1. Introduction
Invasive weeds in agricultural fields provide competition for crucial resources to crops. For most crops, weeds cause higher losses in production than pathogens and animal pests [
1], underscoring the importance of control. Weed control has proven to be a significant challenge. Herbicides have been the go-to method of controlling weeds for decades [
2,
3], in addition to other common solutions like mechanical weeding [
4,
5,
6] and even hand-picking.
The evolution of herbicide-resistant weed populations threatens agricultural productivity [
7,
8]. In addition to this, herbicides and other conventional methods of weed control such as mechanical techniques are labor-intensive and expensive [
9]. Technology provides an opportunity to increase efficiency in control and reduce costs. Weed control solutions that automate the entire process or part of the process such as automatic sprayers [
9,
10,
11] and precision mechanical weed controllers [
12,
13] have been researched and implemented.
Precision weed control methods demand knowledge of the types and location of weeds in the field; therefore, weed detection solutions are essential for this task. Research into weed detection technologies has resulted in various solutions that have proven valuable for precision weed control. Some solutions have used infrared spectroscopy [
14], fluorescence [
15], or computer vision [
16,
17,
18]. The availability of low-cost high-resolution cameras and advances in computing hardware have sparked interest in computer vision solutions. Some scholars have used a combination of simple image-processing techniques that utilize the extraction of features like color, shape, or texture and machine learning algorithms like support vector machines or random forest to identify weeds. For example, the authors of [
16,
17,
18] used a combination of image feature extraction and support vector machines to discriminate weeds from crops. While these methods perform well in stable environments, they may not be robust in harsh outdoor conditions with changes in illumination, occlusions, and shadows. Progress in deep learning technologies has led to an increase in the use of convolutional neural networks (CNNs) for weed detection and classification, achieving impressive results. For instance, the authors of [
19,
20,
21,
22] used CNN frameworks to detect weeds in crop fields with a great level of stability and accuracy. Individual weed detection makes it possible to implement weed removal solutions that can precisely target individual weed species without interfering with other plants in the field. These solutions include methods like spot spraying [
23], electricity [
24], or lasers [
25].
Researchers have compared the effectiveness and efficiency of different deep learning models in detecting different weed species, aiding informed decision making for field implementation. For example, ref. [
26] compared two deep learning models, the single-shot detector (SSD) and Faster RCNN, according to their detection performance on UAV imagery and found Faster RCNN to be the superior model. In another study, the authors of [
27] evaluated 35 deep learning models on 15 weed species, establishing a benchmark for weed identification. Most of the performance evaluations and comparisons for deep learning models have been conducted on powerful computers capable of handling the computational demands of deep learning; however, given our focus on robotic applications, many solutions require portable computers, which are often less powerful. For real-time applications in agricultural fields, robotic platforms such as ground rovers and UAVs usually use embedded computers that are not comparable to most powerful GPU-enabled computers used for deep learning tasks.
This paper compares the performance of three single-stage deep learning models that are lightweight enough for real-time applications: YOLOv4 [
28], EfficientDet [
29], and CenterNet [
30]. The comparison focuses on the real-time detection of thirteen common species of weeds found in cotton and peanut fields. The comparisons were conducted in a deep learning computer with powerful GPUs (RTX 2080Ti, Nvidia, Santa Clara, CA, USA) and an embedded deep-learning-enabled computer (Nvidia Jetson Xavier AGX). These models were chosen due to their reputation as state-of-the-art object detection models for real-time applications. Detecting multiple species of weeds individually can help in making real-time decisions about how to remove the weed; for example, if a robotic platform is performing spot spraying and encounters an herbicide-resistant weed, an alternative method can be employed.
2. Materials and Methods
2.1. Data Collection
More than 5000 color or RGB (Red, Green, Blue) images of 13 different weed species—Palmer amaranth (
Amaranthus palmeri), smallflower morningglory (
Jaquemontia tamnifolia), sicklepod (
Senna obtusifolia), crabgrass (
Digitaria spp.), Florida beggarweed (
Desmodium tortuosum), Florida pusley (
Richardia scabra), pitted morningglory (
Ipomoea lcunos), goosegrass (
Eleusine indica), crowfoot grass (
Dactyloctenium aegyptium), purple nutsedge (
Cyperus rotundus), yellow nutsedge (
Cyperus esculentus), ivyleaf morningglory (
Ipomoea hederacea), and Texas panicum (
Urochloa texana), seen in
Figure 1—were collected from University of Georgia research fields near Ty Ty, GA (31.509730 N, 83.655880 W) and the University of Georgia Tifton campus, GA (31.473410° N, 83.530475° W) using smartphone cameras or hand-held digital cameras. Images were captured at early stages of weed growth (from 1 to 3 weeks) at different camera angles, under different weather conditions, and at different times of the day.
2.2. Data Labeling
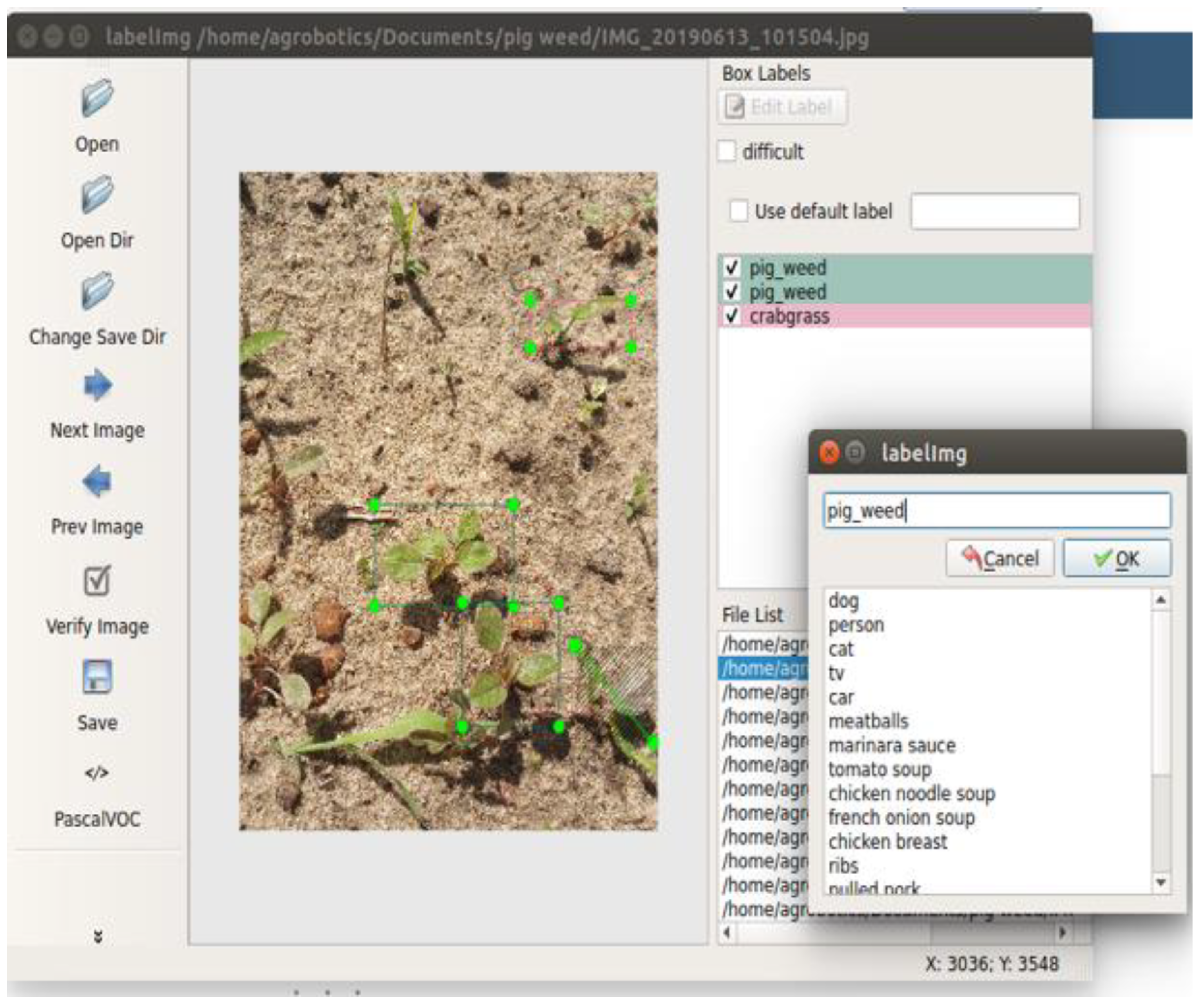
More than 3500 images were labeled using an open-source annotation tool, LabelImg v1.8.6 (
https://github.com/HumanSignal/labelImg, accessed on 10 February 2022). This tool allows for the drawing of boundaries around objects in images to identify them and creates records that indicate the object’s location in the image, as seen in
Figure 2. Labeling was conducted in both PASCAL VOC [
31] format for TensorFlow model training and YOLO [
32] format for YOLO model training in darknet.
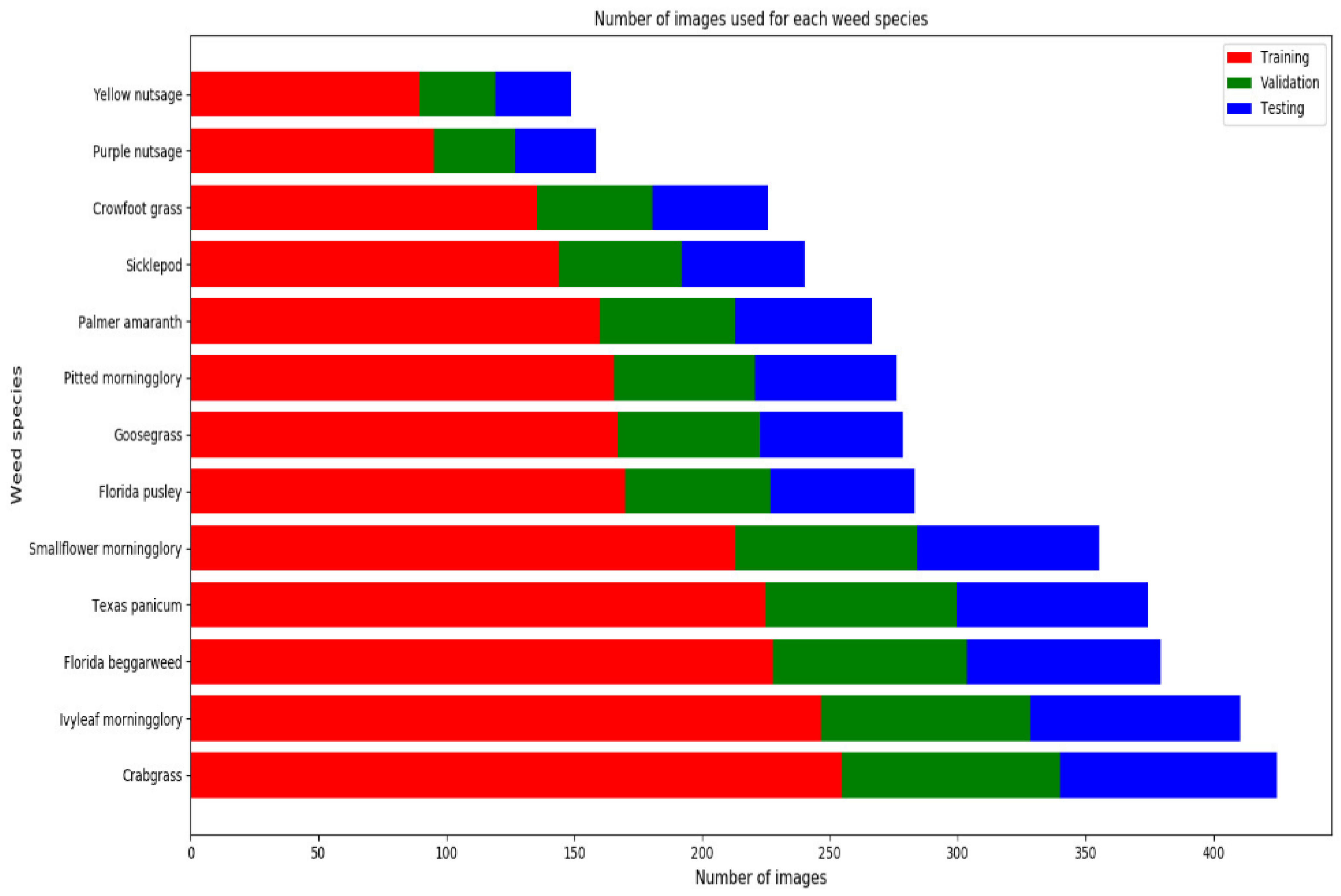
2.3. Train–Test Split
The labeled data were divided into a training set (60%) for training the models to learn the features, a validation set (20%) to validate the model’s precision and avoid overfitting, and a testing set (20%) for benchmarking, as shown in
Figure 3.
2.4. Data Augmentation
Since deep learning models rely heavily on extensive data for improved accuracy and to prevent overfitting, any additional data are valuable. Data augmentation involves techniques that add slightly modified copies of the existing data to the training set to enhance the size and quality of training data [
33].
The training data were augmented through techniques such as rotation, shearing, blurring, and cropping using an open-source image augmentation library, CLoDSA (
https://github.com/joheras/CLoDSA, accessed on 2 May 2022). This increased the training set to more than 67,000 images.
2.5. Training
Training was conducted using transfer learning, a technique of transferring knowledge between different but related domains [
34]. In deep learning, this is accomplished by reusing previously trained models for new problems to reduce training time and enhance the performance of targeted models. In training, the models take labeled images of different resolutions and then change the resolution to the required model input size.
2.5.1. YOLOv4
YOLOv4 (You Only Look Once version 4) is a real-time object detection model developed as a continuation of previous YOLO versions to address their limitations. It is a single-stage object detection model trained to analyze the image only once and identify a subset of object classes. The YOLO network architecture is renowned for its speed in object detection, and YOLOv4 has prioritized real-time detection.
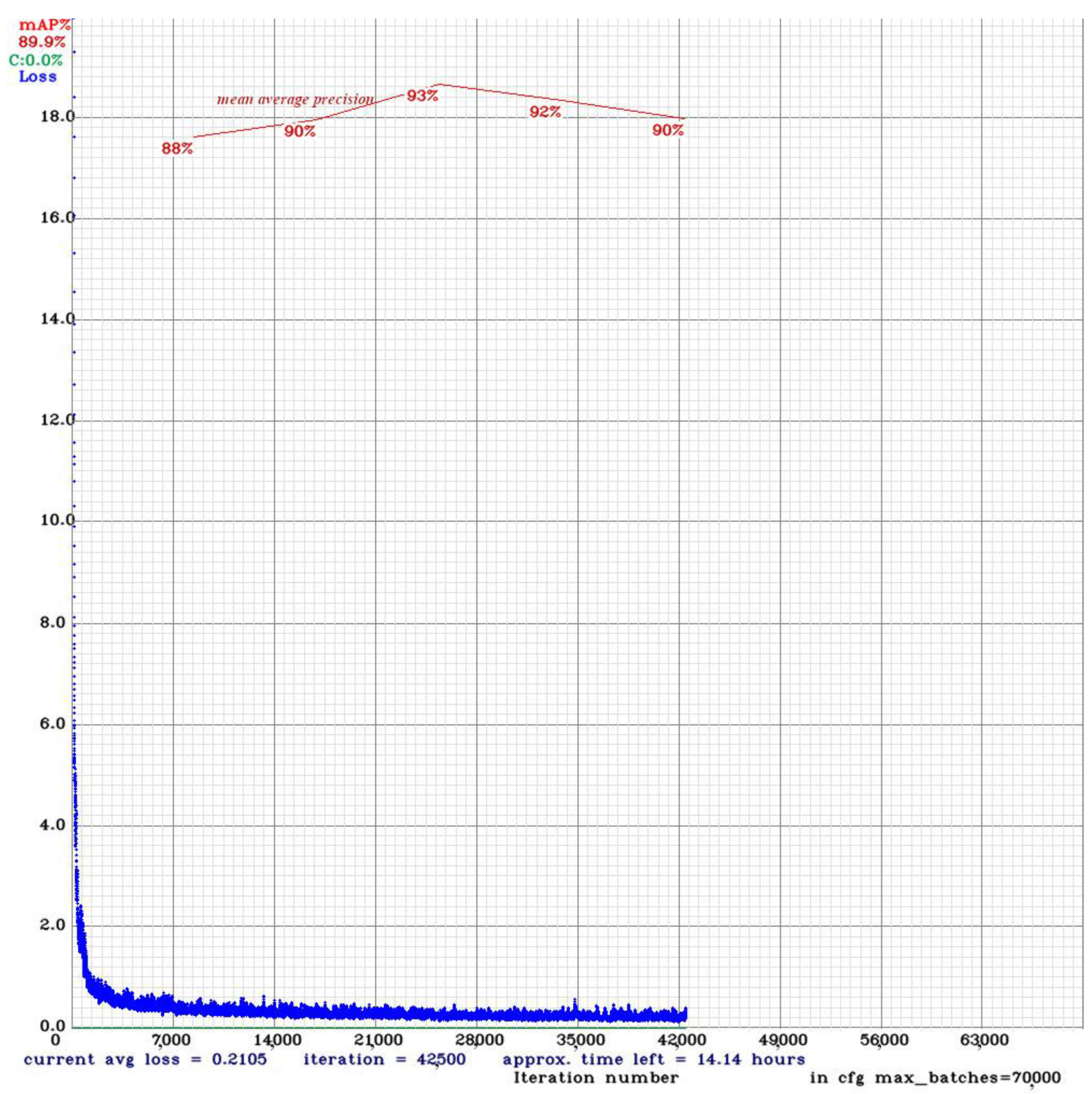
YOLOv4 training was conducted under the darknet environment [
35], which is an open-source neural network framework that supports object detection and image classification tasks and serves as the basis for the YOLO algorithm. As part of the transfer learning, YOLOv4 training started with pre-trained weights that were originally trained on the MS-COCO (Microsoft Common Objects in Context) dataset [
36], which contains a wide range of 80 object classes. Training was conducted on the training set, while evaluation was performed on the validation set. When the mean average precision of the model evaluated on the validation set did not increase, the training was stopped, as seen in
Figure 4. The best weights with the highest mean average precision were taken for the designated weed detection model.
2.5.2. EfficentDet
EfficientDet is a real-time object detection model written in Tensorflow [
37] and Keras [
38] that utilizes a weighted bi-directional feature pyramid network (BiFPN) to learn input features while incorporating multi-scale feature fusing for box/class prediction.
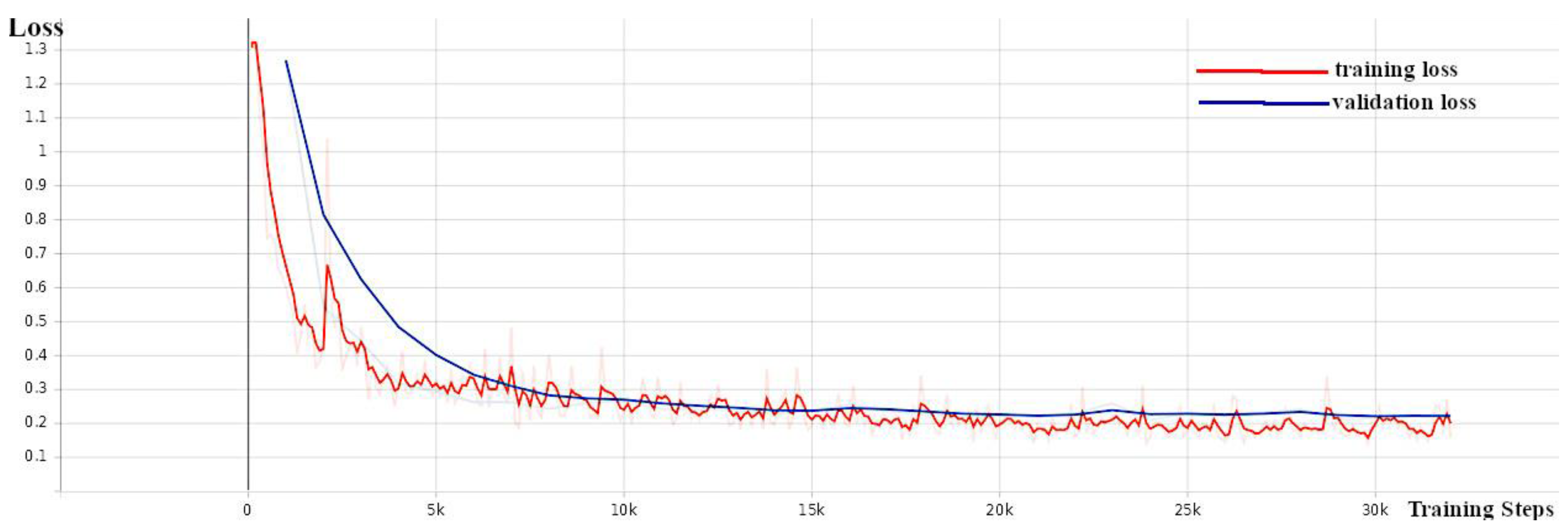
A pre-trained model (EfficientDet D0 512 × 512) from a collection of models pre-trained on the COCO 2017 dataset provided by Tensorflow 2 Detection Model Zoo [
39] served as the starting point for training the EfficientDet weed detection model. The training was carried out while monitoring the validation loss (
Figure 5), average precision (
Figure 6), and recall (
Figure 7) and stopped when the loss did not decrease and the precision and recall did not increase (around 30 K).
2.5.3. CenterNet
CenterNet represents objects as a set of keypoints, reducing the need for anchor boxes and simplifying the process by predicting the bounding boxes directly.
The training of the CenterNet model utilized a pre-trained model (CenterNet Resnet101 V1 FPN 512 × 512) from Tensorflow 2 Detection Model Zoo, which was trained over the Resnet101 [
40] backbone as the starting network. Total validation loss (
Figure 8), precision (
Figure 9), and recall (
Figure 10) were monitored during the training.
Table 1 shows the architecture differences between the models used in this study.
2.6. Platforms
The weed detection models were trained on a deep-learning-capable computer equipped with a 32-core Intel I9 CPU (Intel, Santa Clara, CA, USA, Nvidia RTX 2080 Ti GPUs (4352-CUDA cores), and 128 GB RAM. Inference speed and accuracy were compared between the deep learning computer and an artificial intelligence (AI)-embedded computer designed specifically for autonomous machines, an Nvidia Jetson Xavier AGX (
Figure 11) equipped with an 8-core NVIDIA Carmel Arm
®v8.2 64-bit CPU 8 MB L2 + 4 MB L3, 512-core NVIDIA Volta architecture GPU with 64 Tensor Cores, and 32 GB of RAM.
2.7. Evaluation Metrics
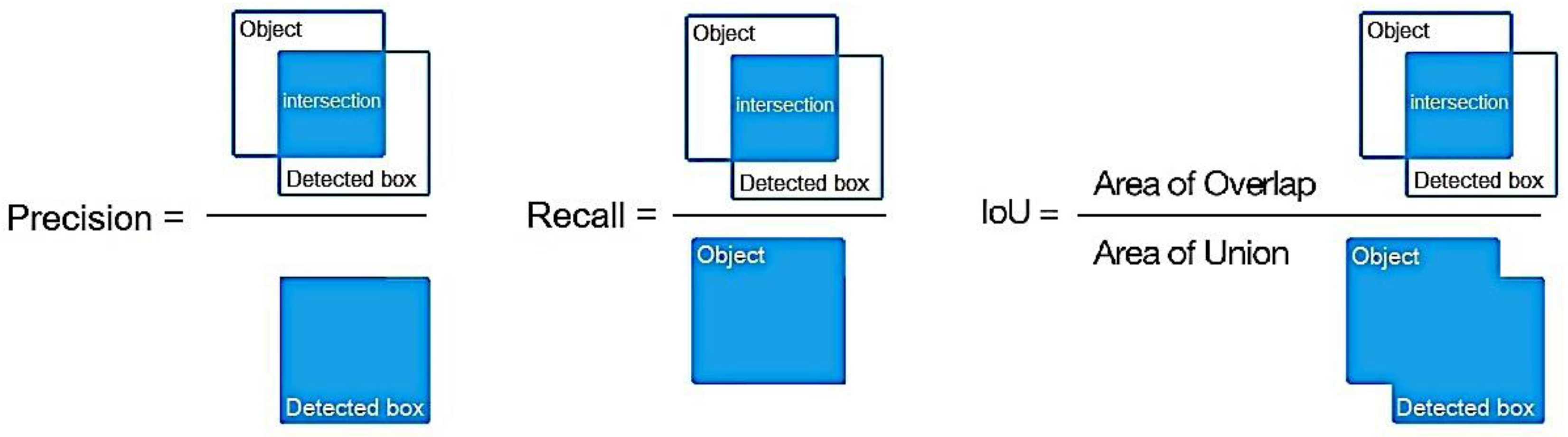
As the focus lay on the inference of the detection models, several metrics were compared when running on the two platforms. Model accuracy metrics such as precision and recall, which were summarized by the average precision (AP) value and mean average precision (mAP) evaluated under different Intersection-over-Union (IoU) thresholds, and speed metrics such as inference time and frames per second (fps) were considered.
Precision measures how well the positive predictions match the ground truth.
Recall measures how many relevant predictions are made out of all predictions.
The average precision (AP) represents the weighted average of all precision values at each precision–recall curve threshold, where the weight is the increase in recall. This value summarizes the precision–recall curve into a single value.
The Intersection over Union (IoU) indicates the overlap of the predicted bounding box coordinates with the ground-truth box [
41], as shown in
Figure 12. When the predicted bounding box closely resembles the ground-truth box, the IoU is higher. In deep learning object detection models, multiple bounding boxes are predicted for objects, but only those with an IoU higher than a certain threshold are considered as positively predicted boxes.
The Mean average precision (mAP) represents the average of the weighted means of precision at each IoU threshold. It is calculated by averaging the average precision (AP) for each class across a number of classes.
The inference time refers to the time it takes for a model to make a prediction on a single image, while the number of frames per second (fps) indicates the frequency at which inference is performed on consecutive images in a video stream. For real-time applications, these are crucial metrics because an excessive inference delay can lead to the machine being unable to respond in time. The inference time was calculated by running the models on a set of weed images and averaging the time over the number of images. On the other hand, fps was obtained by running the models on weed videos while recording the reciprocal of execution time for each frame. These two metrics varied among the models as well as platforms, while the other metrics only varied among the models.
2.8. Mobile Optimized Solution
The prediction speed is a critical aspect of a real-time detection system, and due to the fact that in real scenarios the embedded computer runs other applications for robot control in addition to the detection program, the inference speed may be impacted further. Other variants of deep learning models optimized for speed have been developed by sacrificing some precision through reducing the neural network size. YOLOv4 has a lightweight compressed version, YOLOv4-tiny, with a simpler network structure and reduced parameters to make it ideal for mobile and embedded devices. YOLOv4-tiny can be used for faster training and inference than YOLOv4; however, its accuracy suffers. YOLOv4 was also compared to its lighter version YOLOv4-tiny in terms of its viability for weed detection on the embedded platform.
4. Discussion
Real-time weed detection is crucial for precision mapping and the removal of weeds in agricultural fields. To achieve effective precision weed removal, robotic platforms are commonly employed. As these platforms often use embedded computers for their portability, it becomes important to evaluate the performance of various weed detection models on these embedded systems and identify the ideal model for real-time weed detection. Despite the prevalence of research in weed detection, there has been limited testing of these solutions on embedded computers to assess their practicality. Our approach involved comparing the performance of three real-time deep learning models—YOLOv4, EfficientDet, and CenterNet—in detecting 13 different species of weeds. This comparison focused on the accuracy of the models and their inference speed.
Our weed dataset was meticulously curated, encompassing images captured under various weather conditions and at different times of the day, growth stages, and camera angles. Additionally, data augmentation was employed to enhance the diversity of the training samples, following methodologies outlined in studies such as [
42,
43].
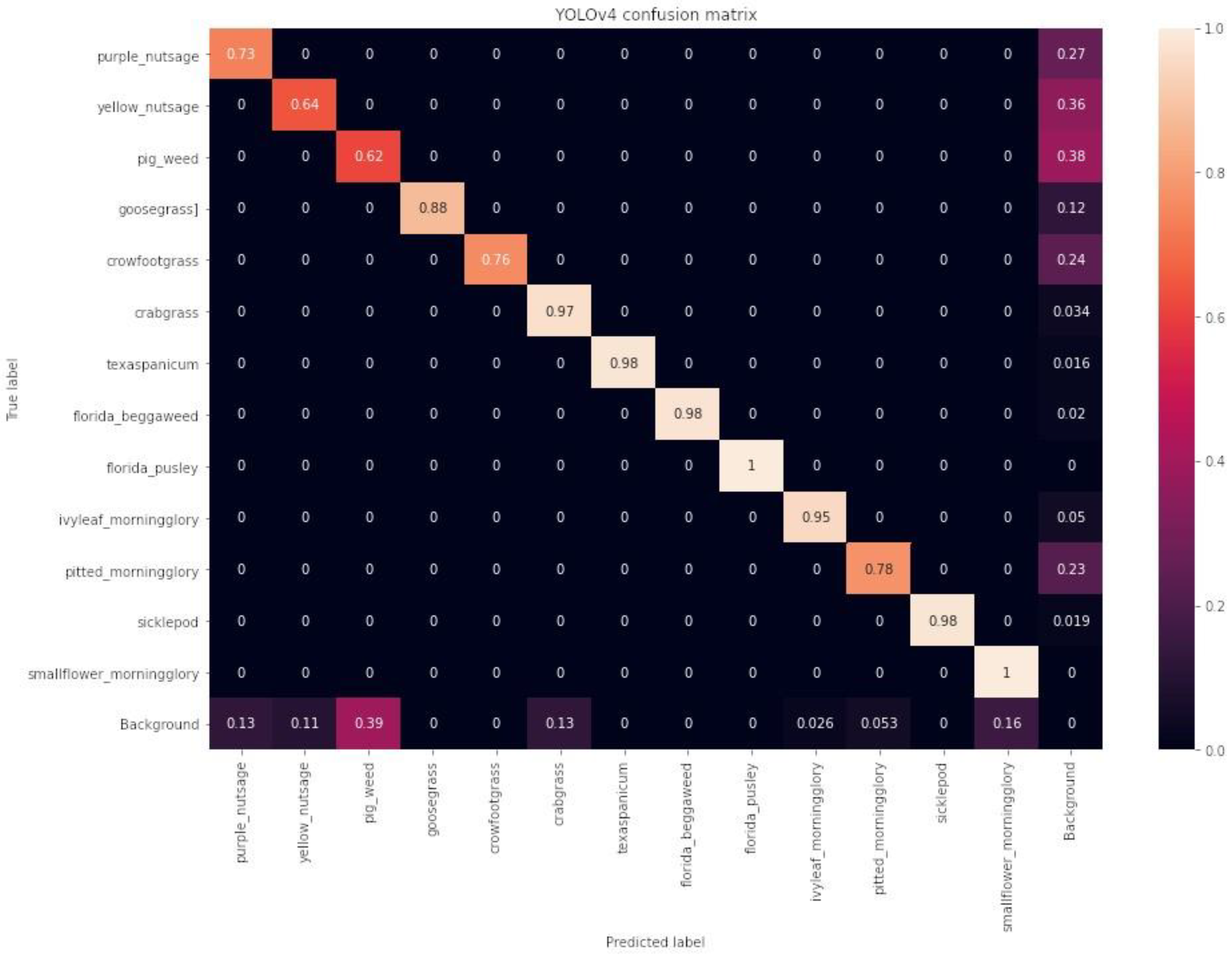
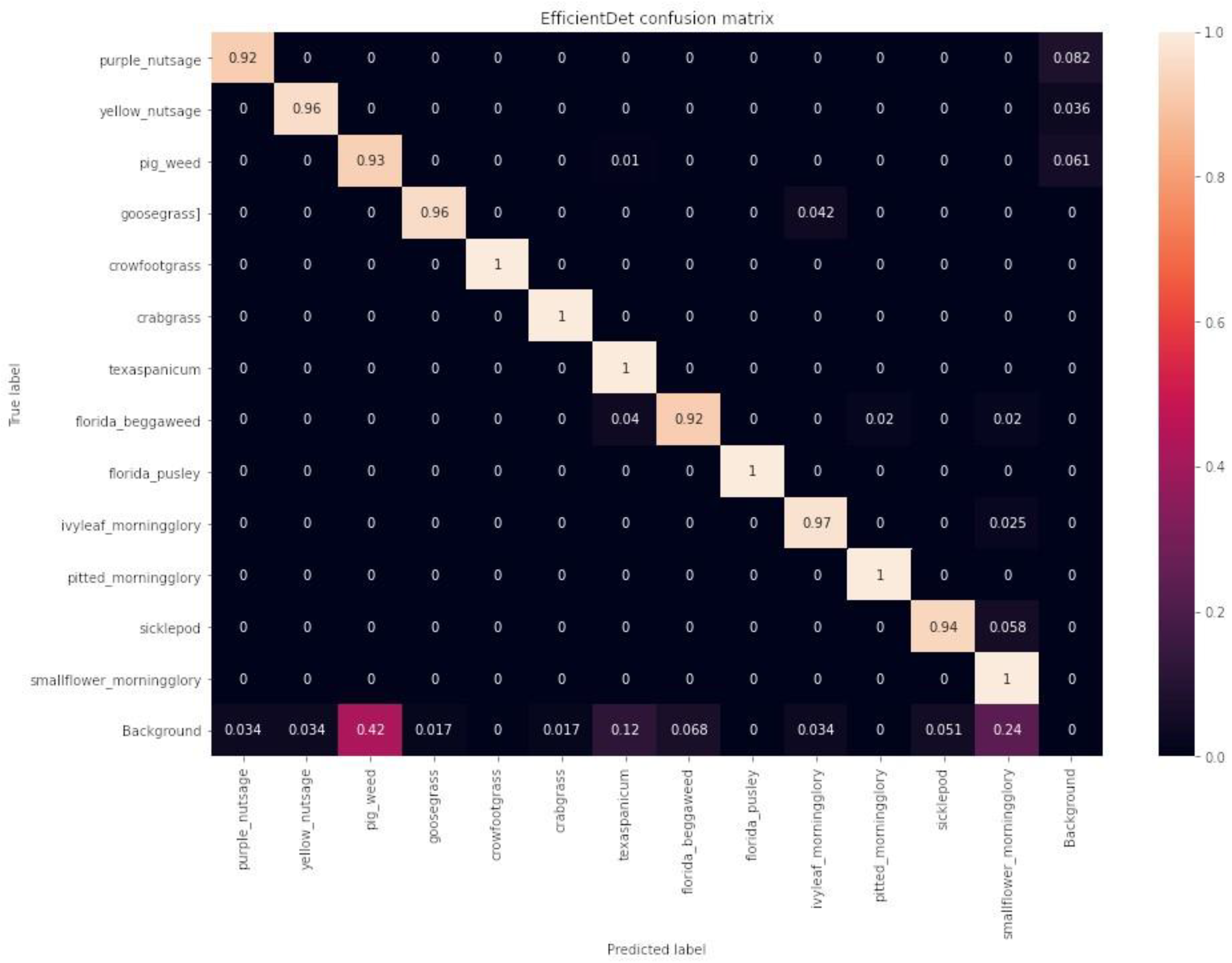
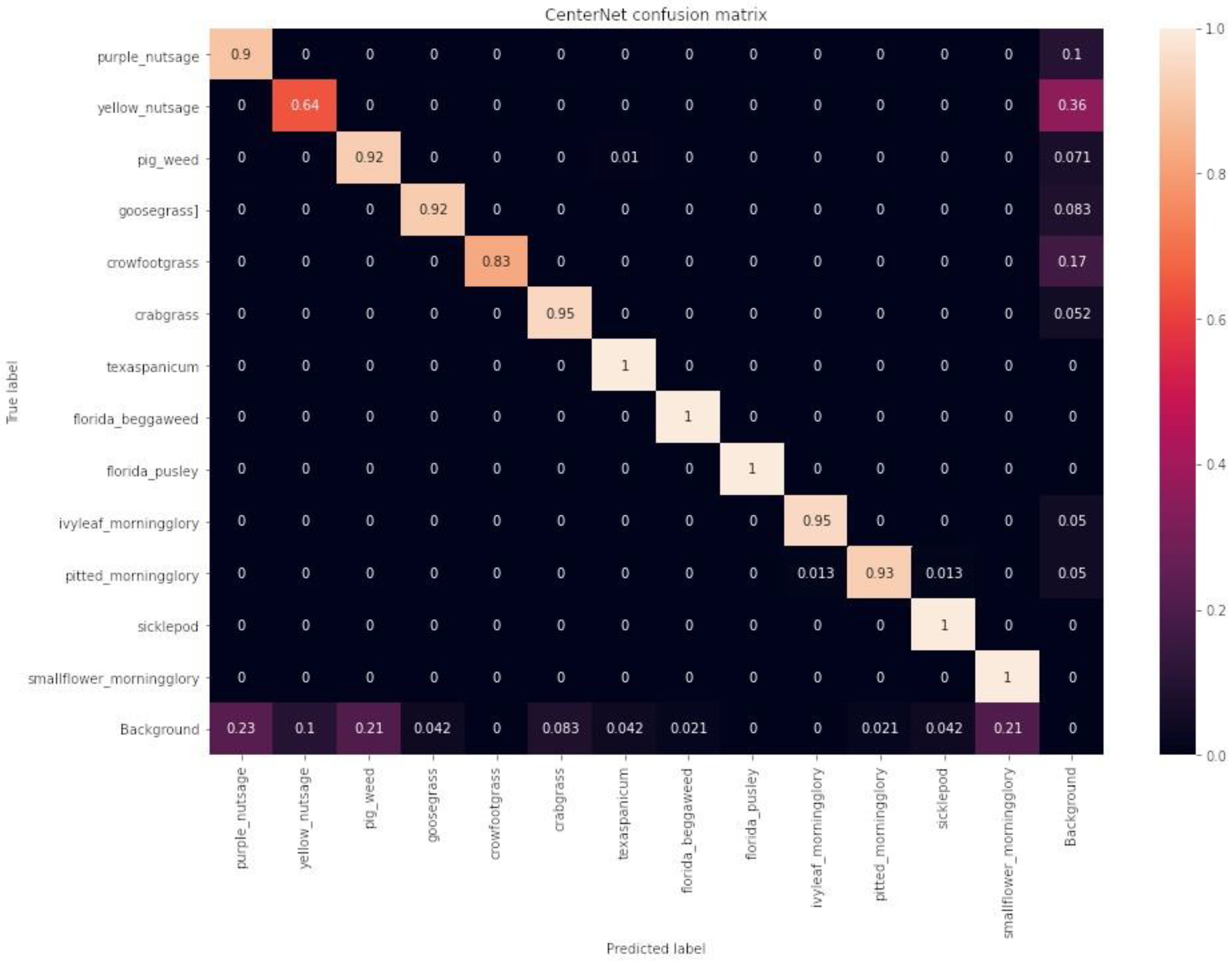
Each of the three deep learning models achieved a mean average precision greater than 93% at a 50% Intersection over Union (IoU) threshold. The models YOLOv4, EfficientDet, and CenterNet exhibited COCO mean average precision values of 61.6%, 71.3%, and 70.6%, respectively. In terms of inference times, the models performed at 18 ms, 66 ms, and 44 ms on a deep learning computer and at 80 ms, 102 ms, and 140 ms on an embedded computer, respectively.
Comparing our results to other weed detection studies, refs. [
14] and [
15] achieved accuracy levels exceeding 87% and 91%, respectively, in weed classification. However, these studies were conducted in controlled environments, and there was no indication of inference speed or tests on embedded computers. Conversely, solutions using computer vision algorithms like [
16,
17,
18] achieved over 90% accuracy in discriminating weeds from plants. However, these solutions classified only a few weed species compared to our 13 species, and there was no indication of inference speed to evaluate their real-time capabilities.
When considering similar solutions utilizing deep learning, the accuracies align closely with our observations. For example, ref. [
22] achieved average precision values ranging from 75% for the VGG16 network to 97% using the ResNet-50 and Xception networks on 12 different plant species. Another comparable deep learning method [
27], evaluating the performance of 35 models on 15 weed classes, achieved accuracies from 50% for the low-performing model MnasNet to 98% for the top-performing ResNext101 model. However, their reported inference times ranging from 188 ms to 338 ms were slower than our models’ inference times.
Considering practical robot usage in the field, embedded computers are preferred. The authors of [
19] attempted to evaluate the performance of segmenting weeds using customized MobileNet and DenseNet networks on an embedded computer (Raspberry Pi). The solution achieved an inference time of 50 ms to 100 ms. Although this inference time was impressively shorter than our best inference time on an embedded computer obtained through YOLOv4 (80 ms), it is noteworthy that our recommended solution for embedded systems, YOLOv4-tiny, boasts the best inference time of 24.5 ms. Future studies should evaluate the real-time performance on a robotic platform in an agricultural field.
5. Conclusions
Three deep learning models—YOLOv4, EfficientDet, and CenterNet—were trained and tested for their effectiveness in detecting thirteen different species of weed using two platforms: a deep-learning-capable computer and an embedded computer. The experiment aimed to assess their suitability for real-time robotic applications. It was observed that, with a mean average precision of 93.4% at an IoU threshold of 50%, an inference speed of 80 ms, and 14 fps on an embedded computer, YOLOv4 is better suited for real-time robotic applications due to its balanced performance between accuracy and inference speed. Furthermore, recognizing that some real-time robotic applications require a higher speed without compromising the accuracy too much, a lightweight version of YOLOv4, YOLOv4-tiny, was trained and tested in an embedded system. Despite its smaller size, YOLOv4-tiny impressively achieved a mean average precision of 89% at a 50% IoU threshold, which is approximately 4.7% less precise than YOLOv4. The model performed inference very rapidly on an embedded computer, with a speed of 24.5 ms and 52 fps.
Due to its speed of detection in an embedded system and its satisfactory accuracy, YOLOv4-tiny is recommended for real-time robotic applications that involve weed detection.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}