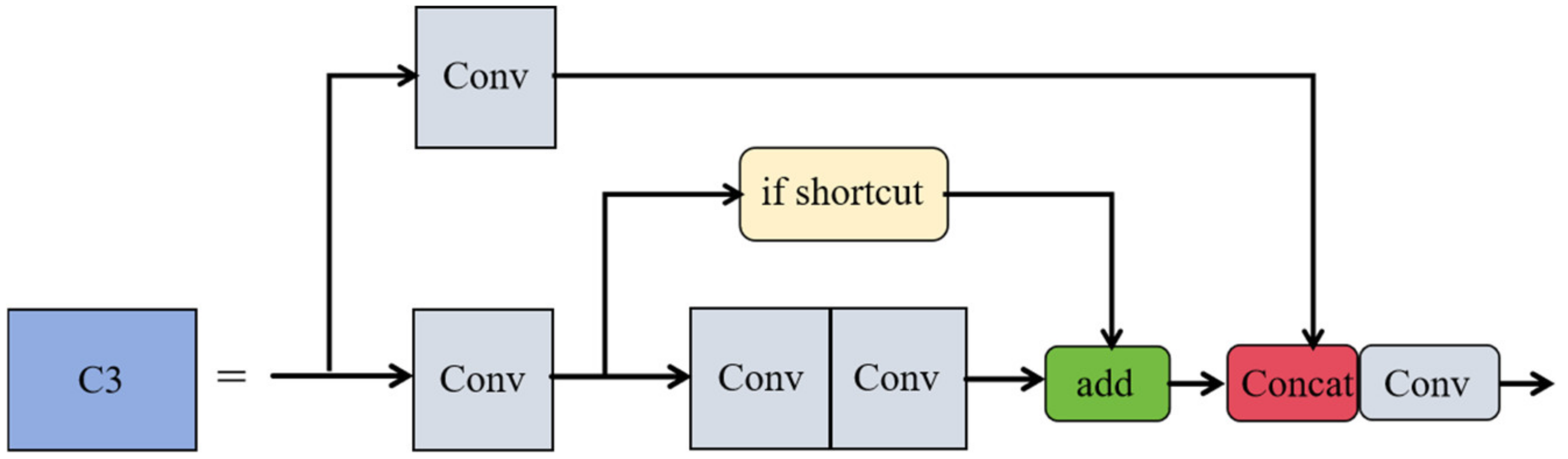
- Integrate the Convolutional Block Attention Module (CBAM) into the YOLOv5 model, that is, include the CBAM [19] attention mechanism into the C3 module of the backbone network to improve its feature representation capabilities, to improve the model’s capture ability for important parts of the image to increase the accuracy of detecting image fragments.
- Replace the Spatial Pyramid Pooling-Fast (SPPF) module with the Receptive Field Block (RFB) module [20] to expand the receptive field of the original model and better and correct use of contextual information, which may improve the perception of objects of different sizes and shapes by the transformed model and may lead to an increase in the accuracy of detecting small objects.
- Adapt the basic model by adding a new detection and identification layer on top of the existing network architecture, focused on identifying small objects and making full use of shallow features for more accurate localization of small targets in the image, with the aim of further increasing the accuracy and correctness of detecting small objects.
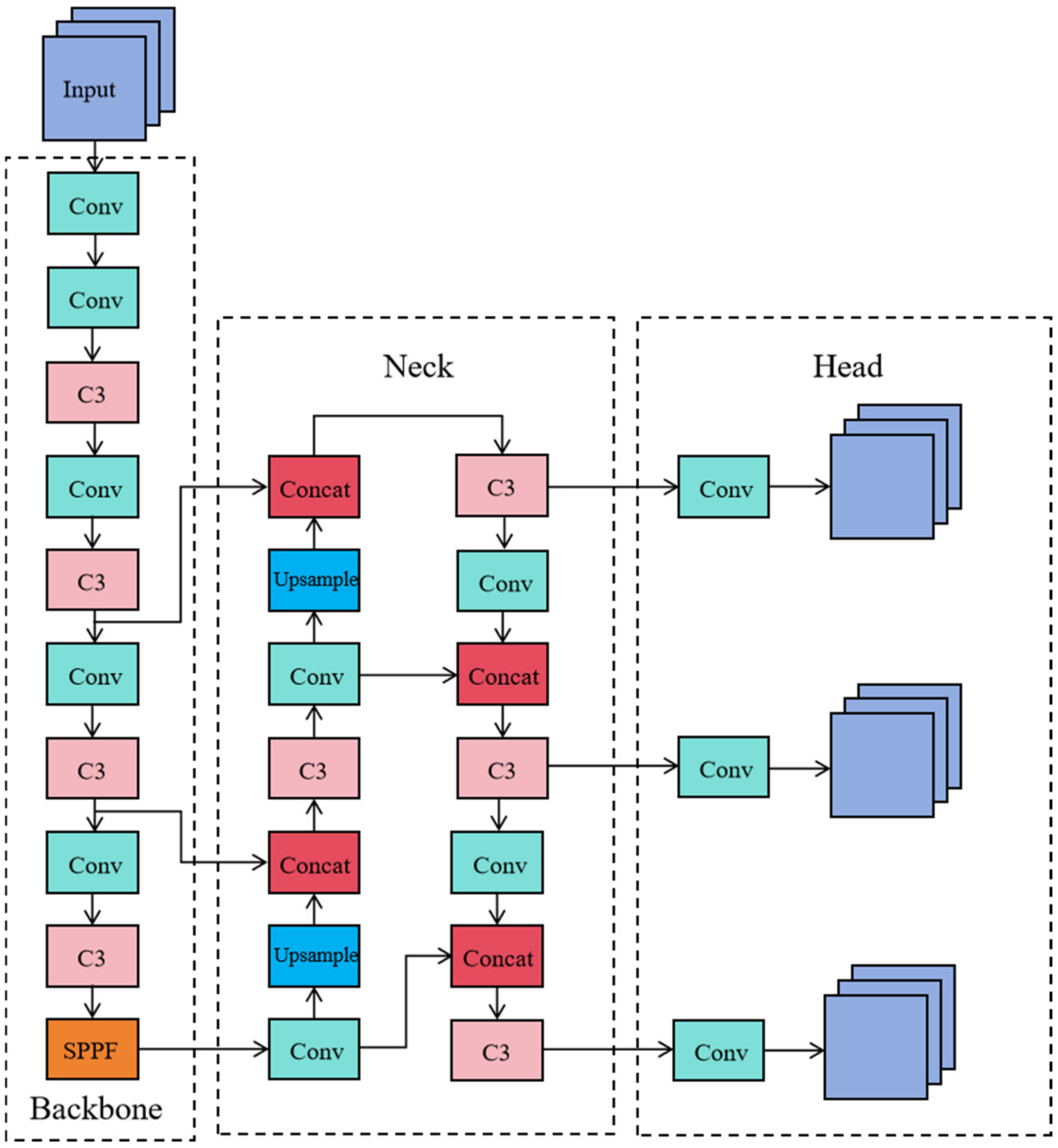
2. Materials and Methods
2.1. C3_CBAM Module
2.2. RFB Module
2.3. Adding a Dedicated Small Object Detection Layer
3. Experiments and Analysis
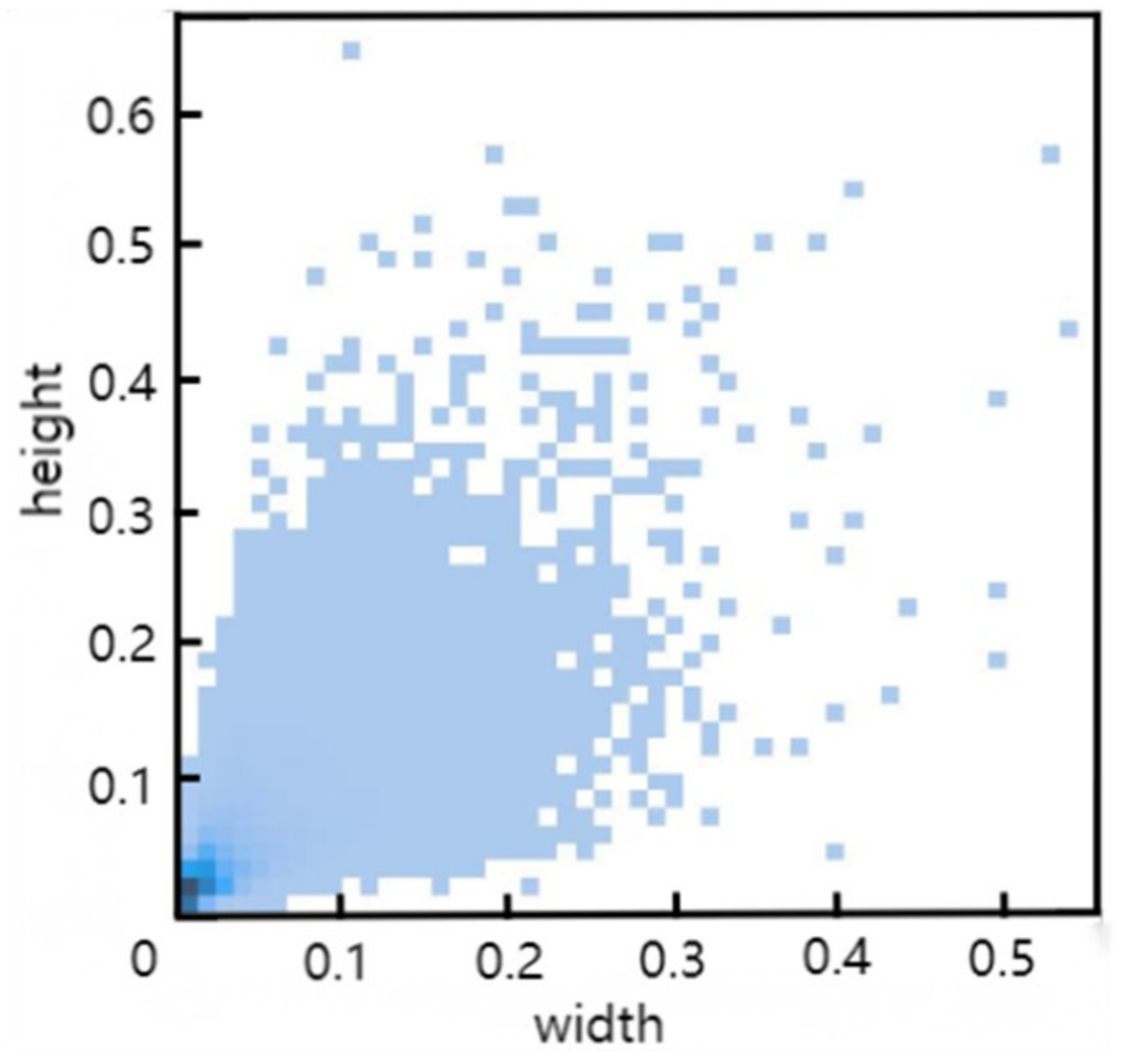
3.1. Experimental Data and Environment
3.2. Evaluation Metrics
3.3. Ablation Study and Analysis of Algorithm Effectiveness
3.4. Comparative Experiments
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jia, S.; Yichang, Q.; Ze, J.; Jing, W. Small Object Detection Algorithm Based on ATO-YOLO. J. Comput. Eng. 2024, 60, 68. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R.J. Fast R-CNN. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Yang, R.; Li, W.; Shang, X.; Zhu, D.; Man, X. KPE-YOLOv5: An improved small target detection algorithm based on YOLOv5. Electronics 2023, 12, 817. [Google Scholar] [CrossRef]
- Zhang, H.; Hao, C.; Song, W.; Jiang, B.; Li, B. Adaptive slicing-aided hyper inference for small object detection in high-resolution remote sensing images. Remote Sens. 2023, 15, 1249. [Google Scholar] [CrossRef]
- Kim, M.; Jeong, J.; Kim, S. ECAP-YOLO: Efficient channel attention pyramid YOLO for small object detection in aerial image. Remote Sens. 2021, 13, 4851. [Google Scholar] [CrossRef]
- Mahaur, B.; Mishra, K. Small-object detection based on YOLOv5 in autonomous driving systems. Pattern Recognit. Lett. 2023, 168, 115–122. [Google Scholar] [CrossRef]
- Guo, Z.; Wang, C.; Yang, G.; Huang, Z.; Li, G. MSFT-YOLO: Improved YOLOv5 based on transformer for detecting defects of steel surface. Sensors 2022, 22, 3467. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Yang, W.; Wang, L.; Chen, D.; Wei, F.; KeZiErBieKe, H.; Liao, Y. FE-YOLOv5: Feature enhancement network based on YOLOv5 for small object detection. J. Vis. Commun. Image Represent. 2023, 90, 103752. [Google Scholar] [CrossRef]
- Dong, X.; Yan, S.; Duan, C. A lightweight vehicles detection network model based on YOLOv5. Eng. Appl. Artif. Intell. 2022, 113, 104914. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Dong, Z.; Gao, M. Improved YOLOv5 network for real-time multi-scale traffic sign detection. Neural Comput. Appl. 2023, 35, 7853–7865. [Google Scholar] [CrossRef]
- Liu, W.; Quijano, K.; Crawford, M.M. YOLOv5-Tassel: Detecting tassels in RGB UAV imagery with improved YOLOv5 based on transfer learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 8085–8094. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Chen, Y.; Ding, Y.; Zhao, F.; Zhang, E.; Wu, Z.; Shao, L.J.A.S. Surface defect detection methods for industrial products: A review. Appl. Sci. 2021, 11, 7657. [Google Scholar] [CrossRef]
- Luo, X.; Wu, Y.; Wang, F. Target detection method of UAV aerial imagery based on improved YOLOv5. Remote Sens. 2022, 14, 5063. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| C3_CBAM Quantity | mAP50/% | mAP50-95/% | Params/M | GFLOPs |
|---|---|---|---|---|
| 0 | 33.8 | 18.7 | 7.05 | 16.0 |
| 1 | 33.9 | 18.8 | 6.72 | 15.0 |
| 2 | 34.1 | 18.8 | 6.72 | 15.0 |
| 3 | 34.2 | 18.9 | 6.72 | 15.0 |
| 4 | 34.4 | 18.9 | 6.73 | 15.0 |
| YOLOv5s | A | B | C | mAP50/% | mAP50-95/% | P/% | R/% | Params/M | GFLOPs |
|---|---|---|---|---|---|---|---|---|---|
| √ | 33.8 | 18.7 | 45.4 | 34.5 | 7.05 | 16.0 | |||
| √ | √ | 34.4 | 19.0 | 48.8 | 34.6 | 6.73 | 15.0 | ||
| √ | √ | 39.0 | 22.1 | 49.8 | 39.1 | 7.19 | 18.9 | ||
| √ | √ | 34.4 | 19.1 | 47.6 | 34.9 | 7.71 | 16.6 | ||
| √ | √ | √ | 39.0 | 22.1 | 50.3 | 38.5 | 7.21 | 19.0 | |
| √ | √ | √ | √ | 39.2 | 22.3 | 50.5 | 38.7 | 7.87 | 19.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Men, S.; Bai, Y.; Yuan, Y.; Wang, J.; Wang, K.; Zhang, L. Improved Small Object Detection Algorithm CRL-YOLOv5. Sensors 2024, 24, 6437. https://doi.org/10.3390/s24196437
Wang Z, Men S, Bai Y, Yuan Y, Wang J, Wang K, Zhang L. Improved Small Object Detection Algorithm CRL-YOLOv5. Sensors. 2024; 24(19):6437. https://doi.org/10.3390/s24196437
Chicago/Turabian StyleWang, Zhiyuan, Shujun Men, Yuntian Bai, Yutong Yuan, Jiamin Wang, Kanglei Wang, and Lei Zhang. 2024. "Improved Small Object Detection Algorithm CRL-YOLOv5" Sensors 24, no. 19: 6437. https://doi.org/10.3390/s24196437